Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[d-hacks Docker講座] Dockerで動かすローカルLLM入門
Search
Aokiti
May 15, 2025
90
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[d-hacks Docker講座] Dockerで動かすローカルLLM入門
d-hacks 新人向け講習 2025s
Dockerで動かすローカルLLMハンズオン
Aokiti
May 15, 2025
More Decks by Aokiti
See All by Aokiti
d-hacks 今期運営 2025f
sakusaku3939
0
550
[論文輪読会] A survey of model compression strategies for object detection
sakusaku3939
0
38
[論文輪読会] ViT-1.58b
sakusaku3939
0
270
d-hacks PyTorchモデル実装会 2024f
sakusaku3939
0
58
[論文輪読会] Binarized Neural Networks
sakusaku3939
0
70
一般物体検出とLSTMを用いた画像に基づく屋内位置推定 - IPSJ UBI82
sakusaku3939
0
510
MoodTune 東京AI祭ハッカソン決勝
sakusaku3939
0
620
d-hacks PyTorch実装会 2023f
sakusaku3939
0
32
[DL勉強会] 第5章 ディープラーニングを活用したアプリケーション 後半
sakusaku3939
0
22
Featured
See All Featured
Optimizing for Happiness
mojombo
378
71k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Making the Leap to Tech Lead
cromwellryan
135
10k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
RailsConf 2023
tenderlove
30
1.5k
BBQ
matthewcrist
89
10k
It's Worth the Effort
3n
188
29k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
For a Future-Friendly Web
brad_frost
183
10k
Transcript
Dockerで動かすローカルLLM入門 B3 aokiti d-hacks Docker講座 2025s
