: Subfield of computer science, solving tasks humans are good at (Natural language, Speech, Image recognition, etc) - Machine Learning : The field of study that gives computers the ability to learn without being explicitly programmed * * Arthur L Samuel. "Some Studies in machine learning using the game of checkers", IBM Journal of research and development 3.3 (1959), pp. 210-229 • Regression • Classification
family of machine learning methods based on artificial neural networks with representation learning - Artificial Neural Network : Computing systems vaguely inspired by the biological neural networks that constitute animal brains - Representation Learning : A set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data [Source] [Source]
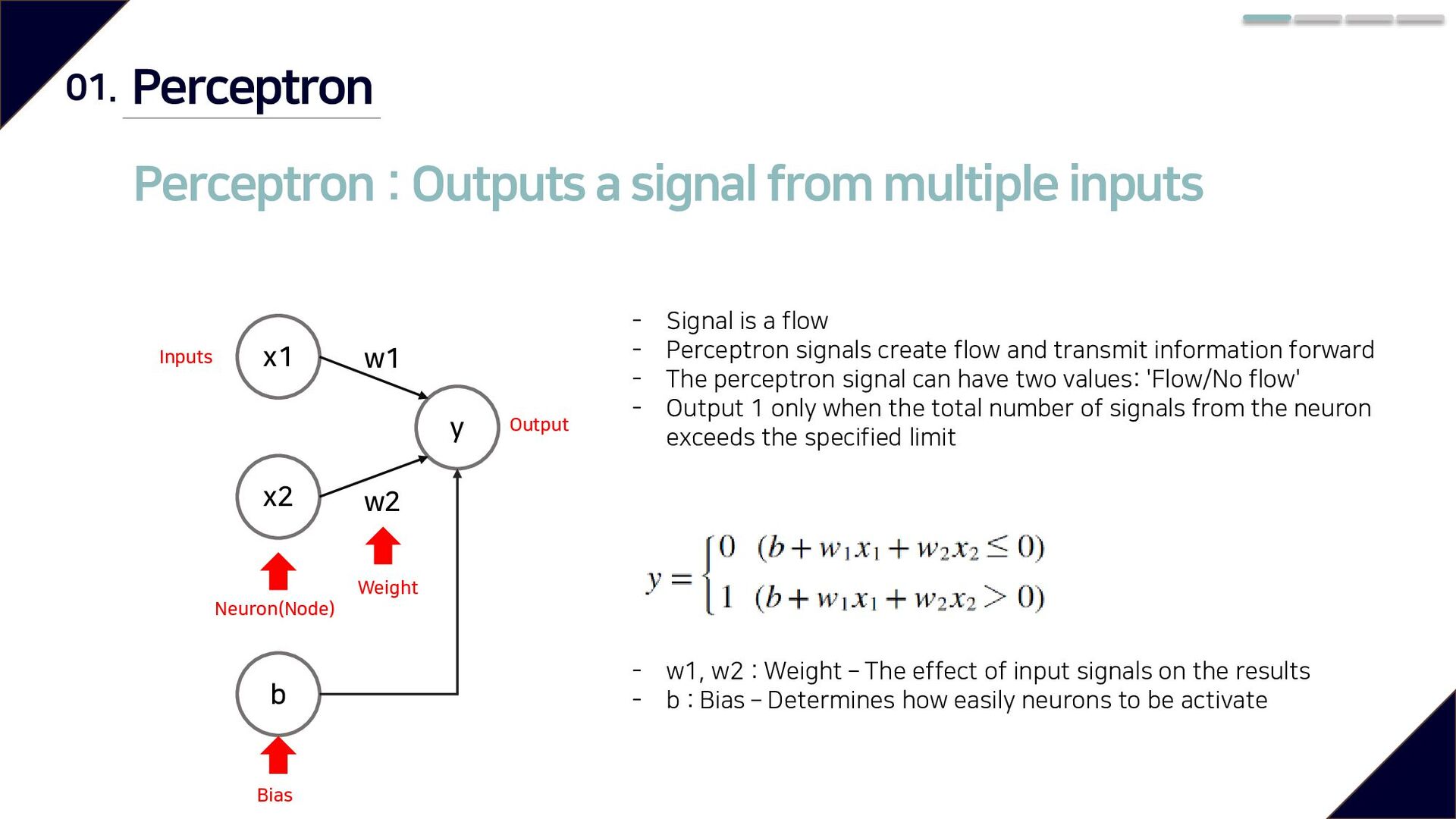
