Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
少人数PJにおける MLOps事例
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Yamaguchi Toshihiro
October 11, 2021
Technology
940
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
少人数PJにおける MLOps事例
Yamaguchi Toshihiro
October 11, 2021
Other Decks in Technology
See All in Technology
OPENLOGI Company Profile for engineer
hr01
1
74k
穢れた技術選定について
watany
19
6k
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
200
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
320
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
900
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
210
そのドキュメント、自動化しませんか?
yuksew
1
390
現場との対話から始める “作る前に問い直す”業務改善
mochico50
1
170
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.2k
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
400
Featured
See All Featured
Six Lessons from altMBA
skipperchong
29
4.3k
Mind Mapping
helmedeiros
PRO
1
290
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
380
The Invisible Side of Design
smashingmag
301
52k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
270
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Transcript
少人数PJにおける MLOps事例 日本経済新聞社 山口敏弘 2021/09/17
本日話す内容 • 推薦システム • Databricksについて • 開発・運用上の問題 • Databricksによる実装例 •
Q&A ◦ Q. MLFlowでモデルの学習に利用したデータもトラッキングできますか? ◦ A. DeltaLakeのスナップショット機能を利用すれば可能です。
推薦システムの概要 • 目的 ◦ アプリに配信した記事のクリック率の向上 • 推薦アイテム ◦ 発行されてから1日以内の記事 ◦
