🎥 https://www.youtube.com/watch?v=rQlLzVbXEXk
🧑 Nicolas Charles
📅 Configuration Management Camp 2020
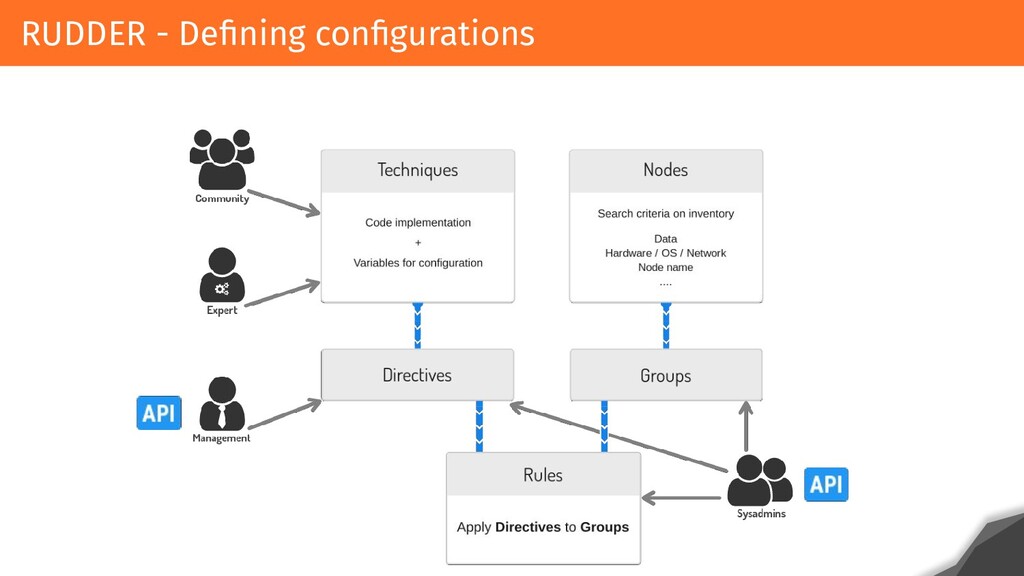
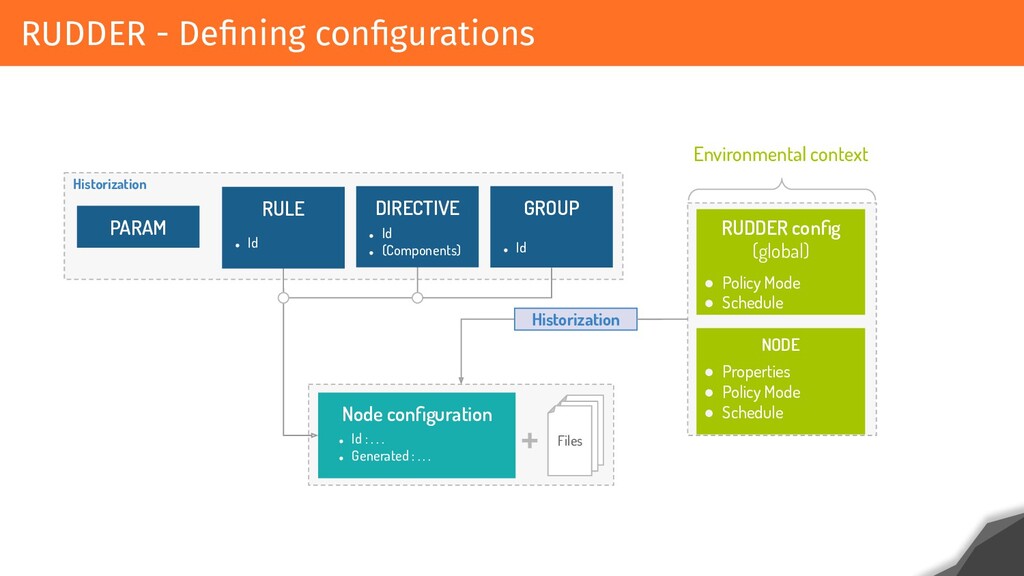
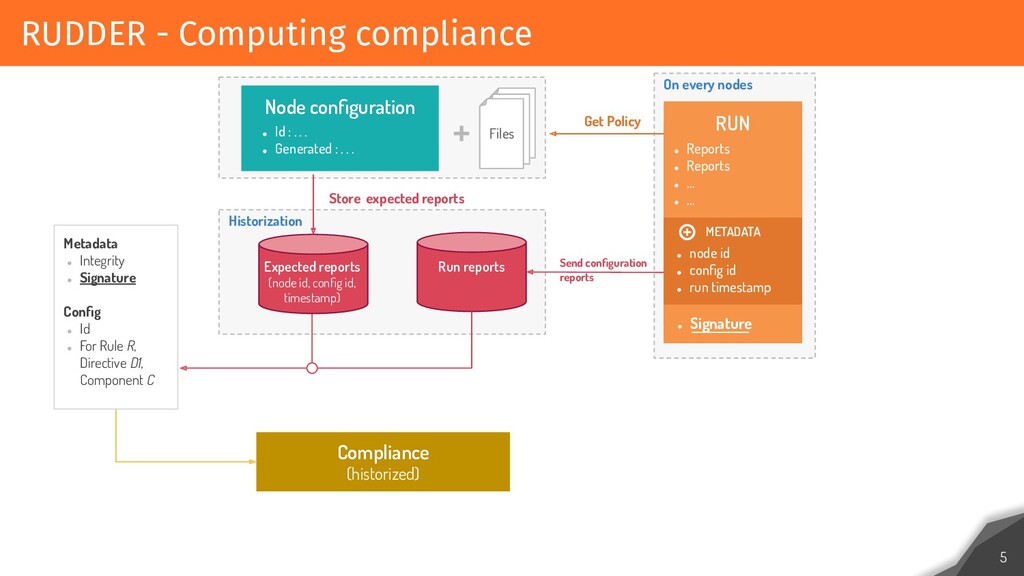
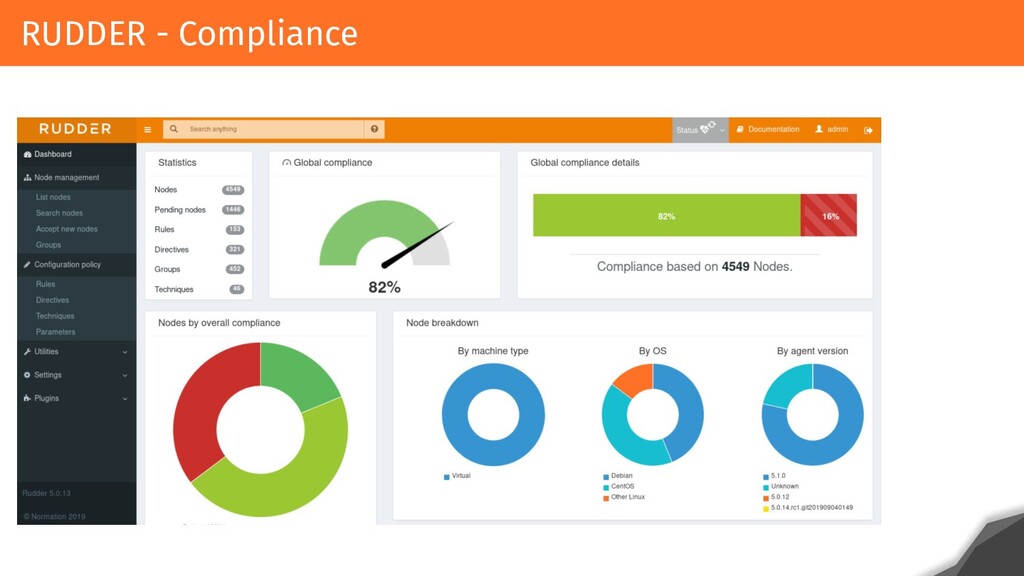
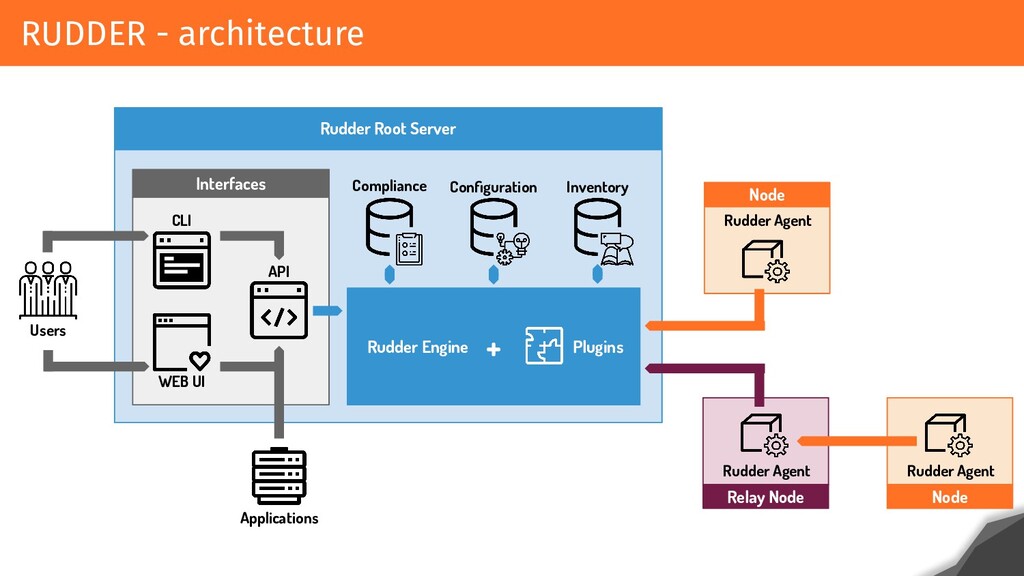
RUDDER is based on API/Web application that allows users to configure and verify their configurations. Relying on agents on every system, it checks and remediates configurations every 5 minutes and centralizes the result of application. Each result is made up of hundreds of events that are historized, and each configuration changes involves calculating and displaying the configurations and conformities for users within a reasonable time.
