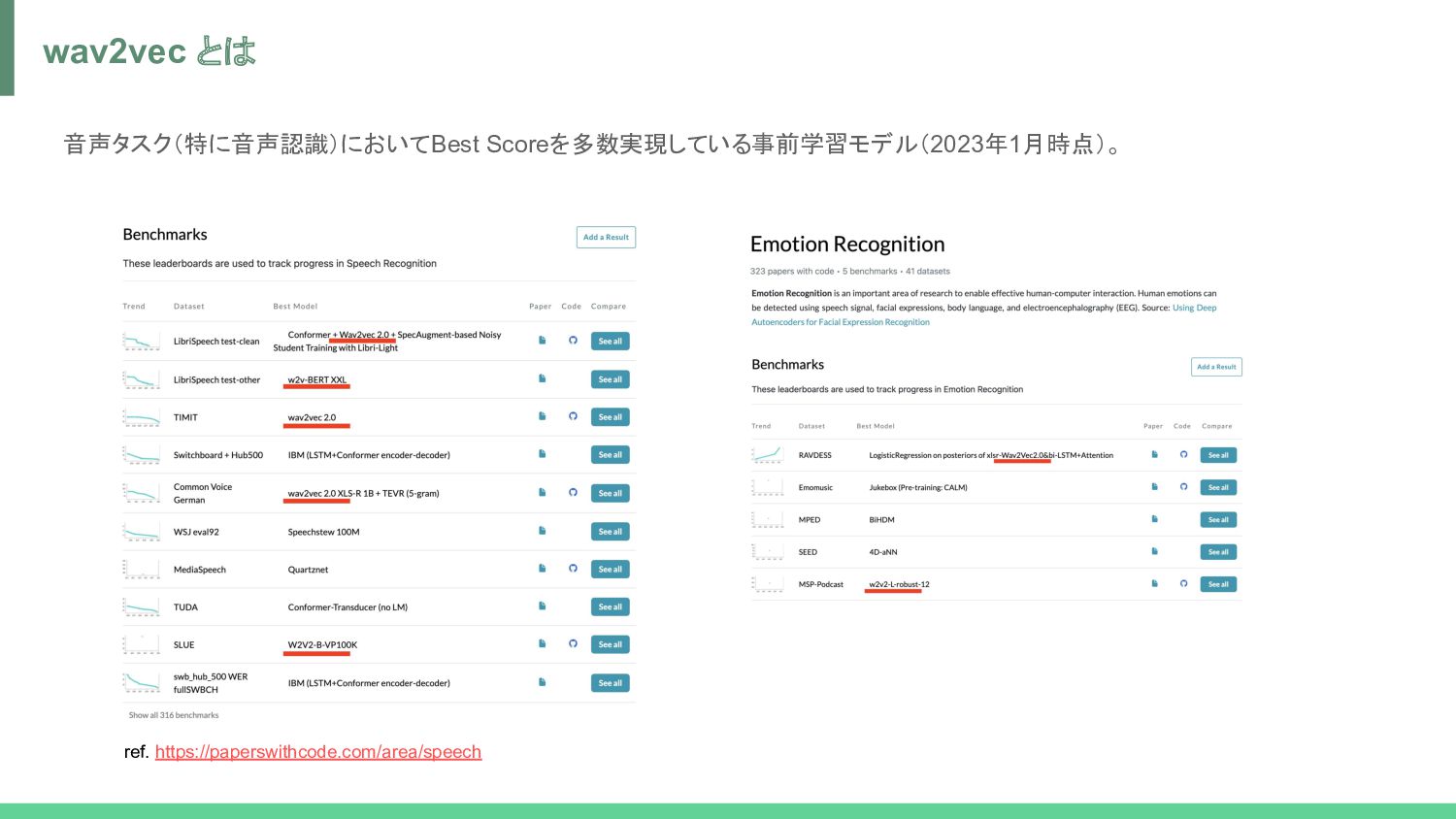
Wav2vec 2.0: a framework for self-supervised learning of speech representations. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS'20). Curran Associates Inc., Red Hook, NY, USA, Article 1044, 12449–12460. • 音声データのための事前学習モデル ◦ 他モデル(e.g., Transformer)と組み合わせて推論 • 生の音声波形データから学習 ◦ フィルタバンクやスペクトログラムを使わない(!) • ラベルなしデータから自己教師あり学習 ◦ BERTと同様にマスキングでベクトル表現を学習 • 10 分間データの転移学習で WER 4.8/8.2 (Librispeech clean/other) ◦ 53,000 時間のラベルなしデータの事前学習 +10 分間のラベルデータの教師あり学習 ◦ 960時間のラベルデータだと WER 1.8/3.3 (Librispeech clean/other) wav2vec 2.0: 概要
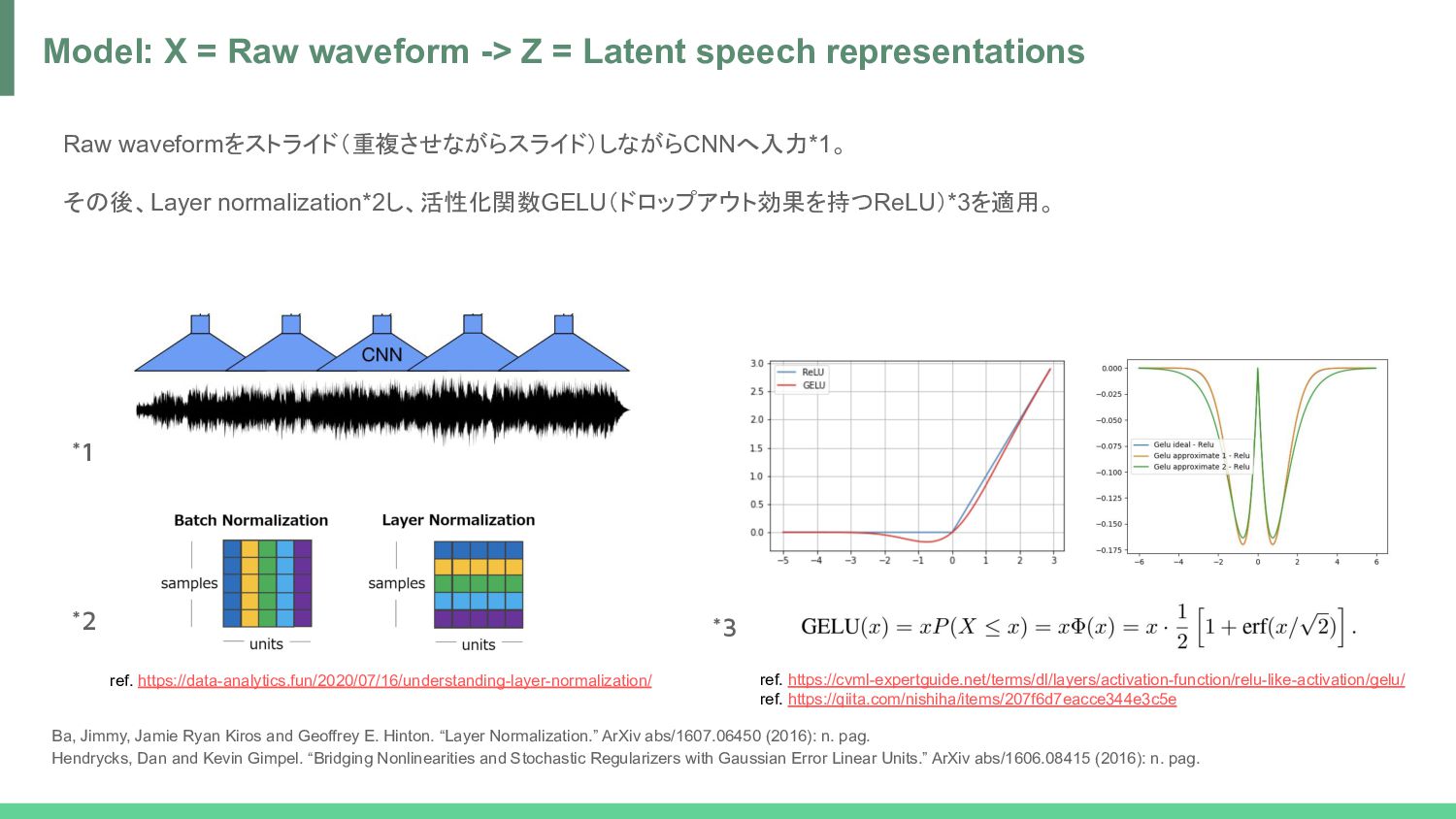
