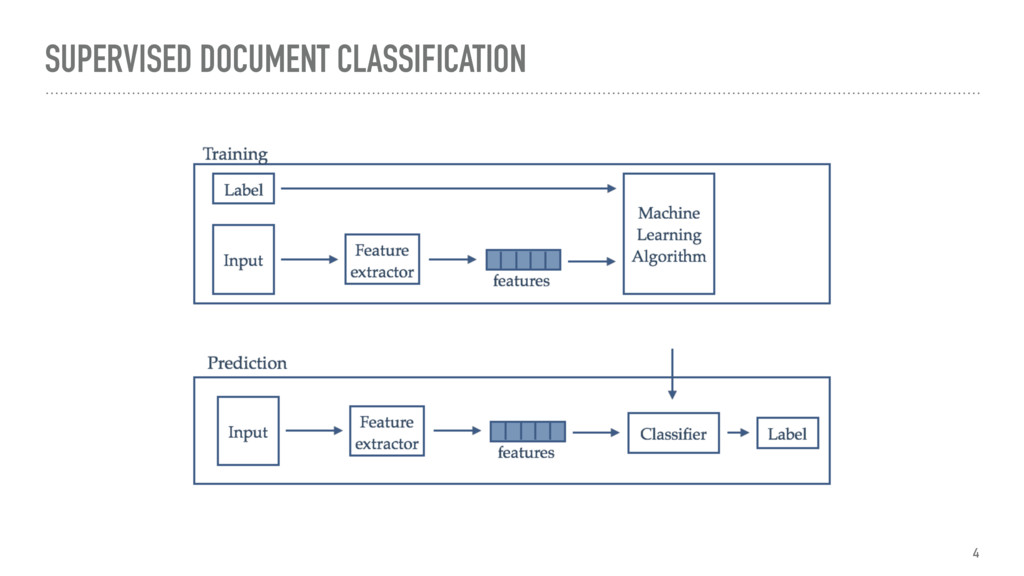
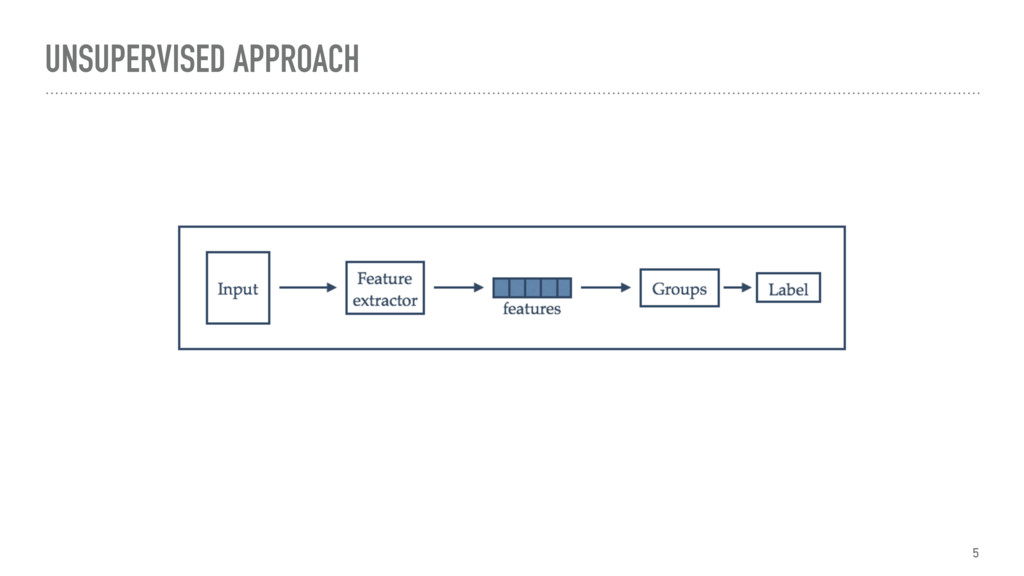
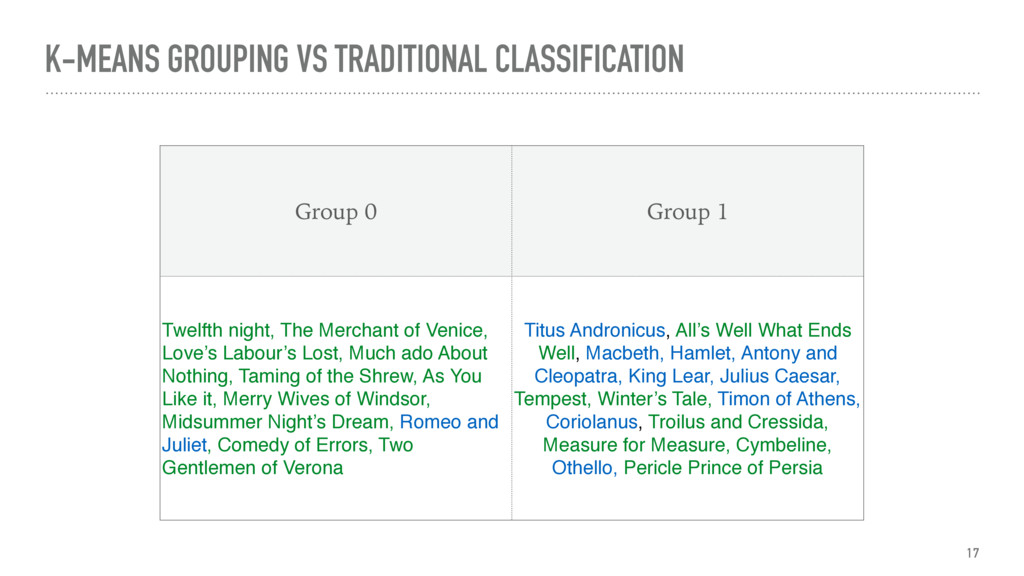
Unsupervised document classification addresses the problem of assigning categories to documents without the use of a training set or predefined categories. This is useful to enhance information retrieval, the basic assumption being