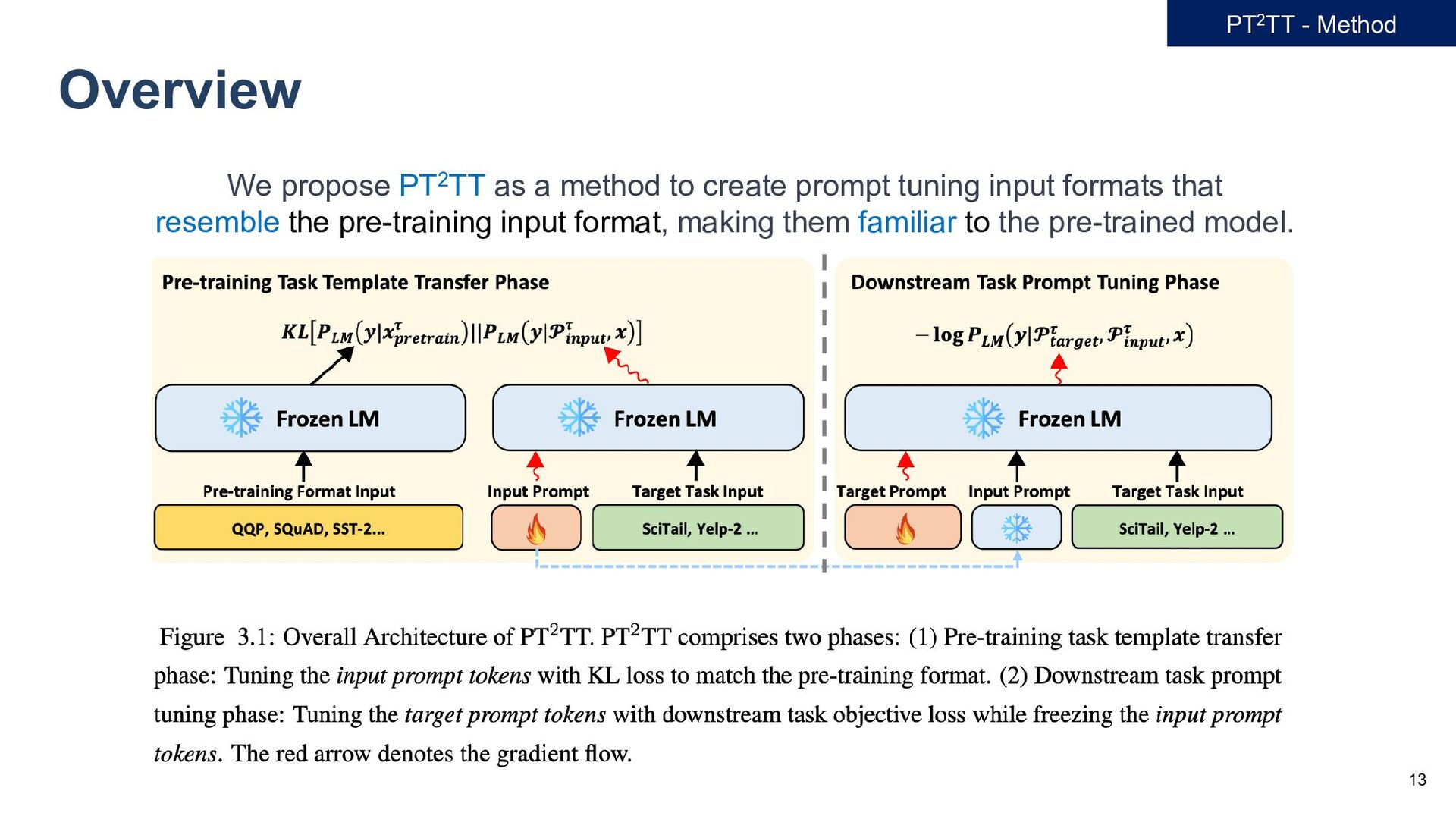
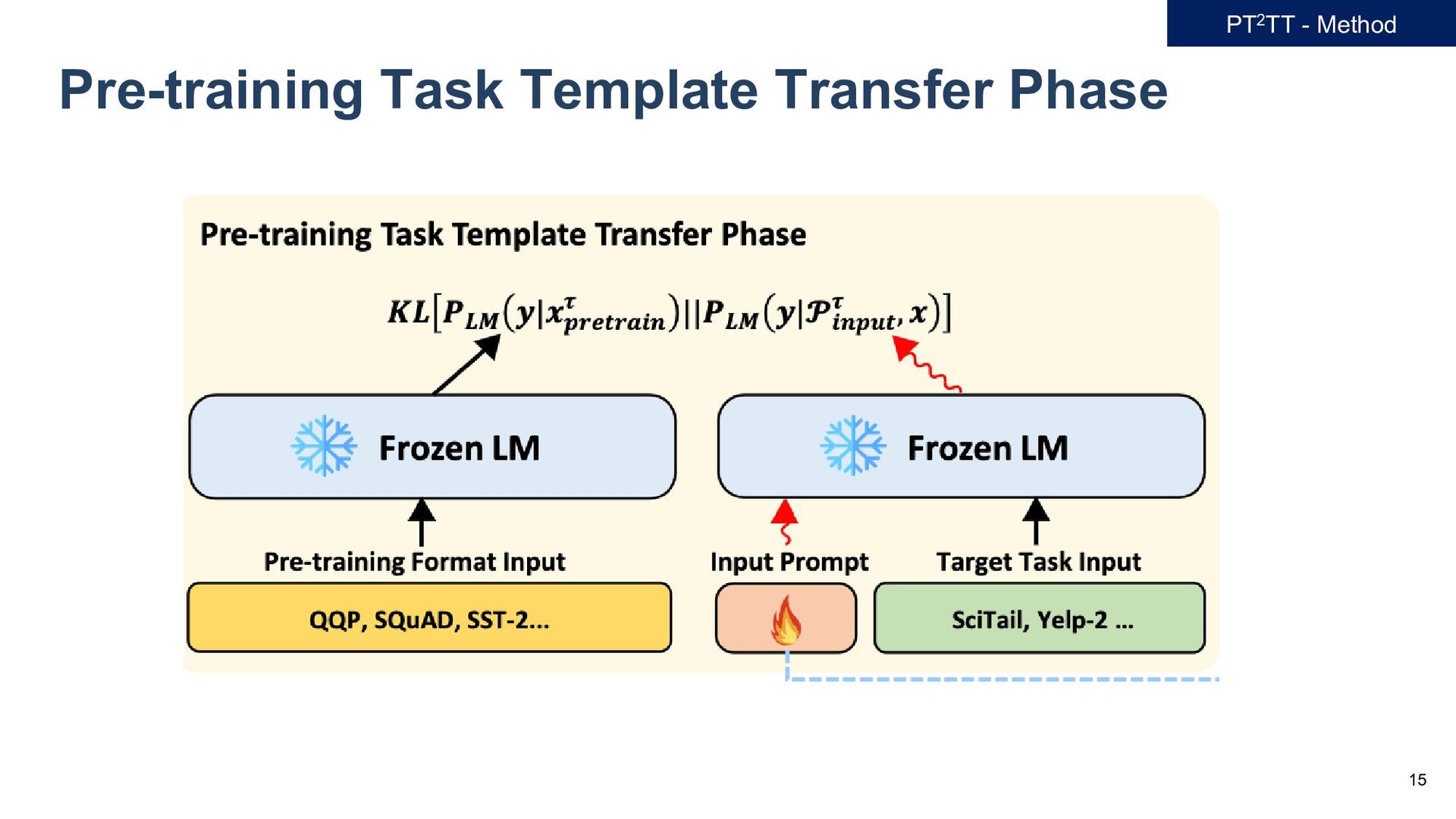
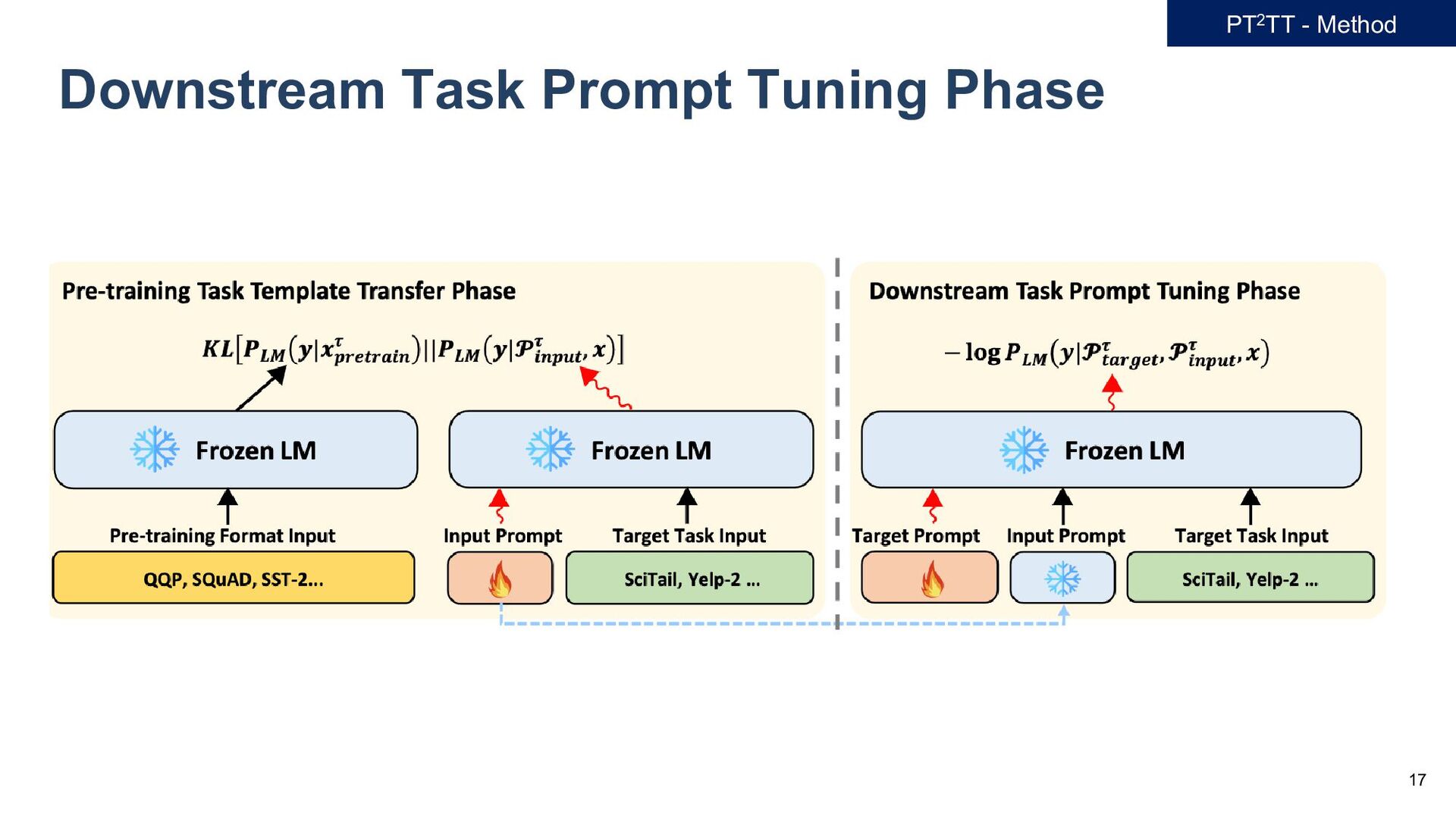
𝐷𝐷 = 𝑥𝑥𝑖𝑖 , 𝑦𝑦𝑖𝑖 𝑖𝑖=1 𝑁𝑁 , - we adopt preprocessor function 𝑓𝑓𝜏𝜏1 , 𝑓𝑓𝜏𝜏2 , … 𝑓𝑓𝜏𝜏𝐾𝐾 for each task 𝜏𝜏1 , 𝜏𝜏2 , … , 𝜏𝜏𝐾𝐾 . - Given raw input text 𝑥𝑥 and preprocessor function 𝑥𝑥𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝 𝜏𝜏 = 𝑓𝑓𝜏𝜏 (𝑥𝑥) - Define a vector of soft prompt tokens, input prompt tokens, denote as 𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏 = 𝒑𝒑1 𝜏𝜏, … , 𝒑𝒑𝑚𝑚 𝜏𝜏 ∈ ℝ𝑚𝑚×𝑑𝑑 - Pre-trained LM, then receives an input embedding, represented as [𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏 ; 𝑒𝑒𝑒𝑒𝑒𝑒 𝑥𝑥 ] - We generate the 𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏 that achieves the smallest KL loss, as follows: min 𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏 𝔼𝔼 𝒙𝒙~𝐷𝐷 𝐾𝐾𝐾𝐾 𝑃𝑃𝐿𝐿𝐿𝐿 𝒚𝒚 𝒙𝒙𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝 𝜏𝜏 ||𝑃𝑃𝐿𝐿𝐿𝐿 𝒚𝒚 𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏 , 𝒙𝒙 (1) - In this formulation, 𝑃𝑃𝐿𝐿𝐿𝐿 denotes the likelihood determined by the pre-trained LM. - Optimizing Eq. (1), we derive 𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏1 , 𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏2 ,…, 𝓟𝓟𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝜏𝜏𝐾𝐾 for all pre-training tasks. PT2TT - Method
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Demystifying Prompts via Perplexity Estimation[1] 6 [1] Gonen, Hila, et](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_4.jpg){kind=link}
![Different Input Processing Methods 7 [1] Raffel, Colin, et al.](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_5.jpg){kind=link}
![Input Tuning[1] 8 [1] An, Shengnan, et al. "Input-tuning: Adapting](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1] Wang et al. "GLUE: A multi-task benchmark and analysis](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_18.jpg){kind=link}
![21 Model details - Default setting : T5-base[1], total 100](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_19.jpg){kind=link}
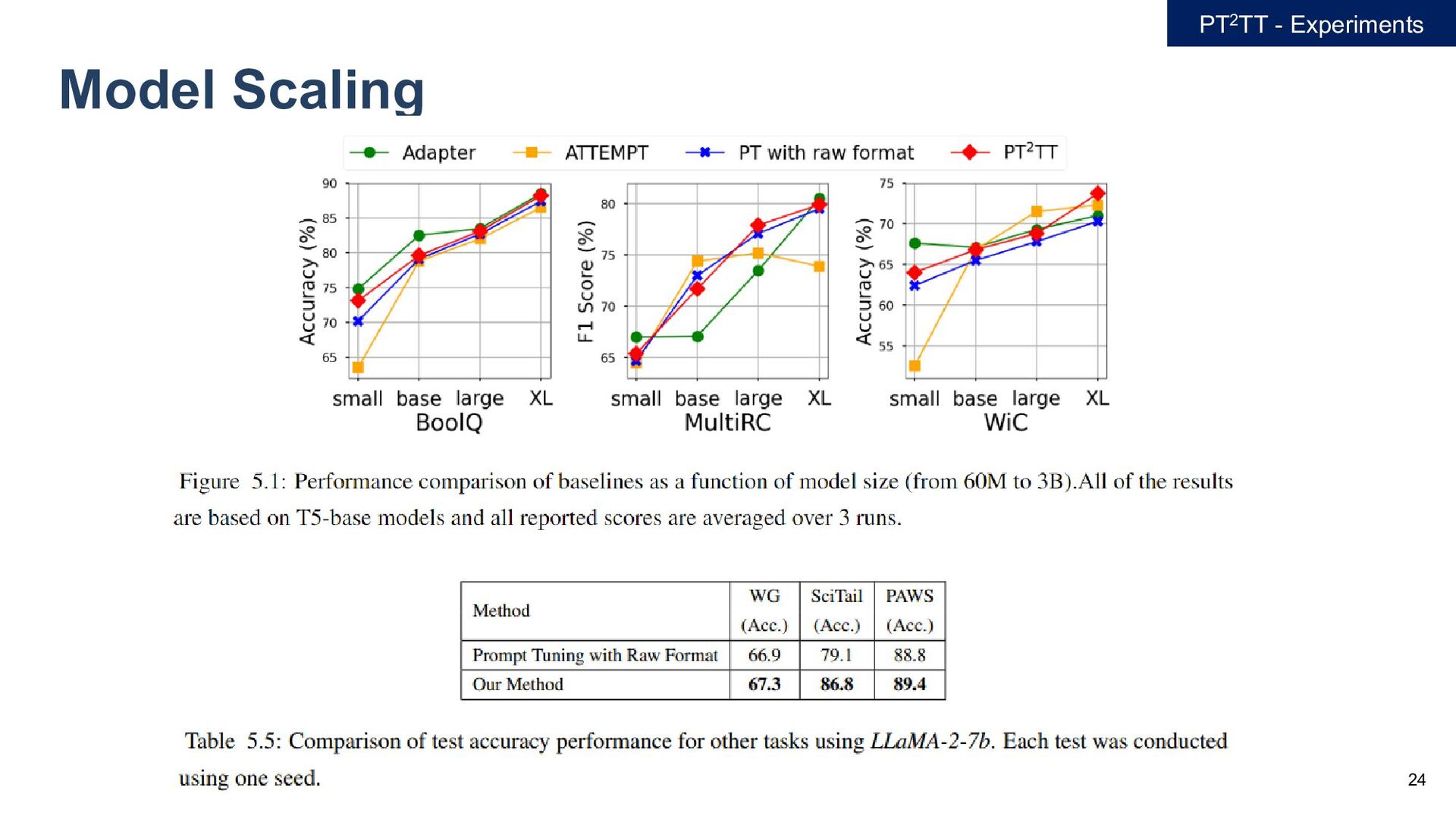
