Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MercariにおけるKubernetesのリソース最適化のこれまでとこれから
Search
sanposhiho
April 26, 2023
Technology
4.2k
8
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MercariにおけるKubernetesのリソース最適化のこれまでとこれから
Kubernetes Meetup Tokyo #57
アーカイブもあります:
https://www.youtube.com/watch?v=DczWeNL-4-A
sanposhiho
April 26, 2023
More Decks by sanposhiho
See All by sanposhiho
Understanding the Kubernetes Scheduler: Internals, Roadmap, and Contributions
sanposhiho
1
160
kube-scheduler: from 101 to the frontier
sanposhiho
1
290
A Tale of Two Plugins: Safely Extending the Kubernetes Scheduler with WebAssembly
sanposhiho
0
260
人間によるKubernetesリソース最適化の”諦め” そこに見るリクガメの可能性
sanposhiho
2
2.2k
Don't try to tame your autoscalers, tame Tortoises!
sanposhiho
0
840
メルカリにおけるZone aware routing
sanposhiho
4
1.9k
A tale of two plugins: safely extending the Kubernetes Scheduler with WebAssembly
sanposhiho
1
630
メルカリにおけるプラットフォーム主導のKubernetesリソース最適化とそこに生まれた🐢の可能性
sanposhiho
1
1k
The Kubernetes resource management and the behind systems in Mercari
sanposhiho
0
370
Other Decks in Technology
See All in Technology
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
160
OPENLOGI Company Profile for engineer
hr01
1
75k
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
1
280
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
1.1k
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
180
発表と総括 / Presentations and Summary
ks91
PRO
0
190
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
260
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
750
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
130
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
2
140
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
240
reFACToring
moznion
0
220
Featured
See All Featured
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
ラッコキーワード サービス紹介資料
rakko
1
4M
The Limits of Empathy - UXLibs8
cassininazir
1
540
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
380
The Cost Of JavaScript in 2023
addyosmani
55
10k
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
A designer walks into a library…
pauljervisheath
211
24k
My Coaching Mixtape
mlcsv
0
180
It's Worth the Effort
3n
188
29k
Transcript
1 Confidential MercariにおけるKubernetesのリソース最適化 のこれまでとこれから Kensei Nakada / @sanposhiho
2 Mercari JP Platform Infra team / 2022卒新卒
Kubernetes upstream reviewer (SIG-Scheduling) Kubernetes Contributor award 2022 winner Kensei Nakada / sanposhiho
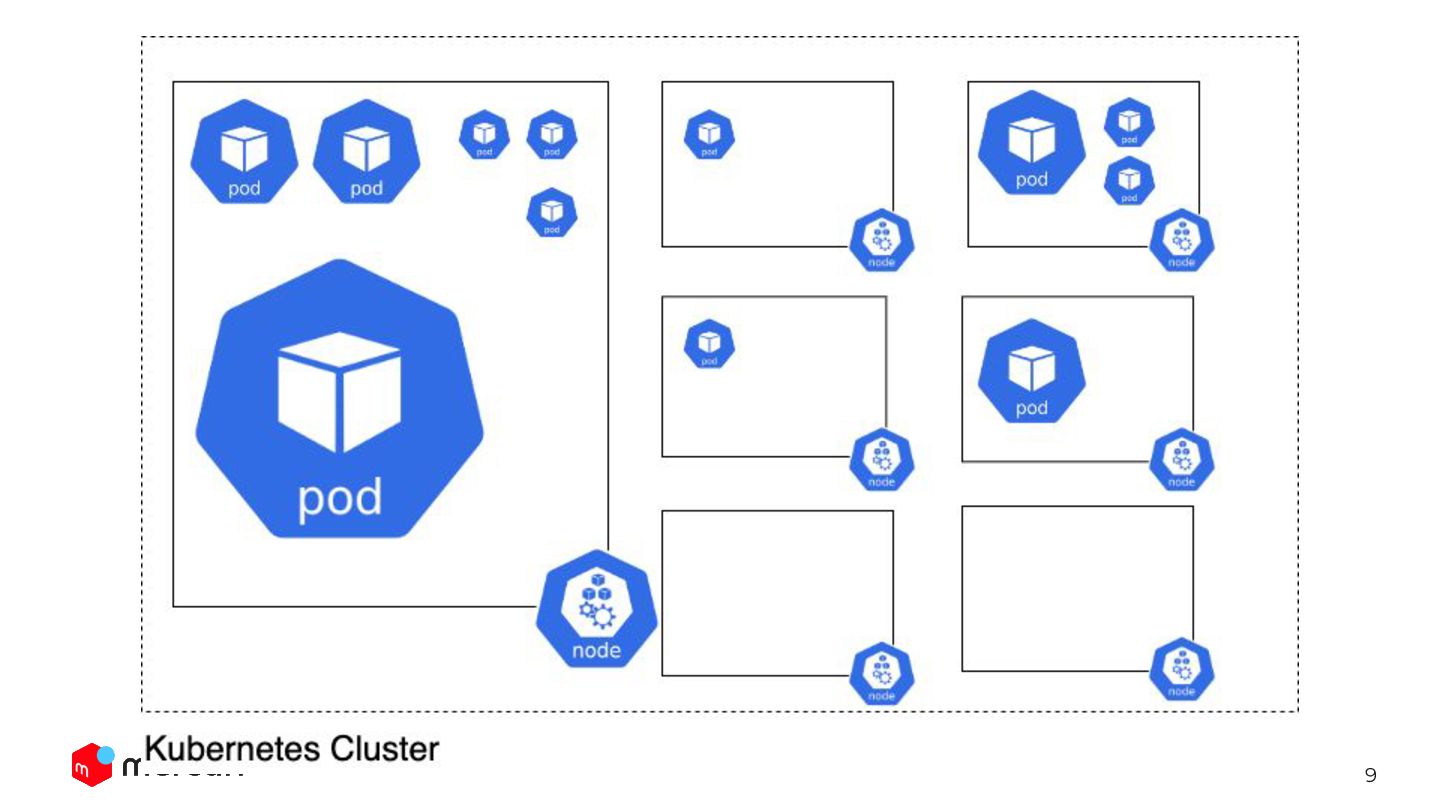
3 Mercari Kubernetes Cluster Overview Agenda 01 Workloads on cluster
+ About FinOps a. Node Level Optimization 02 Cluster Autoscaling a. Node machine type b. Workload Optimization 03 Workload Autoscaling (HPA & VPA) / Resource recommender a. HPA fine tuning b. 🐢を使用したWorkload Autoscaling 04
4 Kubernetes Cluster Overview Workloads on cluster + FinOps
5 Kubernetesクラスター概要 - GKEを使用 (Standard mode) - 一つのClusterで、Mercari/Merpayほぼ全てのWorkloadが動いている - namespace:
500+ / deployment 1000+ - PlatformチームがCluster adminとして運用
6 Workload について - ほとんどがGoで実装されたWorkload - この登壇に含まれる調査結果等はGoのWorkloadと いうことを前提としてください - その他、ElasticSearch,
php 等も居る - Istioを一部namespaceで使用 (全体の半分ほど) (拡大予定) - sidecarコンテナーがついているPodが割と存在する - ほとんどの大規模workloadがHPAを使用 (全体の半分ほど) (拡大予定)
7 FinOps! - 直近メルカリでは全社的な目標としてFinOpsを掲げている - Monolith -> Microserviceのマイグレーションを経 て、アーキテクチャを洗練していくフェーズ -
Platformチームでもインフラリソースの効率化を推進 - 殆どのサービスが乗っているのでインパクトが超絶大き い - あくまでも安全性を担保しつつ、リソースの効率化を行う