x1 x2 y w1 w2 Bias Weight Output Inputs - Signal is a flow - Perceptron signals create flow and transmit information forward - The perceptron signal can have two values: 'Flow/No flow' - Output 1 only when the total number of signals from the neuron exceeds the specified limit b Neuron(Node) - w1, w2 : Weight – The effect of input signals on the results - b : Bias – Determines how easily neurons to be activate
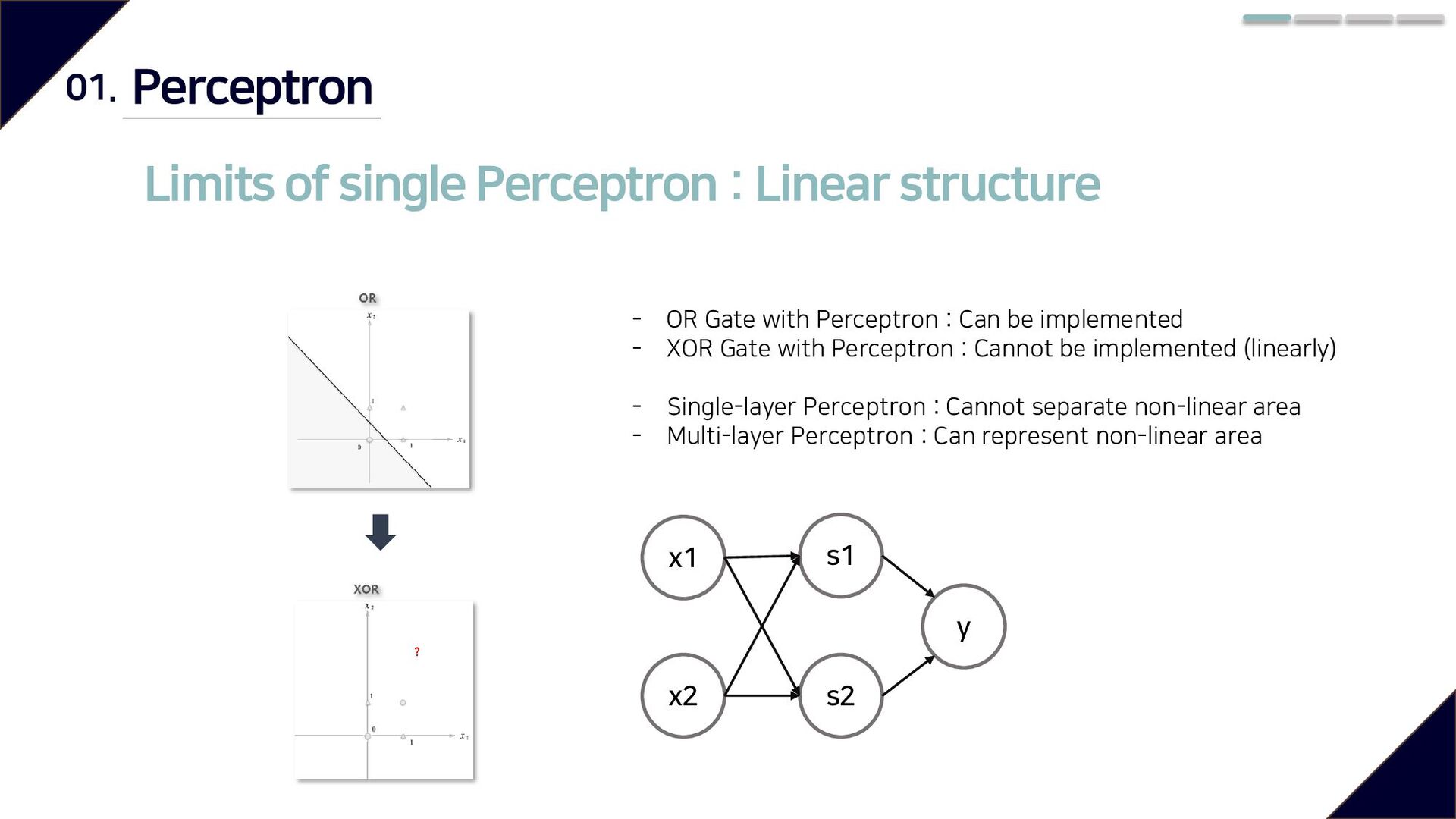
OR Gate with Perceptron : Can be implemented - XOR Gate with Perceptron : Cannot be implemented (linearly) - Single-layer Perceptron : Cannot separate non-linear area - Multi-layer Perceptron : Can represent non-linear area s1 s2 y x1 x2
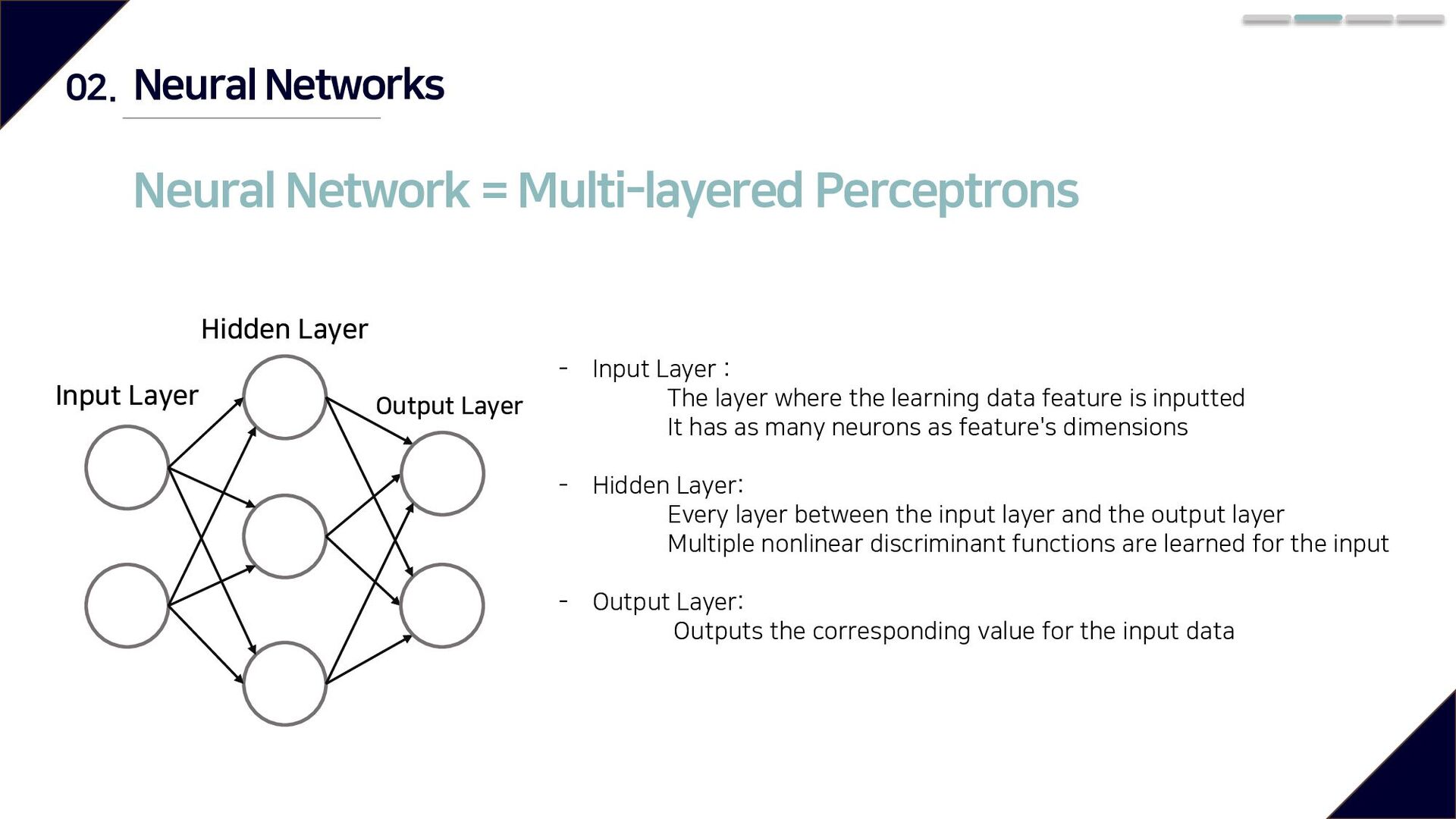
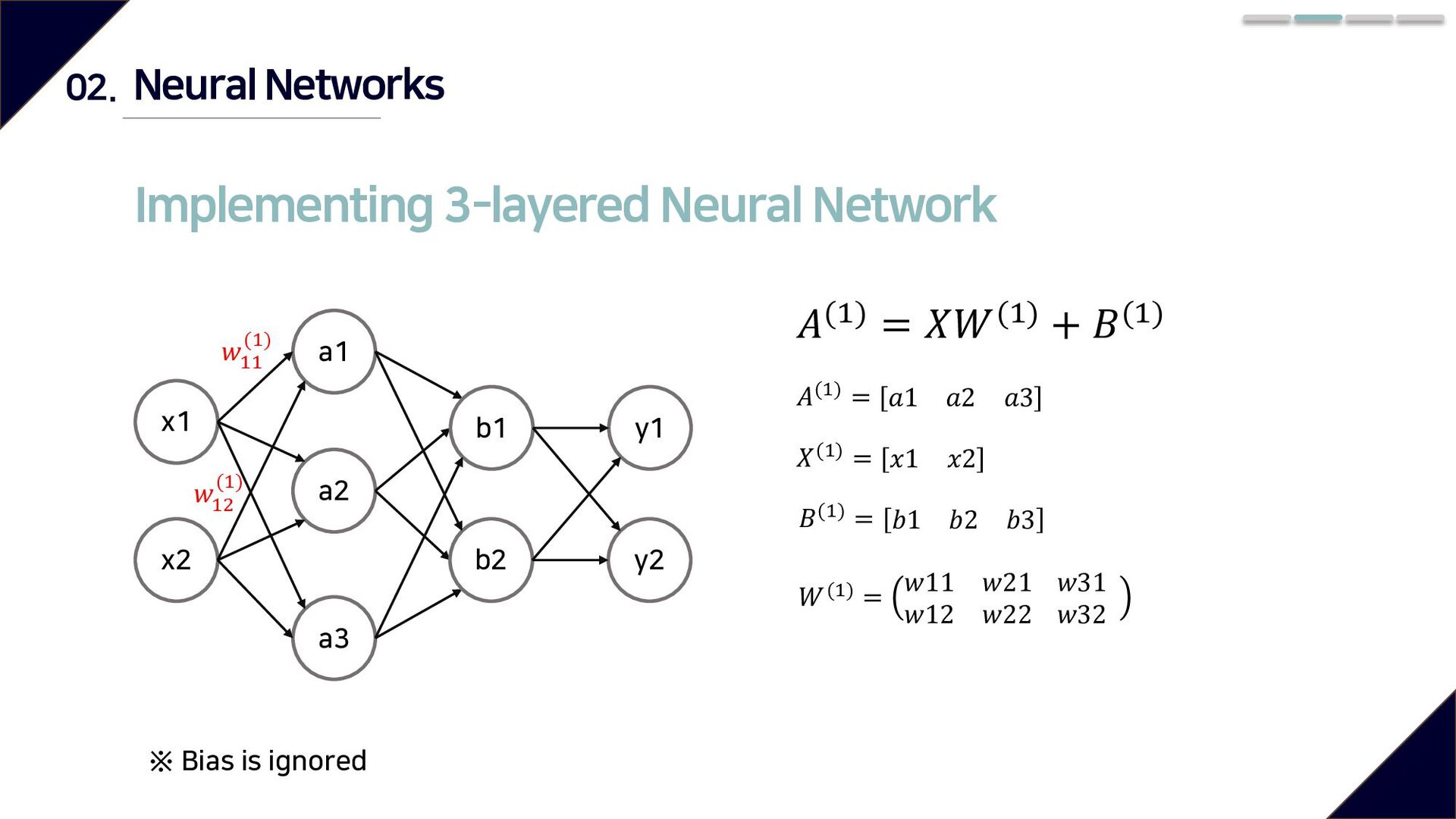
