Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse H. Engel, Douglas Eck:, ”Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset”, ICLR 2019 • Curtis Hawthorne, Erich Elsen, Jialin Song, Adam Roberts, Ian Simon, Colin Raffel, Jesse H. Engel, Sageev Oore, Douglas Eck, ”Onsets and Frames: Dual-Objective Piano Transcription”, ISMIR 2018 • Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Ian Simon, Curtis Hawthorne, Noam Shazeer, Andrew M. Dai, Matthew D. Hoffman, Monica Dinculescu, Douglas Eck: ”Music Transformer: Generating Music with Long-Term Structure”. ICLR (Poster) 2019 • J. W. Kim and J. P. Bello, “ADVERSARIAL LEARNING FOR IMPROVED ONSETS AND FRAMES MUSIC TRANSCRIPTION,” p. 8, 2019. http://archives.ismir.net/ismir2019/paper/000081.pdf • Oord, Aaron van den, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. “WaveNet: A Generative Model for Raw Audio.” ArXiv:1609.03499 [Cs], September 12, 2016. http://arxiv.org/abs/1609.03499 • Curtis Hawthorne, Talk at ICLR 2019, https://youtube.videoken.com/embed/1ohtSlux9EQ?tocitem=38 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
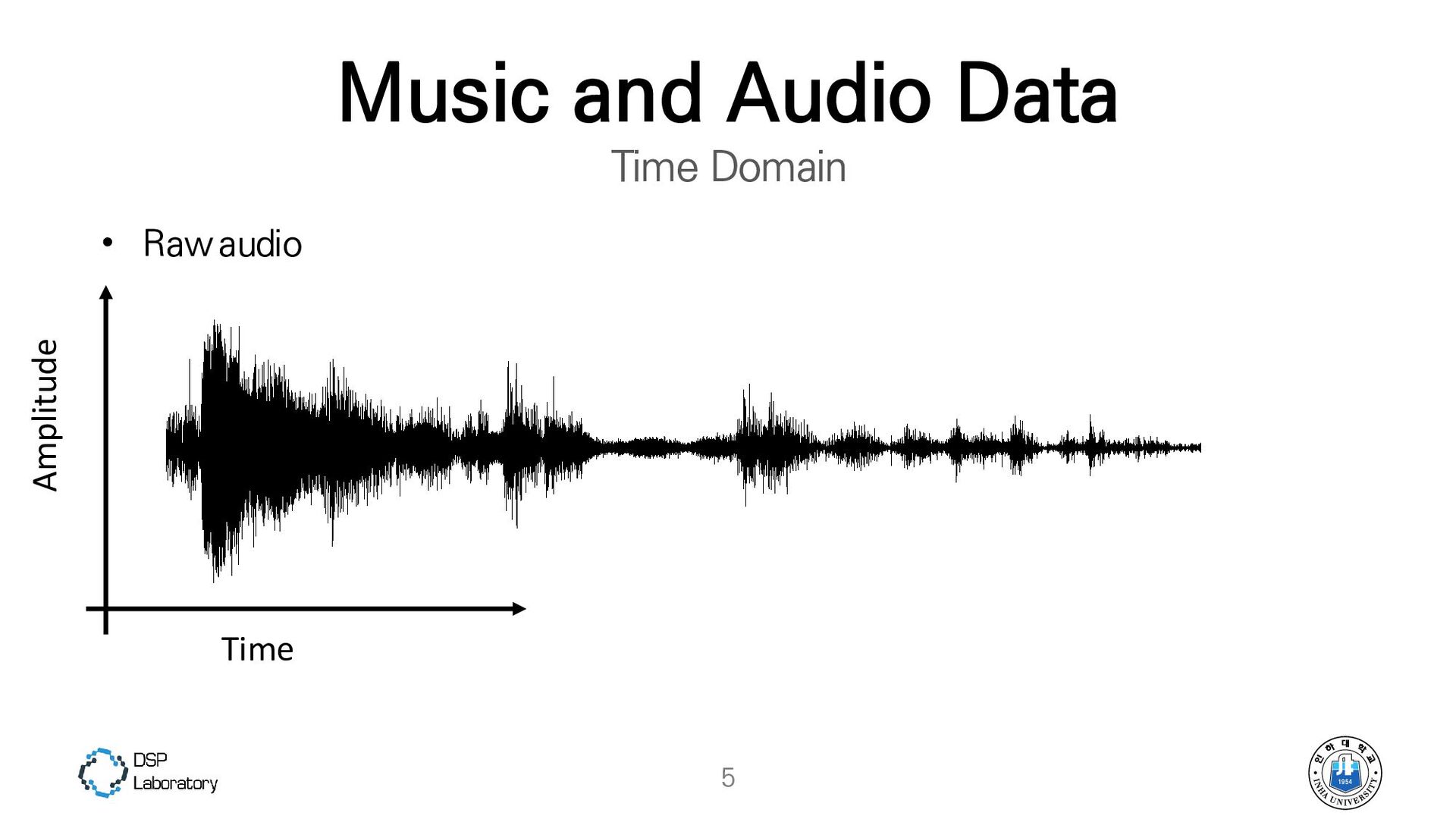{kind=link}
{kind=link}