8 Node Level Optimization Cluster Autoscaling
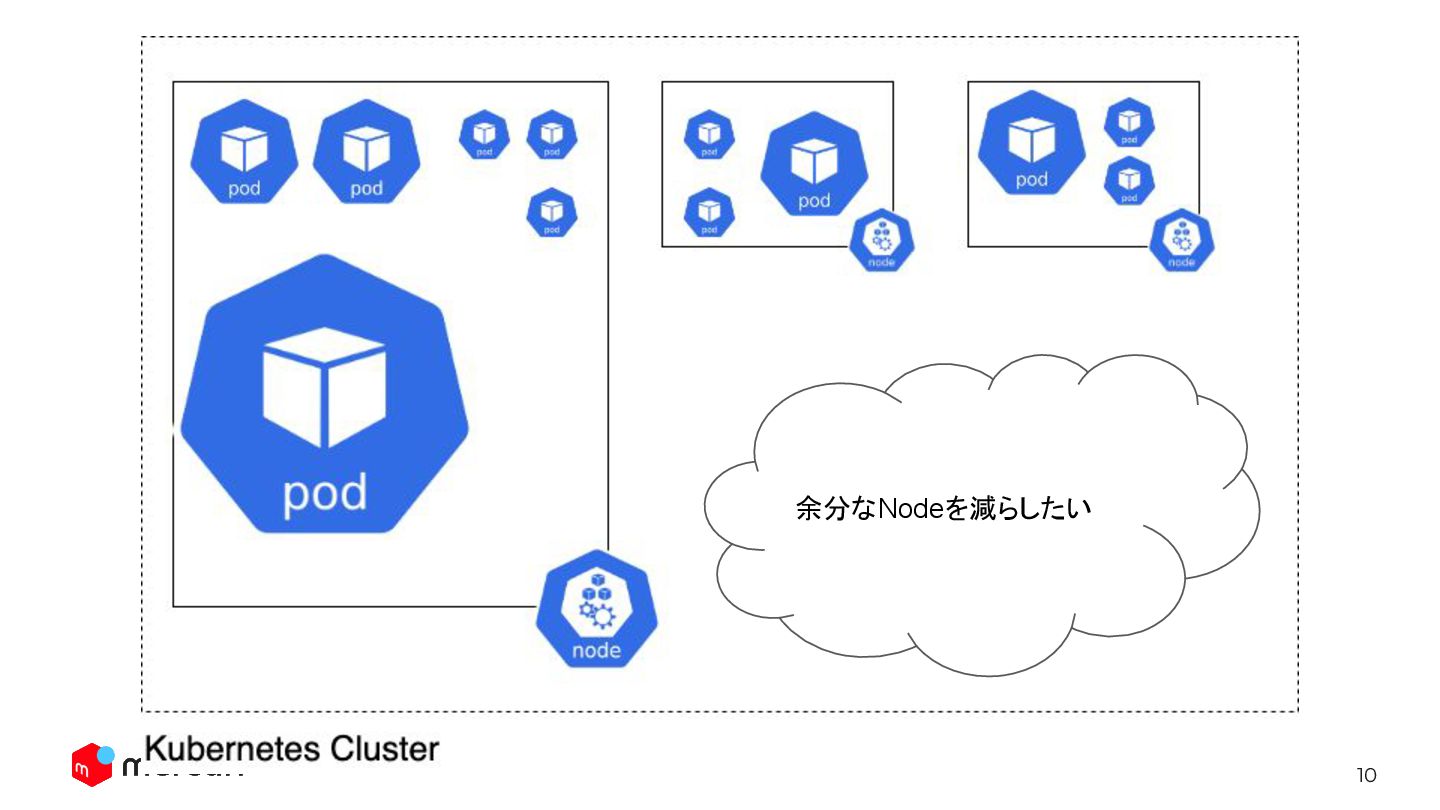
9
10 余分なNodeを減らしたい
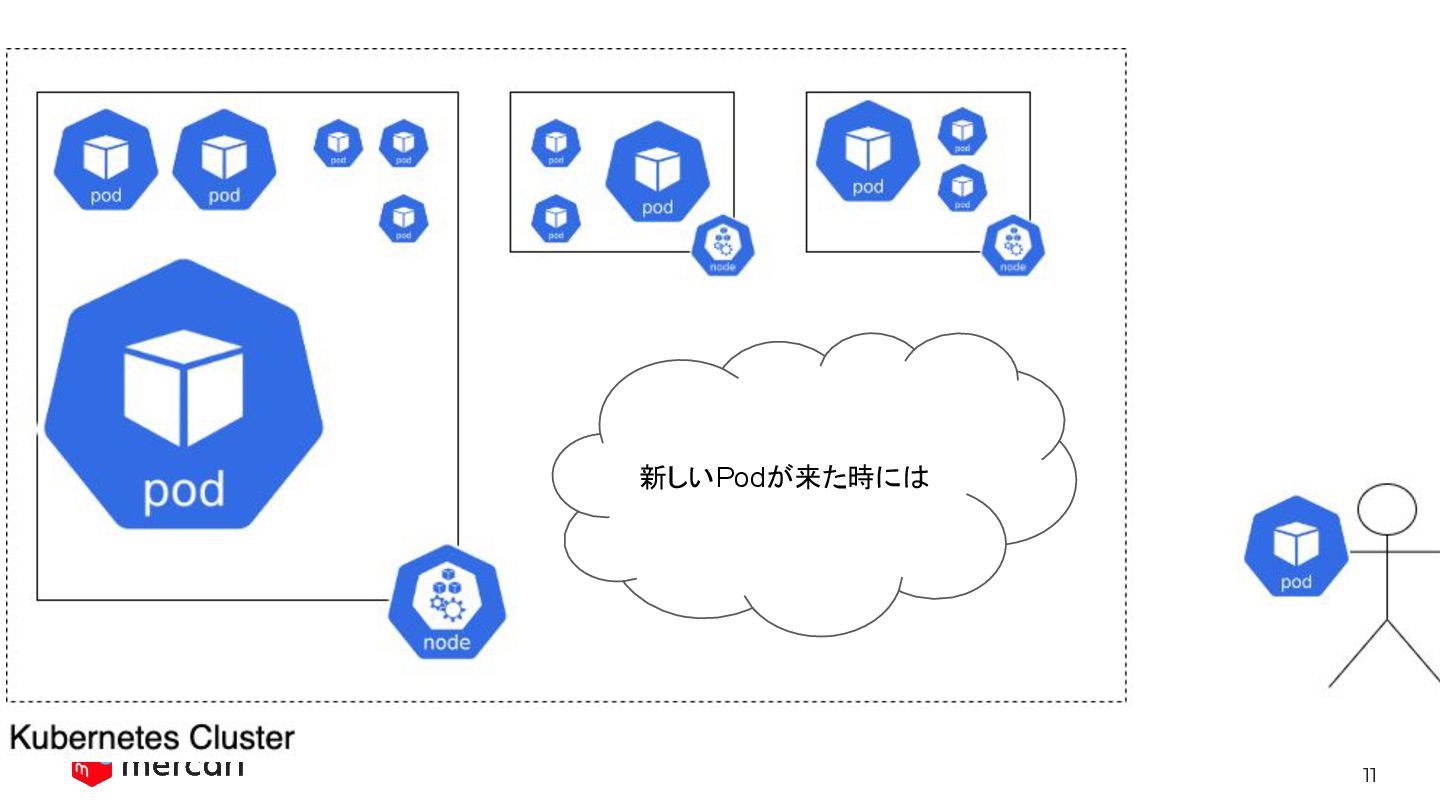
11 Probably, we want to change the placement for cost
reduction. 新しいPodが来た時には
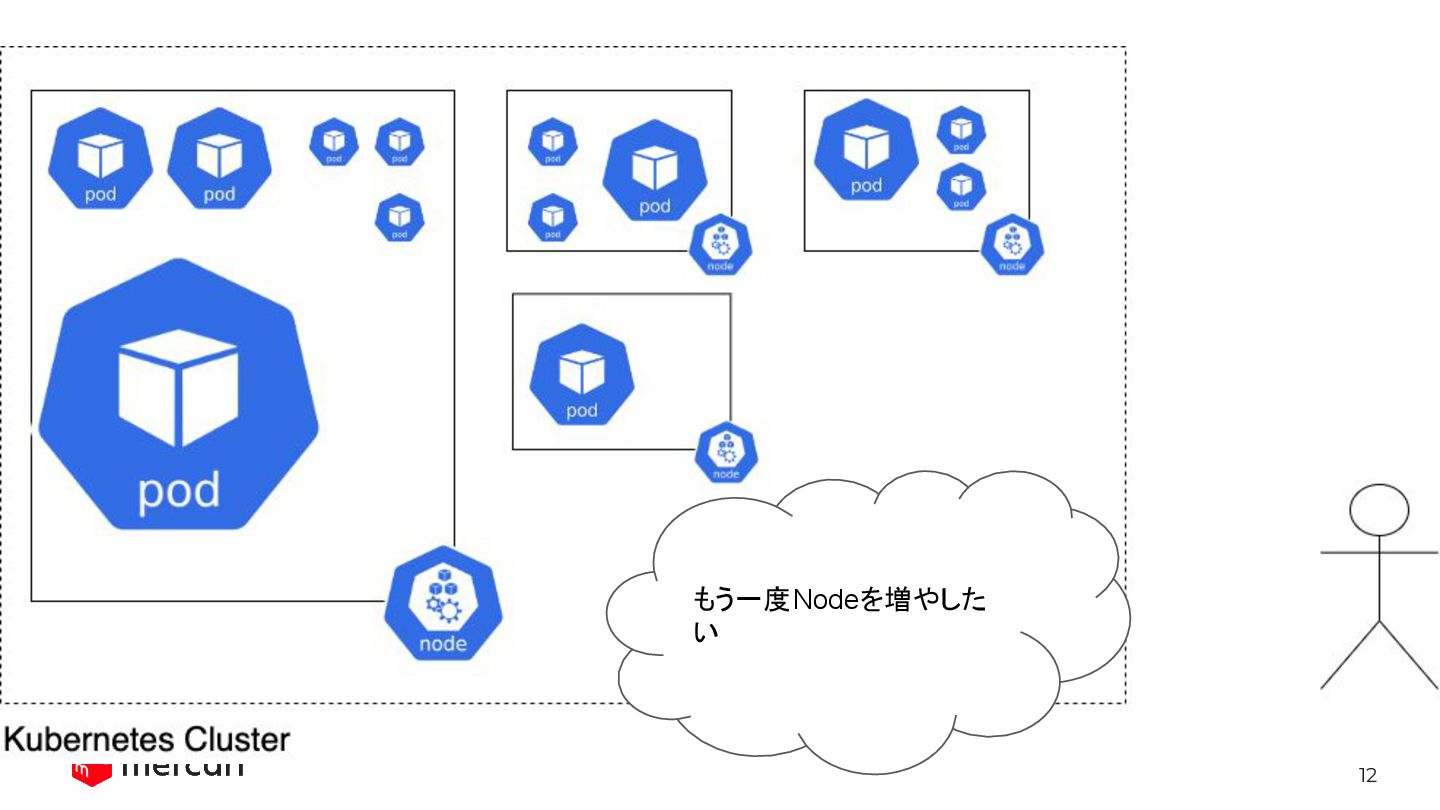
12 But… what if new Pods come after reducing Nodes?
もう一度Nodeを増やした い
13 Automated way: Cluster Autoscaler Cluster Autoscalerがいい感じに: - リソースがスカスカだったら、Podを詰めてNodeを減らす -
Unschedulable Podsが居たら、Nodeを増やす をやってくれる
14 Trade-off: Cost 💴 vs Reliability🛡 Nodeの空きを常に余裕を持っておくことで -> 👍 🛡
Nodeの障害やリソースの需要の急増に強くなる -> 👎 💸 常に余分にお金がかかる
15 GKE Autoscaling profiles GKE では Autoscaling profile を通して optimize-utilization
💴 or balanced🛡 を選択できる: - Cluster Autoscaler がどのようにNodeを削除していくか - Aggressive 💴 vs Conservative🛡 - SchedulerがどのようにPodをスケジュールするか - MostAllocated(Bin packing) 💴 or LeastAllocated🛡
16 GKE Autoscaling profiles Mercariではoptimize-utilization 💴を選択 - Cluster Autoscaler がどのようにNodeを削除していくか
- Aggressive 💴 vs Conservative🛡 - SchedulerがどのようにPodをスケジュールするか - MostAllocated(Bin packing) 💴 or LeastAllocated🛡
17 overprovisioning Pods Nodeに空きが無くなりすぎるのを防ぐoverprovisioning Podsを採用 - overprovisioning Pods = 低いPriorityのPod
- 他のPodがunschedulableになるとoverprovisioning Podsが Preemptされ、リソースに空きを生んでくれる - Cluster AutoscalerはUnschedulableになった overprovisioning Podsに気がついてNodeを増や す