Hidden Layer Output Layer - Input Layer : The layer where the learning data feature is inputted It has as many neurons as feature's dimensions - Hidden Layer: Every layer between the input layer and the output layer Multiple nonlinear discriminant functions are learned for the input - Output Layer: Outputs the corresponding value for the input data
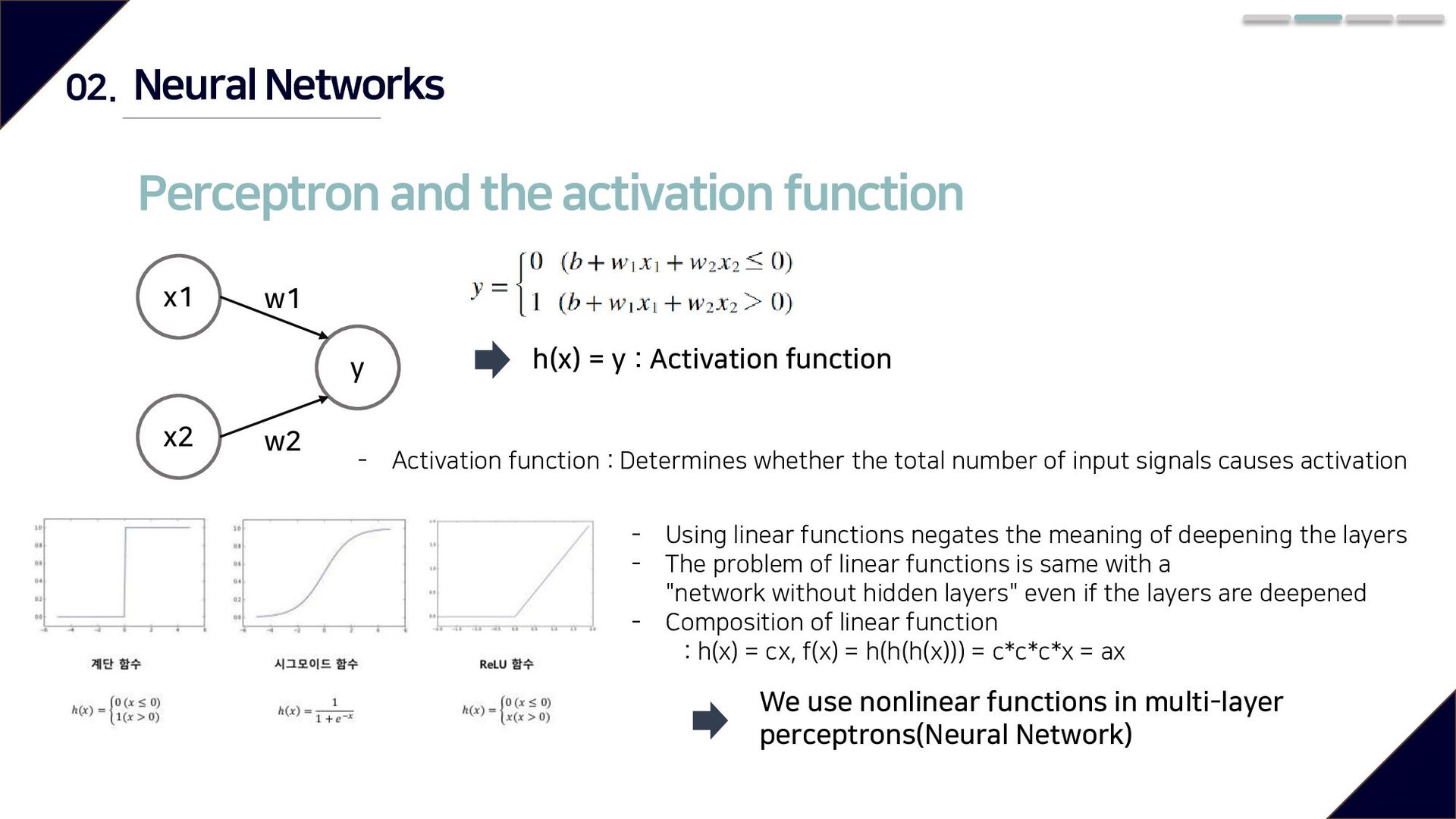
w2 h(x) = y : Activation function - Activation function : Determines whether the total number of input signals causes activation - Using linear functions negates the meaning of deepening the layers - The problem of linear functions is same with a "network without hidden layers" even if the layers are deepened - Composition of linear function : h(x) = cx, f(x) = h(h(h(x))) = c*c*c*x = ax We use nonlinear functions in multi-layer perceptrons(Neural Network) Neural Networks
