you an expert of kube-scheduler so that you will be confident enough to understand the recent works, and contribute to kube-scheduler. • Understand the recent works around kube-scheduler. • Understand how you can contribute to kube-scheduler, or Kubernetes, in general. Feel free to give me questions while I’m presenting. You can ask questions even in Vietnamese, then someone will help translate it (please!).
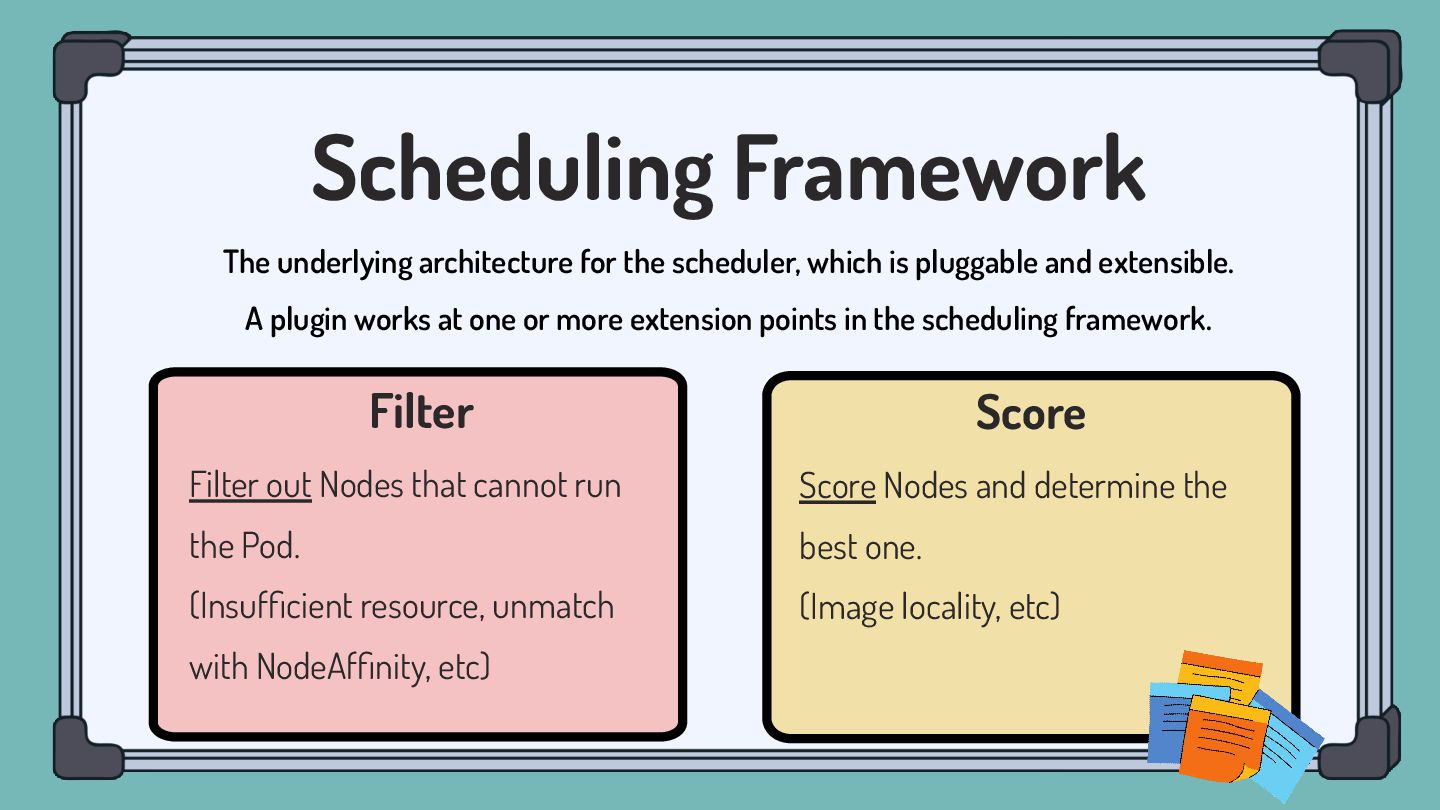
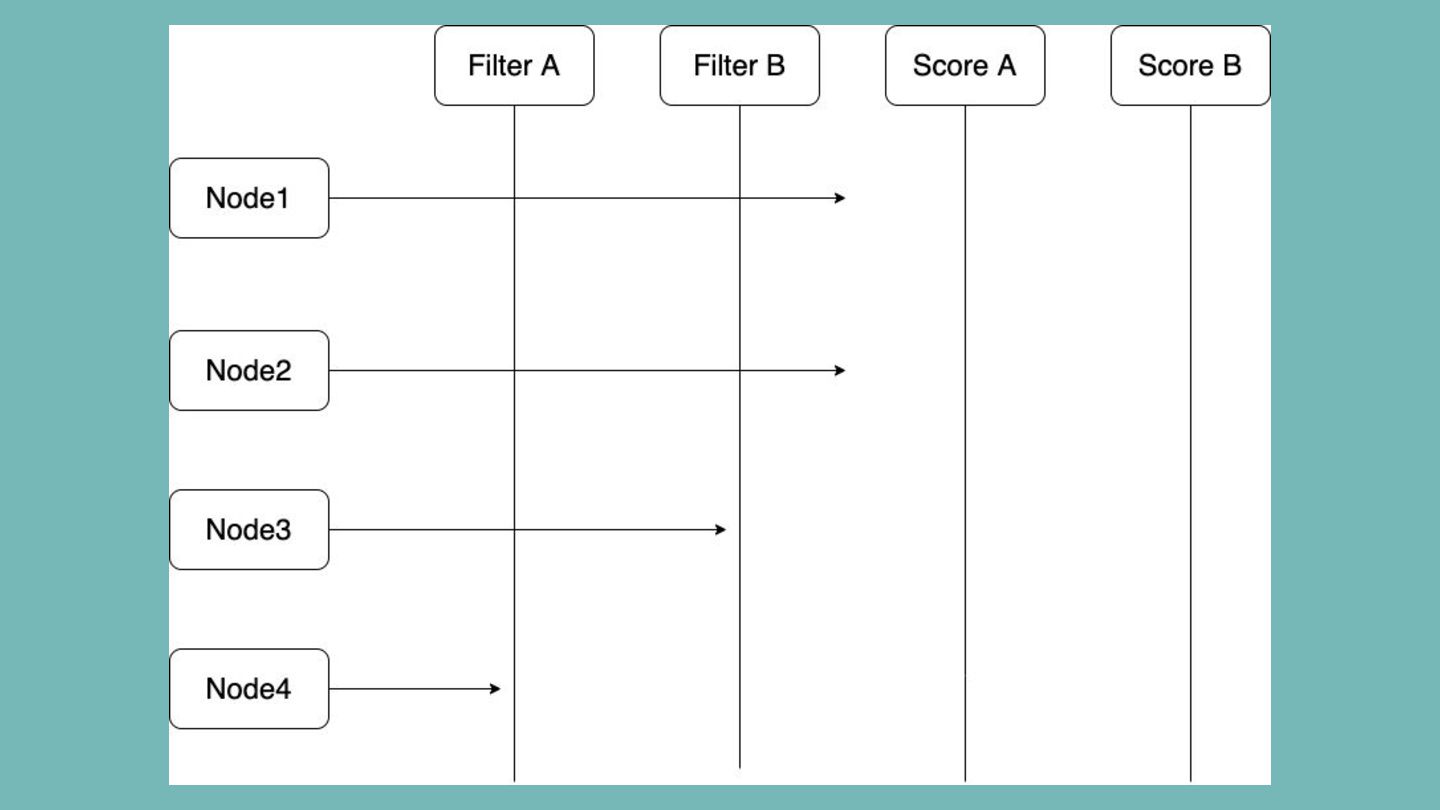
