In this talk, Shane will discuss the design and architecture of Scrapinghub’s systems for storing and analysing big data. He will introduce HBase, dive into the architecture, and share what he learned designing, implementing and scaling a platform based on it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Key Selection Examples OpenTSDB: Row key: <metric_uid><timestamp><tagk1><tagv1>[...<tagkN><tagvN>] Google web table:](https://files.speakerdeck.com/presentations/45cc2c7140a84c3a982a64f7cf1b06eb/slide_20.jpg){kind=link}
{kind=link}
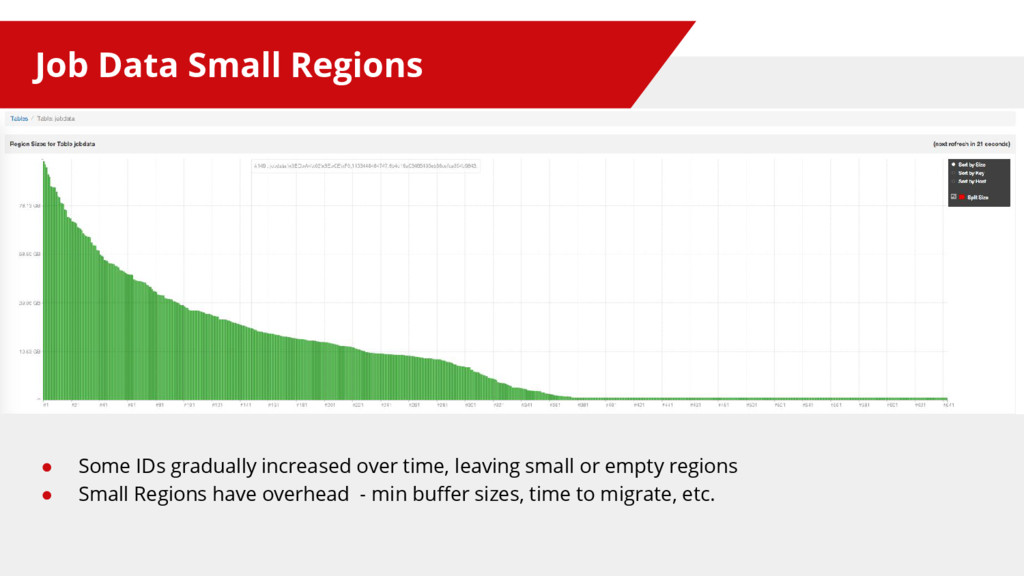{kind=link}
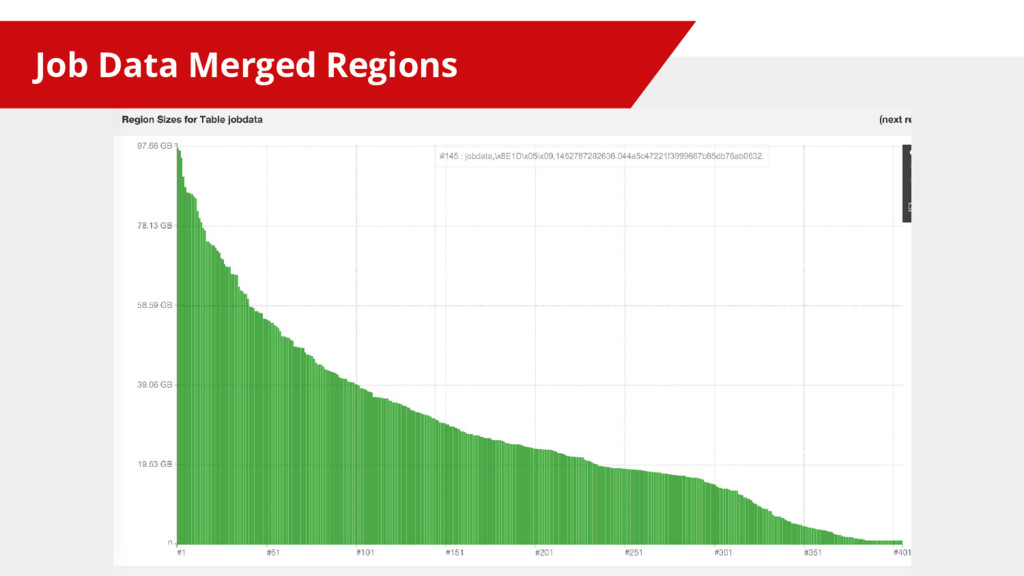{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Shane Evans [email protected] scrapinghub.com Thank you!](https://files.speakerdeck.com/presentations/45cc2c7140a84c3a982a64f7cf1b06eb/slide_32.jpg){kind=link}