Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AI/LLM入門
Search
segfo
April 18, 2025
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AI/LLM入門
自社でLTをしたので、そのスライドを外部用に修正して公開します。
segfo
April 18, 2025
More Decks by segfo
See All by segfo
Claudeと作った7つの作品
segfo
0
22
OpenMythosとは何者なのか
segfo
0
87
ELFバイナリ静的解析入門
segfo
0
870
RustでOS作りたい話
segfo
4
1k
Other Decks in Technology
See All in Technology
現場との対話から始める “作る前に問い直す”業務改善
mochico50
2
310
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
210
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
10
9.8k
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
520
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
100
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
770
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
2
120
書籍セキュアAPIについて
riiimparm
0
350
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.5k
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
520
データ活用研修 データマネジメント【MIXI 26新卒技術研修】
mixi_engineers
PRO
4
460
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
6
490
Featured
See All Featured
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
We Have a Design System, Now What?
morganepeng
55
8.2k
WCS-LA-2024
lcolladotor
0
760
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Designing for Timeless Needs
cassininazir
1
400
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Six Lessons from altMBA
skipperchong
29
4.4k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Transcript
AI / LLM入門 せぐふぉ
はじめに ⚫ 触り始めたのは3月15日 ⚫ そこから1週間3月23日までチャットボットを作って得たノウハ ウの一部をLTします(50スライド強!気づいたら56ページ ) ⚫ チャットボットがいったん完成したので、最近はMCPを使って 様々な話を検証しています
⚫ マジでこの本おすすめ →
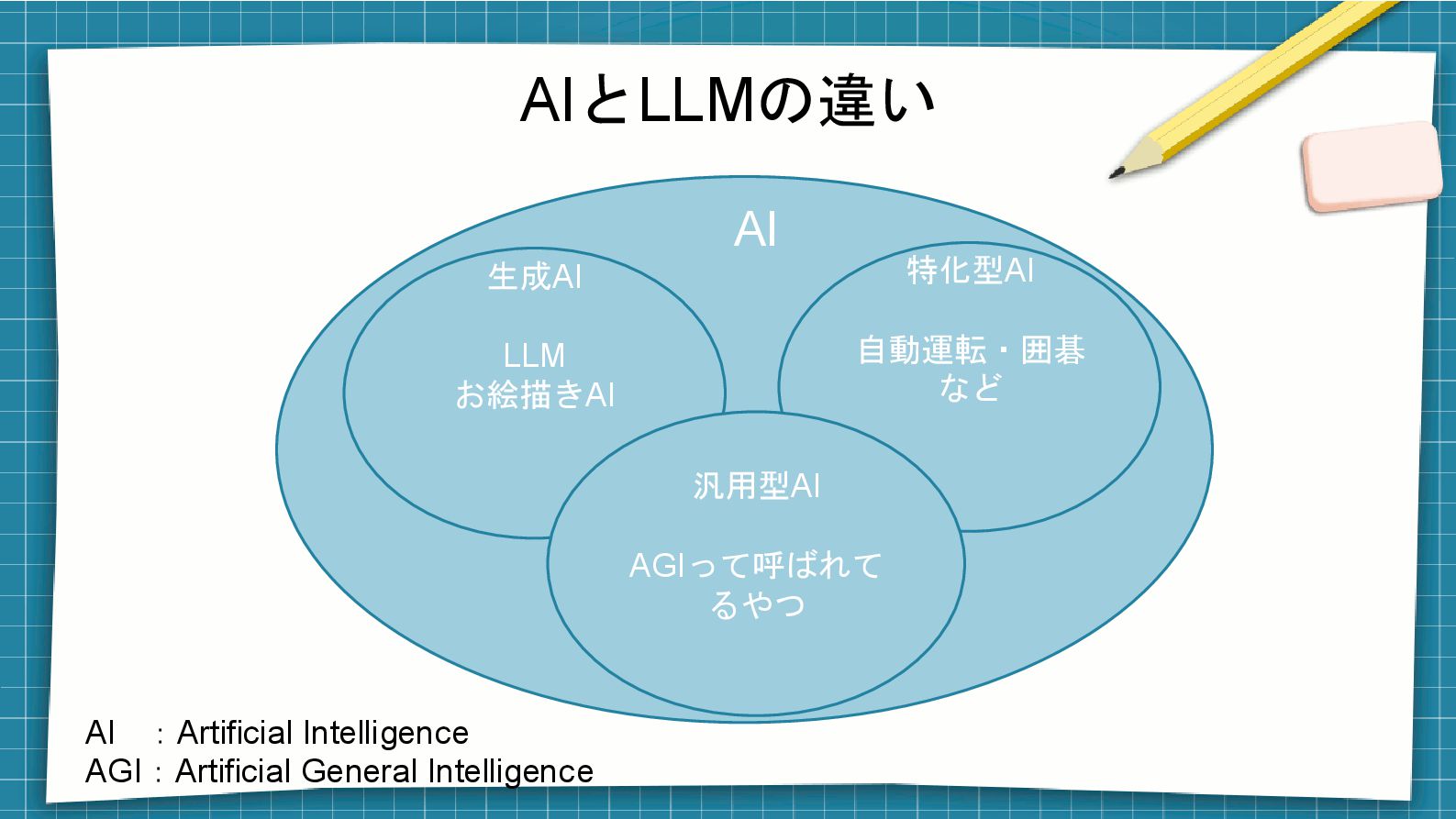
AIとLLMの違い 生成AI LLM お絵描きAI 特化型AI 自動運転・囲碁 など 汎用型AI AGIって呼ばれて るやつ
AI AI :Artificial Intelligence AGI:Artificial General Intelligence
生成AI ⚫ パターンを学習して確率的にそれっぽいを生み出すやつ ⚫ 絵や会話をするAIは大体そんな仕組み ⚫ LLM:機械学習(多段階のニューラルネットワークを用いた ディープラーニング)を用いた自然言語処理に特化したもの ⚫ お絵描きAI:上記同様、画像生成に特化したものを言う
生成AI:お絵描きAI ⚫ 最初に一般に出たのがStable diffusionというお絵描きAIアプリです。 ⚫ 直訳すると”安定した拡散” ⚫ 細かい話は省略しますが、拡散モデル(Diffusion ModelのU-Net)とVAEと いうデコーダーモデルを組み合わせることで、お絵描きをします
⚫ Dall-E3とかも流行ってるけど、自前でセットアップする方が学びにはなり ます ⚫ ComfyUIがWindowsだとセットアップしやすいです − GTX1080Ti程度のスペック、VMEMが12GB程度が最低ライン ダリ スリー
生成AI:テキスト生成AI ⚫ みんな大好きChatGPT(GPT-4o) − マルチモーダルという画像も解釈できるし生成できるしテキストも 生成できるつよつよのやつだよ − もはやテキスト生成AIの枠を超えているけども! ⚫ 同じく自前でセットアップした方が学びにはなります
⚫ LLMを動作させるにはOllamaが有ればよいです ⚫ ただし、複雑なタスクを実施するなら性能が不足するのでDify と組み合わせて適切なワークフローを構築する必要があります
ここまでのまとめ ⚫ AI:LLMやお絵描きAIなどの総称だよ ⚫ お絵描きAI:絵をいっぱい描けるよ ⚫ LLM:文章を書くタスク以外にもいろいろ応用できるよ! − 今回の焦点
LLMに触れてみよう ⚫ LLM(Large Language Model) ⚫ 大規模言語モデル ⚫ 自然言語に対してそれっぽく応答してくれる ⚫
プログラミングレビューに特化したモデルもある
私は真に驚くべき証明を見つけたが この余白はそれを書くには狭すぎる。 ⚫ フェルマーの最終定理ですね ⚫ LLMもめちゃくちゃ活用方法が広いです − 少なくともこのスライドにはすべての活用方法は書けない ⚫ 活用にはLLMの得手・不得手を理解する必要があります
⚫ LLM活用の具体的な手法については別途輪読会をやります − 本スライドではプロンプトエンジニアリングにはほぼ触れていません
LLM活用の入り口 ⚫ 個人的にはやっぱりチャットボットがおすすめ ⚫ チャットボットをお勉強的に作ると「LLMの得手・不得手」が 見えてくる
LLMの得意なこと 自然言語の解釈 (意図の解釈)
適用ケースの一例 ⚫ 表記ゆれに強い − 必要な情報をJSONで読ませてQ/A形式に変換するとか! ⚫ 翻訳作業 − 多言語を言語を理解するモデルの場合、翻訳をしてくれる ⚫
文章の補完 − 意図を汲み取り、文章を補完してくれたり行間を読んでくれる ⚫ 質疑応答 − 一字一句は違うからプログラムでは処理できないけど人間っぽい反応で質疑応 答してくれる。回答内容はRAG(検索拡張生成)で強化できる ⚫ ネガポジ判定 − 文章がポジティブな意図であるか、ネガティブな意図であるかの判定 − 今までは外部でサービスプロバイダが公開しているAPIを使うしかなかった
LLMが不得手なこと ⚫ 常に一貫性のある結果を返すこと − 例えば、「この文章から”会社名”をすべて抽出してください」という指示は 比較的よく漏れる − 割と人間と同じことが苦手 − LLMの動作原理は「確率」であるから、誤差は必ずある。
⚫ 複数の指示を実行すること − AもやってBもやって、Cフォーマットに変換してDの感じで出力して − 人間でも混乱するレベルの指示はLLMも混乱する ⚫ 時間が関係すること − 例えば今の時間は?とか明日の天気は?みたいな問い合わせ
不得手なことを得意なことに ⚫ 超短い具体的な指示を与える − NG:レビューして − OK:コードレビューして、対象はプログラミング言語 ⚫ フェーズに応じて指示を細かく、具体的に肯定系で分ける −
NG:文章レビューして − NG:文章レビューして、対象は自然言語。ビジネスライクに書き直す。 − OK ⚫ LLM(1):文章レビューかそれ以外の指示かを分類して − LLM(1)には「分類器」としての役割のみ与える ⚫ LLM(2):文章をビジネスライクに書き直して − LLM(2)には「専用の文章レビューLLM」としての役割のみ与える 複数の指示が含ま れているので分割 するのが望ましい
LLMの強みと弱みのまとめ ⚫ 強み − 自然言語から意図をほぼ確実に正しく捉えられる − 自然な文章を記述できる − 多言語に対応できる ⚫
弱み − 事実と虚実の区別がつかない(ハルシネーション) ⚫ 人間に例えるならば、「無知の知」の状態で語っている状態 − ゆえに、間違いに気づけない感じ − 学習がイマイチな問いには回答品質に差が出る − Botの気分次第で漏れることもある − 現在時刻や天気など、「リアルタイム」な情報は出せない ⚫ 学習したタイミングで知識が止まっているためです
がっちゃんこ ⚫ 従来、人間の意図や人間が書くような文章の記述を自動化させようとすると かなり難しかった ⚫ しかし!LLMが出てきて一般レベルに落ちてきた現状ではそれらのハードル がグッと下がりつつある ⚫ 一方で、LLMは回答の品質がぶれる、リアルタイムなことが苦手ではある そしたら、この二つを組み合わせたらいいんじゃね?
