Apache Kafka is an open-source message broker project developed by the Apache Software Foundation written in Scala.
Kafka is a fast, scalable, durable, and fault-tolerant publish-subscribe messaging system.
may be lost by are never delivered. • At least once – Messages are never lost byt may be redliverd. • Exactly once – This is what people actually want.
traditional messaging systems such as ActiveMQ and RabbitMQ. • Kafka provides customizable latency • Kafka has better throughput • Kafka is highly Fault-tolerance
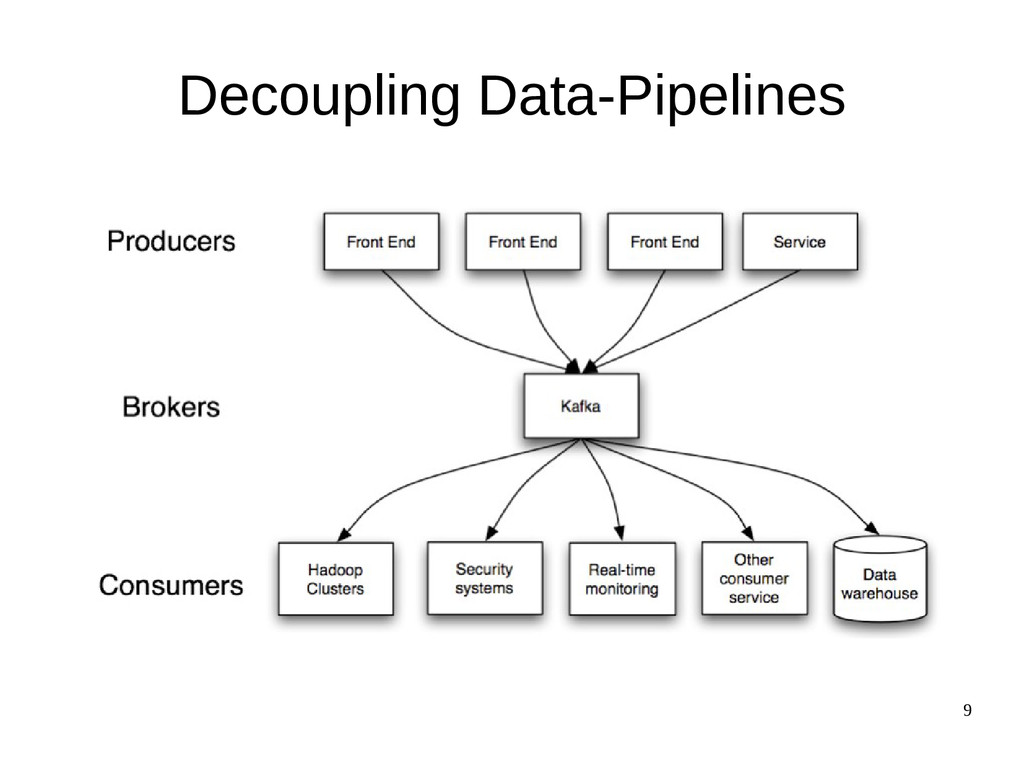
Kafka as a replacement for a log aggregation solution. – Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. – In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency. • Lower-latency • Easier support
are popular frameworks for stream processing. They both use Kafka. • Event Sourcing – Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka's support for very large stored log data makes it an excellent backend for an application built in this style. • Commit Log – Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re- syncing mechanism for failed nodes to restore their data.
