with only one endpoint URI POST 2 Different endpoints and resources POST 3 Different endpoints and resources GET, POST, PUT, DELETE, … 4 Different endpoints and resources, HATEOAS GET, POST, PUT, DELETE, … (Typically level 3 is implemented)
hyperlinks to other resources Kind of finite state machine Not widely used { "name": "Foo", "links": [ { "rel": "self", "href": "http://localhost:8080/customer/1" } ], "details": "/details/1" }
Body GET Read Y Y Y Response only HEAD Same as GET without body Y Y Y N POST Create N N Y Request/Response PUT Upsert N Y N Request/Response DELETE Delete N Y N Response only OPTIONS returns the HTTP methods that the server supports Y Y N Response only PATCH, TRACE, CONNECT, etc. are out of scope here
DELETE Collection List of elements or URIs Replace entire collection create new collection delete complete collection Element Return element Replace or create element - delete element
time Adding new resources or response parts is not critical but Renaming and/or deletion is Two possibilities to solve this Encode version of the API in the URI Encode version of the API in a header Depends especially on the type of client (Browser or other)
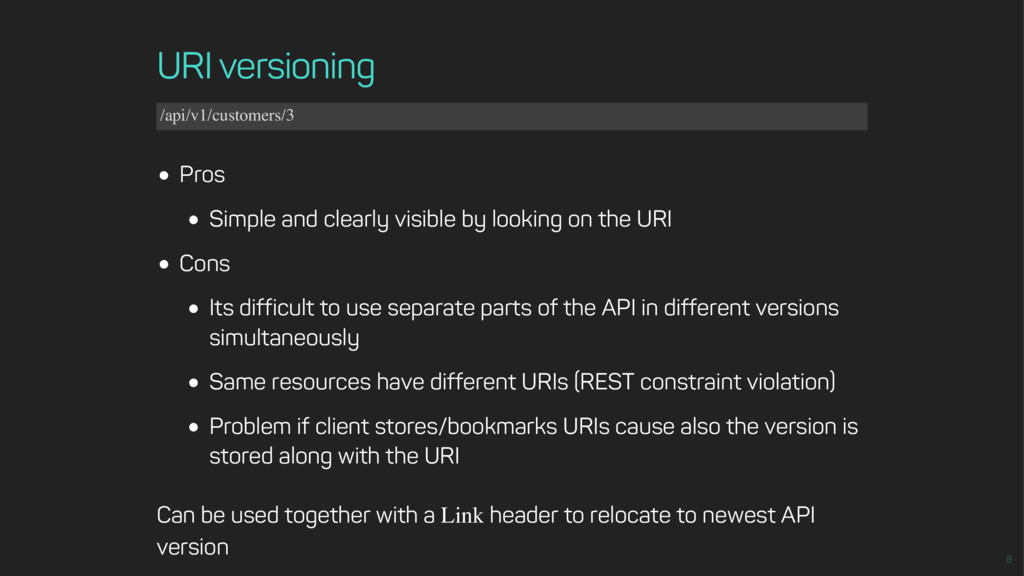
the URI Cons Its difficult to use separate parts of the API in different versions simultaneously Same resources have different URIs (REST constraint violation) Problem if client stores/bookmarks URIs cause also the version is stored along with the URI Can be used together with a Link header to relocate to newest API version /api/v1/customers/3
parts of the API in different versions simultaneously Same resources have same URIs No problems with stored/bookmarked URIs Accept Header supports more than one version Accept: application/vnd.myapp-v1+json
need own (self defined) mime types (thats no a real problem so far) To make HTTP caching work a Vary: Accept header is needed to make the Accept header part of the cache key Not widely spread (most devs are unfamiliar with that approach)
developers and implement URI versioning Provide a non versioned URI alias which point to the most recent version For more complicated situations use Link header
clients support HTTP 1.1 Purpose is to decrease utilization of network bandwith/latency and discharge load on backend systems/HTTP server and therefore gain more performance (handle more load, increase responsiveness) Only GET and HEAD is cacheable If you not have such problems (and you don’t expect them in the future) do not use caching because there are several downsides
network bandwith and load on backend systems Clients are responsible, needs probably programming If client is a browser it depends on the implementation of the browser (IE and Safari might show bugs) It also depends on the infrastructure between the client and the originating server (proxies, webcaches, … ) For browser caches or HTPP 1.1 compliant client it work May i cache? If cached is it fresh? If stale is it valid on the server?
