Градиентный спуск, двоичная классификация, адаптивный линейный нейрон ADALINE
- Мыслящая машина класса "Перцептрон" научилась различать левое и правое после пятидесяти попыток. Позже перцептроны смогут распознавать людей и называть их по имени. В принципе, можно построить мозги, которые смогут воспроизводить себя на конвейере и которые будут осознавать собственное существование. Интервью Фрэнка Розенблатта газете New Yourk Times, 1958 год.
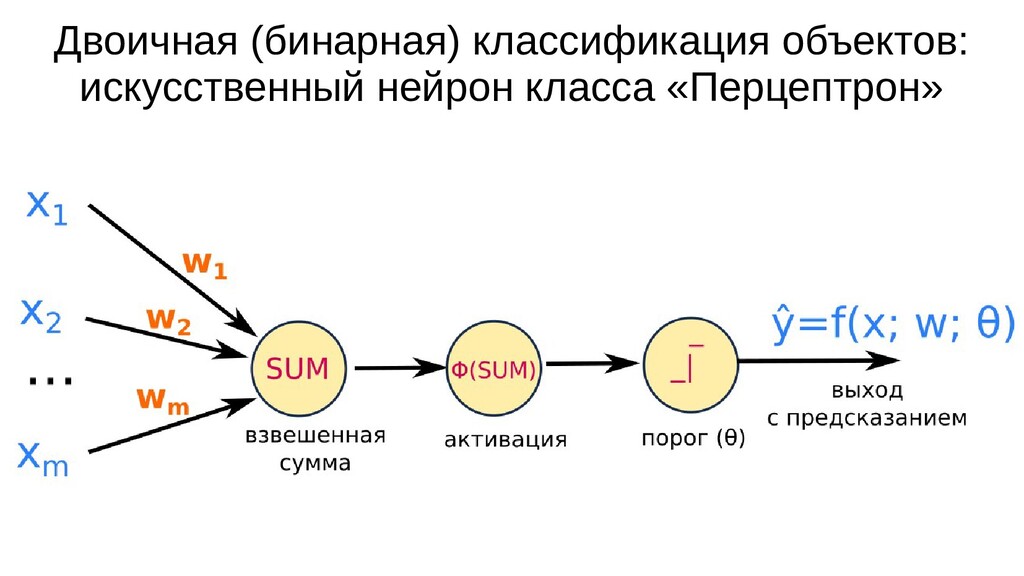
- Архитектура искусственного нейрона класса "Перцептрон": взвешенная сумма, активация, порог - двоичная классификация
- Линейная активация (взвешенная сумма в качестве активации): адаптивный линейный нейрон
- Математическое представление нейрона
- Постановка задачи: подобрать параметры нейрона
- Геометрический смысл задачи
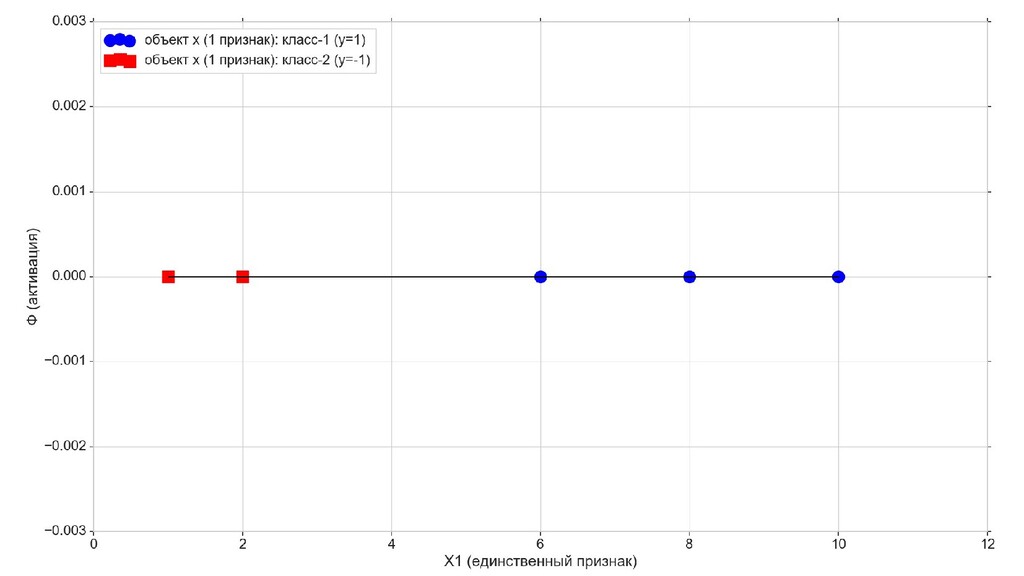