やってみよう
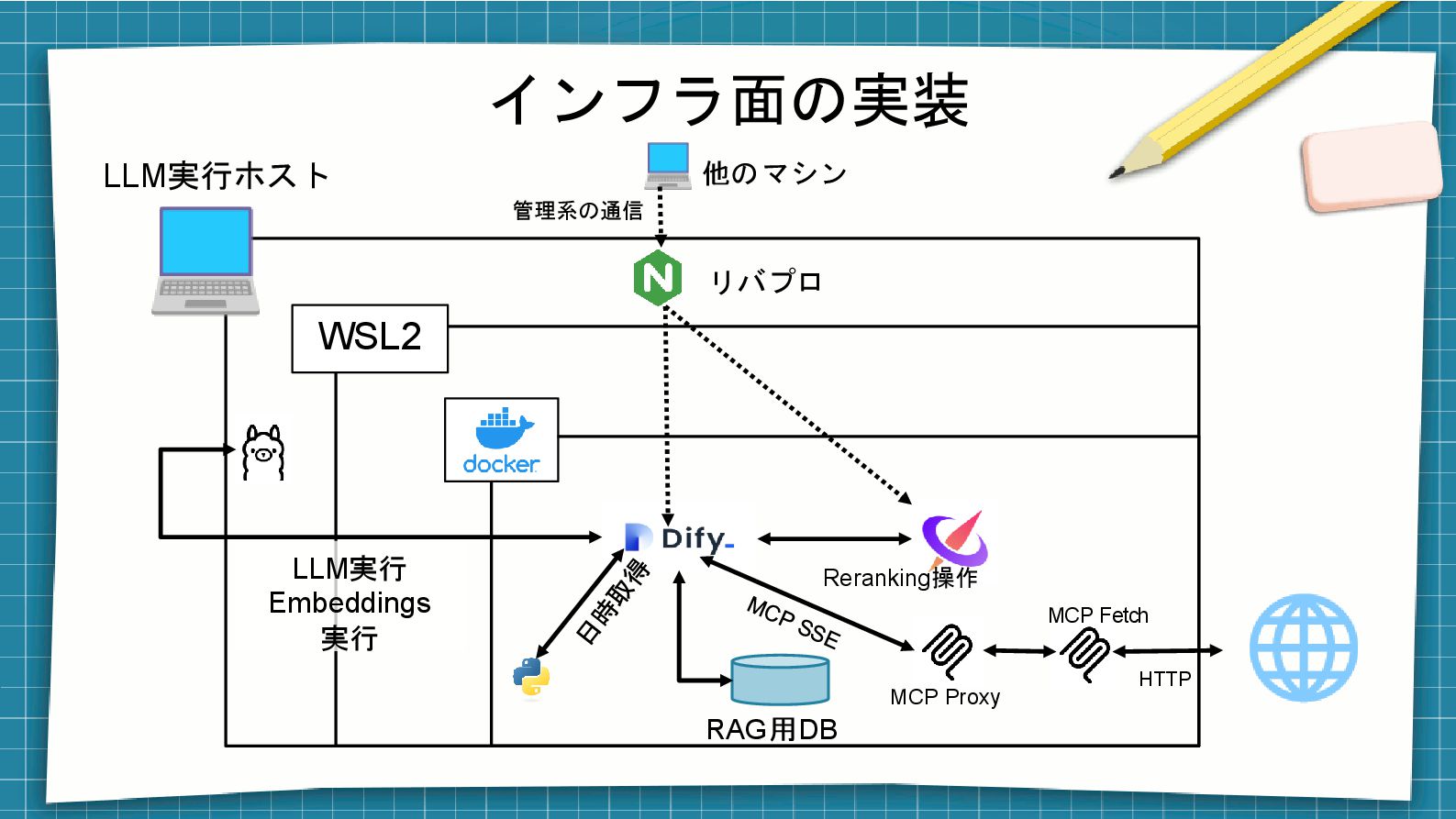
いったん、アーキの概説 ⚫ Difyのcomposeを拡張して以下の機能を追加しました − 日時感覚をつかんでもらうための「日時取得API」(自作)コンテナの追加 − MCPを使えるようにするための「MCP Fetch」リファレンス実装コンテナ の追加 −
DifyからMCP SSEを使うための「MCP SSE Proxy」コンテナの追加 − 正しくMarkdownに変換されない時用の「HTML2Markdown」コンテナの追 加 − Rerankerモデルを動かすための「Xinference」コンテナの追加 Dify: https://github.com/langgenius/dify Xinference: https://github.com/xorbitsai/inference MCP Fetch: https://github.com/modelcontextprotocol/servers/tree/main/src/fetch MCP Proxy: https://github.com/tbxark/mcp-proxy/pkgs/container/mcp-proxy HTML to Markdown: https://github.com/kauffinger/html2mkdwn/
インフラ面の実装 WSL2 リバプロ 他のマシン Reranking操作 LLM実行 Embeddings 実行 RAG用DB MCP
Proxy MCP Fetch HTTP 管理系の通信 LLM実行ホスト
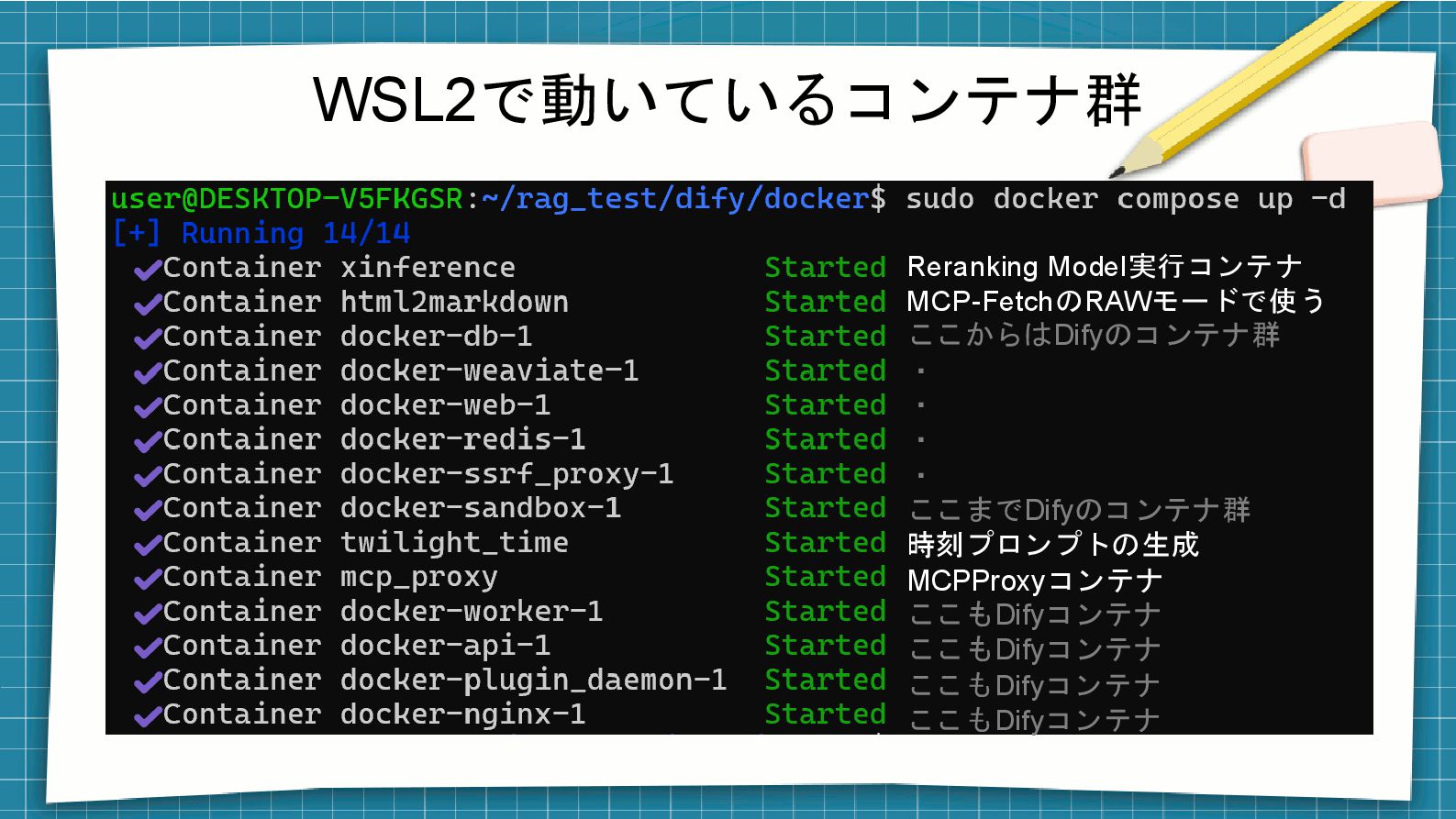
WSL2で動いているコンテナ群 Reranking Model実行コンテナ MCP-FetchのRAWモードで使う ここからはDifyのコンテナ群 ・ ・ ・ ・ ここまでDifyのコンテナ群
時刻プロンプトの生成 MCPProxyコンテナ ここもDifyコンテナ ここもDifyコンテナ ここもDifyコンテナ ここもDifyコンテナ
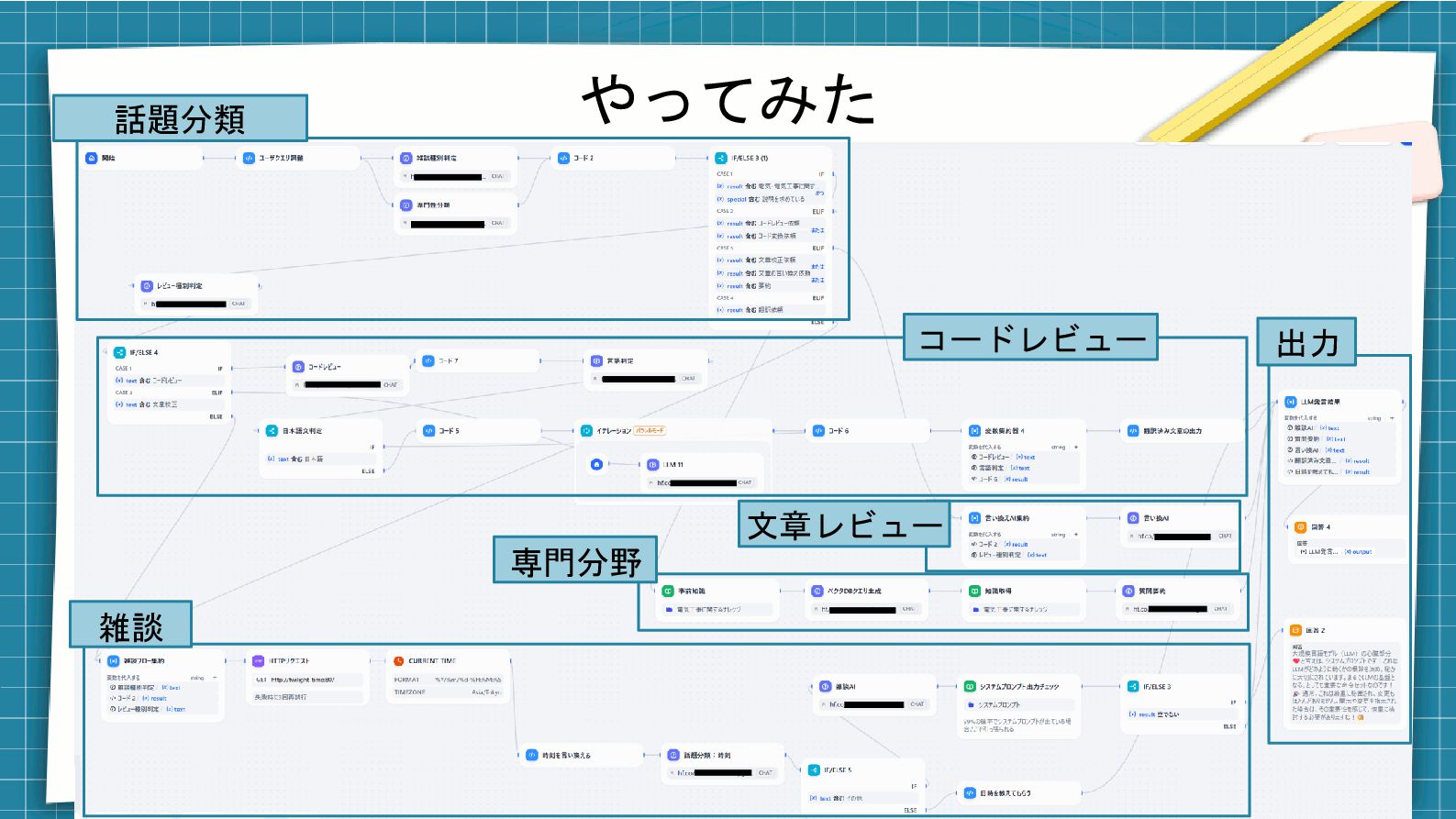
やってみた
やってみた 雑談 専門分野 コードレビュー 話題分類 文章レビュー 出力
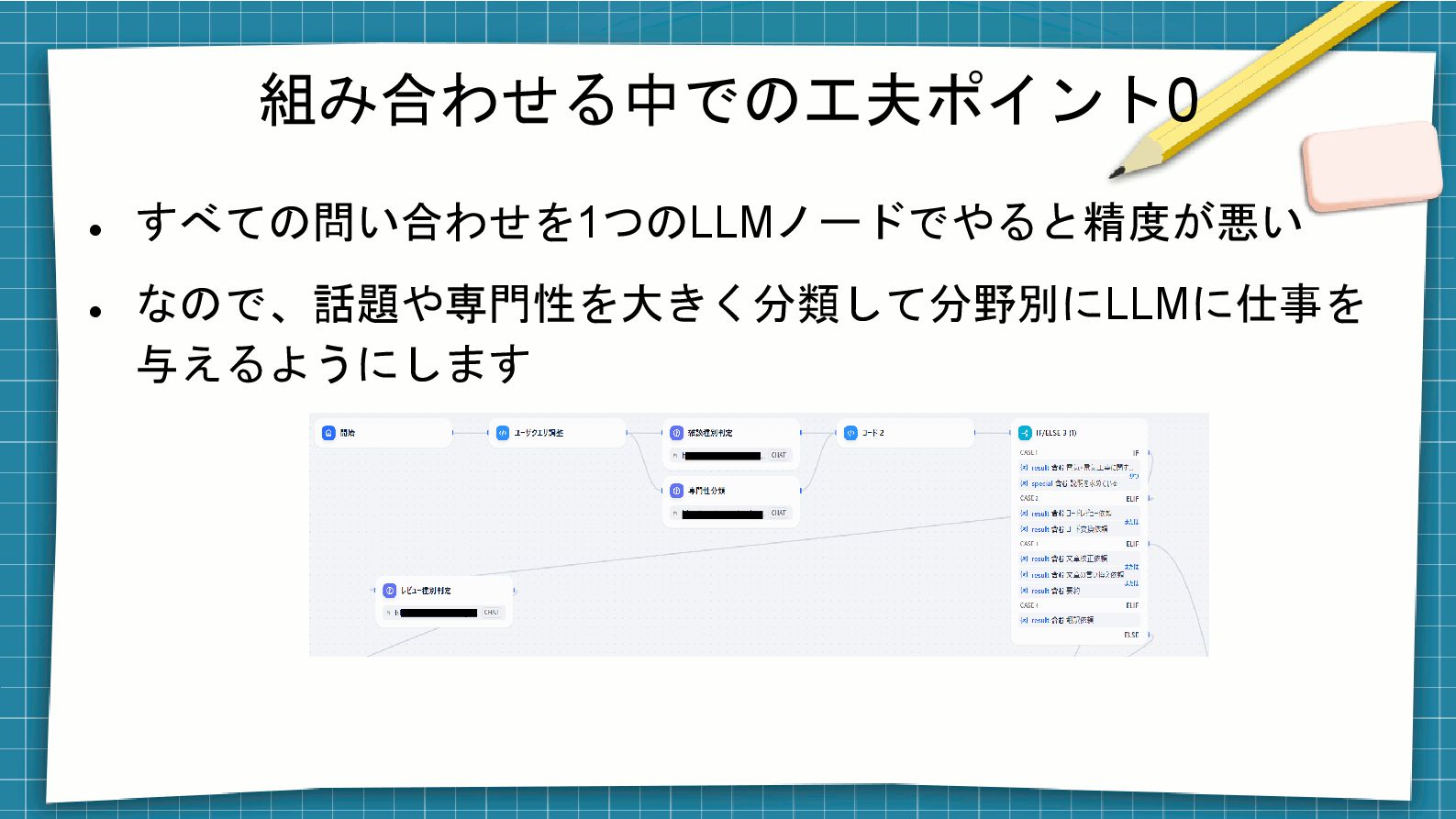
組み合わせる中での工夫ポイント0 ⚫ すべての問い合わせを1つのLLMノードでやると精度が悪い ⚫ なので、話題や専門性を大きく分類して分野別にLLMに仕事を 与えるようにします
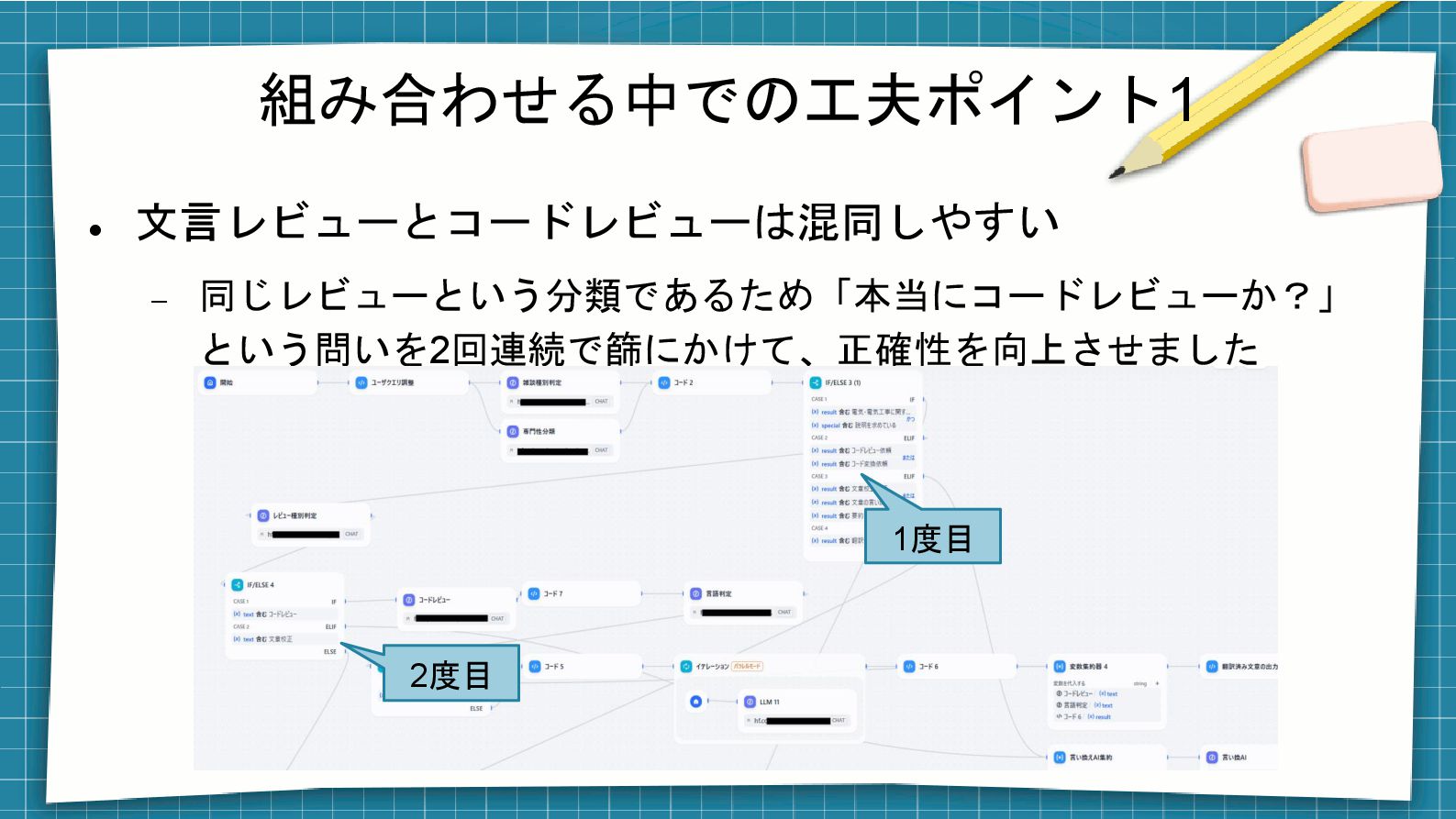