classification and regression - Regression : Identity function - Classification : Softmax function Identity function - Outputs input signal a1 a2 y1 𝜎() y2 𝜎() Softmax function - Regards output signal as probability - Like probability, when all output values are added, the sum is 1 Neural Networks
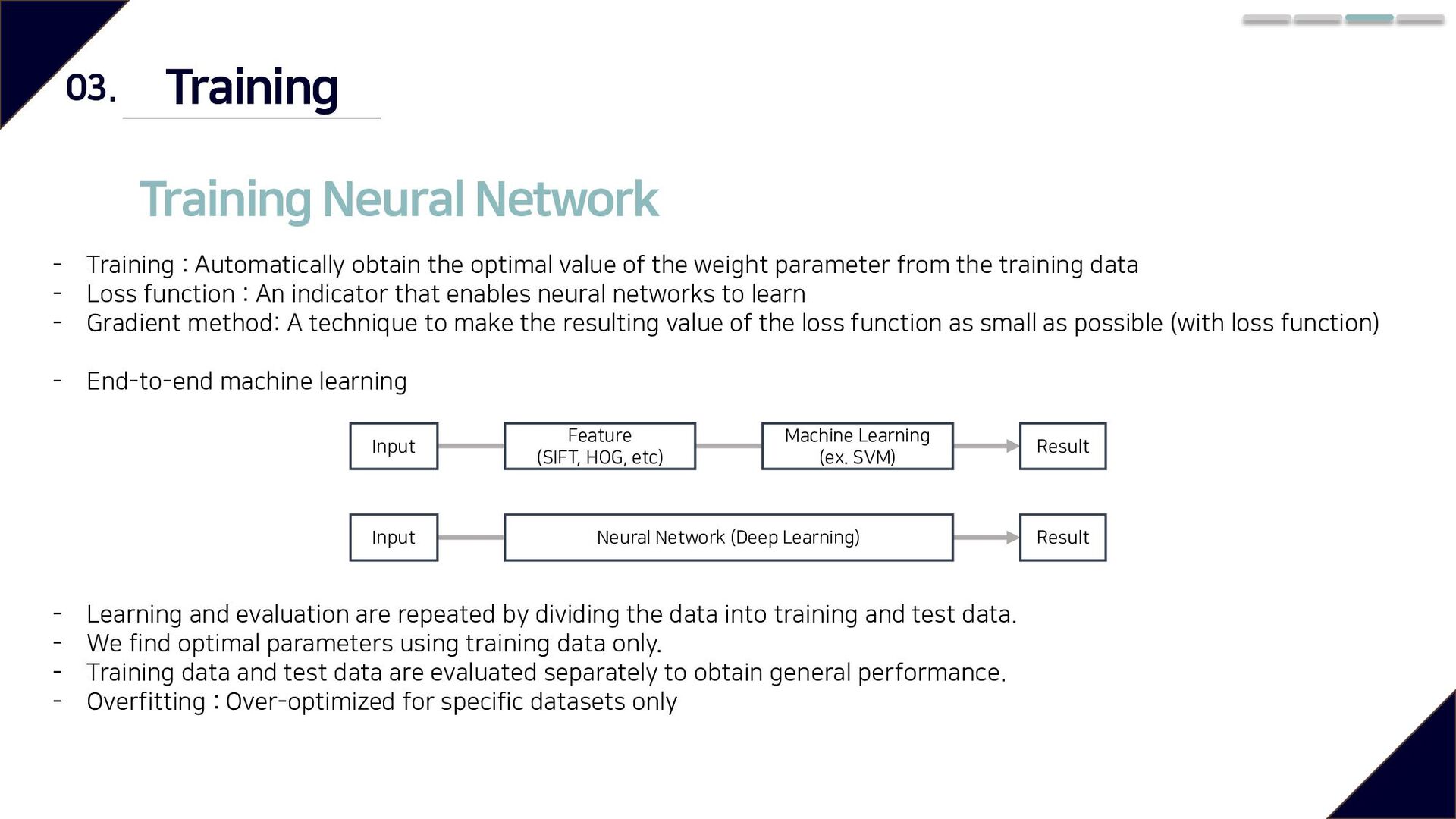
the optimal value of the weight parameter from the training data - Loss function : An indicator that enables neural networks to learn - Gradient method: A technique to make the resulting value of the loss function as small as possible (with loss function) - End-to-end machine learning - Learning and evaluation are repeated by dividing the data into training and test data. - We find optimal parameters using training data only. - Training data and test data are evaluated separately to obtain