Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
増え続けるトランザクションデータと向き合う
Search
nakaryo
December 23, 2020
Technology
550
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
増え続けるトランザクションデータと向き合う
RDBで増えていくデータについて、事前にどういうことが考えられるか、増えた時にどういう手段が取れるかについて。
nakaryo
December 23, 2020
More Decks by nakaryo
See All by nakaryo
エラー処理の温故知新 / history of error handling technic
ryotanakaya
7
2.1k
Ruby で gRPC を使おう / ruby-grpc
ryotanakaya
1
150
ギフティの技術ブログ 再出発とこれから / restart of giftee tech blog 2024
ryotanakaya
0
370
再利用パターン / Pattern of code reuse
ryotanakaya
0
210
エンジニアリングエッセイのススメ
ryotanakaya
0
520
ソフトウェアアーキテクチャについて 語るときに 僕の語ること
ryotanakaya
2
1.7k
エンジニアと要件定義
ryotanakaya
4
1.2k
Go と並行処理
ryotanakaya
0
420
ワクワク!Rubyクイズ!!
ryotanakaya
0
1.6k
Other Decks in Technology
See All in Technology
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
190
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
kaonavi Tech Night#1
kaonavi
0
150
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
360
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
590
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
850
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
300
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
230
OPENLOGI Company Profile for engineer
hr01
1
74k
Featured
See All Featured
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Believing is Seeing
oripsolob
1
170
Paper Plane
katiecoart
PRO
2
52k
Agile that works and the tools we love
rasmusluckow
331
22k
The Spectacular Lies of Maps
axbom
PRO
1
870
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Making the Leap to Tech Lead
cromwellryan
135
10k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Statistics for Hackers
jakevdp
799
230k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Transcript
増え続ける トランザクションデータと向き 合う By Nakaya Ryota 2020/12/23
自己紹介 ギフティ入社:2019年1月 所属:CC Div. ProductUnit2 前職:バックオフィス系のパッケージベンダー(上流工程メイン) 好きなスタバメニュー:スターバックスラテ 最近は Go より
Ruby 書いてる インフラも頑張りたい
みなさん RDBで増えすぎたレコードの管理って どうしてますか?
(スキーマ変更したいけど、データ多すぎて安全に alter table かけら れないな...) 僕「古いデータ消してもいいですか」 顧客「物理削除は困っちゃうよねえ、監査とかあればデータ出さな いといけないし。論理削除ならいいんじゃない?」 僕「そうっすよねえ、はは」
None
そもそもデータの削除って 何を元に意思決定すればいいんだっけ...?
トランザクションデータとは トランザクションデータとは、企業の情報システムなど が扱うデータの種類の一つで、業務に伴って発生した 出来事の詳細を記録したデータのこと。 (IT用語辞典)
データは過去から未来に向かって 増え続ける(自明の理)
データが増えすぎると RDBMS では一般的に以下のような問題が起こる • パフォーマンス劣化 • チューニング性劣化する • スキーマ変更にかか るコストの増大
RDBMS 以外でも問題は起こる • 記憶媒体(ハードディスク)の限界 • アプリケーションサーバーでの意図せぬメモリ圧迫 • select all したら100万行釣れちゃったてへぺろ
データが増えすぎると データベースのスケーラビリティをあらかじめ検討して おかないと、気づいた時にはメンテ不可能になってい るかもしれない きちんと正規化して index を張ってあっても、大規模 テーブルのスキーマ変更をダウンタイムなしで行うの はハードルが高い
じゃあどうすれば...?
