Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
How to Dissect a Muppet: The Structure of Trans...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
hajime kiyama
August 31, 2023
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
How to Dissect a Muppet: The Structure of Transformer Embedding Spaces
Japanese explanation
hajime kiyama
August 31, 2023
More Decks by hajime kiyama
See All by hajime kiyama
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Idiosyncrasies in Large Language Models
rudorudo11
0
63
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
280
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices.
rudorudo11
0
230
Using Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
rudorudo11
0
110
Analyzing Semantic Change through Lexical Replacements
rudorudo11
0
370
意味変化分析に向けた単語埋め込みの時系列パターン分析
rudorudo11
1
210
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
rudorudo11
0
340
Word Sense Extension
rudorudo11
0
160
Featured
See All Featured
How GitHub (no longer) Works
holman
316
150k
Ethics towards AI in product and experience design
skipperchong
2
330
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
My Coaching Mixtape
mlcsv
0
170
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Six Lessons from altMBA
skipperchong
29
4.3k
Transcript
論文紹介 TACL2022 発表者 : B4 木山 朔 発表日 : 1/13
1
Introduction • Transformer を使った事前学習済み埋め込み表現が主流 • Transformer の embedding を数学的に再構築 ◦
4つのベクトルの和で埋め込み表現を定式 ◦ BERTで実験 • component の影響を調査 ◦ MHA や FF が downstream task で等しく有用 ◦ fine-tuning の効果を定量的に計測 • 様々な先行研究との関連を発見 2
Additive structure in transformers e_t : トークン t に対する埋め込み i_t
: 入力時の静的埋め込み h_t : MHA の埋め込み f_t : FF の埋め込み c_t : モデルのバイアス(上記以外) (数学的な導出は論文の付録に記載) 3
