Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[論文輪読会] A survey of model compression strategie...
Search
Aokiti
December 12, 2024
38
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[論文輪読会] A survey of model compression strategies for object detection
RG 中澤大越研 論文輪読会
12/12 発表スライド
Aokiti
December 12, 2024
More Decks by Aokiti
See All by Aokiti
d-hacks 今期運営 2025f
sakusaku3939
0
550
[d-hacks Docker講座] Dockerで動かすローカルLLM入門
sakusaku3939
0
90
[論文輪読会] ViT-1.58b
sakusaku3939
0
270
d-hacks PyTorchモデル実装会 2024f
sakusaku3939
0
58
[論文輪読会] Binarized Neural Networks
sakusaku3939
0
70
一般物体検出とLSTMを用いた画像に基づく屋内位置推定 - IPSJ UBI82
sakusaku3939
0
510
MoodTune 東京AI祭ハッカソン決勝
sakusaku3939
0
620
d-hacks PyTorch実装会 2023f
sakusaku3939
0
32
[DL勉強会] 第5章 ディープラーニングを活用したアプリケーション 後半
sakusaku3939
0
22
Featured
See All Featured
Building the Perfect Custom Keyboard
takai
2
820
Designing for Timeless Needs
cassininazir
1
400
Thoughts on Productivity
jonyablonski
76
5.3k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Test your architecture with Archunit
thirion
1
2.3k
30 Presentation Tips
portentint
PRO
1
350
Six Lessons from altMBA
skipperchong
29