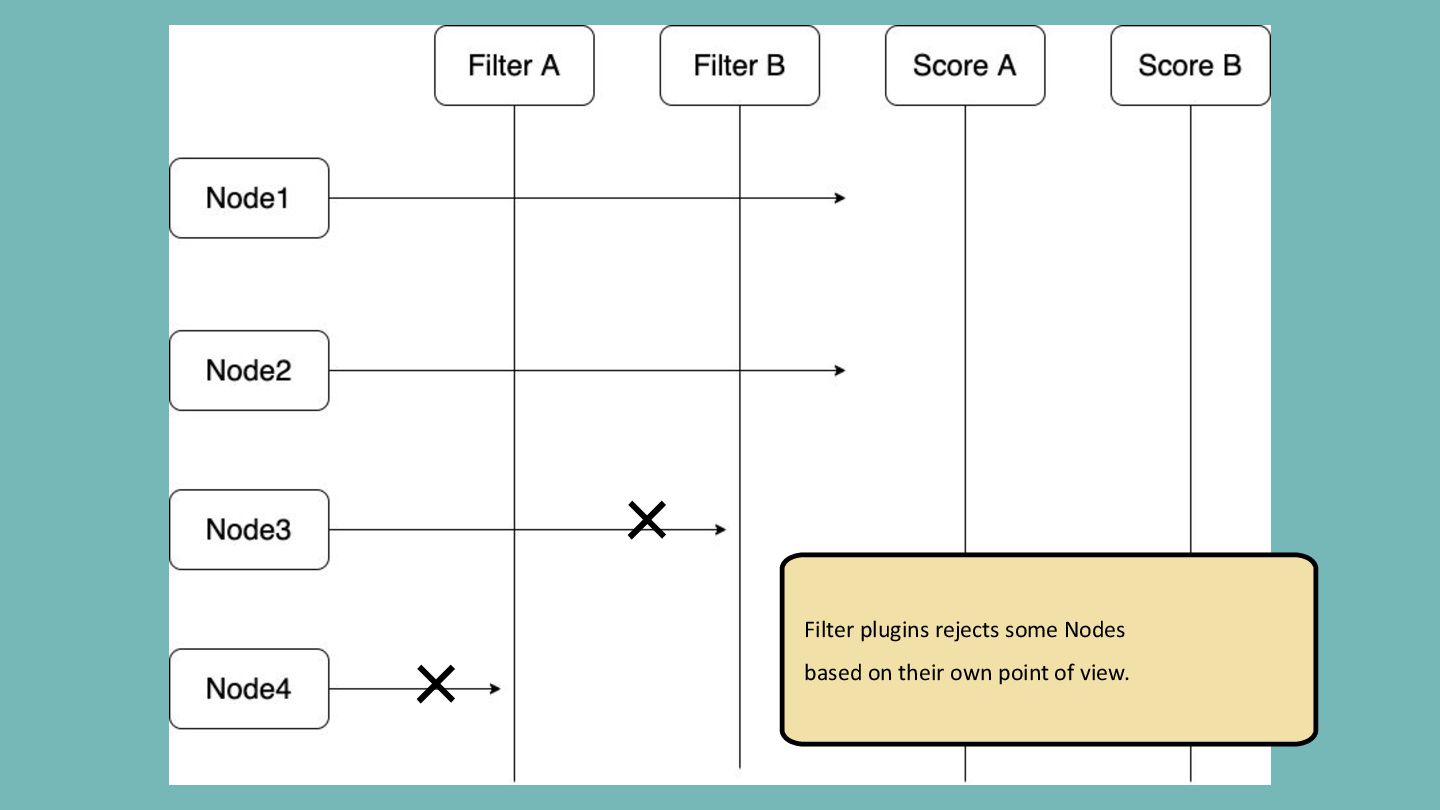
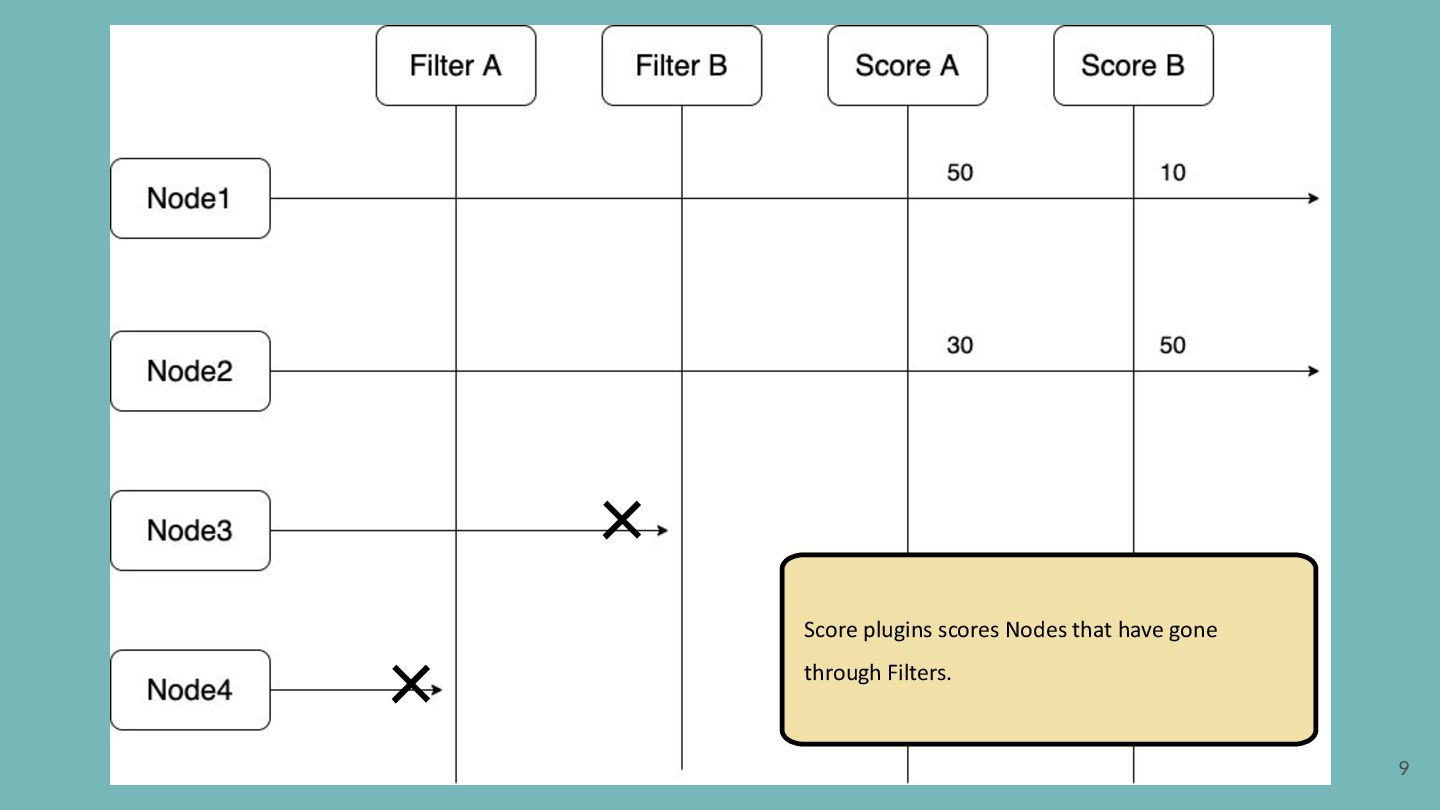
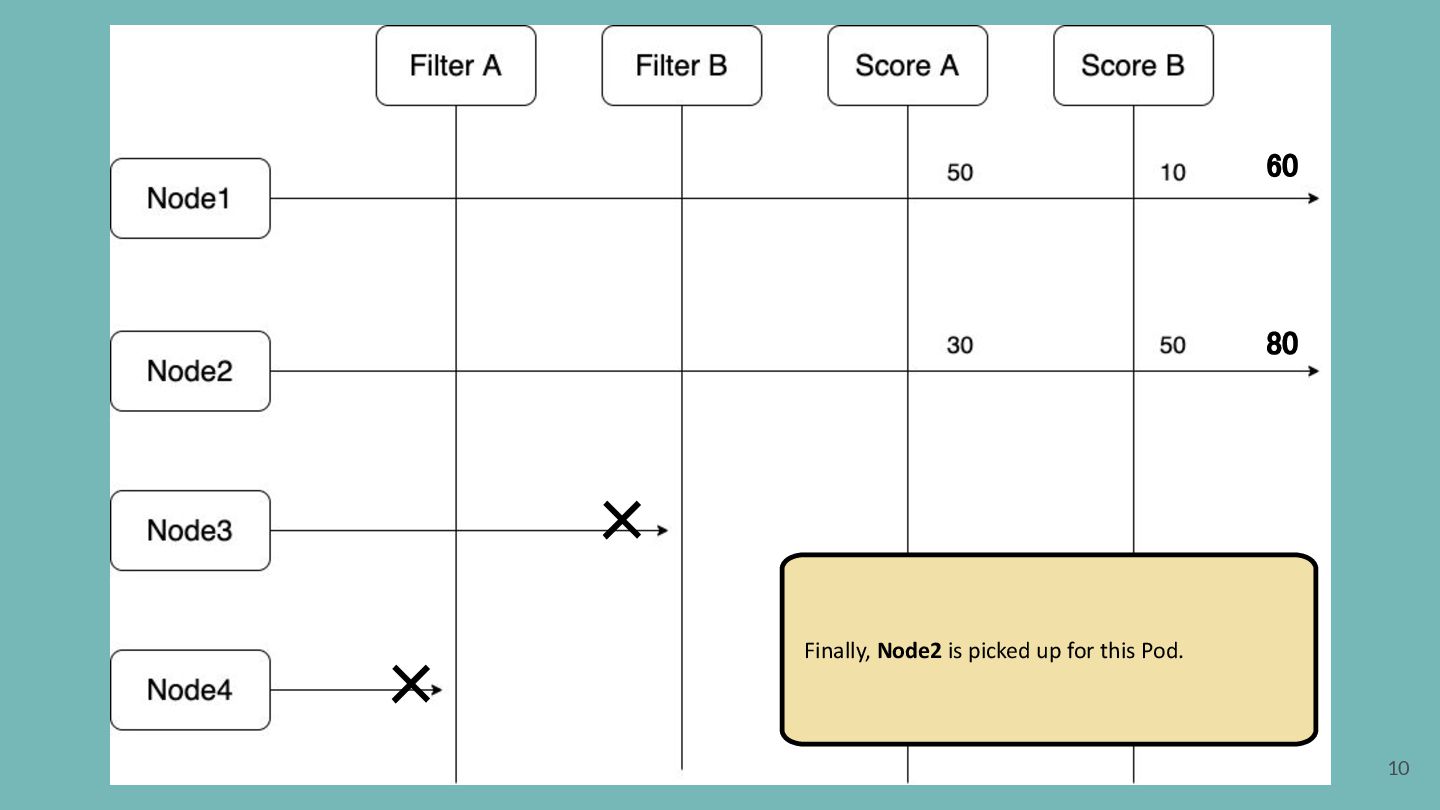
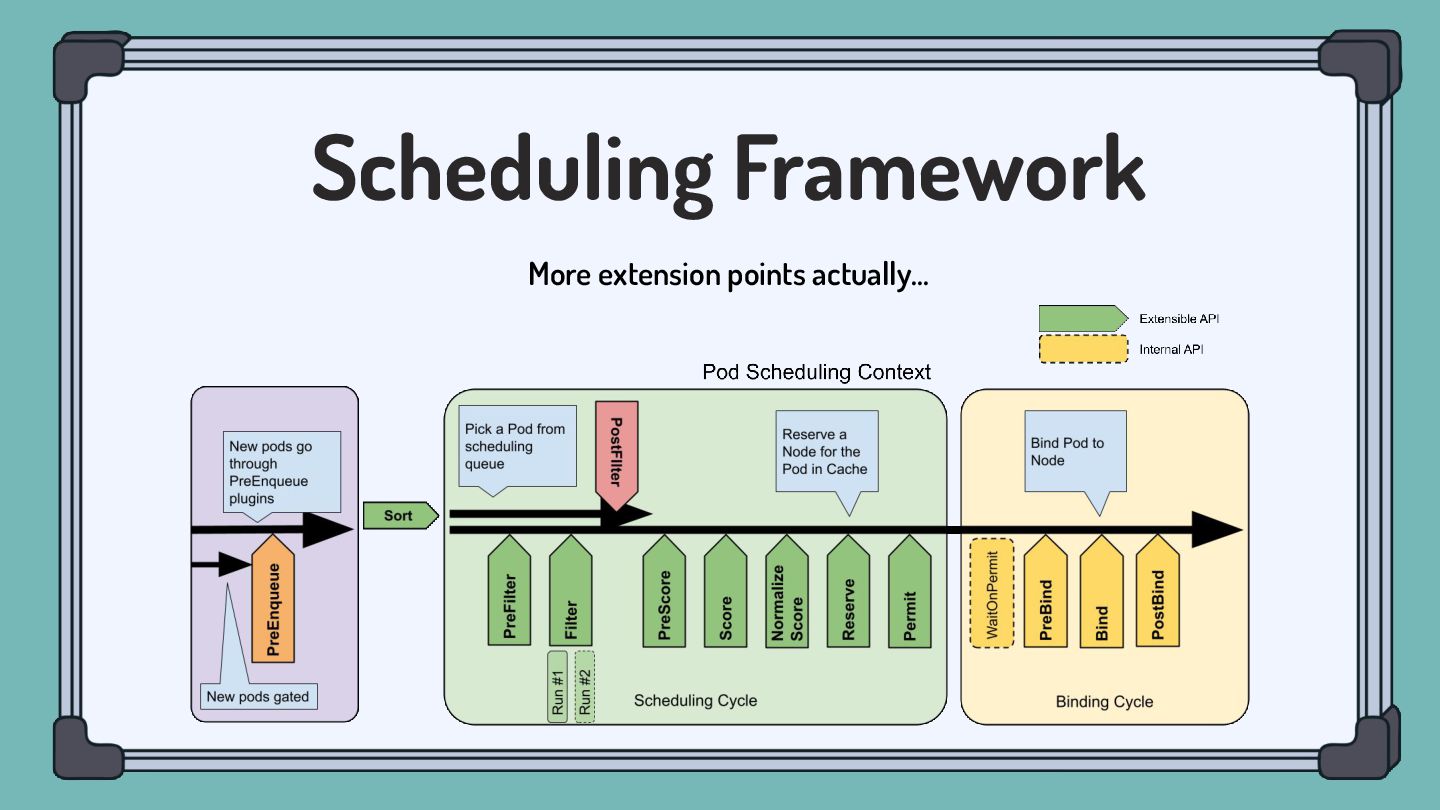
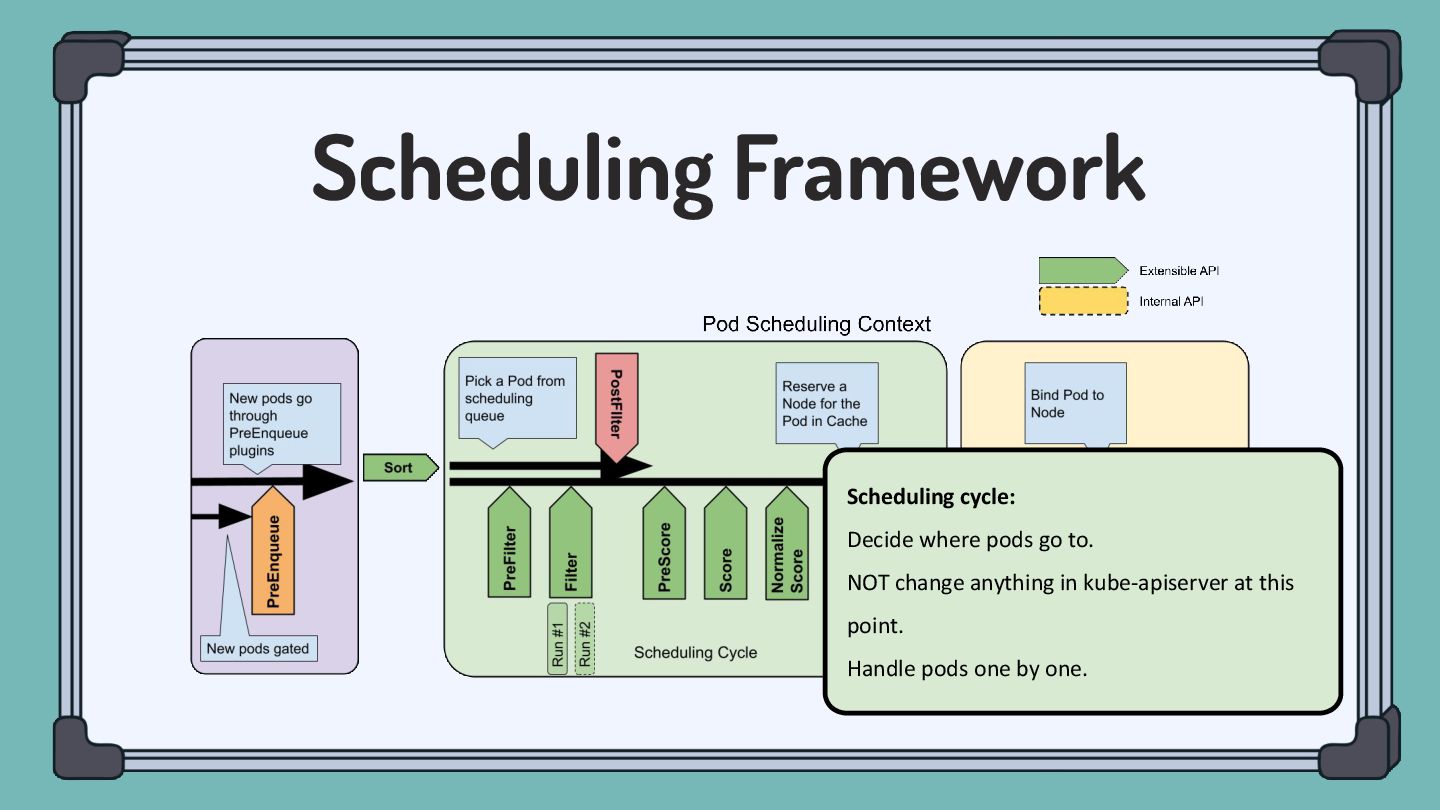
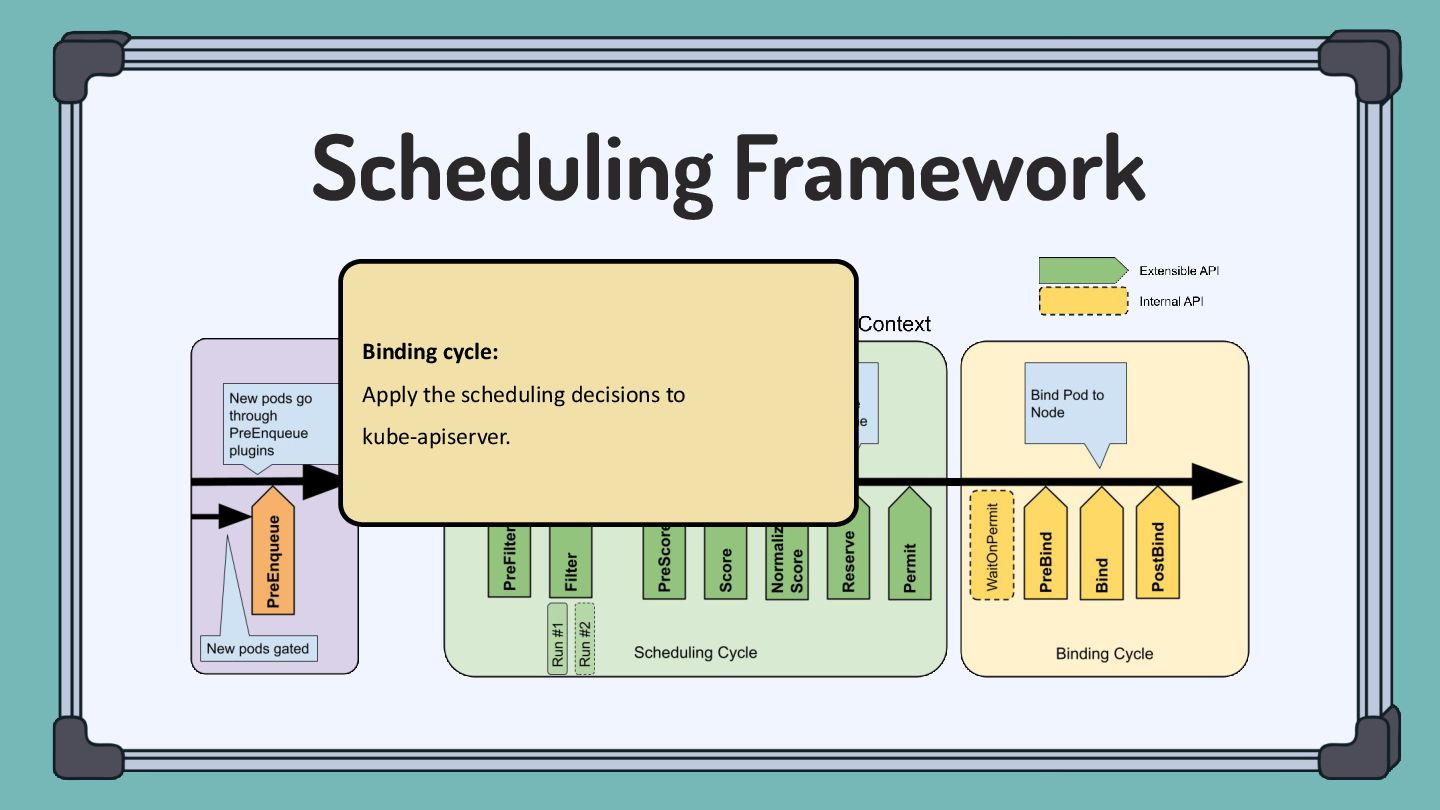
pluggable and extensible. A plugin works at one or more extension points in the scheduling framework. Filter Filter out Nodes that cannot run the Pod. (Insufficient resource, unmatch with NodeAffinity, etc) Score Score Nodes and determine the best one. (Image locality, etc)