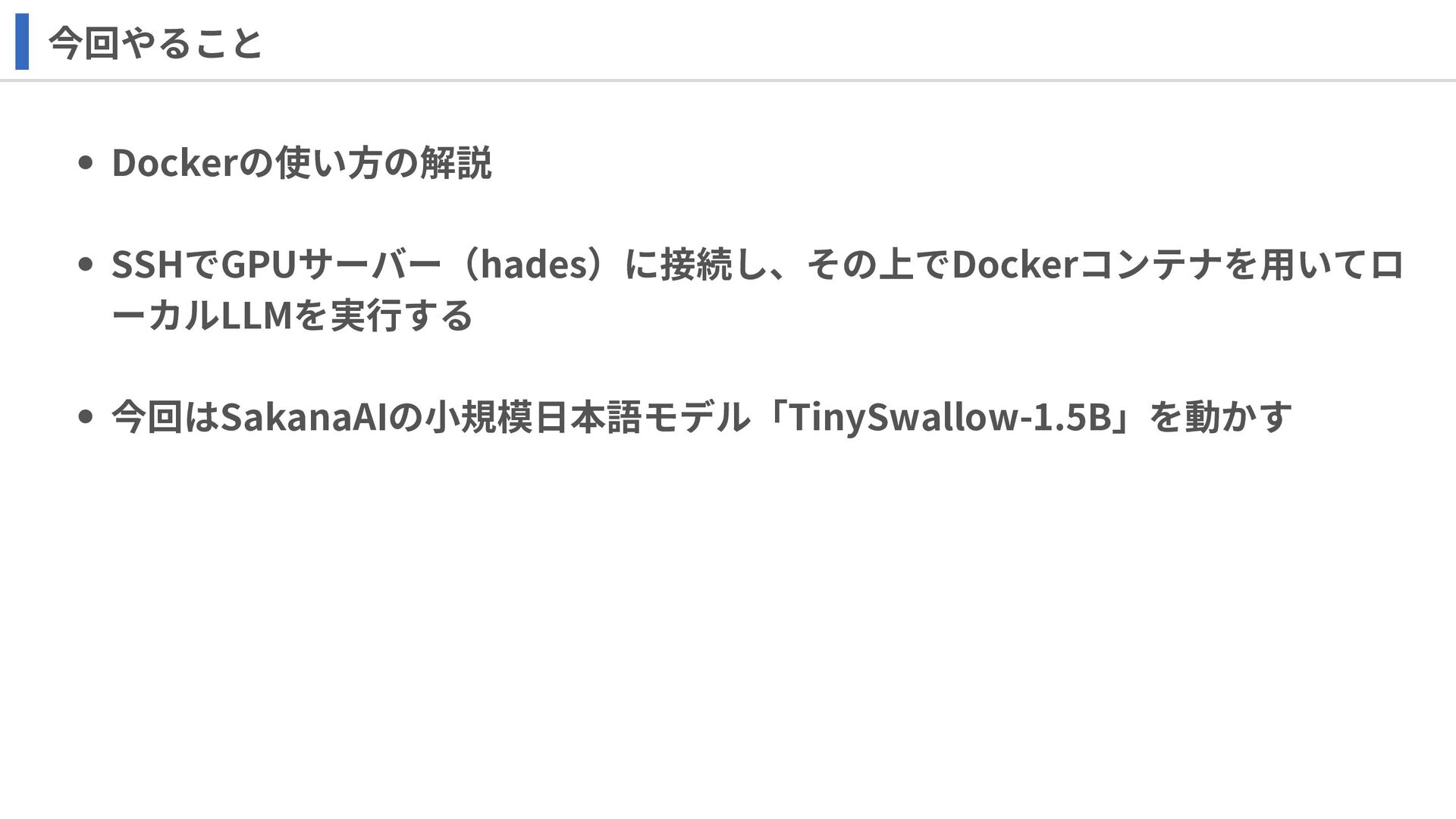
今回やること Dockerの使い方の解説 SSHでGPUサーバー(hades)に接続し、その上でDockerコンテナを用いてロ ーカルLLMを実行する 今回はSakanaAIの小規模日本語モデル「TinySwallow-1.5B」を動かす
事前準備 ✅ hadesへのSSH接続ができる 出来てない人は5/8のGPU講習のスライド or 以下を参照する → https://scrapbox.io/d- hacks/JN_VPN,_GPU%E3%82%B5%E3%83%BC%E3%83%90%E3%83%BC% E3%81%AE%E4%BD%BF%E3%81%84%E6%96%B9_2025s
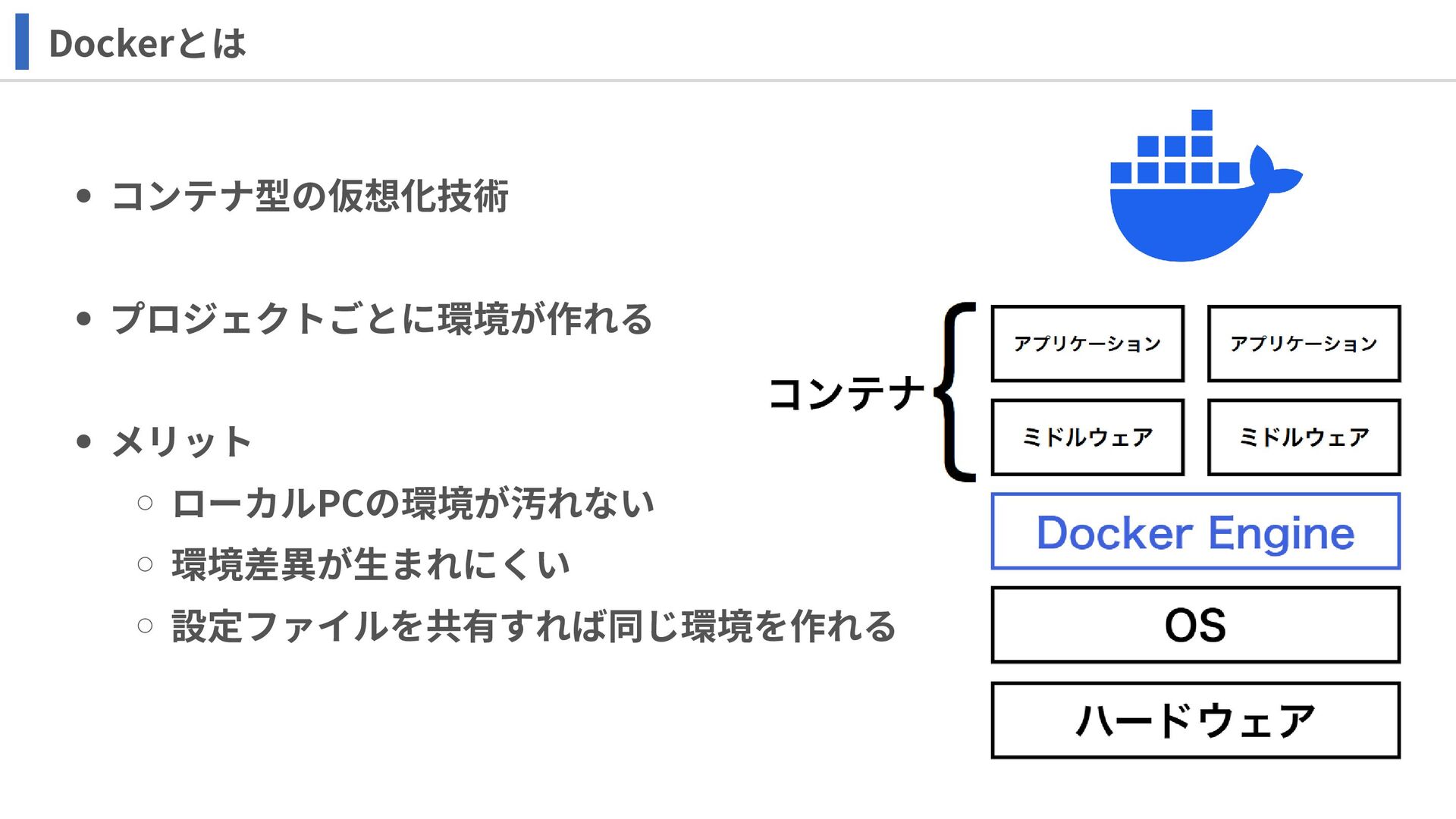
コンテナ型の仮想化技術 プロジェクトごとに環境が作れる メリット ローカルPCの環境が汚れない 環境差異が生まれにくい 設定ファイルを共有すれば同じ環境を作れる Dockerとは
なぜGPUサーバーでDockerを使う必要があるのか? A. GPUサーバーは、他の人も共用で使う環境で、パッケージのインストールなどが影 響を与えてしまう可能性があるため 解決策 → Dockerを使用することで、個人の実行環境(コンテナ)を作ることができる あるプロジェクトではnumpy==2.1、もう一方はnumpy==1.26が必要、といった場合でも別々に環境を作ることができる PythonバージョンやCUDAバージョンも含めて実行環境を柔軟に構築できるので、 「先行研究のコードが4年前で古くて動