4.3k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
380
What's in a price? How to price your products and services
michaelherold
247
13k
Navigating Team Friction
lara
192
16k
Transcript
A survey of model compression strategies for object detection 2024.12.12
論文輪読 B2 aokiti https://link.springer.com/article/10.1007/s11042-023-17192-x 1
論文詳細 ▪ A survey of model compression strategies for object
detection(2024年) ▪ 著者: Zonglei Lyu, Tong Yu, Fuxi Pan, Yilin Zhang, Jia Luo, Dan Zhang, Yiren Chen, Bo Zhang & Guangyao Li ▪ 被引用数: 18 ▪ 学会: Multimedia Tools and Applications 2024 ▪ Multimedia Tools and Applications ▪ 国際ジャーナル ▪ Impact Factor 3.0 2
導入 ▪ ロボット・自動運転・スマートフォンなど、計算能力の弱いハードウェアの中で、 リアルタイムに物体検出を動かしたい ▪ (1) モデルサイズ、(2) 実行時メモリ、(3)計算回数の 3つが主な課題 ▪
本論文では、物体検出における6つのカテゴリの圧縮技術を体系的にレビュー ▪ 枝刈り (Network Pruning)、軽量ネットワーク設計、NAS、量子化 (Network Quantization)、 知識蒸留 (KD) 、低ランク分解 ▪ n = 252 3
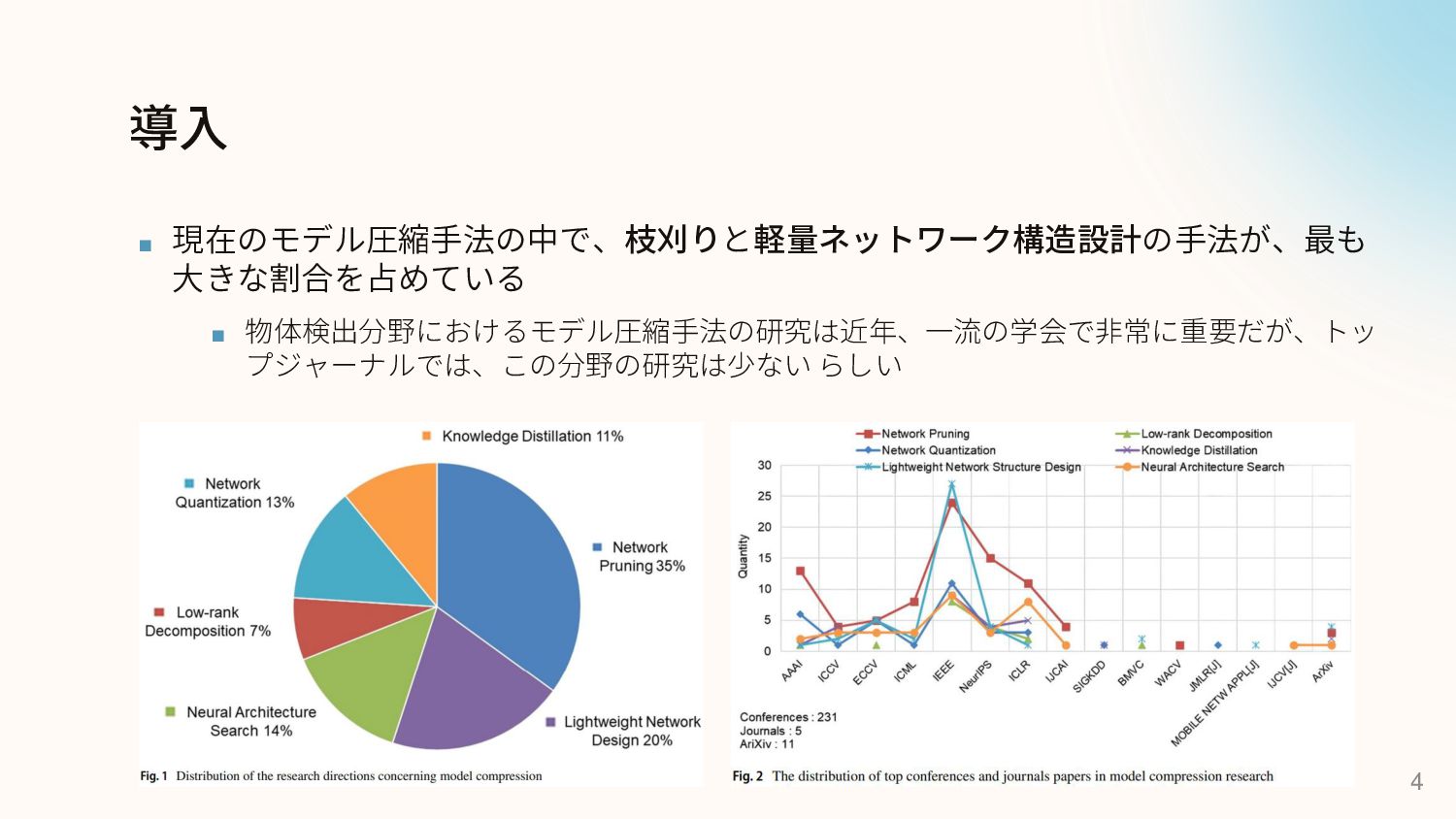
導入 ▪ 現在のモデル圧縮手法の中で、枝刈りと軽量ネットワーク構造設計の手法が、最も 大きな割合を占めている ▪ 物体検出分野におけるモデル圧縮手法の研究は近年、一流の学会で非常に重要だが、トッ プジャーナルでは、この分野の研究は少ない らしい 4
5 ① 枝刈り (Network Pruning)
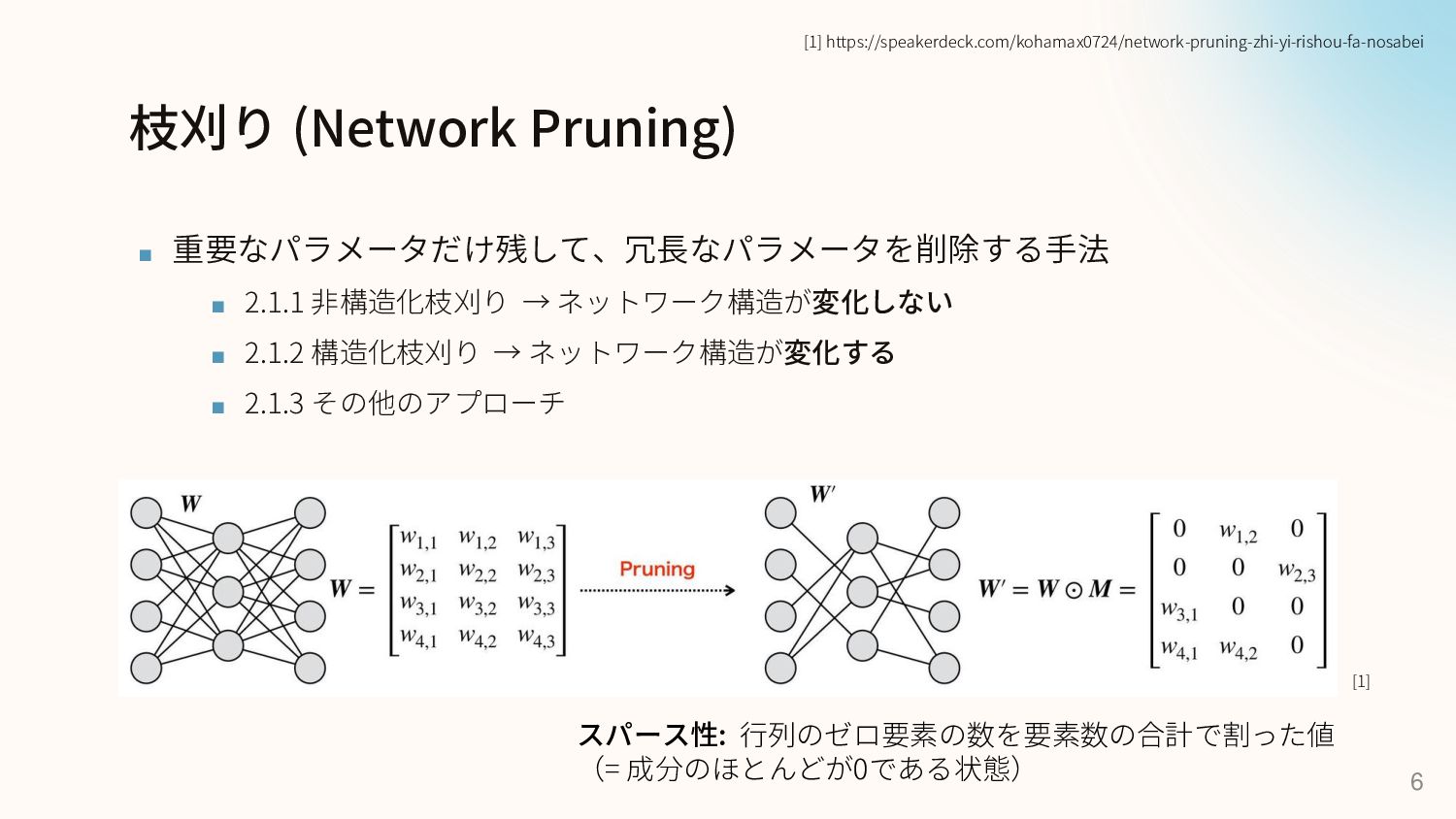
枝刈り (Network Pruning) ▪ 重要なパラメータだけ残して、冗長なパラメータを削除する手法 ▪ 2.1.1 非構造化枝刈り → ネットワーク構造が変化しない
