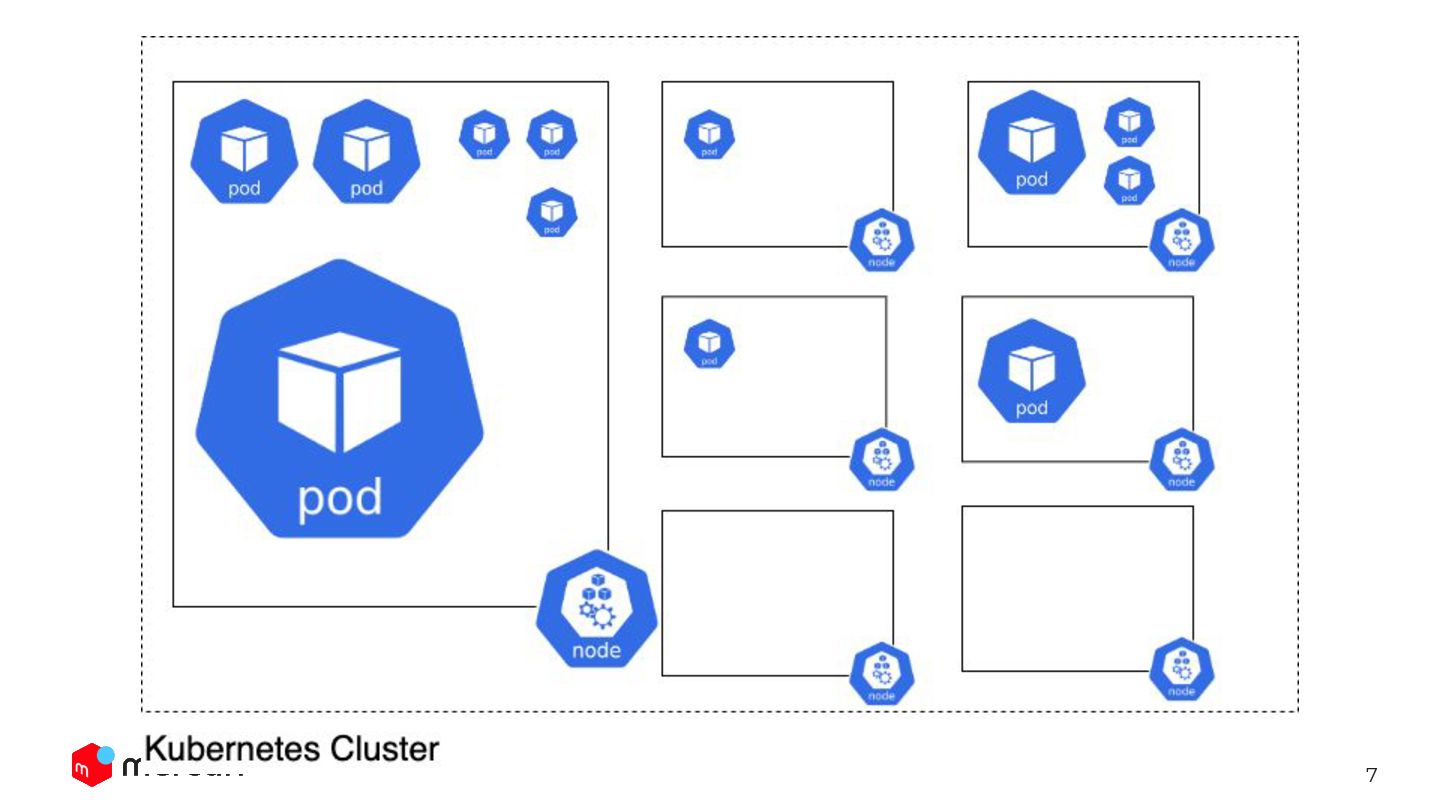
app in Japan. - Mercari is composed of more than 300 microservices. - Almost all microservices are on the one cluster. - The platform team is the cluster admin. And each application team is using our provided cluster.
