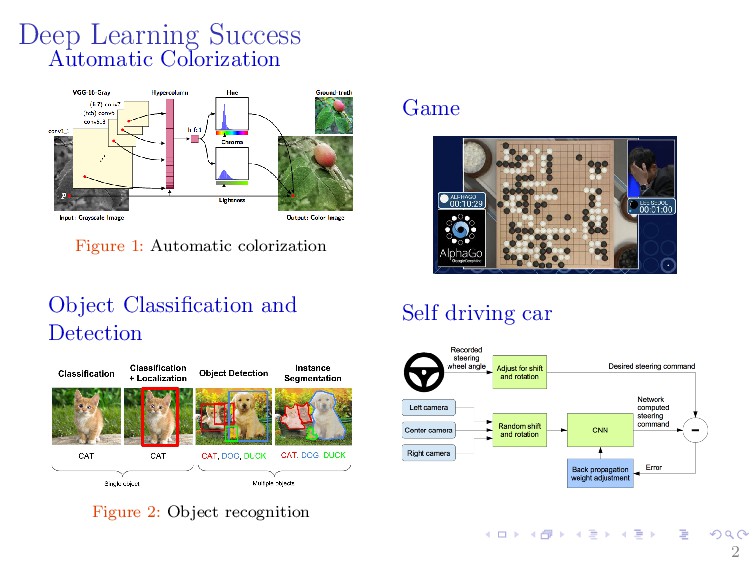
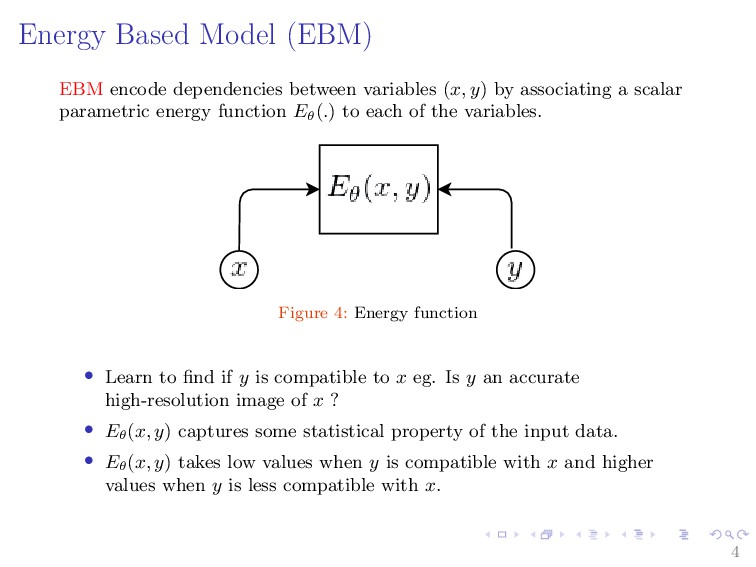
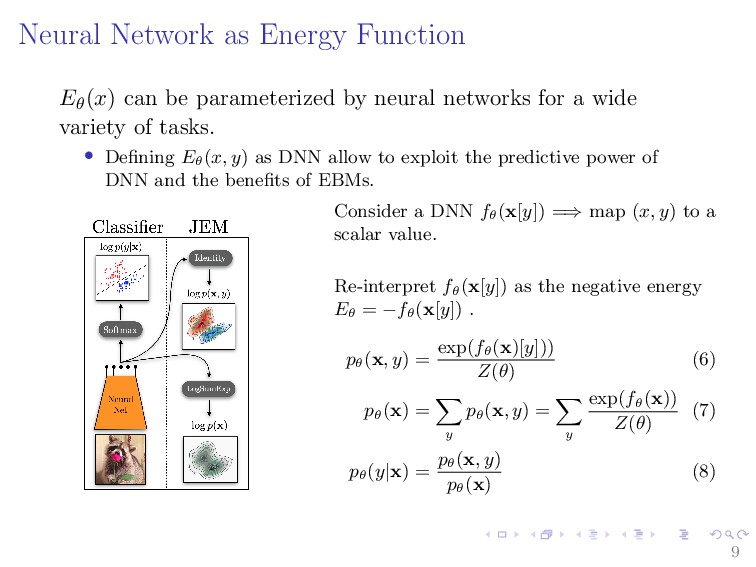
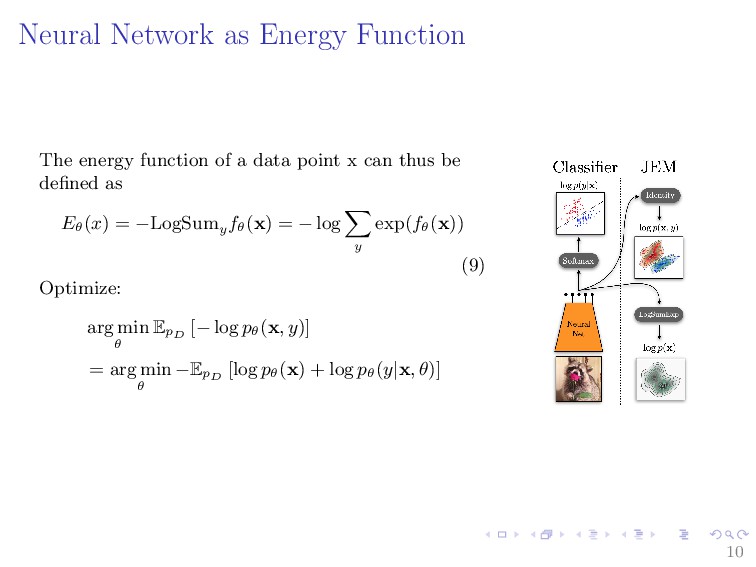
Energy-Based Models (EBMs) belong to the class of data-driven models that encode dependencies between variables by associating a scalar parametric energy function to each of them. EBMs learn a function that assigns low energy values to inputs in the data distribution and high energy values to other data. The resulting models can then be used to either discriminate whether or not a query input comes from the data distribution or generate new samples from the data distribution. This makes EBM as a flexible framework for learning high-dimensional and complex computations dependencies. As