thought prompting elicits reasoning in large language models." 2022. [2] Brown, Tom, et al. "Language models are few-shot learners.“, Neurips 2020 Background Information Unimodal Multi-modal
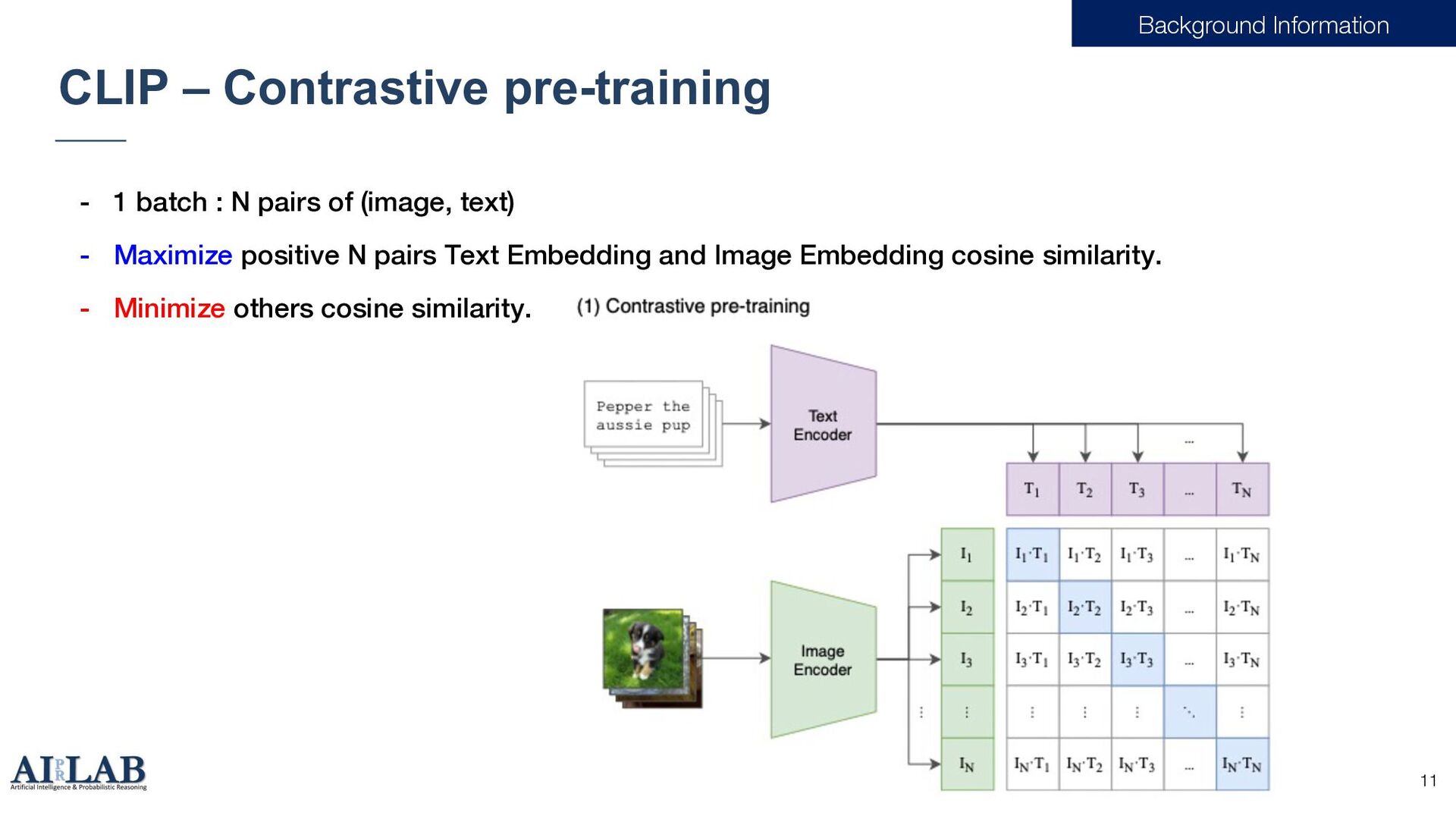
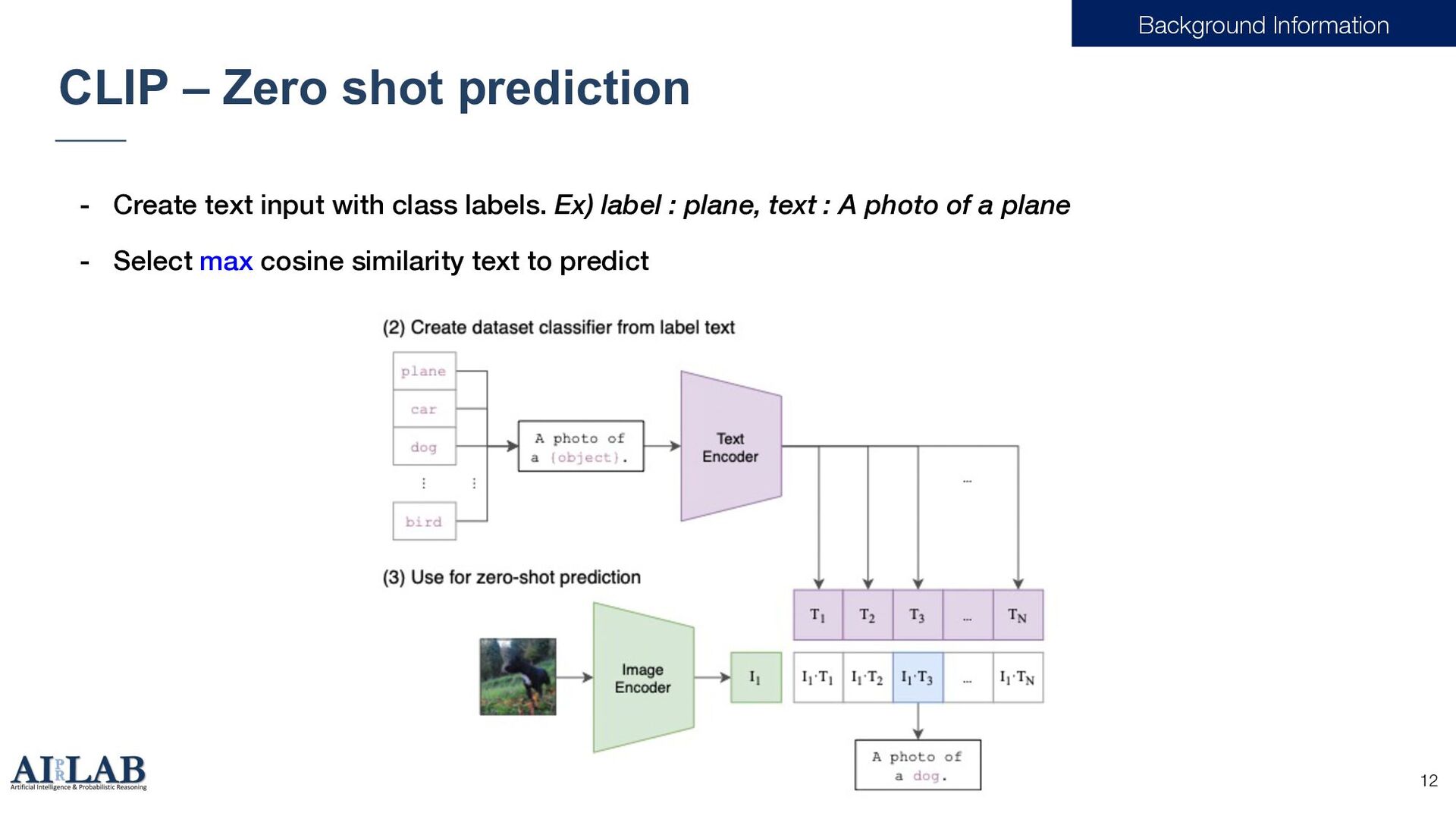