▪ 2.1.2 構造化枝刈り → ネットワーク構造が変化する ▪ 2.1.3 その他のアプローチ 6 [1] https://speakerdeck.com/kohamax0724/network-pruning-zhi-yi-rishou-fa-nosabei [1] スパース性: 行列のゼロ要素の数を要素数の合計で割った値 (= 成分のほとんどが0である状態)
2.1.1 非構造化枝刈り ▪ 各層から重要でない重みを直接除去し、モデルパラメータの数を減らす ▪ 代表研究 ▪ 絶対値が所定の閾値より小さい重みを刈り込む [2015 Han
Song] ▪ 各層に閾値を与えて重みを刈り込む手法(layerwise magnitude-based pruning) ▪ 全体的なモデルの精度に与える影響が少なく、高いスパース率を達成することが できる 7
2.1.2 構造化枝刈り ▪ DNN全体に含まれる重要でない構造を削除する ▪ ニューロン刈り込み (Neuron Pruning)、フィルタ/特徴マップ/カーネル刈り込み、 チャネル刈り込み、レイヤー刈り込みに 分類される
▪ フィルタ刈り込みの研究が最も大きな割合 8
2.1.2 構造化枝刈り ▪ ニューロン刈り込み (Neuron Pruning) ▪ ニューラルネットワークの中で非活性化されたニューロンの出力値を刈り込む ▪ フィルタ/特徴マップ/カーネル刈り込み
▪ CNNにおいて冗長性のある部分を刈り込む ▪ 特徴マップ → ネットワークの出力、フィルタ → ネットワークパラメータ ▪ 代表研究 ▪ 重要でないパラメータにペナルティを与えるための正則化手法 ▪ スパース学習(SL)フレームワークに基づく手法 ▪ 入力画像と現在の特徴マップに応じて動的に刈り込みを行う手法 [Lin 2017] 9
その他の枝刈り ▪ 枝刈りにおいて再学習やファインチューニングを行わない手法 ▪ チャネルやレイヤーの刈り込み手法 ▪ 遺伝的アルゴリズムベース ▪ etc... 著者まとめ
▪ 枝刈り後にネットワーク構造が変化するかどうかによって、構造化枝刈りと非 構造化枝刈りに分けられる 10
著者まとめ ▪ 枝刈り後にネットワーク構造が変化するかどうかによって、構造化枝刈りと非 構造化枝刈りに分けられる ▪ 非構造化枝刈り ▪ 結果として得られる疎なネットワークは特別なライブラリによってサポ ートされる必要がある ▪
構造化枝刈り ▪ 一般的なハードウェアアクセラレーションに適する 11
12 ② 軽量ネットワーク設計
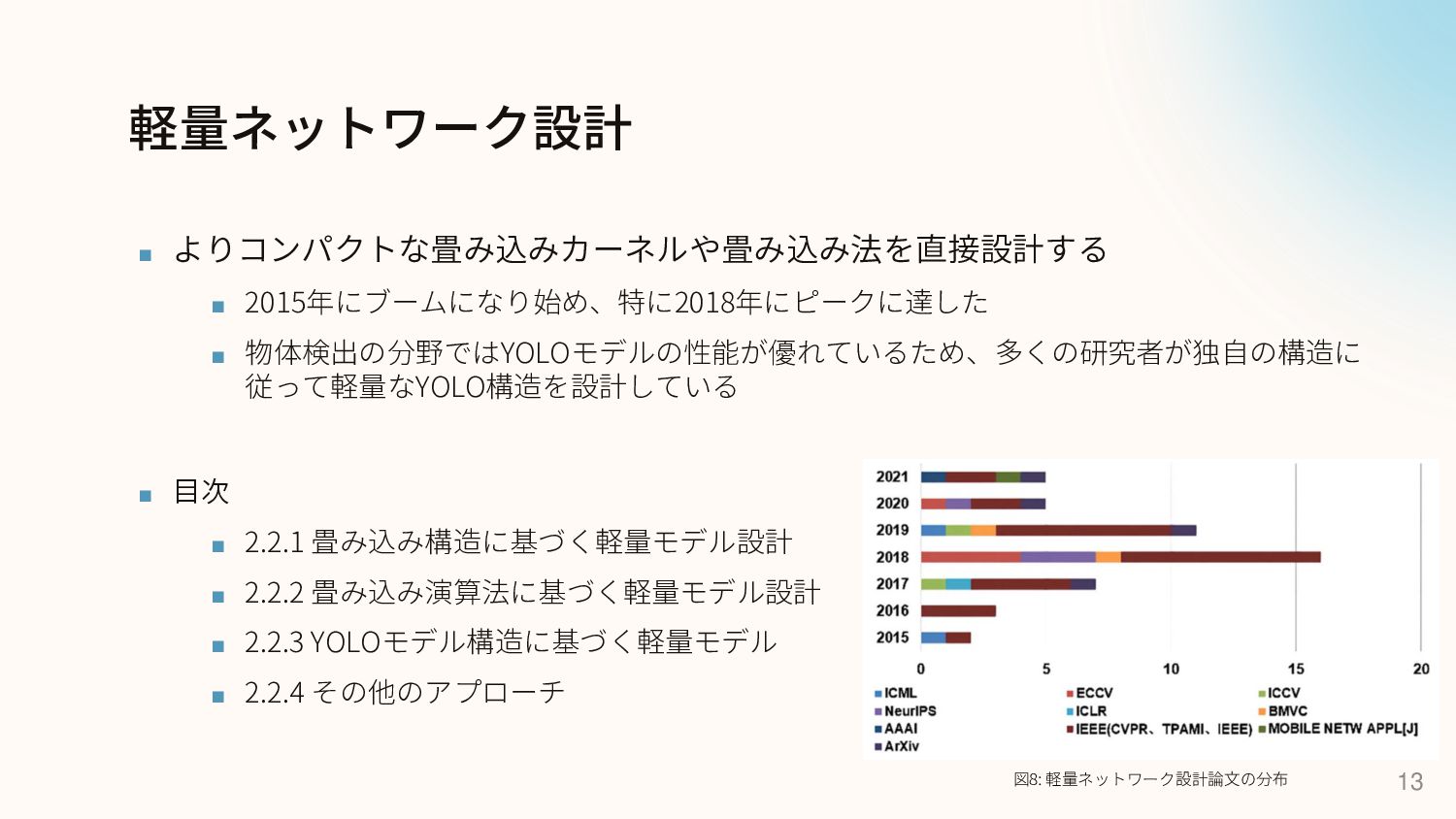