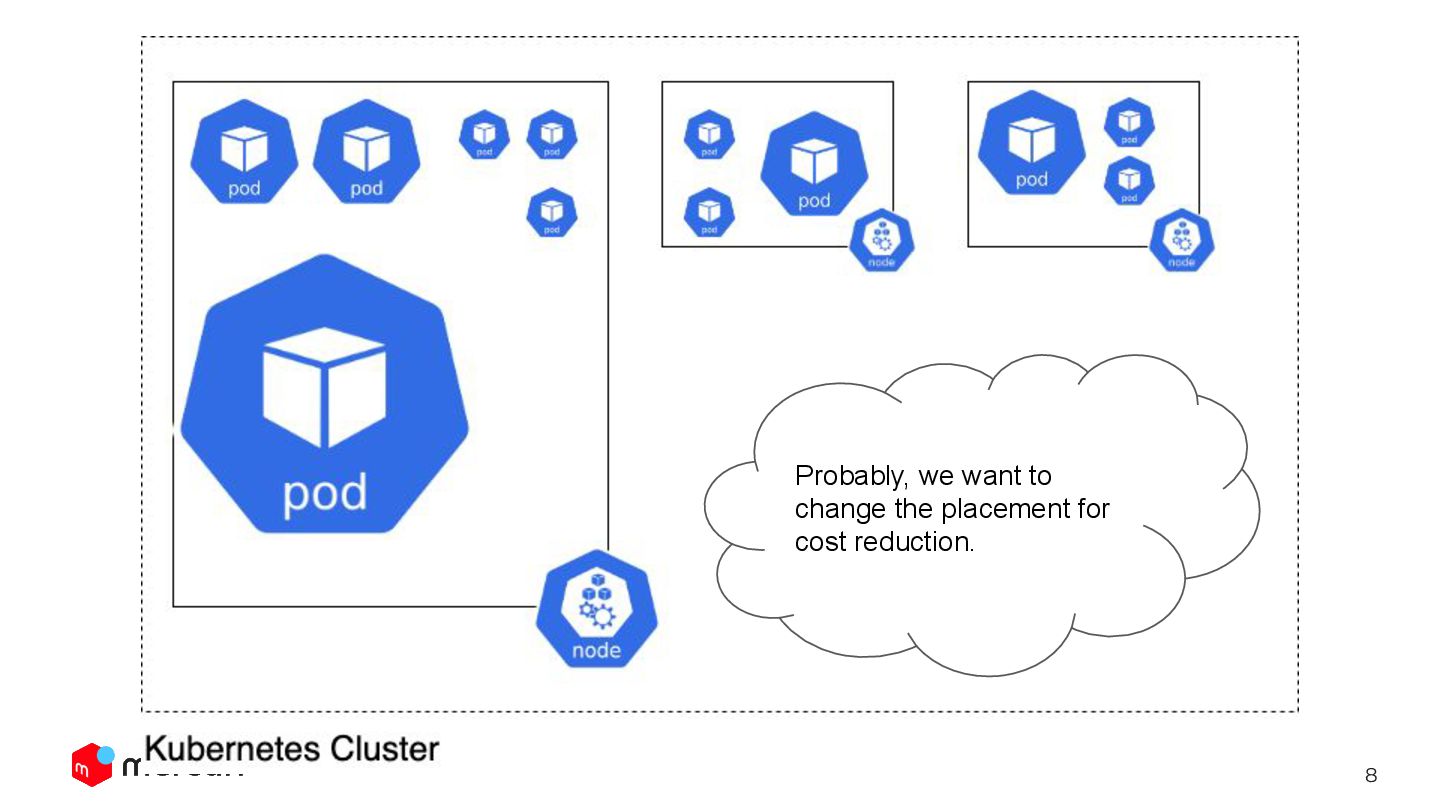
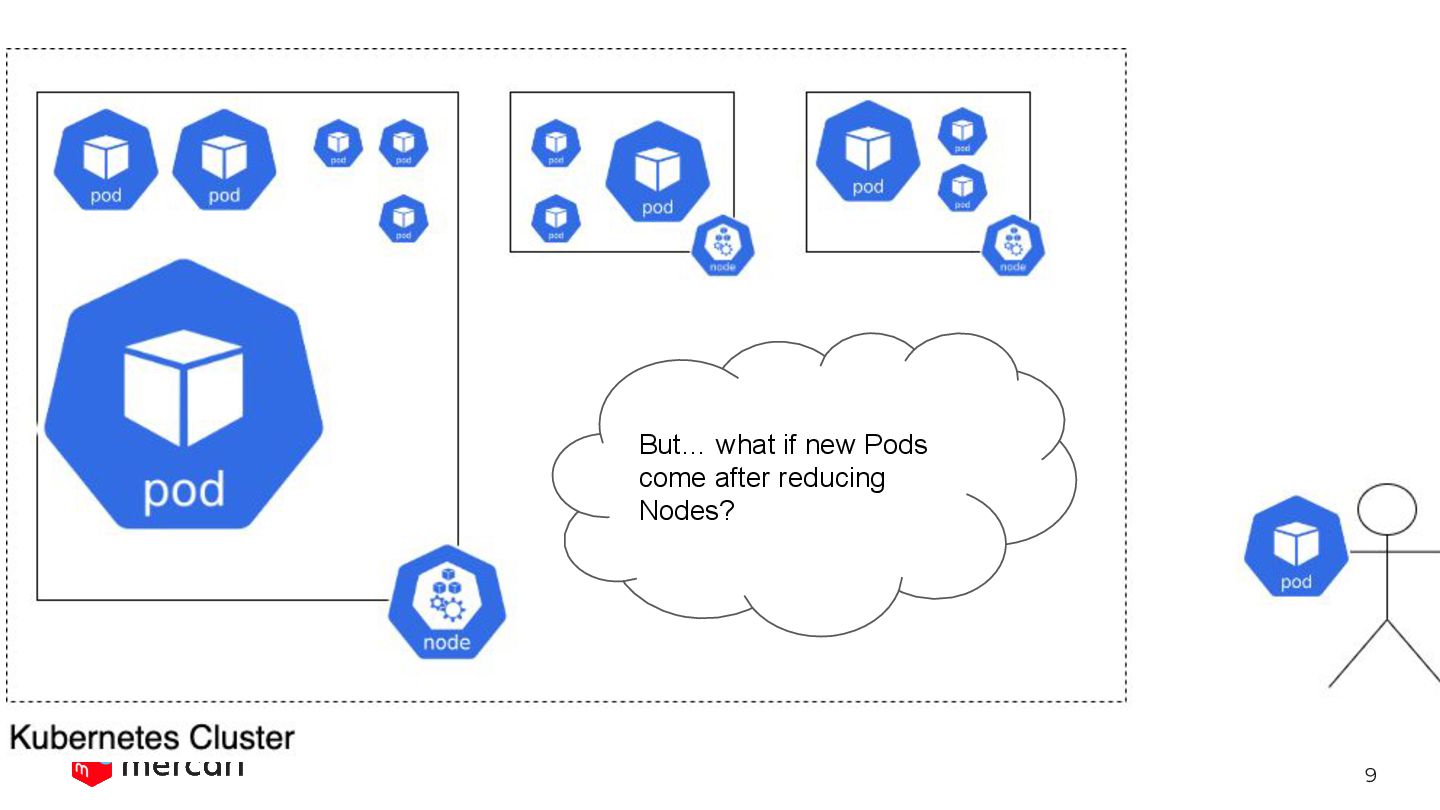
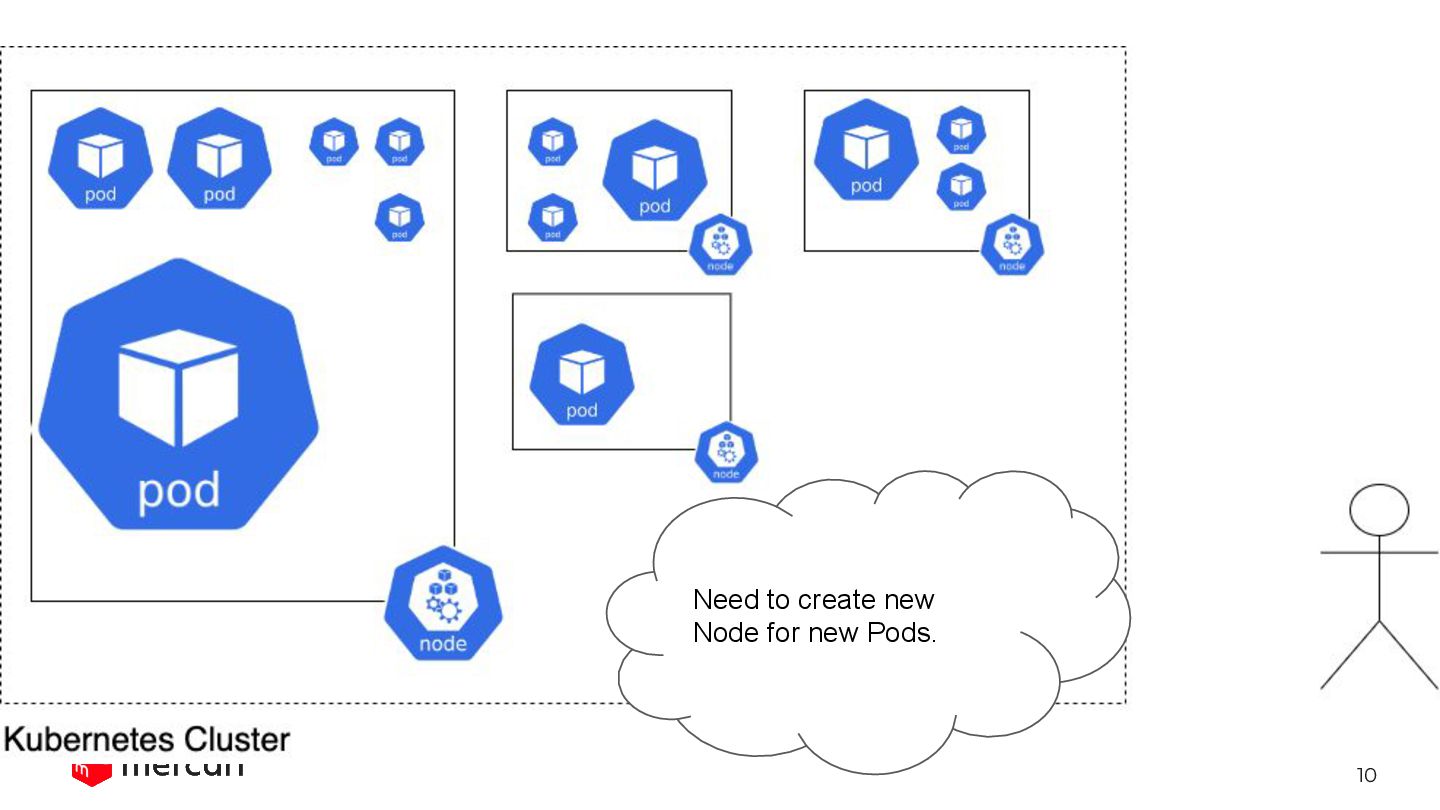
cluster has -> the stronger the system become against Node failure 🛡 -> BUT, the more money we need to pay 💸 We want to reduce cost while keeping the reliability.