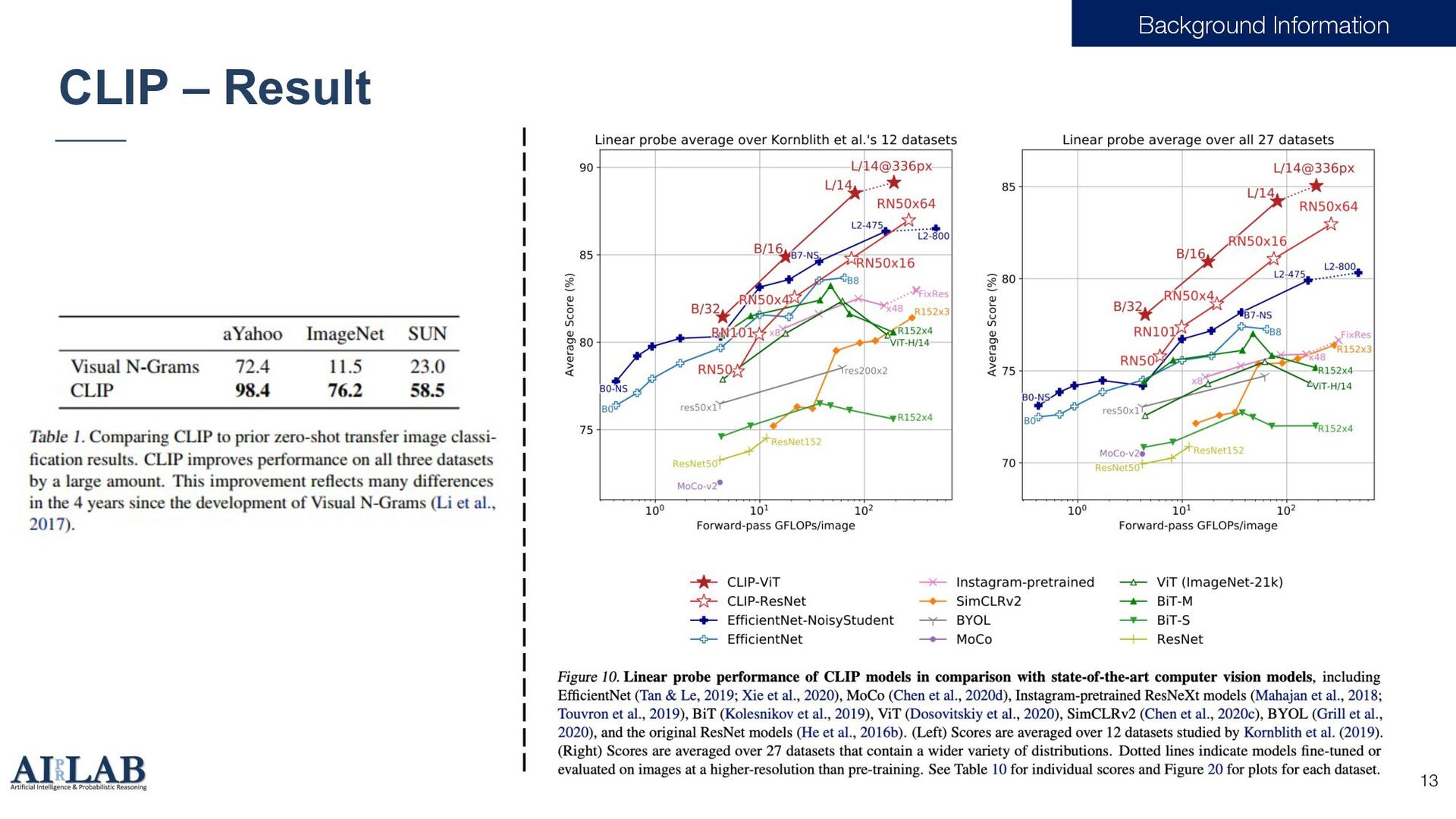
Pretraining CLIP[1] [1] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
12M (CC12M)[1] • Downstream – ImageNet[2], CIFAR-100 and CIFAR-10[3] • Model • Encoder – ViT-B/16, ViT-L/16[4] • Decoder – 8 blocks and 512 width