Лекция курса "Большие данные и машинное обучение" (v2.0-МОТ)
Лекция-4: визуализация данных Python+Pandas+Matplotlib
Часть-1
- Обзор библиотек визуализации данных: Matplotlib, Seaborn, Mayavi
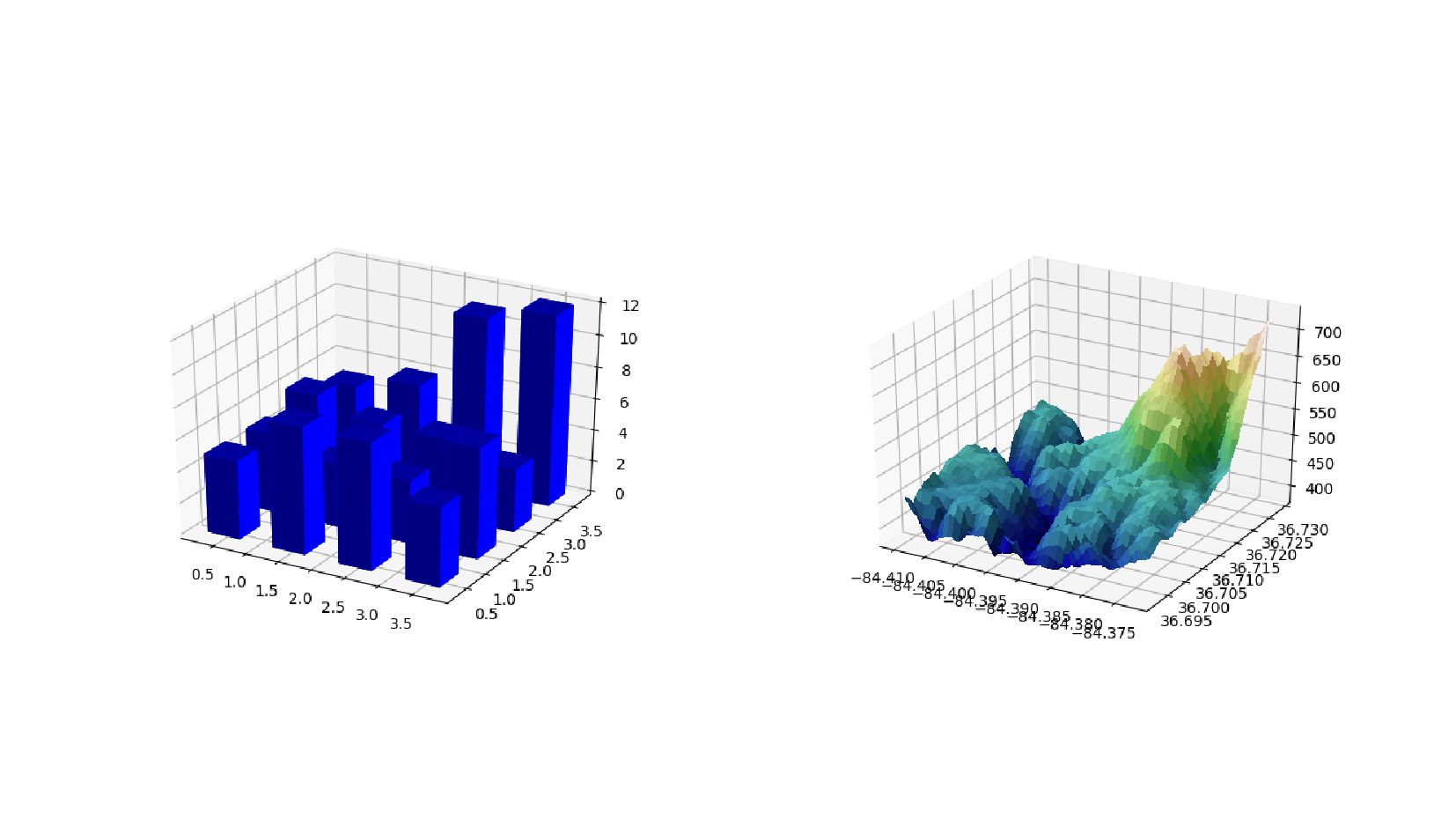
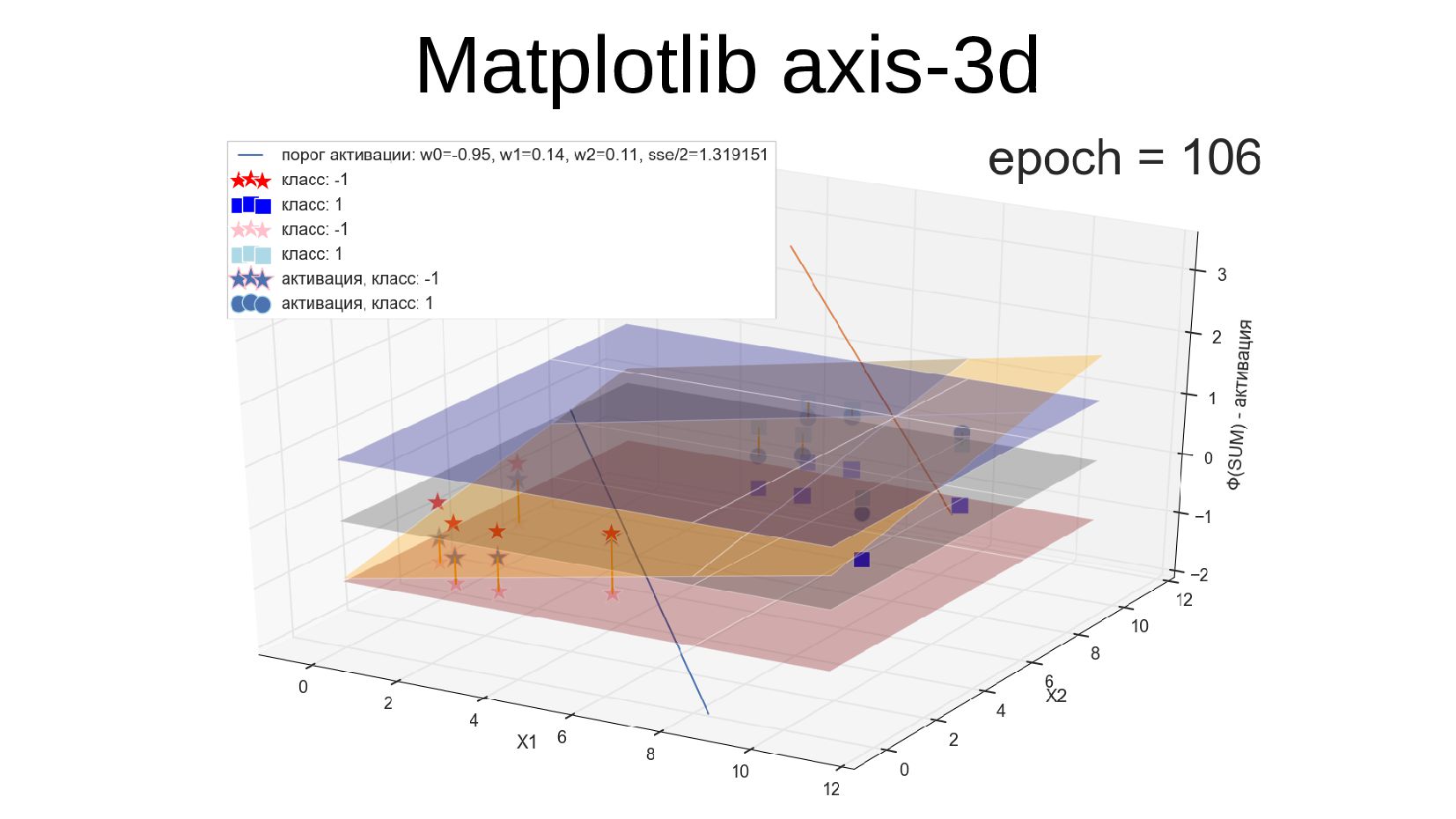
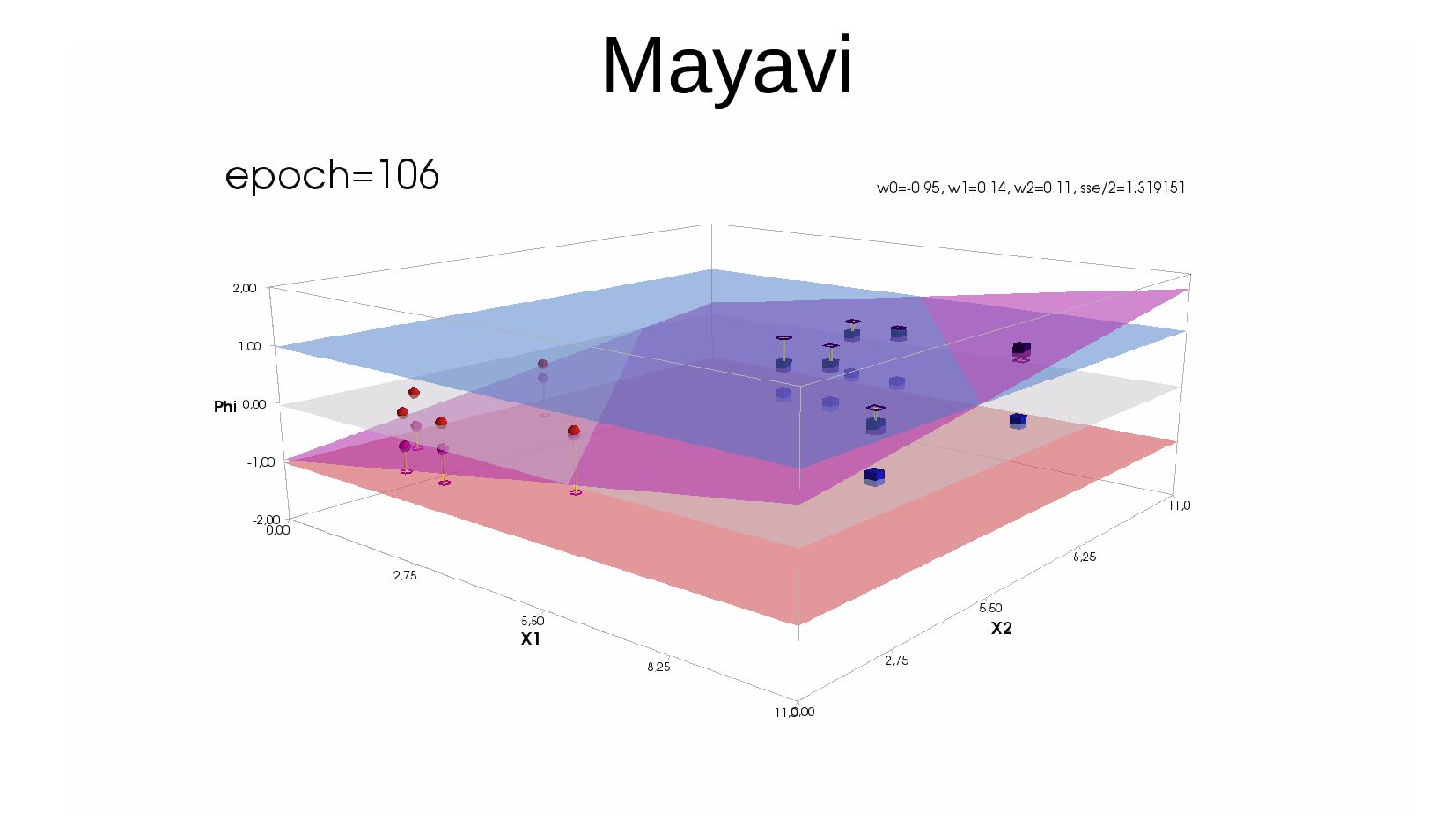
- 3д: Matplotlib axis-3d vs Mayavi
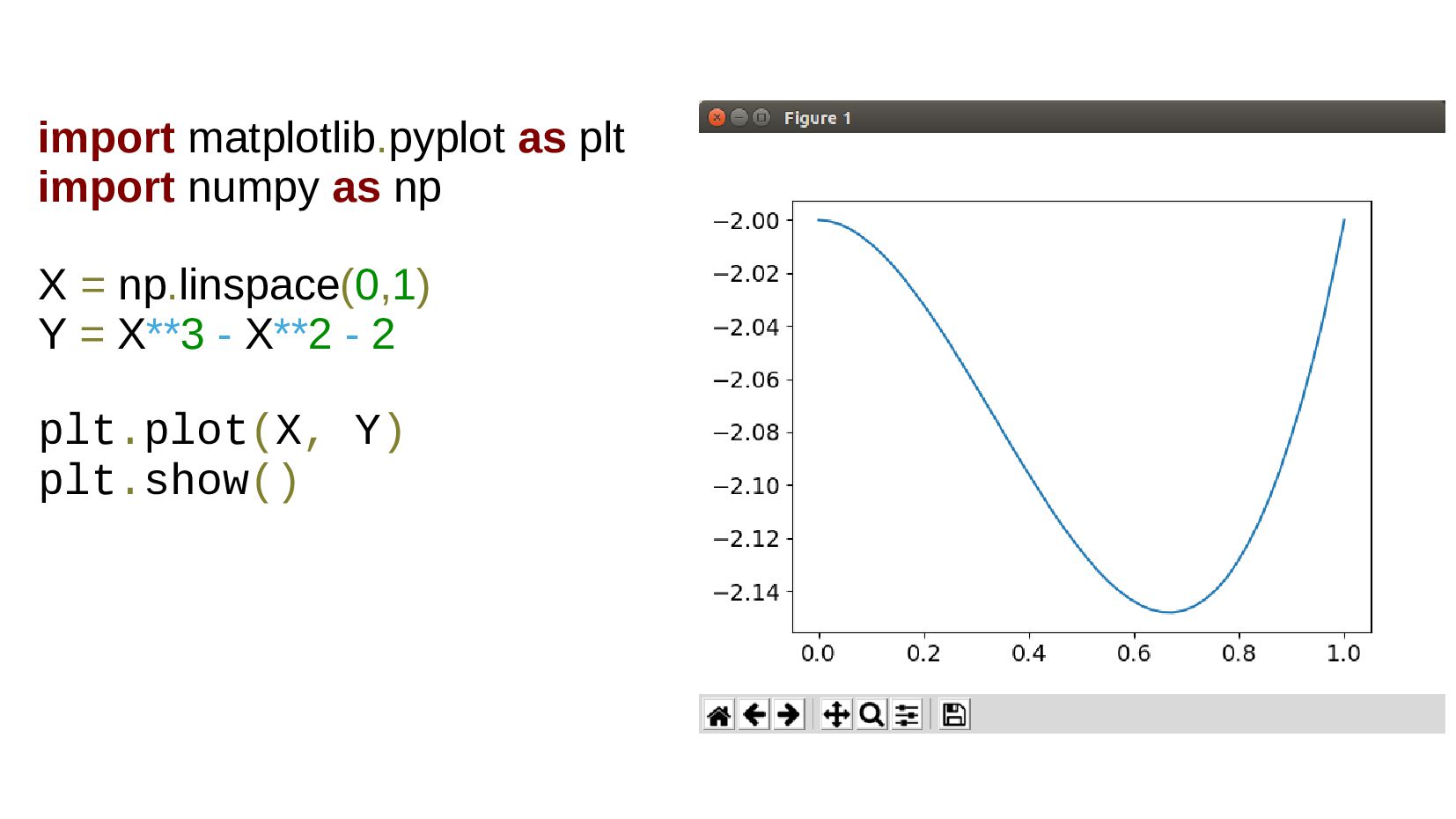
- Matplotlib pyplot + NumPy: математика над вектором значений, график по точкам
- Pandas + Matplotlib: DataFrame.plot
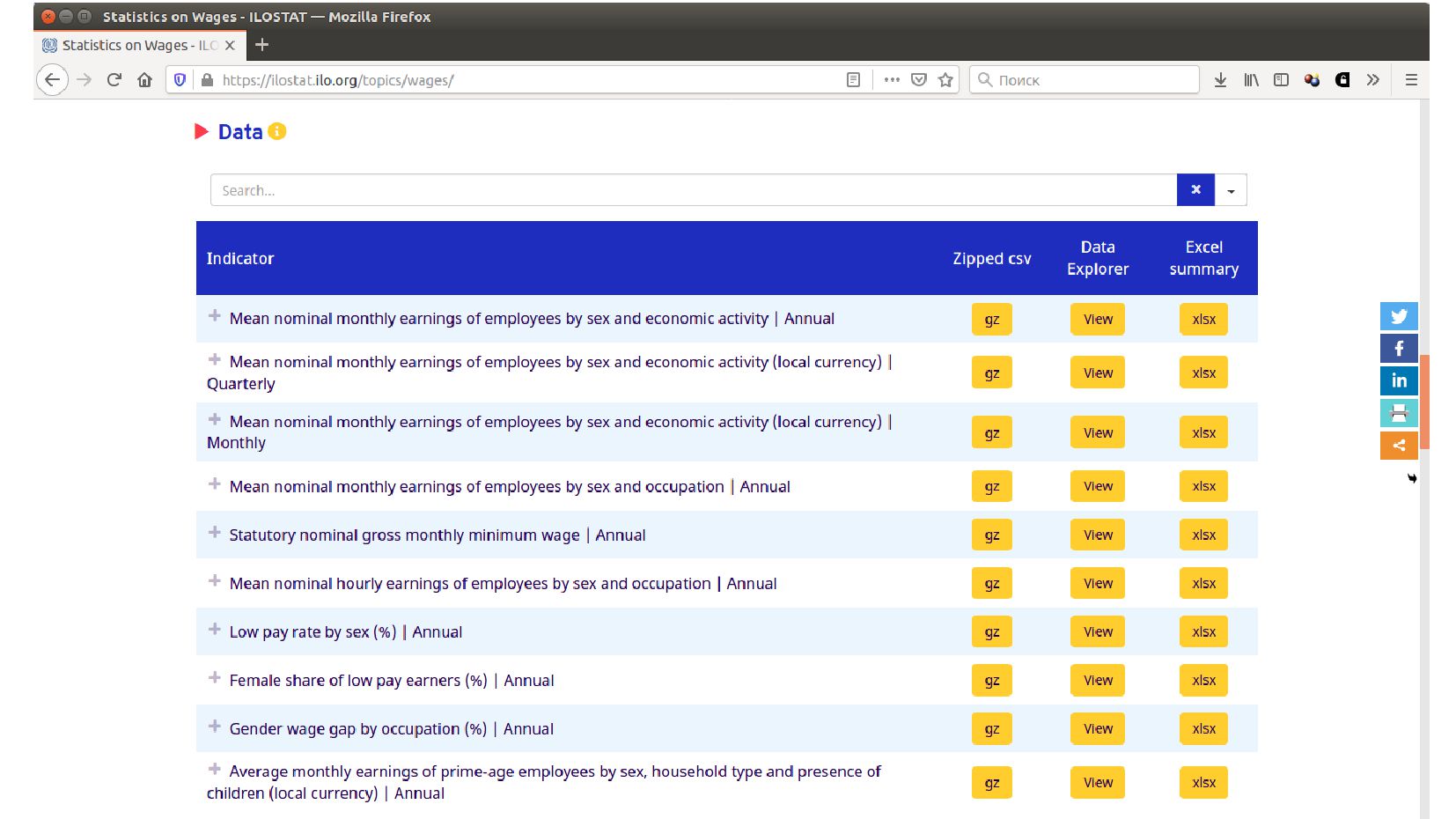
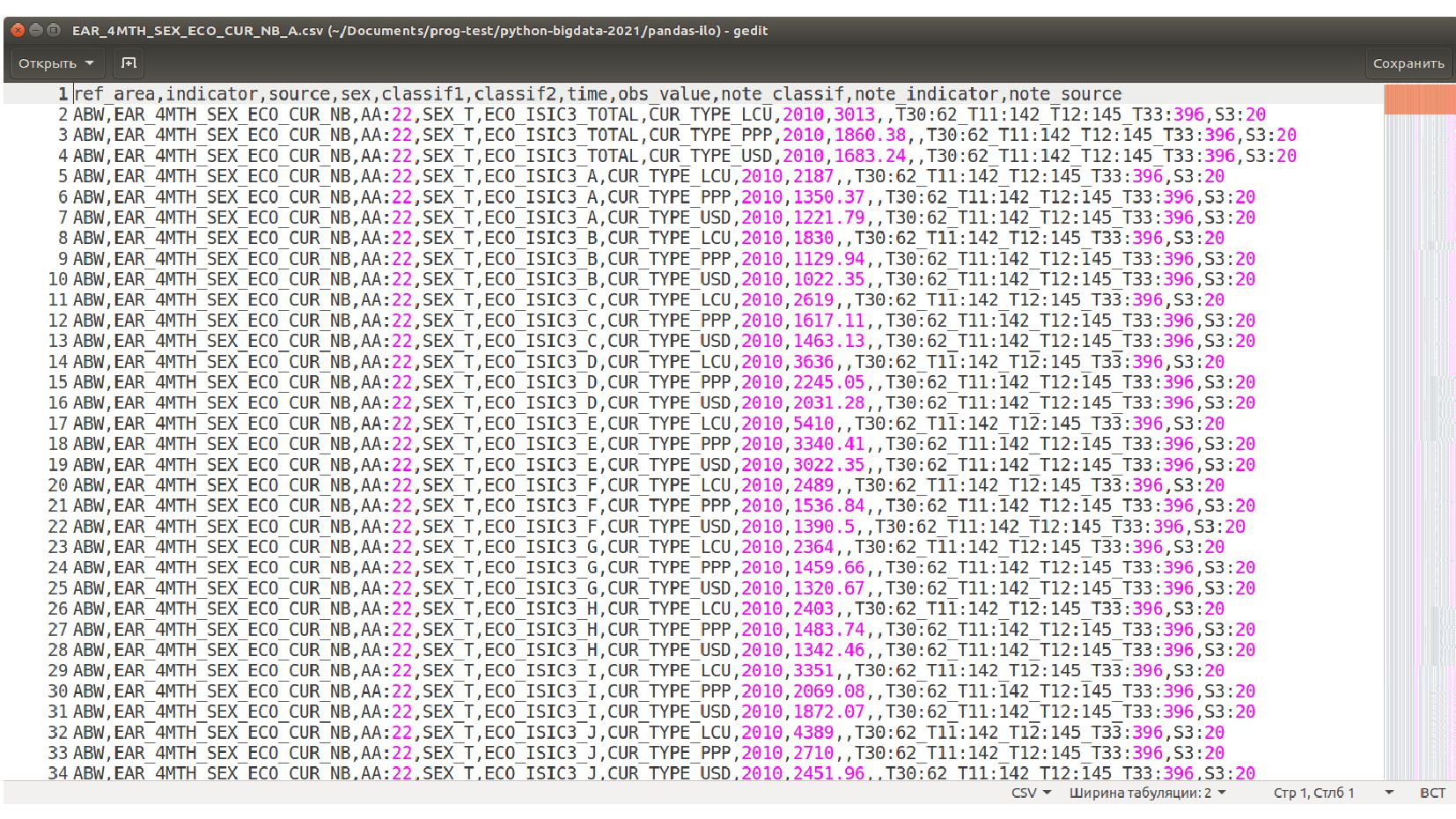
- Данные: датасет ILO (МОТ - Международная организация труда) ilostat.ilo.org
- Таблица для анализа: средня зарплата по видам деятельности, полу, странам и годам
- Этапы решения задачи по визуализации: задать вопрос, на который ответит график, выбрать подходящий типовой график, подготовить данные - фильтрация, группировка, прочие преобразования
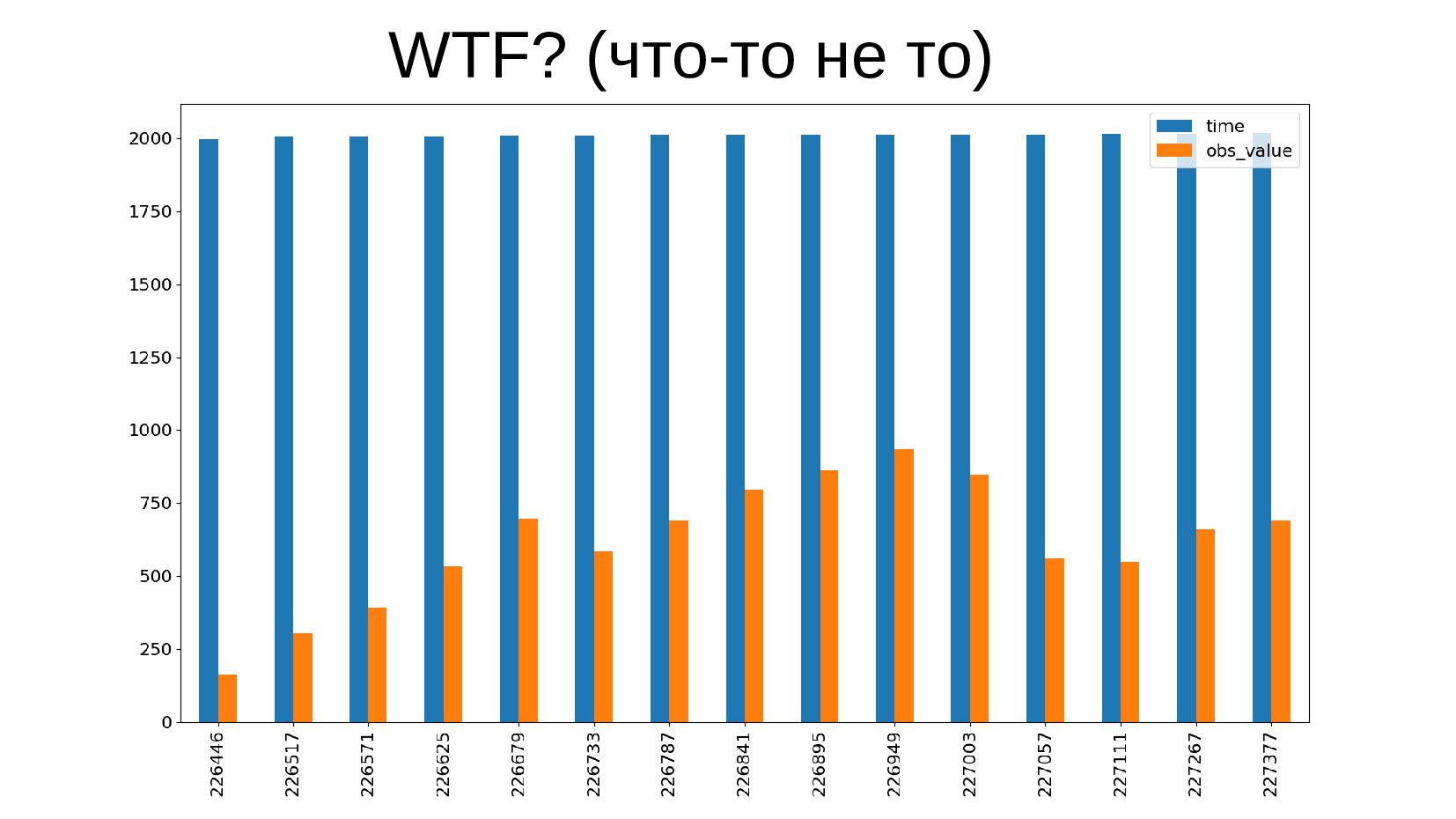
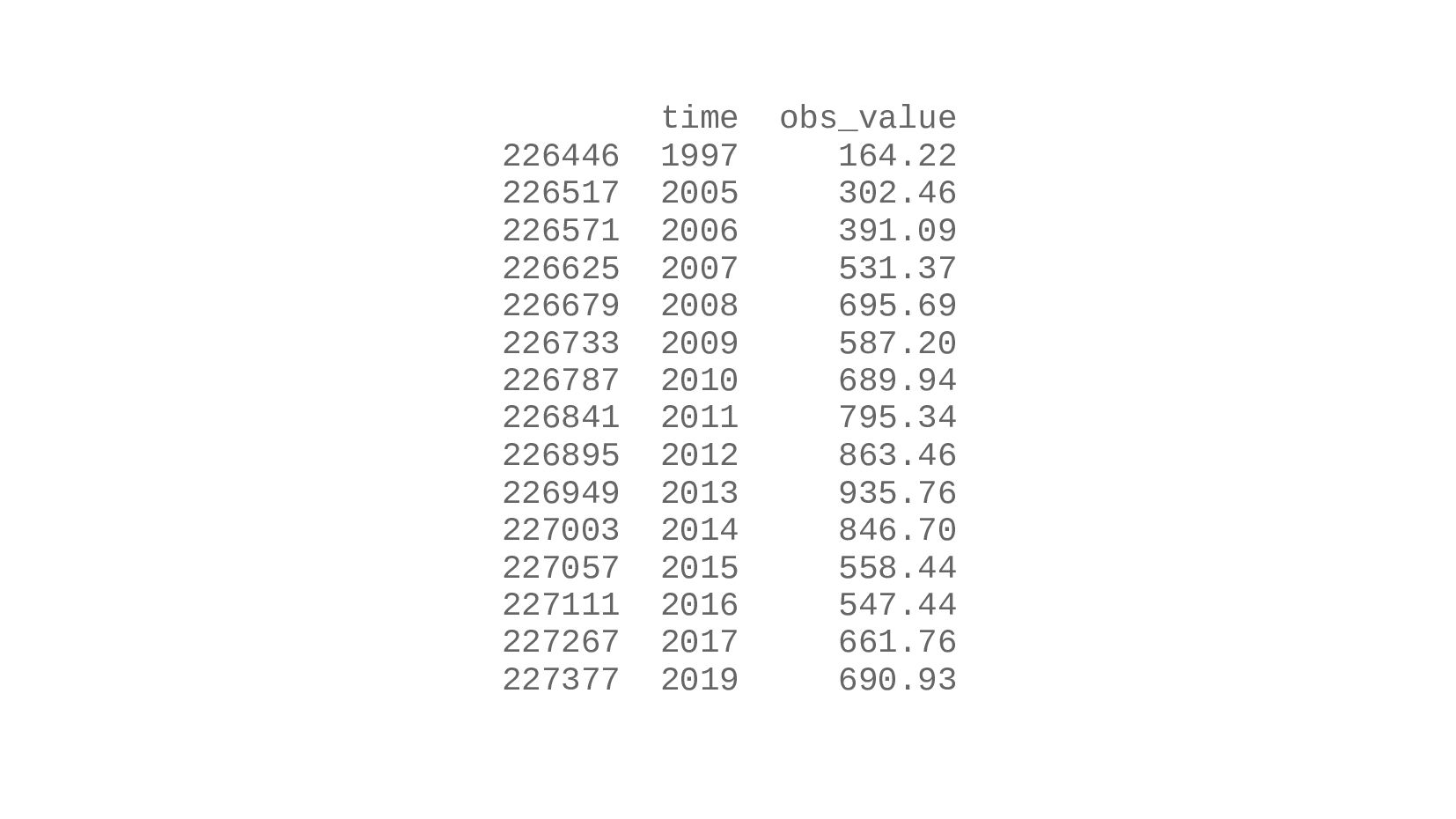
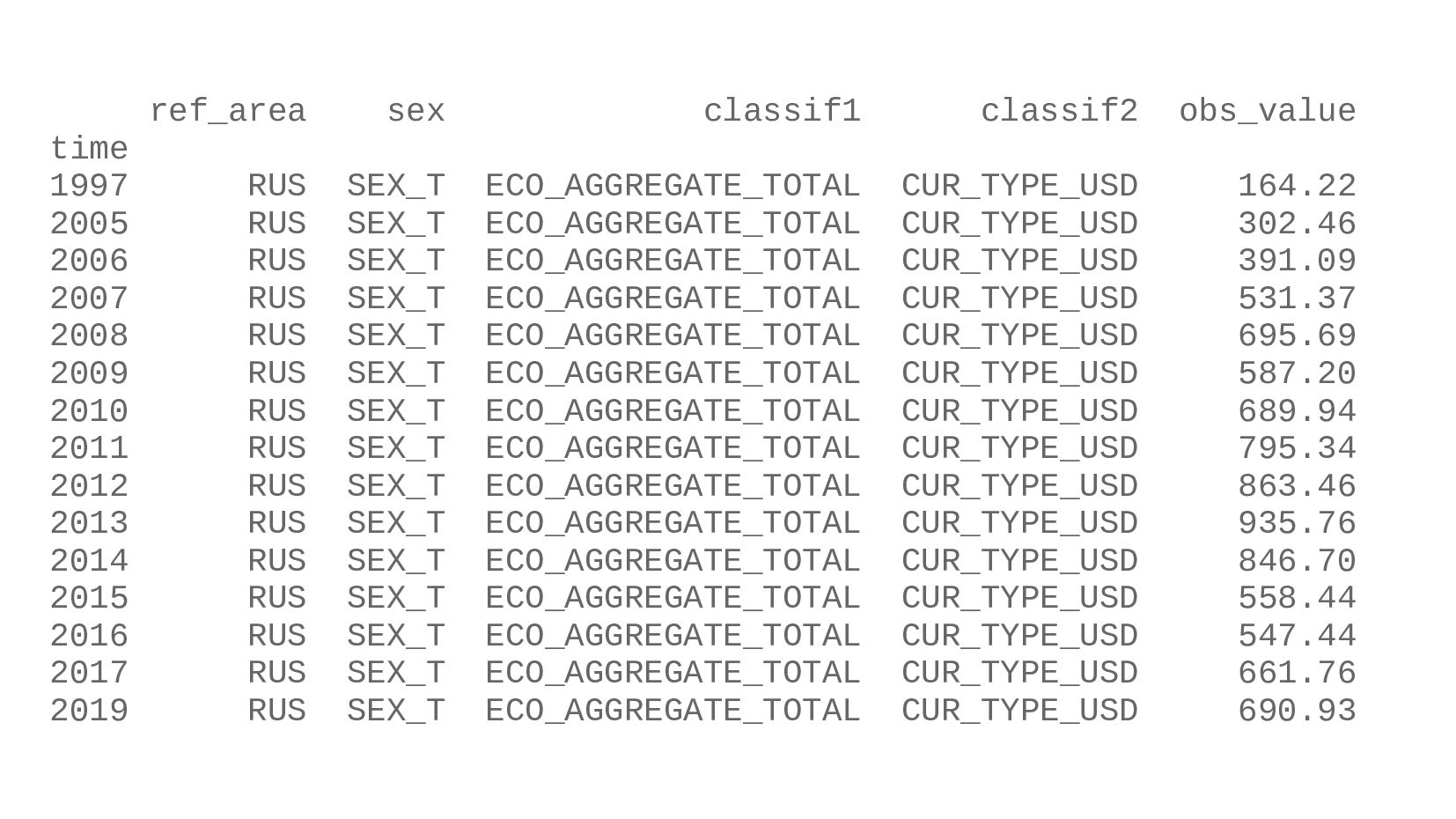
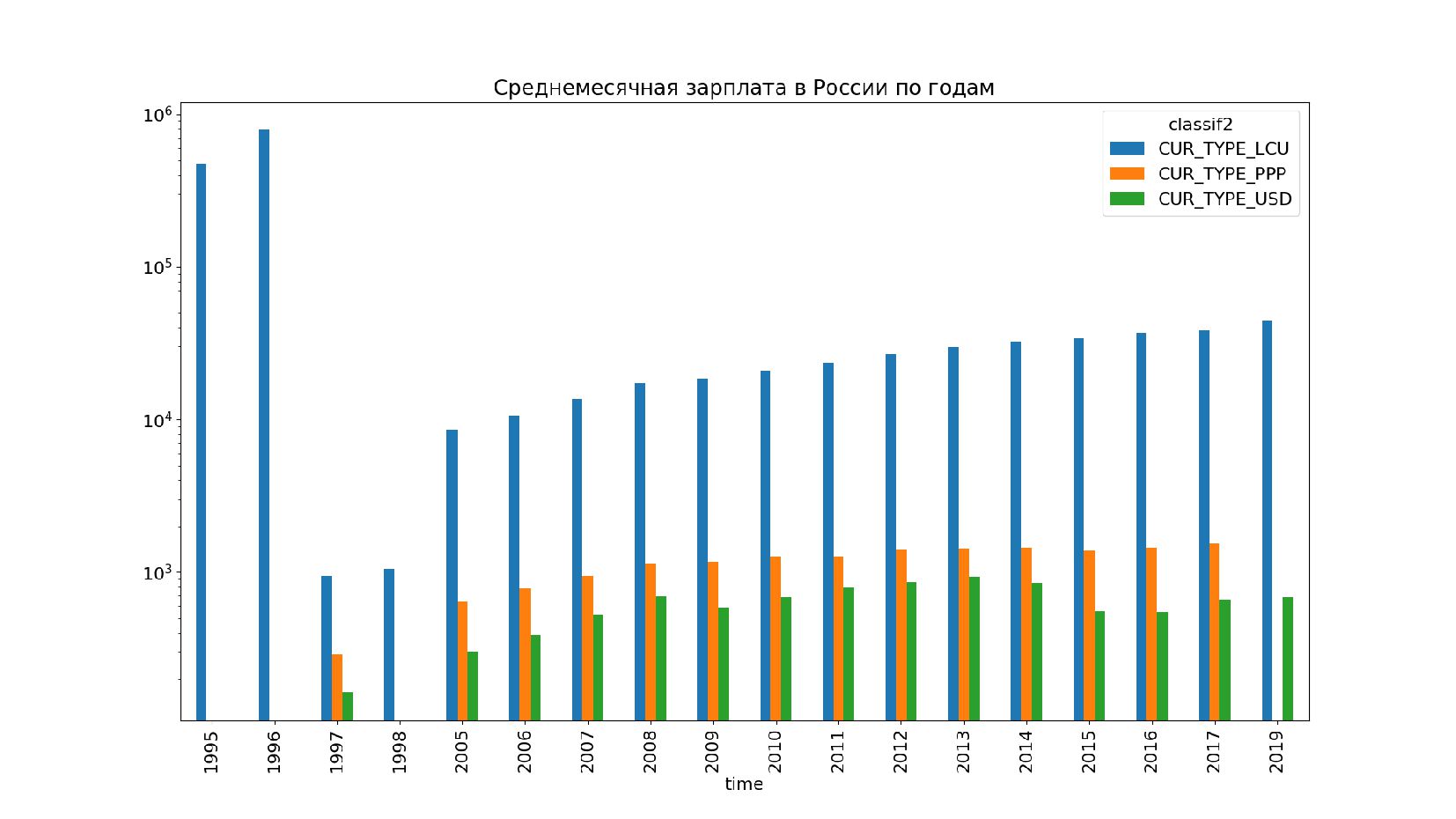
- Строим график: столбчатая диаграмма (bar chart) средней зарплаты в России по годам в долларах США (CUR_TYPE_USD)
- Подготовка данных: фильтрация данных, выбор колонок для столбиков, группировка значений по горизонтаельной оси - DataFrame.set_index
- Заголовок и легенда
