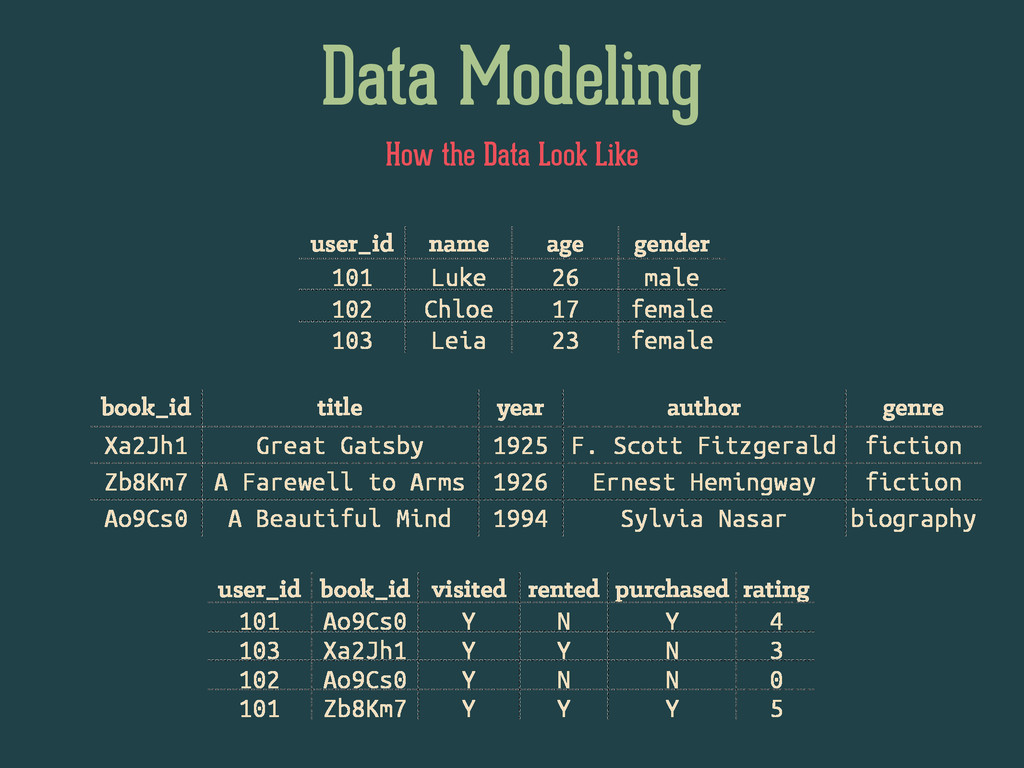
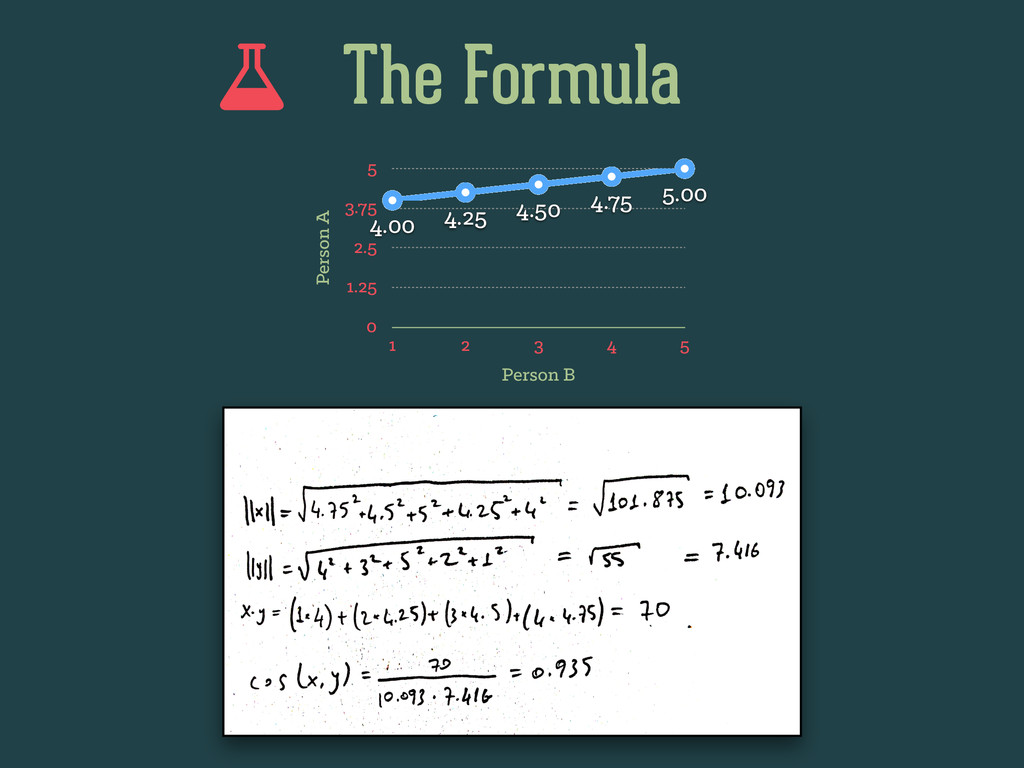
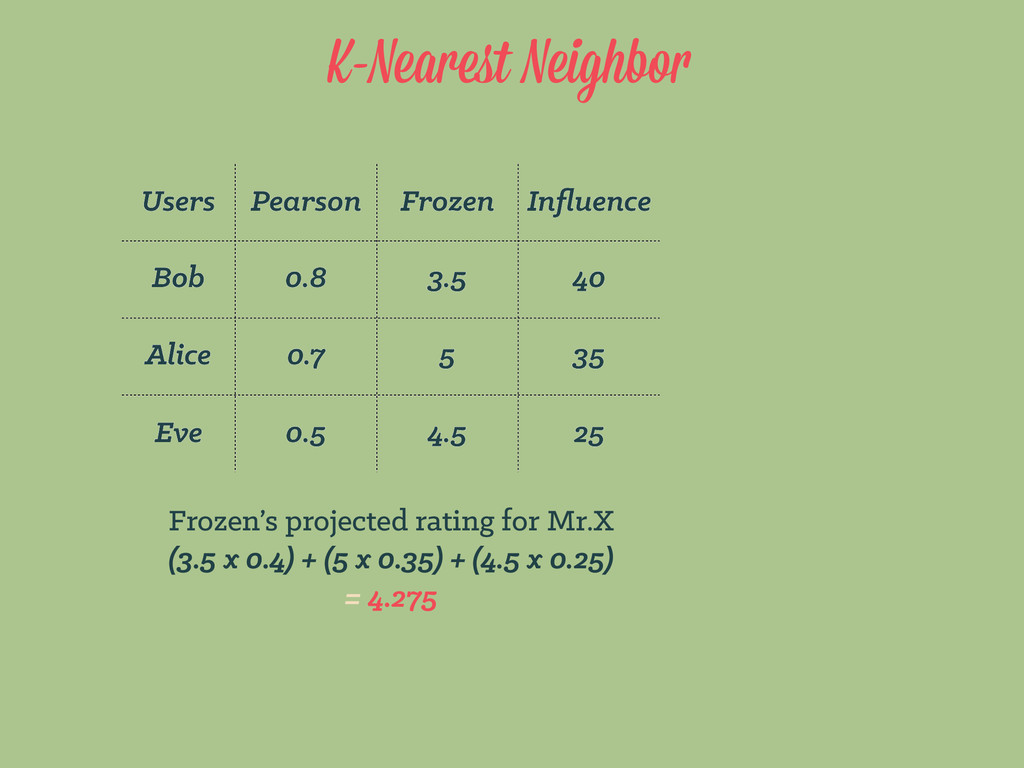
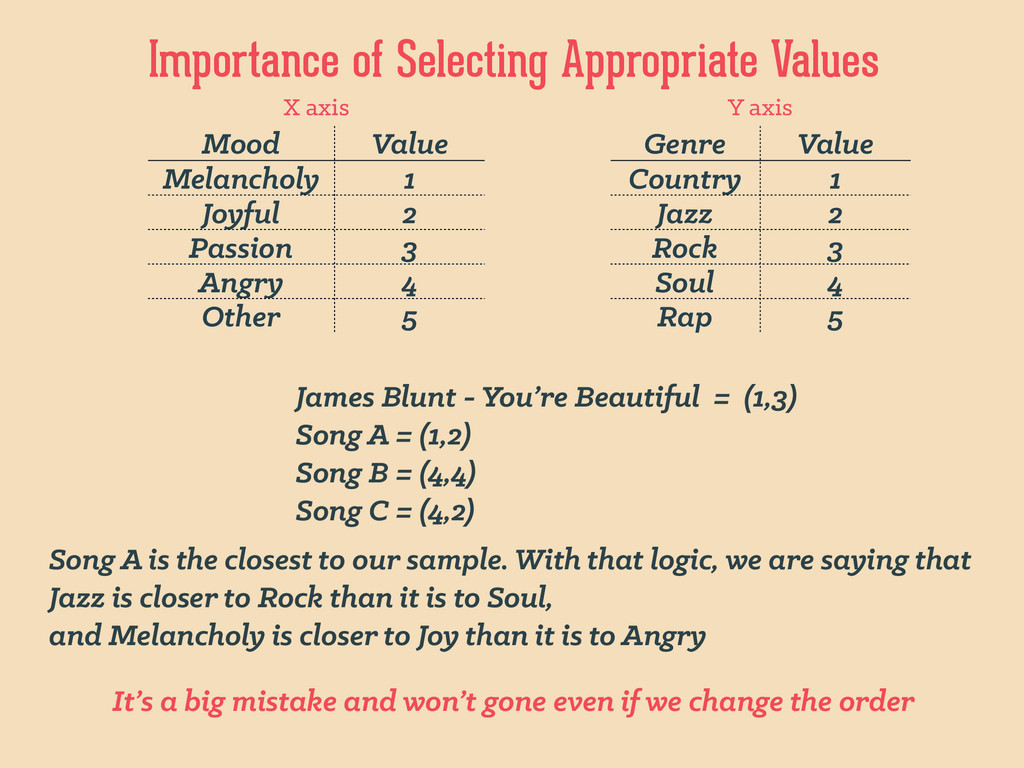
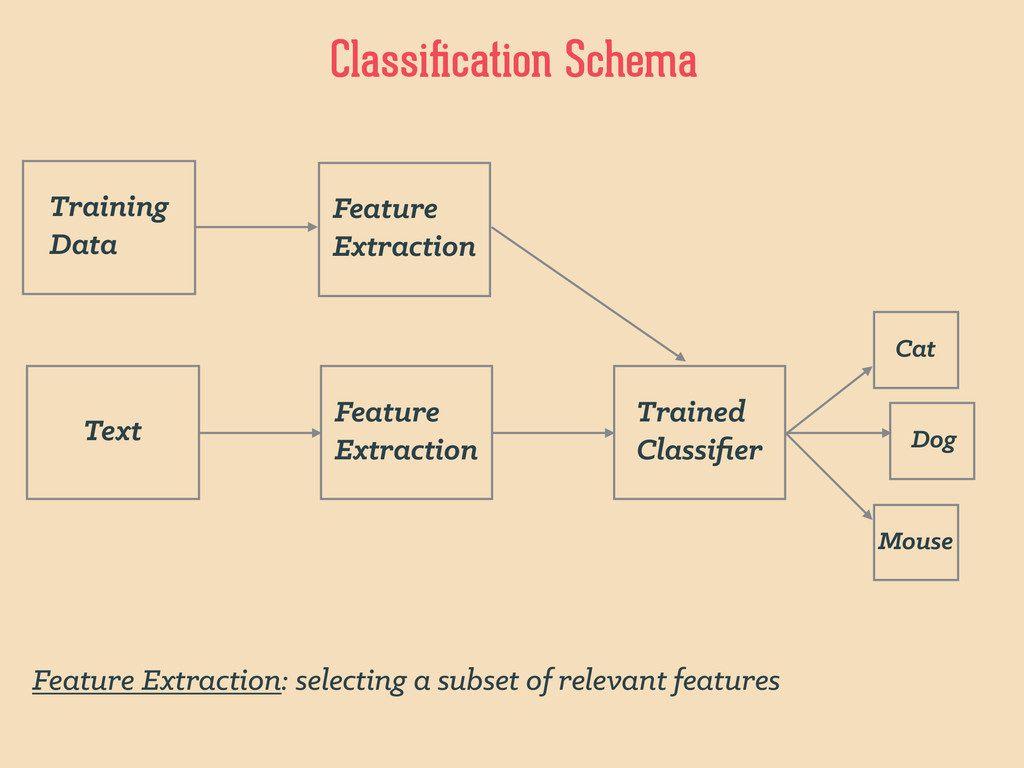
genre author visited rented purchased rating 26 male 1994 young biography Sylvia Nasar Y N Y 4 23 female 