transformer • Text tokenizer – BERT[5] • Hyperparameters • Mask ratio 0.75 / Weights of image prediction and text prediction are 1 and 0.5 [1] Changpinyo, Soravit, et al. "Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts." CVPR. 2021. [2] Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database." CVPR, 2009. [3] Krizhevsky, Alex, and Geoffrey Hinton. "Learning multiple layers of features from tiny images." (2009): 7. [4] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020). [5] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
{kind=link}
{kind=link}
{kind=link}
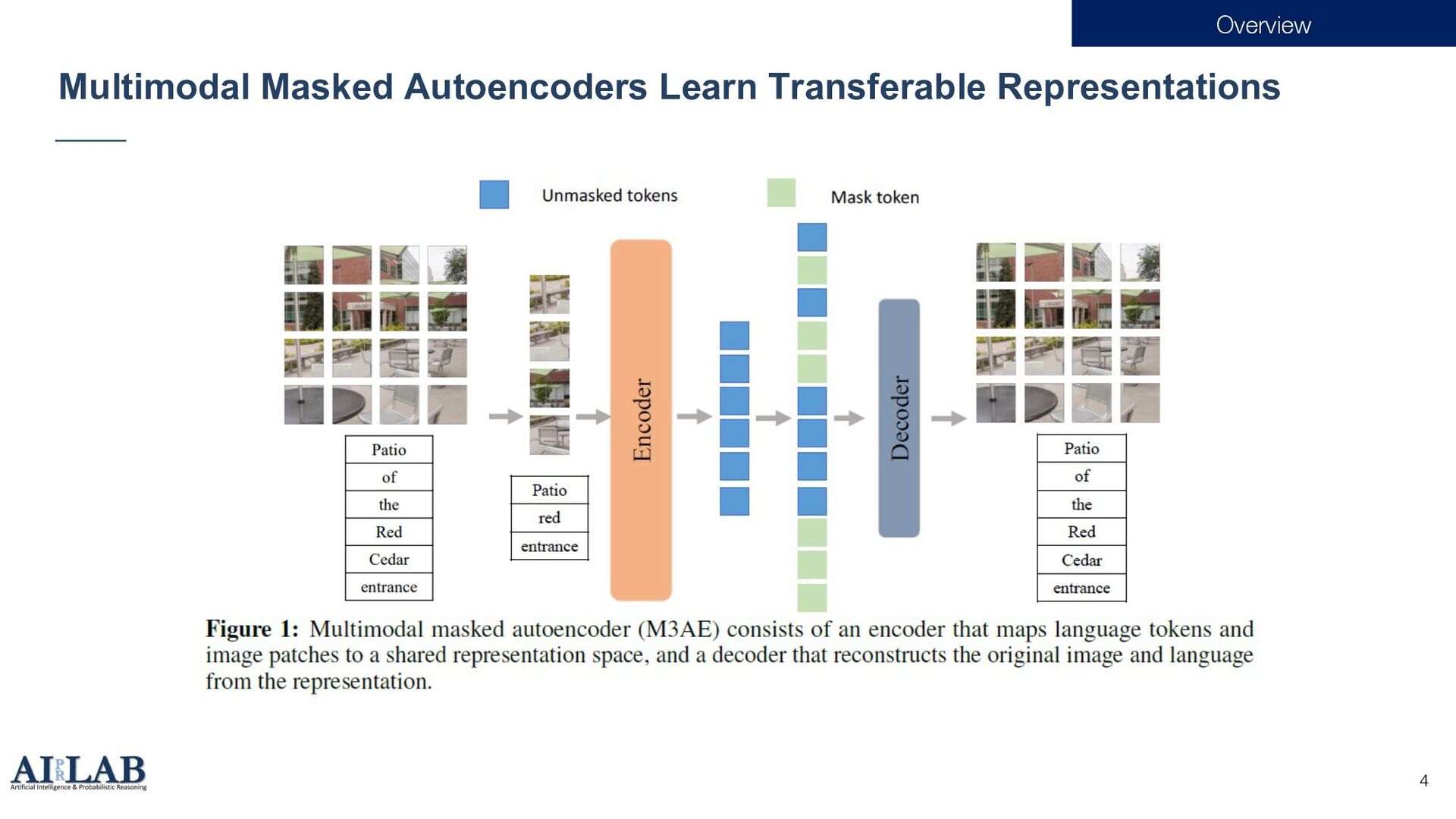{kind=link}
{kind=link}
![Multimodal learning 6 [1] Wei, Jason, et al. "Chain of](https://files.speakerdeck.com/presentations/b6e2dda0899445fcadfabd14ba17e41d/slide_5.jpg){kind=link}