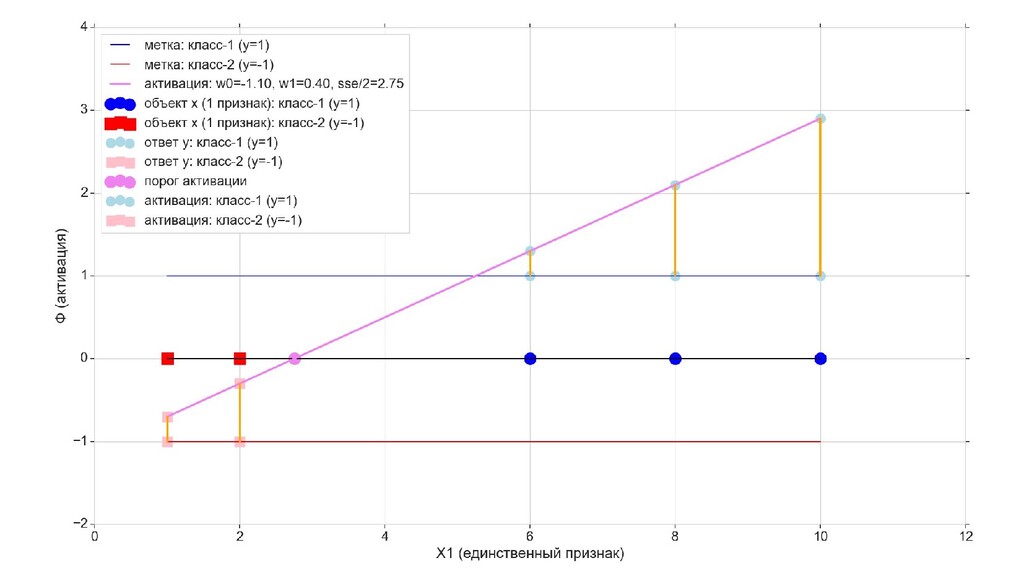
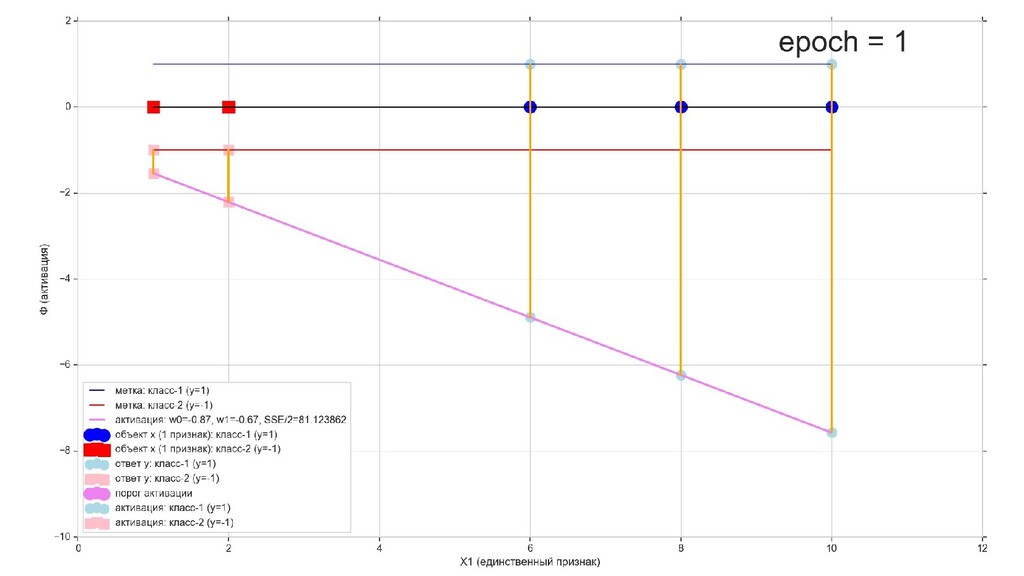
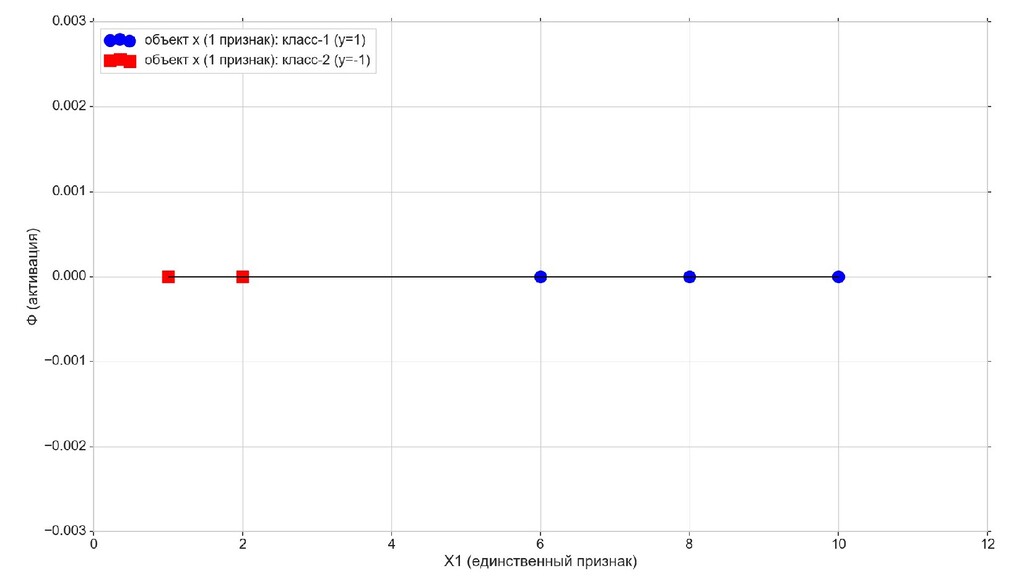
- Решение задачи в 1-мерном пространстве - классификация объектов с единственным признаком
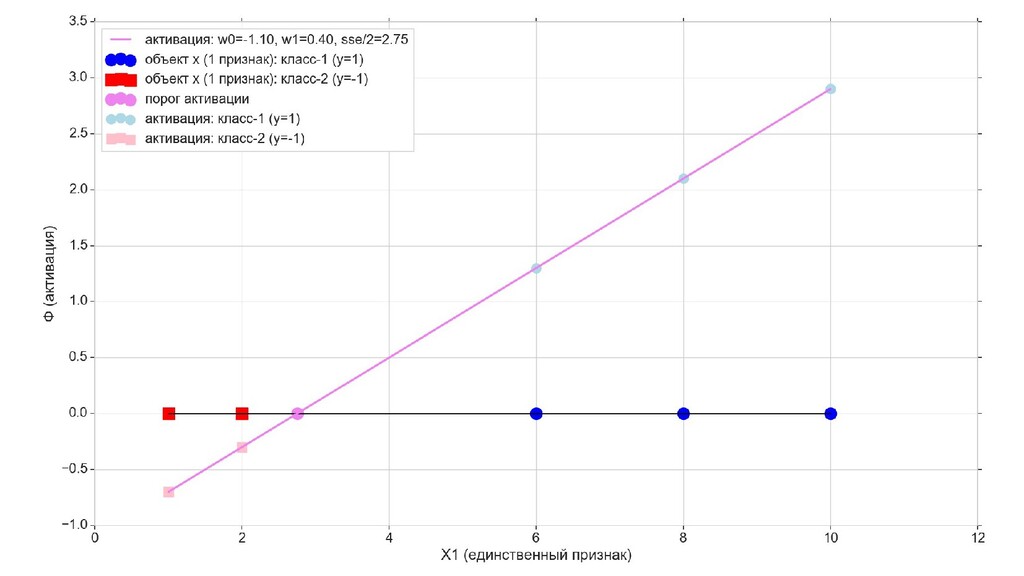
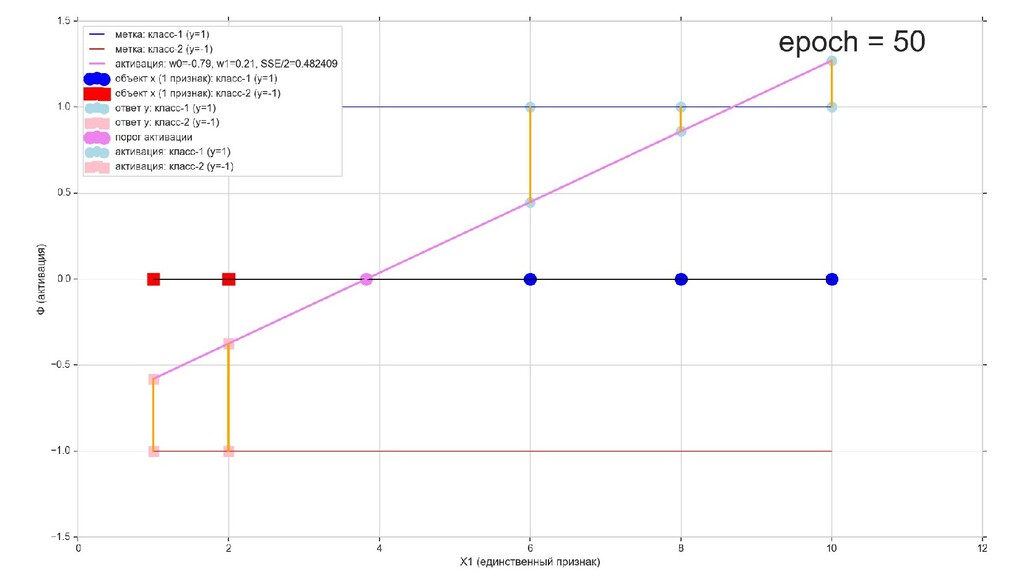
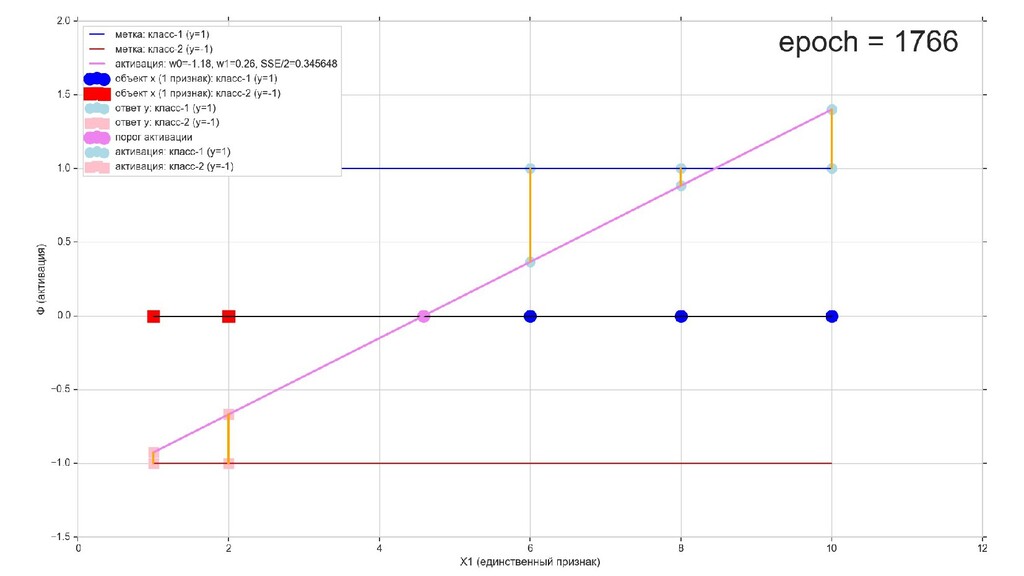
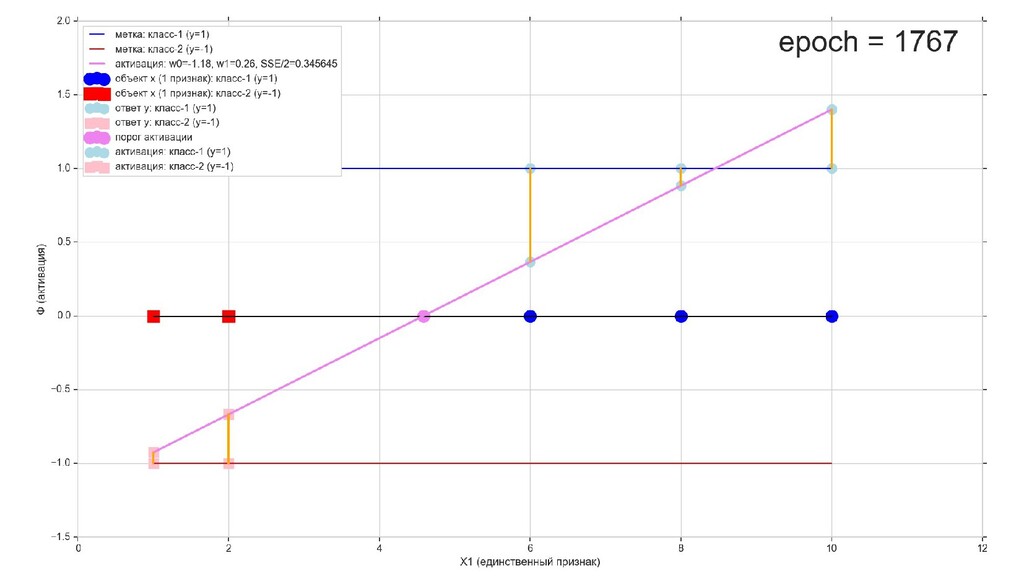
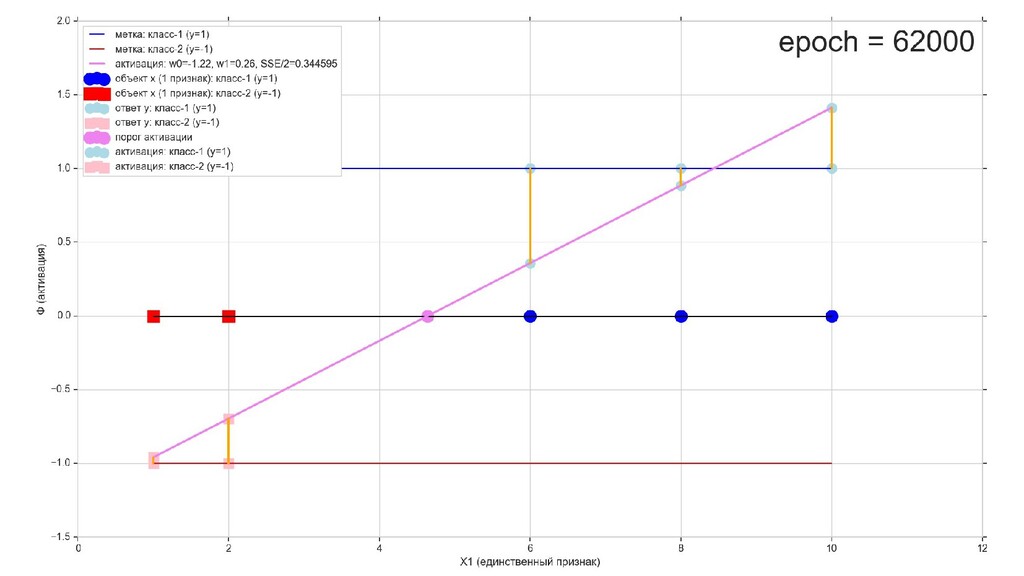
- Геометрический смысл задачи в 1-мерном пространстве
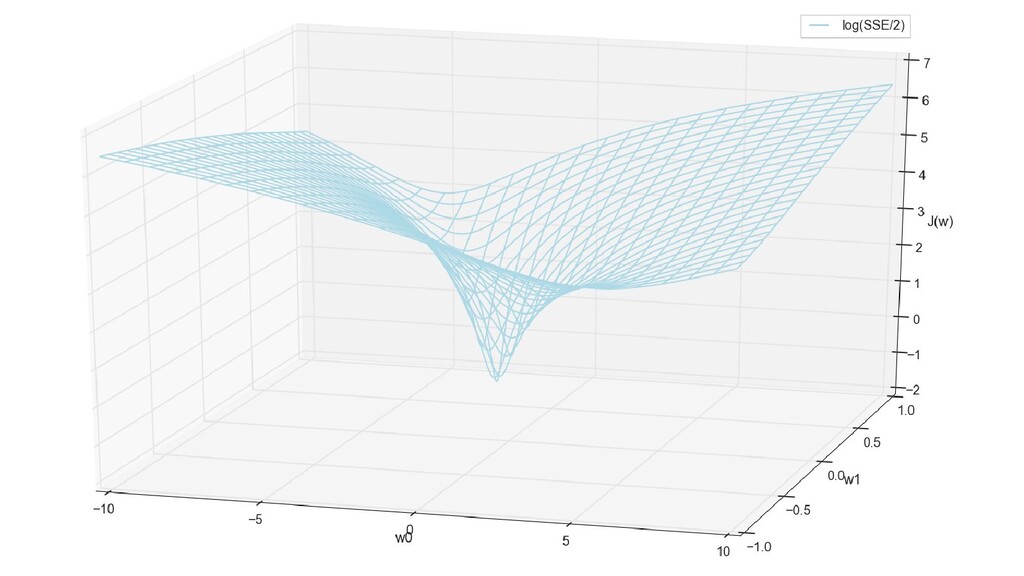
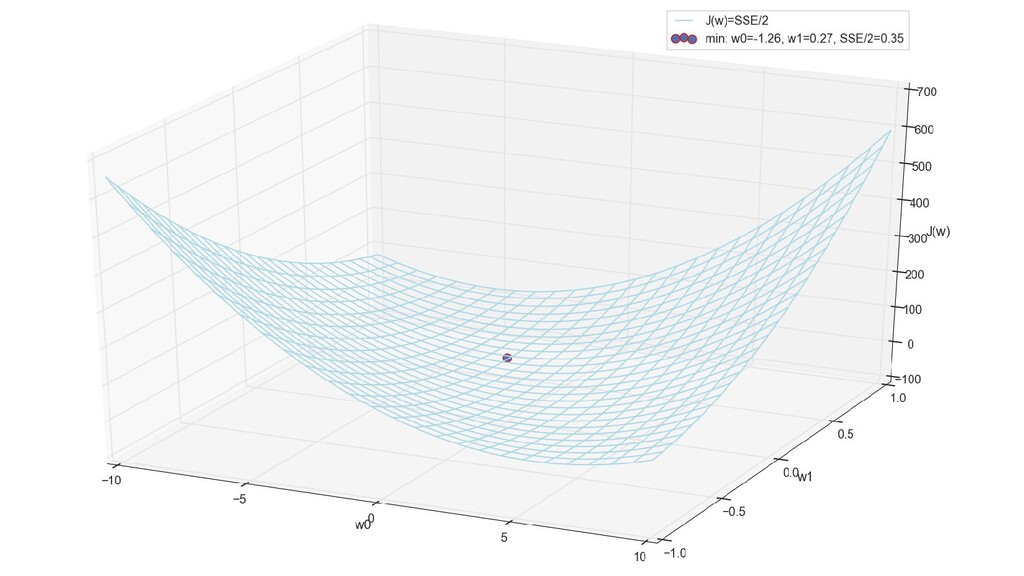
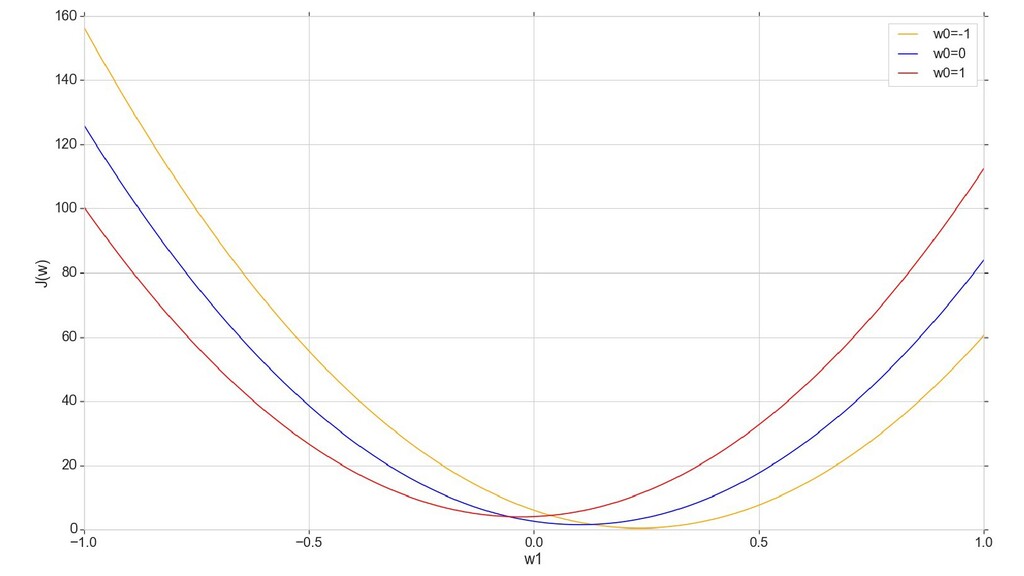
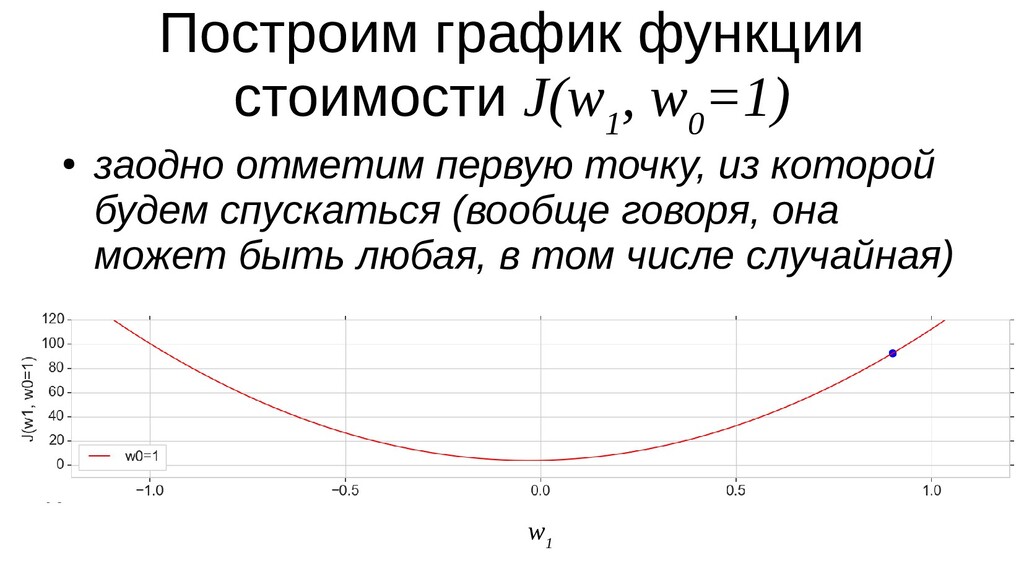
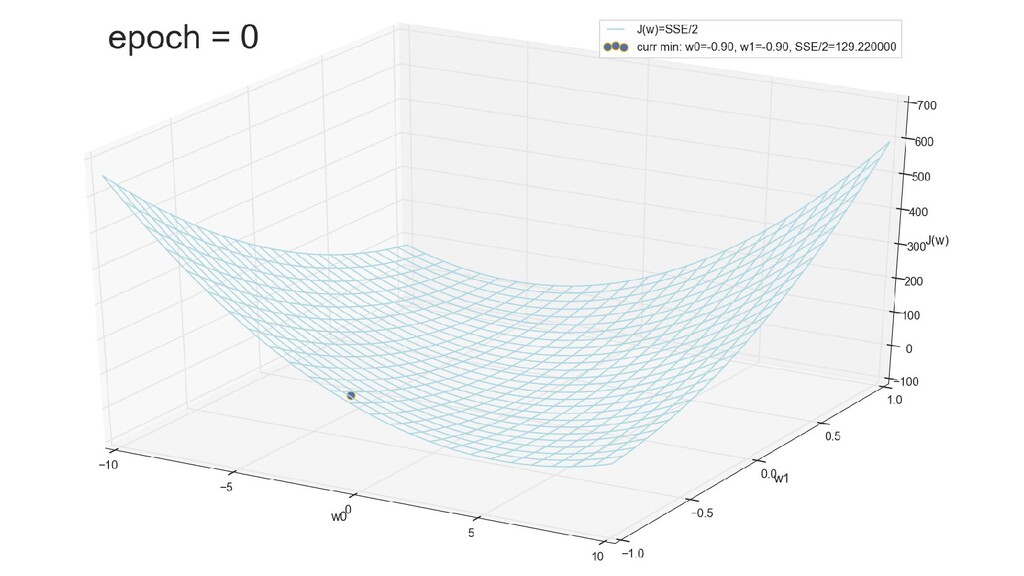
- Введение функции стоимости (она же: функция потерь) - сумма квадратичных ошибок
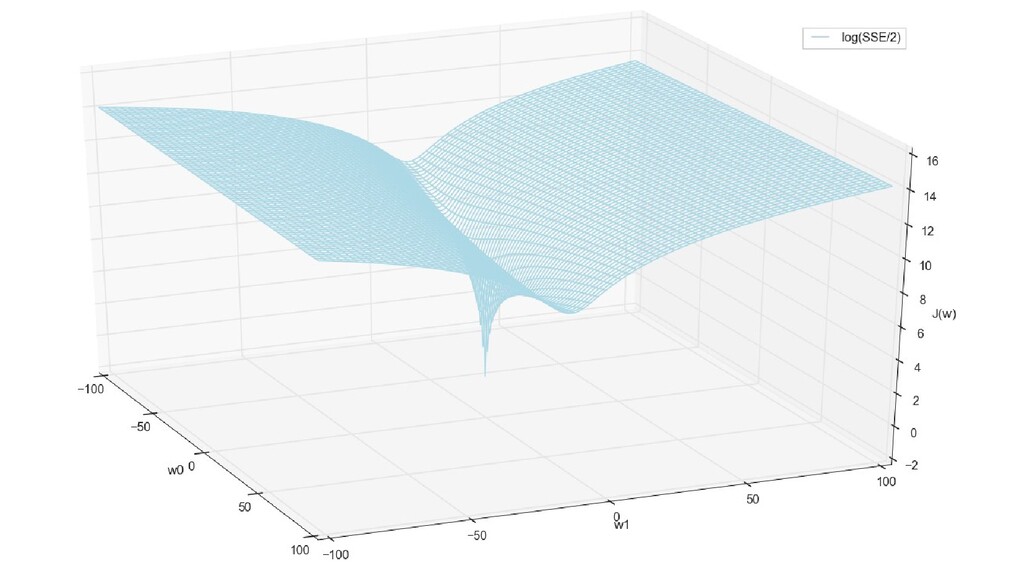
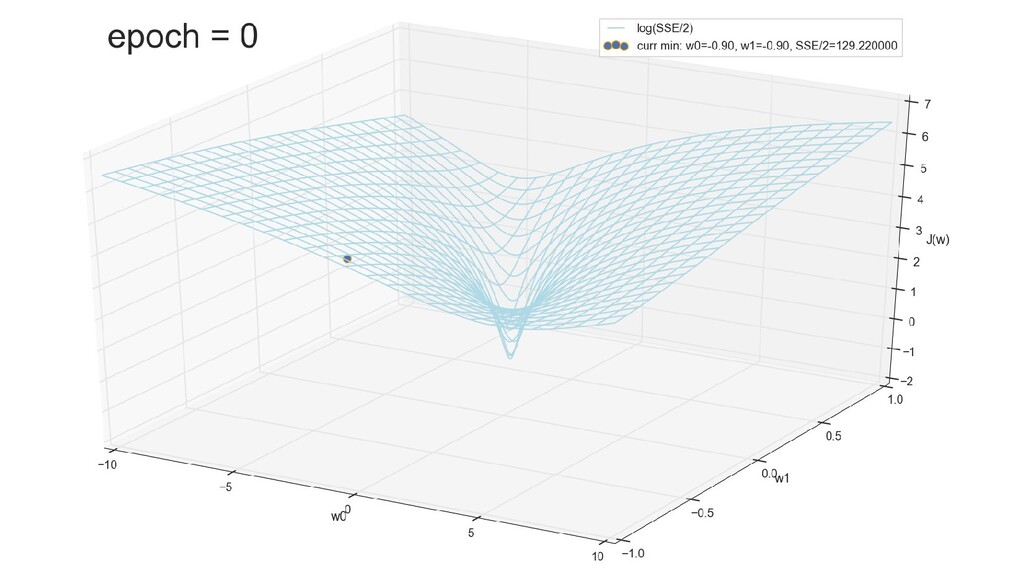
