Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[論文輪読会] Binarized Neural Networks
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Aokiti
July 04, 2024
70
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[論文輪読会] Binarized Neural Networks
RG d-hacks
7/4論文輪読 発表スライド
Aokiti
July 04, 2024
More Decks by Aokiti
See All by Aokiti
d-hacks 今期運営 2025f
sakusaku3939
0
550
[d-hacks Docker講座] Dockerで動かすローカルLLM入門
sakusaku3939
0
90
[論文輪読会] A survey of model compression strategies for object detection
sakusaku3939
0
38
[論文輪読会] ViT-1.58b
sakusaku3939
0
270
d-hacks PyTorchモデル実装会 2024f
sakusaku3939
0
58
一般物体検出とLSTMを用いた画像に基づく屋内位置推定 - IPSJ UBI82
sakusaku3939
0
510
MoodTune 東京AI祭ハッカソン決勝
sakusaku3939
0
620
d-hacks PyTorch実装会 2023f
sakusaku3939
0
32
[DL勉強会] 第5章 ディープラーニングを活用したアプリケーション 後半
sakusaku3939
0
22
Featured
See All Featured
ラッコキーワード サービス紹介資料
rakko
1
4M
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
370
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Un-Boring Meetings
codingconduct
0
350
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Designing for Timeless Needs