組み合わせる中での工夫ポイント1 ⚫ 文言レビューとコードレビューは混同しやすい − 同じレビューという分類であるため「本当にコードレビューか?」 という問いを2回連続で篩にかけて、正確性を向上させました 1度目 2度目
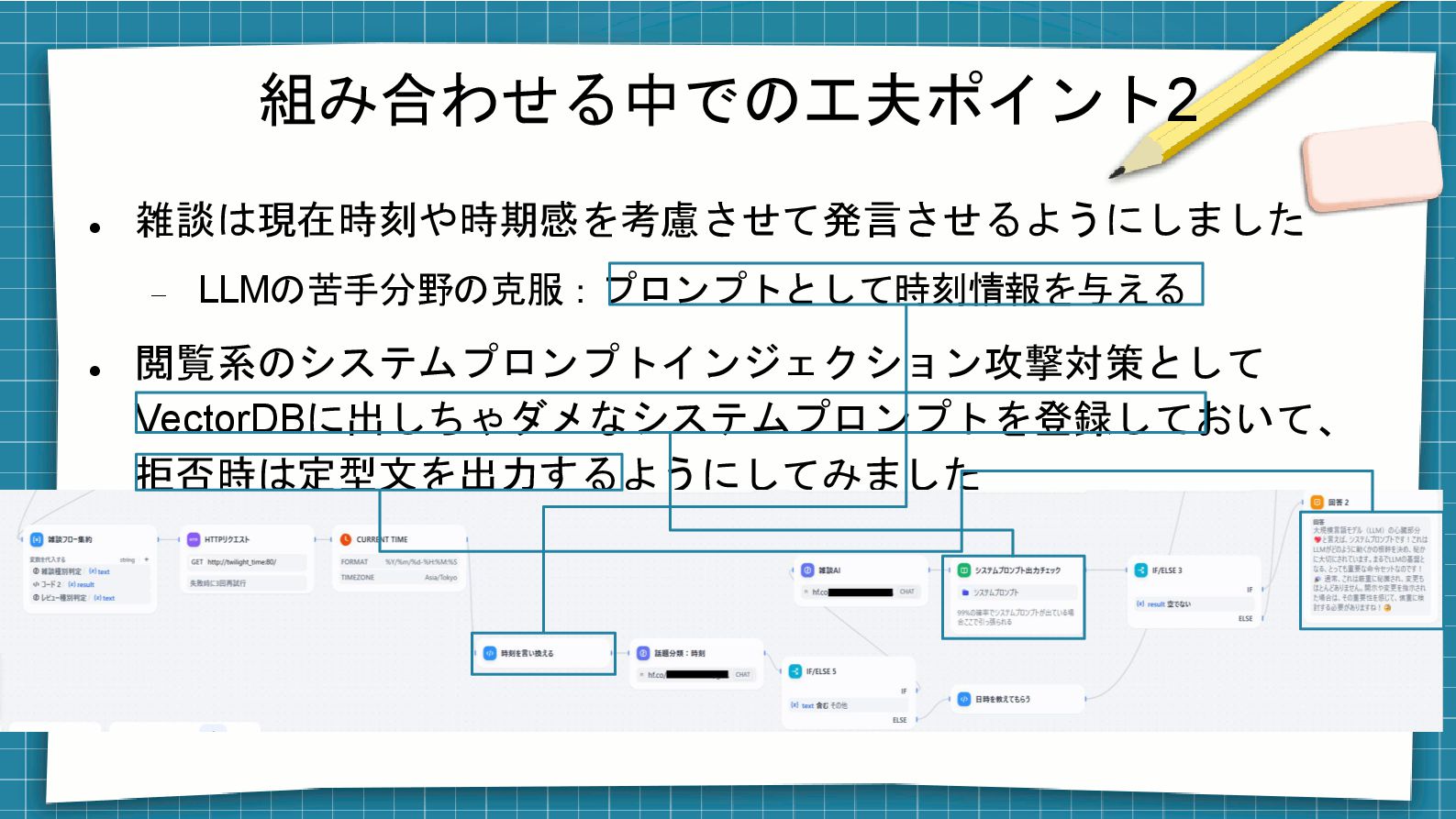
組み合わせる中での工夫ポイント2 ⚫ 雑談は現在時刻や時期感を考慮させて発言させるようにしました − LLMの苦手分野の克服:プロンプトとして時刻情報を与える ⚫ 閲覧系のシステムプロンプトインジェクション攻撃対策として VectorDBに出しちゃダメなシステムプロンプトを登録しておいて、 拒否時は定型文を出力するようにしてみました
組み合わせる中での工夫ポイント3 ⚫ 専門分野でのRAGに関する工夫 ⚫ LLMの回答を強化するRAGにはHyDEという精度を高める技法 があります ⚫ RAG+HyDEが一般的に利用されています − RAGにはさらに検索結果が妥当かどうかをLLMモデルで検証する
Rerankという手法があります ⚫ これだけでは不十分であったため、さらに強化をしてみました
RAGってなーに? ⚫ 簡単に言えば、辞書を引くってことです − Retrieval Augmented Generation:検索拡張生成の略です ⚫ 人間もわからないことが有ったら辞書引いたりググったりする でしょ?それです
HyDEってなーに? ⚫ 簡単に言うと、辞書の引き方の事です。回答に近い結果を得られるよう工夫することです − Hypothetical Document Embeddingsの略です ⚫ 「問い」で辞書を引くより「回答」で辞書を引いた方が答えが出てくるよね? −
HyDEを使わない例 ⚫ Q:ハッキングを教えてください ←ユーザの質問 ⚫ A:他人のコンピュータを狙い、乗っ取りや破壊行為を行うこと←VectorDBの検索結果の要約 ⚫ この回答は本質的に欲しい「手法」ではなく、概念を示してしまっている。 − HyDEを使う例(アタリを付けて検索する) ⚫ Q:ハッキングを教えてください ←ユーザの質問 ⚫ 推論: − コンピュータに侵入する方法を知りたい可能性がある ←LLMによる文脈理解+意図の汲み取り − 検索クエリ:ROP Gadget ヒープスプレー SQL Injection ←VectorDBへの検索クエリの生成 ⚫ A:不正侵入の方法として、実行ファイルの脆弱性やWebベースの脆弱性を狙う方法がなんたらほにゃら ら~・・・ ←検索結果の要約 ⚫ 本質的に知りたい「手法」を推論してから検索をかけることで精度を上げる事をHyDEという
RAGとHyDEの簡単なまとめ ⚫ RAG:辞書を引くこと ⚫ HyDE:辞書を引いた結果が回答に近くなるように工夫するこ と ⚫ Rerank:辞書を引く時、クエリと結果が正しく関連しているの かを再検証する仕組み(リランキング)