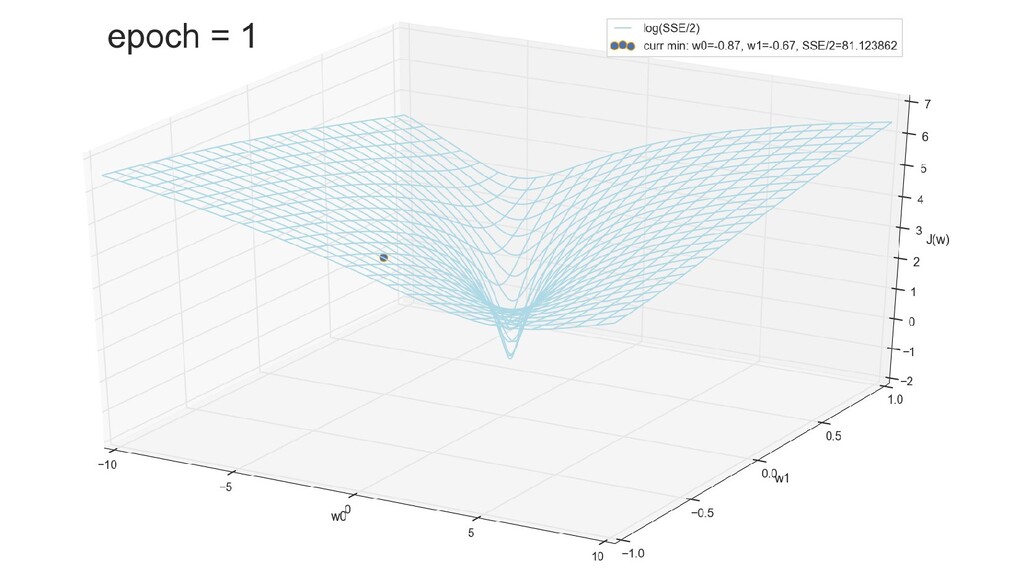
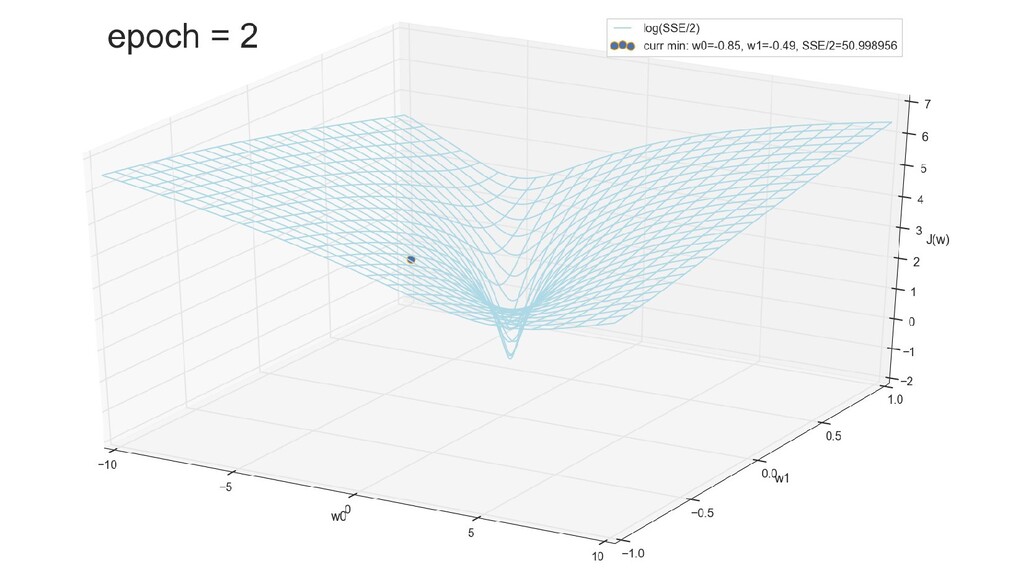
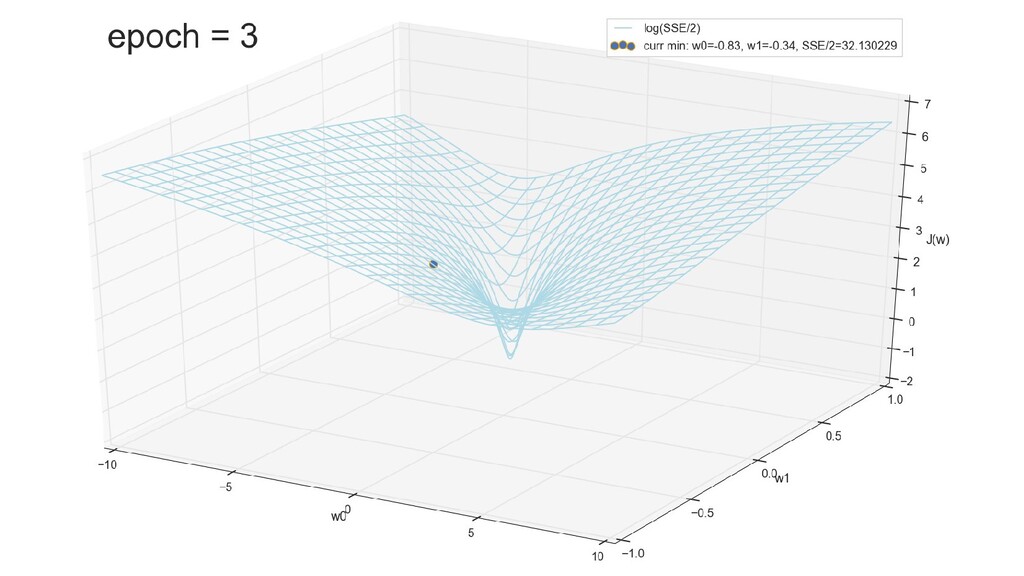
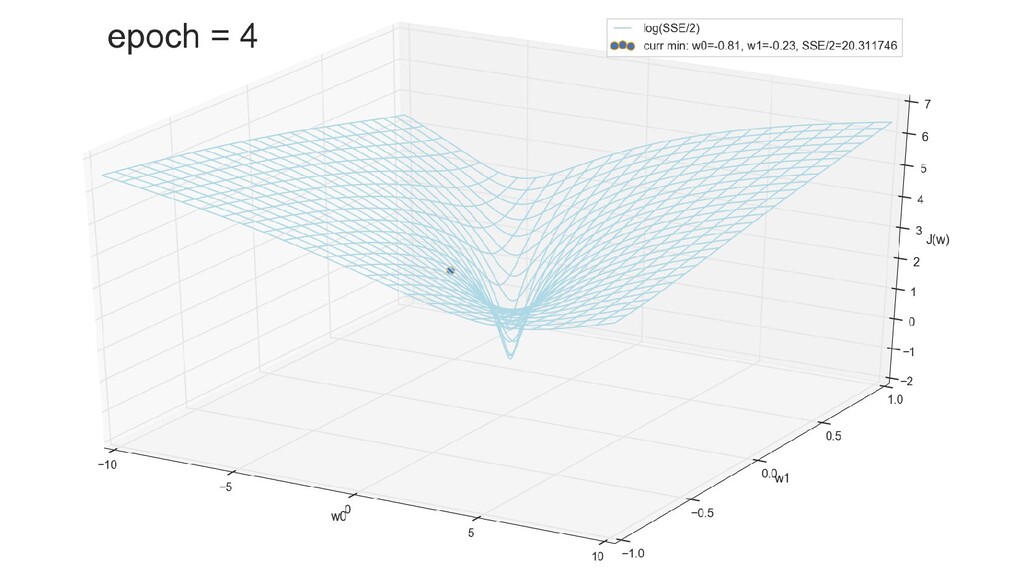
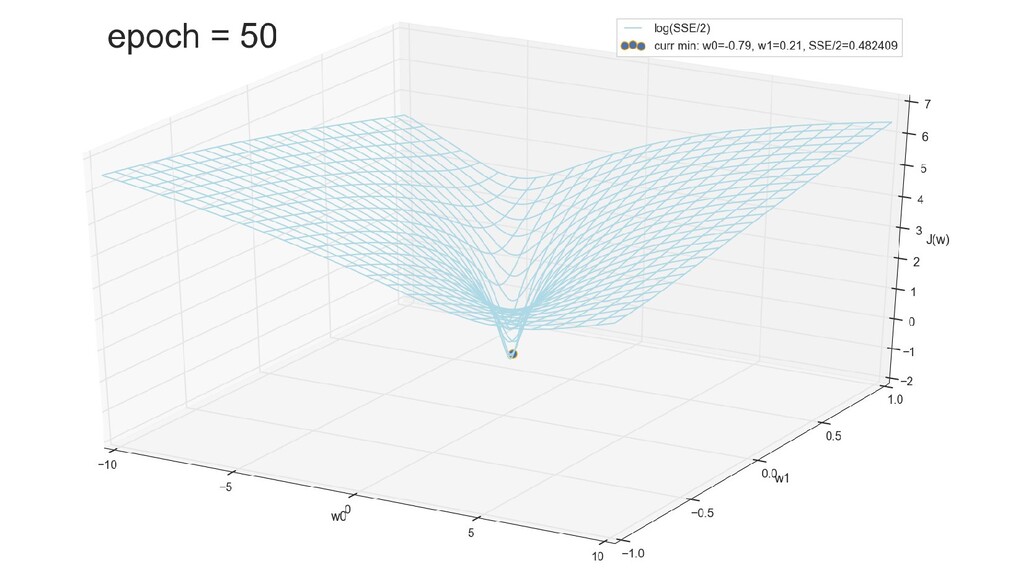
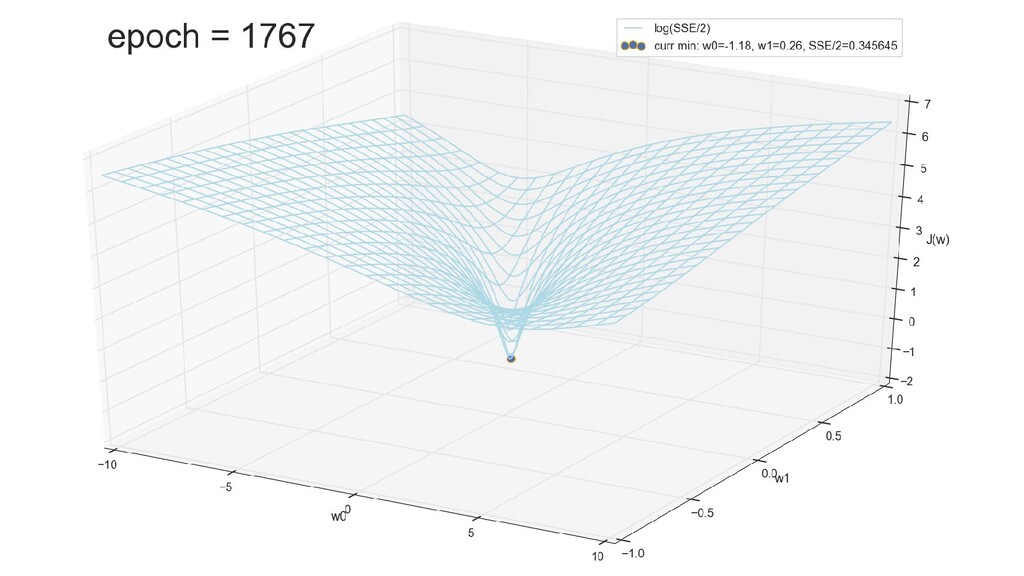
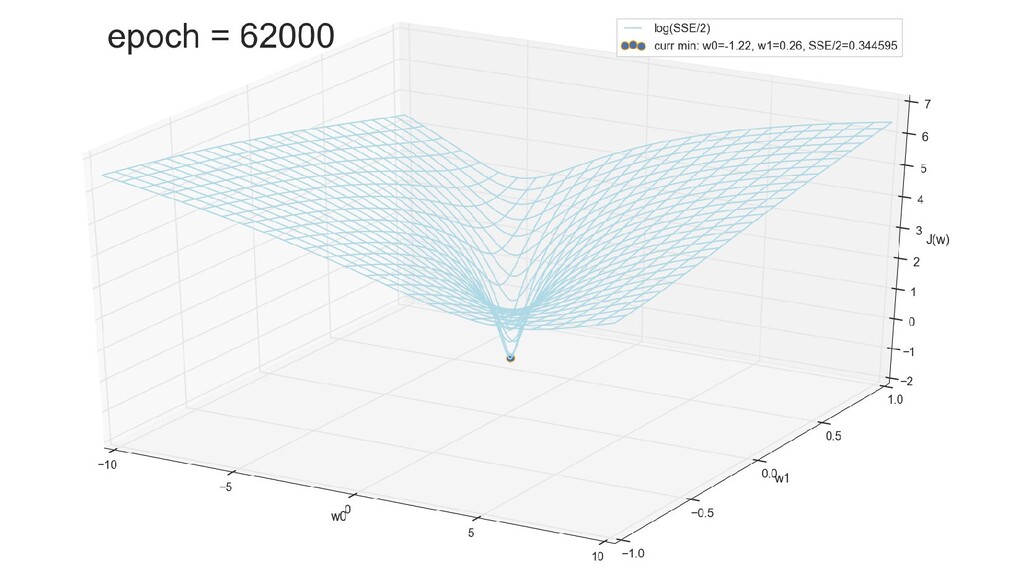
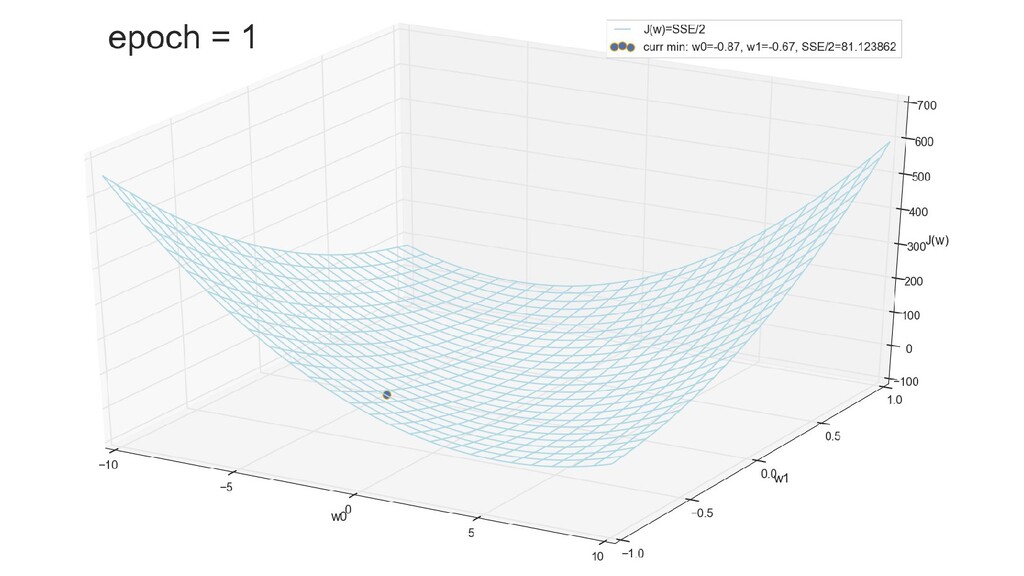
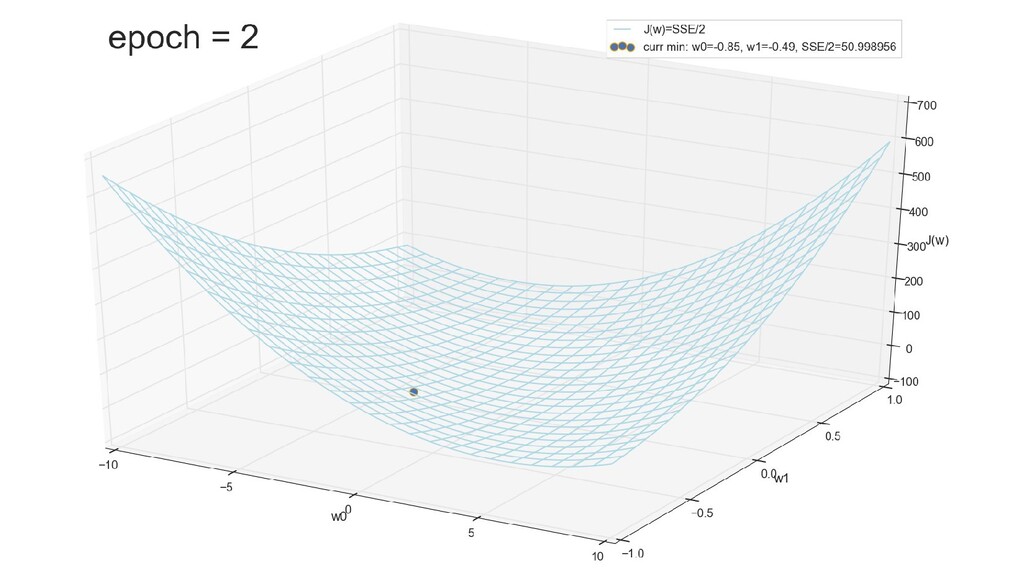
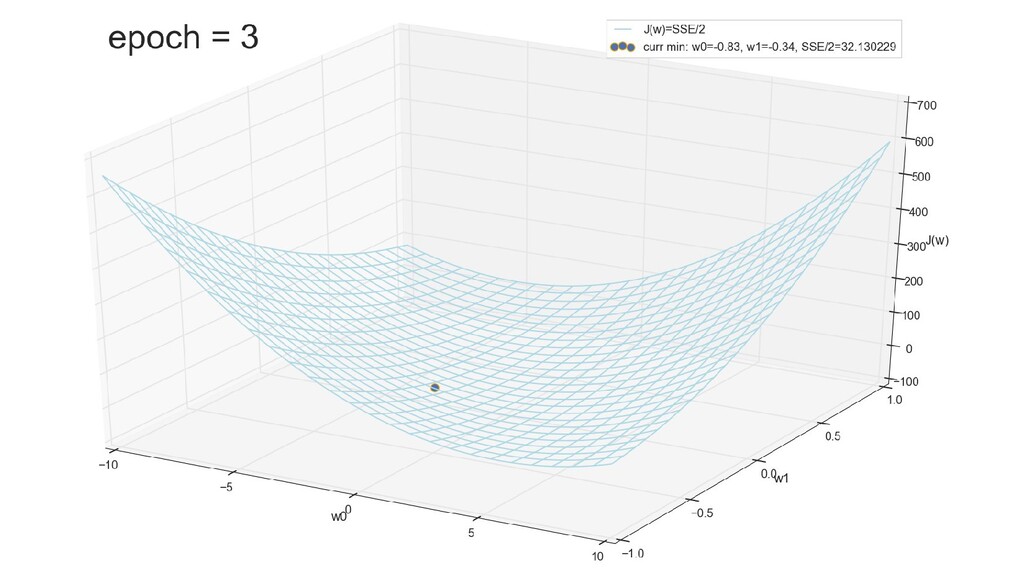
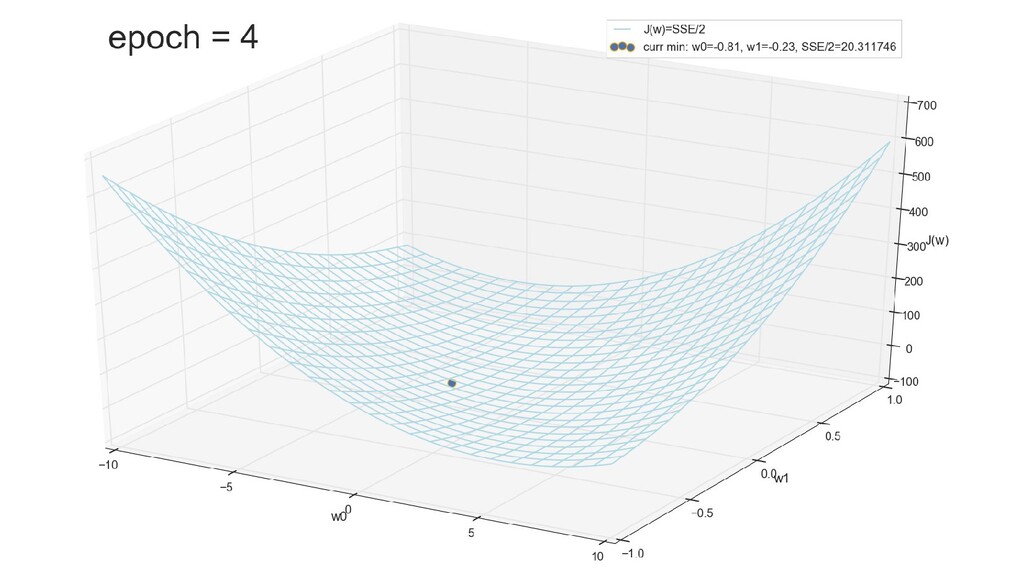
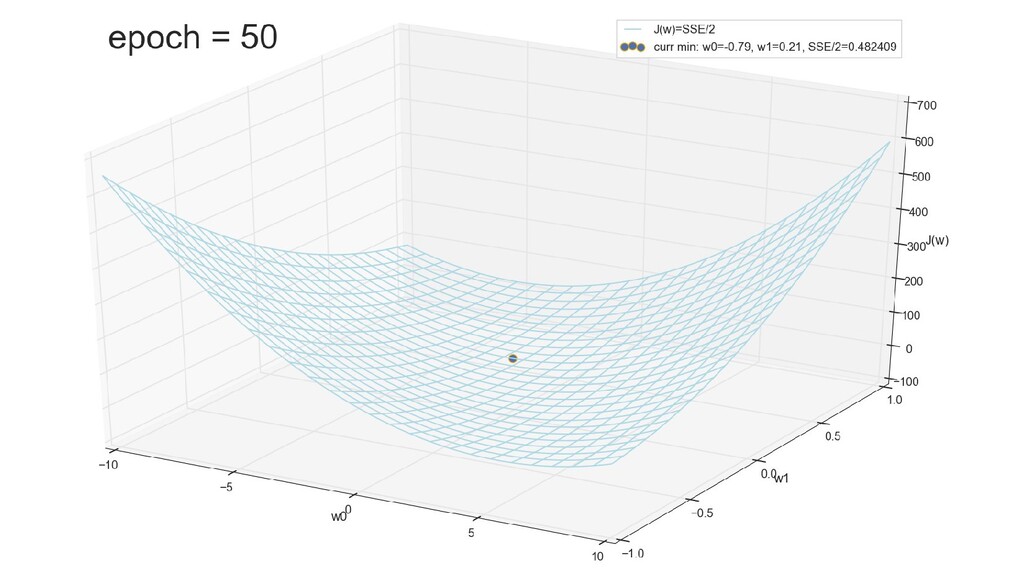
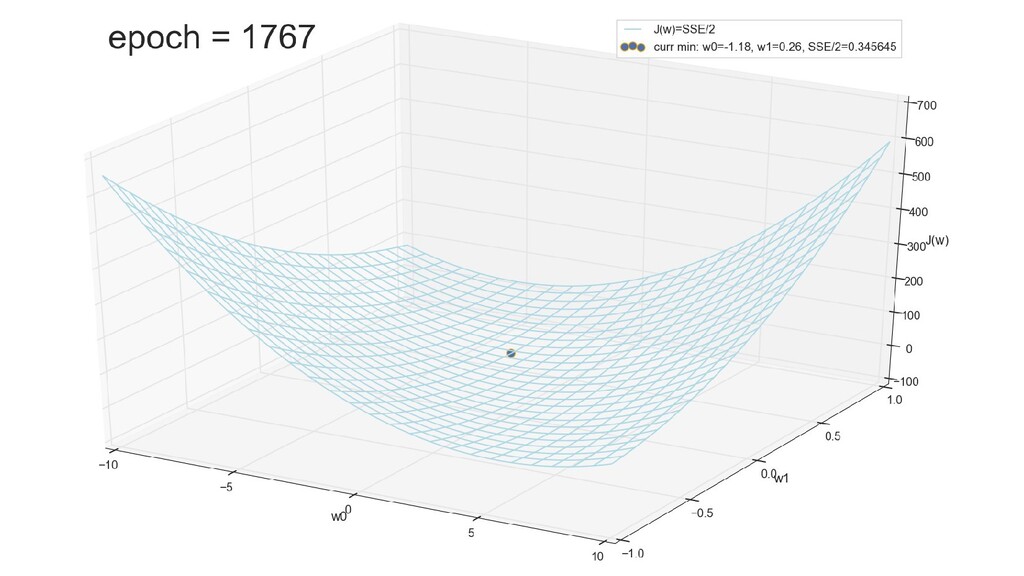
- График функции стоимости в 3-хмерной пространстве (2 параметра полюс значение ошибки): шарик скатывается в воронку
- Поиск минимума: полный перебор по сетке
- Поиск минимума: спуск с постоянным шагом
- Поиск минимума: градиентный спуск
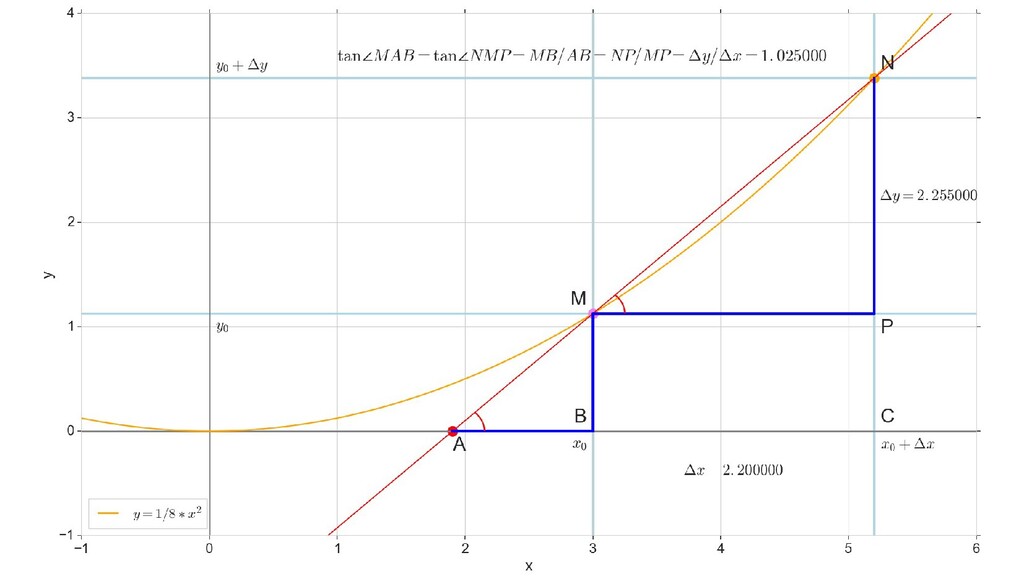
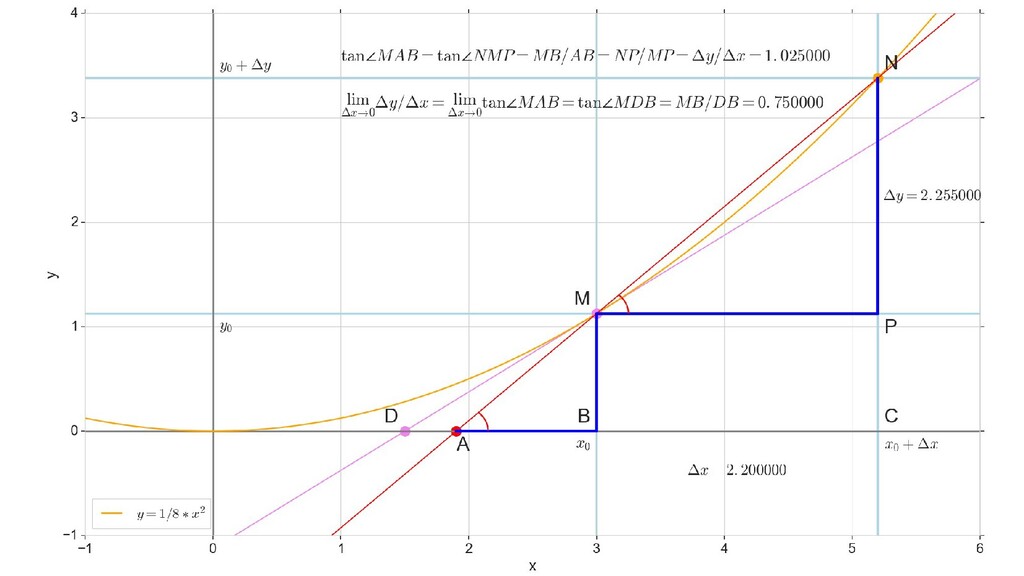