1926 young fiction F.Scott Fitzgerald Y Y N 3 17 female 1994 teen biography Sylvia Nasar Y N N 0 26 male 1926 young fiction Ernest Hemingway Y Y Y 5 even further, machine learning expects something like this… age, gender, age_range, year, genre, author, visited, rented, purchased, rating 26, “male", “young”, 1994, "biography", "Sylvia Nasar", "Y", "N", "Y", 4 23, "female", “young”, 1926, "fiction", "F.Scott Fitzgerald", "Y", "Y", "N", 3 17, "female", “teen”, 1994, "biography", "Sylvia Nasar", "Y", "N", "N", 0 26, "male", “young”, 1926, "fiction", "Ernest Hemingway", "Y", "Y", "Y", 5 book_ratings.csv discretization
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
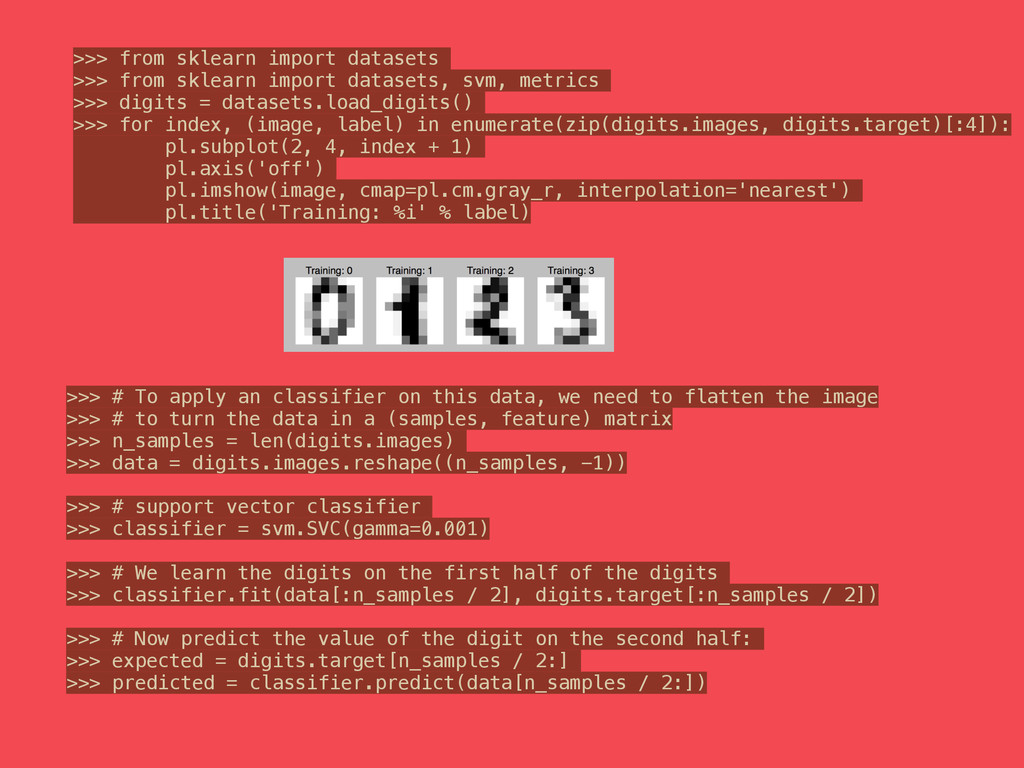
![>>> for index, (image, prediction) in enumerate( zip(digits.images[n_samples / 2:],](https://files.speakerdeck.com/presentations/f83447d0adcb013114e75266f22199ca/slide_57.jpg){kind=link}
{kind=link}