This is the first presentation of a workshop, I am speaking in the School of Computer Science and Engineering of Shahid Beheshti University on Big-Data processing as a workshop on Distributed Databases course.
This presentation starts with setting a Linux cluster up in your notebook and leads you to the other talks such as Intro to Elasticsearch and Hadoop.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
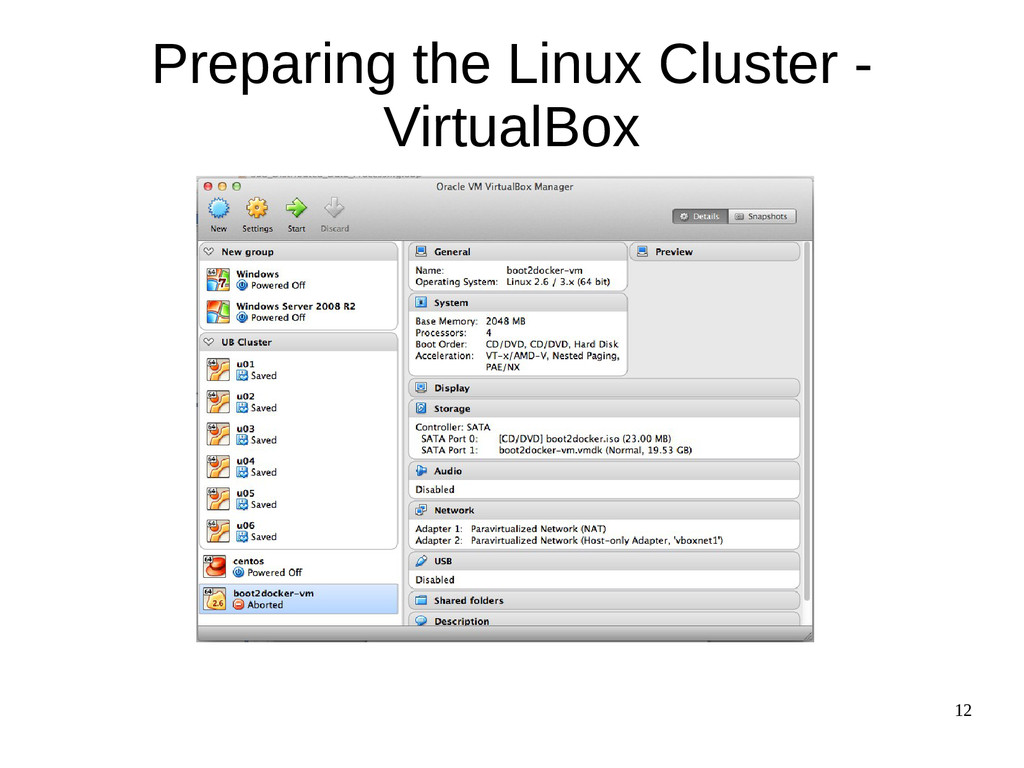{kind=link}
{kind=link}
