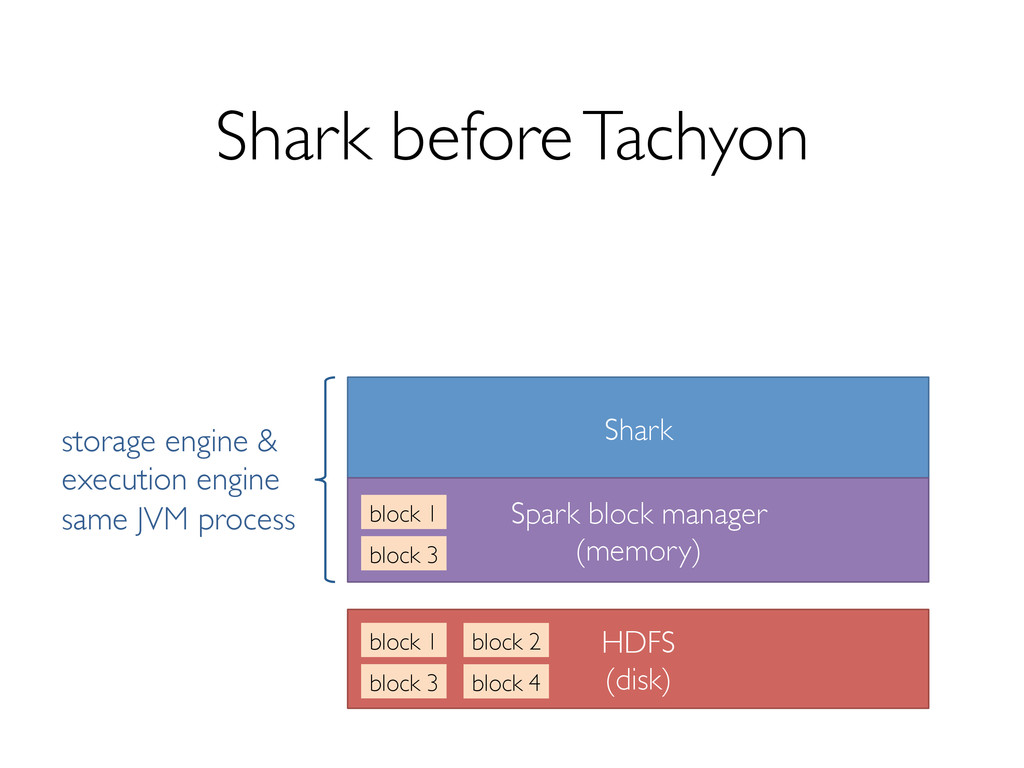
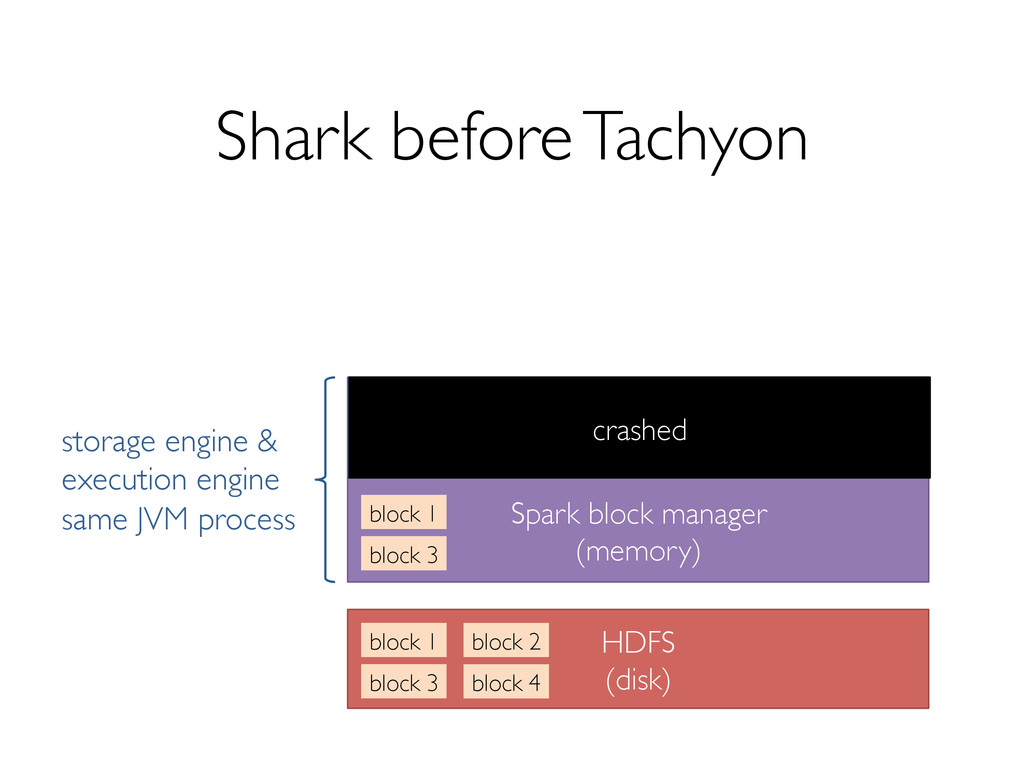
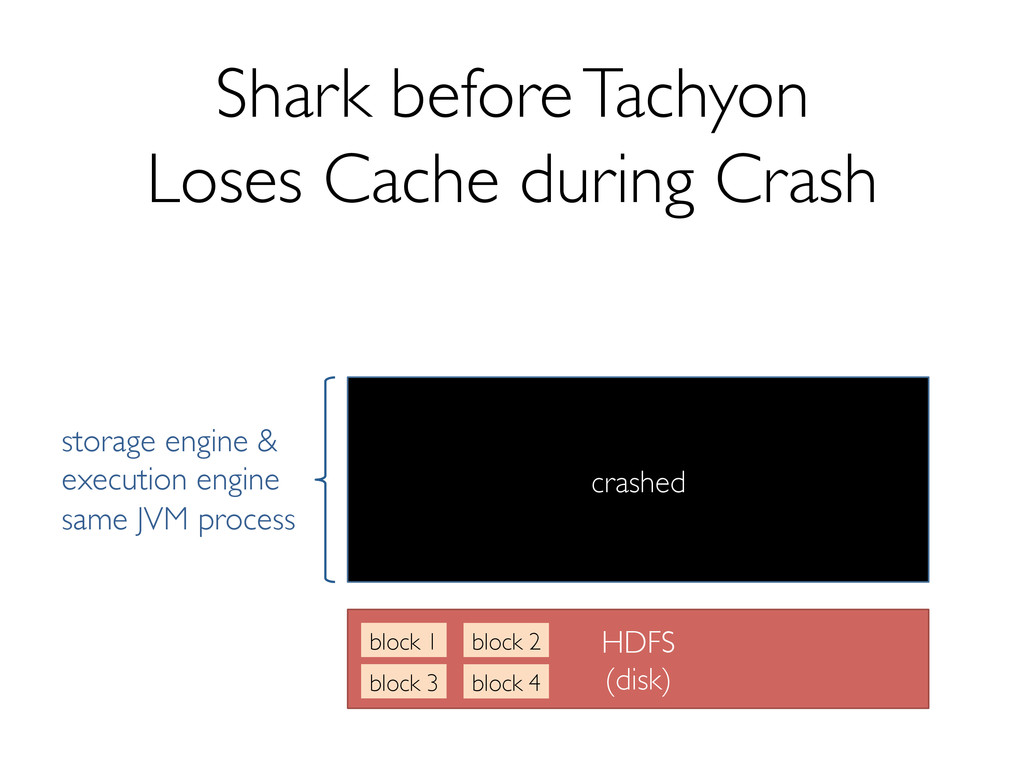
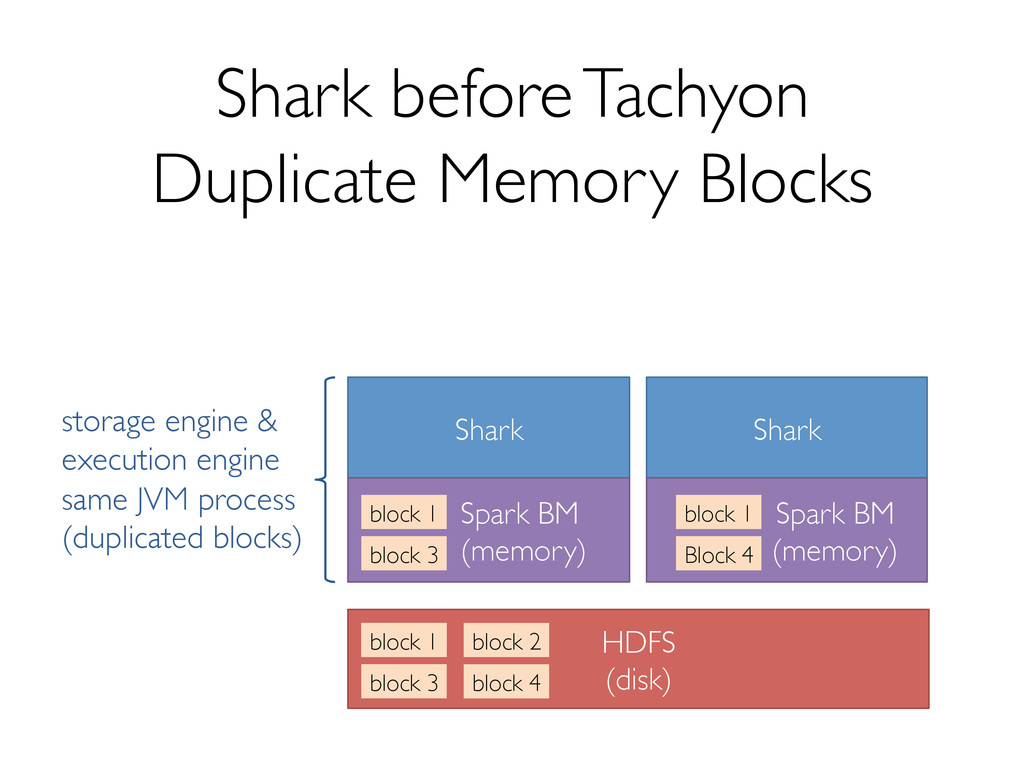