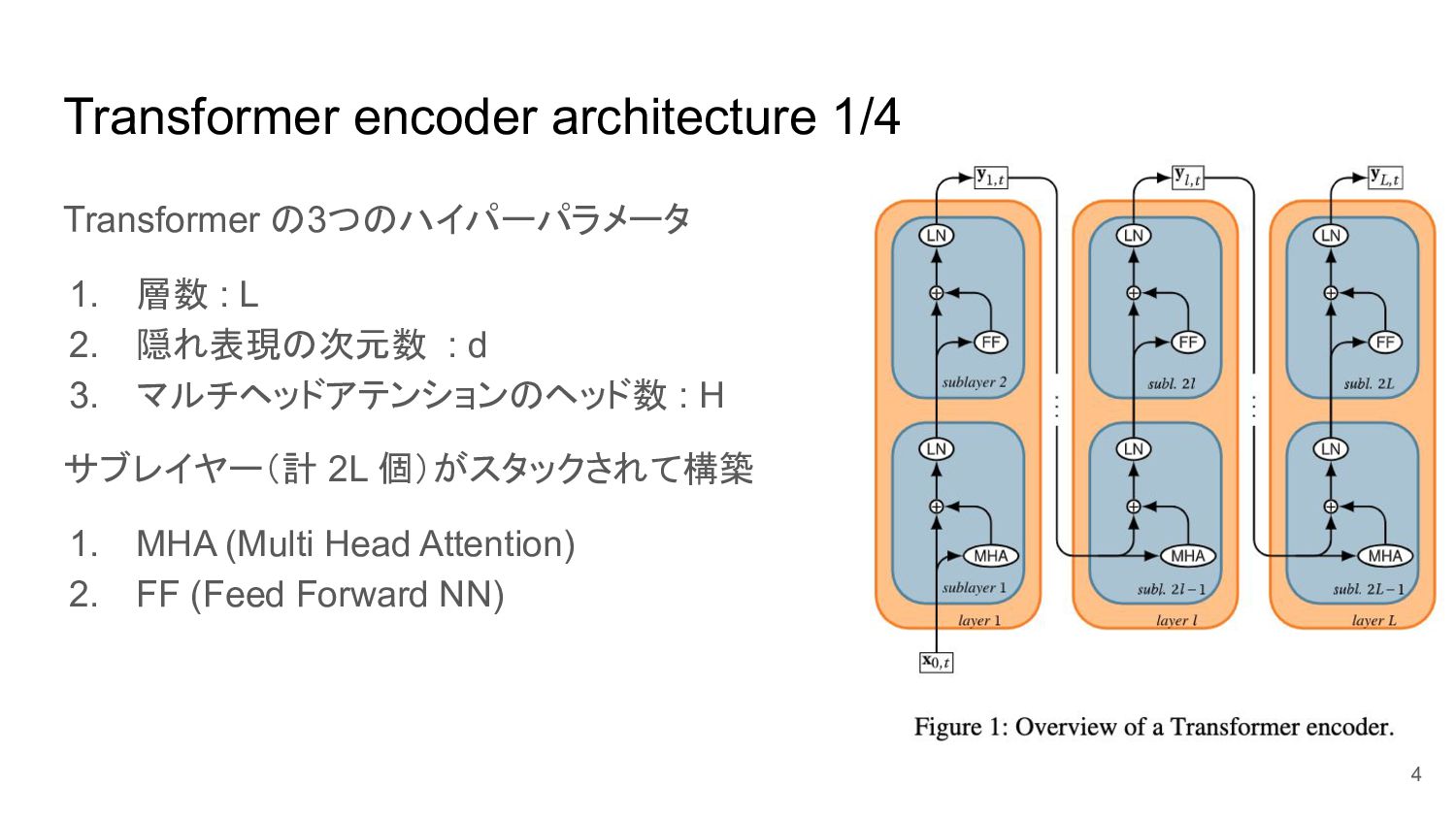
Transformer encoder architecture 1/4 Transformer の3つのハイパーパラメータ 1. 層数 : L
2. 隠れ表現の次元数 : d 3. マルチヘッドアテンションのヘッド数 : H サブレイヤー(計 2L 個)がスタックされて構築 1. MHA (Multi Head Attention) 2. FF (Feed Forward NN) 4
Transformer encoder architecture 2/4 • FF のサブレイヤーの計算式 ◦ Φ :
非線形関数(ReLU, GeLUなど) ◦ x_t : t 番目のトークン ◦ W : 重み ◦ b : バイアス 5
Transformer encoder architecture 3/4 • MHA のサブレイヤーの計算式 ◦ A_h :
h 番目の Attention ▪ (A_h)_t : トークン t の h 番目のAttention ▪ α_h : attention weight 6
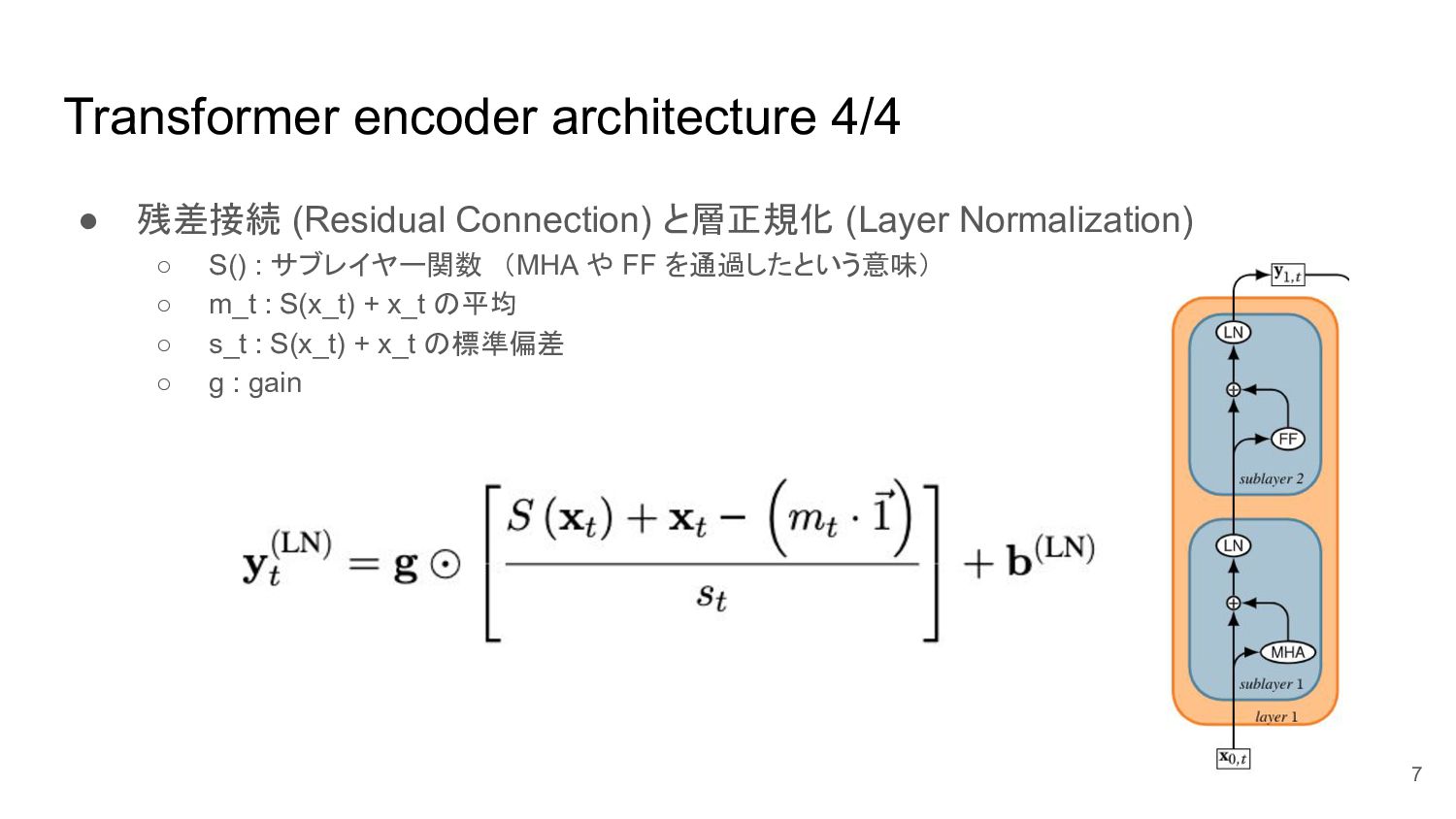
Transformer encoder architecture 4/4 • 残差接続 (Residual Connection) と層正規化 (Layer
Normalization) ◦ S() : サブレイヤー関数 (MHA や FF を通過したという意味) ◦ m_t : S(x_t) + x_t の平均 ◦ s_t : S(x_t) + x_t の標準偏差 ◦ g : gain 7
Additive structure in transformers (再掲) e_t : トークン t に対する埋め込み
