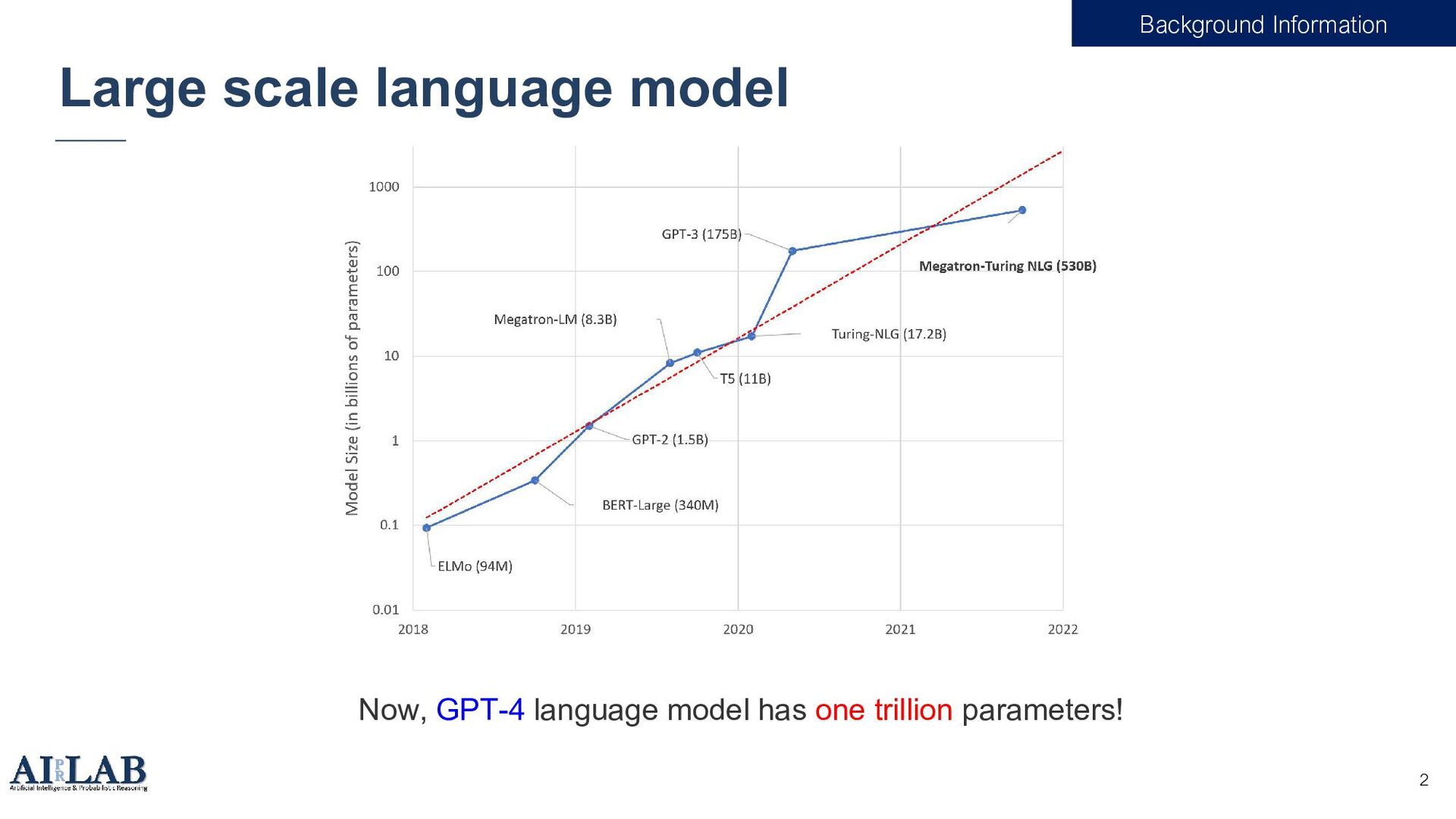
• 14 unique LMs including 4 model families(Neo[2], OPT[3], BLOOM, T0[4]) • 125M-175B parameters • Benchmark dataset • SuperGLUE[5] • NLI[6] • Classification[7] • QA[8] Results [1] Brown, Tom, et al. "Language models are few-shot learners.“, Neurips 2020 [2] Black, Sid, et al. "Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow” 2021. [3] Zhang, Susan, et al. "Opt: Open pre-trained transformer language models." 2022. [4] Sanh, Victor, et al. "Multitask prompted training enables zero-shot task generalization.” 2021. [5] Wang, Alex, et al. "Superglue: A stickier benchmark for general-purpose language understanding systems.“ Neurips 2019. [6] Mostafazadeh, Nasrin, et al. "Lsdsem 2017 shared task: The story cloze test." 2017. [7] Zhang, Xiang, Junbo Zhao, and Yann LeCun. "Character-level convolutional networks for text classification." Neurips 2015. [8] Kasai, Jungo, et al. "RealTime QA: What's the Answer Right Now?." 2022.