データが増えすぎる前に できることを考える
データが増えすぎる前に このデータがいつ作られるのかだけでなく いつ消されるのか(消してもいいのか)も 検討した方が良い ※ 「消す」というのは無効化のことではなくその名の通り削除を表しています
データが増えすぎる前に この世の中には大きく二種類のデータがある • 法定保存文書を電子化したもの • それ以外
データが増えすぎる前に この世の中には大きく二種類のデータがある • 法定保存文書を電子化したもの →法律で保存期間が決められている • それ以外 →保存期間に関する公的な制約がない
法定保存文書とは、 法律で文書の保存が義務付けられており、その保存 期間も決められた文書のこと データが増えすぎる前に
データが増えすぎる前に 法定保存文書の例 • 株主名簿(永年) • 取締役会議事録(10年以上) • 取引に関する帳簿(7年以上) • 仕訳帳、現金出納帳、売掛帳、買掛帳など
• 決算に関して作成された書類(7年以上) etc refs: https://www.storage-channel.jp/blog/legal-document-retention-period.html
以前は必ず紙での保管、提出が義務付けられていた が、近年は法定文書を電子化する動きが活発 データが増えすぎる前に
普段はアクセスされることはないが、 監査の際に開示することが法律的に求められる データが増えすぎる前に (注:画像はイメージです)
開示ができなかったりすると最悪捕まります データが増えすぎる前に (注:画像はイメージです)
どのデータが法定文書に当たるのかは、ケースバイ ケースなので、事前に法務担当者としっかりチェックし ましょう ※ 会計システムに連携済みであったとしても、 raw データを証跡として求められることは全然ある(らしい) データが増えすぎる前に
法定文書以外のデータは どうすればいいの...??
法定文書以外のデータは保護期間を自由に決められ る (法律的にはなんの制約もないので、別に保護しなくてもいい) データが増えすぎる前に
とは言え フリーダムだと判断基準がなくて困るので
SaaS サービスを提供する場合、 SLA(Service Level Agreement)、利用規約によって データの管理方法を定めるのが一般的 データが増えすぎる前に
データが増えすぎる前に 経産省が公開している SaaS 向け SLA ガイドライン https://www.meti.go.jp/policy/netsecurity/secdoc/contents/downloadfils/080121saasgl.pdf
データが増えすぎる前に 経産省が公開している SaaS 向け SLA ガイドライン https://www.meti.go.jp/policy/netsecurity/secdoc/contents/downloadfils/080121saasgl.pdf
データが増えすぎる前に データ消去の要件として、 ゴミデータ(古いトランザクション)の取り扱いを定義しておく
要件定義をする際に、非機能要件として • 性能要件 • セキュリティ要件 みたいなものを定義すると思うんですけど、 その一項目として議論するイメージ データが増えすぎる前に