![22 Main Result PT2TT - Experiments [1] Wang, Zhen, et](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_20.jpg){kind=link}
![23 Main Result PT2TT - Experiments [1] Wang, Zhen, et](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
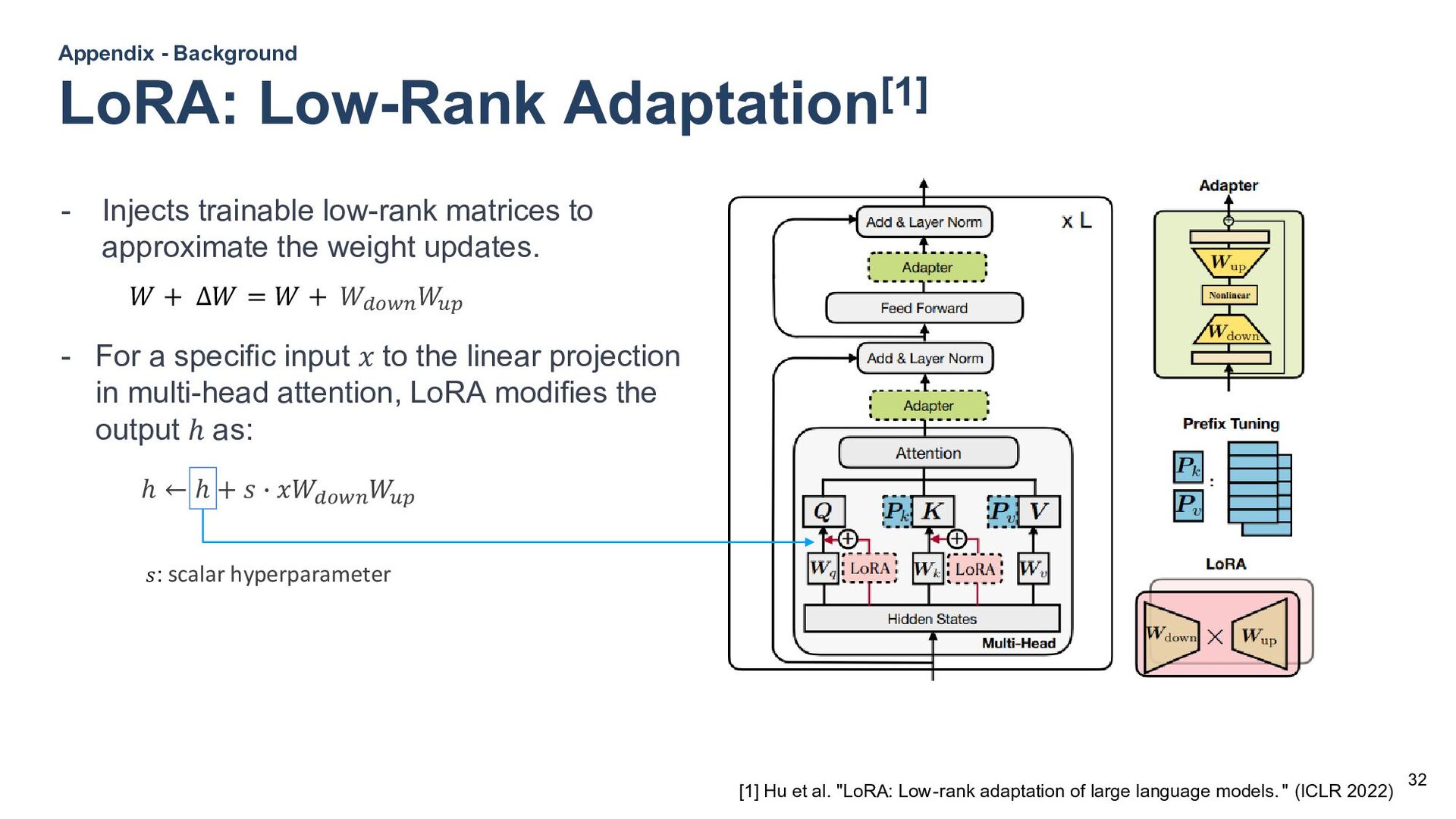
![31 Appendix - Background Prefix-Tuning[1] [1] XL Li, P Liang.](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_26.jpg){kind=link}
{kind=link}
![33 Appendix - Background P-Tuning[1] [1] X Liu, Y Zheng,](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![37 