general performance. - Overfitting : Over-optimized for specific datasets only Input Feature (SIFT, HOG, etc) Machine Learning (ex. SVM) Result Input Neural Network (Deep Learning) Result
neural networks to learn - Neural network learning expresses states as an indicator → Finds the value of the weight parameter that makes the indicator the best - Uses SSE and CEE (See below) - Neural network learning is the process of finding parameters that make the loss function as small as possible - Find the minimum value of the loss function through the differentiation of the loss function of the weight parameter - The reason for using the loss function as an indicator is that it is elastic when the value of the accuracy compared to the parameter changes. Sum of squares for error (SSE) Cross entropy* error, CEE) * Entropy : A measure of uncertainty (calculates the difference between the actual and predicted values) Training
the loss function is minimum - Gradient method : To find the minimum value by moving in the direction in which the slope is pointed and then repeating the method of finding the slope where it is moved 𝜂 ∶ Learning rate * * Hyper parameter : Parameters that must be set by the person themselves - Steps of the Neural Network training 1) Mini-batch : Randomly selects the training data 2) Calculating gradient : Calculate the slope of each weight parameter to reduce the value of the loss function 3) Updating parameters : Update weight parameters very slightly in slope direction 4) Repeat step 1 to 3 - Randomize data as mini-batch → Stochastic gradient descent, SGD) Training
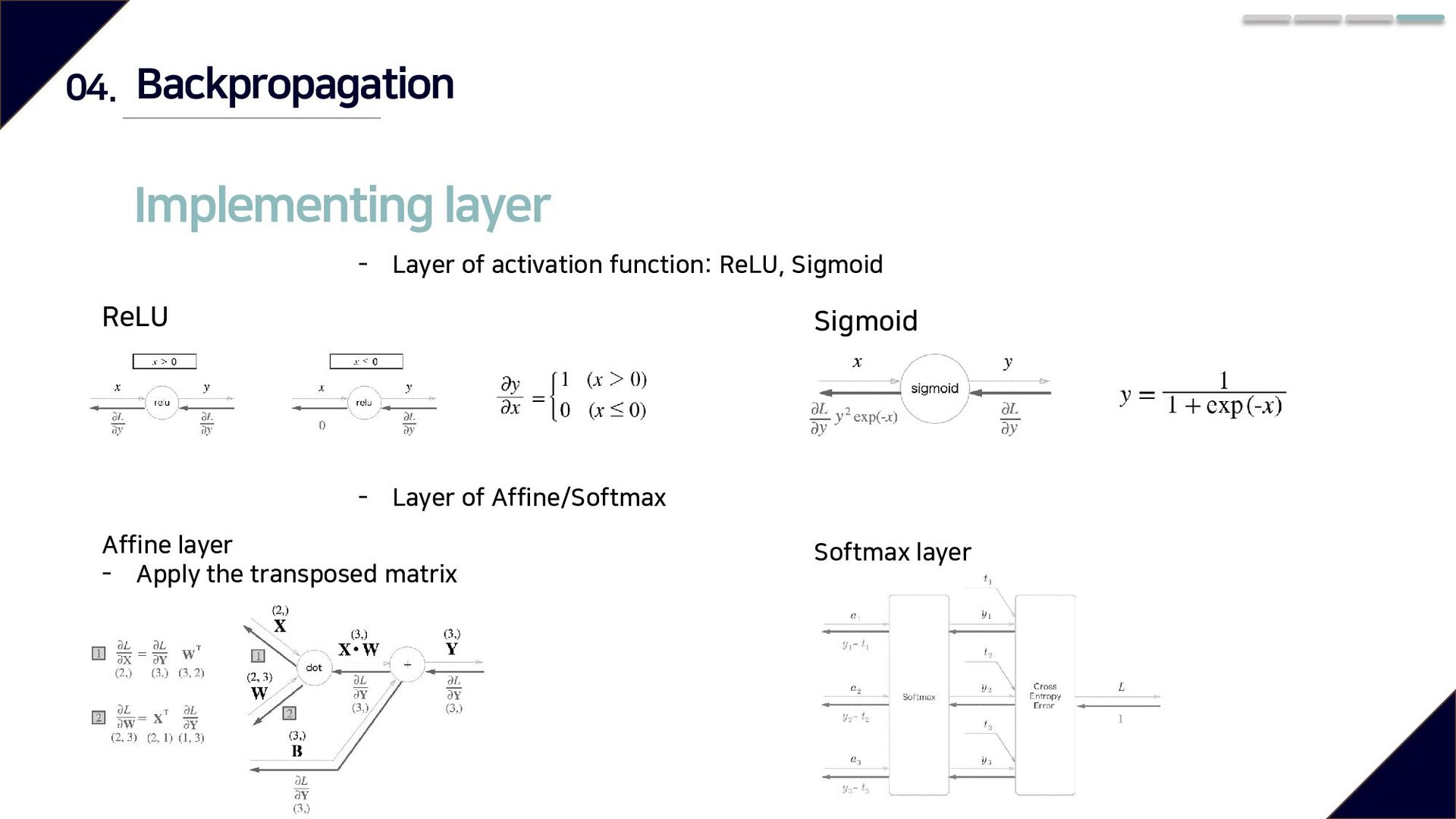