アプリケーションとして必要なデータの定義、不要だと みなせるデータの定義ができていれば、 例えばバッチ処理などで定期的に古いデータを削除/ 退避するなどして、データベースがハイパフォーマンス な状態を維持できる(かもしれない) データが増えすぎる前に
(スキーマ変更したいな、マイグレーション実行や...!!) 僕「古いデータ消してもいいですか」 顧客「物理削除は困っちゃうよねえ、監査とかあればデータ出さな いといけないし。論理削除ならいいんじゃない?」 僕「そうっすよねえ、はは」 そもそもこんな議論が必要ない (かもしれない)
データが増え過ぎちゃった時に できることを考える
データは過去から未来に向かって 増え続ける(2回目)
広がってもせいぜい アイビーリーグまでだ ろ... この設計でヨシッ! (注:筆者はマークのことが大好きです)
2019年時点での facebook のユーザー数
27億
設計時点で未来のトランザクションの ことなんてわからん (っていうか明日何が起こるかもわからんこの御時世 )
未来はわからないけど データが増えすぎちゃった時に 取れる行動を考えておくことはできる
何も考えずに物理的にデータを削除する • DELETE クエリを発行して、記憶媒体からデータを削除する • 削除する量にもよるが、物理削除してデフラグ、インデックスツ リーの更新まで完了すればパフォーマンス的にポジティブな改善 が見られる可能性が高い • 復元不可能なので、選択肢としては現実的ではない
データが増えすぎちゃった時に
古いデータをアーカイブする • ある基準でデータを退避して、アプリケーションからは必要な データのみを扱えるようにする • 古いかどうかはアプリケーションの要件によって決まる • もう参照も更新もしないよ、とか • アーカイブのやり方は色々あって、アーカイブテーブルを作って
退避したり、データベースダンプファイルを作ったり • いづれにせよ大元のテーブルからは物理削除する データが増えすぎちゃった時に
物理設計を見直す • secondary index の設計 • DBのテーブルを水平分割する(horizontal partitioning) • DBのテーブルを垂直分割する(vertical
partitioning) データが増えすぎちゃった時に(というか設計時に)
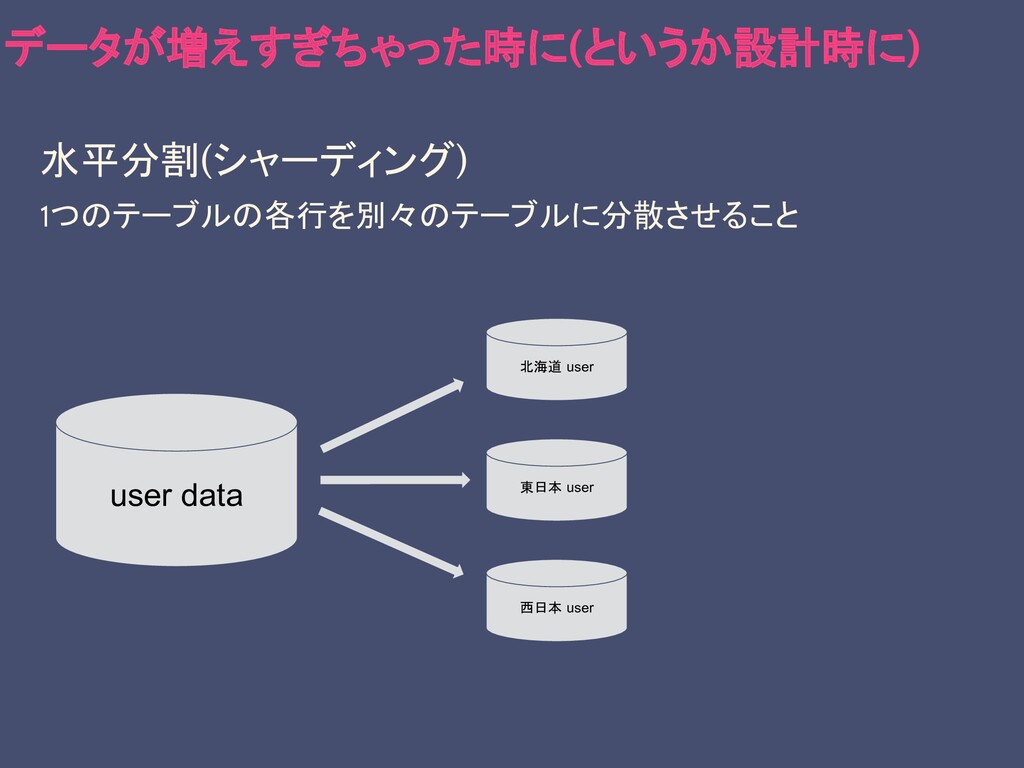
水平分割(シャーディング) 1つのテーブルの各行を別々のテーブルに分散させること データが増えすぎちゃった時に(というか設計時に) user data
水平分割(シャーディング) 1つのテーブルの各行を別々のテーブルに分散させること データが増えすぎちゃった時に(というか設計時に) 北海道 user 東日本 user 西日本 user user
data
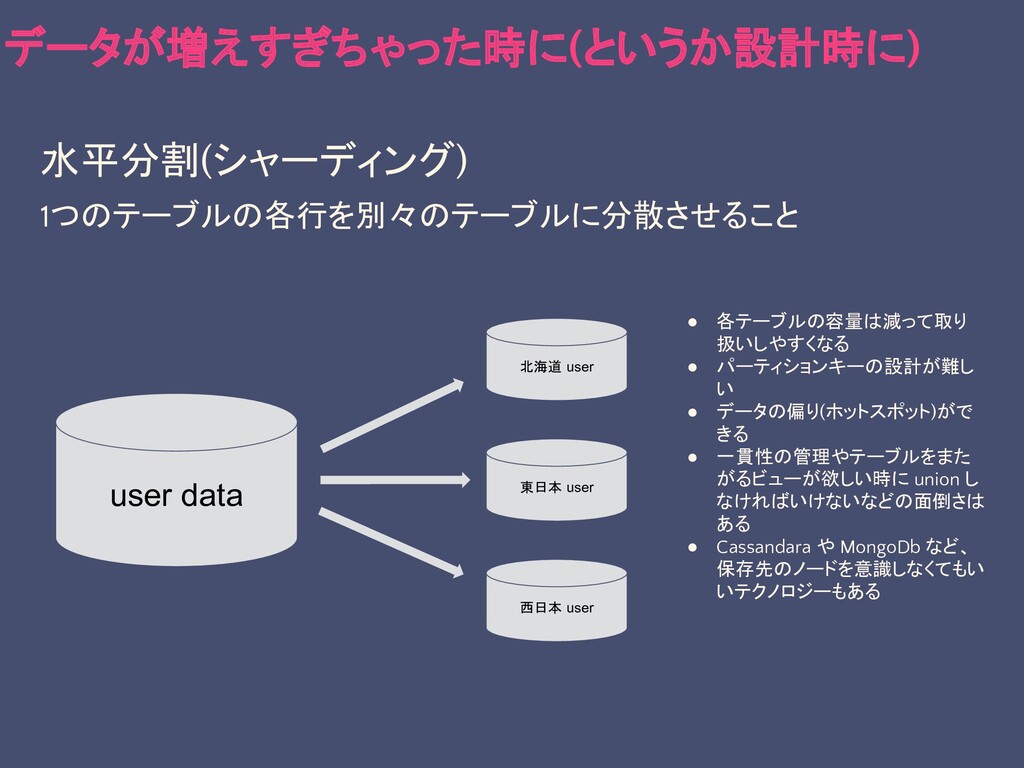
水平分割(シャーディング) 1つのテーブルの各行を別々のテーブルに分散させること • 各テーブルの容量は減って取り 扱いしやすくなる • パーティションキーの設計が難し い • データの偏り(ホットスポット)がで