🛡) to decide: - How Cluster Autoscaler delete Nodes during scaling down. - Aggressive 💴 vs Conservative🛡 - how the scheduler schedules Pods. - Prefer either high-utilized Node 💴 or low-utilized Node 🛡
Cluster Autoscaler delete Nodes during scaling down. - Aggressive 💴 vs Conservative🛡 - how the scheduler schedules Pods. - Prefer either high-utilized Node 💴 or low-utilized Node 🛡
Pods with very low priority. - They’ll be killed when other Pods cannot be scheduled. - So, they’ll be unschedulable instead and Cluster Autoscaler will notice the demand of scaling up, increase the Node.
overprovisioning Pods. The many overprovisioning Pods, the more cost it makes. → need to predict the demand on each time and change the number of overprovisioning Pods.
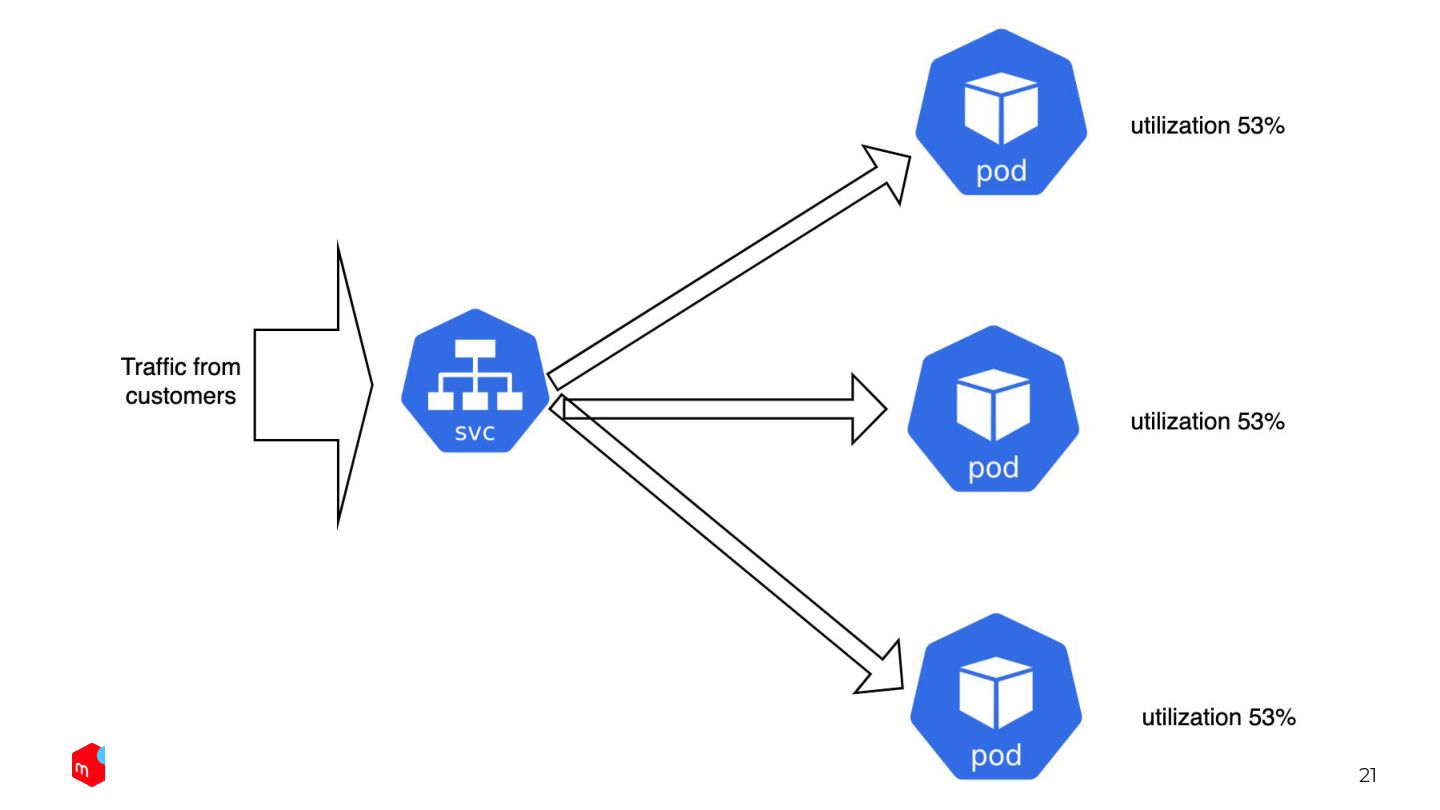
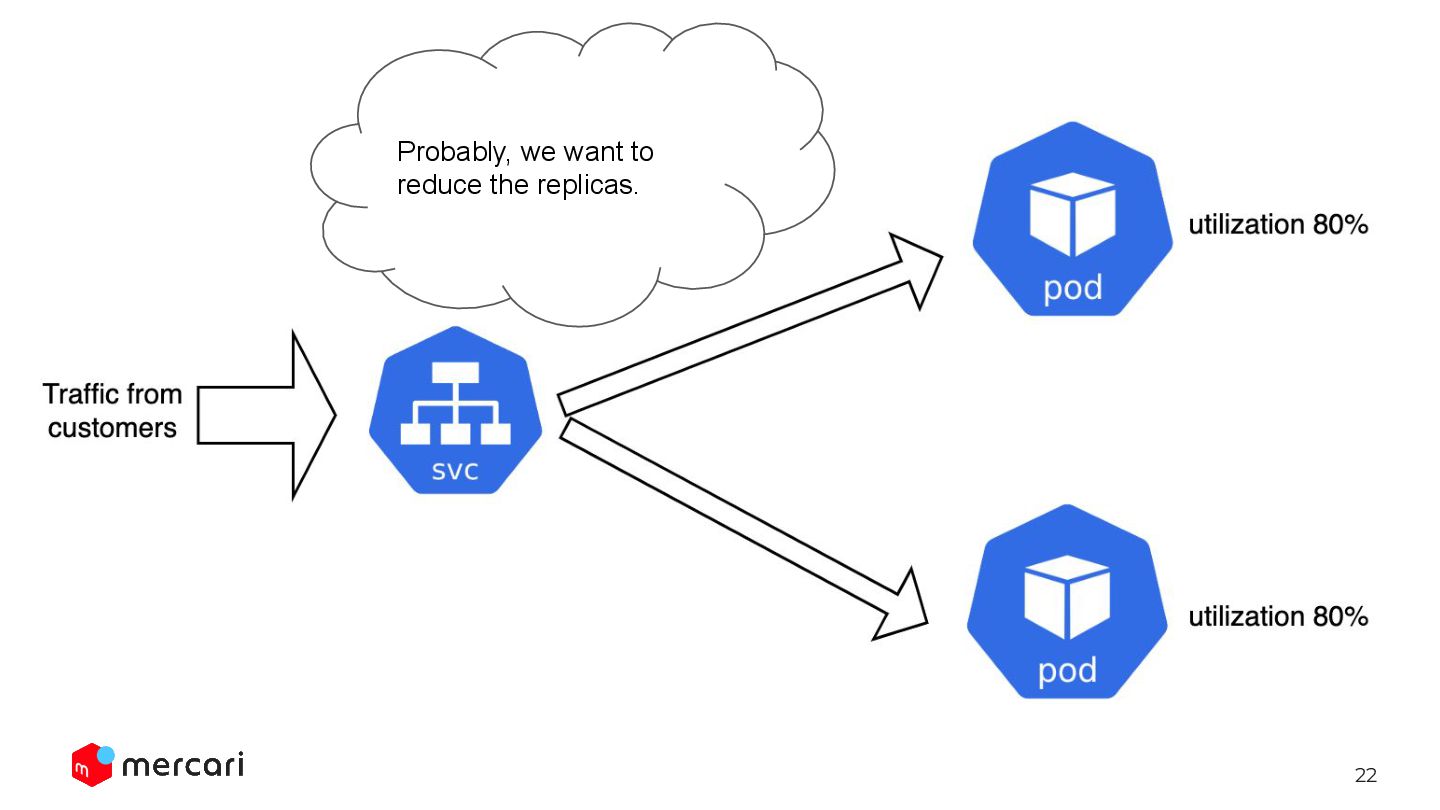
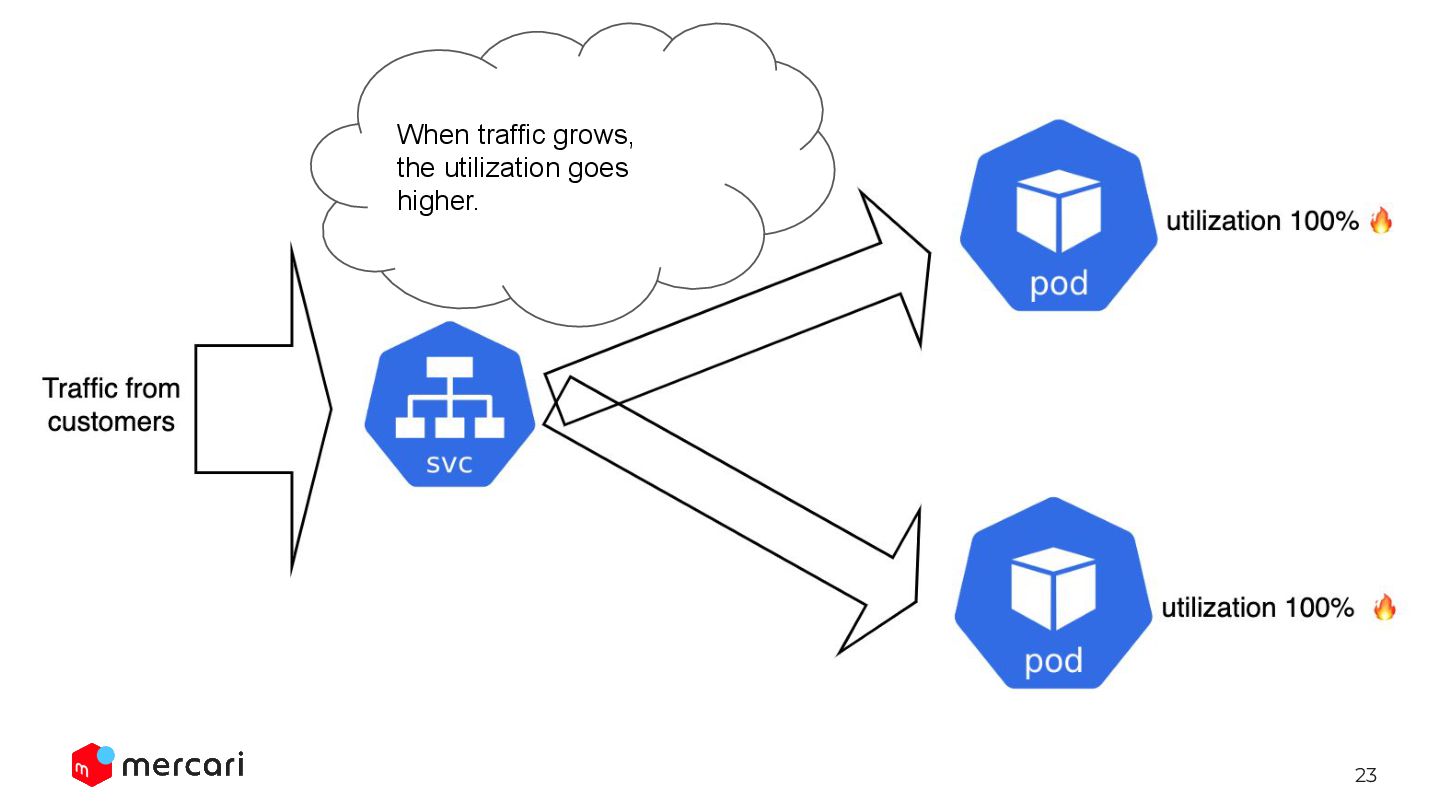
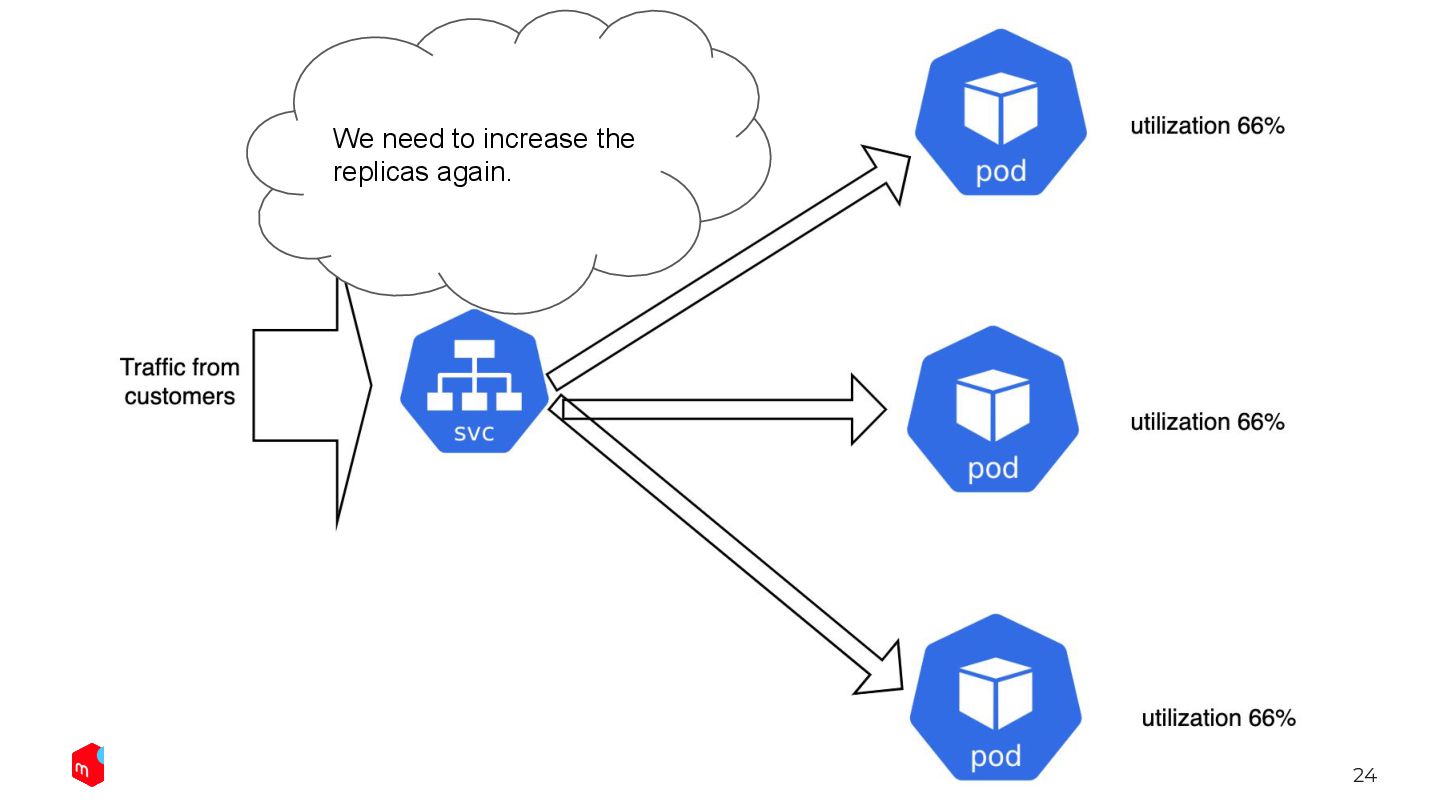
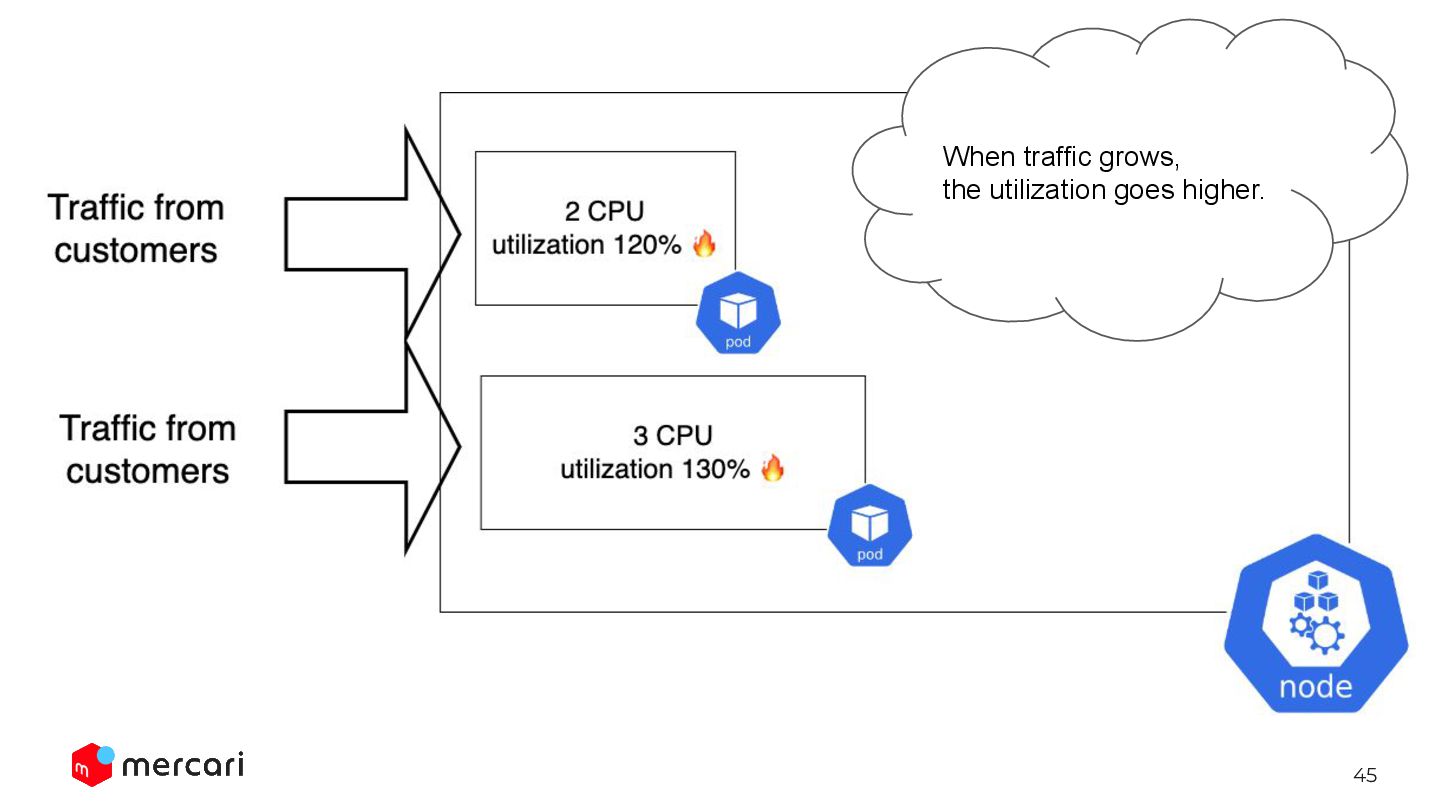
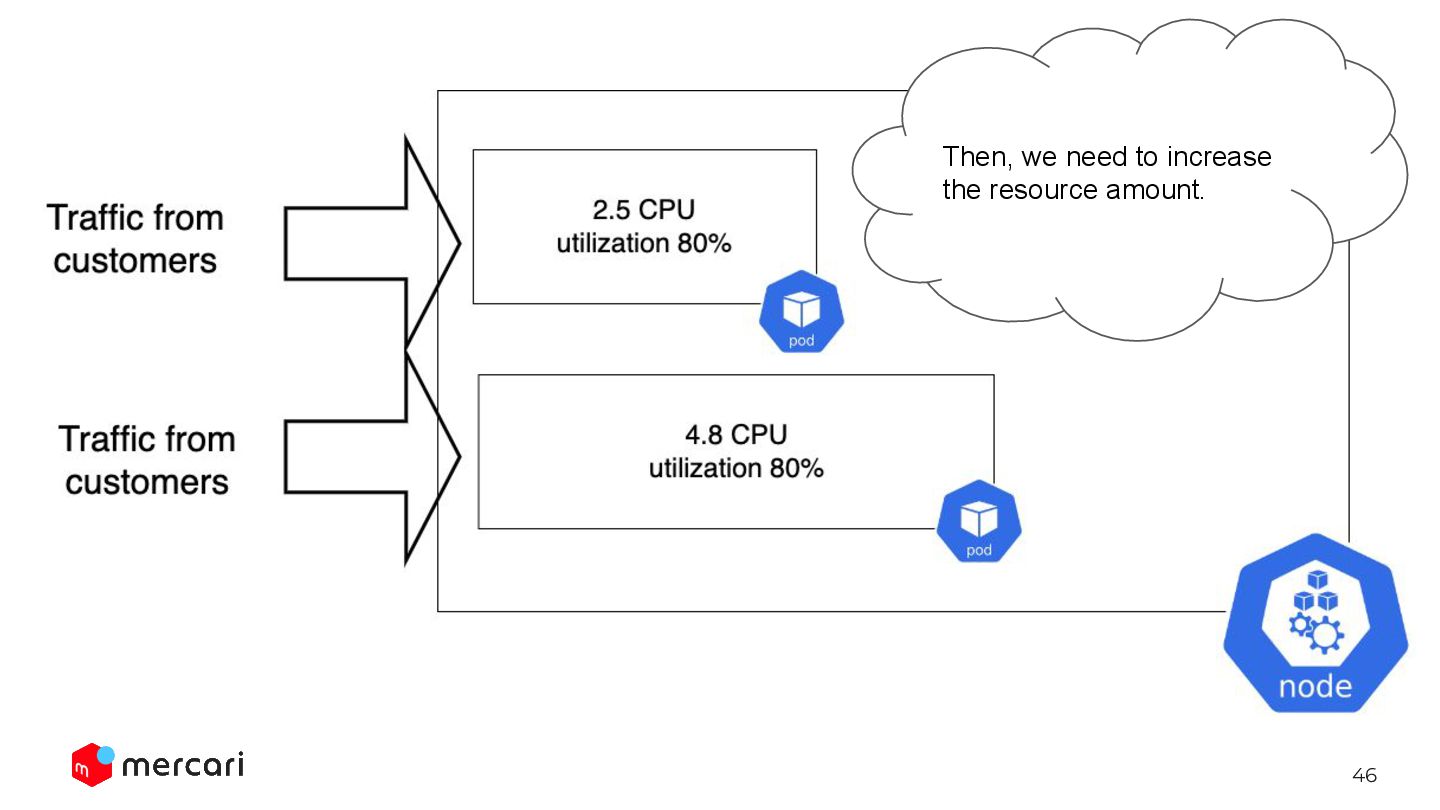
We only need to define the desired resource utilization. Automated