Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
メルカリにおけるプラットフォーム主導のKubernetesリソース最適化とそこに生まれた🐢の可能性
Search
sanposhiho
August 03, 2023
Programming
1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
メルカリにおけるプラットフォーム主導のKubernetesリソース最適化とそこに生まれた🐢の可能性
https://event.cloudnativedays.jp/cndf2023/talks/1846
sanposhiho
August 03, 2023
More Decks by sanposhiho
See All by sanposhiho
Understanding the Kubernetes Scheduler: Internals, Roadmap, and Contributions
sanposhiho
1
160
kube-scheduler: from 101 to the frontier
sanposhiho
1
290
A Tale of Two Plugins: Safely Extending the Kubernetes Scheduler with WebAssembly
sanposhiho
0
260
人間によるKubernetesリソース最適化の”諦め” そこに見るリクガメの可能性
sanposhiho
2
2.2k
Don't try to tame your autoscalers, tame Tortoises!
sanposhiho
0
840
メルカリにおけるZone aware routing
sanposhiho
4
1.9k
A tale of two plugins: safely extending the Kubernetes Scheduler with WebAssembly
sanposhiho
1
630
MercariにおけるKubernetesのリソース最適化のこれまでとこれから
sanposhiho
8
4.2k
The Kubernetes resource management and the behind systems in Mercari
sanposhiho
0
370
Other Decks in Programming
See All in Programming
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
110
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
380
フィードバックで育てるAI開発
kotaminato
1
110
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
15
2.9k
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
180
どこまでゆるくて許されるのか
tk3fftk
0
430
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
7
2.9k
Skillsは効率化、Agentsは"自分の拡張"——Builder時代のエージェント編成(CC Night 2026)
wemra
1
200
OSINT for SRE: 学術論文とポストモーテムから探る システム障害の共通パターン / SRE NEXT 2026
tomoyk
1
2.5k
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
4.7k
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1k
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
140
Featured
See All Featured
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
670
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
410
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Balancing Empowerment & Direction
lara
6
1.2k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Tell your own story through comics
letsgokoyo
1
990
Test your architecture with Archunit
thirion
1
2.3k
Believing is Seeing
oripsolob
1
170
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
30 Presentation Tips
portentint
PRO
1
340
Transcript
1 Confidential メルカリにおけるプラットフォーム主導の Kubernetesリソース最適化と そこに生まれた🐢の可能性 Kensei Nakada / @sanposhiho
2 Mercari JP Platform team / 2022卒新卒 Kubernetes approver (SIG-Scheduling)
Kubernetes Contributor award 2022 winner Kensei Nakada / sanposhiho
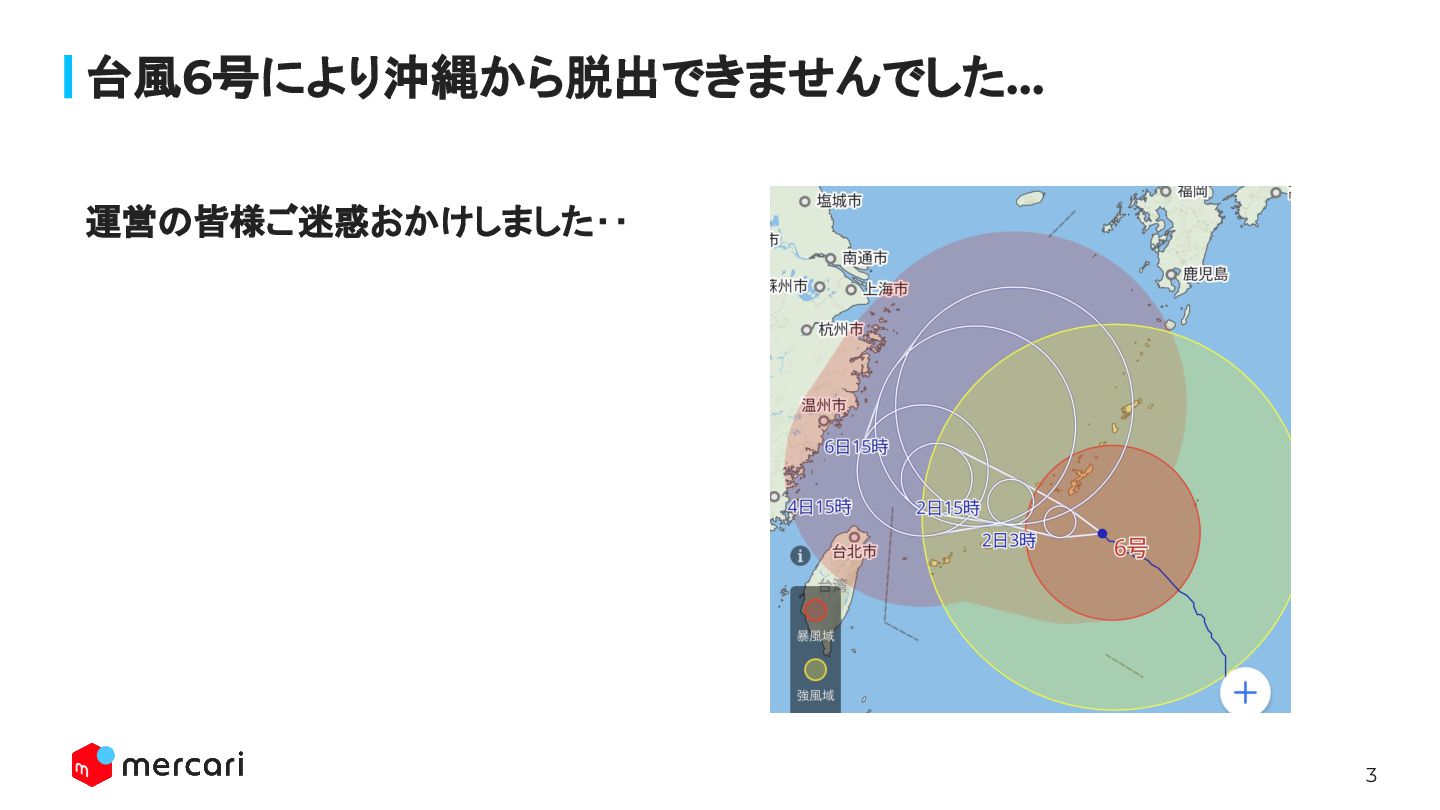
3 台風6号により沖縄から脱出できませんでした… 運営の皆様ご迷惑おかけしました‥
4 Mercari Kubernetes Cluster Overview Agenda 01 Workloads on cluster
+ About FinOps a. Node Level Optimization 02 Cluster Autoscaling a. Node machine type b. Utilize Spot VM instances c.
5 Agenda Workload Optimization 03 VPA / Resource recommender a.
HPA fine tuning b. 🐢を使用したWorkload Autoscaling 04
6 Kubernetes Cluster Overview Workloads on cluster + FinOps
7 Kubernetesクラスター概要 - GKEを使用 (Standard mode) - 一つのClusterで、Mercari/Merpayほぼ全てのWorkloadが動いている - namespace:
500+ / deployment 1000+ - PlatformチームがCluster adminとして運用
8 Workload について - ほとんどがGoで実装されたWorkload - この登壇に含まれる調査結果等はGoのWorkloadと いうことを前提としてください - その他、ElasticSearch,
php 等も居る - Istioを一部namespaceで使用 (全体の半分ほど) (拡大予定) - sidecarコンテナーがついているPodが割と存在する
9 FinOps! - 直近メルカリでは全社的な目標としてFinOpsを掲げている - Monolith -> Microserviceのマイグレーションを経 て、アーキテクチャを洗練していくフェーズ -
Platformチームでもインフラリソースの効率化を推進 - 殆どのサービスが乗っているのでインパクトが超絶大き い - あくまでも安全性を担保しつつ、リソースの効率化を行う
10 このセッションについて メルカリではその他GCPリソースに対するFinOps、Datadogに関するFinOps等 様々行っていますが、 このセッションではあくまでKubernetes周辺のものだけを取り上げます
11 Node Level Optimization Cluster Autoscaling
12 Cluster Autoscaler Cluster Autoscalerがいい感じに: - リソースがスカスカだったら、Podを詰めてNodeを減らす - Unschedulable Podsが居たら、Nodeを増やす
をやってくれる
13 Trade-off: Cost 💴 vs Reliability🛡 Nodeのスペースに常に余裕を持っておくことで -> 👍 Nodeの障害やリソースの需要の急増に強くなる🛡
-> 👎 常に余分にお金がかかる 💸
14 GKE Autoscaling profiles GKE では Autoscaling profile を通して optimize-utilization
💴 or balanced🛡 を選択できる: - Cluster Autoscaler がどのようにNodeを削除していくか - Aggressive 💴 vs Conservative🛡 - SchedulerがどのようにPodをスケジュールするか - MostAllocated(Bin packing) 💴 or LeastAllocated🛡
15 GKE Autoscaling profiles Mercariではoptimize-utilization 💴を選択 - Cluster Autoscaler がどのようにNodeを削除していくか
- Aggressive 💴 vs Conservative🛡 - SchedulerがどのようにPodをスケジュールするか - MostAllocated(Bin packing) 💴 or LeastAllocated🛡
16 Node Level Optimization Node instance type
17 Node machine type 元々MercariではE2 machine typeを広く使用していた → コスパがいいと評判の、新たに追加されたTau T2Dの検討
18 Tau T2D migration いくつかの大きなWorkloadのmachine typeをE2からT2Dに変更 - T2Dのinstance単位の単価はE2よりも高い - しかし、パフォーマンスが高く、多くのWorkloadでCPU使用量の減少を確認
- プログラミング言語等の様々な要素によってCPU使用量の減少率が違う - Goの場合、大体 ~40%の減少 - HPAが正しく動作している場合、CPU使用量の減少はそのままPod数の減少に つながる → 総合的に見てコスパ 👍👍👍 (migration後のnodepoolではコスト3割削減)