cassininazir
1
400
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Transcript
Binarized Neural Networks NeurIPS 2016 d-hacks 2024.7.4 論文輪読 B2 aokiti
https://papers.nips.cc/paper_files/paper/2016/hash/d8330f857a17c53d217014ee776bfd50-Abstract.html https://arxiv.org/abs/1602.02830 1
背景 ▪ 1-bit LLMなど、エッジデバイスでGPUを使わずに大規模言語モデルを動かす研究 が話題になっている 2 ▪ 重みのパラメータを3値(-1,0,1)や、2値(-1,1) にすることで計算を効率化
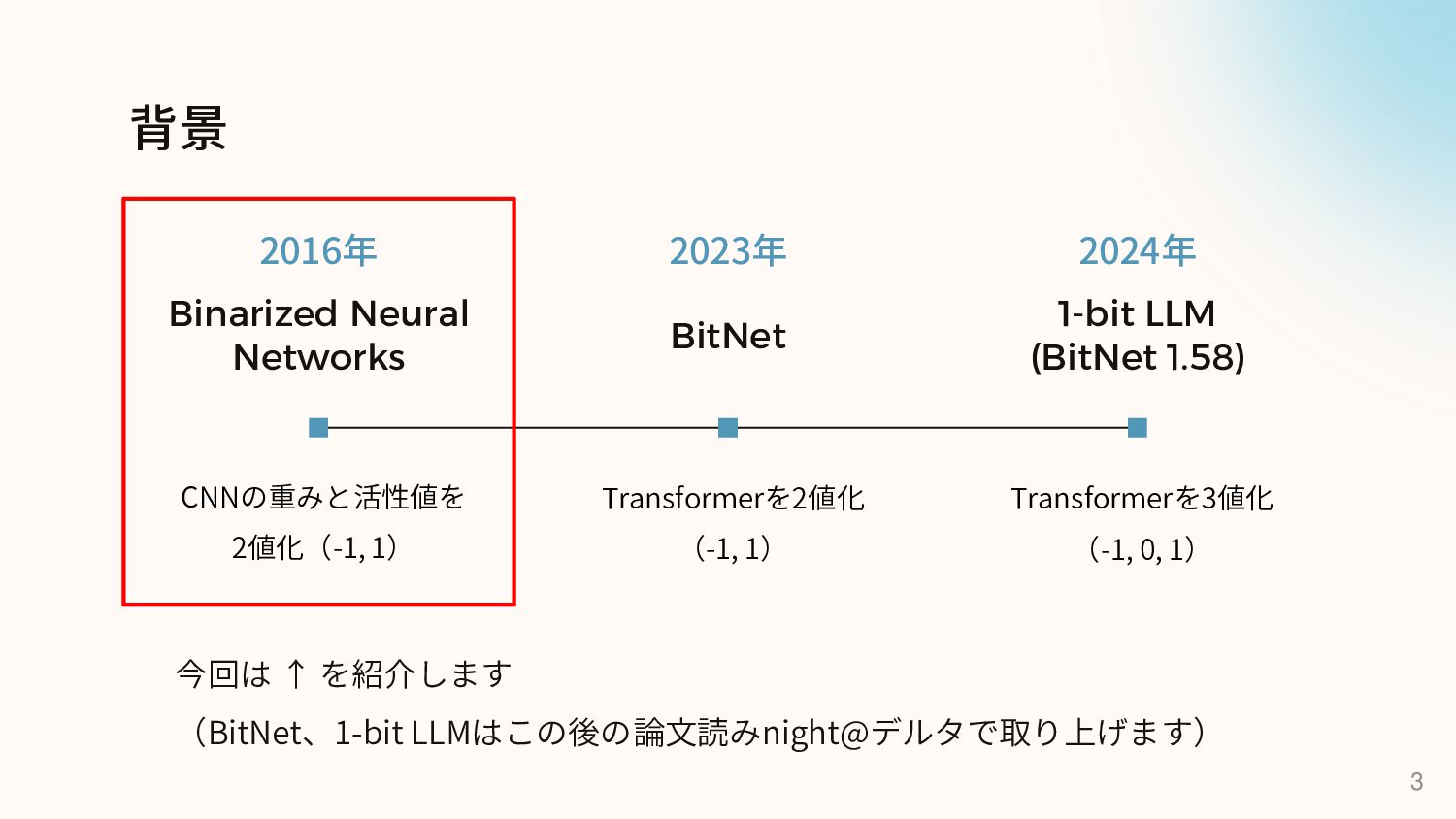
背景 2016年 Binarized Neural Networks 2023年 BitNet 2024年 1-bit LLM