1ユーザーに20ほど推薦する • 学習データ ◦ 記事 ▪ 記事ID、タイトル、本文、発行日時 ... ▪ API経由で1時間に1回取得 ◦ ユーザーの行動ログ ▪ ユーザーID、記事ID、クリックしたかどうか ... ▪ Kinesis Streamingから都度取得 -> ユーザーの行動を素早く推薦に反映させたい • モデル ◦ ロジスティック回帰 ◦ クリックするを1、しないを0としてユーザー毎に各記事をクリックするか推測
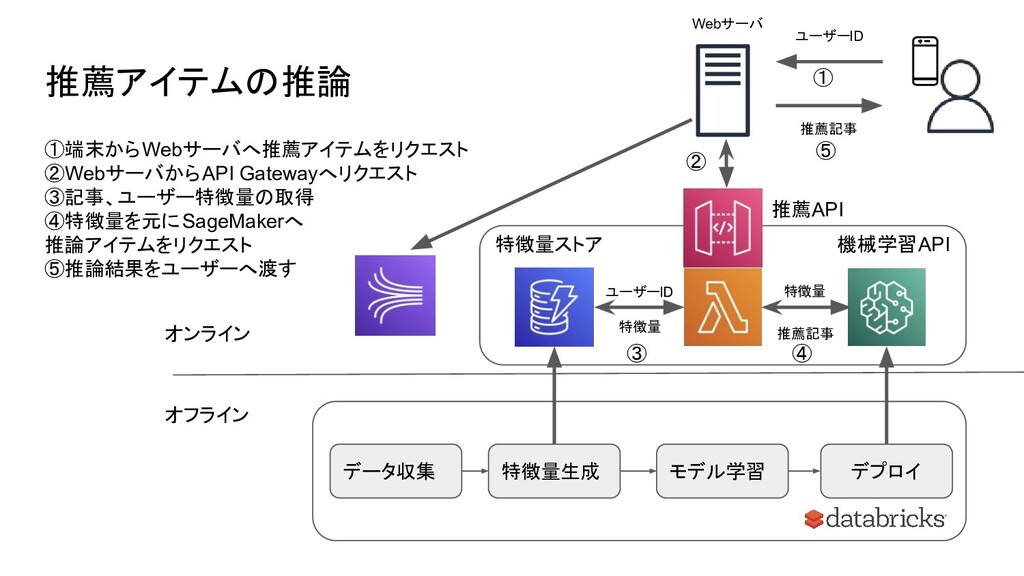
推薦アイテムの推論 Webサーバ ユーザーID 推薦記事 推薦API 機械学習API 特徴量ストア データ収集 特徴量生成 モデル学習
デプロイ ① ② ③ ④ ①端末からWebサーバへ推薦アイテムをリクエスト ②WebサーバからAPI Gatewayへリクエスト ③記事、ユーザー特徴量の取得 ④特徴量を元にSageMakerへ 推論アイテムをリクエスト ⑤推論結果をユーザーへ渡す ⑤ 推薦記事 ユーザーID 特徴量 特徴量 オンライン オフライン
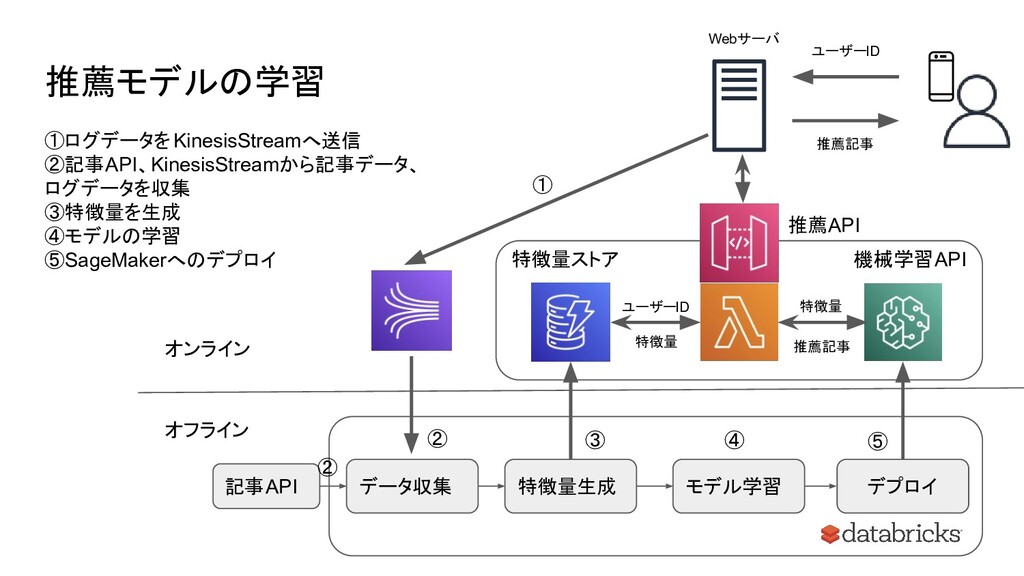
推薦モデルの学習 Webサーバ ユーザーID 推薦記事 推薦API 機械学習API 特徴量ストア データ収集 特徴量生成 モデル学習
デプロイ ① ② ③ ④ 推薦記事 ユーザーID 特徴量 特徴量 オンライン オフライン 記事API ①ログデータをKinesisStreamへ送信 ②記事API、KinesisStreamから記事データ、 ログデータを収集 ③特徴量を生成 ④モデルの学習 ⑤SageMakerへのデプロイ ⑤ ②