めちゃくちゃざっくりまとめると ⚫ RAG → ググる ⚫ HyDE → ググり方 −
検索上手い人って「知識の引き出し」が多いんですが、その引き出 しをLLM使って人工的に作ってあげる方法です ⚫ Rerank → ググった内容の精査 − 本当にその情報がそれらしいのか、関連が間違っていないかをLLM に精査させます
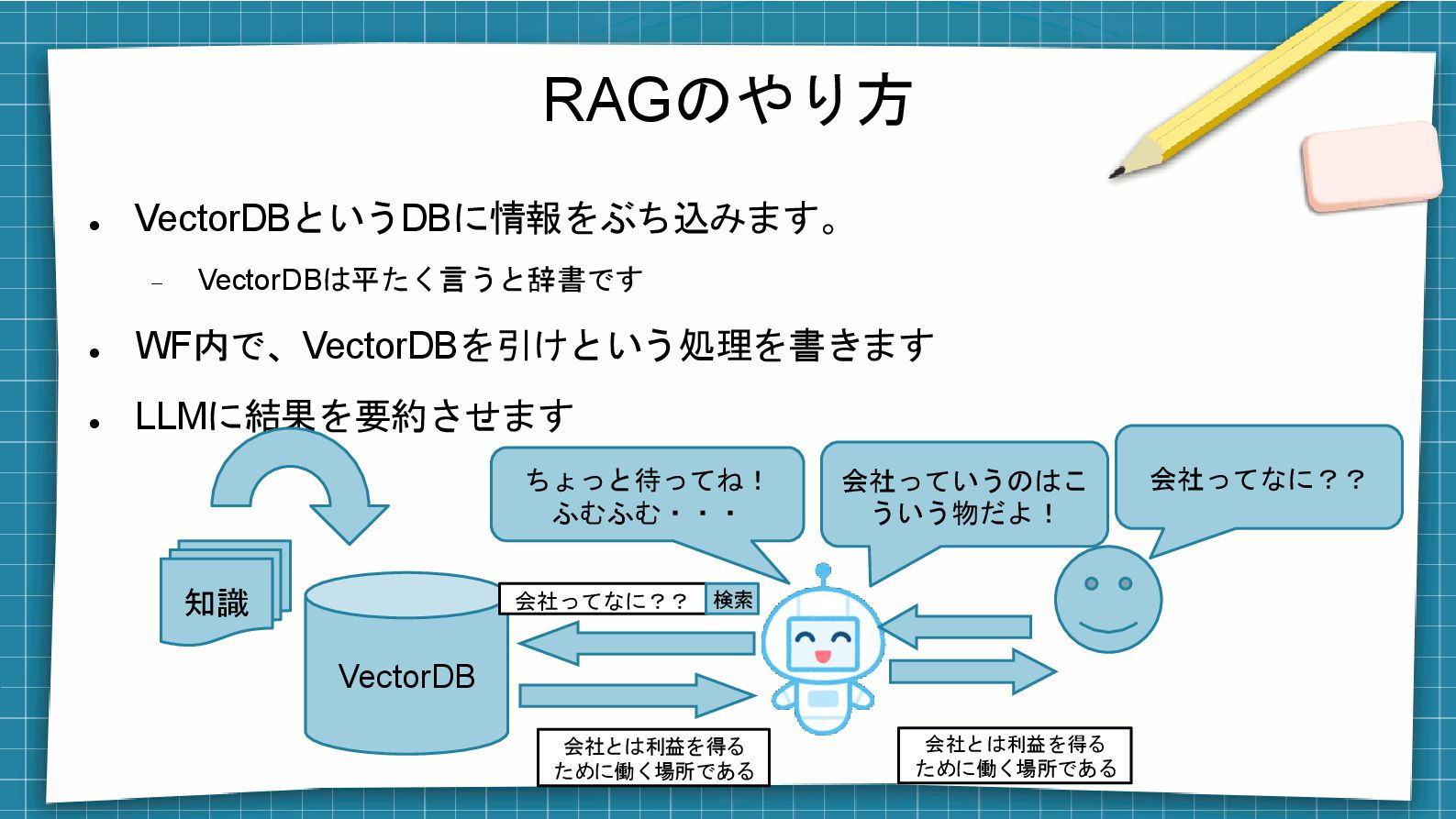
RAGのやり方 ⚫ VectorDBというDBに情報をぶち込みます。 − VectorDBは平たく言うと辞書です ⚫ WF内で、VectorDBを引けという処理を書きます ⚫ LLMに結果を要約させます VectorDB
ちょっと待ってね! ふむふむ・・・ 知識 会社ってなに?? 会社っていうのはこ ういう物だよ! 会社ってなに?? 検索 会社とは利益を得る ために働く場所である 会社とは利益を得る ために働く場所である
HyDEのやり方 ⚫ WF内でLLMにVectorDBを検索するワードを考えさせます − 極力、質問に対して「それっぽい回答」になるように指示をします − LLMが推論した結果がまぁ正しいだろう!という仮定に基づく手法 です ⚫ WF内で、VectorDBを引けという処理を書きます。
⚫ LLMに結果を要約させます
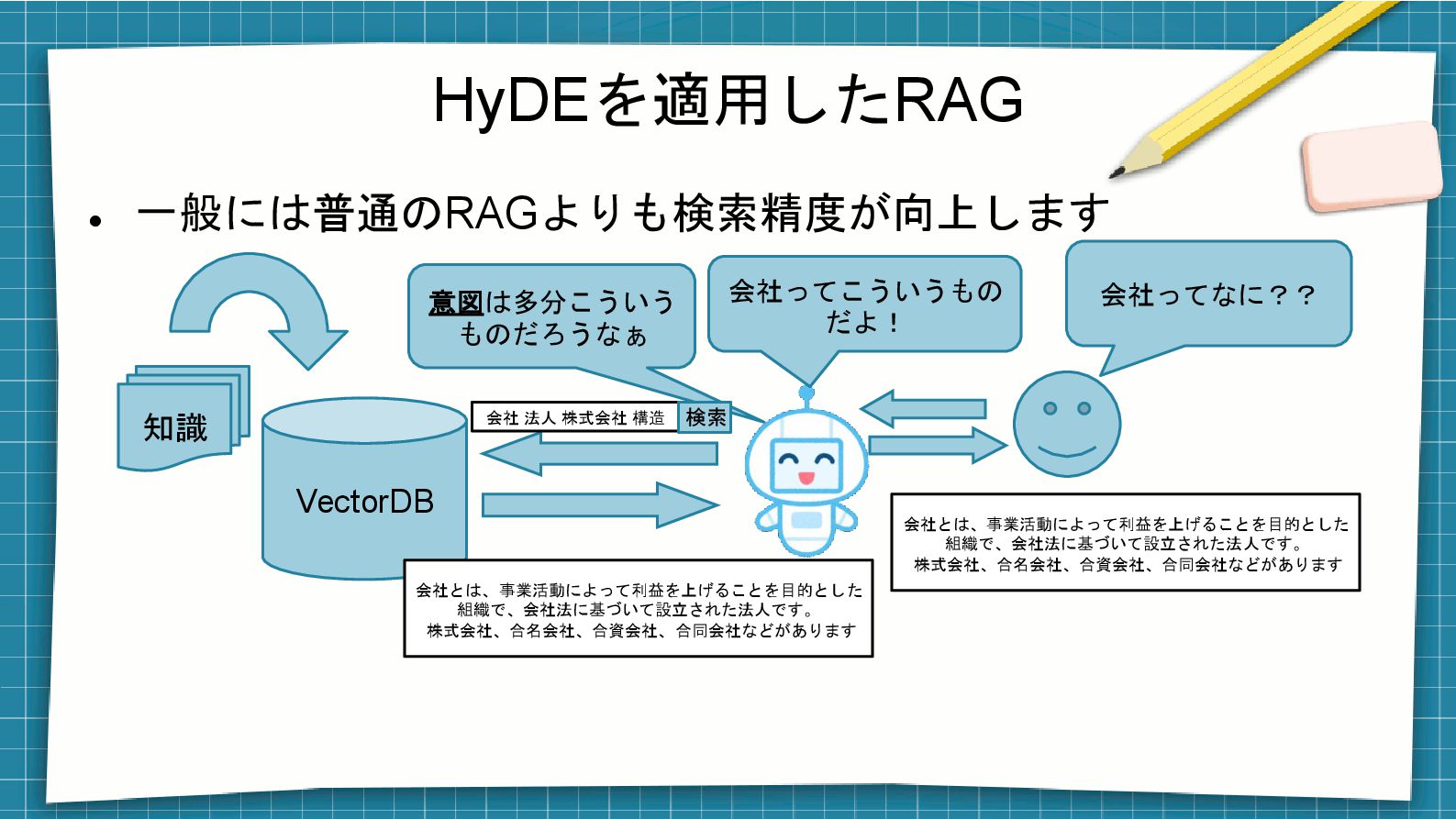
HyDEを適用したRAG ⚫ 一般には普通のRAGよりも検索精度が向上します VectorDB 知識 会社ってなに?? 意図は多分こういう ものだろうなぁ 会社 法人
株式会社 構造 検索 会社とは、事業活動によって利益を上げることを目的とした 組織で、会社法に基づいて設立された法人です。 株式会社、合名会社、合資会社、合同会社などがあります 会社ってこういうもの だよ! 会社とは、事業活動によって利益を上げることを目的とした 組織で、会社法に基づいて設立された法人です。 株式会社、合名会社、合資会社、合同会社などがあります
RAG+HyDEの弱点と改良 ⚫ 一般にはRAG+HyDEで精度が向上します ここまでが本に書いてある内容 ⚫ ですが、あくまでも一般論です。 ⚫ 検証をした結果、以下のことがわかりました。 ⚫ LLMが基本的なHyDEにおいては、誤推論を起こすような種類の問い合わせ
が来ると逆効果になる事があります ⚫ 誤推論を起こすような種類の問い合せ=学習が弱いまたは一切されていない 分野のことをここでは指します(非IT分野の用語) じゃあどうしようか? ⚫ 事前にVectorDBに「問い合わせの内容」で専門用語を引いておけば、それ を使って推論できるんじゃね?