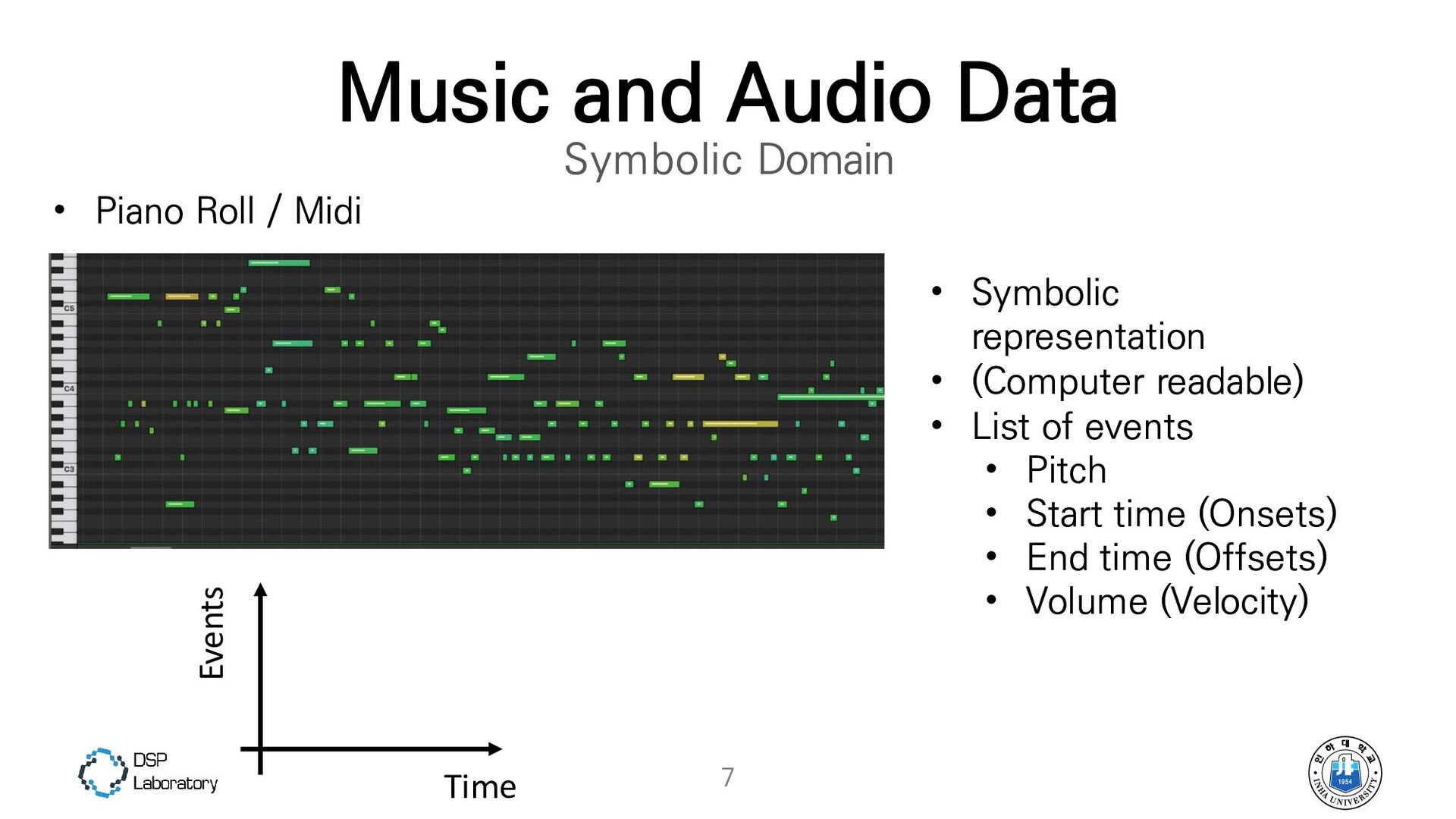{kind=link}
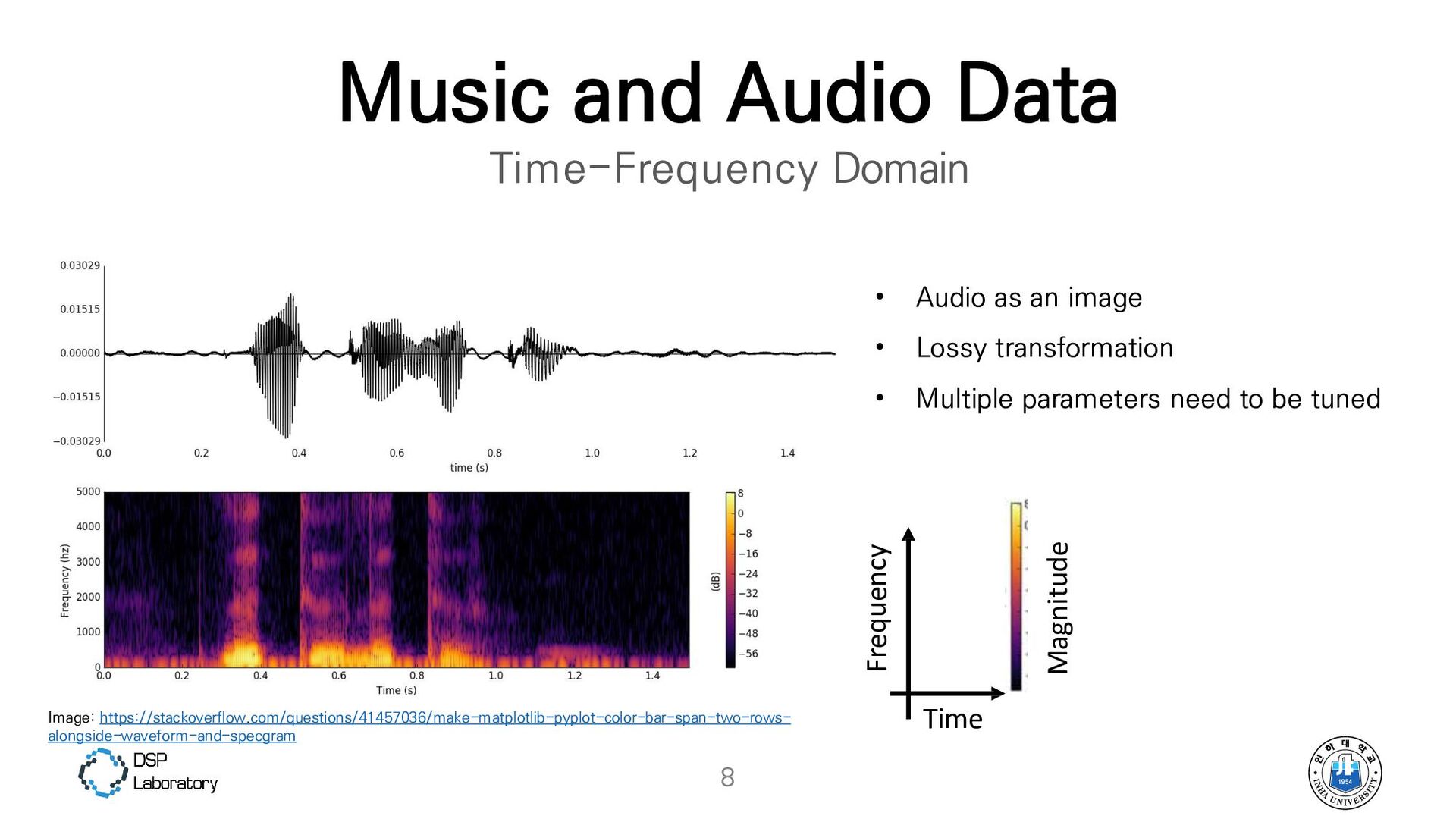{kind=link}
{kind=link}
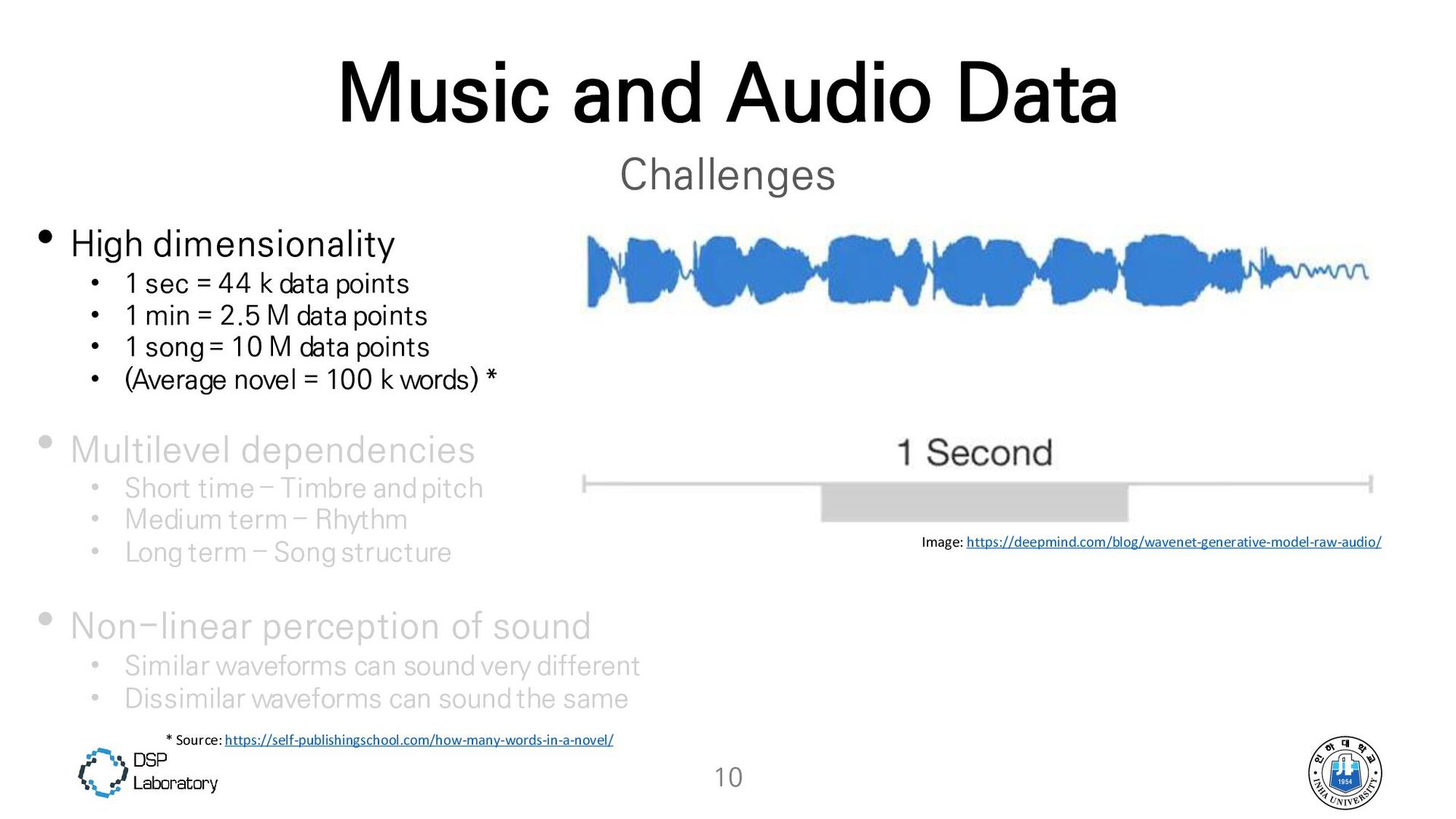{kind=link}
{kind=link}
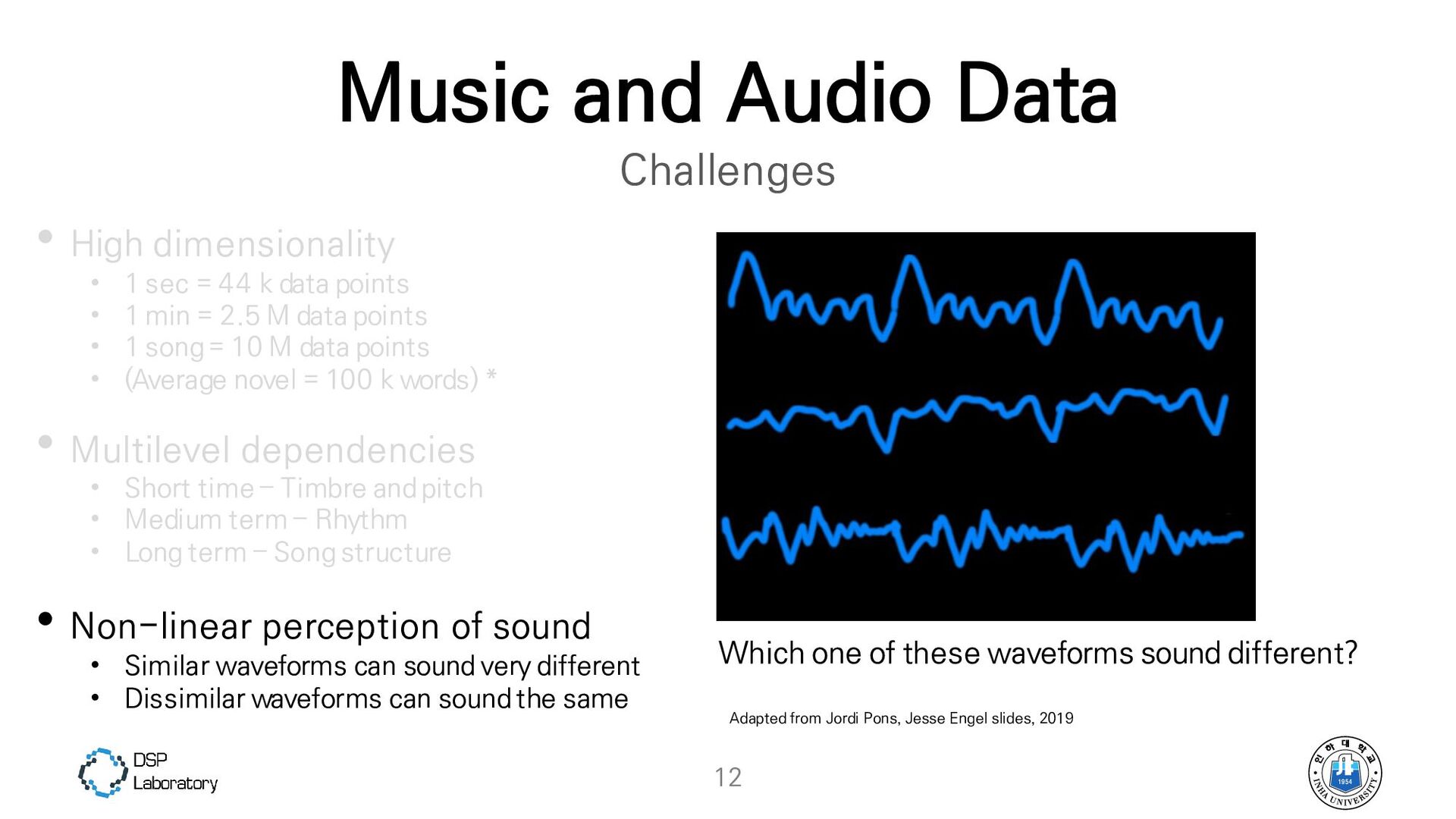{kind=link}
{kind=link}