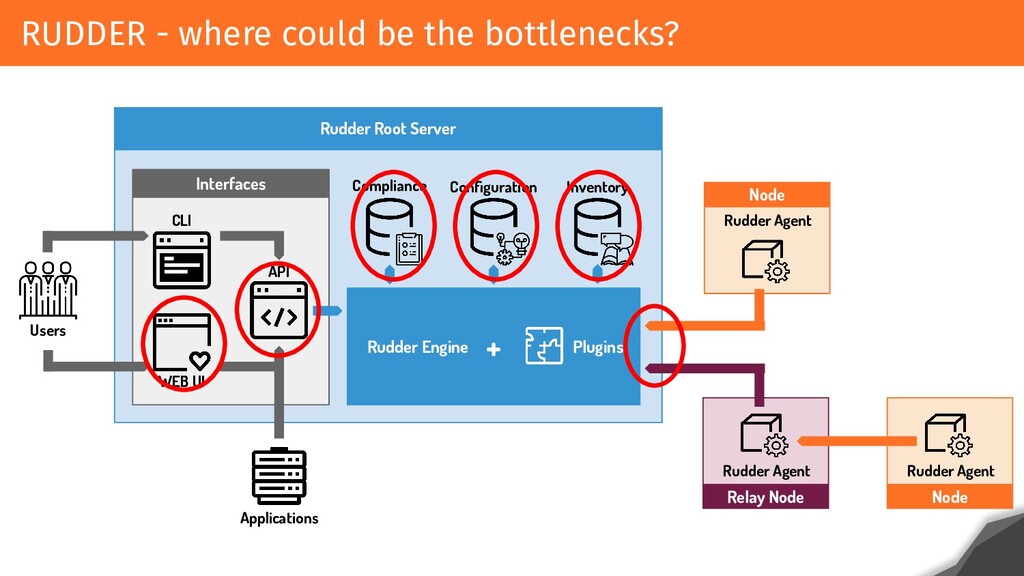
A RUDDER instance can handle 20 000 nodes. Can you imagine what this implies from a network, CPU and storage point of view? How to reach and maintain these performances? What are the different steps that made this possible? And what tools have been put in place?
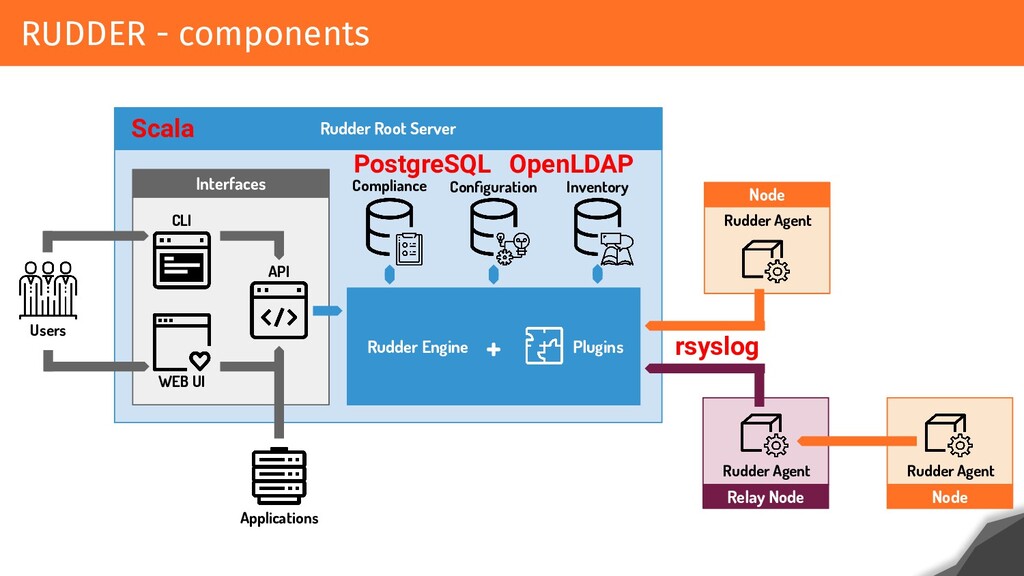
This presentation will explain the technical stack used (Scala, PostgreSQL, C and Rust), as well as the path, failures and successes that allow us today to reproduce the environments, and also to test and validate the hypotheses to achieve and keep these results.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}