Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
kube-scheduler: from 101 to the frontier
Search
sanposhiho
October 10, 2024
290
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
kube-scheduler: from 101 to the frontier
Kubernetes Meetup Tokyo #67
https://k8sjp.connpass.com/event/330635/
sanposhiho
October 10, 2024
More Decks by sanposhiho
See All by sanposhiho
Understanding the Kubernetes Scheduler: Internals, Roadmap, and Contributions
sanposhiho
1
160
A Tale of Two Plugins: Safely Extending the Kubernetes Scheduler with WebAssembly
sanposhiho
0
260
人間によるKubernetesリソース最適化の”諦め” そこに見るリクガメの可能性
sanposhiho
2
2.2k
Don't try to tame your autoscalers, tame Tortoises!
sanposhiho
0
840
メルカリにおけるZone aware routing
sanposhiho
4
1.9k
A tale of two plugins: safely extending the Kubernetes Scheduler with WebAssembly
sanposhiho
1
630
メルカリにおけるプラットフォーム主導のKubernetesリソース最適化とそこに生まれた🐢の可能性
sanposhiho
1
1k
MercariにおけるKubernetesのリソース最適化のこれまでとこれから
sanposhiho
8
4.2k
The Kubernetes resource management and the behind systems in Mercari
sanposhiho
0
370
Featured
See All Featured
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
380
Writing Fast Ruby
sferik
630
63k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Prompt Engineering for Job Search
mfonobong
0
380
Design in an AI World
tapps
1
260
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Mobile First: as difficult as doing things right
