Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449
• BC※アノテーションの半自動化 • BCの有無だけでなくどういった BCを出 力するかまで予測 • マルチモーダルBCの検討 • Big Five特性を踏まえたキャラクタ性 の再現 Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449 ※BC=backchannel: 会話に対する反応(うなずき,あいづち,笑顔など)
• ほぼPhDの生徒 • 1:1対話 • トークテーマは選択制 • マルチモーダル(映像+音声) • Big Five特性 ◦ Goldbergの質問票 ◦ スコアで2クラス分類 Khan, Shahid Nawaz, Maitree Leekha, Jainendra Shukla and Rajiv Ratn Shah. “Vyaktitv: A Multimodal Peer-to-Peer Hindi Conversations based Dataset for Personality Assessment.” 2020 IEEE Sixth International Conference on Multimedia Big Data (BigMM) (2020): 103-111.
BCの有無 (0.86) ◦ nod (0.71), head-shake (0.64), mouth (0.63), eyebrow(0.45) short-utterance (0.49). • BCの開始/終了は1秒以内の誤差なら合体 ◦ 時刻ラベルは平均を採用 • 合計: 2781backchannel signal ◦ Eyebrowは少量すぎるため対象外に • 平均BC継続時間: 1.8sec Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449
Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449
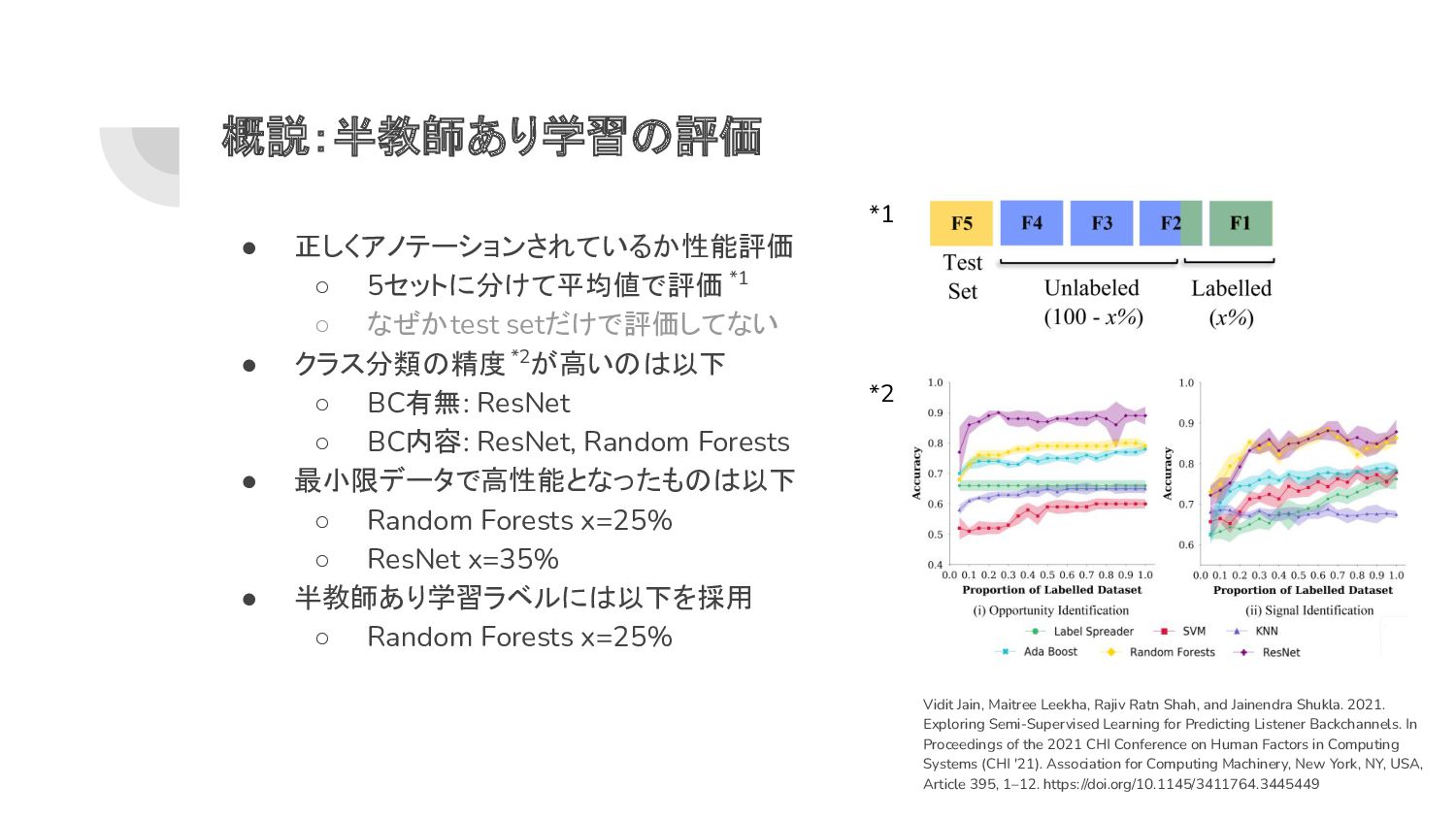
◦ BCがほぼ無い被験者がいたのも一因 • BCの内容は大まかに visual, verbal, both で分類 • ラベルデータを使ってモデルを構築*1 ◦ 初回データセット(L)を決めてモデル(C)を学習 ◦ ラベルなしデータ(U)へ推論を実行し、推論結果が 0.9以上になったら(L)に追加 ◦ 追加データがゼロになるまで再学習+再追加 • モデル構築に利用するデータセット割合(x%)を調整 ◦ どこまで少ないxで効果が出るのか検証 • どの学習方法が一番か検証 ◦ Random Forests (RF) ◦ Support Vector Machine Classifer (SVC) ◦ K-Nearest Neighbour Classifer (KNN) ◦ AdaBoost (ADA) ◦ ResNet (ResNet) Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449 *1
◦ BC有無: ResNet ◦ BC内容: ResNet, Random Forests • 最小限データで高性能となったものは以下 ◦ Random Forests x=25% ◦ ResNet x=35% • 半教師あり学習ラベルには以下を採用 ◦ Random Forests x=25% 概説:半教師あり学習の評価 Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449 *1 *2
以下すべて検証 ▪ Random Forests (RF) ▪ Support Vector Machine Classifer (SVC) ▪ AdaBoost (ADA) ▪ K-Nearest Neighbors (KNN) ▪ Multi-Layered Perceptron model (MLP) • BC内容予測データを加工 ◦ visual: 1593, verbal: 326, both: 835 ◦ データの不均衡に対応するため SVM-SMOTEを活用 Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449 *1
• verbalが最も精度がよい*3 ◦ visualとbothは結果が似通っていた ▪ verbalだけ学習データが少な かったのが理由の可能性も ◦ bothは半教師のが高精度 ▪ アノテーションのばらつきが多 かった? Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449 *1 *2 *3
visualであっても、性格特性に応じた ルール*2とinverse transform sampling で unimodal か multimodal かを判断 ◦ どういった仕草かもルール*2で規定 ▪ ルールベースとなると魅力減。。 • 性格特性ごとに別々にモデルを学習 • ビデオ通話をみてもらってアンケート評価 ◦ 27名のヒンディーネイティブの大学生 • 以下3パターン別々に点数をつける ◦ ランダム出力 ◦ 教師あり学習(ADA) ◦ 半教師あり学習(ADA, RF and ResNet, x=25%) Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449 *1 *2