way: HorizontalPodAutoscaler HPA keep changing the replicas so that the avg utilization will be 60%
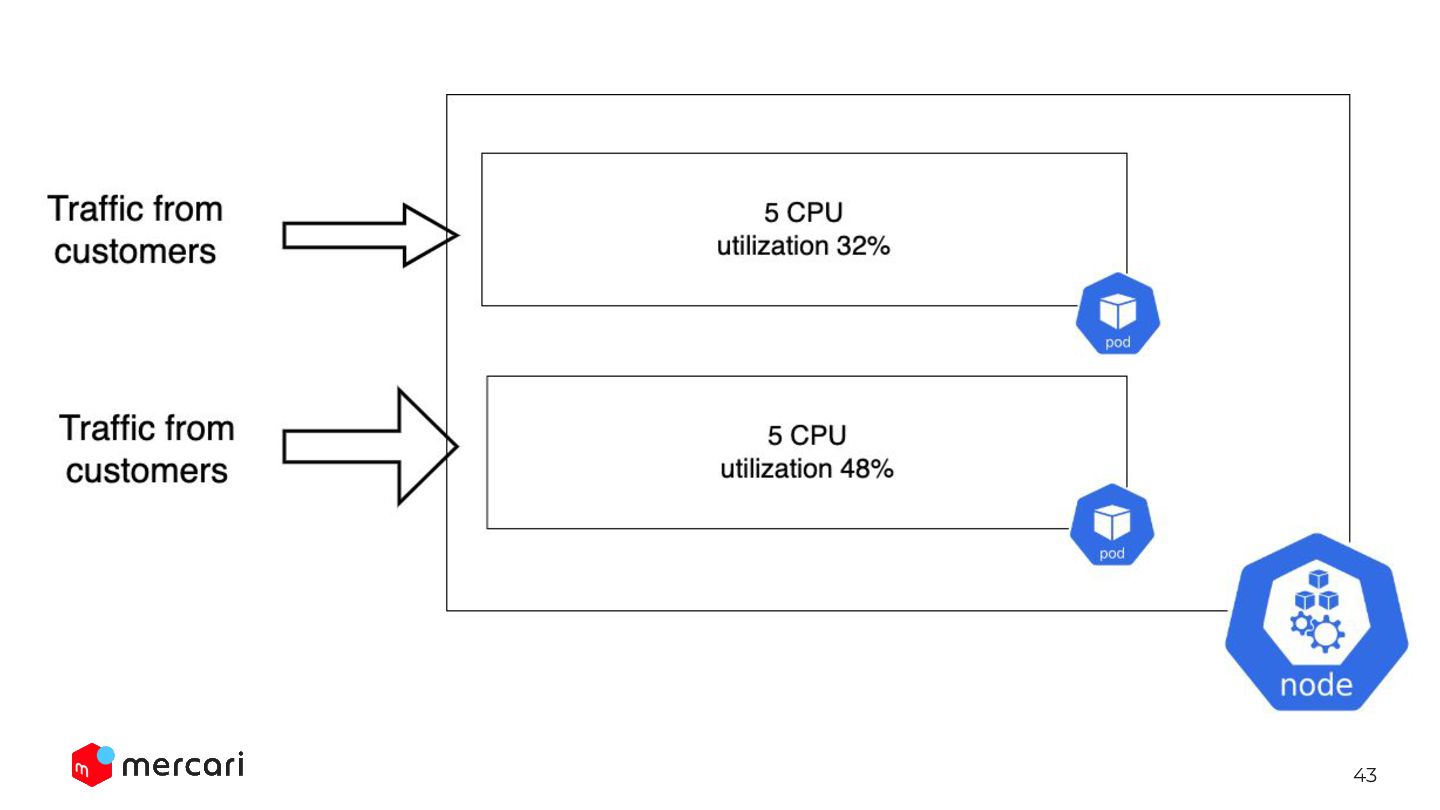
Let’s say: - container A: the current utilization 10% - container B: the current utilization 90% - Thus, the average is 50% We need to scale up in this situation, BUT, HPA won’t scale up because the avg is still low.
