2. TransformerのEncoderで処理 ※1 3. MLP Headによって最終的な予測値や分 類クラスに変換する [4] Dosovitskiy, Alexey, et al. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” International Conference on Learning Representations, 2021, https://openreview.net/forum?id=YicbFdNTTy. ① ② ③ Transformerを画像認識タスクに適用したモデル ※1 オリジナルのEncoderとほぼ同じ。ただし、Pre-Normと活性化関数のGELUに変更している
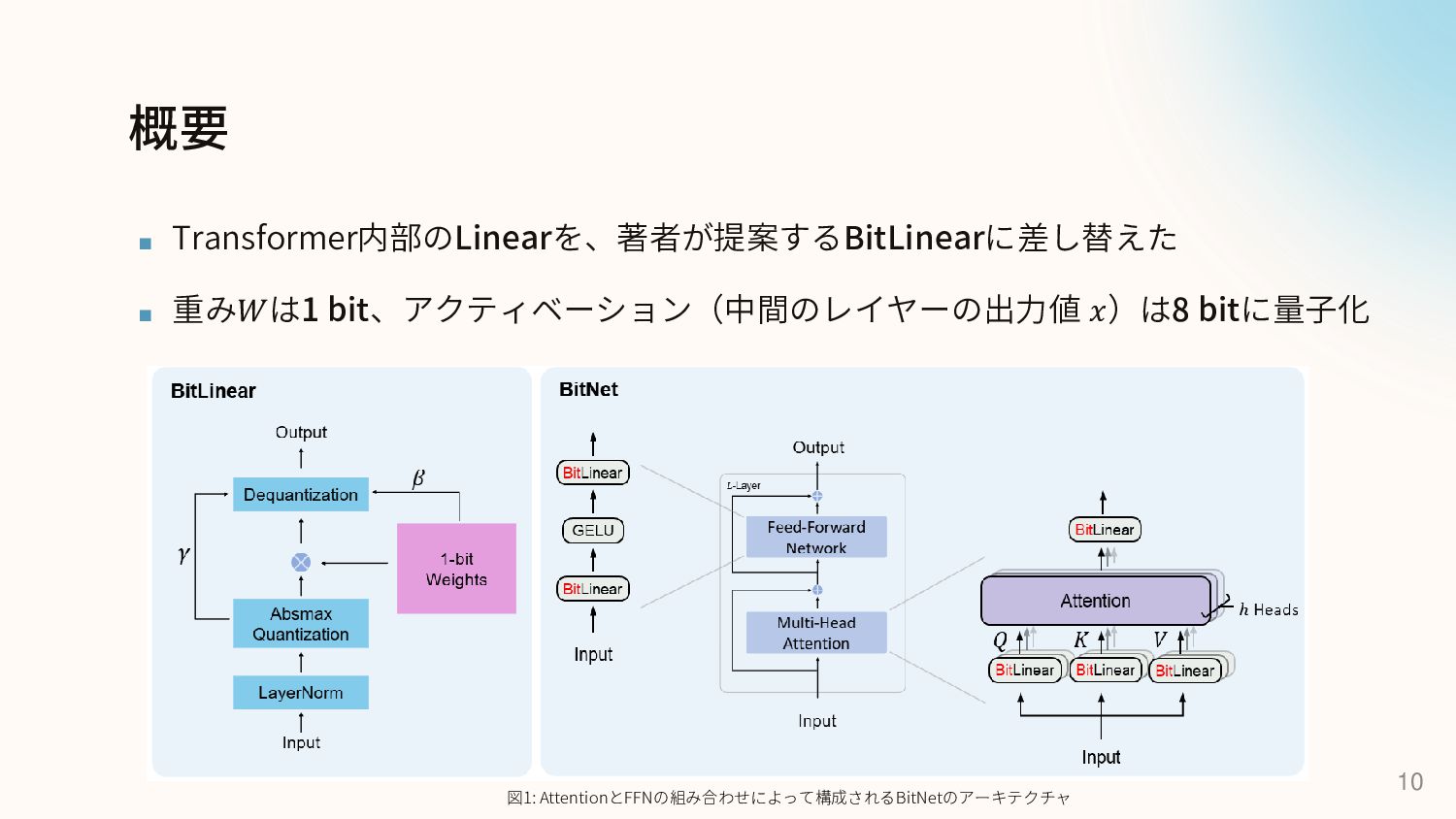
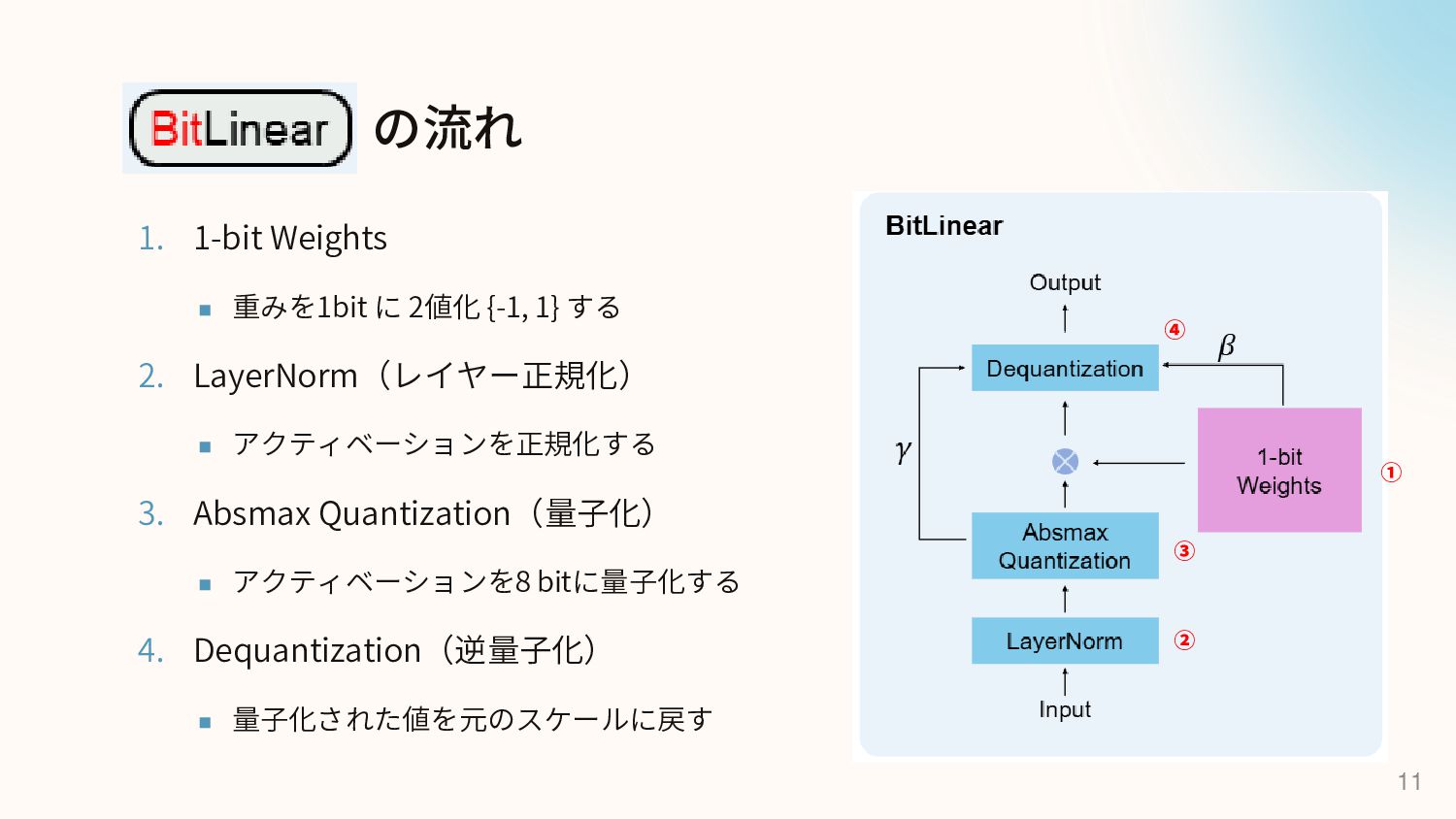
Foundation Transformer.” Proceedings of the 40th International Conference on Machine Learning, 2023, pp. 36077–36092, https://proceedings.mlr.press/v202/wang23u.html. アクティベーションを正規化する ◼ FP32の計算では、重みの初期化によって出力の分散が1 になる → 学習が安定する ◼ 8 bitに量子化するとこれが使えないため、アクティベー ション前に SubLN[6] によるレイヤー正規化を行う
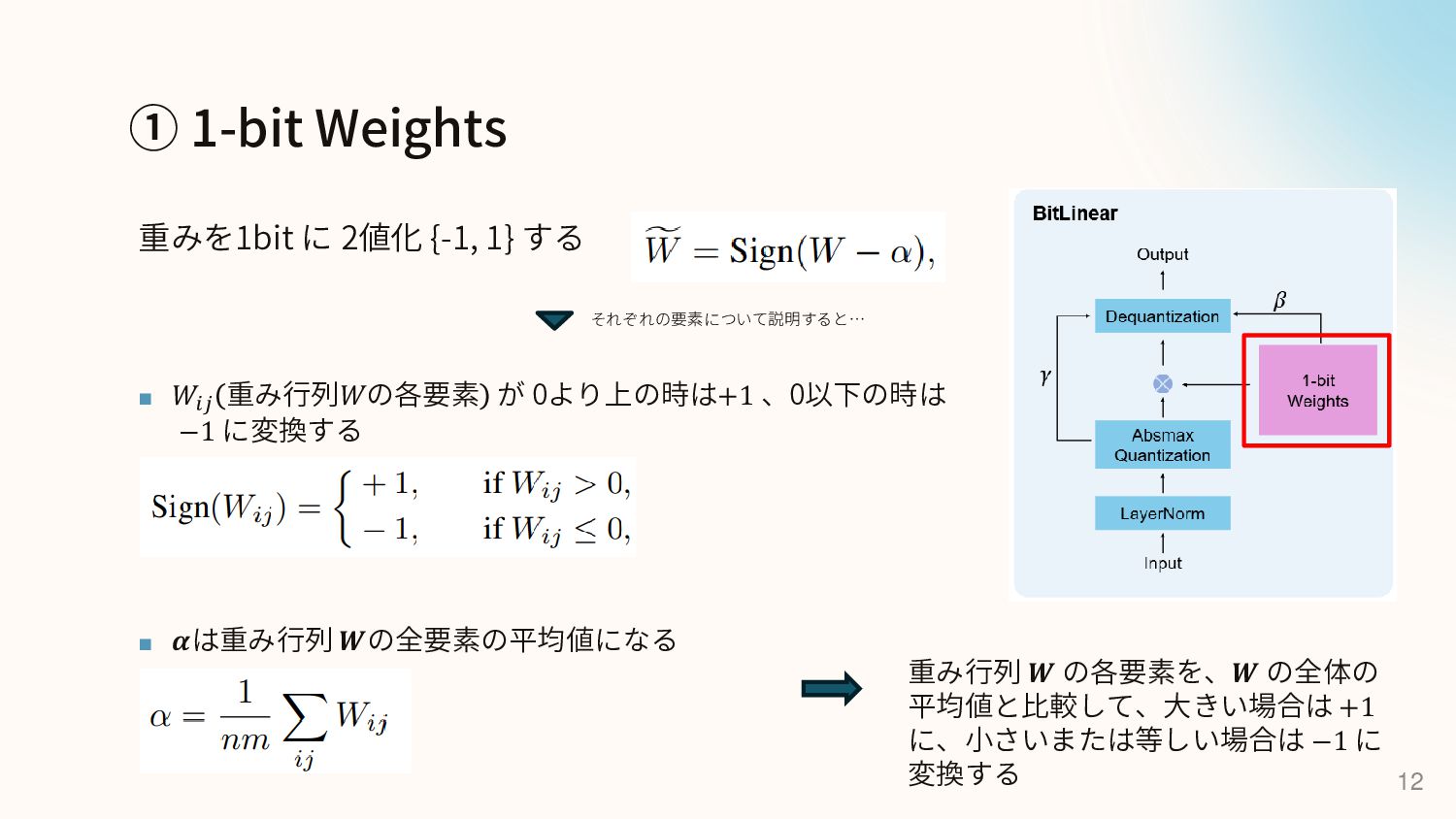
All Large Language Models are in 1.58 Bits (2024) [7] ▪ 重みを2値 {-1, 1}から、3値 {-1, 0, 1} に変更 [7] Ma, Shuming, et al. “The Era of 1-bit LLMs: All