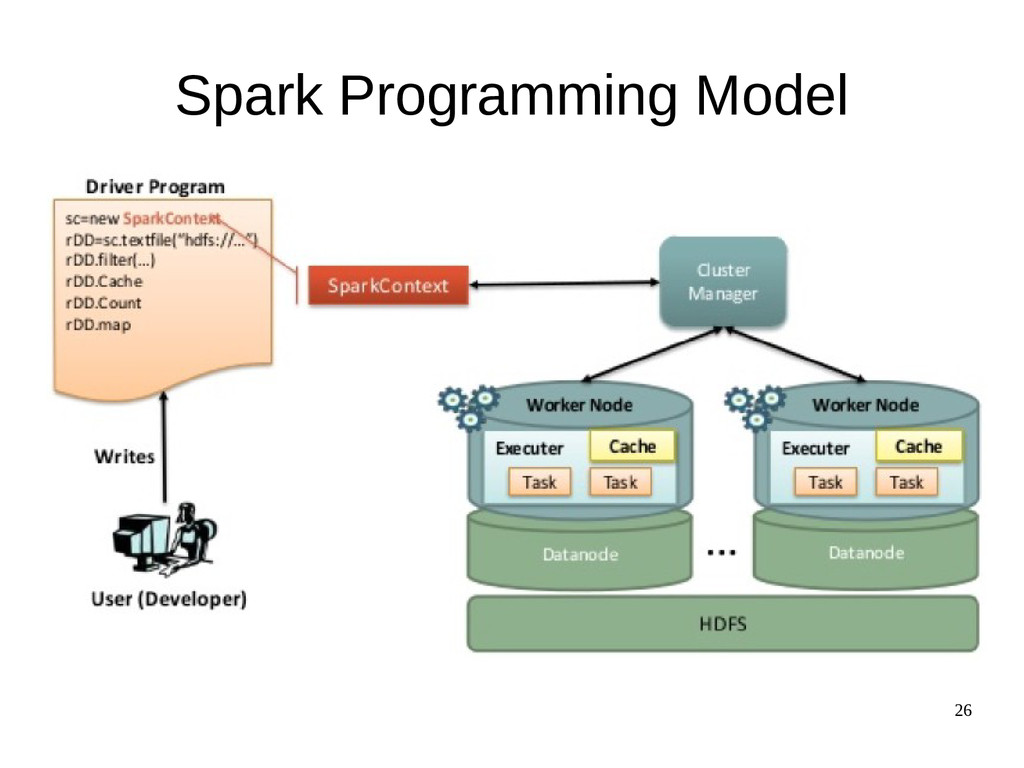
"Apache Spark is a cluster computing engine. It abstracts away the underlying distributed storage and cluster management aspects, making it possible to