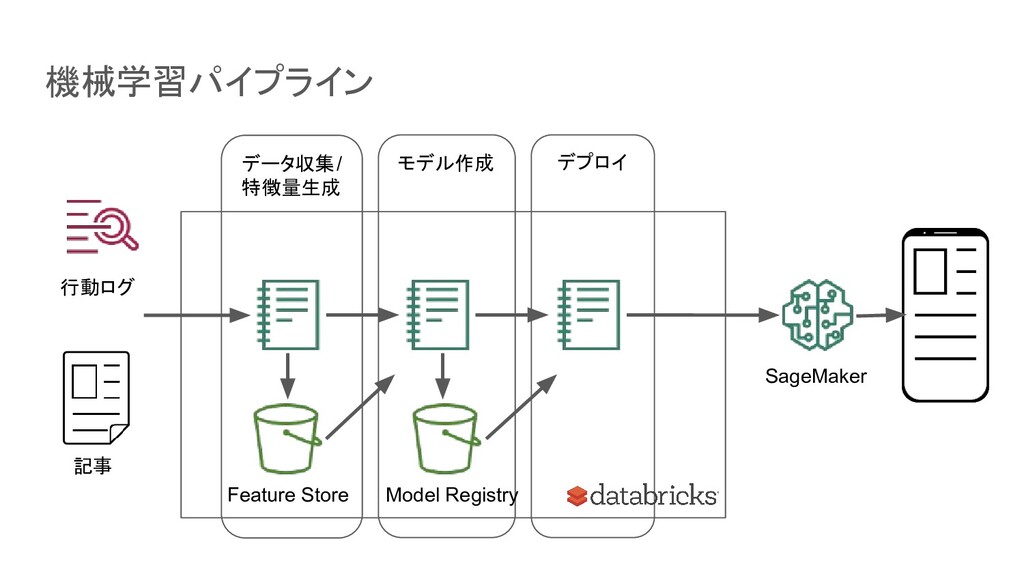
データ収集/ 特徴量生成 機械学習パイプライン モデル作成 デプロイ Feature Store 行動ログ 記事 Model
Registry SageMaker
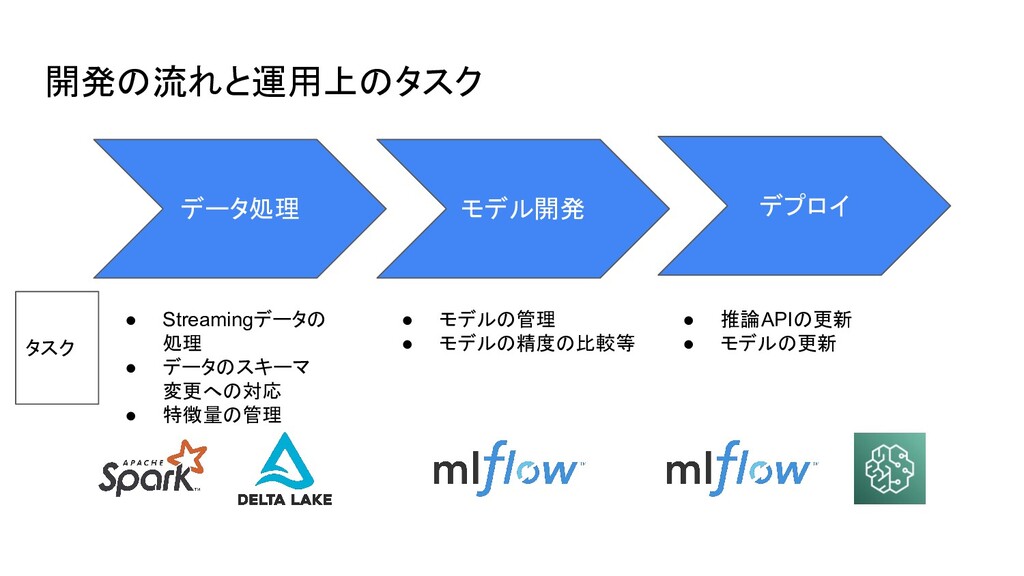
開発の流れと運用上のタスク データ処理 モデル開発 デプロイ • Streamingデータの 処理 • データのスキーマ 変更への対応
• 特徴量の管理 • モデルの管理 • モデルの精度の比較等 タスク • 推論APIの更新 • モデルの更新
利用ツール(1) Databricks クラウド上で実行できるデータ分析・機械 学習プラットフォーム 機械学習に必要な機能がマネージドされ ている • Jupyter Notebook •
MLFlow • Spark • DeltaLake
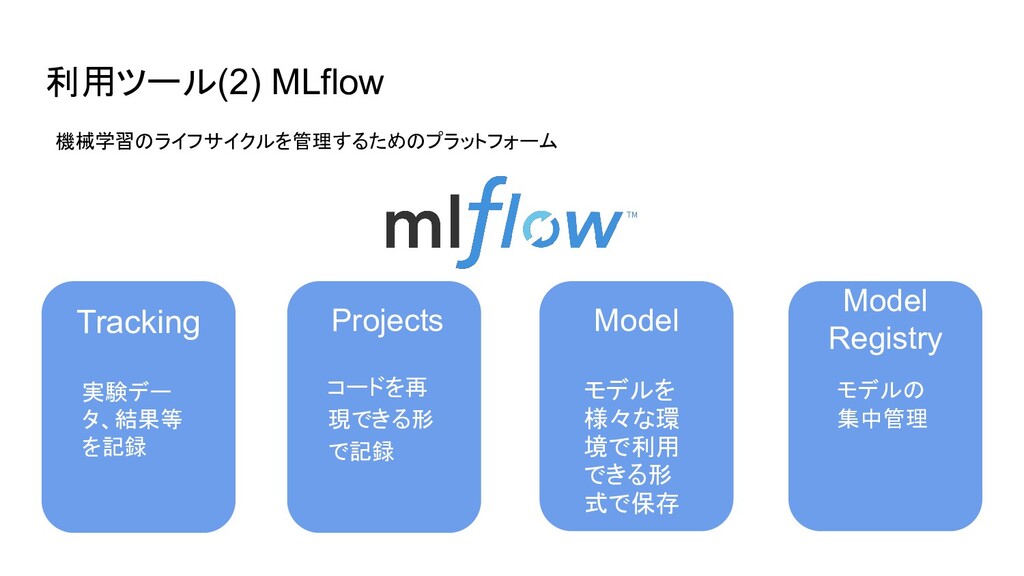
利用ツール(2) MLflow 実験デー タ、結果等 を記録 Projects Model Model Registry Tracking
コードを再 現できる形 で記録 モデルを 様々な環 境で利用 できる形 式で保存 モデルの 集中管理 機械学習のライフサイクルを管理するためのプラットフォーム