swwweet
225
10k
Designing Experiences People Love
moore
143
24k
Transcript
Kube-scheduler: from 101 to the frontier Kensei Nakada (@sanposhiho)
本日の目標 SIG-Scheduling は最近特に大きな機能追加をしていません。
本日の目標 SIG-Scheduling は最近特に大きな機能追加をしていません。 だからと言ってサボっているわけではなく、 内部で色々な改善を行っているわけです。
本日の目標 SIG-Scheduling は最近特に大きな機能追加をしていません。 だからと言ってサボっているわけではなく、 内部で色々な改善を行っているわけです。 色々大きな内部の改善をやってきているのですが、理解には Schedulerの深めの知識が 必要であり、あまり日の目に浴びることはない ...
本日の目標 SIG-Scheduling は最近特に大きな機能追加をしていません。 だからと言ってサボっているわけではなく、 内部で色々な改善を行っているわけです。 色々大きな内部の改善をやってきているのですが、理解には Schedulerの深めの知識が 必要であり、あまり日の目に浴びることはない ... このセッションは、最近私たちがやっていることを周辺知識を全て拾いながら
解説していくことで、 皆さんも知識が深まりハッピー、僕も自慢できてハッピーを目指すセッションです
Hello! こんにちは ! 👋 Kensei Nakada (@sanposhiho) • Software Engineer
@ • Kubernetes maintainer (SIG-Scheduling approver, SIG-Autoscaling) • Kubernetes contributor award 2022, 2023
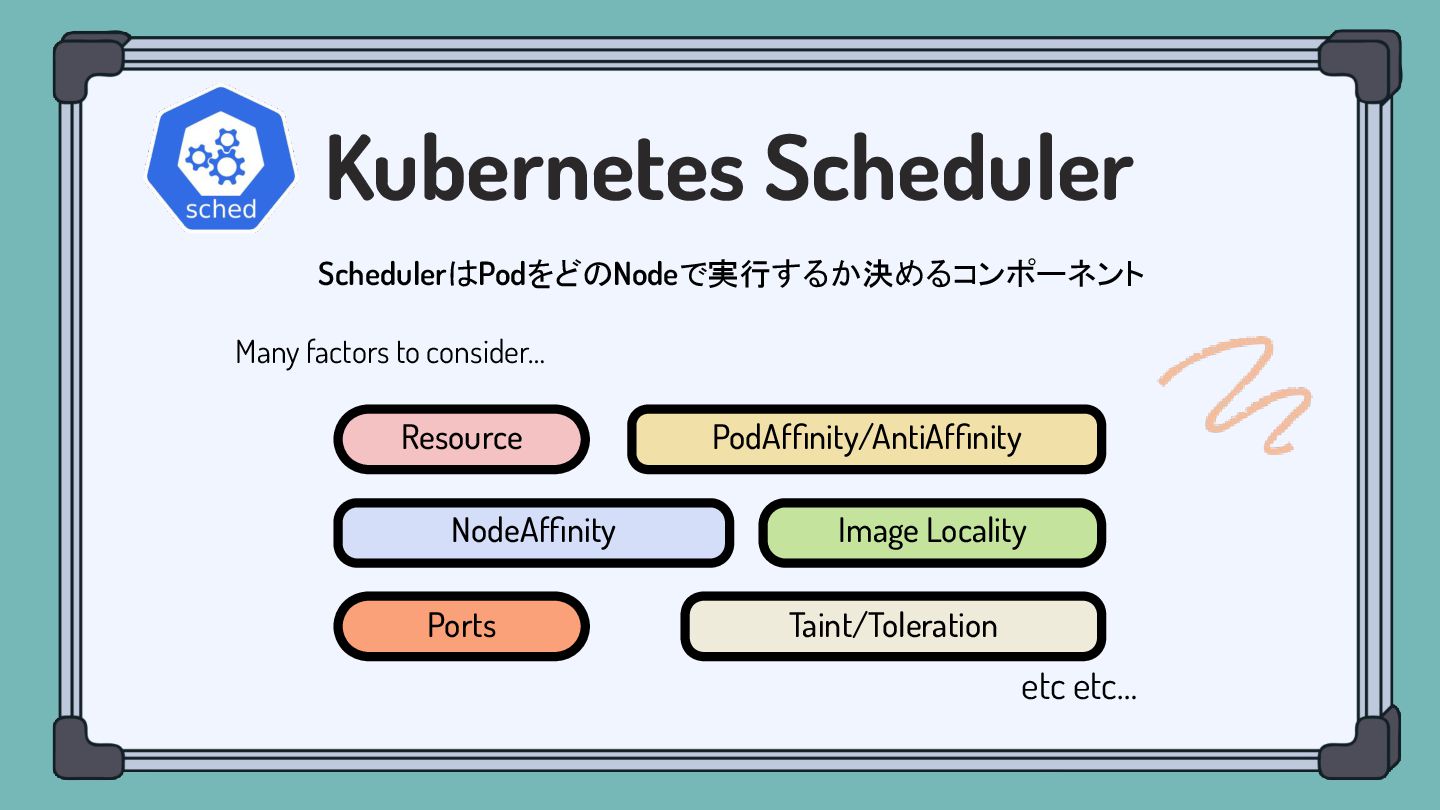
Image Locality Taint/Toleration Kubernetes Scheduler SchedulerはPodをどのNodeで実行するか決めるコンポーネント Resource Ports NodeAffinity PodAffinity/AntiAffinity
etc etc… Many factors to consider…
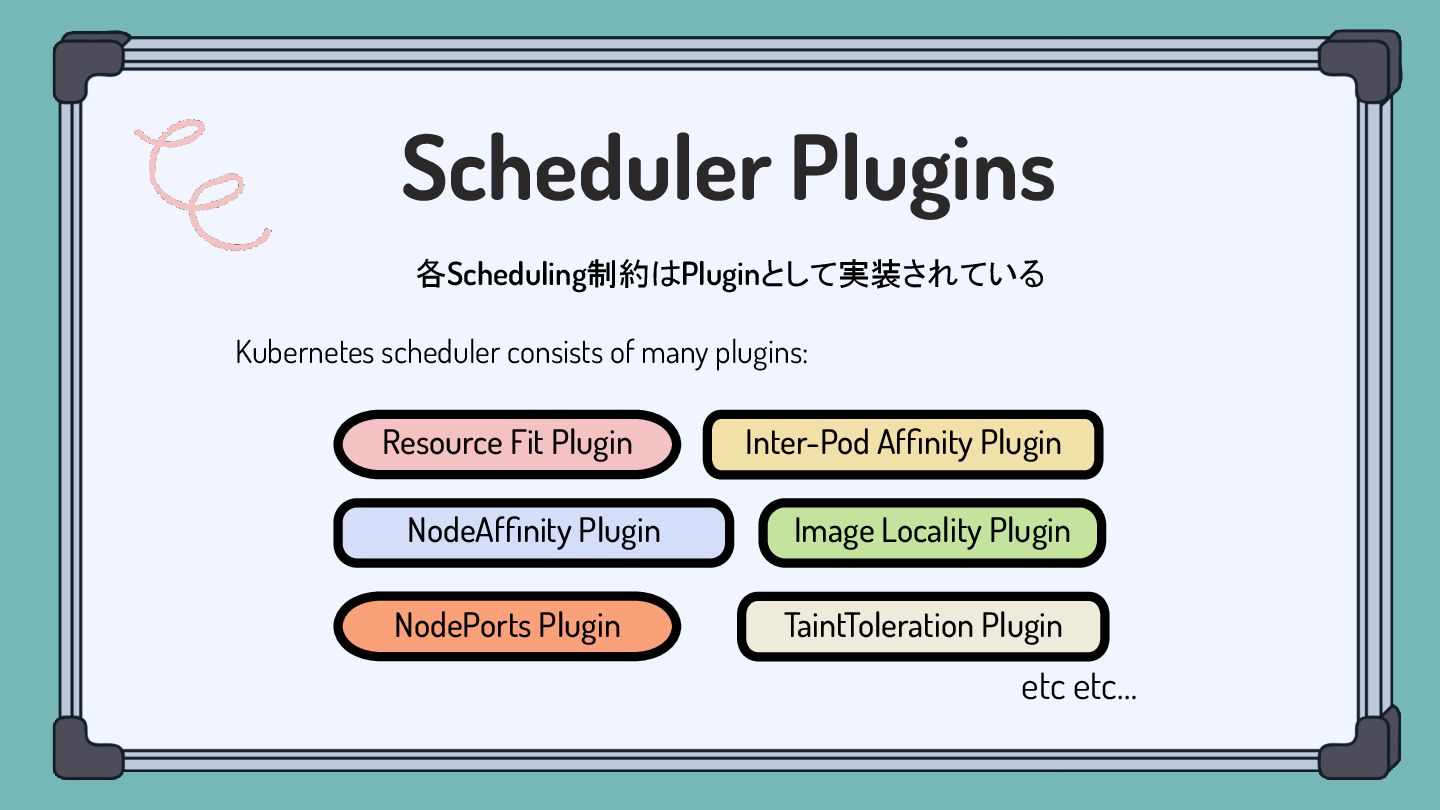
Scheduler Plugins 各Scheduling制約はPluginとして実装されている Image Locality Plugin TaintToleration Plugin Resource Fit
Plugin NodePorts Plugin NodeAffinity Plugin Inter-Pod Affinity Plugin etc etc… Kubernetes scheduler consists of many plugins:
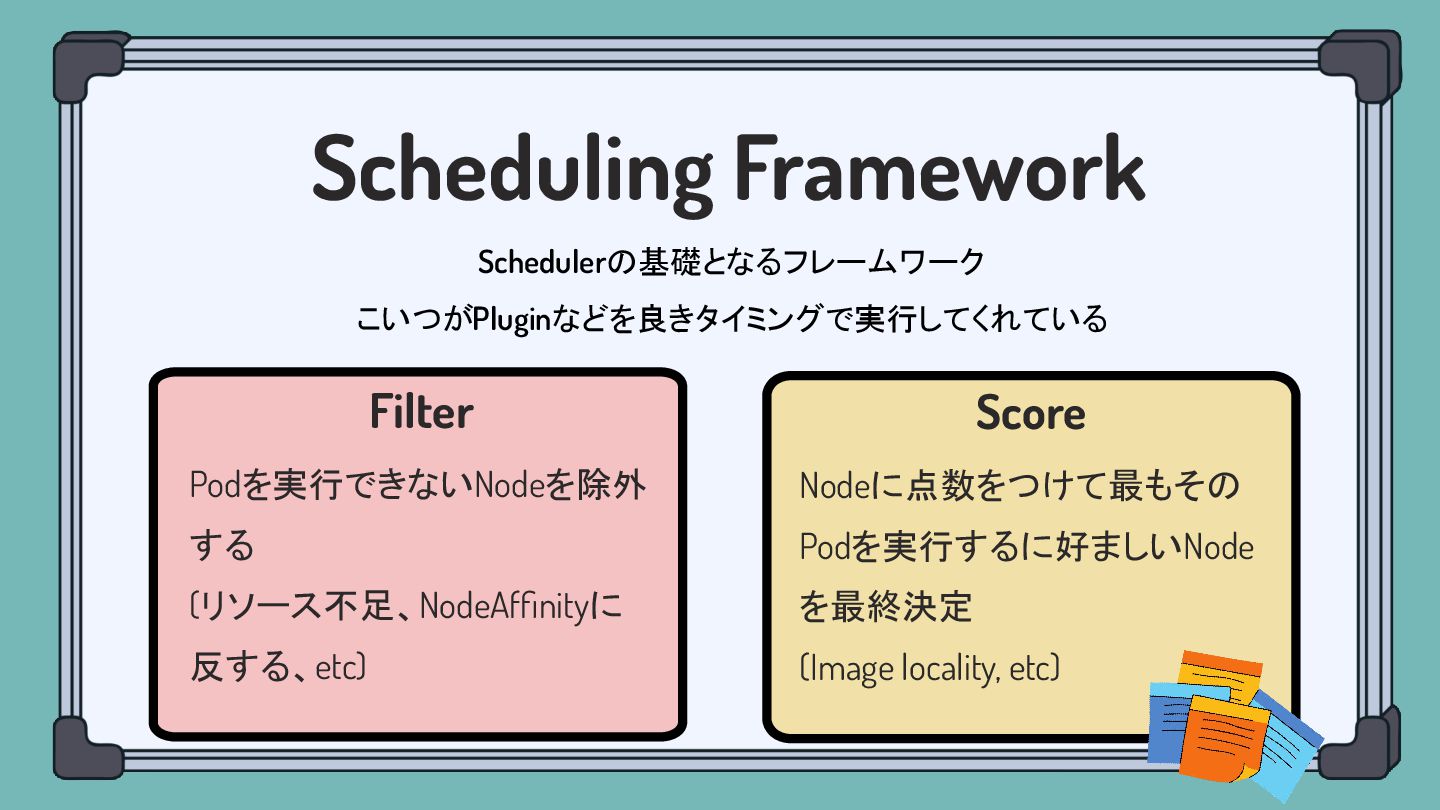
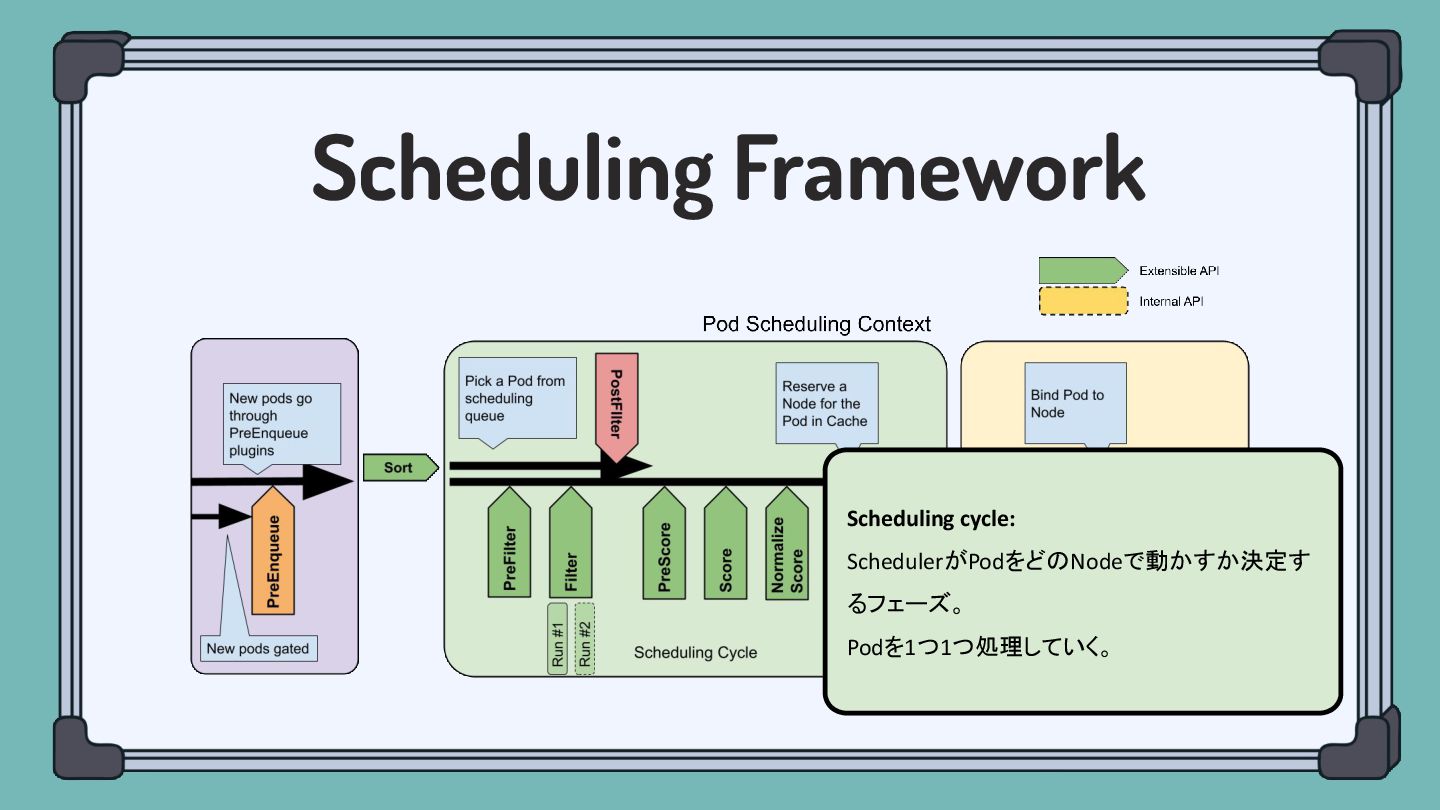
Scheduling Framework Schedulerの基礎となるフレームワーク こいつがPluginなどを良きタイミングで実行してくれている Filter Podを実行できないNodeを除外 する (リソース不足、NodeAffinityに 反する、etc) Score
Nodeに点数をつけて最もその Podを実行するに好ましいNode を最終決定 (Image locality, etc)
None
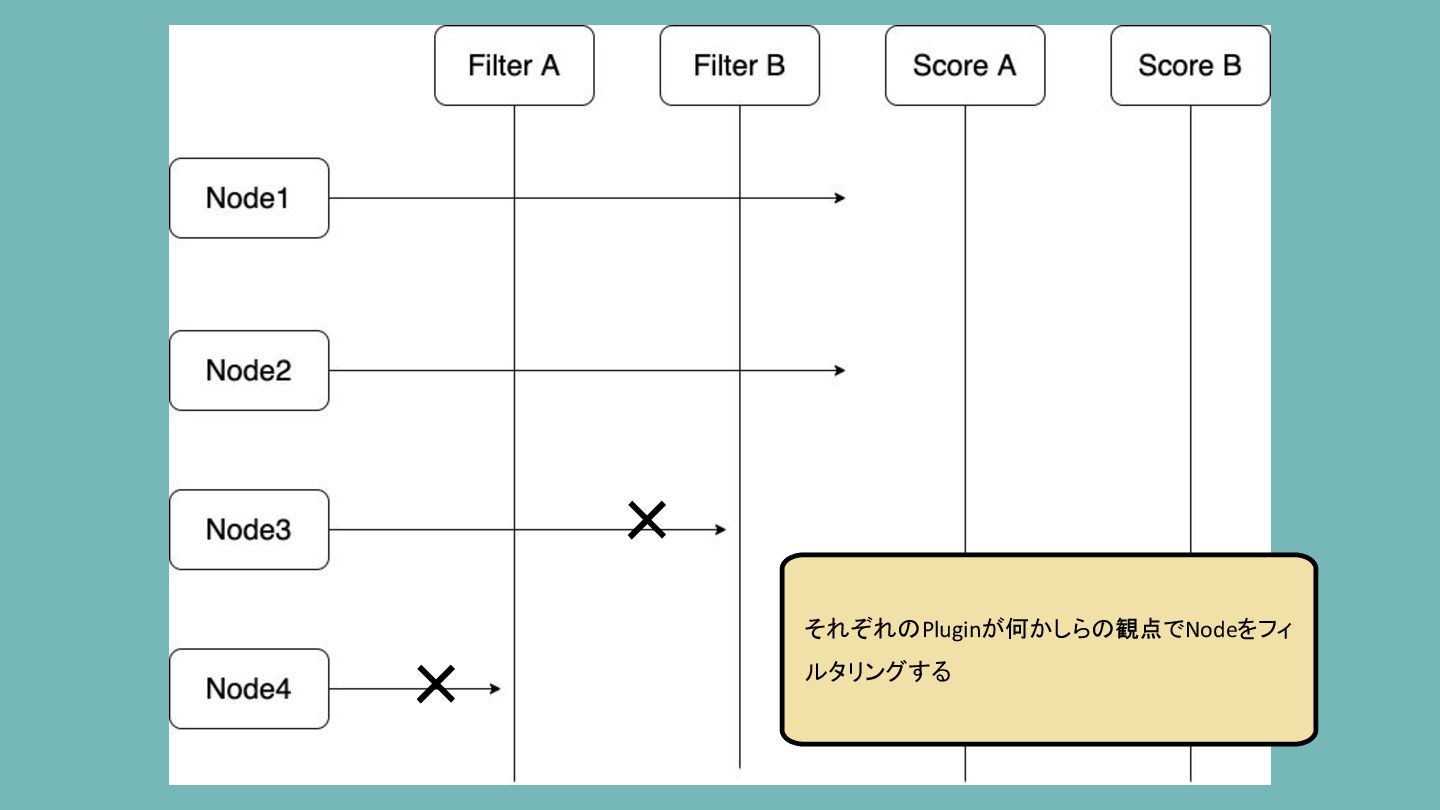
× × それぞれのPluginが何かしらの観点でNodeをフィ ルタリングする
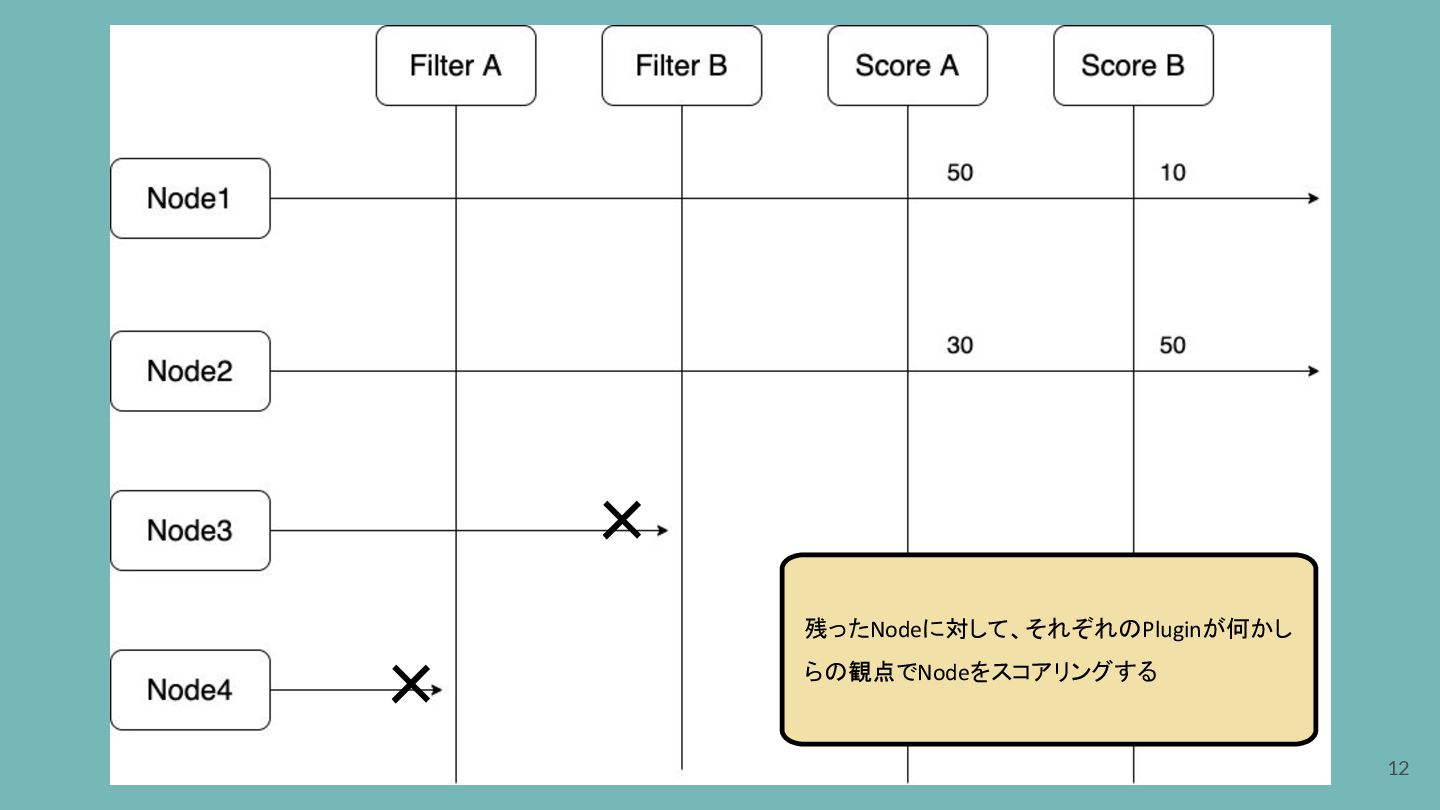
× × 12 残ったNodeに対して、それぞれのPluginが何かし らの観点でNodeをスコアリングする
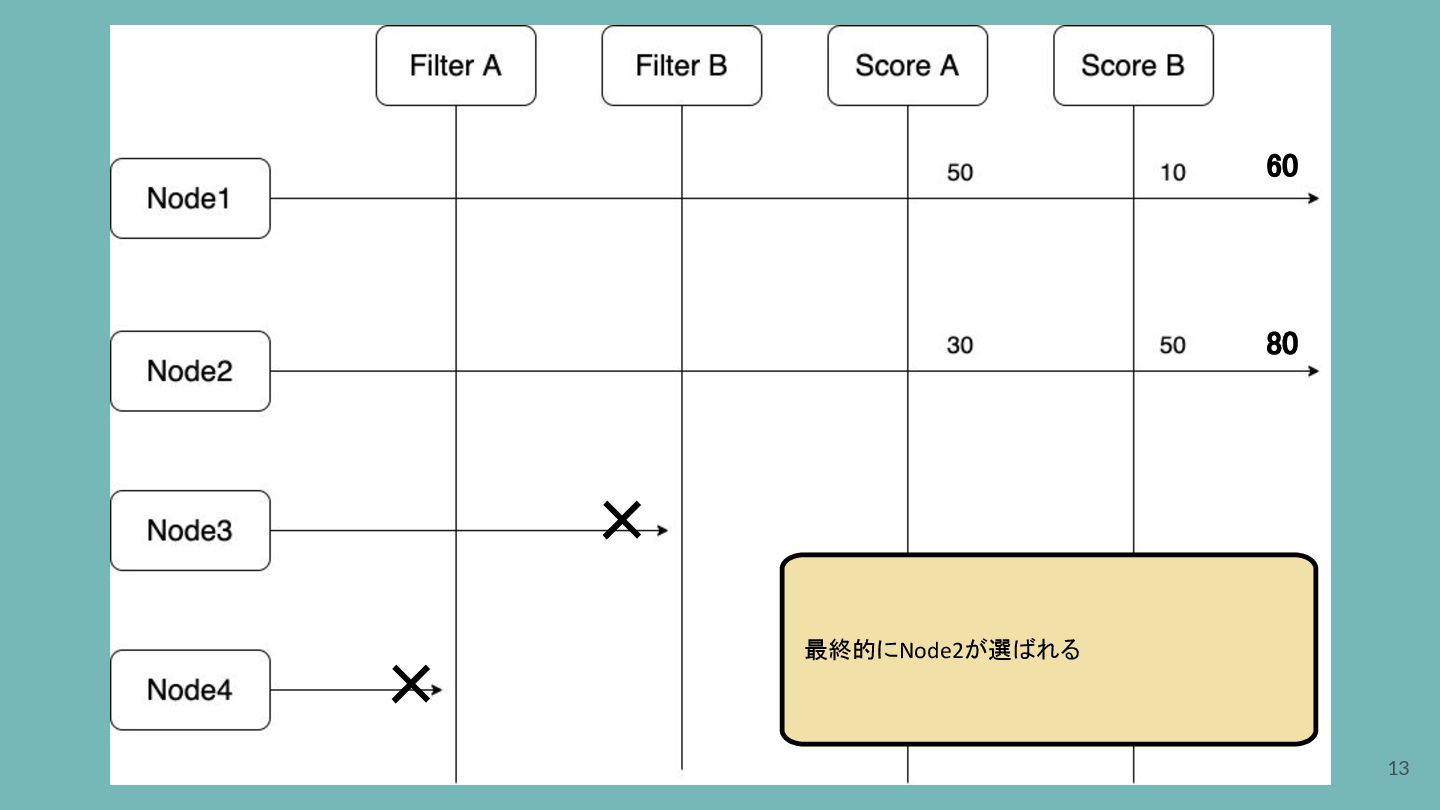
80 60 × × 13 最終的にNode2が選ばれる
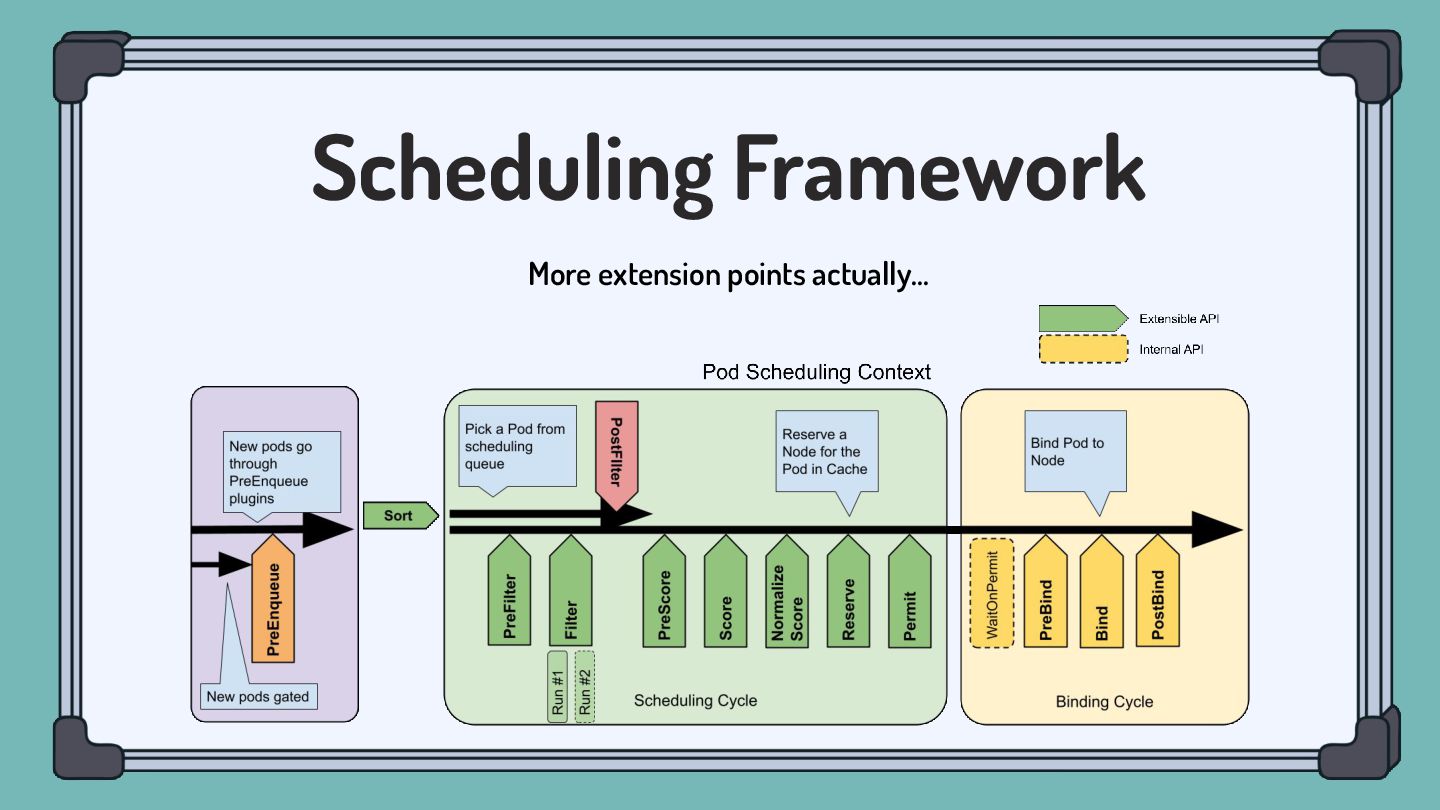
Scheduling Framework More extension points actually…
Scheduling Framework Scheduling cycle: SchedulerがPodをどのNodeで動かすか決定す るフェーズ。 Podを1つ1つ処理していく。
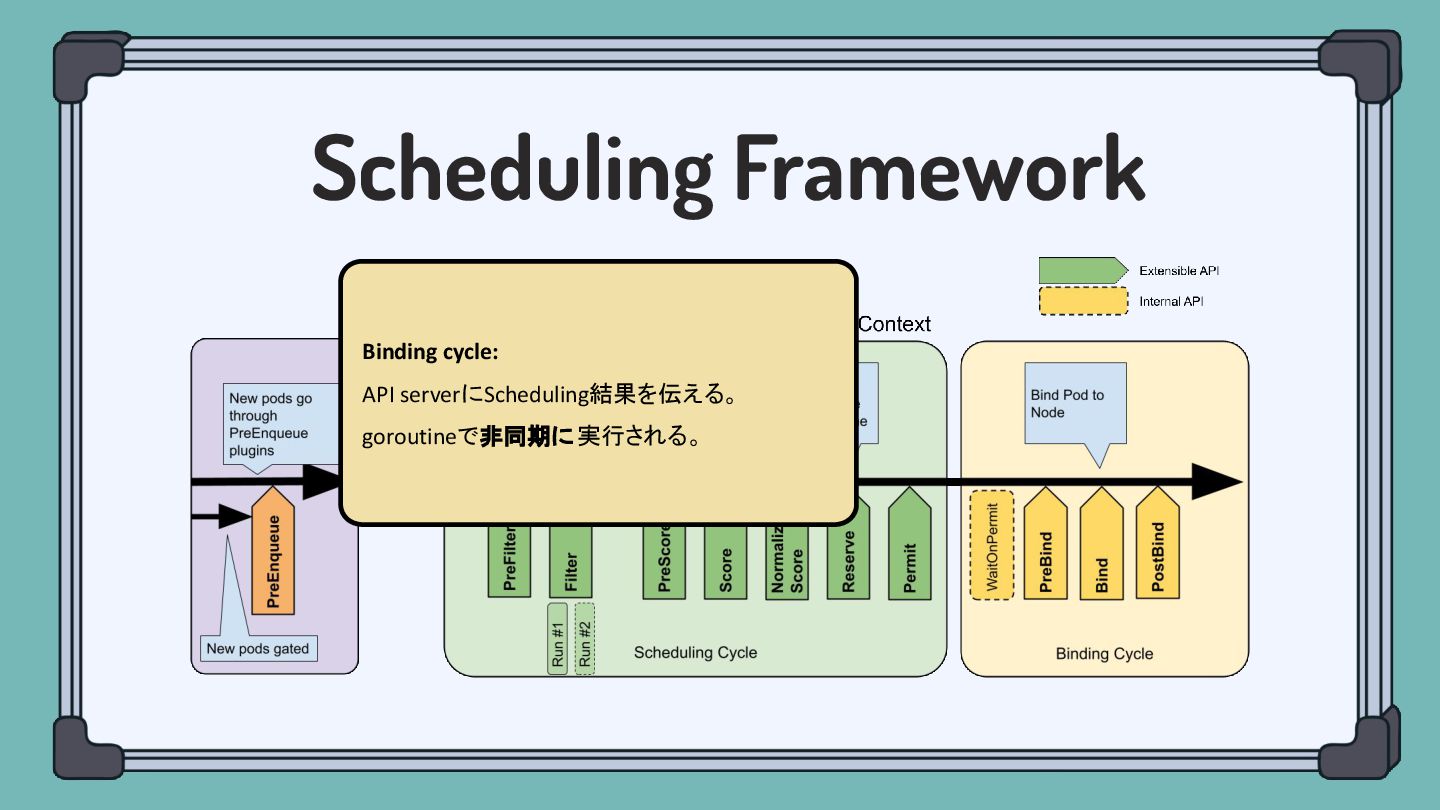
Scheduling Framework Binding cycle: API serverにScheduling結果を伝える。 goroutineで非同期に実行される。
The recent developments • 最近は大きな機能の追加などを行なっていない ◦ KEPもv1.28スタートのQueueingHint (後述) が最後 •
内部ではPerformanceの改善に集中
Performance matters! • Schedulerは基本的にクラスター内に1つだけ ◦ Scheduling ThroughputがクラスターのPod作成速度よりも下回るとスケジュールされてない Podが溜まっていってしまう。 ◦ アップストリームでは全てのシナリオで
300 Pods/s以上キープを目標にしている。 scheduler-perf(後述)で計測。 • Scheduler のパフォーマンス改善は複数のエリアにまたがる ◦ Scheduling Framework自体のパフォーマンス ◦ Pluginのパフォーマンス ◦ Requeueingの正確性 (scheduling cycleの無駄使いを減らす)
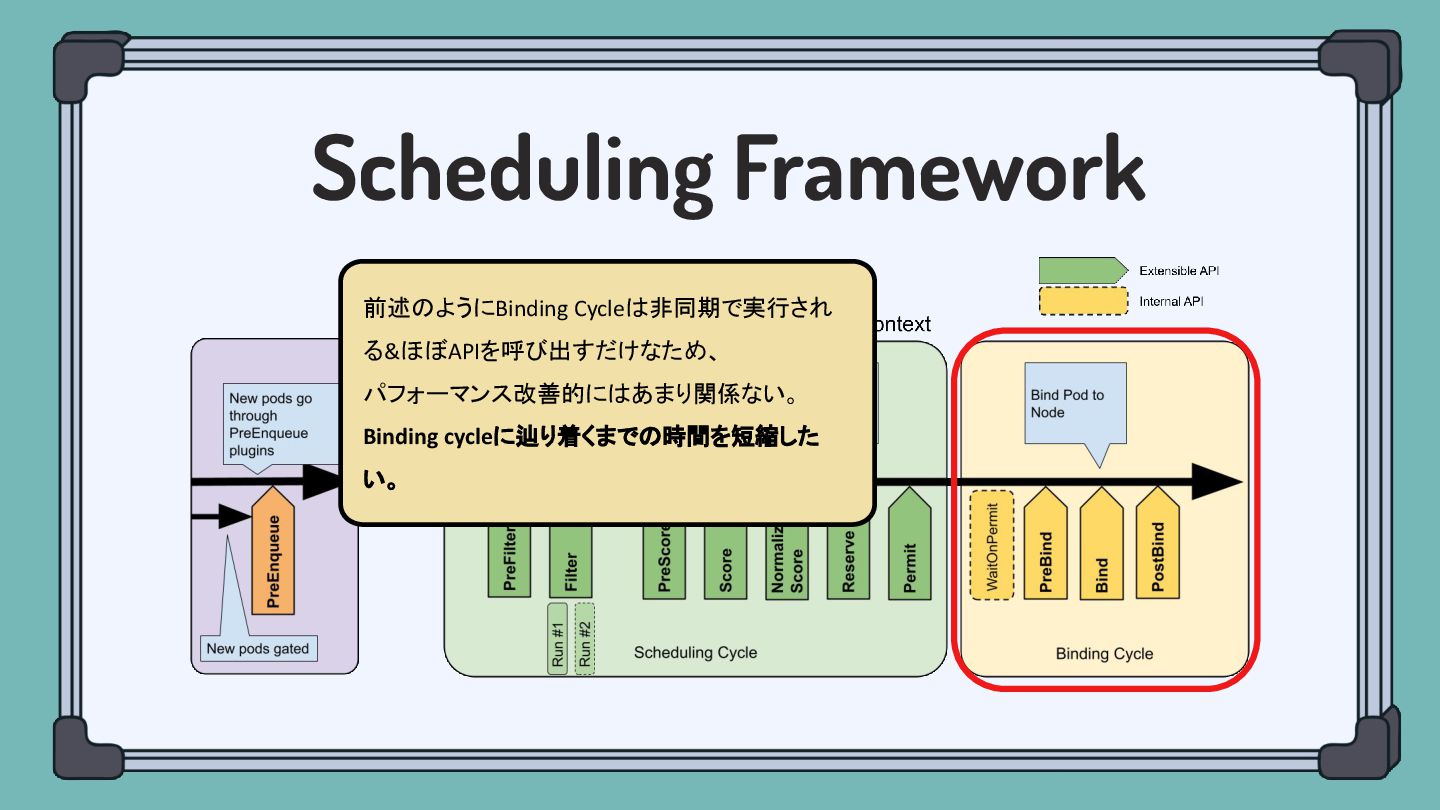
Scheduling Framework 前述のようにBinding Cycleは非同期で実行され る&ほぼAPIを呼び出すだけなため、 パフォーマンス改善的にはあまり関係ない。 Binding cycleに辿り着くまでの時間を短縮した い。