かない」という場合でも、Dockerだと当時の環境を再現したコンテナが簡単に作れる
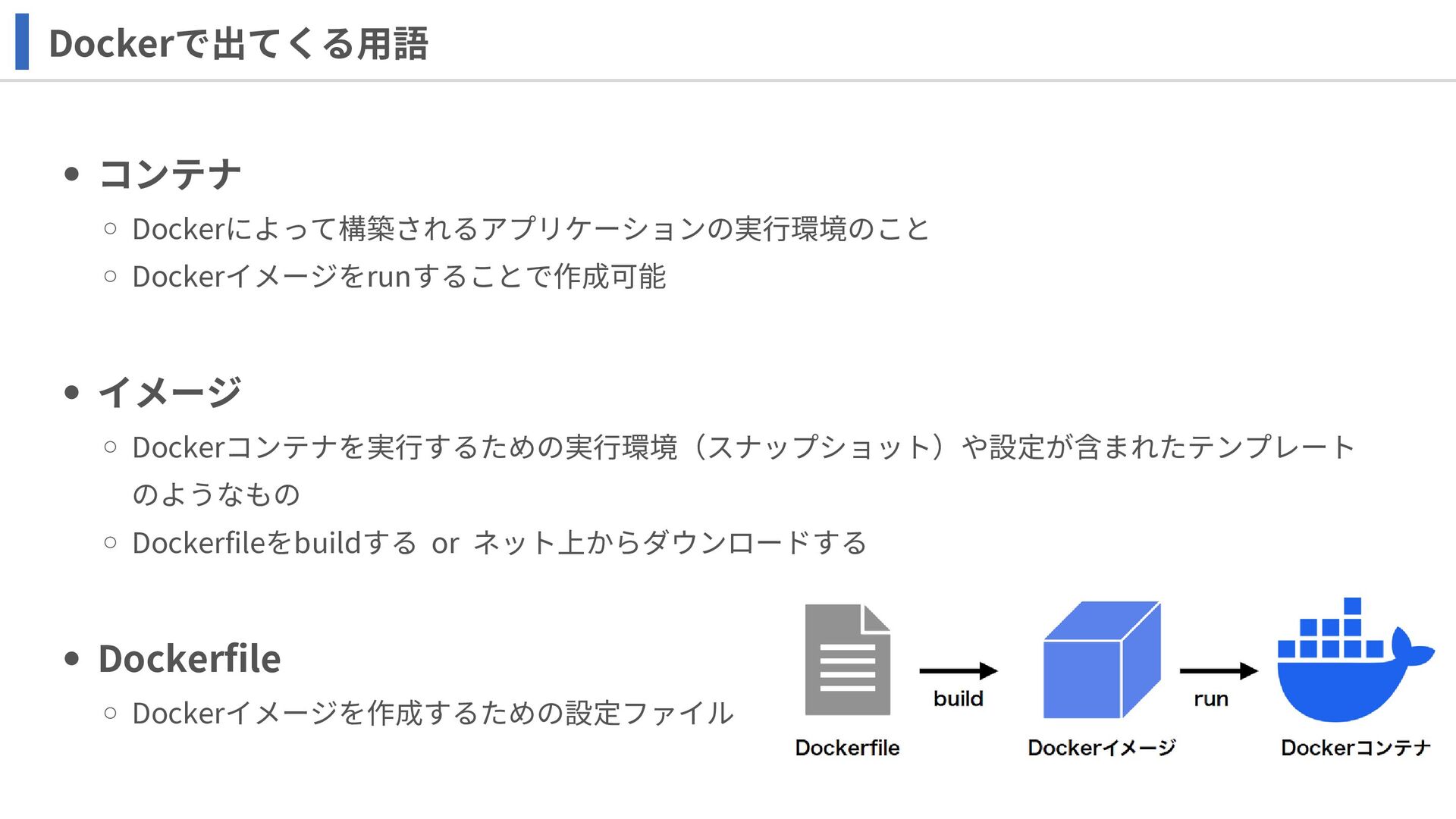
コンテナ Dockerによって構築されるアプリケーションの実行環境のこと Dockerイメージをrunすることで作成可能 イメージ Dockerコンテナを実行するための実行環境(スナップショット)や設定が含まれたテンプレート のようなもの Dockerfileをbuildする or ネット上からダウンロードする Dockerfile
Dockerイメージを作成するための設定ファイル Dockerで出てくる用語
TinySwallow-1.5Bを実際に動かしてみる
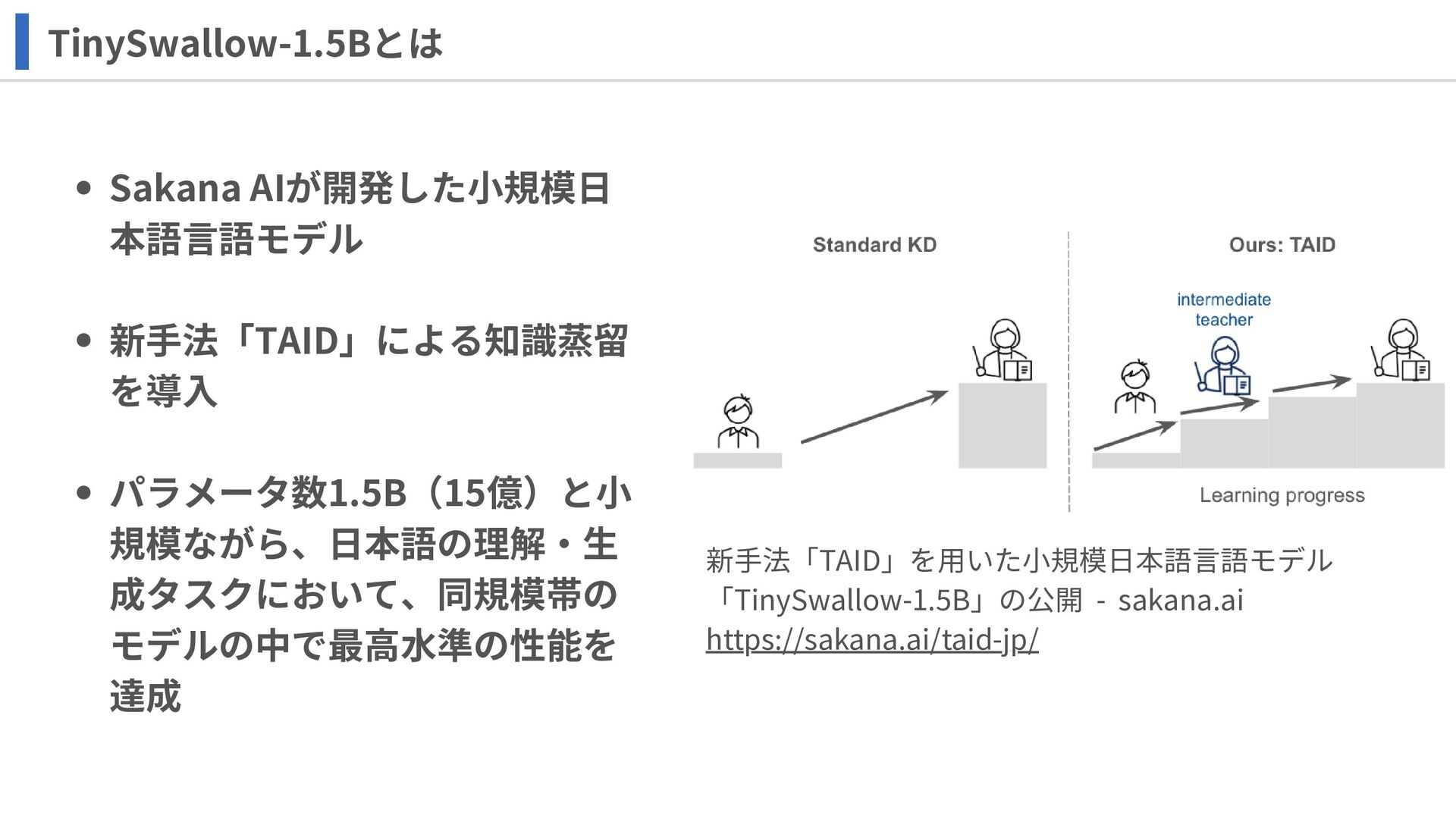
TinySwallow-1.5Bとは 新手法「TAID」を用いた小規模日本語言語モデル 「TinySwallow-1.5B」の公開 - sakana.ai https://sakana.ai/taid-jp/ Sakana AIが開発した小規模日 本語言語モデル 新手法「TAID」による知識蒸留
を導入 パラメータ数1.5B(15億)と小 規模ながら、日本語の理解・生 成タスクにおいて、同規模帯の モデルの中で最高水準の性能を 達成