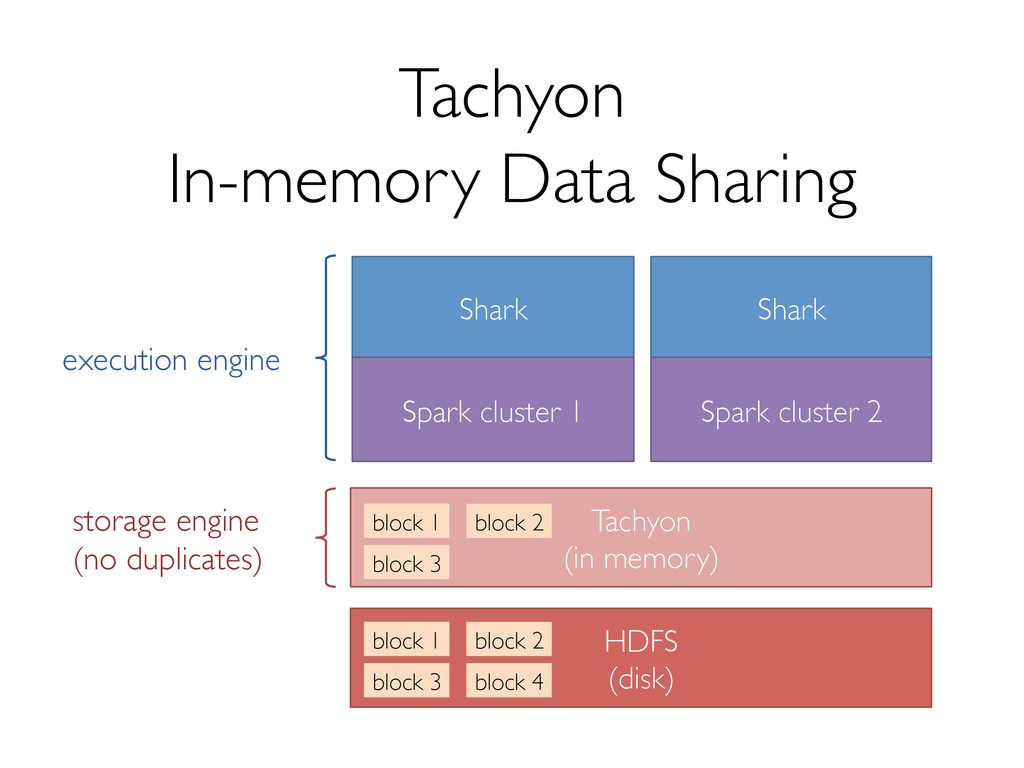
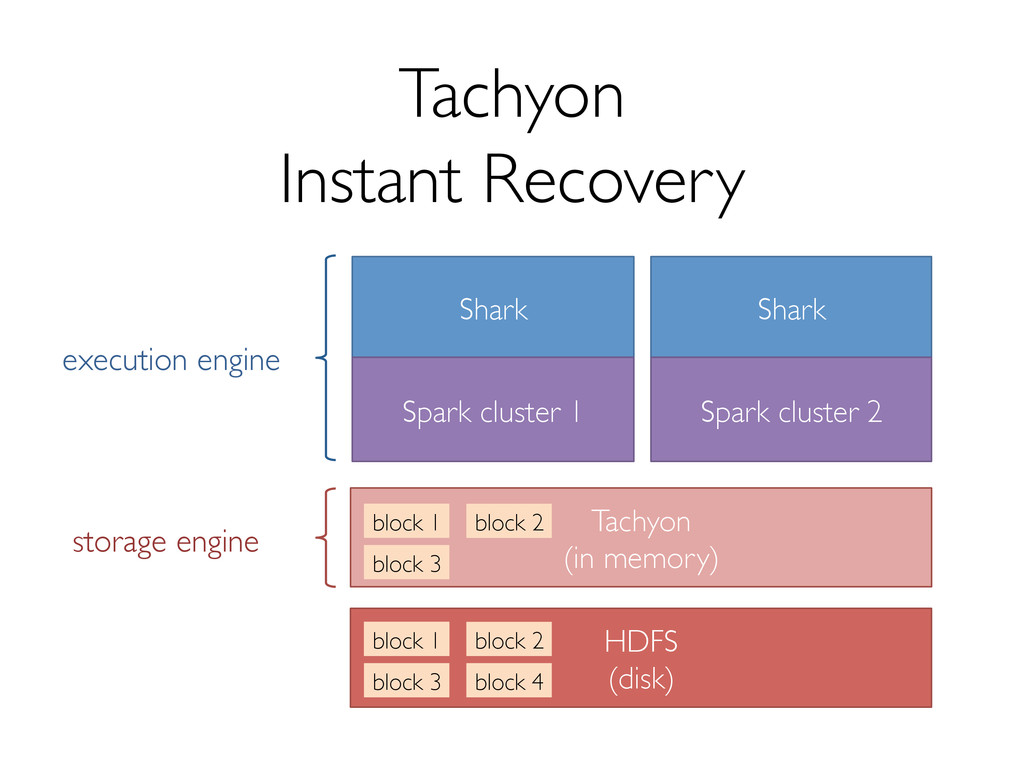
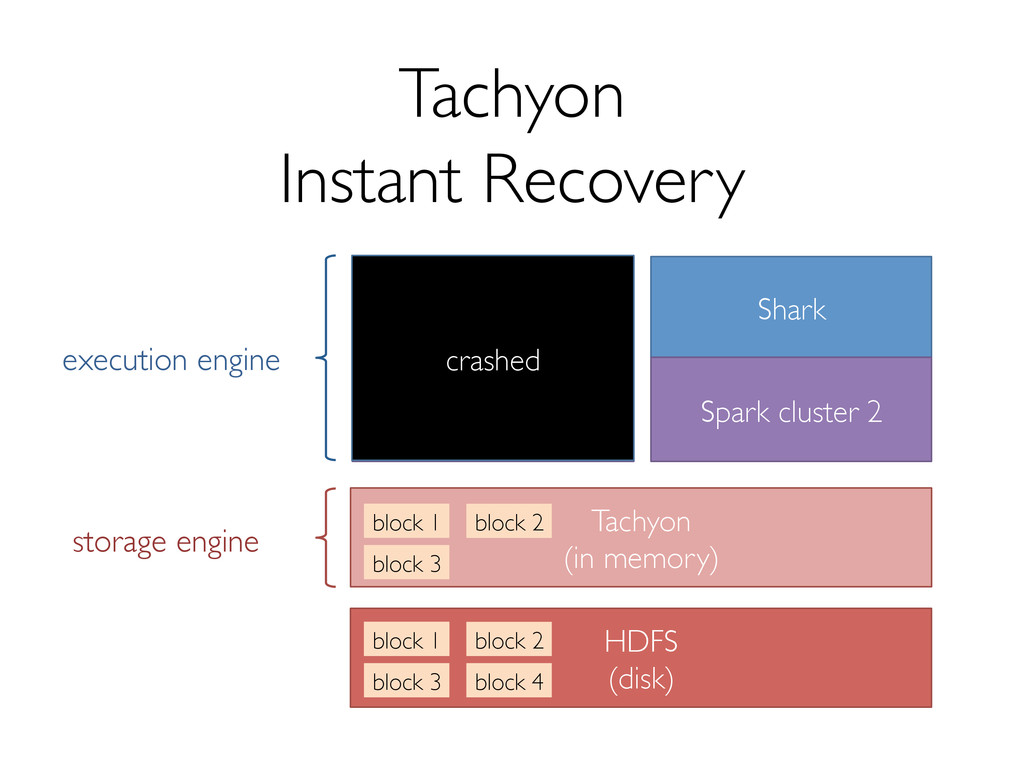