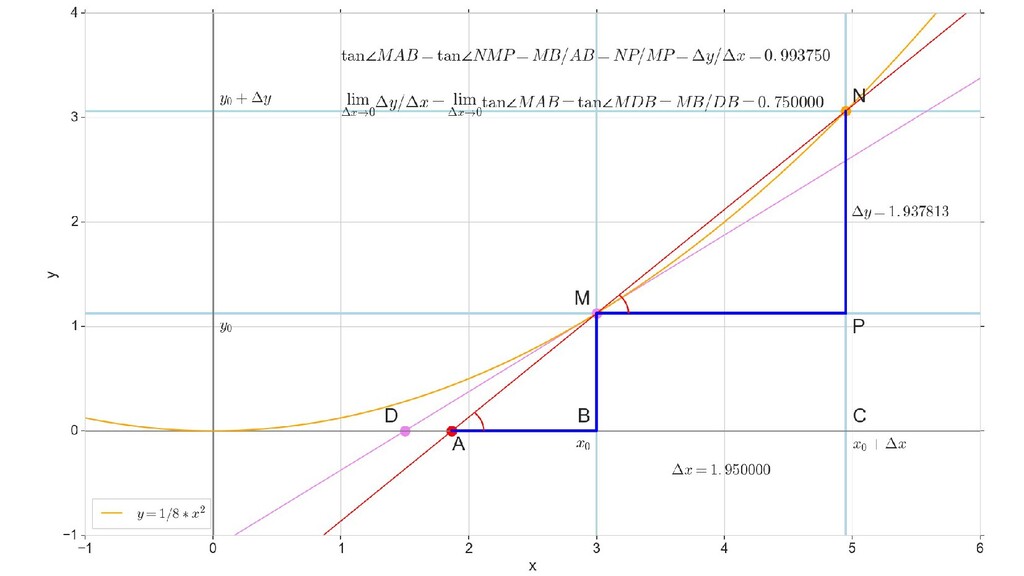
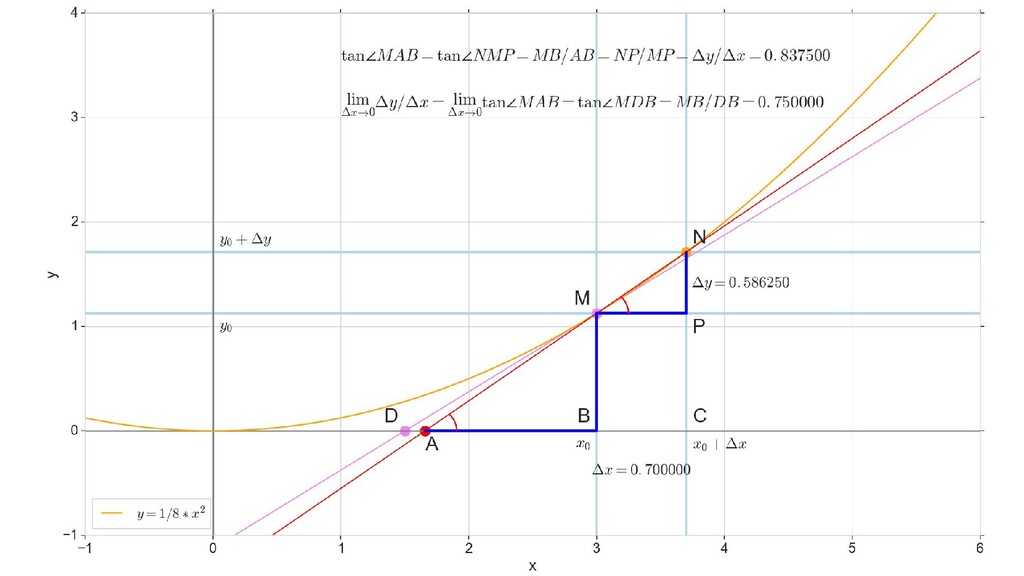
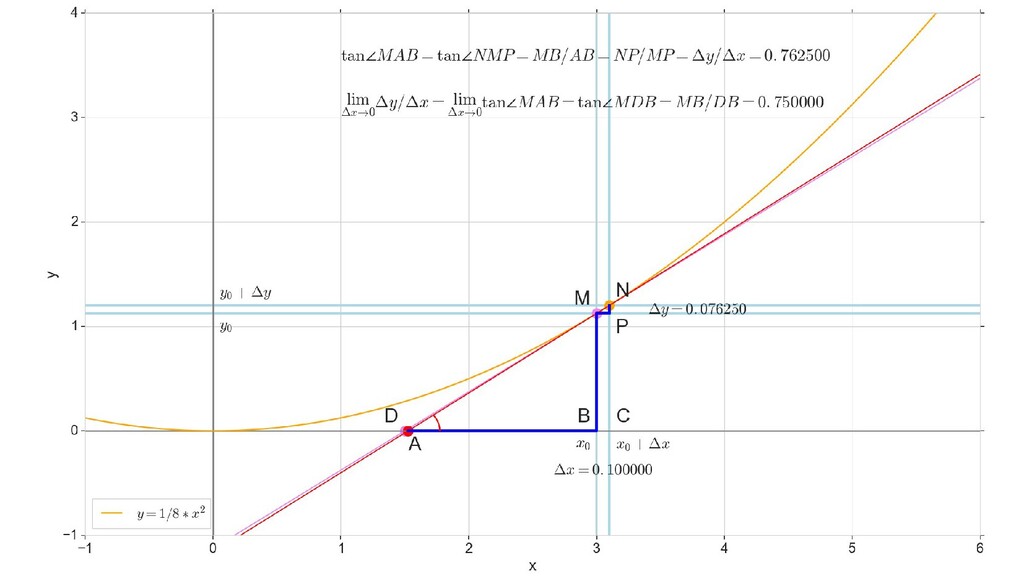
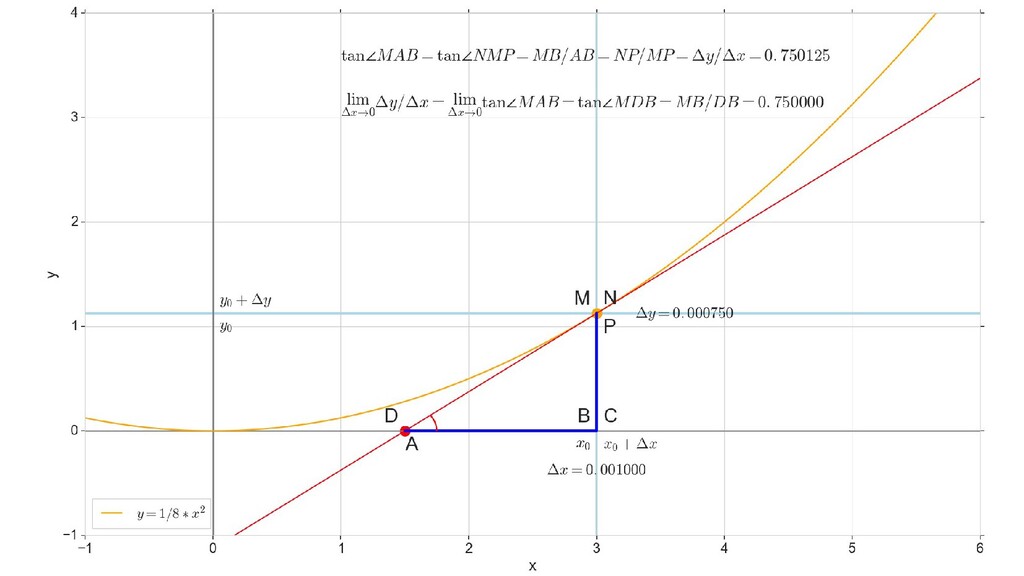
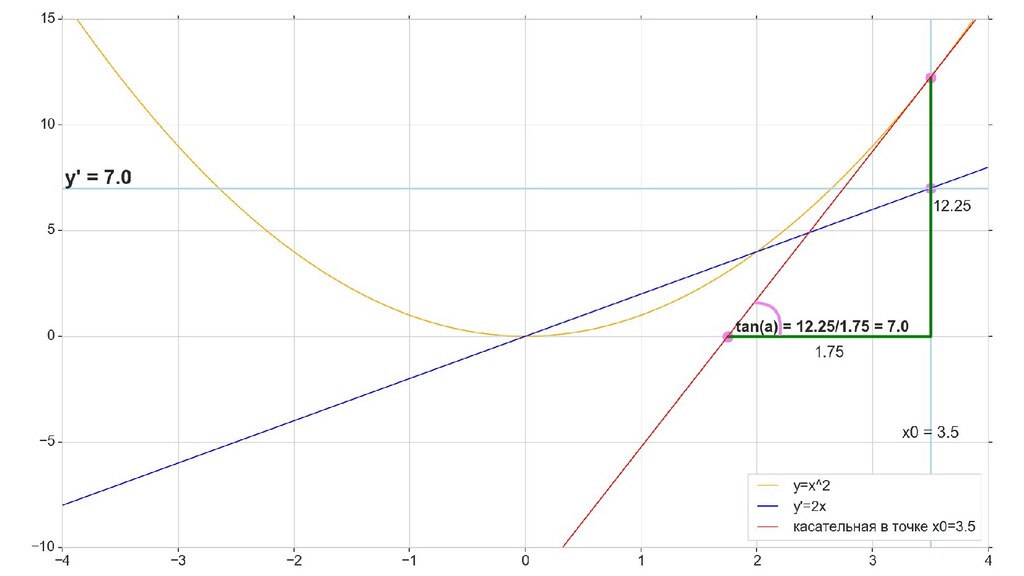
- Геометрический смысл производный
- Производная как индикатор направления и крутизны/пологости спуска
- Частная производная по вектору, вектор частных производных - градиент
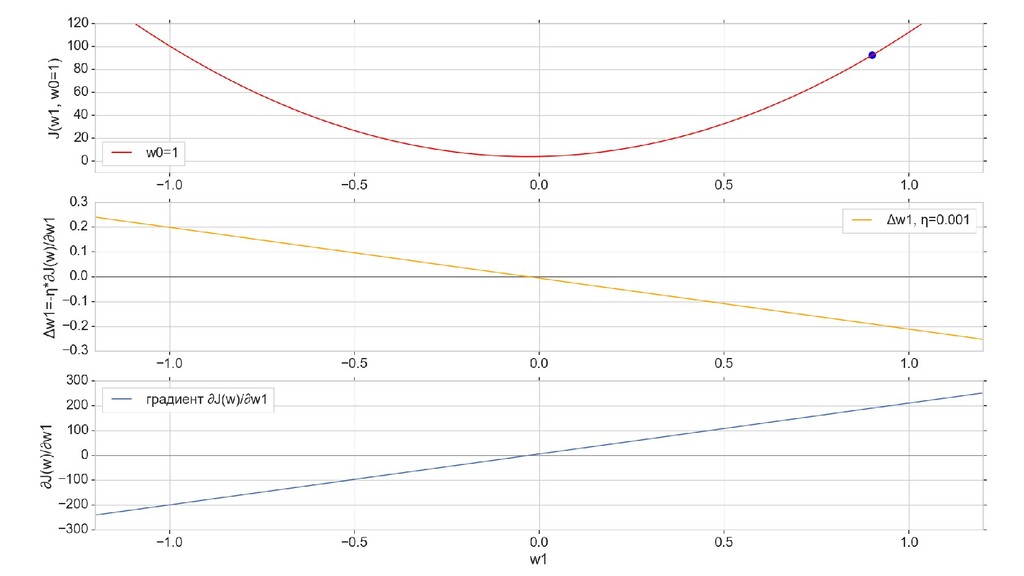
- Градиент функции ошибки для случая 1-д: частная производная функции ошибки по каждому из 2-х параметров
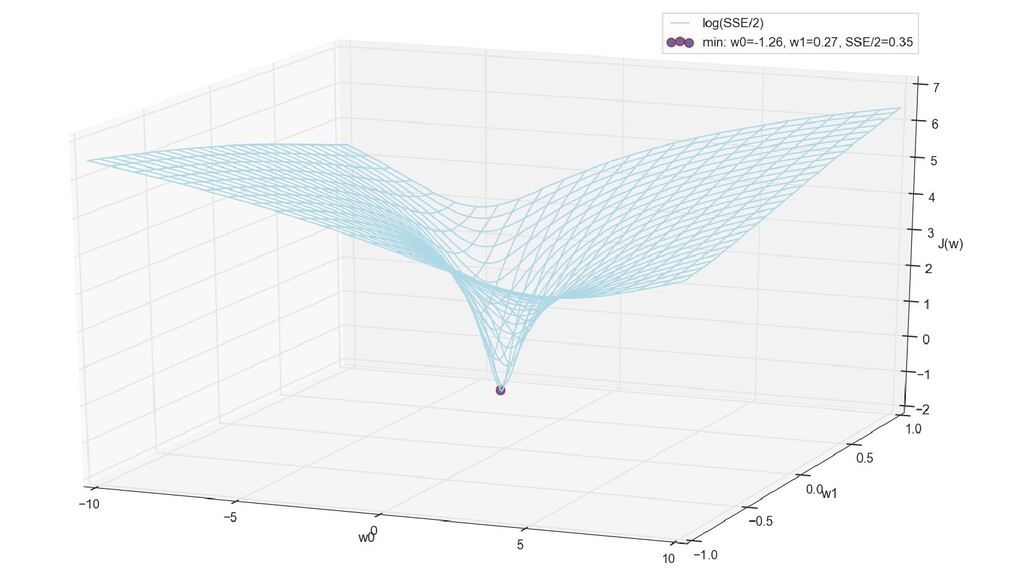
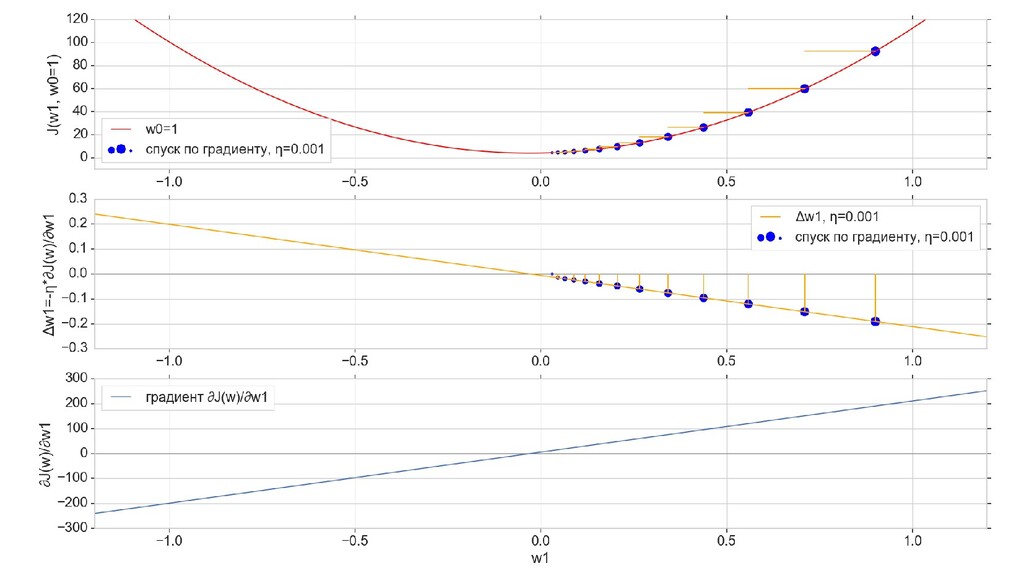
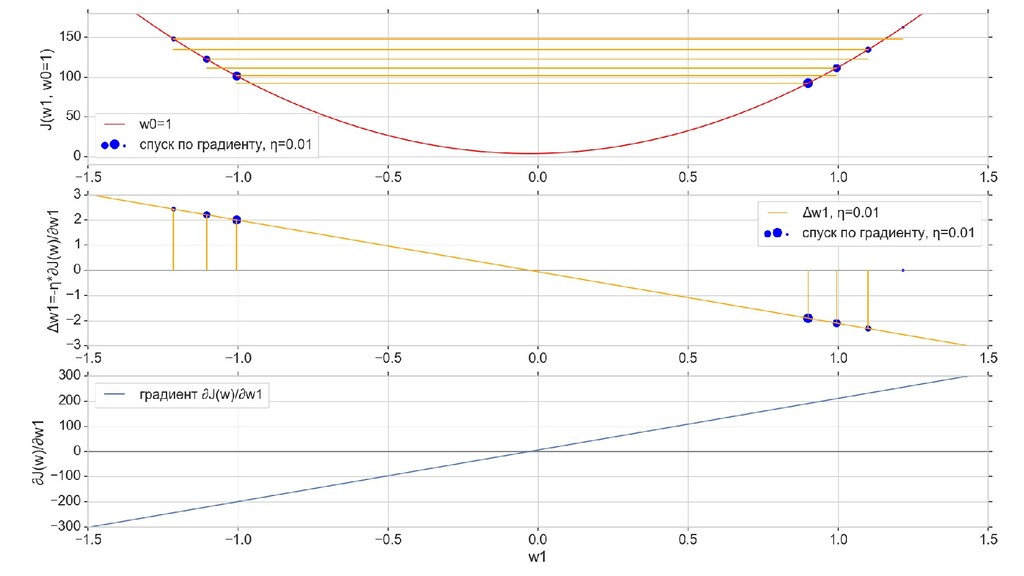
- Итеративный спуск к минимуму функции ошибки по каждому из измерений с использованием градиента: шаг спуска - производная со знаком минус умножить на коэффициент обучения, отвечающий за масштаб