i_t : 入力時の静的埋め込み h_t : MHA の埋め込み f_t : FF の埋め込み c_t : モデルのバイアス(上記以外) (数学的な導出は論文の付録に記載) 8
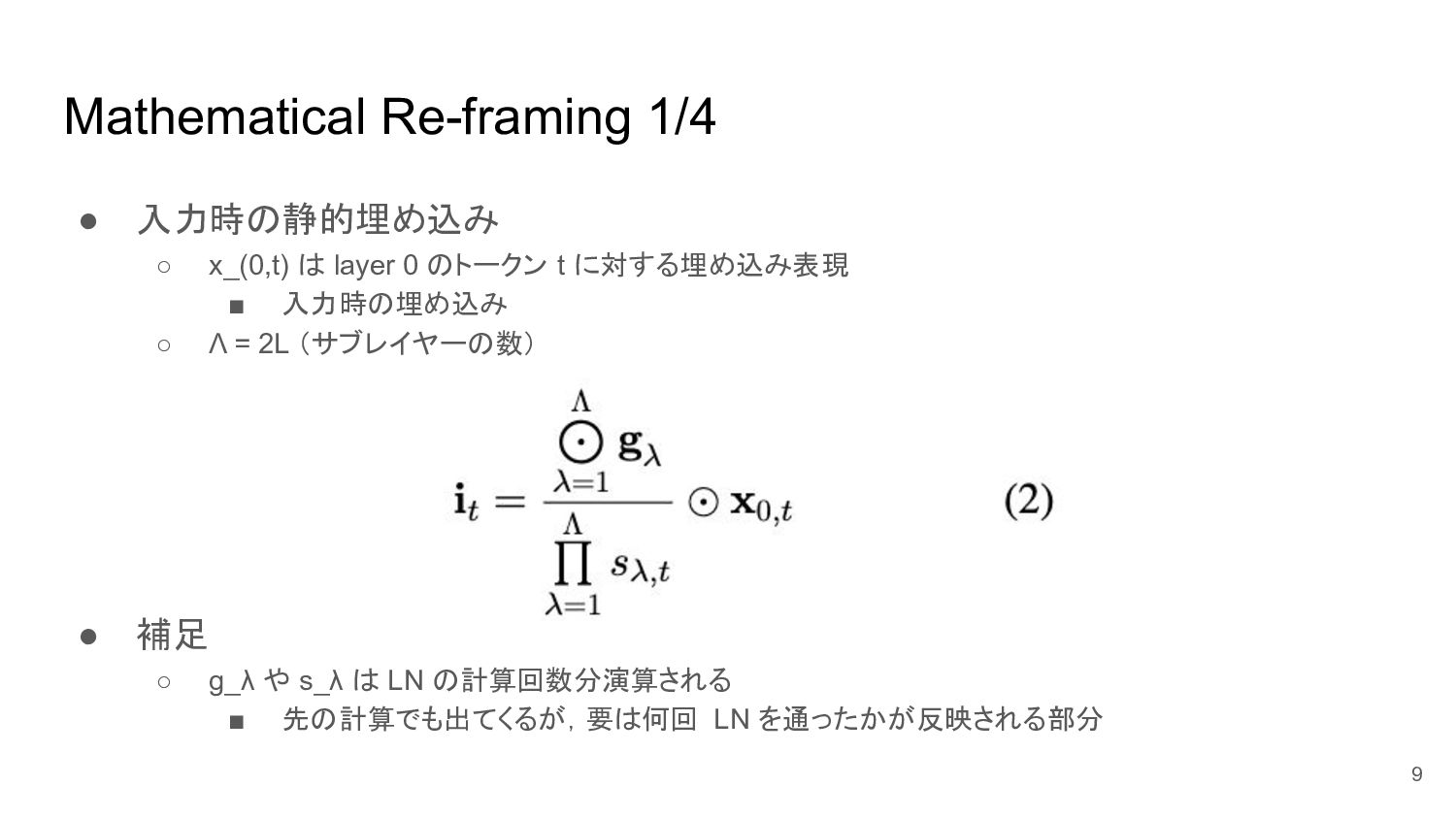
• 入力時の静的埋め込み ◦ x_(0,t) は layer 0 のトークン t に対する埋め込み表現
▪ 入力時の埋め込み ◦ Λ = 2L (サブレイヤーの数) • 補足 ◦ g_λ や s_λ は LN の計算回数分演算される ▪ 先の計算でも出てくるが,要は何回 LN を通ったかが反映される部分 Mathematical Re-framing 1/4 9
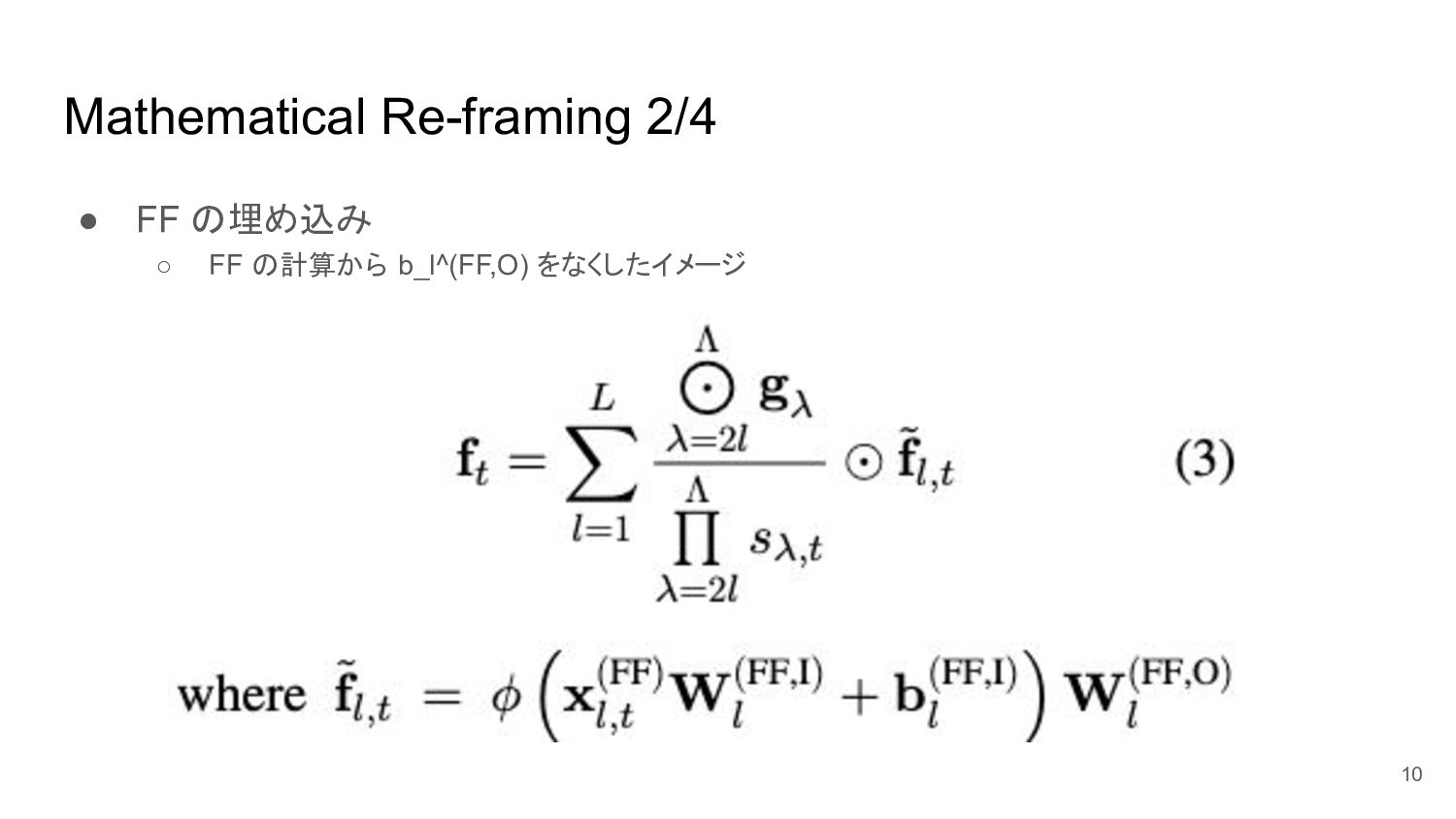
Mathematical Re-framing 2/4 • FF の埋め込み ◦ FF の計算から b_l^(FF,O)
をなくしたイメージ 10
Mathematical Re-framing 3/4 • MHA の埋め込み ◦ attention の重みにトークンとバリューの重み, MHAの重みをかけたイメージ
11
Mathematical Re-framing 4/4 • バイアス項 ◦ 以下の総和 i. LN でのバイアス
ii. 残差接続での平均 iii. MHA でのバイアス iv. FF でのバイアス 12
Additive structure in transformers (再掲) e_t : トークン t に対する埋め込み
i_t : 入力時の静的埋め込み h_t : MHA の埋め込み f_t : FF の埋め込み c_t : モデルのバイアス(上記以外) (数学的な導出は論文の付録に記載) 13
Limitations of equation(1) • 式(1)は各項が独立ではない • f_t 項が問題 ◦ 非線形関数があるためベクトルの線形合成として扱えない