that similar contents are also relevant to the same query. A similar assumption is made in literature to define literary genres and sub-genres, where works which share specific conventions in terms of form and content are described by the same genre.
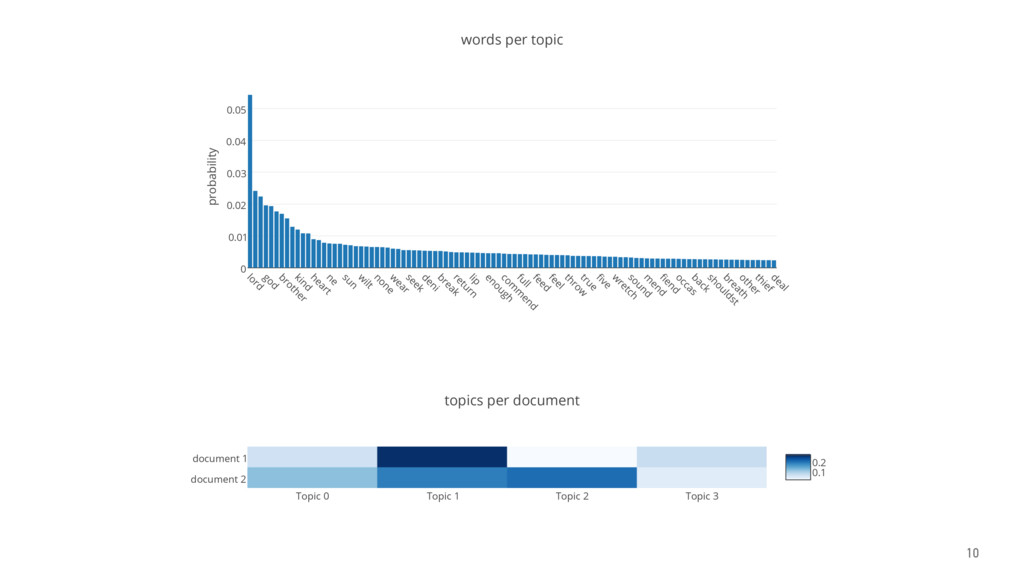
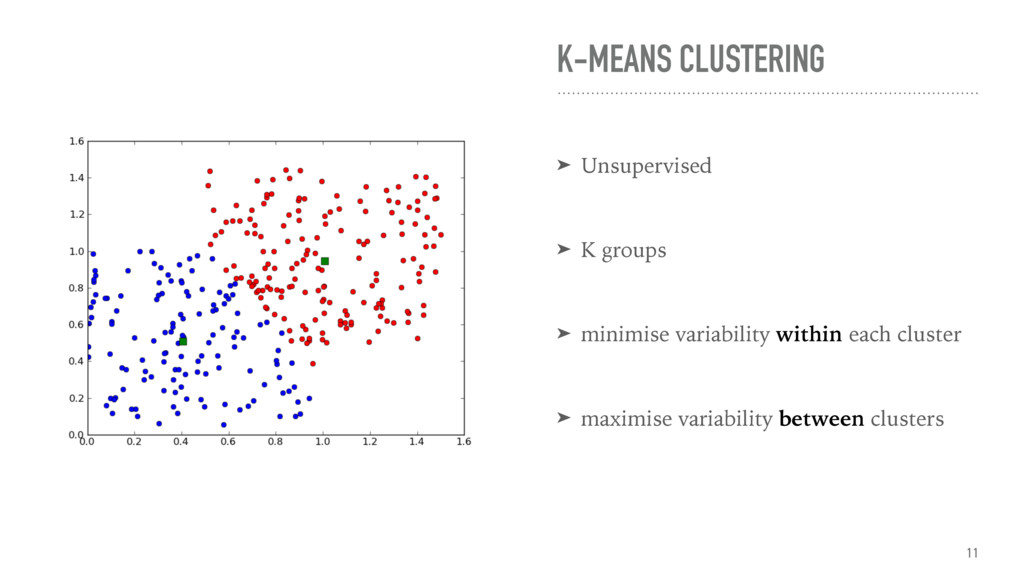
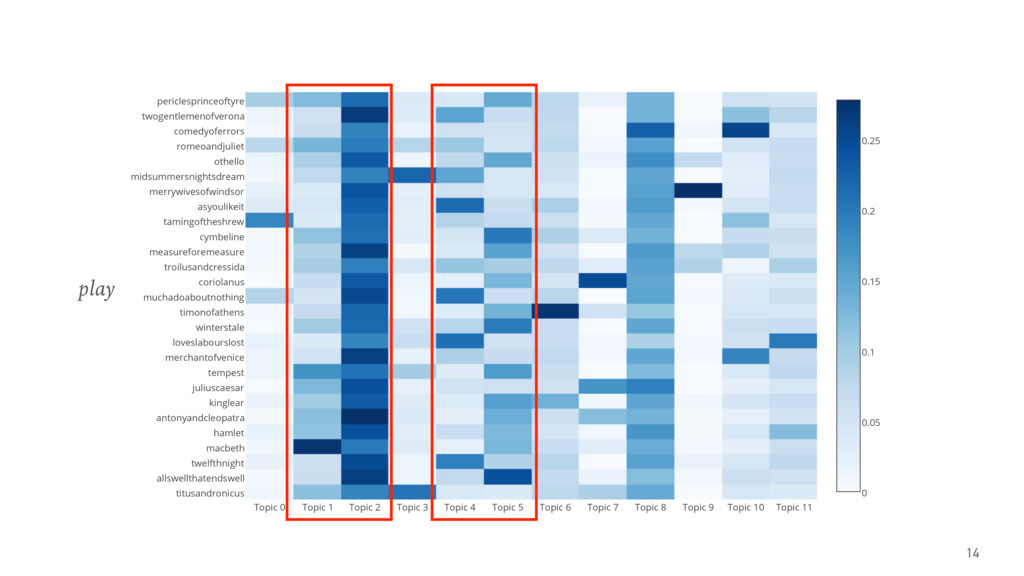
