of gaining insight from them How many people using iPhone to access my website? NOW You have even more data, and also have cool toys to asses that MapReduce, HBase, Hive Storm, Druid, Dremel and many many more
machines are beginning to think and respond more like humans, This can lead to more interesting questions: What is a feeling or emotion exactly? Can it be simulated by machines? How can a machine decide how to respond based on feelings and experiences? How can they arrive to emotional+logical conclusions? Can we get it beyond just a simulation? Ability to process large amounts of data in very short amount of time will be able to answer these questions. And help us implement them.
(latency, completion/failed ratios, etc.) to be viewed, compared with warehoused historic data, and trended in real- time. ! Advanced implementations allow threshold detection, alerting and providing feedback to the process execution systems themselves, thereby 'closing the loop'. Process-Aware
data directly from its source. ! Provides the potential for real-time access. ! Ideal for real-time, simple dashboards. Multiple Source - Simple Output
use some techniques to enable events to be analyzed without being first transformed and stored in a database. ! Advantage: In-Memory High rates of events can be monitored, and since data does not have to be written into databases data latency can be reduced to milliseconds. ! Example If VIP subscribers are exposed to 3 stop transactions in 60 minutes, generate an alert on the screen and send an e-mail.
Warehouse. ! Therefore, update the data more frequently. ! These can achieve near-real-time. ! This means minutes-hours of latency. ! Significantly slower than event-based architecture
isn’t an issue. We are doing that for decades. ! Now, there is an explosion of techniques to analyze these huge data sets. ! Heterogeneous is the New Black We are moving from tabular data to mixed data. They can be in form of anything. This is more challenging. (And more fun!)
which it is used. ! This is the ability of processing data as it arrives (present), rather than storing the data and retrieving it afterwards (future). ! But what is present? The present varies too, depending on the context. (customer at amazon.com vs. a stock trader) ! We will of course act for the worst case (must deliver as fast as possible). For that, we need to consider one important thing.
space complexity of a given algorithm (their growth rates)! ! Think linear search for example. O(n) time complexity. On a huge, unsorted data. What distributed computing doing is, converting this to O(n/k) where k = # of machines you have. Know Thy Complexities!
the time and space complexities. ! If you “unbound” them to allow more data, they can no longer function as real-time algorithms. They have limits too. ! We want minimize the latency between when an event occurs and when it is reflected in our query results. "Take-Home Lesson: Always put your bounds into account
elements from a stream of data. ! You have a very large stream of data (search queries, usage data) ! You want to efficiently return sample of 1000 elements evenly distributed from this stream. ! ? How would you do it?
the elements at those indices and there you go! # FOLLOW-UP: You don’t know N and you can’t index directly into it. ! You can count, but the data is too large and you’ll have to make 2 passes. And heuristics will either not work in one pass or will not be evenly distributed. ! What do you do?
as you see them in the stream, and then always keep the top 1,000 numbered elements at all times. ! “ORDER BY DBMS_RANDOM.VALUE” works like that :) This strategy requires additionally storing the randomly generated number for each element. ! ! A better way: 1) Create an array reservoir[0..k-1] and copy first k items of stream[] to it. 2) One by one compare all items from (k+1)th item to nth item. a) Generate a random number from 0 to i where i is index of current item in stream[]. Let the generated random number is j. b) If j is in range 0 to k-1, replace reservoir[j] with arr[i]
# for i in {1..100}; do echo $i; done | python .! /reservoir_sampling.py k! ! import sys, random! ! k = int(sys.argv[1])! S, c = [], 0! ! for x in sys.stdin:! if c < k: ! S.append(x)! else:! r = random.randint(0,c-1)! if r < k: S[r] = x! c += 1! ! print ''.join(S)!