format of an N byte message is the following: • * If magic byte is 0 • * 1. 1 byte "magic" identifier to allow format changes • * 2. 4 byte CRC32 of the payload • * 3. N - 5 byte payload • * If magic byte is 1 • * 1. 1 byte "magic" identifier to allow format changes • * 2. 1 byte "attributes" identifier to allow annotations on the message independent of the version (e.g. compression enabled, type of codec used) • * 3. 4 byte CRC32 of the payload • * 4. N - 6 byte payload • */
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
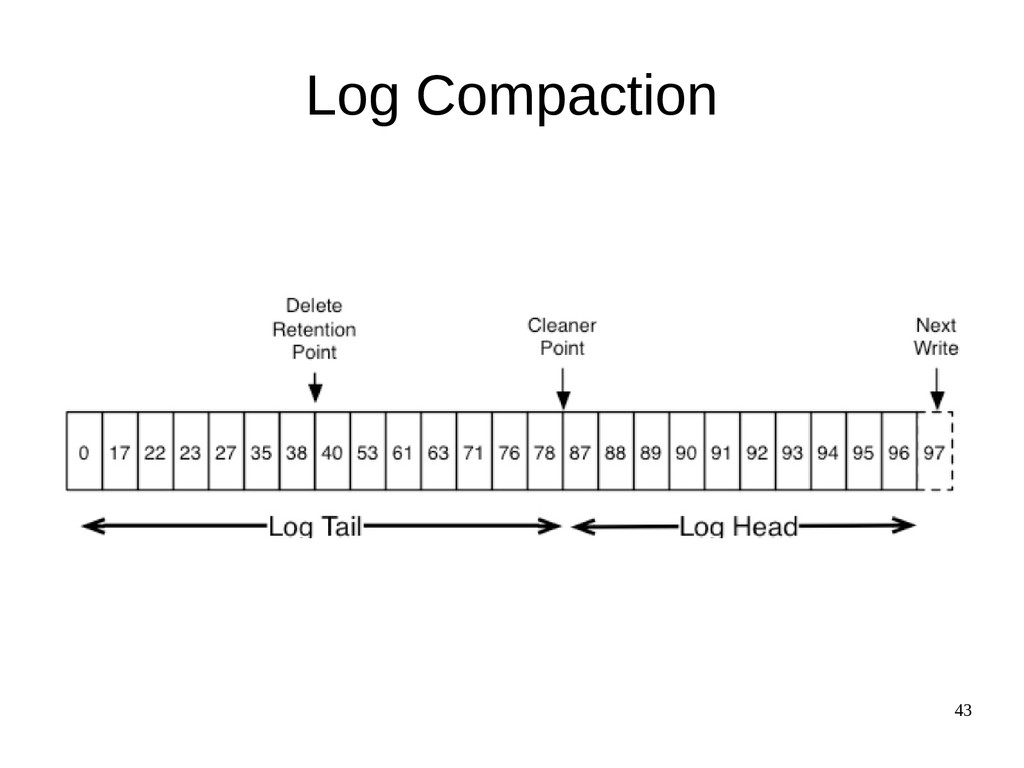{kind=link}
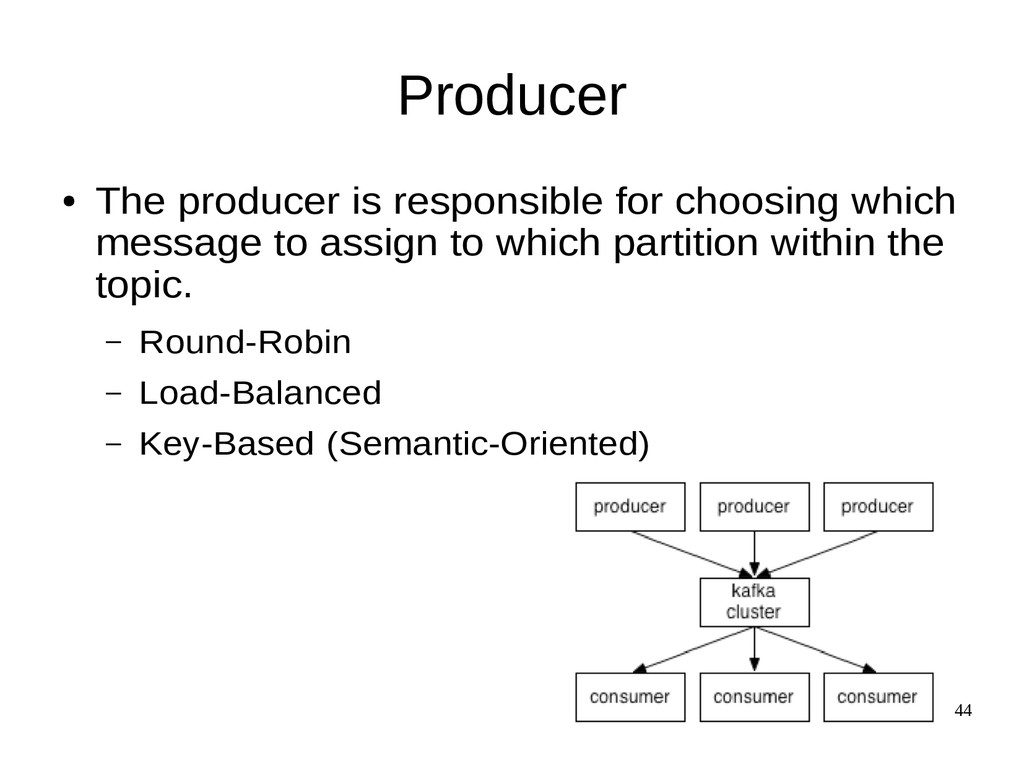{kind=link}
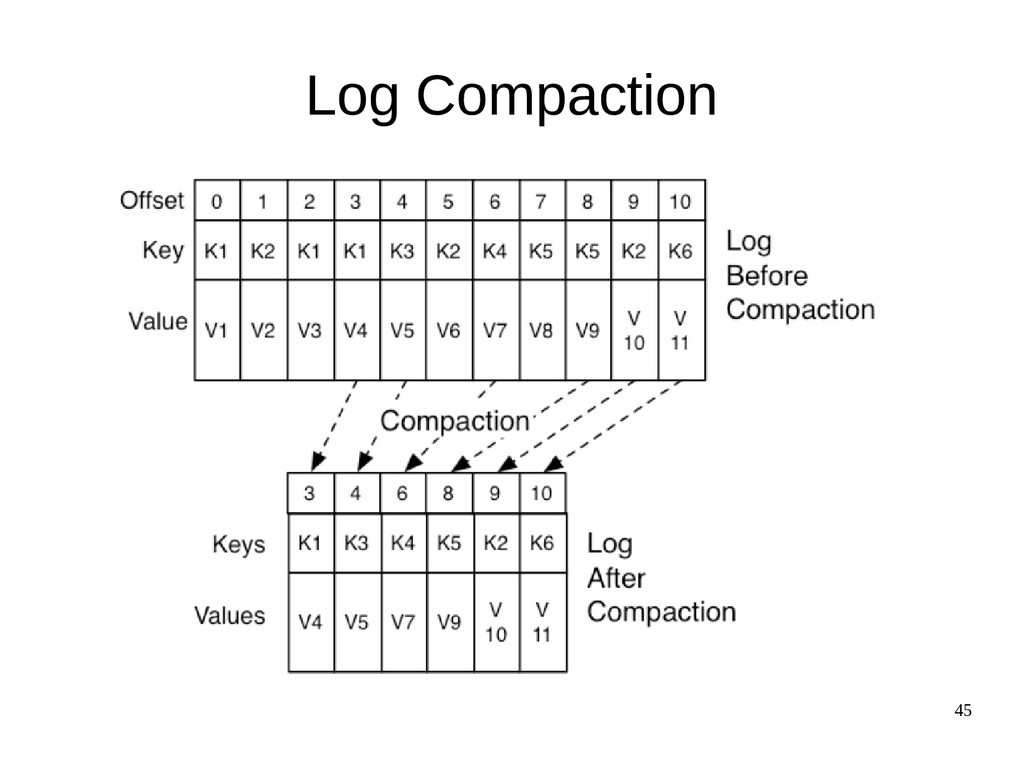{kind=link}