▪ ブラックボックス ◦ f_t を最小2乗線形回帰として学習 ▪ 線形近侍の品質を r2スコアで測定 • 完全に近似はできない ▪ f_t 項は大事な役割を持つ • Transformerのレイヤーの可換性とサブレイヤーの追加 ◦ (1)式の分析を活用できる可能性 • 実際の研究に使えるかどうかはわからない ◦ 分解によって可能となる分析を紹介 14
Visualizing the contents of embeddings 1/4 • (1)式の4つの項のうちどの項が重要なのか? ◦ 以下の式に基づき項の重要度を計算
• モデル ◦ bert-base-uncased ◦ bert-base-NER-uncased (CONLL 2003 NER [Tjong Kim Sang and De Meulder, 2003] ) ◦ bert-base-uncased-squad2 (SQuAD v2 (Rajpurkar+, 2018) ) • データセット ◦ Europarl English section から10000 文を random sampling ◦ 10000 文の埋め込みを使って比較 15
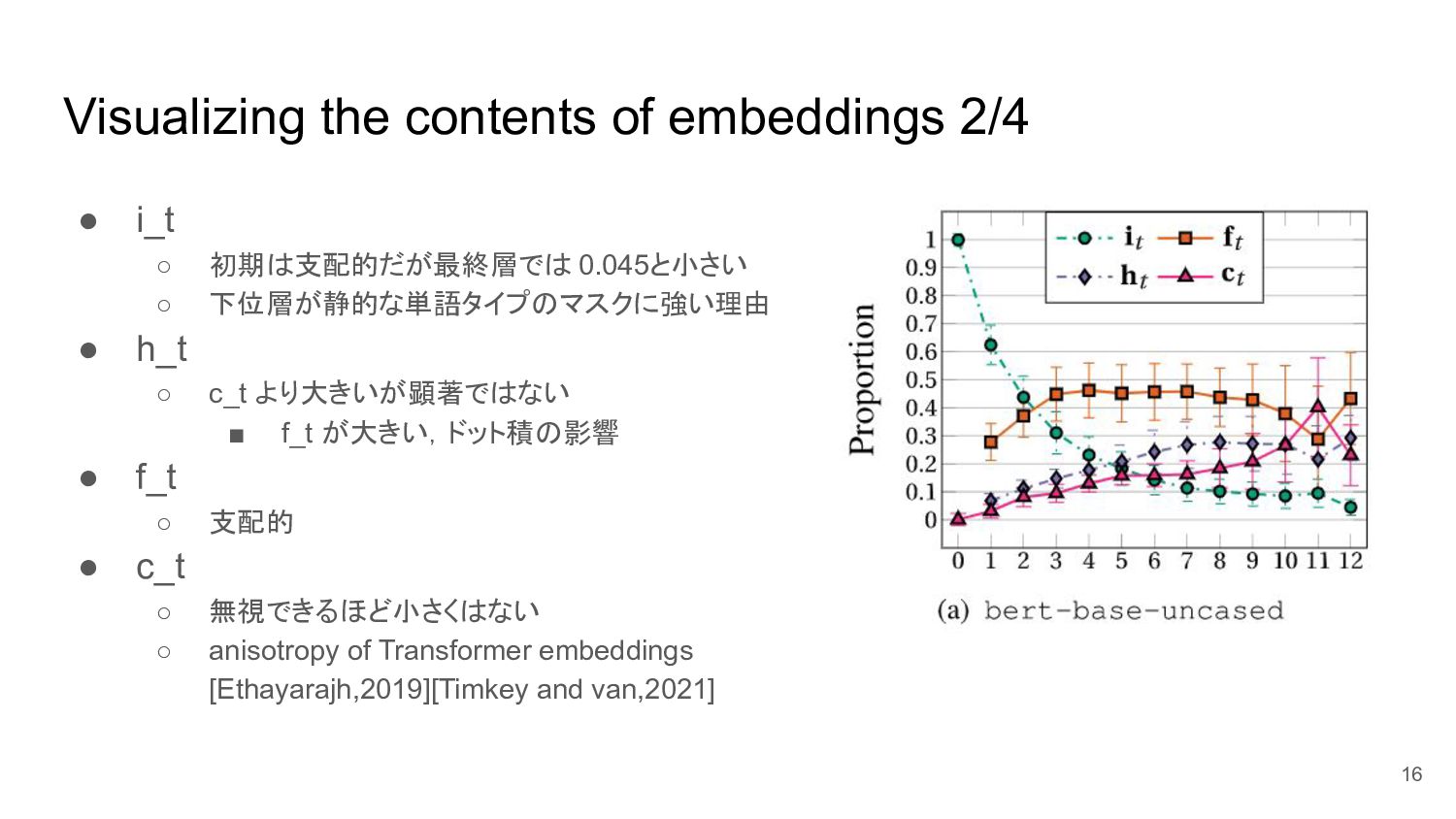
Visualizing the contents of embeddings 2/4 • i_t ◦ 初期は支配的だが最終層では
0.045と小さい ◦ 下位層が静的な単語タイプのマスクに強い理由 • h_t ◦ c_t より大きいが顕著ではない ▪ f_t が大きい,ドット積の影響 • f_t ◦ 支配的 • c_t ◦ 無視できるほど小さくはない ◦ anisotropy of Transformer embeddings [Ethayarajh,2019][Timkey and van,2021] 16