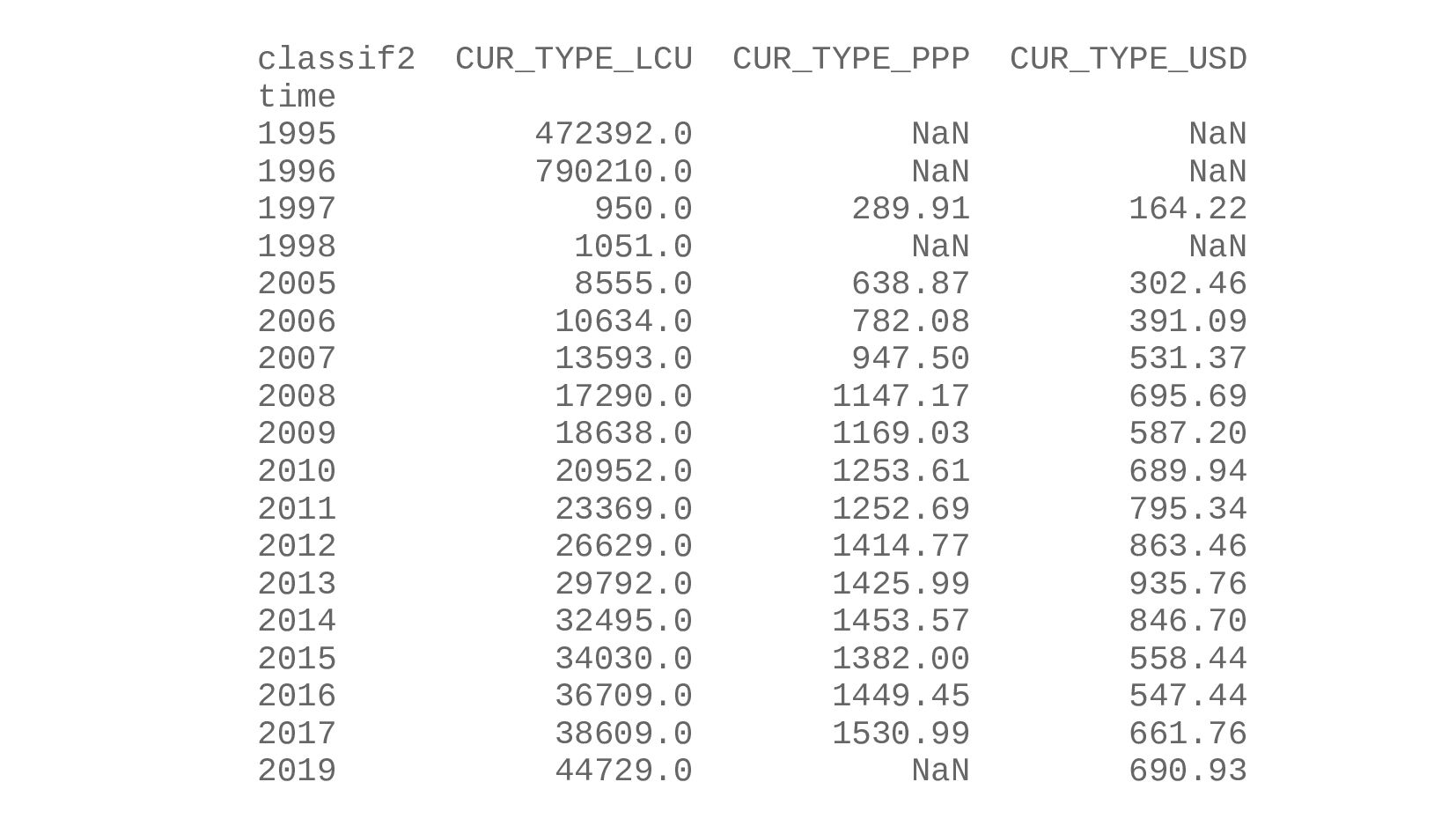
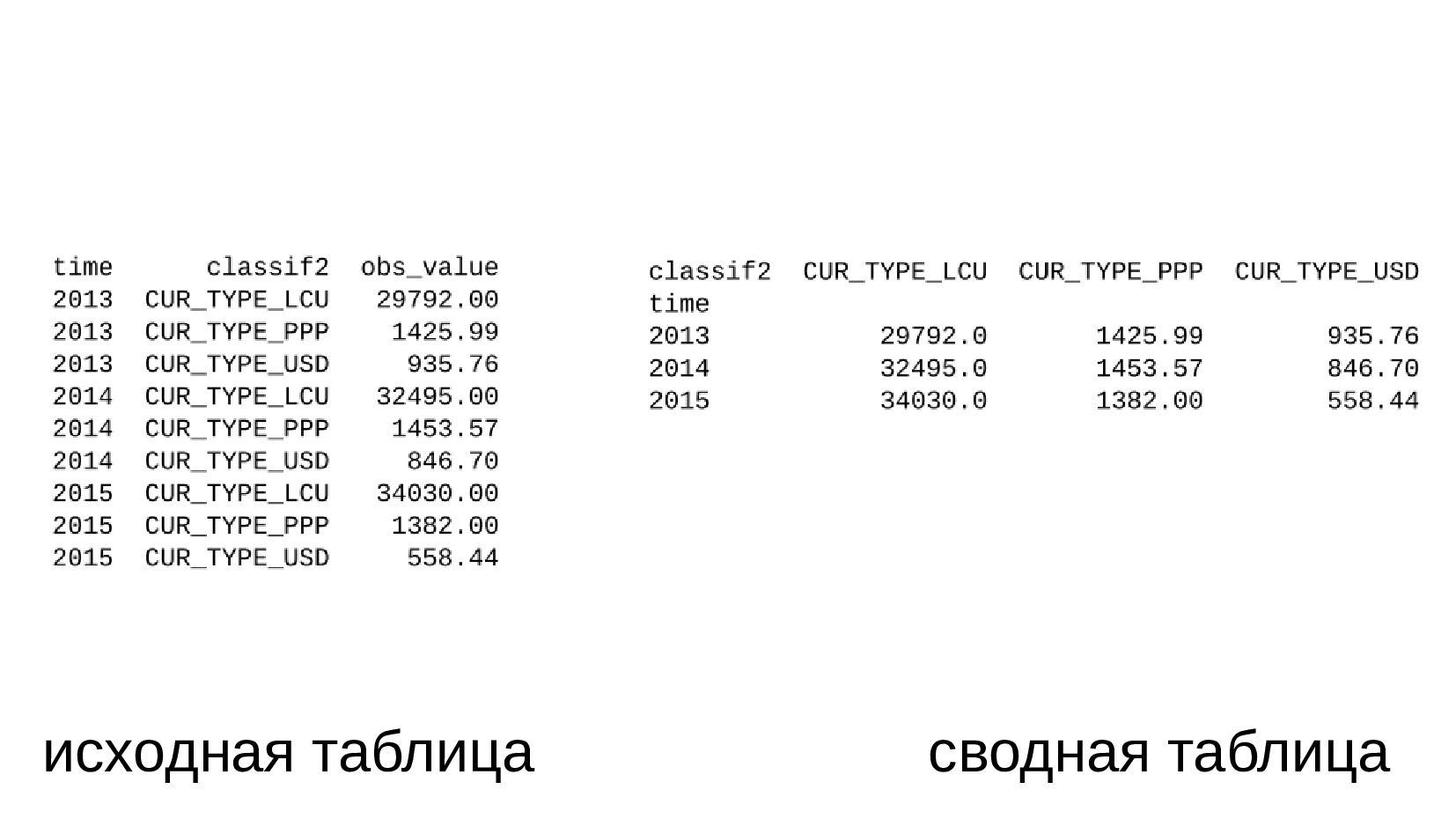
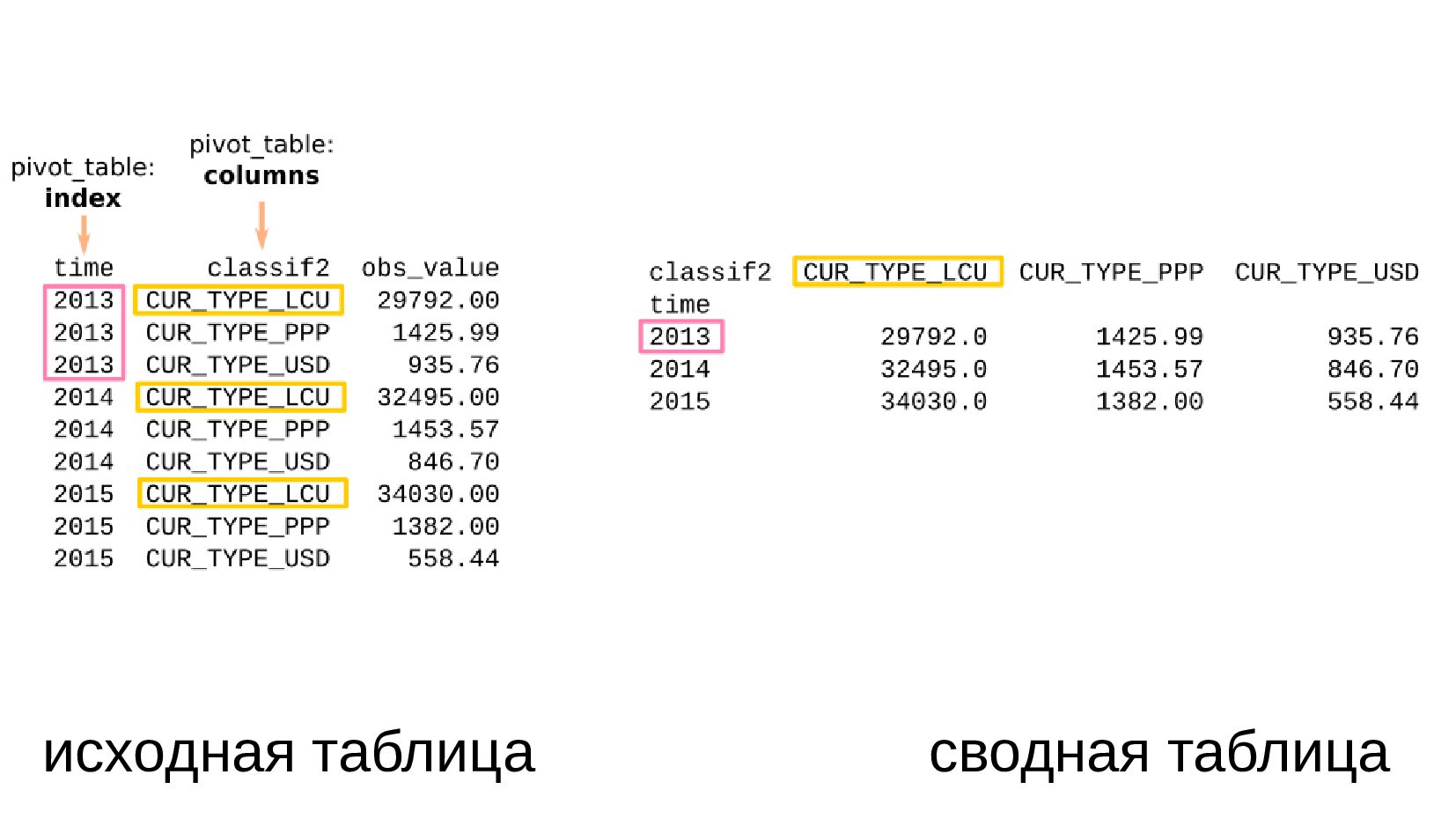
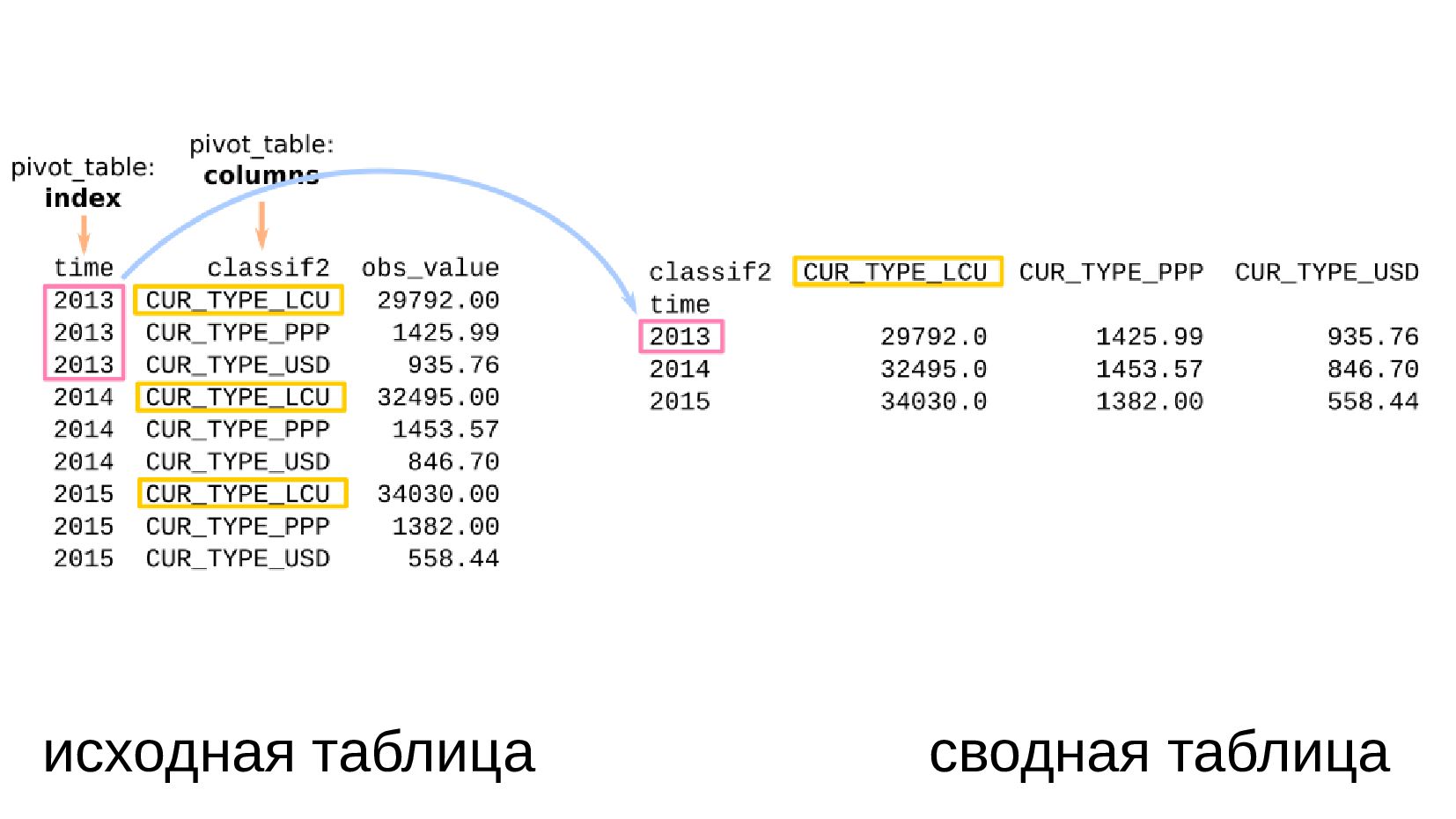
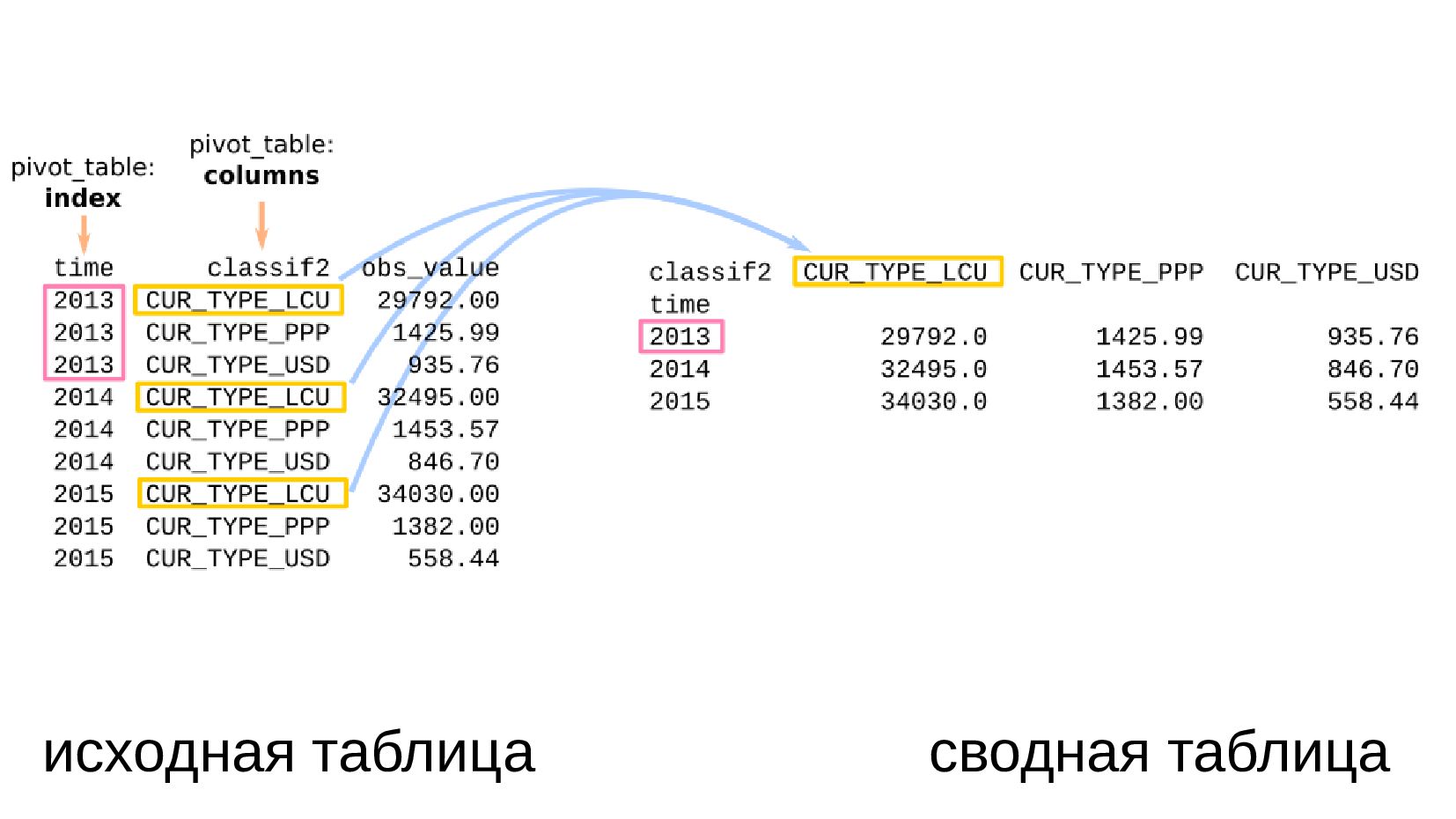
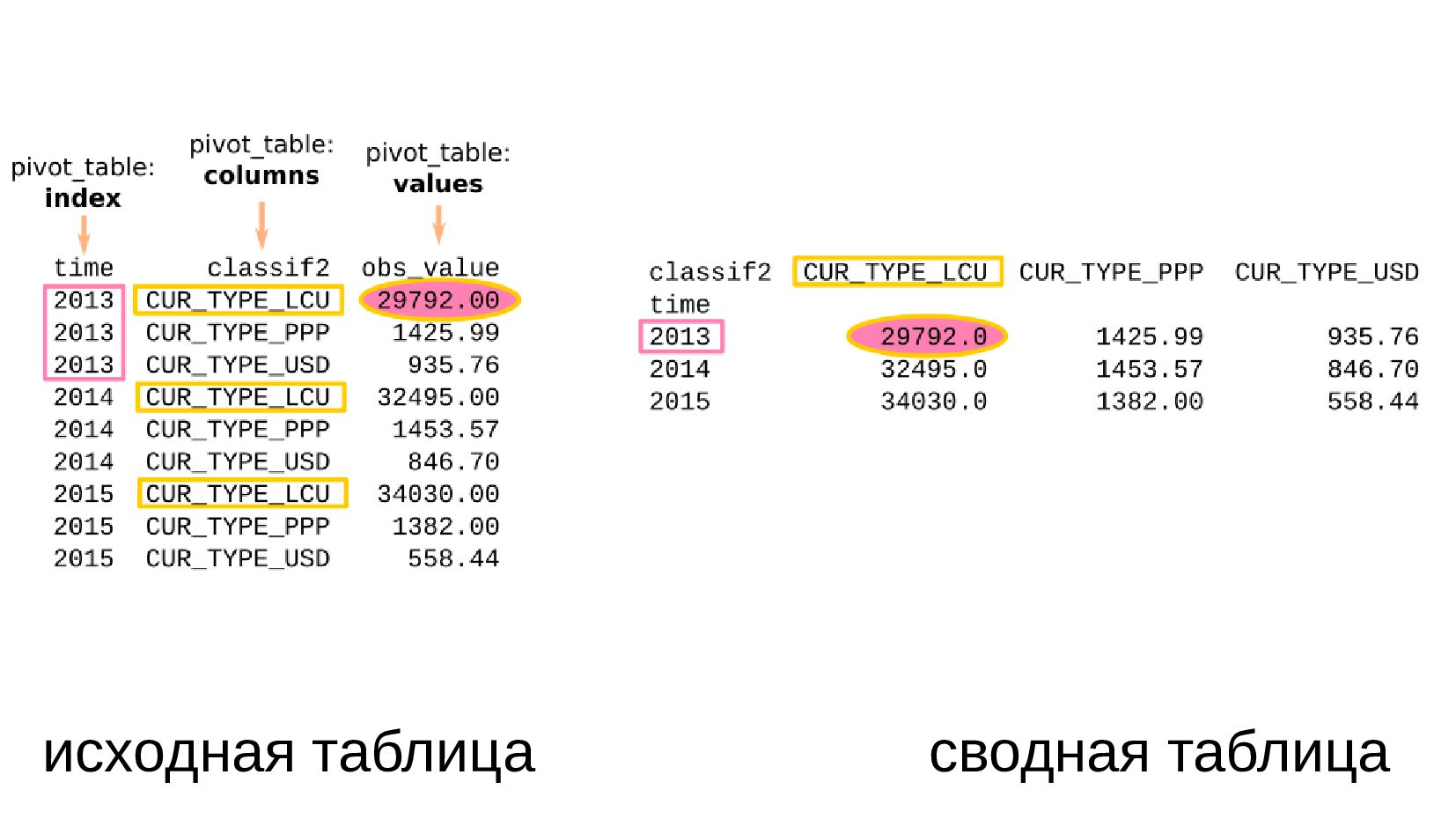
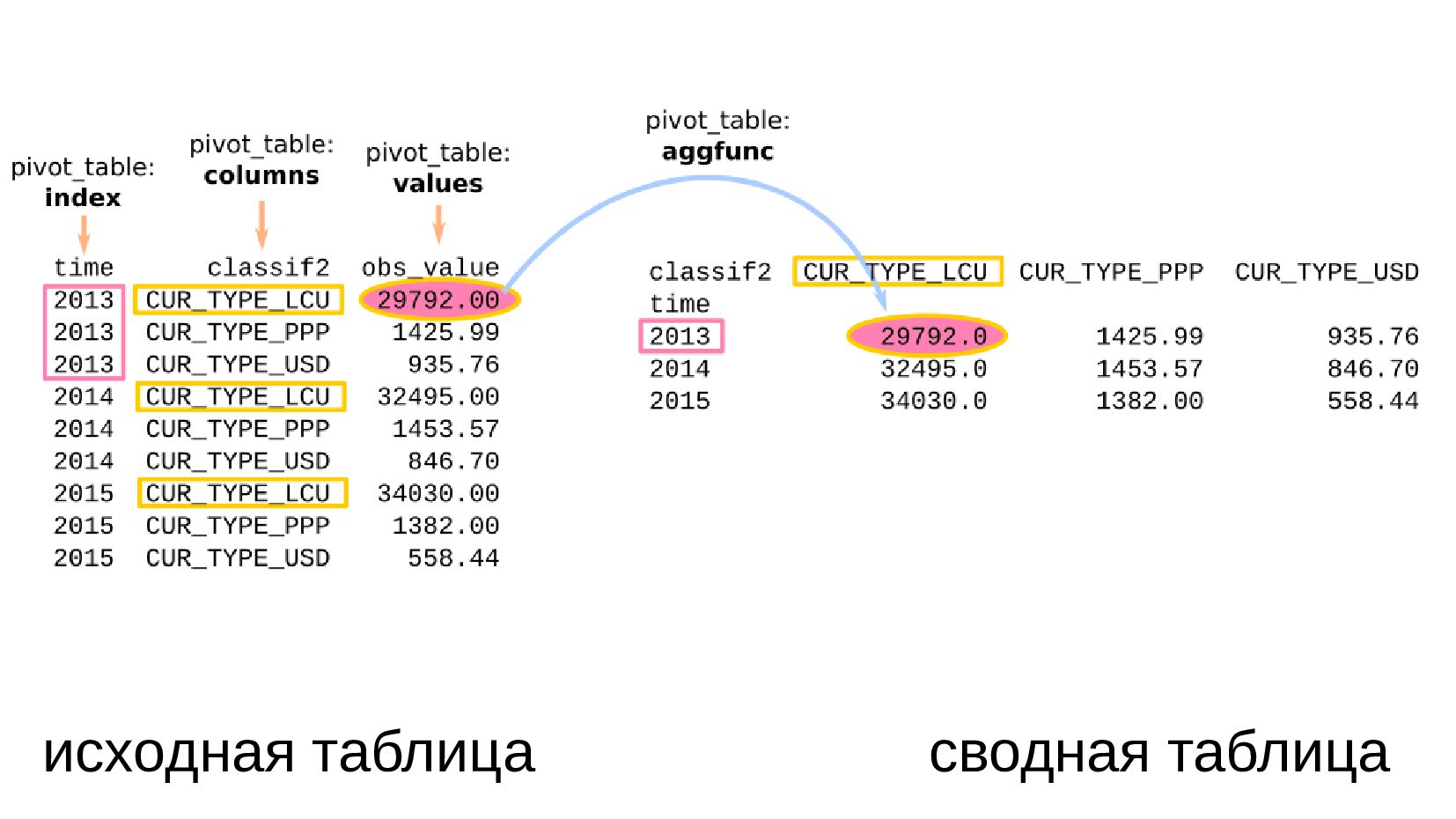
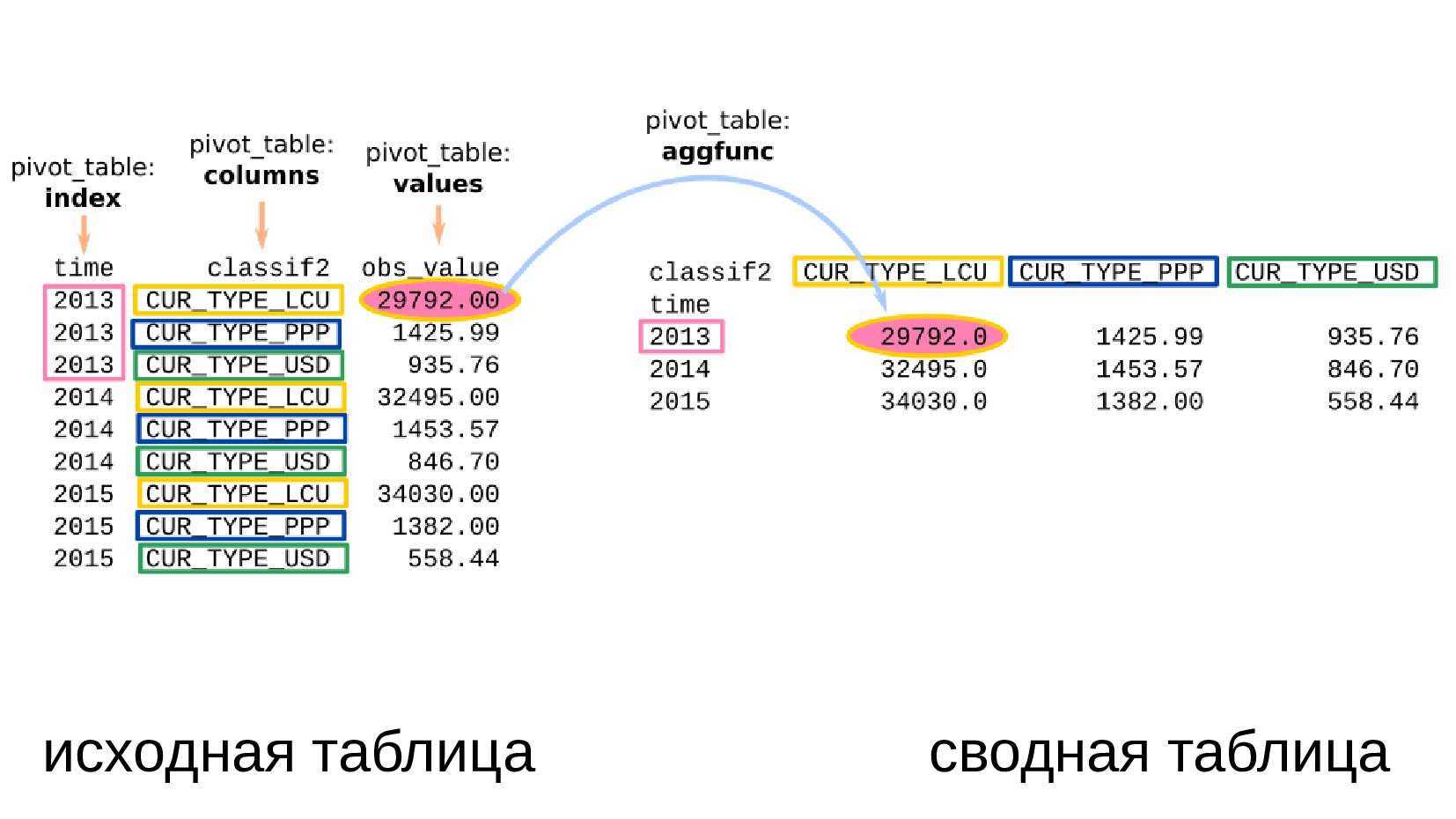
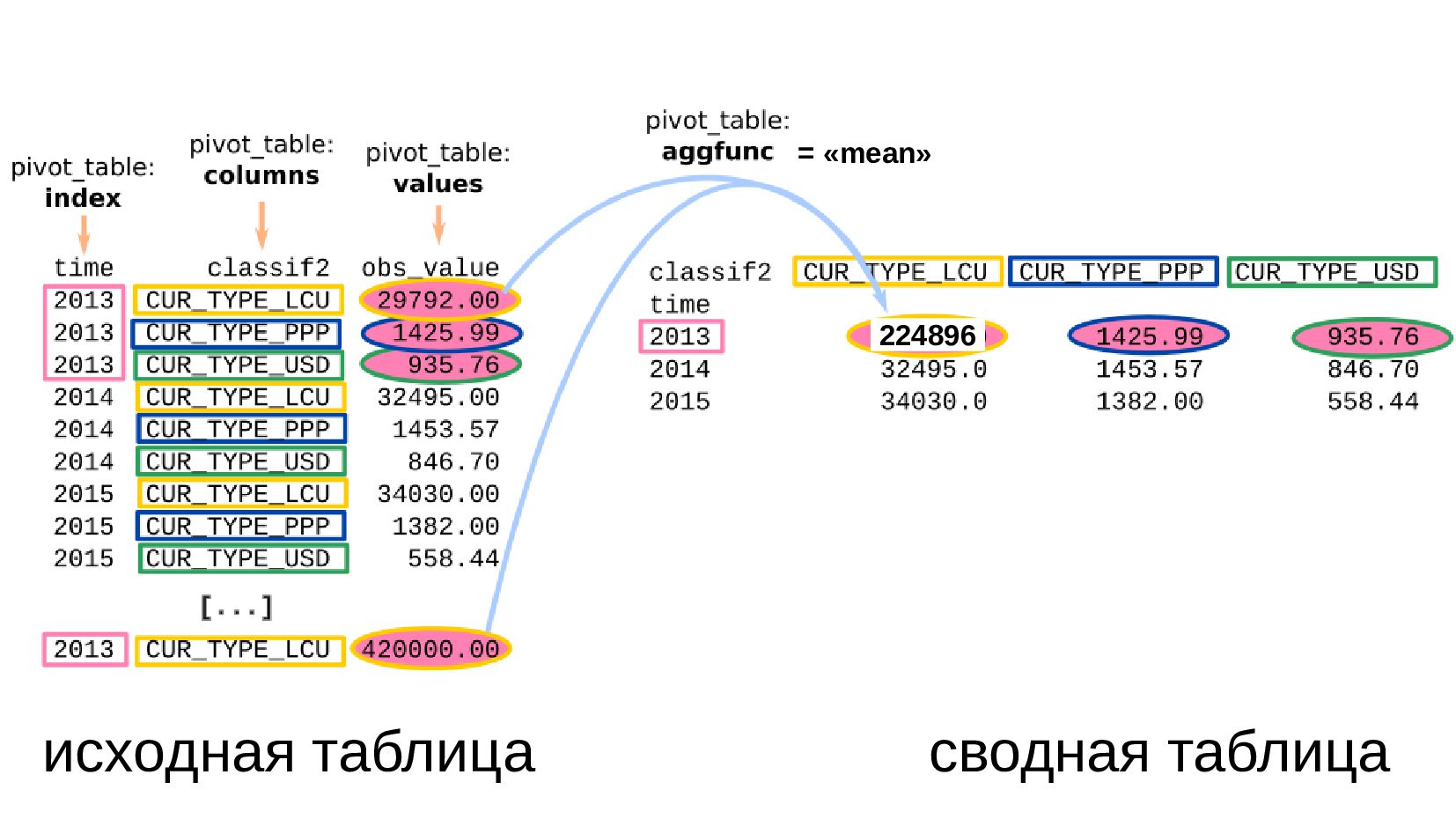
- Несколько стобликов внутри групп, рубли и доллары на одном графике: простой set_index не подойдет, необходимо перегруппировать данные
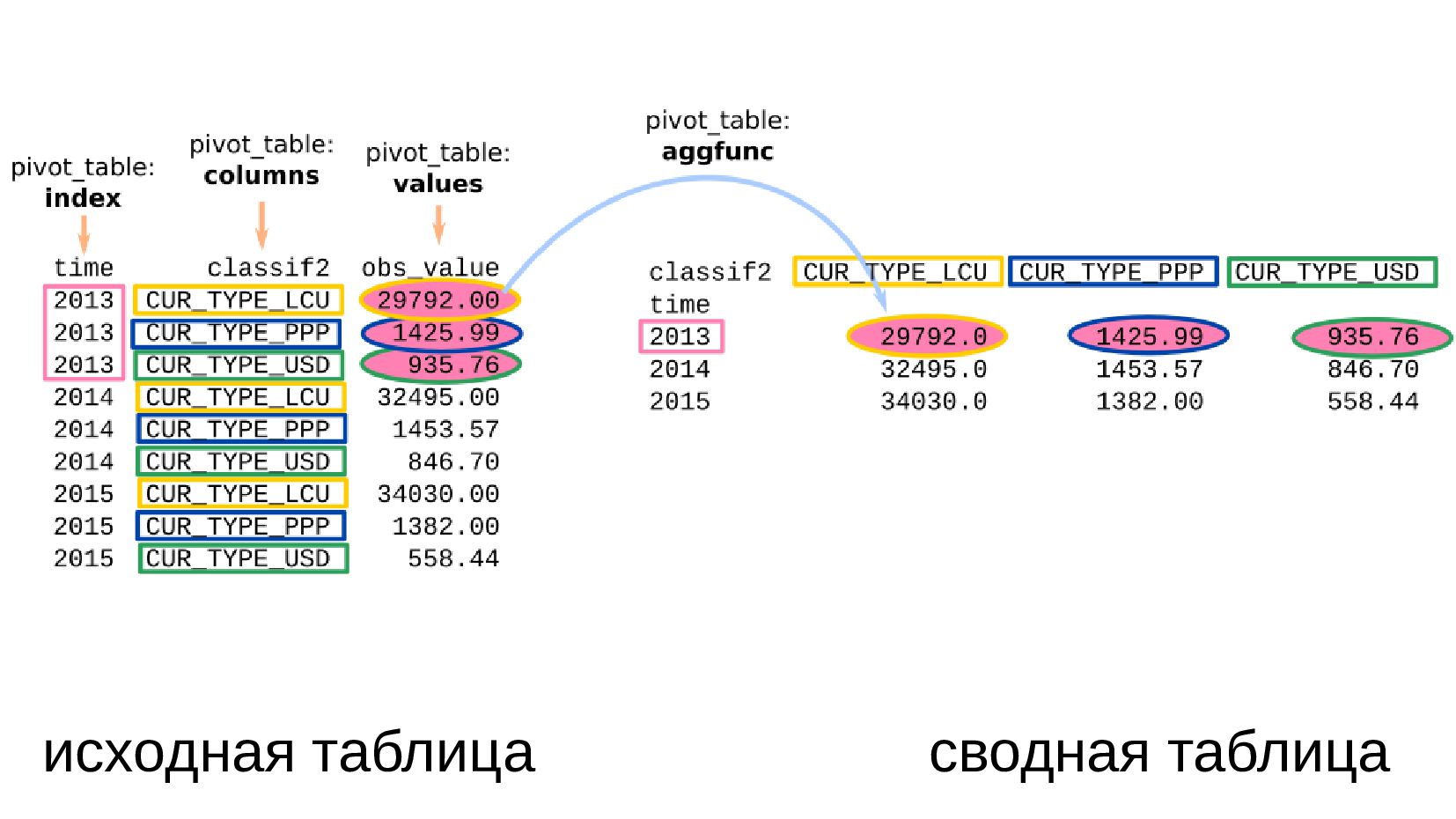
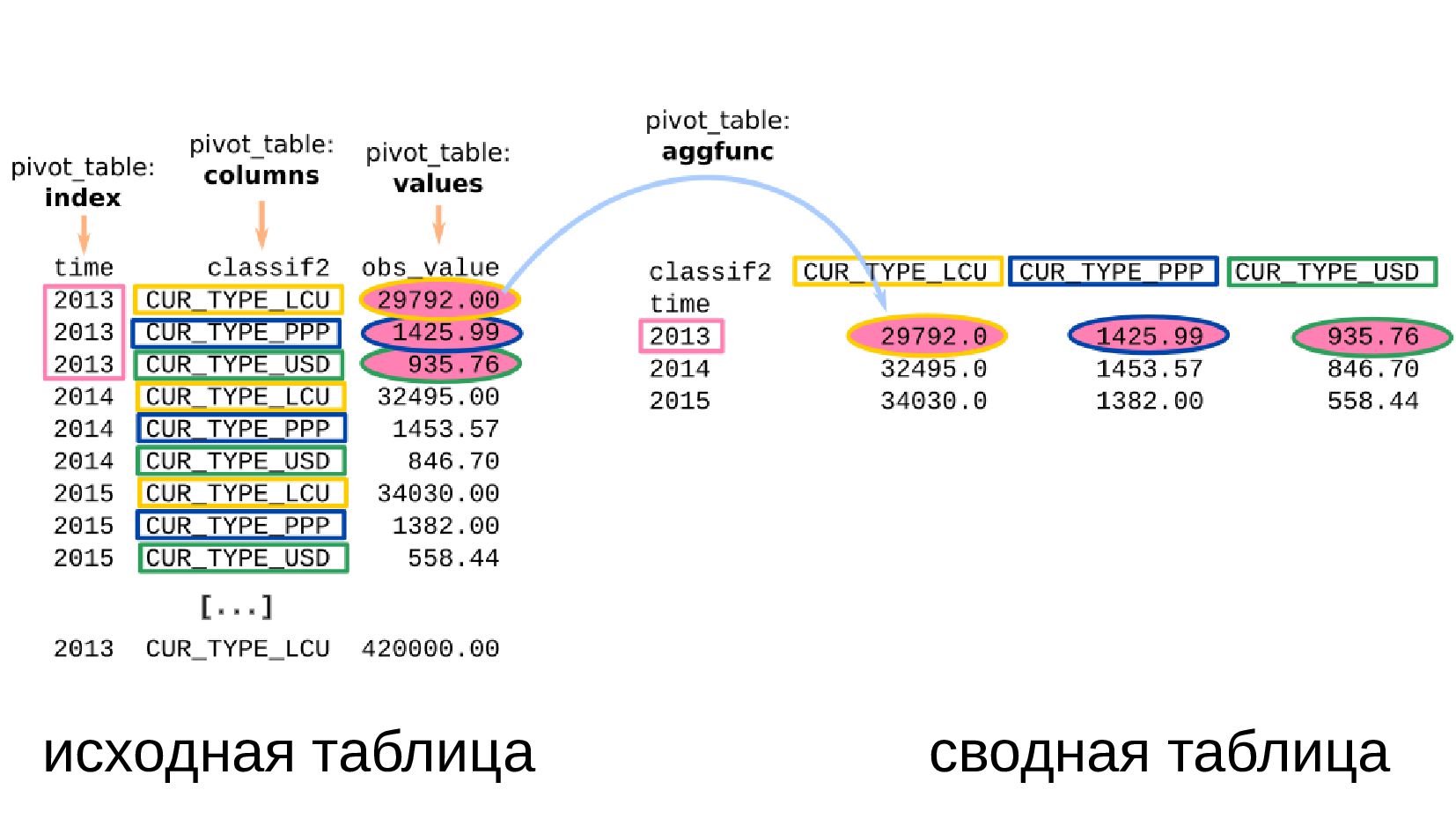
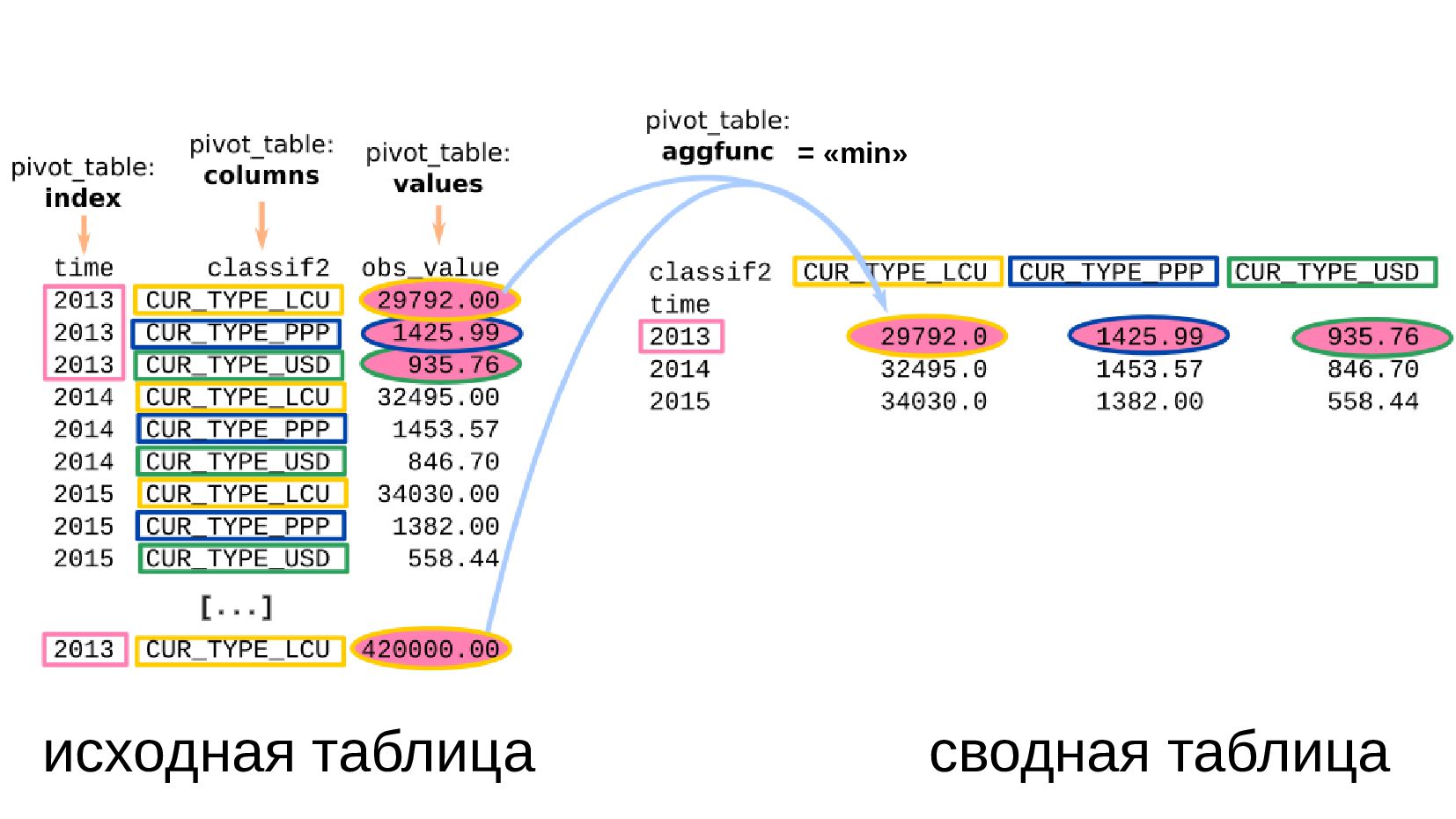
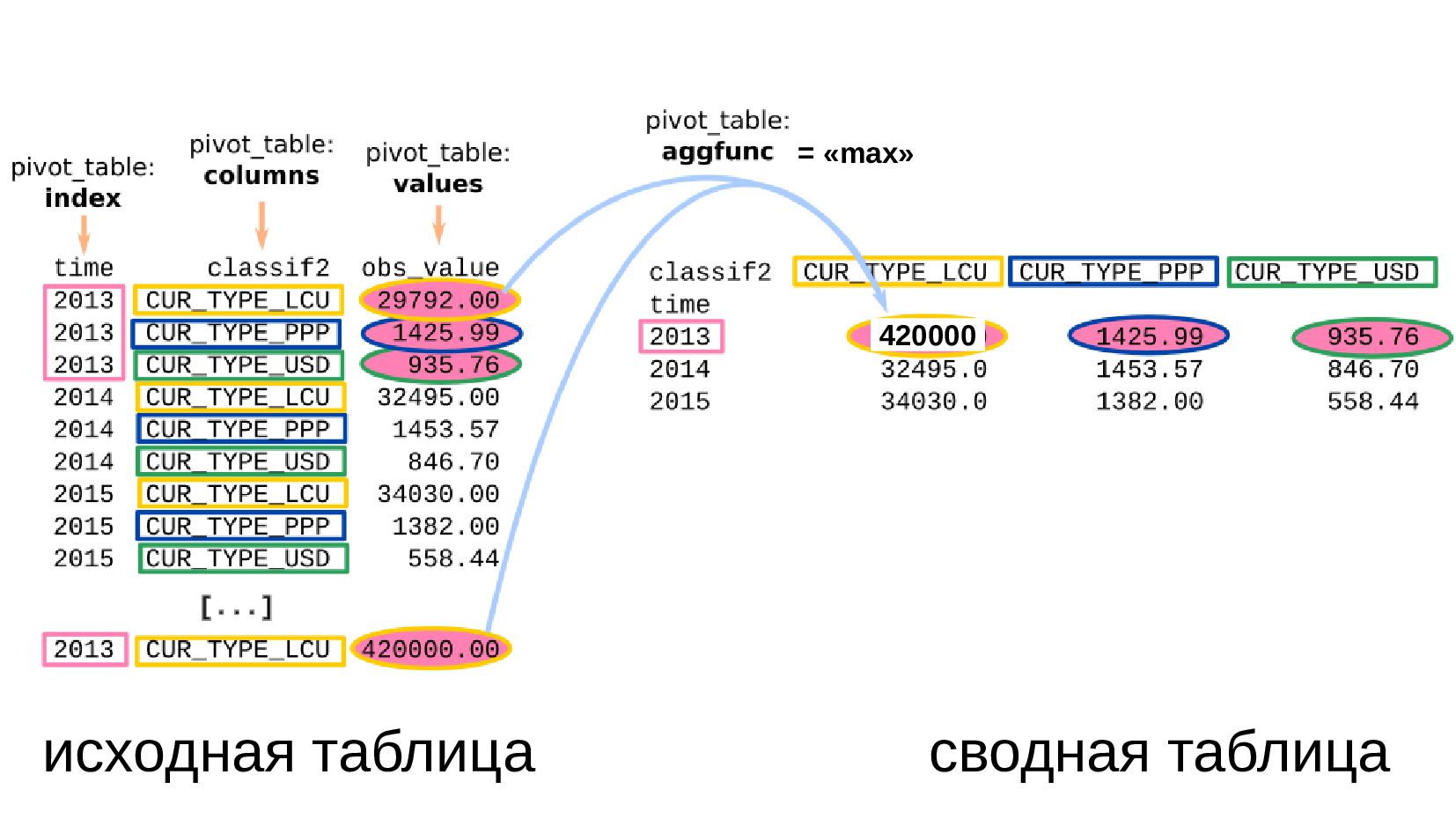
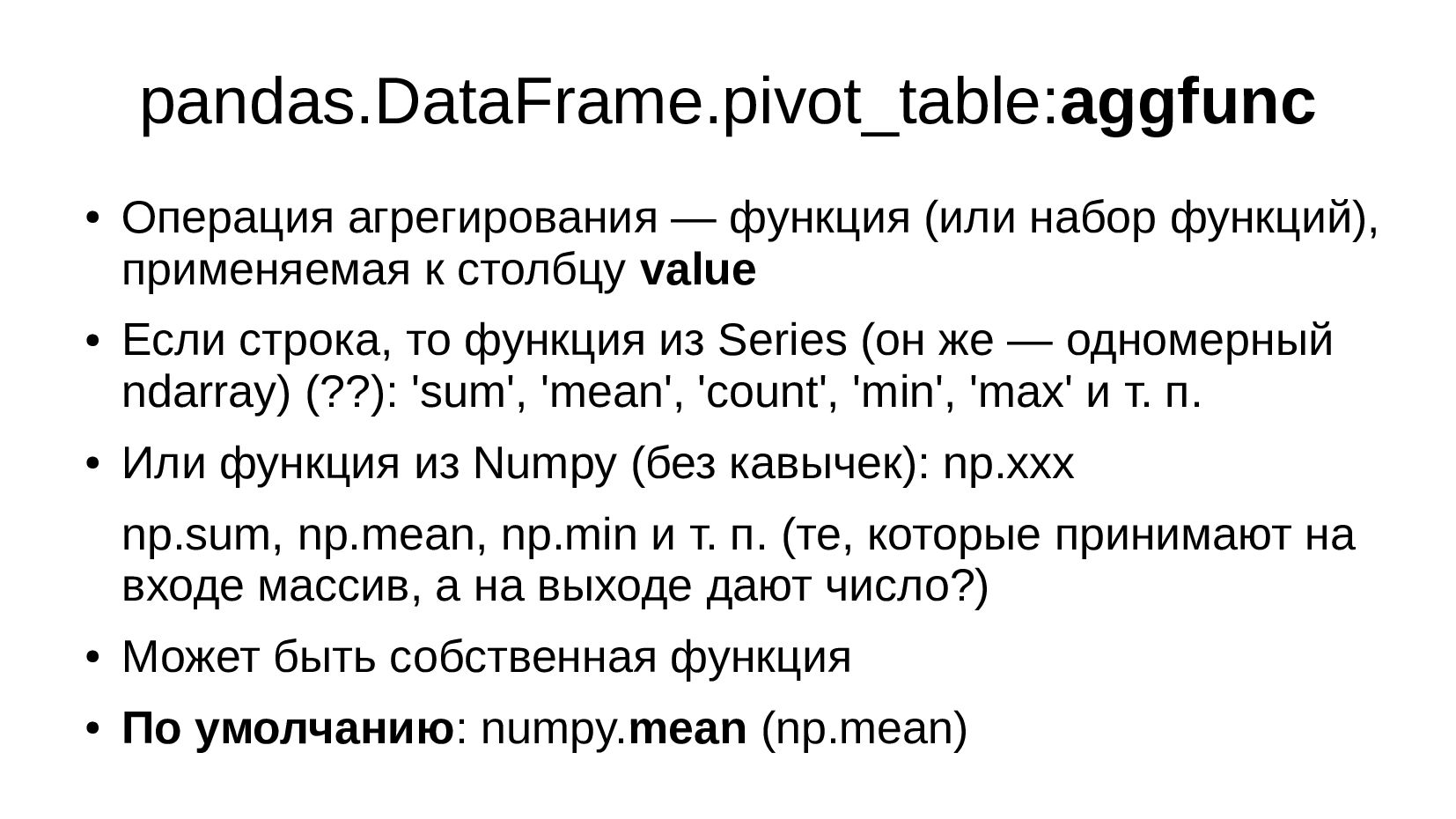
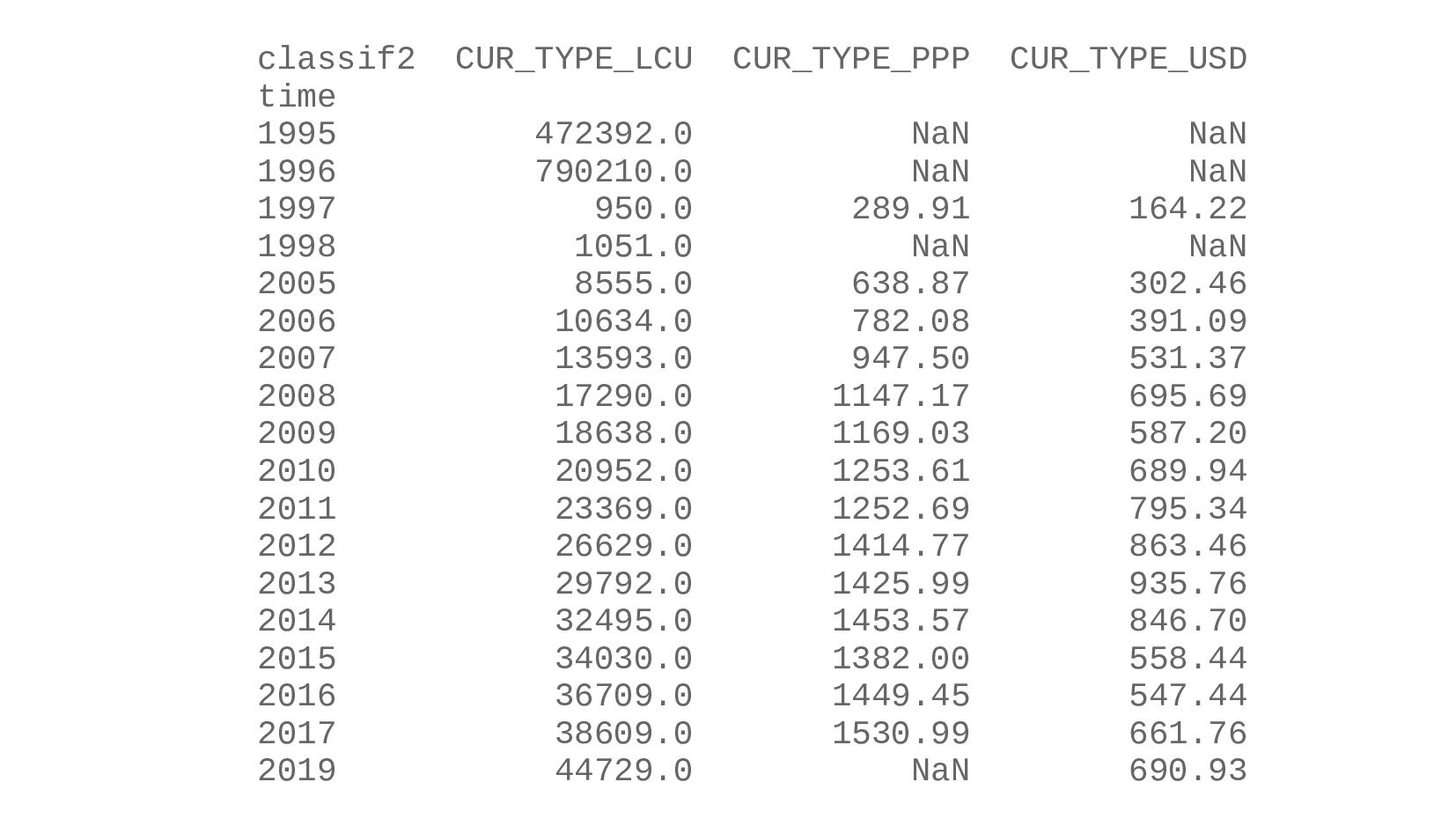
- Сводная таблица DataFrame.pivot_table: превратить повторяющиеся категории в колонки
- Несколько стобликов внутри групп, рубли и доллары на одном графике: после перегруппировки сводной таблицей получилось ок
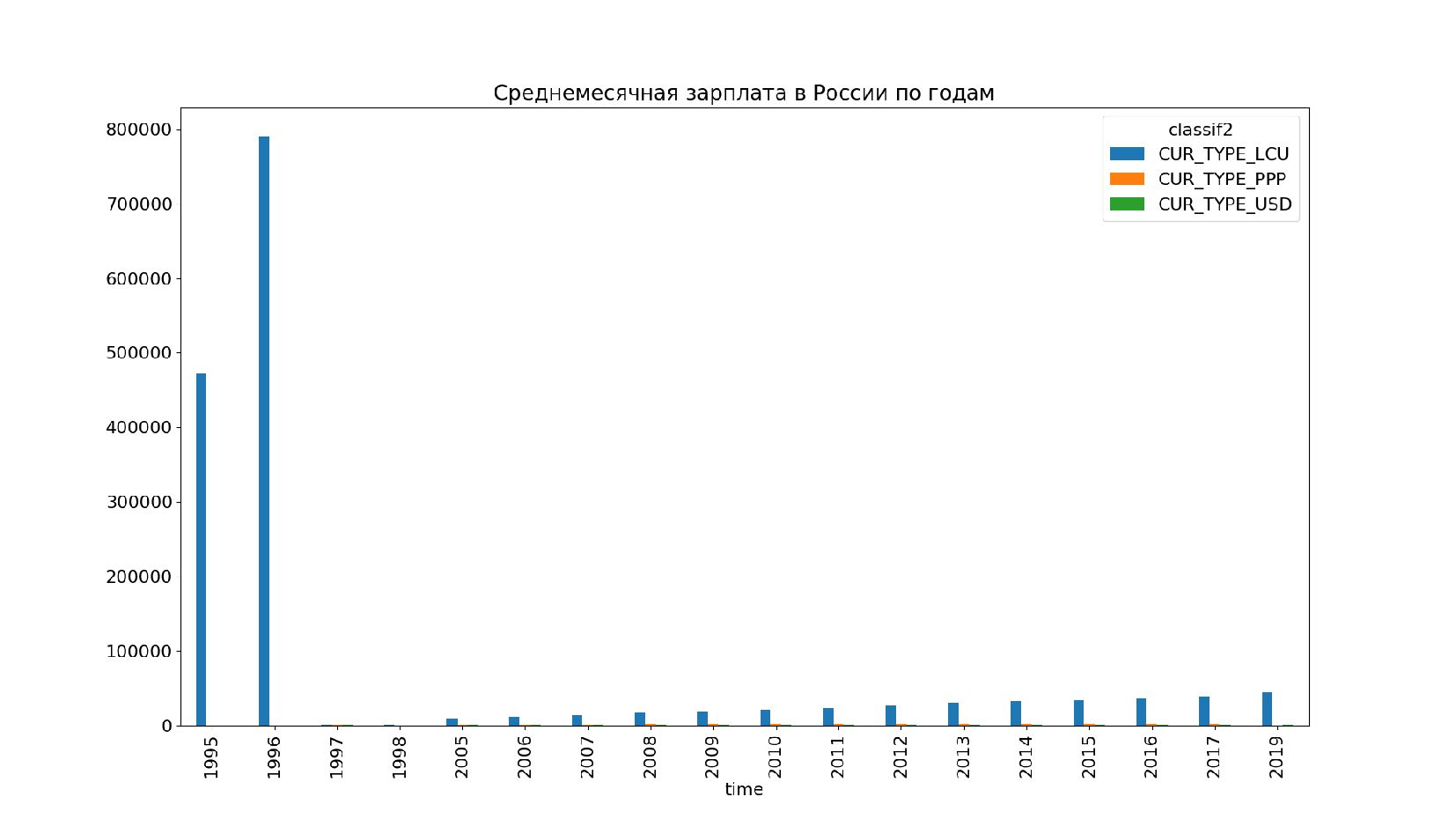
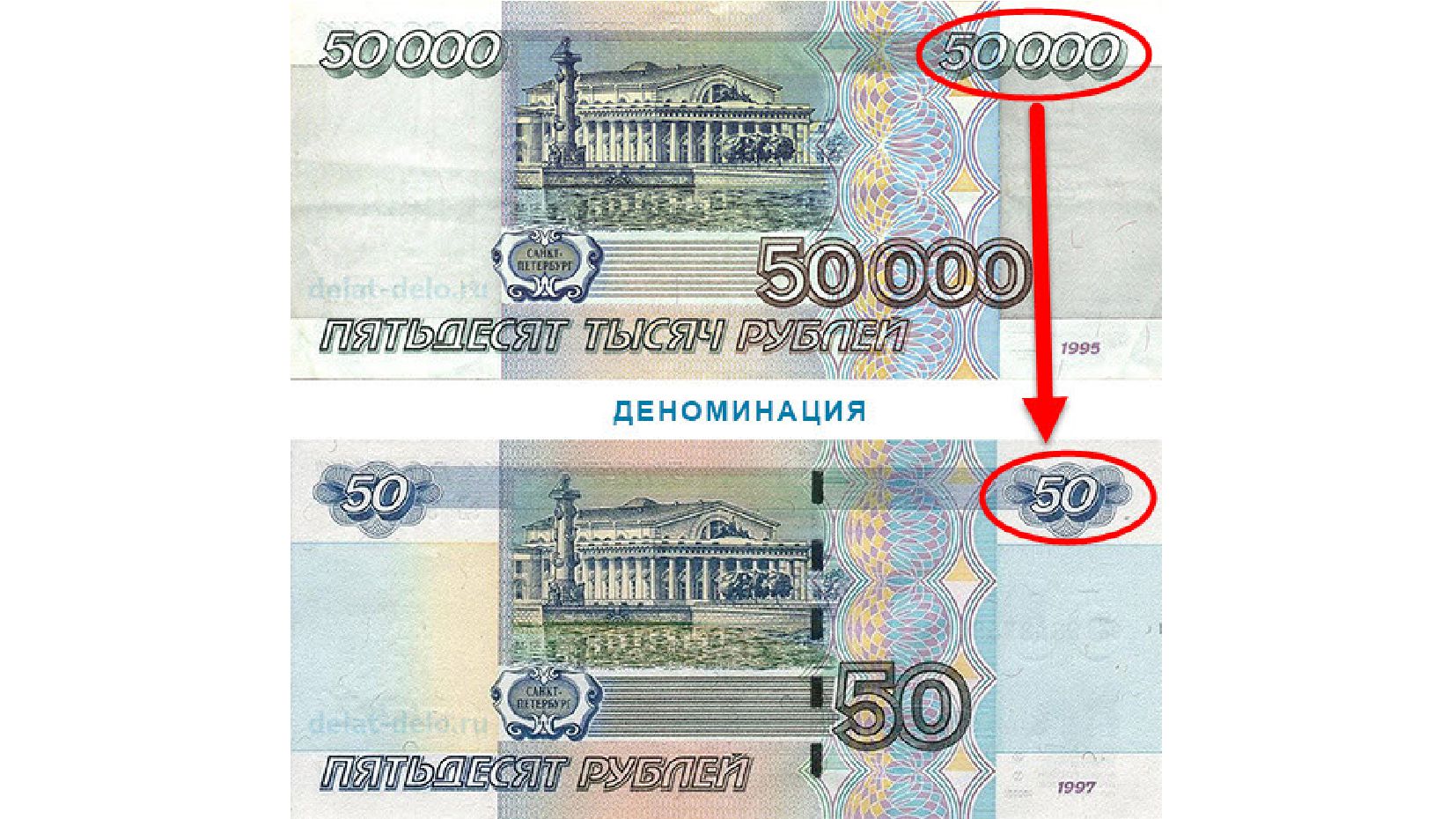
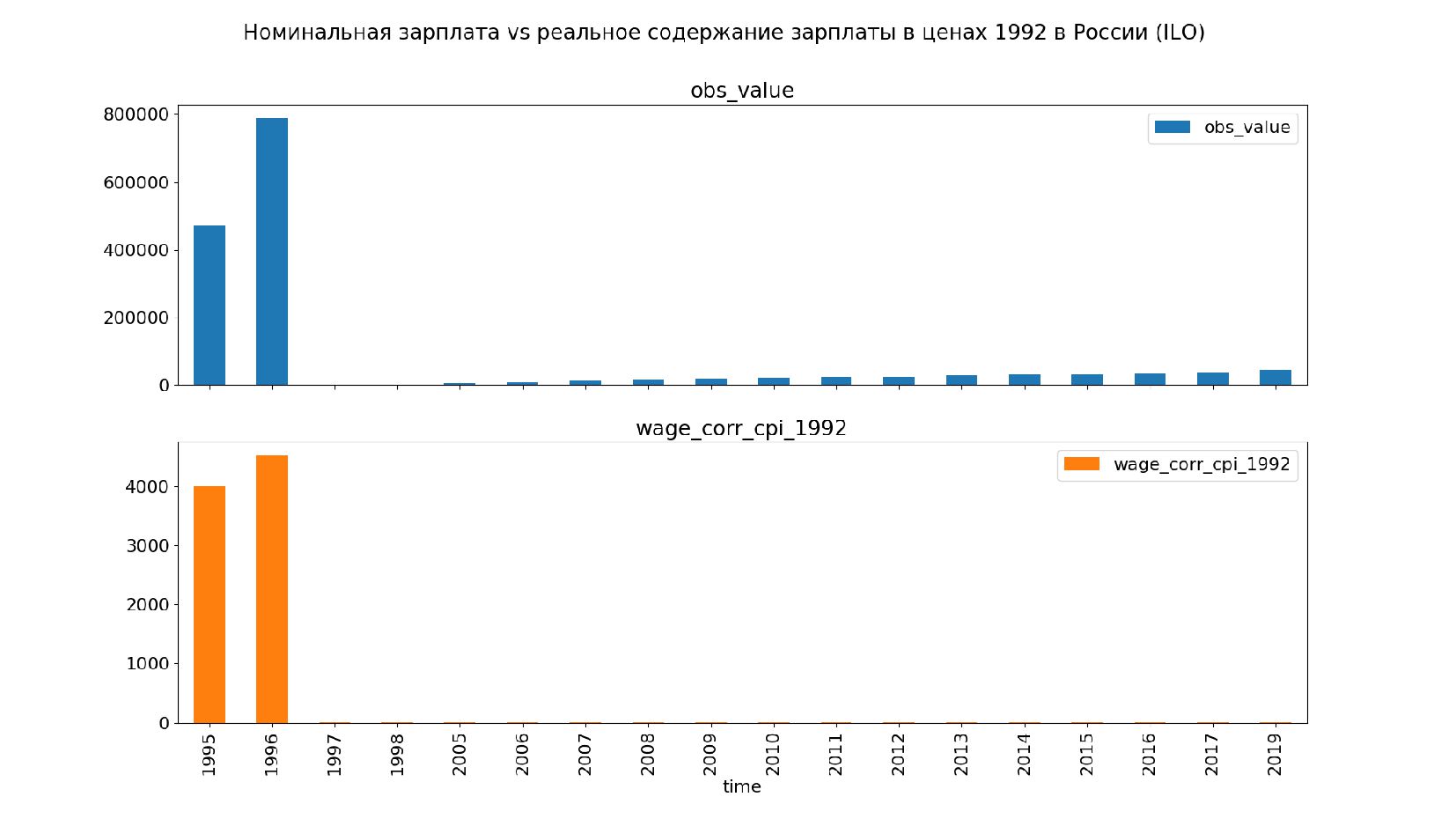
- Галопирующая инфляция и деноминация: несопоставимый масштаб данных на одном графике
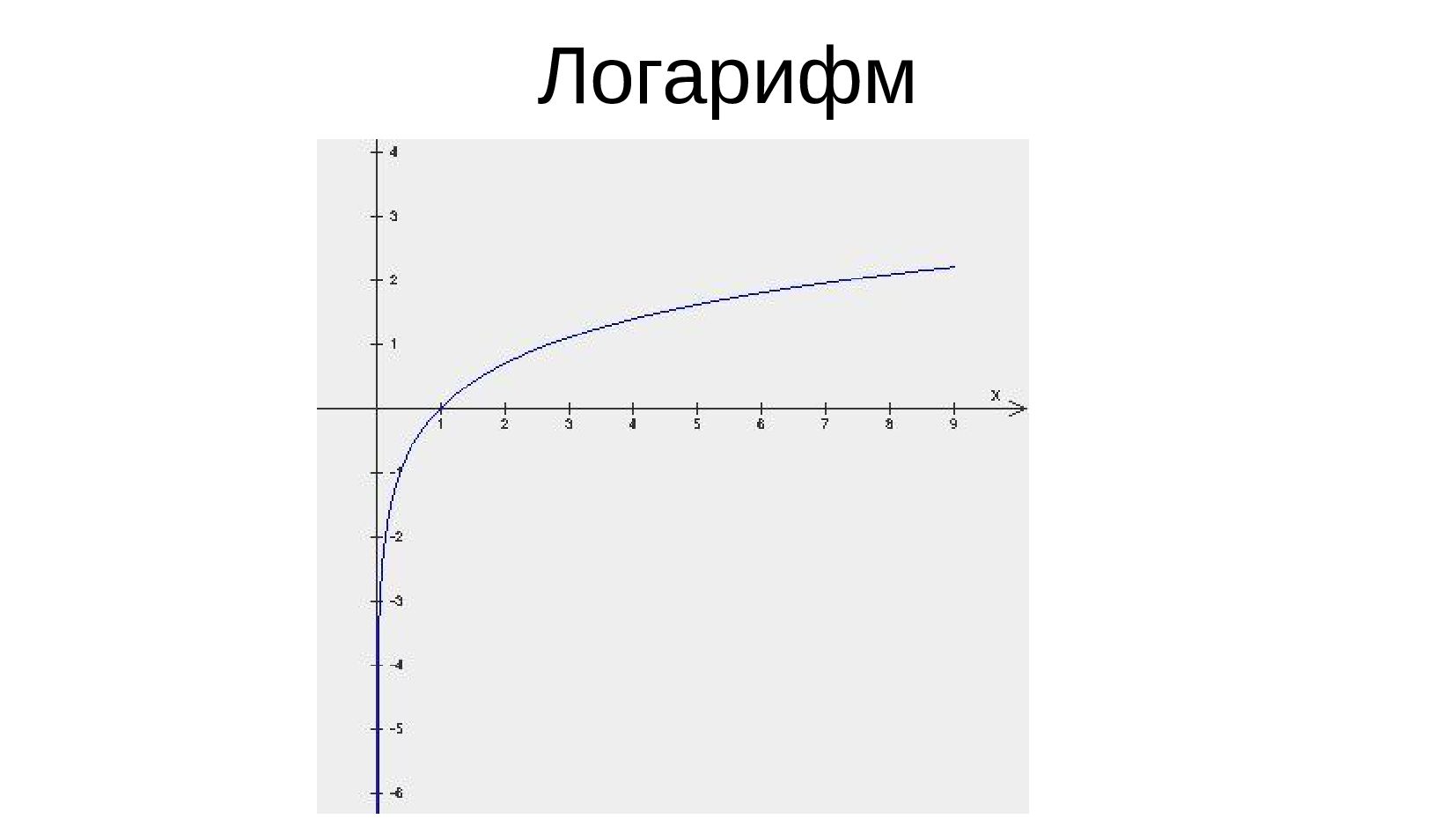
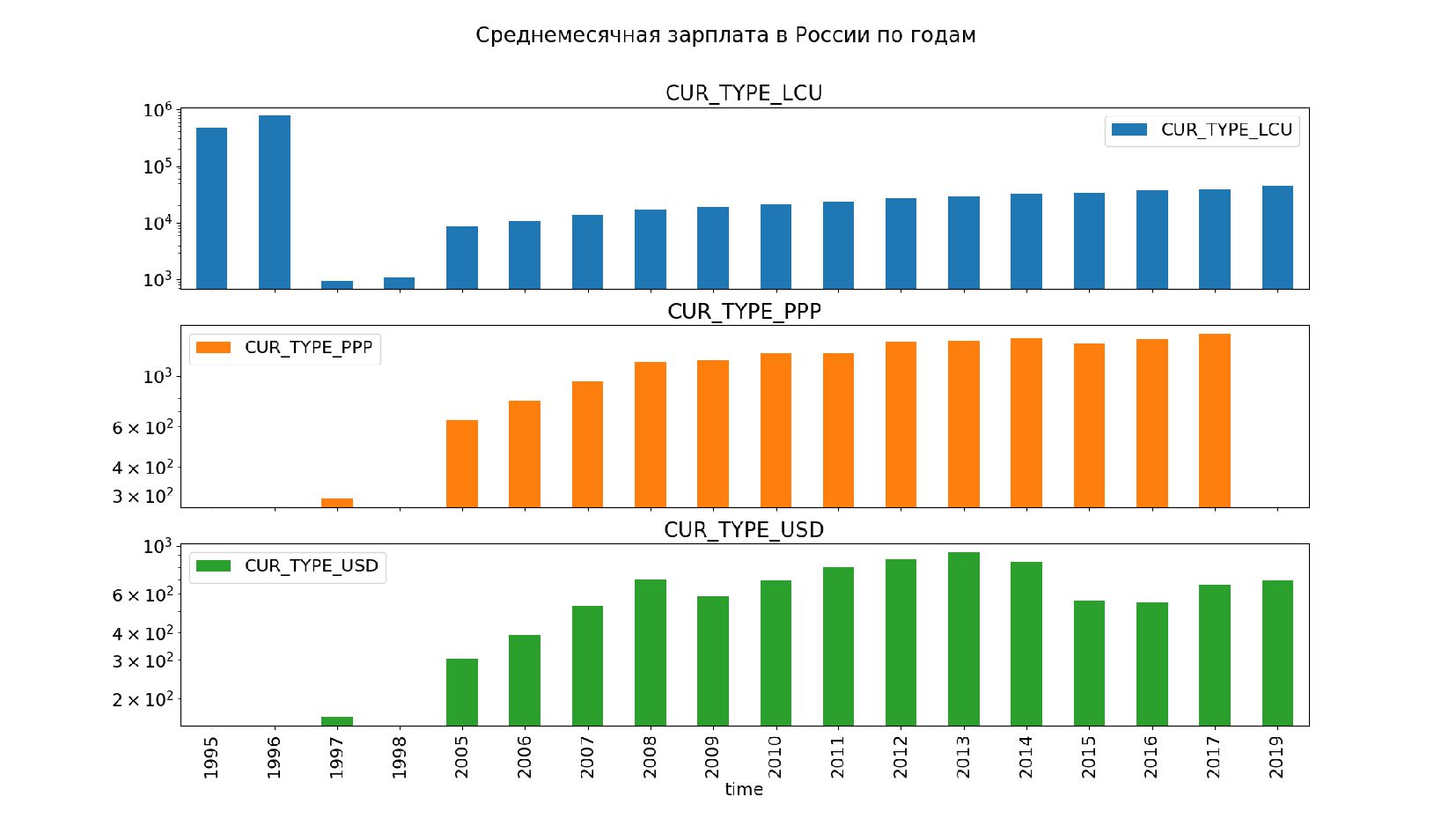
- Логарифмическая шкала, подводные камни логарифма
- Несколько графиков в одном окне (subplots=True)