利用ツール(3) Apache Spark ストリーミングデータの 読み込み Delta Lakeへの保存 期間を指定したデータ の抽出 データの集計等
利用していない 機械学習を利用した特 徴量生成 Streaming SQL GraphX MLlib 分散処理を行うためのライブラリ ビッグデータを用いたデータ処理、学習が可能
利用ツール(4) Delta Lake Sparkからの呼び出しが可能なデータレイク 非構造データを保存でき、その後構造データに変換する
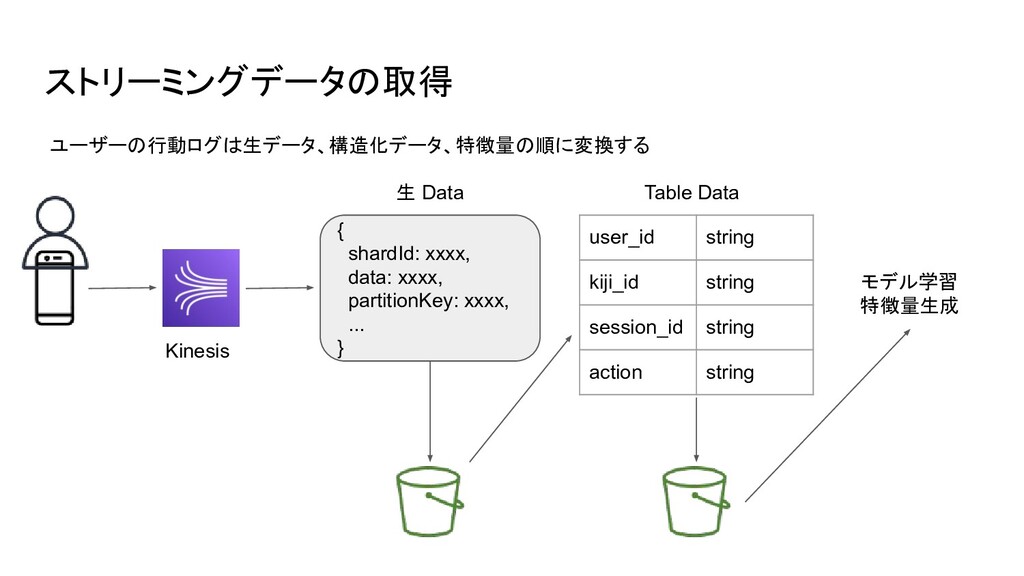
ストリーミングデータの取得 Kinesis 生 Data { shardId: xxxx, data: xxxx, partitionKey:
xxxx, ... } Table Data user_id string kiji_id string session_id string action string モデル学習 特徴量生成 ユーザーの行動ログは生データ、構造化データ、特徴量の順に変換する
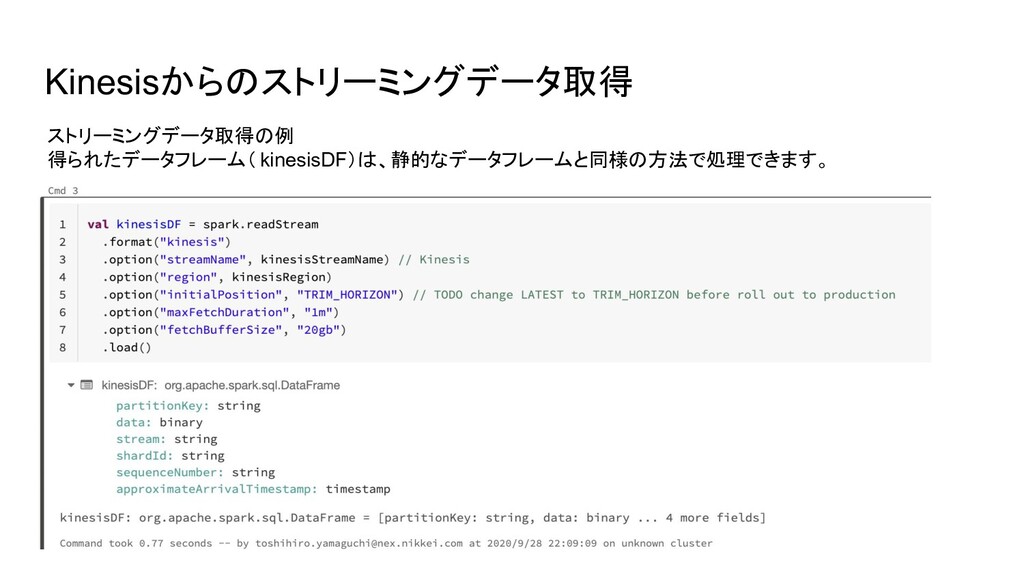
Kinesisからのストリーミングデータ取得 ストリーミングデータ取得の例 得られたデータフレーム( kinesisDF)は、静的なデータフレームと同様の方法で処理できます。
ストリーミングデータのDelta Tableへの保存 ストリーミングデータ保存の例
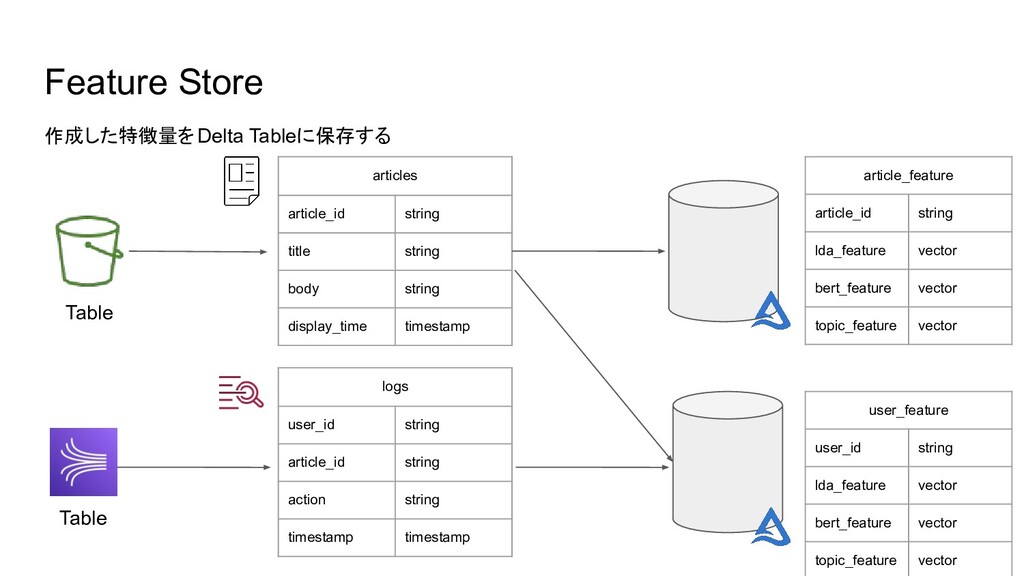