Processing Batch Processing is fundamentally high-latency. ! So if you’re trying to look at a terabyte of data all at once, you’ll never be able to do that computation in less than a second with batch processing. ! Stream processing looks at smaller amounts of data as they arrive.
find information stored on disk • Databases find the needle in the haystack • Streams analyzes variety of data before you store it (Structured, unstructured, video, audio) • And finds the needle as it’s blowing by
• Find and analyze information stored on disk ! • Batch paradigm, pull model ! • Query-driven: submits queries to static data • Current fact finding ! • Analyze data in motion – before it is stored ! • Low latency paradigm, push model ! • Data driven: bring the data to the query
data from other streams and can produce new streams - An operator reads in a stream but outputs a different stream ! Stream: Data flow between any two operators – Tuple: data record in the stream, with fixed set of Attributes ! – Attribute: variable
• Jobs run to completion ! • Stateful nodes • Real-time processing ! • Topologies run forever ! • Stateless nodes • Scalable • Guarantees no data loss • Most implementations are open source
ad-hoc query system for analysis of read-only nested data. - Columnar data layout - Drill is more generalist at the cost of some performance - %100 Java based Tech N Stack
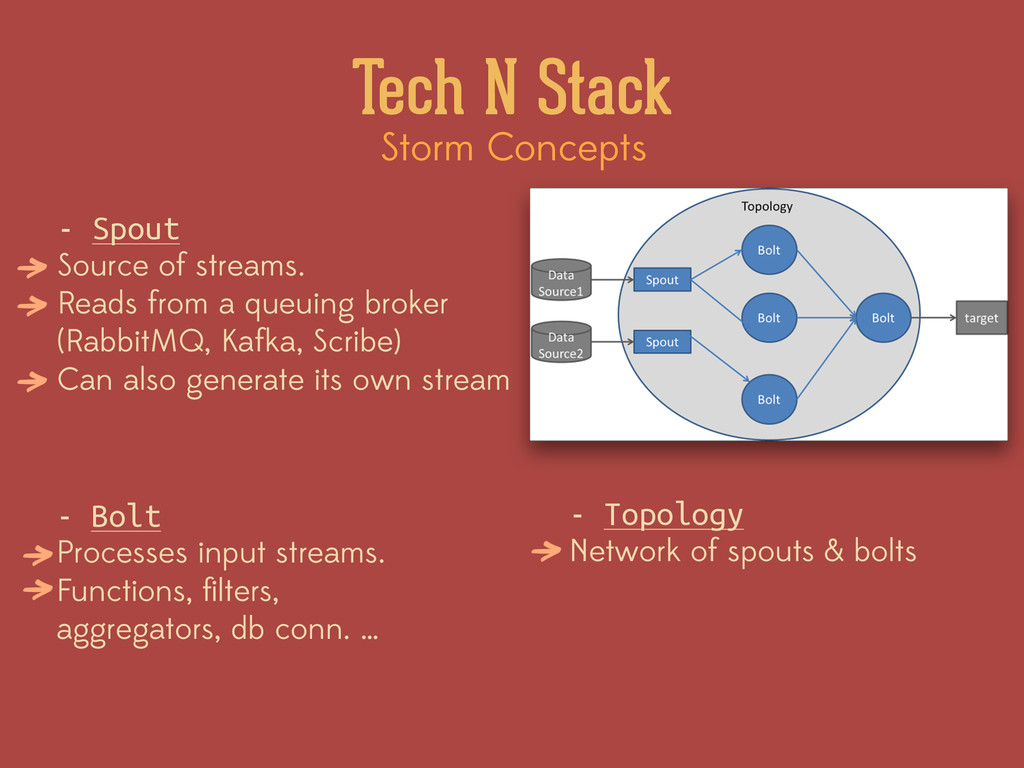
on an ongoing basis, so you can react to data as it happens. ! - It’s like MapReduce for data streams - Distributed Real-Time computation system - Java / Clojure based - It just works - Used at - Open-Source ! (strong community support) Tech N Stack %
Reads from a queuing broker (RabbitMQ, Kafka, Scribe) Can also generate its own stream - Bolt Processes input streams. Functions, filters, aggregators, db conn. … - Topology Network of spouts & bolts → → → → → →
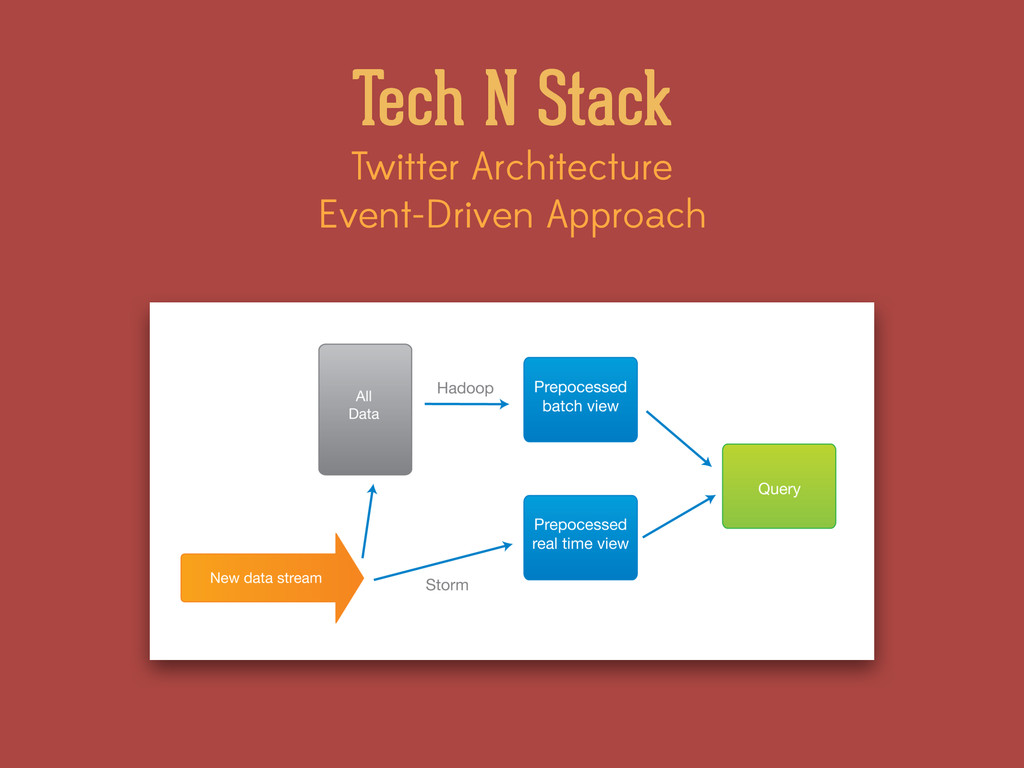
for real-time processing. ! • With Storm, it is possible to perform a large range of complex aggregation while the data flows through the system. ! • This has a significant impact on the complexity of the processing. ! • Asynchronous events = easier to parallelize. Twitter Architecture Event-Driven Approach
is calculating trending words. ! With the event-driven approach, we can assume that we have the current state and just make the change to that state to update the list of trending words (think Viterbi Algorithm it’s also how they asses user status -activeness-) ! In contrast, a batch system will have to read the entire set of words, re-calculate, and re-order the words for every update. This is why those operations are often done in long batches.