(BitNet 1.58) 3 CNNの重みと活性値を 2値化(-1, 1) Transformerを2値化 (-1, 1) Transformerを3値化 (-1, 0, 1) 今回は ↑ を紹介します (BitNet、1-bit LLMはこの後の論文読みnight@デルタで取り上げます)
BNN ▪ Binarized Neural Networks: Training Deep Neural Networks with
Weights and Activations Constrained to +1 or -1 ▪ NeurIPS 2016に採択 ▪ 被引用件数 3503件 ▪ 重みと活性化関数の出力(= 活性値)の両方を2値化(+1、-1)したもの ▪ 決定論的(Deterministic)なバイナリ化を提案 ▪ バイナリ化 = 2値化(+1、-1)のこと 4
2値化処理の手法①: 確率論的(Stochastic) ▪ ハードシグモイド関数を使用した、確率的な2値化 5 ▪ σ: ハードシグモイド関数 ▪ 𝑥+1
2 の値が0以上、かつ1以下の範囲に収められる ▪ 通常のシグモイド関数を使わない理由は、計算量を減らすため 図: ハードシグモイド関数(σ)のプロット
2値化処理の手法②: 決定論的(Deterministic) ▪ 𝑥が0以上のとき +1、 それ以外を -1 とする単純な2値化 6 利点
▪ 確率論的な手法と比べて、量子化時のランダムビット列の生成が必要ないため軽い BNNでは、重みと活性値の両方に決定論的な2値化を適用する (一部実験を除く)
学習時の勾配計算(1/2) ▪ 実数値重みを保持しつつ、バイナリの重みを用いて計算 ▪ 実数値の重みは、確率的勾配降下法(SGD)を機能させるために必要 ▪ BNNの学習方法は、Dropoutの変形と見なすことができる ▪ パラメータ勾配を計算する際に重みと活性値にノイズを加えることで、正則化 の効果を得られるらしい
7
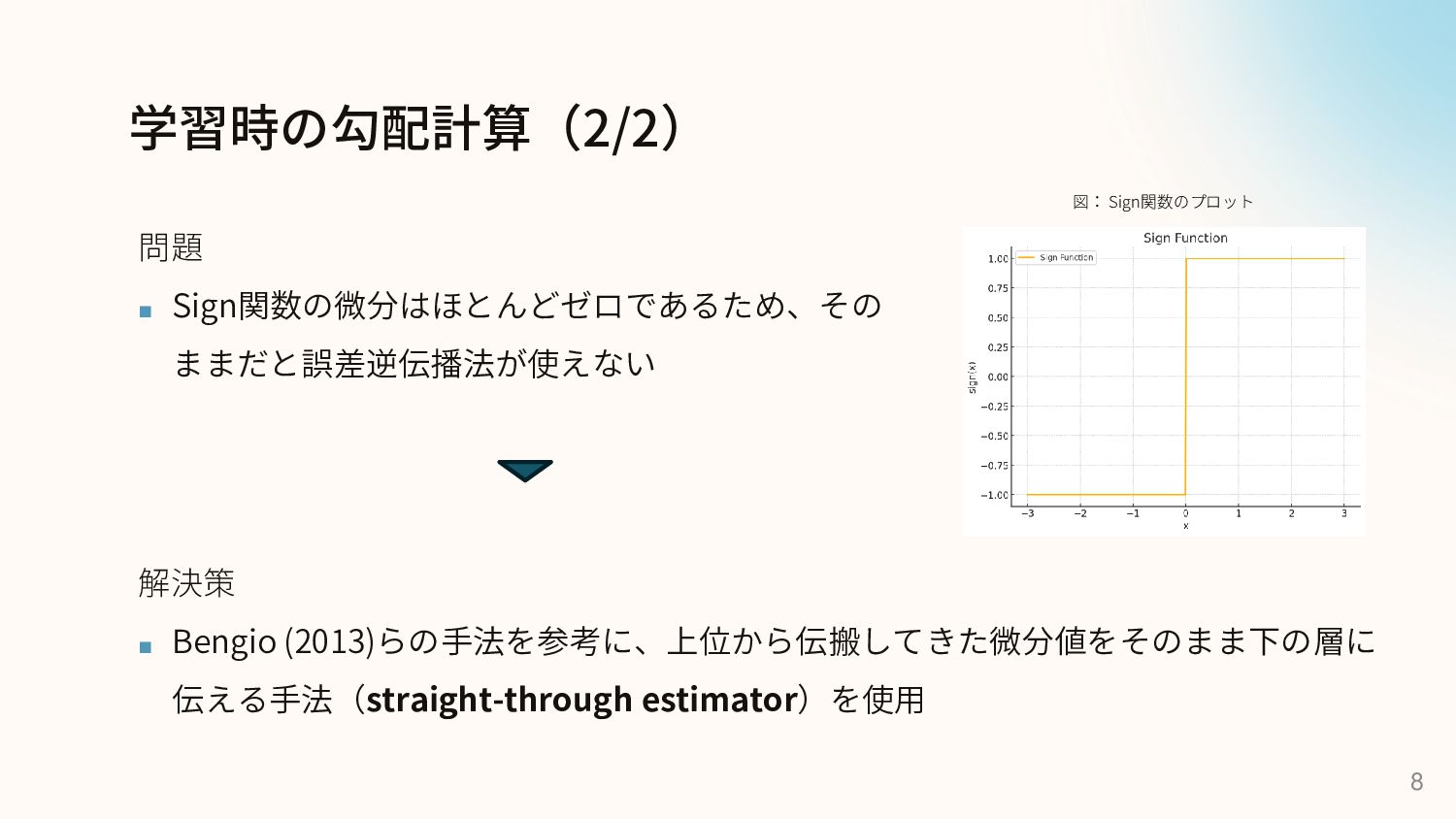
学習時の勾配計算(2/2) 問題 ▪ Sign関数の微分はほとんどゼロであるため、その ままだと誤差逆伝播法が使えない 8 解決策 ▪ Bengio (2013)らの手法を参考に、上位から伝搬してきた微分値をそのまま下の層に
伝える手法(straight-through estimator)を使用 図: Sign関数のプロット
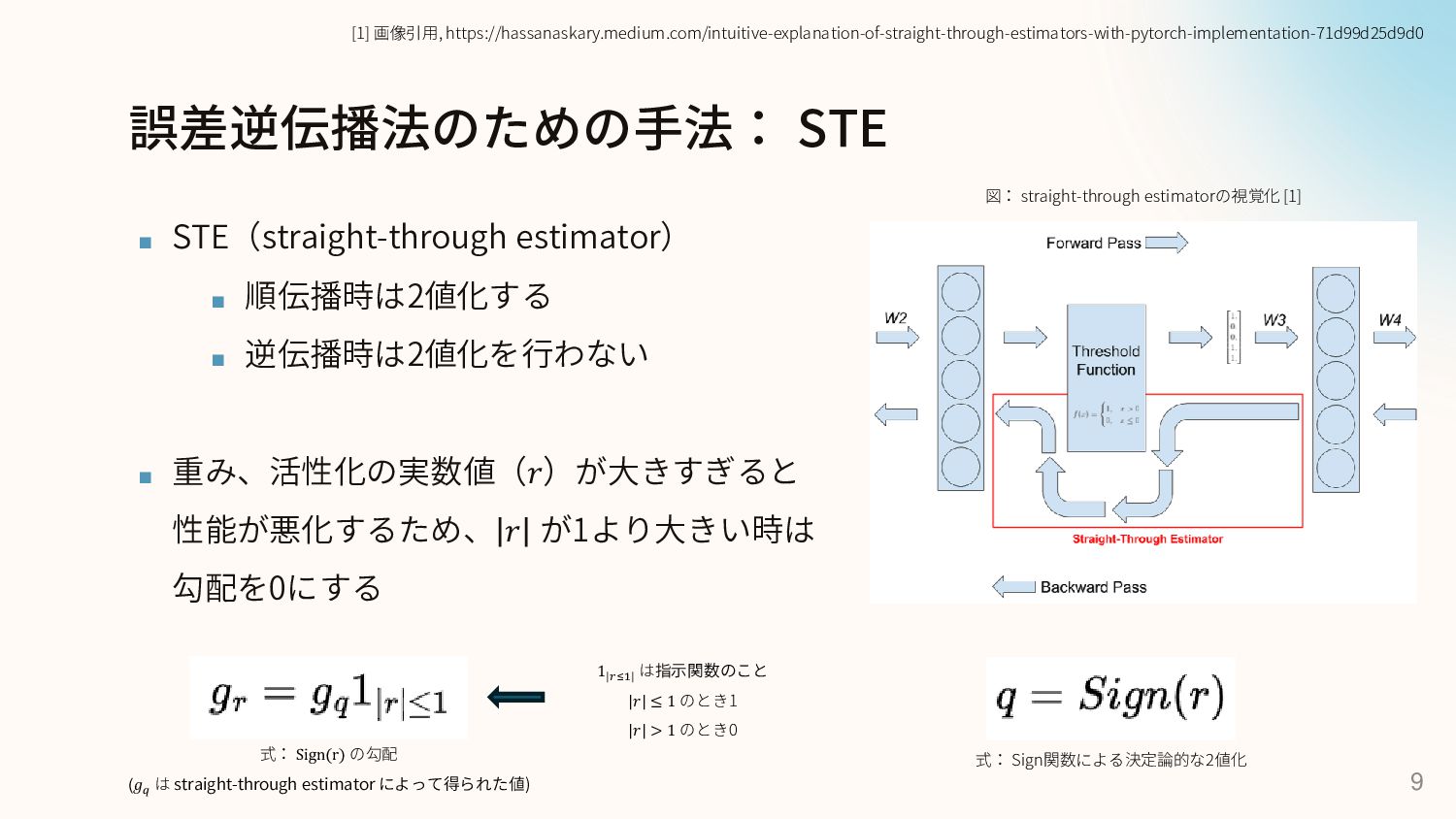