Z = Latent speech representations Ba, Jimmy, Jamie Ryan Kiros and Geoffrey E. Hinton. “Layer Normalization.” ArXiv abs/1607.06450 (2016): n. pag. Hendrycks, Dan and Kevin Gimpel. “Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units.” ArXiv abs/1606.08415 (2016): n. pag. *1 *2 *3 ref. https://cvml-expertguide.net/terms/dl/layers/activation-function/relu-like-activation/gelu/ ref. https://qiita.com/nishiha/items/207f6d7eacce344e3c5e ref. https://data-analytics.fun/2020/07/16/understanding-layer-normalization/
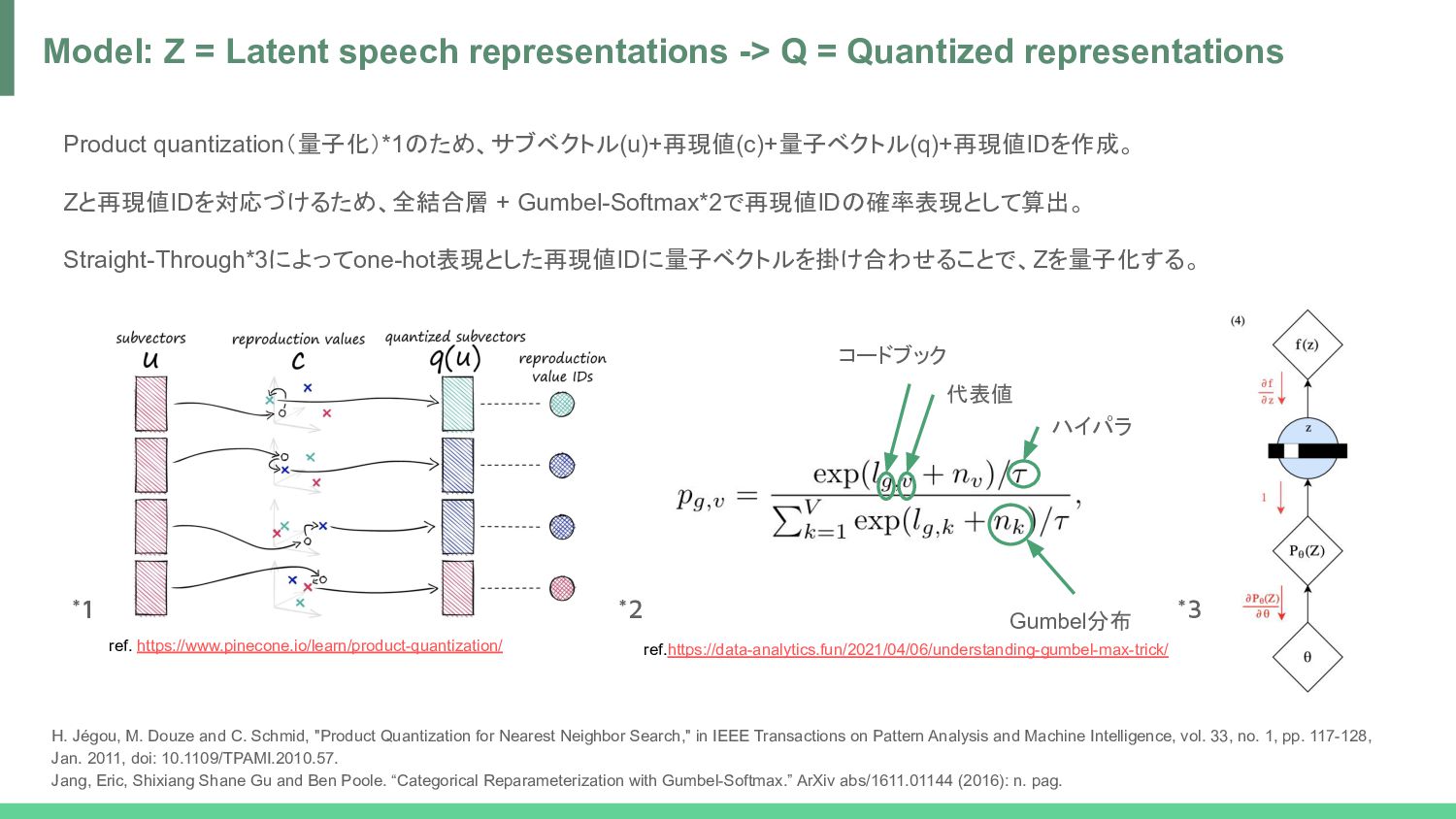
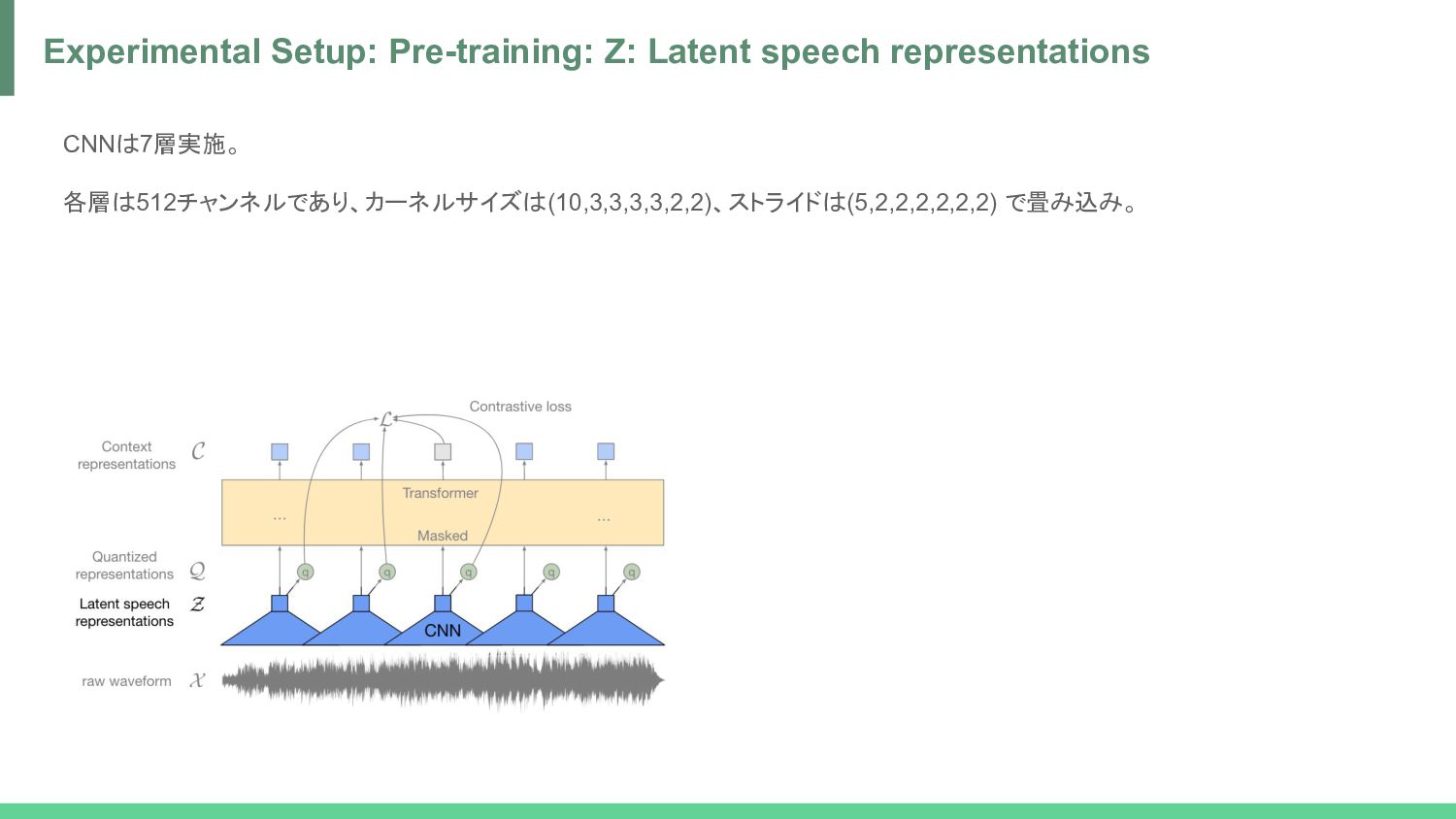
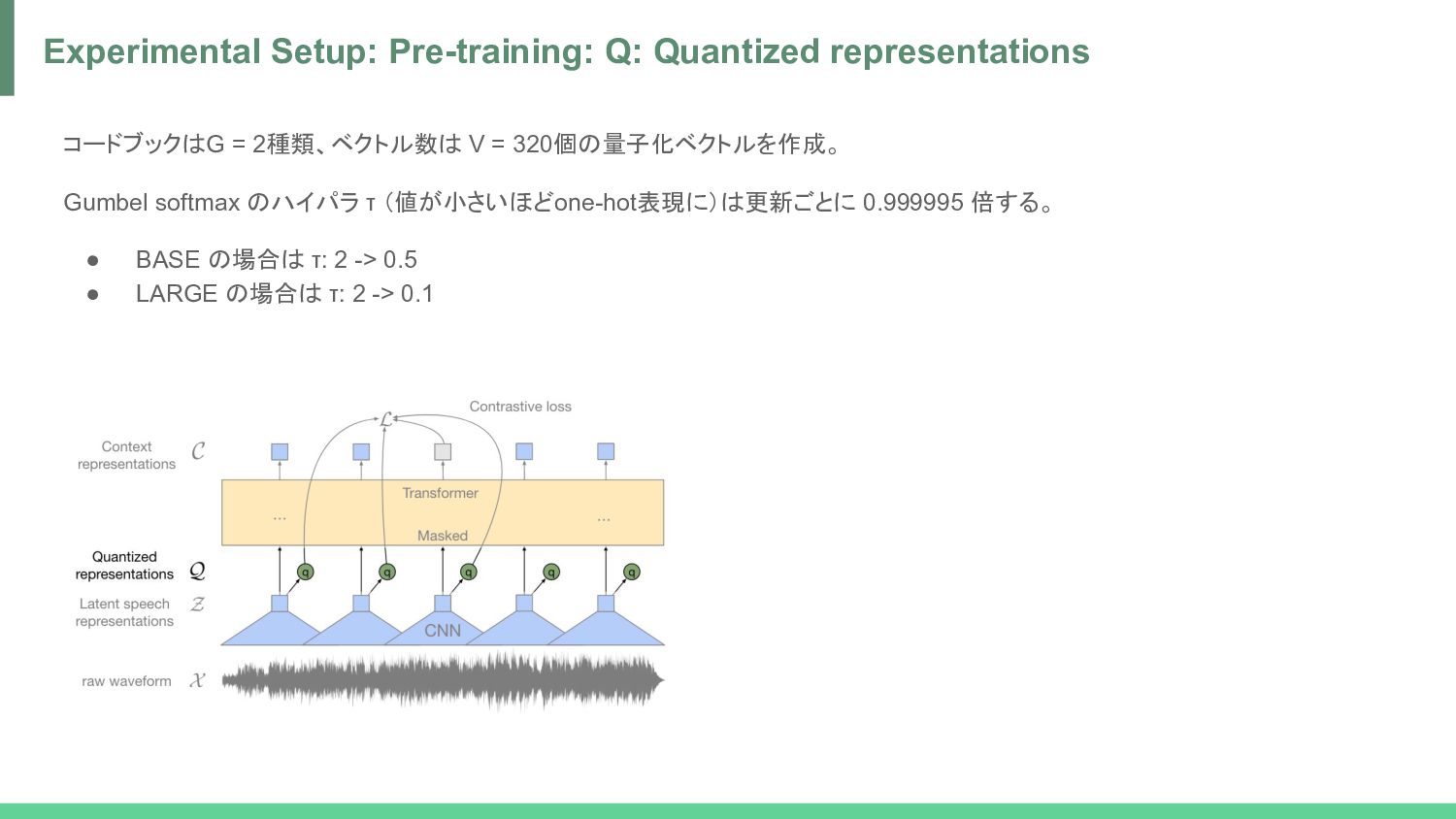