18 overprovisioning Pods Overprovisioning Podsが多すぎると、bin Packingの意味が無い → Overprovisioning Podsの数をNodeの全体数に対して自動で調整 (sigs/cluster-proportional-autoscaler)
将来的にはもう少し賢く調整したい (先週のNode数の変化から需要の変化の予測とかできそう、等のアイデアはある)
19 Node Level Optimization Node instance type
20 Node machine type 現状MercariではE2 machine typeを広く使用している。 → コスパがいいと評判の、新たに追加されたTau T2Dの検討
21 Tau T2D migration いくつかの大きなWorkloadのmachine typeをE2からT2Dに変更 - T2Dのinstance単位の単価はE2よりも高い - しかし、パフォーマンスが高く、多くのWorkloadでCPU使用量の減少を確認
- プログラミング言語等の様々な要素によってCPU使用量の減少率が違う - Goの場合、大体 ~50%の減少 - HPAが正しく動作している場合、CPU使用量の減少はそのままPod数の減少に つながる → 総合的に見てコスパ 👍👍👍 (migration後のnodepoolではコスト3割削減)
22 Workload Level Optimization Workload Autoscaling (HPA & VPA) /
Resource recommender
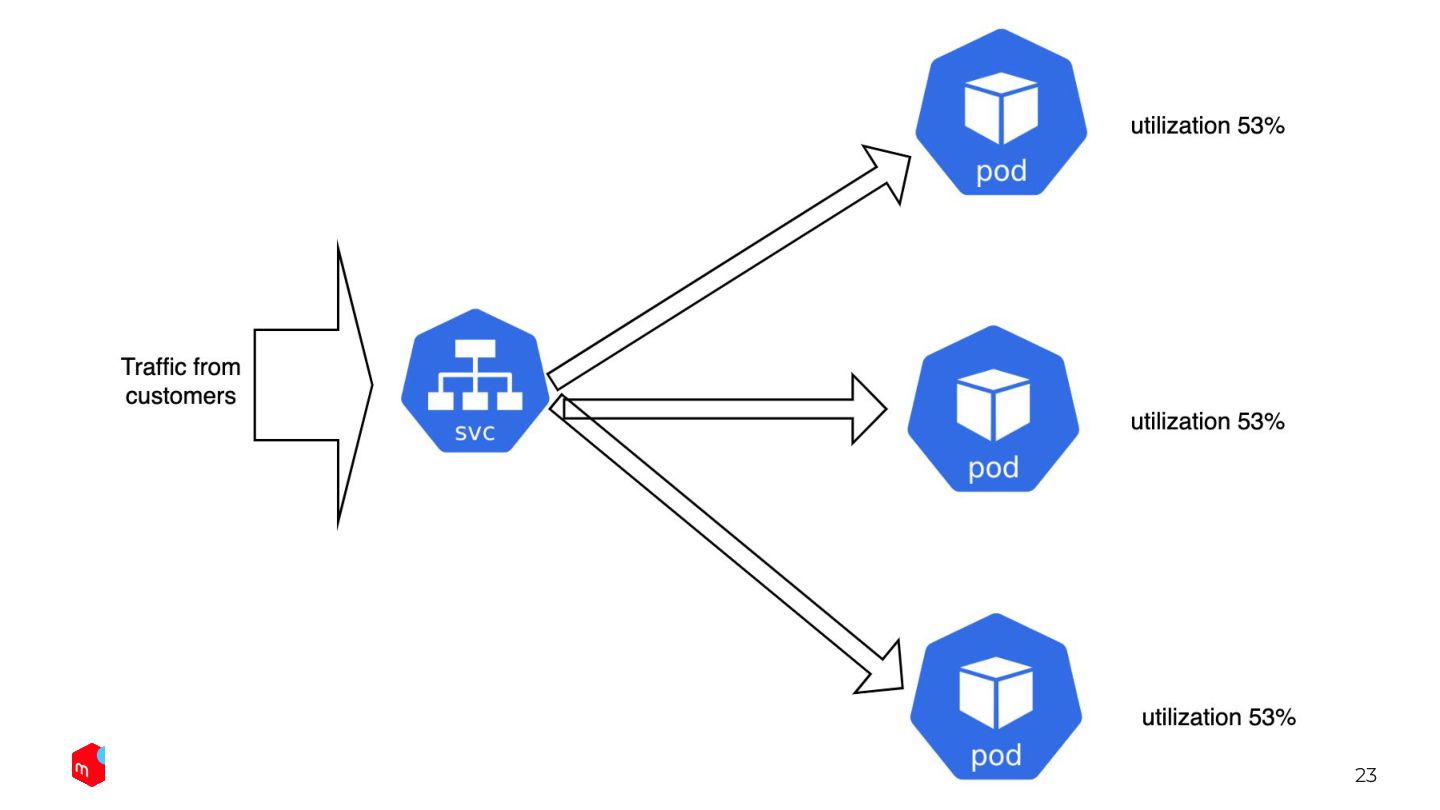
23
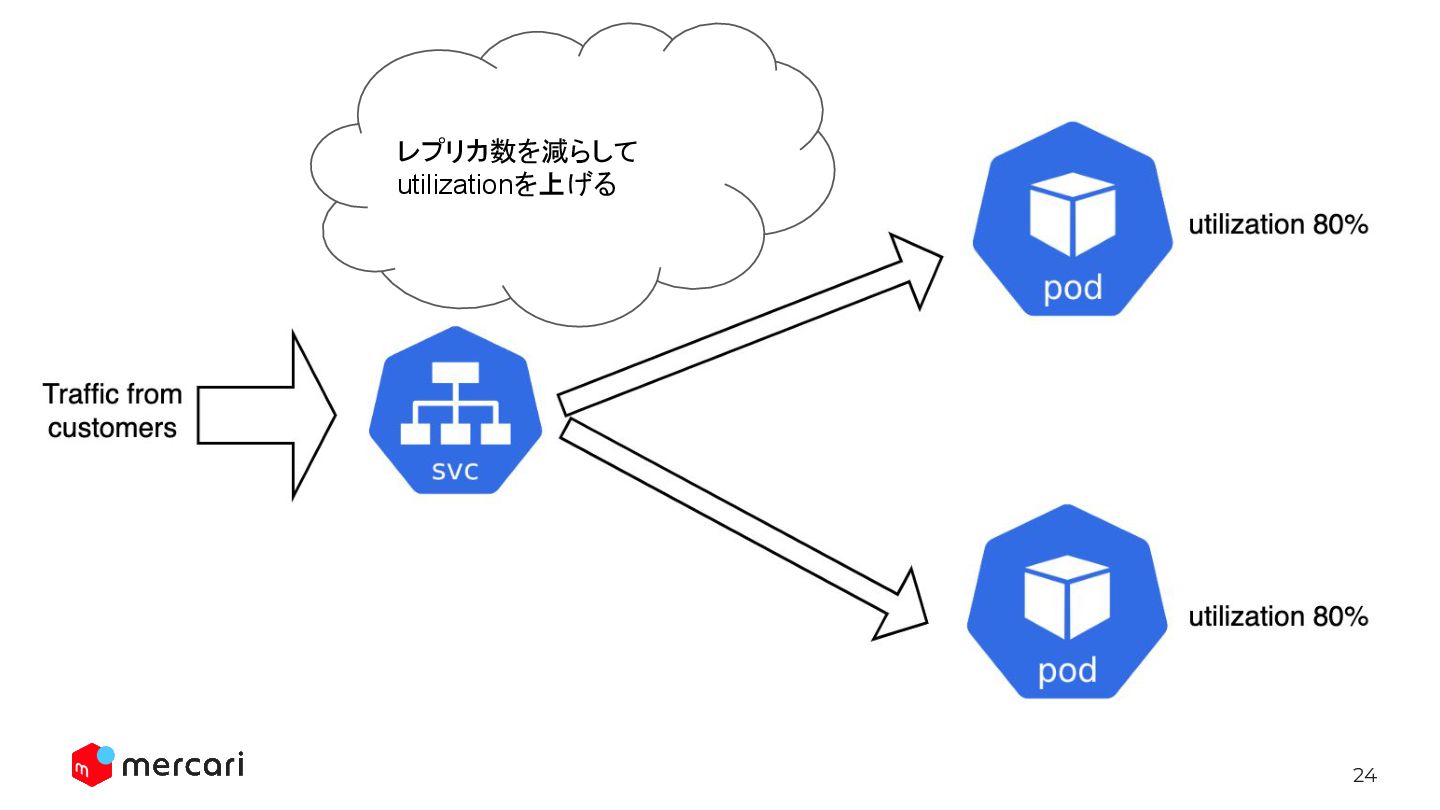
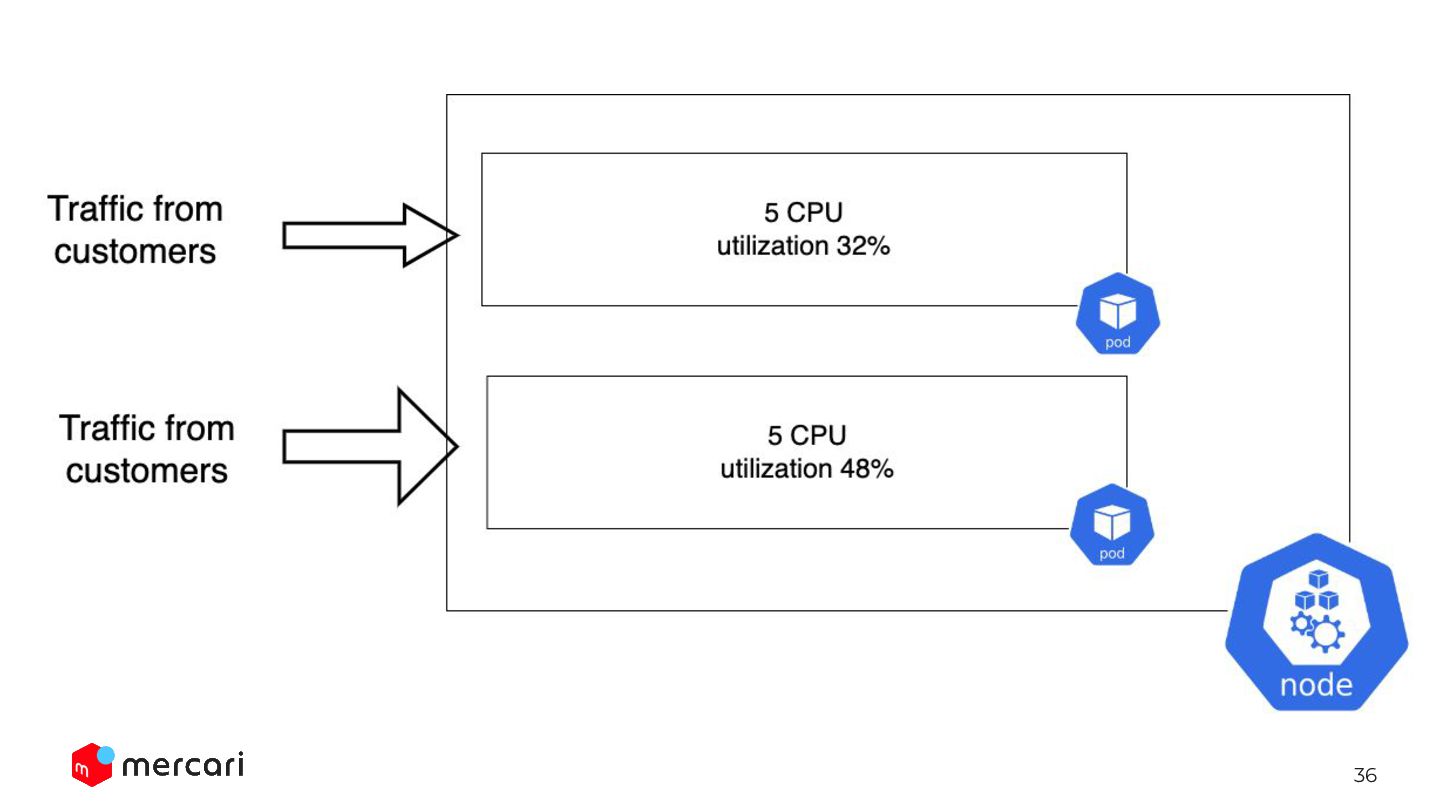
24 レプリカ数を減らして utilizationを上げる
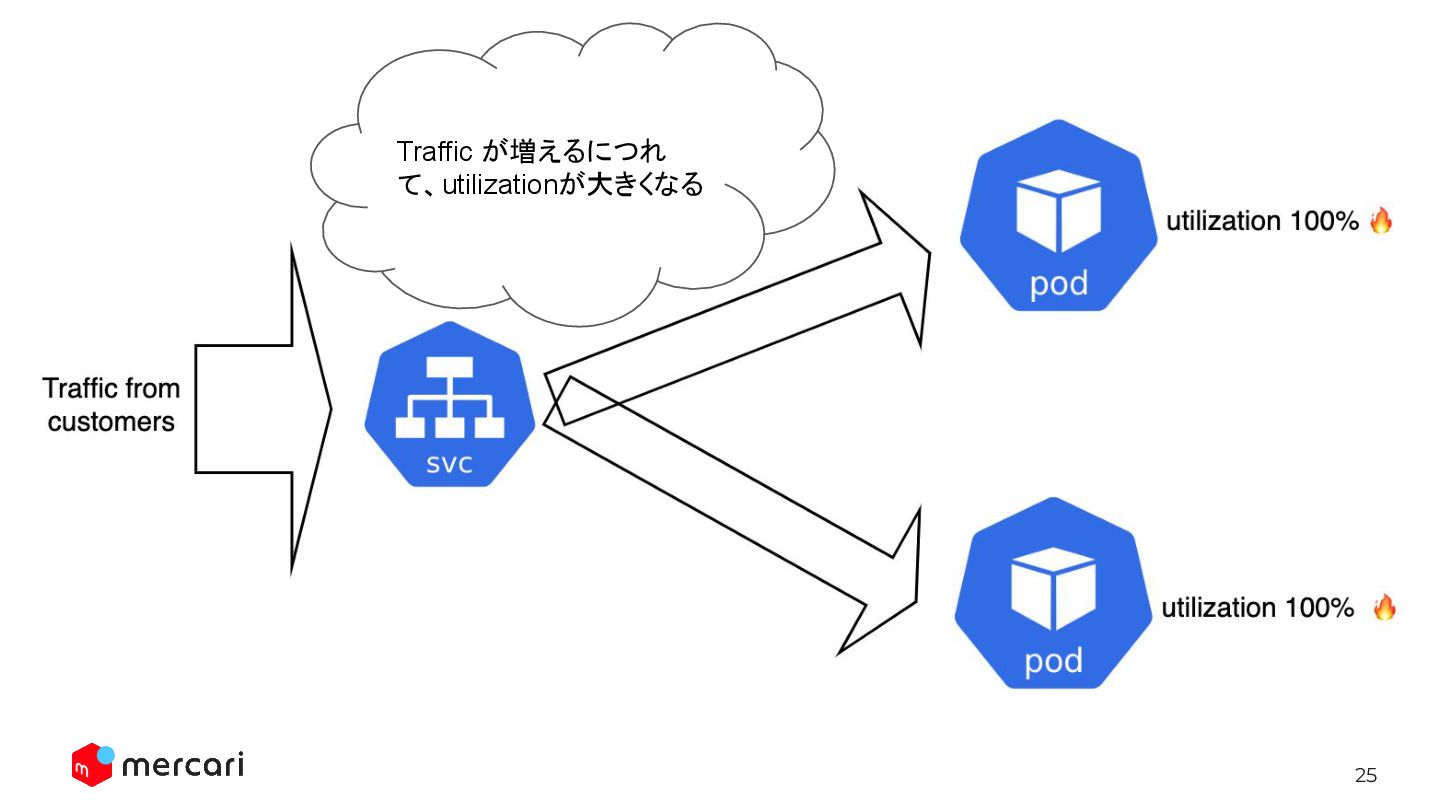
25 Traffic が増えるにつれ て、utilizationが大きくなる
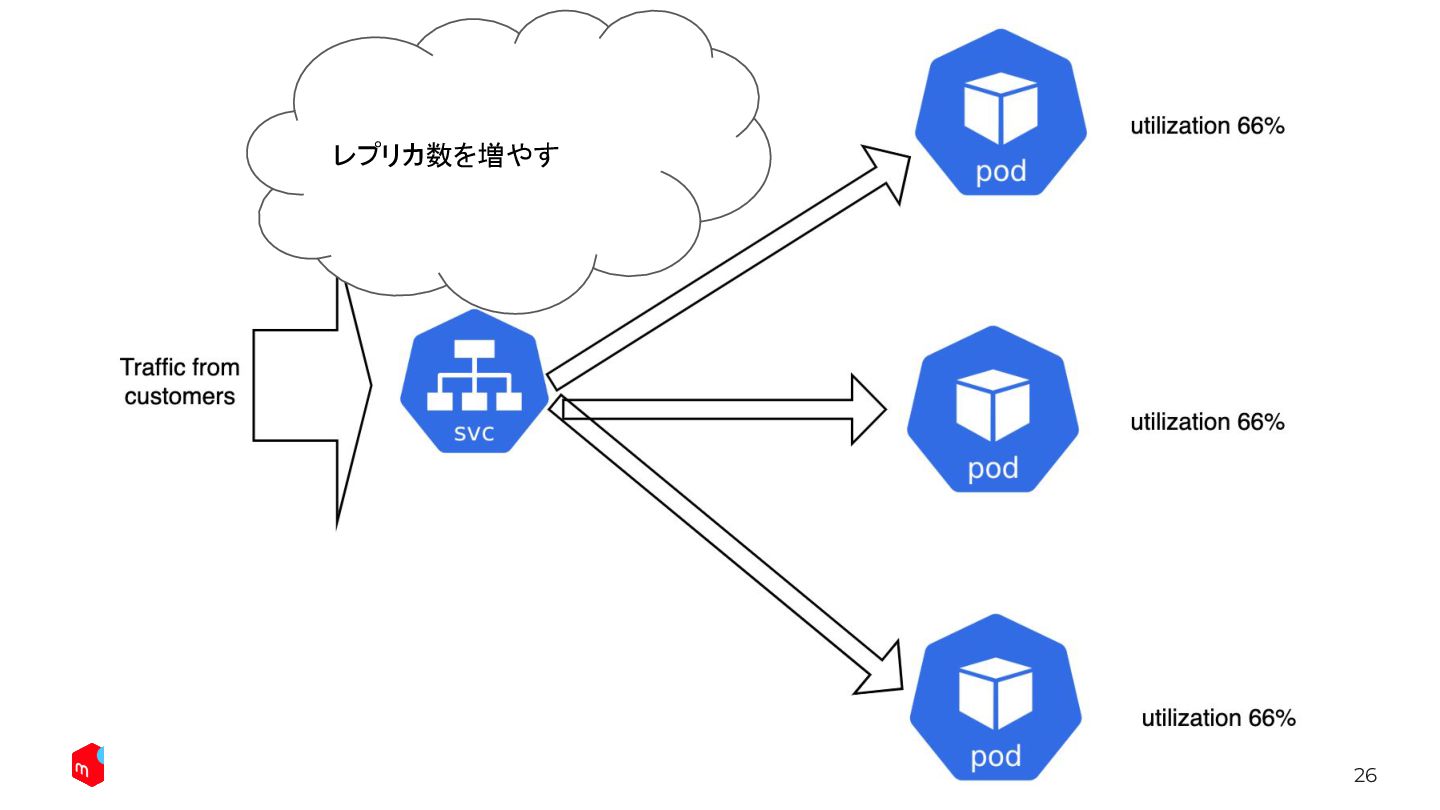
26 レプリカ数を増やす
27 HorizontalPodAutoscaler: resource utilizationをベースに いい感じにScalingしてくれる Automated way: HorizontalPodAutoscaler CPU utilizationが常に
54 - 66%になるように調 整してくれる
28 HPA for multi-containers Pods type: Resource は個々のcontainerのresource utilizationではなく、Pod 全体でのresource
utilizationを使用する
29 HPA for multi-containers Pods type: Resource は個々のcontainerのresource utilizationではなく、Pod全体 でのresource