誤差逆伝播法のための手法: STE ▪ STE(straight-through estimator) ▪ 順伝播時は2値化する ▪ 逆伝播時は2値化を行わない ▪
重み、活性化の実数値(𝑟)が大きすぎると 性能が悪化するため、 𝑟 が1より大きい時は 勾配を0にする 9 図: straight-through estimatorの視覚化 [1] [1] 画像引用, https://hassanaskary.medium.com/intuitive-explanation-of-straight-through-estimators-with-pytorch-implementation-71d99d25d9d0 式: Sign(r) の勾配 (𝑔𝑞 は straight-through estimator によって得られた値) 1|𝑟≤1| は指示関数のこと |𝑟| ≤ 1 のとき1 |𝑟| > 1 のとき0 式: Sign関数による決定論的な2値化
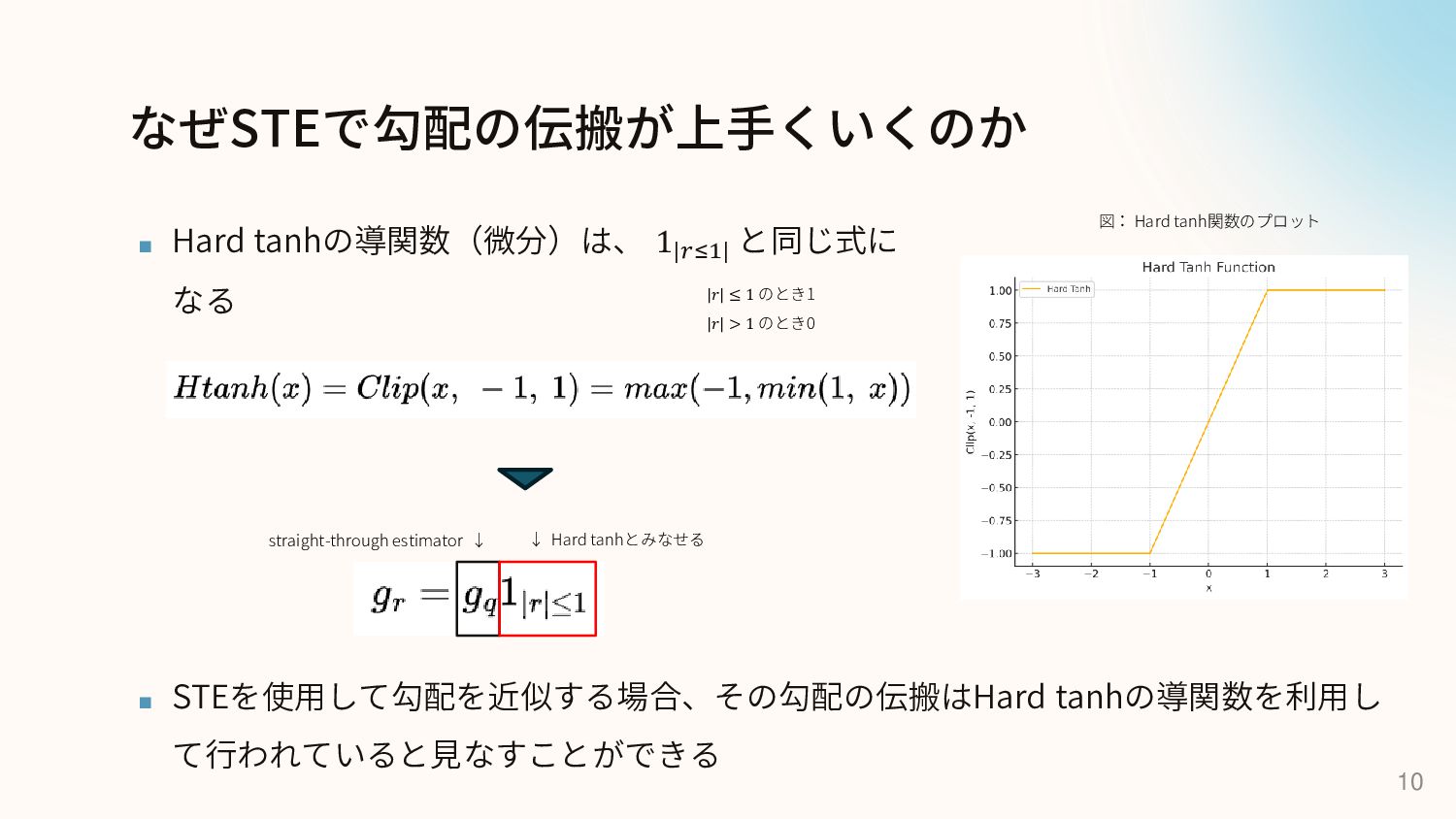
なぜSTEで勾配の伝搬が上手くいくのか ▪ Hard tanhの導関数(微分)は、 1|𝑟≤1| と同じ式に なる 10 ▪ STEを使用して勾配を近似する場合、その勾配の伝搬はHard