speech representations -> Q = Quantized representations H. Jégou, M. Douze and C. Schmid, "Product Quantization for Nearest Neighbor Search," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 1, pp. 117-128, Jan. 2011, doi: 10.1109/TPAMI.2010.57. Jang, Eric, Shixiang Shane Gu and Ben Poole. “Categorical Reparameterization with Gumbel-Softmax.” ArXiv abs/1611.01144 (2016): n. pag. *1 *2 *3 コードブック 代表値 ref. https://www.pinecone.io/learn/product-quantization/ Gumbel分布 ハイパラ ref.https://data-analytics.fun/2021/04/06/understanding-gumbel-max-trick/
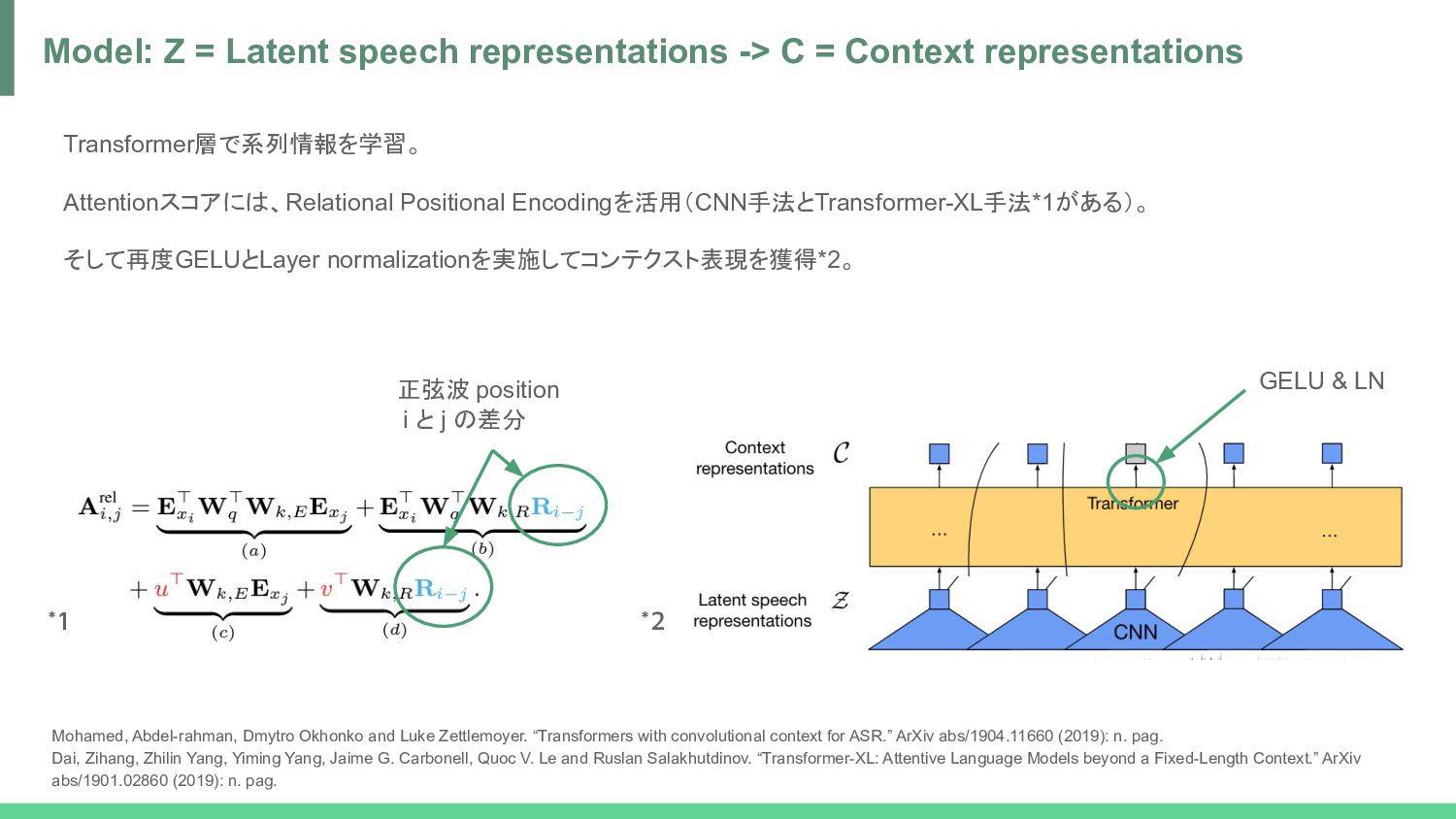
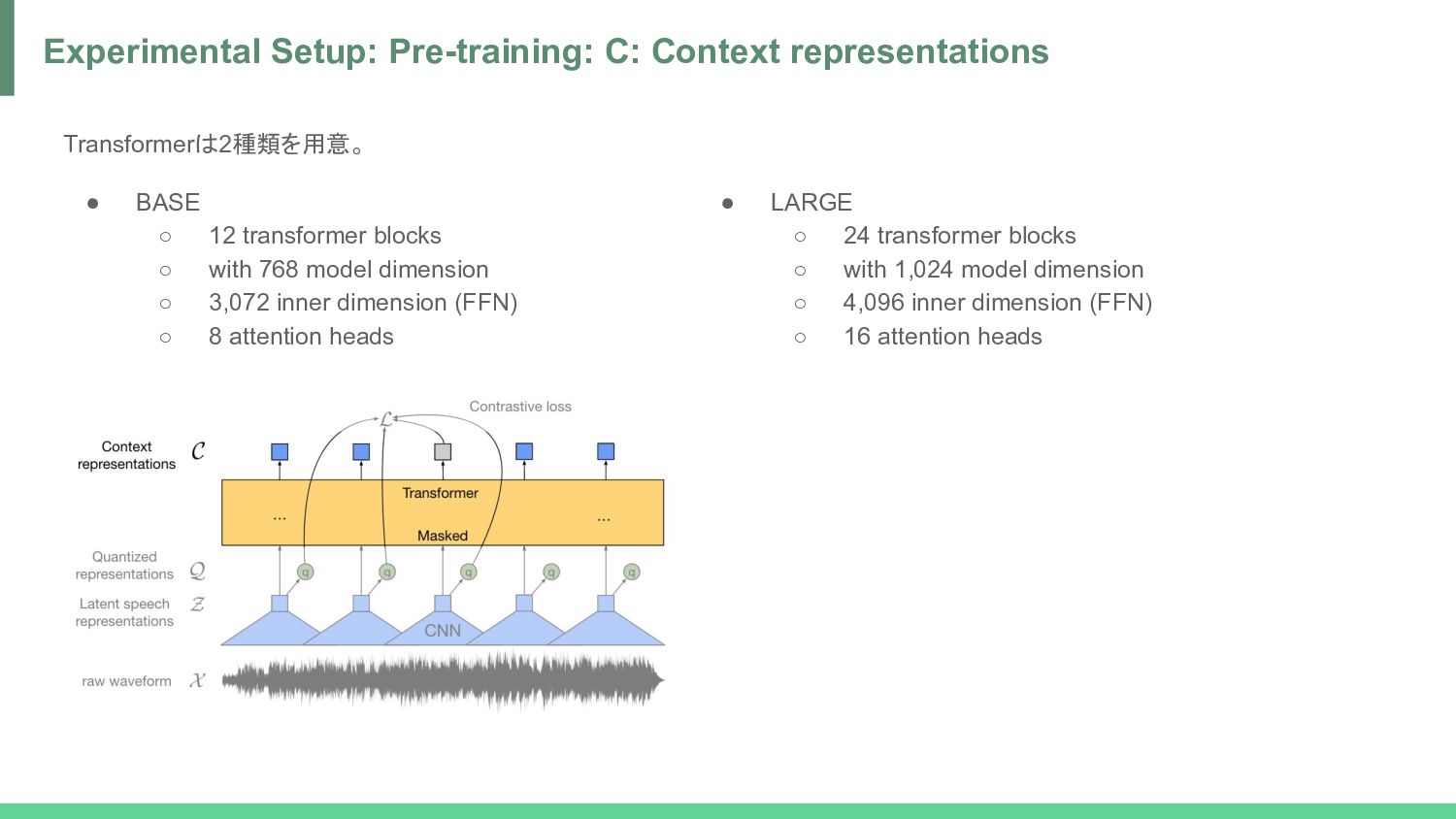