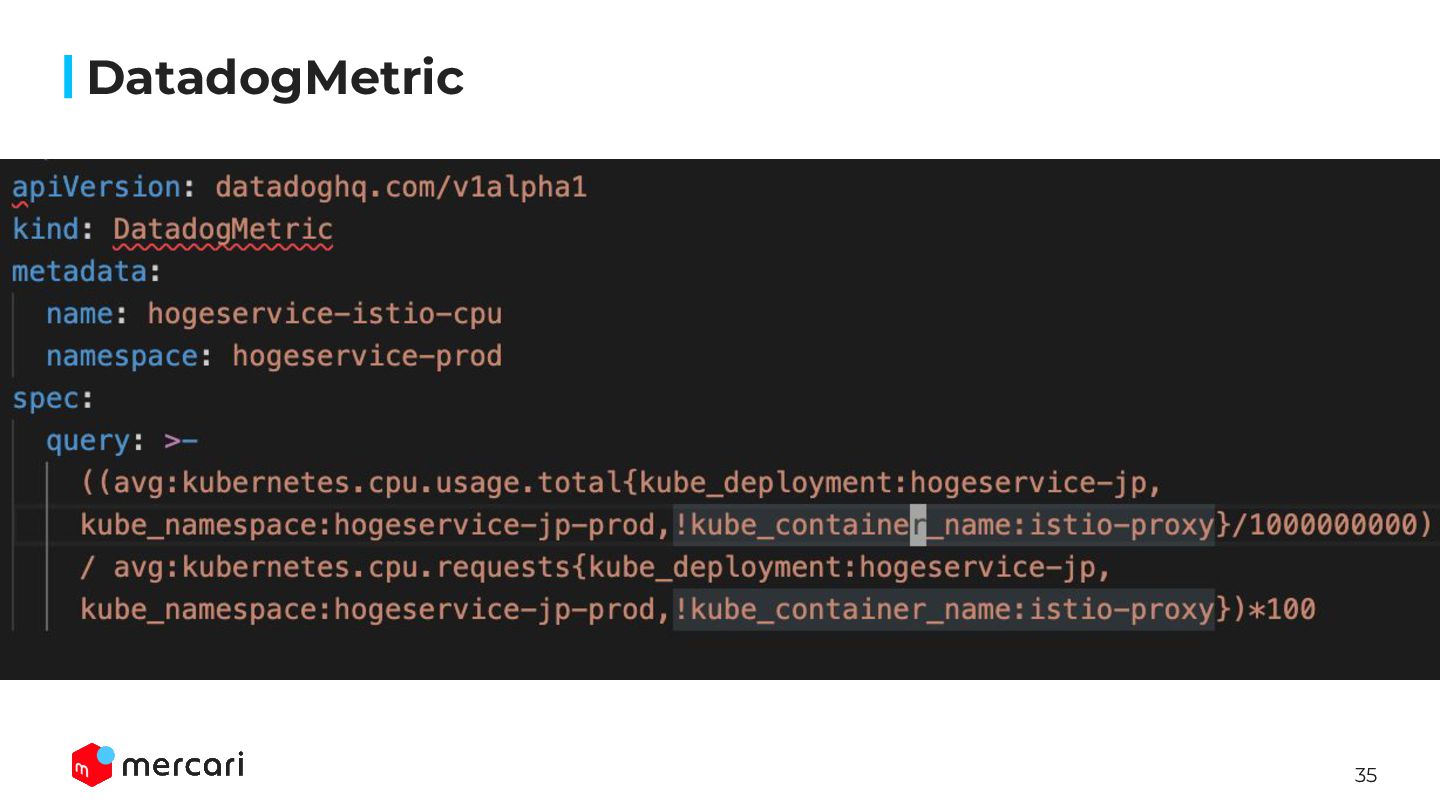
can define the datadog query in DatadogMetric CRD, and HPA refers to it as an external metric. -> It allows HPA to scale up/down based on the query result from the metric values in datadog.
- The upstream service died accidentally - No traffic went to downstream services during the incident - The downstream’s resource utilization went down. Then, the HPAs in downstream services scale down the workloads.
When the upstream incident got resolved, the huge traffic came back, and downstream service was completely overwhelmed. Such unusual scaling down could happen in any services with HPA.