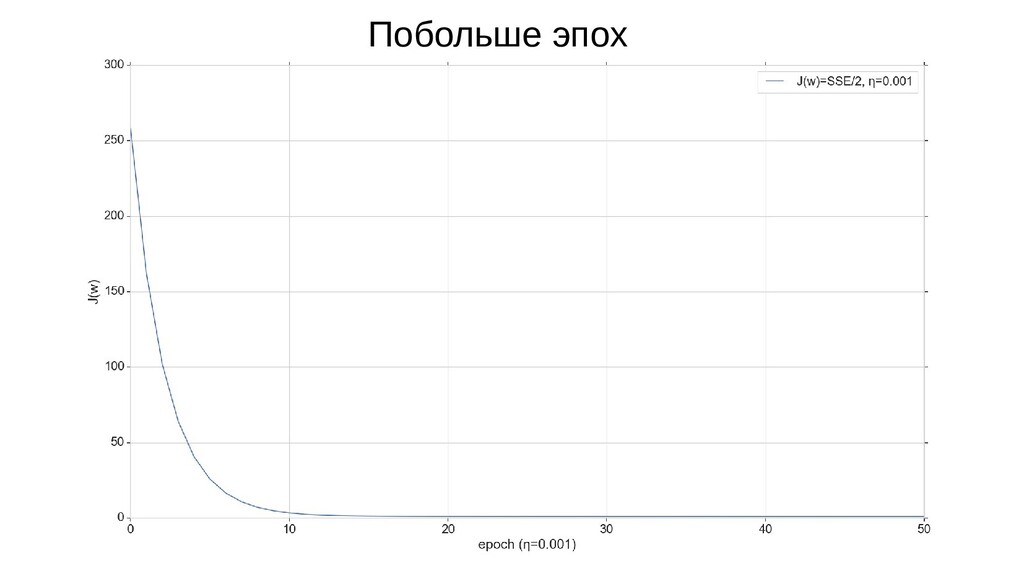
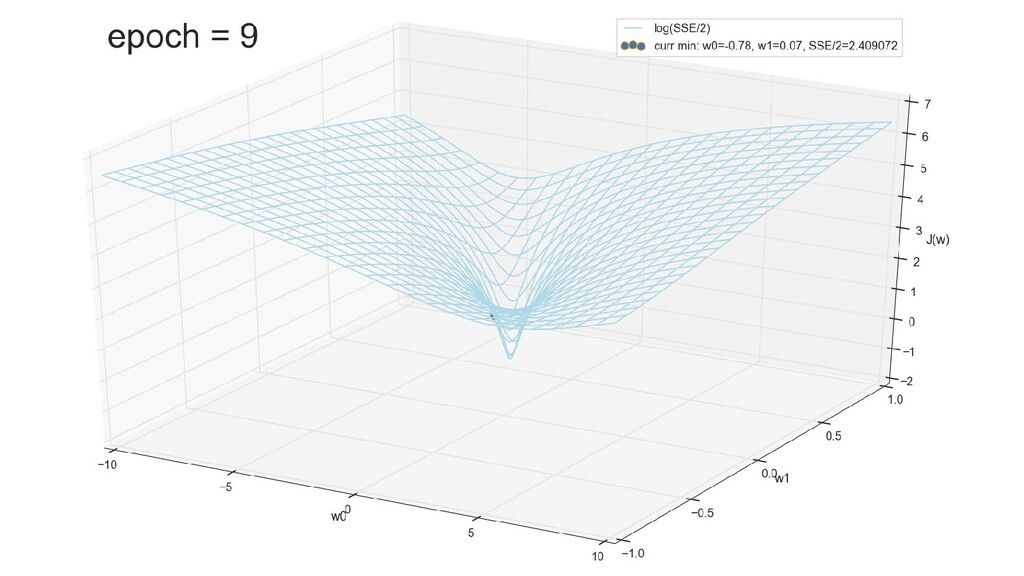
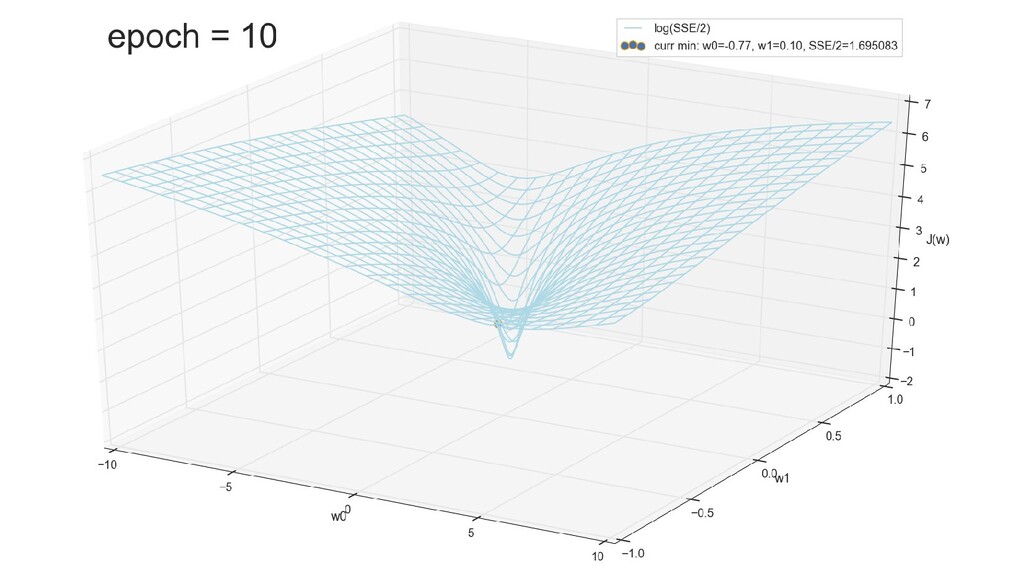
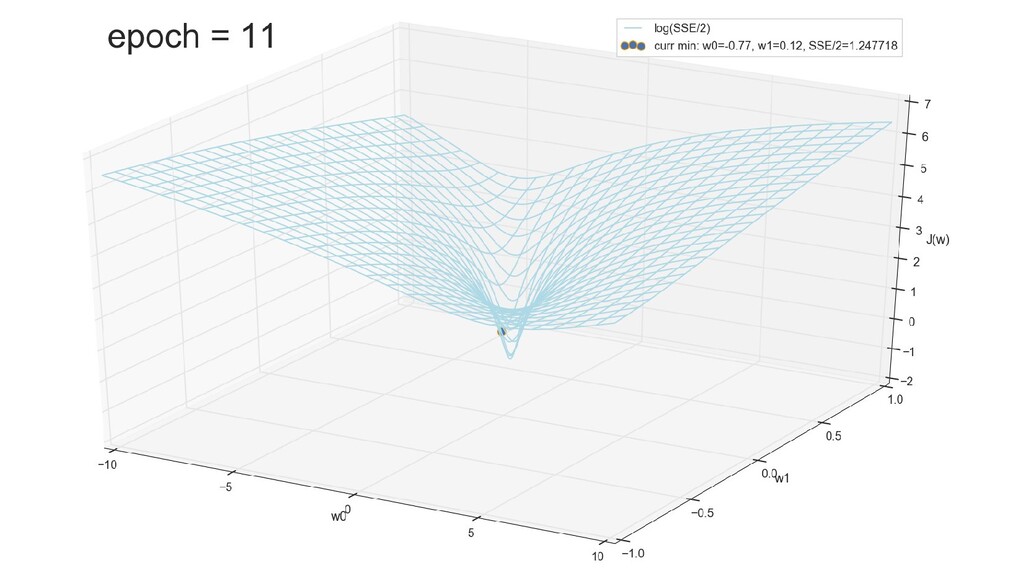
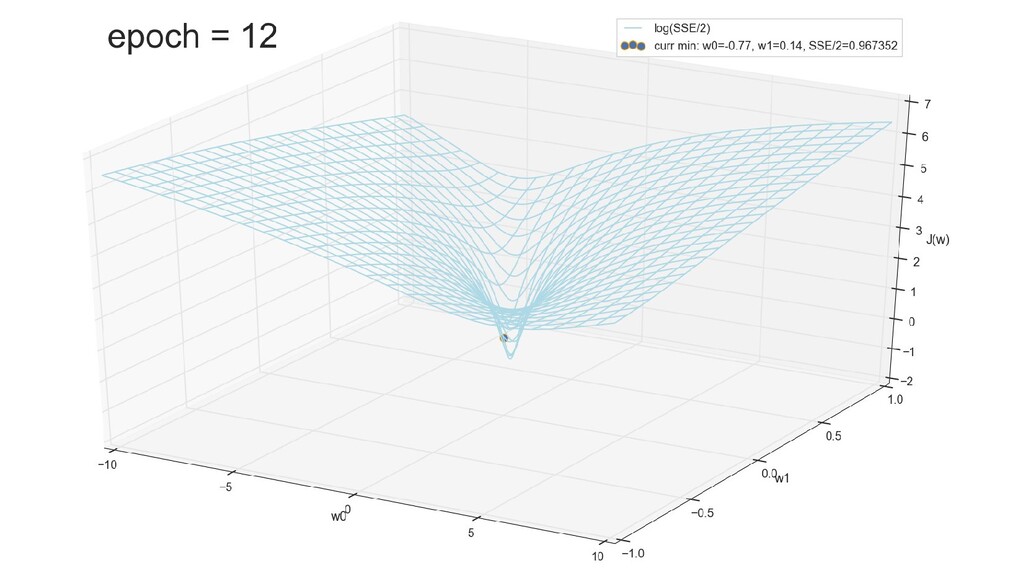
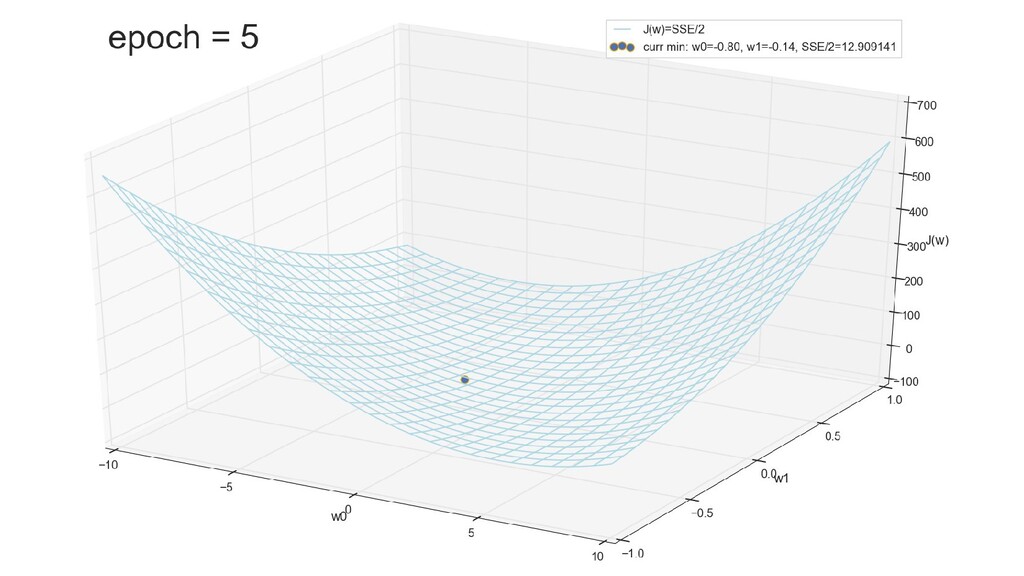
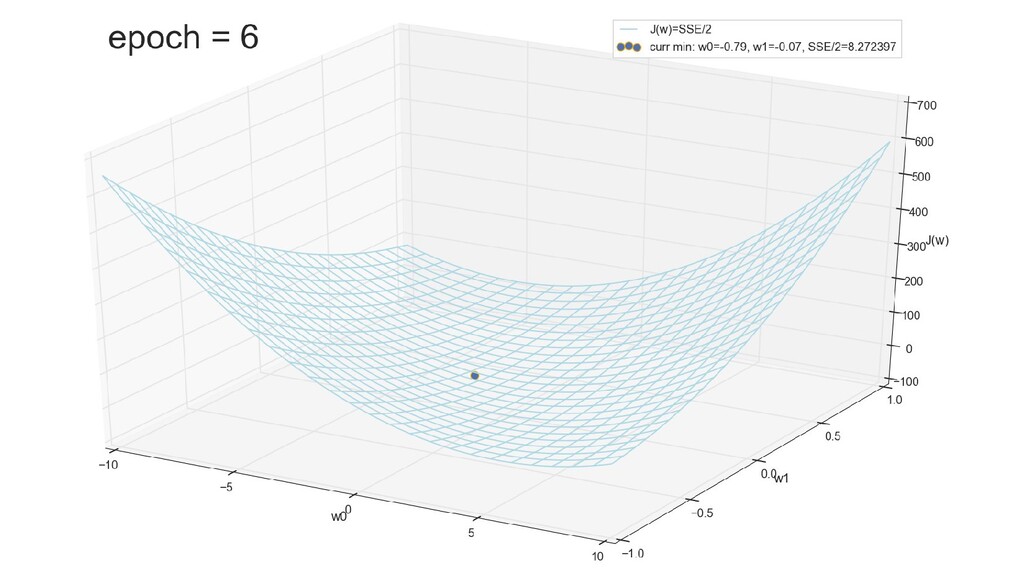
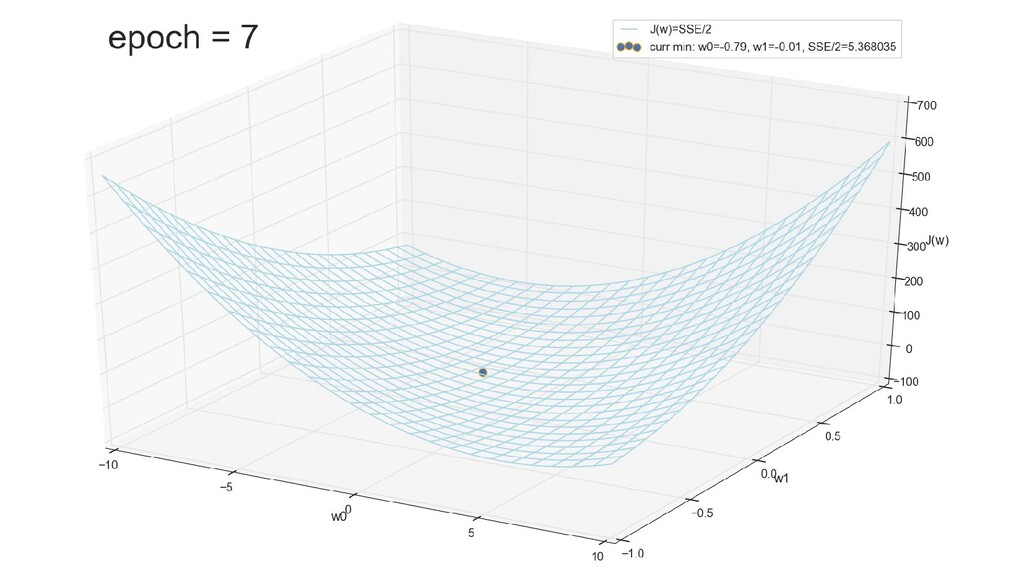
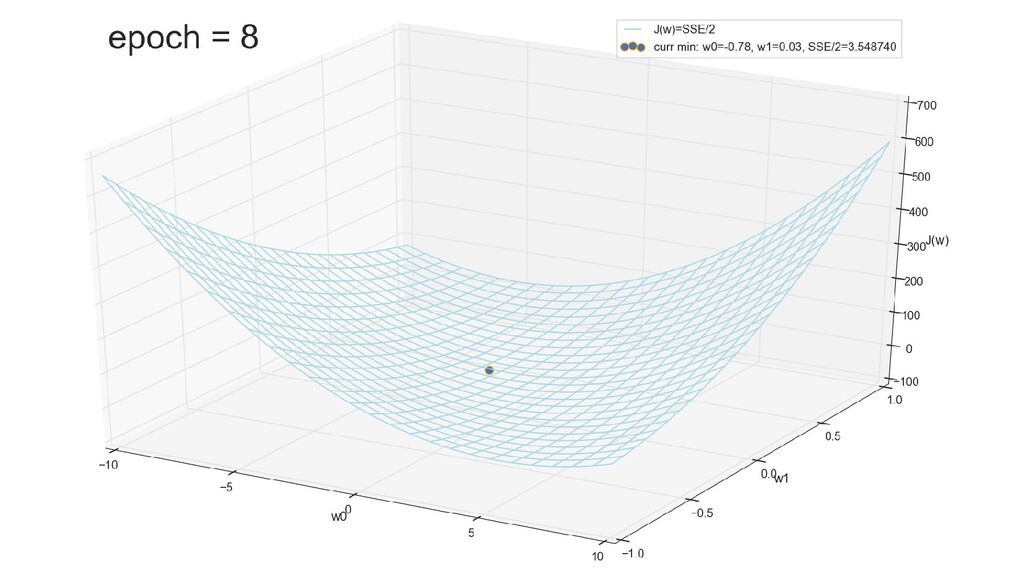
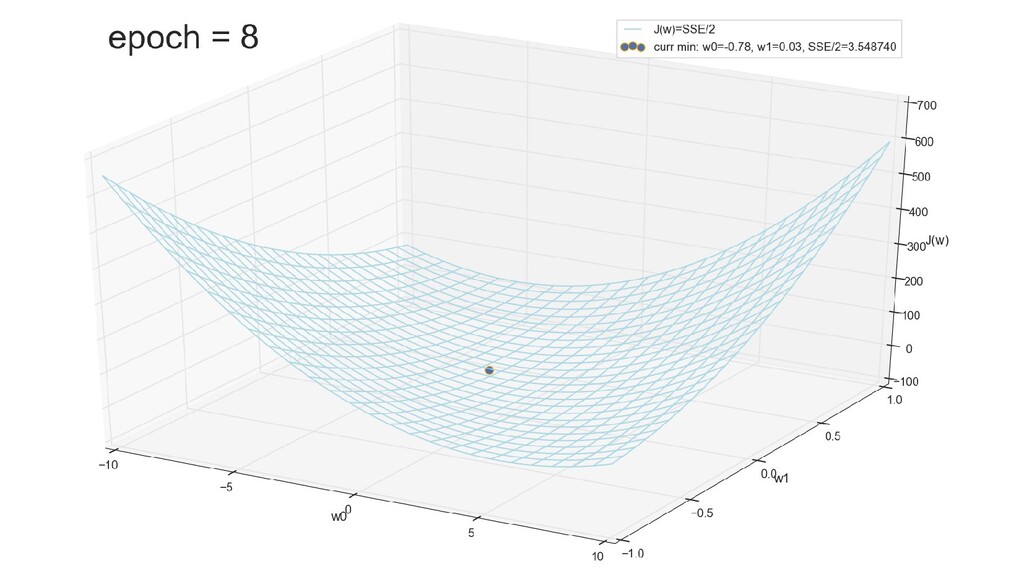
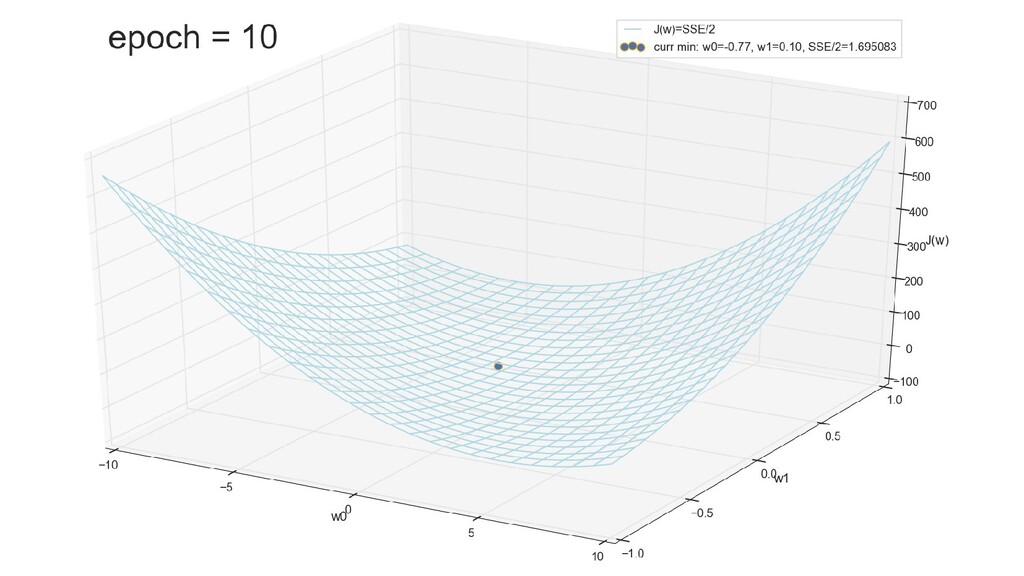
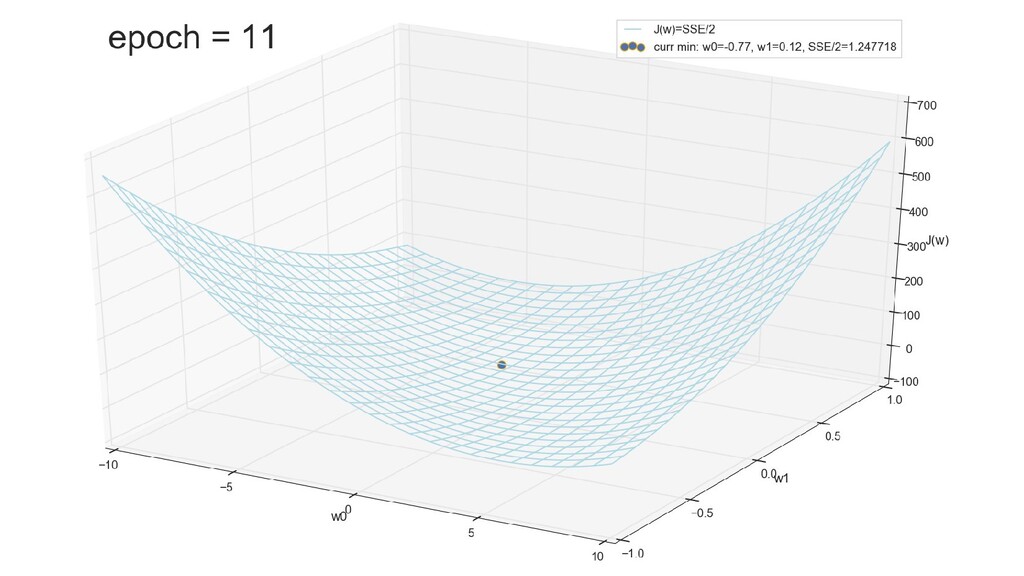
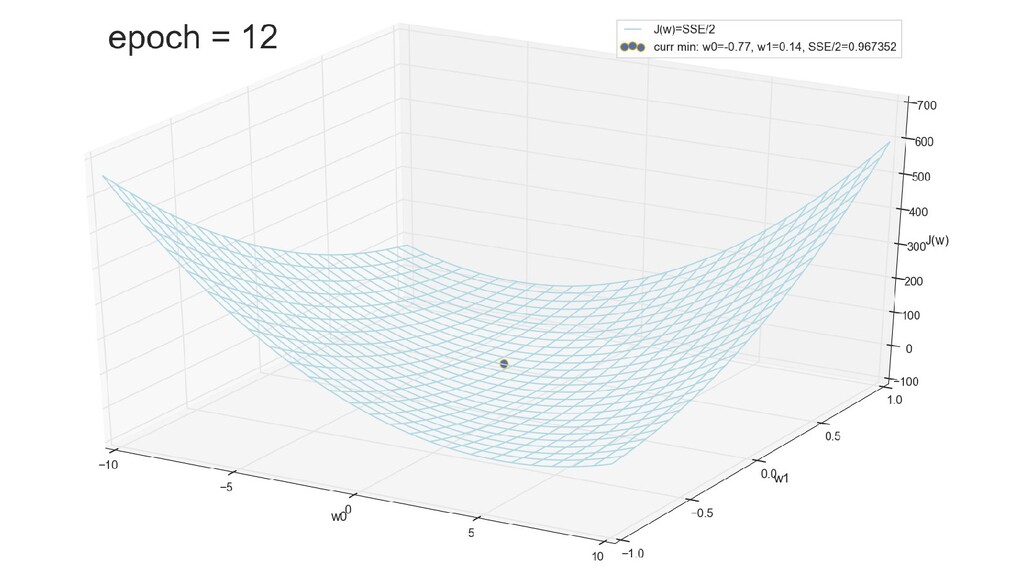
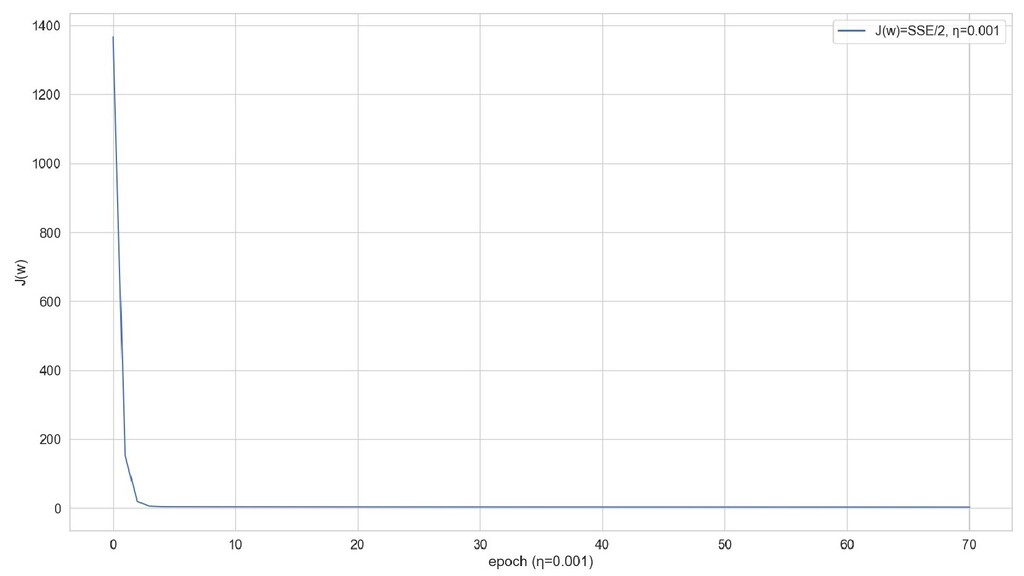
- График сходимости
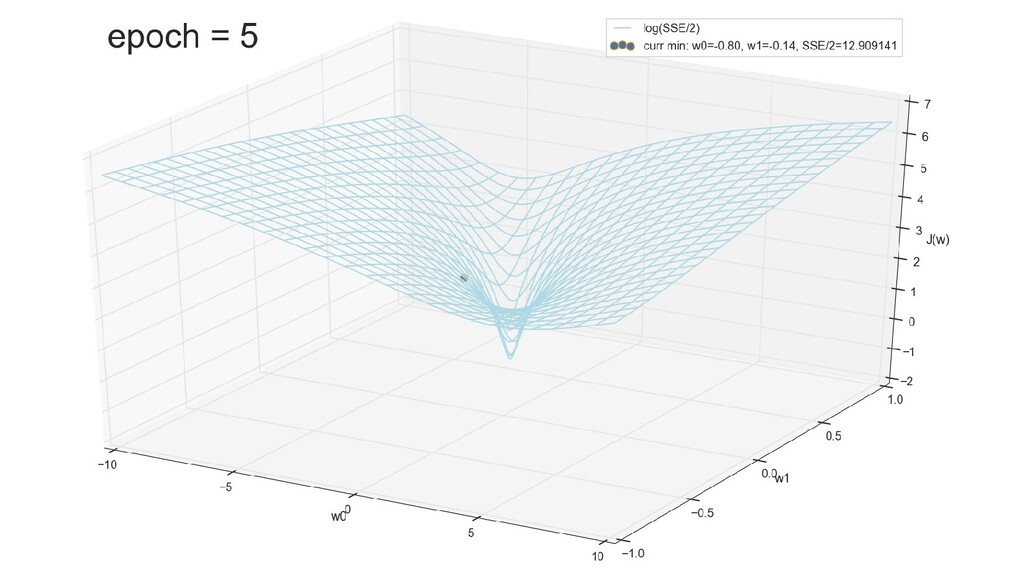
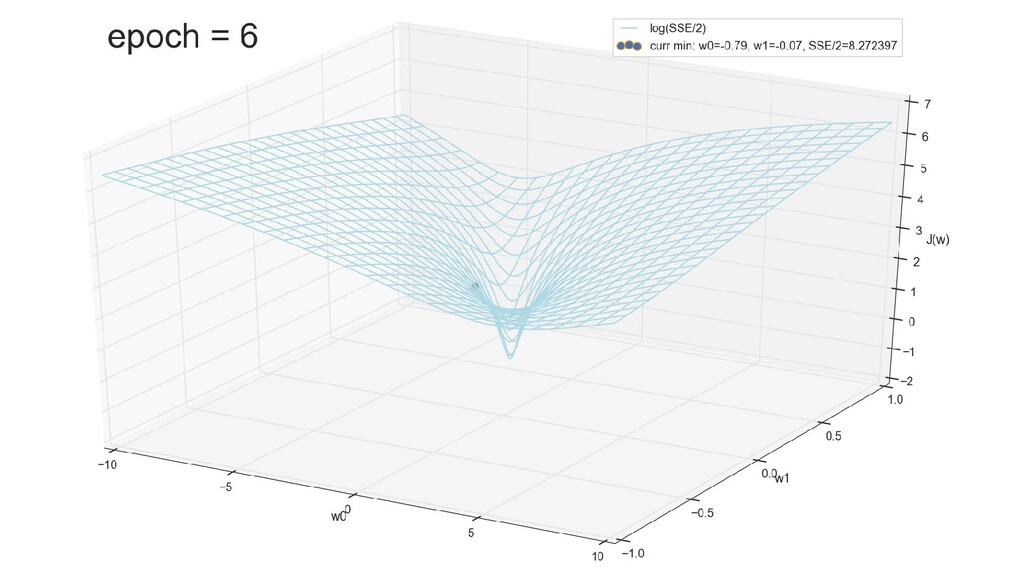
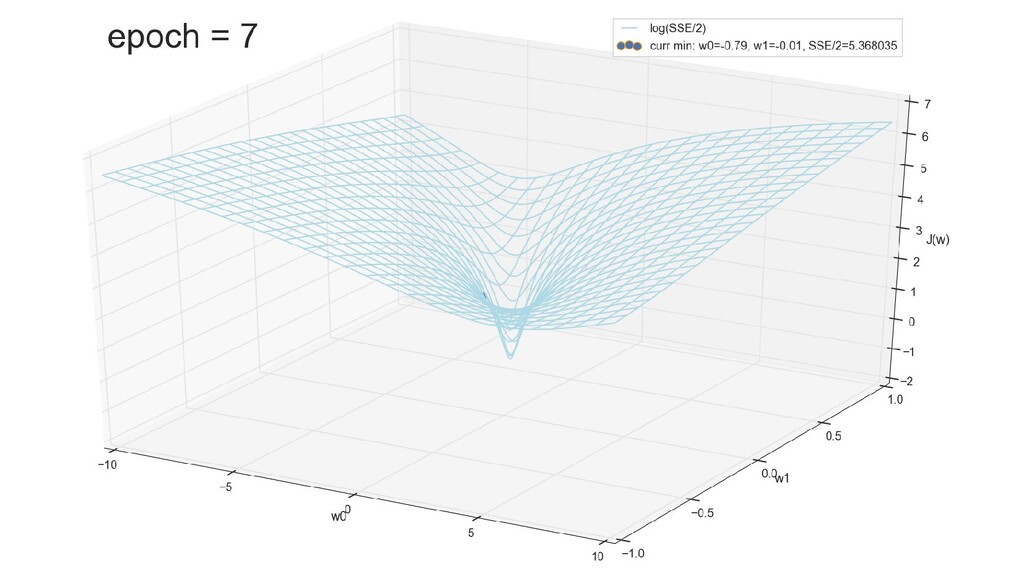
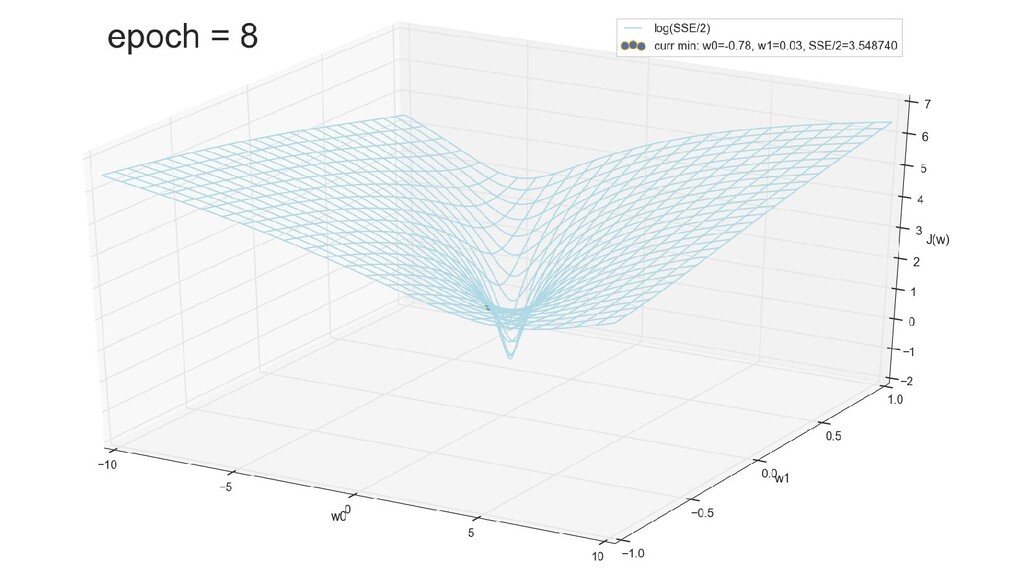