plug in a lot of specialized storage and cluster management tools. Spark support HDFS, Cassandra, local storage, S3, even tradtional database for the storage layer. Spark can work with cluster management tools like YARN, Mesos. It also has its own standalone mode for cluster management purpose." - https://rahulkavale.github.io
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
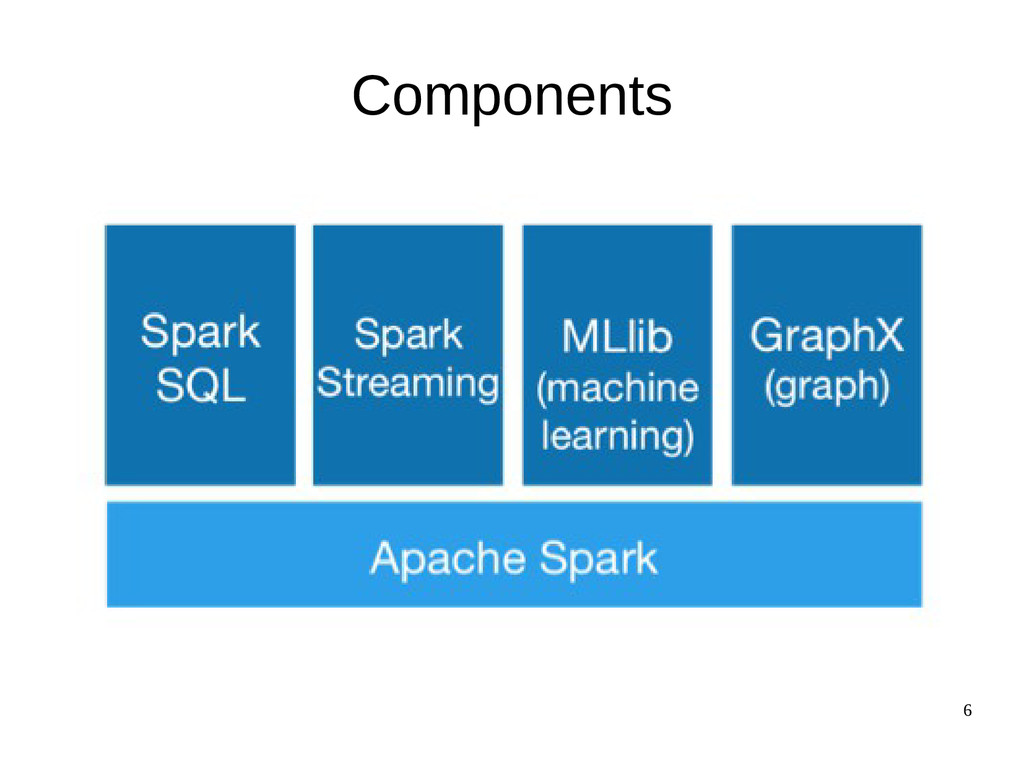{kind=link}
{kind=link}
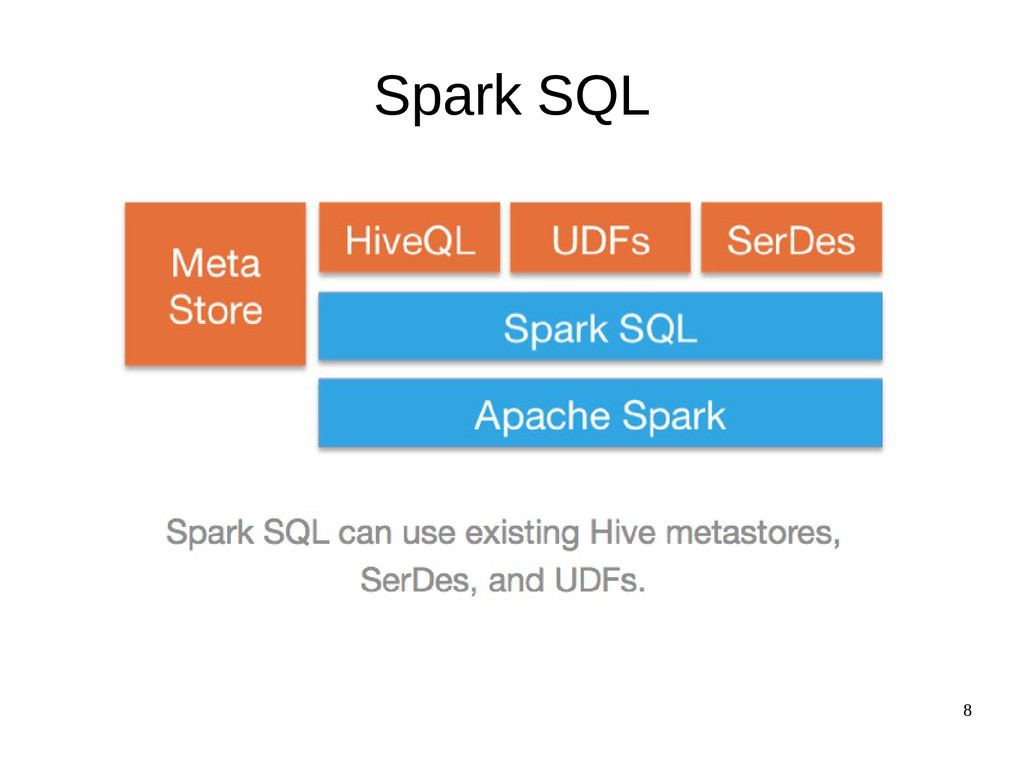{kind=link}
{kind=link}
{kind=link}
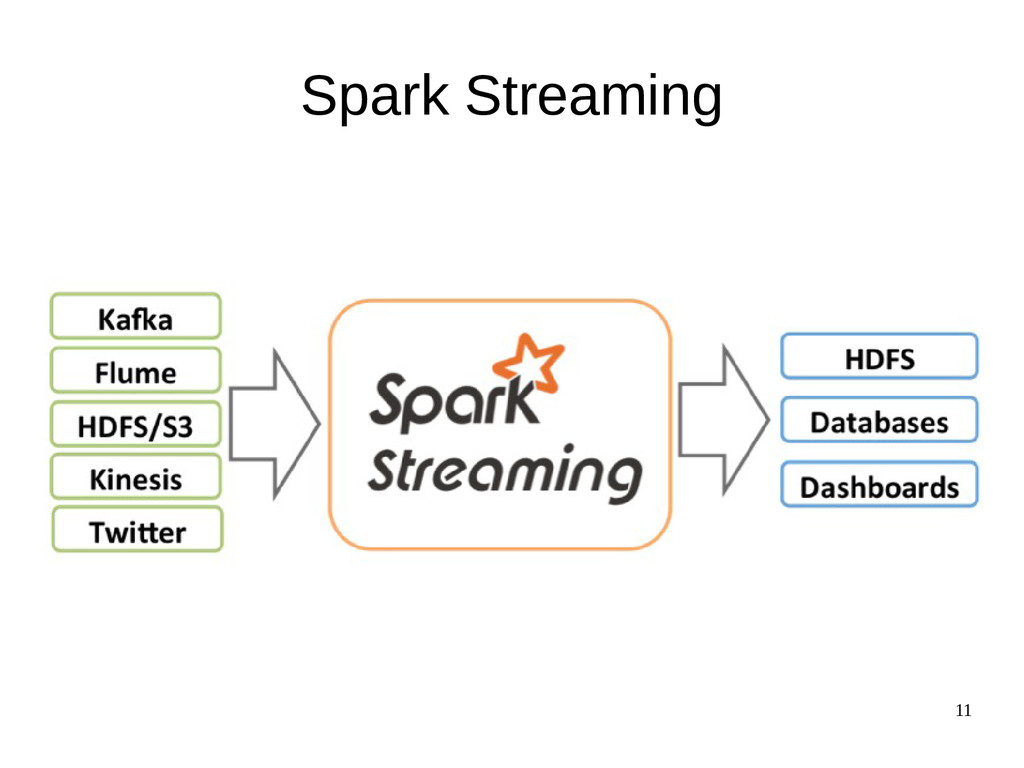{kind=link}