tanhの導関数を利用し て行われていると見なすことができる 図: Hard tanh関数のプロット ↓ Hard tanhとみなせる straight-through estimator ↓ |𝑟| ≤ 1 のとき1 |𝑟| > 1 のとき0
損失関数 ▪ 平方ヒンジ損失(square hinge loss) ▪ 正解値t も 推定値y も
-1 または +1 ▪ お互い -1 か +1 で正解しているとき損失は 0となる ▪ 誤差があるときは、(1 − (−1))2 = 22 = 4 となる 学習設定: 損失関数 11
学習設定: シフトベースによる計算量削減 最適化関数 ▪ Shift-based AdaMax ▪ ビット演算(シフト)ベースのAdaMaxによって乗算を無くした ▪ AdaMax
≒ Adamの変形バージョンのようなもの 正規化 ▪ Shift-based Batch Normalization ▪ 乗算を用いることなく、バッチ正規化(Batch Normalization)を近似した 12
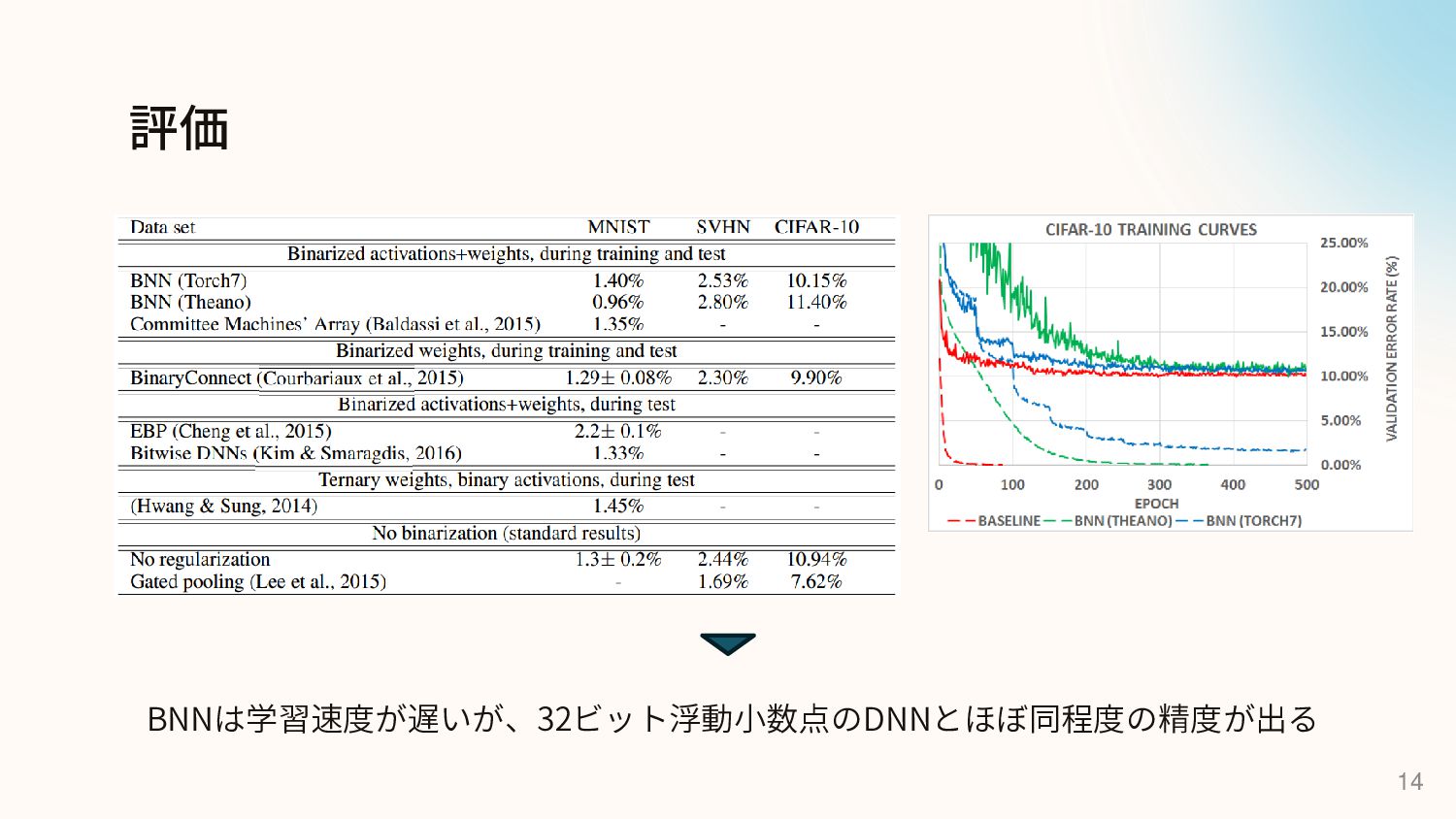