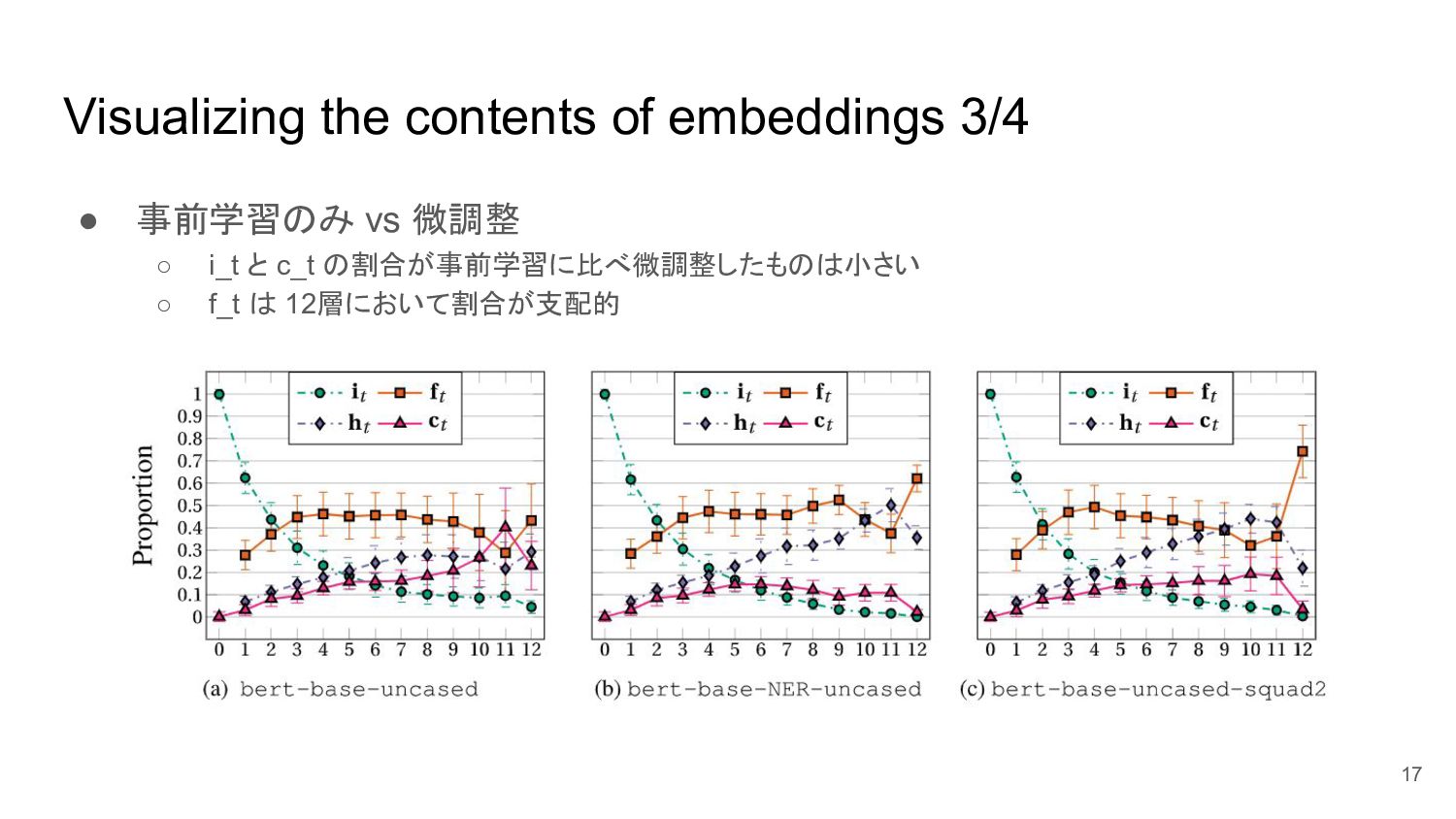
Visualizing the contents of embeddings 3/4 • 事前学習のみ vs 微調整
◦ i_t と c_t の割合が事前学習に比べ微調整したものは小さい ◦ f_t は 12層において割合が支配的 17
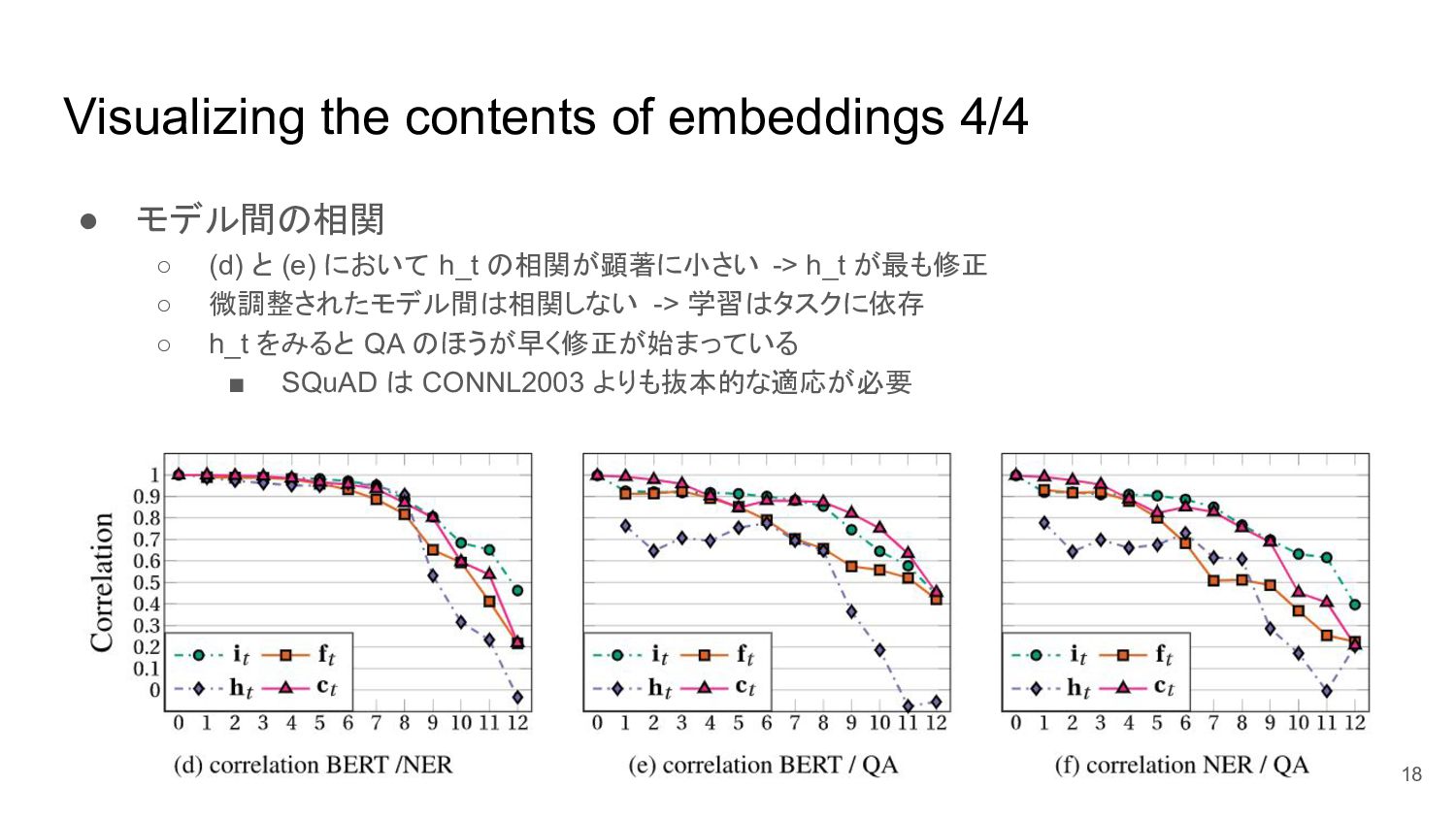
Visualizing the contents of embeddings 4/4 • モデル間の相関 ◦ (d)
と (e) において h_t の相関が顕著に小さい -> h_t が最も修正 ◦ 微調整されたモデル間は相関しない -> 学習はタスクに依存 ◦ h_t をみると QA のほうが早く修正が始まっている ▪ SQuAD は CONNL2003 よりも抜本的な適応が必要 18
The MLM objective 1/4 • どの項がトークンの予測に役立つか? ◦ ablation として4つの項の組み合わせを検証(全 16通り)
• モデル ◦ ベースライン:bert-uncased-base ◦ 比較モデル:カテゴリ分類を学習した bert • データセット ◦ Europarl のサンプルの15%の単語 ◦ 80%はマスク,10%はランダムなトークンに置換, 10%はそのまま ◦ train : valid : test = 8 : 1 : 1 19
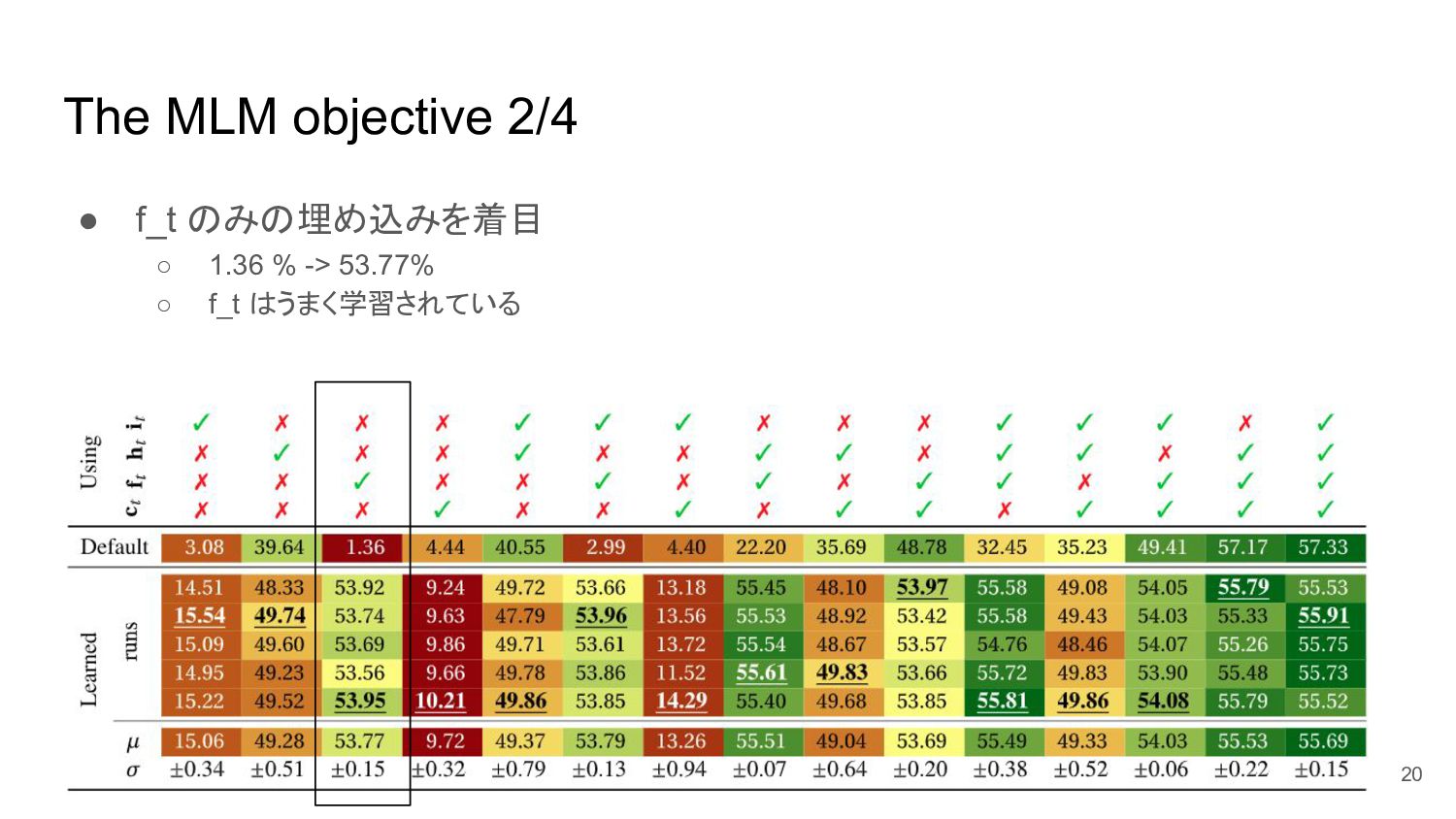
The MLM objective 2/4 • f_t のみの埋め込みを着目 ◦ 1.36 %
-> 53.77% ◦ f_t はうまく学習されている 20
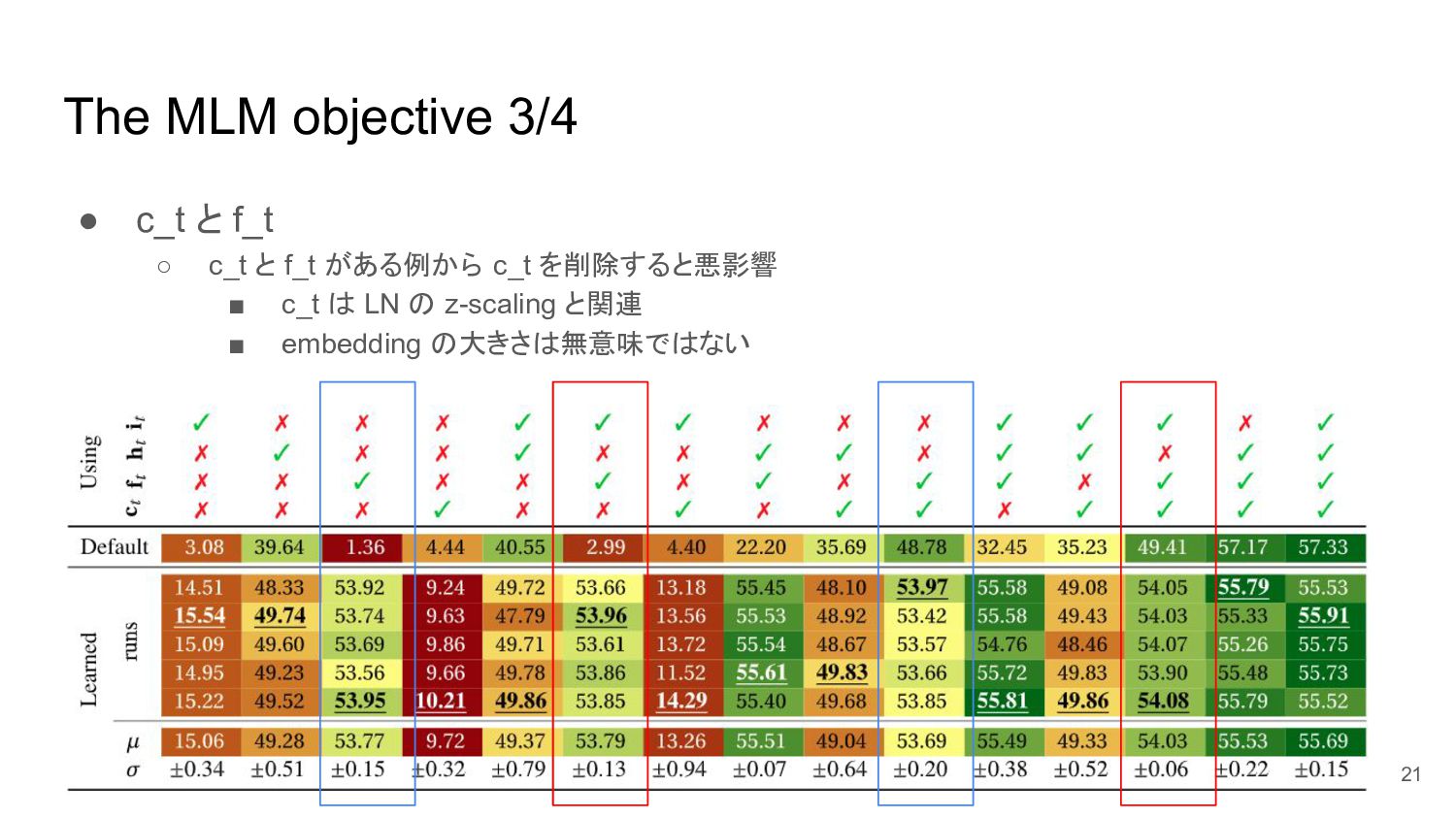
The MLM objective 3/4 • c_t と f_t ◦ c_t