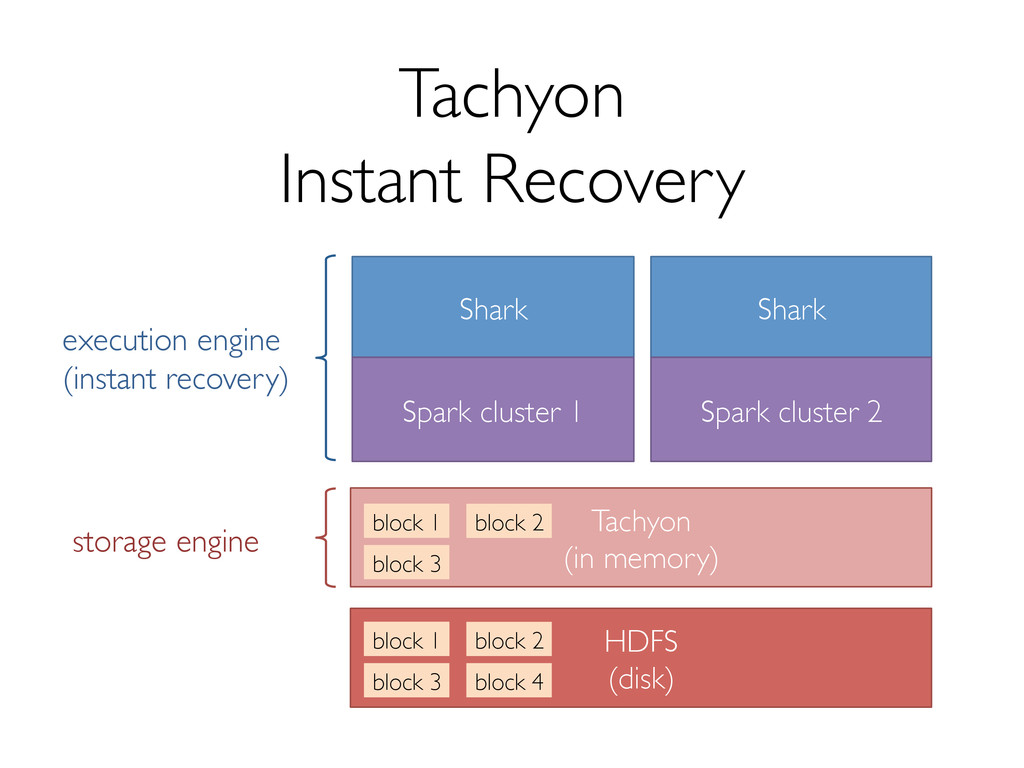
Shark has seen several key changes in the past few months. One of the major ones is a new storage format to support efficiently reading data from Tachyon, which enables data sharing and isolation across instances of Shark. In addition, we're making several optimizations to both Shark and Spark that promise significant performance boosts.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}