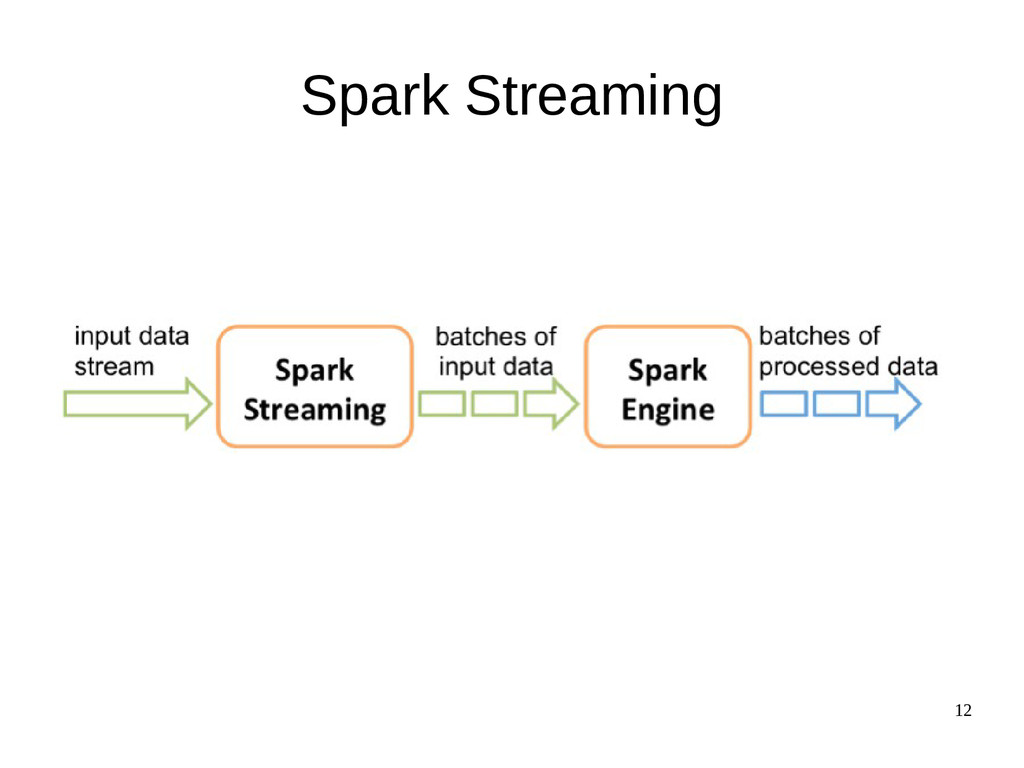{kind=link}
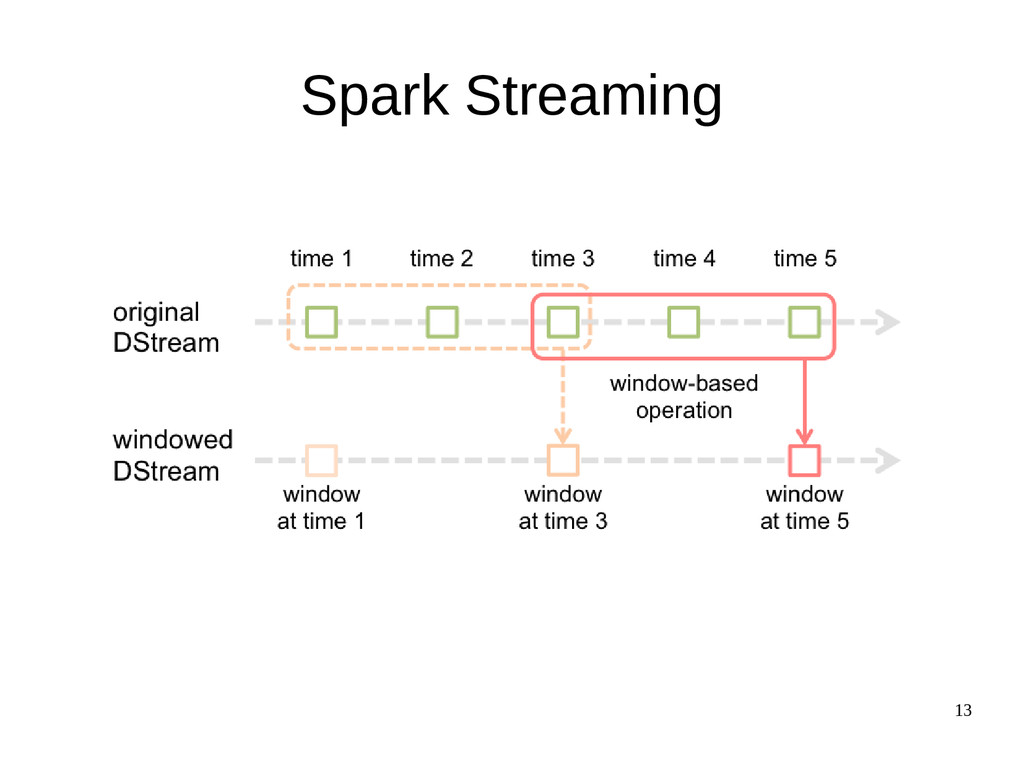{kind=link}
{kind=link}
{kind=link}
{kind=link}
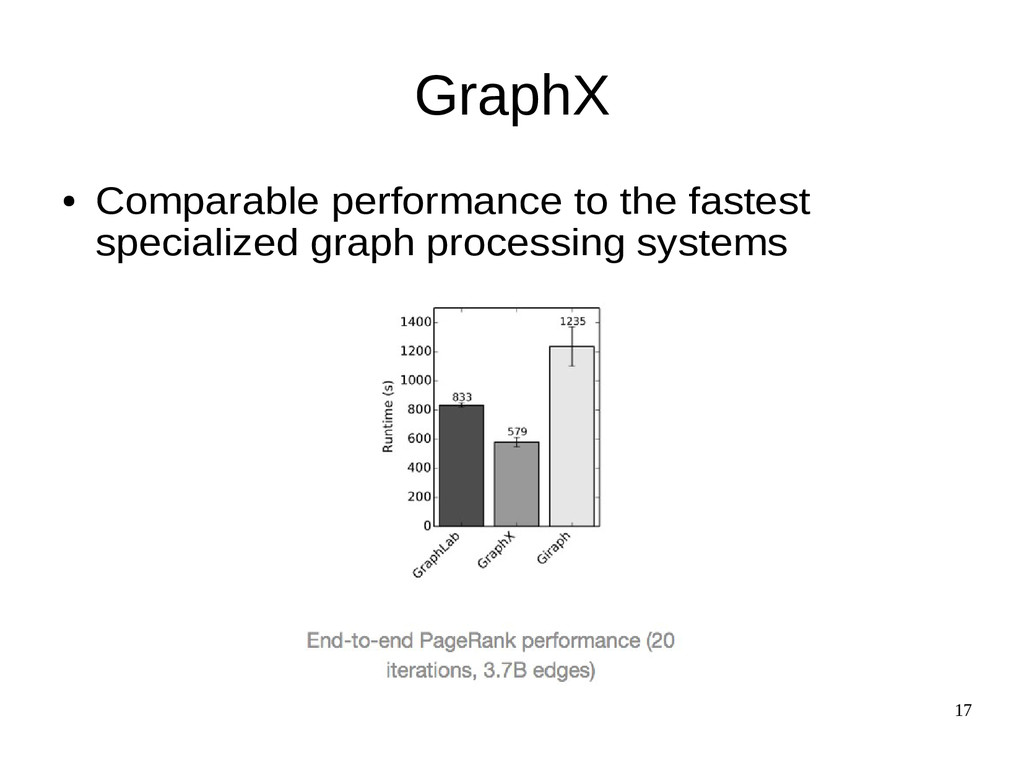{