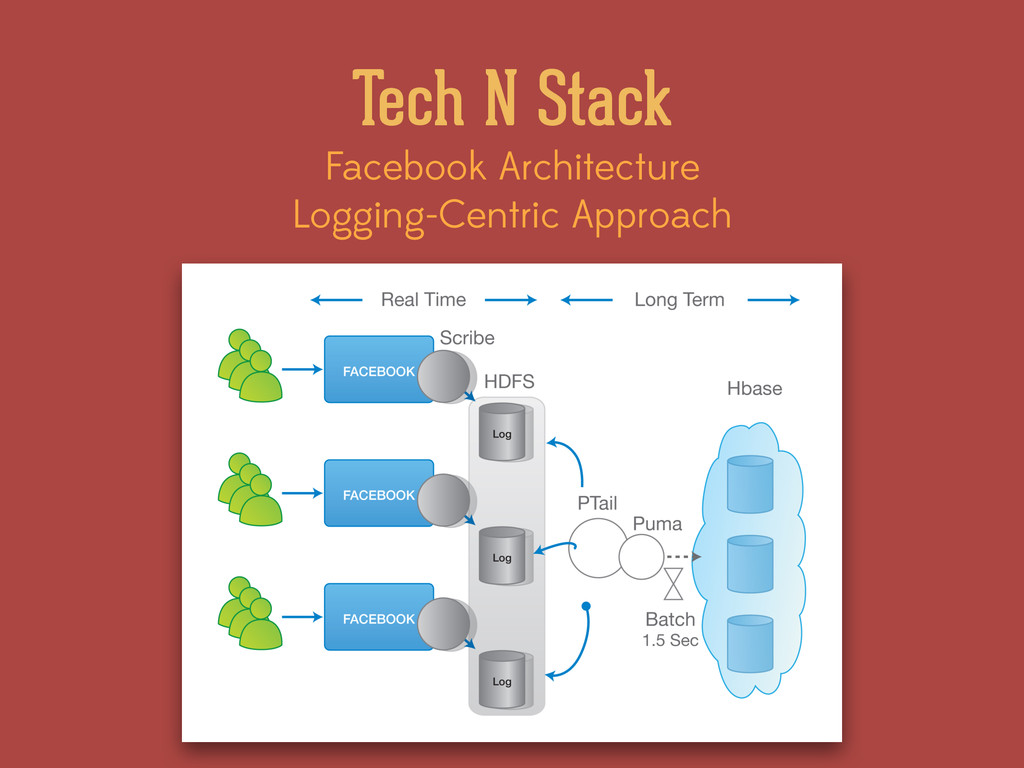
real-time and batch (map/ reduce) processing. ! • Collects user click streams through Ajax listener, then sends them to data centers. The info is stored on HDFS via Scribe and collected by PTail. ! • Because of the logging nature of the Facebook architecture, most of the heavy lifting of processing cannot be done in real-time and is often pushed into the backend system. ! • Puma aggregates logs in-memory, batching them in windows of 1.5 seconds and stores the information in Hbase. Facebook Architecture Logging-Centric Approach
into an understandable format. (adslNo, cdrType, timestamp, …) Teradata DB → Used for enrichment (with incoming parsed data) Connected with good old JDBC IBM InfoSphere Streams → Where the magic happens. In-Memory CEP. We run our scenarios algorithms on various data structures here.
Used for real-time queries (e.g. call center). 6 regions. Hive → DWH infra. built on top of Hadoop. For providing data summarization, query, and analysis. Cognos → Reporting environment. Custom and built-in real-time dashboards are here.
3. Enrichment 4. Funnel through operators (which carries the algorithms). 5. Outputs to HBase, HDFS, and/or Cognos 6. End users query from HBase, Hive or Cognos
applied to many areas • Need to understand the application needs. What is real-time for you? • Code responsibly (don’t forget your complexities) • Stream Processing is a big advancement
Off-Line Algorithms: How much is it worth the future? TR-92-044, July 1992 - Berkeley, CA http://www.icsi.berkeley.edu/pubs/techreports/TR-92-044.pdf ! [2] Pavlos S. Efraimidis, Paul G. Spirakis : Weighted random sampling with a reservoir - Information Processing Letters Vol. 97 issue 5, 16-Mar-2006 Pg. 181 - 185 http://dl.acm.org/citation.cfm?id=1138834 ! [3] Melnik, Andrey, Jlong, Gromer, Shiva, Mtolton, Theov : Dremel: Interactive Analysis of Web-Scale Datasets http://static.googleusercontent.com/media/research.google.com/en//pubs/ archive/36632.pdf ! [4] Viterbi Algorithm http://en.wikipedia.org/wiki/Viterbi_algorithm
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Further Reading [1] Richard M. Karp : On-Line Algorithms Versus](https://files.speakerdeck.com/presentations/08641e60bc47013110bd6a2948adcf2e/slide_38.jpg){kind=link}
{kind=link}