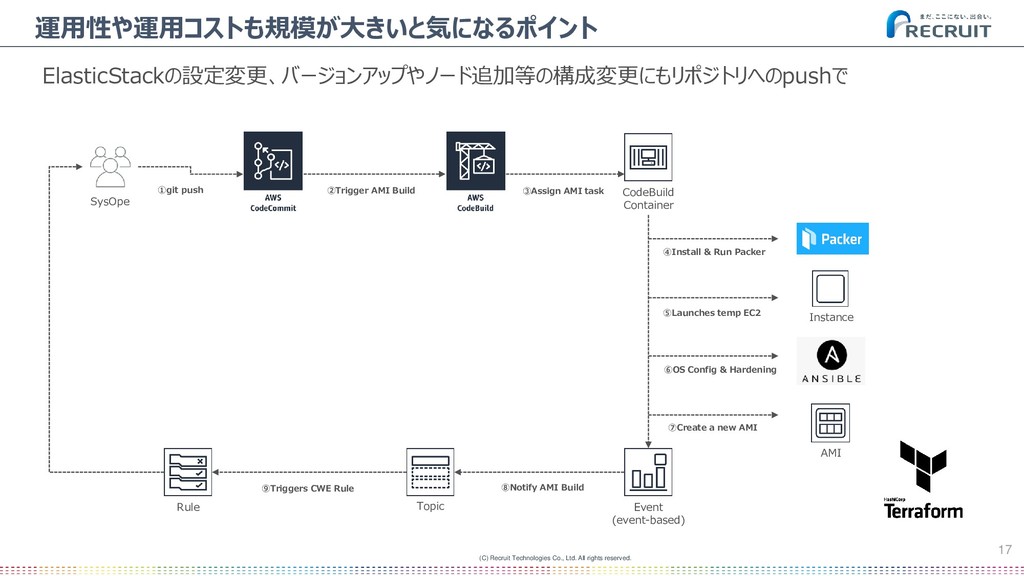
ElasticStackの設定変更、バージョンアップやノード追加等の構成変更にもリポジトリへのpushで AMI Instance Event (event-based) Rule Topic CodeBuild Container SysOpe ①git push ②Trigger AMI Build ③Assign AMI task ④Install & Run Packer ⑤Launches temp EC2 ⑥OS Config & Hardening ⑦Create a new AMI ⑧Notify AMI Build ⑨Triggers CWE Rule
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}