{kind=link}
{kind=link}
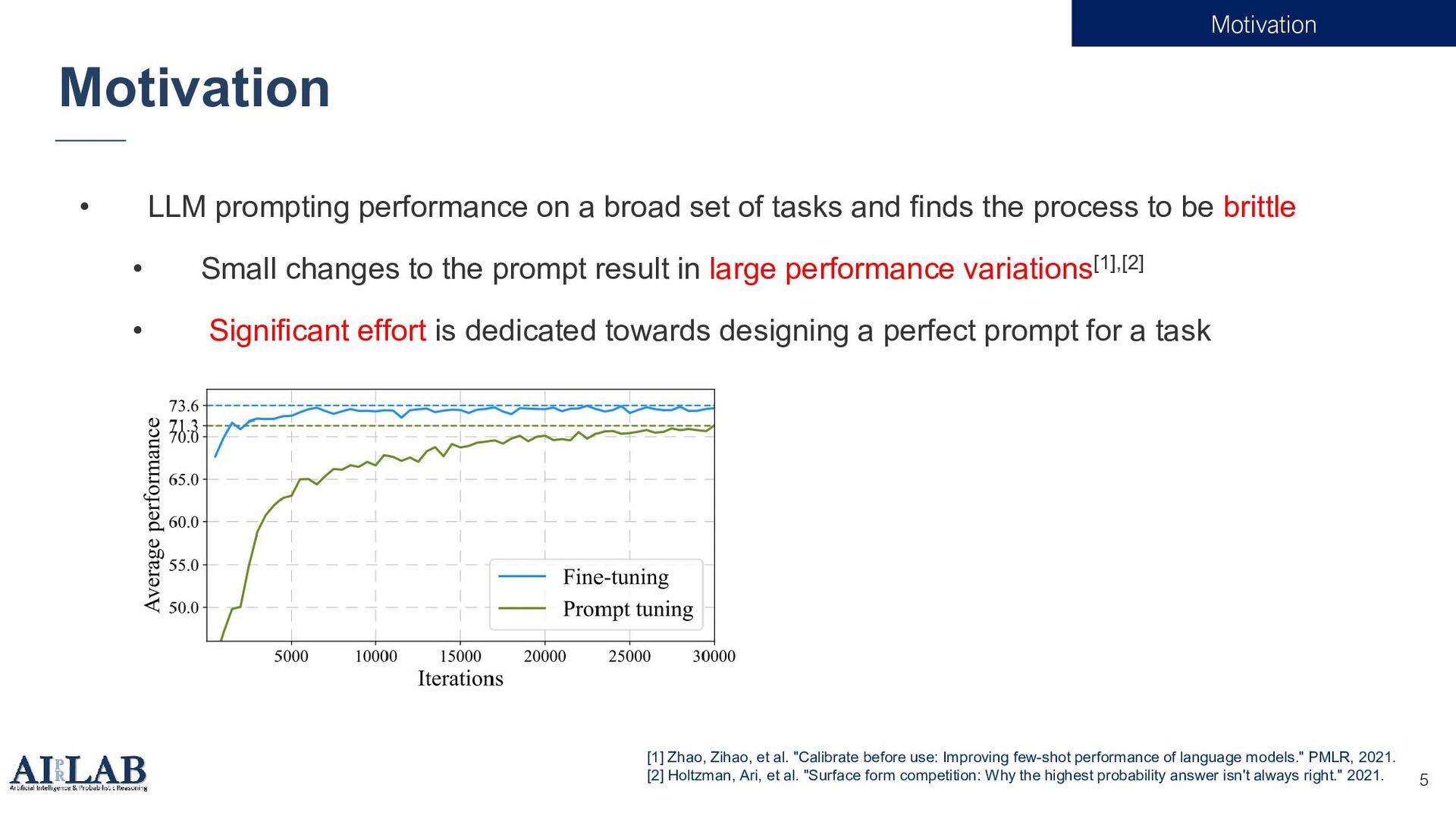
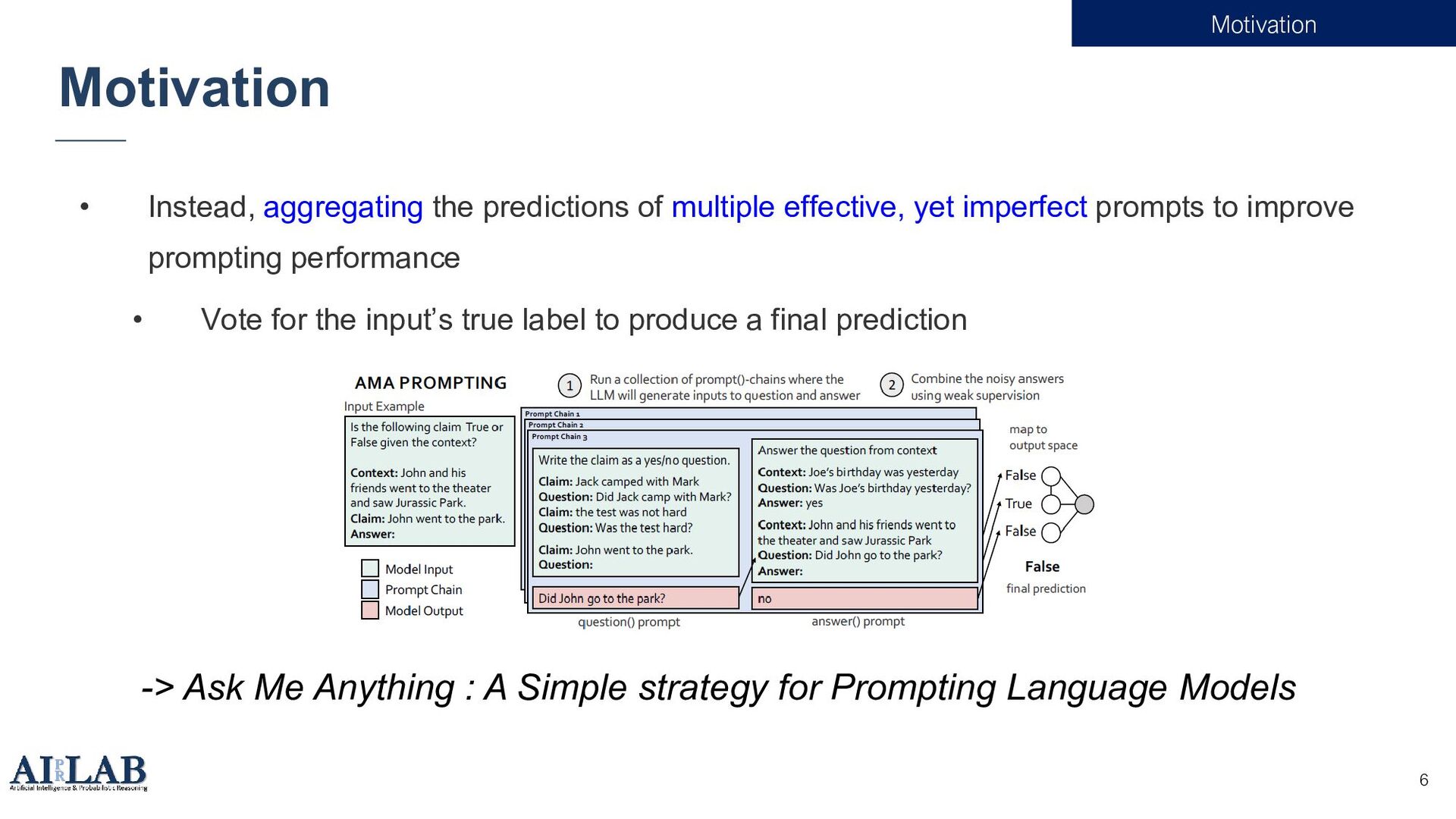
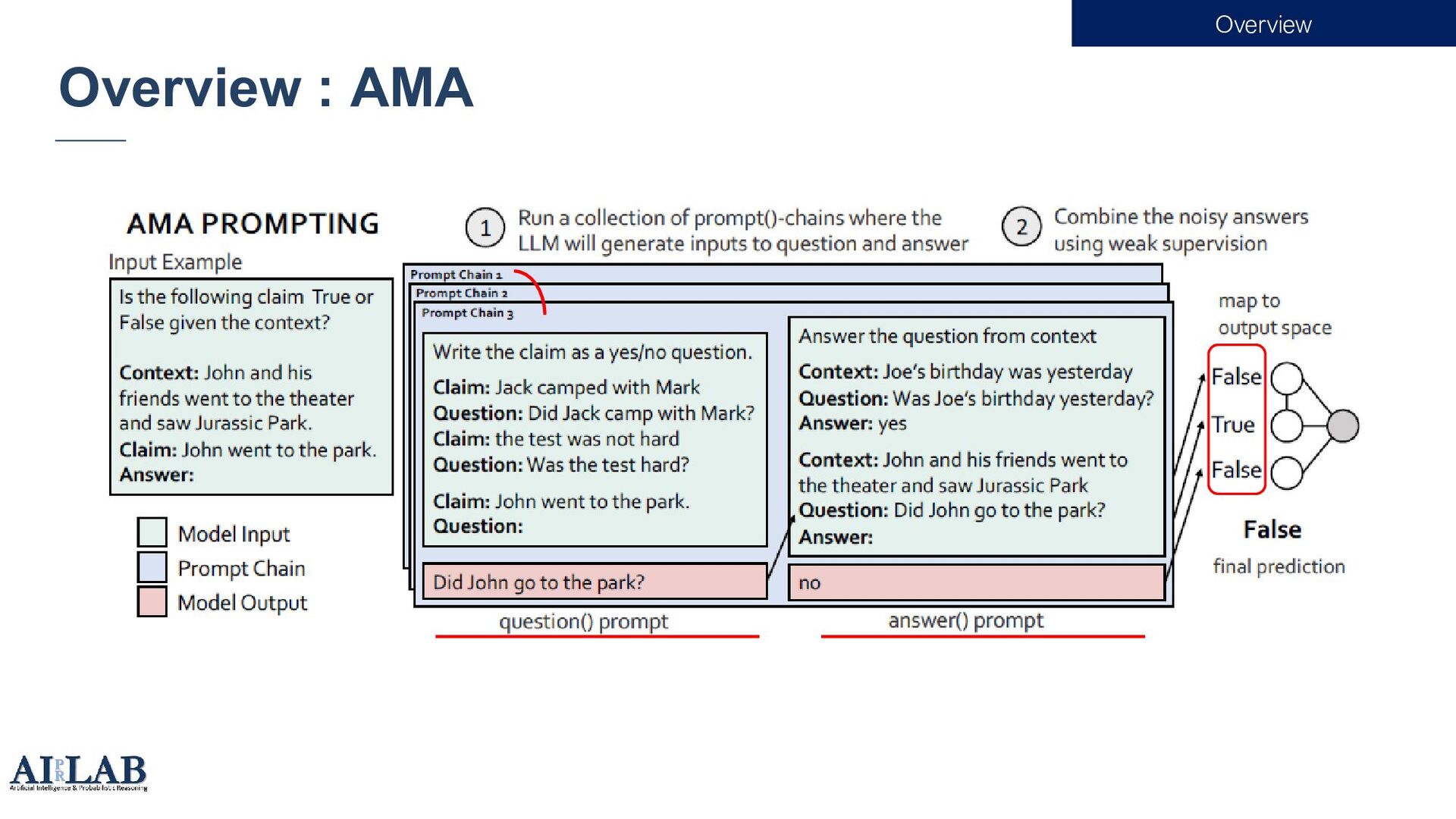
