Share
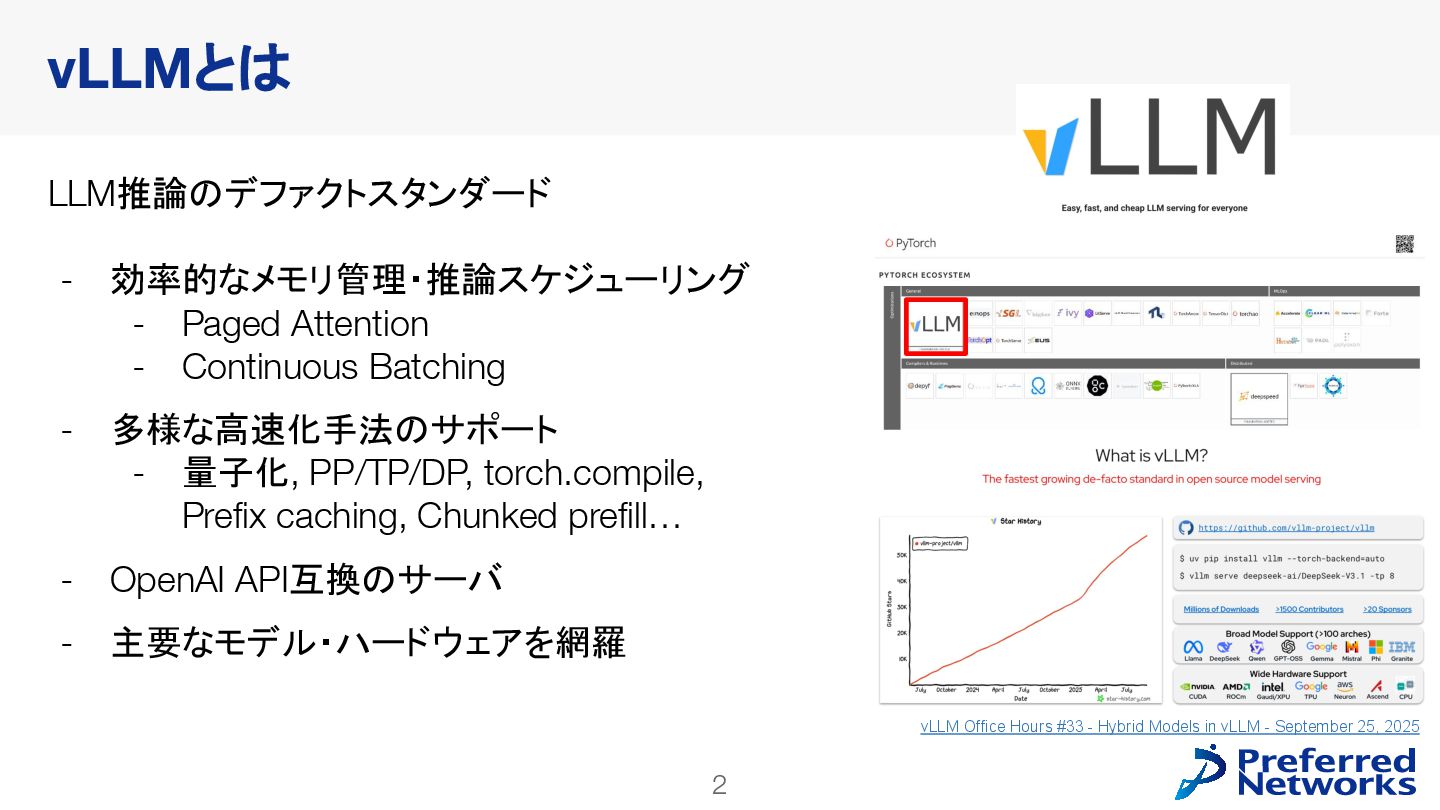
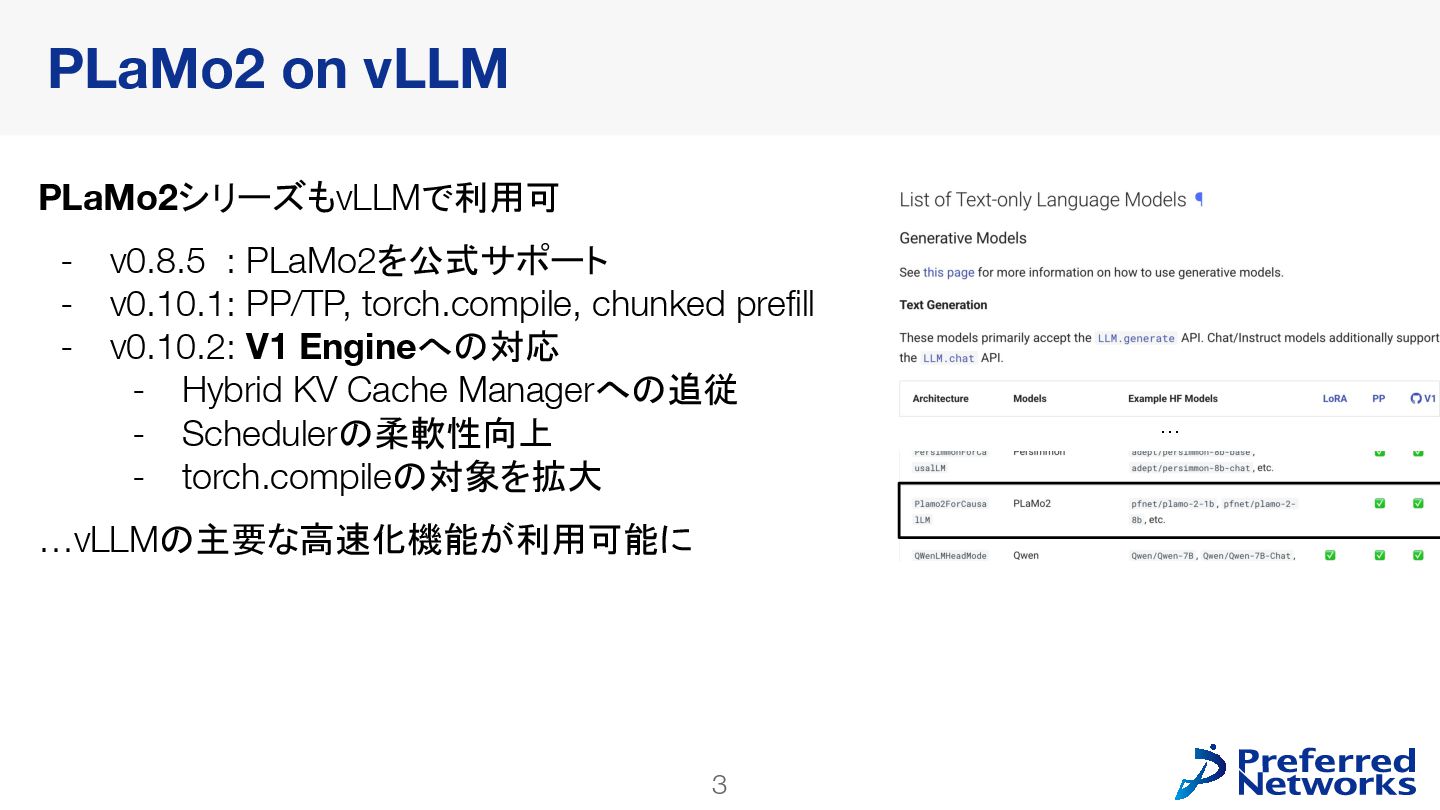