- Визуальное представление спуска к минимуму с использованием градиента: шарик скатывается в воронку к минимуму функции ошибки (или шарик скатывается по одеялу, если не брать логарифмическую шкалу)
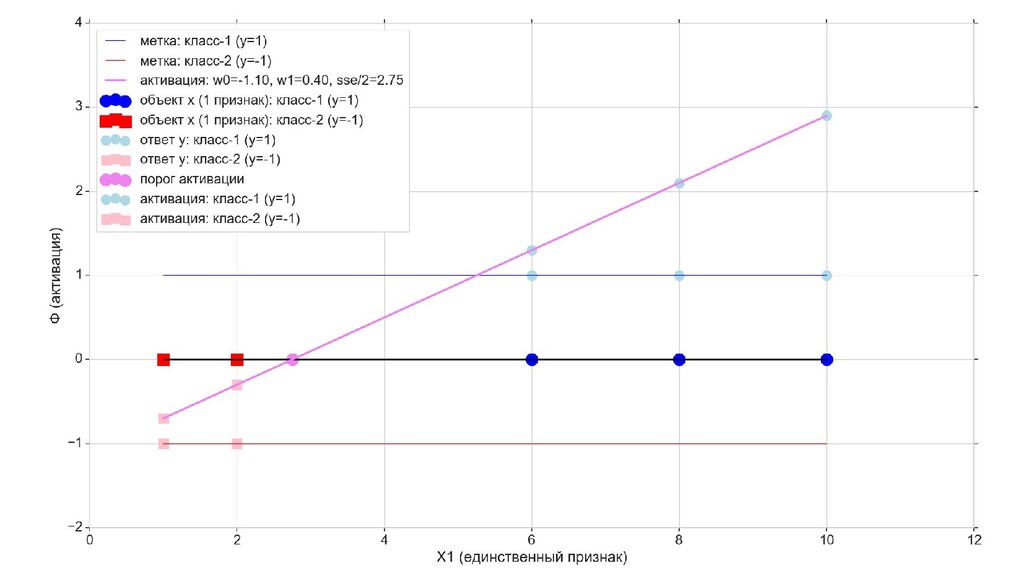
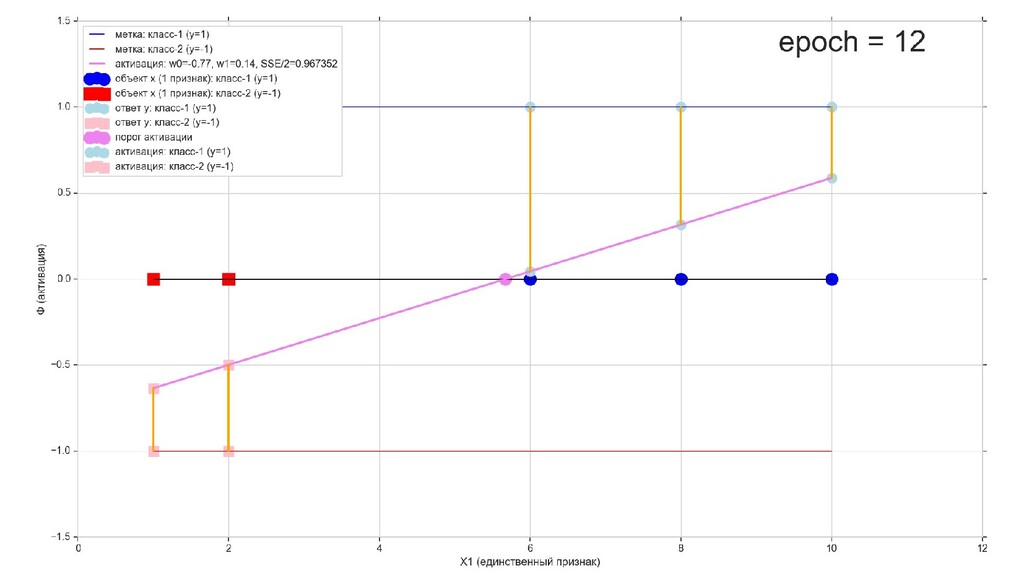
- Визуальное представление спуска: поиск оптимального положения прямой активации в пространстве единственного признака объекта плюс измерение для значений активации: пересечение с порогом, разделяющее точки на классы, и направление наклона, назначающего точкам класс.
- Итожим 1-мерный случай: мы научили искусственный нейрон класса "Перцептрон" отличать красные точки слева от синих точек справа после 12-ти попыток.
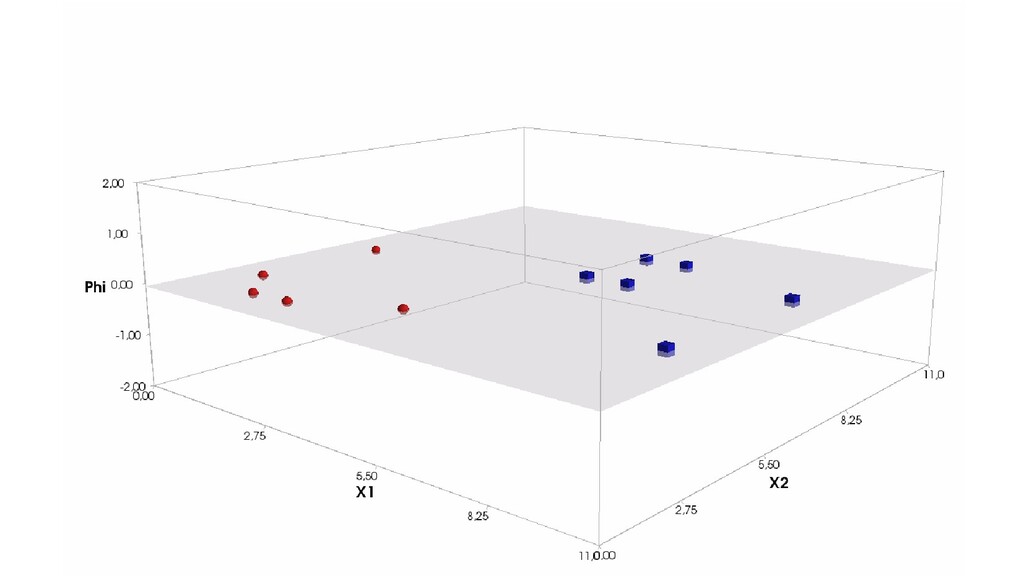
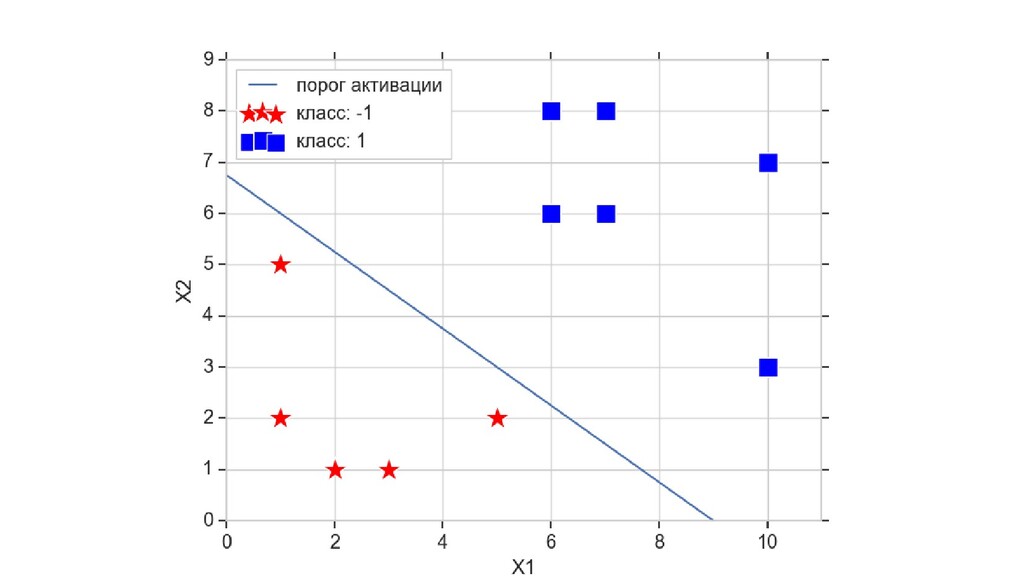
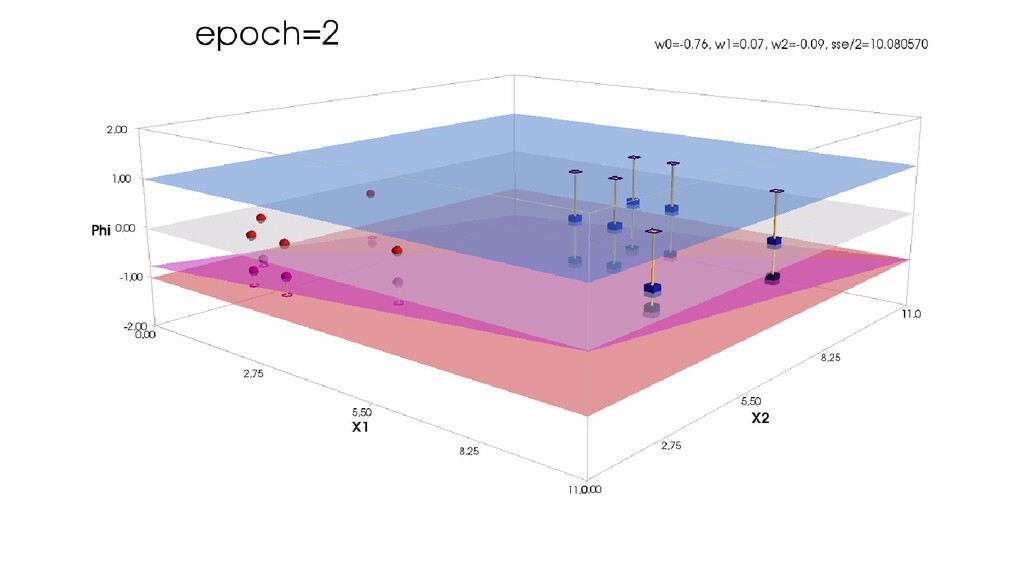
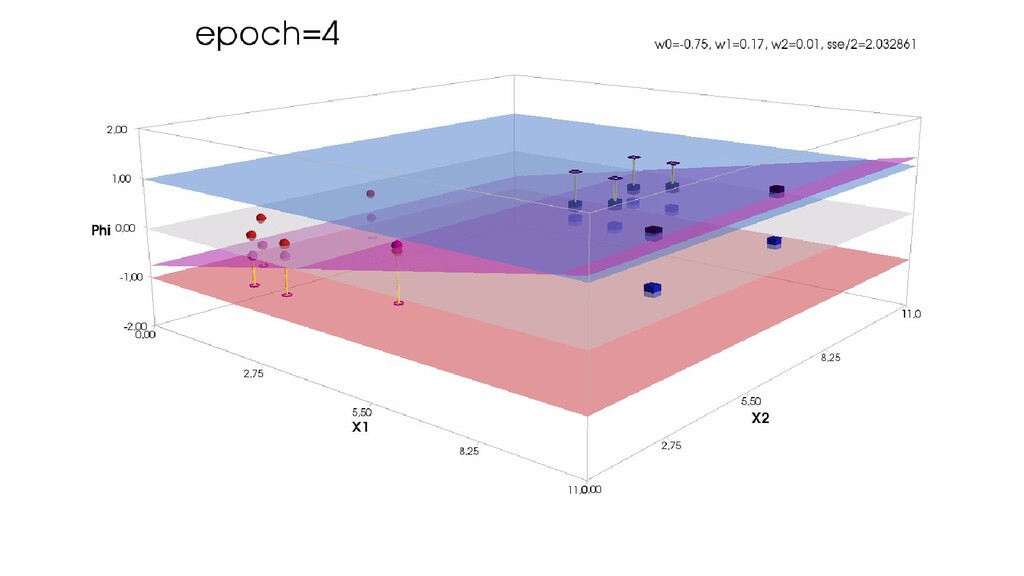
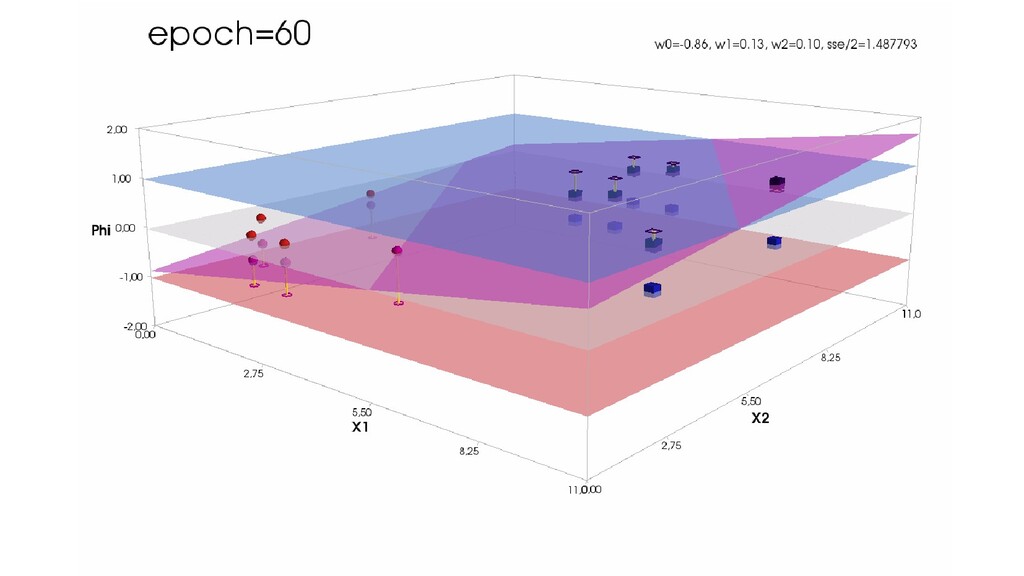