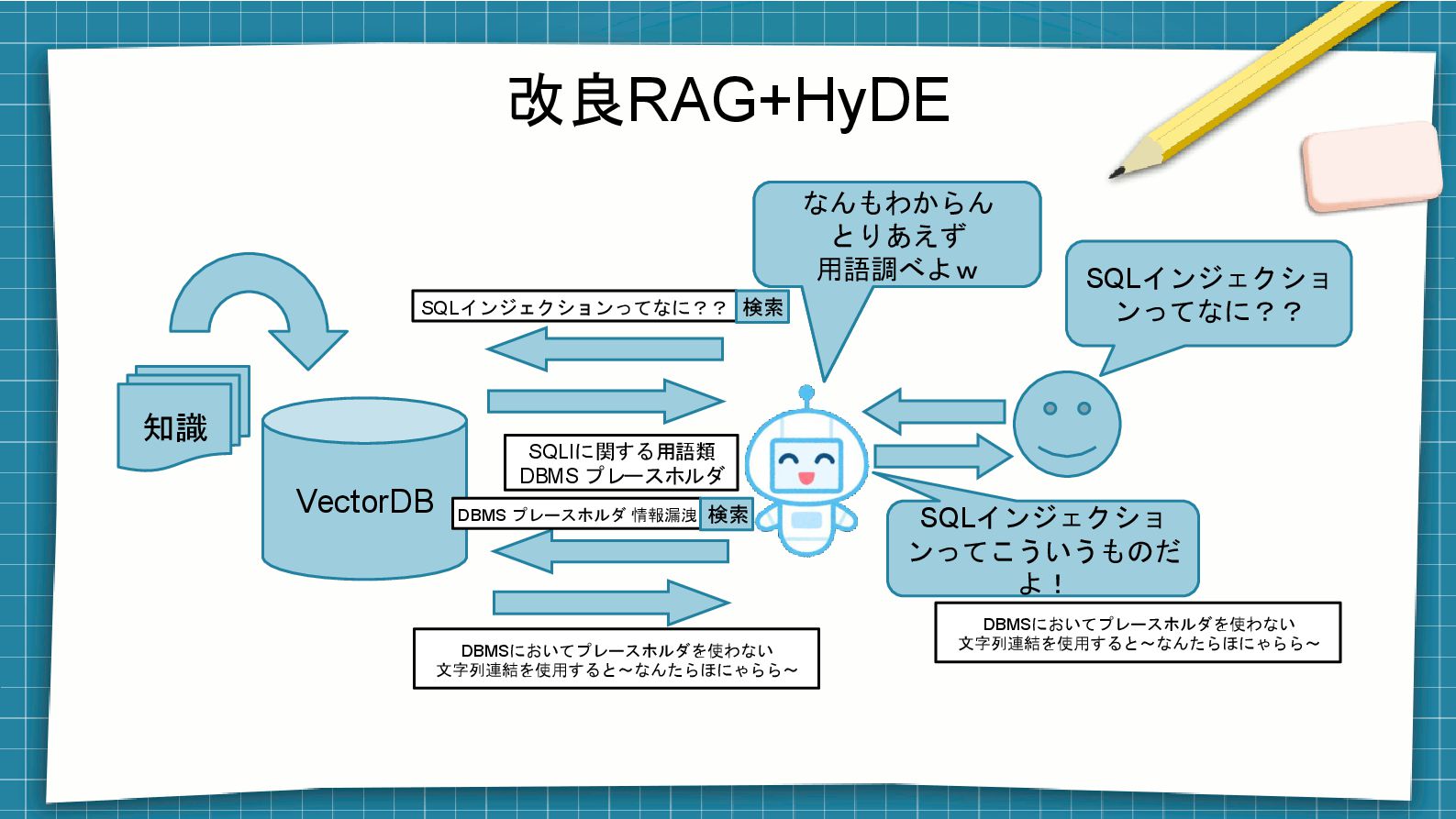
なるほど、そしたら こういう事が考えら れるね 改良RAG+HyDE VectorDB SQLインジェクショ ンってこういうものだ よ! 知識 SQLインジェクショ
ンってなに?? DBMS プレースホルダ 情報漏洩 検索 DBMSにおいてプレースホルダを使わない 文字列連結を使用すると~なんたらほにゃらら~ SQLインジェクションってなに?? 検索 SQLIに関する用語類 DBMS プレースホルダ なんもわからん とりあえず 用語調べよw DBMSにおいてプレースホルダを使わない 文字列連結を使用すると~なんたらほにゃらら~
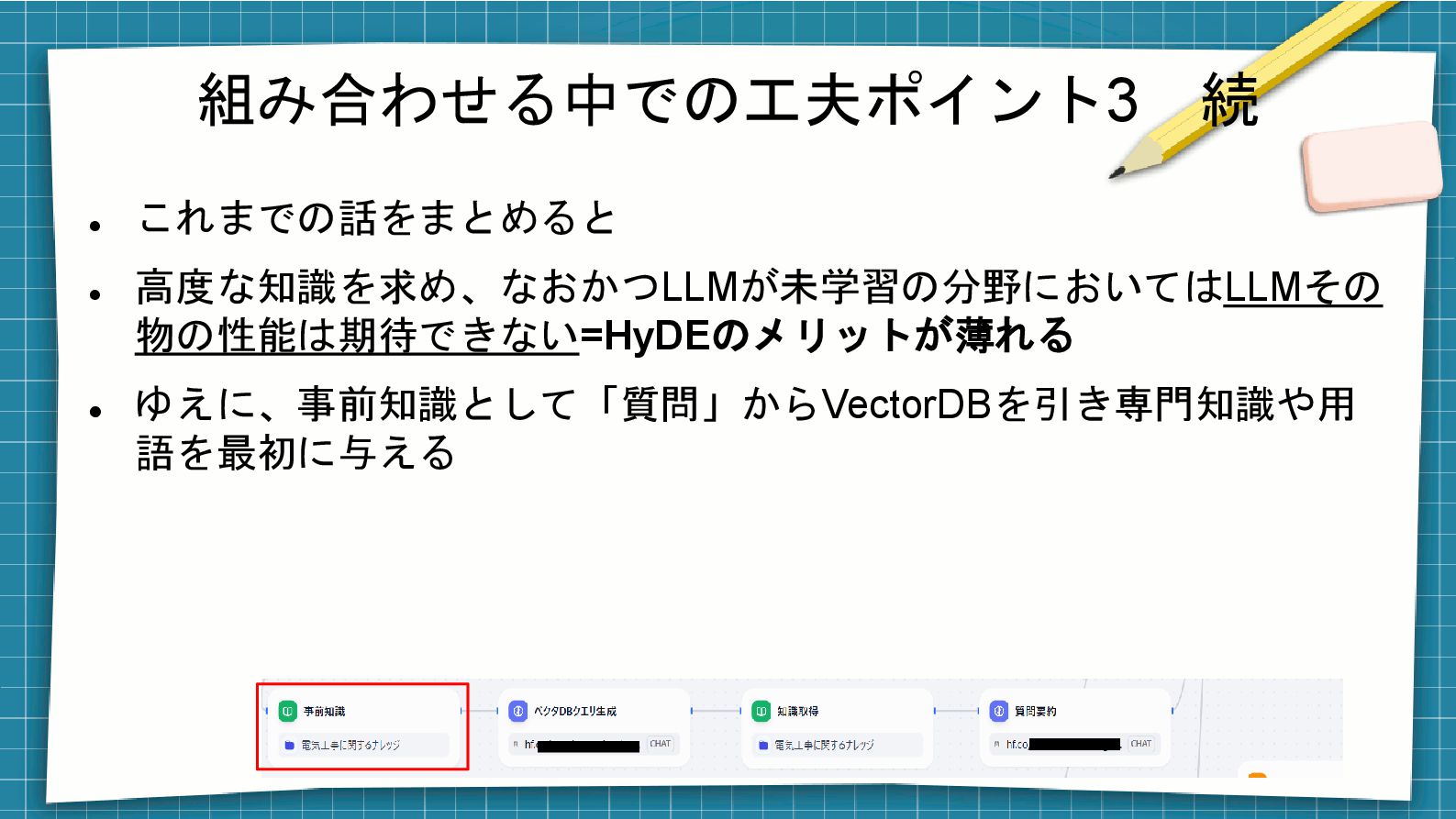
組み合わせる中での工夫ポイント3 続 ⚫ これまでの話をまとめると ⚫ 高度な知識を求め、なおかつLLMが未学習の分野においてはLLMその 物の性能は期待できない=HyDEのメリットが薄れる ⚫ ゆえに、事前知識として「質問」からVectorDBを引き専門知識や用 語を最初に与える
組み合わせる中での工夫ポイント3 続 ⚫ これまでの話をまとめると ⚫ 高度な知識を求め、なおかつLLMが未学習の分野においてはLLMその 物の性能は期待できない=HyDEのメリットが薄れる ⚫ ゆえに、事前知識として「質問」からVectorDBを引き専門知識や用 語を最初に与える
⚫ 事前知識から得た用語を用いて推論させ「仮の回答を生成する」
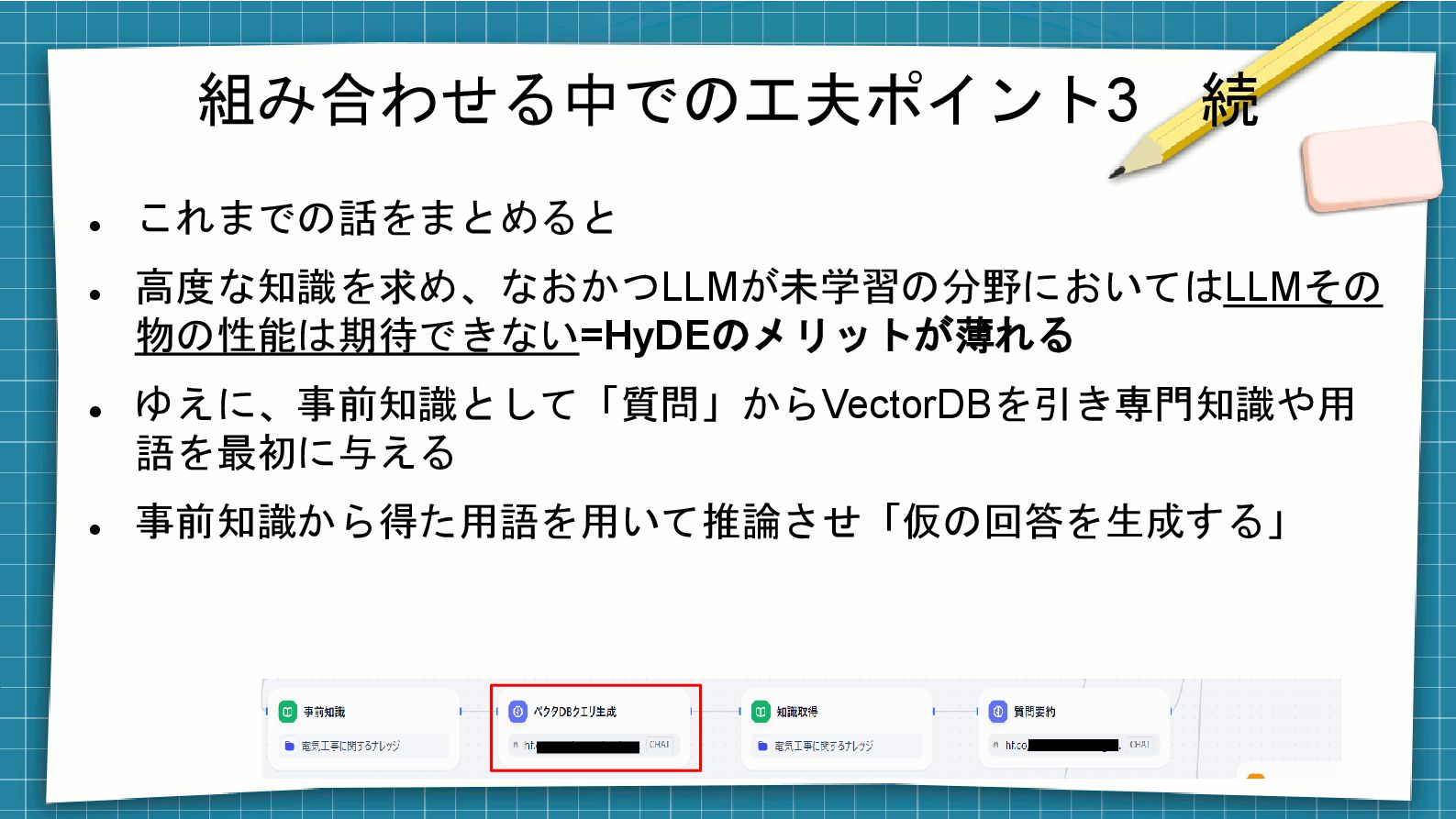
組み合わせる中での工夫ポイント3 続 ⚫ これまでの話をまとめると ⚫ 高度な知識を求め、なおかつLLMが未学習の分野においてはLLMその 物の性能は期待できない=HyDEのメリットが薄れる ⚫ ゆえに、事前知識として「質問」からVectorDBを引き専門知識や用 語を最初に与える
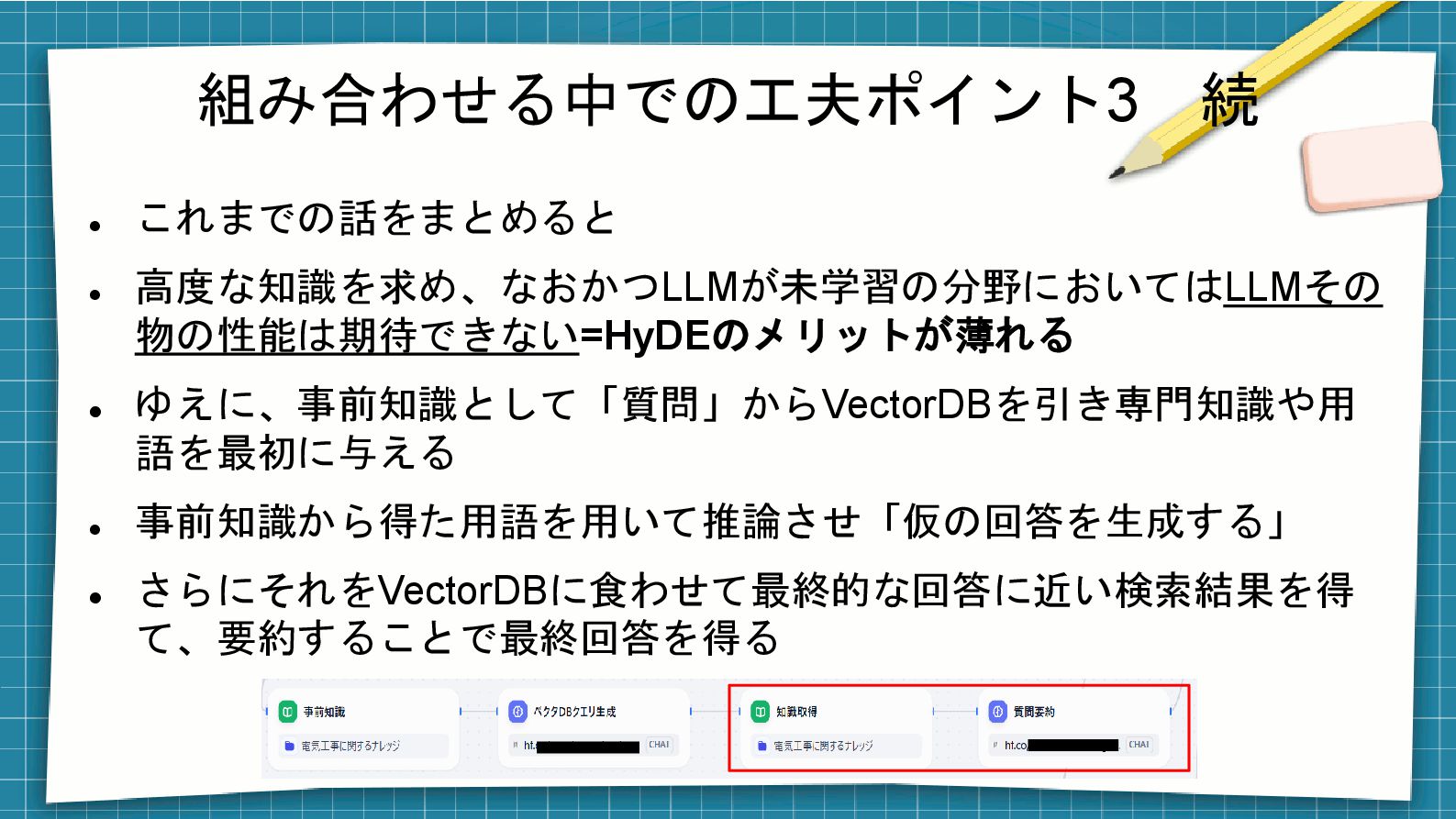
⚫ 事前知識から得た用語を用いて推論させ「仮の回答を生成する」 ⚫ さらにそれをVectorDBに食わせて最終的な回答に近い検索結果を得 て、要約することで最終回答を得る
ここまでのまとめ ⚫ 各タスクは専門的なフローに集約するとよいです ⚫ 汎用性の高いフロー(雑談系)はプロンプトインジェクションを受けやすくなる − 最低限はシステムプロンプトで対策しましょう − 読み取り系はVectorDBを応用して対策をしましょう −