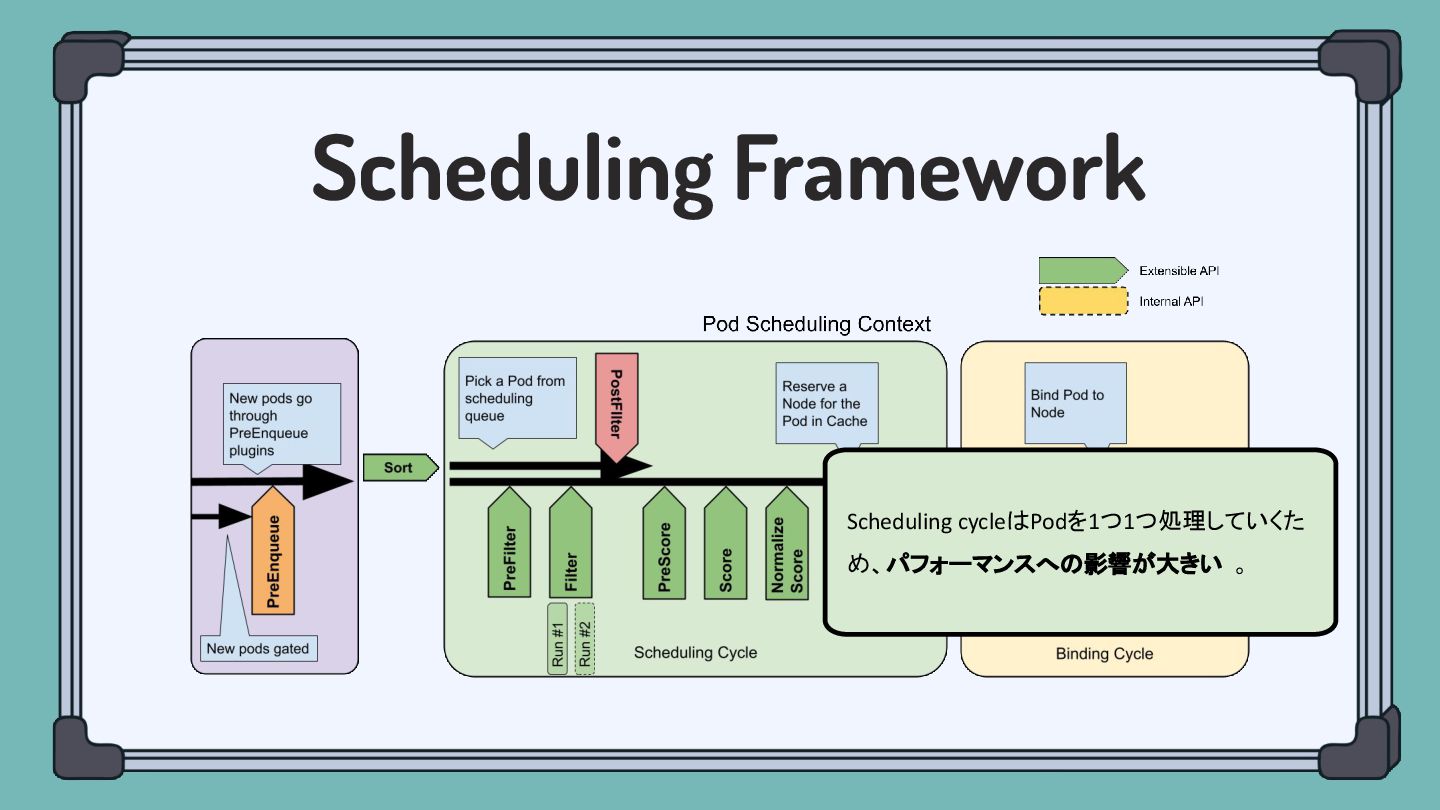
Scheduling Framework Scheduling cycleはPodを1つ1つ処理していくた め、パフォーマンスへの影響が大きい 。
パフォーマンス改善 1: Scheduling Cycle Pod1つあたりのSchedulingにかかる時間を減らす • Plugin自体の処理効率を上げる ◦ 事前に計算できる部分は PreXXXXに処理を移す
• FrameworkのInterfaceに手を加えてより効率的にPluginが動けるようにする ◦ PreFilterResult: 複数のNodeをPreFilter時点で除外できるようにする ◦ Skip: 不要なPluginはその後の拡張点で呼ばれないようにする • PreemptionのAPIの呼び出しを非同期に (KEP-4832, 計画中未実装)
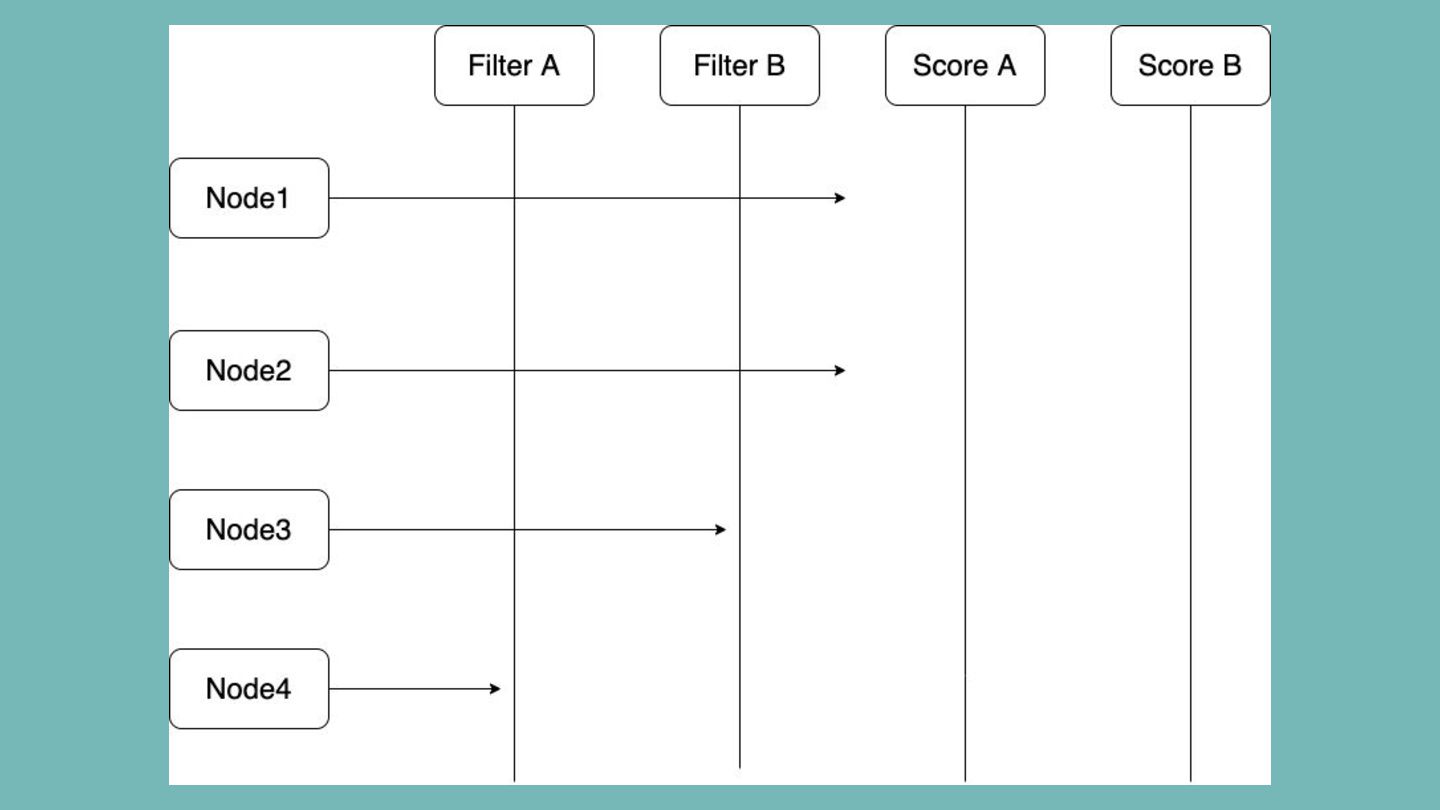
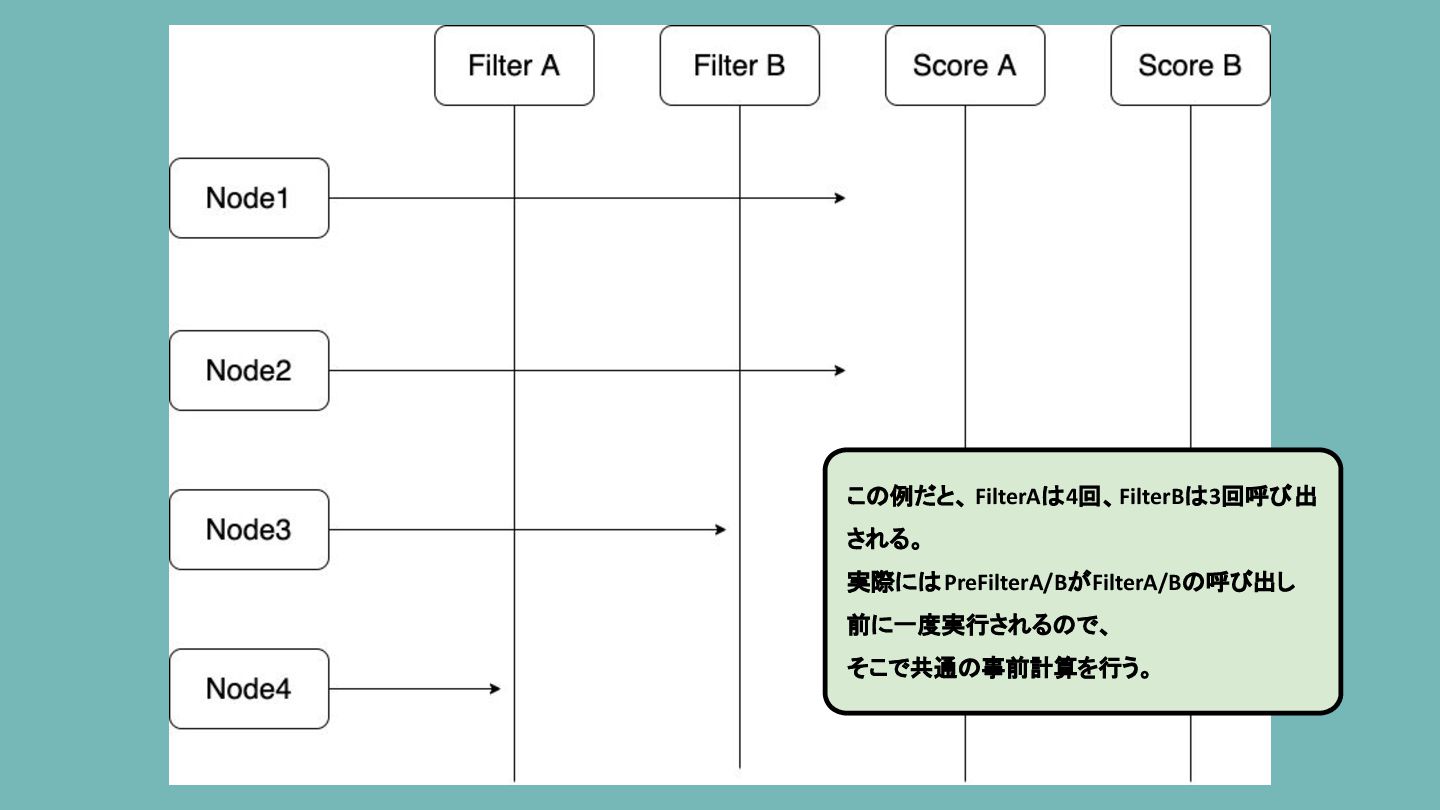
パフォーマンス改善 1-1: plugins Plugin自体の処理効率を上げるために、 PreXXXXを活用した事前処理を行う。 • PreFilterはScheduling cycle中に一度だけ呼び出され、 Filterを実行する前に共通の事前計算を行える •
FilterはそれぞれのNodeに対して実行されるため、 できるだけ事前計算できる部分は PreFilterに移動した方が効率が良い
この例だと、 FilterAは4回、FilterBは3回呼び出 される。 実際にはPreFilterA/BがFilterA/Bの呼び出し 前に一度実行されるので、 そこで共通の事前計算を行う。
パフォーマンス改善 1-2: framework • PreFilterResult: 複数のNodeをPreFilter時点で除外できるようにする ◦ 例: metadata.nameに対するNodeAffinityがPodに指定されている時、PreFilterの段階で、その指 定Node以外を除外できる
• Skip: 不要なPluginはその後の拡張点で呼ばれないようにする ◦ 例: NodeAffinityを持っていないPodのSchedule中、NodeAffinityを呼び出す必要はない → NodeAffinity#PreFilterがSkipを返すことでFilterが呼ばれなくなる
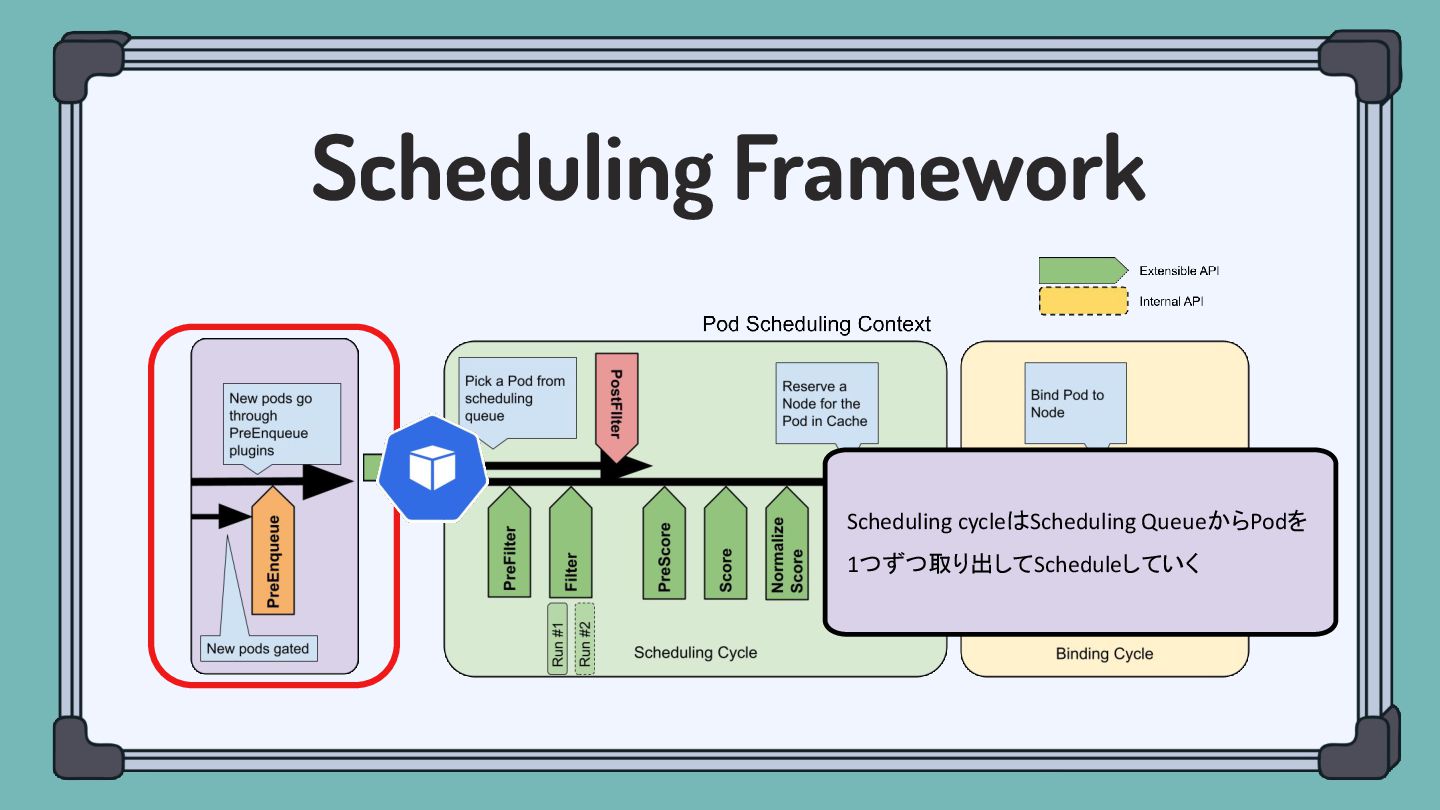
Scheduling Framework Scheduling cycleはScheduling QueueからPodを 1つずつ取り出してScheduleしていく
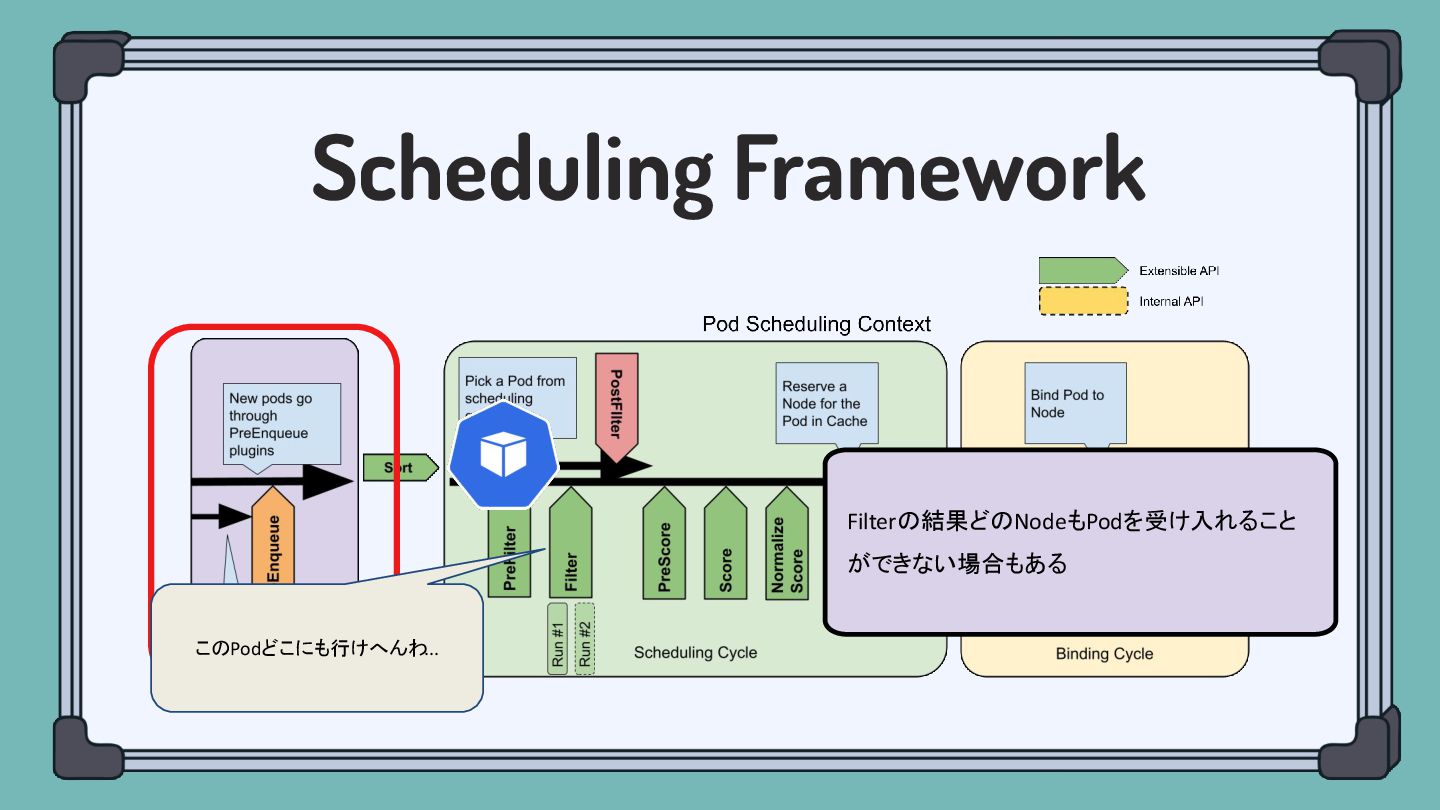
Scheduling Framework Filterの結果どのNodeもPodを受け入れること ができない場合もある このPodどこにも行けへんわ ...