Feature Store articles article_id string title string body string display_time
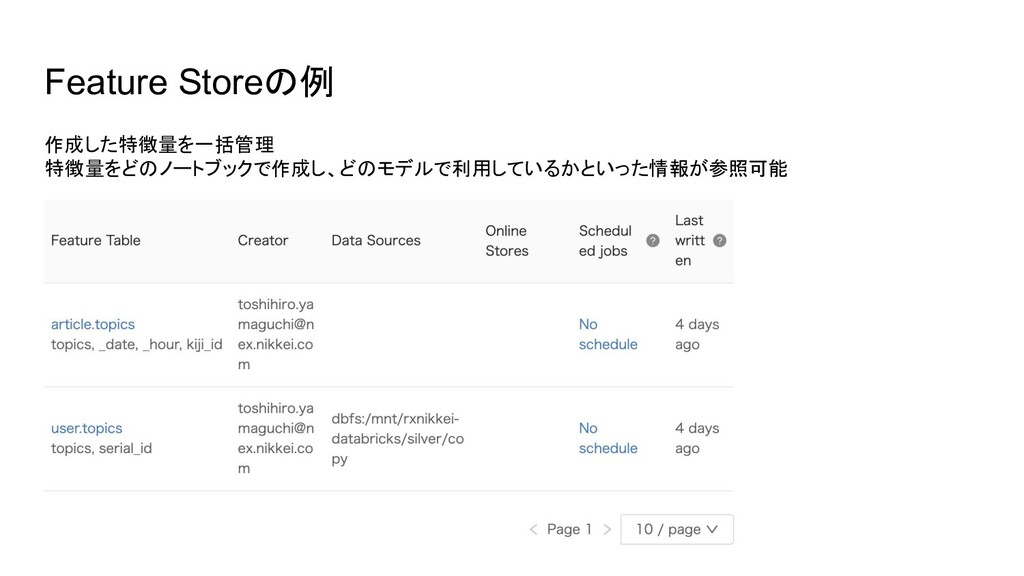
timestamp logs user_id string article_id string action string timestamp timestamp article_feature article_id string lda_feature vector bert_feature vector topic_feature vector user_feature user_id string lda_feature vector bert_feature vector topic_feature vector Table Table 作成した特徴量をDelta Tableに保存する
Feature Storeの例 作成した特徴量を一括管理 特徴量をどのノートブックで作成し、どのモデルで利用しているかといった情報が参照可能
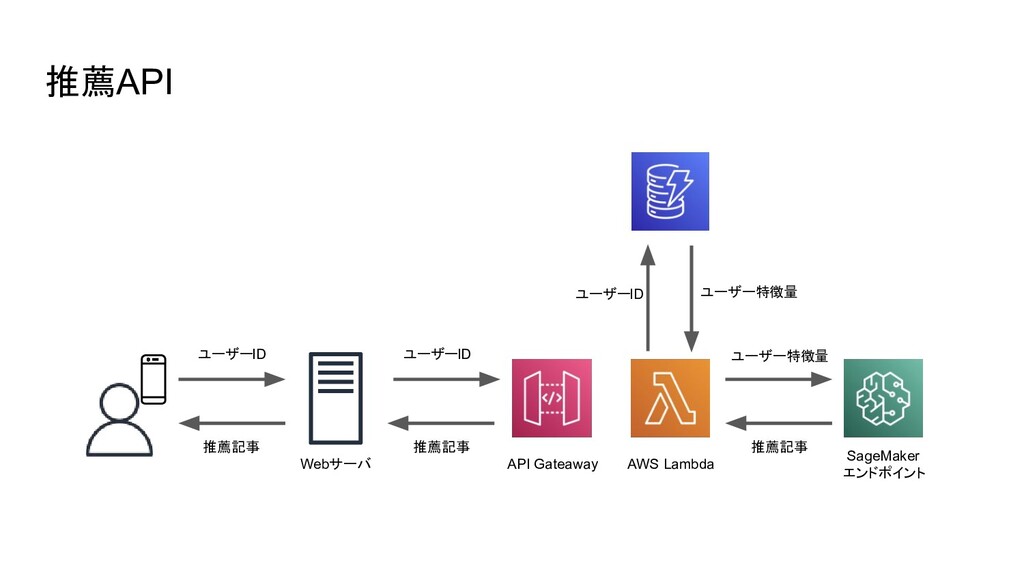
推薦API SageMaker エンドポイント AWS Lambda API Gateaway Webサーバ ユーザーID ユーザーID
ユーザー特徴量 推薦記事 推薦記事 推薦記事 ユーザー特徴量 ユーザーID
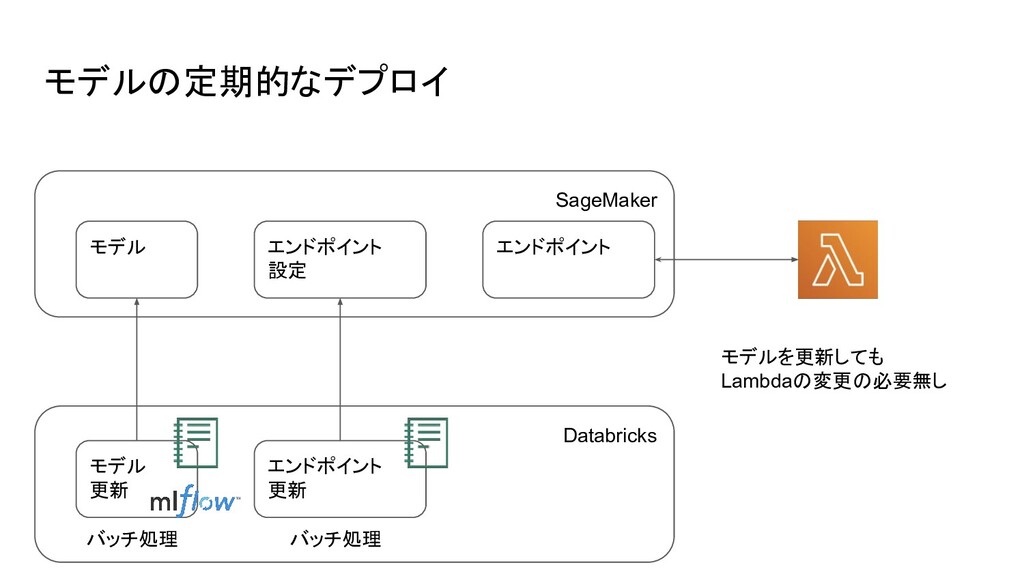
モデルの定期的なデプロイ SageMaker モデル エンドポイント 設定 エンドポイント Databricks モデル 更新 エンドポイント