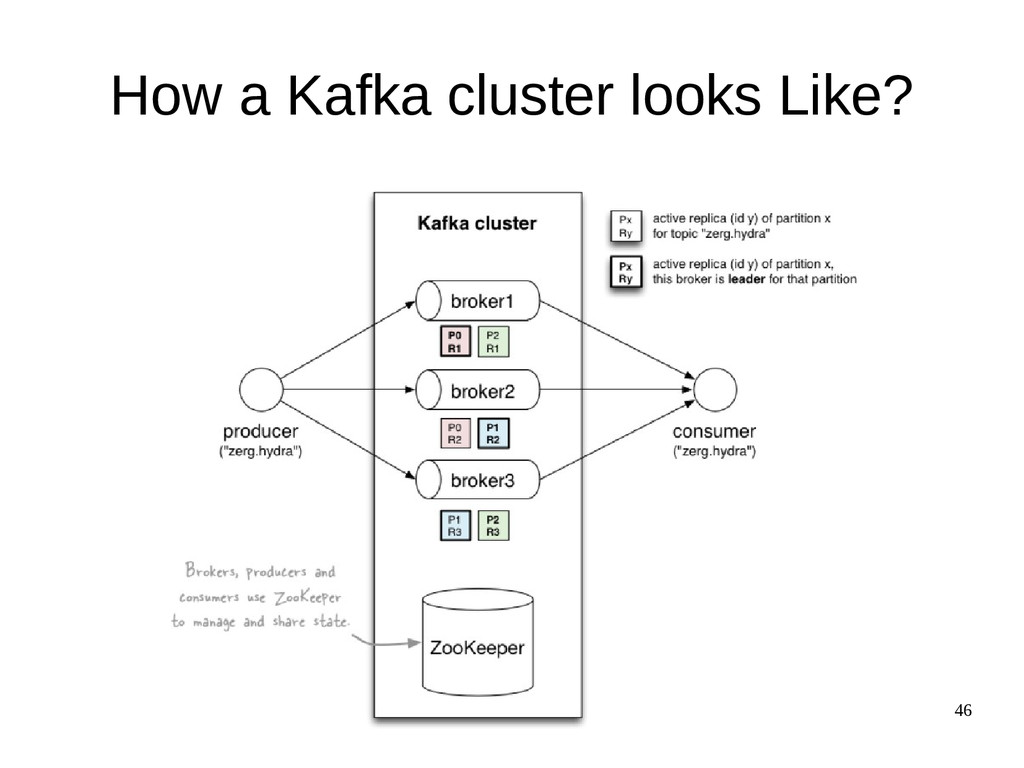{kind=link}
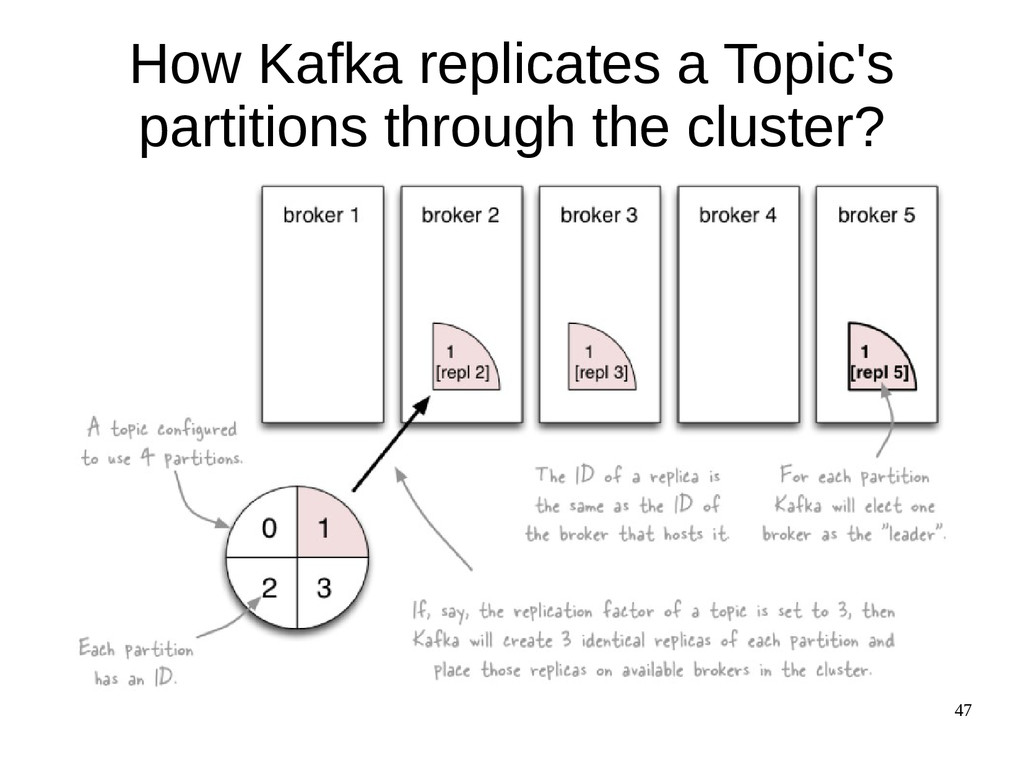{kind=link}
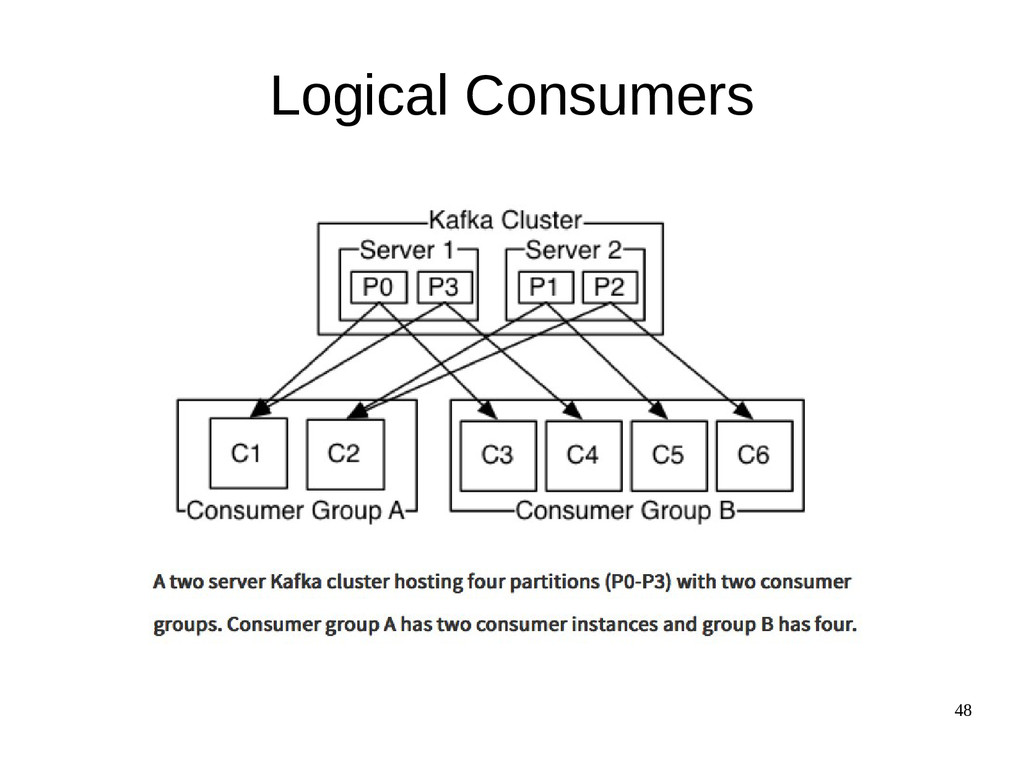{kind=link}
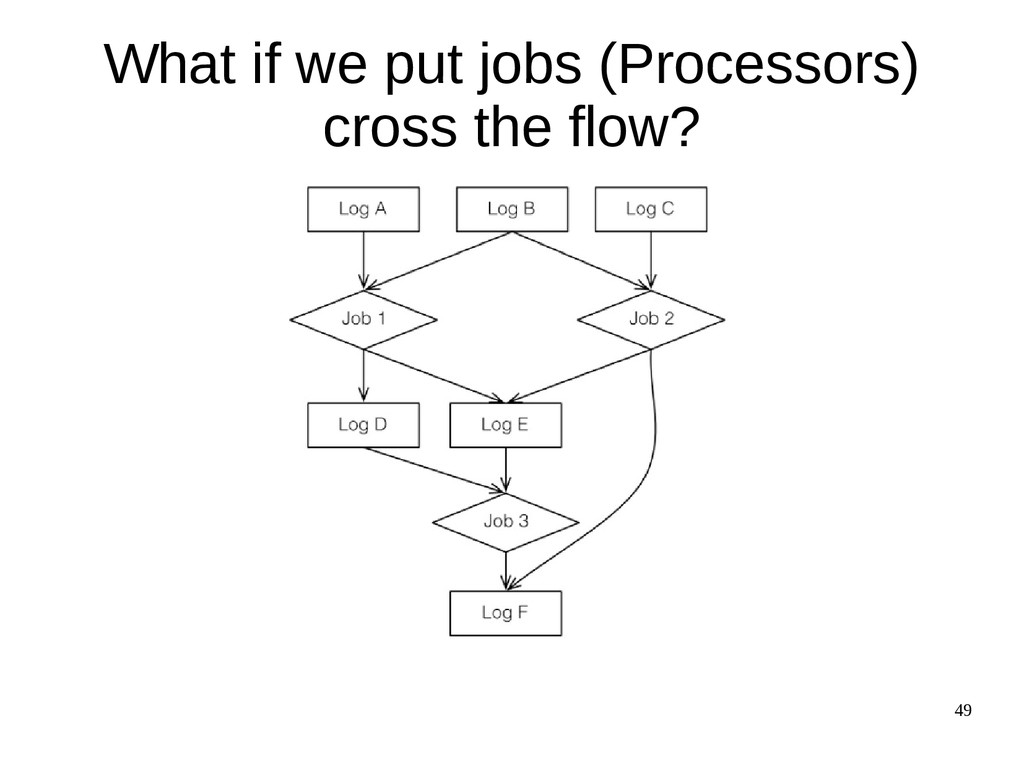{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}