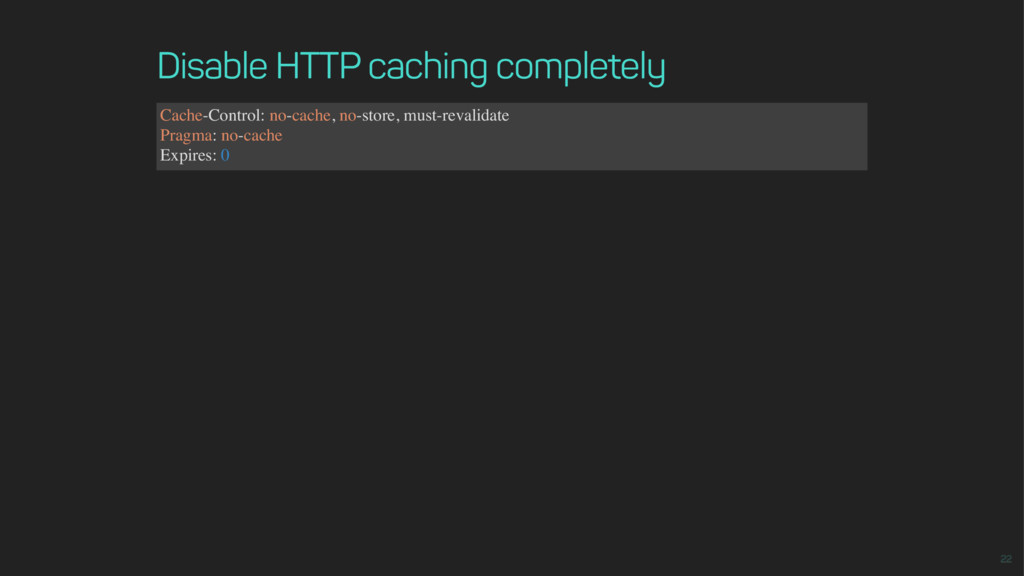
use the HTTP 1.1 Cache-Control header to indicate when a resource response is outdated. Until this point in time the browser will not connect to the rest endpoint but will server the response from its cache. What May be Stored by Caches (request/response) no-store no caching at all What is Cacheable (response only) public by any cache, no revalidation if fresh private by any non shared cache, no revalidation if fresh no-cache by any cache, enforce revalidation even if fresh (request/response)
willing to accept a response whose age is no greater than the specified time Cache Revalidation and Reload Controls (response only) must-revalidate do an end-to-end revalidation every time proxy-revalidate sames as must-revalidate but not for private caches
static resources like CSS, Javascript, Images, etc. and not recommended for representations of business domain objects. Therefore do not use it for API caching.
ETag header to maintain a kind of hashcode for the content. Every time the content changes on the server side the value of the ETag does change. sent by origin server or the user agent Sometimes ETag is hard to maintain, especially in a distributed backend environment HTTP/1.1 200 OK ETag: "hgt5398j" GET /customer/1 HTTP/1.1 IF-None-Match: "hgt5398j" HTTP/1.1 304 Not Modified ETag: "hgt5398j"
load on backend systems by caching data in memory Guava cache (which ships with Dropwizard) for costly database queries Simple Maps/Lists Needs enough memory to be available Invalidation is perfectly under control
an Accept header too then we need to set the HTTP Vary Header (which is broken in IE and Safari) Normally content in the browser cache is matched agains its URI and HTTP Method. With the Vary Header additional constraints, like the Accept or Authorization header, can be included in the cache key. Vary: Accept
If a resource needs authentication this have to be included in the Vary header and Cache-control: private must be set to prevent shared caching of a security token Vary header is broken for some browsers and some types
at all If you must cache because of backend utilization Consider server side application level caching Consider HTTP content based caching with ETag validation Cache-Control: no-cache, max-age=0 for client Cache-Control: public, max-age=0, must-revalidate + ETag for server If you must cache because of network utilization Consider client side application level caching That is because of Browsers and intermediate infrastructure (like proxies are) are subject to change, sometimes buggy and sometimes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}