更新 モデルを更新しても Lambdaの変更の必要無し バッチ処理 バッチ処理
ABテスト用のエンドポイント設定例
MLFlowとDeltaLakeによる学習データの再現 機械学習モデルを改善するために、テーブルのスキーマに変更を加える場合がありま す。しかし、以前に作成したモデルを再現したい場合など、変更前のテーブルを利用した いことがあります。 そのような場合には、Delta Tableのバージョンを指定することで、学習データの再現が 可能です。 参考ノートブック https://docs.databricks.com/applications/mlflow/tracking-ex-delta.html)
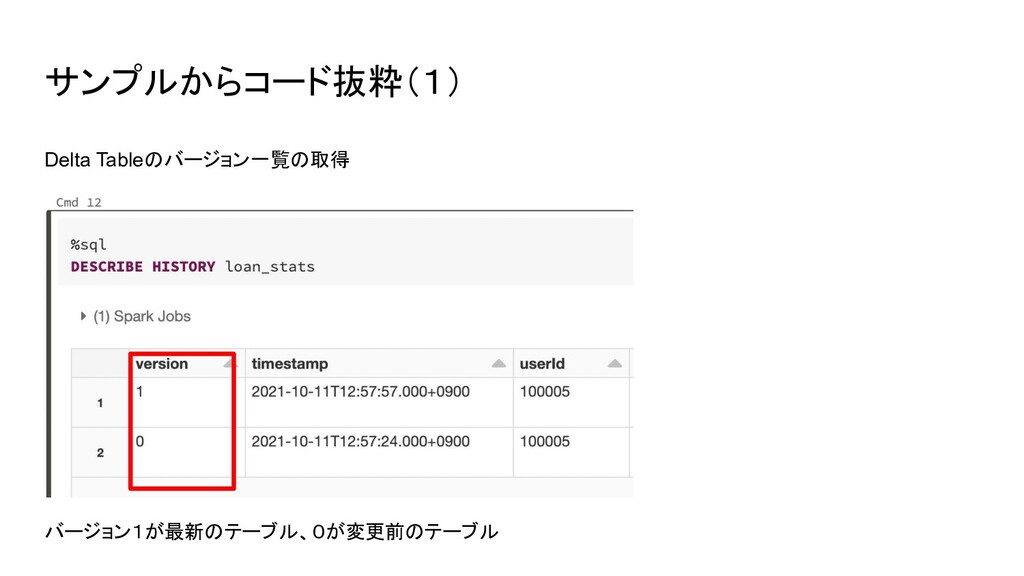
サンプルからコード抜粋(1) Delta Tableのバージョン一覧の取得 バージョン1が最新のテーブル、0が変更前のテーブル
サンプルからコード抜粋(2) モデルの学習に利用した Delta Tableのバージョン取得 spark.mlを利用して学習した場合、テーブルのバージョン情報は MLFlowに自動で記録されま す。 それ以外の方法で学習させる場合には、例えば mlflow.log_paramを利用することでバージョン 情報を記録することができます。
サンプルからコード抜粋(3) テーブルのバージョンを指定したデータ読み込み
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}