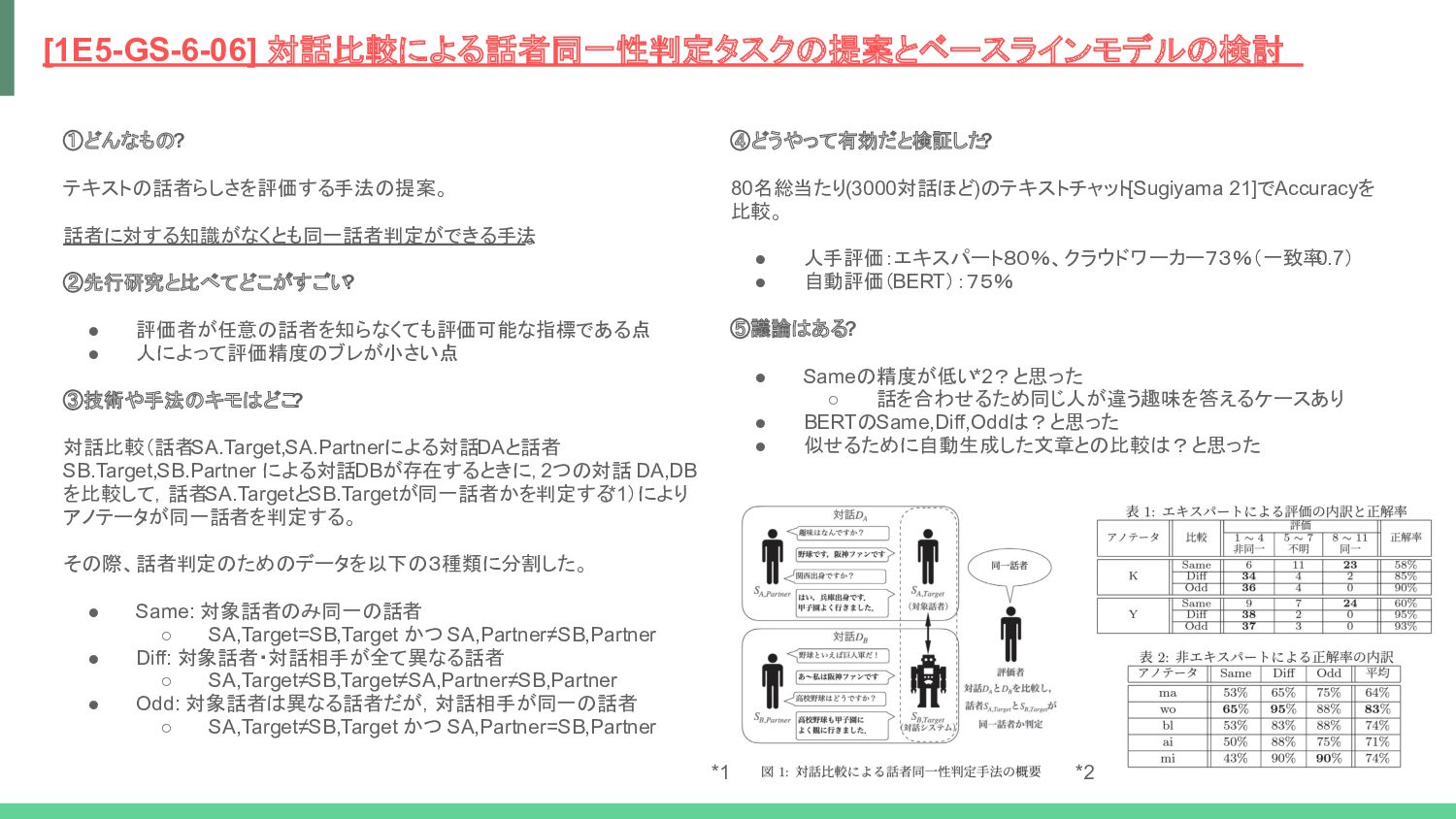
③技術や手法のキモはどこ ? 対話比較(話者SA.Target,SA.Partnerによる対話DAと話者 SB.Target,SB.Partner による対話DBが存在するときに,2つの対話 DA,DB を比較して,話者SA.TargetとSB.Targetが同一話者かを判定する *1)により アノテータが同一話者を判定する。 その際、話者判定のためのデータを以下の3種類に分割した。 • Same: 対象話者のみ同一の話者 ◦ SA,Target=SB,Target かつ SA,Partner≠SB,Partner • Diff: 対象話者・対話相手が全て異なる話者 ◦ SA,Target≠SB,Target≠SA,Partner≠SB,Partner • Odd: 対象話者は異なる話者だが,対話相手が同一の話者 ◦ SA,Target≠SB,Target かつ SA,Partner=SB,Partner [1E5-GS-6-06] 対話比較による話者同一性判定タスクの提案とベースラインモデルの検討 ④どうやって有効だと検証した ? 80名総当たり(3000対話ほど)のテキストチャット[Sugiyama 21]でAccuracyを 比較。 • 人手評価:エキスパート80%、クラウドワーカー73%(一致率 0.7) • 自動評価(BERT):75% ⑤議論はある? • Sameの精度が低い*2?と思った ◦ 話を合わせるため同じ人が違う趣味を答えるケースあり • BERTのSame,Diff,Oddは?と思った • 似せるために自動生成した文章との比較は?と思った *1 *2