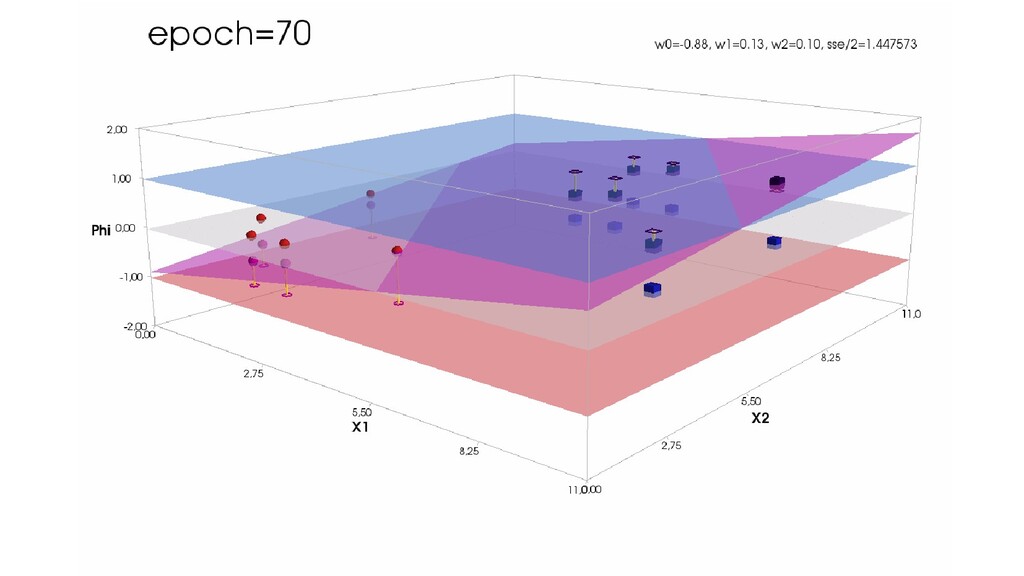
- Пространство 2-д: классификация объектов с 2-мя признаками
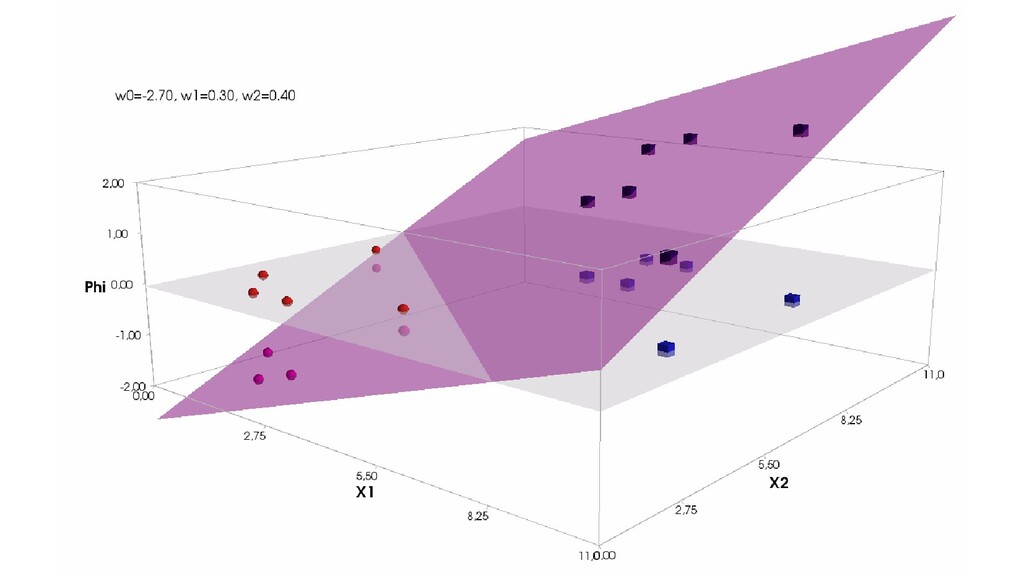
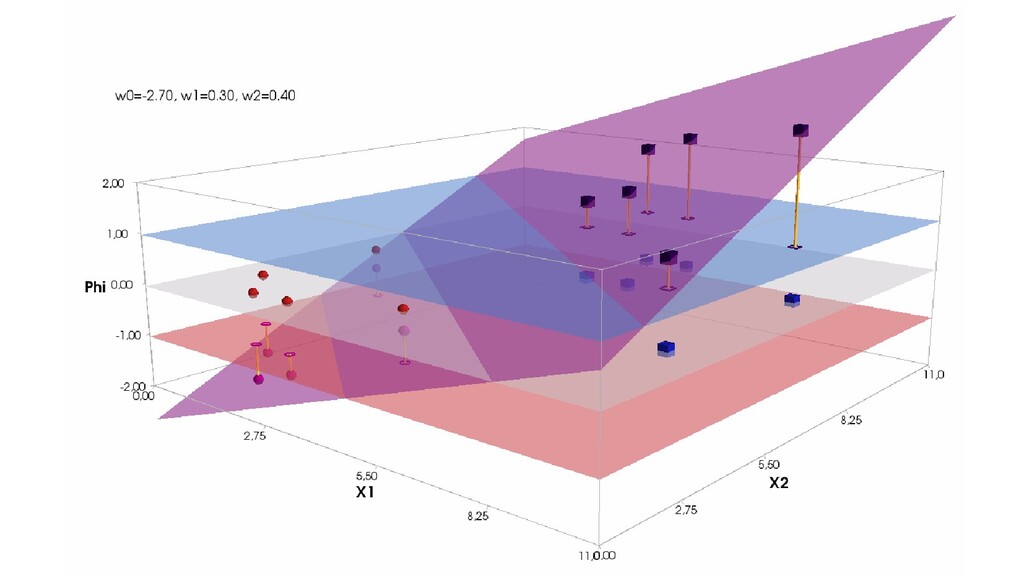
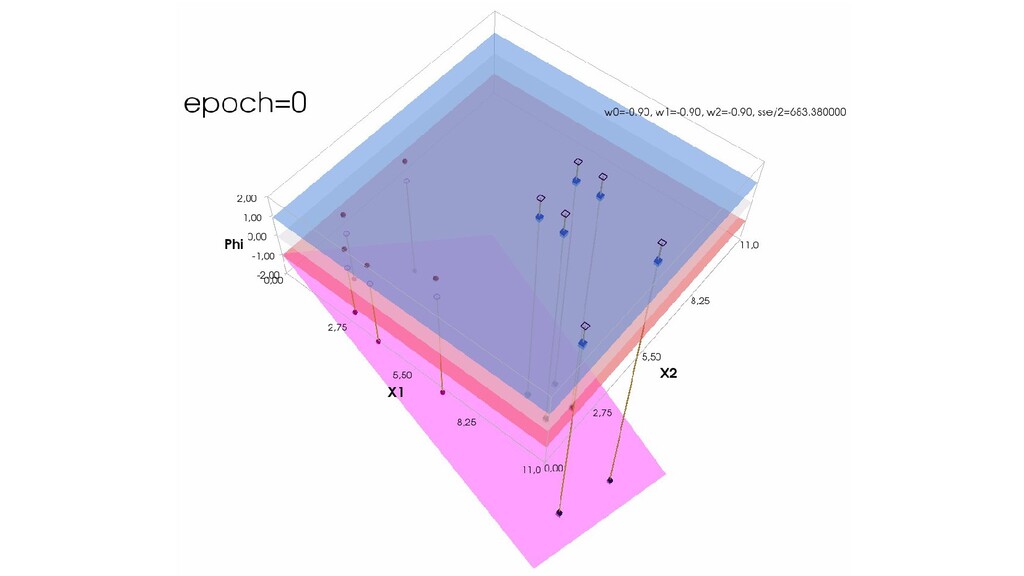
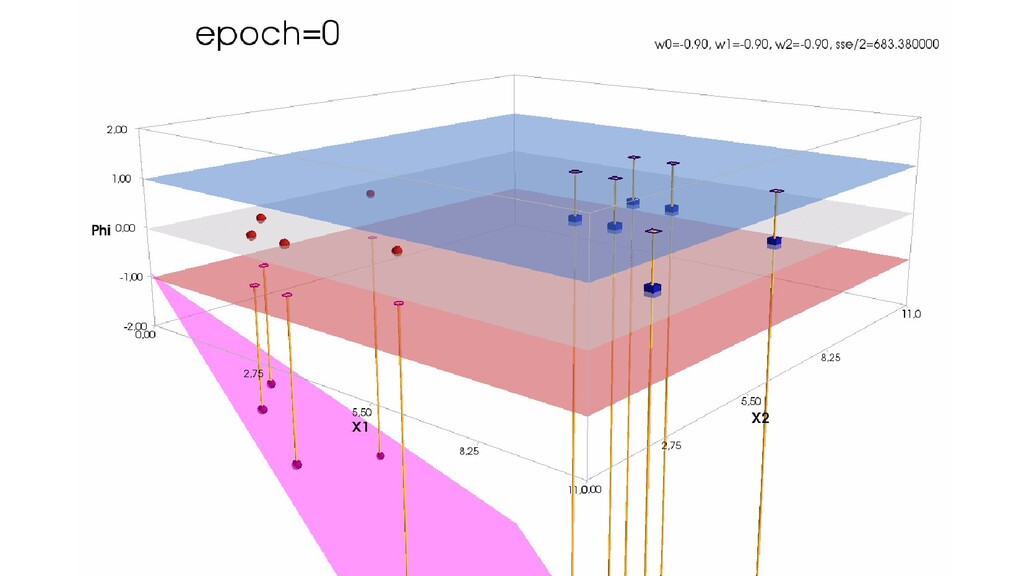
- Геометрическое представление задачи: активация теперь плоскость в пространстве 3д: два измерения - признаки объекта плюс значение активации. Порог активации - линия разделяющая объекты на плоскости на классы, наклон активации - назначение классов для каждой из групп.
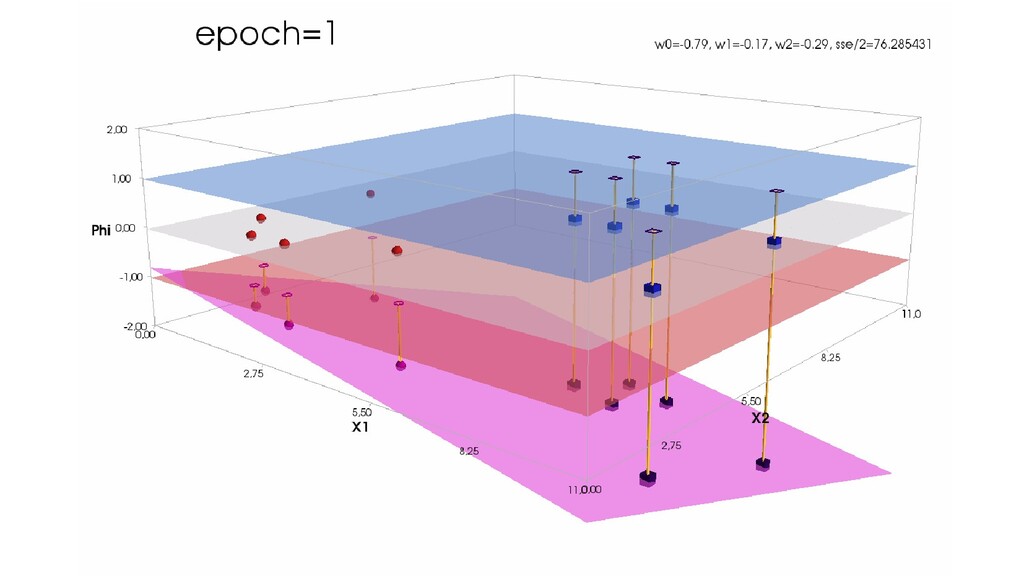
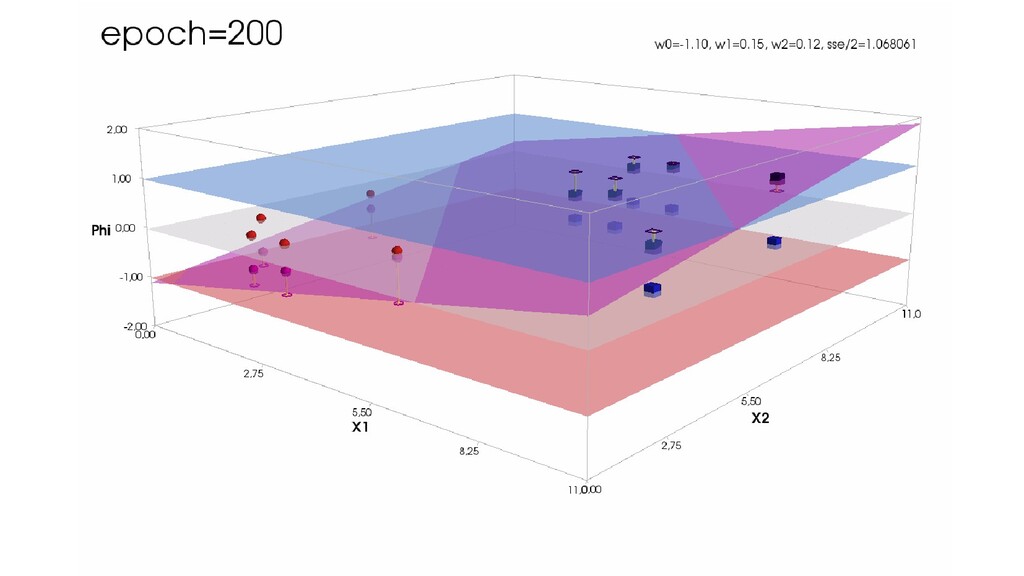
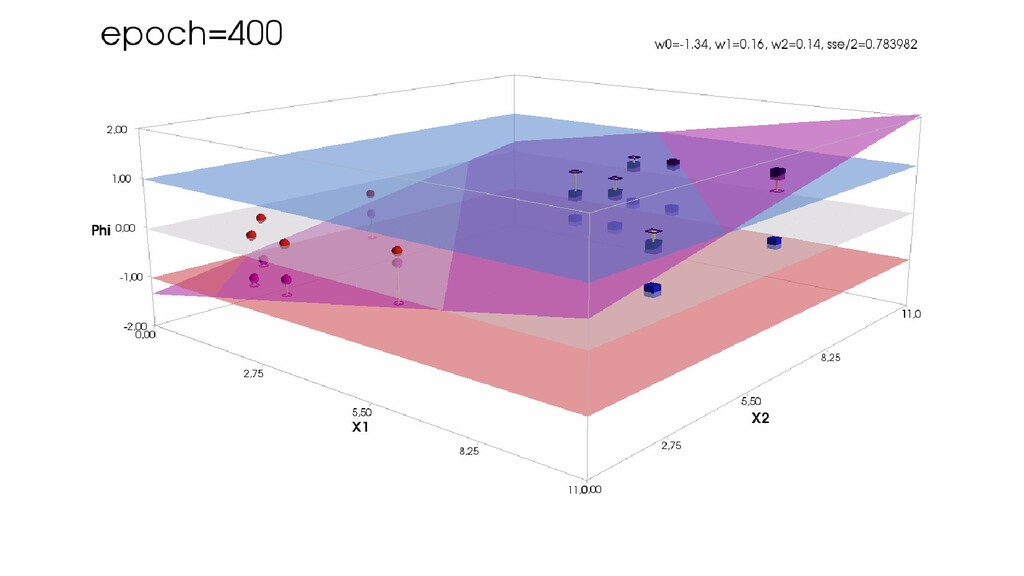
- Градиентный спуск в динамике: плоскость активации находит оптимальное положение
- Функция ошибки - поверхность в 4-хмерном пространстве, 4-д график стройте самостоятельно.
- Итог лекции
Обновлено: 28.04.2020