19
20 Node Level Optimization Utilize Spot instances (検証段階)
21 Spot VM instances (検証段階) Spot VMはかなりの低価格で使用可能なインスタンス (60-91% cost down!)
ただし... 1. GKE側の都合で急に停止される可能性がある 2. いつでも利用可能か保証されていない
22 Spot VM instances (検証段階) 1. GKE側の都合で急に停止される可能性がある → 一旦以下のようなPodのみを対象に利用の拡大を計画
- 15s以内にシャットダウンできる - ステートレスである - Batch workloads
23 Spot VM instances (検証段階) 2. いつでも利用可能か保証されていない → Spot
VM Nodeの数が足りずPodがスケジュールできない場合は on-demand Nodeにスケジュールする (preferred NodeAffinity) また、定期的にon-demand上のPodをSpotへ移動し直すようなコンポーネントを実装予 定
24 Workload Level Optimization VPA / Resource recommender
25 リソースの使用量を常に確認し、良さげなresource request/limitの推奨値を計算 して、設定してくれる。 →メルカリでは直接VPAはまだあまり使用されていない VerticalPodAutoscaler
26 Multidimensional Pod autoscaling Multidimensional Pod autoscalingという HPAをCPUに、VPAをMemoryに使用するAutoscalerがGKEに存在 Mercariでもいくつかのサービスで検証を行い、 今後はこの方針に舵を切りつつある
(MPAを直接使用するのではなく、HPA(CPU) + VPA(mem)を設定する)
27 Resource Recommender Resource Recommenderと呼ばれるSlack botが動作している ユーザーは月に一度リソースの推奨のresource requestの値を受け取る Hoge deployment
appcontainer XXX XXX
28 Resource Recommender Resource Recommenderは過去1ヶ月のVPAの推奨値の最大値を取得し、 「プラットフォーム推奨のresource request」としてユーザーに送っている
29 Resource Recommender Resource Recommenderは過去1ヶ月のVPAの推奨値の最大値を取得し、 「プラットフォーム推奨のresource request」としてユーザーに送っている CPUやMemoryの推奨値には時間帯等でばらつきがあるため、 1ヶ月のVPAの推奨値の最大値とすることで安全値をとっている
30 Workload Level Optimization HPA fine tuning
31 クラスター上のすべてのサービスにHPAを作成すれば、クラスターのリソース使用率 も上がる? ↓ 現実はそれほど簡単ではない • HPAの各種パラメーターの調整 • リソースのRequestの調整 をしないとHPAがパワーを発揮できない
HPAの難しさ
32 1) Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる
この場合にDownstreamのサービスではHPAによるScale inが発生する