と f_t がある例から c_t を削除すると悪影響 ▪ c_t は LN の z-scaling と関連 ▪ embedding の大きさは無意味ではない 21
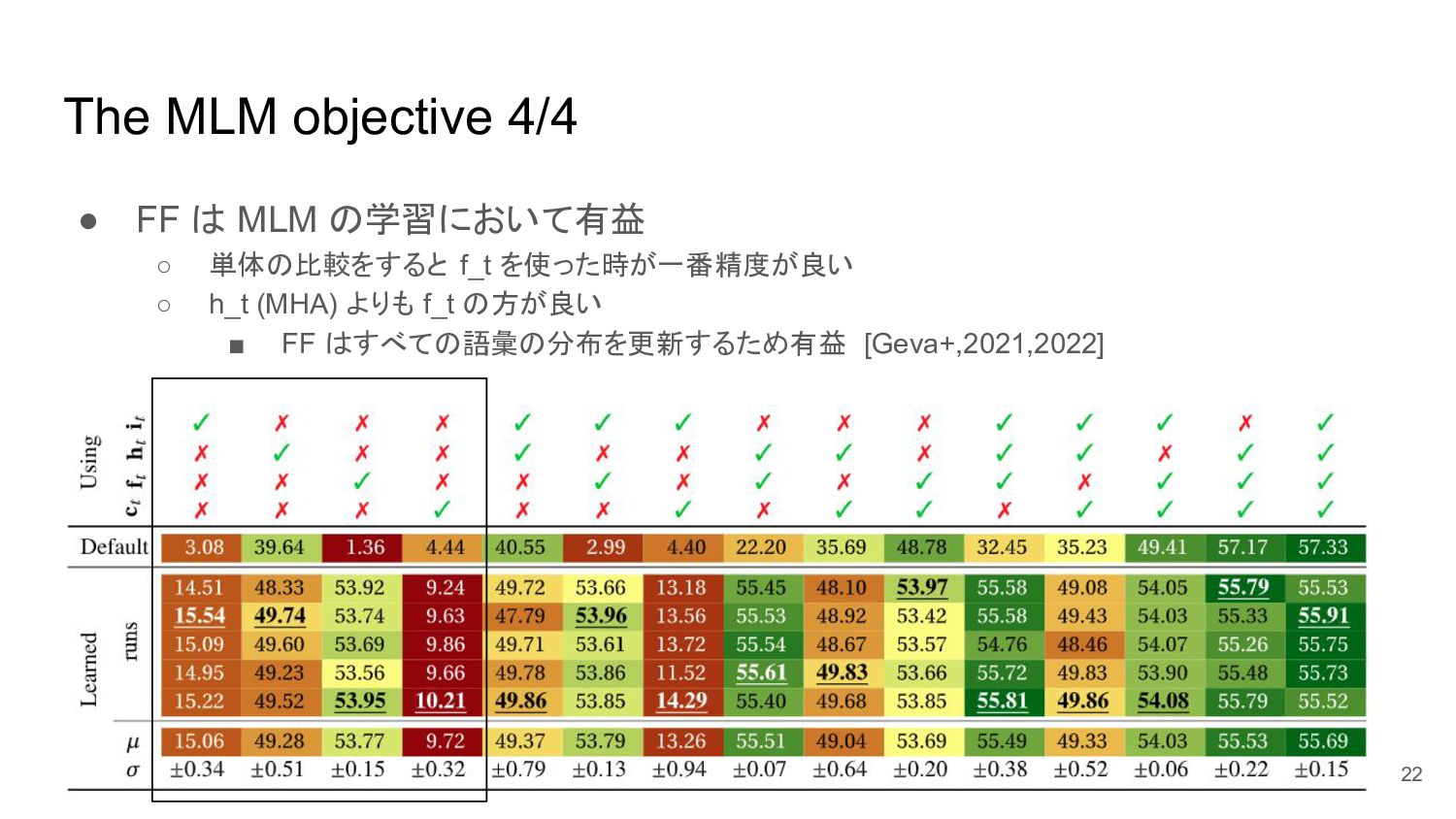
The MLM objective 4/4 • FF は MLM の学習において有益 ◦
単体の比較をすると f_t を使った時が一番精度が良い ◦ h_t (MHA) よりも f_t の方が良い ▪ FF はすべての語彙の分布を更新するため有益 [Geva+,2021,2022] 22
Lexical contents and WSD 1/3 • どの項が言語的に適切な空間を生み出すのか? ◦ WSD のタスクについて分析
◦ ablation として4つの項の組み合わせを検証(全 16通り) • モデル ◦ KNN [Wiedemann+,2019] ▪ 近傍を同じアノテーションのレンマを持つ単語に限定 ▪ コサイン距離を用いて k=5 を使用 ◦ probing [Du+, 2019] ▪ 2層 MLPを使用 • 第1層はすべての単語で共有で,第 2層はレンマ特有 • データセット ◦ NLTK Semcor [Landes+,1998][Bird+,2009] ◦ train : valid : test = 8:1:1 ◦ 単数または複数レンマを削除 ◦ 単語単位で和をとり1単語表現に変換 23
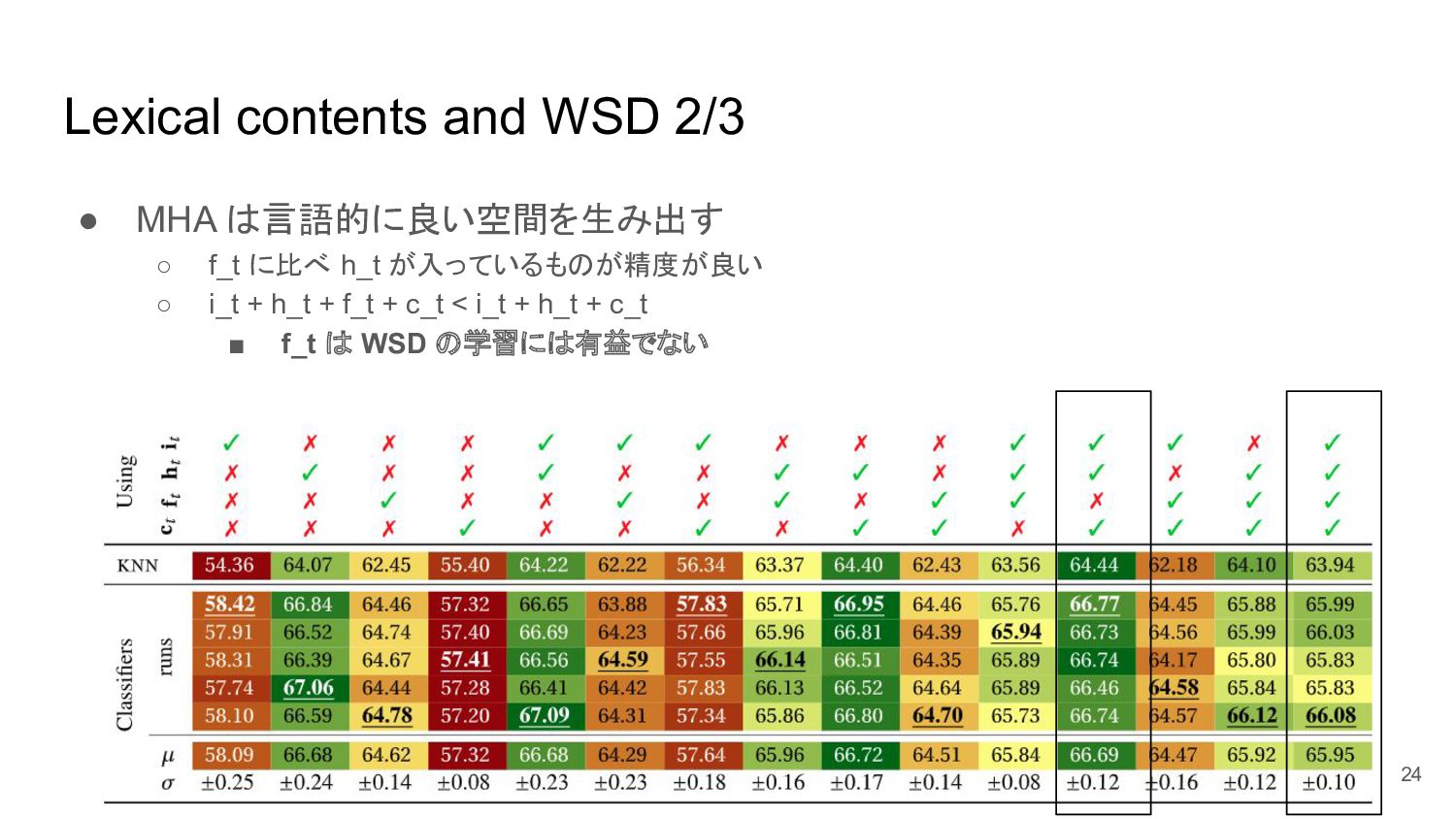
Lexical contents and WSD 2/3 • MHA は言語的に良い空間を生み出す ◦ f_t
に比べ h_t が入っているものが精度が良い ◦ i_t + h_t + f_t + c_t < i_t + h_t + c_t ▪ f_t は WSD の学習には有益でない 24