utilizationを使用する → 複数のcontainerがPod内に存在する場合、正確にScalingできない場合があ る
30 The container based HPA type: ContainerResourceの使用を 検討
31 The beta graduation is done in v1.27 UpstreamでのBeta graduationを推進
(GKEではalpha機能が使えないため)
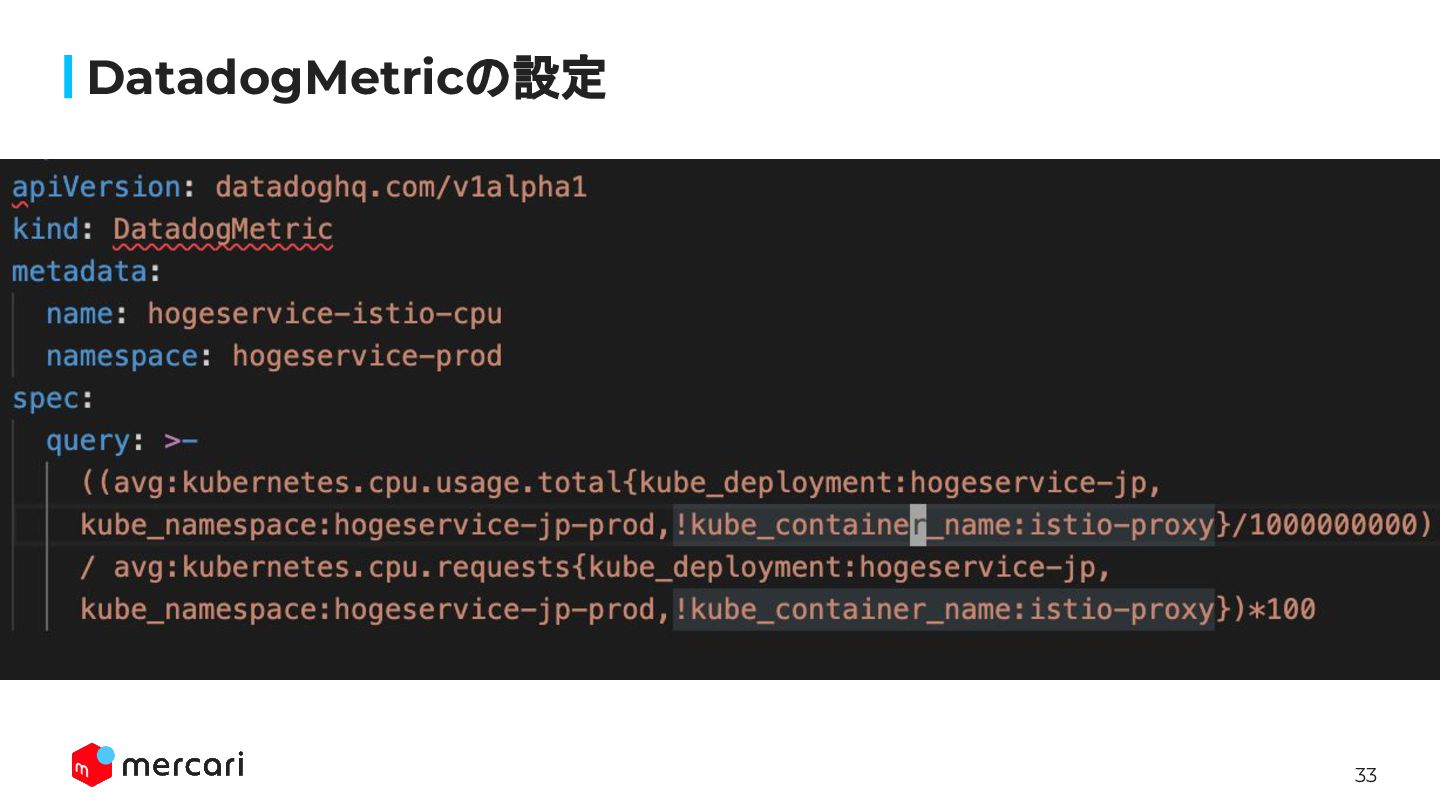
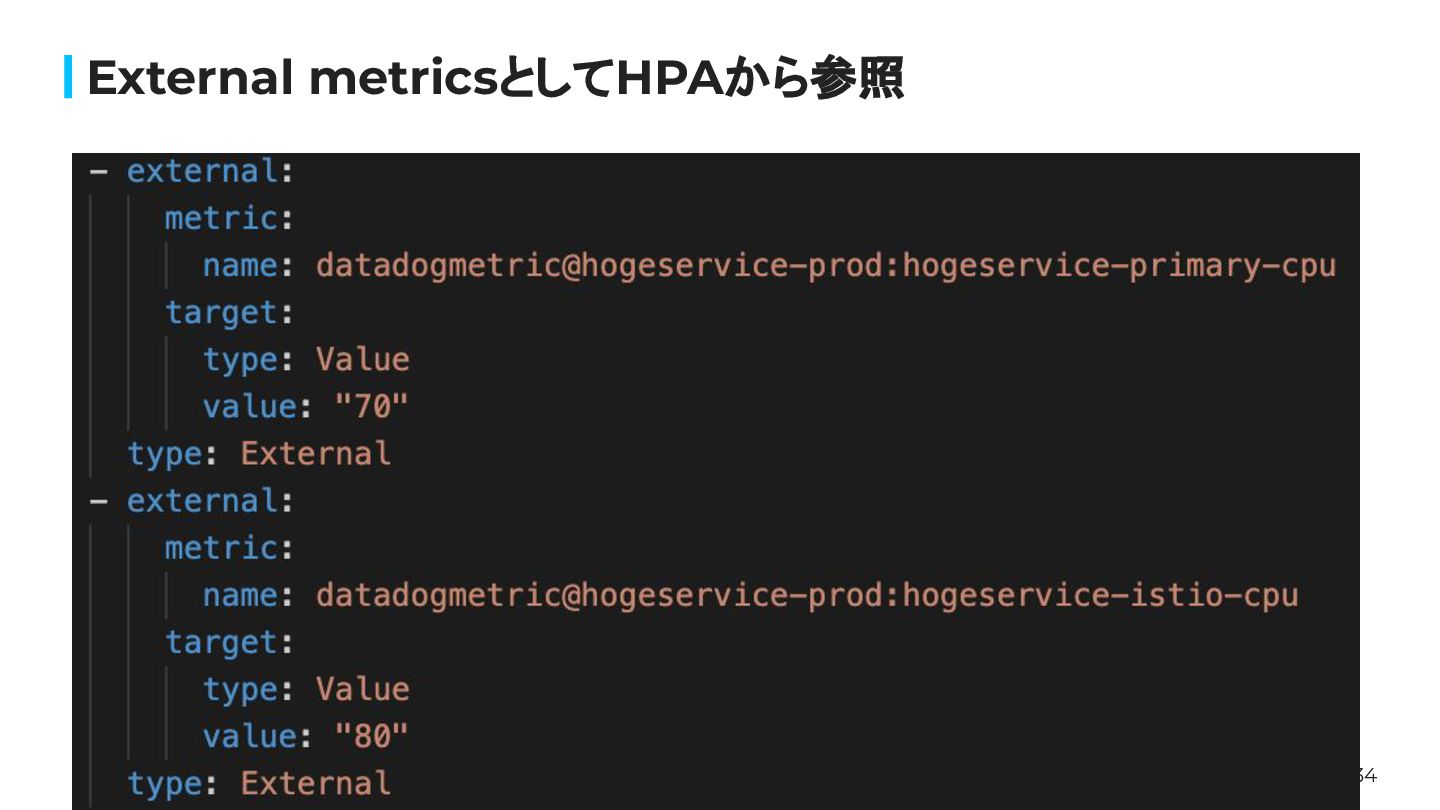
32 Then, what’s alternative for now? 現状DatadogMetric(external metrics)を使用して、type: ContainerResourceを実現している DatadogMetric:
Datadogのqueryの結果をHPAのexternal metricsから 参照できる
33 DatadogMetricの設定
34 External metricsとしてHPAから参照
35 For more detail ↓
36
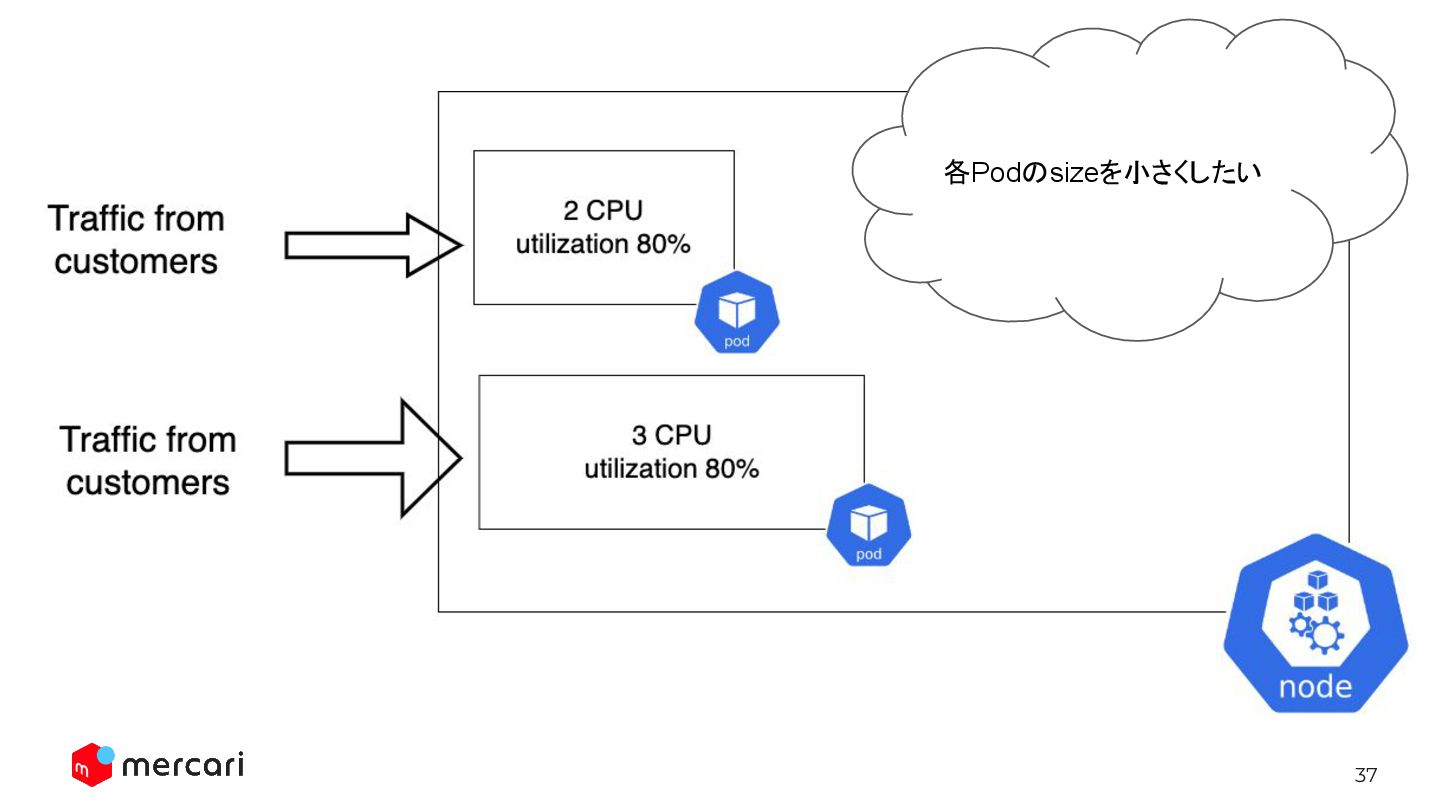
37 各Podのsizeを小さくしたい
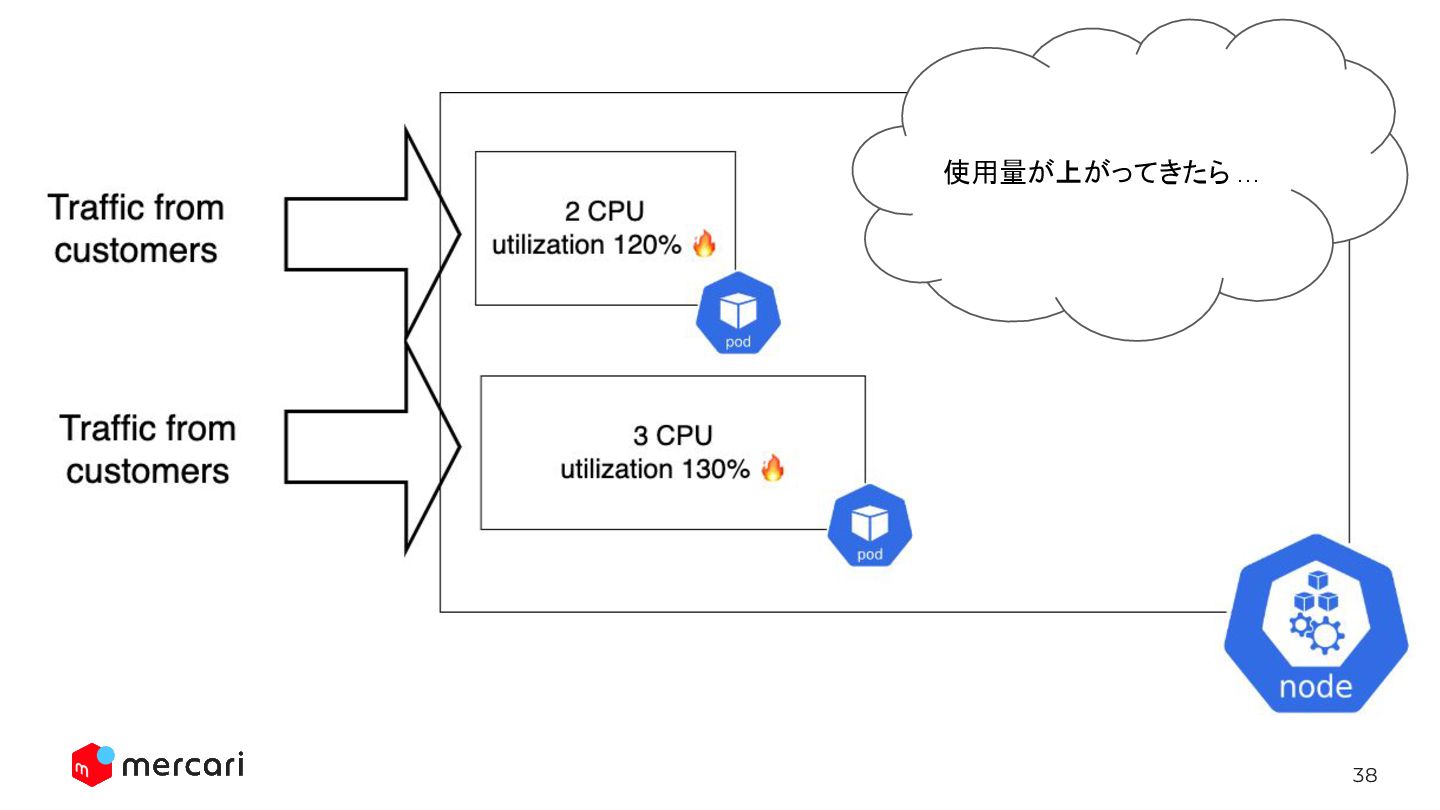
38 使用量が上がってきたら …
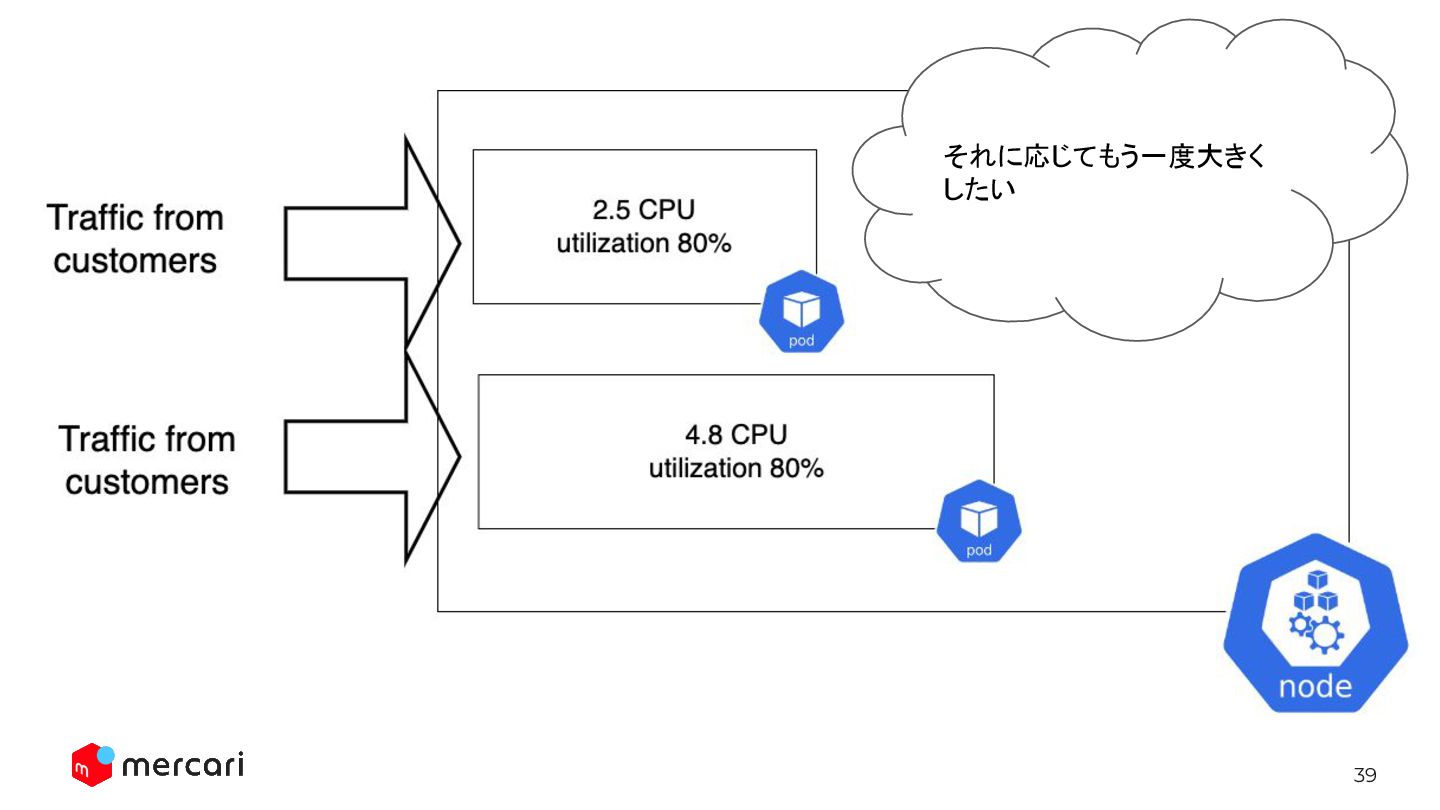
39 それに応じてもう一度大きく したい
40 リソースの使用量を常に確認し、良さげなresource request/limitの推奨値を計 算して、設定してくれる。 memoryの場合OOM Killも考慮に入れられる Automated way: VerticalPodAutoscaler
41 Resource Recommender Resource Recommenderと呼ばれるSlack botが動作している ユーザーは月に一度リソースの推奨のresource requestの値を受け取る Hoge deployment
appcontainer XXX XXX
42 Resource Recommender Resource Recommenderは過去1ヶ月のVPAの推奨値の最大値を取得し、 「プラットフォーム推奨のresource request」としてユーザーに送っている
43 Resource Recommender HPAが設定されているPodのresourceにはRecommendationを適応してはい けないため、送らない等の工夫 XXX XXX Fuga Deployment appcontainer