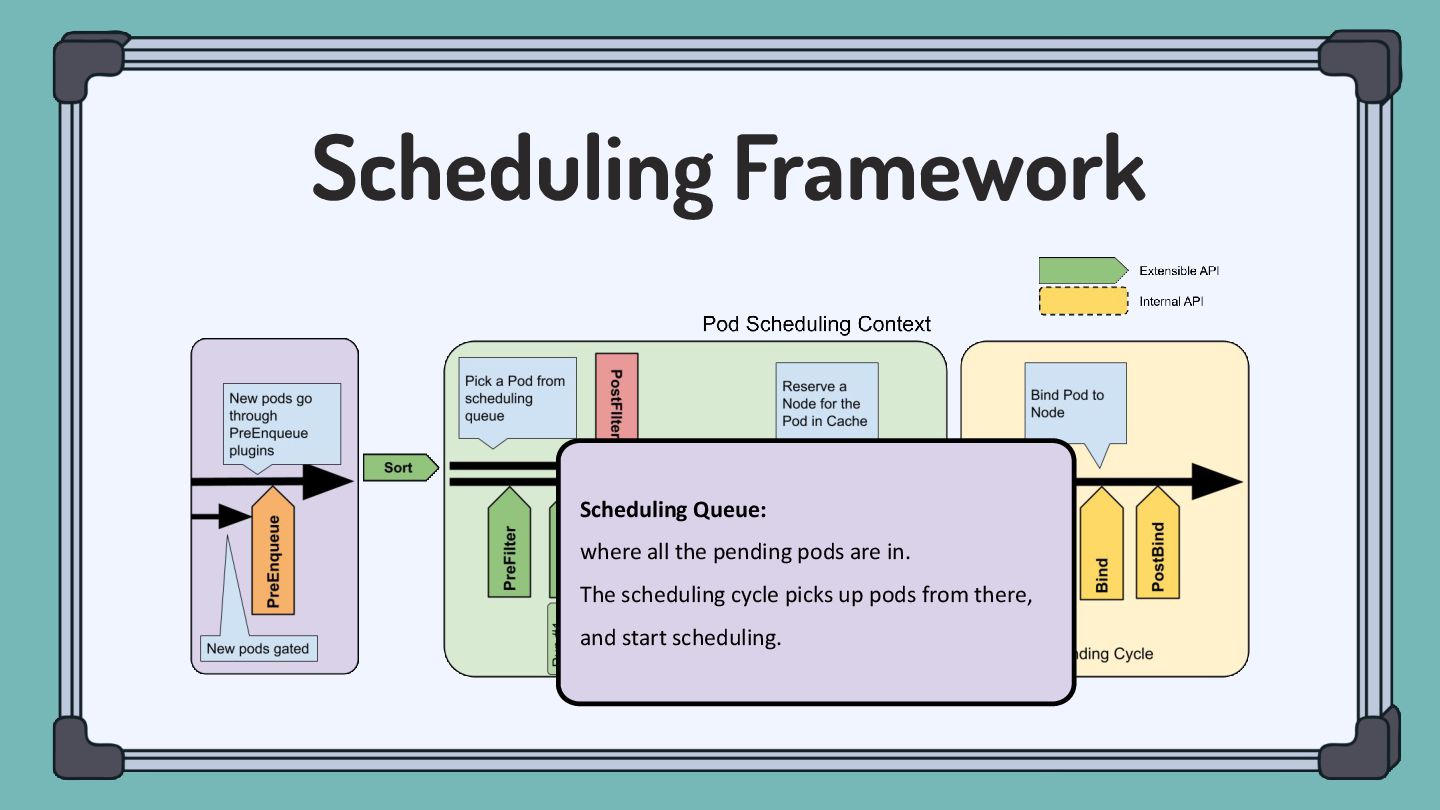
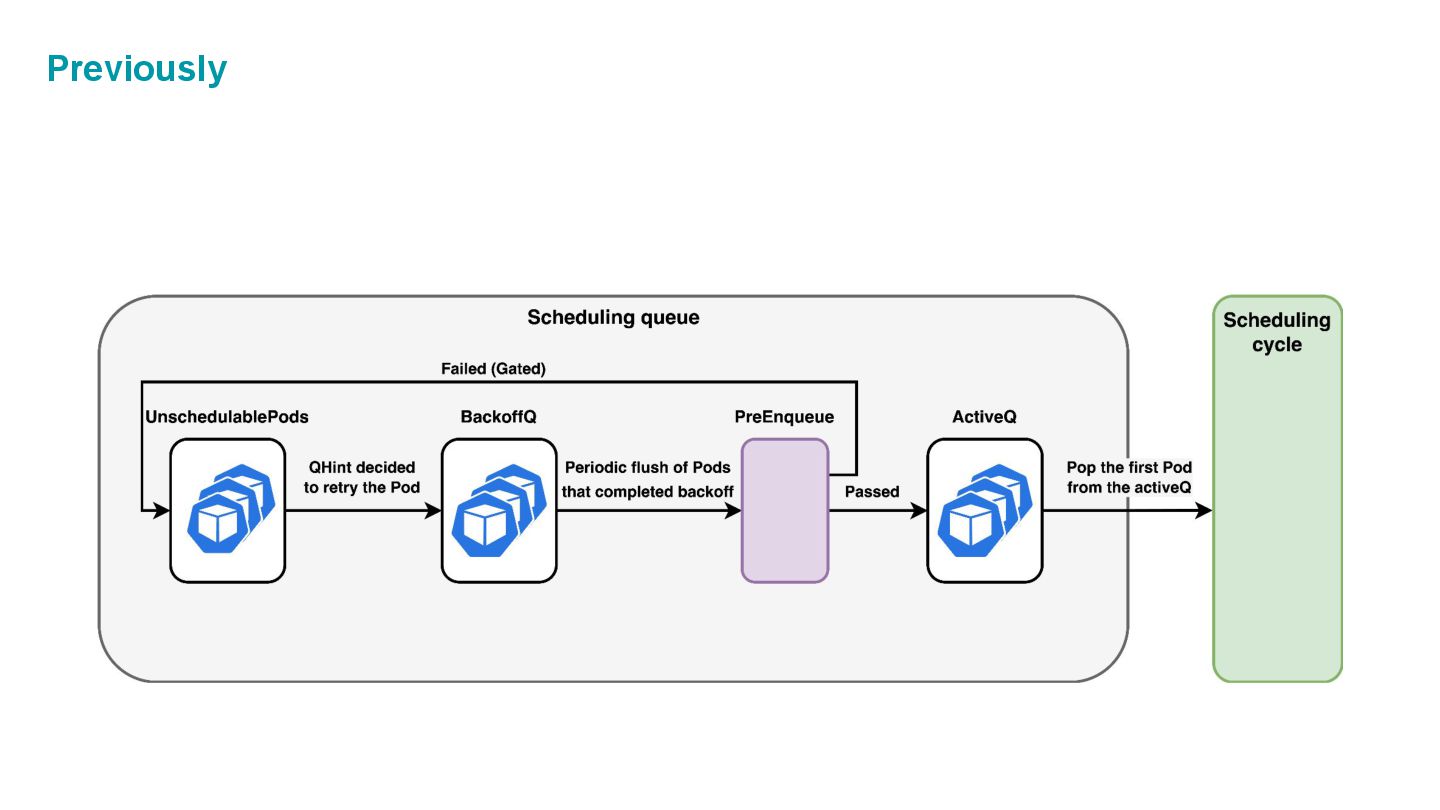
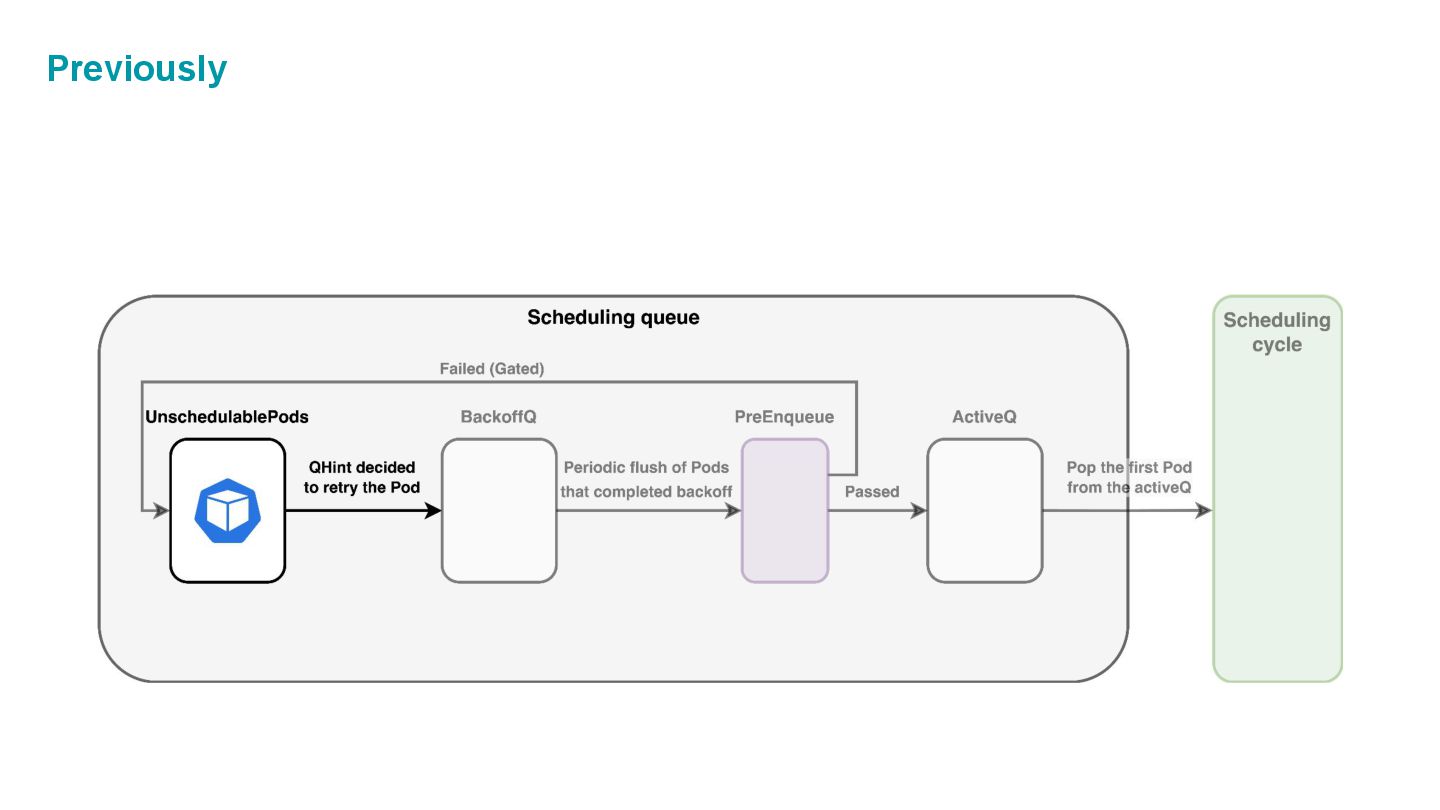
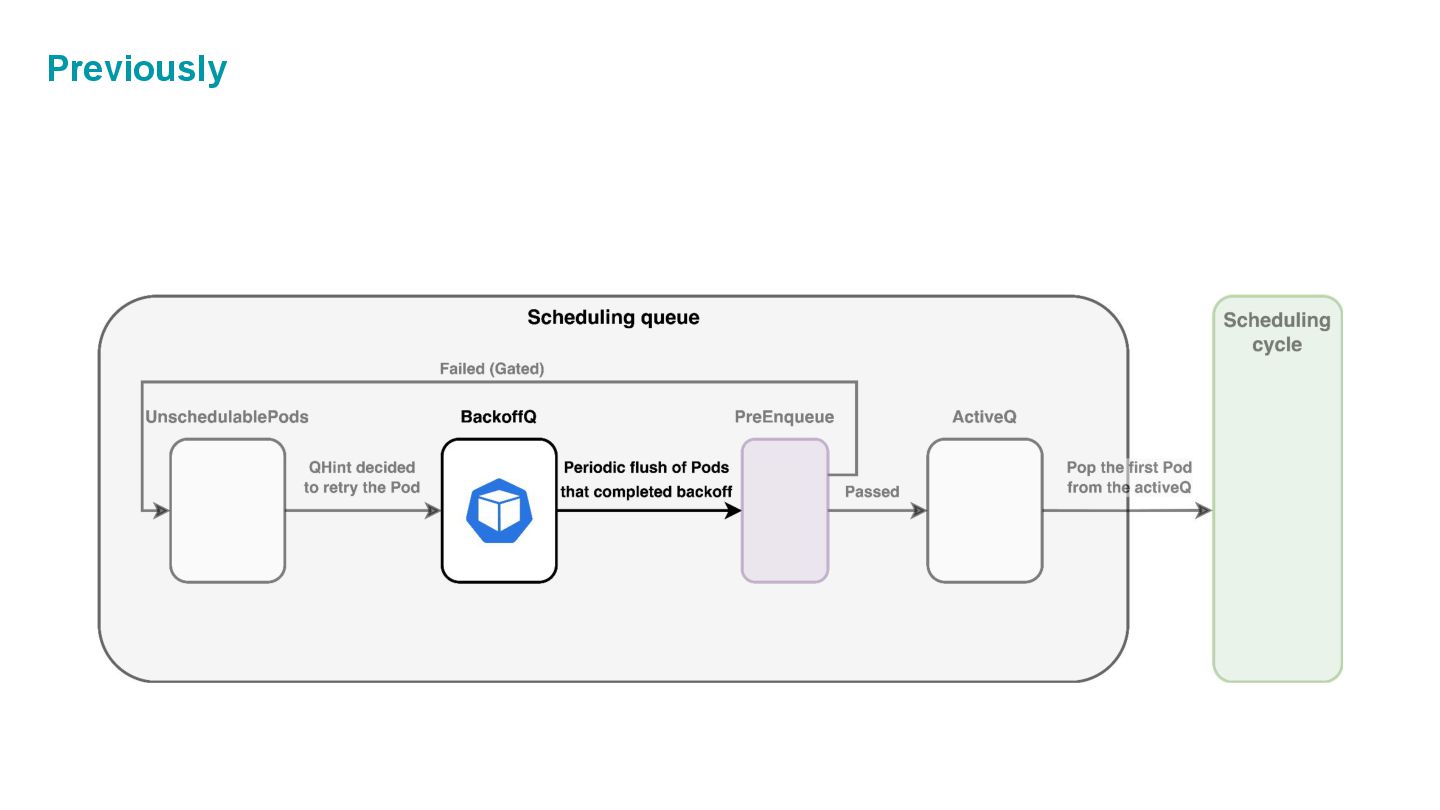
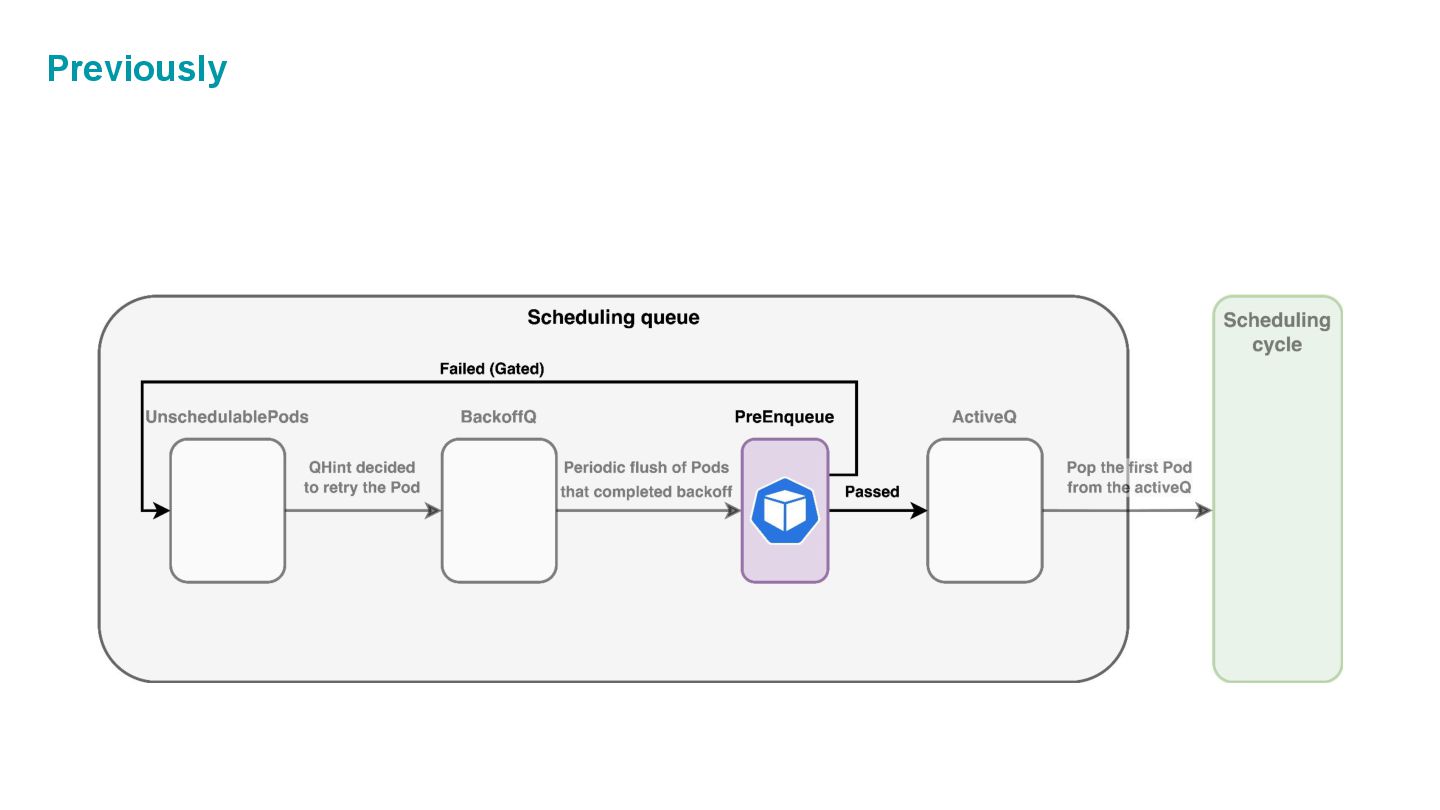
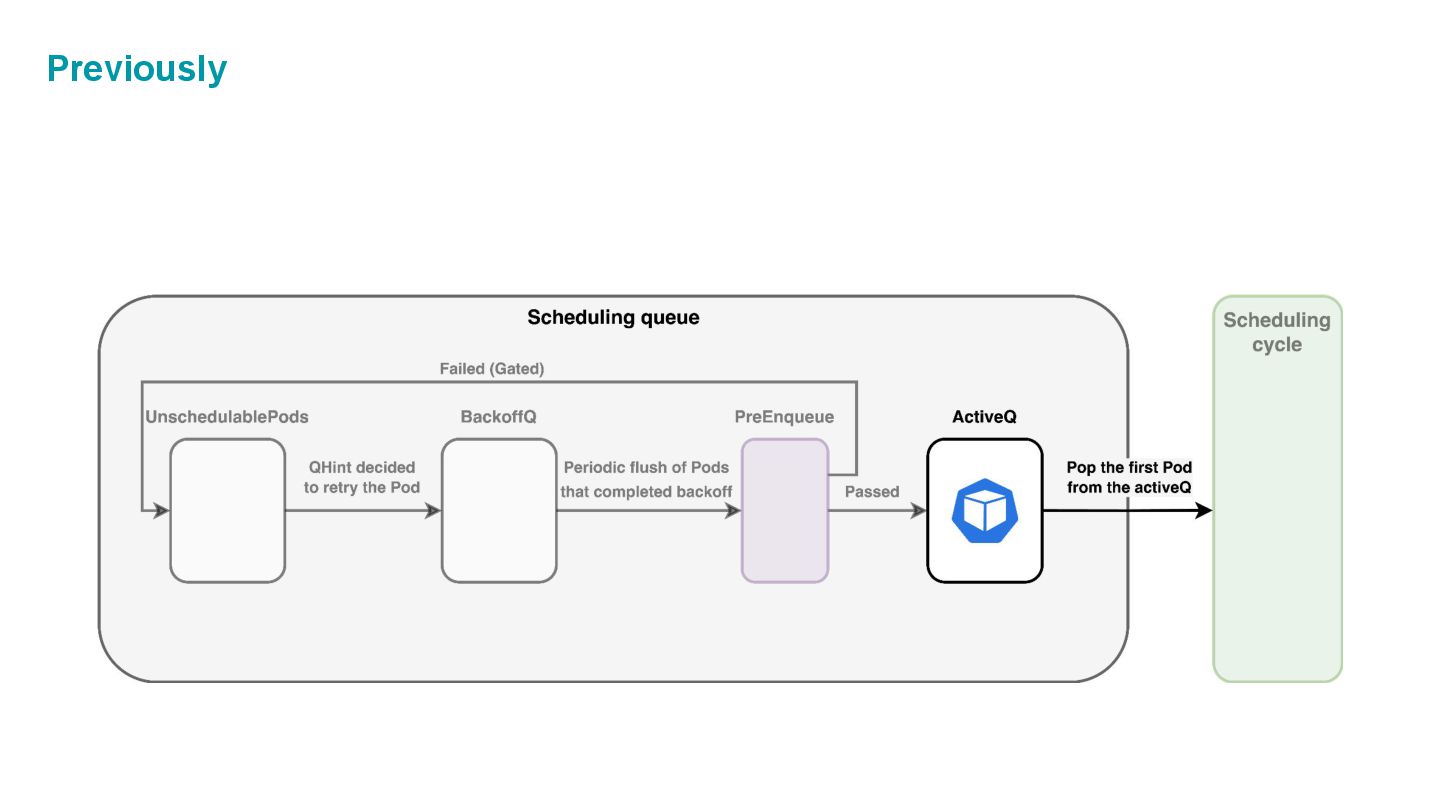
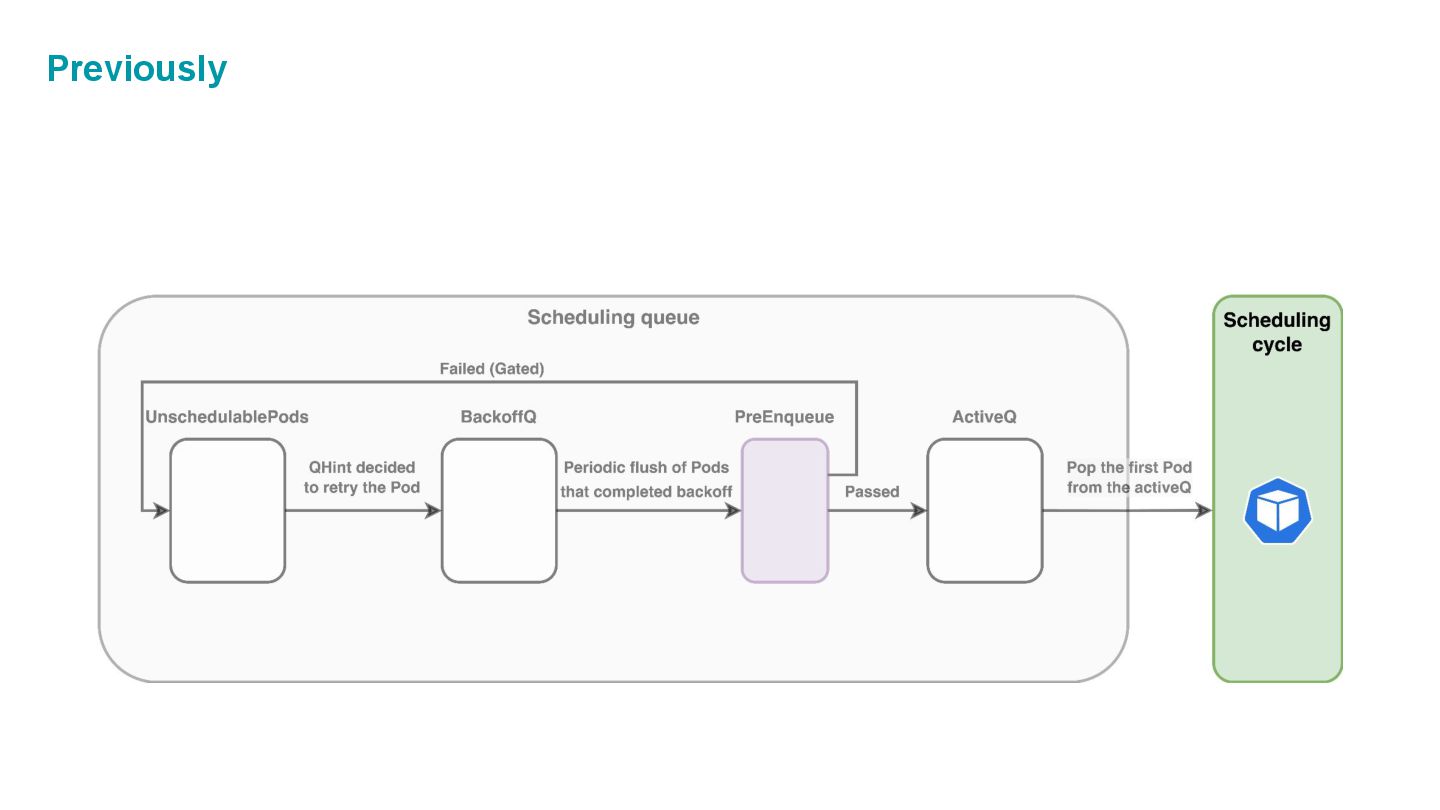
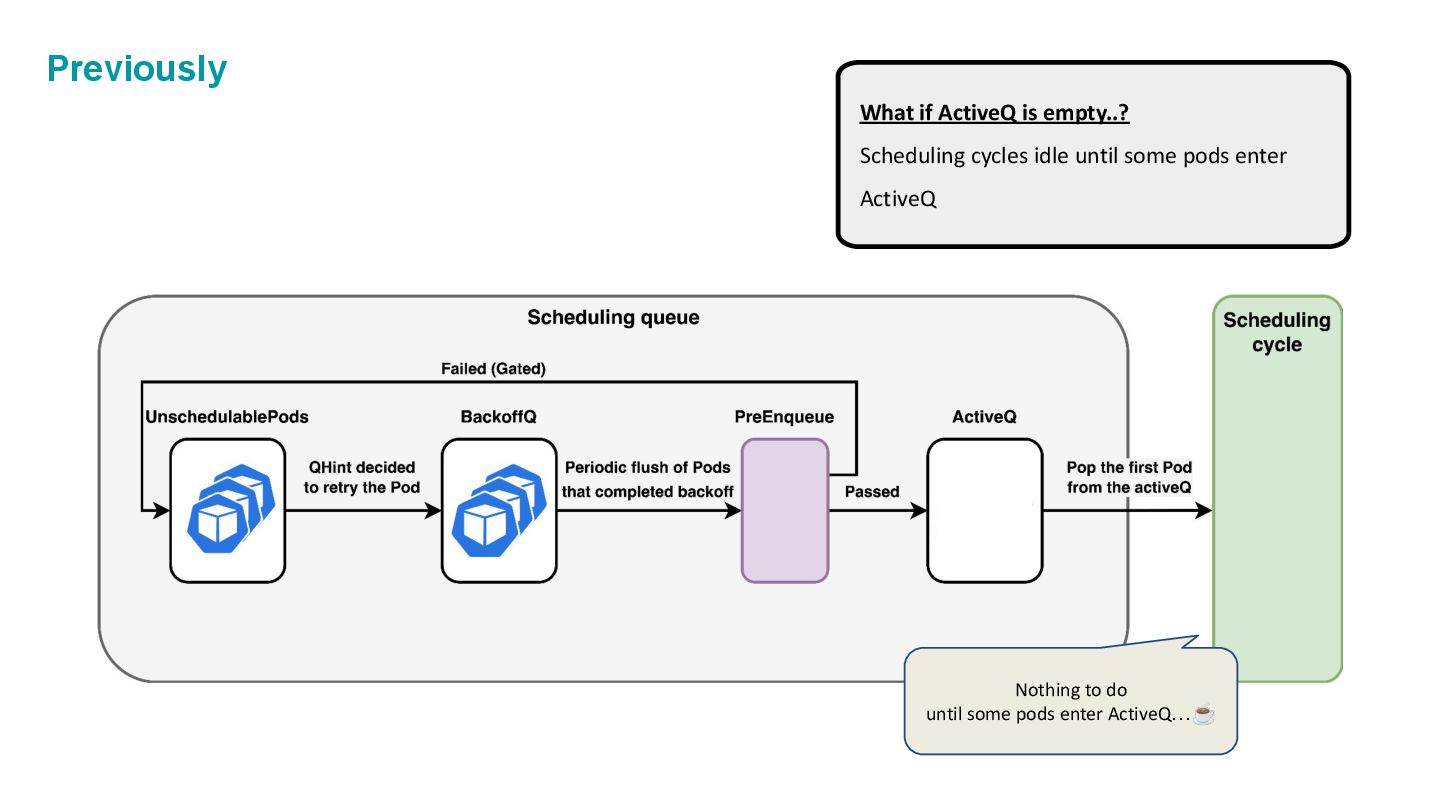
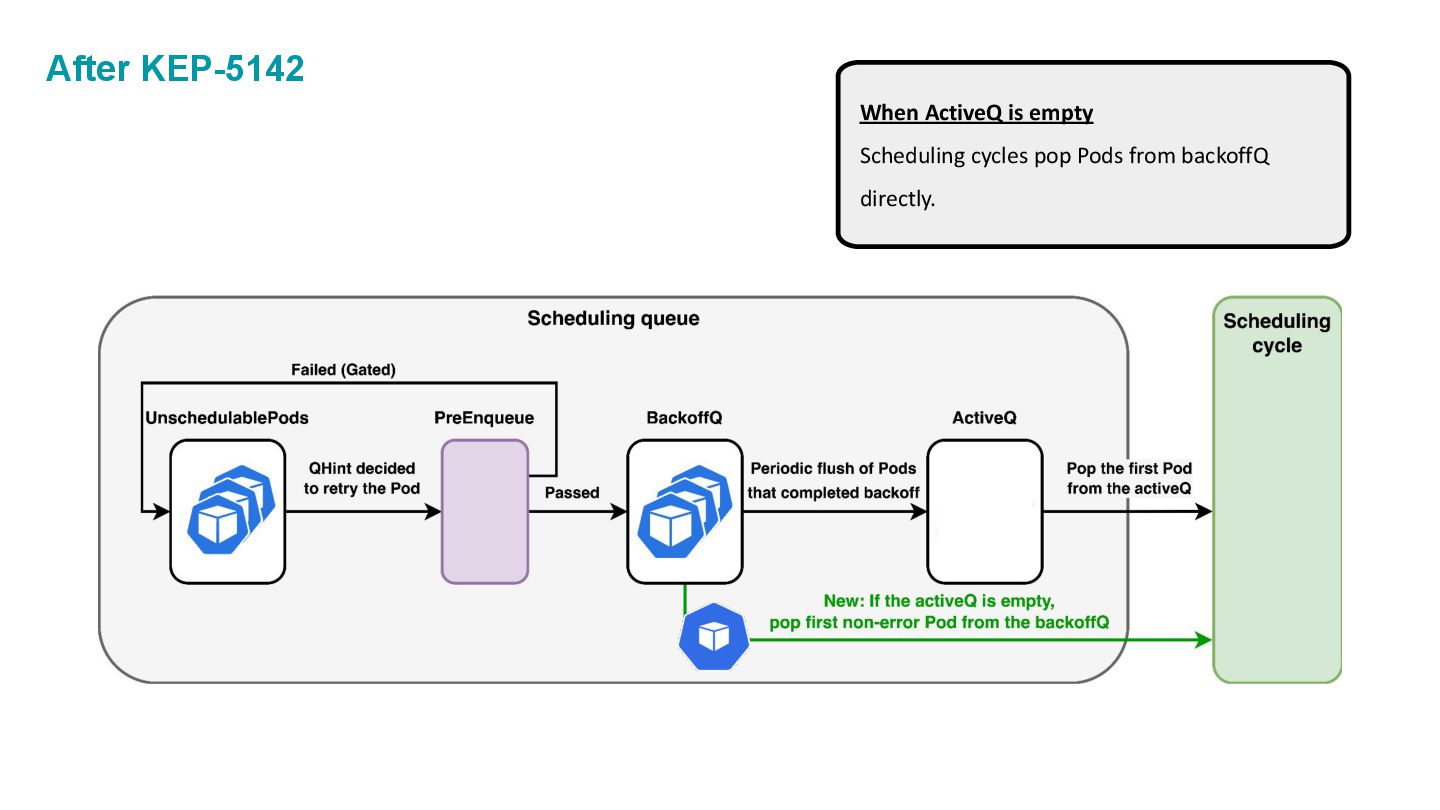
which is composed of three internal spaces: • ActiveQ: hold Pods that are ready to get scheduling. • BackoffQ: hold Pods