speech representations -> C = Context representations Mohamed, Abdel-rahman, Dmytro Okhonko and Luke Zettlemoyer. “Transformers with convolutional context for ASR.” ArXiv abs/1904.11660 (2019): n. pag. Dai, Zihang, Zhilin Yang, Yiming Yang, Jaime G. Carbonell, Quoc V. Le and Ruslan Salakhutdinov. “Transformer-XL: Attentive Language Models beyond a Fixed-Length Context.” ArXiv abs/1901.02860 (2019): n. pag. *1 *2 GELU & LN 正弦波 position i と j の差分
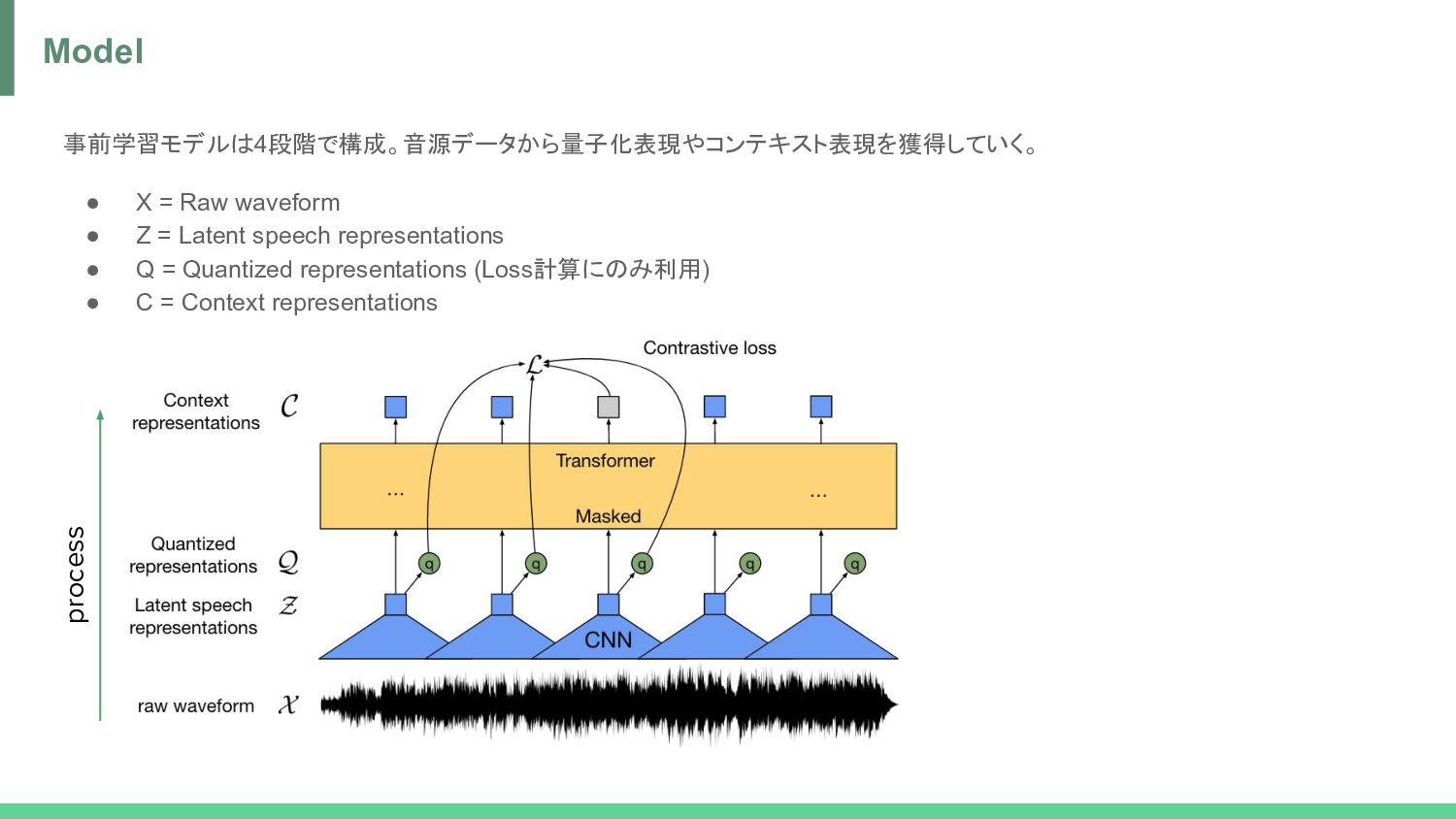
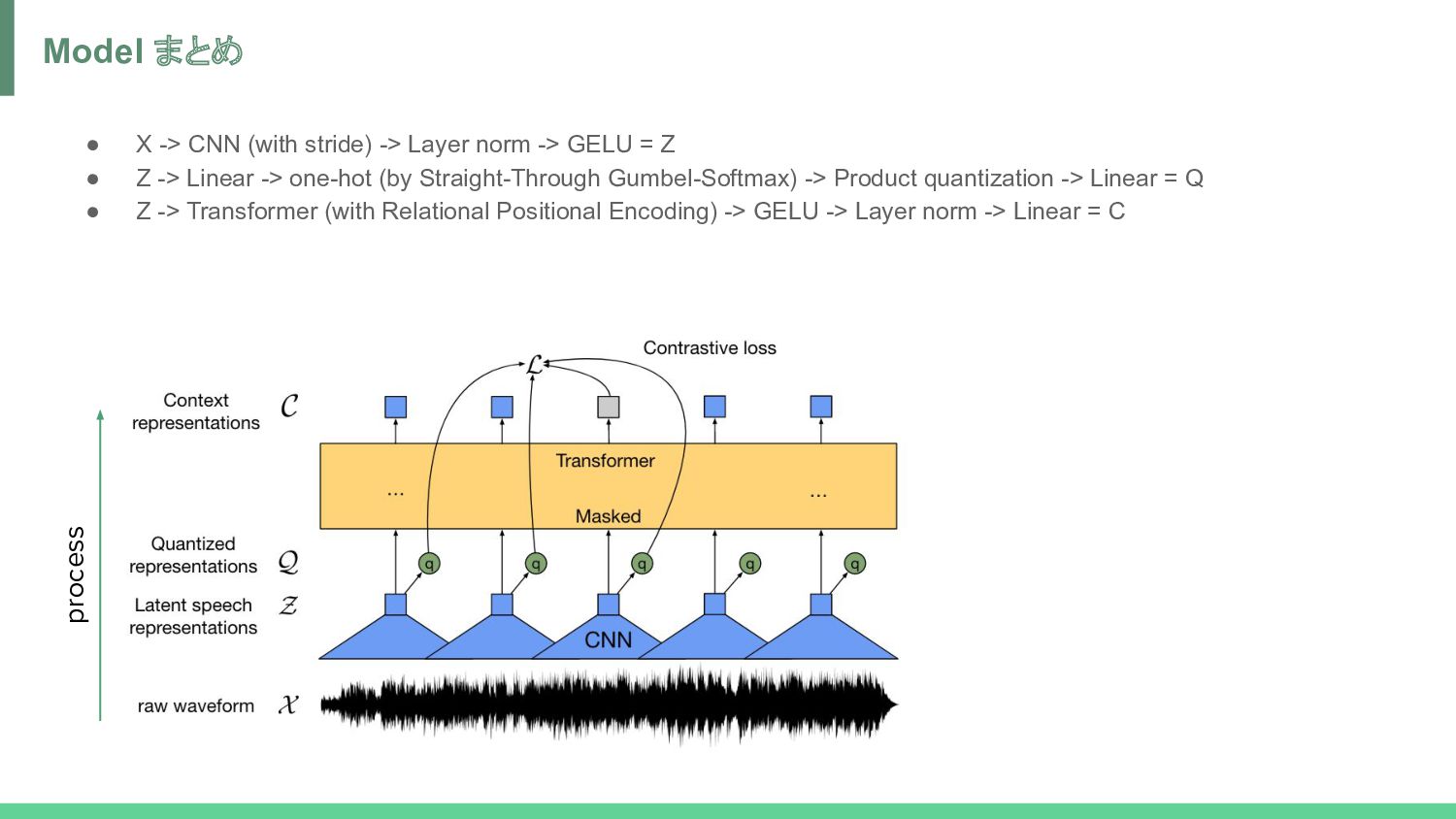
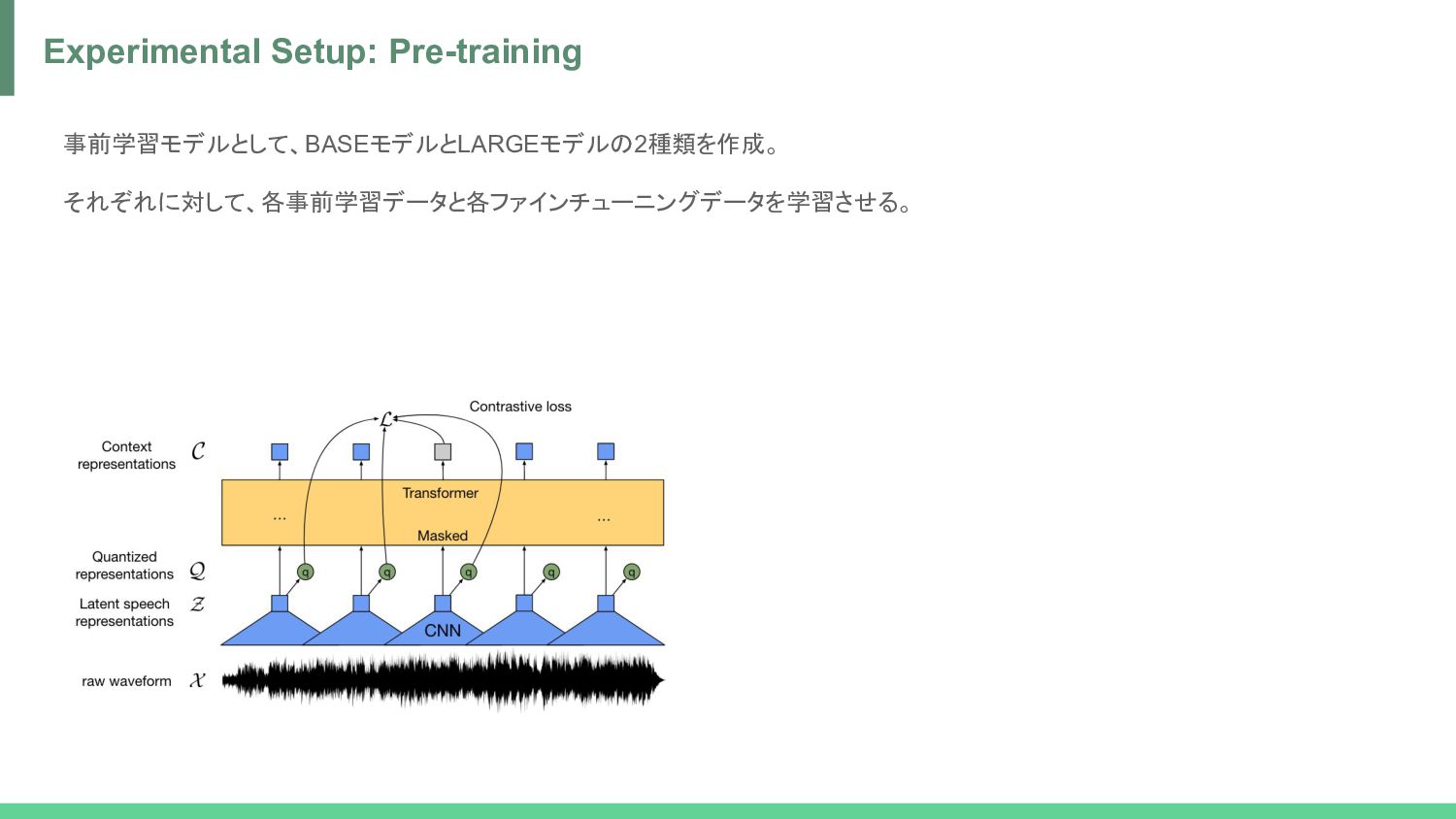
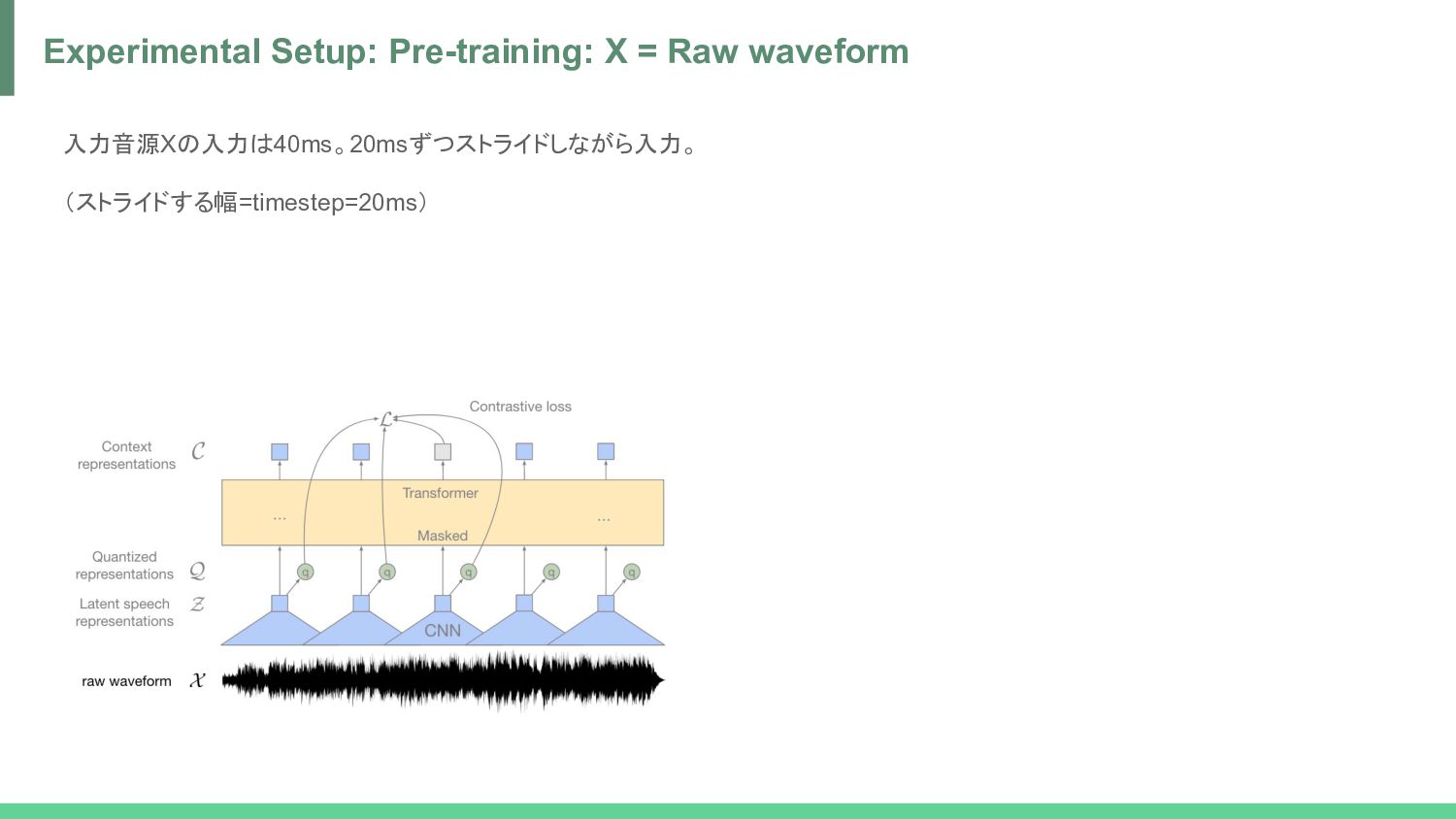