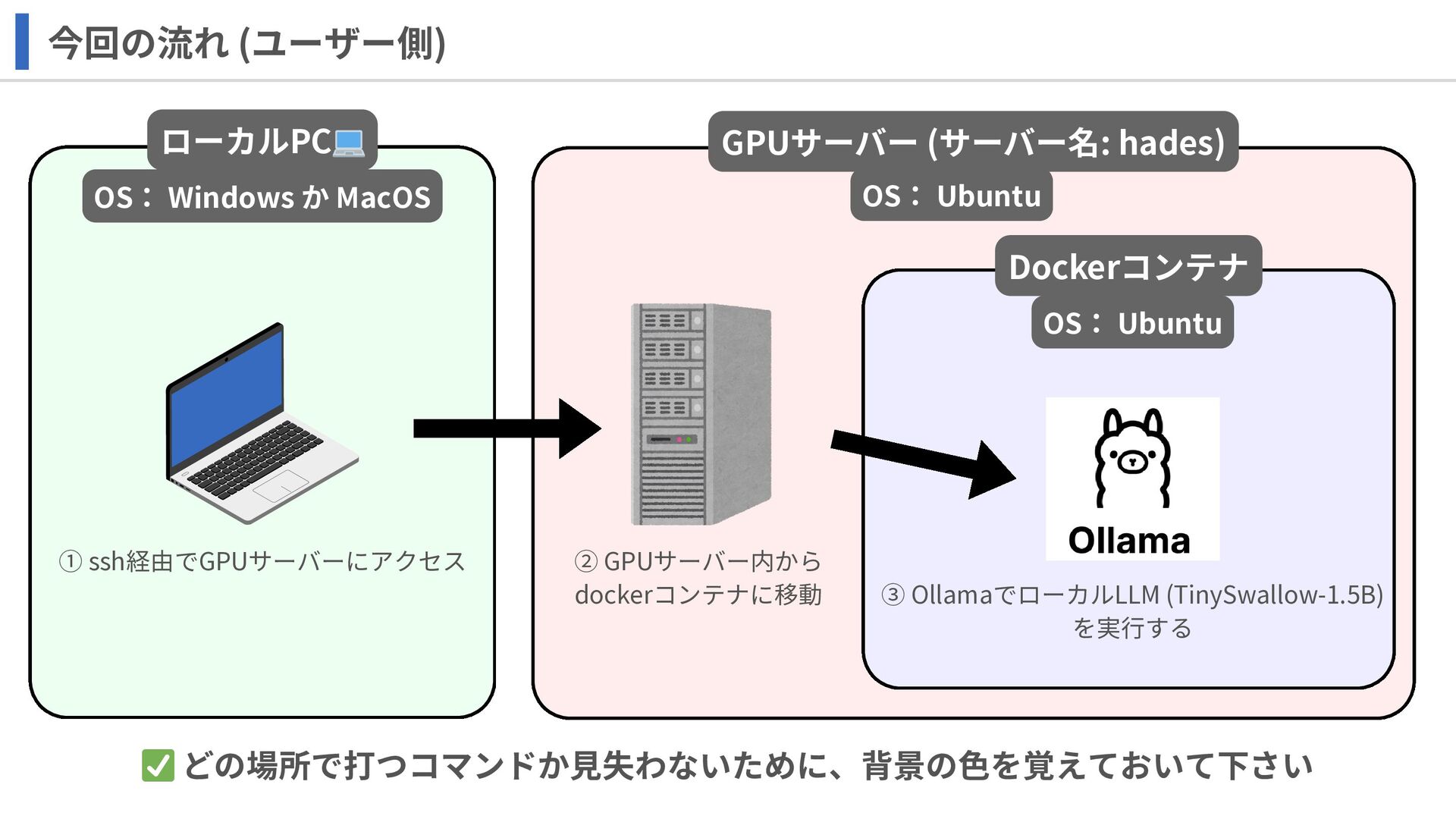
今回の流れ (ユーザー側) GPUサーバー (サーバー名: hades) ローカルPC 💻 Dockerコンテナ OS: Windows
か MacOS OS: Ubuntu OS: Ubuntu ① ssh経由でGPUサーバーにアクセス ② GPUサーバー内から dockerコンテナに移動 ③ OllamaでローカルLLM (TinySwallow-1.5B) を実行する ✅ どの場所で打つコマンドか見失わないために、背景の色を覚えておいて下さい
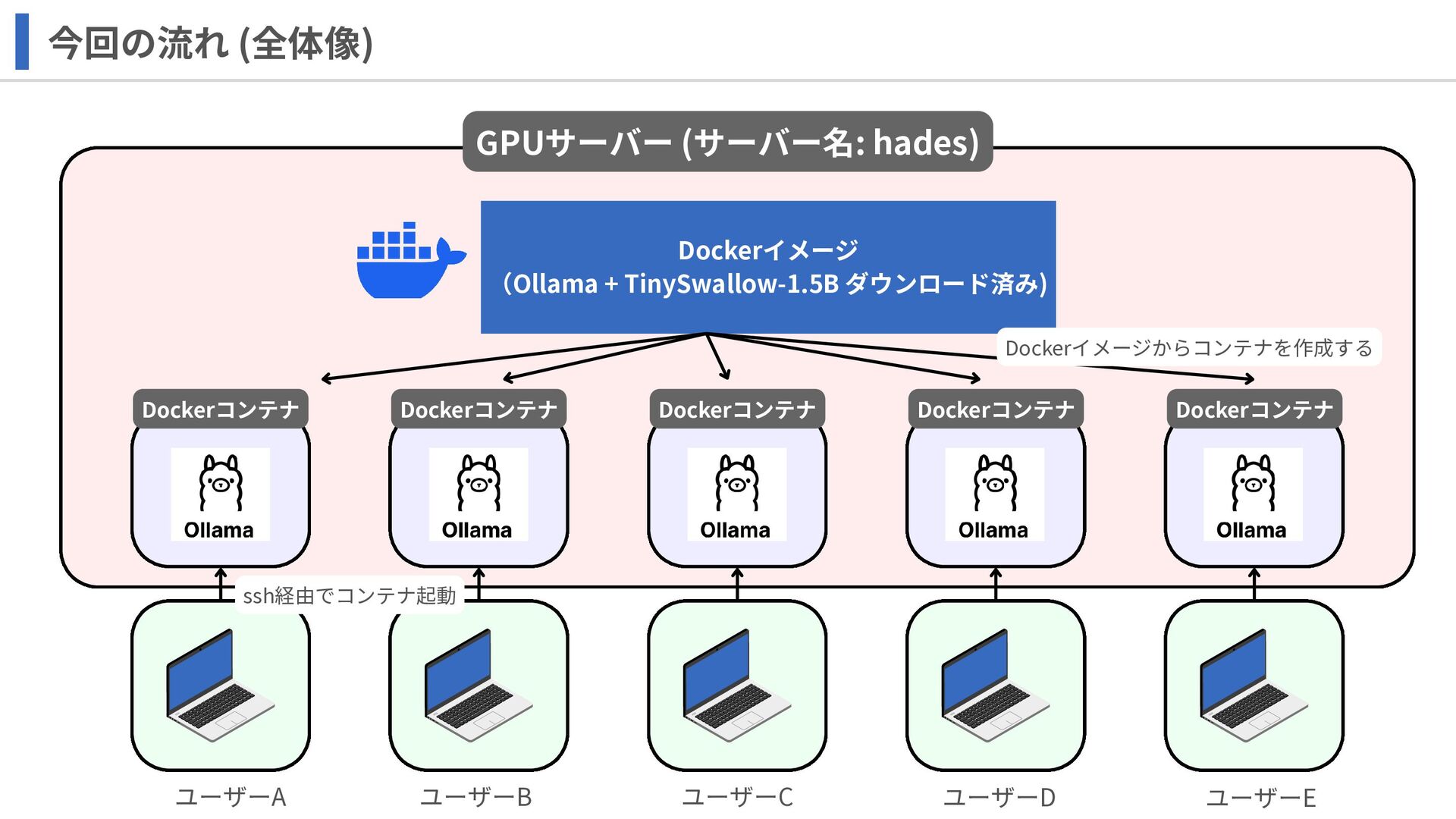
今回の流れ (全体像) GPUサーバー (サーバー名: hades) ユーザーA ユーザーB ユーザーC ユーザーD ユーザーE
Dockerイメージ (Ollama + TinySwallow-1.5B ダウンロード済み) Dockerコンテナ Dockerコンテナ Dockerコンテナ Dockerコンテナ Dockerコンテナ Dockerイメージからコンテナを作成する ssh経由でコンテナ起動
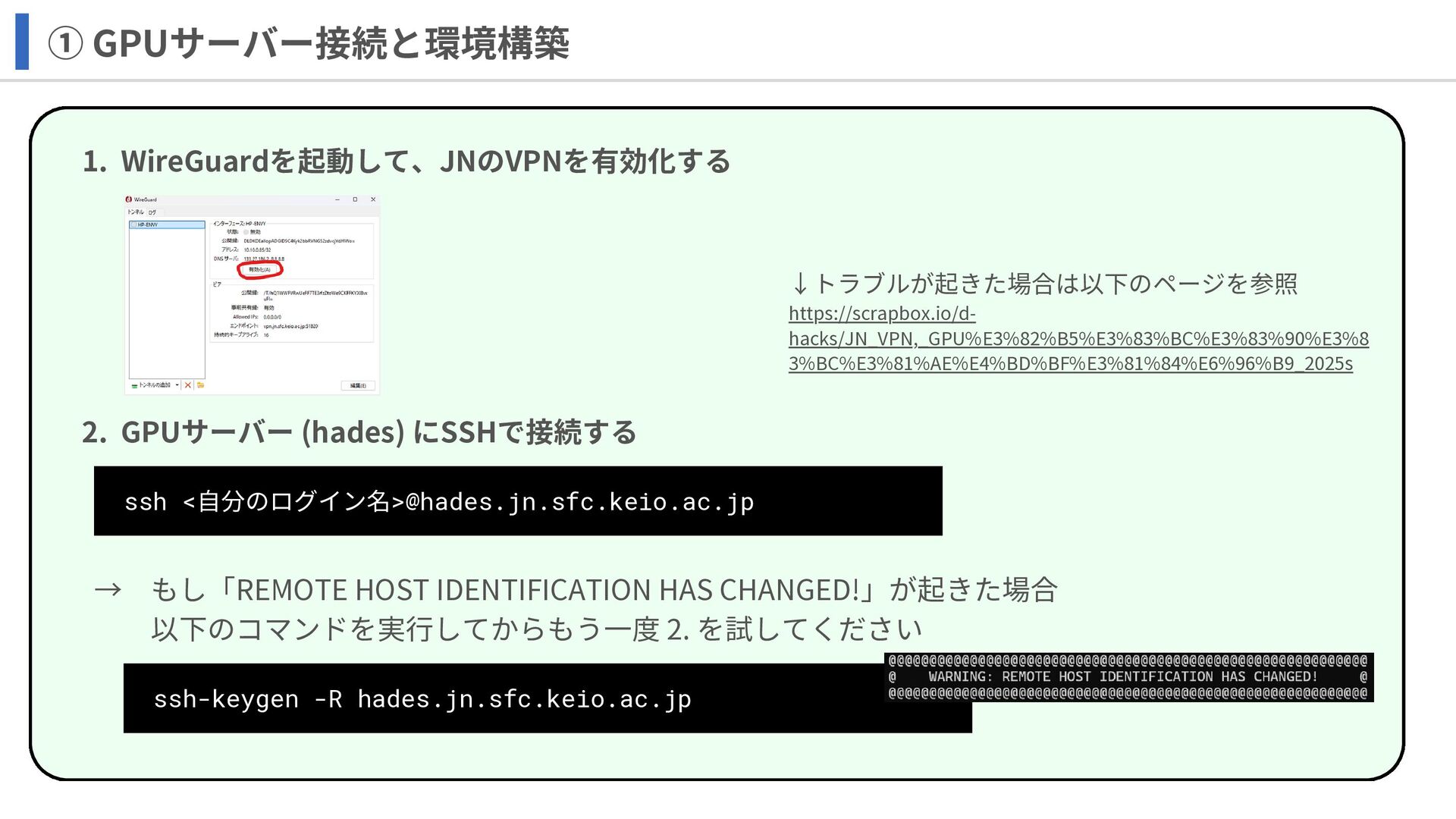
ssh <自分のログイン名>@hades.jn.sfc.keio.ac.jp ① GPUサーバー接続と環境構築 1. WireGuardを起動して、JNのVPNを有効化する 2. GPUサーバー (hades) にSSHで接続する