軽量ネットワーク設計 ▪ よりコンパクトな畳み込みカーネルや畳み込み法を直接設計する ▪ 2015年にブームになり始め、特に2018年にピークに達した ▪ 物体検出の分野ではYOLOモデルの性能が優れているため、多くの研究者が独自の構造に 従って軽量なYOLO構造を設計している ▪ 目次
▪ 2.2.1 畳み込み構造に基づく軽量モデル設計 ▪ 2.2.2 畳み込み演算法に基づく軽量モデル設計 ▪ 2.2.3 YOLOモデル構造に基づく軽量モデル ▪ 2.2.4 その他のアプローチ 13 図8: 軽量ネットワーク設計論文の分布
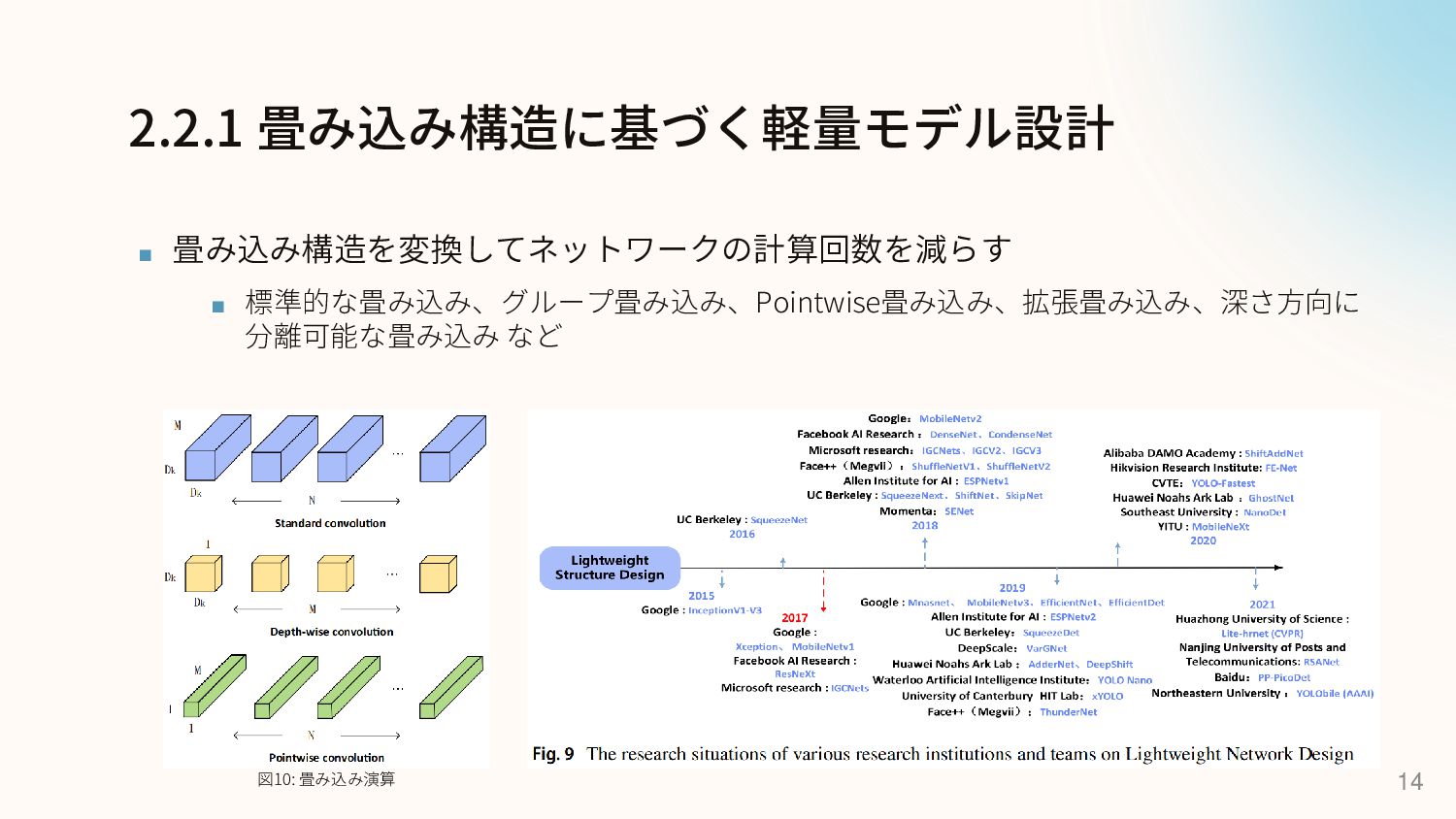
2.2.1 畳み込み構造に基づく軽量モデル設計 ▪ 畳み込み構造を変換してネットワークの計算回数を減らす ▪ 標準的な畳み込み、グループ畳み込み、Pointwise畳み込み、拡張畳み込み、深さ方向に 分離可能な畳み込み など 14 図10:
畳み込み演算
2.2.1 畳み込み構造に基づく軽量モデル設計 ▪ 深さ方向の分離可能な畳み込み (Depth-wise Separable Convolution) ▪ 通常の畳み込みを、Depthwise畳み込み と
Pointwise畳み込み(1 × 1のフィ ルター)の2つに分けることで、パラメータ数を削減 ▪ モデル ▪ InceptionV1 ~ V3 [Google 2015-2016] ▪ Xception [Google 2017] ▪ MobileNetV1 ~ V2 [Google 2017-2018] 15 MobileNet論文で用いられた図 [2] [2] https://arxiv.org/abs/1704.04861 Depth-wise Separableによってなぜ早くなるかの解説 → https://www.youtube.com/watch?v=T7o3xvJLuHk
2.2.1 畳み込み構造に基づく軽量モデル設計 ▪ グループ畳み込み ▪ 従来の畳み込みを複数のグループ化畳み込みに分解し、必要なパラメータの数を減らす ▪ ResNeXt(ResNet + Inception)[Facebook
2016] ▪ CondenseNet(DenseNetの改善版) ▪ Pointwise畳み込み ▪ ShuffleNetV1 ~ V2 [Megvii 2018] ▪ Plug-and-Play (PnP) ▪ 最適化アルゴリズムにDNNを取り入れる枠組み ▪ GhostNet [Huwai 2020] → MobileNetV3を上回る性能 16