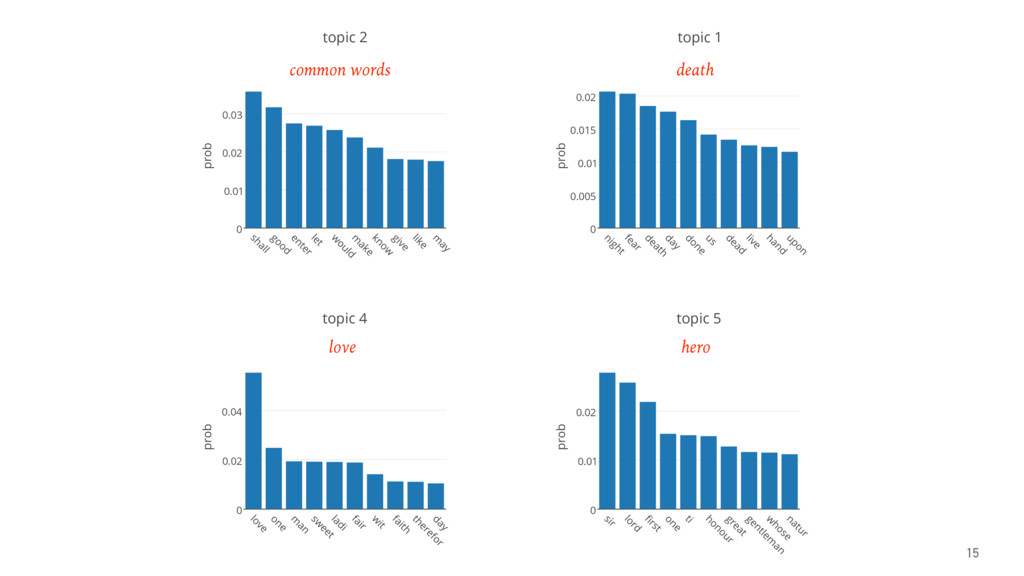
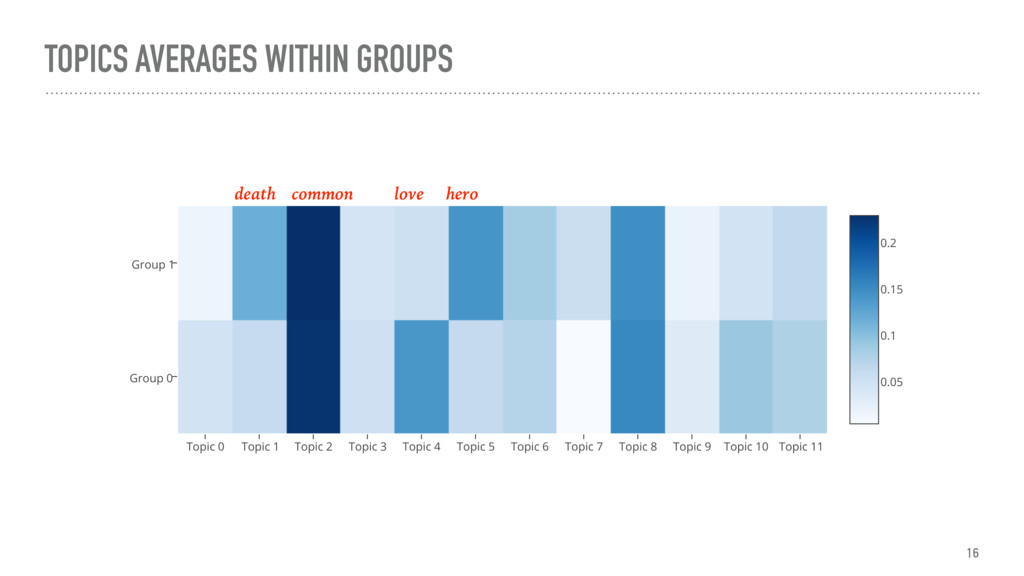
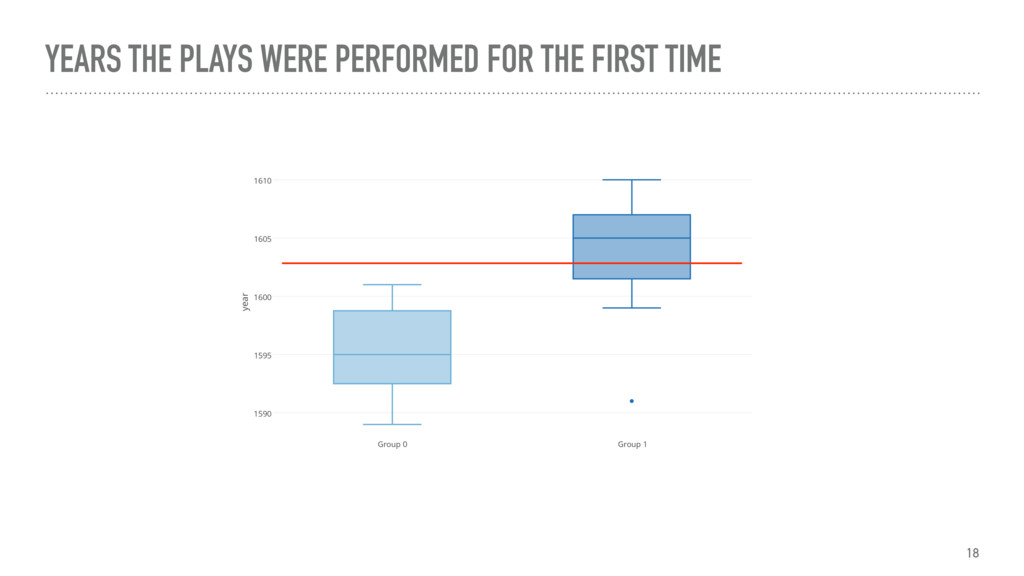
The talk gives an overview of document clustering and its challenges, with a focus on dimensionality reduction and how to address it with topic modelling techniques like LDA (Latent Dirichlet Allocation). Using Shakespeare’s body of work as a case study, the talk describes how to use nltk, sklearn and gensim to process and analyse theatrical works with the final goal of testing whether document clustering yields to the same classification given by literature experts.
Deck as presented at PyData Amsterdam 2016
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}