Appendix - Baseline SPoT: Soft Prompt Transfer [1] -](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_32.jpg){kind=link}
![38 Appendix - Baseline ATTEMPT: Attentional Mixture of Prompt Tuning[1]](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_33.jpg){kind=link}
![39 Appendix - Baseline MPT: Multitask Prompt Tuning[1] - Decompose](https://files.speakerdeck.com/presentations/0492e702bf084898b7bcb080a0659e7d/slide_34.jpg){kind=link}
{kind=link}
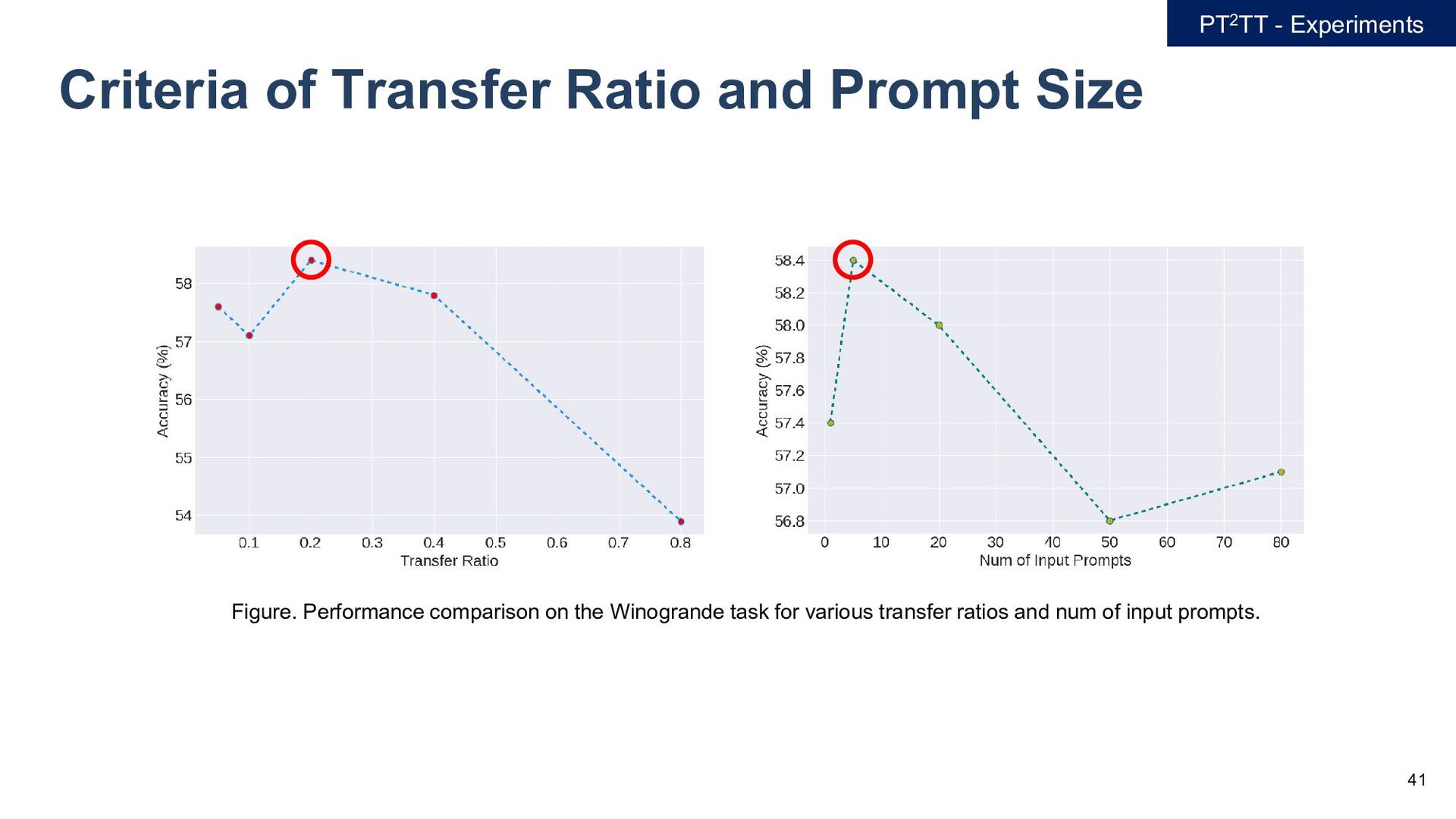{kind=link}