method : Numerical differentiation → Requires lots of time - Using backpropagation to efficiently calculate the slope of the weight parameter X X X 100 200 220 2 1.1 Forward propagation Backward propagation
left, which is the opposite of forward propagation - Can be proved with Chain rule - Backpropagation of Addition node : Multiply 1 (Send input data to next node) - Backpropagation of Multiplication node : Swap each value and multiply themselves f x y E E(𝜕𝑦 𝜕𝑥 ) Backpropagation http://wiki.hash.kr/index.php/%EC%97%AD%EC%A0%84%ED%8C%8C
Neural networks consist of multiple composite functions of activation functions 3. The activation function determines the output value through weights and biases 4. Neural network learning is to determine weights and biases using pre-known results 5. The purpose of learning weights is to minimize the loss function 6. The method to minimize the loss function is to compute differentials by gradient descent 7. Since the numerical differential requires huge computing time, backpropagation is applied
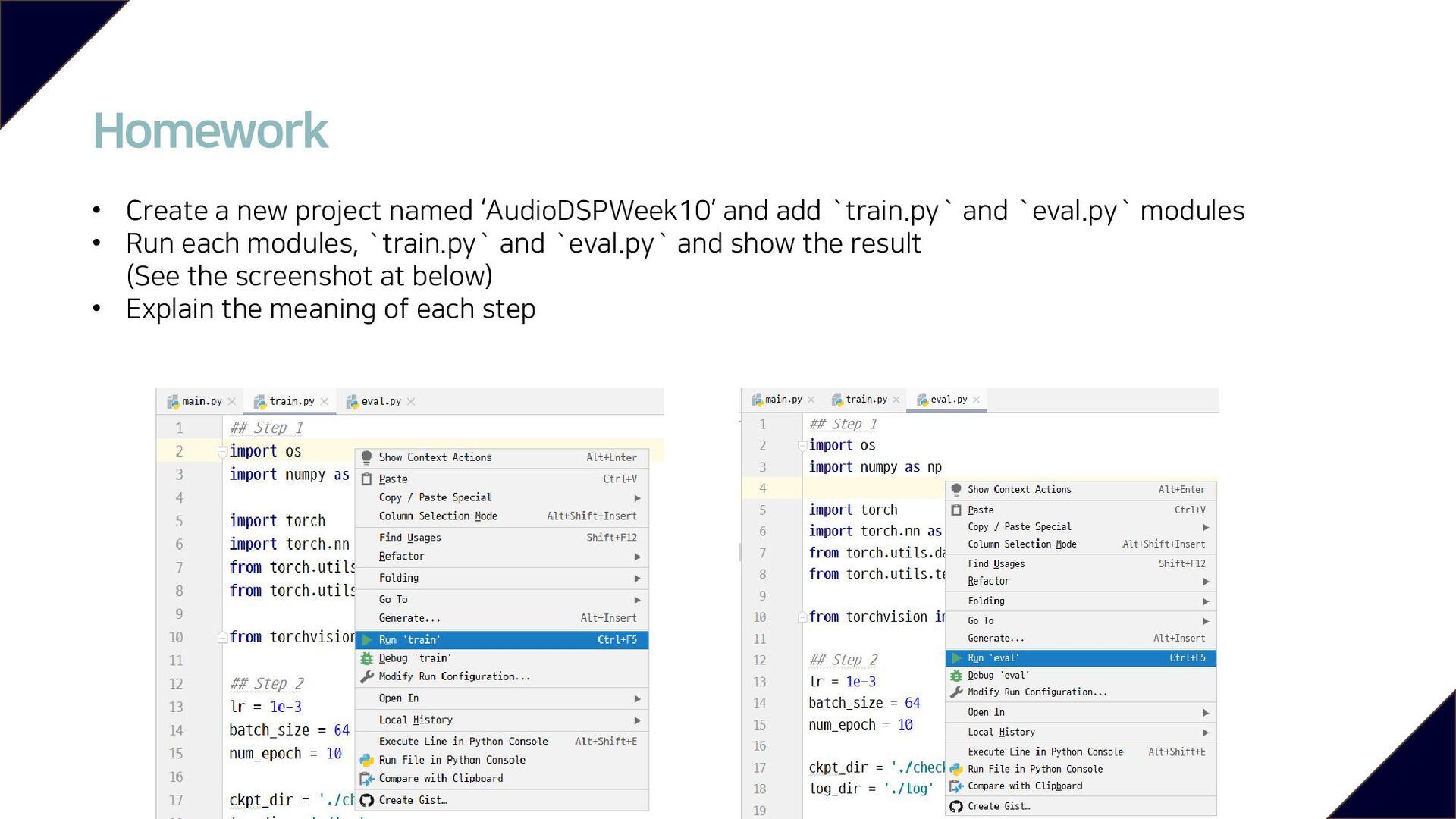
`train.py` and `eval.py` modules • Run each modules, `train.py` and `eval.py` and show the result (See the screenshot at below) • Explain the meaning of each step
![Deep Learning Basics Taein Kim [email protected] 2021.05.06](https://files.speakerdeck.com/presentations/1f394c87d516463e9820caaccc27a0ef/slide_0.jpg){kind=link}
{kind=link}
![Machine Learning Source: [Link] page 19 - Artificial Intelligence (AI)](https://files.speakerdeck.com/presentations/1f394c87d516463e9820caaccc27a0ef/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}