↓トラブルが起きた場合は以下のページを参照 https://scrapbox.io/d- hacks/JN_VPN,_GPU%E3%82%B5%E3%83%BC%E3%83%90%E3%8 3%BC%E3%81%AE%E4%BD%BF%E3%81%84%E6%96%B9_2025s → もし「REMOTE HOST IDENTIFICATION HAS CHANGED!」が起きた場合 以下のコマンドを実行してからもう一度 2. を試してください ssh-keygen -R hades.jn.sfc.keio.ac.jp
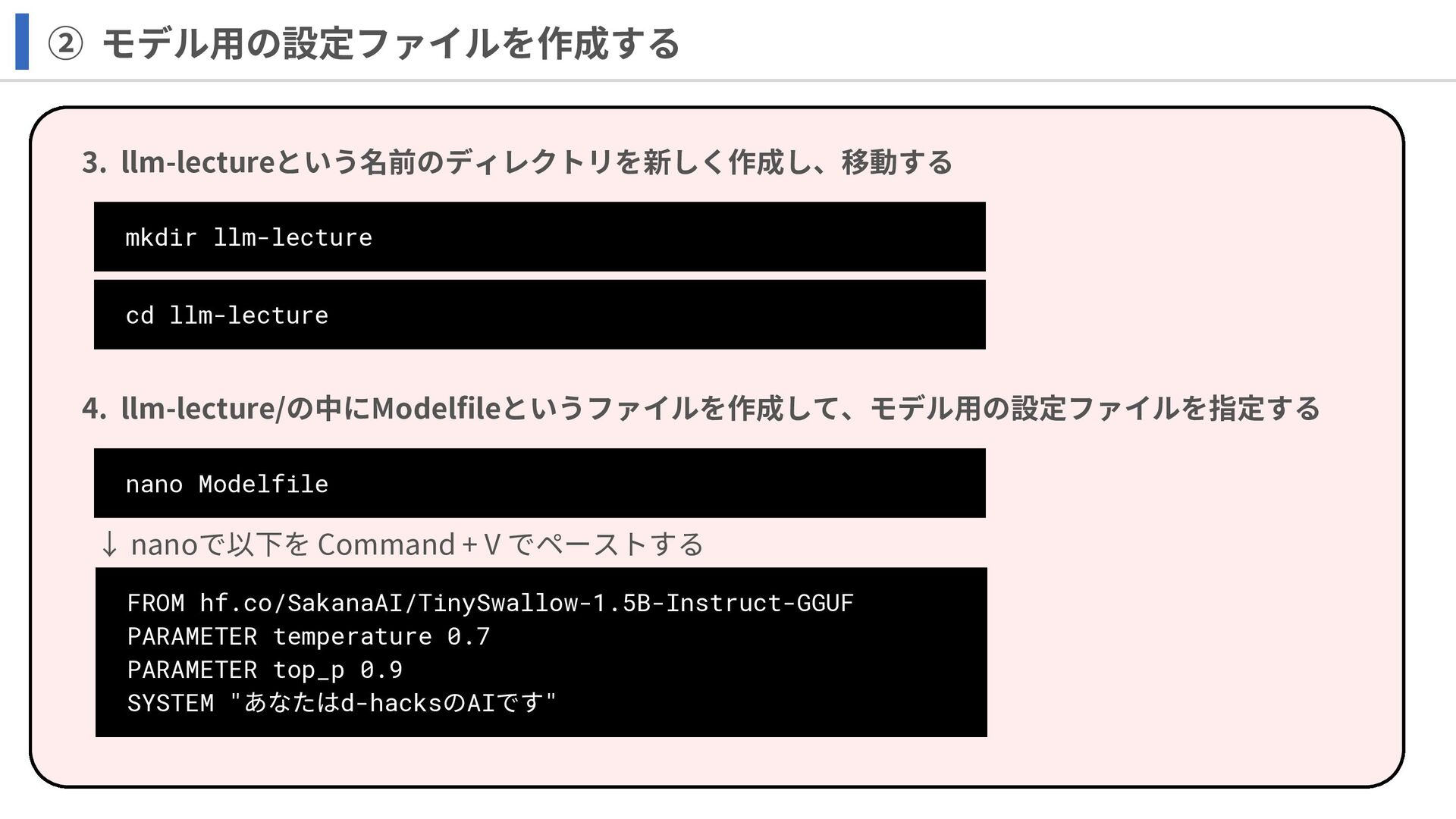
② モデル用の設定ファイルを作成する 4. llm-lecture/の中にModelfileというファイルを作成して、モデル用の設定ファイルを指定する nano Modelfile 3. llm-lectureという名前のディレクトリを新しく作成し、移動する mkdir llm-lecture
cd llm-lecture FROM hf.co/SakanaAI/TinySwallow-1.5B-Instruct-GGUF PARAMETER temperature 0.7 PARAMETER top_p 0.9 SYSTEM "あなたはd-hacksのAIです" ↓ nanoで以下を Command + V でペーストする