2.2.1 畳み込み構造に基づく軽量モデル設計 ▪ その他 ▪ SqueezeNet ▪ SENet ▪ Lite-HRNet
▪ PeleeNet ▪ MobileNeXt ▪ etc... ▪ グループ化畳み込みとDepthwise畳み込みを用いて設計されたモデルは、現在比較 的成熟しており、高性能である 17
2.2.2 畳み込み演算法に基づく軽量モデル設計 ▪ ネットワーク演算の回数を減らすために、畳み込み演算を畳み込み演算法の観点か ら最適化する ▪ 主にシフト畳み込み演算と乗算演算の2種類 ▪ 乗算なしニューラルネットワーク ▪
加算演算やシフト演算、符号反転を利用する高速化 ▪ DeepShift [2019 Elhoushi] ▪ ShiftAddNet [2020 You] 18
2.2.3 YOLOモデル構造に基づく軽量モデル ▪ YOLOv2 ~ v5 モデルに基づいてより軽い重みを構築する ▪ YOLO-LITE [2018
Huang] ▪ xYOLO [2019 Wong] ▪ YOLO-Fast [2020 Qiuqiu] ▪ YOLObile [2020 Cai] → 新しいブロックパンチ枝刈り方式とGPU-CPU協調方式を提案 19 [3] https://arxiv.org/abs/1506.02640 YOLOのアーキテクチャ [3]
2.2.4 その他のアプローチ ▪ 計算層を実行するかどうかを決定するゲートモジュール追加、次元の均等なスケー リングなど ▪ EfficientNet ▪ etc... 20
著者まとめ ▪ 軽量ネットワーク設計は、全般的にモデルを大きく圧縮することができる ▪ 一方で、モデルの特徴表現能力は犠牲になりやすい ▪ YOLOモデル自体のリアルタイム検出を活用し、物体検出タスクのためだけの軽量 モデル設計もある 21
22 ③ NAS
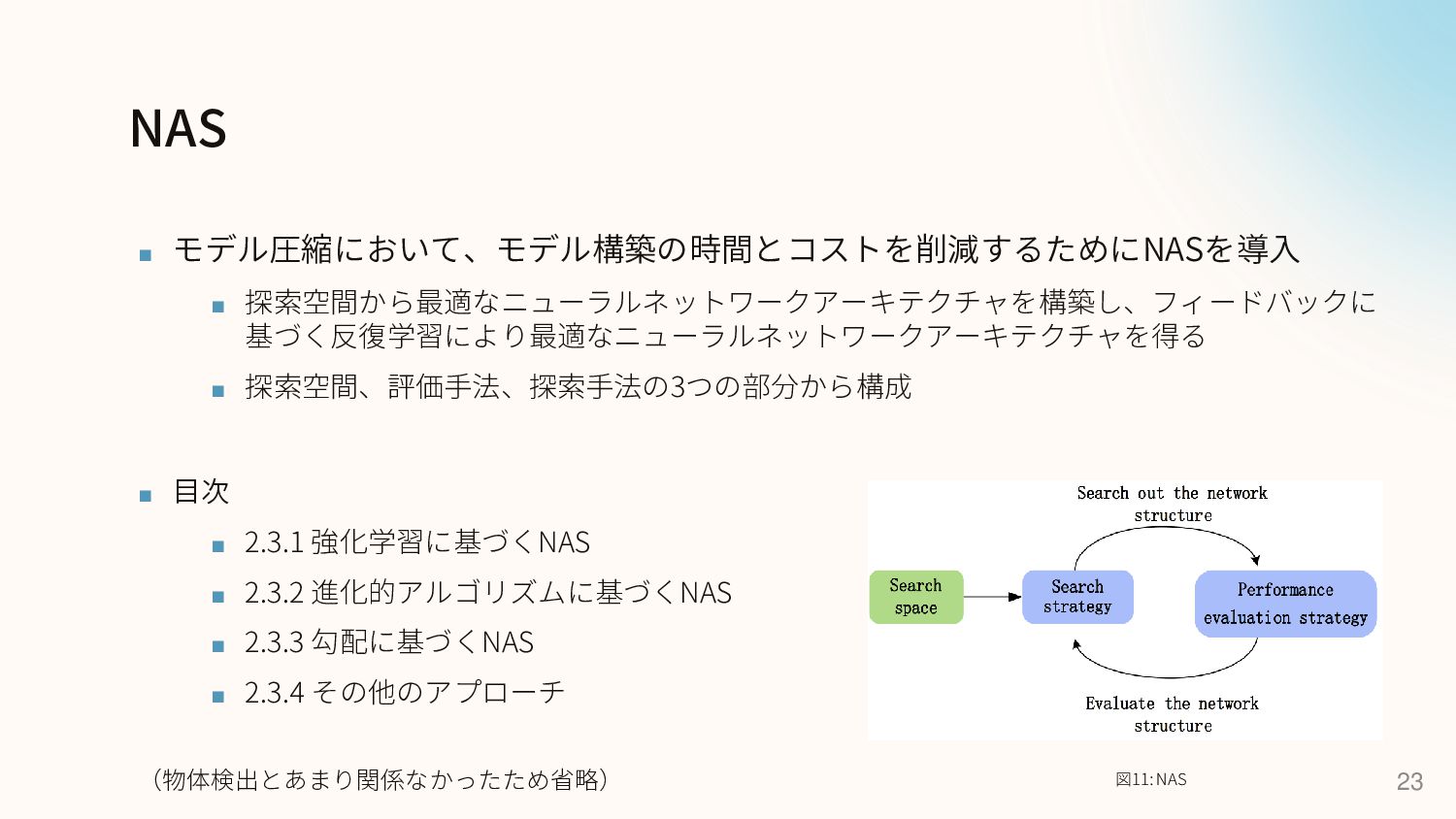
NAS ▪ モデル圧縮において、モデル構築の時間とコストを削減するためにNASを導入 ▪ 探索空間から最適なニューラルネットワークアーキテクチャを構築し、フィードバックに 基づく反復学習により最適なニューラルネットワークアーキテクチャを得る ▪ 探索空間、評価手法、探索手法の3つの部分から構成 ▪ 目次
▪ 2.3.1 強化学習に基づくNAS ▪ 2.3.2 進化的アルゴリズムに基づくNAS ▪ 2.3.3 勾配に基づくNAS ▪ 2.3.4 その他のアプローチ (物体検出とあまり関係なかったため省略) 23 図11: NAS
24 ④ 量子化