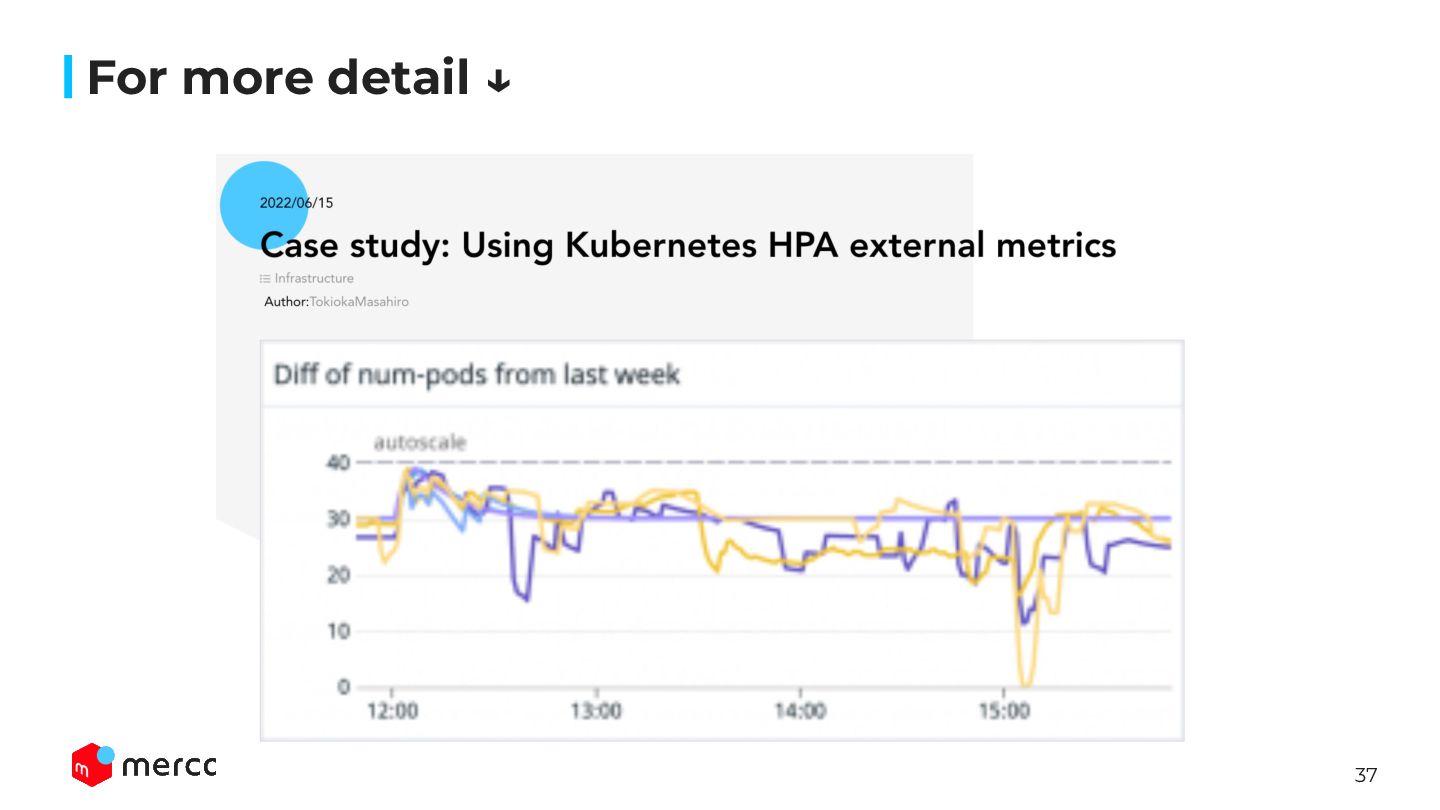
stores it as historical data. ↓ Calculate the recommended resource amount, and change the Pod’s resource request when the current given resource and the recommendation is very different.
shared, we’re trying to use other autoscalers like MPA, VPA. Many of our services are Go’s server and we’d like to provide the information about a good default autoscaler for us.
has too many HPA objects that easily exceeds the recommendation from GKE. If HPA controller takes more time to realize the high resource utilization and scale up the workload, it affect the reliability badly.
case scenario on scaling up is when no Node is available. As shared, we’d like to have some way to adjust the number of overprovisioning Pods by referring the past demand of resources.
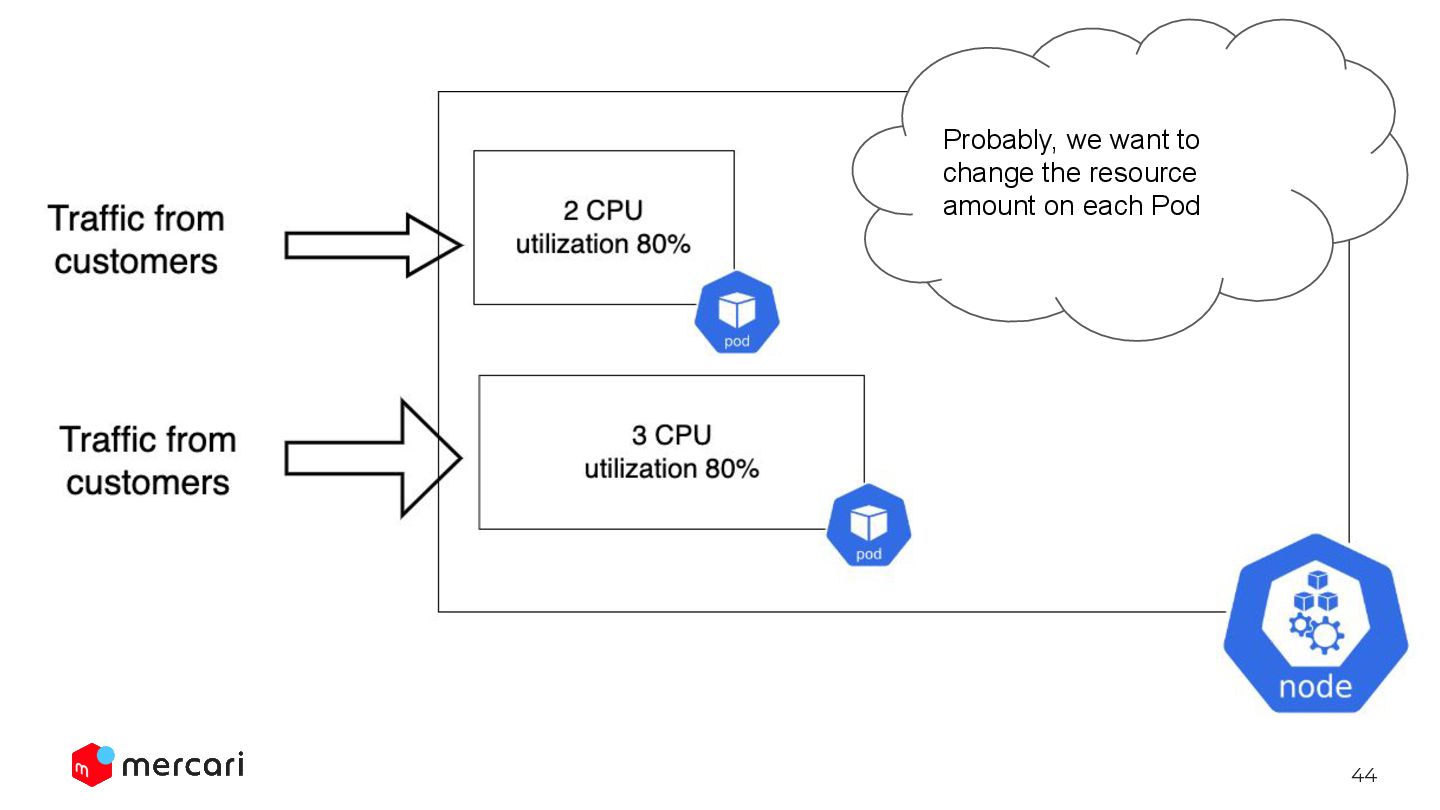
each application team has responsibility for setting the target resource utilization value in HPA. But, feel like it should be done by some automatic way. We’re considering providing the way to automatically set (or just recommend) the best target resource utilization value calculated from the past behavior of that service.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}