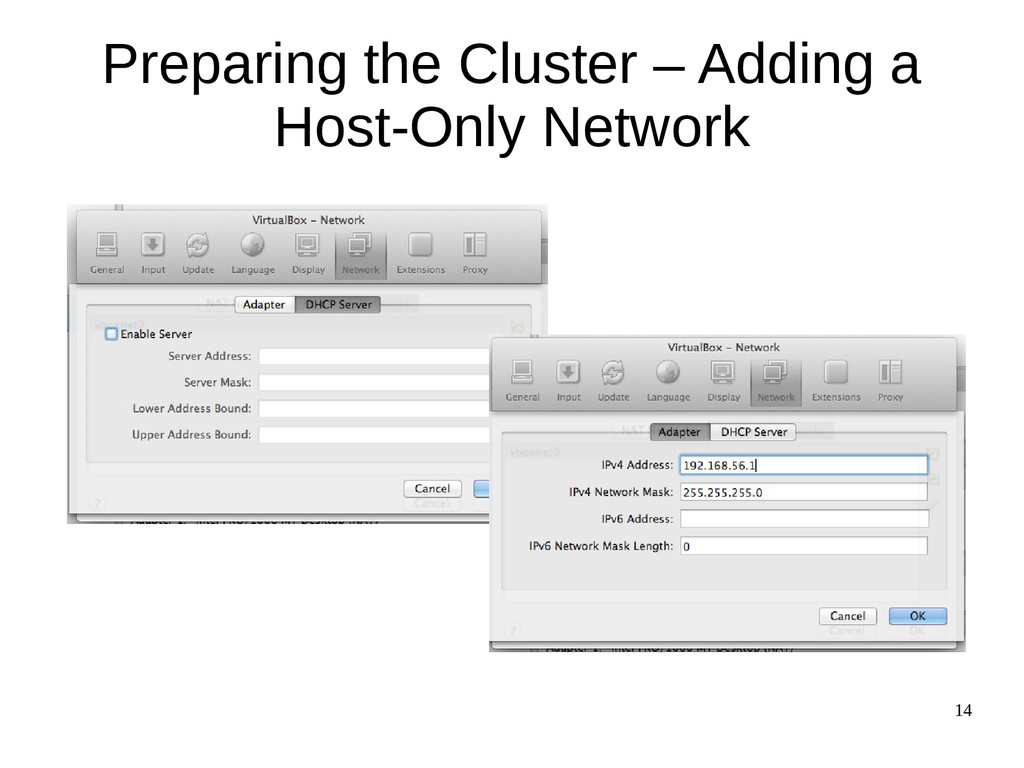{kind=link}
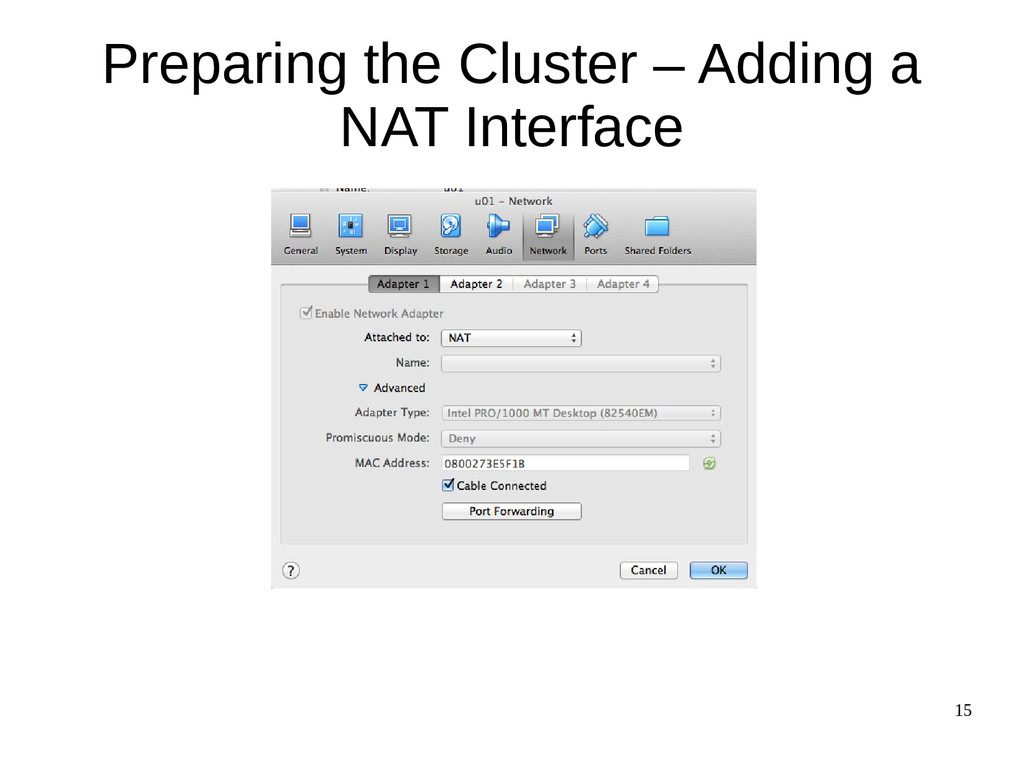{kind=link}
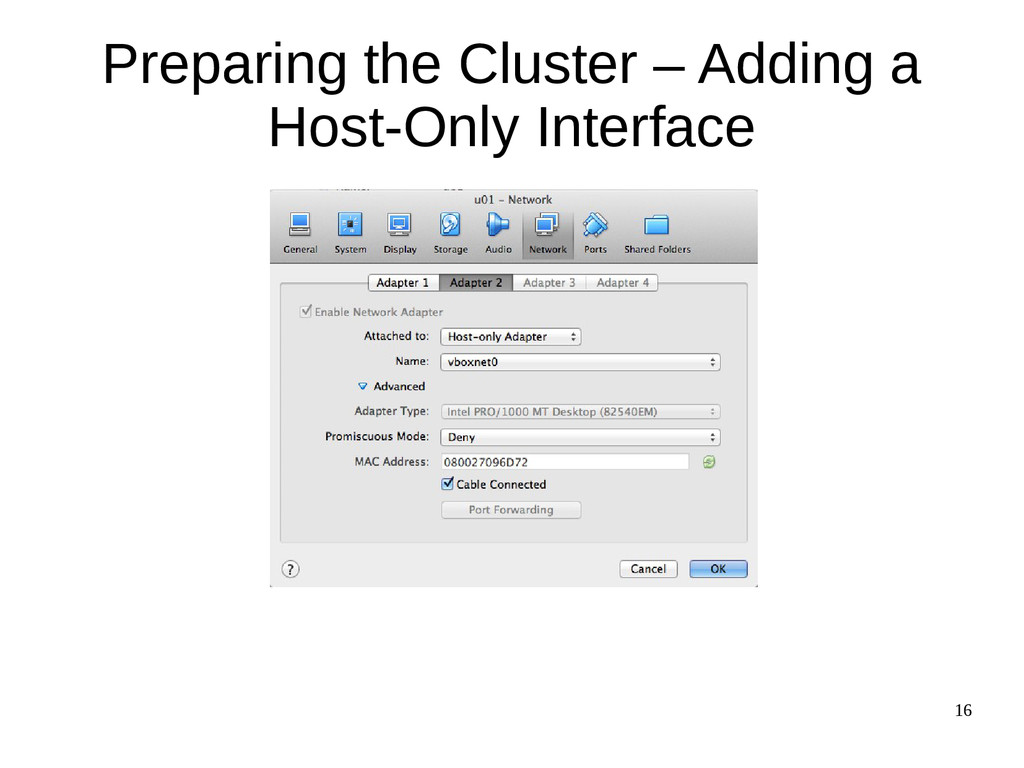{kind=link}
{kind=link}
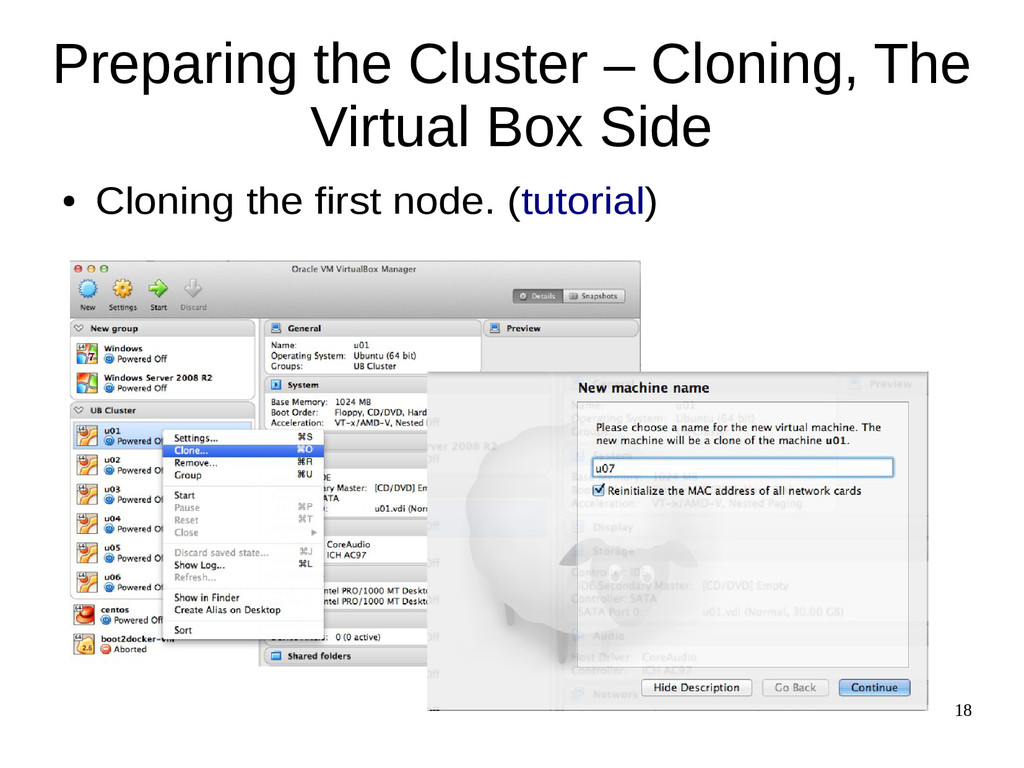{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}