a consequence, EBMs have received attention for most of machine learning applications. This talk will provide a brief overview of EBMs and how they can be used with deep learning on various machine learning applications such as density estimation, regression, classification, out of distribution detection, model calibrations, and reinforcement and learning.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DNN-EBM: Classification • Joint Energy based Model applying SGLD3 [2]](https://files.speakerdeck.com/presentations/bacce96e3a844364a07c6340eed03484/slide_21.jpg){kind=link}
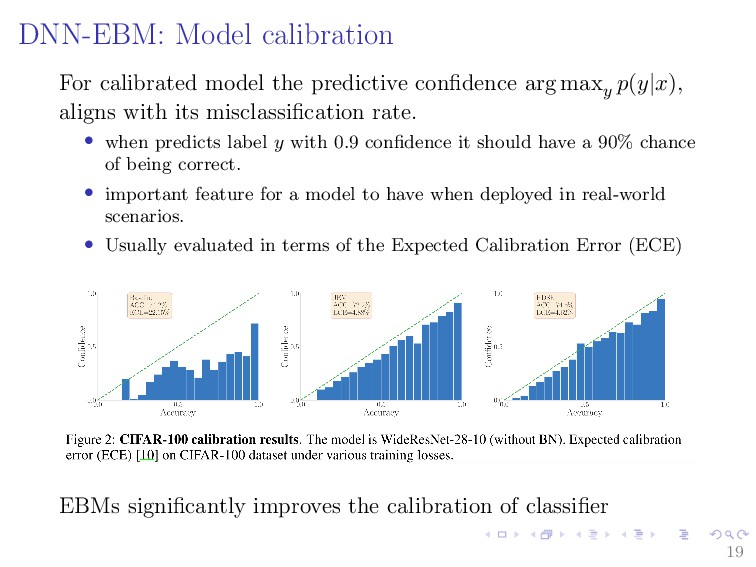{kind=link}
{kind=link}
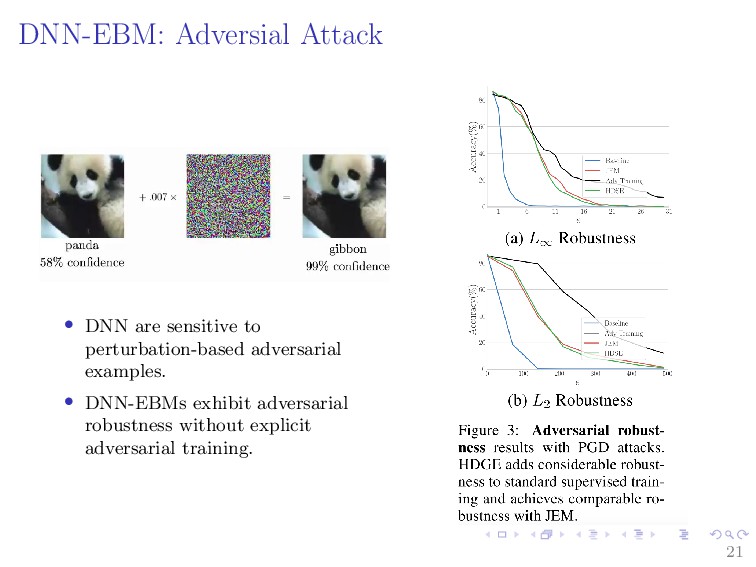{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}