that are waiting for a backoff time to be completed. • Unschedulable Pod Pool: hold Pods that are back from scheduling cycle, and waiting for some changes in the cluster that make them schedulable.
KEP-4832: Async preemption. ◦ KEP-4247: Queueing Hints. ◦ KEP-5142: Pop pod from backoffQ when activeQ is empty. • TOO MANY works around Dynamic resource allocations. ◦ (We’re not going to look into those.)
◦ If the Scheduling Throughput falls below the Pod creation speed of the cluster, unscheduled Pods will accumulate. • The major performance blockers for the throughput ◦ API calls ◦ Backoff time ◦ Unschedulable pods
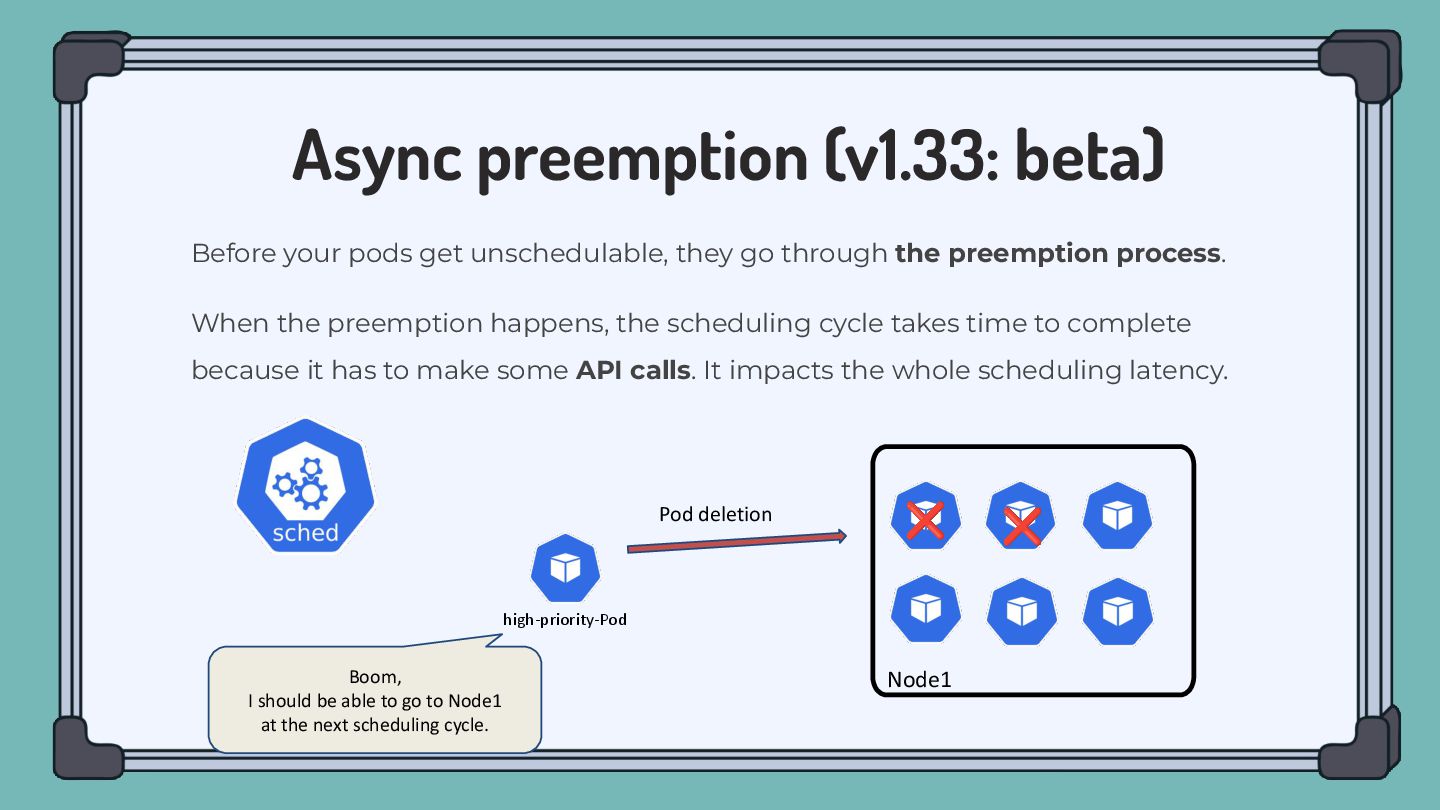
Node1 if I delete two Pods there… Before your pods get unschedulable, they go through the preemption process. When the preemption happens, the scheduling cycle takes time to complete because it has to make some API calls. It impacts the whole scheduling latency.
able to go to Node1 at the next scheduling cycle. Before your pods get unschedulable, they go through the preemption process. When the preemption happens, the scheduling cycle takes time to complete because it has to make some API calls. It impacts the whole scheduling latency. Pod deletion ❌ ❌
unschedulable, they go through the preemption process. When the preemption happens, the scheduling cycle takes time to complete because it has to make some API calls. It impacts the whole scheduling latency. Pod deletion ❌ ❌ Starts the next scheduling after the preemption is completed.