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
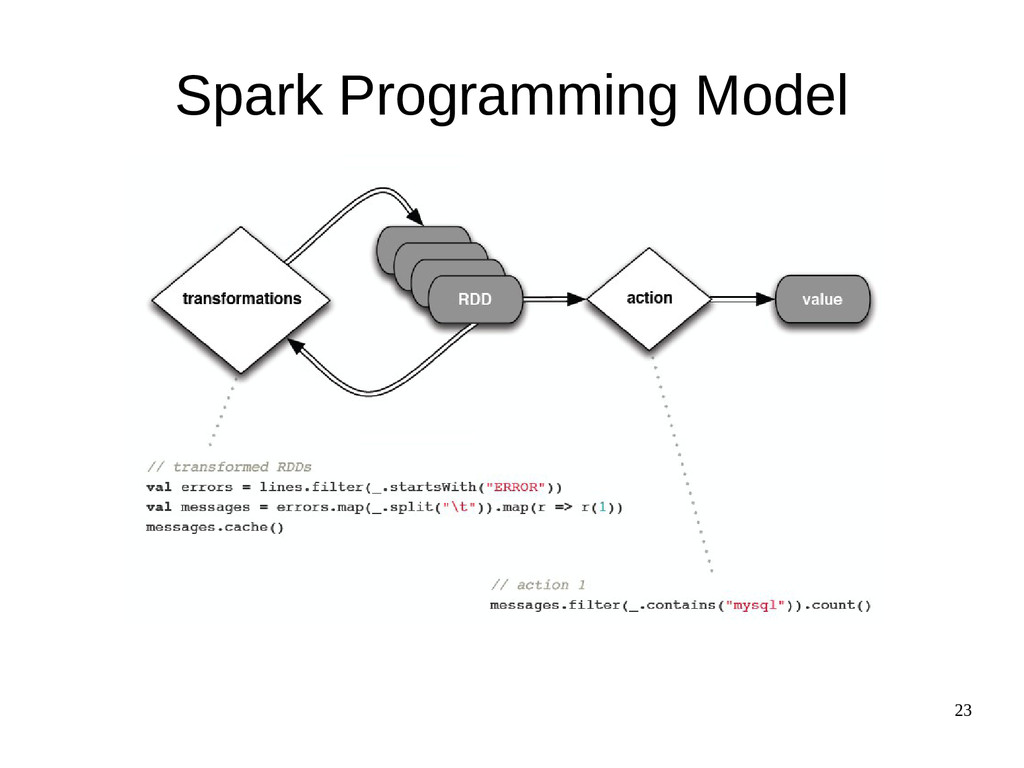{kind=link}
{kind=link}
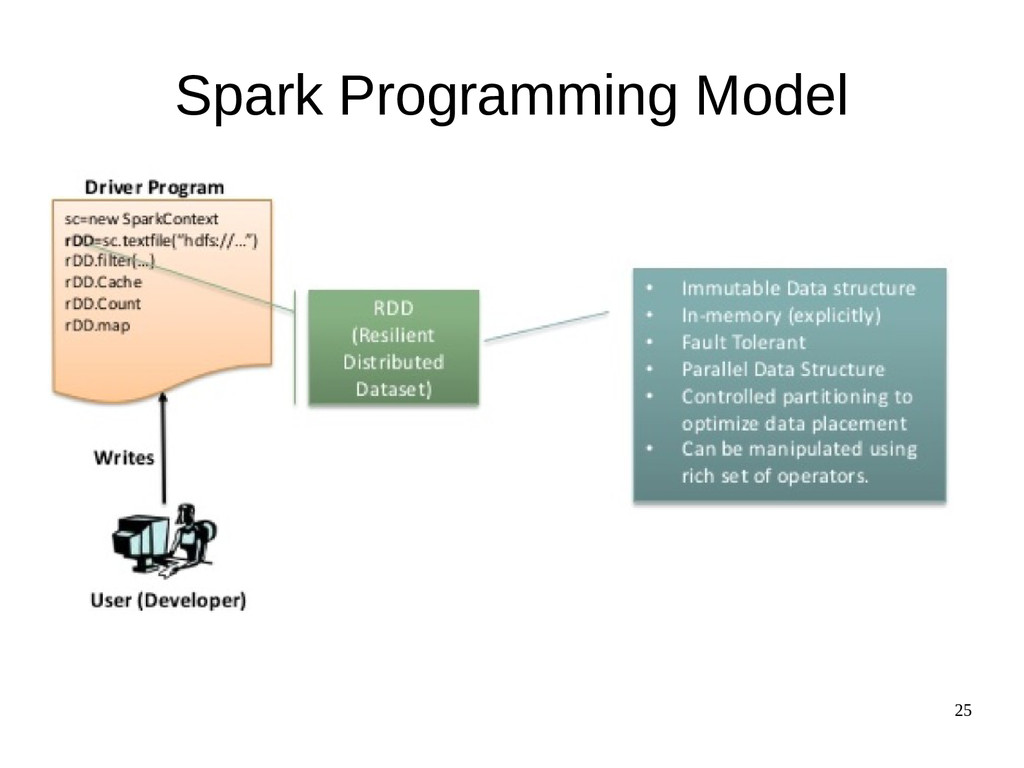{kind=link}
{kind=link}
{kind=link}
{kind=link}