Python is a fantastic language for writing web scrapers. There is a large ecosystem of useful projects and a great developer community. However, it can be confusing once you go beyond the simpler scrapers typically covered in tutorials.
In this talk, from EuroPython 2015, we explore some common real-world scraping tasks. You will learn best practises and get a deeper understanding of what tools and techniques can be used and how to deal with the most challenging of web scraping projects.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
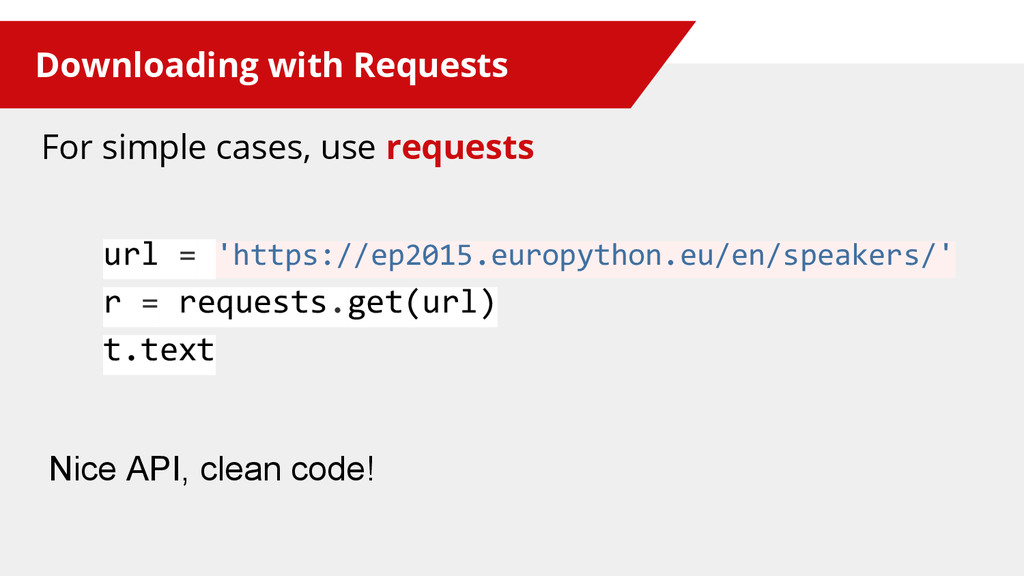{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
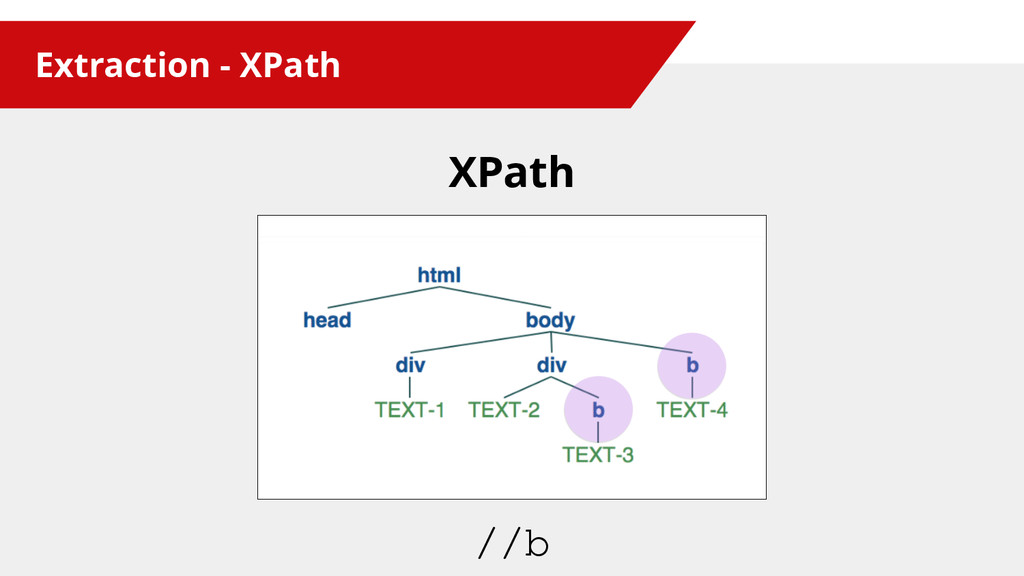{kind=link}
{kind=link}
![Extraction - XPath XPath //div[2]/text()](https://files.speakerdeck.com/presentations/64fcf63adcb340cc9695999c66960022/slide_21.jpg){kind=link}
![Extraction - XPath XPath //div[2]//text()](https://files.speakerdeck.com/presentations/64fcf63adcb340cc9695999c66960022/slide_22.jpg){kind=link}
![Scrapy Selectors name = response.xpath('//section[@class="profile-name"]//h1/text()').extract_first() avatar = response.urljoin(response.xpath('//img[@class="avatar"]/@src').extract_first() for talk](https://files.speakerdeck.com/presentations/64fcf63adcb340cc9695999c66960022/slide_23.jpg){kind=link}
![BeautifulSoup name = soup.find('section', attrs={'class': 'profile-name'}).h1.text item['avatar'] = self.base_url +](https://files.speakerdeck.com/presentations/64fcf63adcb340cc9695999c66960022/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
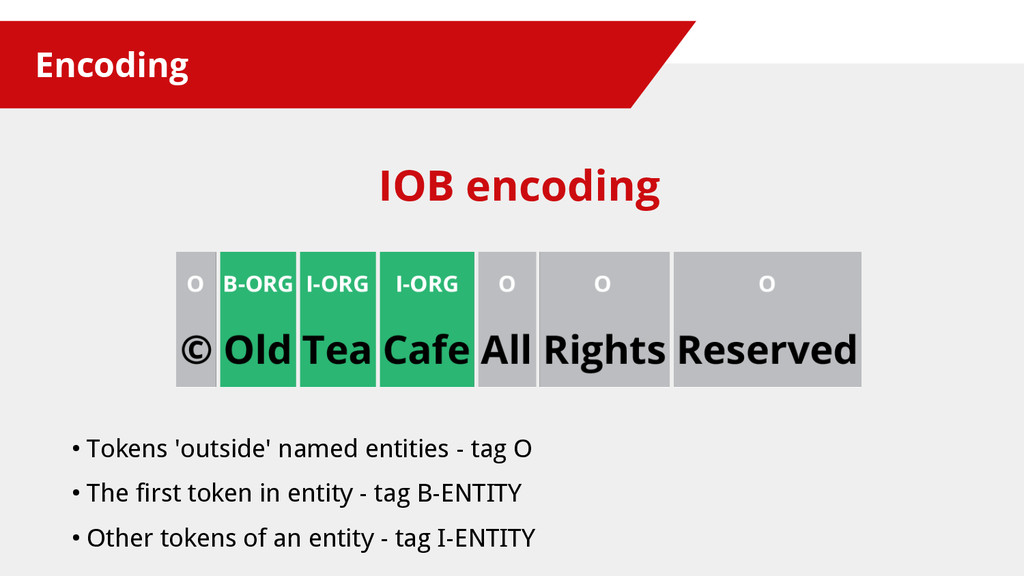{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}