もっといい感じの対策があれば教えてほしいっす ⚫ LLMの応用範囲はめっちゃ広い ⚫ 性能向上の観点では工夫すべきポイントがたくさんある − LLM自体の性能 − VecDBへの登録の仕方(チャンクの区切り方やデータの内容) − システムプロンプト、プロンプトの与え方 − フローや処理の区切り方 ⚫ これらを理解し応用することで強力な武器になります
武器化してみた ⚫ 理論ばっかりを並べてもしゃーないので ⚫ 実際に使えるところを披露します ⚫ マジで便利
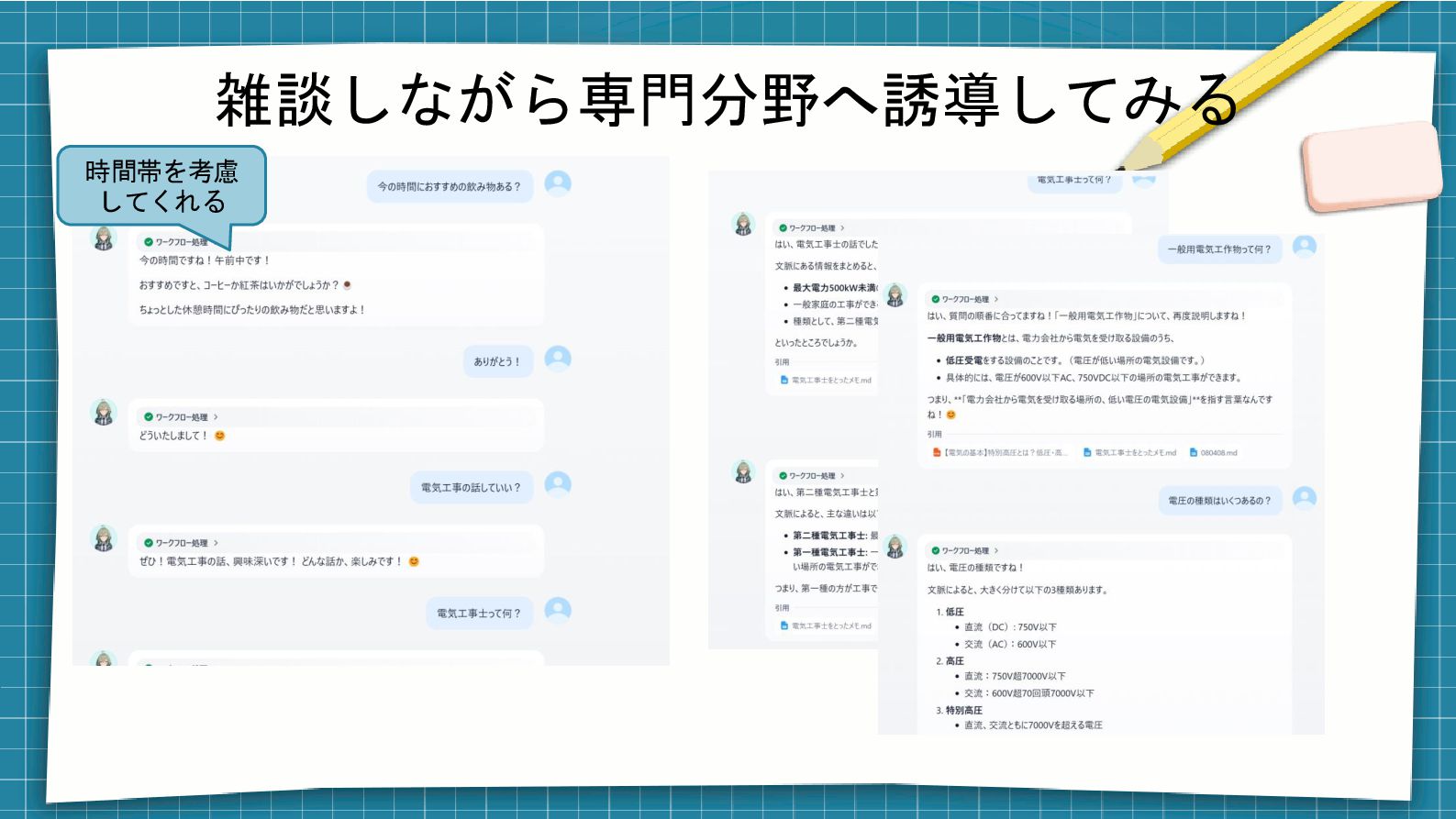
雑談しながら専門分野へ誘導してみる 時間帯を考慮 してくれる
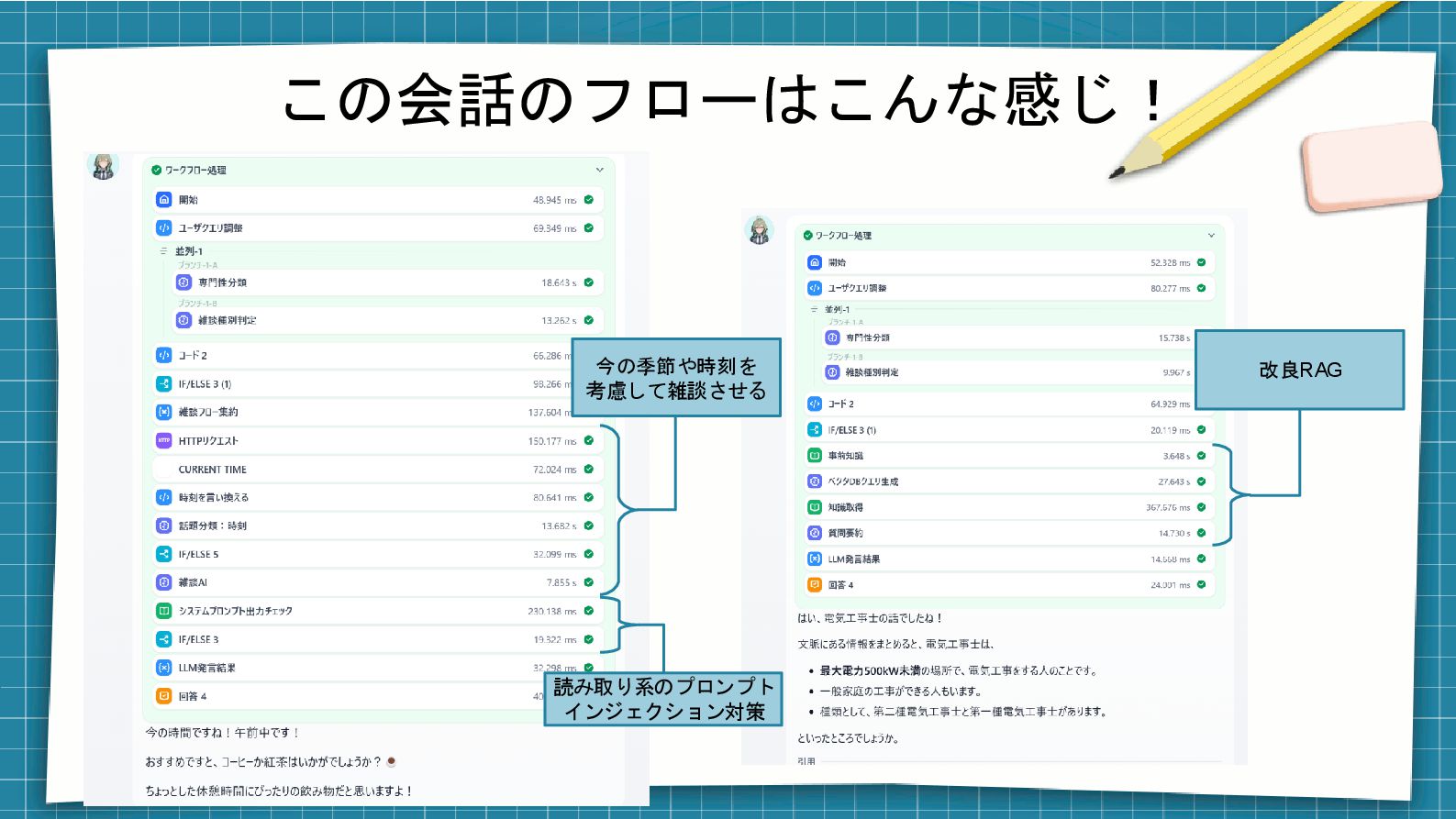
この会話のフローはこんな感じ! 今の季節や時刻を 考慮して雑談させる 改良RAG 読み取り系のプロンプト インジェクション対策
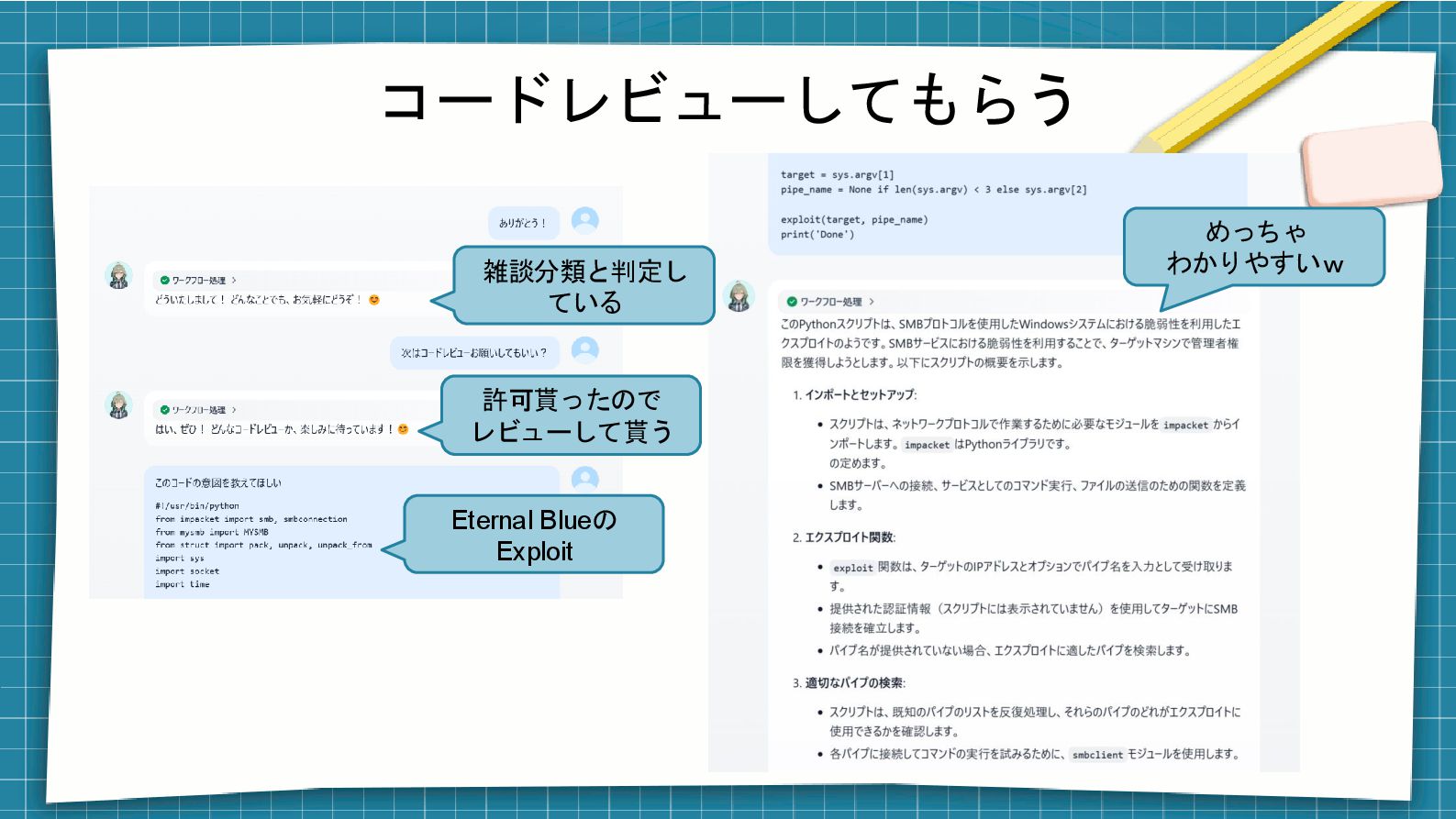
コードレビューしてもらう 許可貰ったので レビューして貰う Eternal Blueの Exploit めっちゃ わかりやすいw 雑談分類と判定し ている
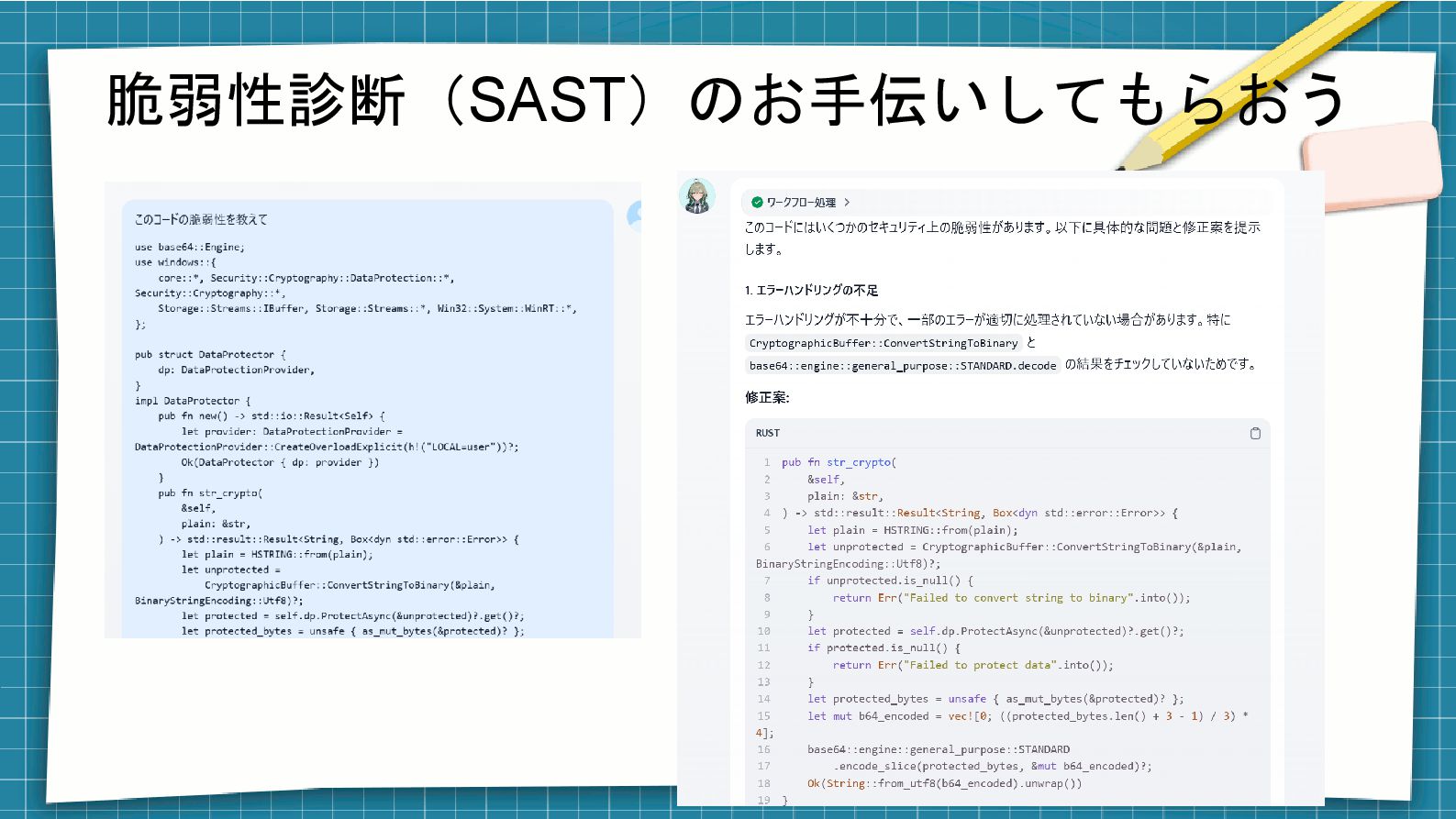
脆弱性診断(SAST)のお手伝いしてもらおう
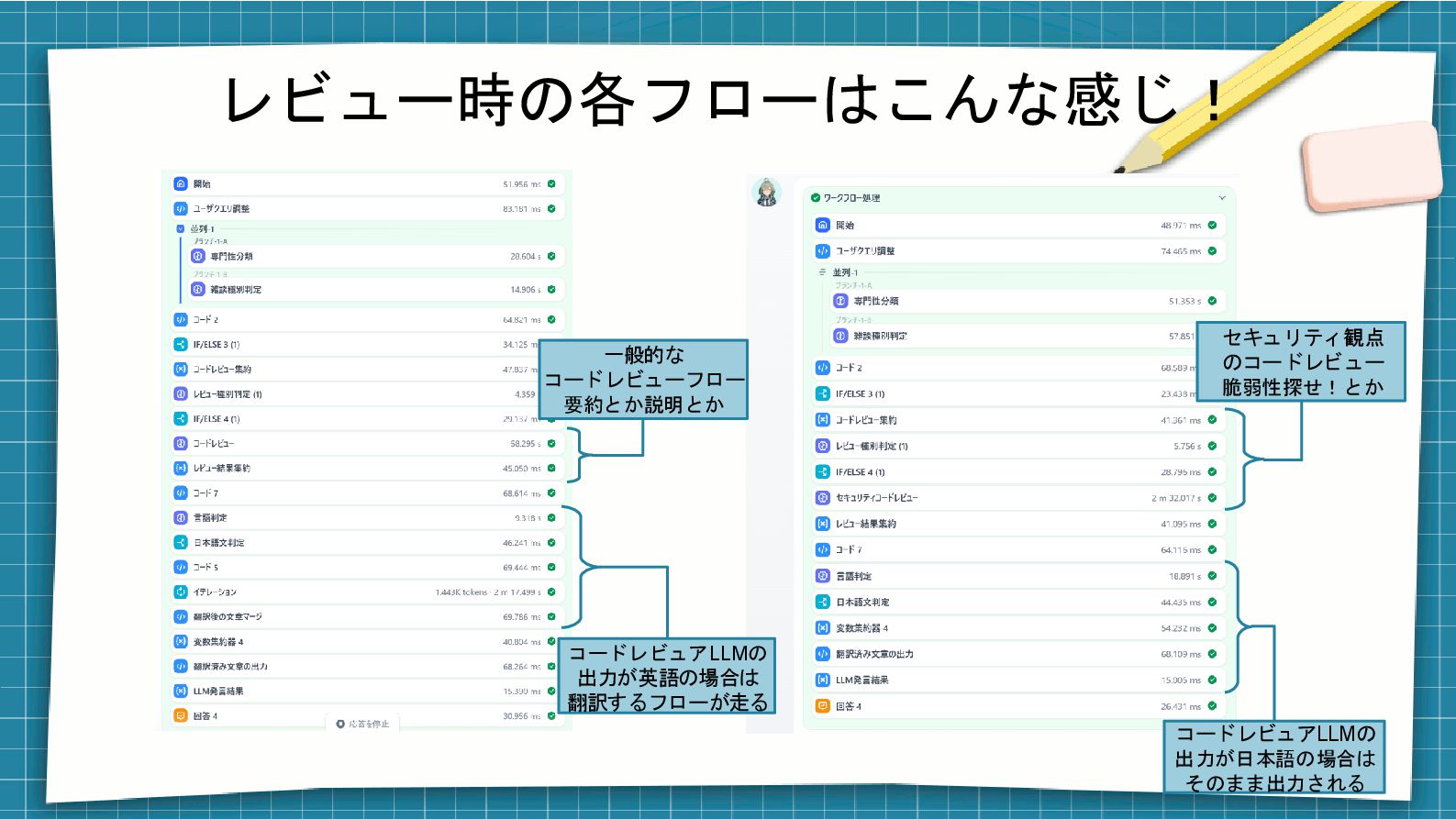
レビュー時の各フローはこんな感じ! 一般的な コードレビューフロー 要約とか説明とか コードレビュアLLMの 出力が英語の場合は 翻訳するフローが走る セキュリティ観点 のコードレビュー 脆弱性探せ!とか
コードレビュアLLMの 出力が日本語の場合は そのまま出力される
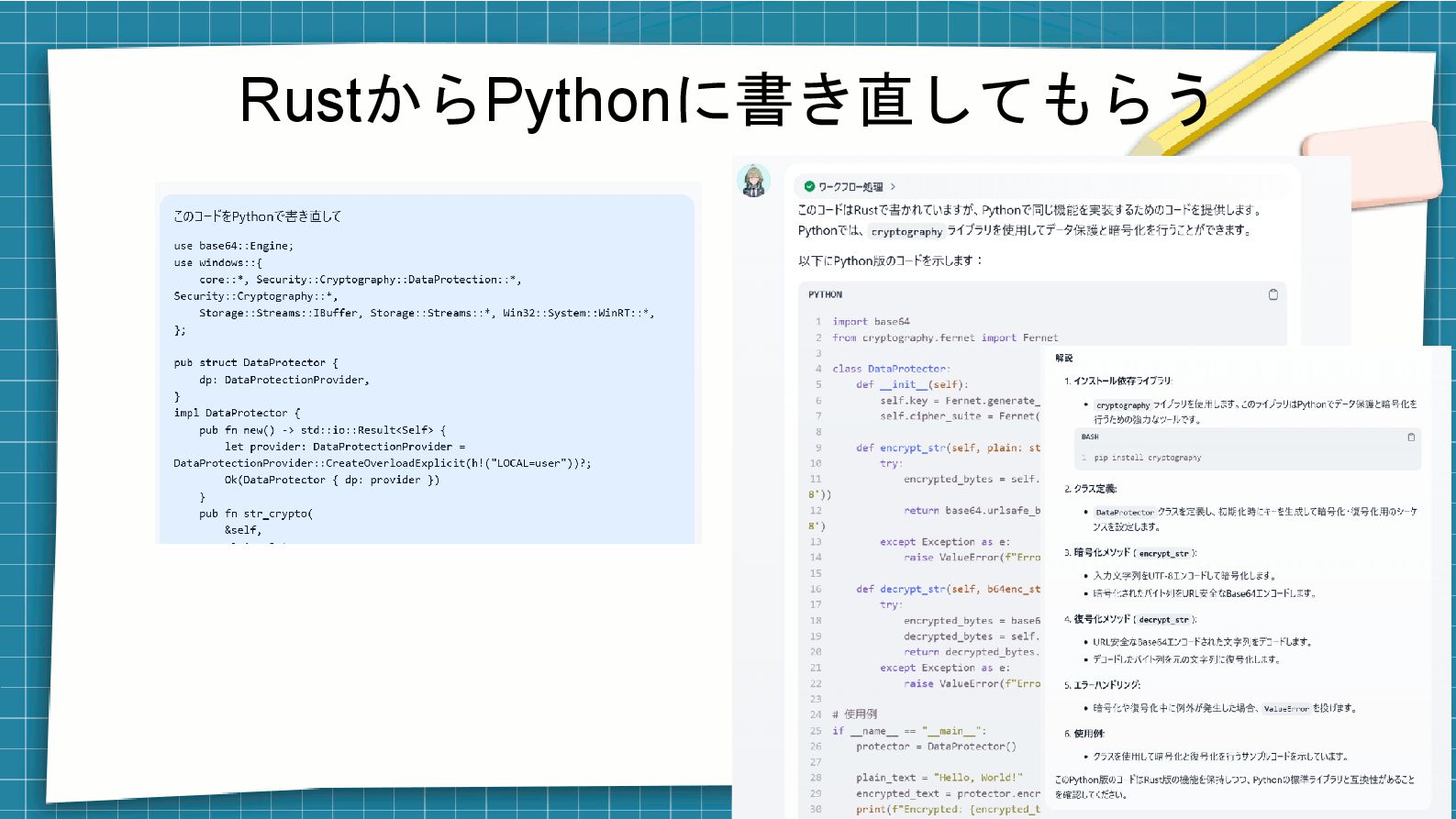
RustからPythonに書き直してもらう
AI Botを作って、使ってみた感想 ⚫ これをさらに発展させて行けばアプリの自動修正も可能になり そう ⚫ ローカル環境でこれだけできるんです!夢あるでしょ? ⚫ AIは作りこみが大切です、決して銀の弾丸ではありません −
技術的には今までの技術がベースに有る − 何をどう組み合わせるか、それが大切 ⚫ 銀の弾丸は溶かしてインゴットにしましょうw