- Ручное масштабирование данных: ретроспективная деноминация
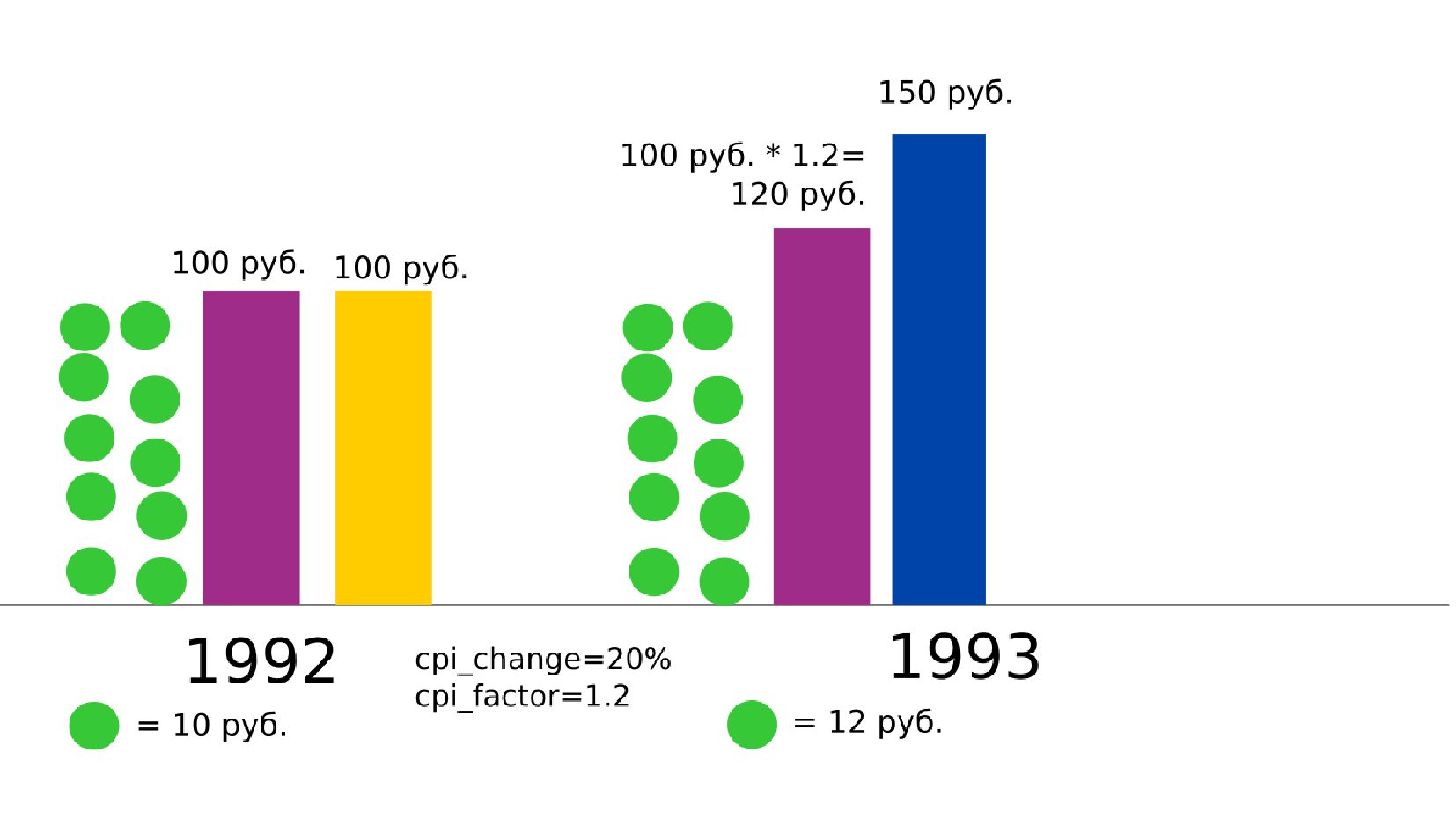
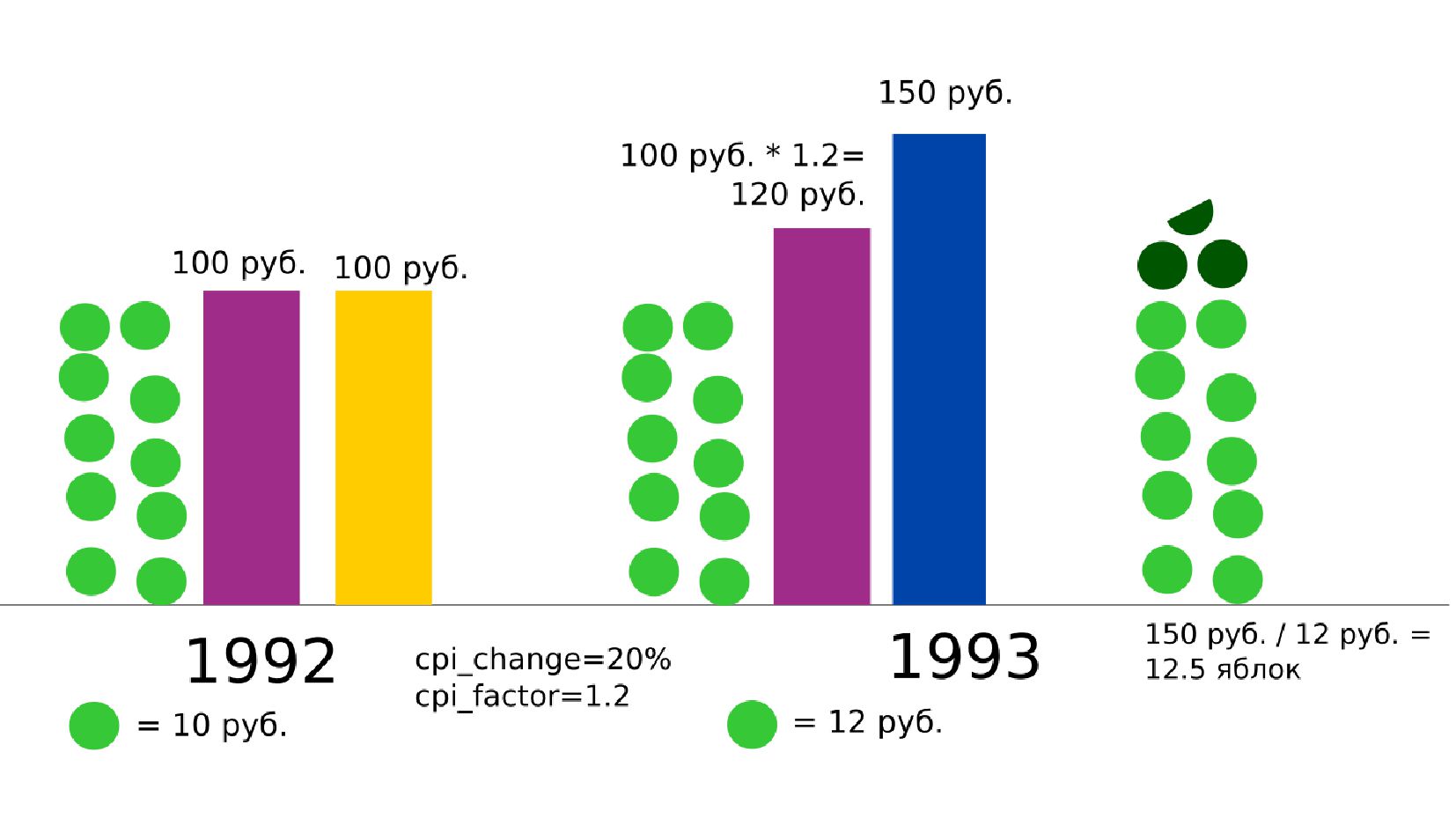
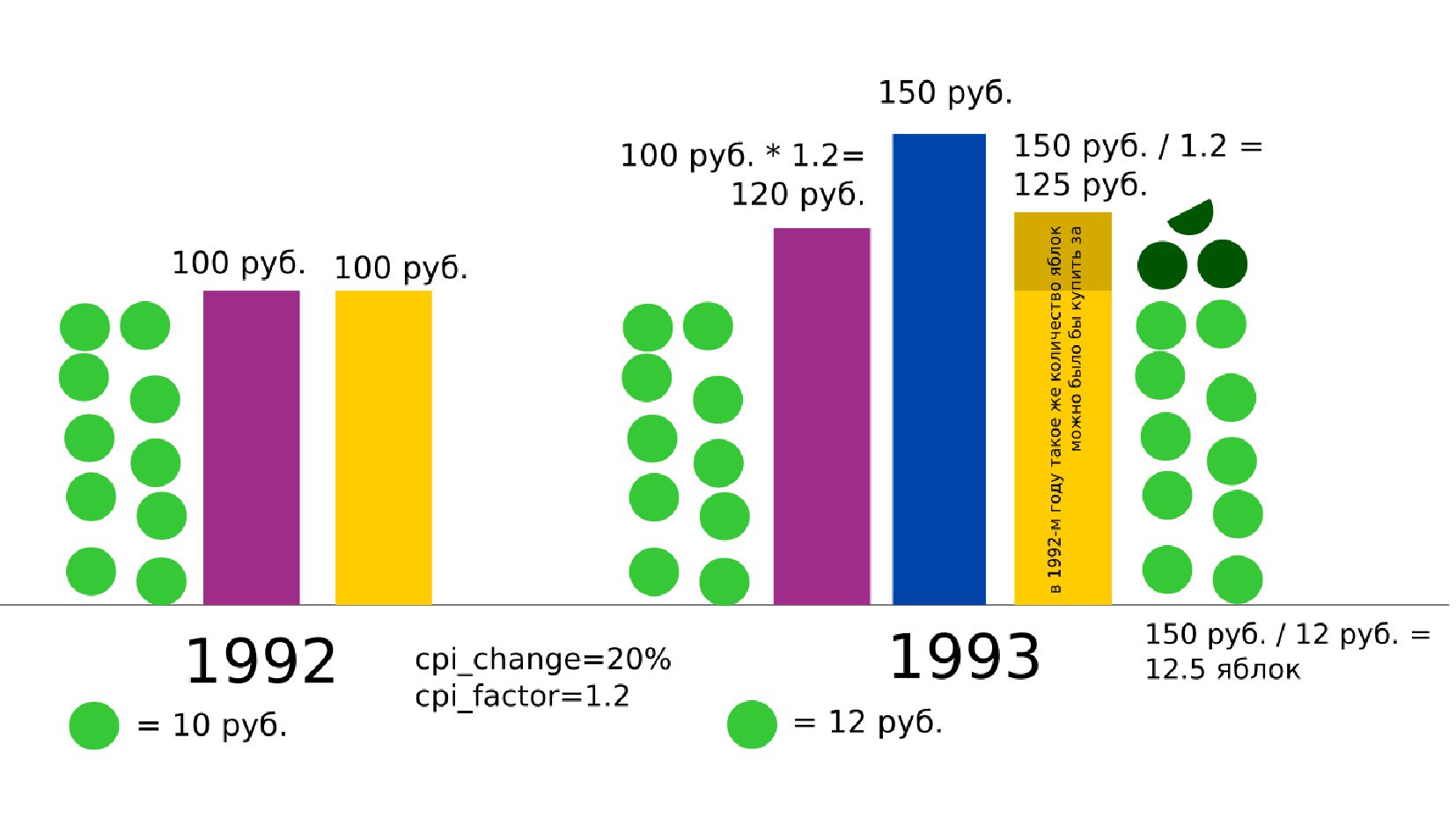
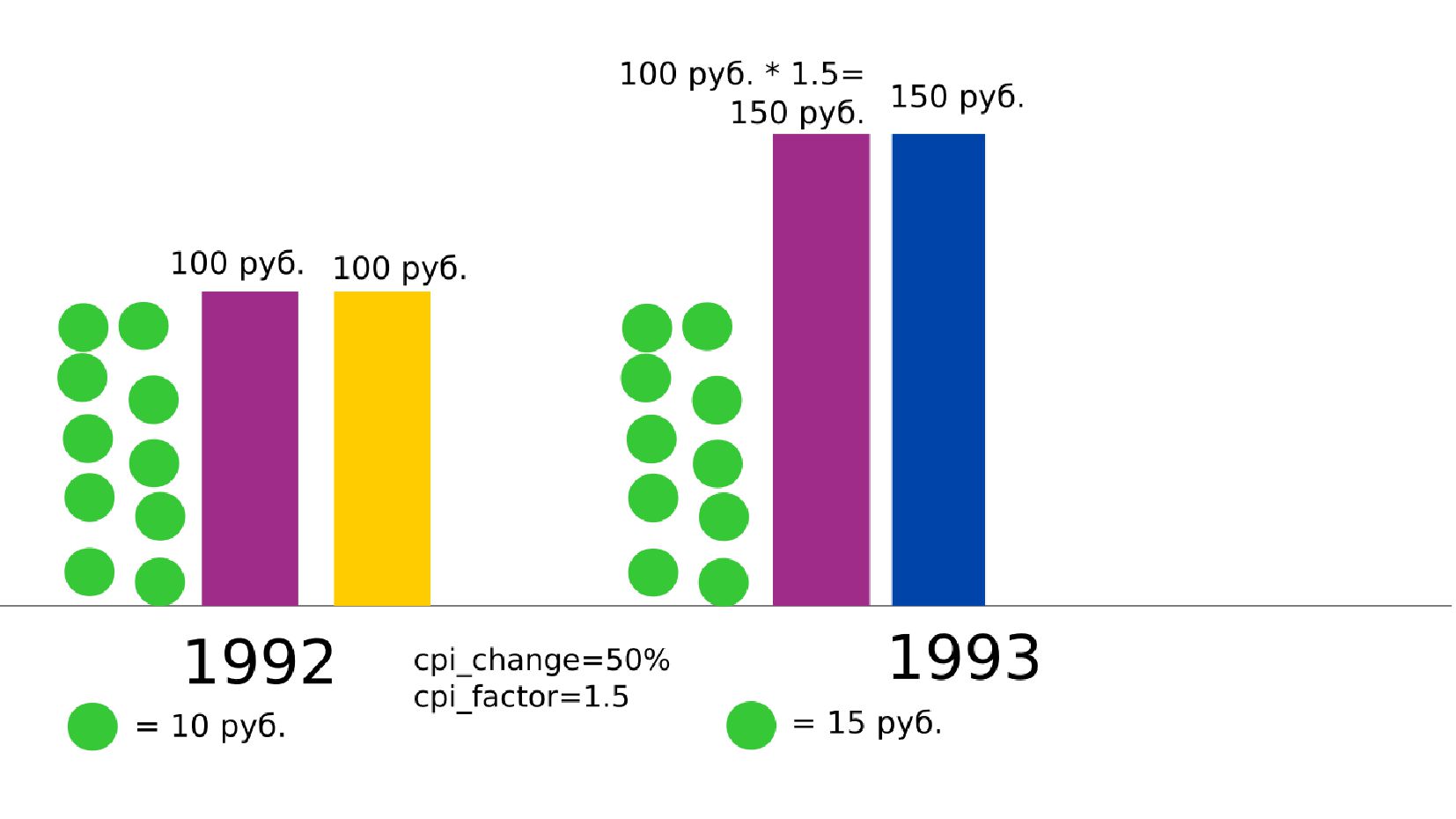
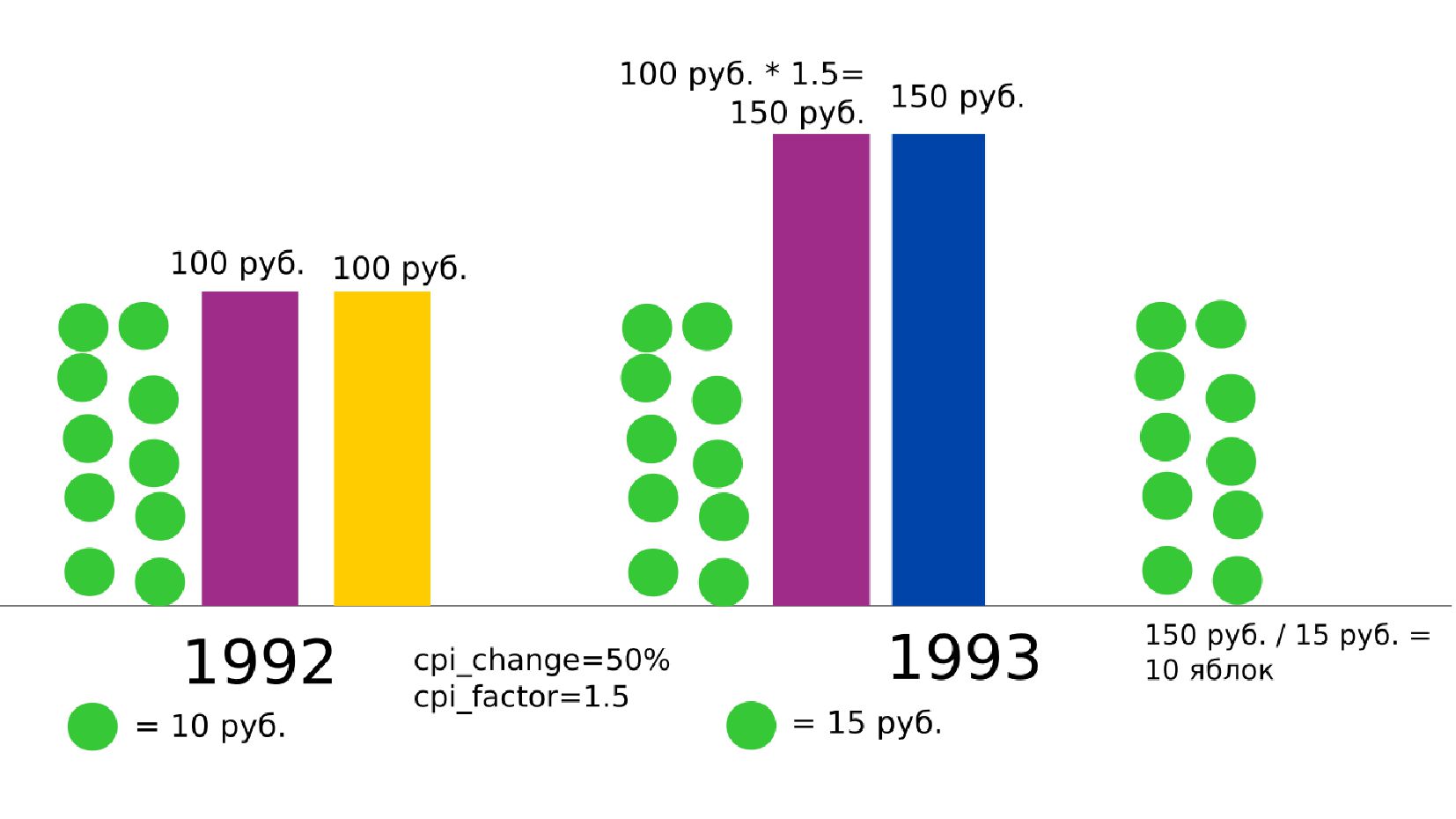
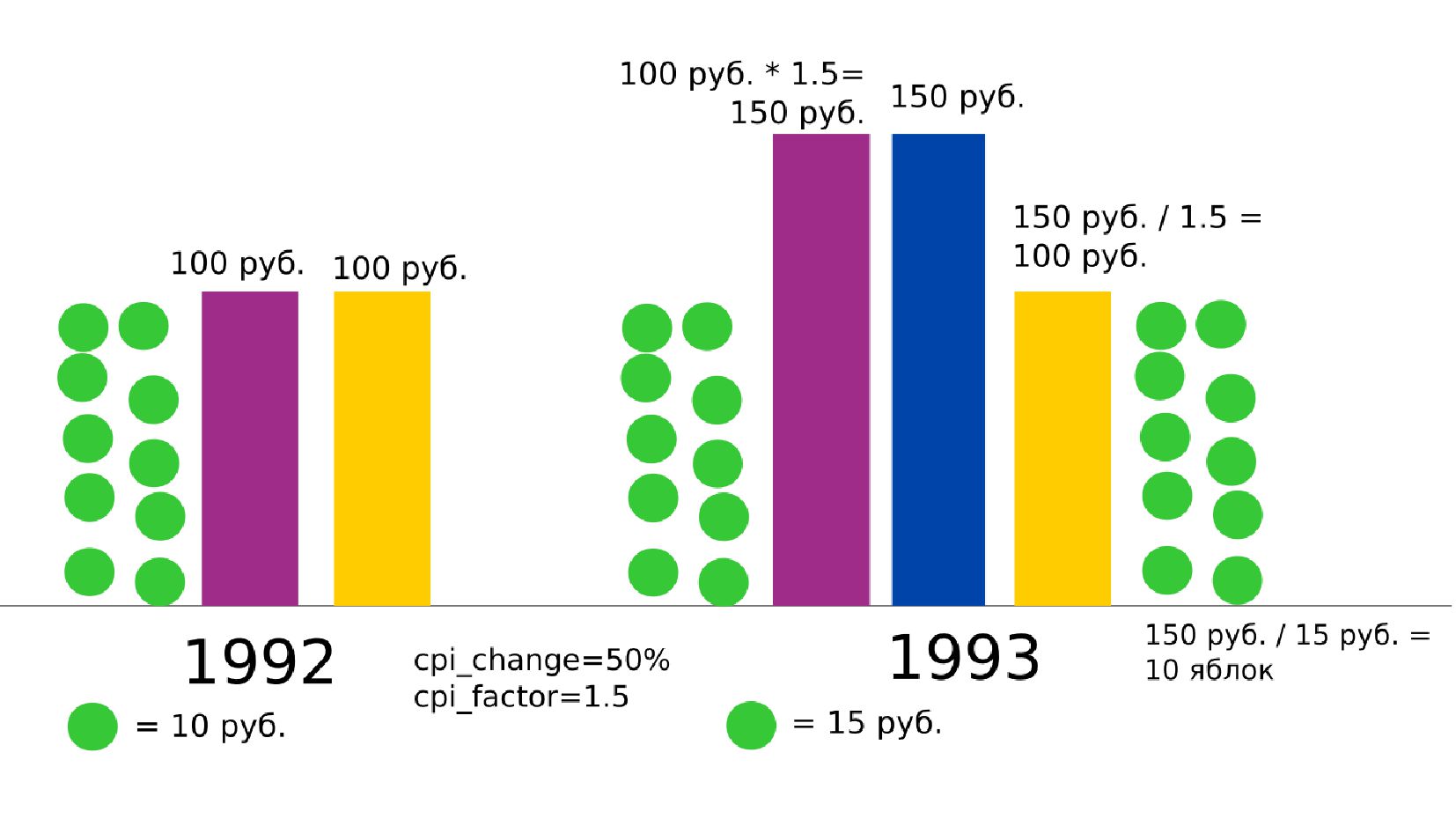
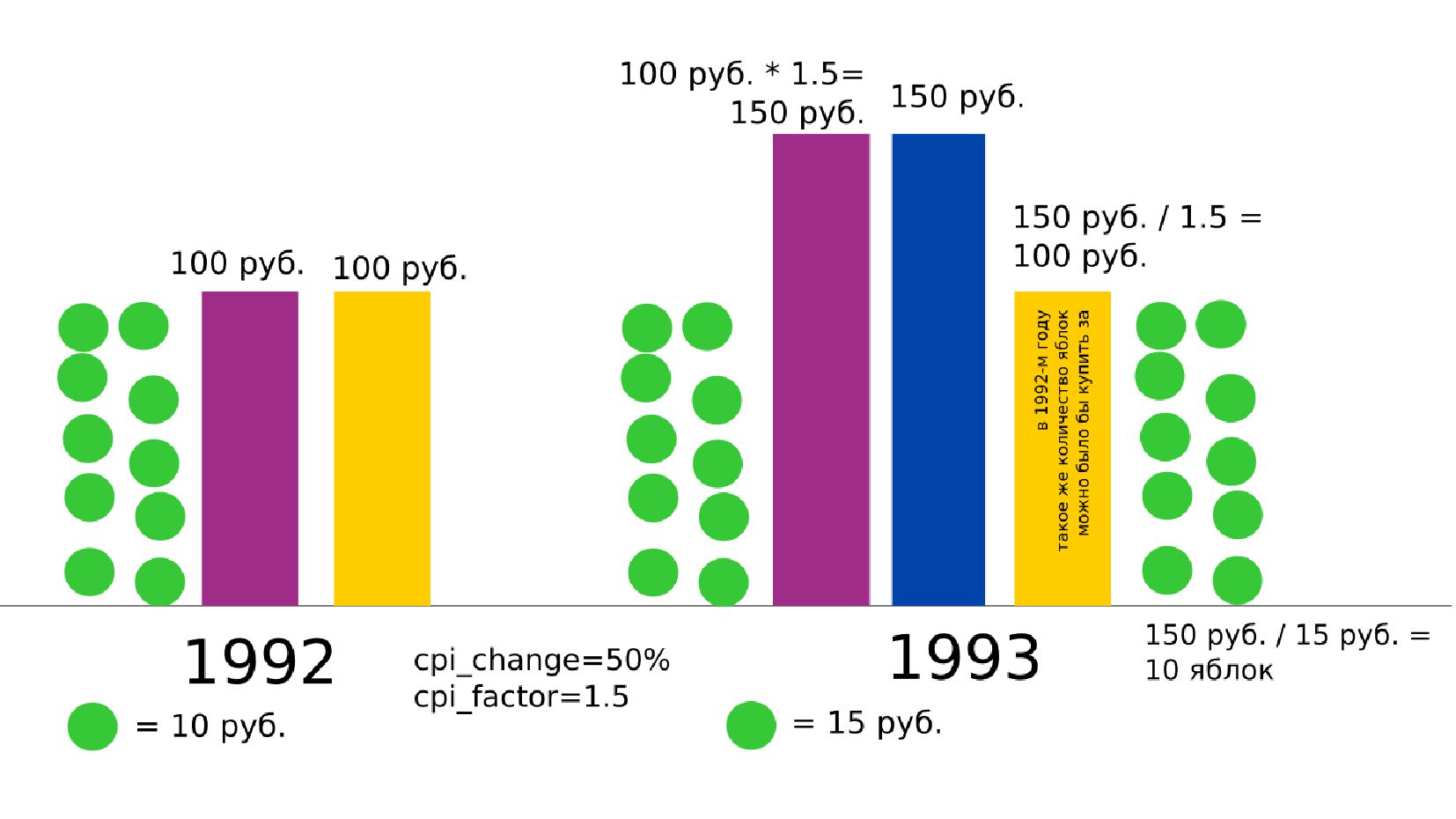
- Номинальная зарплата, реальное содержание заработной платы, индекс потребительских цен (инфляция)
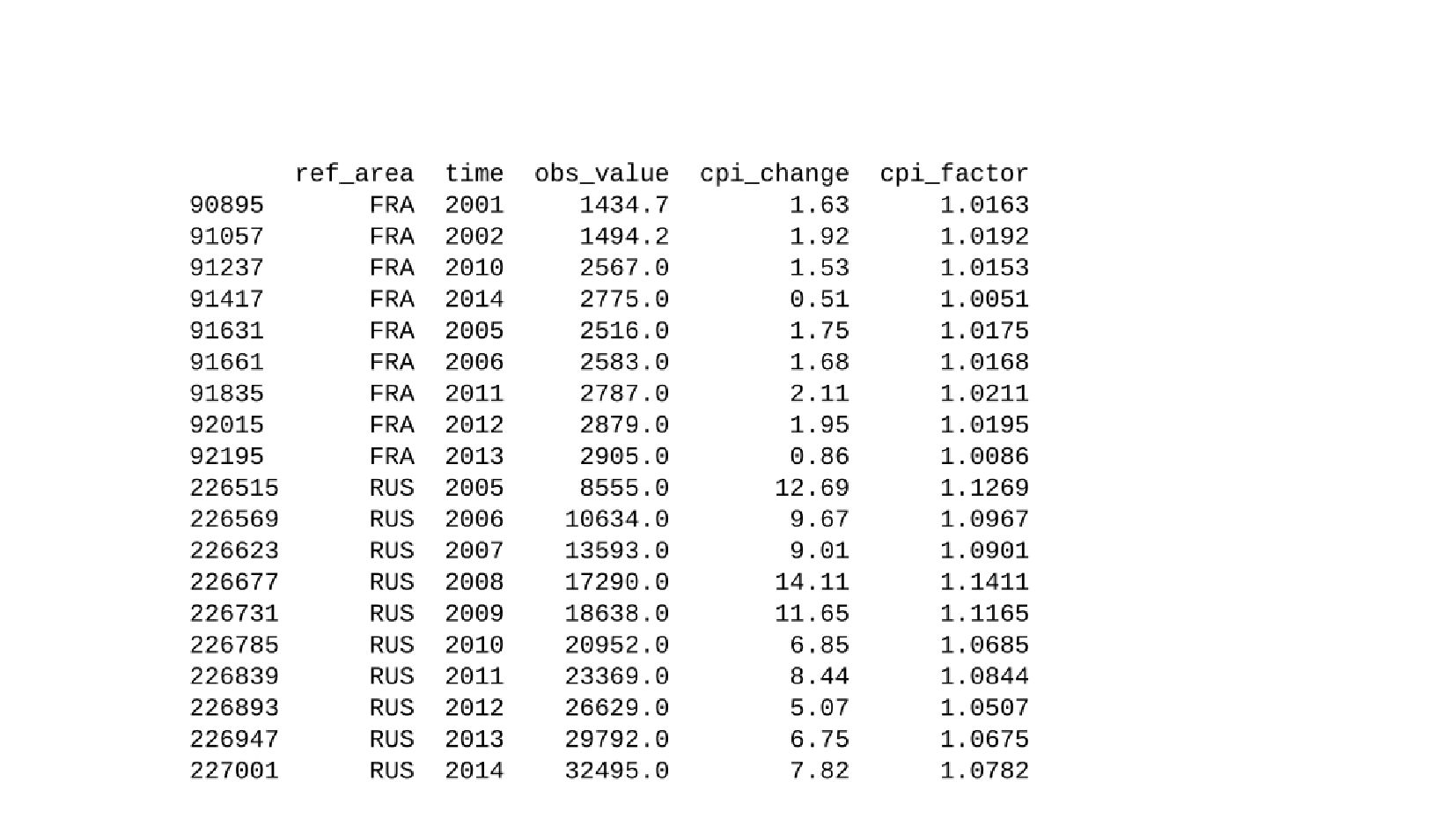
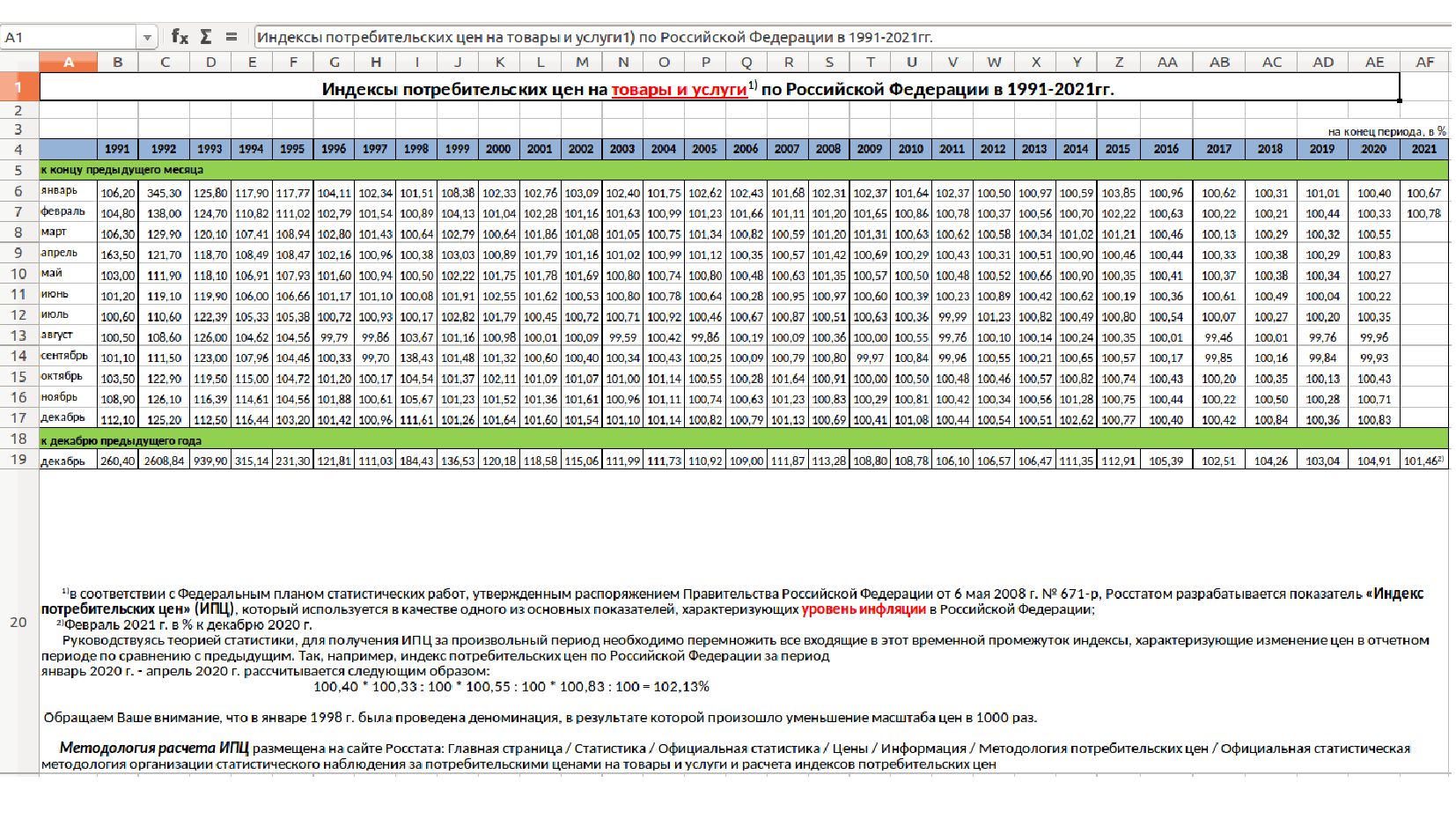
- Данные по индексам потребильских цен: МОТ, Росстат
Часть-2
- Номинальная зарплата, реальное содержание заработной платы, индекс потребительских цен (ИПЦ),
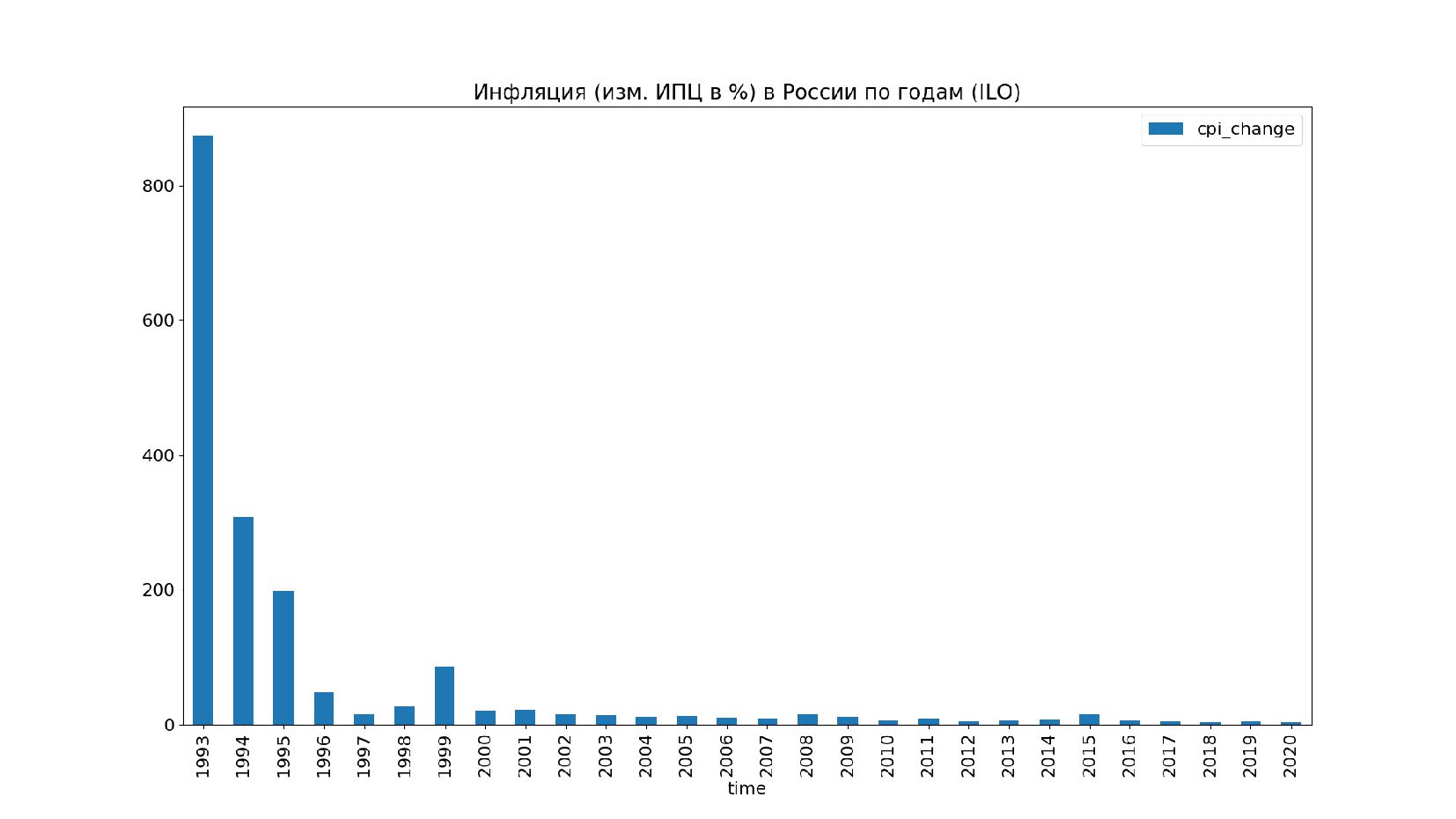
- Изменение ИПЦ в % (инфляция)
- Данные: датасет ILO (МОТ - Международная организация труда) ilostat.ilo.org
- Таблица для анализа: средня зарплата по видам деятельности, полу, странам и годам
- Данные по индексам потребильских цен: МОТ, Росстат
- График инфляции по годам
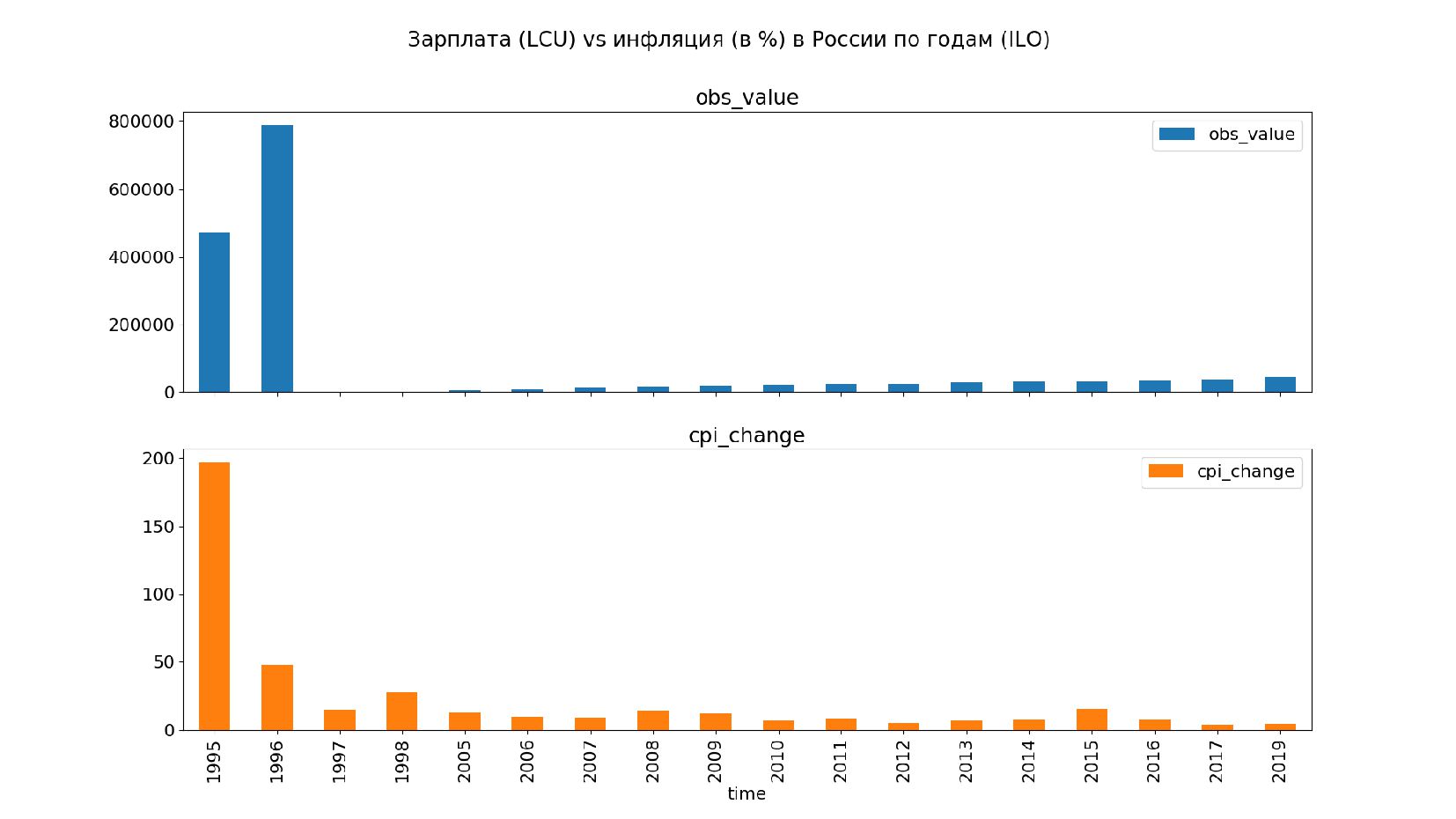
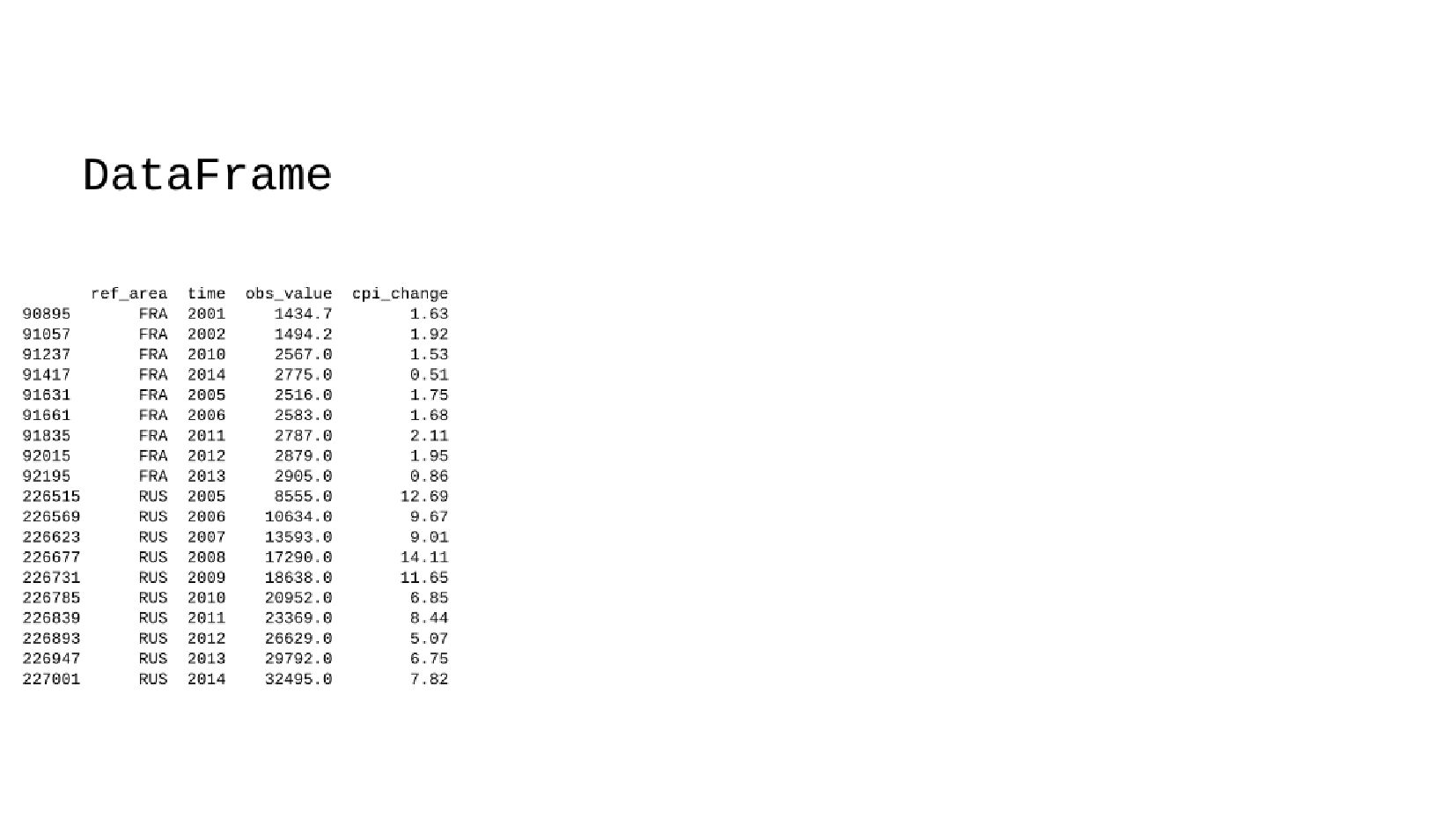
- Мультииндекс, объединение таблиц средней зарплаты и ИПЦ по мультииндексу
- График: зарплата vs инфляция
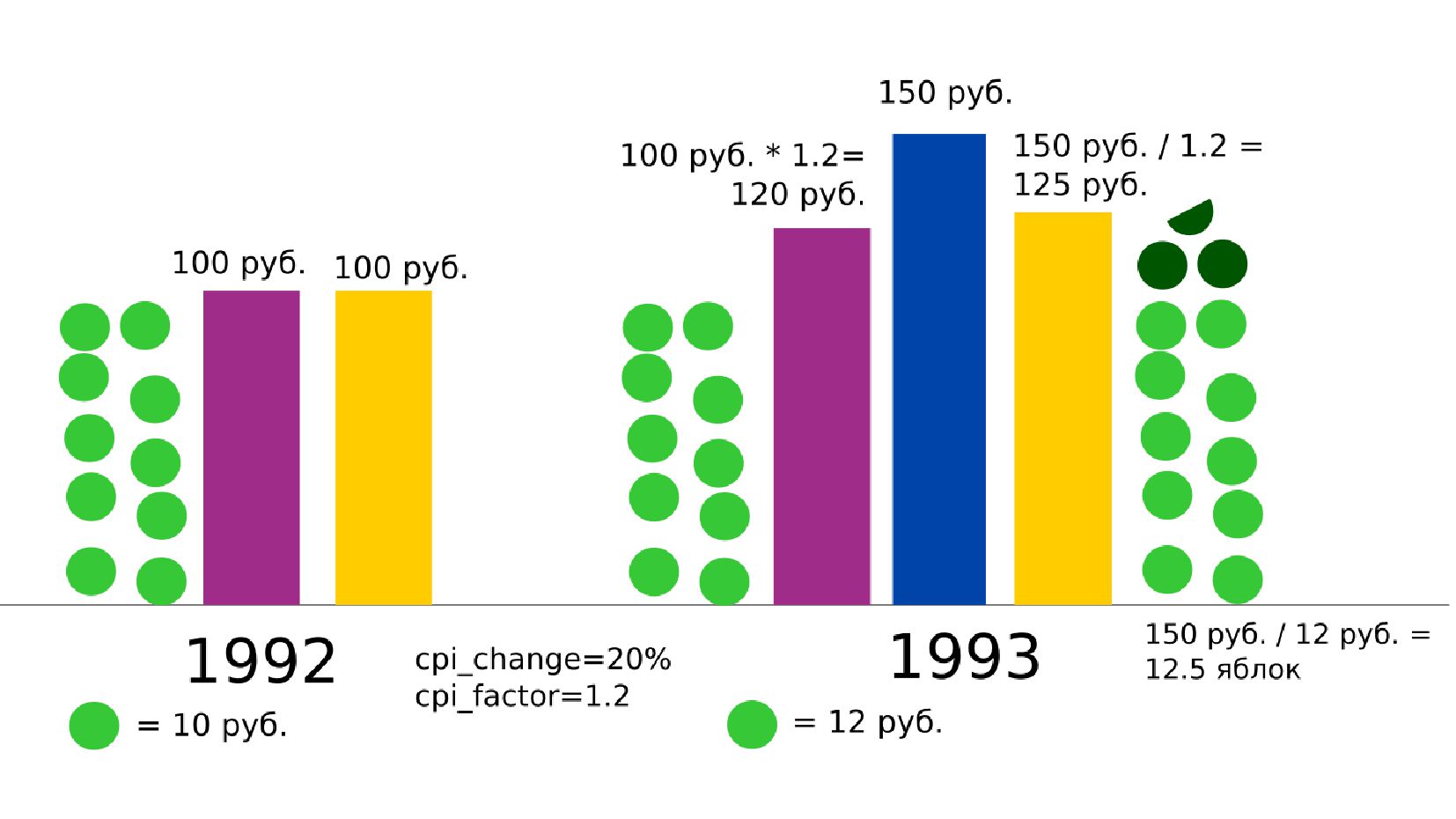
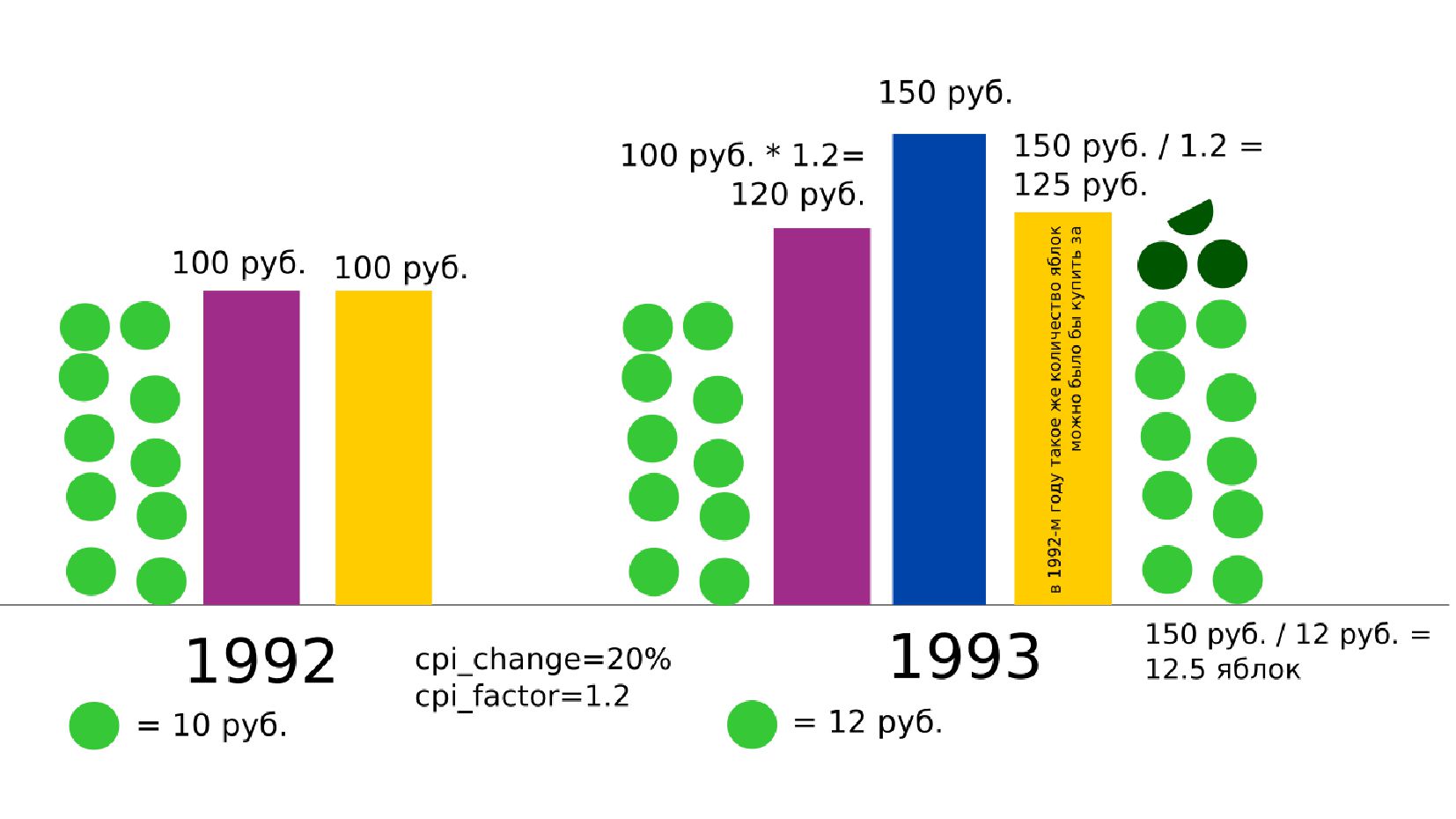
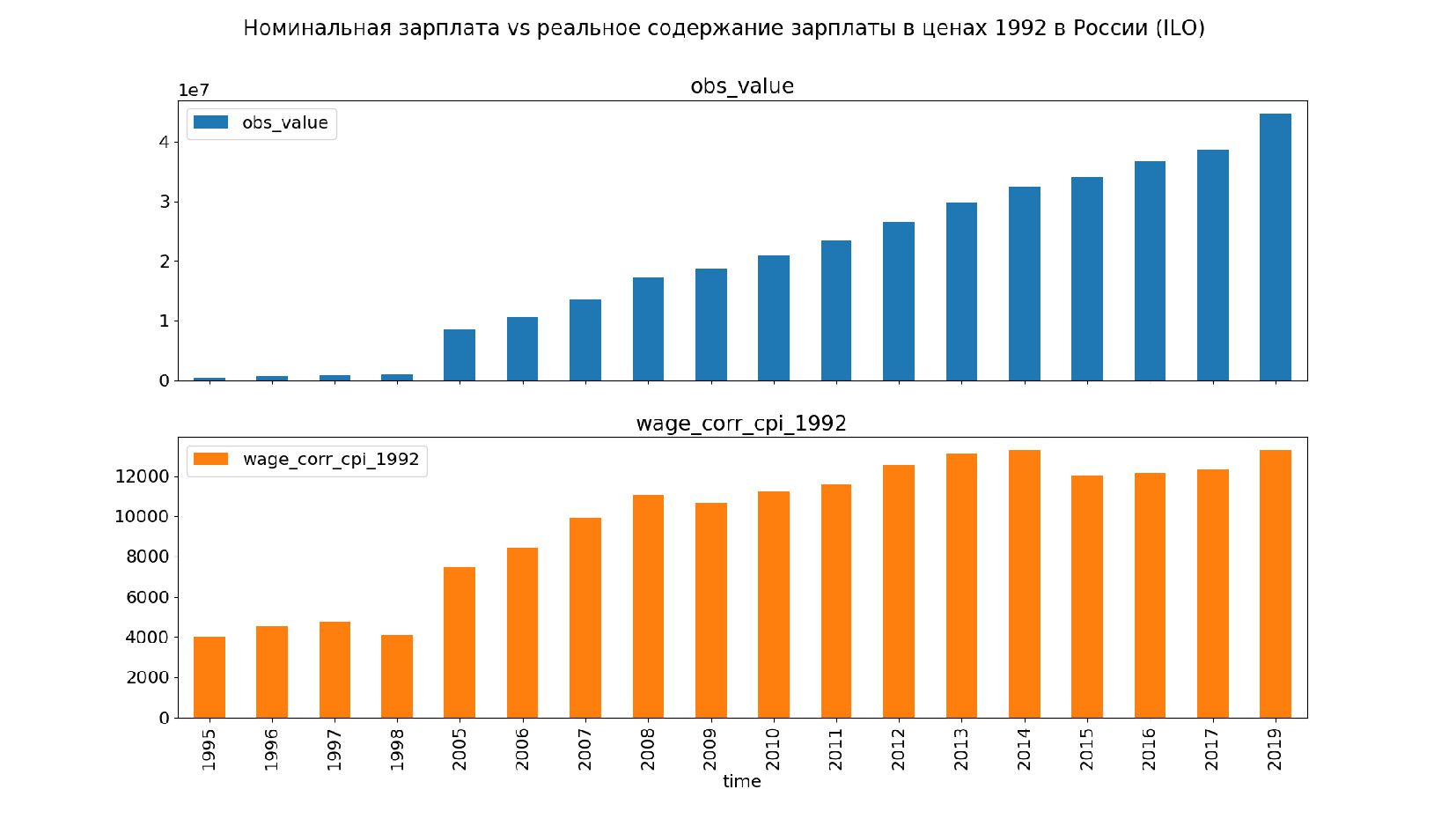
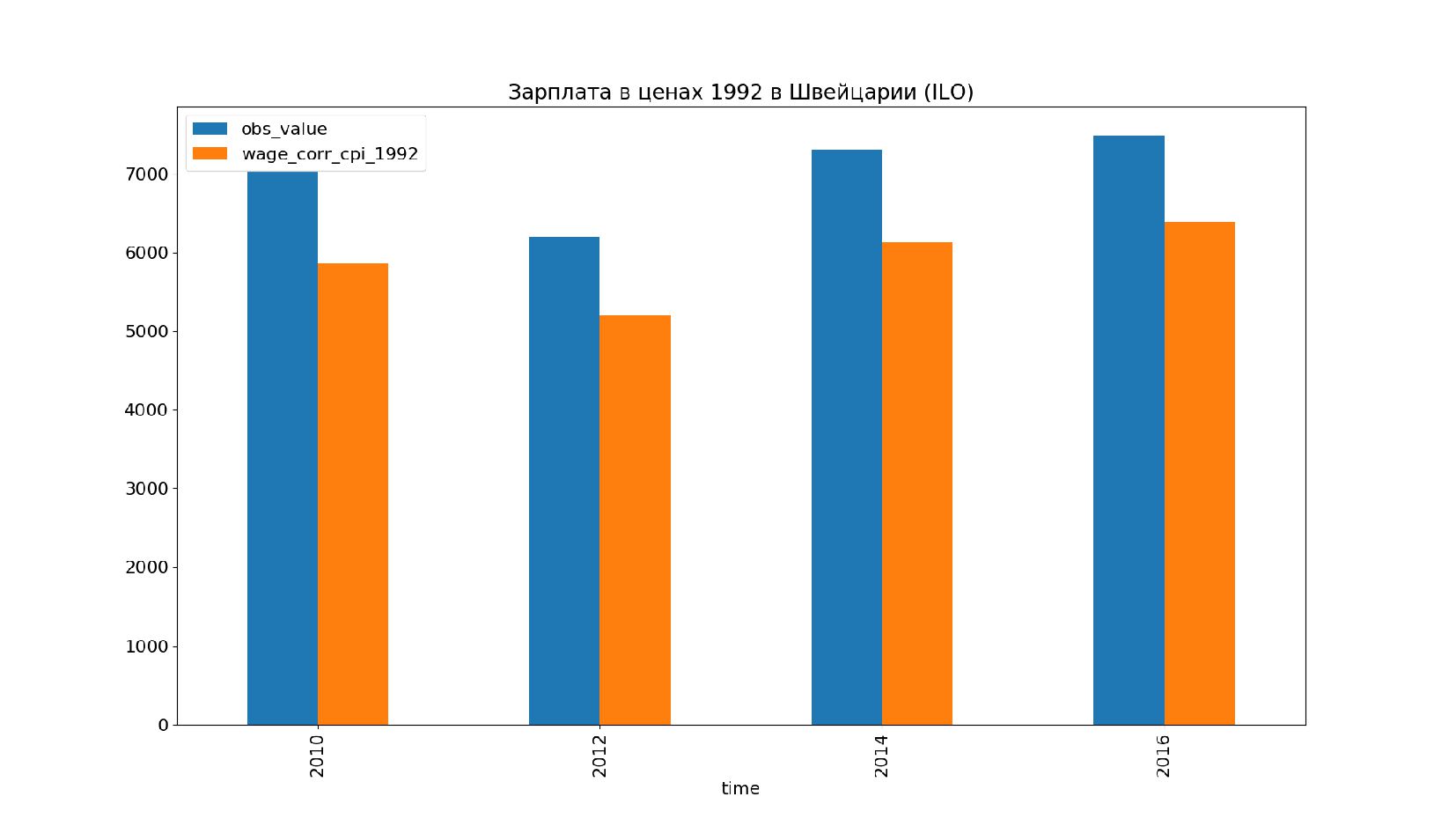
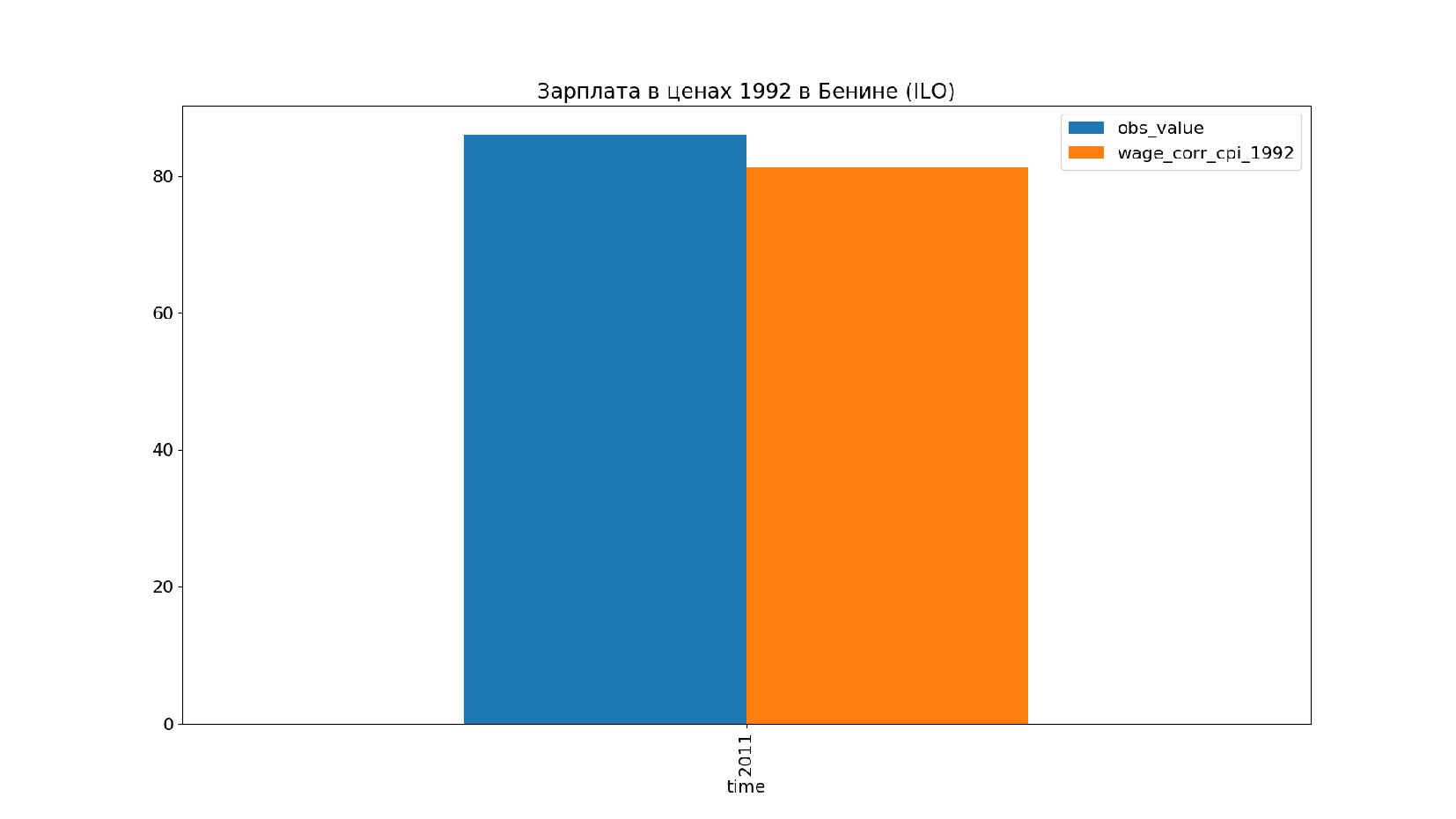