norm -> GELU = Z • Z -> Linear -> one-hot (by Straight-Through Gumbel-Softmax) -> Product quantization -> Linear = Q • Z -> Transformer (with Relational Positional Encoding) -> GELU -> Layer norm -> Linear = C process
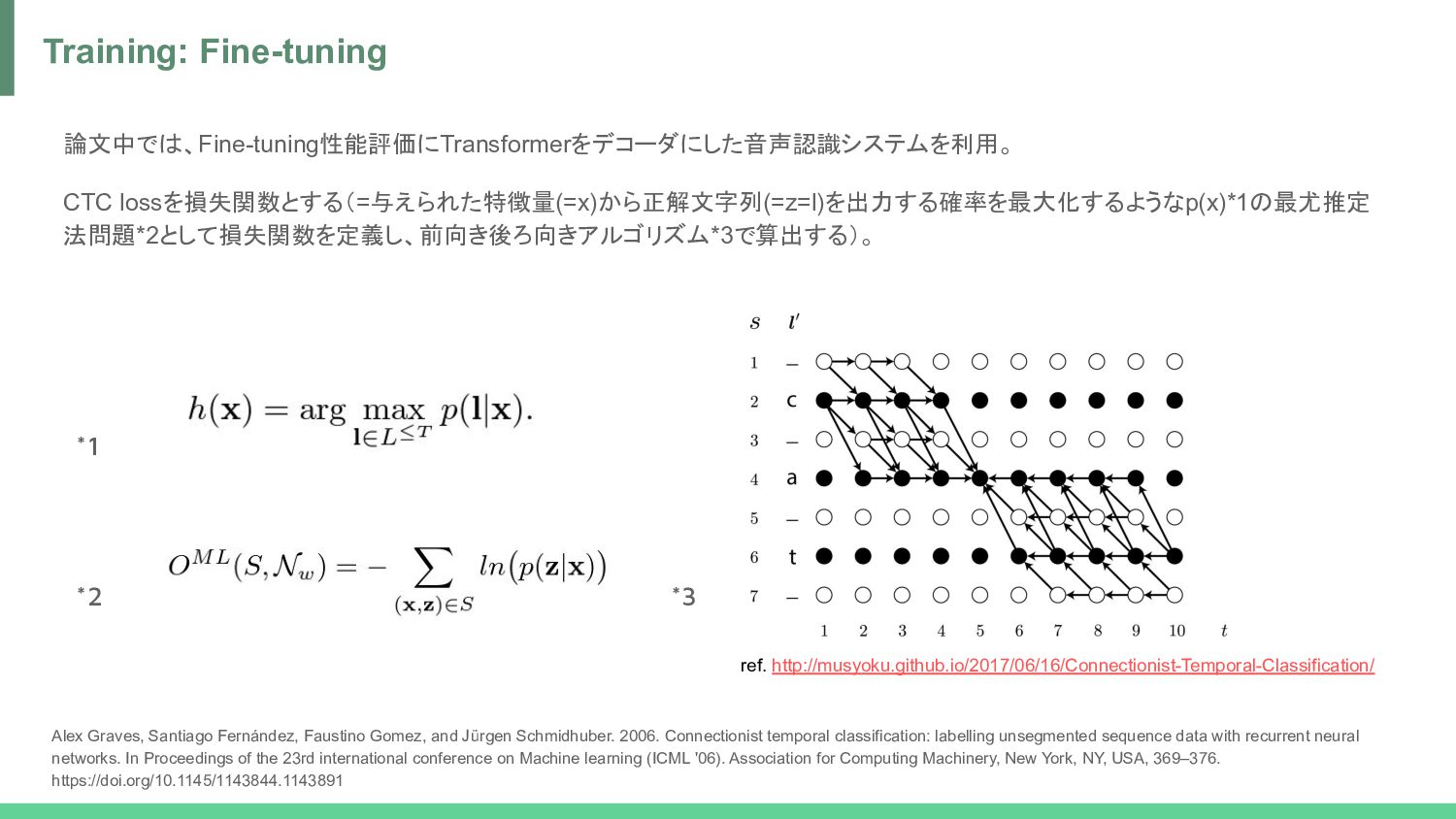
Faustino Gomez, and Jürgen Schmidhuber. 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning (ICML '06). Association for Computing Machinery, New York, NY, USA, 369–376. https://doi.org/10.1145/1143844.1143891 *1 *3 *2 ref. http://musyoku.github.io/2017/06/16/Connectionist-Temporal-Classification/
Park, Daniel S., William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin Dogus Cubuk and Quoc