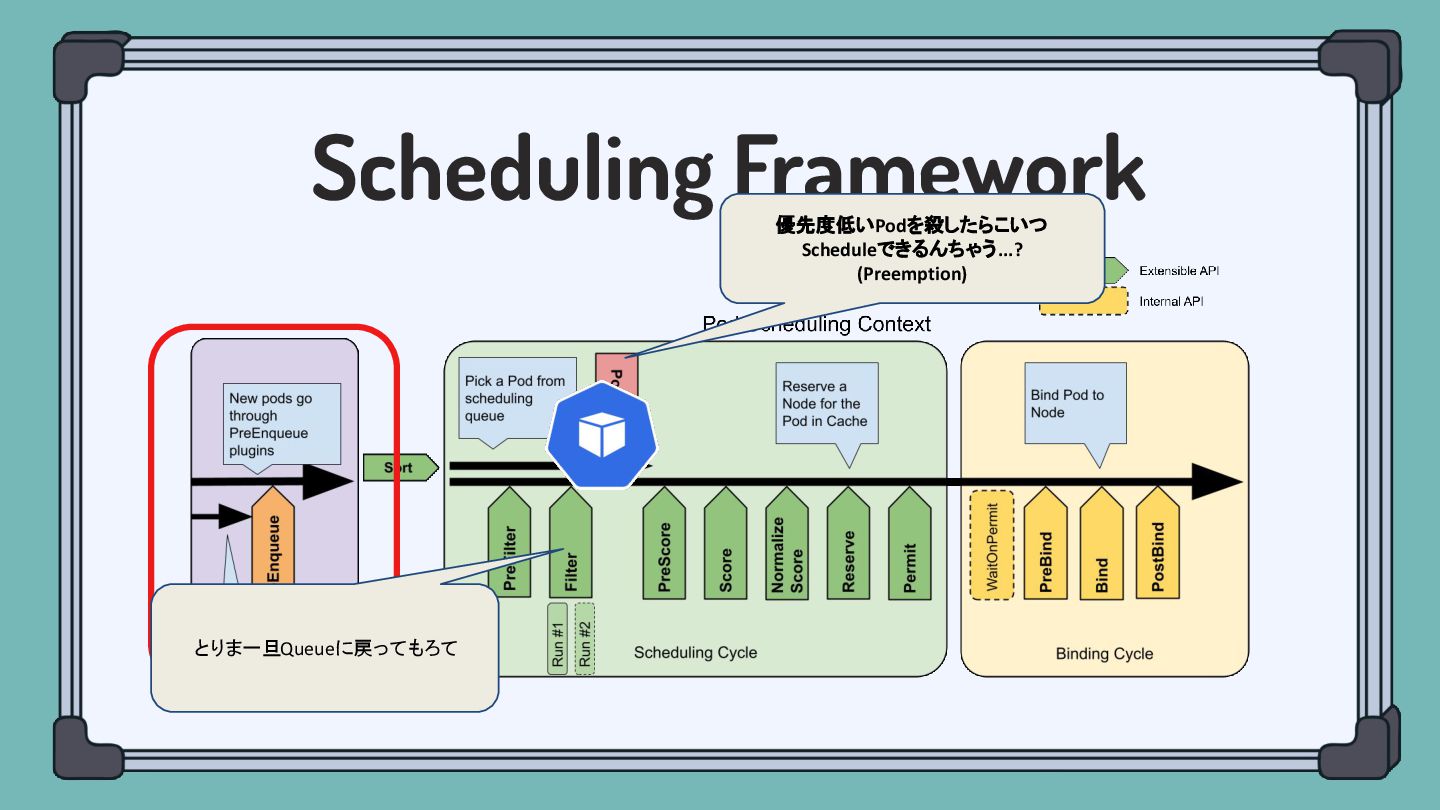
Scheduling Framework とりま一旦Queueに戻ってもろて 優先度低いPodを殺したらこいつ Scheduleできるんちゃう...? (Preemption)
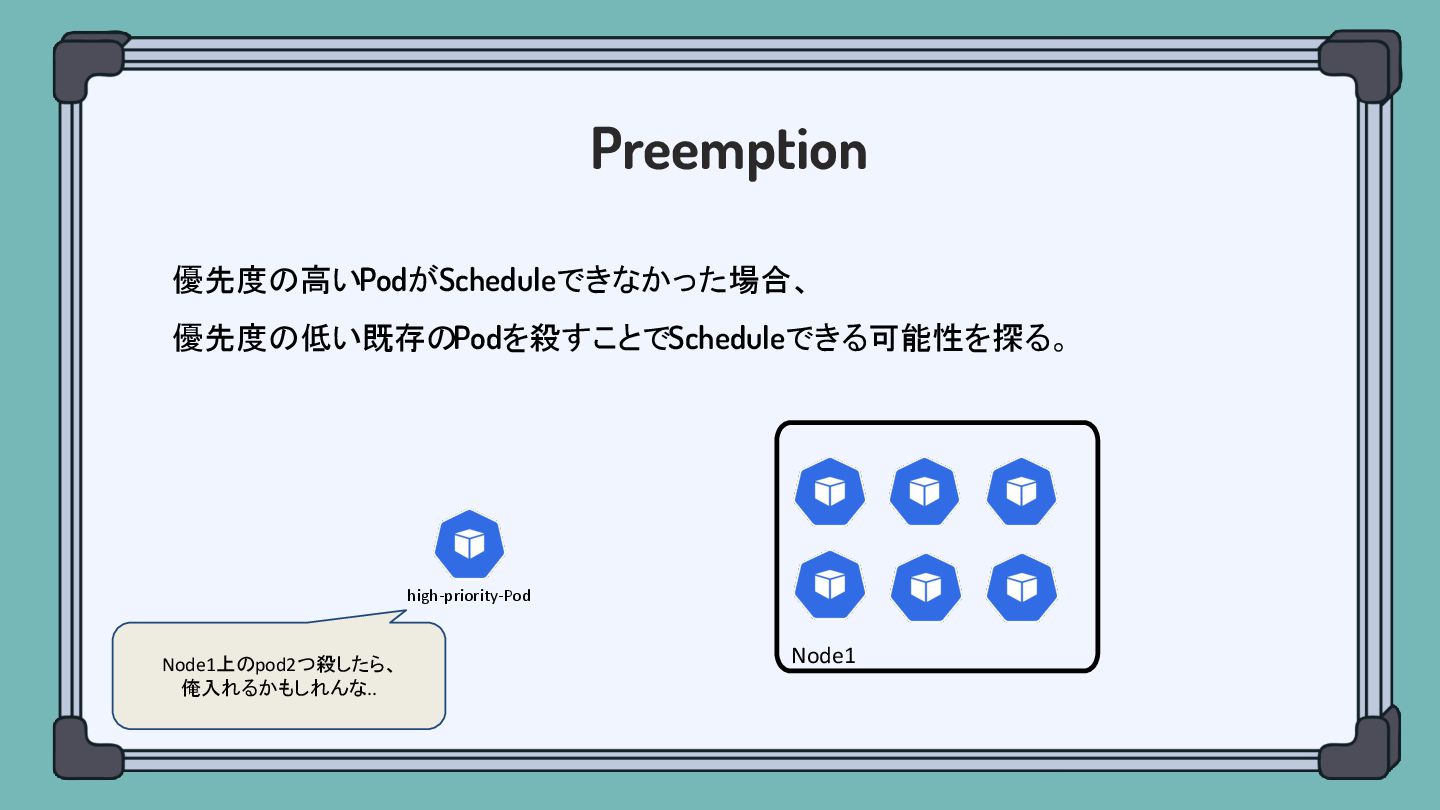
Preemption 優先度の高いPodがScheduleできなかった場合、 優先度の低い既存のPodを殺すことでScheduleできる可能性を探る。 Node1 high-priority-Pod Node1上のpod2つ殺したら、 俺入れるかもしれんな ...
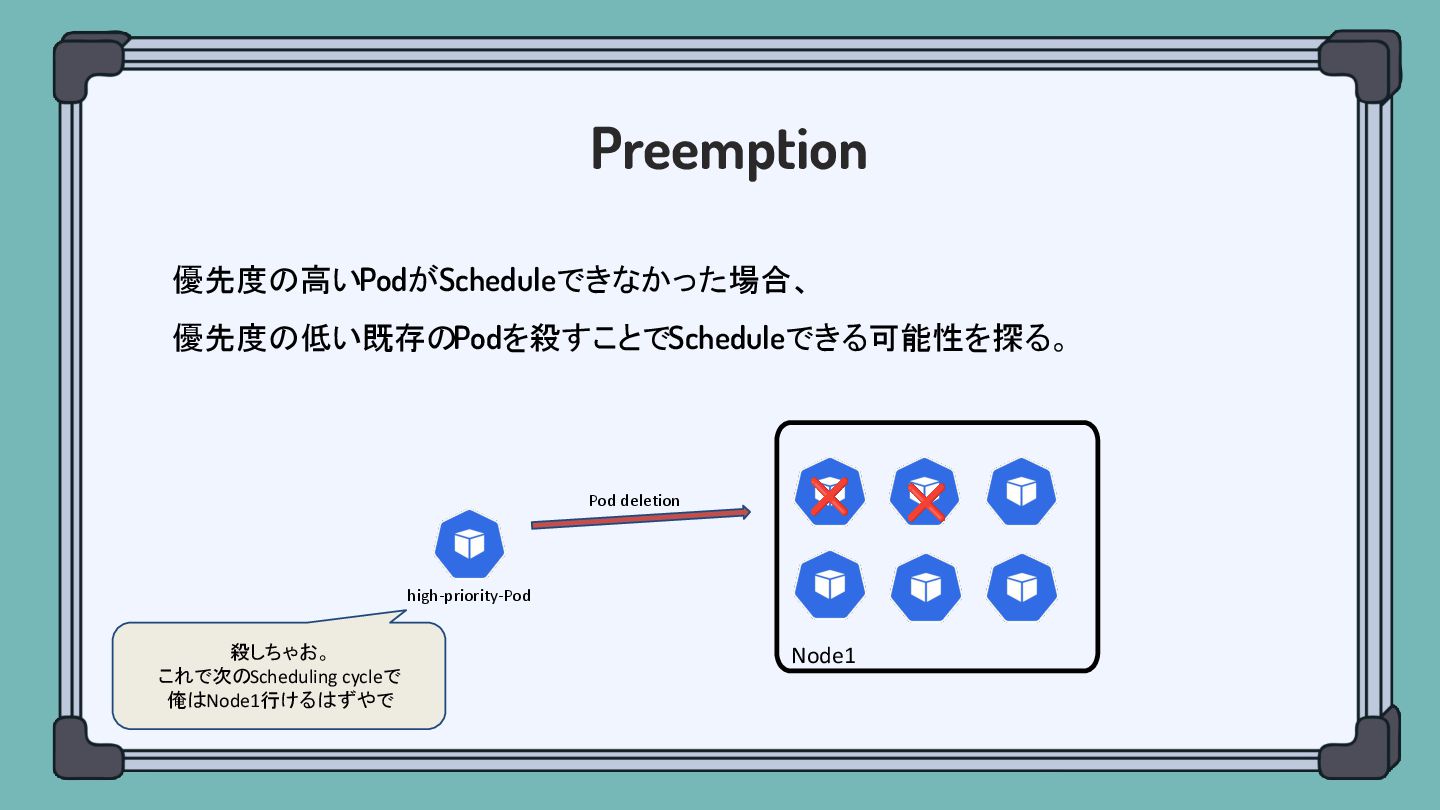
Preemption 優先度の高いPodがScheduleできなかった場合、 優先度の低い既存のPodを殺すことでScheduleできる可能性を探る。 Node1 high-priority-Pod 殺しちゃお。 これで次のScheduling cycleで 俺はNode1行けるはずやで ❌
❌ Pod deletion
パフォーマンス改善 1-3: preemption (WIP) Preemptionが発生する場合、Pod削除などのAPI呼び出しの部分で時間がかかってしま い、全体のScheduling throughputに影響が出る。 Binding cycleを非同期に実行しているように、 PreemptionのAPI呼び出し部分も非同期に行って、他の
PodのSchedulingをブロックしない ようにしたい (KEP-4832として議論中)
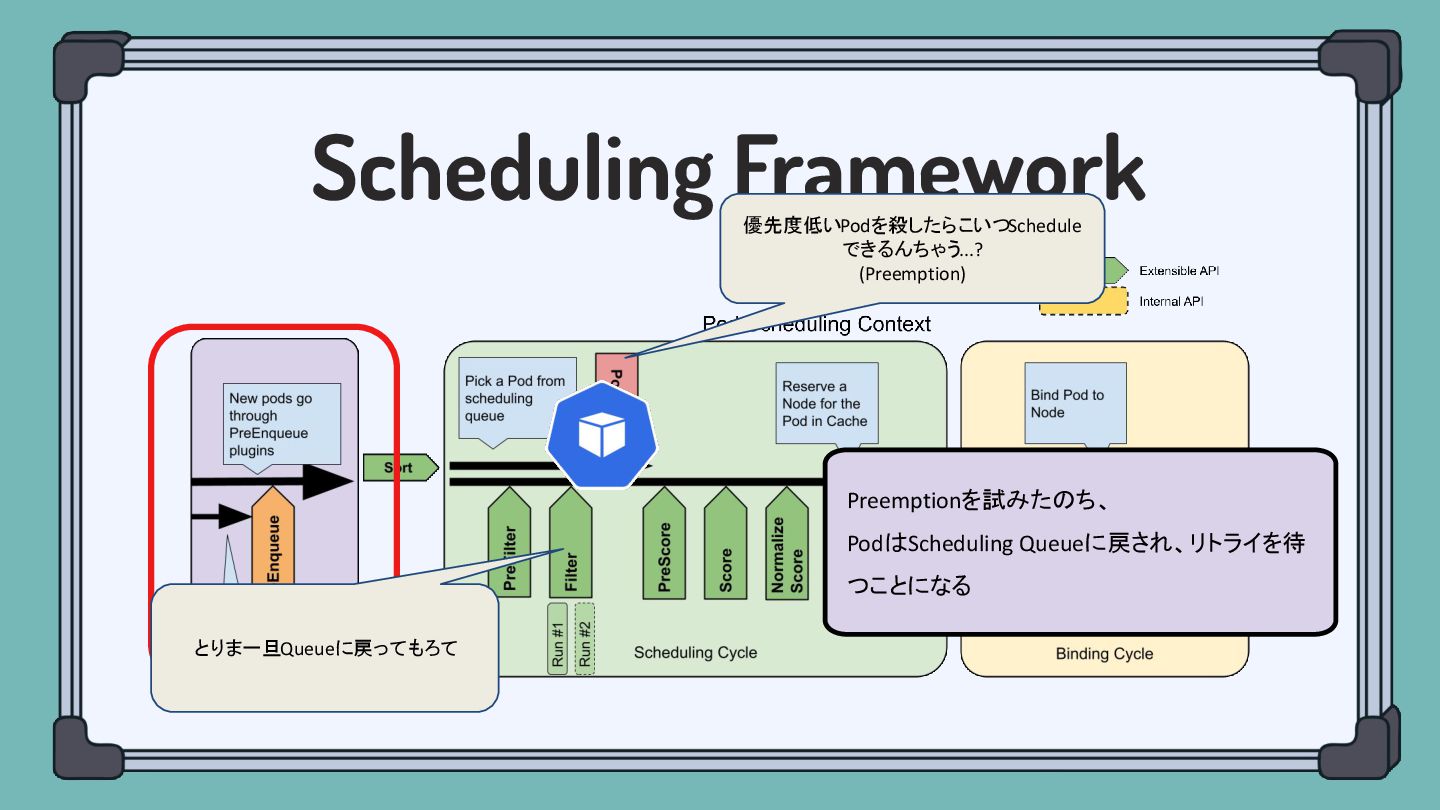
Scheduling Framework Preemptionを試みたのち、 PodはScheduling Queueに戻され、リトライを待 つことになる とりま一旦Queueに戻ってもろて 優先度低いPodを殺したらこいつSchedule できるんちゃう...? (Preemption)
Scheduling Framework Preemptionを試みたのち、 PodはScheduling Queueに戻され、リトライを待 つことになる とりま一旦Queueに戻ってもろて 優先度低いPodを殺したらこいつSchedule できるんちゃう...? (Preemption)
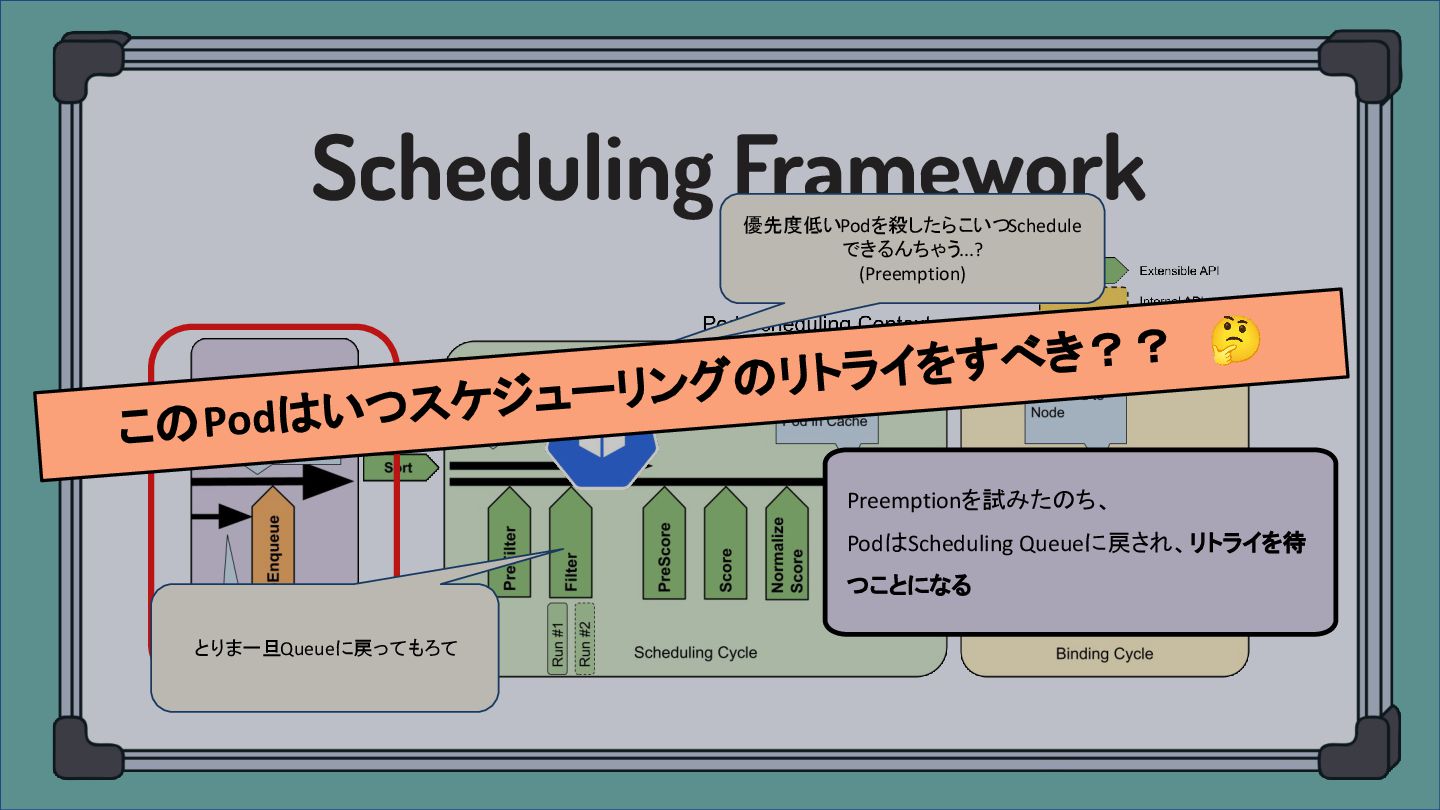
このPodはいつスケジューリングのリトライをすべき?? 🤔
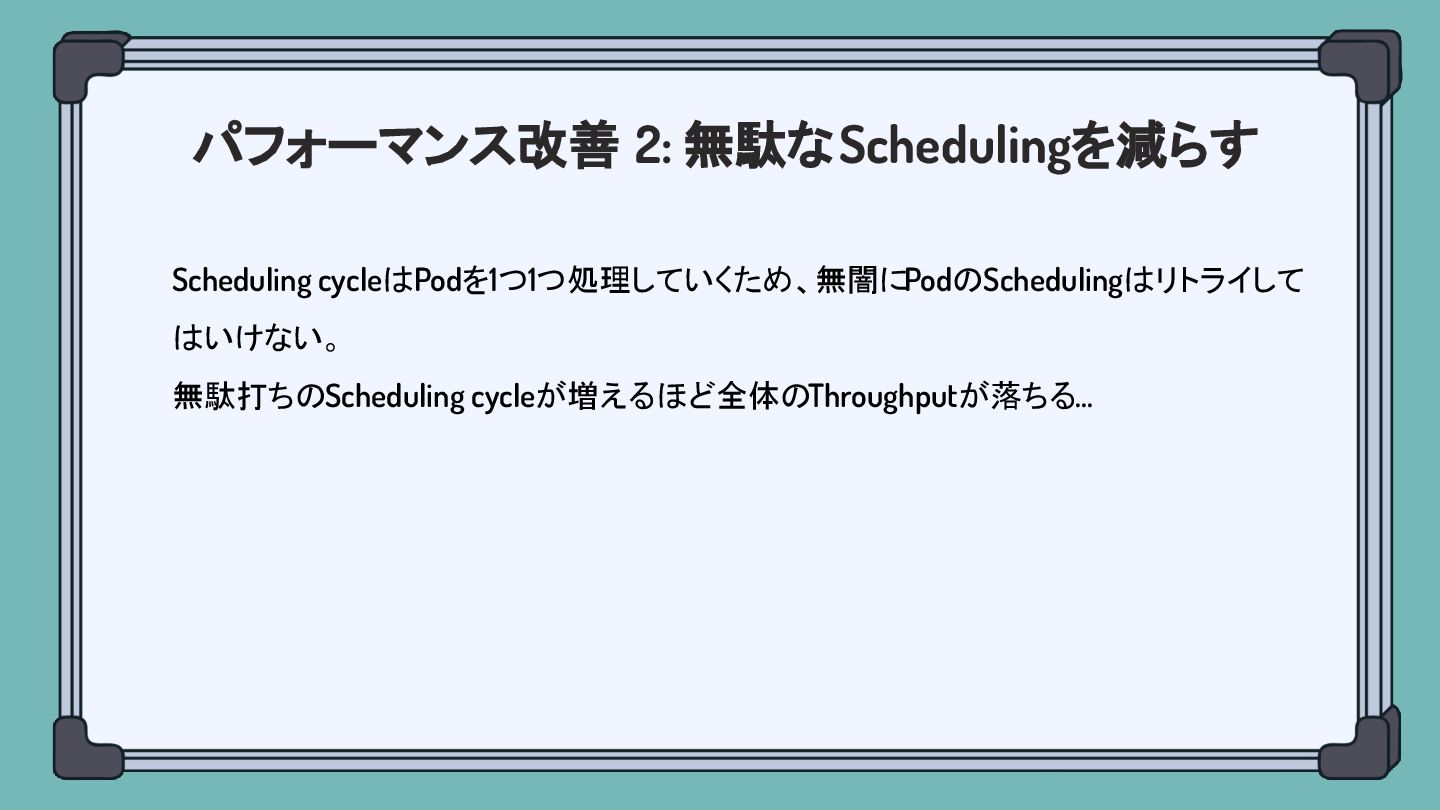
パフォーマンス改善 2: 無駄なSchedulingを減らす Scheduling cycleはPodを1つ1つ処理していくため、無闇にPodのSchedulingはリトライして はいけない。 無駄打ちのScheduling cycleが増えるほど全体のThroughputが落ちる...