![Prompt 3 • For super-large models like 175B GPT-3[1], fine](https://files.speakerdeck.com/presentations/afe3eea4e71941088146033046731d86/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Experiment 25 • 20 popular language benchmarks used in GPT-3[1]](https://files.speakerdeck.com/presentations/afe3eea4e71941088146033046731d86/slide_24.jpg){kind=link}
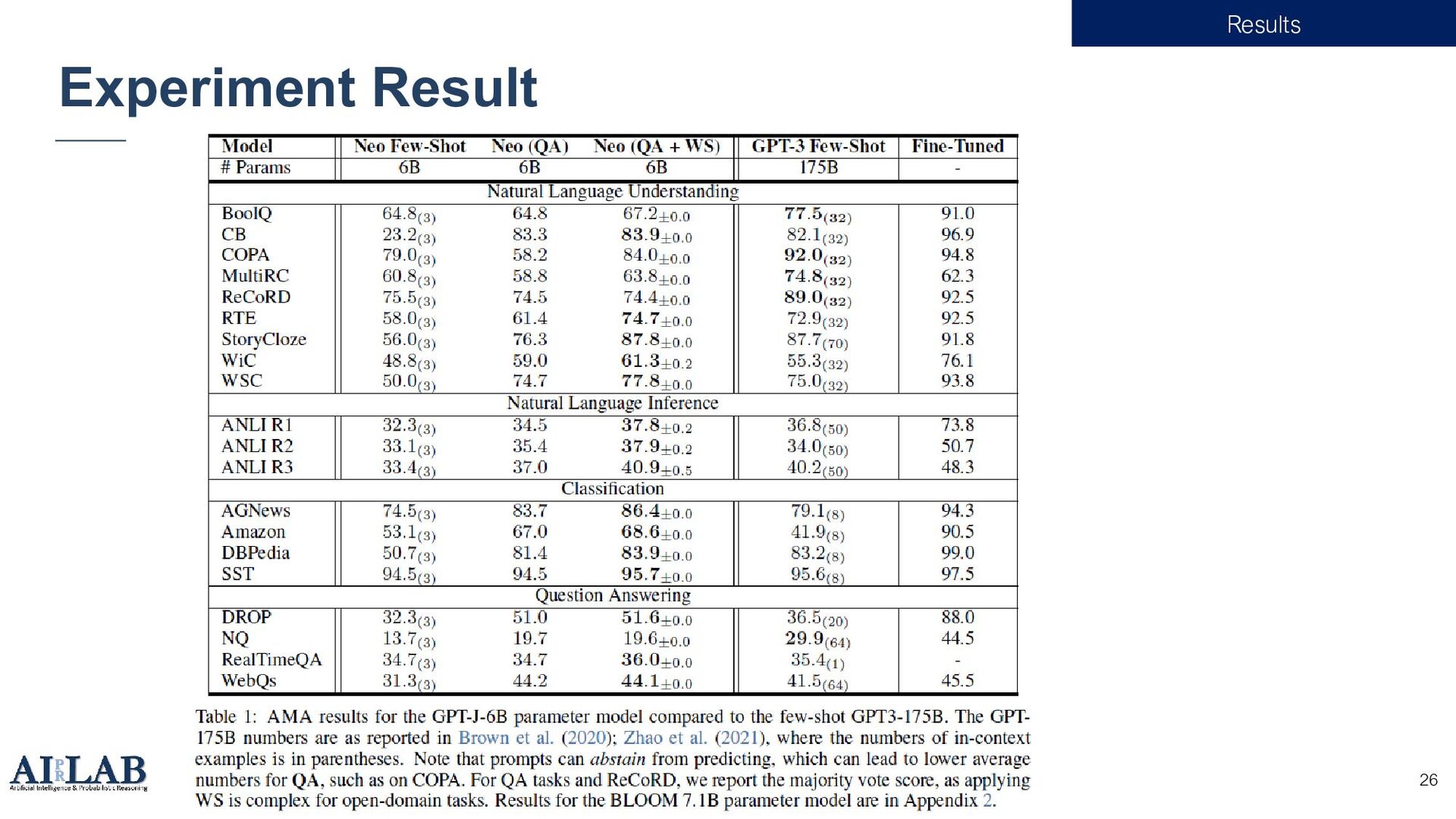{kind=link}
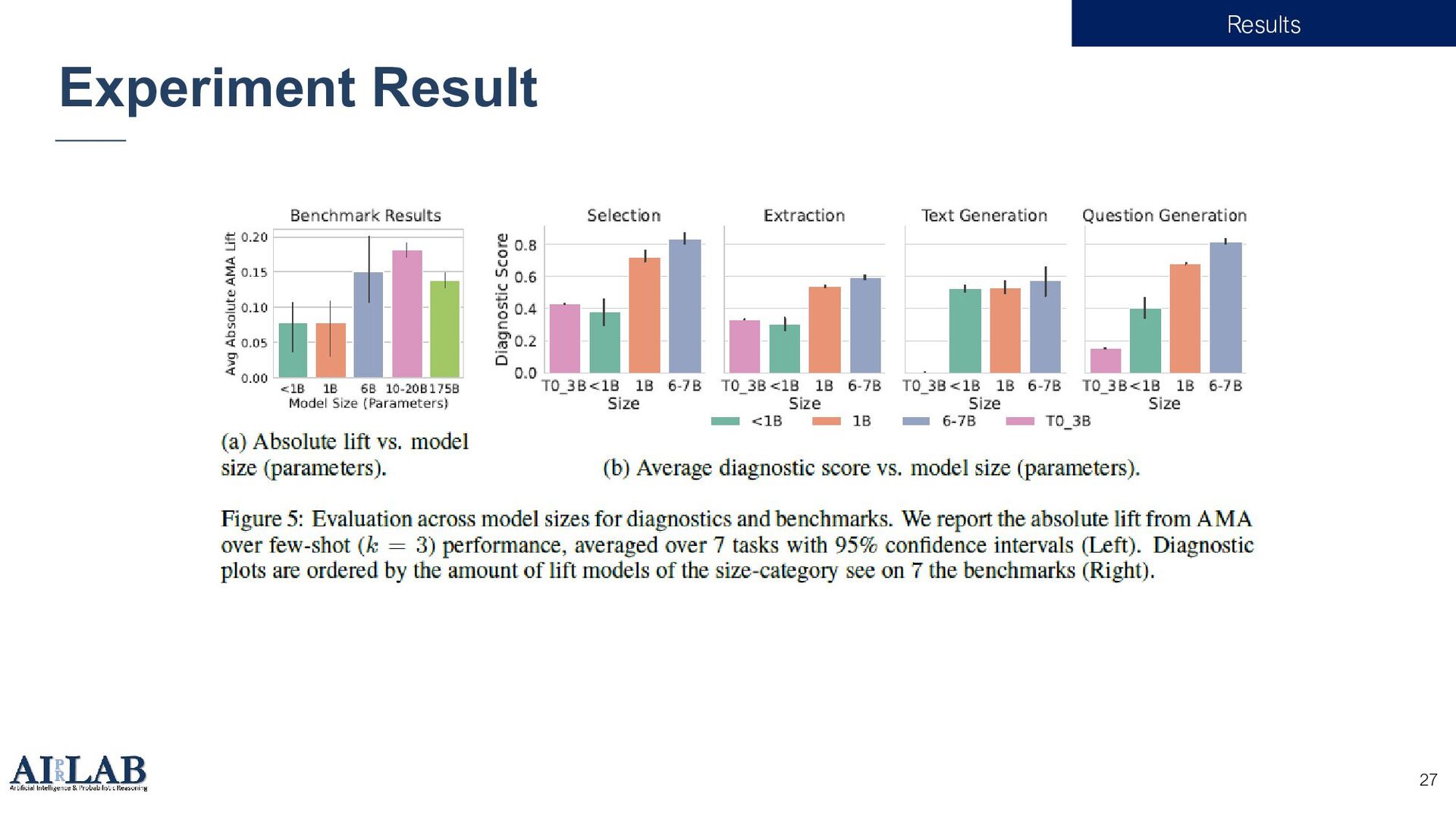