{kind=link}
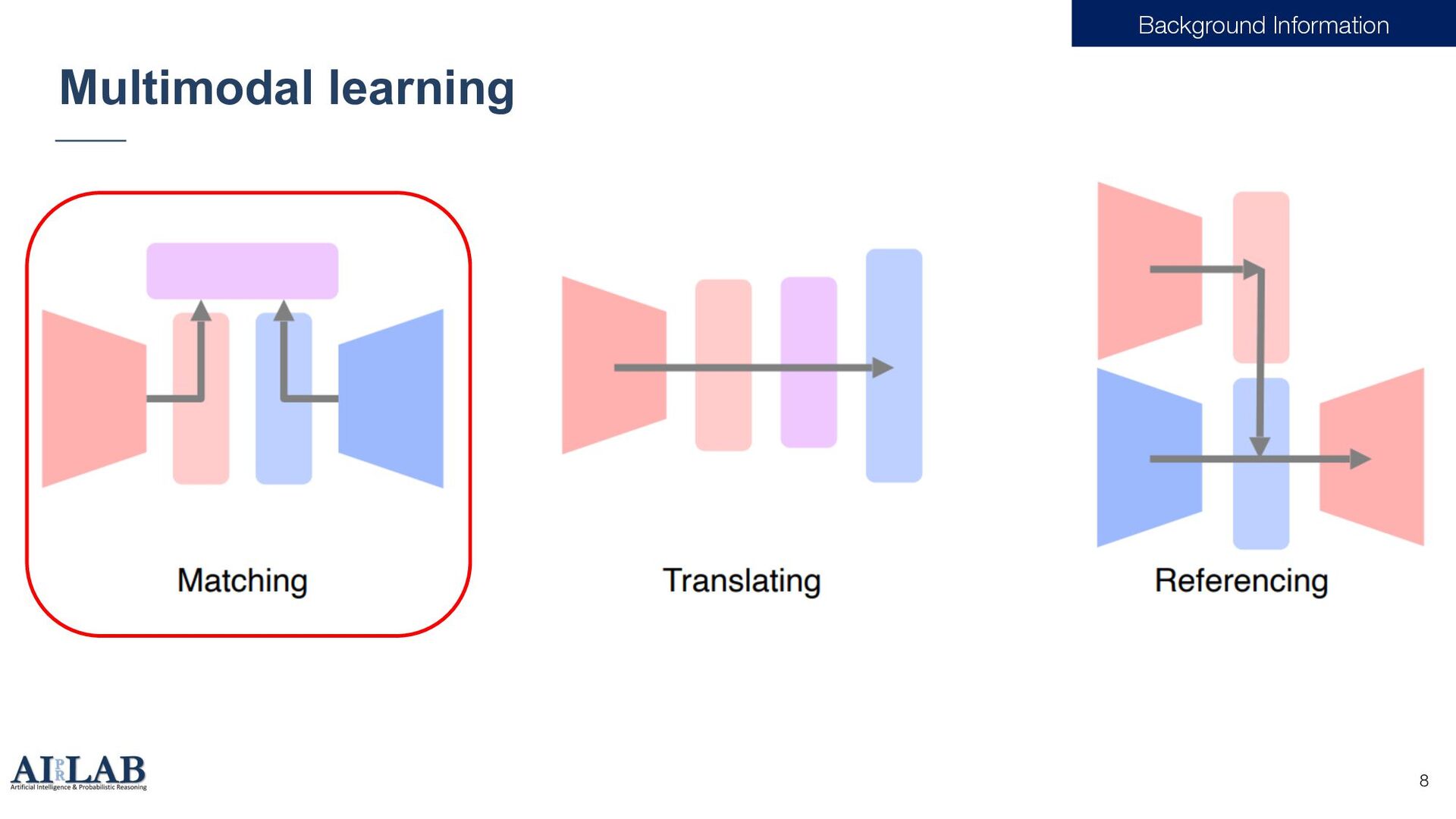{kind=link}
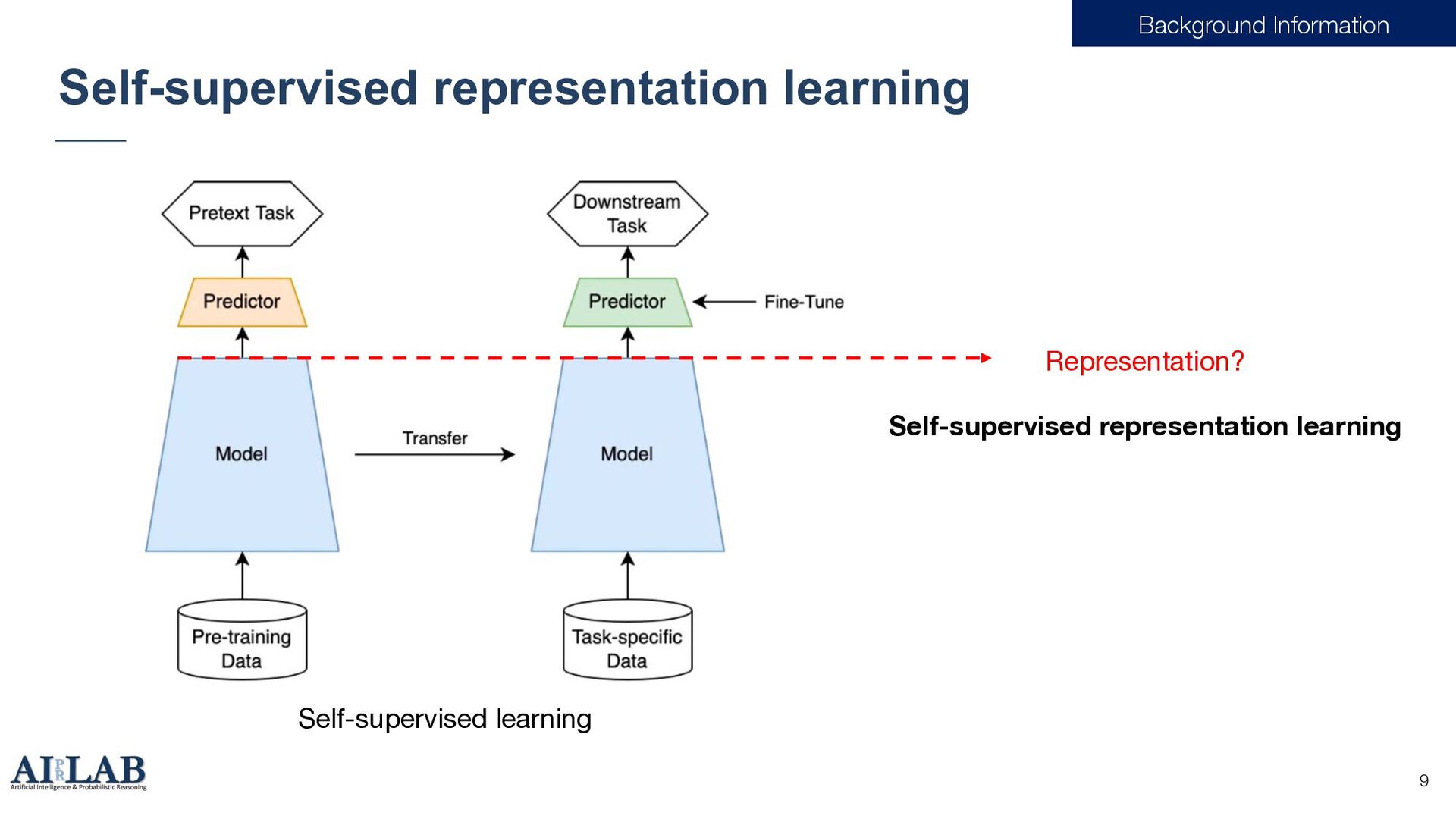{kind=link}
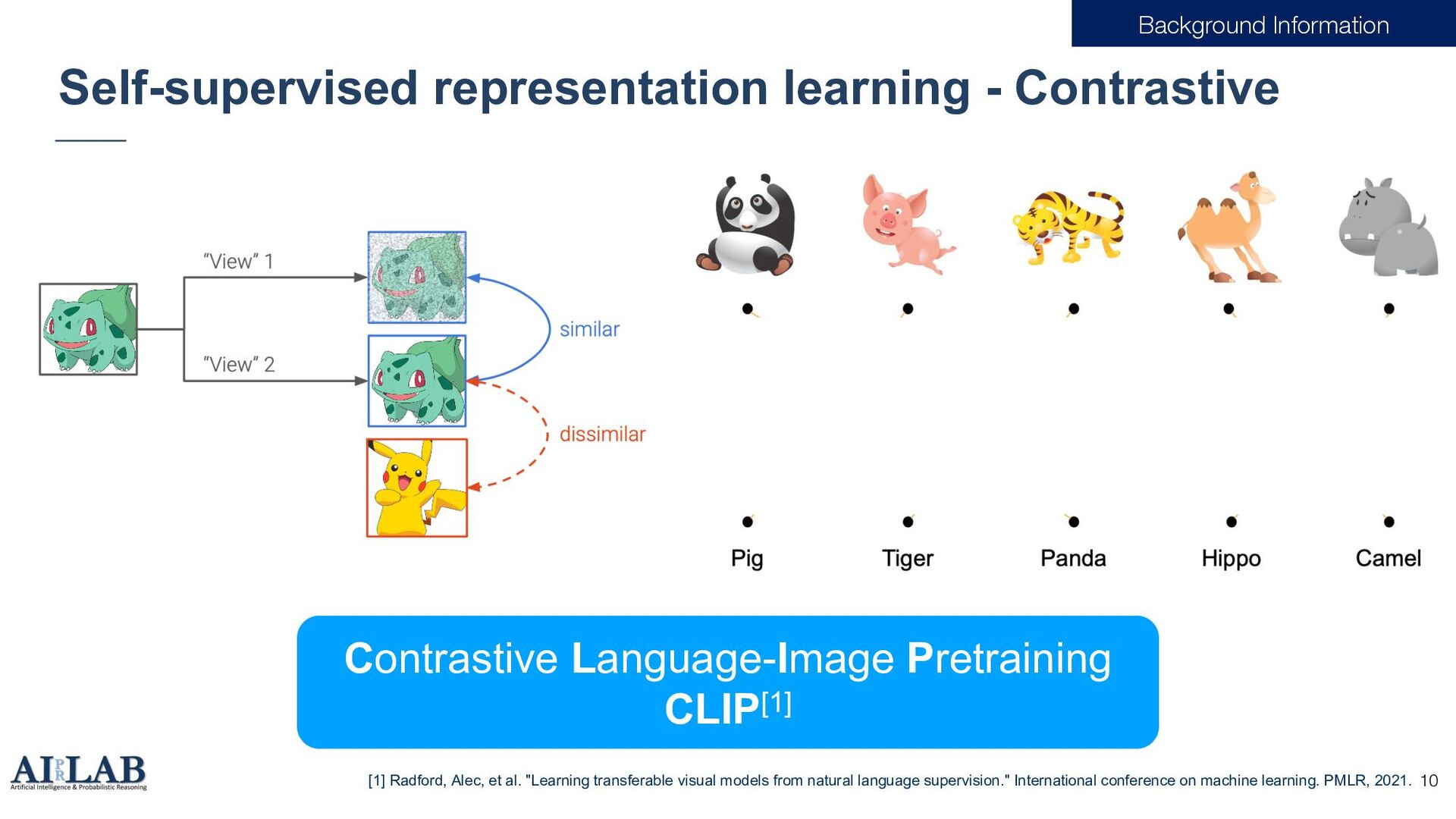{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Masked language model – BERT[1] 15 Background