33 1) Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる
この場合にDownstreamのサービスではHPAによるScale inが発生する ↓ Upstreamのサービスが復活した時に、一気にトラフィックが流れてDownstream のサービスが死ぬというインシデントが稀に発生
34 高めにminReplicasを設定すればよくね? minReplicasを高めに設定しておけば、 確かに解決になるがHPAの機能性を損なうので❌ 例: Pods数が通常のオフピーク時に3個/ピーク時に20個、targetUtilizationが70%の場合、ピーク 時に障害という最悪のケースを考慮すると、minReplicasを14に設定する必要がある
35 dynamic MinReplicasの実装 1週間前の同じ時間のレプリカ数の1/2のレプリカ数をsuggestする DatadogMetricsを全てのHPAに導入 ↓ HPAは複数の指標のレプリカ数の提案から一番大きいものを採用するため、 Incidentの時など通常に比べて異常にレプリカ数が減少している時にのみ動作す る
36 2) HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。
37 2) HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。 この際、Podのサイズを大きくし、レプリカ数を小さく抑えた方が、省エネになる場合 がある。 とあるサービスでは、この最適化を行うことで、リソースコストが40%減少 (ピーク時のレプリカ数は200->30に変化)
38 3) HPAがレプリカ全然増やさない問題 Deploymentのresource requestが大きすぎると、HPAを設定していても 「レプリカ数がずっとminReplicasで制限されてる」みたいなケースが起こりうる この場合、HPAが機能していないに等しいためCPU使用率も低くなる
39 3) HPAがレプリカ全然増やさない問題 この場合、 - Podのサイズを十分に小さくしてHPAが動作するようにする - VPAにCPUも任せる 等を考える必要がある
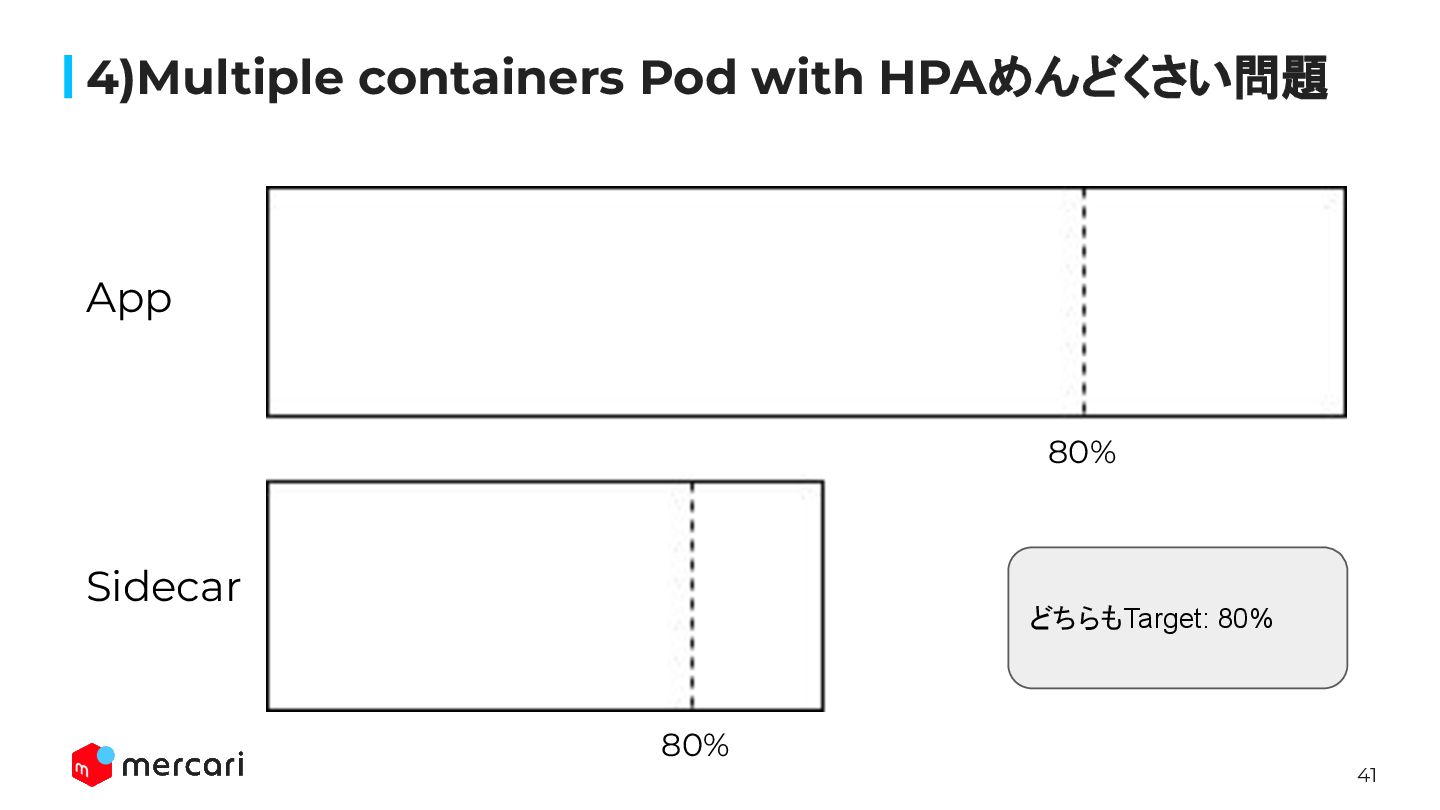
40 4) Multiple containers Pod with HPAめんどくさい問題 例: HPAのtarget utilization:
sidecar: 80%/app container: 80% この場合、HPAはどちらかのcontainerのresource utilizationが80%を 大きく超えた時にスケールアウトを行う。 ↓ これによって、sidecar or app のどちらかのリソースが常に余っているということに なり得る。
41 4)Multiple containers Pod with HPAめんどくさい問題 80% 80% App Sidecar
どちらもTarget: 80%
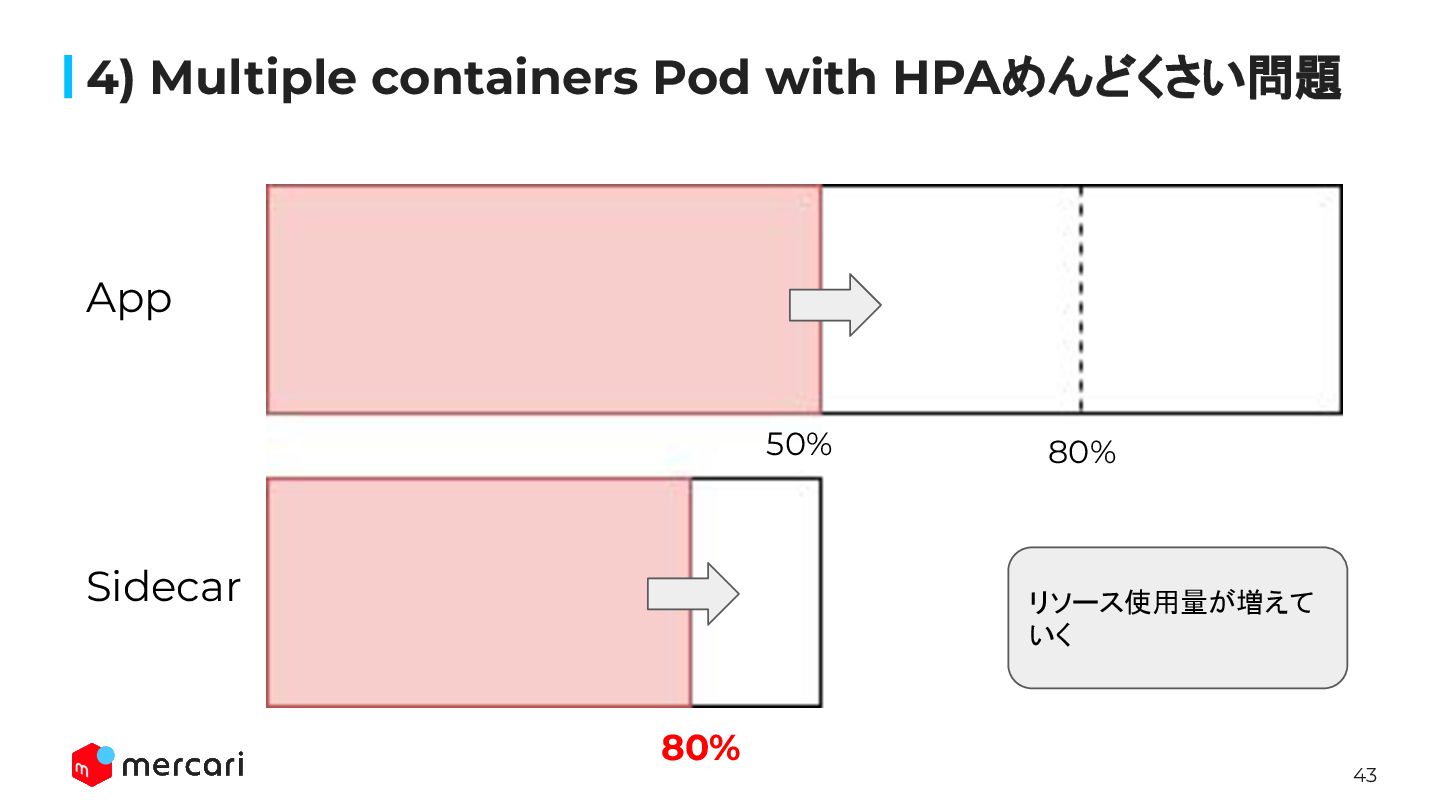
42 4)Multiple containers Pod with HPAめんどくさい問題 80% 80% App Sidecar
リソース使用量が増えて いく 50% 30%
43 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar リソース使用量が増えて いく 50%
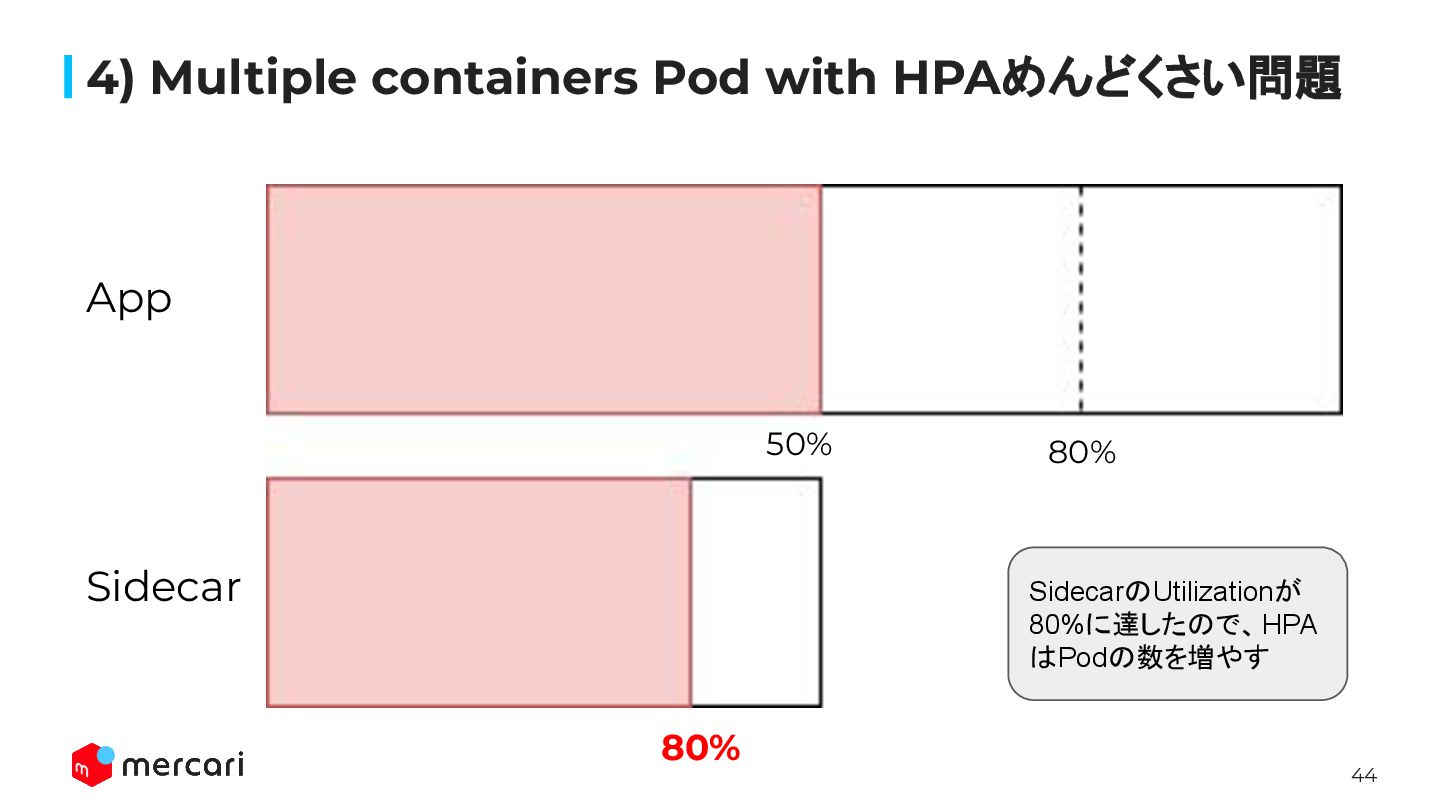