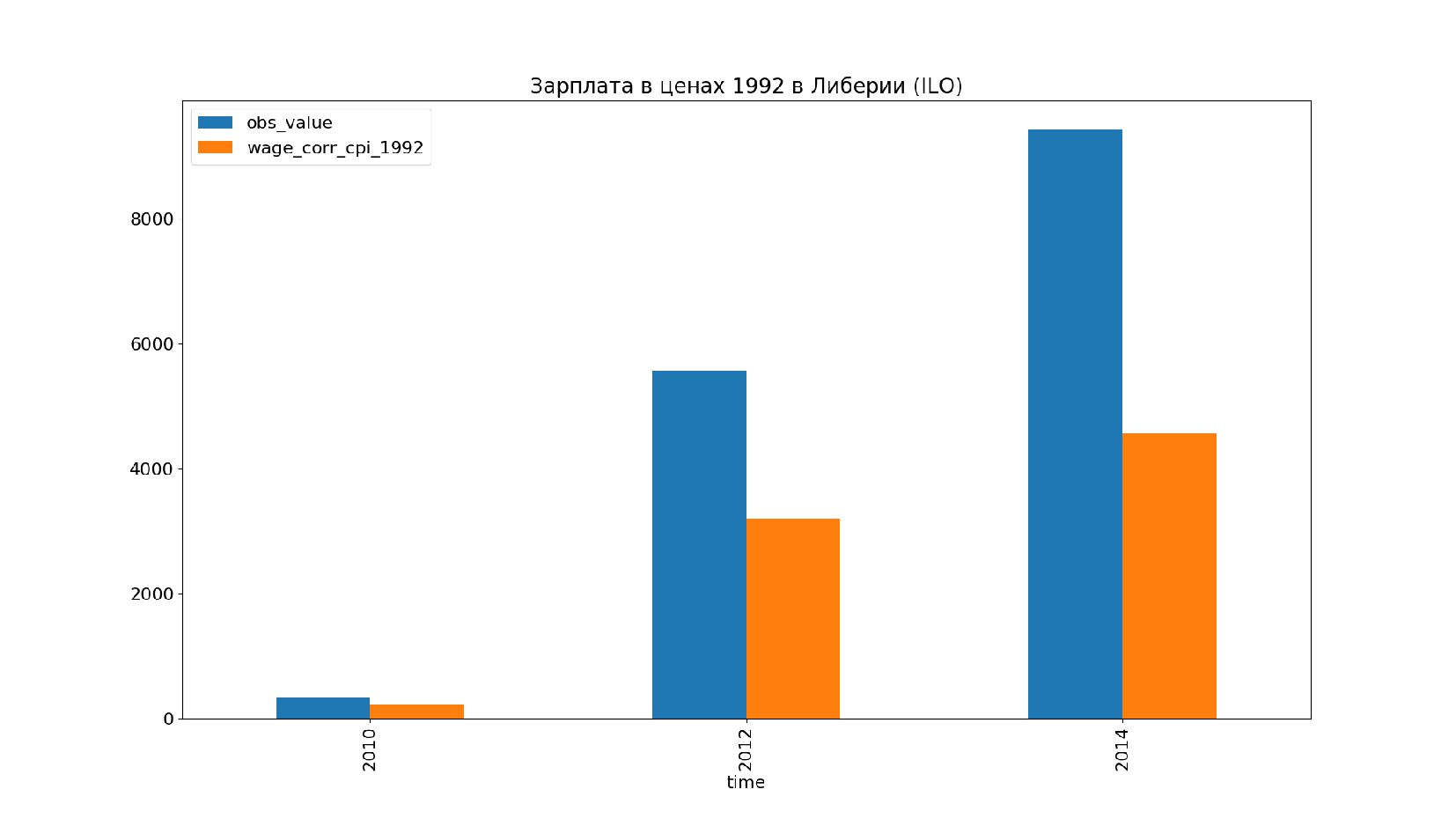
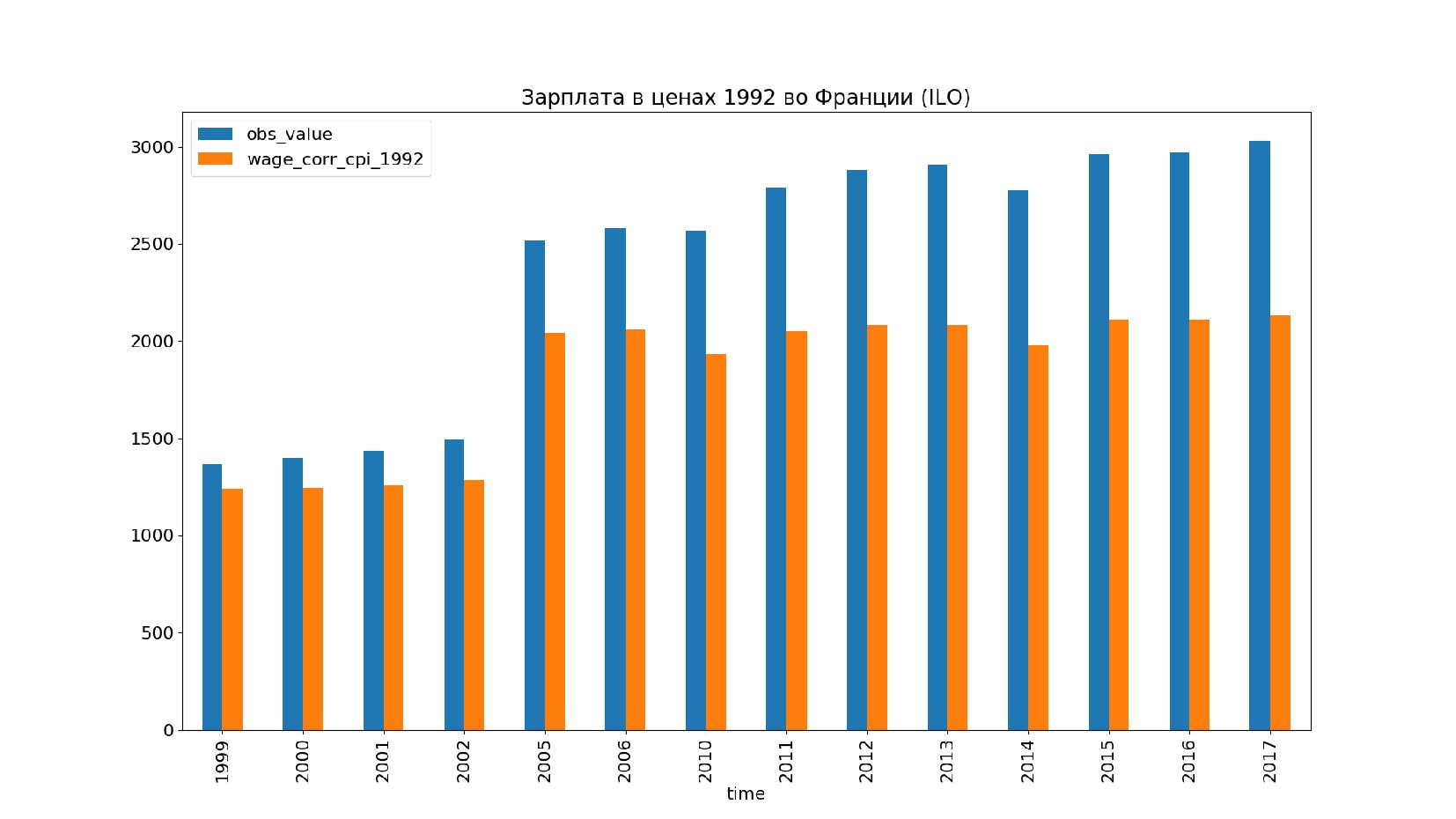
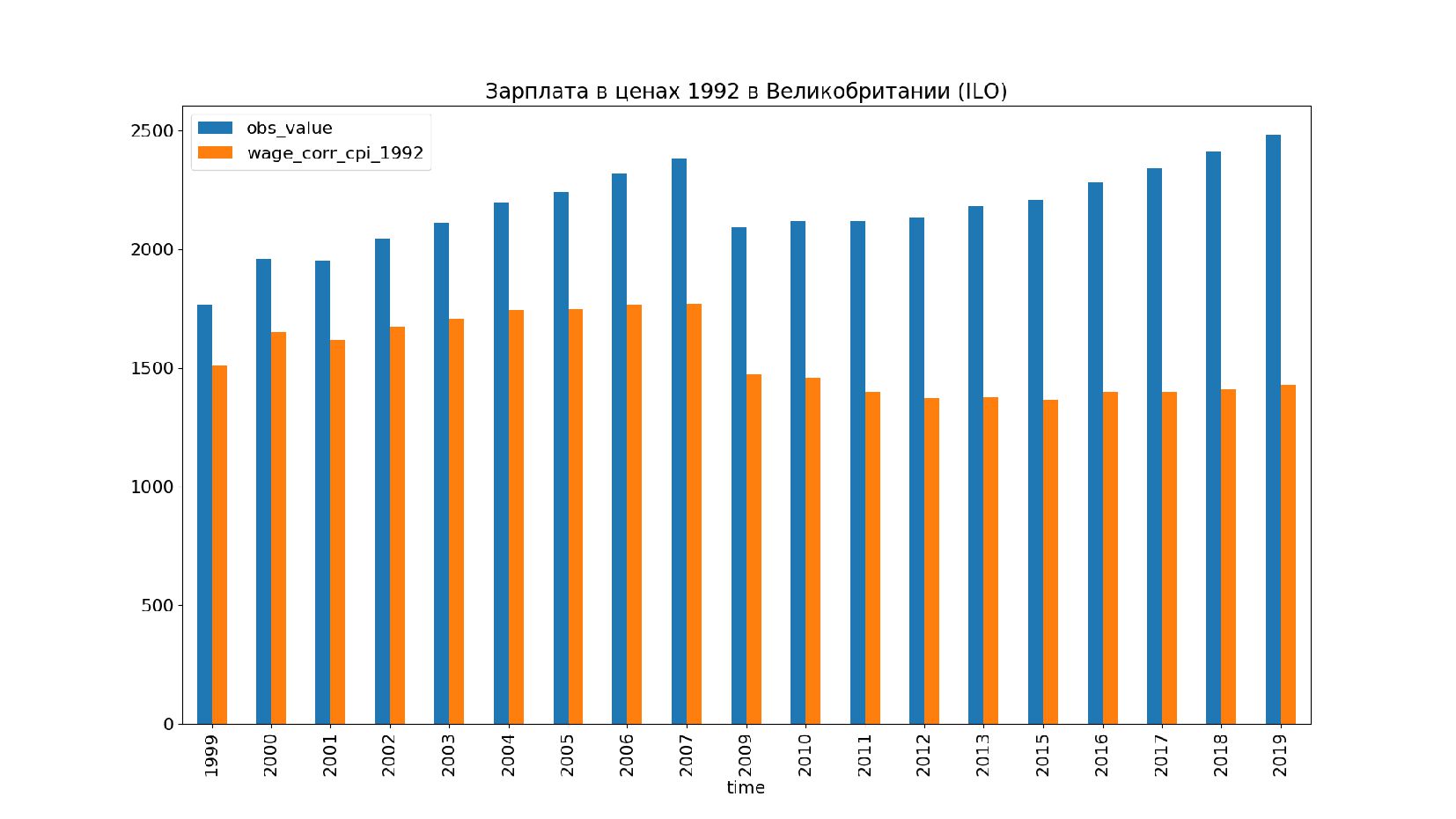
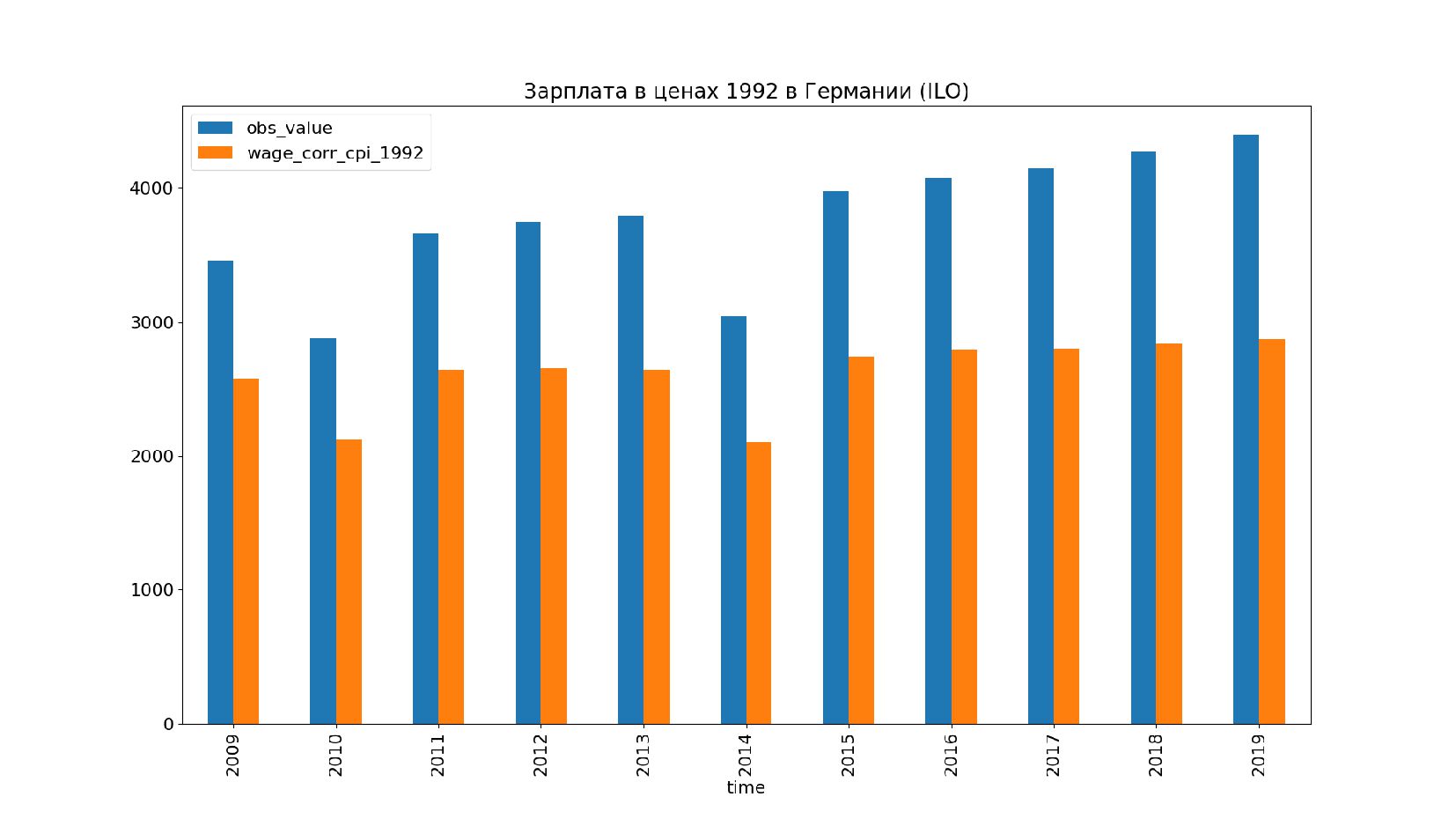
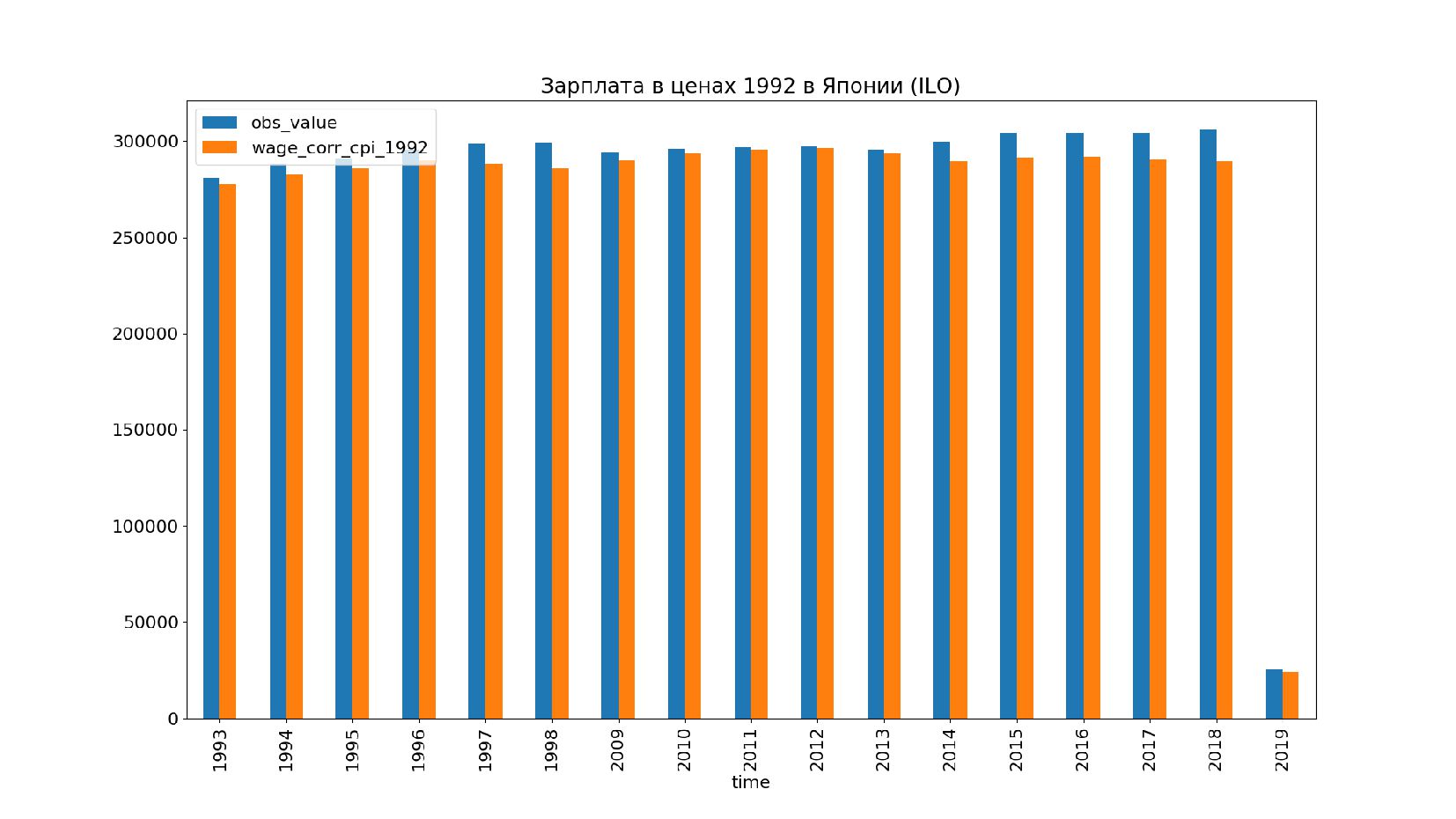
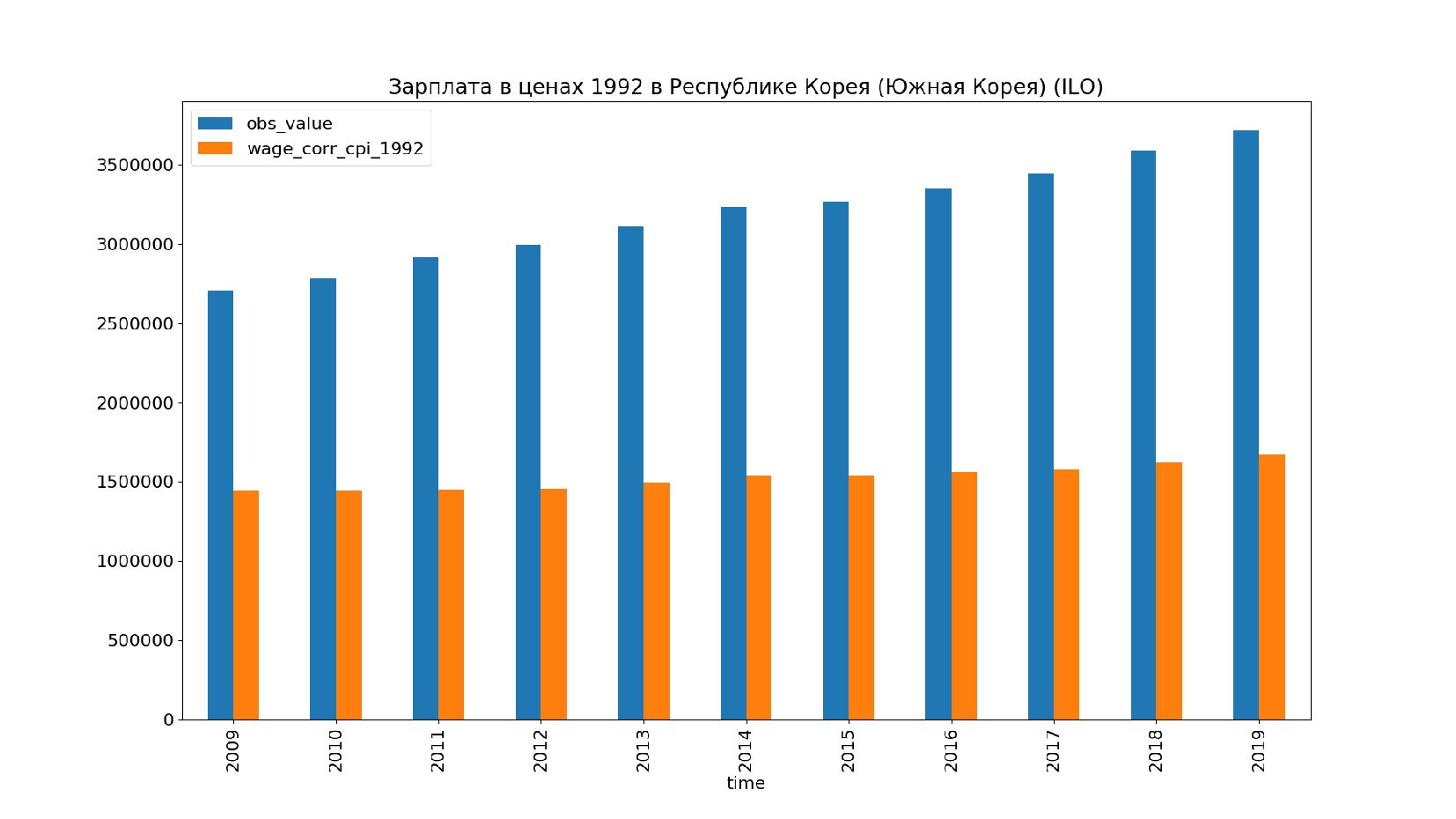
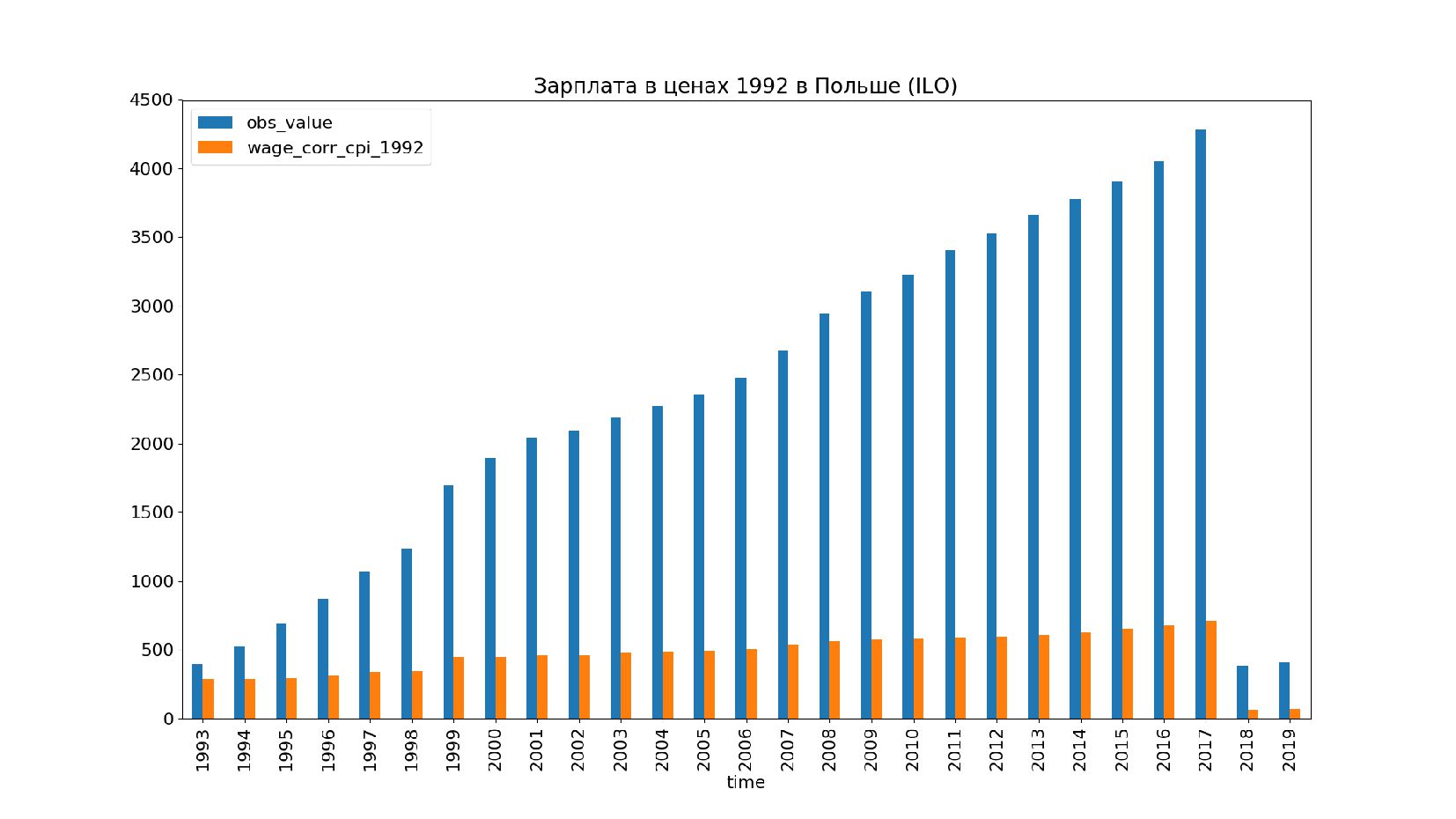
- Номинальное значение заработной платы vs реальное содержание заработной платы в ценах 1992 года
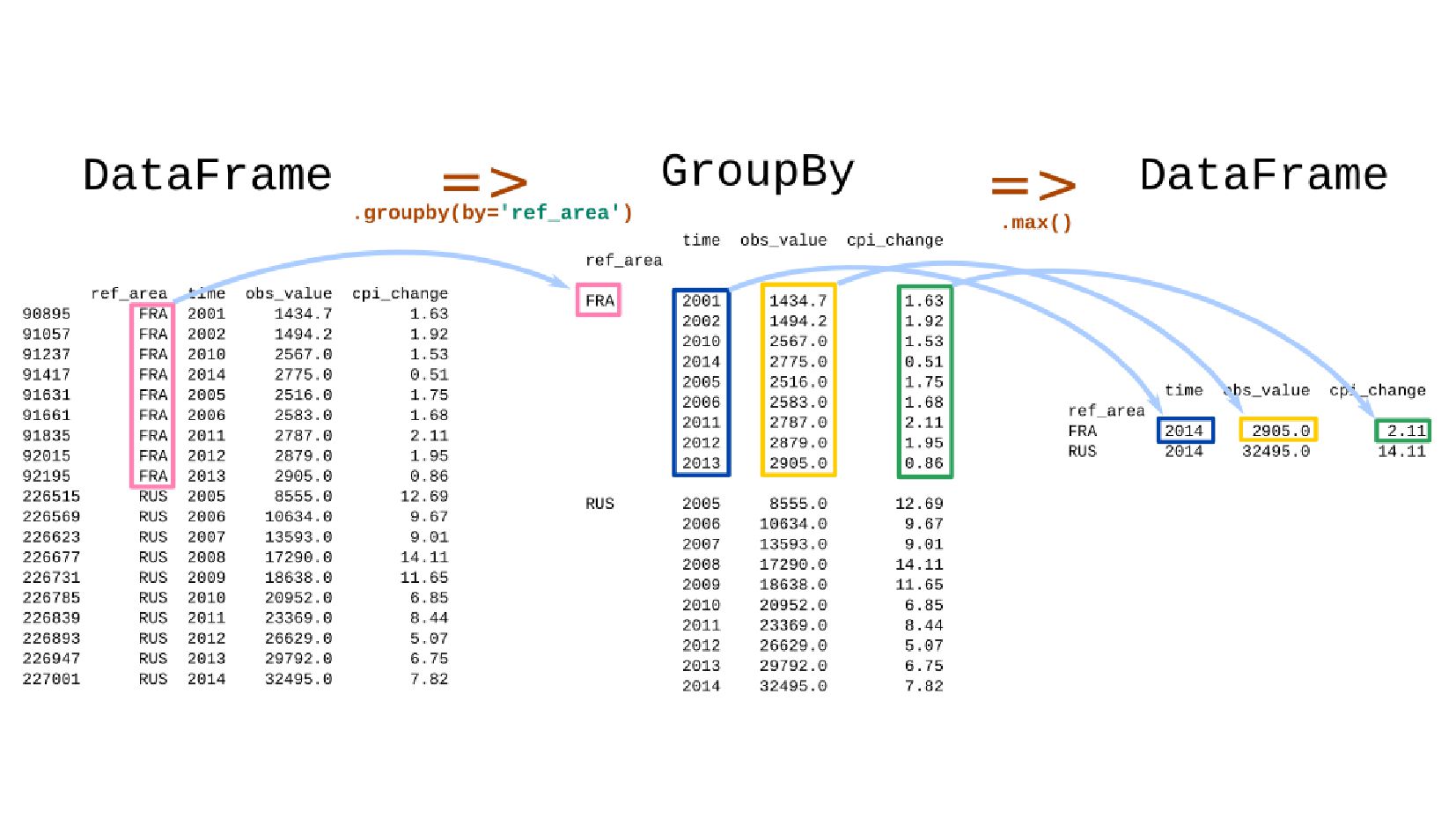
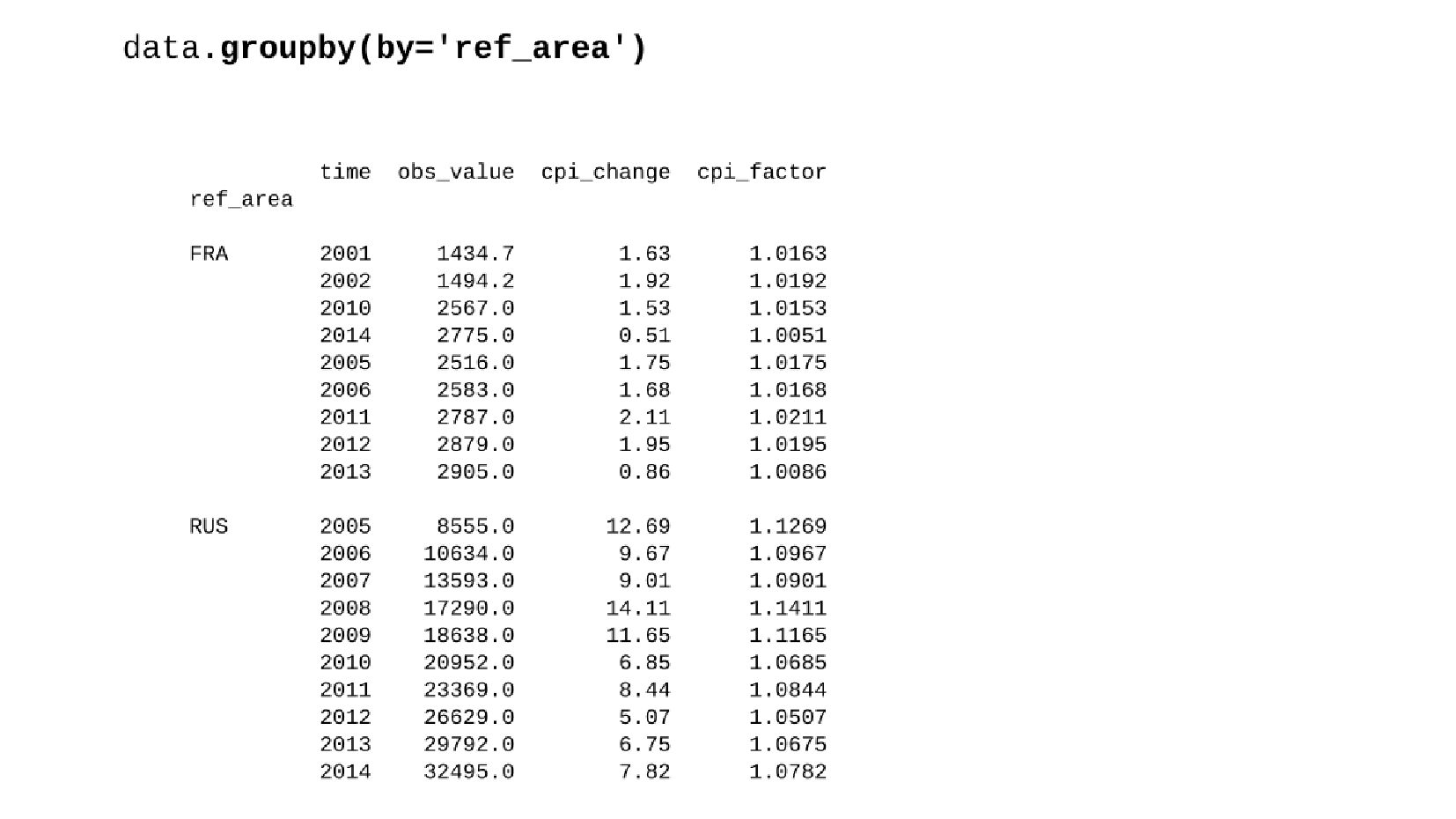
- Группировка данных, групповые операции DataFrame → GroupBy → DataFrame
- Кумулятивное (накопленное) произведение GroupBy.cumprod
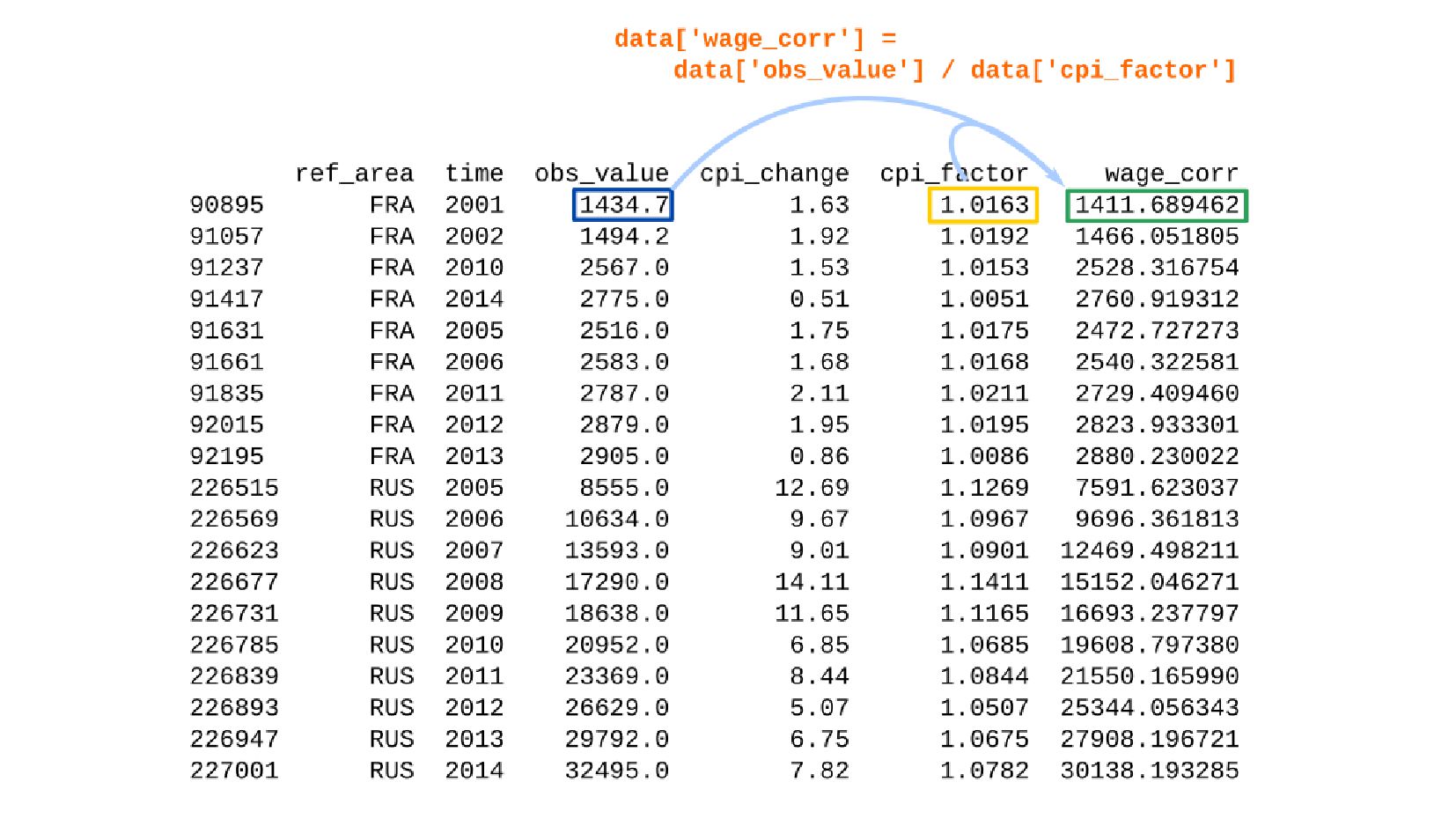
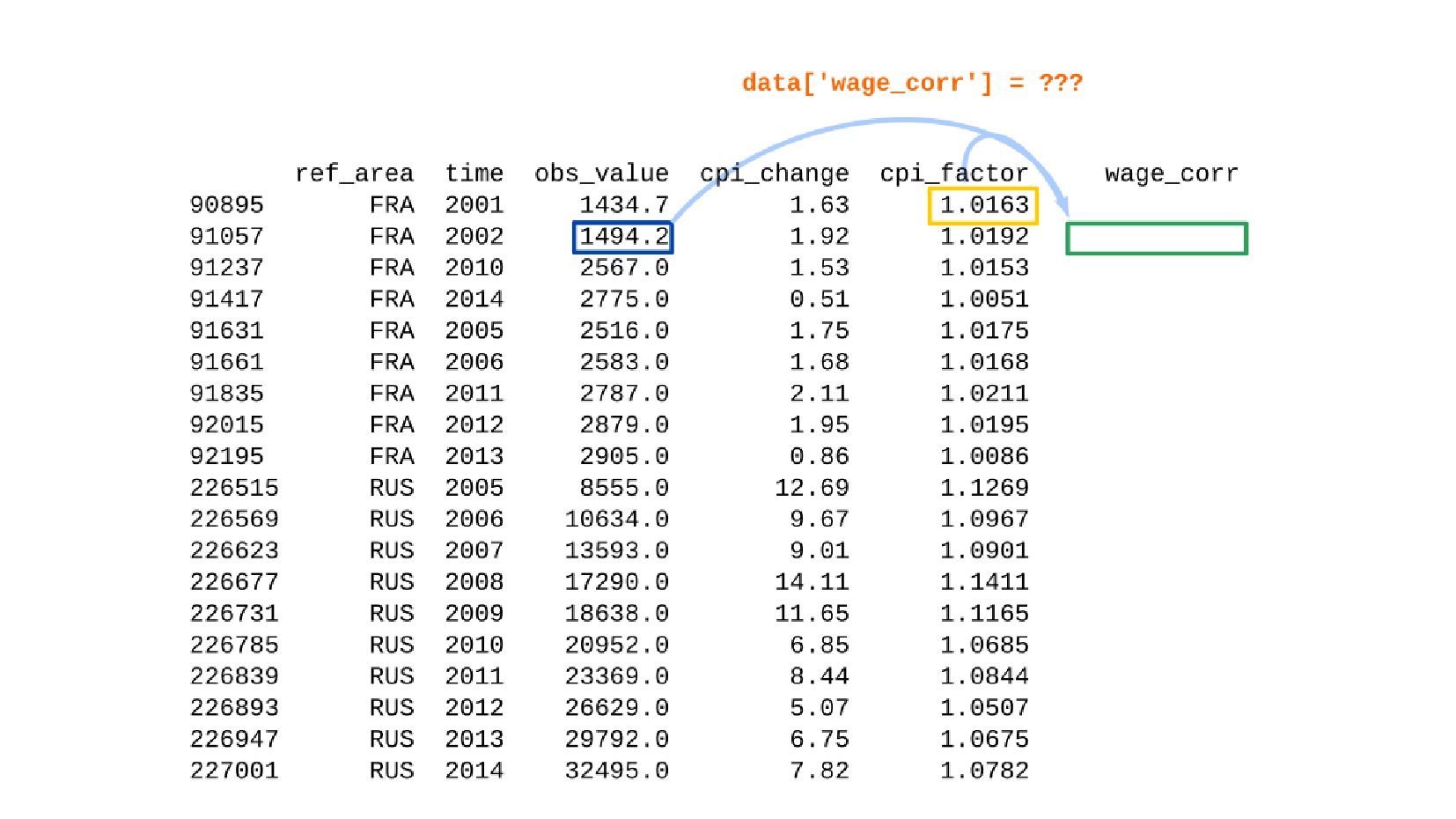
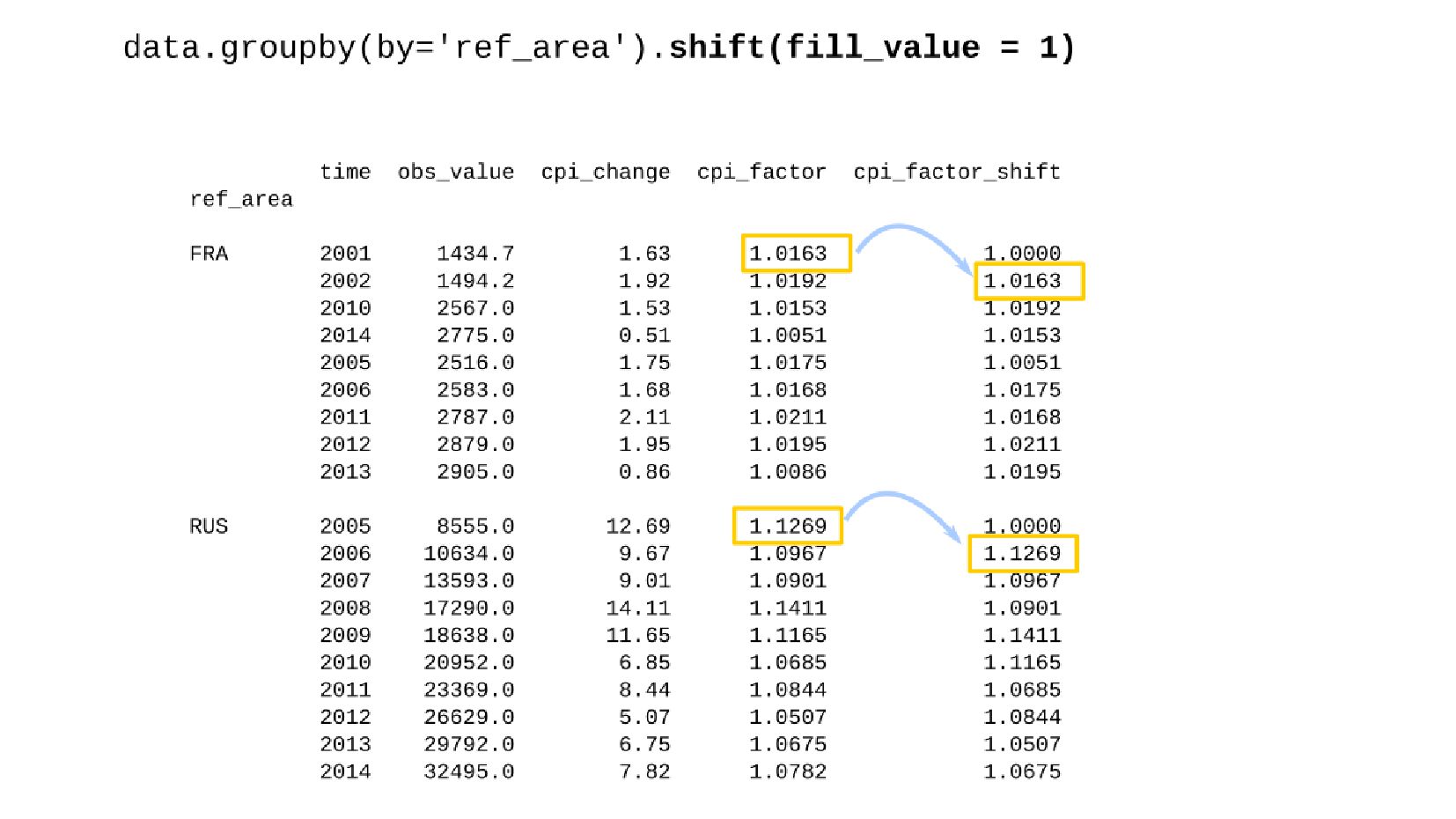
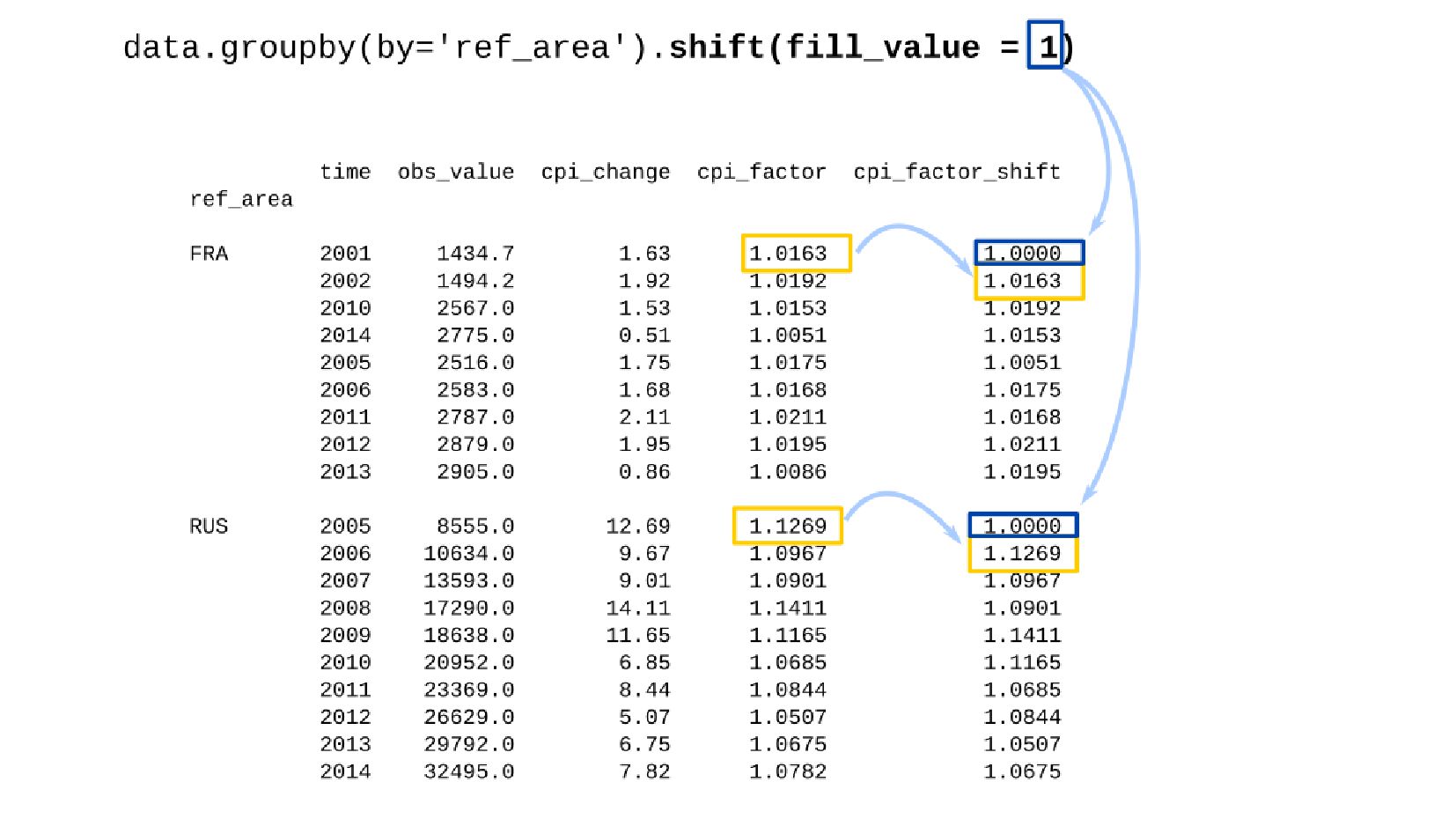
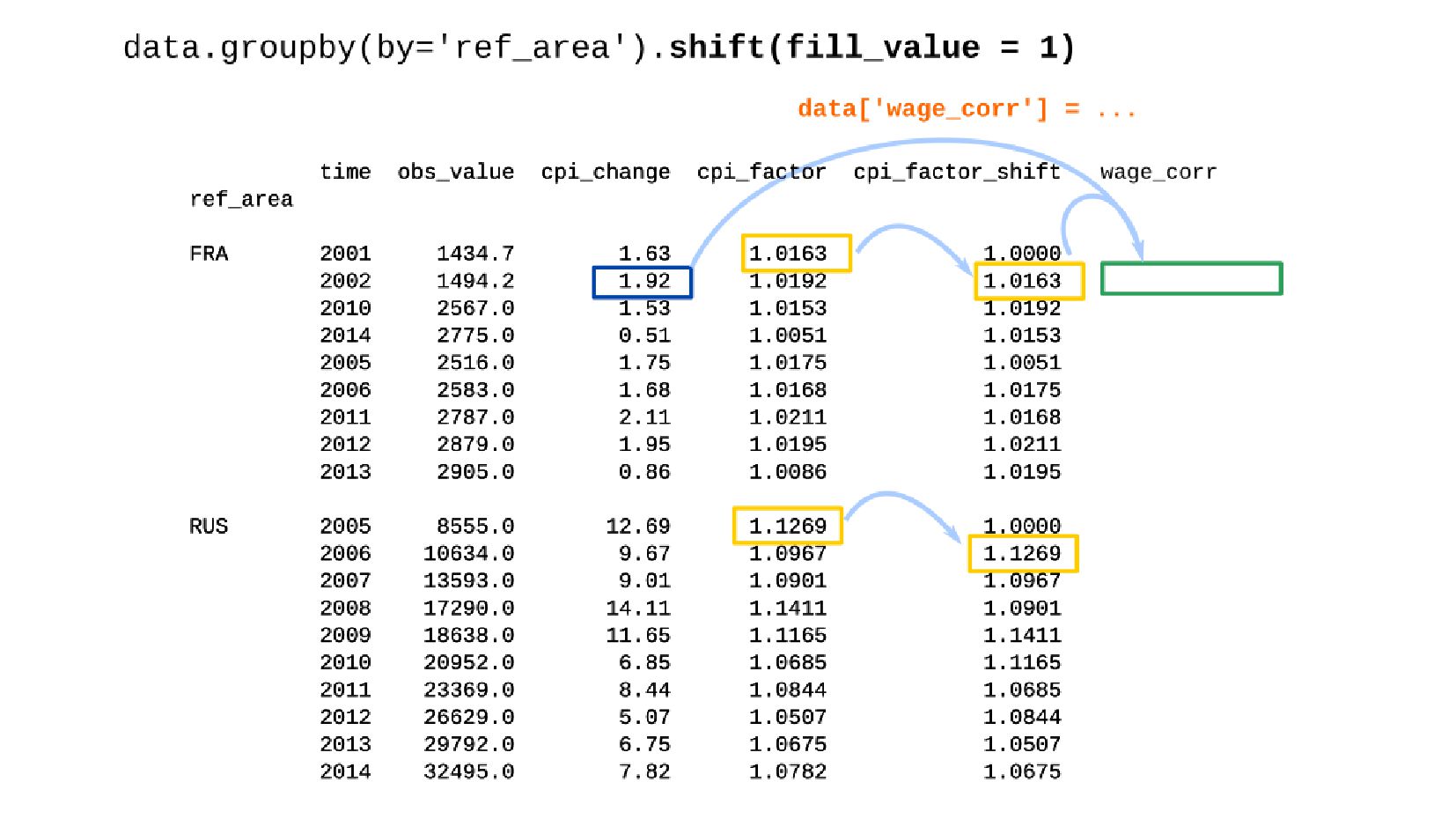
- Корректировка значения средней заработной платы на значения инфляции по годам в группах по странам
- График: реальное содержание заработной платы vs номинальная заработная плата в ценах 1992 года по годам в России
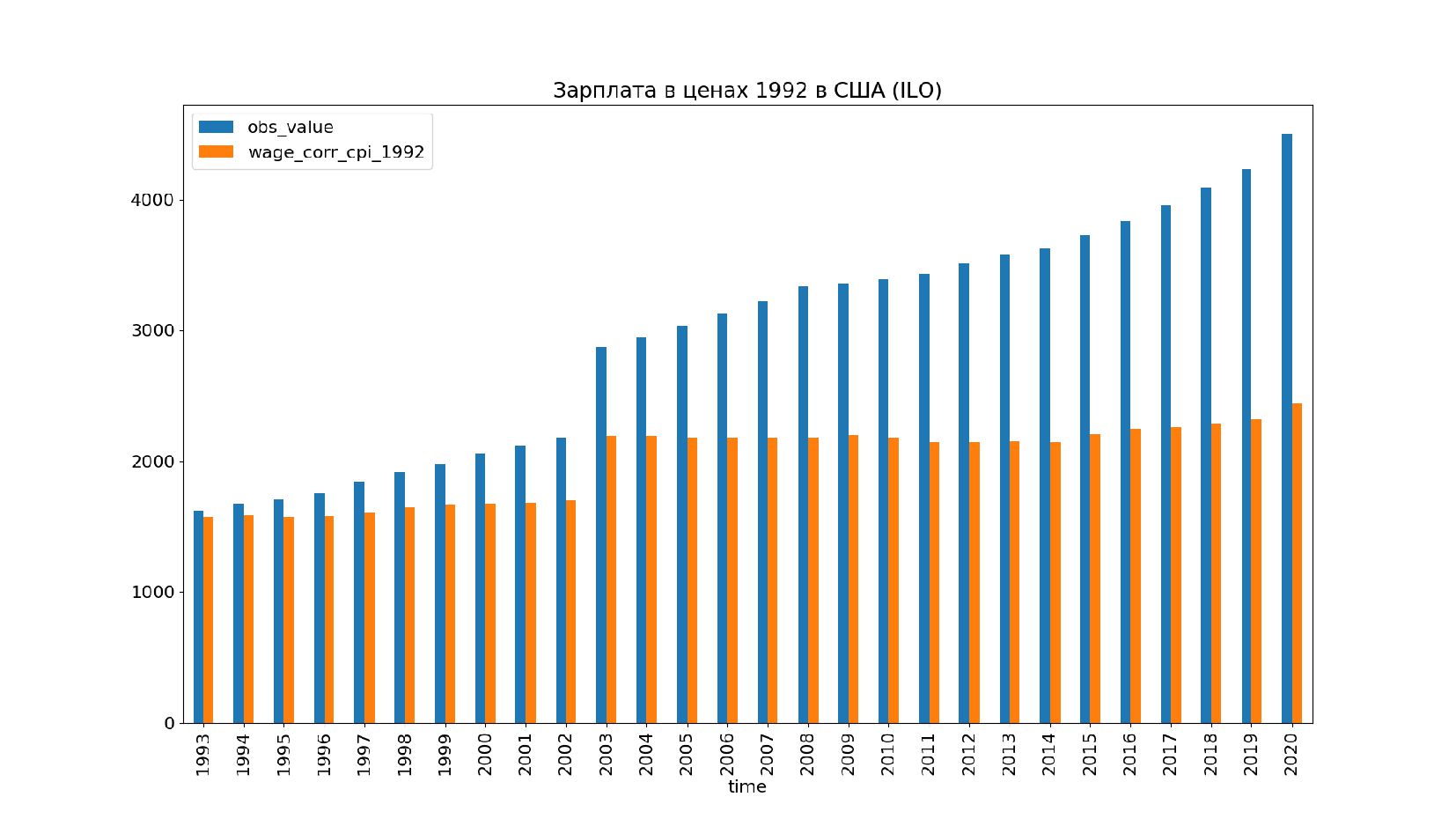
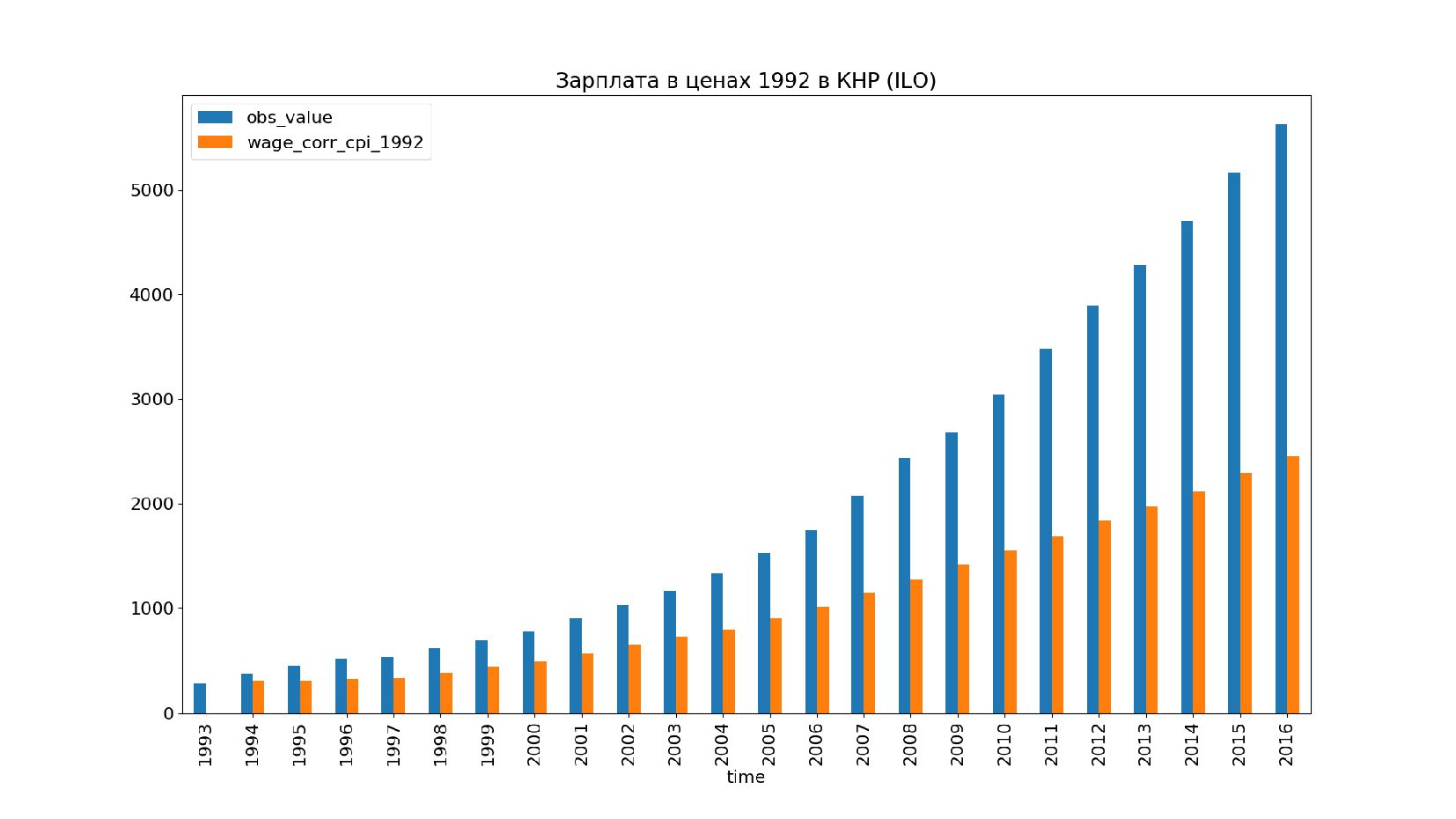
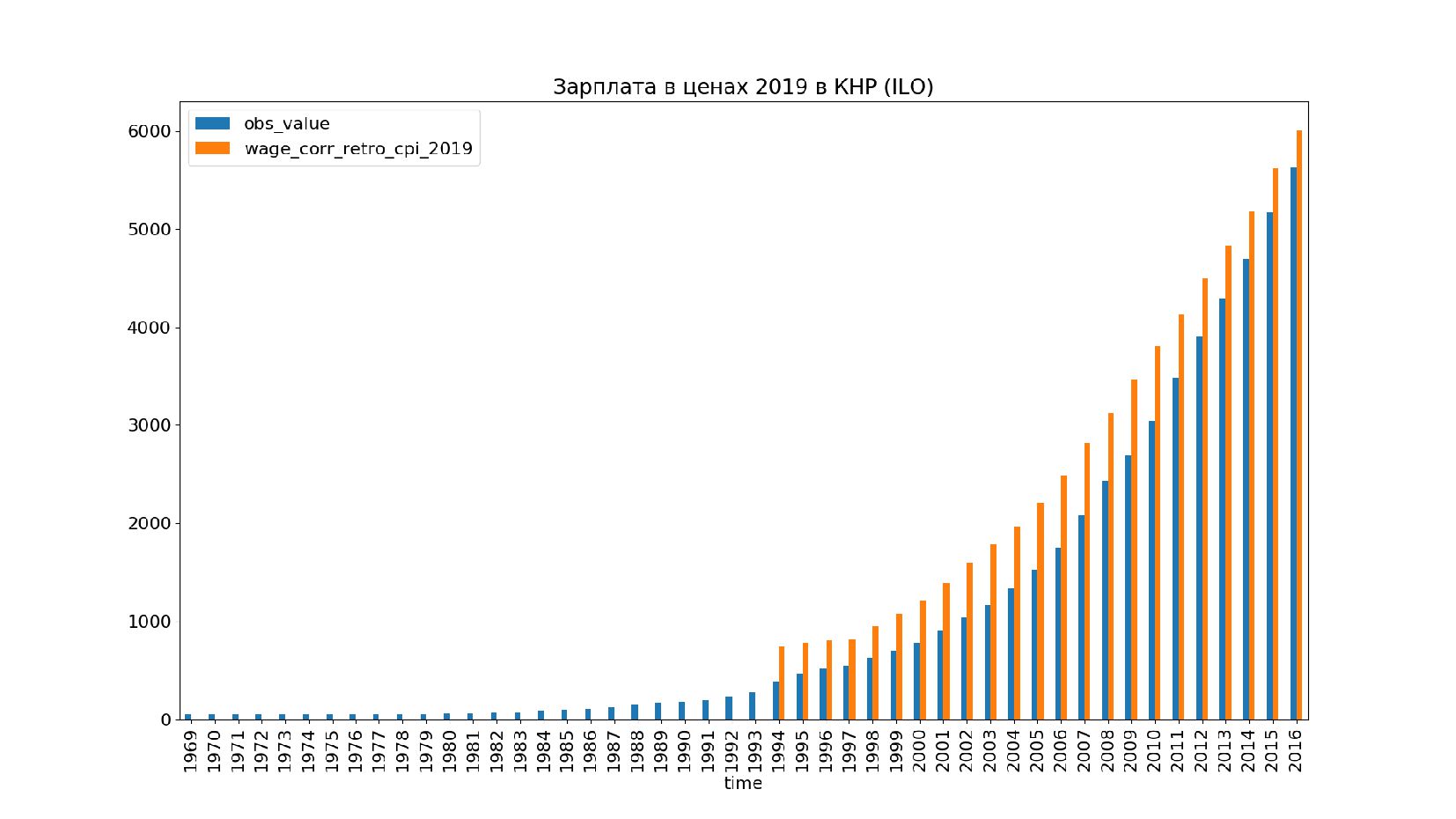
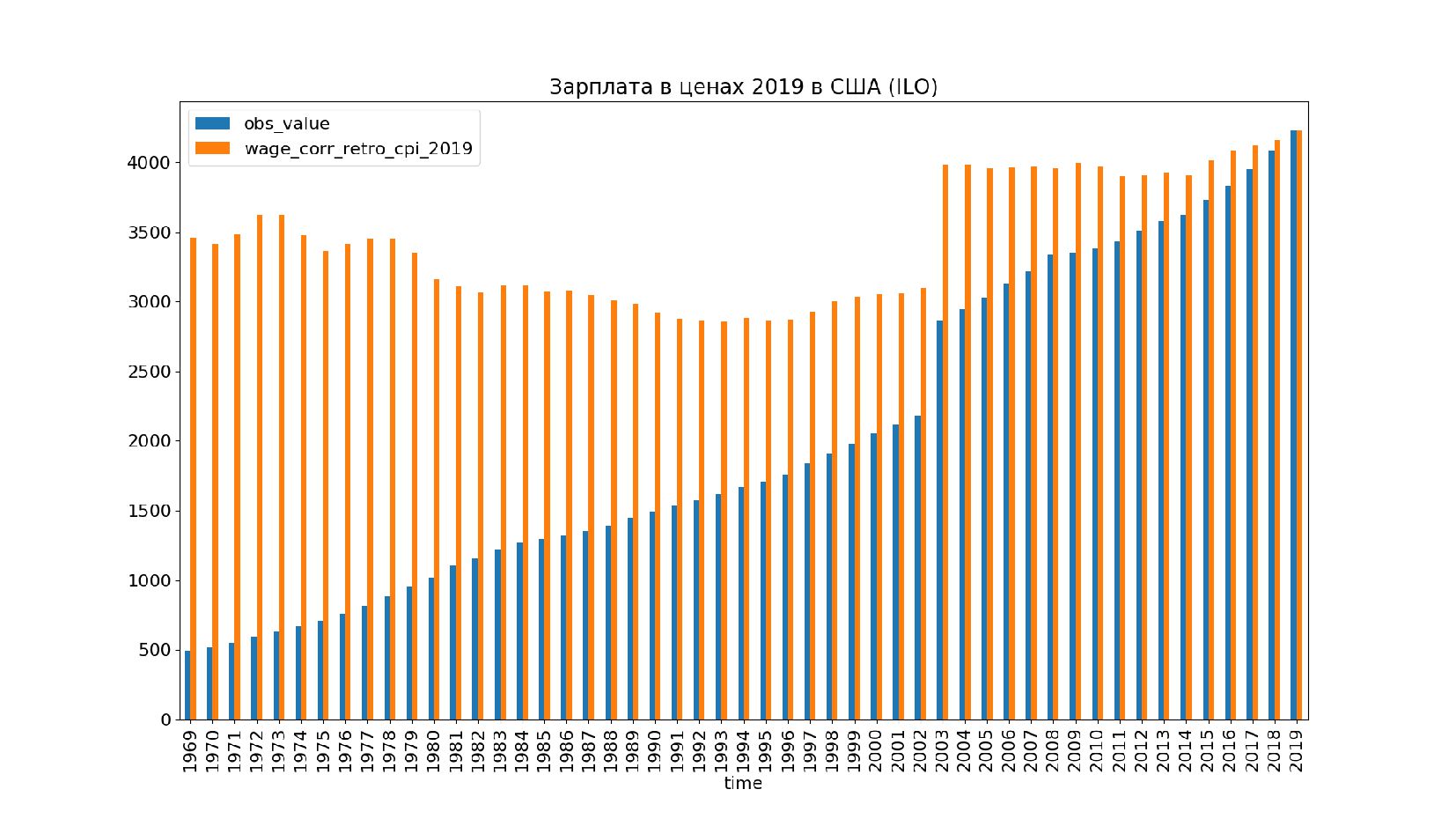
- Графики: реальное содержание заработной платы в ценах 1992 года vs номинальная заработная плата по годам, страны: США, КНР, Польша, Япония и т.п.
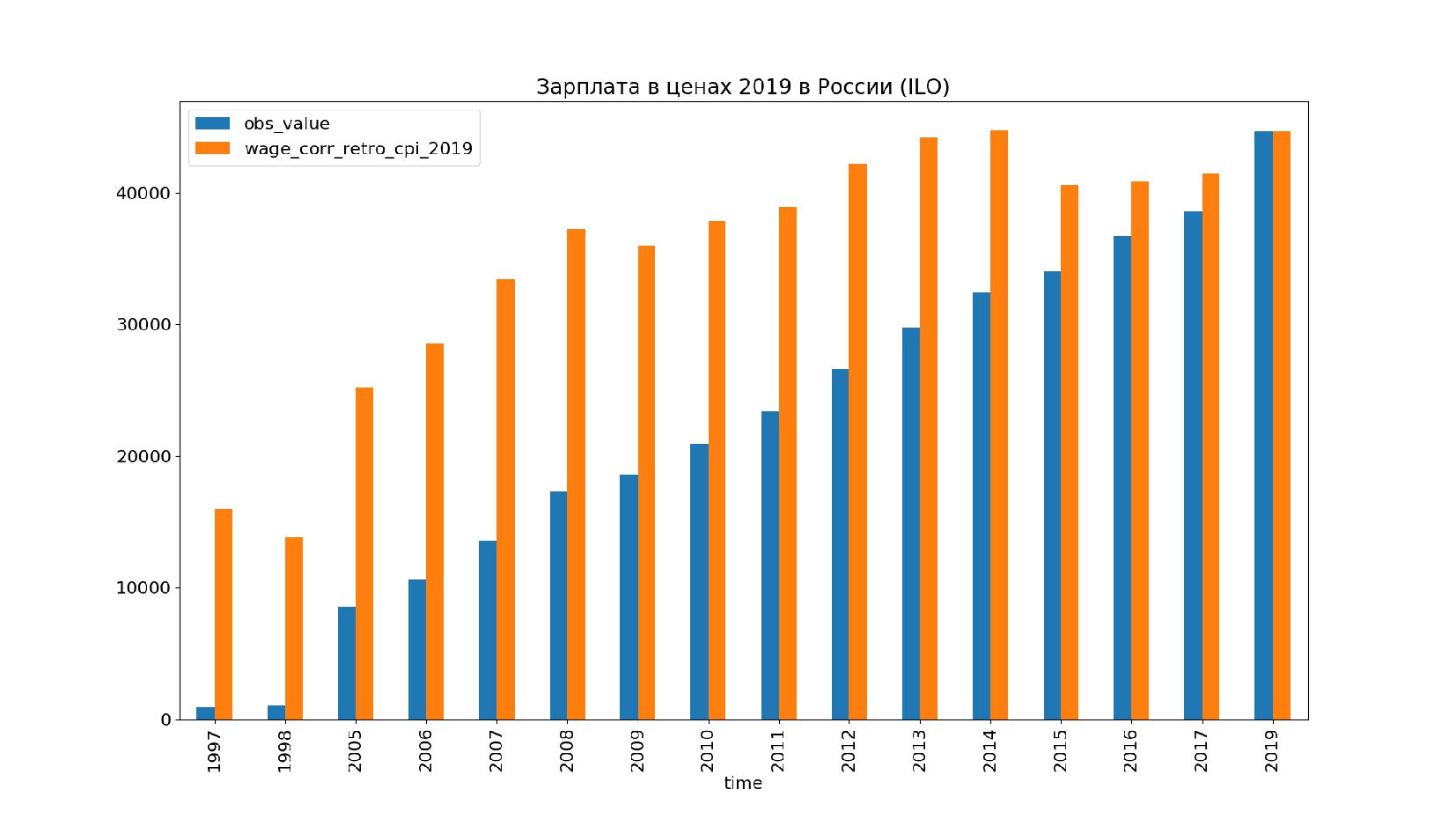