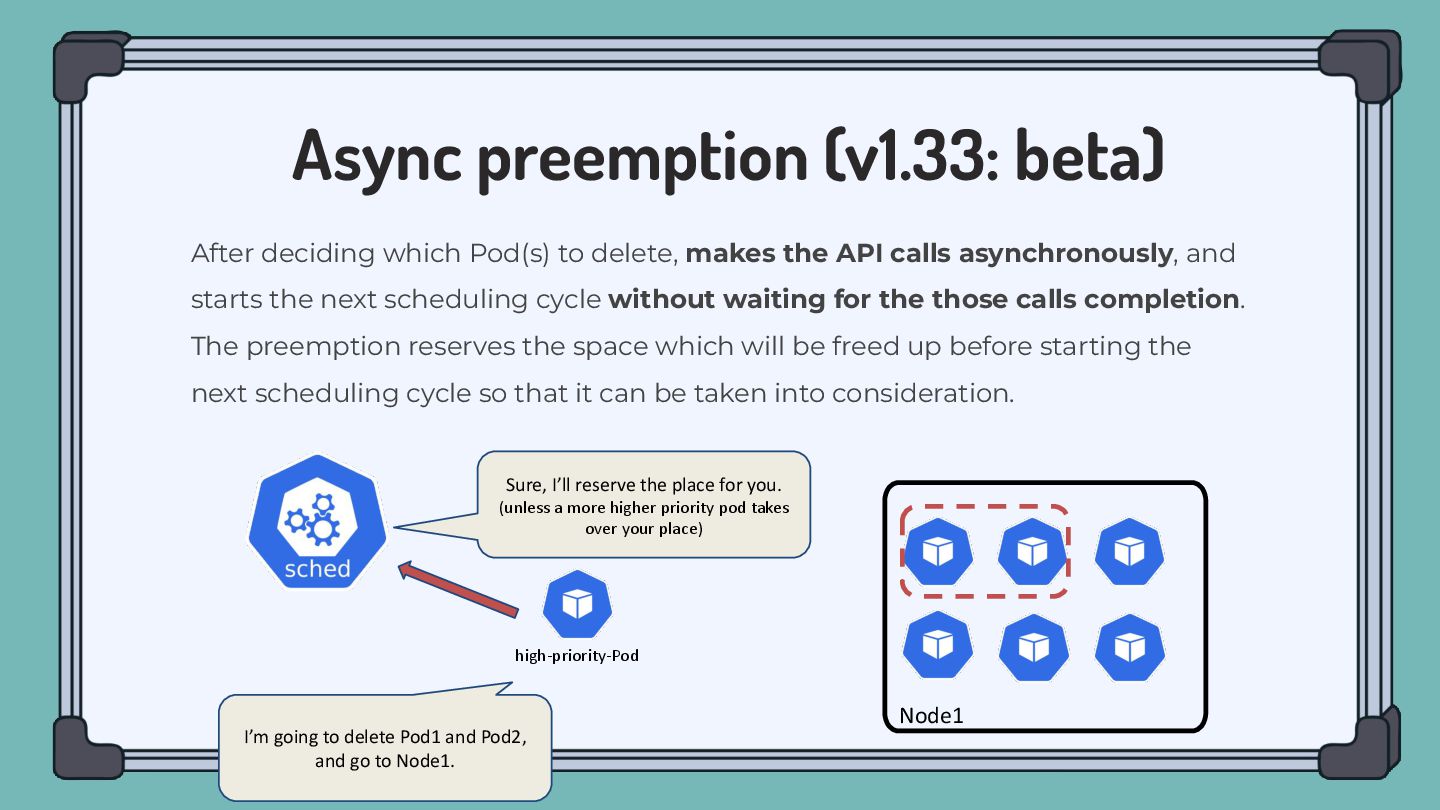
to delete, makes the API calls asynchronously, and starts the next scheduling cycle without waiting for the those calls completion. The preemption reserves the space which will be freed up before starting the next scheduling cycle so that it can be taken into consideration. I’m going to delete Pod1 and Pod2, and go to Node1. Sure, I’ll reserve the place for you. (unless a more higher priority pod takes over your place)
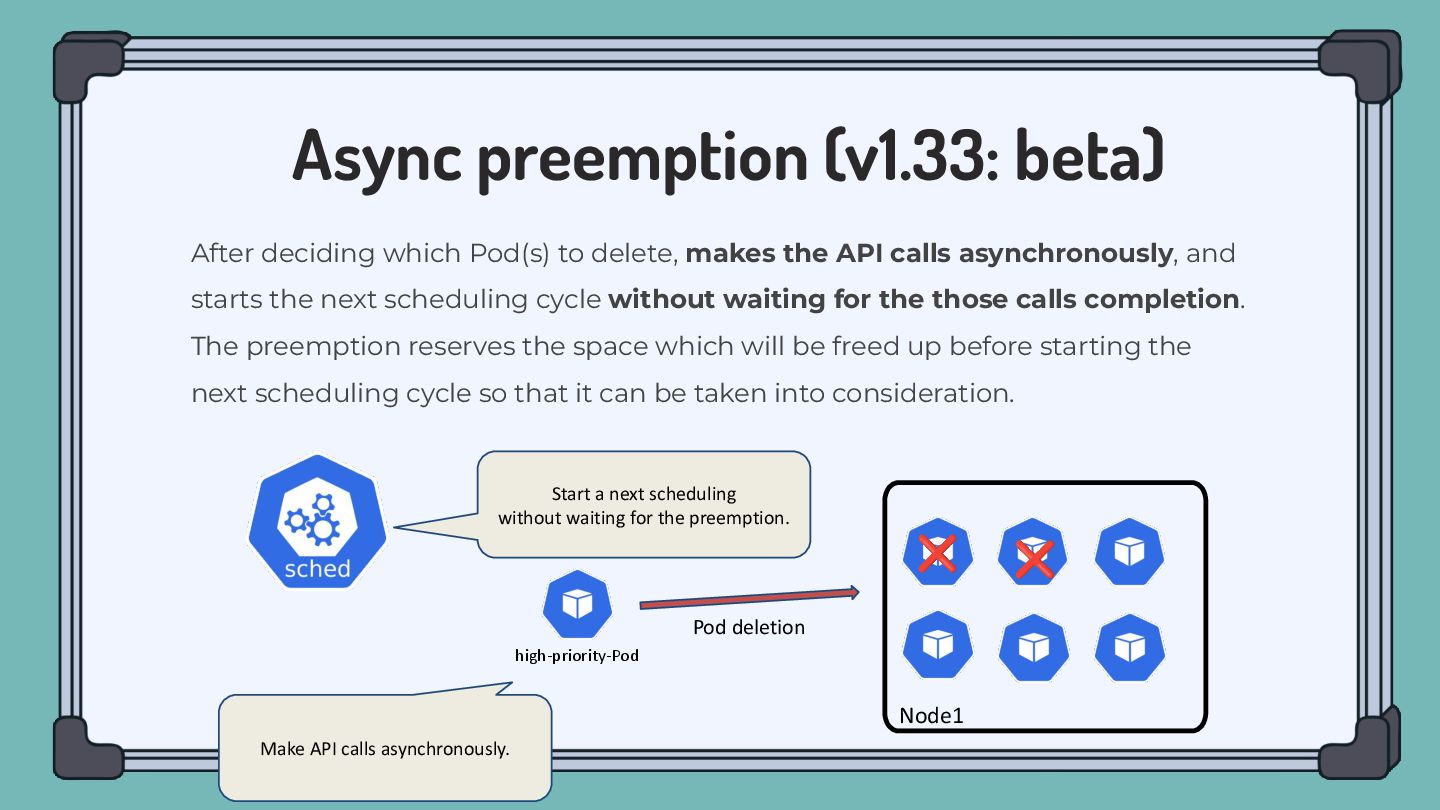
to delete, makes the API calls asynchronously, and starts the next scheduling cycle without waiting for the those calls completion. The preemption reserves the space which will be freed up before starting the next scheduling cycle so that it can be taken into consideration. Make API calls asynchronously. Start a next scheduling without waiting for the preemption. Pod deletion ❌ ❌
which is composed of three internal spaces: • ActiveQ: hold Pods that are ready to get scheduling. • BackoffQ: hold Pods that are waiting for a backoff time to be completed. • Unschedulable Pod Pool: hold Pods that are back from scheduling cycle, and waiting for some changes in the cluster that make them schedulable.
which is composed of three internal spaces: • ActiveQ: hold Pods that are ready to get scheduling. • BackoffQ: hold Pods that are waiting for a backoff time to be completed. • Unschedulable Pod Pool: hold Pods that are back from scheduling cycle, and waiting for some changes in the cluster that make them schedulable. What’s this? 🤔
cycle (= unschedulable) they are going back to Unschedulable Pod Pool in Scheduling Queue. 🤔When should we retry those Pods? → We shouldn’t just keep retrying scheduling, which would waste scheduling cycles. We should retry scheduling ONLY WHEN the next scheduling is likely successful!
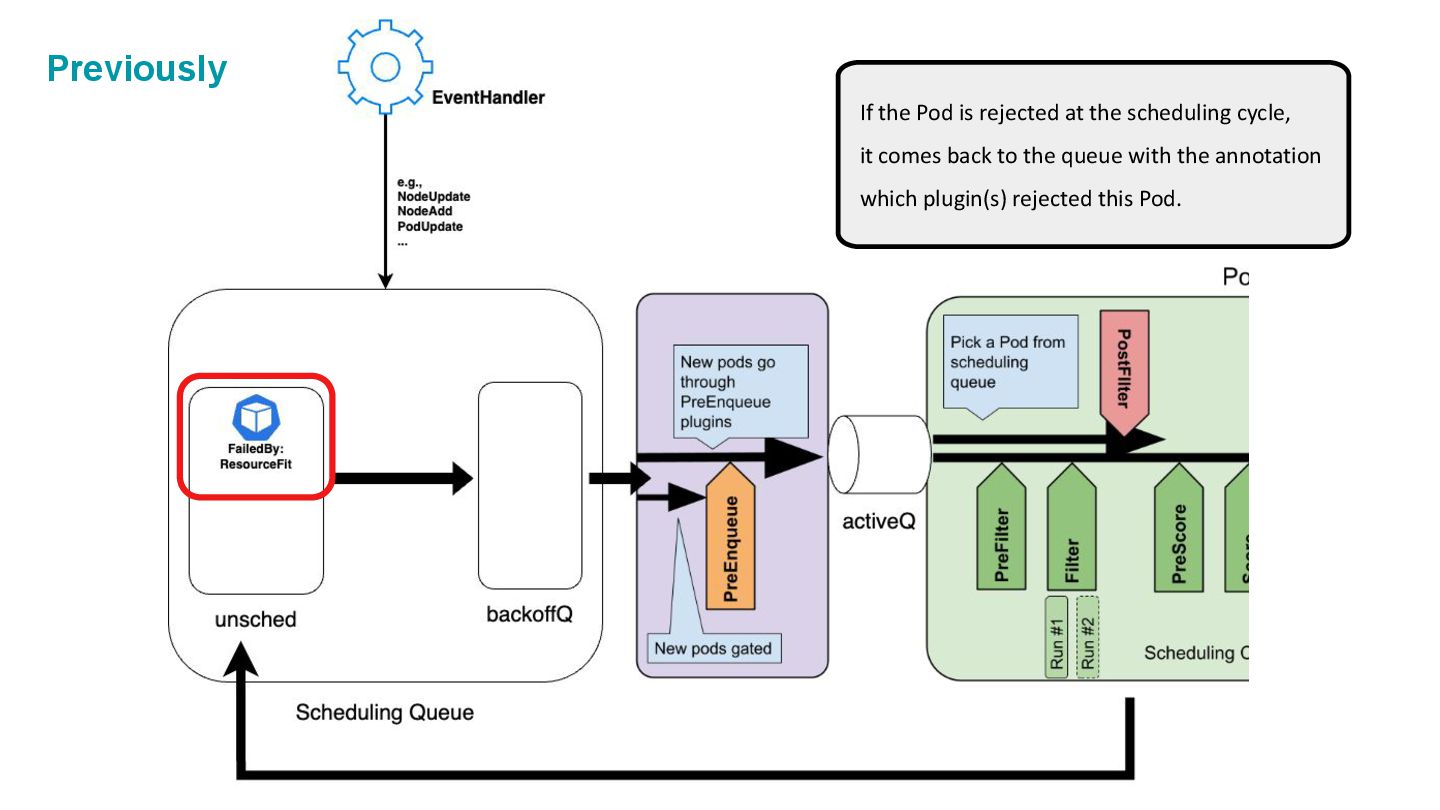
cycle, it comes back to the queue with the annotation which plugin(s) rejected this Pod. NodeResourceFit’s failure could be solved by: • New Node is created. • Node is updated to have more allocatable capacity. • The scheduled Pod is deleted. Previously
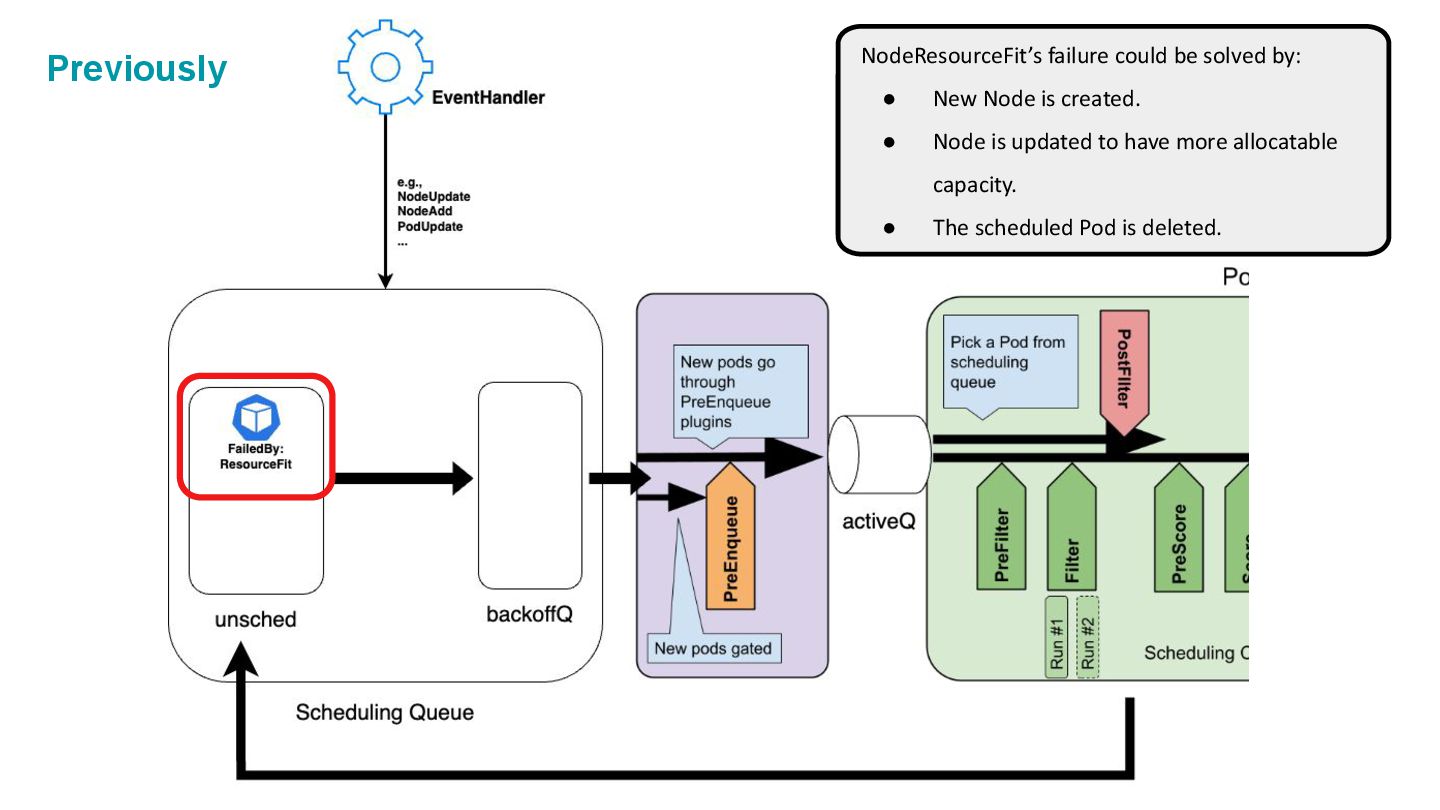
could be solved with. NodeAdd Observes NodeAdd, which the failure from the resource fit plugin could be solved with NodeResourceFit’s failure could be solved by: • New Node is created. • Node is updated to have more allocatable capacity. • The scheduled Pod is deleted. Previously
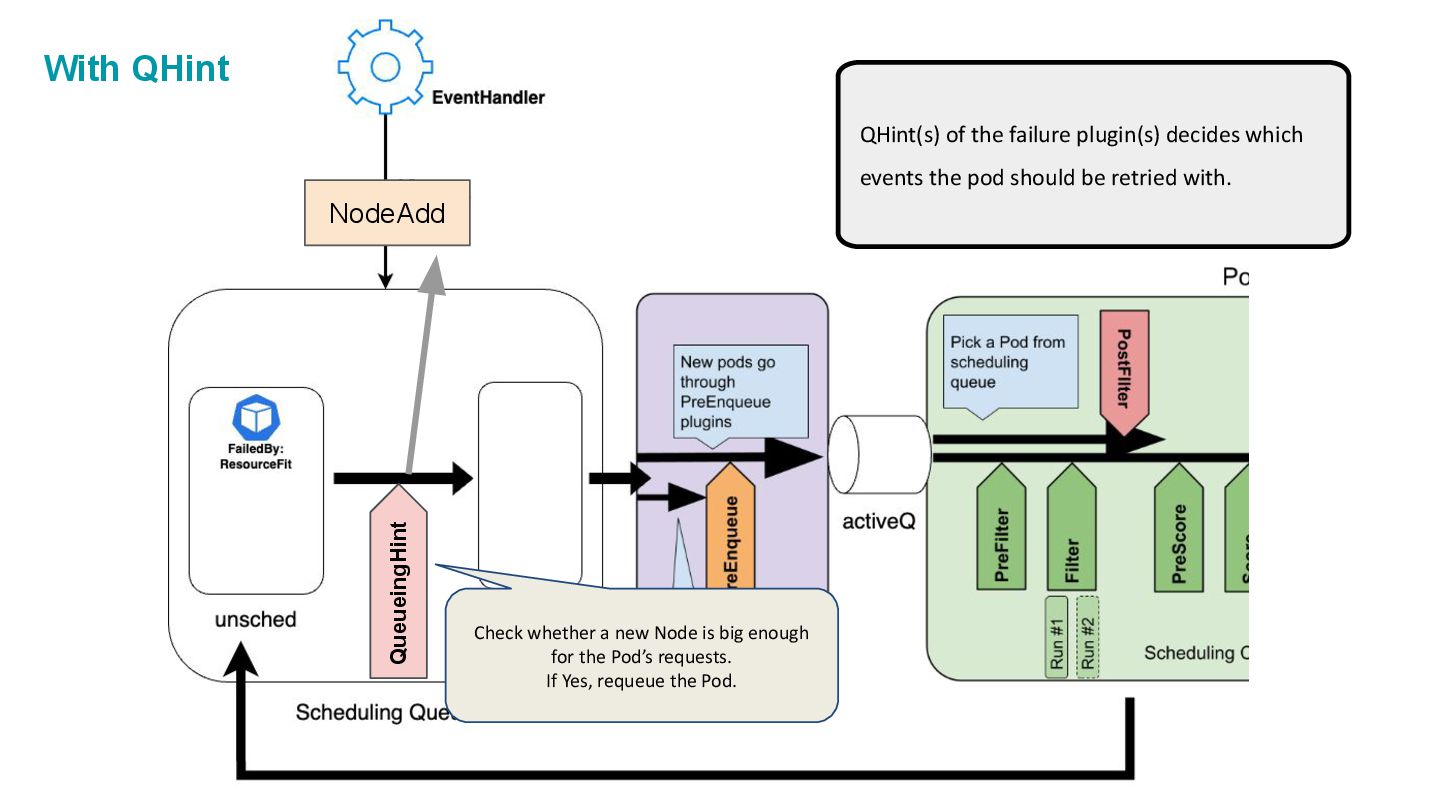
could be solved with. NodeAdd Maybe this new Node is too small to run the Pod… But, the queue couldn’t see such details… NodeResourceFit’s failure could be solved by: • New Node is created. • Node is updated to have more allocatable capacity. • The scheduled Pod is deleted. Previously
unschedulable Pods schedulable. But, this old mechanism was too rough and not extensible for out-of-tree plugins. • Plugins can only declare which types changes can make pods schedulable. ◦ Node created, Node updated, Pod deleted … etc • They cannot see the details of each to make more precise decisions. ◦ Node is created, but what kind of Node? etc
unschedulable Pods schedulable. But, this old mechanism was too rough and not extensible for out-of-tree plugins. • Plugins can only declare which types changes can make pods schedulable. ◦ Node created, Node updated, Pod deleted … etc • They cannot see the details of each to make more precise decisions. ◦ Node is created, but what kind of Node? etc Queue Hints allows plugins to see those details, and make requeueing decisions based on them!
the pod should be retried with. QueueingHint Check whether a new Node is big enough for the Pod’s requests. If Yes, requeue the Pod. NodeAdd With QHint
which is composed of three internal spaces: • ActiveQ: hold Pods that are ready to get scheduling. • BackoffQ: hold Pods that are waiting for a backoff time to be completed. • Unschedulable Pod Pool: hold Pods that are back from scheduling cycle, and waiting for some changes in the cluster that make them schedulable.