verbal, bothの予測 精度だけでそこまで性能差が出るのか • 性格特性アンケート結果も上々だった模様 Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449 *1
a. 少量なら除外 b. 不均衡ならimbalanced-learn(要調査) 3. マルチモーダルデータを利用する意義 a. 出力分類(単一/マルチ)として活用できる b. 映像と音声+映像が識別しづらい? or imbalancedが上手くいかなかった? 4. キャラクタ性の再現方法の参考 a. 結局ルールベースだったのでそこまで参考にならず
with each one lasting 16 minutes and 6 seconds on an average. • Even in the context of the present study, the annotation process took around 90 hours ◦ 30 hours each annotator, taking the average time to annotate one side of a conversation as 35 minutes. The total amount of recorded content being ∼ 13.5 hours long. Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449
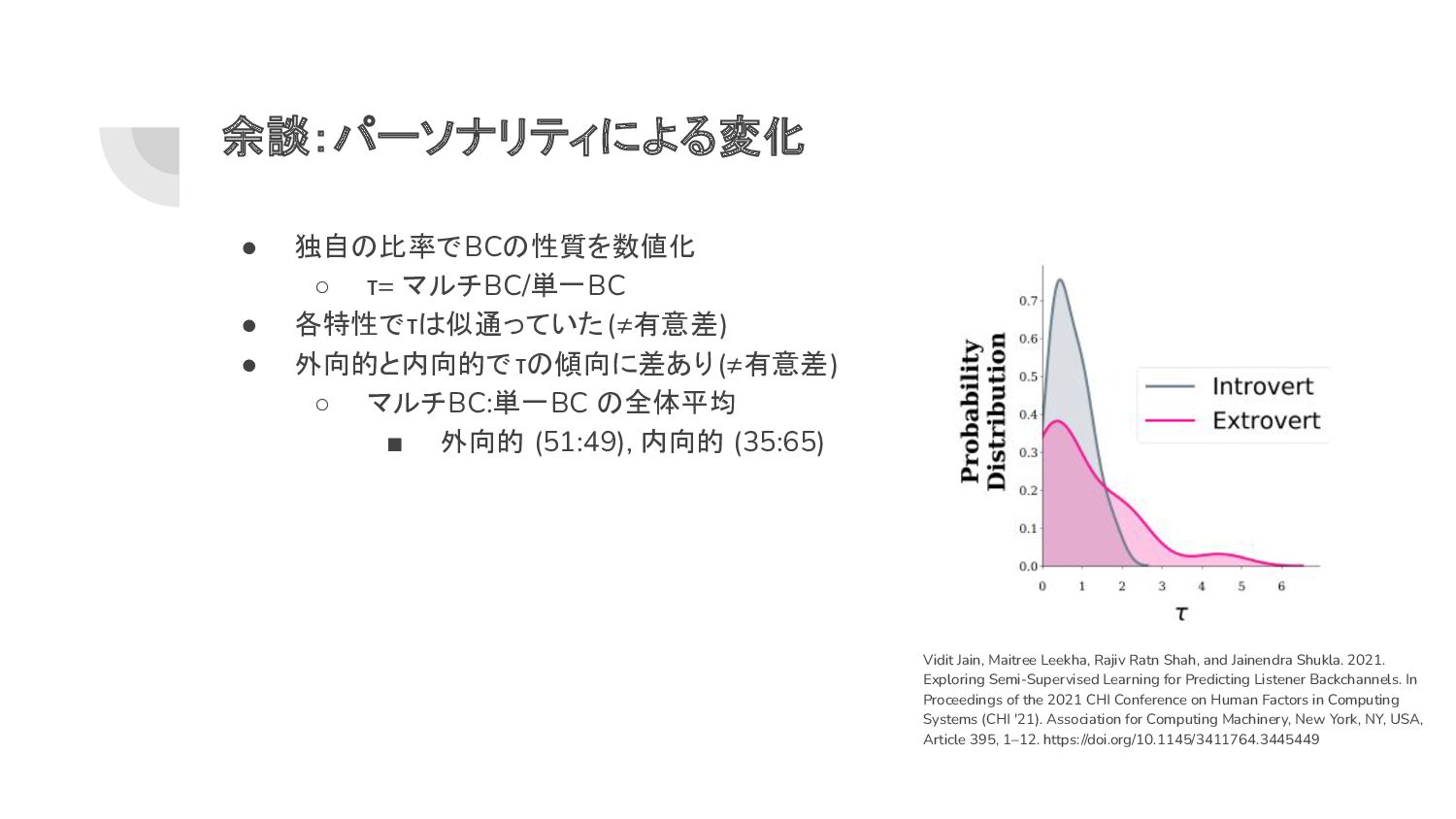
◦ マルチBC:単一BC の全体平均 ▪ 外向的 (51:49), 内向的 (35:65) Vidit Jain, Maitree Leekha, Rajiv Ratn Shah, and Jainendra Shukla. 2021. Exploring Semi-Supervised Learning for Predicting Listener Backchannels. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI '21). Association for Computing Machinery, New York, NY, USA, Article 395, 1–12. https://doi.org/10.1145/3411764.3445449
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}