- Ретроспективное приведение зарплаты к ценам 2019 года
- Сдвиг данных внутри группы: GroupBy.shift
- Графики: номинальная зарплата vs реальное содержание зарплаты в ценах 2019 года по годам, страны: Россия, США, КНР
- Заключение:
-- Визуализация данных - еще один инструмент извлечения знаний из данных.
-- Значительную часть работы составляет подготовка (преобразование) данных для построения графика. Если данные подготовлены, построение графика технически не вызывает проблем.
Большие данные и машинное обучение, лекция-4: визуализация данных Python+Pandas+Matplotlib, часть-1
https://www.youtube.com/watch?v=STedHqTtCHg
Большие данные и машинное обучение, лекция-5: визуализация данных Python+Pandas+Matplotlib, часть-2
https://www.youtube.com/watch?v=99qSuwRyrzE
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![print(Y): [ -2. -2.00040799 -2.00159797 ... -2.03755238 -2.01958368 -2. ]](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
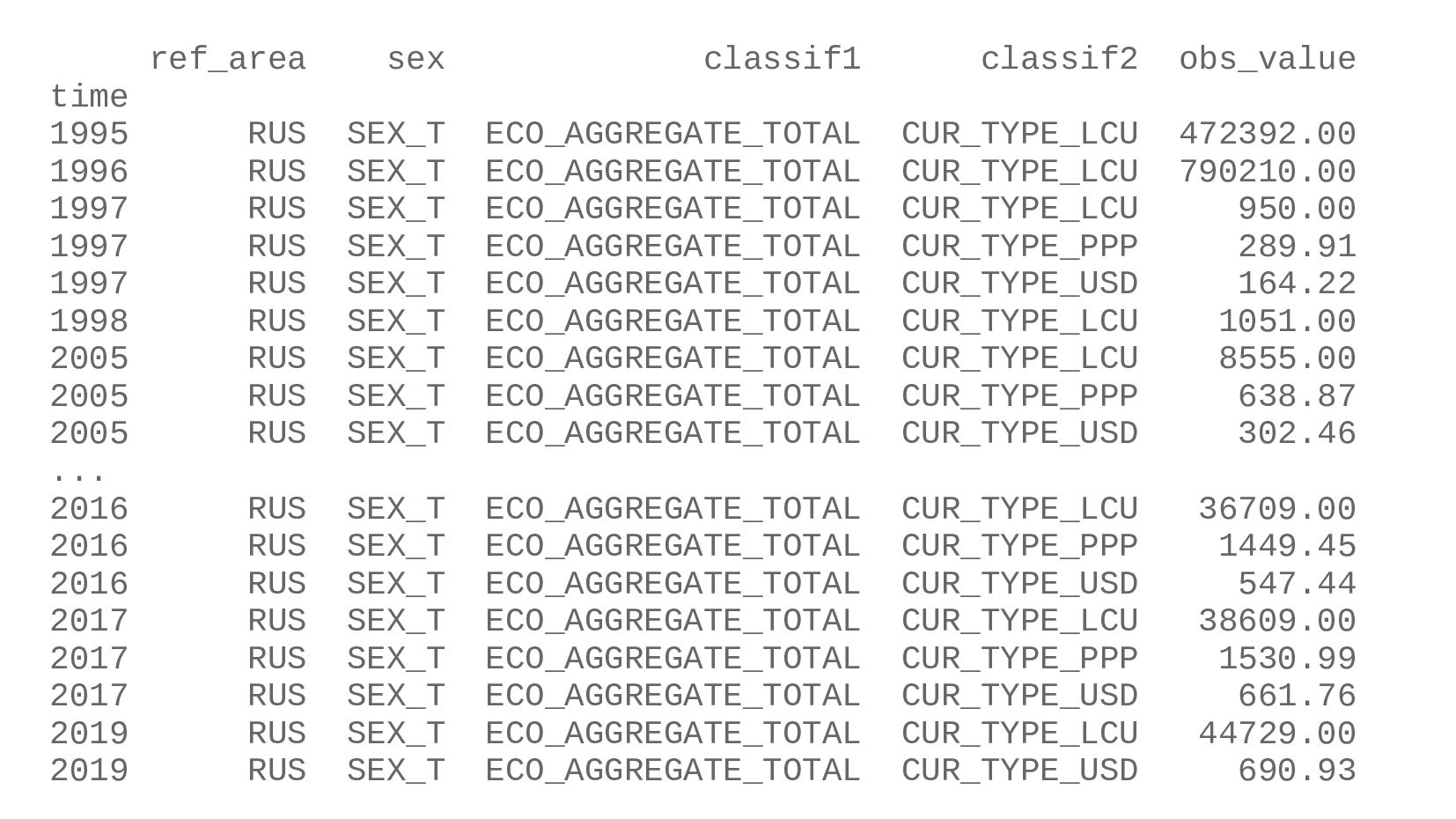
![data[ (data.ref_area == 'RUS') & (data.classif2 == 'CUR_TYPE_USD') ] [['time',](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_43.jpg){kind=link}
![import matplotlib.pyplot as plt plt.rc('font', size=16) […] plt.show()](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_44.jpg){kind=link}
{kind=link}
![print( data[ (data.ref_area == 'RUS') & (data.classif2 == 'CUR_TYPE_USD') ]](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