V. Le. “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition.” ArXiv abs/1904.08779 (2019): n. pag. *1 ref. https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html *2
4-gram ◦ ビームサーチ top 500 • Transformer ◦ ビームサーチ top 50 ◦ [G. Synnaeve et al. 2020]のモデルをそのまま Experimental Setup: Language Models and Decoding *1 G. Synnaeve, Q. Xu, J. Kahn, T. Likhomanenko, E. Grave, V. Pratap, A. Sriram, V. Liptchinsky, and R. Collobert. End-to-end ASR: from Supervised to Semi-Supervised Learning with Modern Architectures. arXiv, abs/1911.08460, 2020 * Ax: https://github.com/facebook/Ax
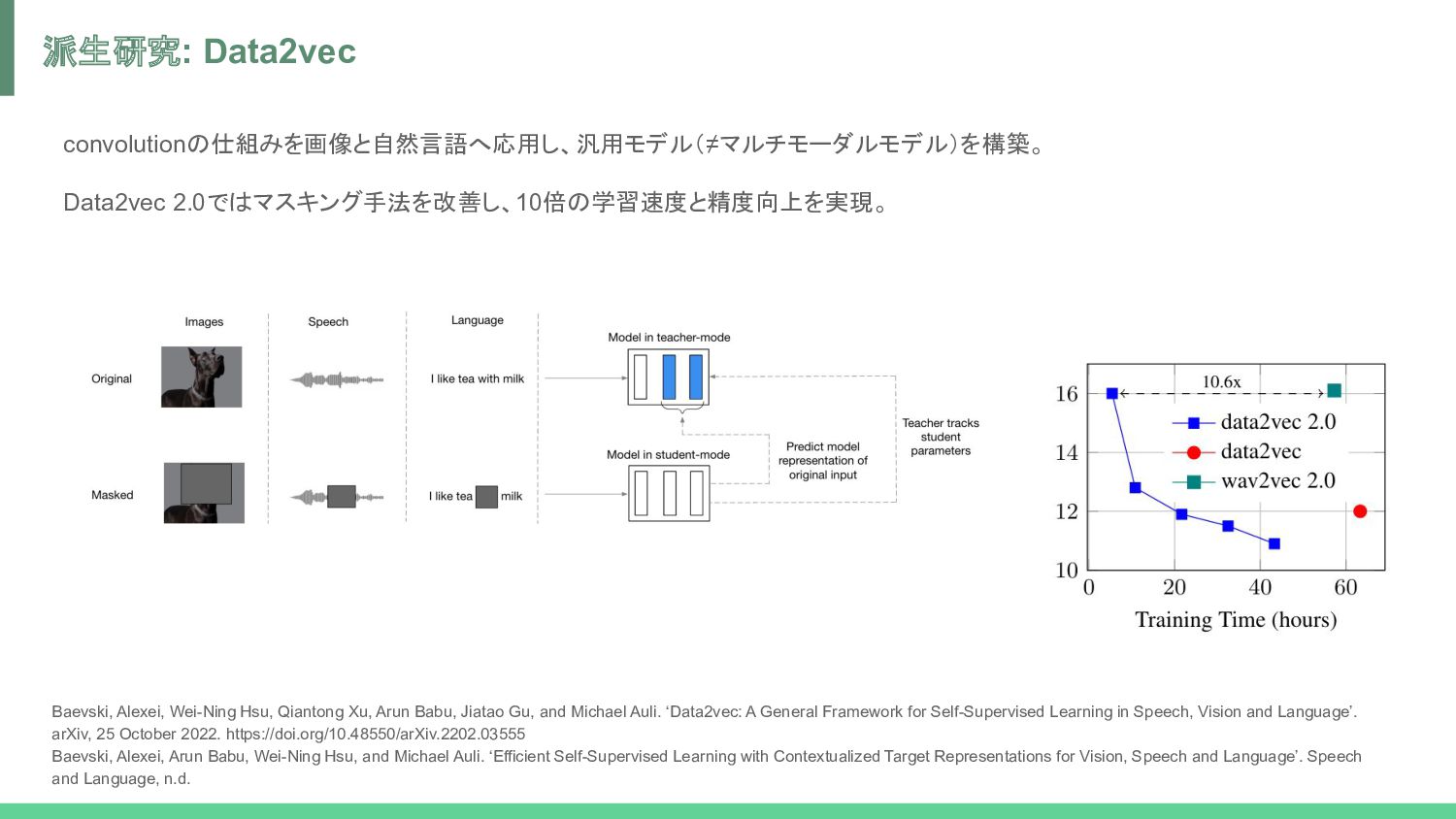