{kind=link}
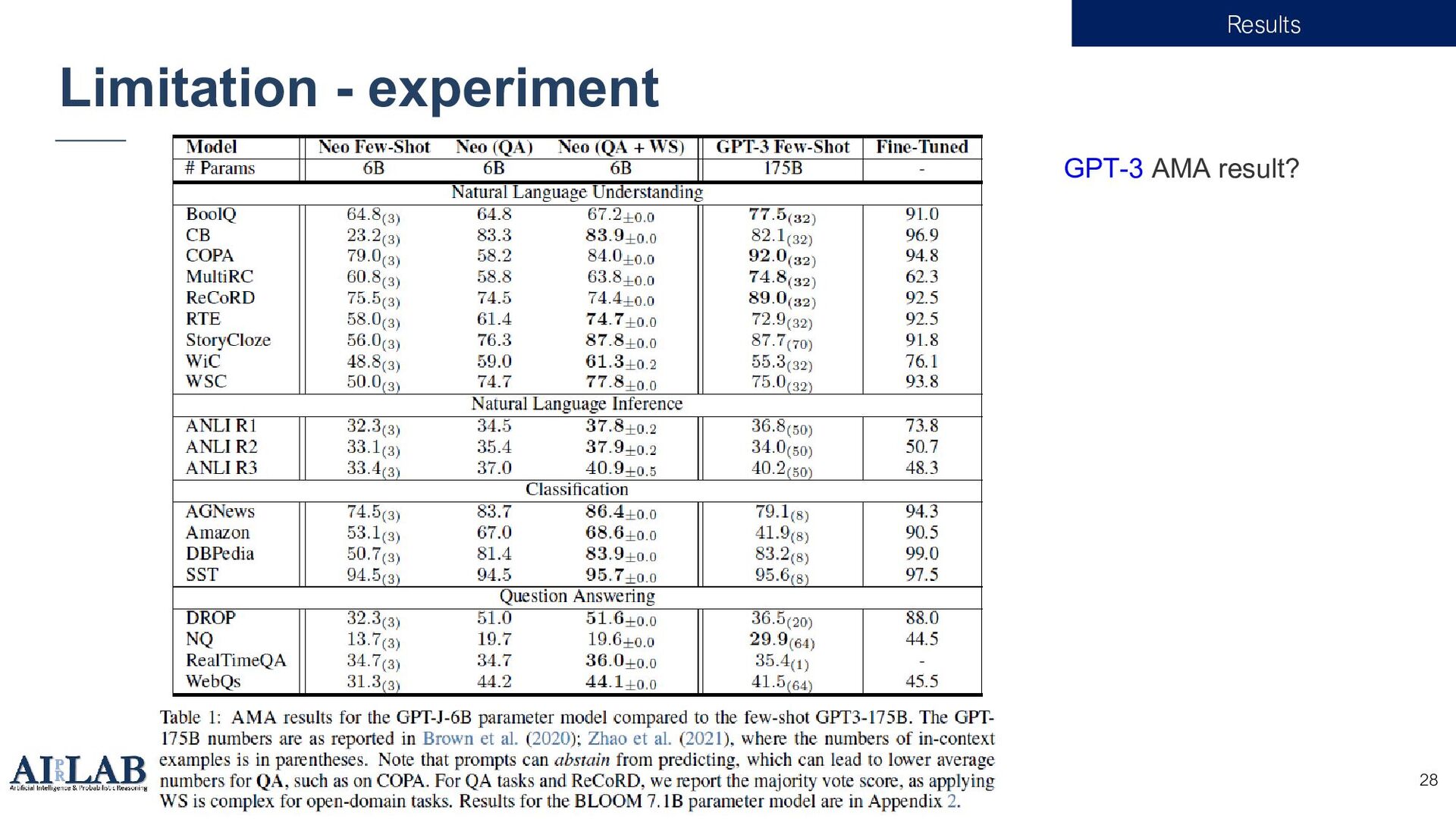{kind=link}
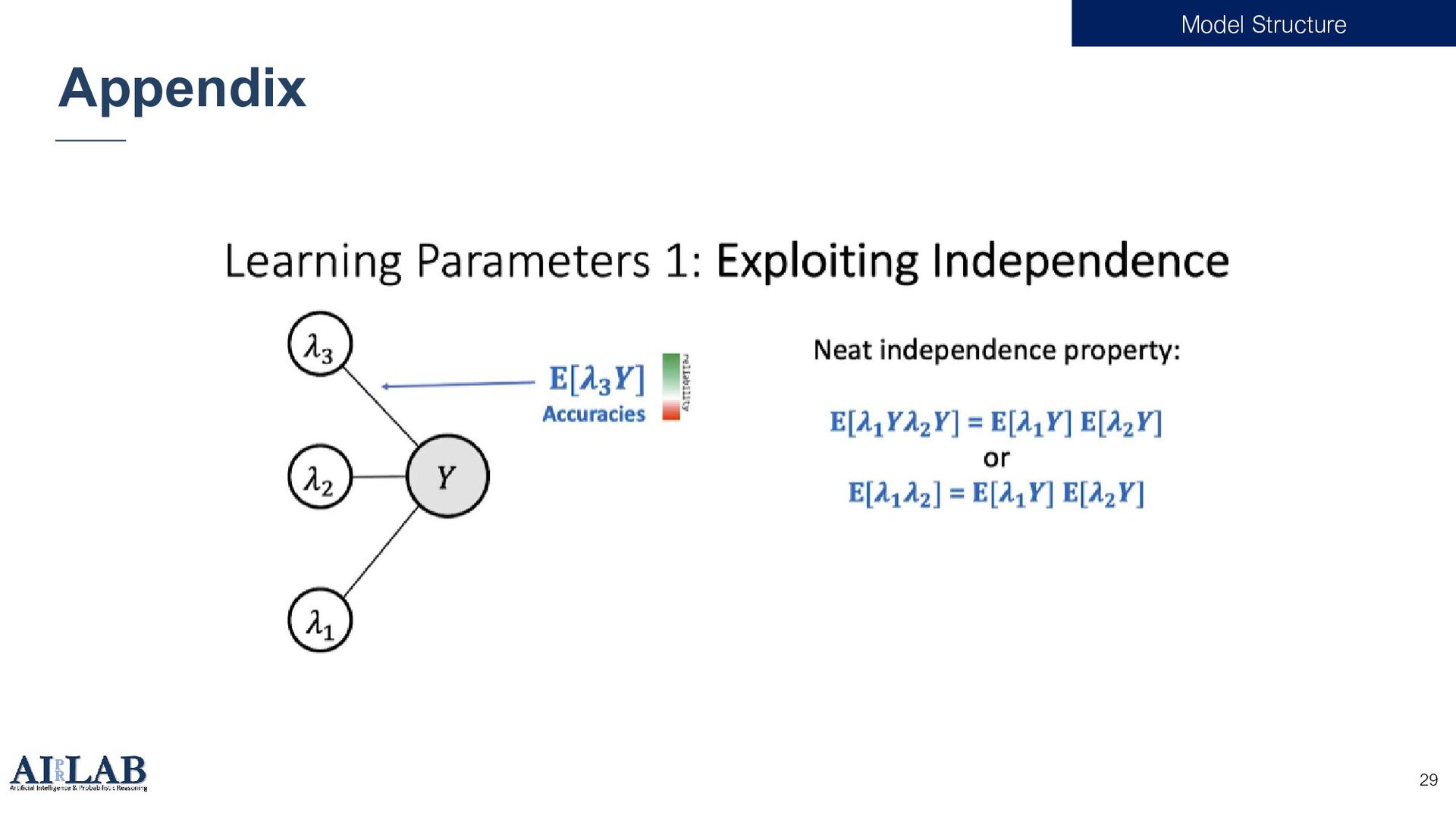{kind=link}