![data_rus = data[data.ref_area == 'RUS'] data_rus = data_rus.set_index('time').sort_index() print( data_rus[](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
![data_rus[data_rus.classif2 == 'CUR_TYPE_USD'] [['obs_value']].plot(kind='bar')](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_52.jpg){kind=link}
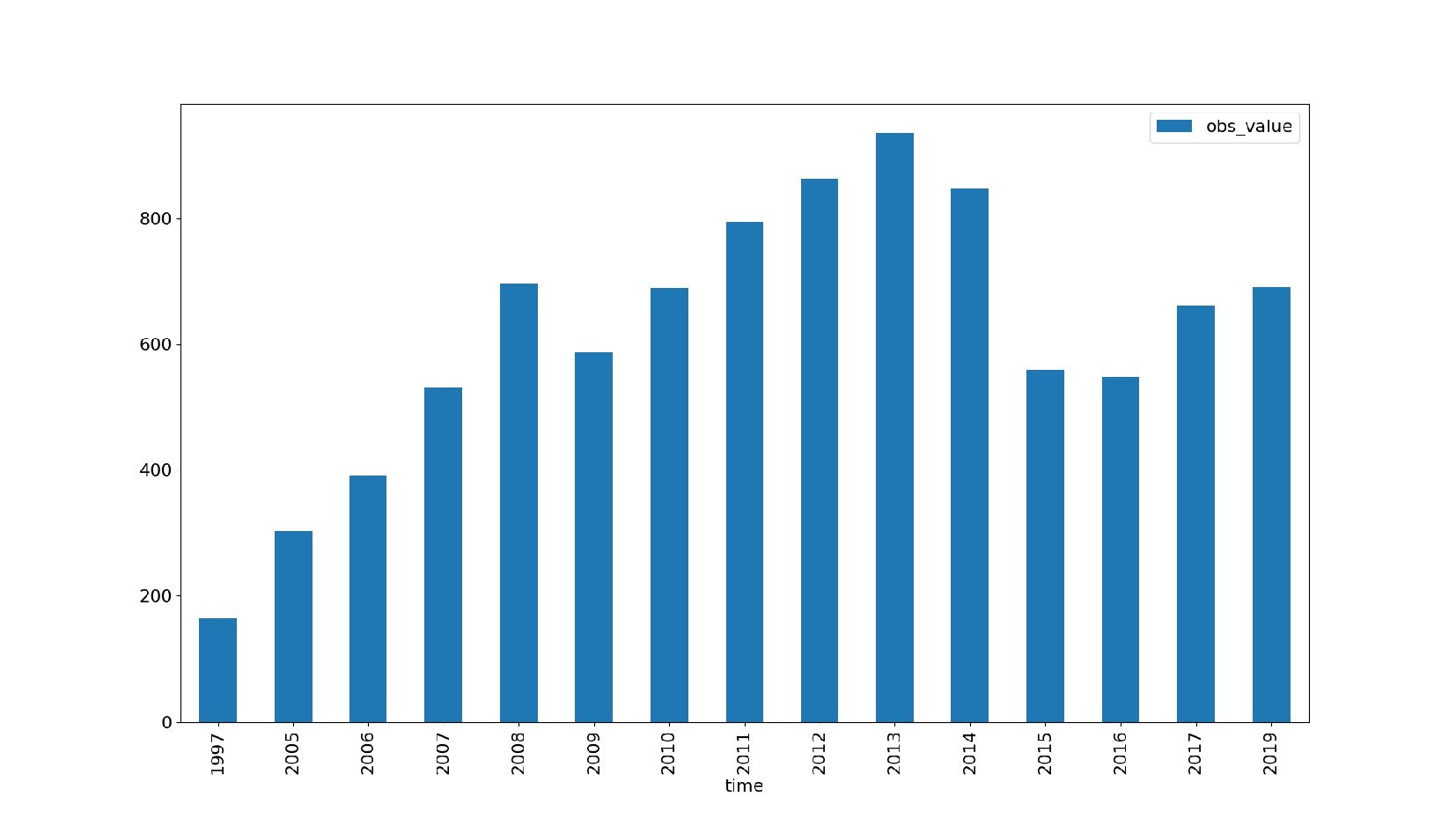{kind=link}
{kind=link}
![Добавим заголовок и поправим легенду ax = data_rus[data_rus.classif2 == 'CUR_TYPE_USD'][['obs_value']].](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_55.jpg){kind=link}
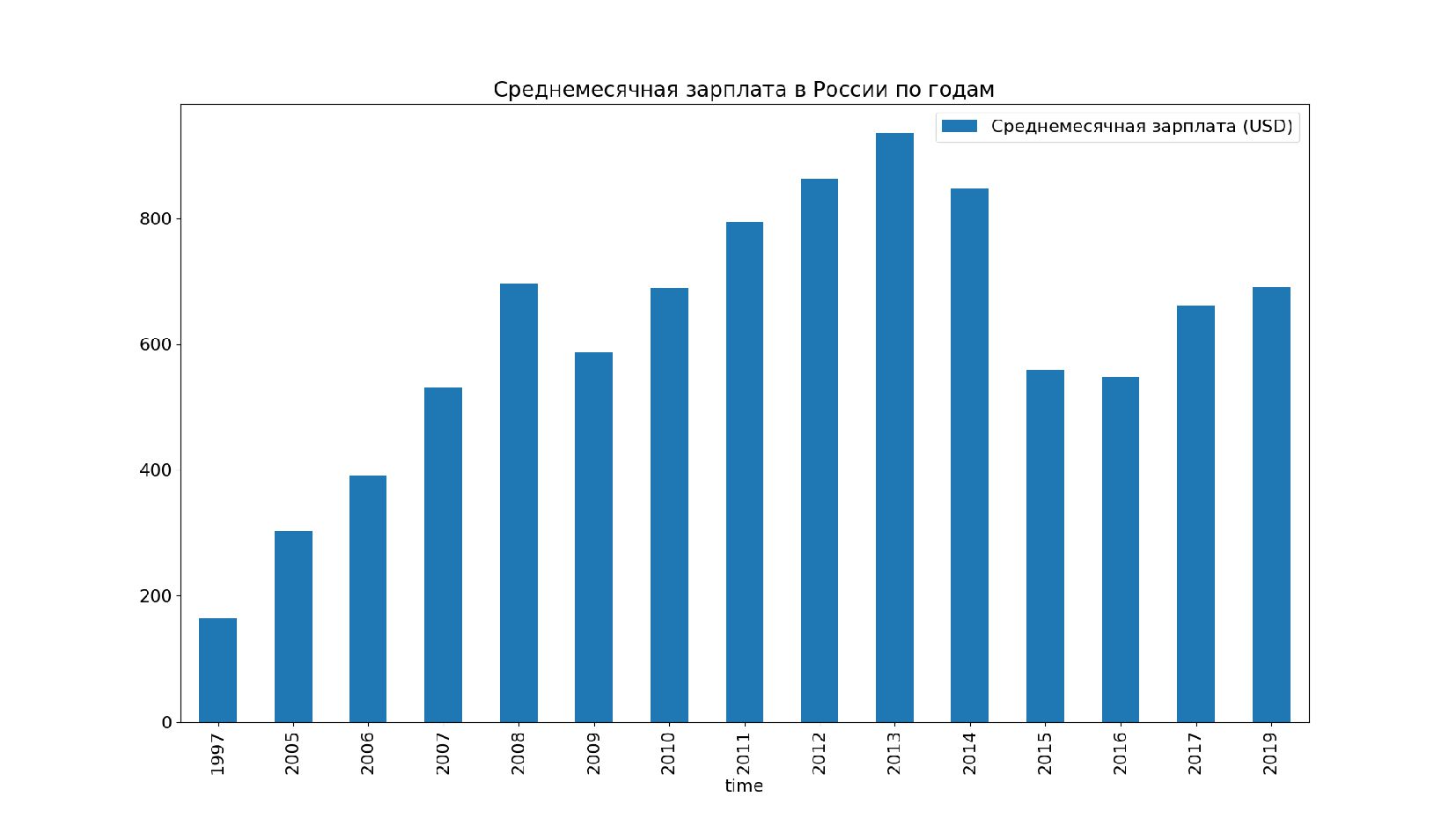{kind=link}
{kind=link}
{kind=link}
{kind=link}
![print( data_rus ) data_rus[['obs_value']].plot( title='Среднемесячная зарплата в России по годам',](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_60.jpg){kind=link}
{kind=link}
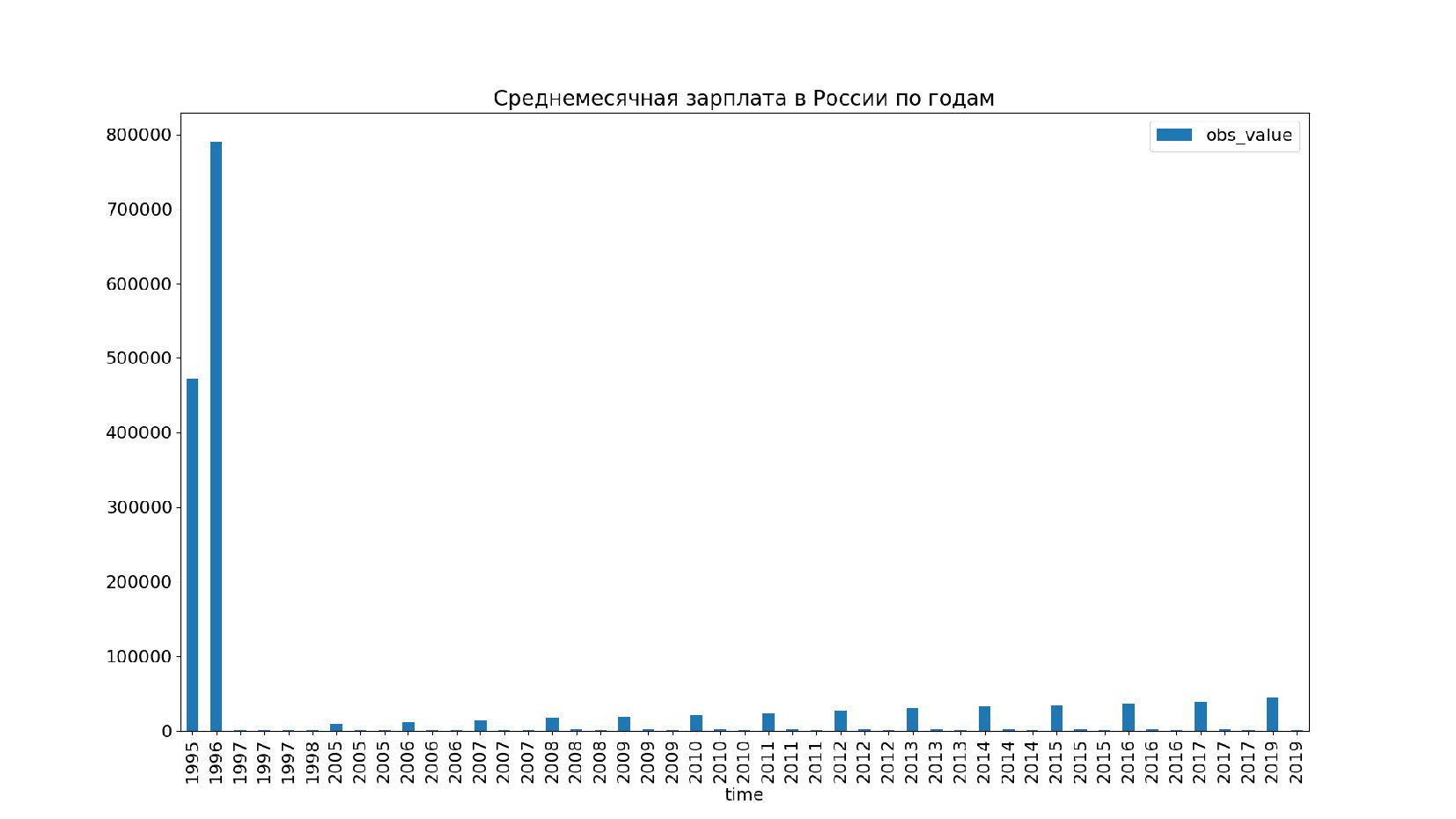{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pivot.loc[ pivot.index <= 1996, 'CUR_TYPE_LCU'] /= 1000 pivot.plot( title='Среднемесячная зарплата](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_100.jpg){kind=link}
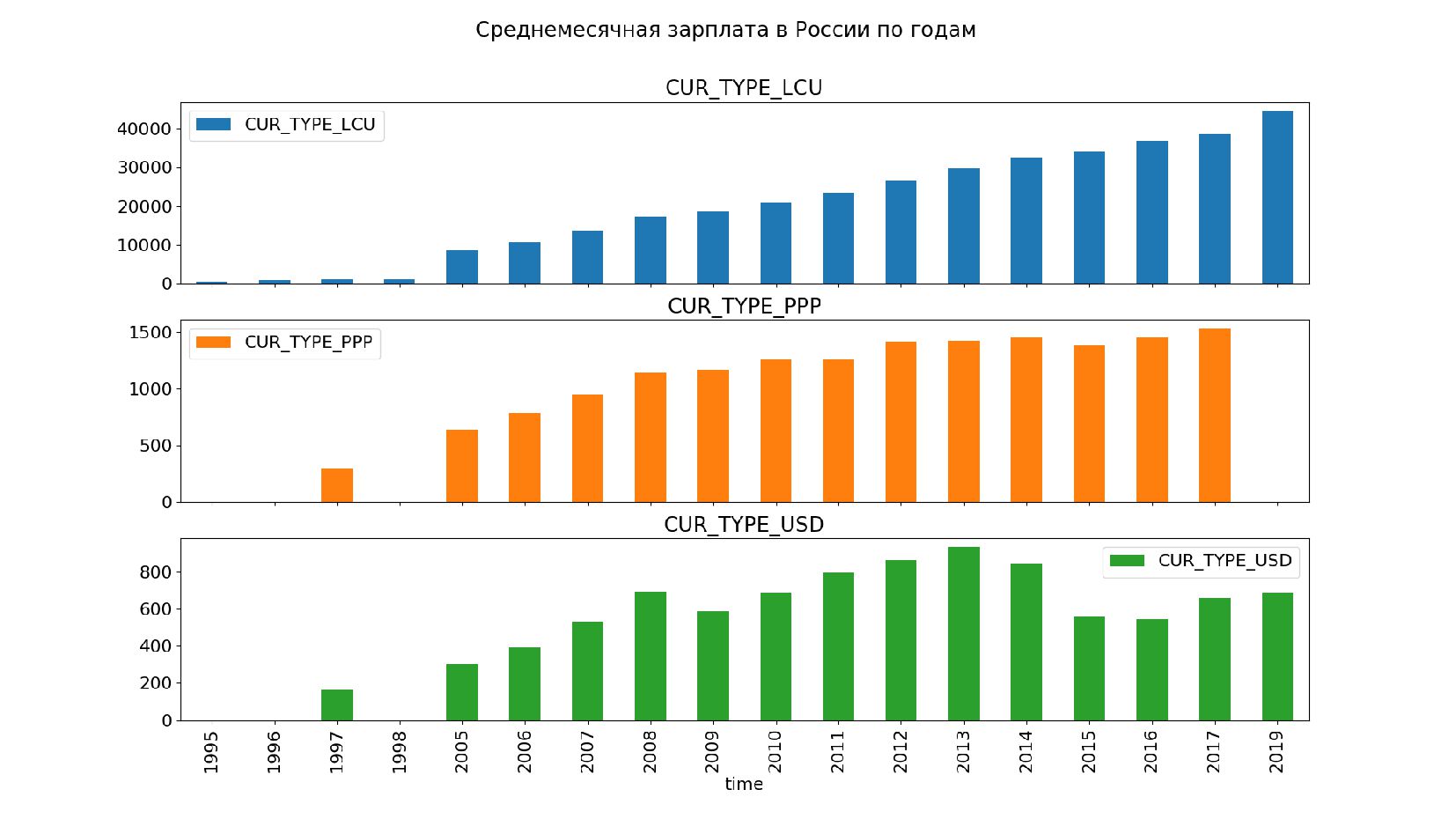{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data_cpi = data_cpi[data_cpi.classif1 == 'COI_COICOP_CP01T12'] [['ref_area', 'time', 'obs_value']] data_cpi =](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_123.jpg){kind=link}
