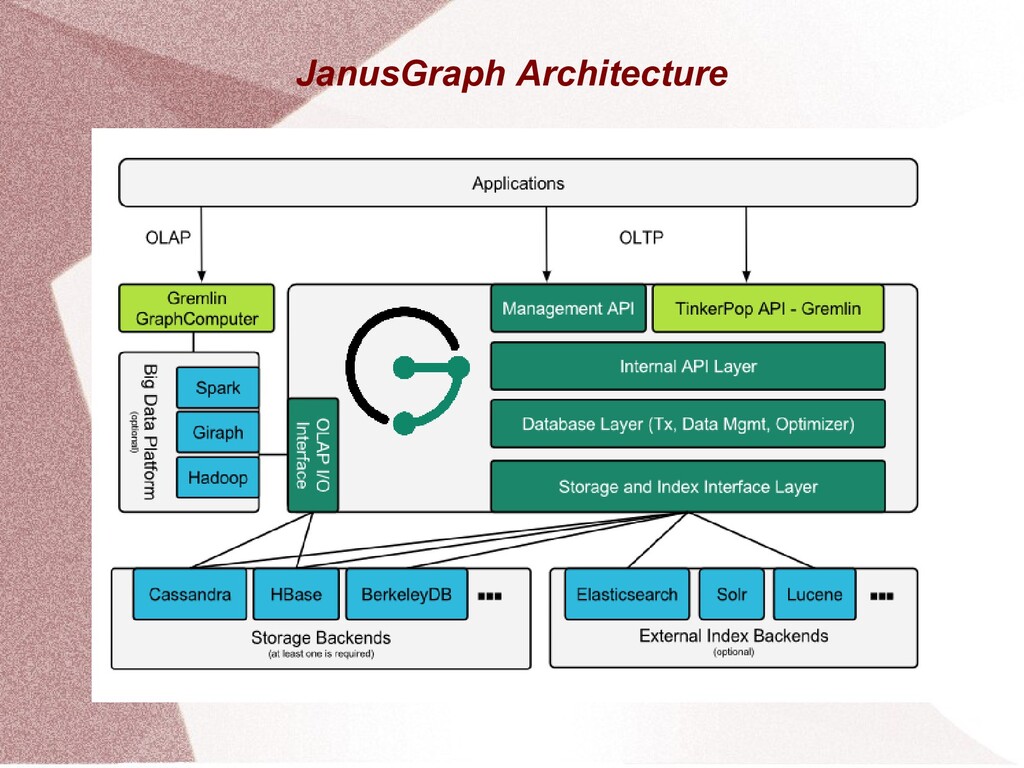
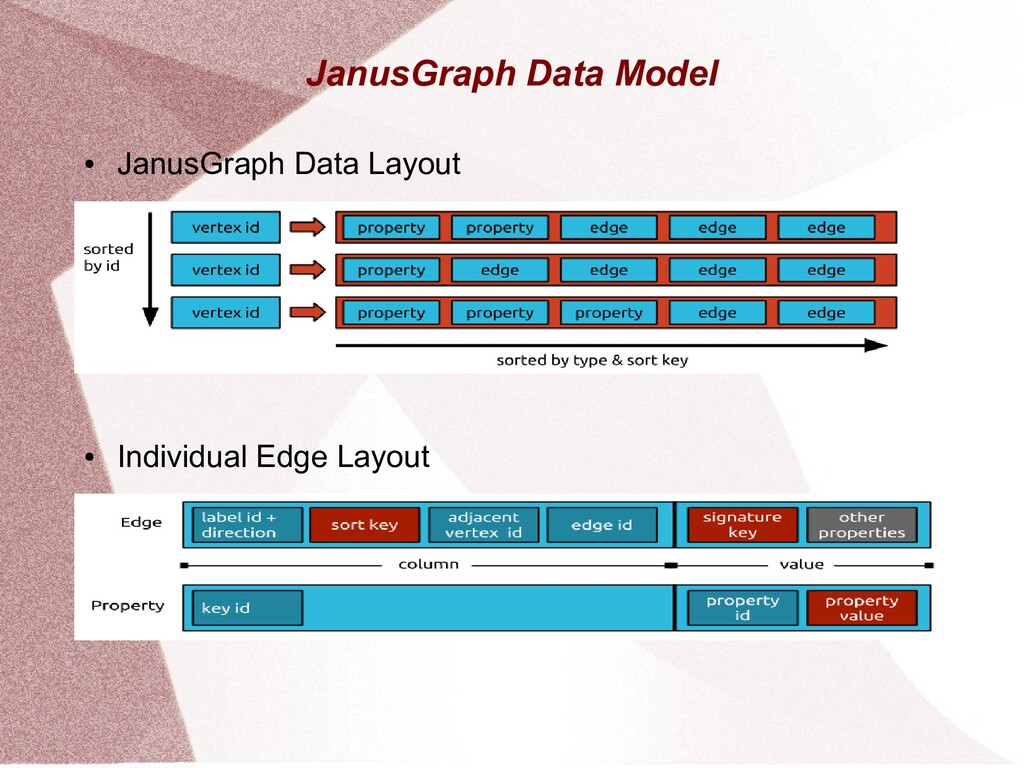
This presentation gives an overview of the JanusGraph DB project. It explains the JanusGraph database in terms of its architecture, storage backends, capabilities and community.
Links for further information and connecting
http://www.amazon.com/Michael-Frampton/e/B00NIQDOOM/
https://nz.linkedin.com/pub/mike-frampton/20/630/385
https://open-source-systems.blogspot.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}