きる • 一貫性の管理やテーブルをまた がるビューが欲しい時に union し なければいけないなどの面倒さは ある • Cassandara や MongoDb など、 保存先のノードを意識しなくてもい いテクノロジーもある データが増えすぎちゃった時に(というか設計時に) 北海道 user 東日本 user 西日本 user user data
垂直分割 テーブルの一部の列だけを抜き出す形で分割を行う データが増えすぎちゃった時に(というか設計時に) serial_number available_until message balance 111…. 2020/XX/YY happy
birthday 500 999... 2020/XX/YY happy new year 200
垂直分割 テーブルの一部の列だけを抜き出す形で分割を行う データが増えすぎちゃった時に(というか設計時に) serial_number available_until message balance 111…. 2020/XX/YY happy
birthday 500 999... 2020/XX/YY happy new year 200 serial_number available_until message 111…. 2020/XX/YY happy birthday 999... 2020/XX/YY happy new year serial_number balance 111…. 500 999... 200
垂直分割 テーブルの一部の列だけを抜き出す形で分割を行う データが増えすぎちゃった時に(というか設計時に) serial_number available_until message balance 111…. 2020/XX/YY happy
birthday 500 999... 2020/XX/YY happy new year 200 serial_number available_until message 111…. 2020/XX/YY happy birthday 999... 2020/XX/YY happy new year serial_number balance 111…. 500 999... 200 • よくあるのは列の内容の利用頻度によって分割するもの • この例だと、balance の更新でテーブルをロックしても、message などの表示のための select が待たされることはなくなる • 巨大な可変長カラム(BLOB、VARCHAR、および TEXT )は、脳死し て select * すると不要にメモリを圧迫しかねないので、切り出して おくというのもあり
NoSQLなどスケーラビリティの高いテクノロジーを採用 する • スキーマ変更も容易 • スキーマレス、列志向 • データ量が増えても select のパフォーマンスが劣化しづらい
• KVS なら 1億件あっても釣るのはほぼ一瞬(らしい) データが増えすぎちゃった時に(というか設計時に)
安全で楽しいデータライフを
~Fin~
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}