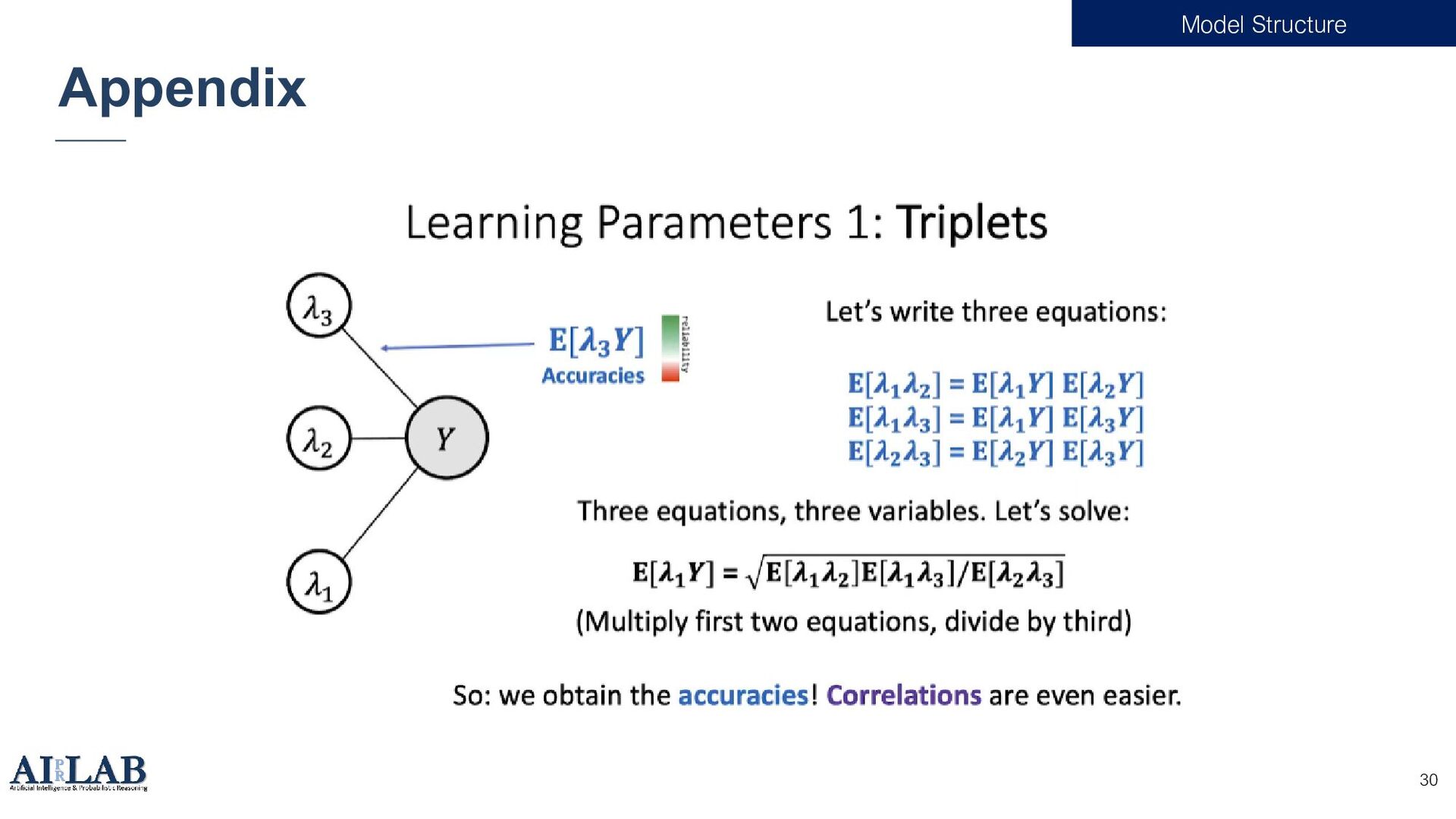{kind=link}
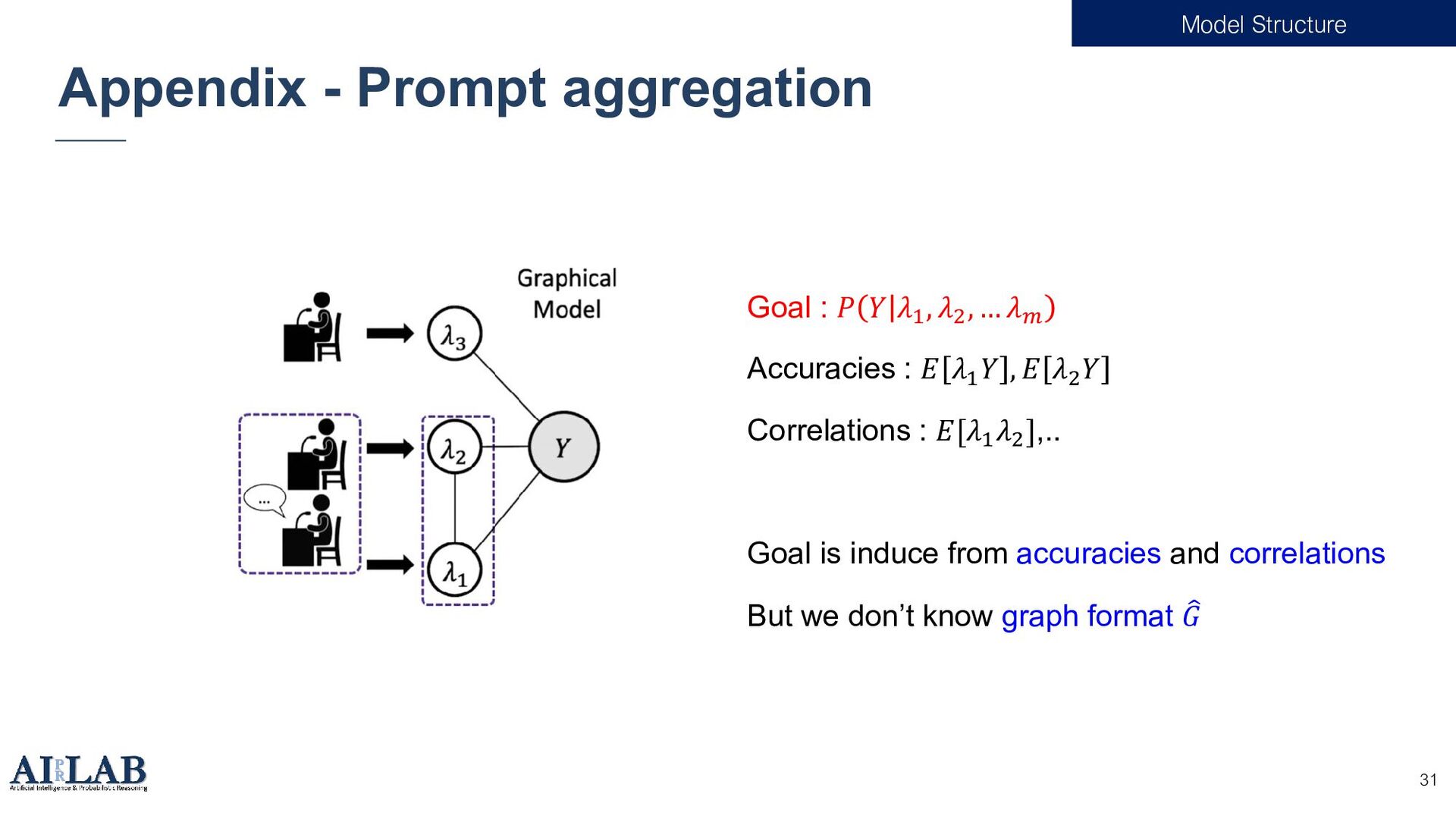{kind=link}
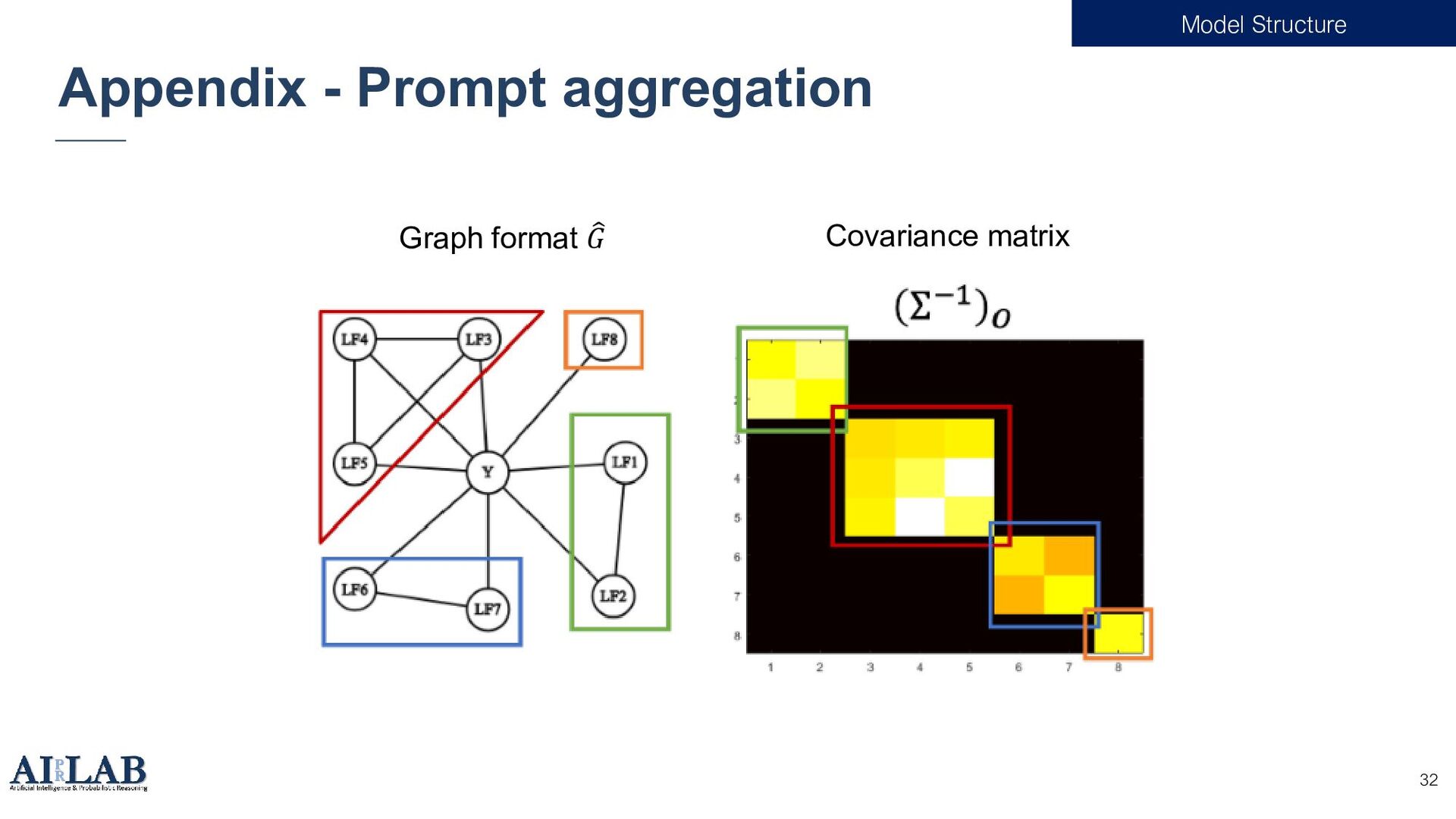{kind=link}