パフォーマンス改善 2: 無駄なSchedulingを減らす Scheduling cycleはPodを1つ1つ処理していくため、無闇にPodのSchedulingはリトライして はいけない。 無駄打ちのScheduling cycleが増えるほど全体のThroughputが落ちる... 次のSchedulingでScheduleされる見込みがある場合のみリトライしたい。
Scheduling Queue Schedule待ちのPodはScheduling Queueにて待機させられる。 内部は3つの待機場所に別れている: • ActiveQ: Schedule待ちのPodたち • BackoffQ:
Backoff中のPodたち。Backoff終了後ActiveQへ移動される。 • Unschedulable Pod Pool: 待機中のPodたち
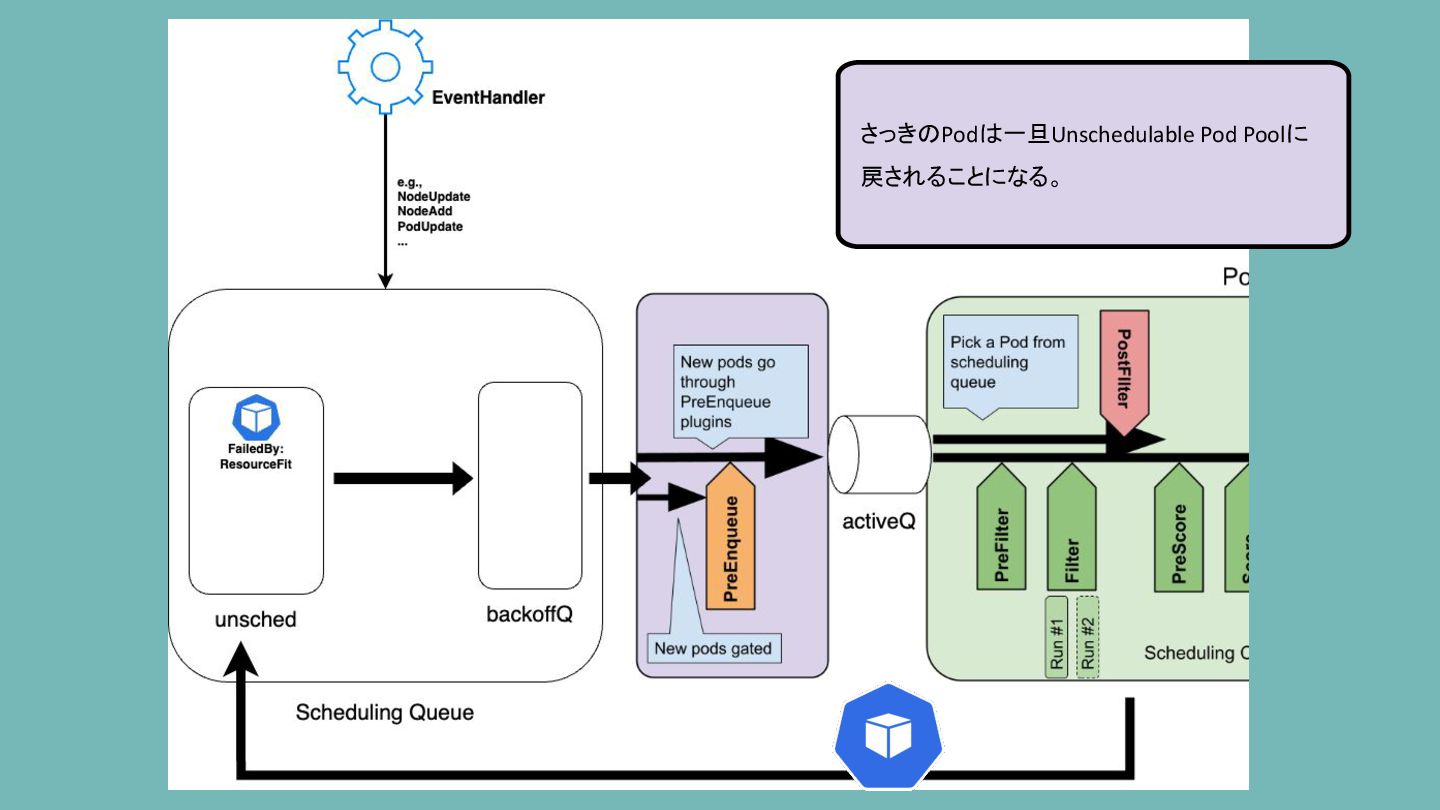
Scheduling Queue さっきのPodは一旦Unschedulable Pod Poolに 戻されることになる。
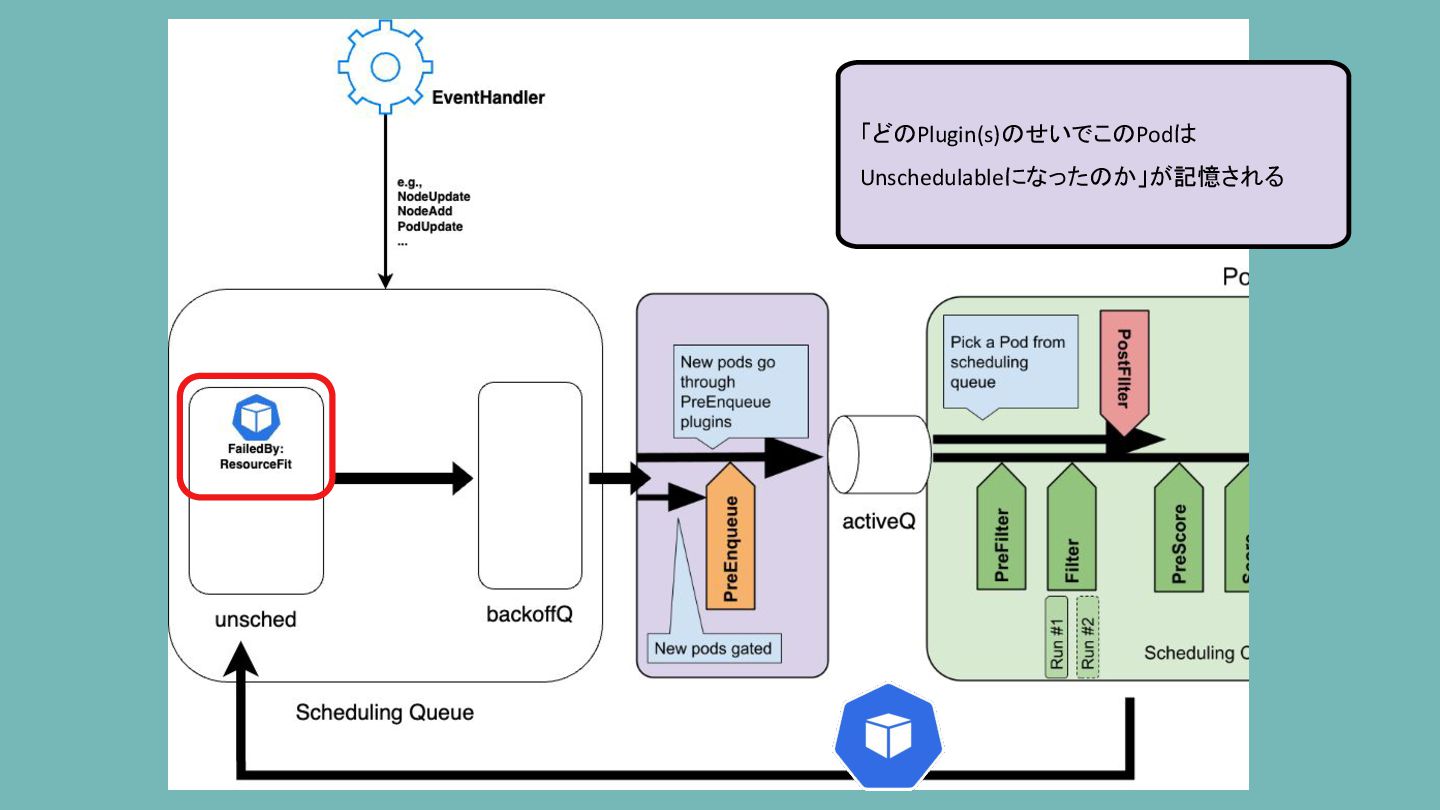
Scheduling Queue 「どのPlugin(s)のせいでこのPodは Unschedulableになったのか」が記憶される
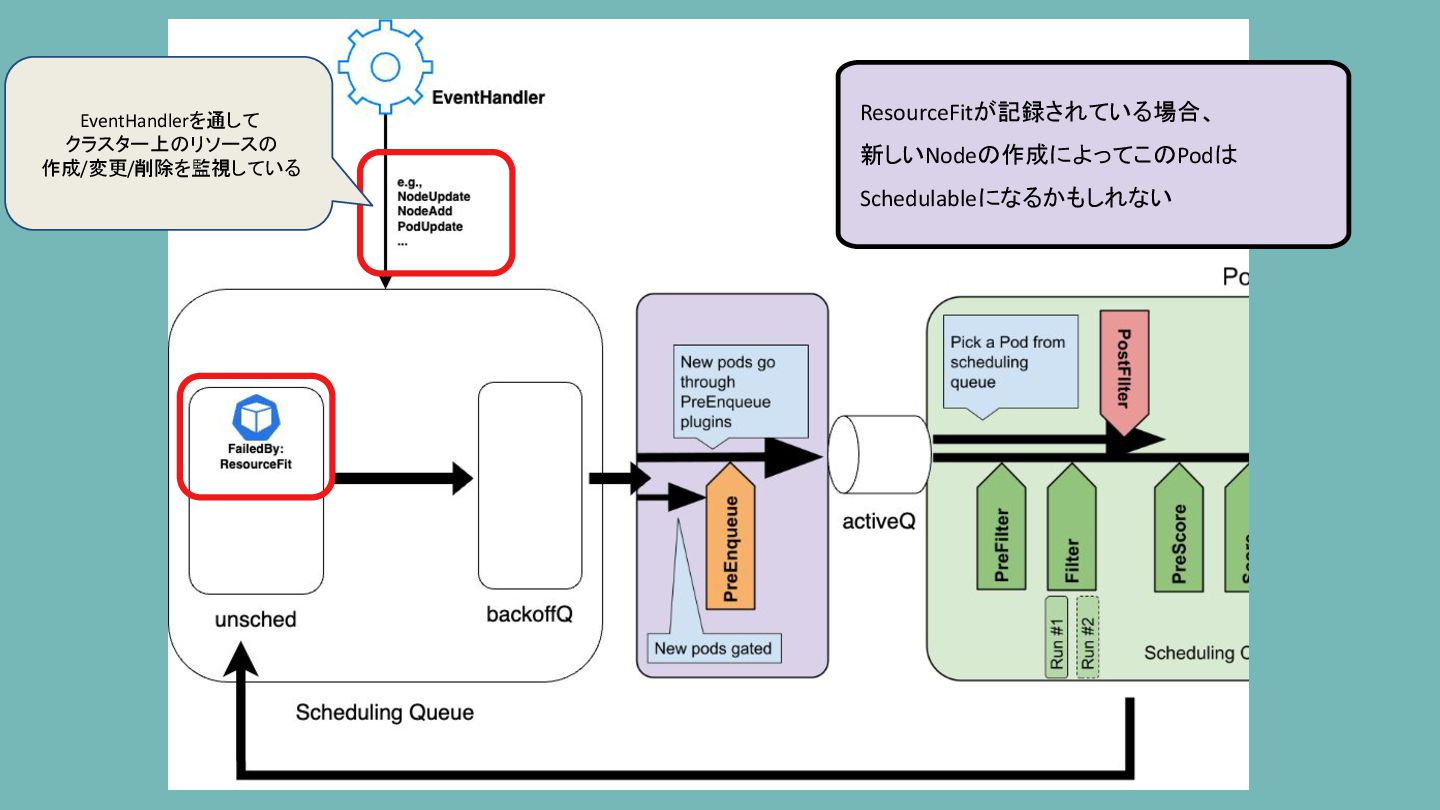
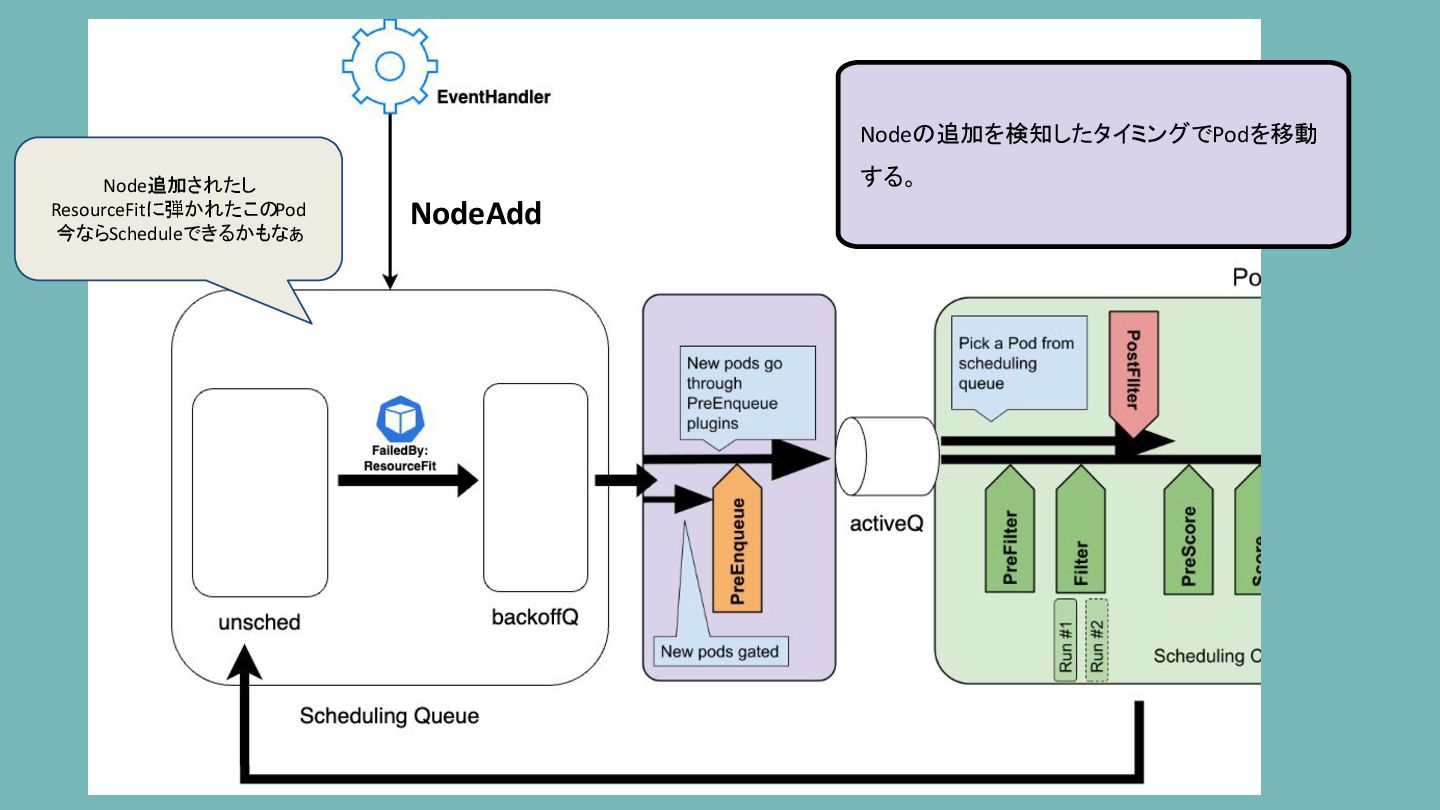
Scheduling Queue ResourceFitが記録されている場合、 新しいNodeの作成によってこのPodは Schedulableになるかもしれない EventHandlerを通して クラスター上のリソースの 作成/変更/削除を監視している
Nodeの追加を検知したタイミングでPodを移動 する。 NodeAdd Node追加されたし ResourceFitに弾かれたこのPod 今ならScheduleできるかもなぁ
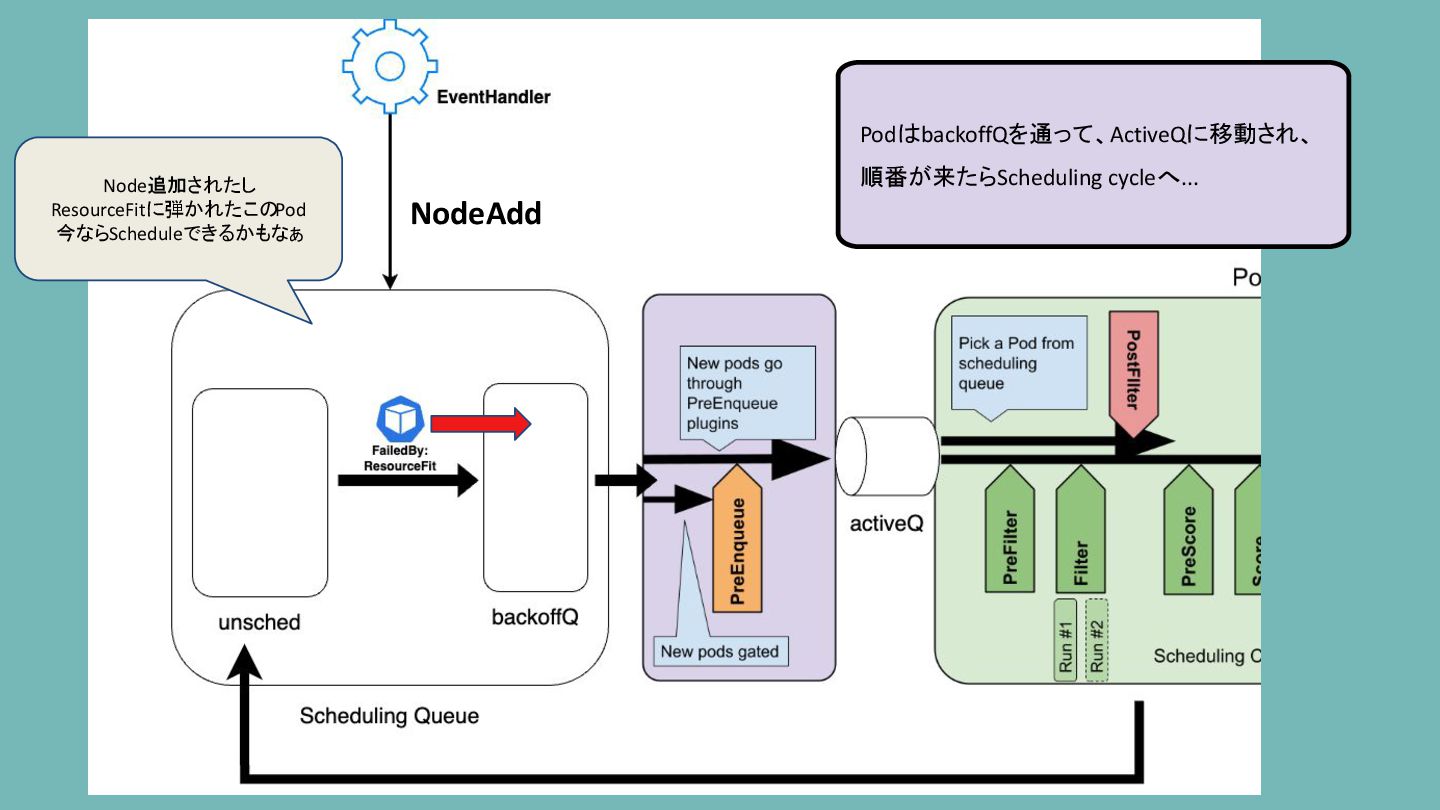
PodはbackoffQを通って、ActiveQに移動され、 順番が来たらScheduling cycleへ... NodeAdd Node追加されたし ResourceFitに弾かれたこのPod 今ならScheduleできるかもなぁ
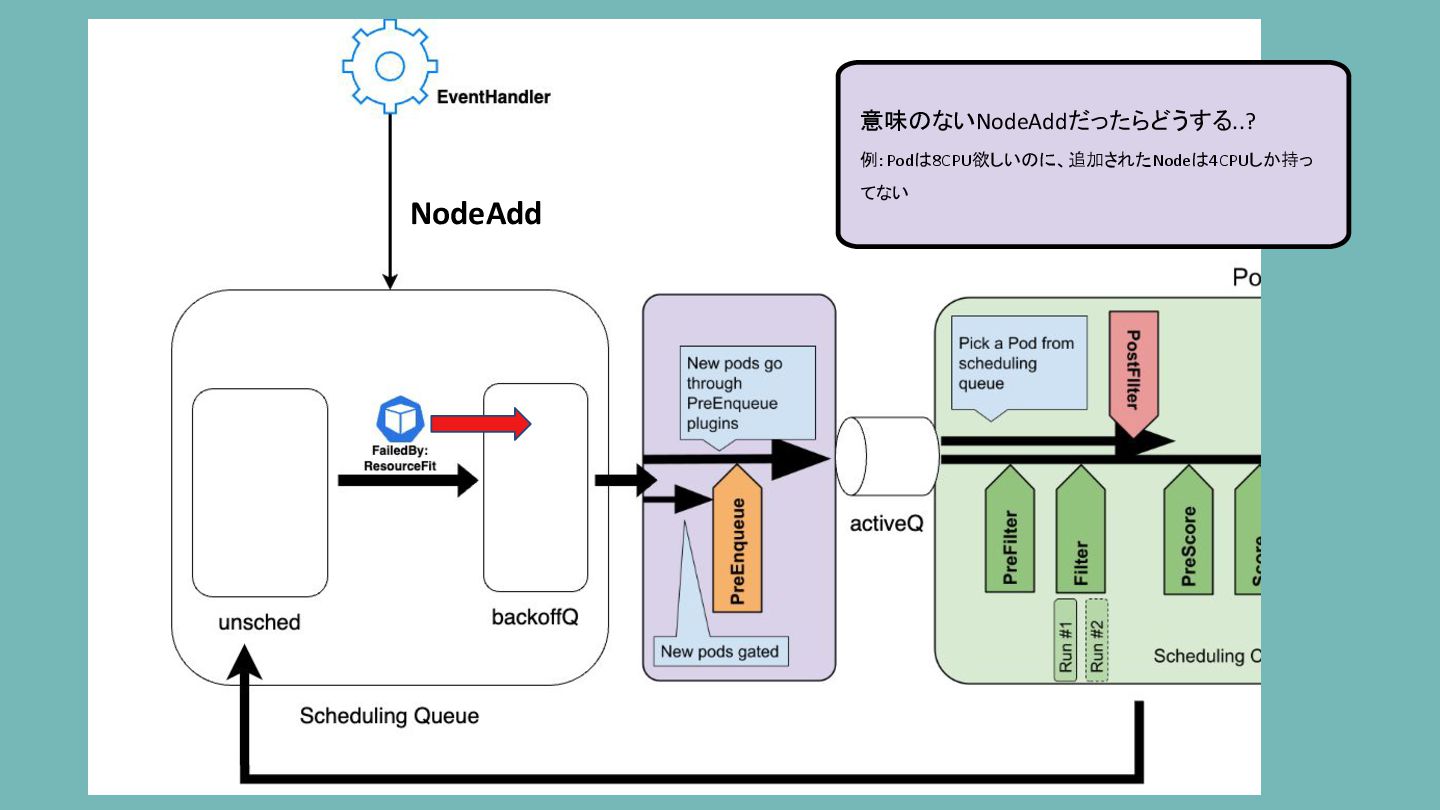
意味のないNodeAddだったらどうする..? 例: Podは8CPU欲しいのに、追加されたNodeは4CPUしか持っ てない NodeAdd
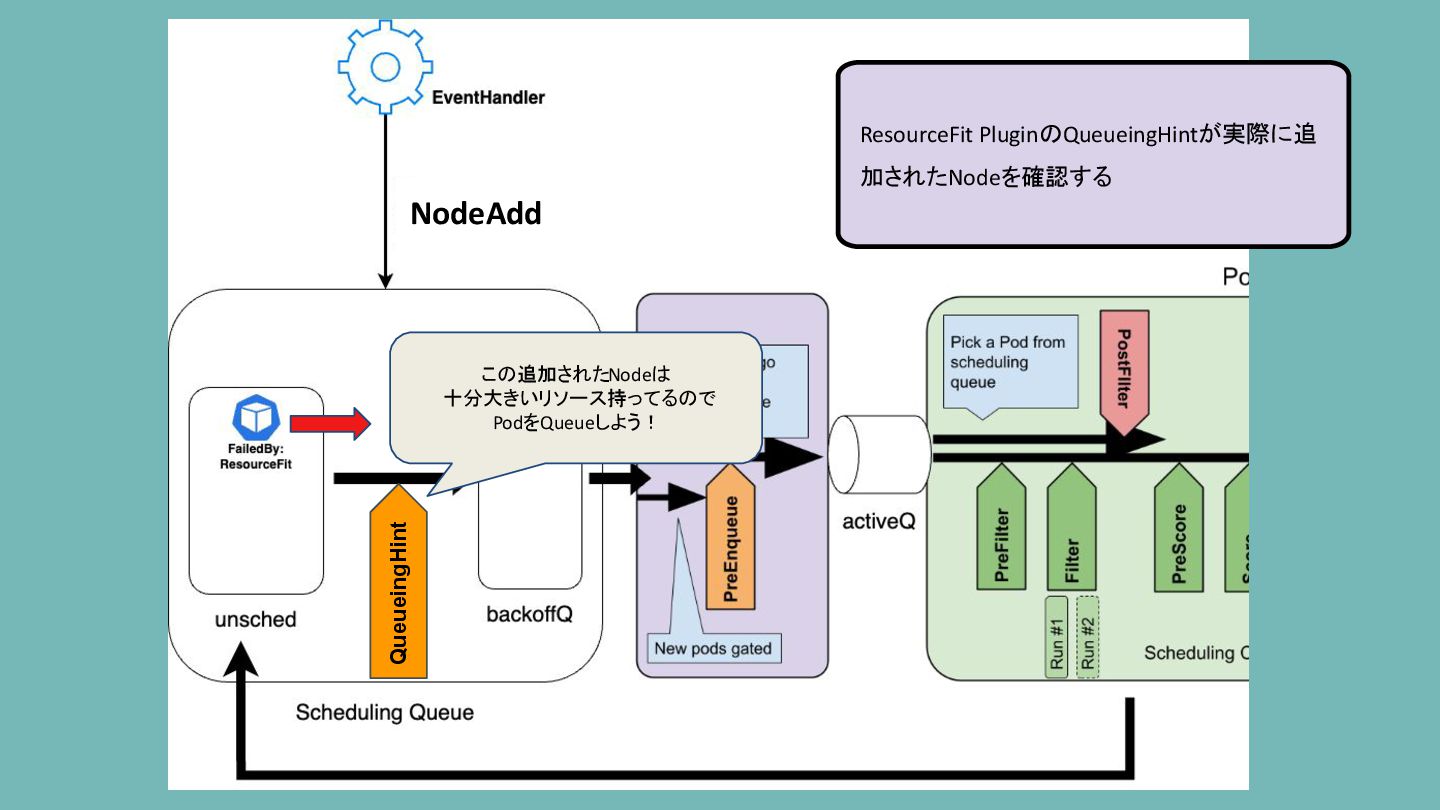