44 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar SidecarのUtilizationが 80%に達したので、HPA はPodの数を増やす 50%
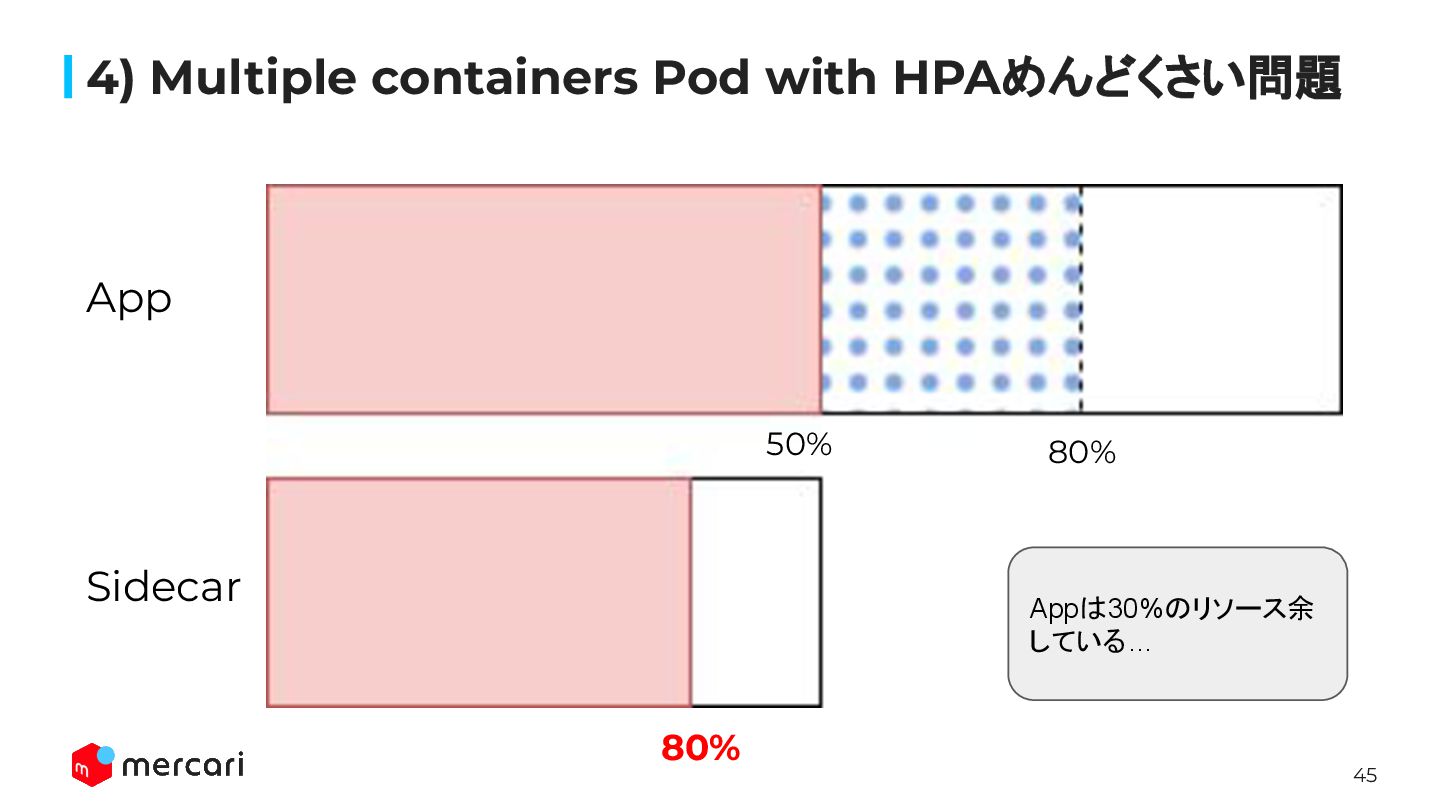
45 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 50% Appは30%のリソース余 している…
46 4) Multiple containers Pod with HPAめんどくさい問題 HPAを設定していても、CPU 使用量を確認しつつ、片方のcontainerの使用量が 常に低い場合、contianerのsizeを調整する必要がある。
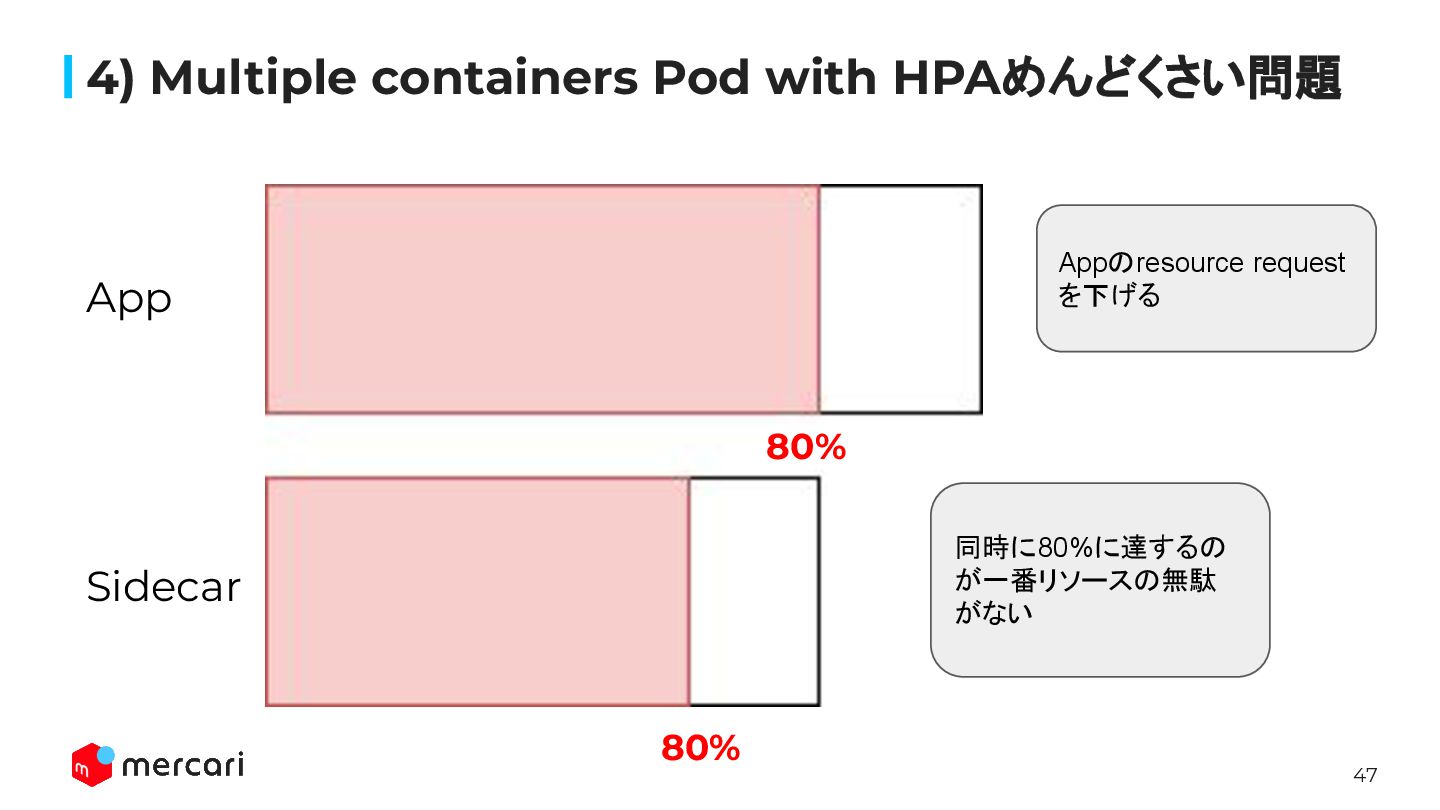
47 4) Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 80% Appのresource request を下げる 同時に80%に達するの が一番リソースの無駄 がない
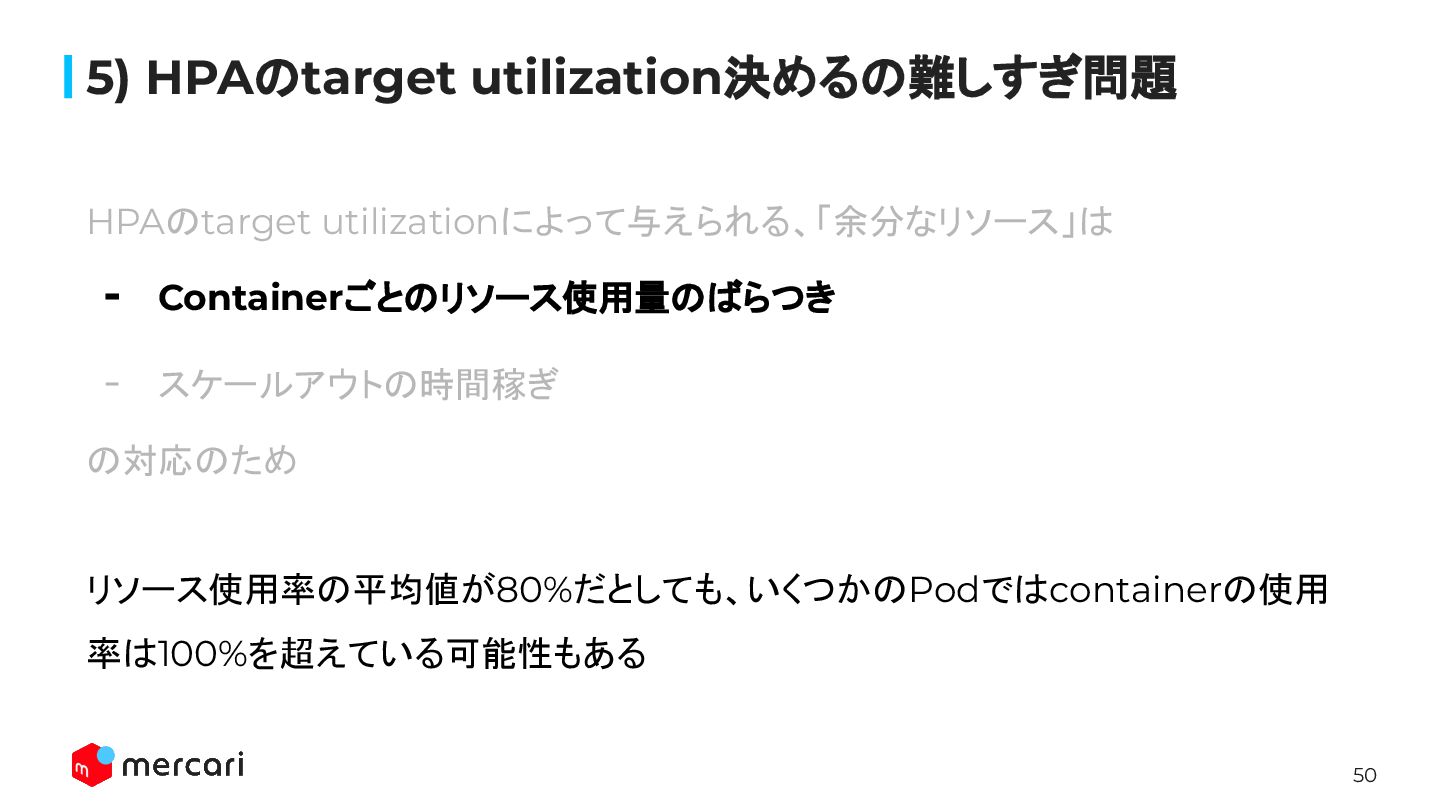
48 5) HPAのtarget utilization決めるの難しすぎ問題 メルカリでは、HPAのtarget utilizationは70%-80%に設定されていることが多 い。 ↓ なぜ20%-30%の余分なCPUを与えておく必要があるのか?
49 5) HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため
50 5) HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため リソース使用率の平均値が80%だとしても、いくつかのPodではcontainerの使用 率は100%を超えている可能性もある
51 5) HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため → (次スライド)
52 5) HPAのtarget utilization決めるの難しすぎ問題 0. トラフィックが増えるにつれて、リソース使用量が増えていく 1. リソース使用率が閾値に達する 2. HPAが気がついてスケールアウトを実行する
3. (Cluster AutoscalerがNodeを増やす) 4. 新しいPodが作られ実際に動き出し、READYになる (1) → (4)にかかる時間の間もリソース使用量が増えているため、 この間の時間稼ぎの必要性
53 5) HPAのtarget utilization決めるの難しすぎ問題 - Containerごとのリソース使用率のばらつき - トラフィックの増加のスピード - HPA
controllerのリコンサイルの間隔 - (Nodeに空きができるまでの時間 (via Cluster Autoscaler) - Podが動き出すまでにかかる時間 これらを踏まえて、適切な「余分リソース」をtarget utilizationを通してPodに与え る必要がある
54 5) HPAのtarget utilization決めるの難しすぎ問題 - Containerごとのリソース使用率のばらつき - トラフィックの増加のスピード - HPA
controllerのリコンサイルの間隔 - (Nodeに空きができるまでの時間 (via CA or overprovisioning Pods)) - Podが動き出すまでにかかる時間 これらを踏まえて、適切な「余分リソース」をtarget utilizationを通してPodに与え る必要がある 無理じゃね…?