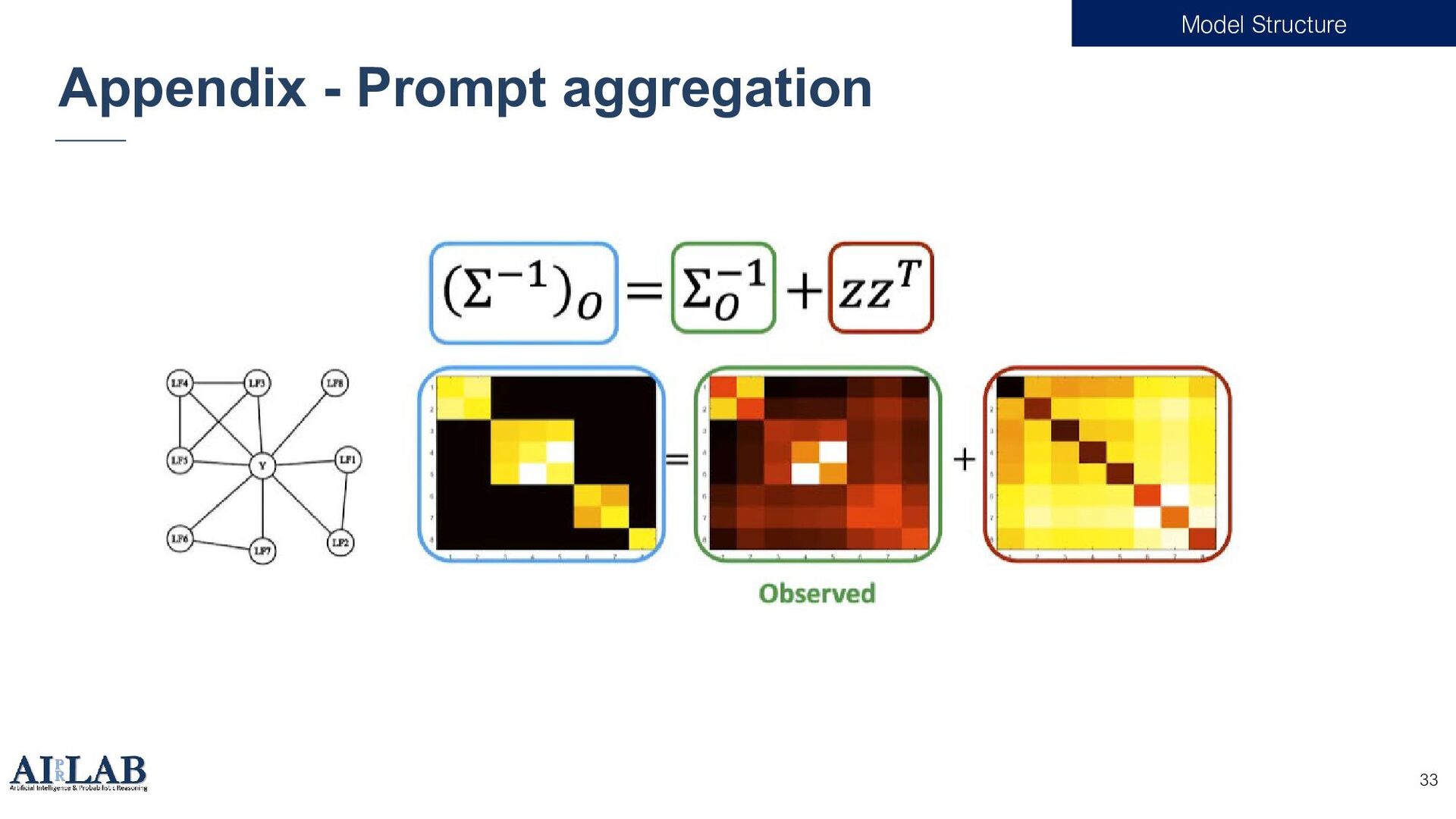{kind=link}
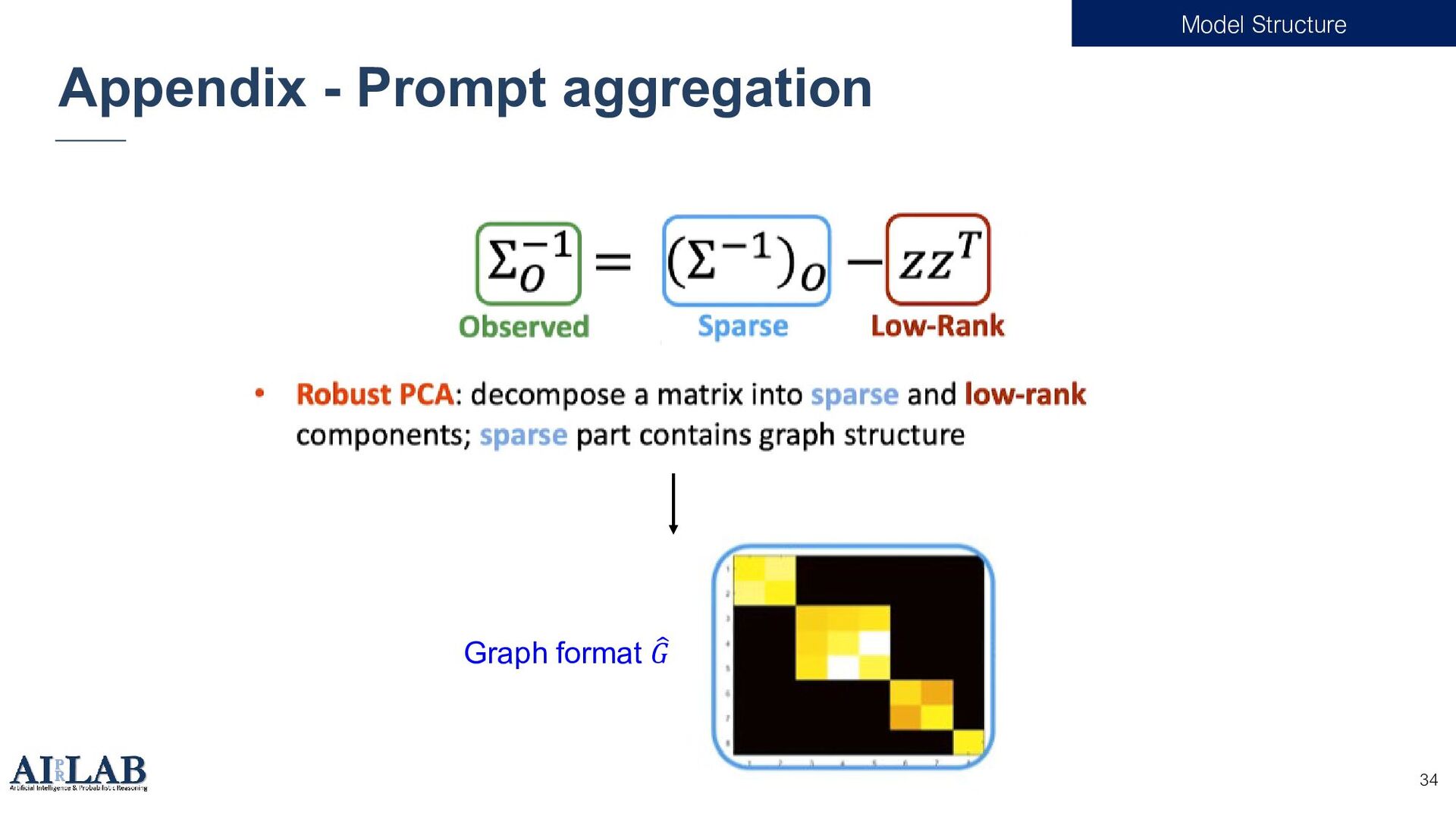{kind=link}
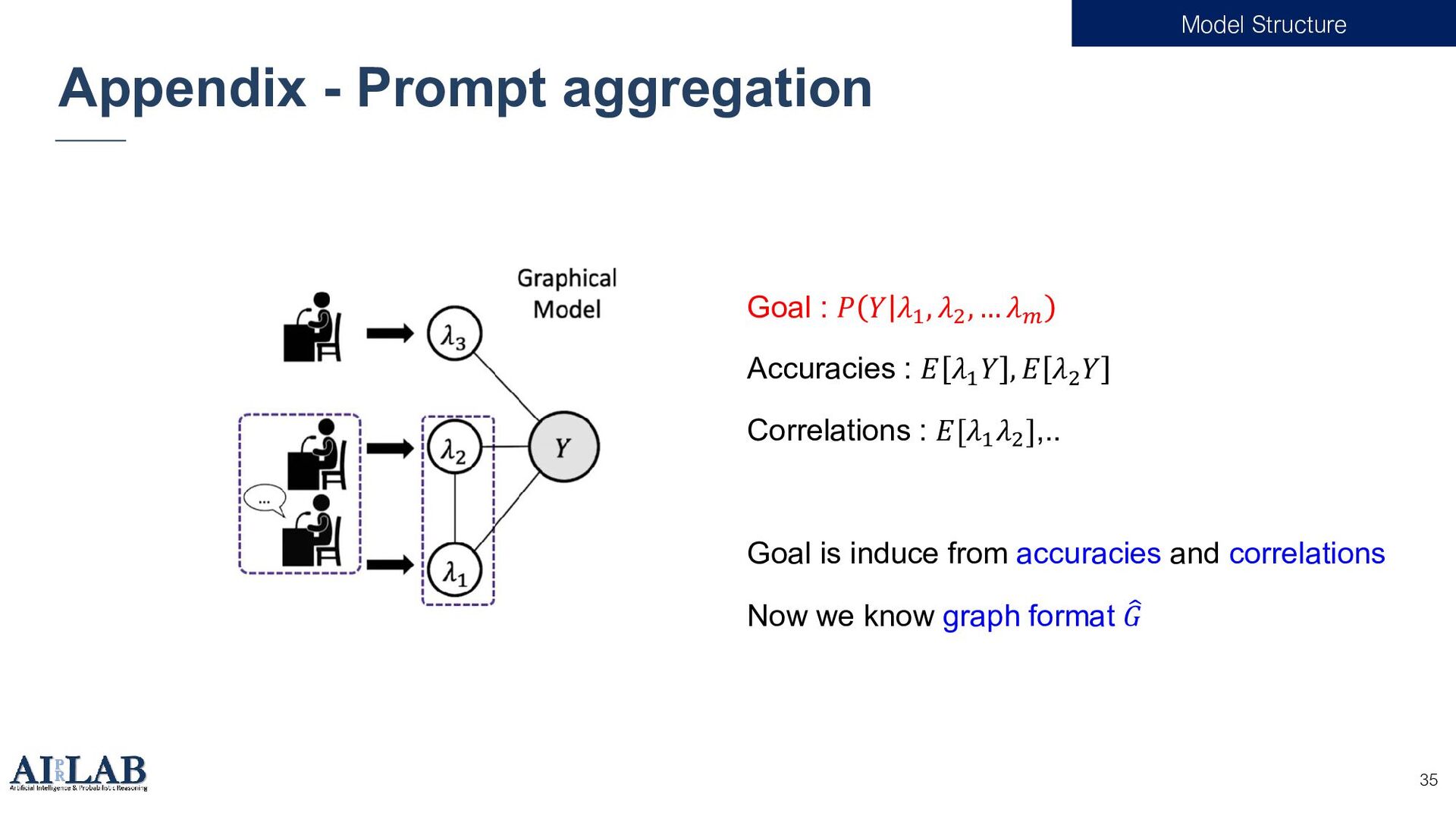{kind=link}