44 Multidimensional Pod autoscaling Multidimensional Pod autoscalingという HPAをCPUにVPAをMemoryに使用するAutoscalerがGKEに存在 Mercariでもいくつかのサービスで検証を行い、 今後はこの方針に舵を切りつつある
(MPAを直接使用するのではなく、HPA(CPU) + VPA(mem)を設定する) 将来的にRecommenderはautoscalerが設定されていないサービス向けになる
45 Workload Level Optimization HPA fine tuning
46 Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる この場合にDownstreamのサービスではHPAによるScale
inが発生する
47 Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる この場合にDownstreamのサービスではHPAによるScale
inが発生する ↓ Upstreamのサービスが復活した時に、一気にトラフィックが流れて Downstreamのサービスが死ぬというインシデントが稀に発生
48 Setting higher minReplicas? minReplicasを高めに設定しておけば、 解決になるがHPAの機能性を損なうので❌ 例: Pods数が通常のオフピーク時に3個/ピーク時に20個、targetUtilizationが70%の場合、ピー ク時に障害という最悪のケースを考慮すると、minReplicasを14に設定する必要がある
49 dynamic minimum replica num 1週間前の同じ時間のレプリカ数の1/2のレプリカ数をsuggestする DatadogMetricsを全てのHPAに導入 ↓ HPAは複数の指標のレプリカ数の提案から一番大きいものを採用するため、 Incidentの時など通常に比べて異常にレプリカ数が減少している時にのみ動作す
る
50 dynamic minimum replica num このDatadogMetricsで高めに設定されていたMinReplicasを安全に下げること にも繋がった (一律で3に変更)
51 HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとて も多くなる。
52 HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとて も多くなる。 この際、Podのサイズを大きくし、レプリカ数を小さく抑えた方が、省エネになる場合 がある。 とあるサービスでは、この最適化を行うことで、GKEコストが40%減少 (ピーク時のレプリカ数が200->30に変化)
53 HPAがレプリカ全然増やさない問題 Deploymentのresource requestが大きすぎると、HPAを設定していても 「レプリカ数がずっとminReplicasで制限されてる」みたいなケースが起こりうる この場合、HPAが機能していないに等しいためCPU使用率も低くなる