{kind=link}
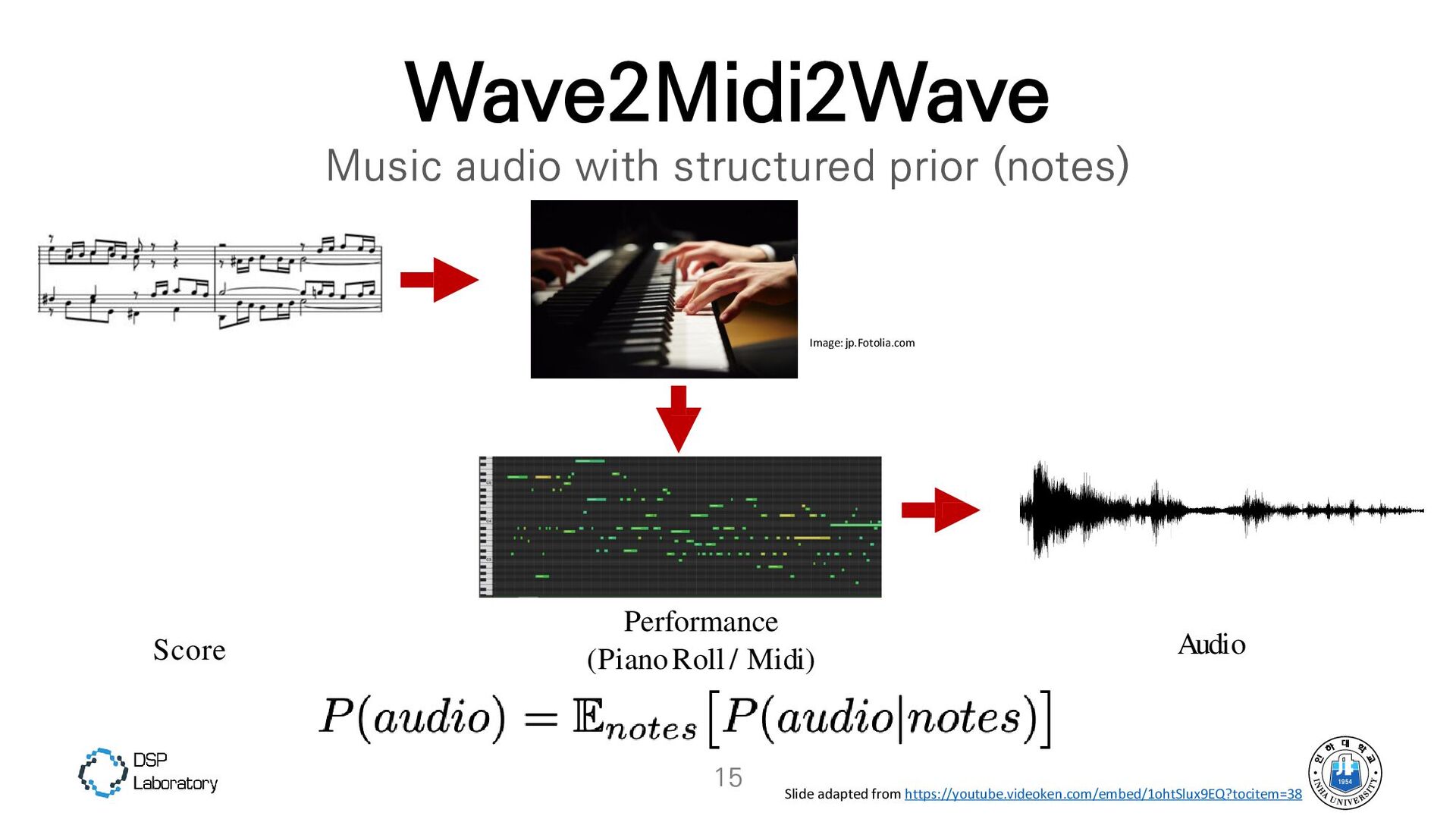{kind=link}
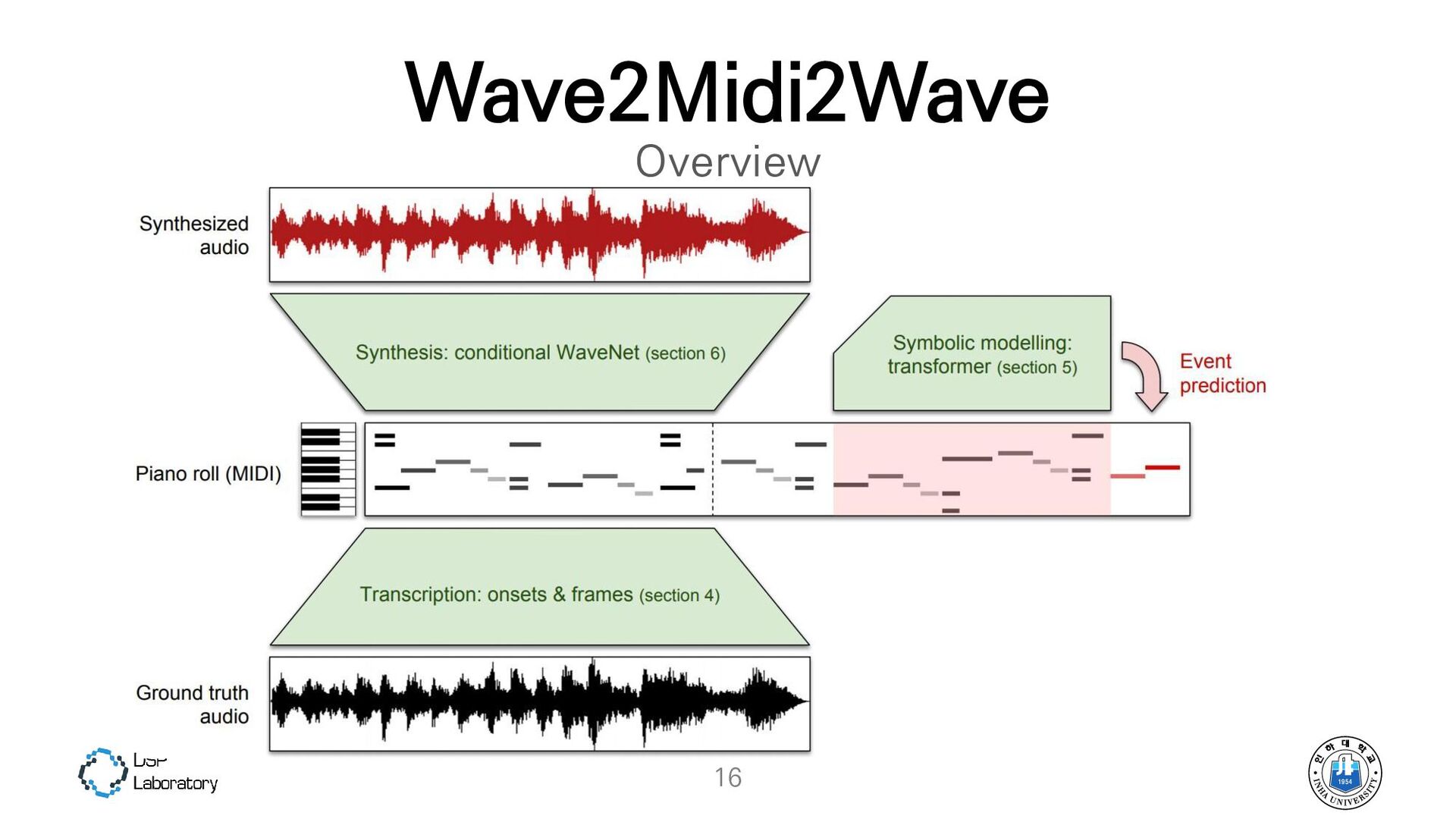{kind=link}
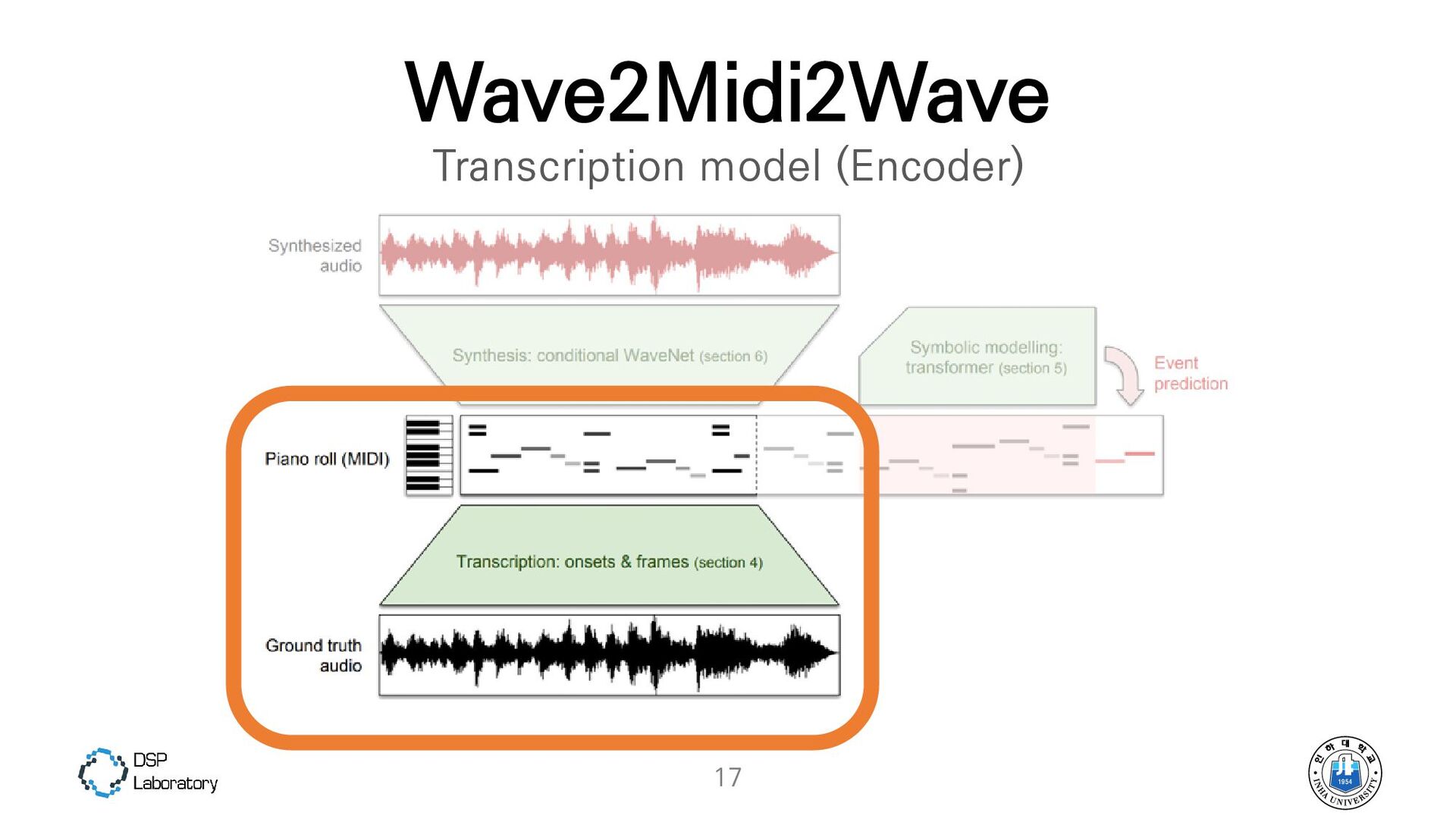{kind=link}
{kind=link}
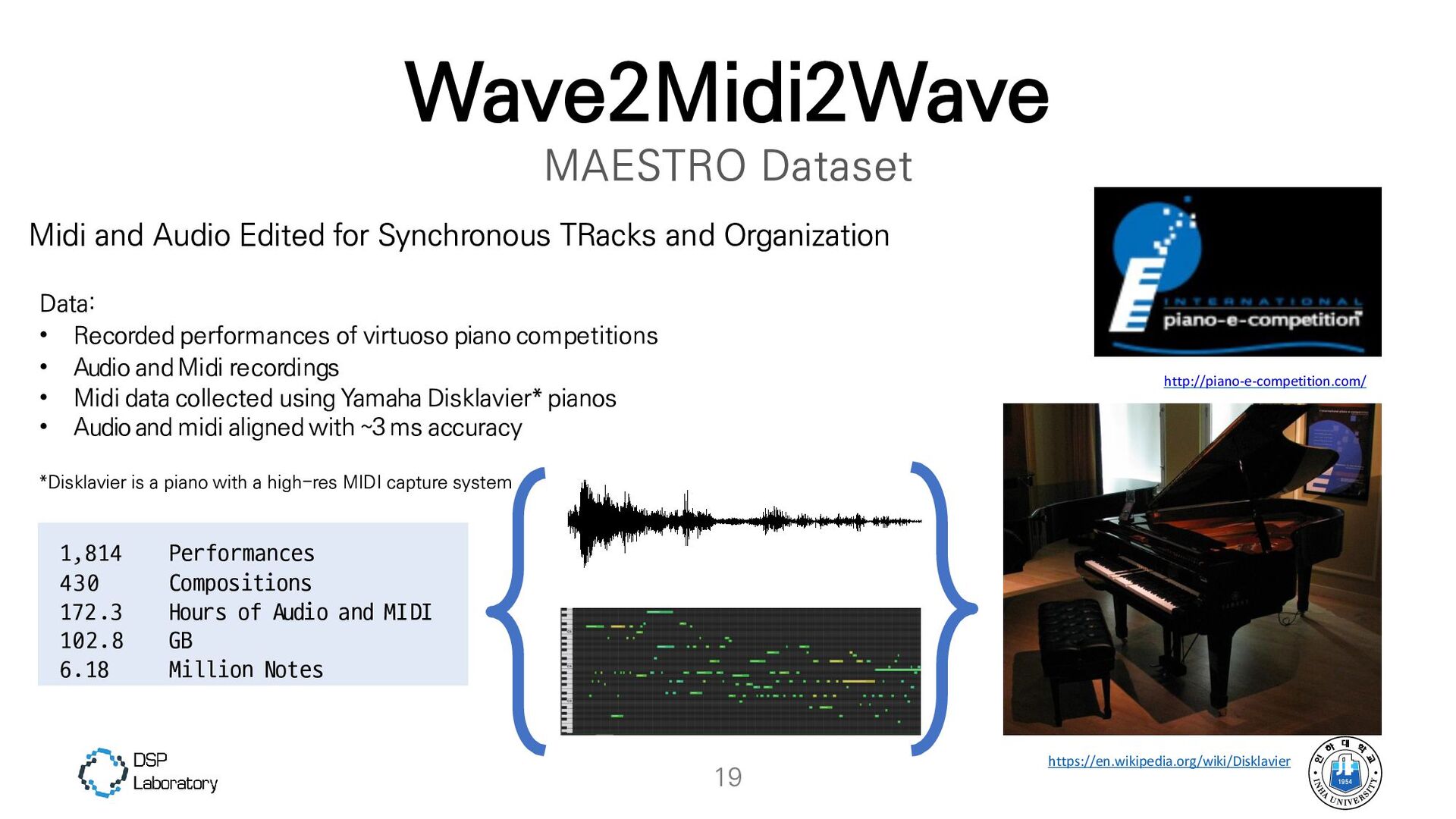{kind=link}