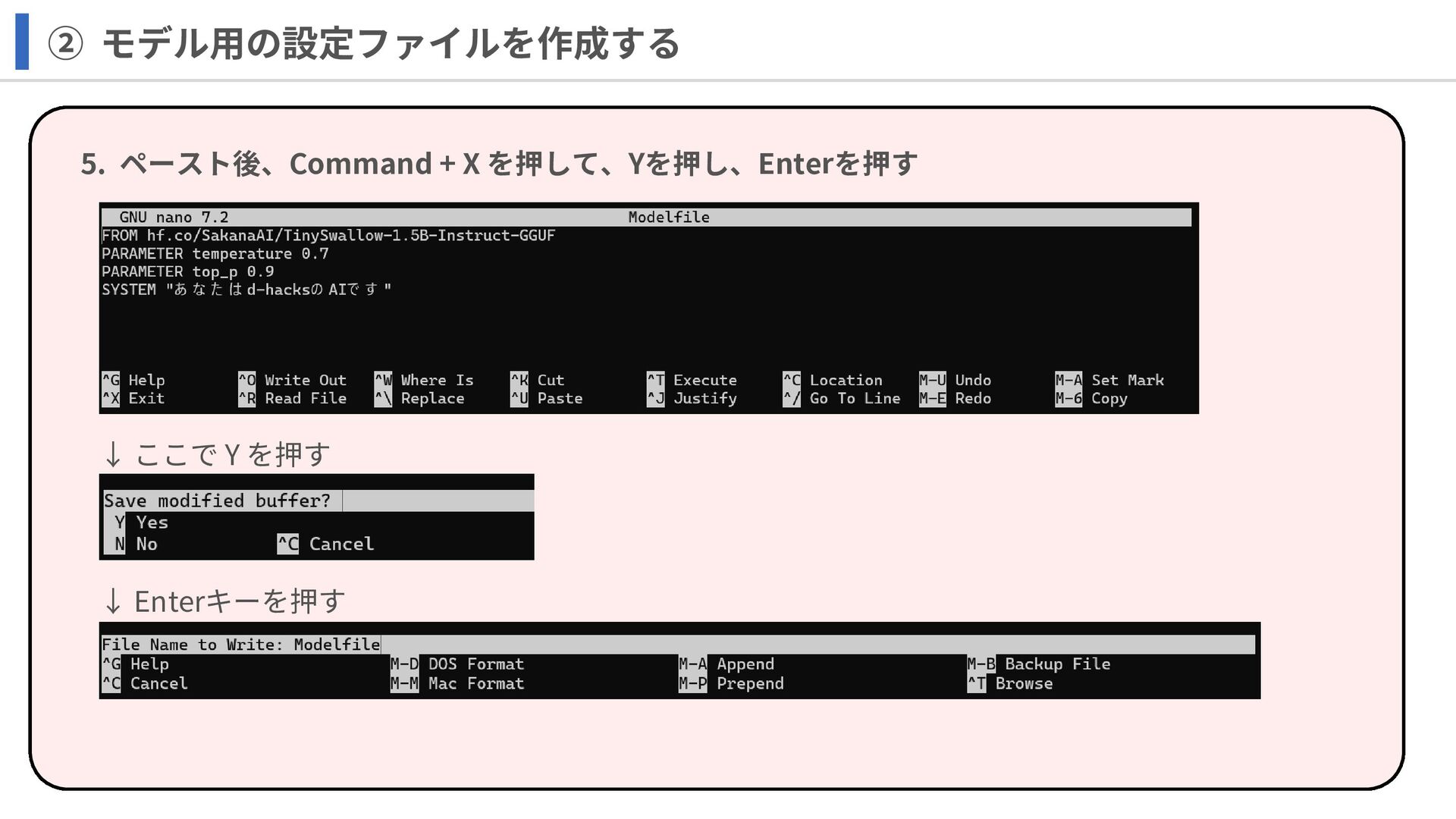
② モデル用の設定ファイルを作成する 5. ペースト後、Command + X を押して、Yを押し、Enterを押す ↓ ここで Y
を押す ↓ Enterキーを押す
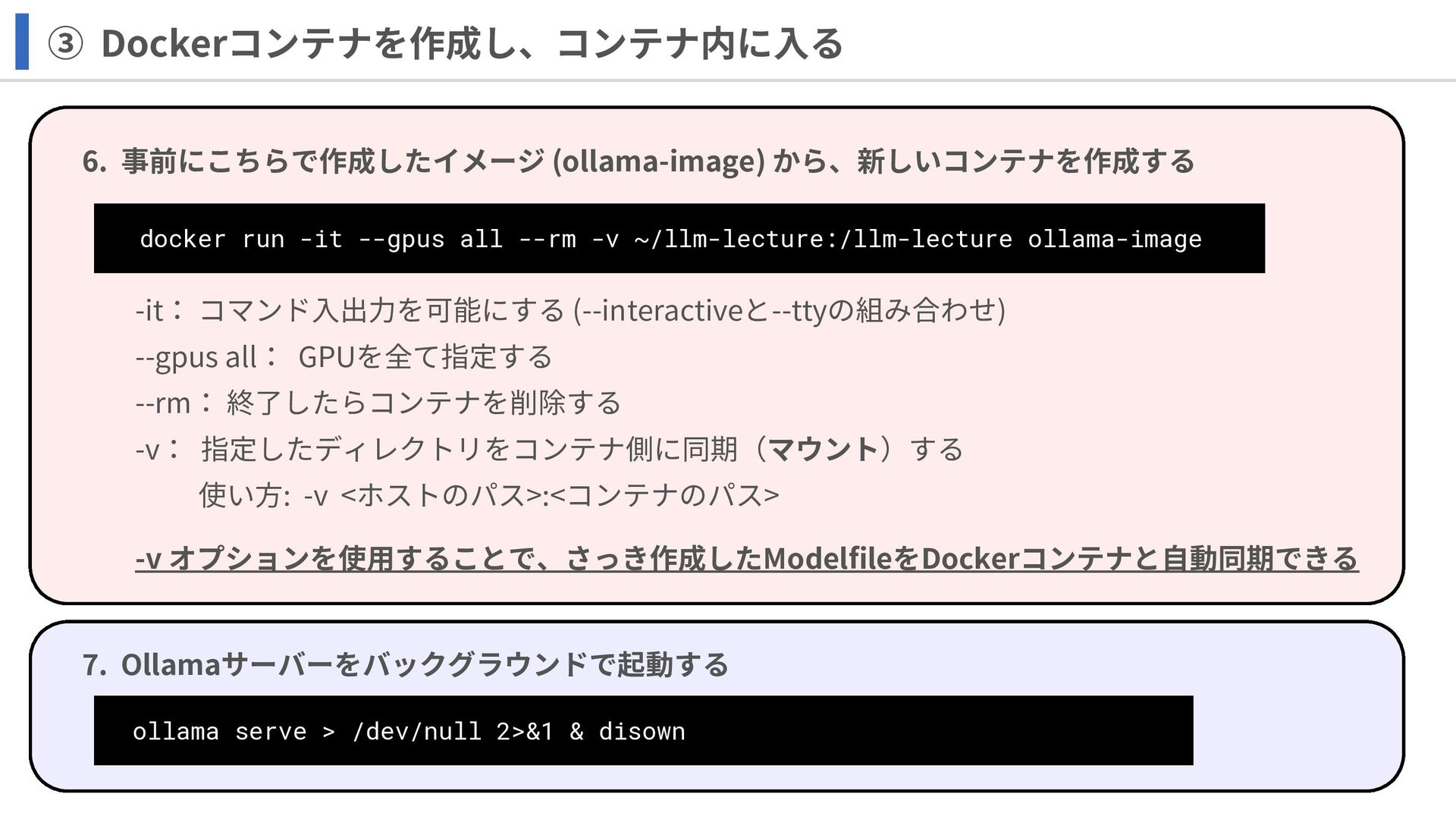
③ Dockerコンテナを作成し、コンテナ内に入る 6. 事前にこちらで作成したイメージ (ollama-image) から、新しいコンテナを作成する docker run -it --gpus
all --rm -v ~/llm-lecture:/llm-lecture ollama-image -it: コマンド入出力を可能にする (--interactiveと--ttyの組み合わせ) --gpus all: GPUを全て指定する --rm: 終了したらコンテナを削除する -v: 指定したディレクトリをコンテナ側に同期(マウント)する 使い方: -v <ホストのパス>:<コンテナのパス> ollama serve > /dev/null 2>&1 & disown 7. Ollamaサーバーをバックグラウンドで起動する -v オプションを使用することで、さっき作成したModelfileをDockerコンテナと自動同期できる
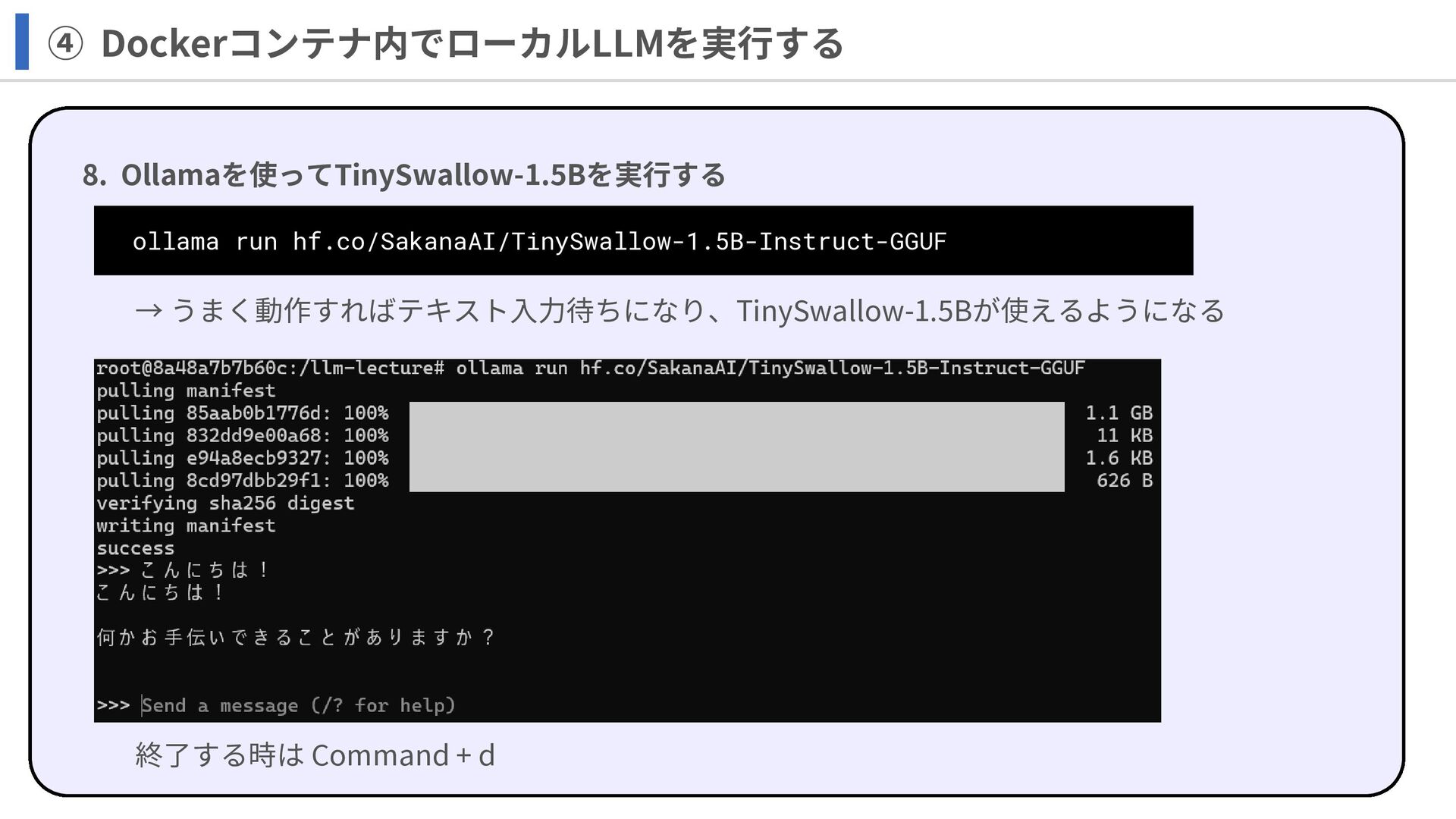
ollama run hf.co/SakanaAI/TinySwallow-1.5B-Instruct-GGUF ④ Dockerコンテナ内でローカルLLMを実行する 8. Ollamaを使ってTinySwallow-1.5Bを実行する → うまく動作すればテキスト入力待ちになり、TinySwallow-1.5Bが使えるようになる 終了する時は
Command + d
exit ④ Dockerコンテナ内でローカルLLMを実行する 8. (Dockerを終了したい時) exit 9. (sshを終了したい時)
FROM ベースとなるイメージを指定 WORKDIR コンテナ内の作業ディレクトリを設定 RUN イメージを作る際に実行されるコマンド CMD コンテナが起動された際に実行されるコマンド ENV 環境変数を設定
ビルドにかかる時間と容量の関係上、今回は事前にこちらでDockerイメージ を用意しておきました (補足) 今回用意したDockerイメージ この後に、 でイメージの作成を行っている docker build -t ollama-image .
参考資料など ・What is Docker? https://docs.docker.com/get-started/docker-overview/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}