54 HPAがレプリカ全然増やさない問題 この場合、 - Podのサイズを十分に小さくしてHPAが動作するようにする - VPAにCPUも任せる 等を考える必要がある
55 Multiple containers Pod with HPAめんどくさい問題 例: HPAのtarget utilization: sidecar:
80%/app container: 80% この場合、HPAはどちらかのcontainerのresource utilizationが88%を超え た時にスケールアウトを行う。 ↓ これによって、sidecar or app のどちらかのリソースが常に余っているということに なり得る。
56 Multiple containers Pod with HPAめんどくさい問題 HPAを設定していても、CPU 使用量を確認しつつ、片方のcontainerの使用量が 常に低い場合、contianerのsizeを調整する必要がある。
57 HPAのtarget utilization決めるの難しすぎ問題 メルカリでは、HPAのtarget utilizationは70%-80%に設定されていることが多 い。
58 HPAのtarget utilization決めるの難しすぎ問題 メルカリでは、HPAのtarget utilizationは70%-80%に設定されていることが多 い。 なぜ20%-30%の余分なCPUを与えておく必要があるのか?
59 HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ の対応のため
60 HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ の対応のため
リソース使用率の平均値が80%だとしても、いくつかのcontainerの使用率は 100%を超えている可能性もある
61 HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ の対応のため
→ (次スライド)
62 HPAのtarget utilization決めるの難しすぎ問題 0. ピークタイムが近づくにつれて、リソース使用量が増えていく 1. リソース使用率が閾値に達する 2. HPAが気がついてスケールアウトを実行する 3.
(Cluster AutoscalerがNodeを増やす) 4. 新しいPodが実際に動き出し、READYになる (1) → (4)にかかる時間の間もリソース使用量が増えているため、 この間の時間稼ぎの必要性
63 HPAのtarget utilization決めるの難しすぎ問題 - Containerごとのリソース使用率のばらつき - トラフィックの増加のスピード - HPA controllerのリコンサイルの間隔
- (Nodeに空きができるまでの時間 (via CA or overprovisioning Pods)) - Podが動き出すまでにかかる時間 これらを踏まえて、適切な「余分リソース」をtarget utilizationを通してPodに与え る必要がある