KEP-4247: QueueingHint どのClusterEventでPodをRequeueするか問い合わせることで正確なリトライを行う 例: NodeAdd or Updateが発生した時にisSchedulableAfterNodeChangeが呼び出される。 isSchedulableAfterNodeChangeがそのNodeAdd/UpdateでPodをQueueすべきか否かを決定する。
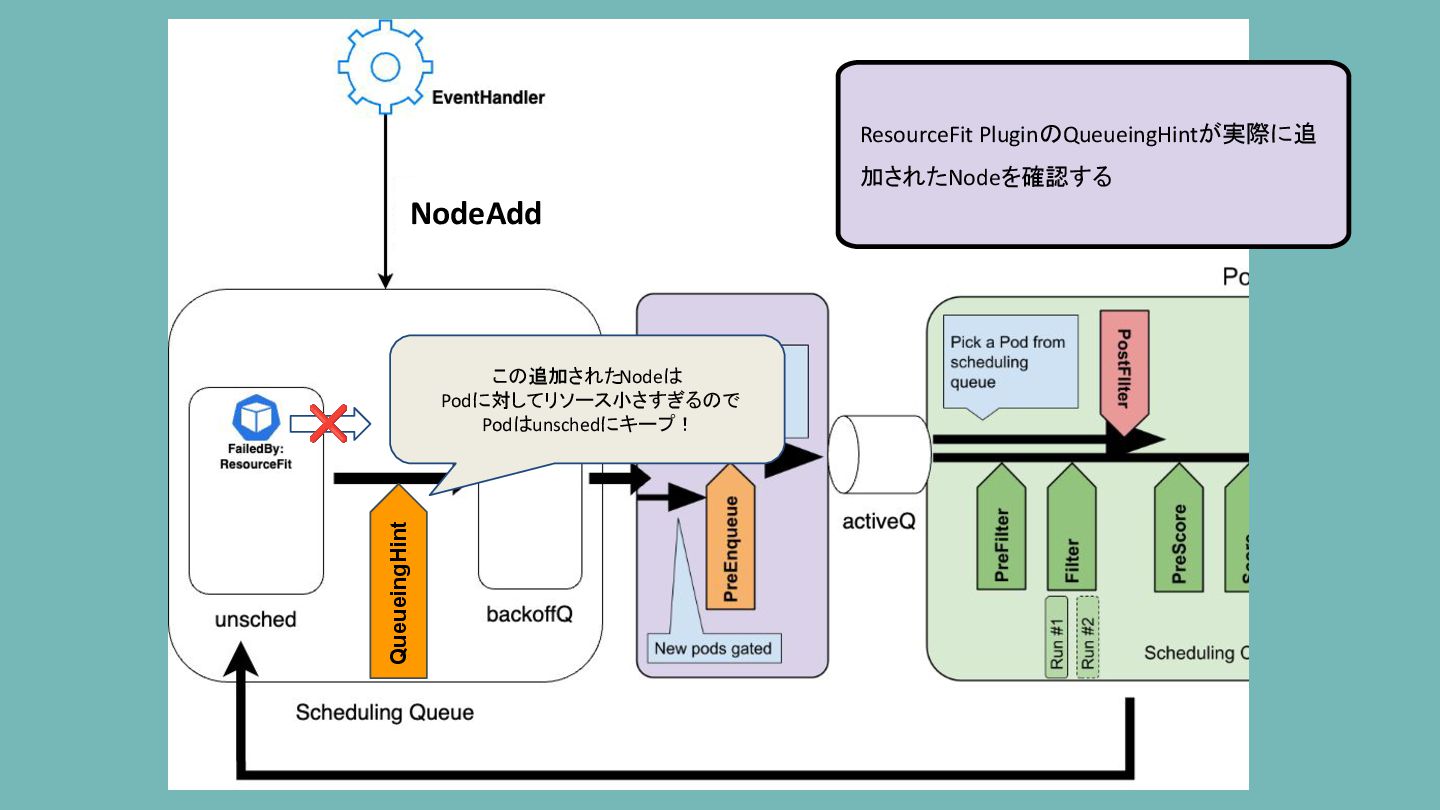
ResourceFit PluginのQueueingHintが実際に追 加されたNodeを確認する NodeAdd QueueingHint この追加されたNodeは 十分大きいリソース持ってるので PodをQueueしよう!
ResourceFit PluginのQueueingHintが実際に追 加されたNodeを確認する NodeAdd QueueingHint この追加されたNodeは Podに対してリソース小さすぎるので Podはunschedにキープ! ❌
パフォーマンス改善 2: 無駄なSchedulingを減らす QueueingHintによって、Queueのタイミングをより正確に決定できるようになった 2つのメリット • 無駄なScheduling cycle消費が減る。
パフォーマンス改善 2: 無駄なSchedulingを減らす QueueingHintによって、Queueのタイミングをより正確に決定できるようになった 2つのメリット • 無駄なScheduling cycle消費が減る。 • Podが受けるBackoffの時間が短くなる。 ←
🤔
[復習] Scheduling Queue Schedule待ちのPodはScheduling Queueにて待機させられる。 内部は3つの待機場所に別れている: • ActiveQ: Schedule待ちのPodたち •
BackoffQ: Backoff中のPodたち。Backoff終了後ActiveQへ移動される。 • Unschedulable Pod Pool: 待機中のPodたち
BackoffQ…? そもそもなぜBackoffQが必要なのか? • Schedulerにおける、BackoffとはScheduling cycleを浪費した罰である ◦ Scheduling cycleを浪費すればするほどその PodのBackoffは長くなっていく •
特定のPodがScheduling cycleを浪費しまくって、他のPodのSchedulingが遅れるのを 防ぐために必要
パフォーマンス改善 2: 無駄なSchedulingを減らす QueueingHintによって、Queueのタイミングをより正確に決定できるようになった 2つのメリット • 無駄なScheduling cycle消費が減る。 • Podが受けるBackoffの時間が短くなる。
