machine • Assign a host name and static IP address to each machine • Names used here – hc1nn ( hadoop cluster 1 name node ) – hc1r1m1 ( hadoop cluster 1 rack 1 machine 1 ) – hc1r1m2 ( hadoop cluster 1 rack 1 machine 2 ) • Install ssh daemon on each server • Install vsftpd ( ftp ) deamon on each server • Update /etc/host with all hostnames on each server www.semtech-solutions.co.nz [email protected]
under hadoop user • Copy keys to all server's hadoop account • Install java 1.6 ( we used openjdk ) • Obtain the Hadoop software from – hadoop.apache.org – Unpack Hadoop software to /usr/local • Now consider cluster architecture www.semtech-solutions.co.nz [email protected]
node (hc1nn) to both data nodes – From each machine to itself • Create symbolic link – Named hadoop – Pointing to /usr/local/hadoop-1.2.0 • Set up Bash .bashrc on each machine hadoop user set – HADOOP_HOME – JAVA_HOME www.semtech-solutions.co.nz [email protected]
temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property> www.semtech-solutions.co.nz [email protected]
all servers ) <property> <name>mapred.job.tracker</name> <value>localhost:54311</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. </description> </property> www.semtech-solutions.co.nz [email protected]
all servers ) <property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property> www.semtech-solutions.co.nz [email protected]
on all servers ) – hadoop namenode -format – Dont do this on a running HDFS you will lose all data !! • Now start Hadoop ( on all servers ) – $HADOOP_HOME/bin/start-all.sh • Check Hadoop is running with – sudo netstat -plten | grep java – you should see ports like 54310 and 54311 being used. • All Good ? Stop Hadoop on all servers – $HADOOP_HOME/bin/stop-all.sh www.semtech-solutions.co.nz [email protected]
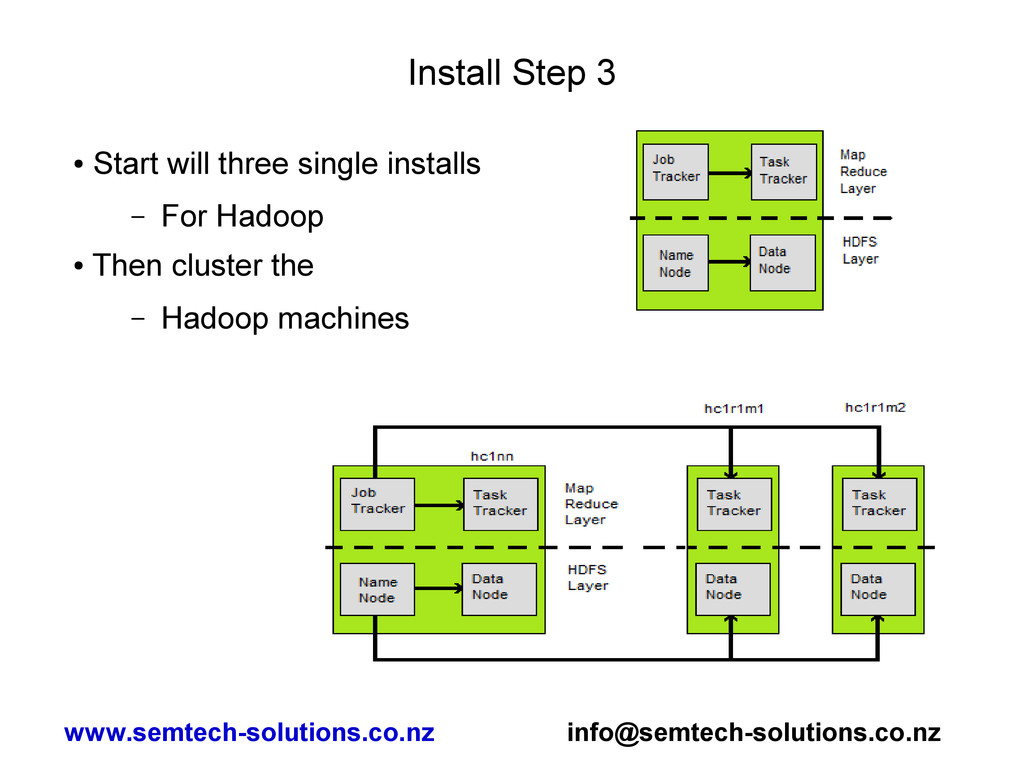
do on all servers • Set $HADOOP_HOME/conf/masters file to contain – hc1nn • Set $HADOOP_HOME/conf/slaves file to contain – hc1r1m1 – hc1r1m2 – hc1nn • We will be using the name node as a data node as well www.semtech-solutions.co.nz [email protected]
29% 13/07/30 19:35:18 INFO mapred.JobClient: map 100% reduce 29% 13/07/30 19:35:23 INFO mapred.JobClient: map 100% reduce 33% 13/07/30 19:35:27 INFO mapred.JobClient: map 100% reduce 100% 13/07/30 19:35:28 INFO mapred.JobClient: Job complete: job_201307301931_0001 13/07/30 19:35:28 INFO mapred.JobClient: Counters: 29 13/07/30 19:35:28 INFO mapred.JobClient: Job Counters 13/07/30 19:35:28 INFO mapred.JobClient: Launched reduce tasks=1 13/07/30 19:35:28 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=119572 13/07/30 19:35:28 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 13/07/30 19:35:28 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 13/07/30 19:35:28 INFO mapred.JobClient: Launched map tasks=18 13/07/30 19:35:28 INFO mapred.JobClient: Data-local map tasks=18 13/07/30 19:35:28 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=61226 13/07/30 19:35:28 INFO mapred.JobClient: File Output Format Counters 13/07/30 19:35:28 INFO mapred.JobClient: Bytes Written=725257 13/07/30 19:35:28 INFO mapred.JobClient: FileSystemCounters 13/07/30 19:35:28 INFO mapred.JobClient: FILE_BYTES_READ=6977160 13/07/30 19:35:28 INFO mapred.JobClient: HDFS_BYTES_READ=17600721 13/07/30 19:35:28 INFO mapred.JobClient: FILE_BYTES_WRITTEN=14994585 13/07/30 19:35:28 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=725257 13/07/30 19:35:28 INFO mapred.JobClient: File Input Format Counters 13/07/30 19:35:28 INFO mapred.JobClient: Bytes Read=17598630 13/07/30 19:35:28 INFO mapred.JobClient: Map-Reduce Framework www.semtech-solutions.co.nz [email protected]
A working HDFS cluster – With three data nodes – One name node – Tested via a Map Reduce job • Detailed install instructions available from our site shop www.semtech-solutions.co.nz [email protected]
www.semtech-solutions.co.nz – [email protected] • We offer IT project consultancy • We are happy to hear about your problems • You can just pay for those hours that you need • To solve your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}