{kind=link}
{kind=link}
![print( data_cpi.loc['RUS'] ) data_cpi.loc['RUS'].sort_index()[['cpi_change']]. plot(title='Инфляция (изм. ИПЦ в %) в](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_126.jpg){kind=link}
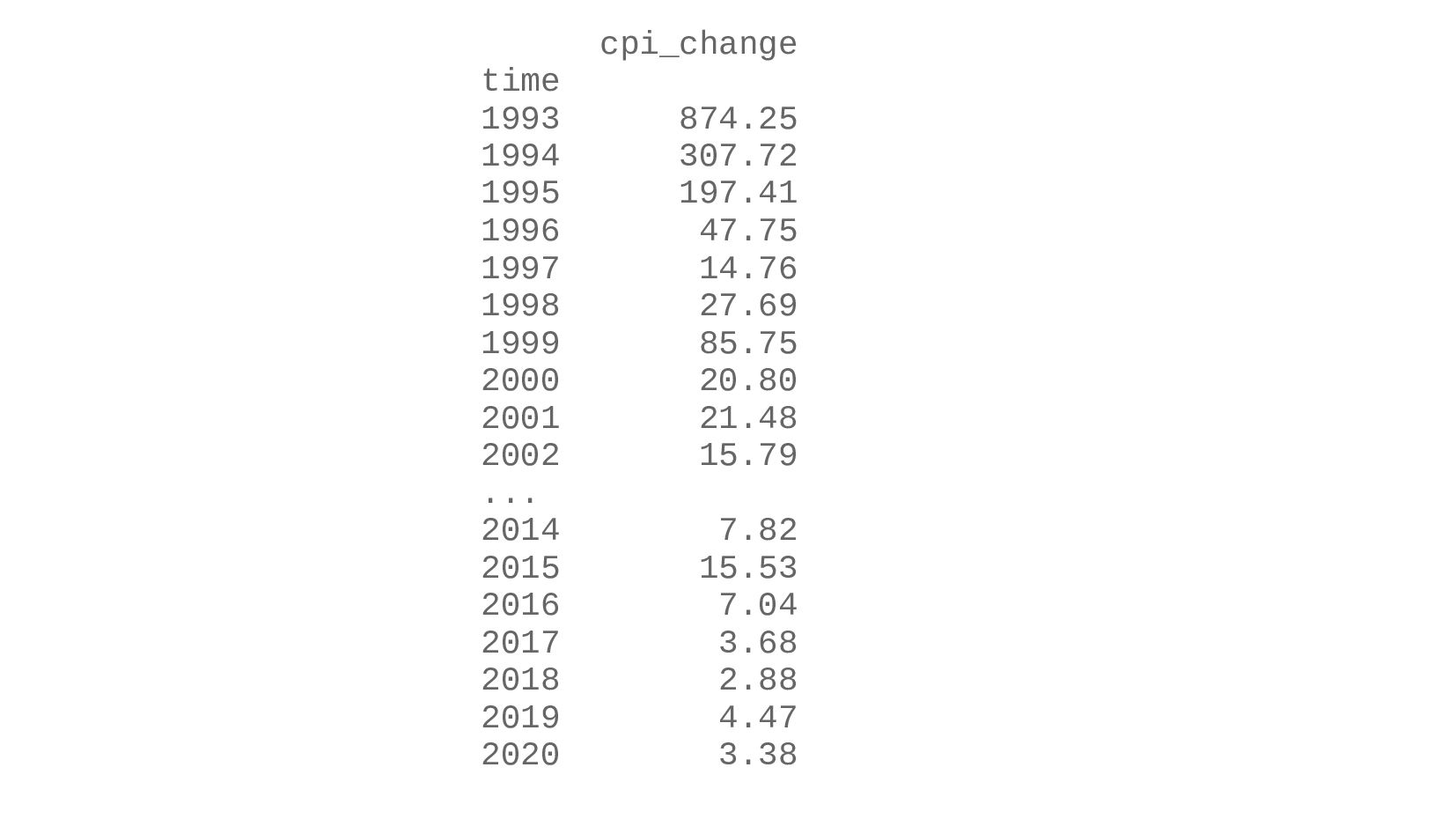{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
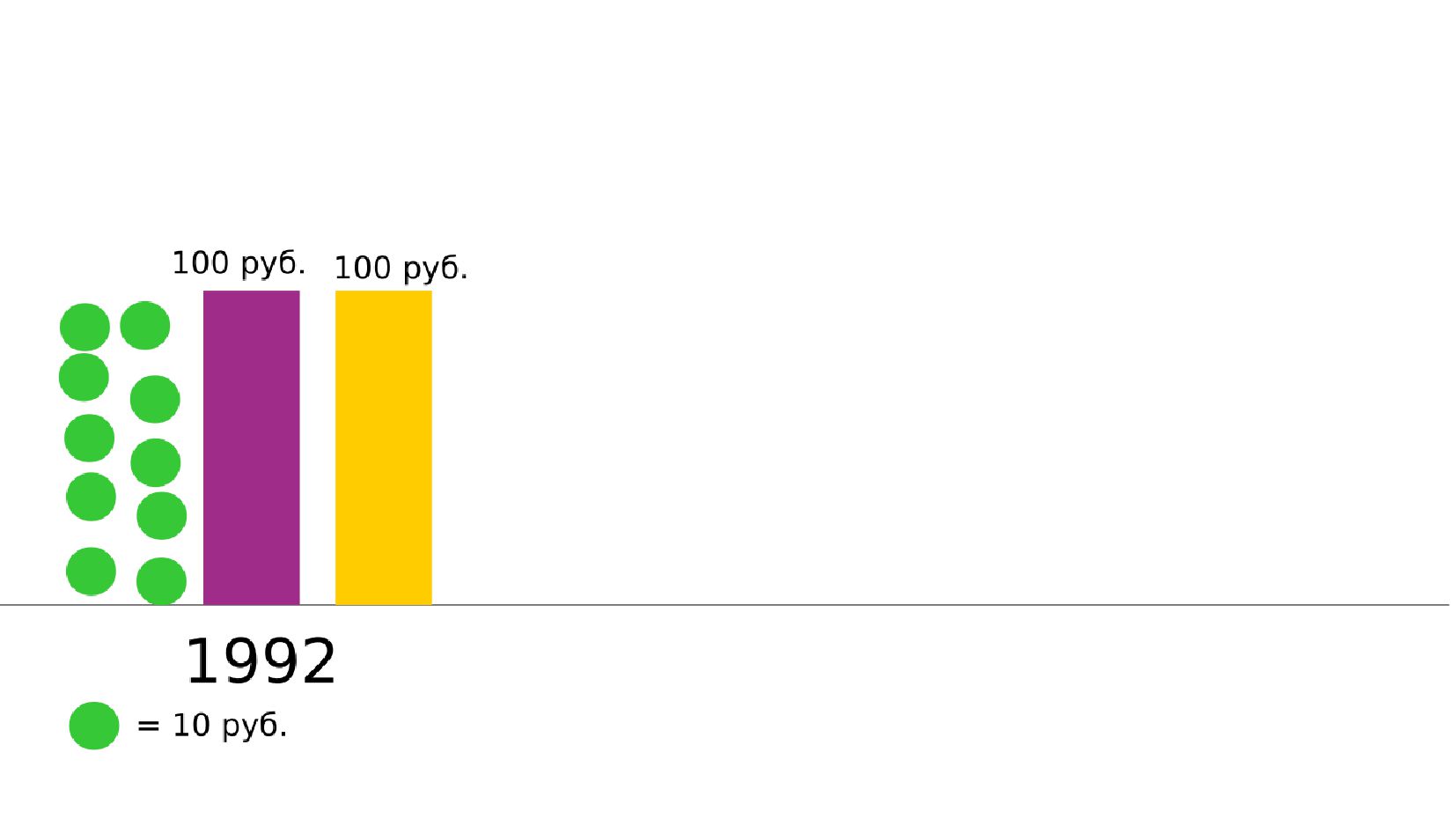{kind=link}
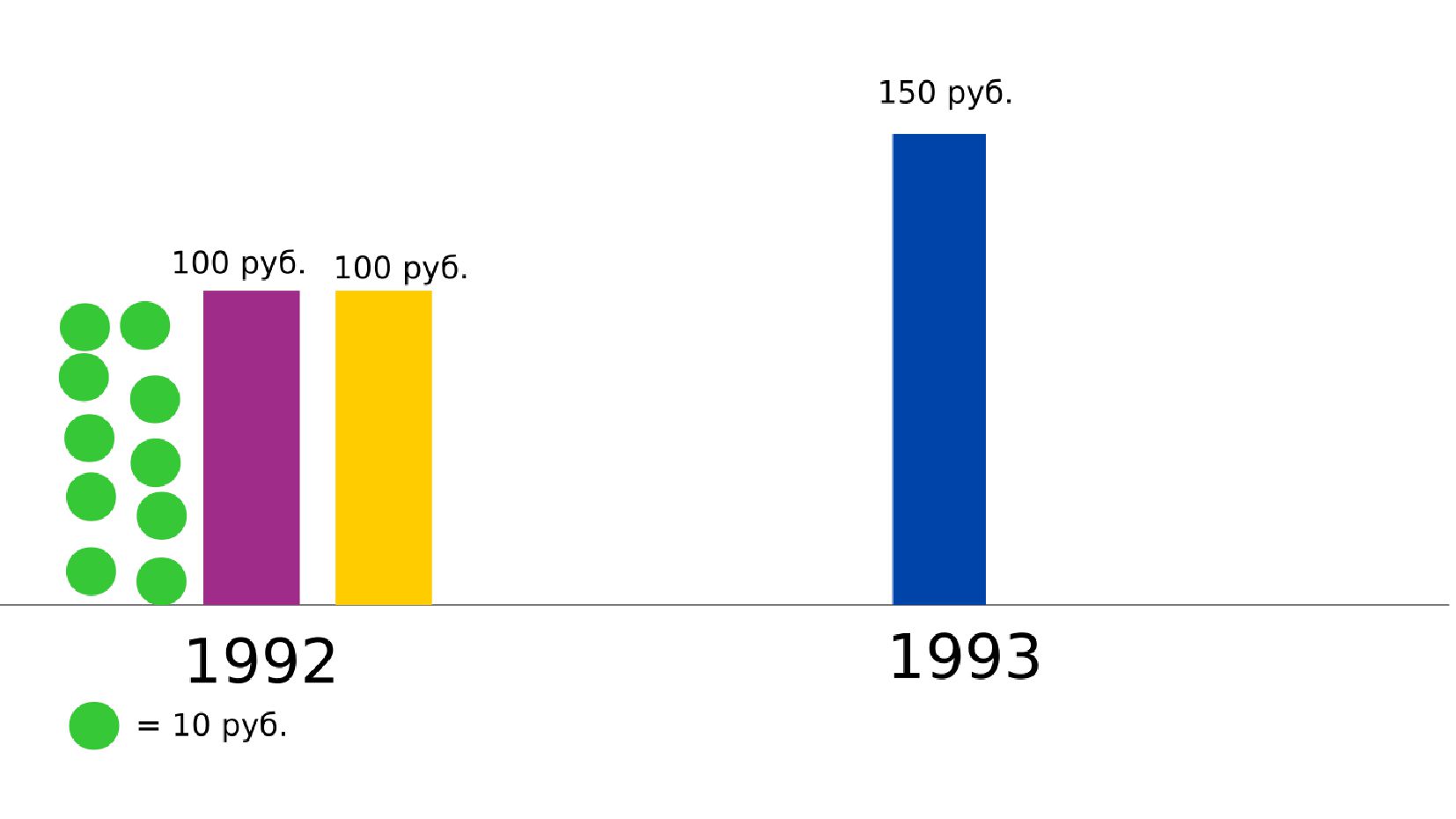{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
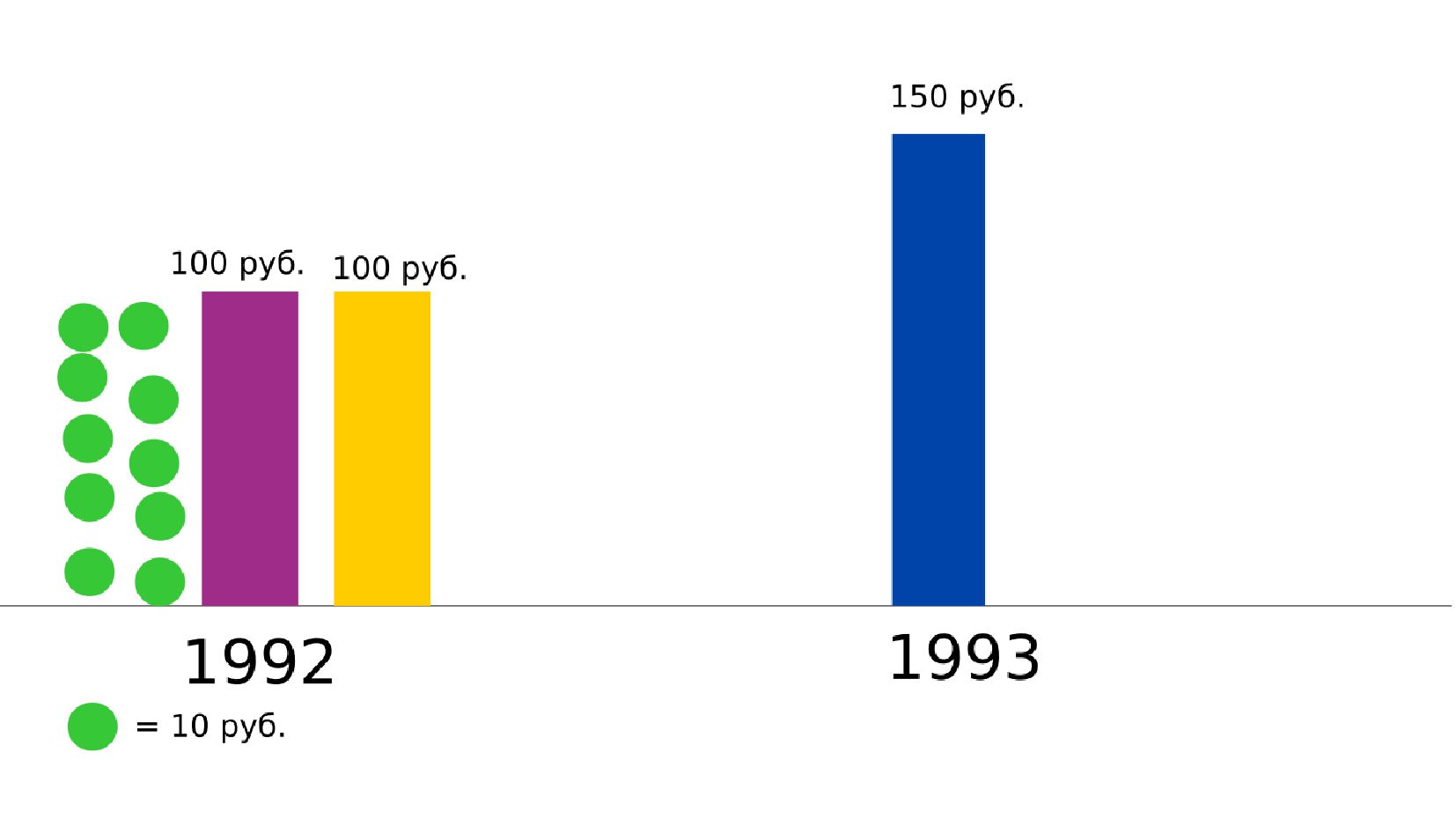{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data_cpi_1993 = data_cpi.loc[data_cpi.index.get_level_values(1) > 1992] data_cpi_1993['cpi_factor_1992'] = data_cpi_1993.sort_index(). groupby(by=['ref_area'])['cpi_factor'].cumprod() print(](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_163.jpg){kind=link}
{kind=link}
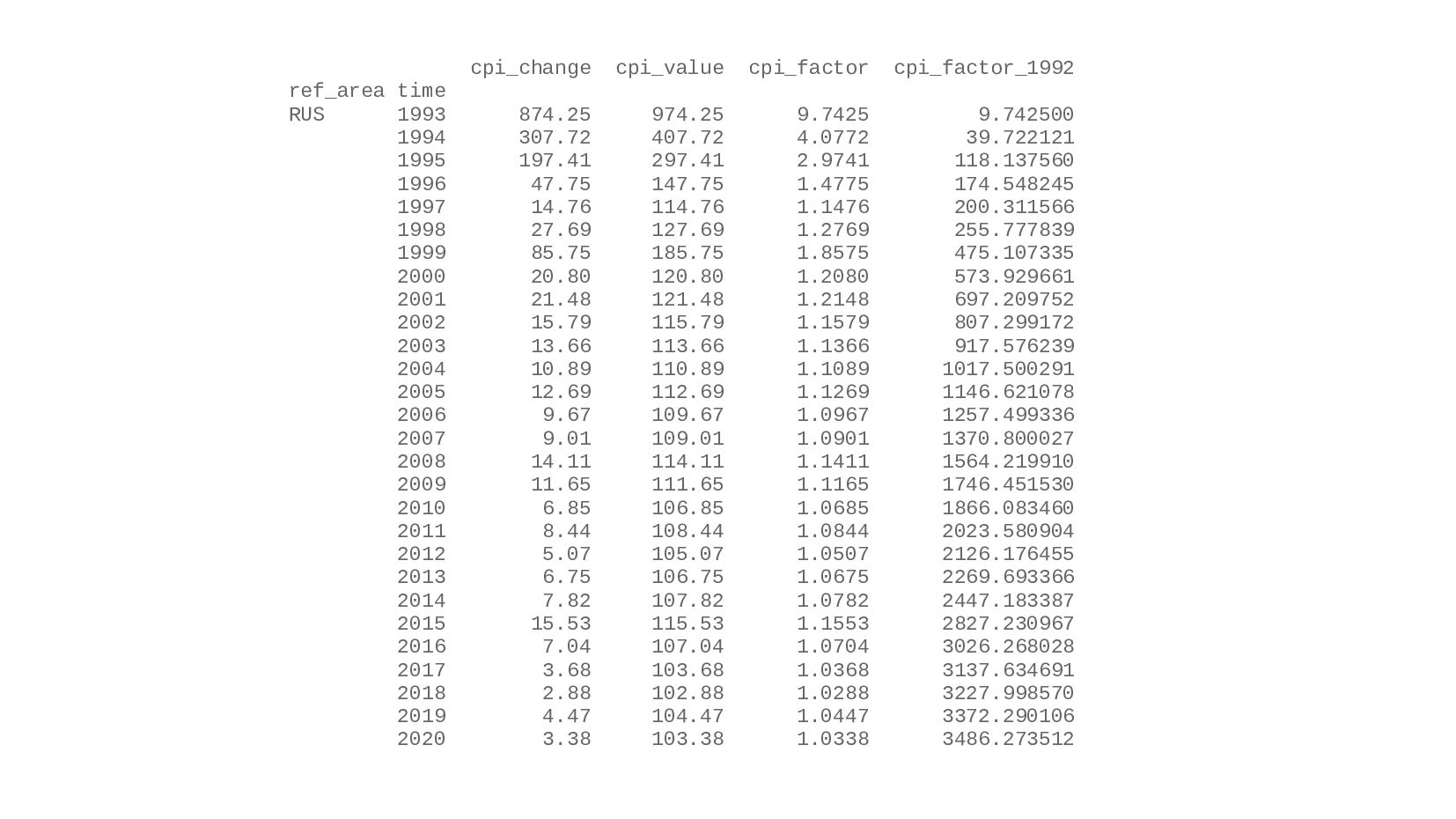{kind=link}
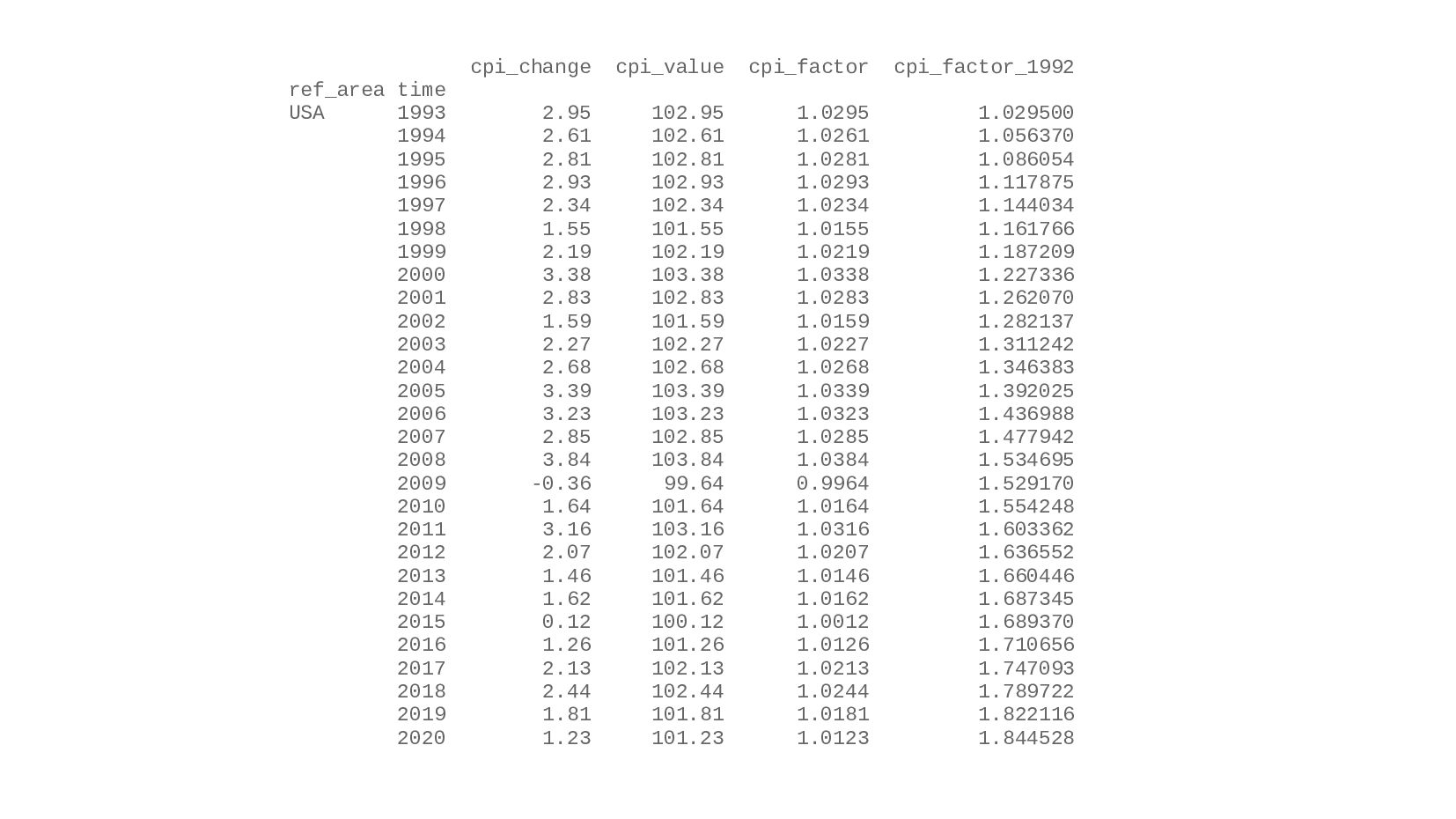{kind=link}
{kind=link}
![data_cpi_1993.loc['RUS'].sort_index() [['cpi_factor', 'cpi_factor_1992']]. plot(title='Ежегодная инфляция и инфляция по отношению к](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_168.jpg){kind=link}
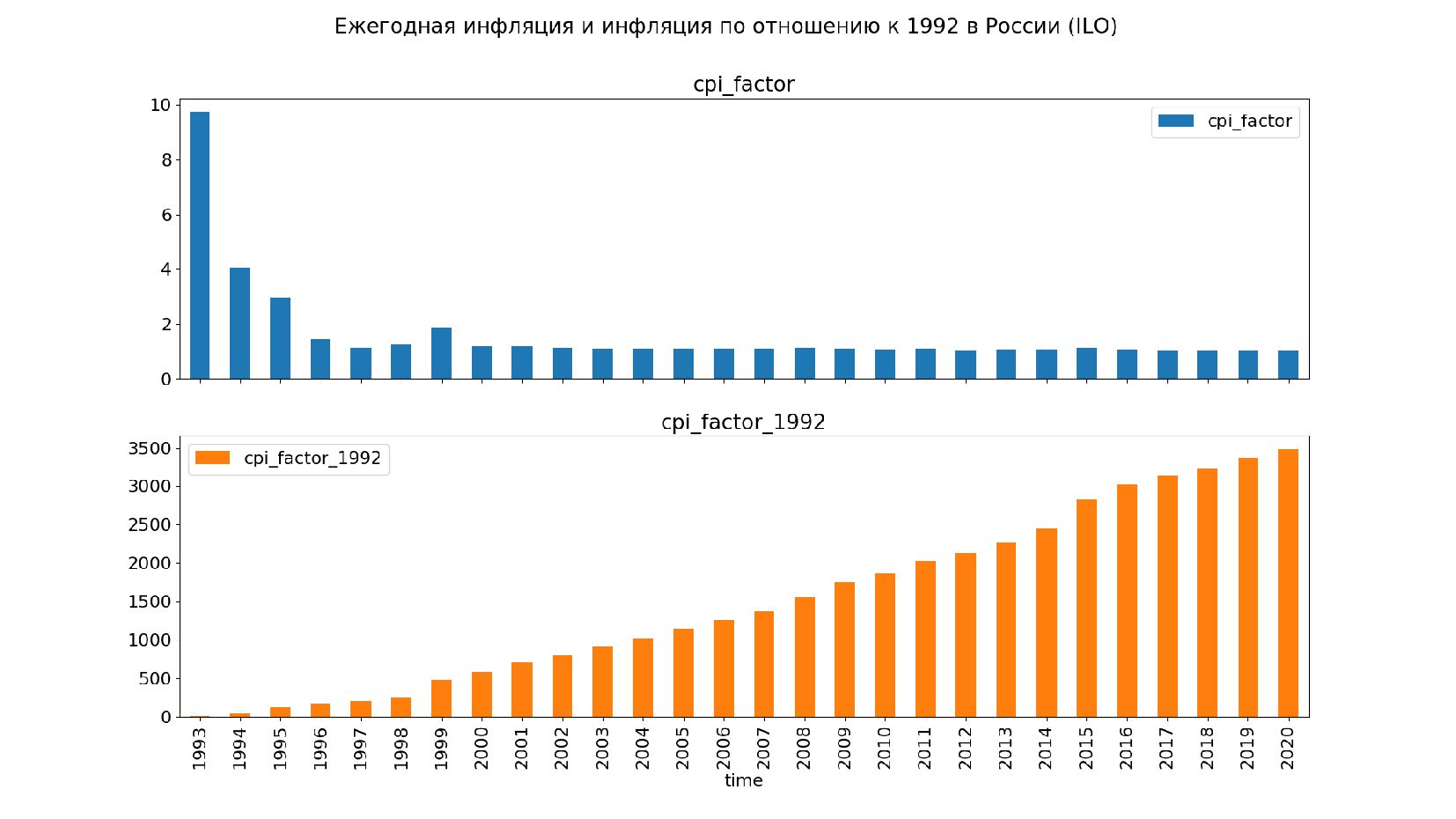{kind=link}
{kind=link}
![data = data.drop(columns=['cpi_change']) data = data.join(data_cpi_1993, on=['ref_area', 'time']) Склеим инфляцию](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_171.jpg){kind=link}