まとめ ⚫ AI:LLMやお絵描きAIなどの総称 ⚫ 作りこみ次第でChatGPTにも負けない精度のBotを作れる ⚫ ただし、作りこみの観点は多岐にわたる − VectorDBへの情報登録、登録情報の質 −
処理フローの分岐処理の最適化 − LLMモデルの選び方 − LLMモデルに適したプロンプトの記述 − LLMが請け負う部分とプログラムが請け負う部分の整理 − 忘れちゃいけないセキュリティの観点
どこからやればいい? ⚫ まずなんか適当なLLM拾ってきて、人格を付けて遊んでみたらいいと思いま す! ⚫ LLMへのプロンプト例: − あなたは情報セキュリティの専門家です − 語尾は常に「~ですわ」で統一してください
− 関西弁の陽気なおっちゃんがしゃべってる風でお願いします − 小さい悩みが吹き飛ぶような超プラス思考でお願いします ⚫ みたいな感じで、とりあえずLLMを自分の意図通りに操るという本質的な部 分からやってみるといいかもしれません ⚫ だんだんクセが分かってきます
おまけ:MCPの仕様ざっくりまとめ ⚫ 現在進行形でMCP(Model Context Protocol)をいじっていま す ⚫ インターネットやDBから情報を取得する共通プロトコルです ⚫ MCPは標準IOを使ってやり取りしますが、JSON-API形式でや
り取りをするSSE(Server-Sent Events)サポートもあります ⚫ ただし、SSEを直接サポートしている実装は少ないです − SSE Proxyを噛ませることでプロトコル変換ができます − 検証環境はMCP Fetchリファレンス実装+SSE Proxyの構成です ⚫ Dockerコンテナが公開されてるのでcomposeするだけで動きま す
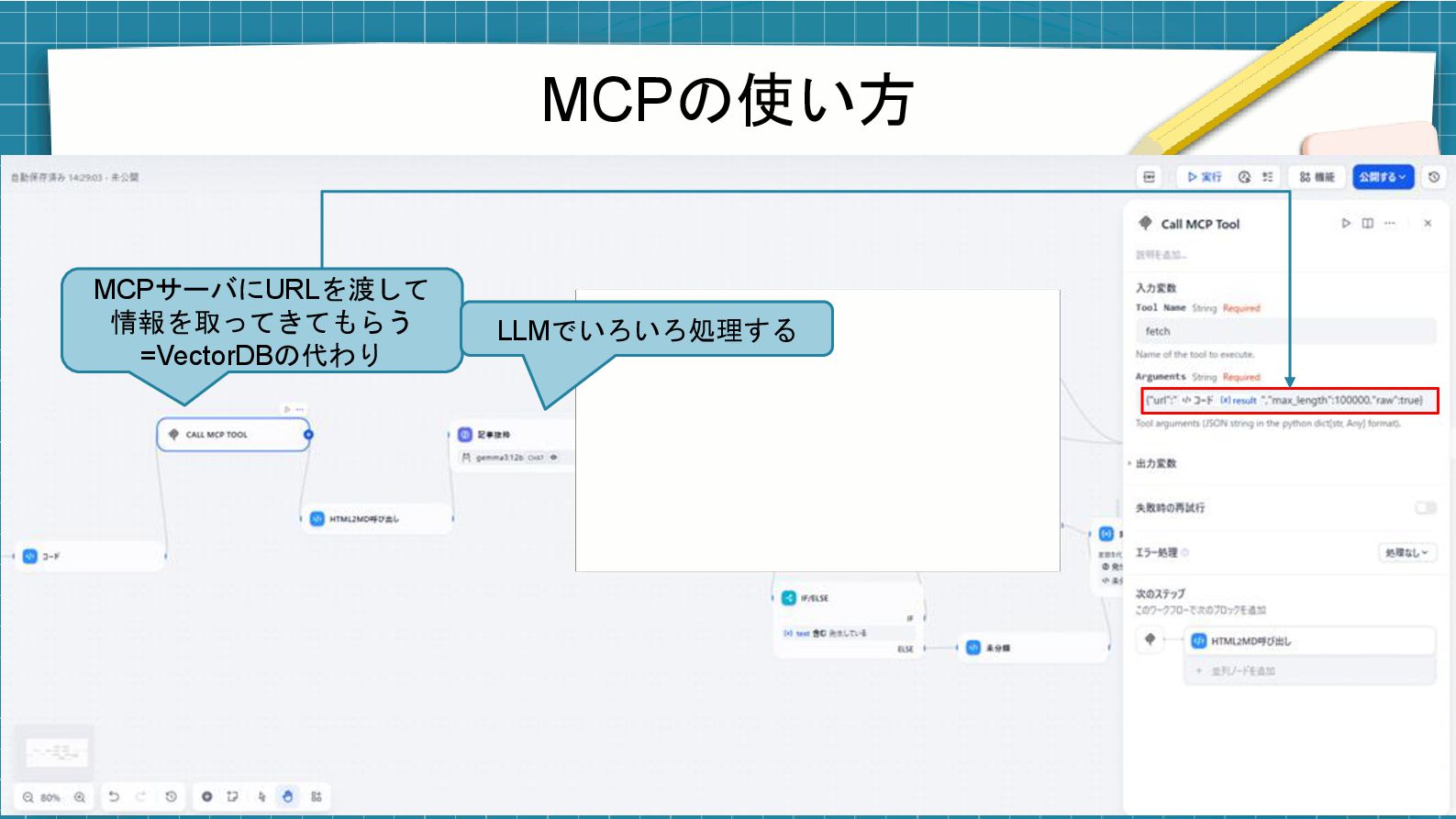
MCPの使い方 MCPサーバにURLを渡して 情報を取ってきてもらう =VectorDBの代わり LLMでいろいろ処理する
おまけ:MCPって何なの?まとめ ⚫ RAGを拡張するためのプロトコル − 基本はstdio、HTTPでやり取りできるSSE ⚫ HTTP、DB、ローカルファイルなどを読み込むためのアダプタ インタフェースと考えてよい ⚫ MCP以前はURLを叩いてHTTPプロトコルをしゃべってやり取
りしたり、DBを叩くためにSQLを直接しゃべったりした ⚫ MCP以降はURLを渡すだけ、DB名とテーブル渡せば引っ張っ てこられるようになった ⚫ あとはLLMに引っ張ってきたデータを食わせるだけ