55 ここまでの話 1. Incident時のHPAのScale in問題 2. HPAがレプリカ増やしすぎる問題 3. HPAがレプリカ全然増やさない問題 4.
Multiple containers Pod with HPAめんどくさい問題 5. HPAのtarget utilization決めるの難しすぎ問題
56 ここまでの話 1. Incident時のHPAのScale in問題 2. HPAがレプリカ増やしすぎる問題 3. HPAがレプリカ全然増やさない問題 4.
Multiple containers Pod with HPAめんどくさい問題 5. HPAのtarget utilization決めるの難しすぎ問題 無理じゃね…?
57 🐢を使用したWorkload Autoscaling
58 mercari/tortoise
59 これからはリクガメに任せる時代です。 過去のWorkloadの振る舞いを記 録し、HPA, VPA, Pod resource request/limitの全てをいい感じに 調節してくれる Kubernetes
controller https://github.com/mercari/to rtoise
60 mercari/tortoiseのモチベ - 人間の手で先ほどの最適化を全て行うのは厳しい - 最適化後もアプリケーションの変化に伴い、定期的な見直しが必要 - Platform推奨の設定や新しい機能適応への移行のコスト - 現状、PRを全てのHPAに送りつけたりしている。めんど
い - Datadog metricを含む外部サービスにautoscalingを依存させたくない - 外部サービスの障害の間、HPAが正しく動かず眠れぬ夜 を過ごすことになる
61 Simplified configuration apiVersion: autoscaling.mercari.com/v1alpha1 kind: Tortoise metadata: name: nginx-tortoise
namespace: tortoise-poc spec: updateMode: Auto targetRefs: deploymentName: nginx-deployment Deployment name ONLY!
62 Simplified configuration - ユーザーは対象のdeploymentの指定のみを行う。 - Optional なフィールドはその他少し存在するが基本使 用不要 -
「コーナーケースのために柔軟な設定を与える」ことはし ない - HPA, VPA, resource req/limの全ては🐢がいい感じに設定する - 一つのTortoiseを設定する => HPA, VPAを全ての
63 mercari/tortoiseの機能 - HPA optimization - 前章で「無理じゃね…?」と言ってたやつを全部自動で行 う - VPA
optimization - HPAとVPAがうまいこと同時に動けるように調整 - Emergency mode
64 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同時 刻の最大レプリカ数} - HPA target utilization: 推奨の値を計 算し、設定
65 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同時 刻の最大レプリカ数} - HPA target utilization: 推奨の値を計 算し、設定 前述のdynamic minReplicasと 同様の振る舞い
66 [復習] Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる
この場合にDownstreamのサービスではHPAによるScale inが発生する