https://vk.com/video53223390_456239456
https://www.youtube.com/watch?v=Uzy_EEhEb-I
https://www.youtube.com/playlist?list=PLSu-UfrQJjQky3LrVLb3hnJ7cnPxjZUQP
Градиентный спуск по косточкам
https://habr.com/ru/post/467185/
https://1i7.livejournal.com/116300.html
https://1i7.livejournal.com/153813.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Градиент — вектор частных производных • ∇ [набла] (перевернутая дельта)](https://files.speakerdeck.com/presentations/4dfbe0545e454d7baca4b34a6a7a36f5/slide_92.jpg){kind=link}
{kind=link}
{kind=link}
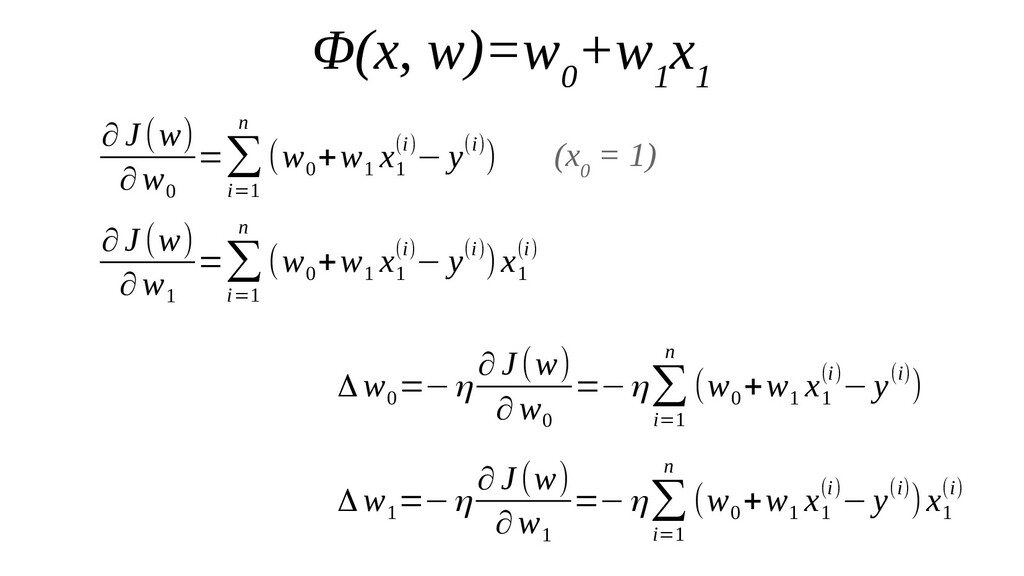{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Подбираем темп обучения η • η [эта] — коэффициент (темп)](https://files.speakerdeck.com/presentations/4dfbe0545e454d7baca4b34a6a7a36f5/slide_114.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}