downstream tasks is a more effective way to use finetuning[1] • Prompts whose embeddings are learned through back-propagation[2] • Prompt tuning is parameter-efficient and becomes more competitive with fine-tuning as the model size grows[3] [1] Brown, Tom, et al. "Language models are few-shot learners.“, Neurips 2020 [2] Liu, Xiao, et al. "GPT understands, too.“, (2021) [3] Lester, Brian, Rami Al-Rfou, and Noah Constant. "The power of scale for parameter-efficient prompt tuning “, (2021). Background Information
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Prompt Tuning 12 • Prompt tuning differs from embedding adapter[1]](https://files.speakerdeck.com/presentations/3505f92bd05b405faac7a12e912dd6ed/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
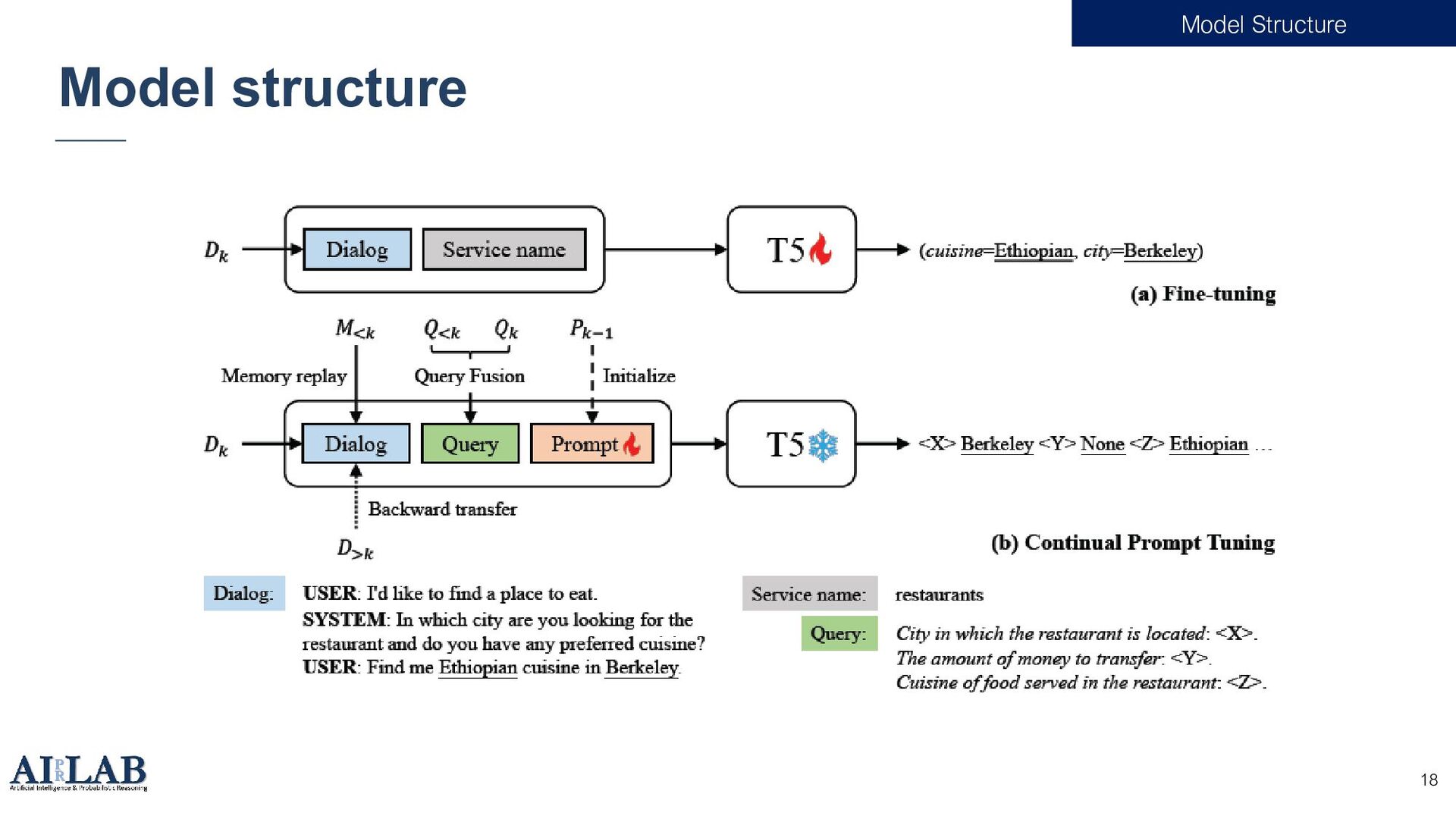{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Experiment setting 24 • Dataset • Schema-Guided Dialog dataset(SGD)[1] •](https://files.speakerdeck.com/presentations/3505f92bd05b405faac7a12e912dd6ed/slide_23.jpg){kind=link}
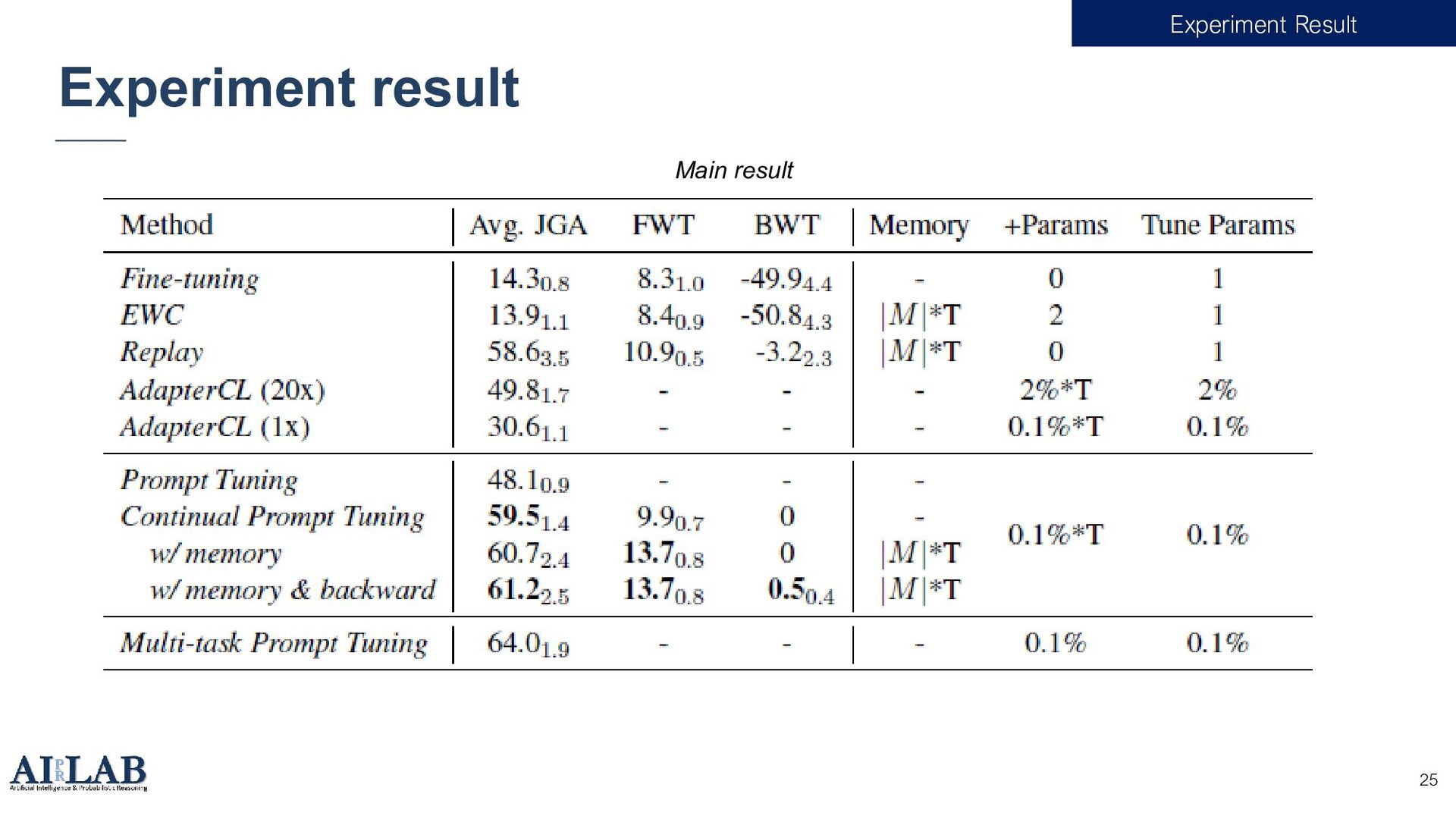{kind=link}
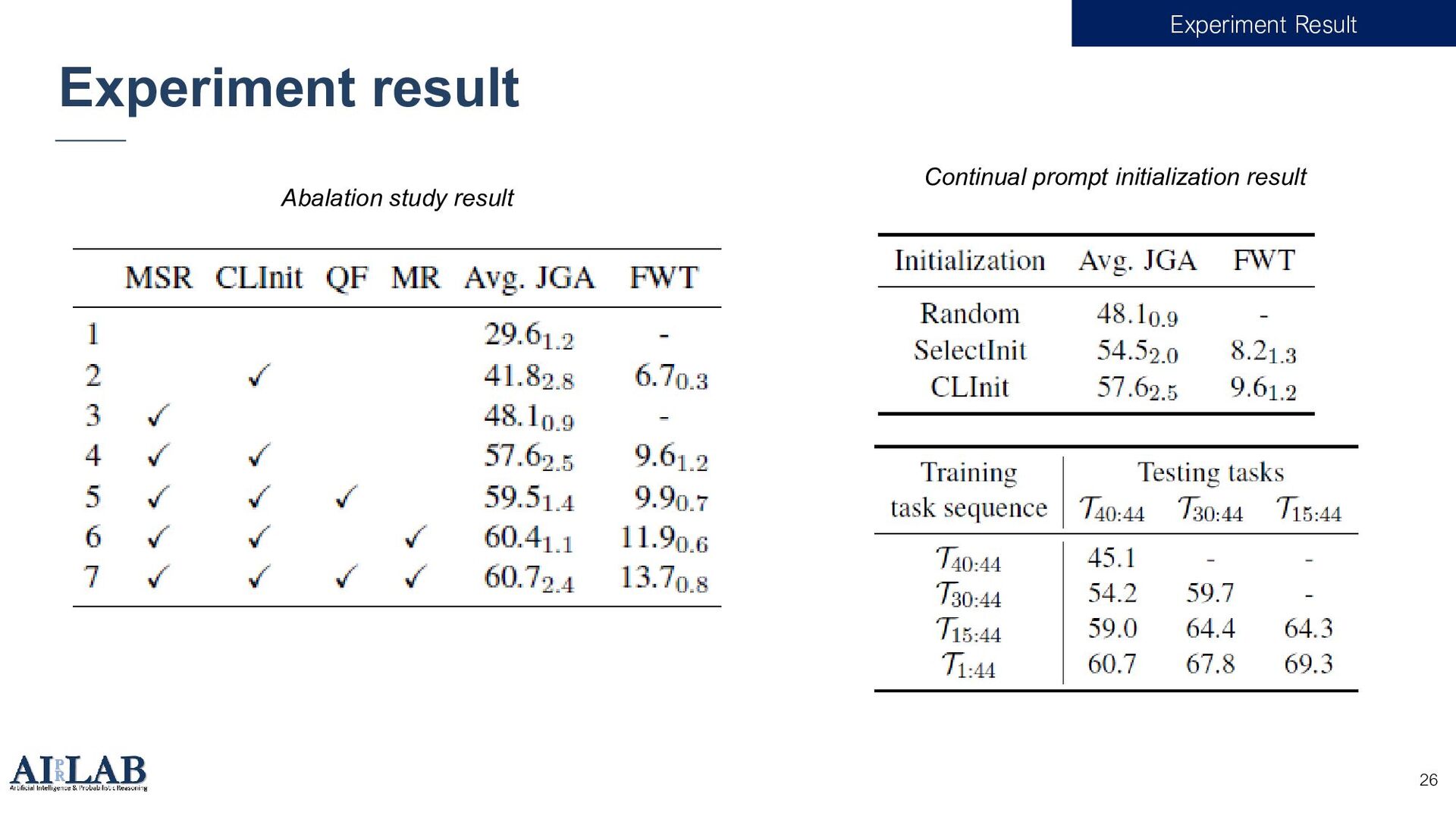{kind=link}
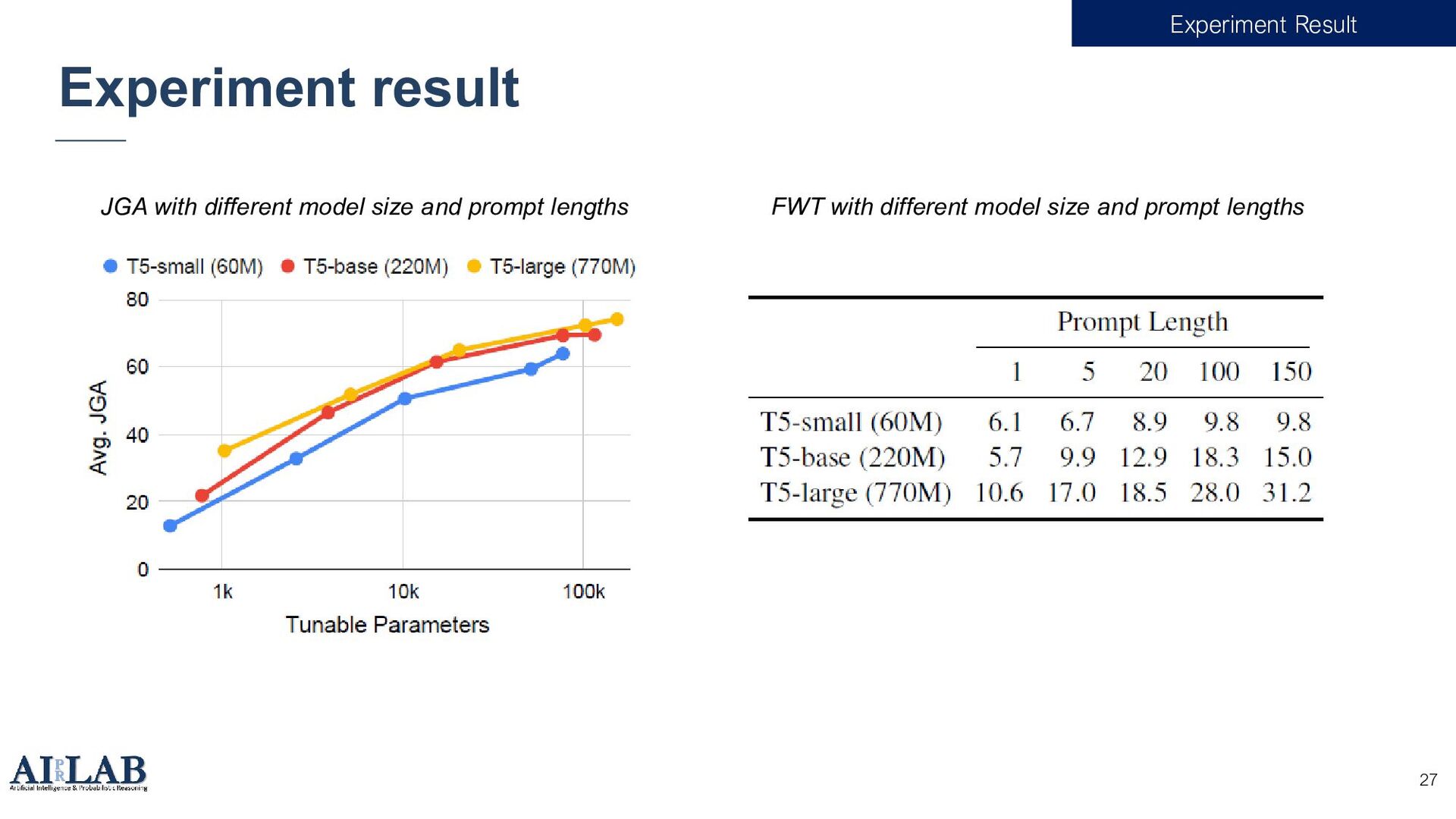{kind=link}