![Реальное содержание зарплаты по годам в ценах 1992 data['wage_corr_cpi_1992'] =](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_172.jpg){kind=link}
{kind=link}
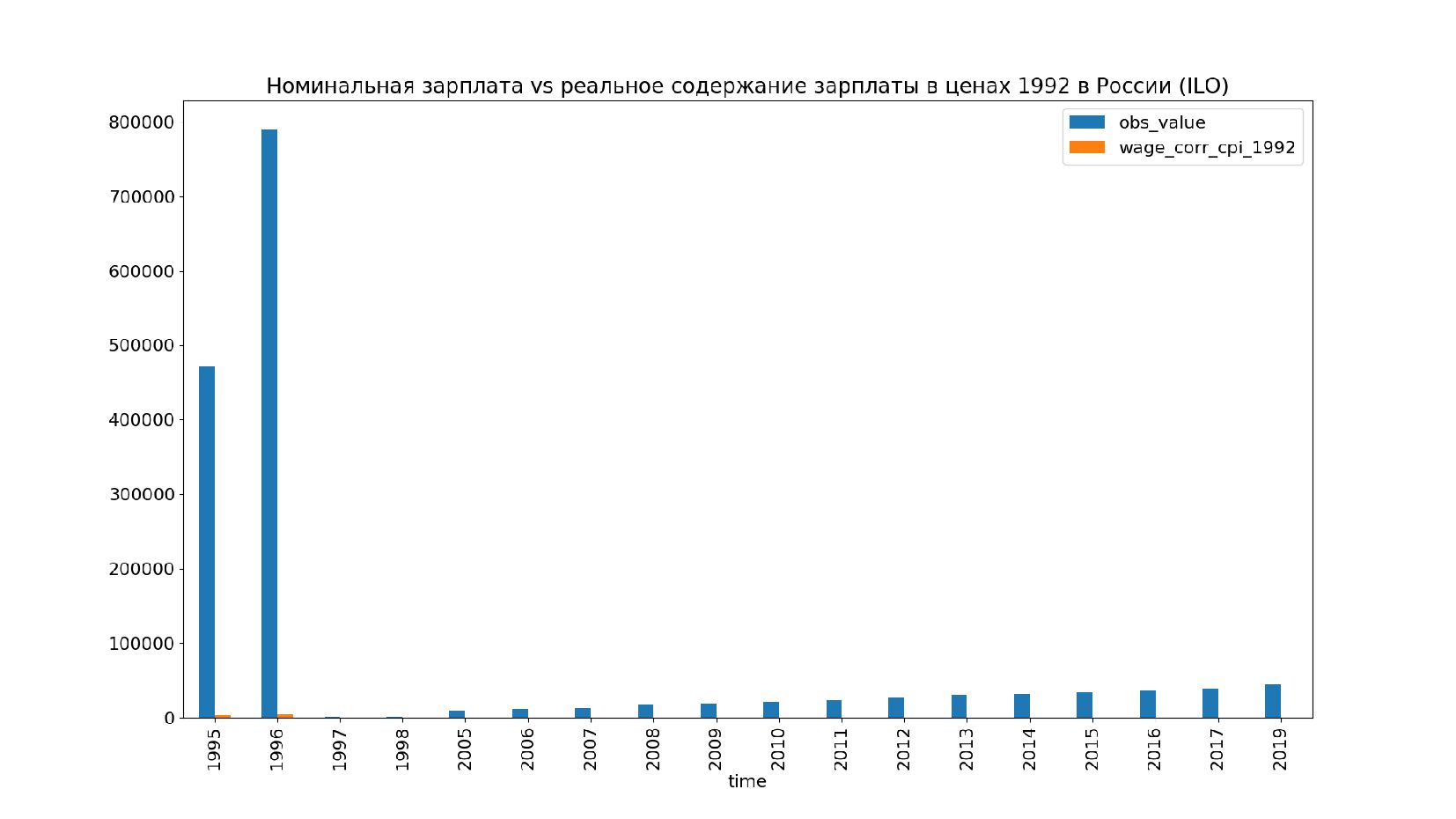{kind=link}
{kind=link}
{kind=link}
![Отменяем деноминацию data_rus_lcu_1993.loc[ data_rus_lcu_1993.time >= 1997, ['obs_value', 'wage_corr_cpi_1992'] ] *=](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_177.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Теперь технически нам нужно • cpi_retro_factor[год] = 1 / cpi_factor[год](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_202.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![print( data_cpi.sort_index(ascending=False) ) print( data_cpi.sort_index(ascending=False). groupby(by=['ref_area'])['cpi_factor'].shift(fill_value=1) ) cpi_change cpi_value cpi_factor](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_212.jpg){kind=link}
{kind=link}
![data_cpi['cpi_retro_factor'] = 1 / data_cpi.sort_index(ascending=False). groupby(by=['ref_area'])['cpi_factor'].shift(fill_value=1) data_cpi_2019_retro = data_cpi.loc[data_cpi.index.get_level_values(1) <=](https://files.speakerdeck.com/presentations/f02f87dc6da3448fa4c2e7c5cc4fde0d/slide_214.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}