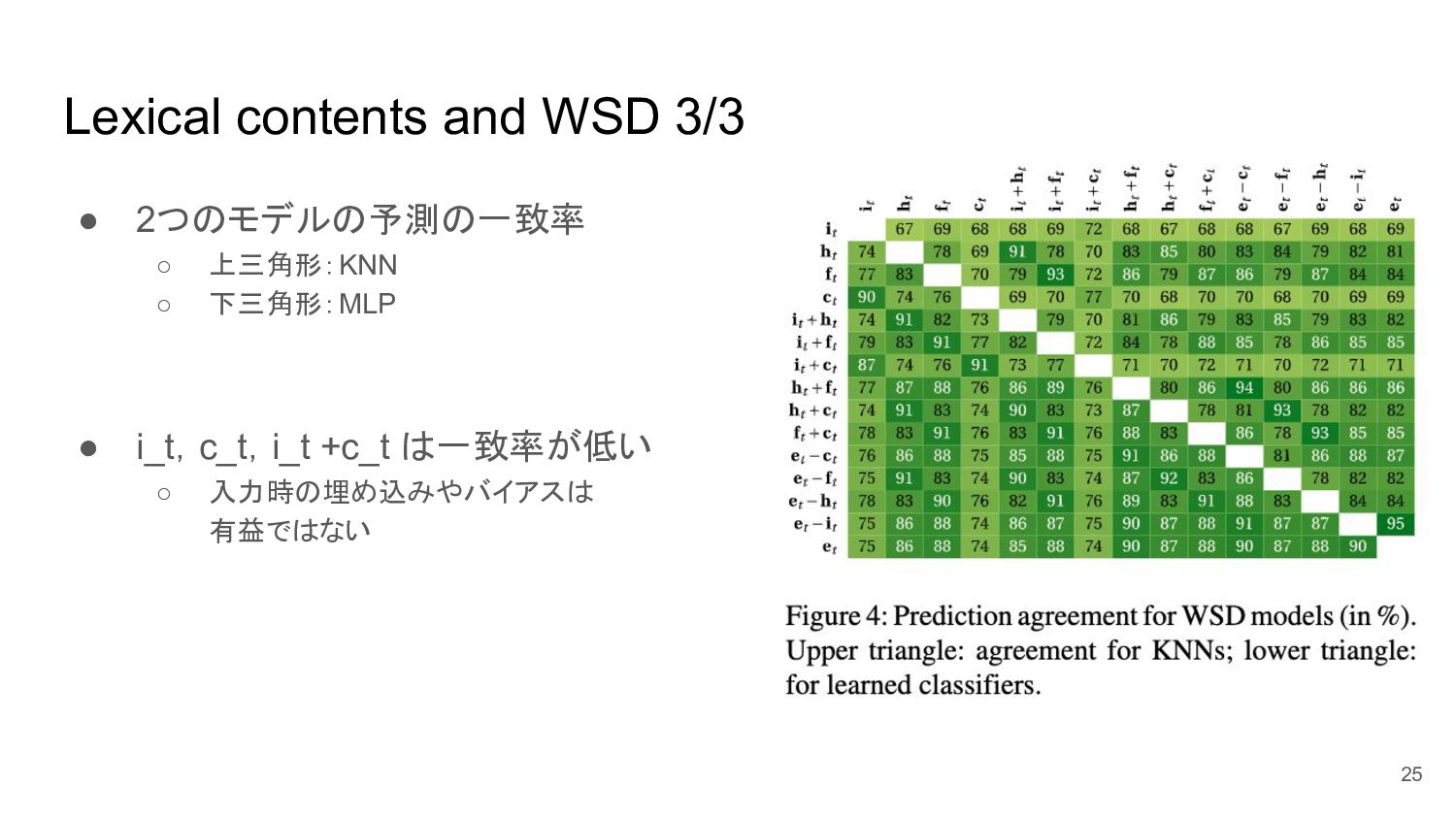
Lexical contents and WSD 3/3 • 2つのモデルの予測の一致率 ◦ 上三角形:KNN ◦
下三角形:MLP • i_t,c_t,i_t +c_t は一致率が低い ◦ 入力時の埋め込みやバイアスは 有益ではない 25
Effect of fine-tuning and NER 1/3 • 微調整後の各項の性質は? ◦ 学習はタスク依存なため網羅的には難しい
◦ ここでは NER での結果を報告 • モデル ◦ bert 事前学習のみ ◦ bert 事前学習+微調整 • データセット ◦ WNUT 2016 [Strauss+,2016] ▪ 50000 文程度の小規模 26
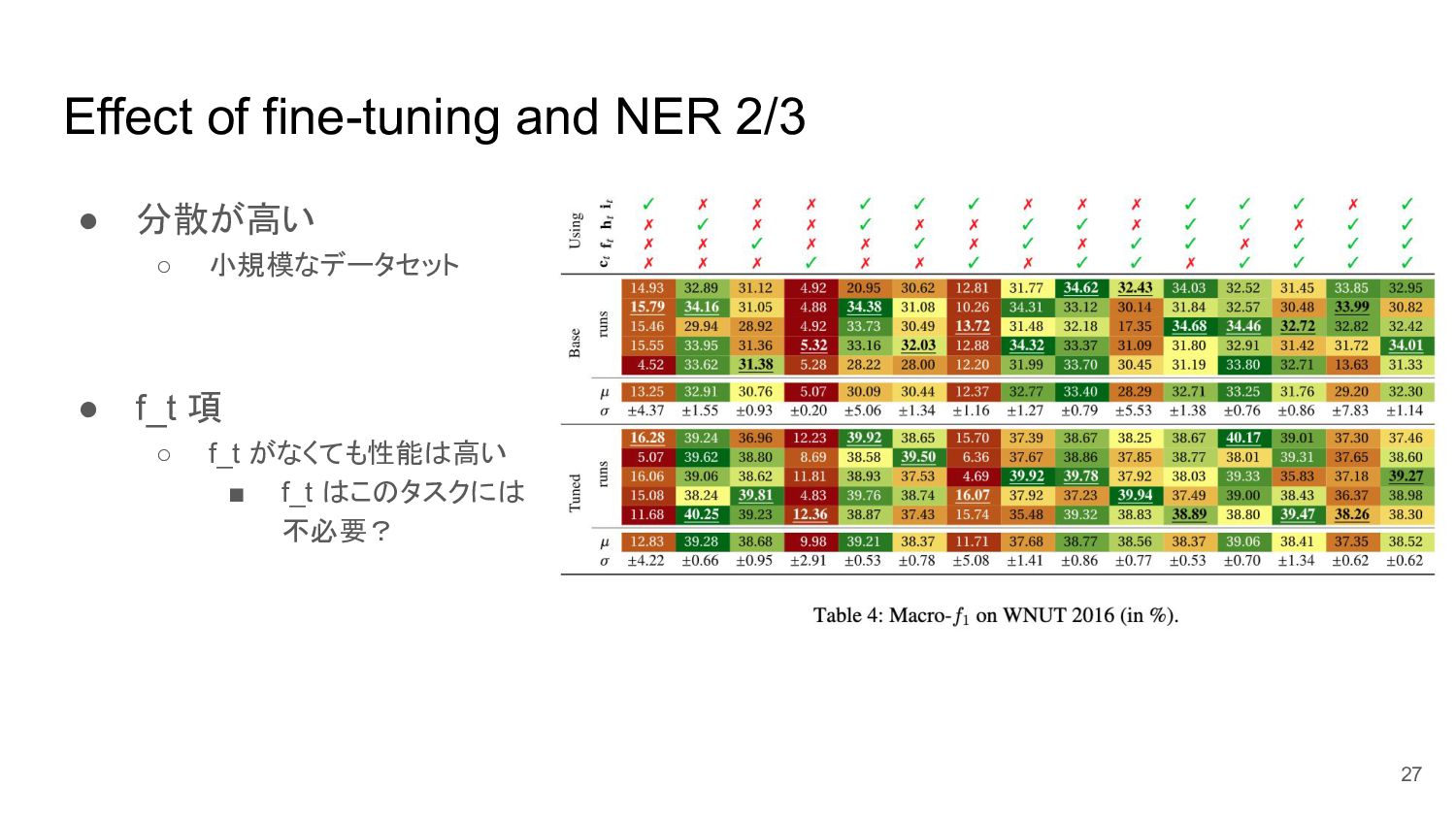
Effect of fine-tuning and NER 2/3 • 分散が高い ◦ 小規模なデータセット
• f_t 項 ◦ f_t がなくても性能は高い ▪ f_t はこのタスクには 不必要? 27
Effect of fine-tuning and NER 3/3 • 2つのモデルの予測の一致率 ◦ 上三角形:事前学習のみ
◦ 下三角形:微調整済み • i_t, c_t, i_t+c_t の挙動 ◦ 一致率がかなり低い ◦ FF や MHA が下流タスク特有に 28
Conclusions and future work • Transformer の埋め込みを分解し構成要素ごとの分析を行なった ◦ FF は
MLM の学習に有益 ◦ MHA は WSD や NER などのタスクに有益 • 今後の展望 ◦ (1)式の拡張 ▪ より細かい粒度や別の観点からの分解 ◦ 今後の Transformer の分析に用いる 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}