◦ ↑ QueueingHintは無駄なScheduling cycleの浪費を減らすことは、 PodがBackoffを受ける回数を減らす(時間も短くする)ことにもなる
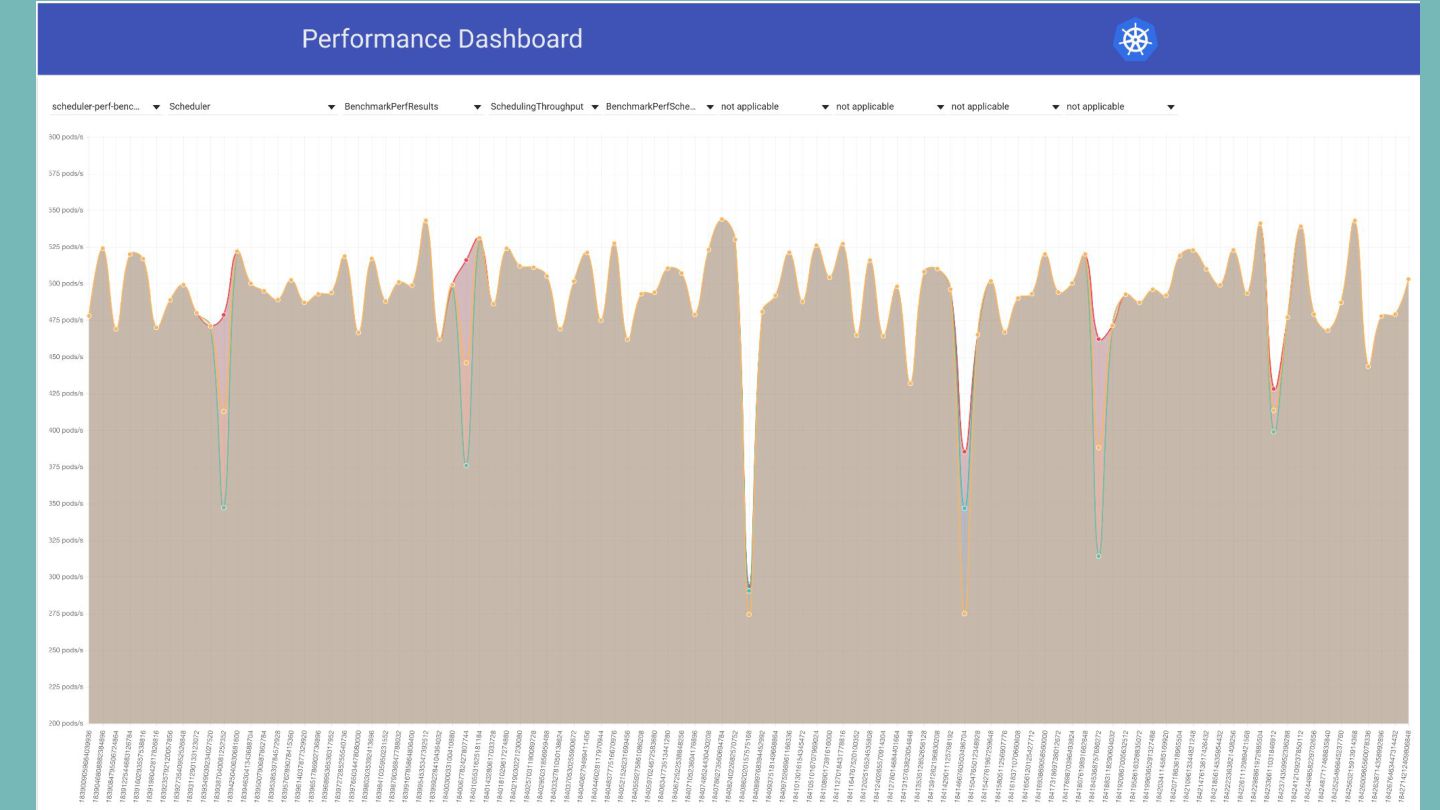
その他: scheduler-perf アップストリームで使用しているパフォーマンステスト。 perf-dash.k8s.io を見にいくとコミットごとに結果がグラフ化されている。
その他: scheduler-perf アップストリームで使用しているパフォーマンステスト。 perf-dash.k8s.io を見にいくとコミットごとに結果がグラフ化されている。
その他: scheduler-perf アップストリームで使用しているパフォーマンステスト。 perf-dash.k8s.io を見にいくとコミットごとに結果がグラフ化されている。 • テストケースごとに閾値を決めて、 Throughputが閾値を下回ったらメンテナにメー ルを飛ばす ◦
今までデグレを見逃しまくってきた過去あり • Queueing周りのテストケースを増やす (QueueingHint向け)
その他: scheduling queueのロック改善 • Scheduling Queueは1つのロックを使用して排他制御していた • QueueingHintの導入等でQueueがイベントの処理にかかる時間が増加 ◦ イベント処理中もロックは取りっぱなし
• Scheduling cycleがQueueからPodを取り出す時にもロックが必要 → イベント処理がロックを取りまくるせいで Scheduling cycleの開始が妨害されThroughput が低下
その他: scheduling queueのロック改善 内部で使用するロックをいい感じに分割しまくることで、イベント処理が Scheduling cycleを 阻害しないように改善。 今までで一番難しい PRレビューだったかも。 絶対Deadlockとかやらかすわ、と思ってたけど、
意外と問題は起こらなかった (今のとこ)
THANK YOU!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[復習] Scheduling Queue Schedule待ちのPodはScheduling Queueにて待機させられる。 内部は3つの待機場所に別れている: • ActiveQ: Schedule待ちのPodたち •](https://files.speakerdeck.com/presentations/3b567b662c7e4021bbaaedacd09dfdd8/slide_46_1742167446.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}