67 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同 時刻の最大レプリカ数} - HPA target utilization: 推奨の値を計 算し、設定 Bug等の想定外ケースの際に、 無制限にscale upするのを防ぐ
68 Horizontal Scaling 過去の振る舞いを元にHPAを調整し続ける - minReplicas: ½ * {過去数週間の同 時刻の最大レプリカ数}
- maxReplicas: 2 * {過去数週間の同時 刻の最大レプリカ数} - HPA target utilization: 推奨の値を 計算し、設定 How?
69 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため
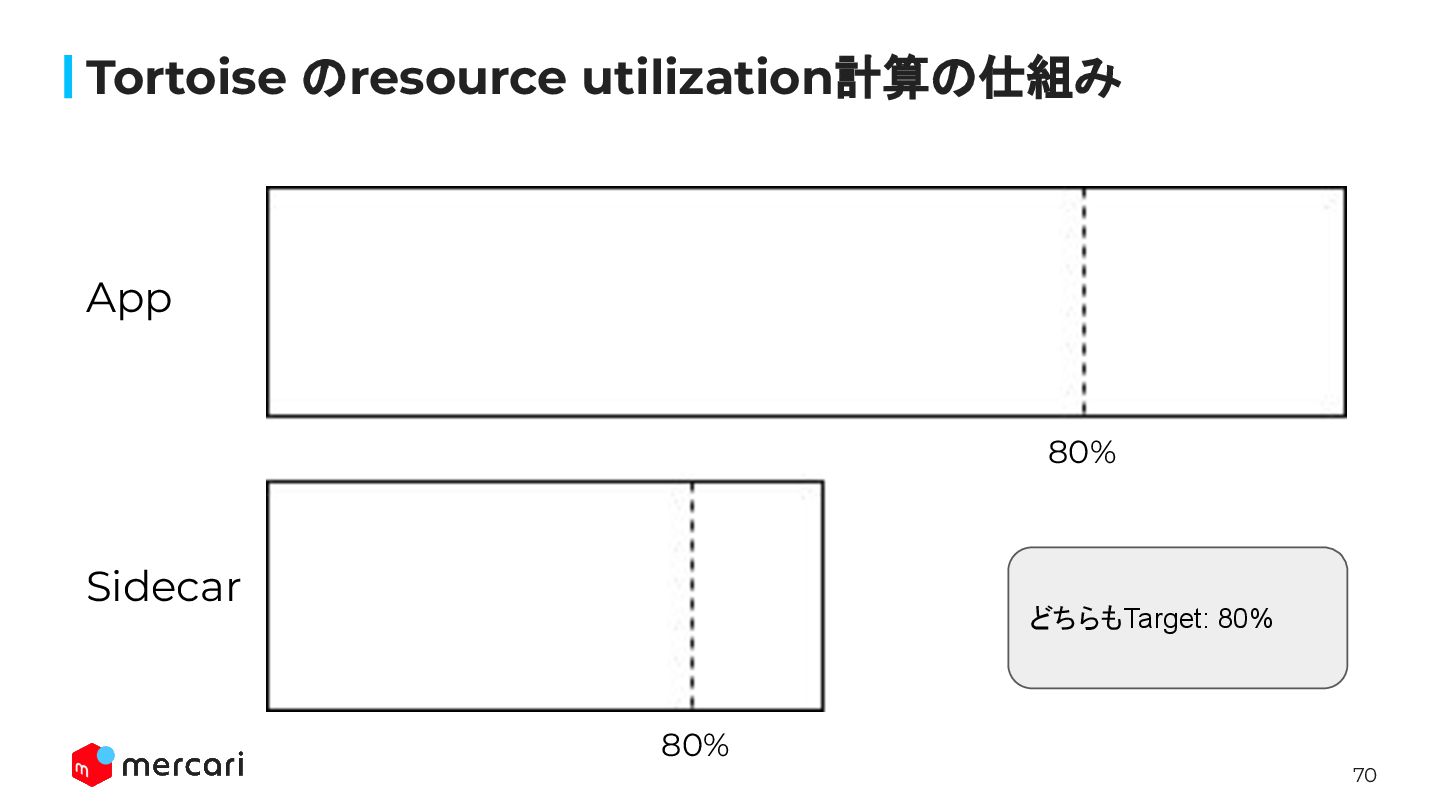
70 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar どちらもTarget: 80%
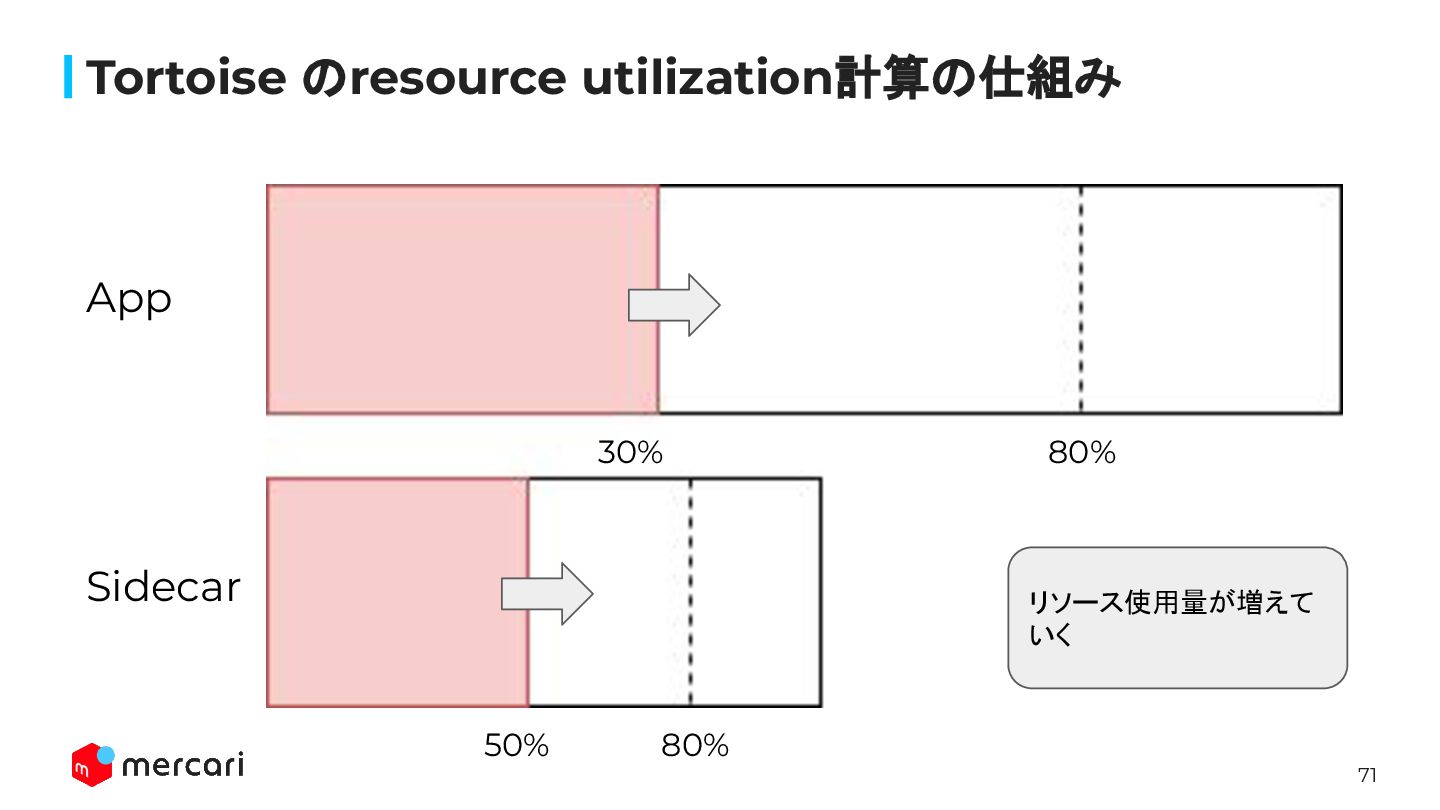
71 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar リソース使用量が増えて いく
50% 30%
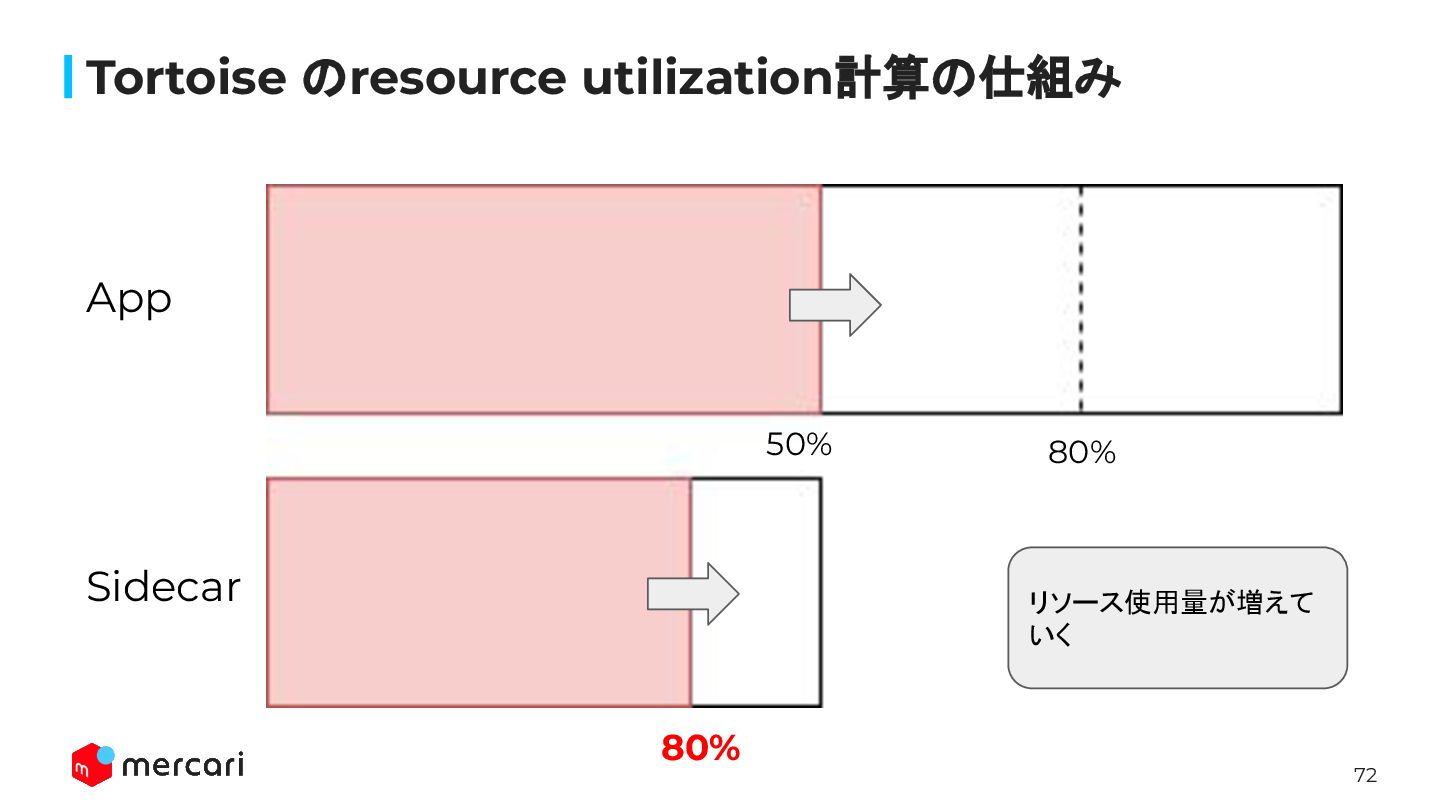
72 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar リソース使用量が増えて いく
50%
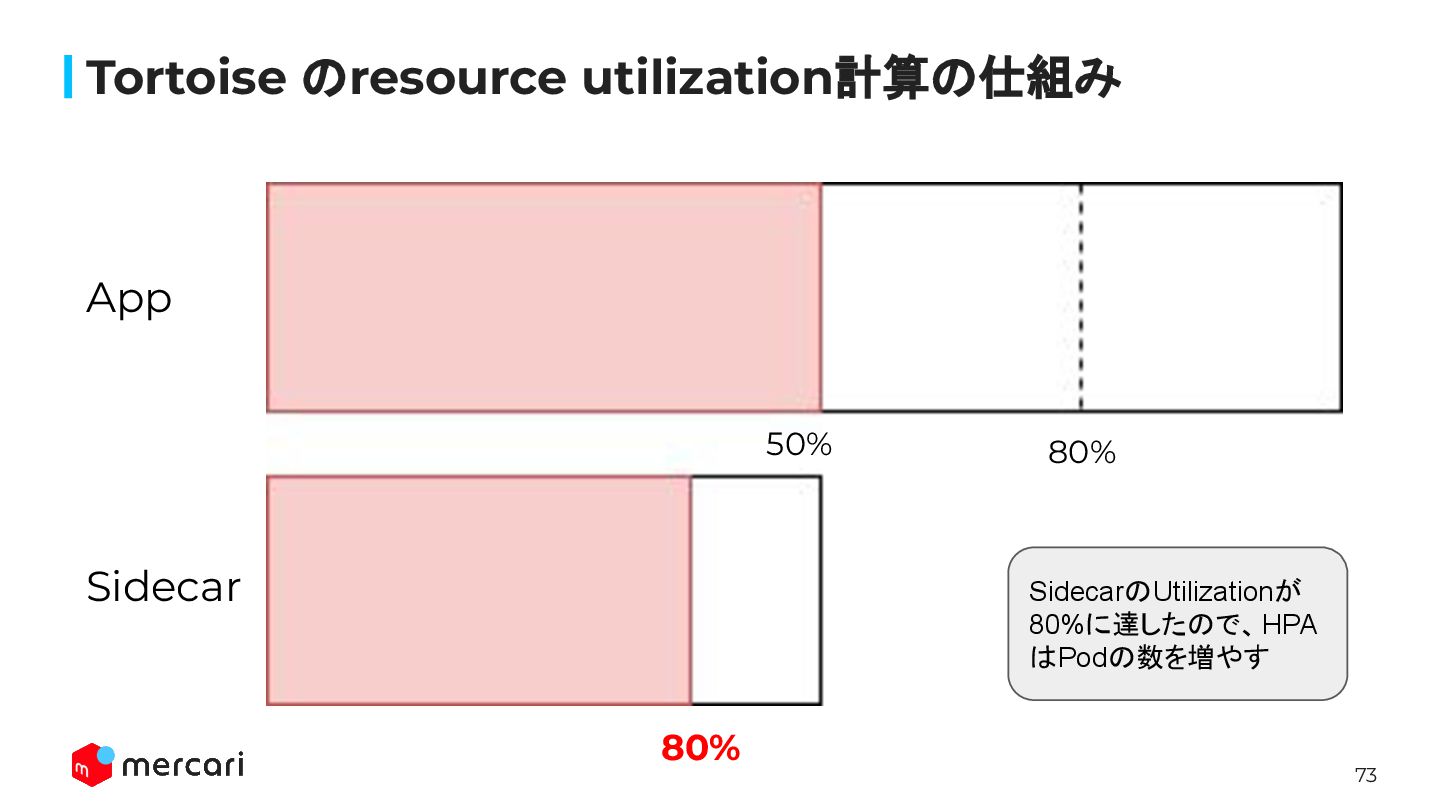
73 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar SidecarのUtilizationが 80%に達したので、HPA
はPodの数を増やす 50%
74 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ
の対応のため
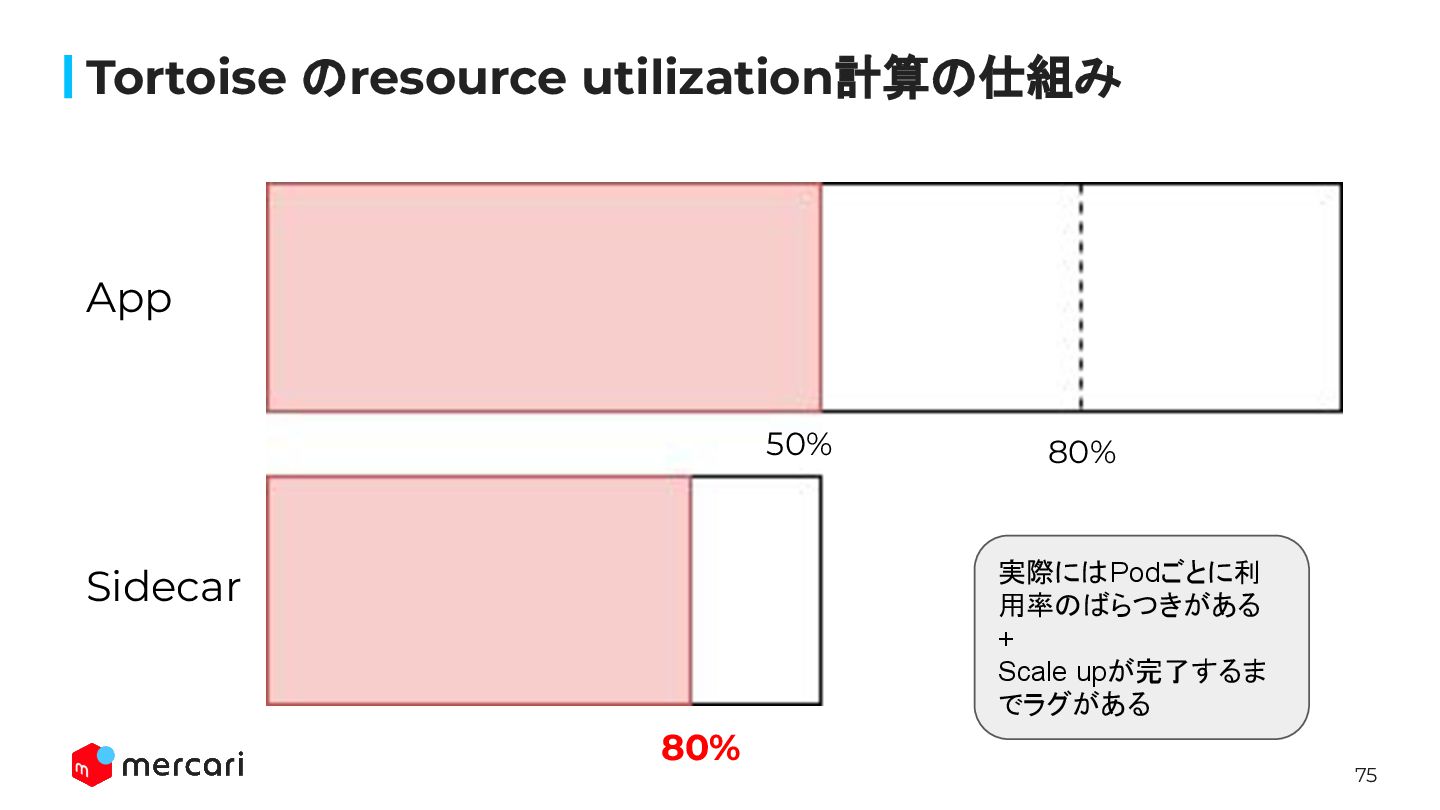
75 Tortoise のresource utilization計算の仕組み 80% 80% App Sidecar 50% 実際にはPodごとに利
用率のばらつきがある + Scale upが完了するま でラグがある
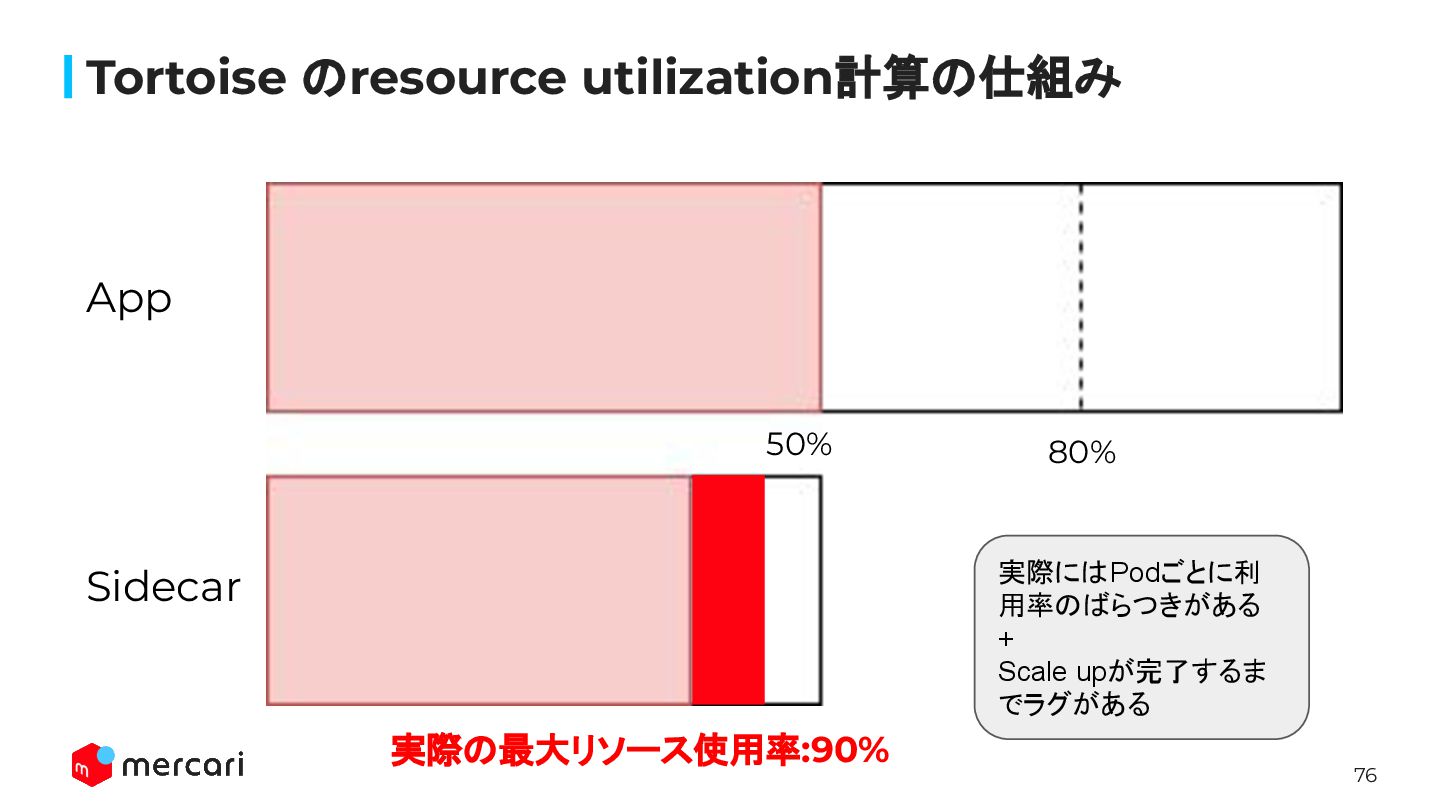
76 Tortoise のresource utilization計算の仕組み 80% 実際の最大リソース使用率:90% App Sidecar 50% 実際にはPodごとに利
用率のばらつきがある + Scale upが完了するま でラグがある
77 VPAがどのように推奨値を計算しているか 過去のリソースの使用量を記録 ↓ p90 - p95 (+ OOMKilledを考慮) の値を「十分なリソースの量」としてResource
requestに適応
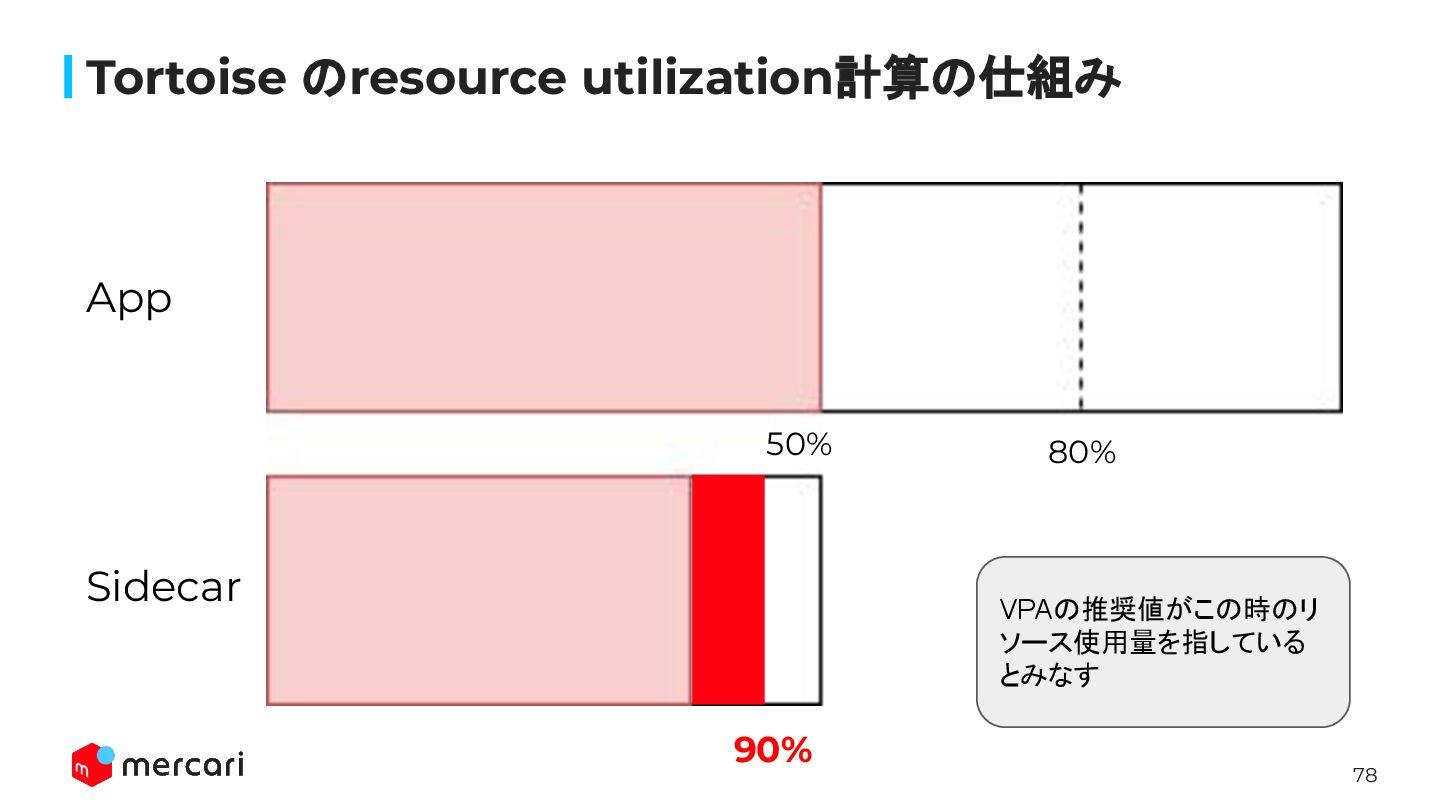
78 Tortoise のresource utilization計算の仕組み 80% 90% App Sidecar VPAの推奨値がこの時のリ ソース使用量を指している
とみなす 50%
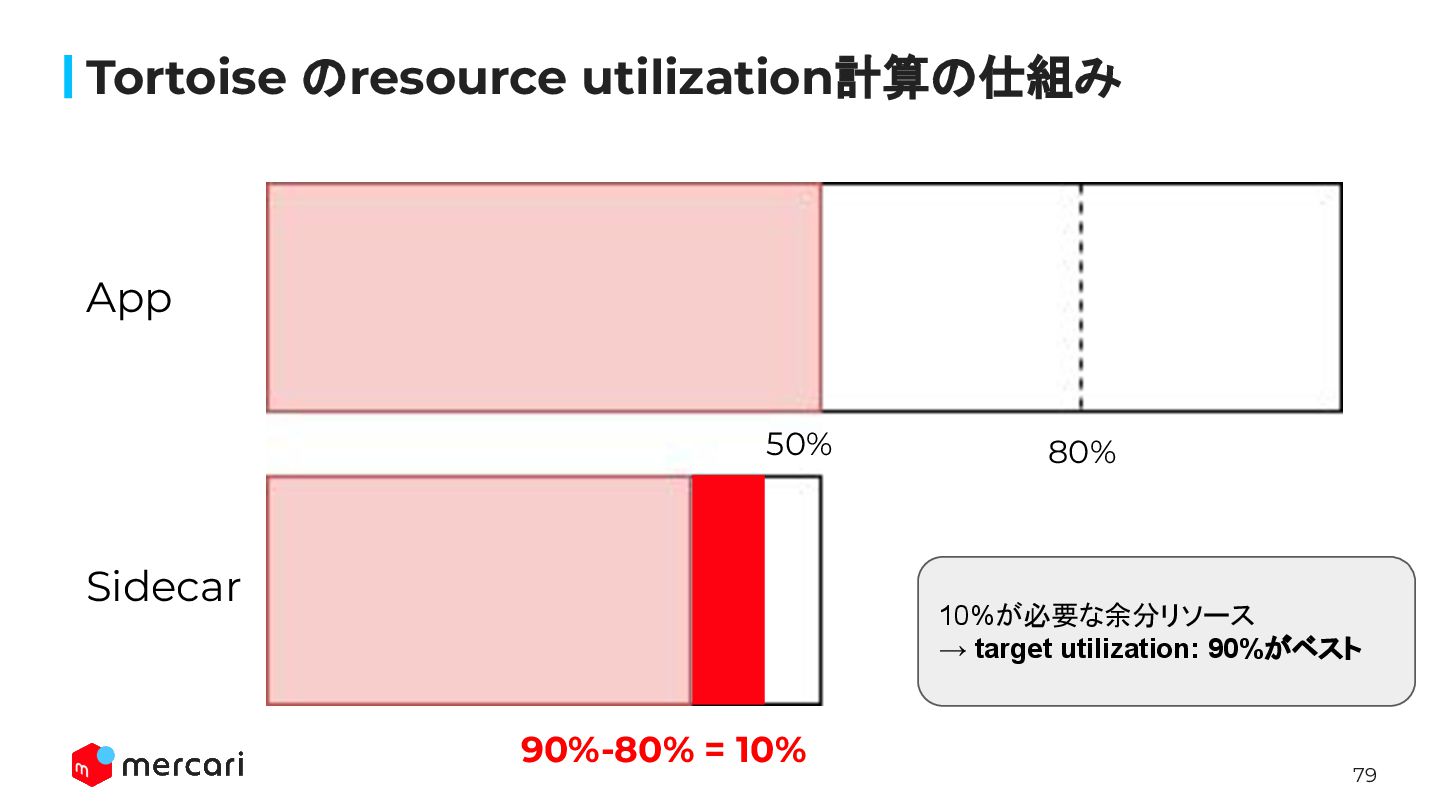
79 Tortoise のresource utilization計算の仕組み 80% 90%-80% = 10% App Sidecar
10%が必要な余分リソース → target utilization: 90%がベスト 50%
80 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
81 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