64 HPAのtarget utilization決めるの難しすぎ問題 - Containerごとのリソース使用率のばらつき - トラフィックの増加のスピード - HPA controllerのリコンサイルの間隔
- (Nodeに空きができるまでの時間 (via CA or overprovisioning Pods)) - Podが動き出すまでにかかる時間 これらを踏まえて、適切な「余分リソース」をtarget utilizationを通してPodに与え る必要がある 無理じゃね…?
65 ここまでの話 - Incident時のHPAのScale in問題 - HPAがレプリカ増やしすぎる問題 - HPAがレプリカ全然増やさない問題 -
Multiple containers Pod with HPAめんどくさい問題 - HPAのtarget utilization決めるの難しすぎ問題
66 ここまでの話 - Incident時のHPAのScale in問題 - HPAがレプリカ増やしすぎる問題 - HPAがレプリカ全然増やさない問題 -
Multiple containers Pod with HPAめんどくさい問題 - HPAのtarget utilization決めるの難しすぎ問題 無理じゃね…?
67 🐢を使用したWorkload Autoscaling
68 🤔
69 mercari/tortoise
70 これからはリクガメに任せる時代です。 過去のWorkloadの振る舞いを記 録し、HPA, VPA, Pod resource request/limitの全てをいい感じ に調節してくれる Kubernetes
controller https://github.com/mercari/ tortoise
71 mercari/tortoiseのモチベ - 人間の手で先ほどの最適化を全て行うのは厳しい - 最適化後もアプリケーションの変化に伴い、定期的な見直しが必要 - Platform推奨の設定や新しい機能適応への移行のコスト - 現状、PRを全てのHPAに送りつけたりしている。めんど
い - Datadog metricを含む外部サービスにautoscalingを依存させたくない - 外部サービスの障害の間、HPAが正しく動かず眠れぬ夜 を過ごすことになる
72 Simplified configuration apiVersion: autoscaling.mercari.com/v1alpha1 kind: Tortoise metadata: name: nginx-tortoise
namespace: tortoise-poc spec: updateMode: Auto targetRefs: deploymentName: nginx-deployment Deployment name ONLY!