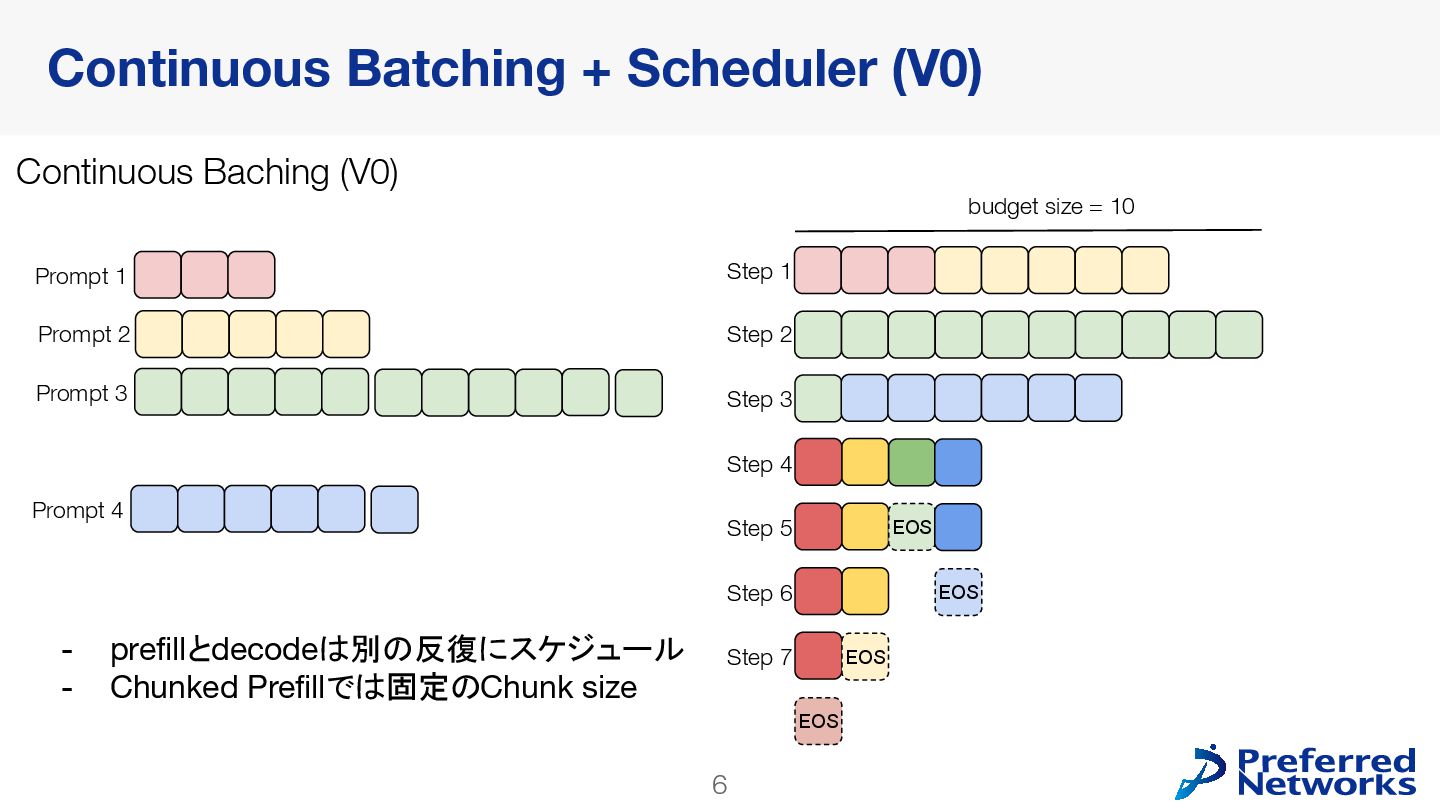
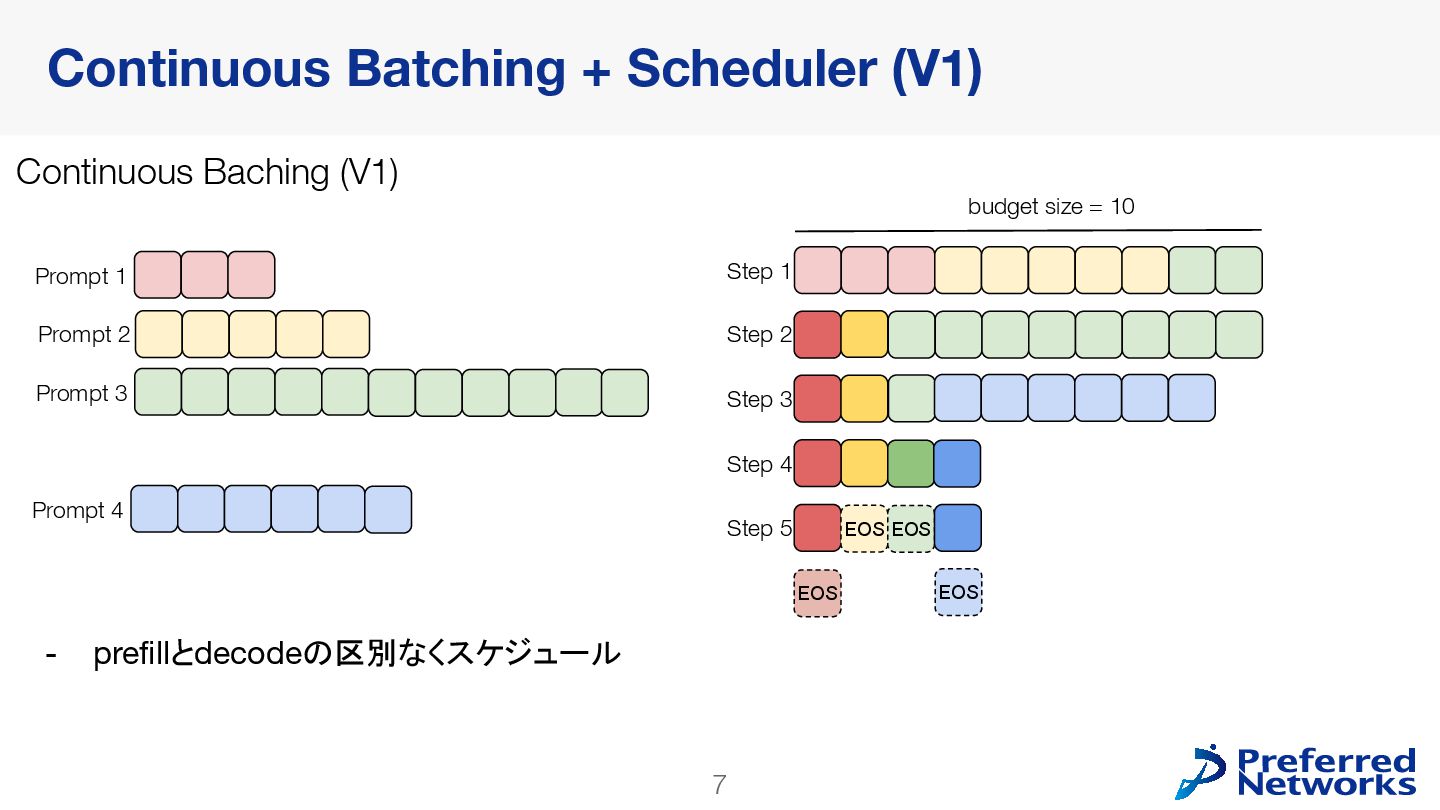
PLaMo2シリーズは、LLM推論のためのOSSとして現在広く使われているvLLMで、公式にサポートされています。本発表では直近の大きなアップデートとなっているV1 Engineへの追従を中心に、vLLMの概要からPLaMo2シリーズ実装の詳細までをご紹介します。
イベントサイト: https://preferred-networks.connpass.com/event/368829/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}