Large Language Models Are in 1.58 Bits.” arXiv, 2024, https://arxiv.org/abs/2402.17764. 2023年 BitNet 2024年 BitNet b1.58 (1-bit LLM) 2024年 ViT-1.58b Transformerを2値化 {-1, 1} Transformerを3値化 {-1, 0, 1} ViTを3値化 {-1, 0, 1}
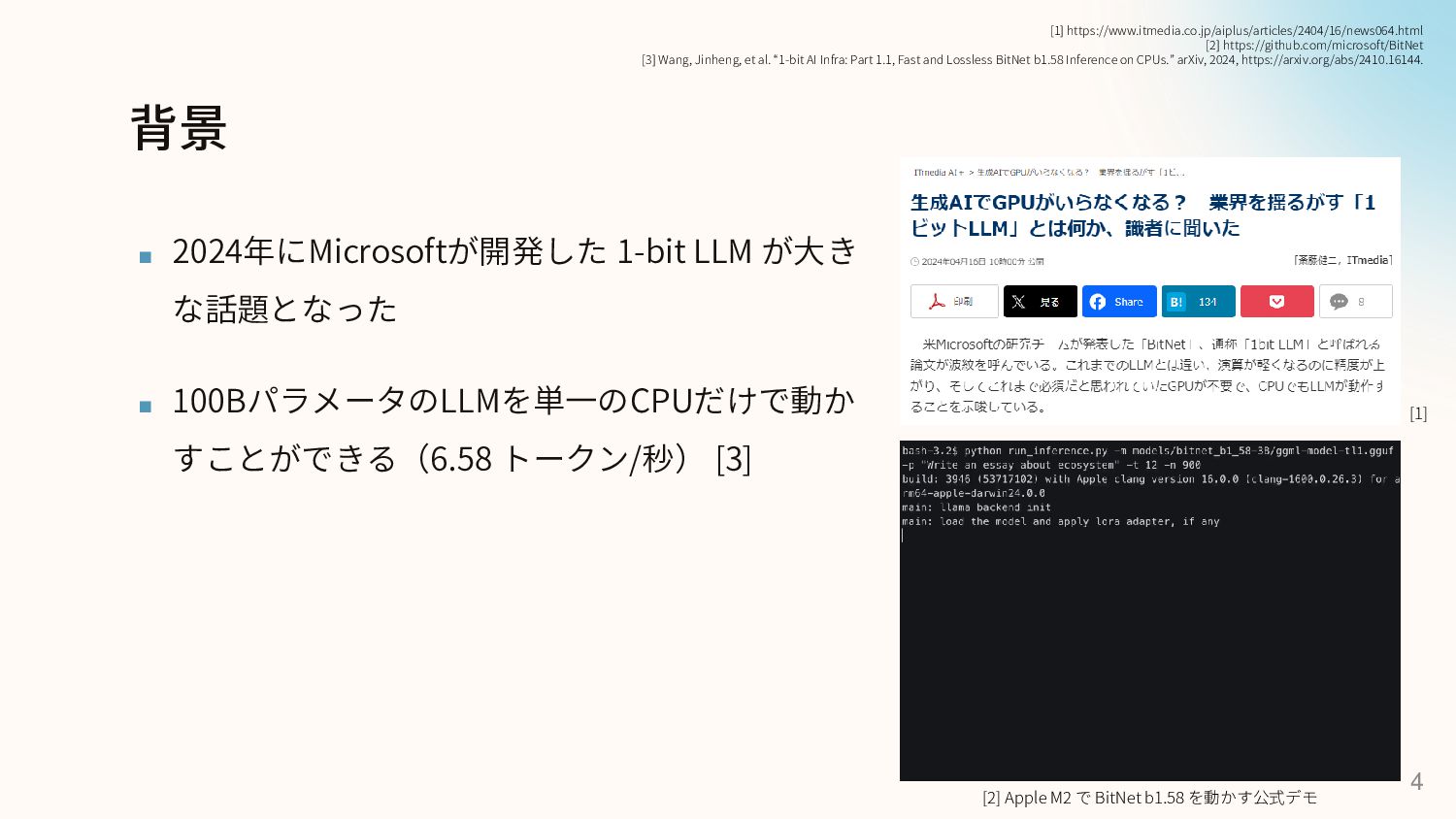