73 Simplified configuration - ユーザーは対象のdeploymentの指定のみを行う。 - Optional なフィールドはその他少し存在するが基本使用不要 - HPA,
VPA, resource req/limの全ては🐢がいい感じに設定する - 「コーナーケースのために柔軟な設定を与える」ことはしない - 一つのTortoiseを設定する => HPA, VPAを全てのcontainerの全てのリ ソースに常に最適化された状態で設定が完了
74 mercari/tortoiseの機能 - HPA optimization - 前章で「無理じゃね…?」と言ってたやつを全部自動で行 う - VPA
optimization - HPAとVPAがうまいこと同時に動けるように調整 - Emergency mode
75 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同 時刻の最大レプリカ数} - HPA target utilization: 推奨の値を 計算し、設定 (計算ロジックは複雑なので説明割愛)
76 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替え る - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
77 Emergency mode 緊急時に一時的にレプリカ数を十分に 大きく変更してくれる - minReplicasをmaxReplicas と同じ値に一時的に変更 - OFFにした際に、安全のため適切
にゆっくりスケールダウンを行う
78 Emergency mode 緊急で十分にスケールアウトしたい時に使用する - 通常にはないようなトラフィックの増加を観測している場合 (テレビ, bot等) - インフラサイドのincidentが発生し、念の為あげておきたい場合
(datadog, GCP等)
79 Emergency mode apiVersion: autoscaling.mercari.com/v1alpha1 kind: Tortoise metadata: name: nginx-tortoise
namespace: tortoise-poc spec: updateMode: Emergency targetRefs: deploymentName: nginx-deployment ←
80 mercari/tortoiseの現状 - Platformで開発しており、検証段階 - 実際に本番で使用はしていない
81 We are めっちゃ hiring!!! Platformで働く仲間をめっちゃ探しています!!!! 今回話したこと以外にも、めっちゃ色んな面白いことやってます!!!!!! - 内製しているCI/CD基盤開発 -
開発者向け抽象化レイヤーの開発 - istioとかのnetworkらへん 「メルカリ Platform 採用」でいますぐ検索!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}