{kind=link}
{kind=link}
![Topics • 対話関連 ◦ [1E5-GS-6-06] 対話比較による話者同一性判定タスクの提案とベースラインモデルの検討 ◦ [3O1-OS-2c-02] 長期雑談対話システムの実現に向けた長期テキストチャットの収集と分析 ◦](https://files.speakerdeck.com/presentations/7e0c82adfa6f4db0aff7f18ccdcdb98c/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![用語: PAN(Predictive Adversarial Learning) ref. [2A4-GS-2-03] 正例とラベル無しデータによる異種ドメイン適応](https://files.speakerdeck.com/presentations/7e0c82adfa6f4db0aff7f18ccdcdb98c/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
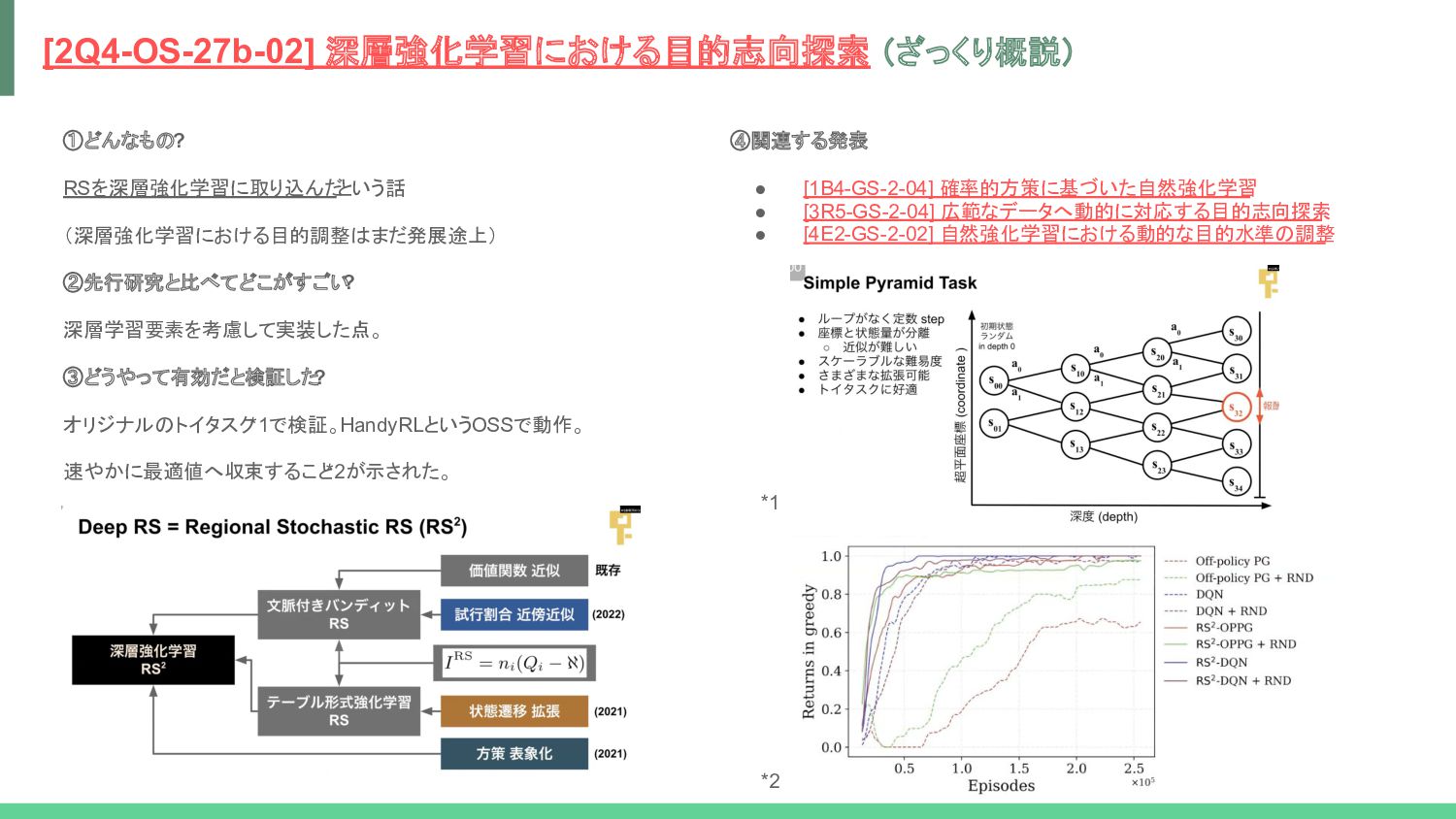