{kind=link}
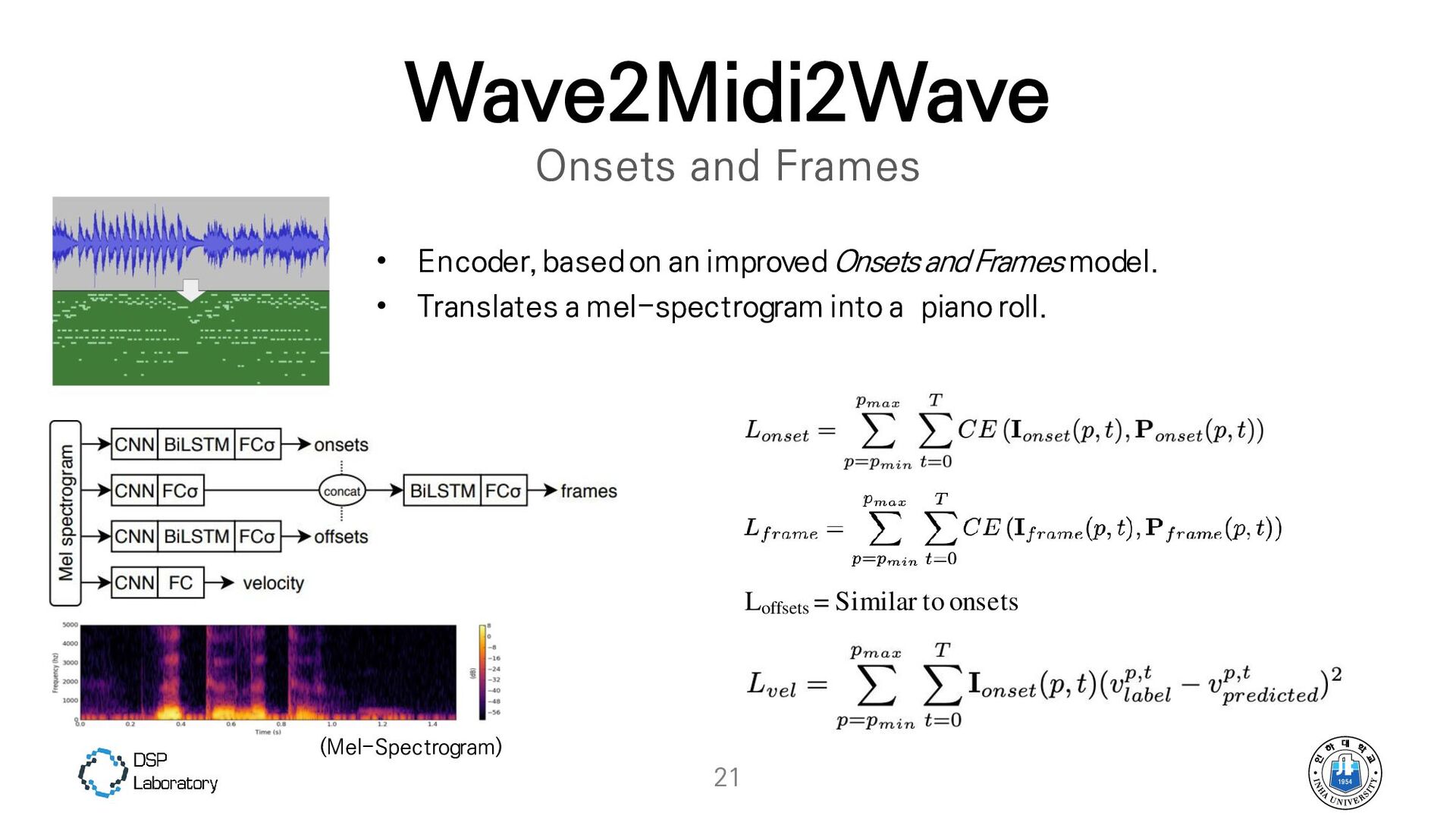{kind=link}
{kind=link}
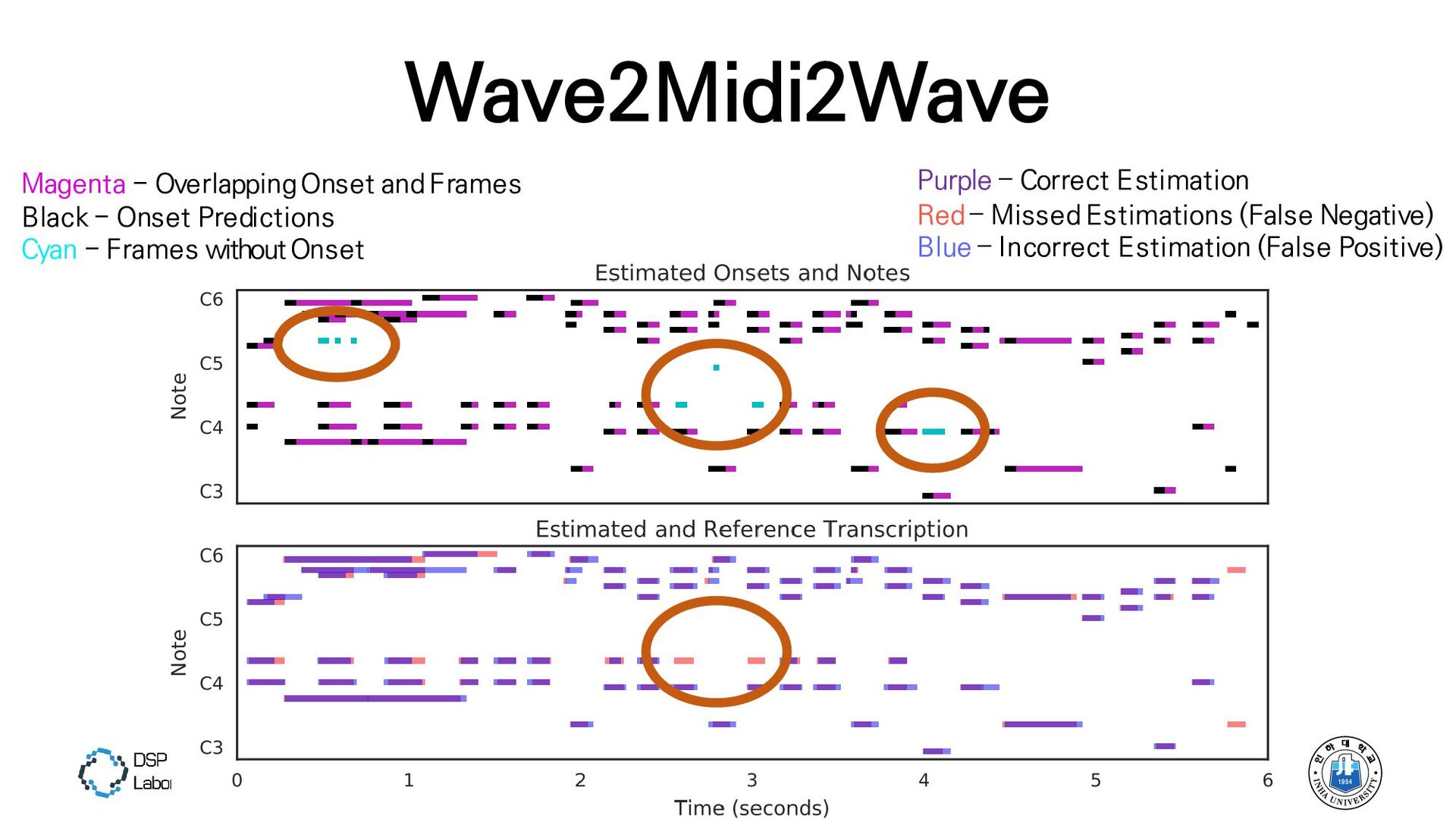{kind=link}
{kind=link}
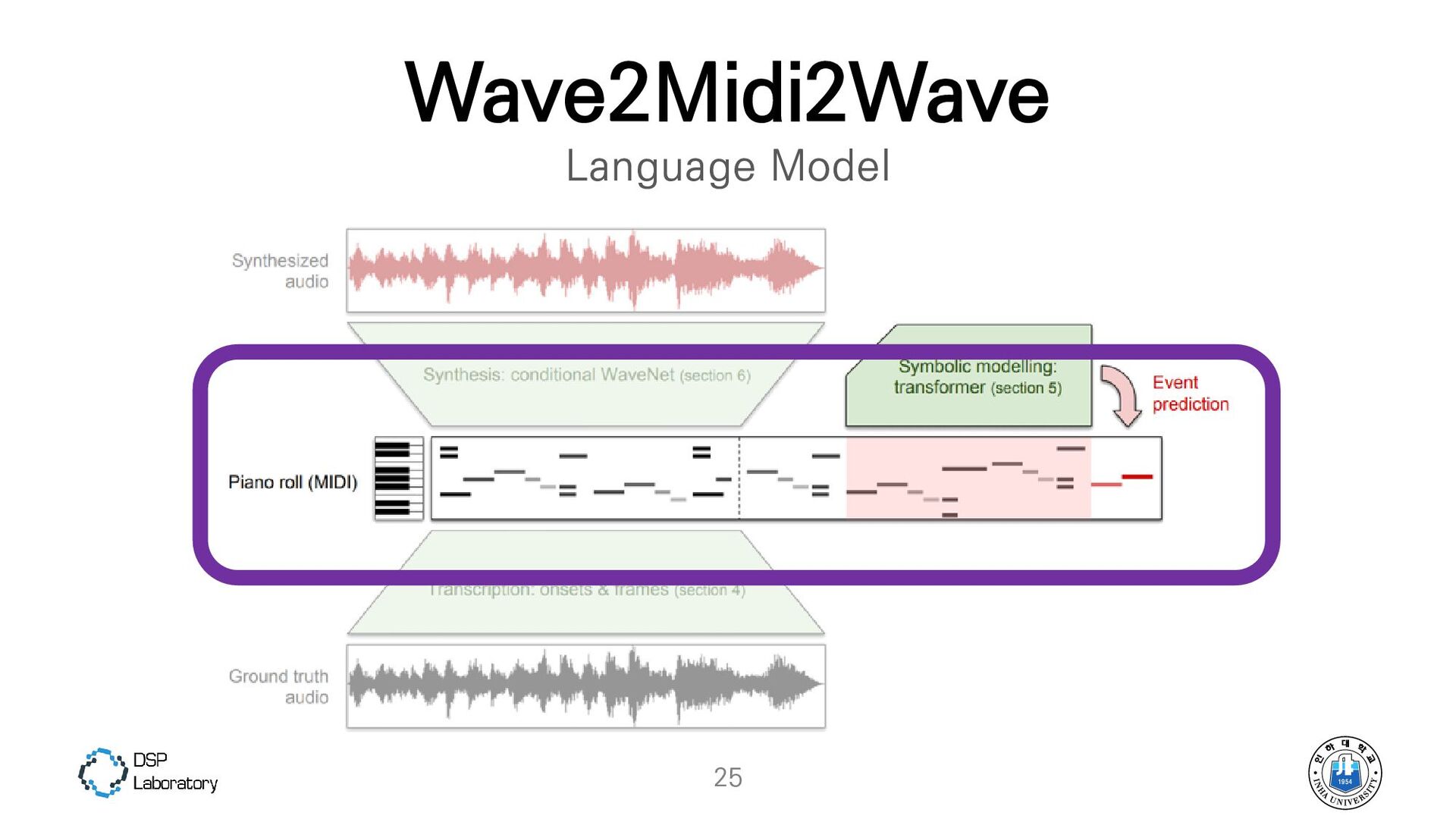{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}