82 [復習] HPAがレプリカ全然増やさない問題 Deploymentのresource requestが大きすぎると、HPAを設定していても 「レプリカ数がずっとminReplicasで制限されてる」みたいなケースが起こりうる この場合、HPAが機能していないに等しいためCPU使用率も低くなる
83 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
84 [復習] HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。 この際、Podのサイズを大きくし、レプリカ数を小さく抑えた方が、省エネになる場合 がある。 とあるサービスでは、この最適化を行うことで、GKEコストが40%減少 (ピーク時のレプリカ数は200->30に変化)
85 Horizontal Scaling 過去の振る舞いからコンテナサイズも調整: - ほぼ常にレプリカ数が3で、リソース使用率 が小さい時、一時的にVerticalに切り替 え、HPAが動作するようにする - 現在のコンテナサイズが小さく、かつピーク
時にレプリカ数が多すぎる傾向にあると、コ ンテナサイズを大きくする - 片方のコンテナのリソース使用率が常に小 さい時、そのコンテナサイズを小さくする
86 [復習] Multiple containers Pod with HPAめんどくさい問題 例: HPAのtarget utilization:
sidecar: 80%/app container: 80% この場合、HPAはどちらかのcontainerのresource utilizationが80%を大きく超 えた時にスケールアウトを行う。 ↓ これによって、sidecar or app のどちらかのリソースが常に余っているということに なり得る。
87 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 50% Appは30%のリソース余 している…
88 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App
Sidecar 80% Appのresource request を下げる 同時に80%に達するの が一番リソースの無駄 がない
89 Emergency mode 緊急時に一時的にレプリカ数を十分に 大きく変更してくれる - minReplicasをmaxReplicasと 同じ値に一時的に変更 - OFFにした際に、安全のため適切
にゆっくりスケールダウンを行う
90 Emergency mode apiVersion: autoscaling.mercari.com/v1alpha1 kind: Tortoise metadata: name: nginx-tortoise
namespace: tortoise-poc spec: updateMode: Emergency targetRefs: deploymentName: nginx-deployment ←
91 Emergency mode 緊急で十分にスケールアウトしたい時に使用する - 通常にはないようなトラフィックの増加を観測している場合 (テレビ, bot等) - インフラサイドのincidentが発生し、念の為あげておきたい場合
(datadog, GCP 等)
92 mercari/tortoiseの現状 - Platformで開発しており、検証段階 - 実際に本番で使用はしていない
93 • インスタンスタイプやGKEのクラスターレベルの設定から始められるリソース最 適化もある • 大量のHPAの最適化を人の手で継続的にやり続けるのは難しい ◦ メルカリでは🐢を検証し育てていく予定です • 台風の時期に沖縄に行くのは慎重になったほうがいい
まとめ
94 We are めっちゃ hiring!!! Platformで働く仲間をめっちゃ探しています!!!! 今回話したこと以外にも、めっちゃ色んな面白いことやってます!!!!!! - 内製しているCI/CD基盤開発 -