![用語: RS(目的志向探索) ref. [1B4-GS-2-04] 確率的方策に基づいた自然強化学習 人間の目的志向探索が強化学習に有効であると考え、目的志向探索の仕組みとその目的調整を強化学習に組み込むことで、作業者が目標値を設定したりドメイン 知識の注入ができるような機構を実現する仕組み *1が提案されている。 RSはその目的志向探索のアルゴリズム *2を指す。(Simon](https://files.speakerdeck.com/presentations/7e0c82adfa6f4db0aff7f18ccdcdb98c/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
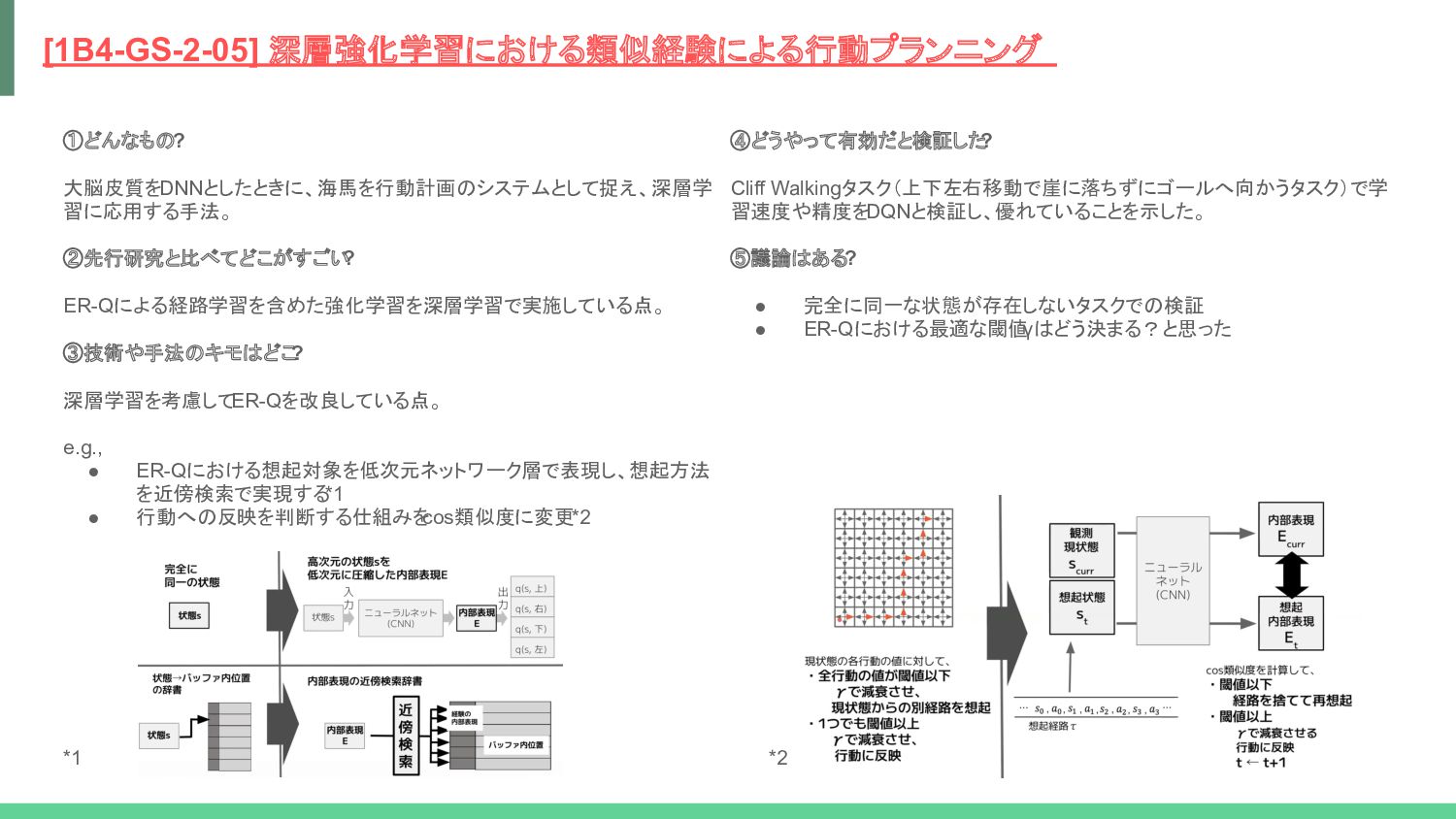
![参考: 脳の役割と深層学習の関係 ref. [1B4-GS-2-05] 深層強化学習における類似経験による行動プランニング ref. Replay in minds and](https://files.speakerdeck.com/presentations/7e0c82adfa6f4db0aff7f18ccdcdb98c/slide_20.jpg){kind=link}
![用語: ER-Q 過去の成功体験から想起されたバイアス値を考慮した行動計画を組み込んだ強化学習アルゴリズム ref. [1B4-GS-2-05] 深層強化学習における類似経験による行動プランニング](https://files.speakerdeck.com/presentations/7e0c82adfa6f4db0aff7f18ccdcdb98c/slide_21.jpg){kind=link}
{kind=link}