which is composed of three internal spaces: • ActiveQ: hold Pods that are ready to get scheduling. • BackoffQ: hold Pods that are waiting for a backoff time to be completed. • Unschedulable Pod Pool: hold Pods that are back from scheduling cycle, and waiting for some changes in the cluster that make them schedulable.
treating them individually. However, as Kubernetes’s use case grows, we’ve got more use cases to schedule groups of pods. • Gang Scheduling (KEP-4671) ◦ Ensure to schedule several Pods at the same time. • Topology Aware Scheduling (Kueue’s feature)
the async preemption feature made the preemption API calls asynchronous, kube-scheduler has several API calls during the scheduling process. We’re trying to implement a general way to make async API calls for a better performance.
Kueue and Cluster Autoscaler simulates the scheduling, and they know “this Pod might be scheduled onto that Node”. We’re trying to use NominatedNodeName field so that those components can give those as hints so that kube-scheduler can skip some scheduling calculations. Maybe pod1 can be scheduled on node1. You may want to try node1 for pod1 first.
are just discussed at GitHub Issues, and Pull Requests are opened based on the discussion. • Major changes are developed with KEP process. ◦ Kubernetes Enhancement Proposal. ◦ kubernetes/enhancement repository hosts proposals. ◦ Proposals are discussed on a certain format, have to be approved by certain stakeholders. ◦ The feature gate is implemented so that big changes don’t break thousands of users.
are all valuable! • Contribute to the implementation ◦ Not only Kubernetes itself, but there’re many sub projects in kubernetes-sigs org! • Contribute to the documentation ◦ May be the easiest to start, to get used to the development process, and get into the community. • Opening GitHub Issues for feature requests/bug reports. Joining the discussion. • Join the release teams. ◦ which manages and helps the Kubernetes release.
◦ If you want to propose a new feature, or even just want to fix a bug, it’s always better to discuss with the maintainers to make sure what you want to change is correct. • Start from easier tasks. ◦ Check GitHub Issues with good-first-issue and help-wanted labels. • Talk to the maintainers (but don’t bother them a lot) ◦ You can also talk to maintainers at Slack DM etc for questions or suggestions. However, you should try hard before asking, and try to elaborate your questions. You should save the energy that maintainers have to spend to answer your questions otherwise you can just get ignored, in the worst case. (They are all busy!)
Code 2021, and continued the contributions even afterwards. There are several mentoring programs: • Google Summer of Code • LFX Mentorship You will get a mentor from the team who assist you in making changes thoroughly.
can aim at while making a contribution. • GitHub Membership of Kubernetes org. ◦ You need a few contributions (~10) and also sponsors from the maintainers. • Reviewer ◦ Reviewers officially make reviews on PRs for the responsible implementation. ◦ You need a certain amount of contributions (e.g., 20 PRs are merged etc). • Approver ◦ Approvers put final approvals on PRs for the responsible implementation. ◦ You need a huge amount of contributions (e.g., 30 PRs are merged etc). • Contributor Award ◦ Not a role, but contributors who have made a huge impact will get awarded from SIGs every year. • SIG Lead (Chair and Tech Lead) ◦ SIG Leads literally leads the SIG’s direction, discussion, and everything.
free time in most cases. The best recommendation to continue the contributions is to keep an enough motivation! • Contribute to what you LOVE or are interested in! • Contribute to what you can get an actual benefit from. Examples: ◦ Contribute to the component you’re using for the company to get more in-depth knowledge. ◦ Contribute to the component that companies you want to move to are using. Contributions are visible experience/expertise! ◦ Contribute and get connected with awesome people.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}