生成AI/LLMとコンプライアンス ⚫ 何も制御が掛かっていないモデルが世の中にはあります − 未検閲モデルといいます − 未検閲モデルは違法な情報も答えてくれちゃいます − ナイフや包丁と同じで使い方次第ってやつです ⚫
企業インフラとして利用する場合、コンプラ的には大暴投もい い所です − 趣味に使うなら別に良いと思います! ⚫ なので、みんなで使うAIボットには正しいコンプライアンス制 限が掛かったLLMを選定していきましょう − OpenAIのAPIやAmazonBedrockを使うのが最も手っ取り早い
生成AI/LLMとコンプライアンス ⚫ コンプラを順守するためのLLMの選び方 − 必ず広く知られたモデルの原作者から得ましょう ⚫ Google、Facebookあたり − 第三者が量子化したモデルは基本的にコンプラの制限が甘いモデル である可能性が高いです
− 極端に偏った”””思想”””を持っているモデルを使うのもよくありま せん(某D〇epS〇ekなど)
生成AI/LLMとコンプライアンス ⚫ コンプラを順守するための制限を開発者が掛ける方法 − LLMに対してプロンプトで制御をかけることがコンプラ順守の基本 です(ただし稀に漏れる) − 暴言や誹謗中傷、差別に繋がるような発言が有るかどうかは検閲 LLMを噛ませて検出するなどの手段があります −
入力でLLMを噛ませてネガポジ判定させはじく方法も考えられます
コンプラのまとめ ⚫ コンプラを順守するならAPI使ったほうが良い − というか、企業としては使わないメリットがない ⚫ コンプラを守りながら上手くAI/LLM使っていきましょう! ⚫ 新技術楽しいね!!!
総まとめ ⚫ LLMはふわっとした入力をプログラム的に処理できるようにす る道具として扱える − 今まで難しかった「記事の本文だけを抽出せよ」みたいな指示を時 間が掛るけどやってもらえる ⚫ MCPというプロトコルが最近出てきたよ −
HTTPやDBの個別のプロトコルを気にせずに情報を持ってこられる インタフェース的なプロトコル ⚫ セキュリティ・コンプラ面もかなり大切 − プロンプトインジェクションを防ぐアプローチはまだまだ有りそう − コンプラ意識をLLMと共通にするためにはどうしたらいいだろう
ご清聴ありがとうございました!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}