開発者向け抽象化レイヤーの開発 - istioとかのnetworkらへん 「メルカリ Platform 採用」でいますぐ検索!
95 Thanks for listening!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![66 [復習] Incident時のHPAのScale in問題 - UpstreamのサービスがIncidentで落ちる - Downstreamのサービスに通信が行かなくなる - DownstreamのサービスのCPU使用量が下がる](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_65_1742167440.jpg){kind=link}
{kind=link}
{kind=link}
![69 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_68_1742167445.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![74 [復習] HPAのtarget utilization決めるの難しすぎ問題 HPAのtarget utilizationによって与えられる、「余分なリソース」は - Containerごとのリソース使用量のばらつき - スケールアウトの時間稼ぎ](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_73_1742167447.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![82 [復習] HPAがレプリカ全然増やさない問題 Deploymentのresource requestが大きすぎると、HPAを設定していても 「レプリカ数がずっとminReplicasで制限されてる」みたいなケースが起こりうる この場合、HPAが機能していないに等しいためCPU使用率も低くなる](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_81_1742167448.jpg){kind=link}
{kind=link}
![84 [復習] HPAがレプリカ増やしすぎる問題 Deploymentのresource requestが小さすぎると、ピーク時のレプリカ数がとても 多くなる。 この際、Podのサイズを大きくし、レプリカ数を小さく抑えた方が、省エネになる場合 がある。 とあるサービスでは、この最適化を行うことで、GKEコストが40%減少 (ピーク時のレプリカ数は200->30に変化)](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_83_1742167448.jpg){kind=link}
{kind=link}
![86 [復習] Multiple containers Pod with HPAめんどくさい問題 例: HPAのtarget utilization:](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_85_1742167449.jpg){kind=link}
![87 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_86_1742167449.jpg){kind=link}
![88 [復習] Multiple containers Pod with HPAめんどくさい問題 80% 80% App](https://files.speakerdeck.com/presentations/b2756161e06b4e6fa4b0e742fc7747ee/slide_87_1742167449.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}