量子化 ▪ 浮動小数点演算 (FP32) を整数の固定小数点演算 (INT8) に変換して、モデルサイズ を圧縮する ▪ INT8量子化はTensorRT、TensorFlow、PyTorchなどで既に導入済み
▪ モデルの量子化によって引き起こされる精度損失をどのように低減するかが主な研究分野 ▪ 目次 ▪ 2.4.1 2値量子化 ▪ 2.4.2 3値量子化 ▪ 2.4.3 クラスター量子化 ▪ 2.4.4 その他のアプローチ 25 図14: ネットワーク量子化
2.4.1 2値量子化 ▪ ネットワークパラメータ(重み、アクティベーション)を 1 または -1 に制限する ▪ 元の乗算演算を加算演算またはシフト演算に変換することでメモリを削減
& 高速化 ▪ 代表研究 ▪ 重み・アクティベーションの2値化(BNN)[Courbariaux 2015] ▪ 2値化演算を使用してCNNを近似(XOR-Net)[Rastegari 2016] ▪ CNNで複数の2値重みベースの線形結合を使用してFP32を近似(ABC-Net) [DJI 2017] ▪ BNNのアンサンブルによる精度向上(BENN)[Zhu 2019] 26 (物体検出での研究はない or 紹介されていなかった)
量子化のアプローチ ▪ 2.4.2 3値量子化 ▪ ネットワークパラメータ(重み、アクティベーション)を 1、0、-1 に制限する ▪ 2.4.3
クラスター量子化 ▪ クラスタリングと量子化法を組み合わせて圧縮を実現する手法 ▪ 畳み込みの重みにK-meansクラスタリングを適用することで、重み共有を行う [Wu 2018] 27
著者まとめ ▪ 量子化は計算速度を速め、検討したモデルのサイズを大幅に縮小することができる ▪ 2値量子化と3値量子化は研究のホットスポットである 28
29 ⑤ 知識蒸留 (KD)
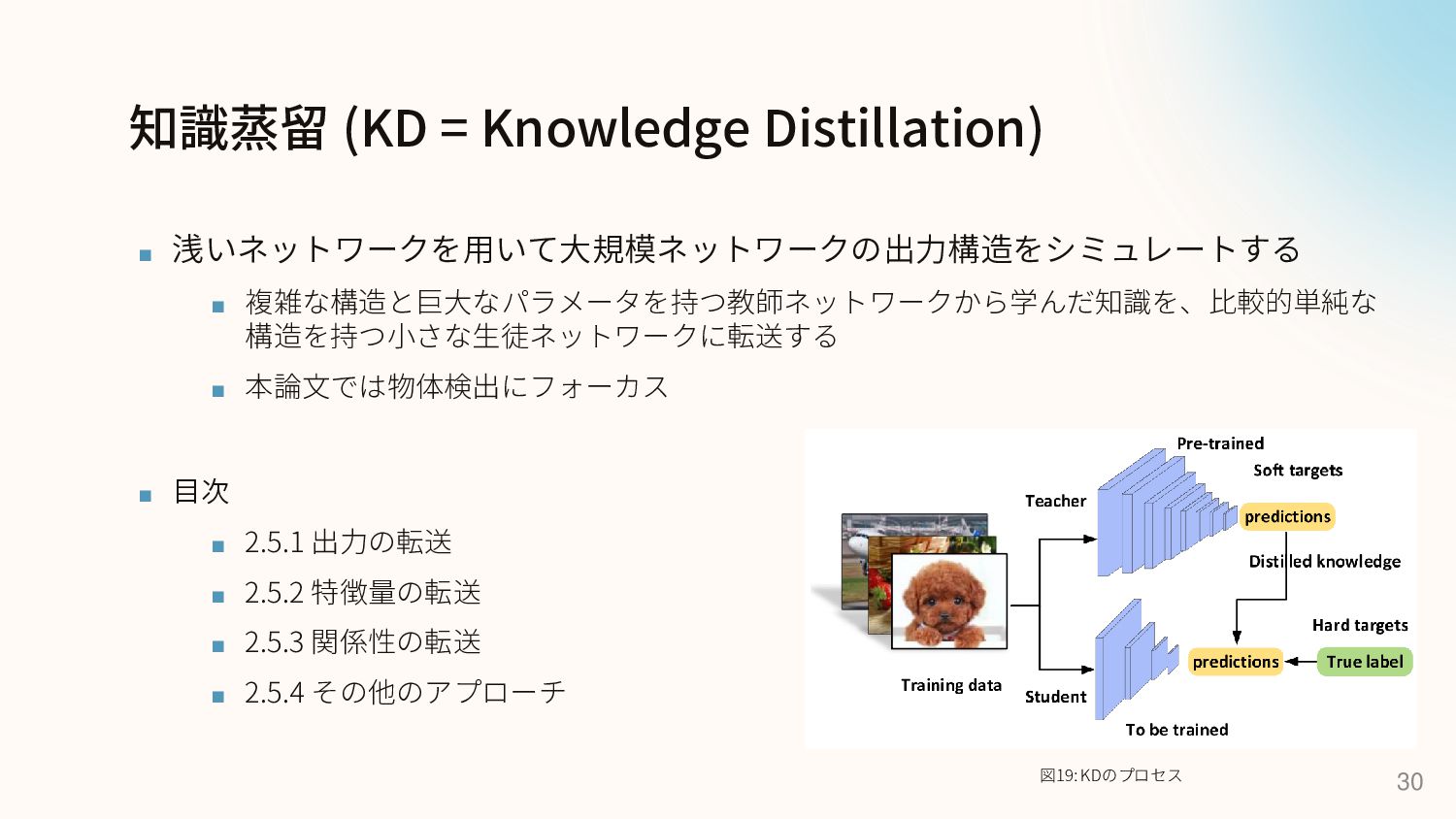
知識蒸留 (KD = Knowledge Distillation) ▪ 浅いネットワークを用いて大規模ネットワークの出力構造をシミュレートする ▪ 複雑な構造と巨大なパラメータを持つ教師ネットワークから学んだ知識を、比較的単純な 構造を持つ小さな生徒ネットワークに転送する
▪ 本論文では物体検出にフォーカス ▪ 目次 ▪ 2.5.1 出力の転送 ▪ 2.5.2 特徴量の転送 ▪ 2.5.3 関係性の転送 ▪ 2.5.4 その他のアプローチ 30 図19: KDのプロセス
2.5.1 出力の転送 ▪ ネットワーク出力を生徒のネットワーク学習のための知識として使用する ▪ 教師モデルはハードターゲットで学習を行い、ソフトマックス層の出力(ハードターゲット とソフトターゲット)を用いて生徒モデルを学習 ▪ → 2つのネットワークのソフトマックス層の出力を全損失に組み込み、生徒モデルの