Xu, Arun Babu, Jiatao Gu, and Michael Auli. ‘Data2vec: A General Framework for Self-Supervised Learning in Speech, Vision and Language’. arXiv, 25 October 2022. https://doi.org/10.48550/arXiv.2202.03555 Baevski, Alexei, Arun Babu, Wei-Ning Hsu, and Michael Auli. ‘Efficient Self-Supervised Learning with Contextualized Target Representations for Vision, Speech and Language’. Speech and Language, n.d.
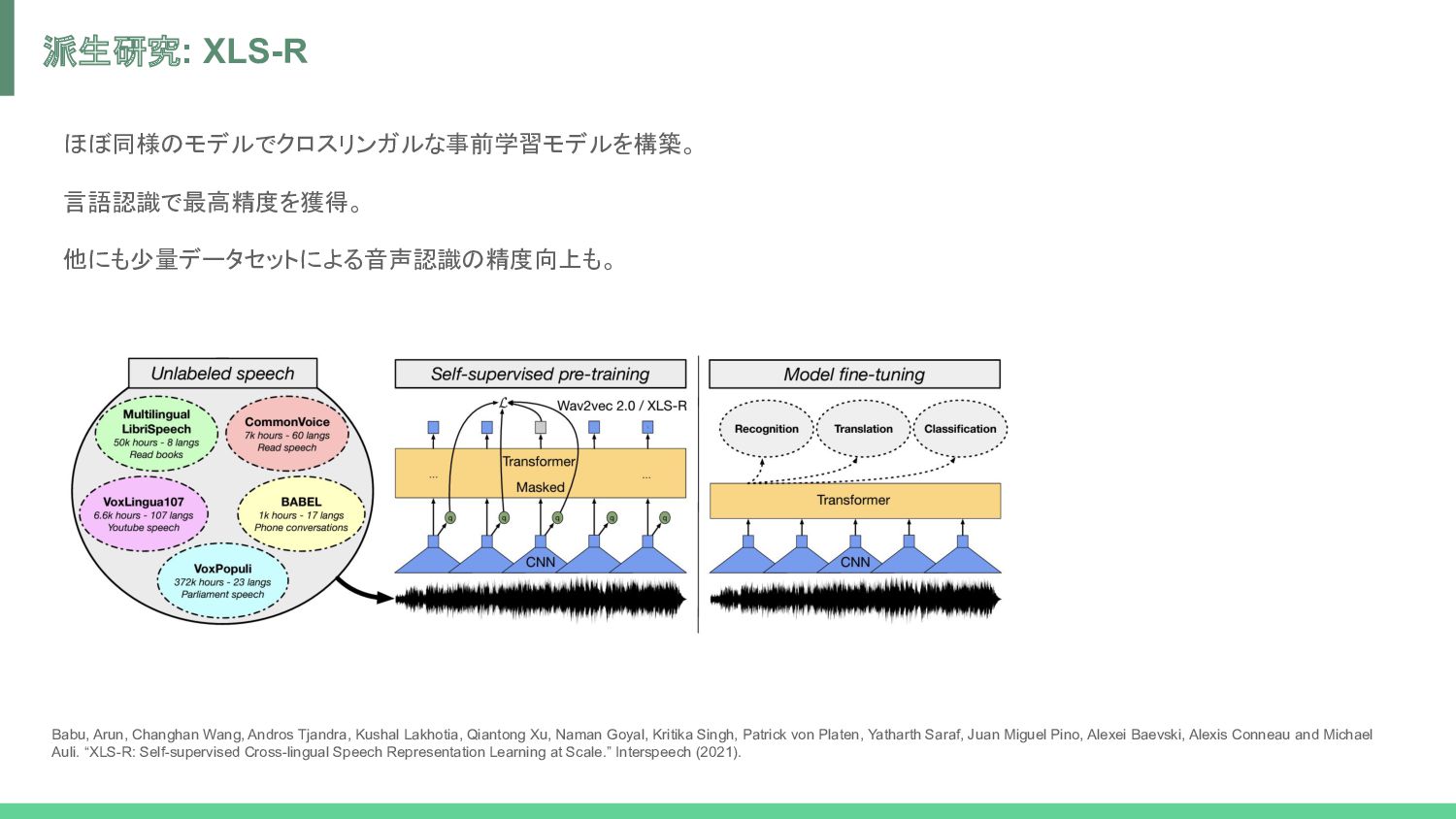
Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Miguel Pino, Alexei Baevski, Alexis Conneau and Michael Auli. “XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale.” Interspeech (2021).