i7-13700Hでは、100Bを1.70 トークン/秒で動かせた [3] Wang, Jinheng, et al. “1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs.” arXiv, 2024, https://arxiv.org/abs/2410.16144. [2] Apple M2 で BitNet b1.58 を動かす公式デモ
{kind=link}
{kind=link}
{kind=link}
![用語: Vision Transformer (ViT) [4] 5 1. 画像をパッチに分け、各パッチを単語 (トークン) とみなして入力する](https://files.speakerdeck.com/presentations/d10763389b23492ca8a7496772b41138/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![② LayerNorm(レイヤー正規化) 13 [6] Wang, Hongyu, et al. “Magneto: A](https://files.speakerdeck.com/presentations/d10763389b23492ca8a7496772b41138/slide_11.jpg){kind=link}
{kind=link}
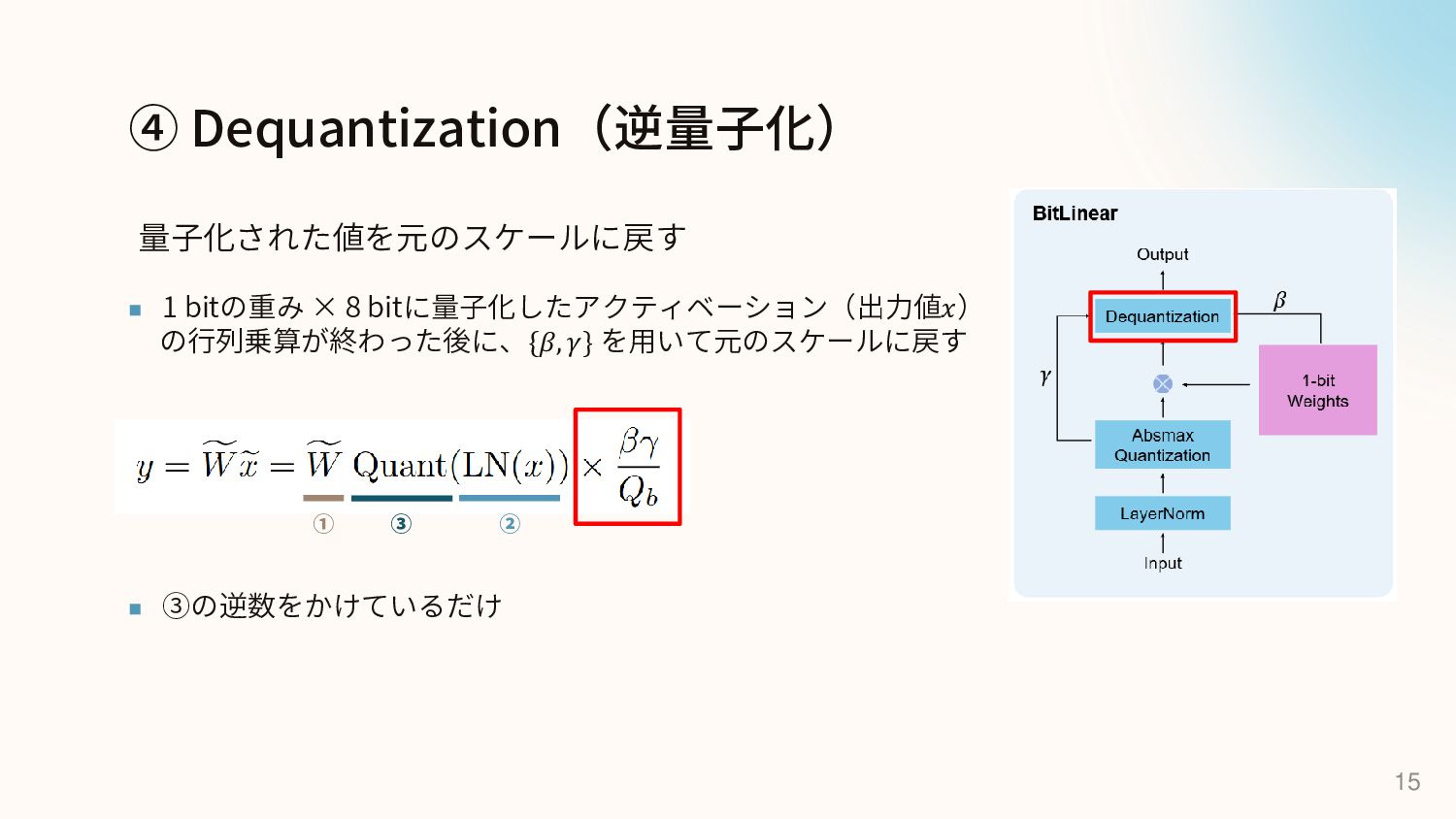{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
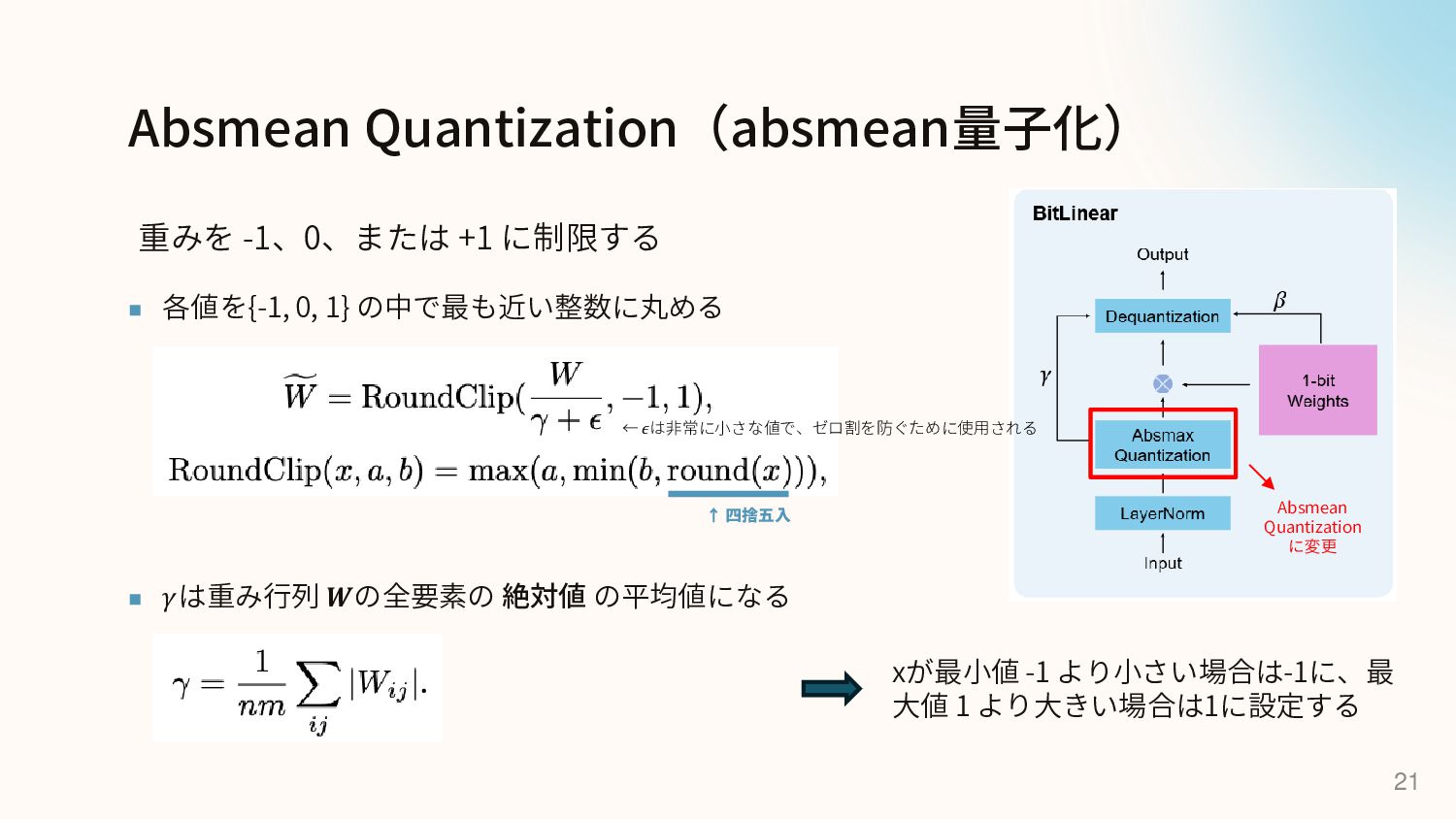{kind=link}
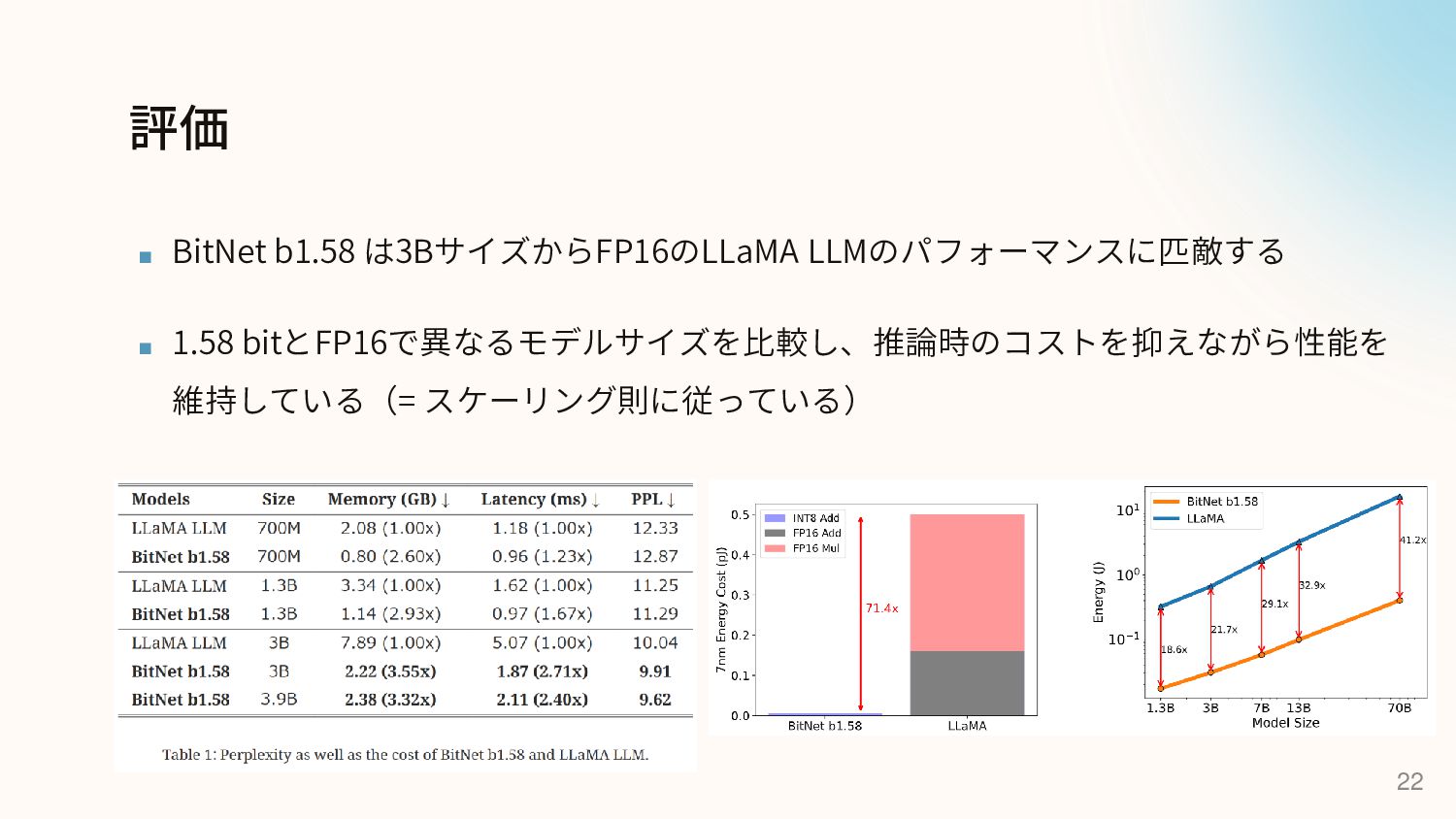{kind=link}
![その他 23 ▪ 2週間前の技術レポート論文より、100BパラメータのLLMを単一のCPU(Apple M2) だけで動かすことができる(6.58 トークン/秒) [3] ▪ Intel](https://files.speakerdeck.com/presentations/d10763389b23492ca8a7496772b41138/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
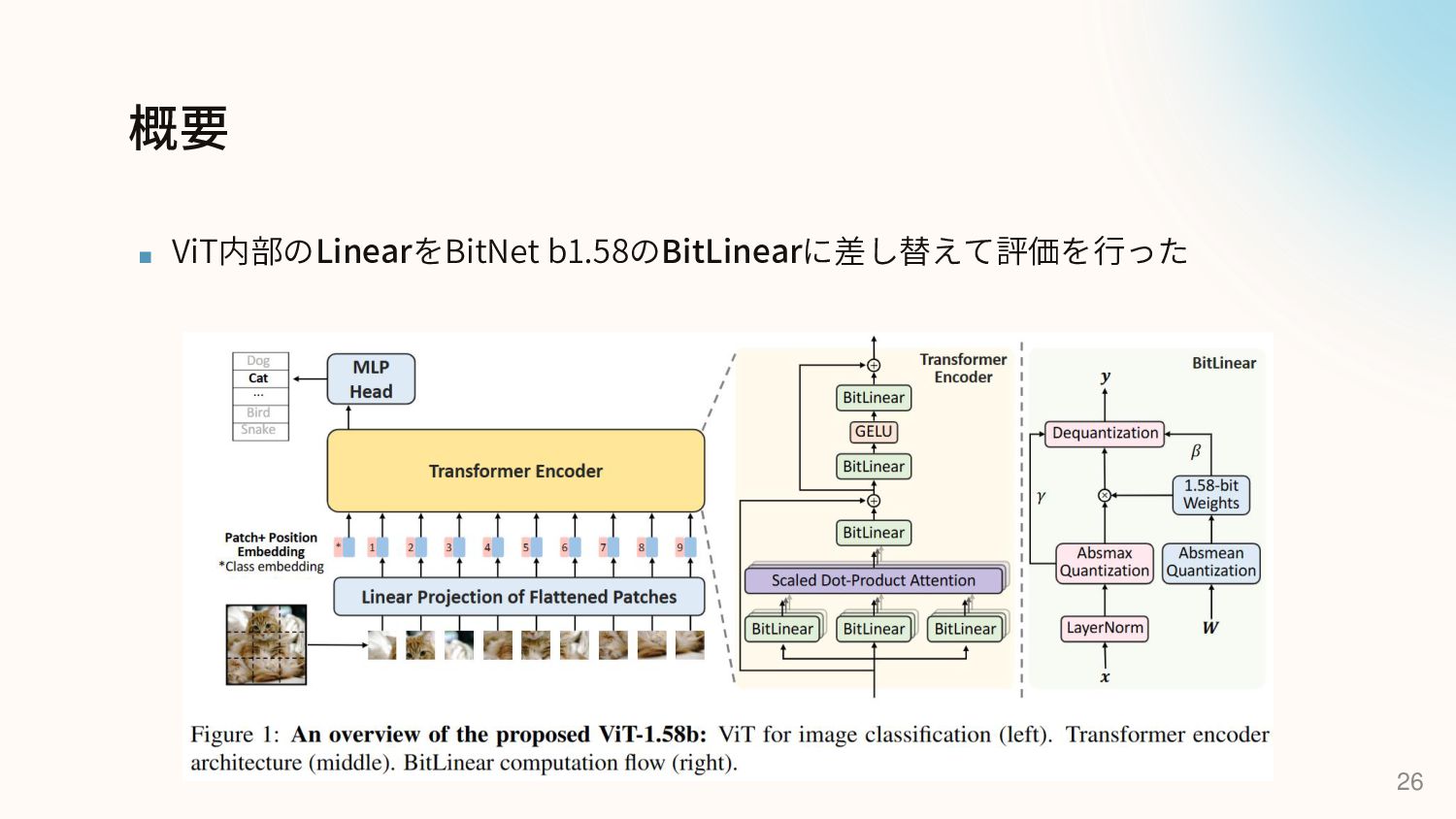{kind=link}
{kind=link}
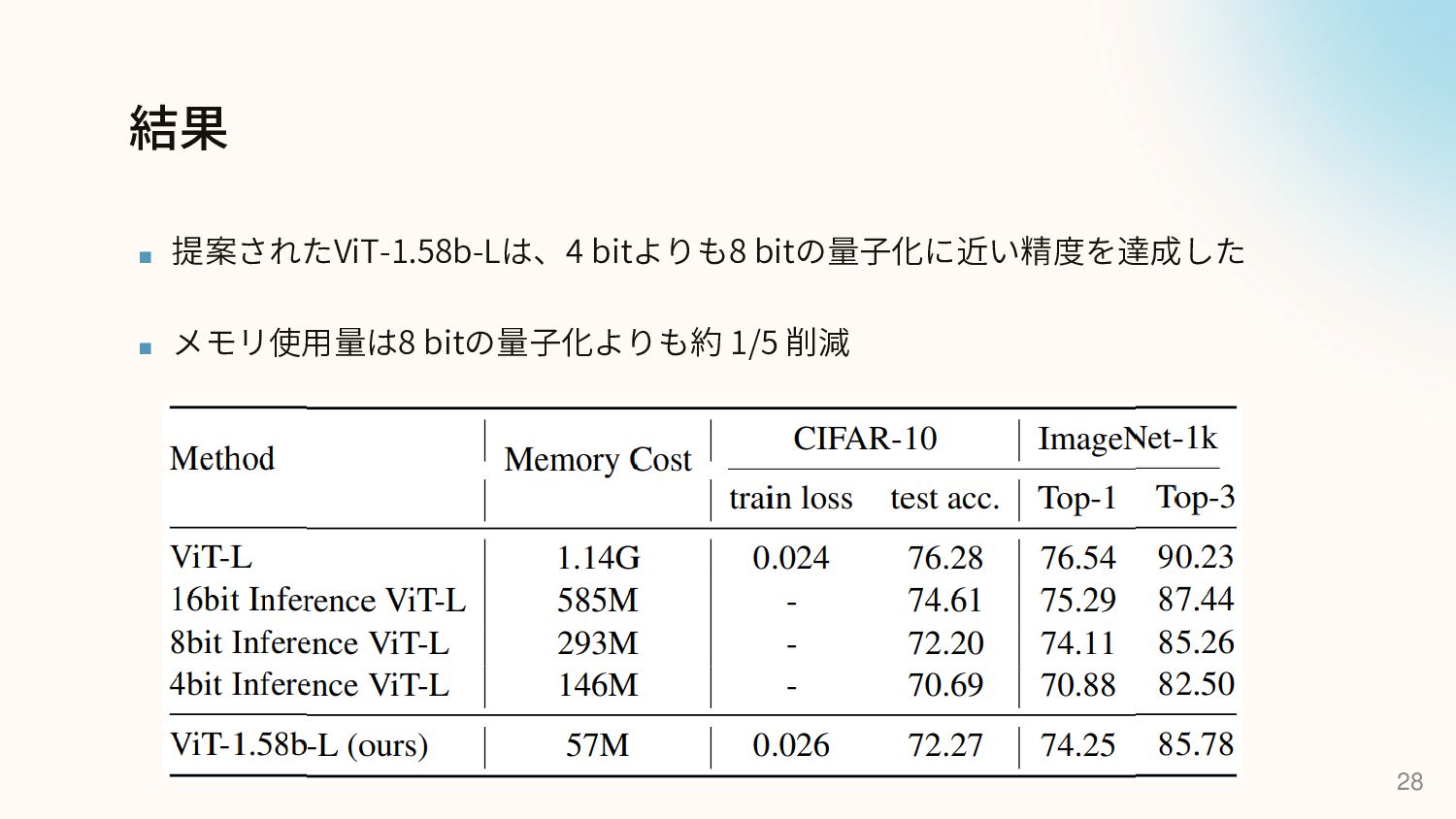{kind=link}
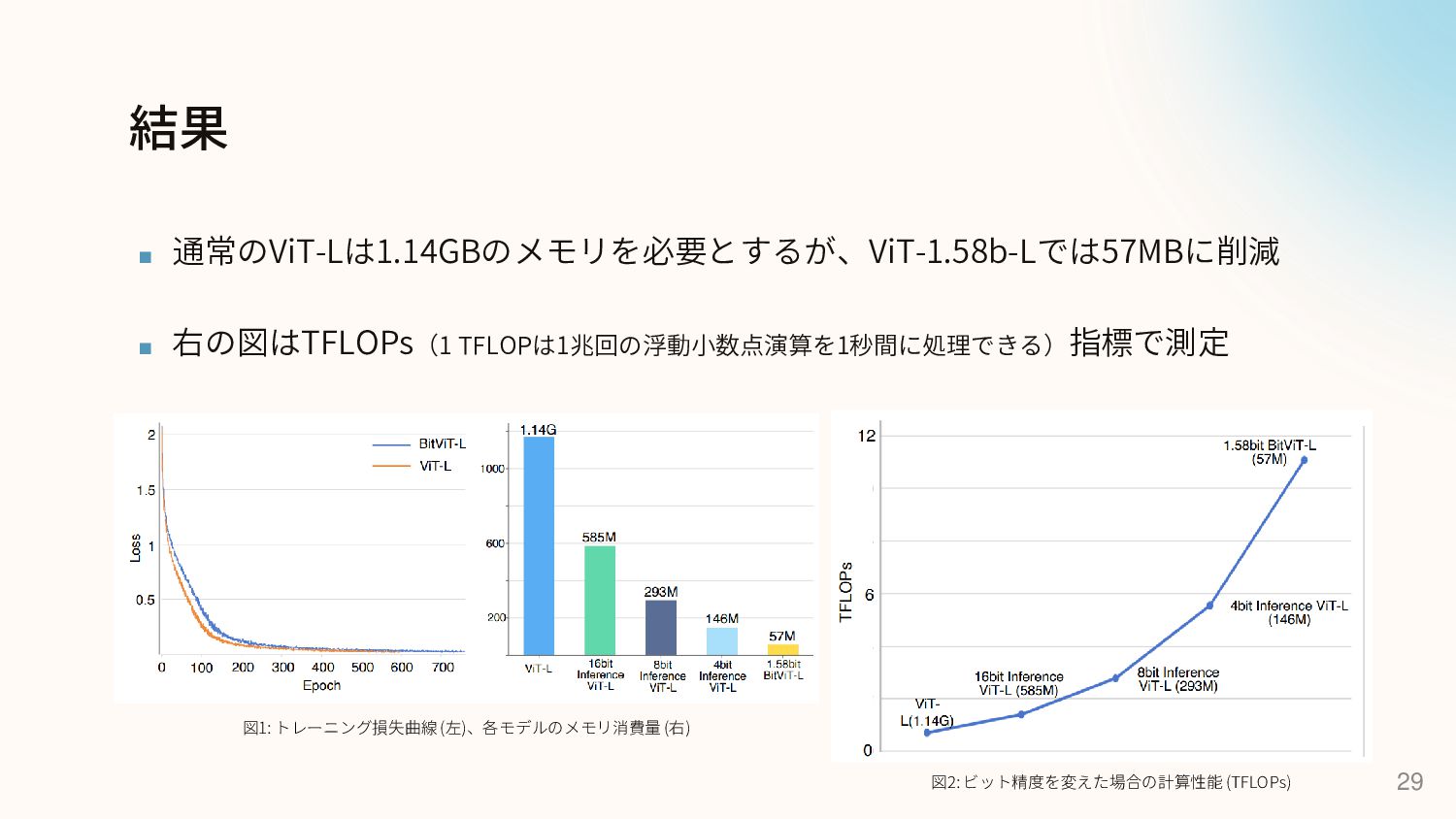{kind=link}
{kind=link}