学習をガイドする ▪ 基本的には、教師と生徒の間には一方通行の伝達だけ ▪ 代表研究 ▪ 複数のネットワークの出力に応じて、生徒が互いに学び教え合う手法 [Zhang 2018] ▪ 古典的なKD損失をターゲットクラス知識蒸留と非ターゲットクラス知識蒸留に再定式化し、 独立したハイパラメータによって制御可能にした(DKD)[Borui 2022] 31
知識蒸留(KD)のアプローチ ▪ 2.5.2 特徴量の転送 ▪ ネットワーク学習の隠れ層の特徴量を、生徒が学習するための知識として利用する ▪ 2.5.3 関係性の転送 ▪
ネットワーク特性の層間の関係やサンプルの関係を、生徒の学習知識として利用する ▪ 2.5.4 その他のアプローチ ▪ 知識蒸留による物体検出SSDモデルの性能向上 [Ko 2020] ▪ 物体検出蒸留を効率的に行うために、ヒント学習、ソフトターゲット、ハードターゲットを 同時に組み合わせる手法 [Chen 2017] 32
著者まとめ ▪ 出力転送と特徴転送の組み合わせは、モデルの情報や特徴をより良く保存することが できる ▪ データなしのKDの問題や、KDの画像分類ではなくターゲット検出の分野への応用は、 今後の研究の焦点となる可能性 33
34 ⑥ 低ランク分解
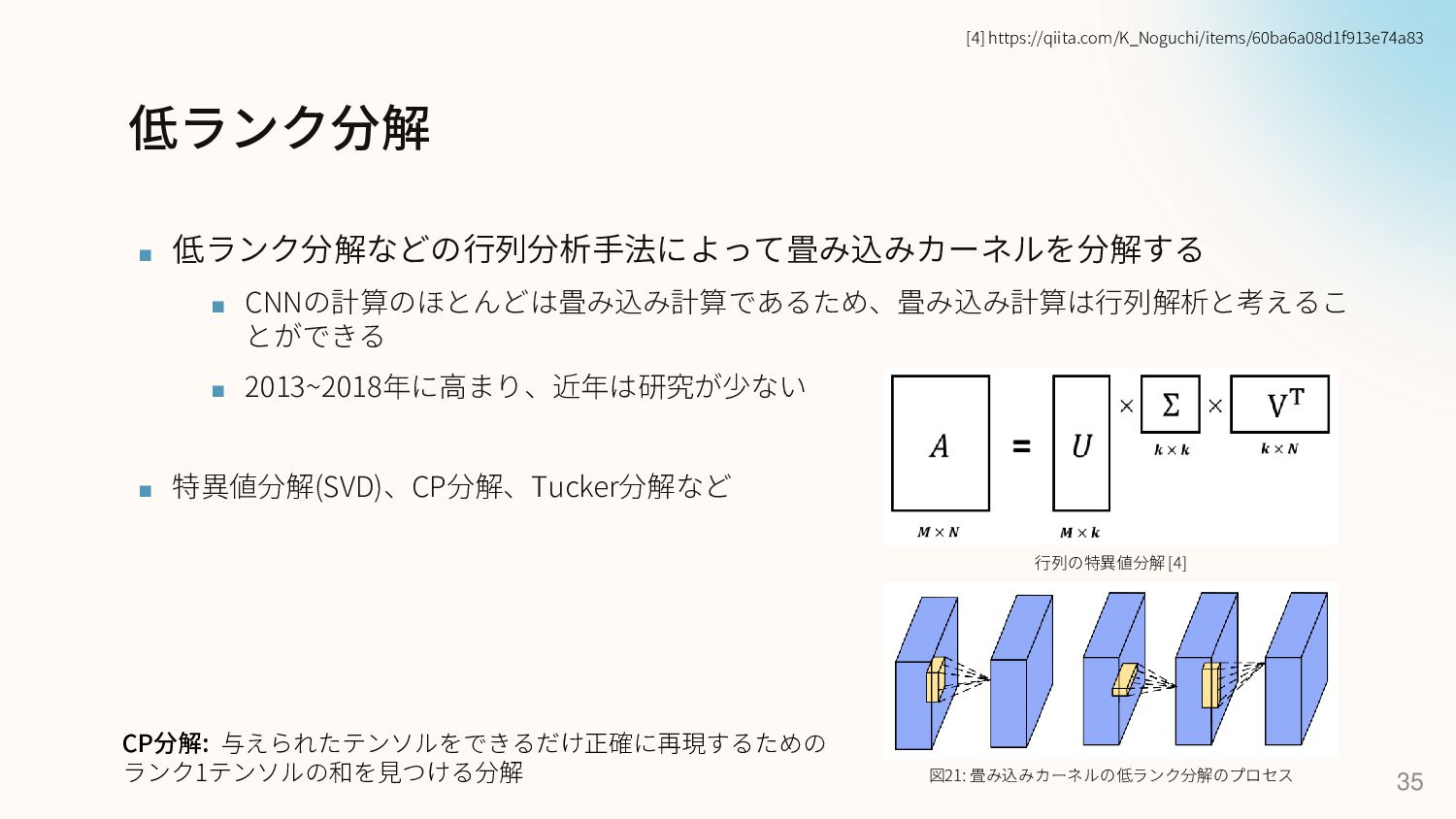
低ランク分解 ▪ 低ランク分解などの行列分析手法によって畳み込みカーネルを分解する ▪ CNNの計算のほとんどは畳み込み計算であるため、畳み込み計算は行列解析と考えるこ とができる ▪ 2013~2018年に高まり、近年は研究が少ない ▪ 特異値分解(SVD)、CP分解、Tucker分解など
35 図21: 畳み込みカーネルの低ランク分解のプロセス 行列の特異値分解 [4] [4] https://qiita.com/K_Noguchi/items/60ba6a08d1f913e74a83 CP分解: 与えられたテンソルをできるだけ正確に再現するための ランク1テンソルの和を見つける分解
低ランク分解 ▪ 代表研究 ▪ 畳み込みカーネルに行列分解を適用することの実現可能性を初めて理論的に説明 & 重み 値の一部を与えることで、残りの値を正確に予測 [Oxford Univ