評価 13 ▪ MNIST、CIFAR-10、SVHNの3つのデータセットで実験 ▪ Torch7、Theanoの2つのライブラリに実装 ▪ Torch7では… ▪ 学習時の活性値は確率論的な2値化、推論時は決定論的な2値化
▪ シフトベースの正規化とAdaMaxを使用 ▪ Theanoでは… ▪ 学習 & 推論どちらも決定論的な2値化 ▪ 通常の正規化とAdaMaxを使用
評価 14 BNNは学習速度が遅いが、32ビット浮動小数点のDNNとほぼ同程度の精度が出る
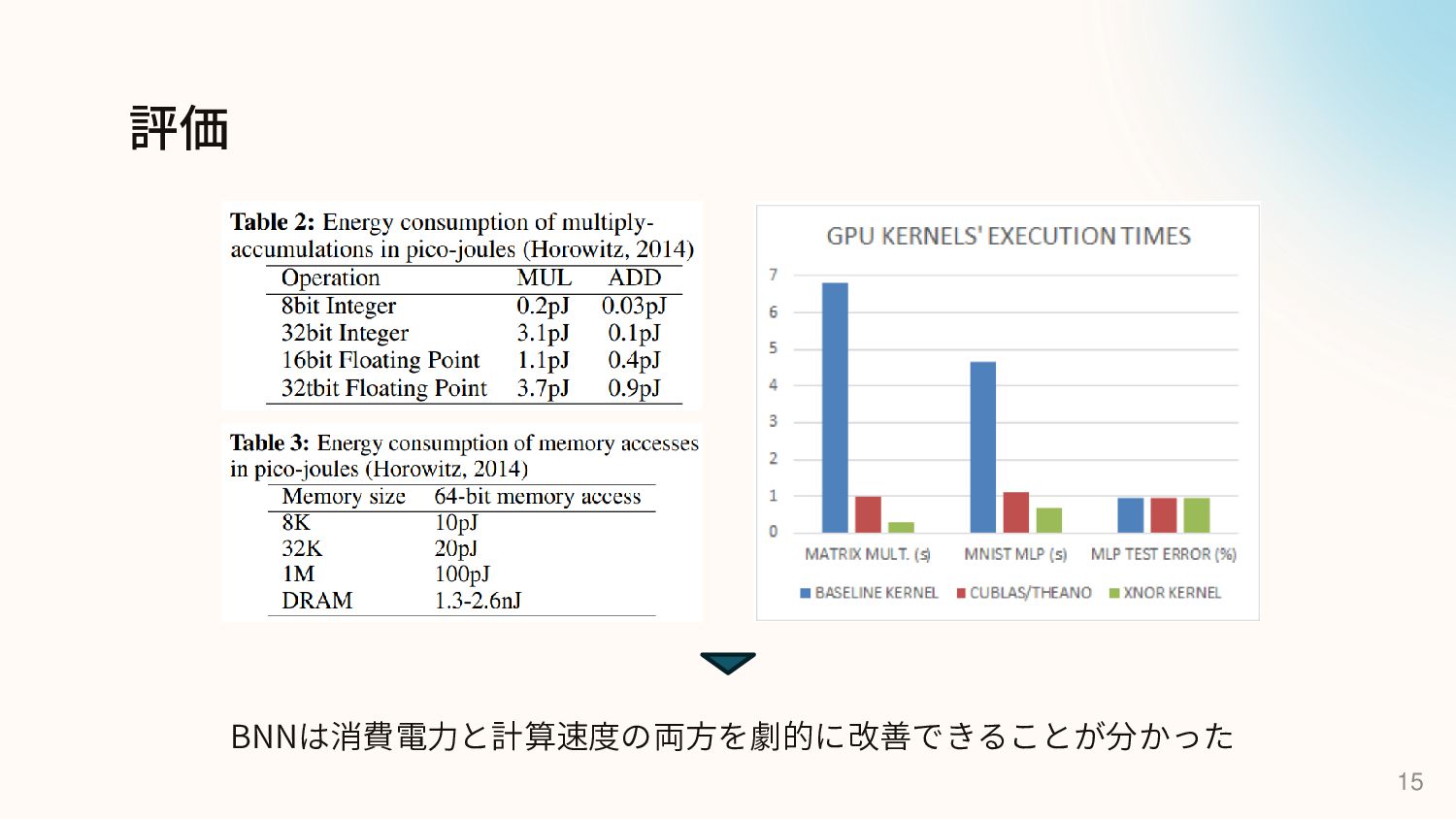
評価 15 BNNは消費電力と計算速度の両方を劇的に改善できることが分かった
まとめ 16 ▪ 32ビット浮動小数点のDNNよりもメモリ効率を大幅に削減しながらも、ほとんど 同等の精度を達成した ▪ ただし、実数値の重みの値を保存しなければならないため、学習時において計算 のボトルネックとなる ▪ 先行研究のBinaryConnectでは重みの2値化だけだったが、BNNでは重みと活性値
の両方を2値化した
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}