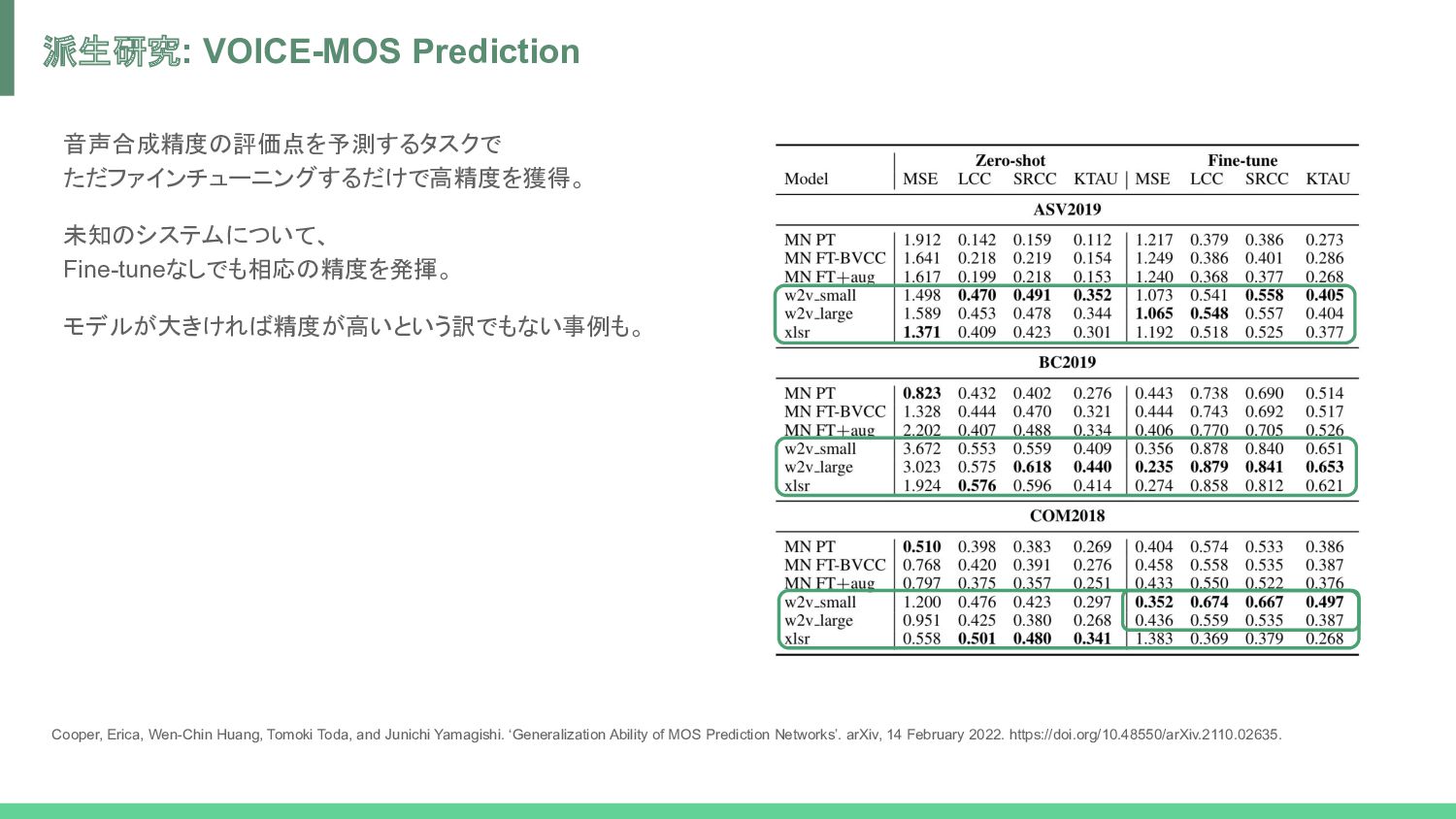
Wen-Chin Huang, Tomoki Toda, and Junichi Yamagishi. ‘Generalization Ability of MOS Prediction Networks’. arXiv, 14 February 2022. https://doi.org/10.48550/arXiv.2110.02635.
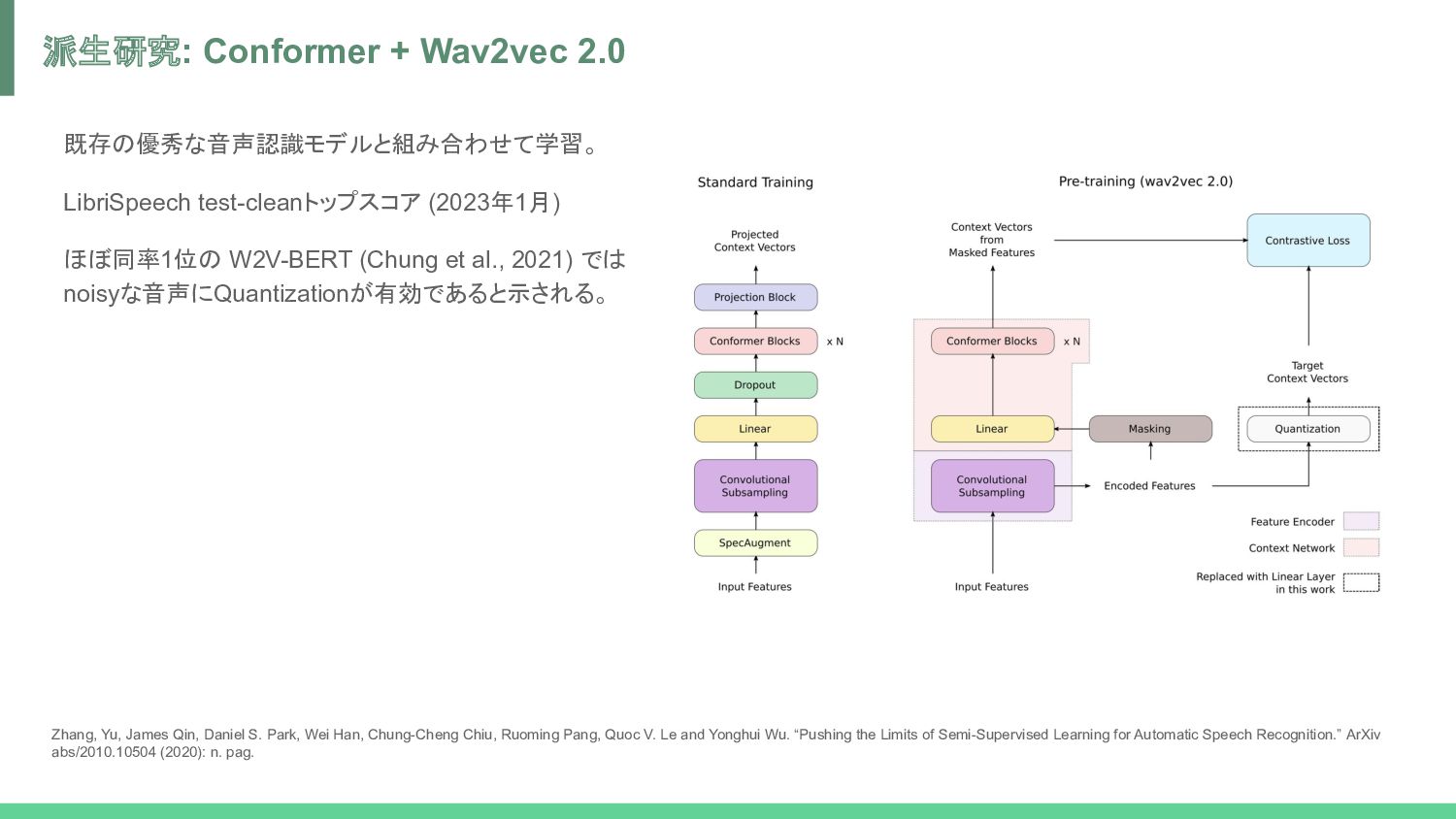
では noisyな音声にQuantizationが有効であると示される。 派生研究: Conformer + Wav2vec 2.0 Zhang, Yu, James Qin, Daniel S. Park, Wei Han, Chung-Cheng Chiu, Ruoming Pang, Quoc V. Le and Yonghui Wu. “Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition.” ArXiv abs/2010.10504 (2020): n. pag.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• BASE ◦ Adamのlr: 5 × 10−4 をピーク ◦ 音声を250kサンプル(15.6[sec/サンプル])に切り取り](https://files.speakerdeck.com/presentations/05c8abbcd2444a7193b878ddb4f0efea/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
![Librispeech LM コーパスから2種類のLM(言語モデル)を定義。(詳細は追いきれず...) Ax*を使って、言語モデル内の重みを[0,5] 単語挿入ペナルティを[-5,5] の範囲でベイズ最適化。 最適化の過程で128 回のビームサーチを試み、dev-other(開発用に分割したデータセットのうち雑音を含むもの。含まないのは dev-clean)でのパフォーマンスに従って最適な重みのセットを選択*1。 •](https://files.speakerdeck.com/presentations/05c8abbcd2444a7193b878ddb4f0efea/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}