2013] ▪ 畳み込みネットワークの畳み込みカーネルを圧縮するCP分解法を提案 [Lebedev 2015] ▪ 重要でないニューロンを低ランクに保つためにSVD行列をスパース化し、画像認識モデル に対するこの圧縮手法の有効性を検証 [Swaminathan 2020] ▪ 低ランク + スパース枝刈りの組み合わせによるDepthwise畳み込みの圧縮 [Hawkins 2021] ▪ MobileNetv3、EfficentNet、Vision Transformerなど 36 [4] https://qiita.com/K_Noguchi/items/60ba6a08d1f913e74a83
著者まとめ ▪ 低ランク分解は、モデルの圧縮と高速化に非常に適している ▪ ただし低ランク分解法の実装は容易ではなく、計算コストが高い 37
38 まとめ + α
考察と今後の方向性 ▪ 6つの圧縮手法は、特定の実装、データセット、アプリケーションシナリオによって 異なる可能性がある 39 方法 将来の方向性 適用シナリオ 枝刈り 他の圧縮手法と枝刈りを組み合わせて、さらなる圧縮を実現する
計算メモリサイズやストレージ容量が小さいデバイス 軽量ネットワーク設計 1. 軽量ネットワーク設計とNASを組み合わせることを検討する 2. より多くの適用タスクやシナリオを探求する 高いリアルタイム要件を持つ組み込みエンドツーエンドプラ ットフォーム 量子化 1. ネットワークの表現力を向上させ、トレーニングの可能性を引き出す 2. 実際のハードウェアデバイスでの加速研究を増やす 推論速度が高く、計算メモリサイズが小さいデバイス NAS 1. セマンティックセグメンテーションやその他のタスクにニューラルネット ワーク探索手法を適用する 2. 探索空間の研究を増やす 特定のストレージや精度要件を持つモバイルデバイス 知識蒸留 (KD) 1. オブジェクト検出など他の分野に拡大する 2. 中間特徴層を組み合わせて、異なる形態の知識を使用する 小規模またはデータセットが存在しない場合 低ランク分解 分解に必要な計算操作を簡素化する方法を研究 全結合層の圧縮 表21: 考察と今後の方向性
まとめ & 感想 ▪ 著者らより、枝刈りや軽量ネットワーク設計は、物体検出の分野で広く使われている ▪ 物体検出の場合、新しいモデル提案が多そう ▪ 圧縮や高速化に関して、教科書的にまとまっていて勉強になった ▪
ただし物体検出の圧縮というよりも、全般的なモデル圧縮手法の話がメインだった ▪ Q-DETR(DETRの低ビット量子化, CVPR2023)など直近の物体検出圧縮は載ってなさそう ▪ 著者らはサーベイ調査に加えて、代表的なDNN圧縮手法 + 研究を実装して大規模なパ フォーマンス比較も本論文で行っていた 40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}