Information [1] Devlin,](https://files.speakerdeck.com/presentations/b6e2dda0899445fcadfabd14ba17e41d/slide_14.jpg){kind=link}
![Masked Autoencoders Are Scalable Vision Learners[1] 16 Background Information MAE](https://files.speakerdeck.com/presentations/b6e2dda0899445fcadfabd14ba17e41d/slide_15.jpg){kind=link}
{kind=link}
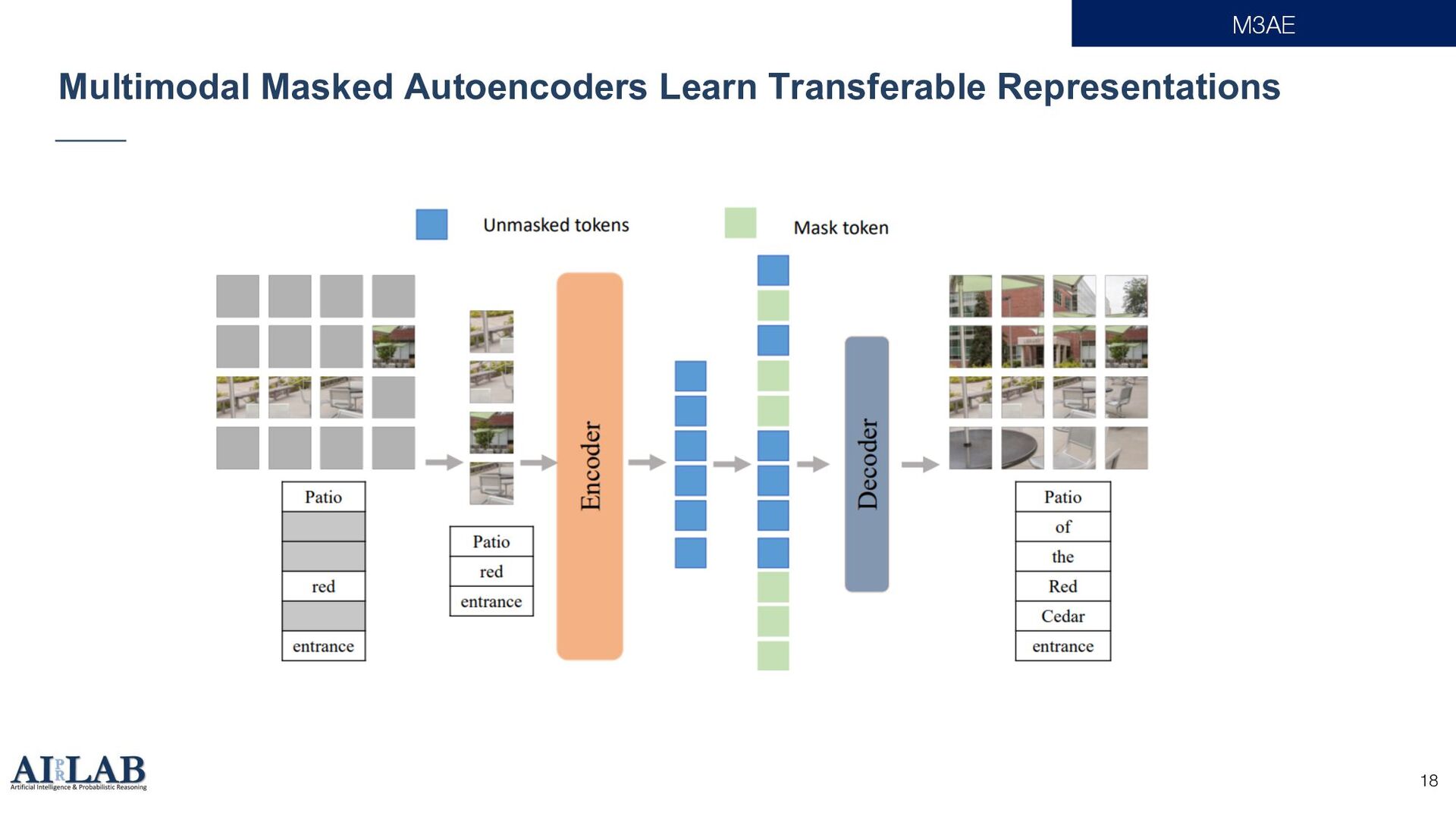{kind=link}
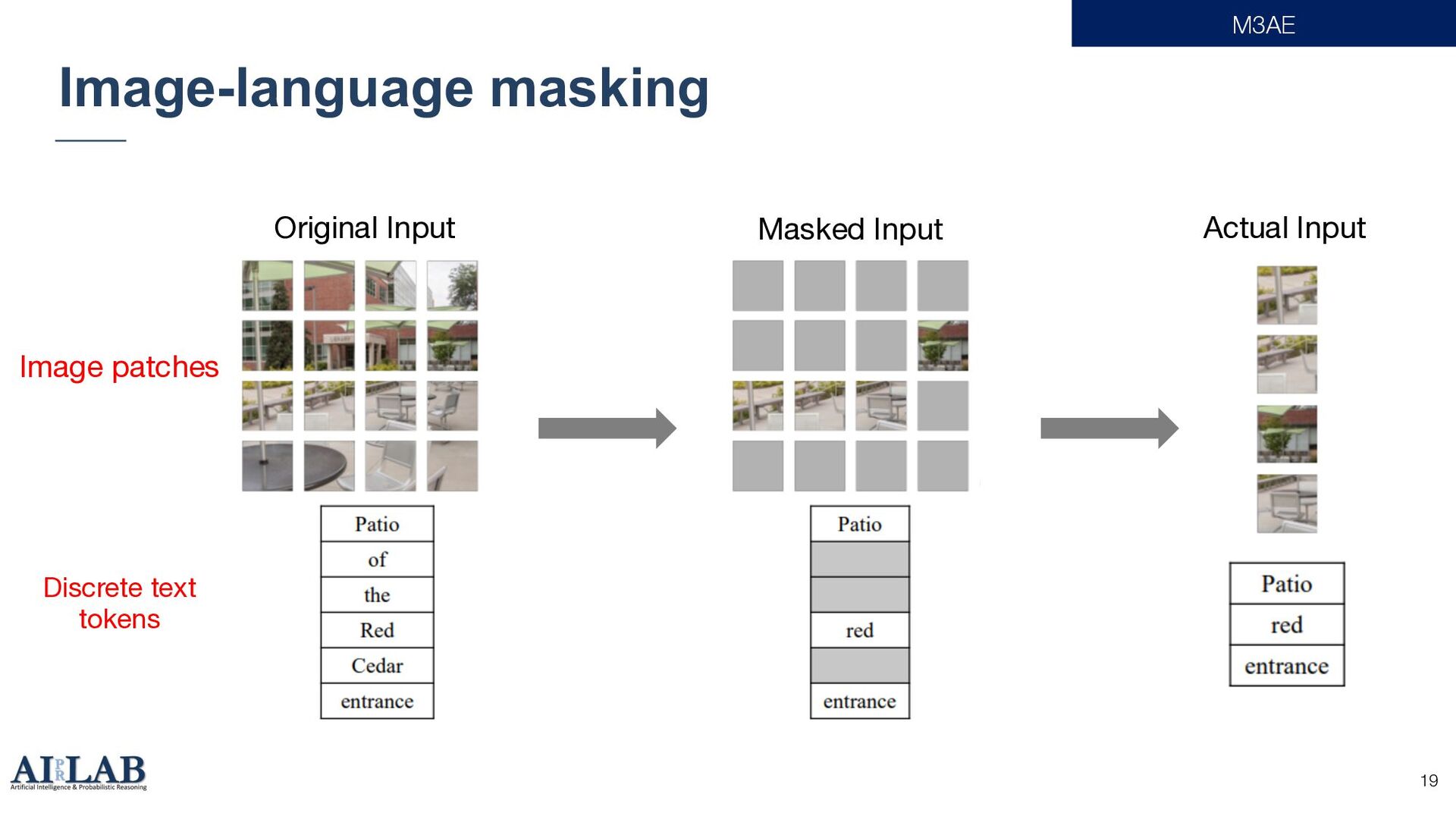{kind=link}
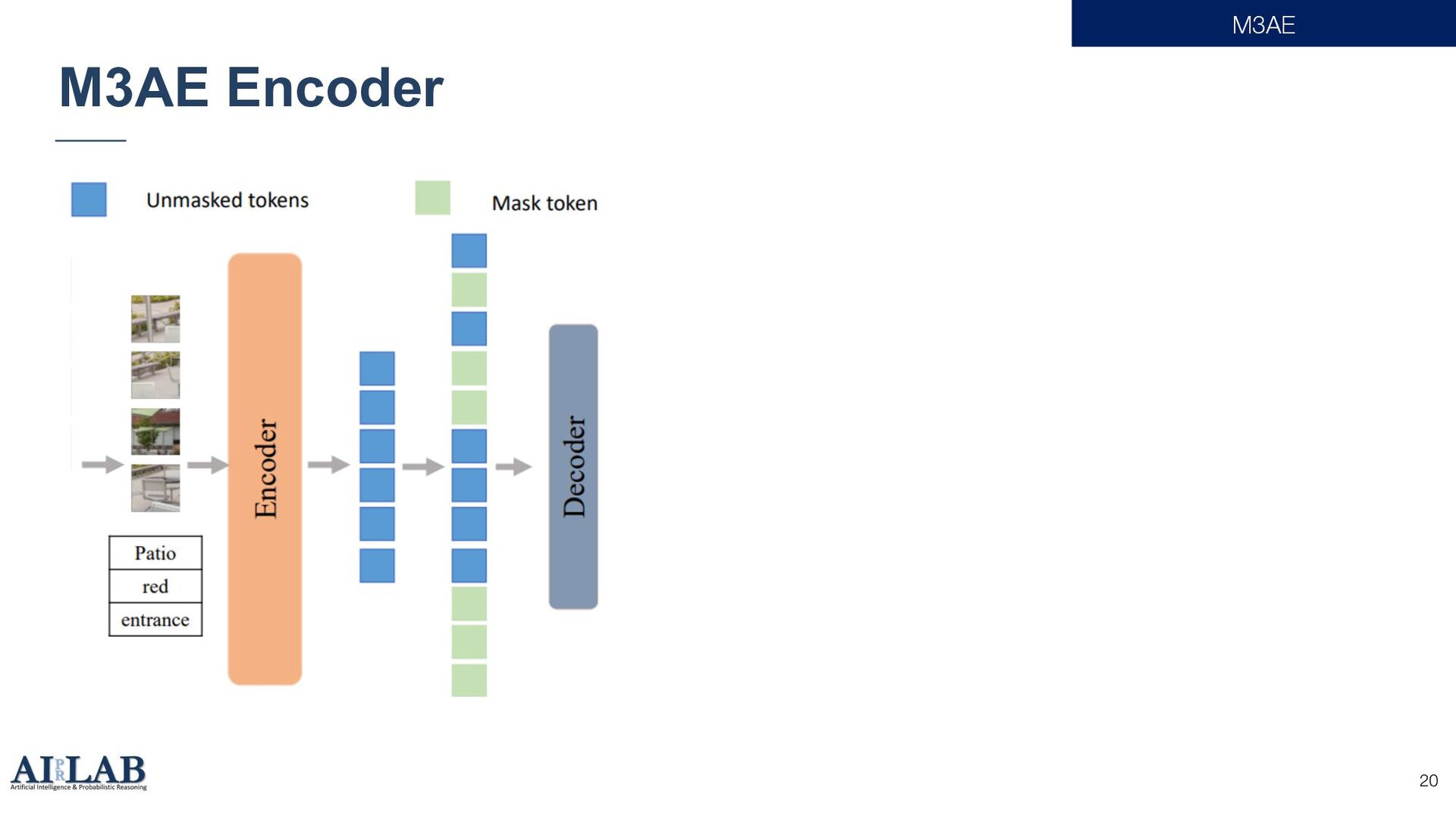{kind=link}
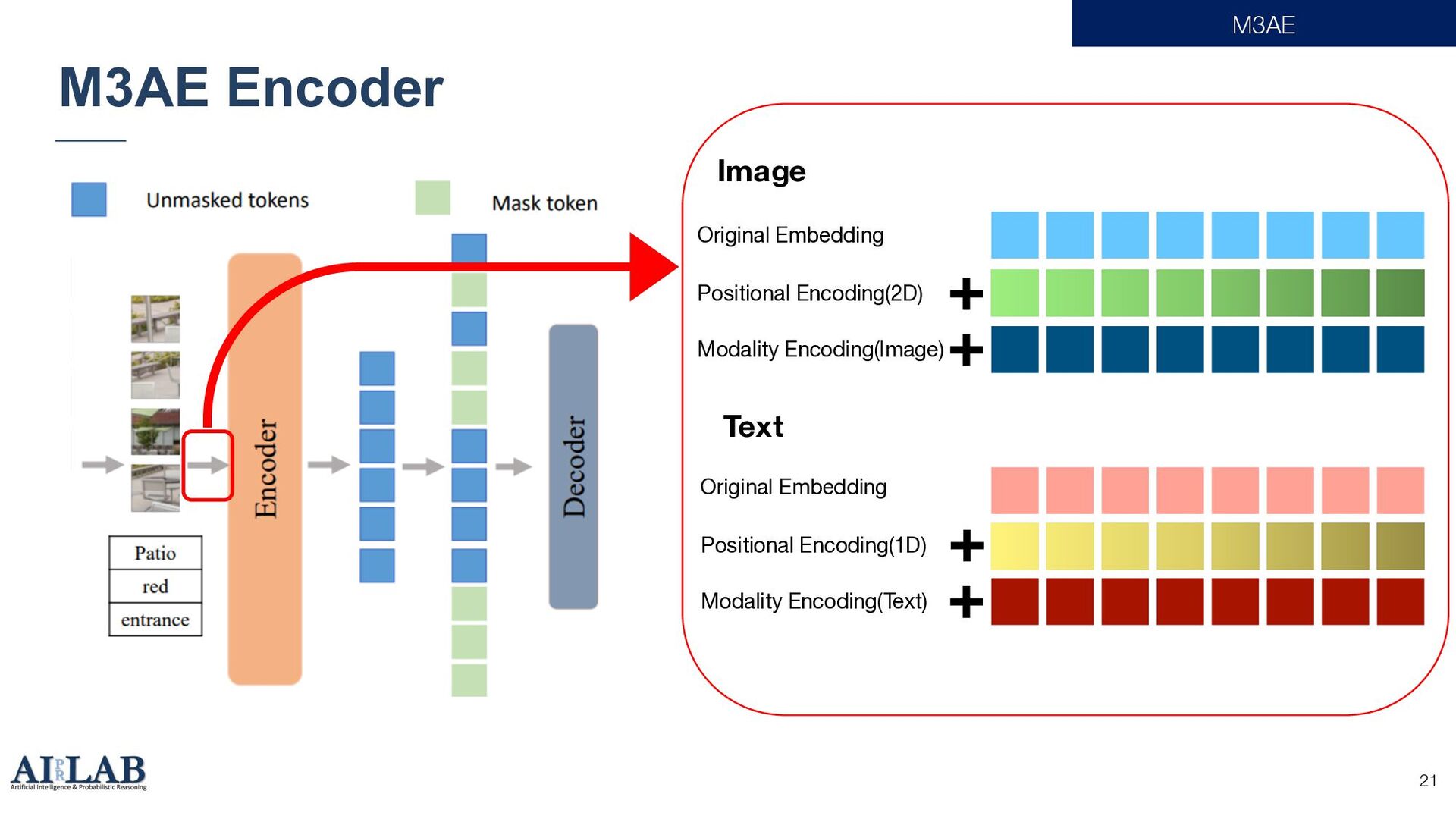{kind=link}
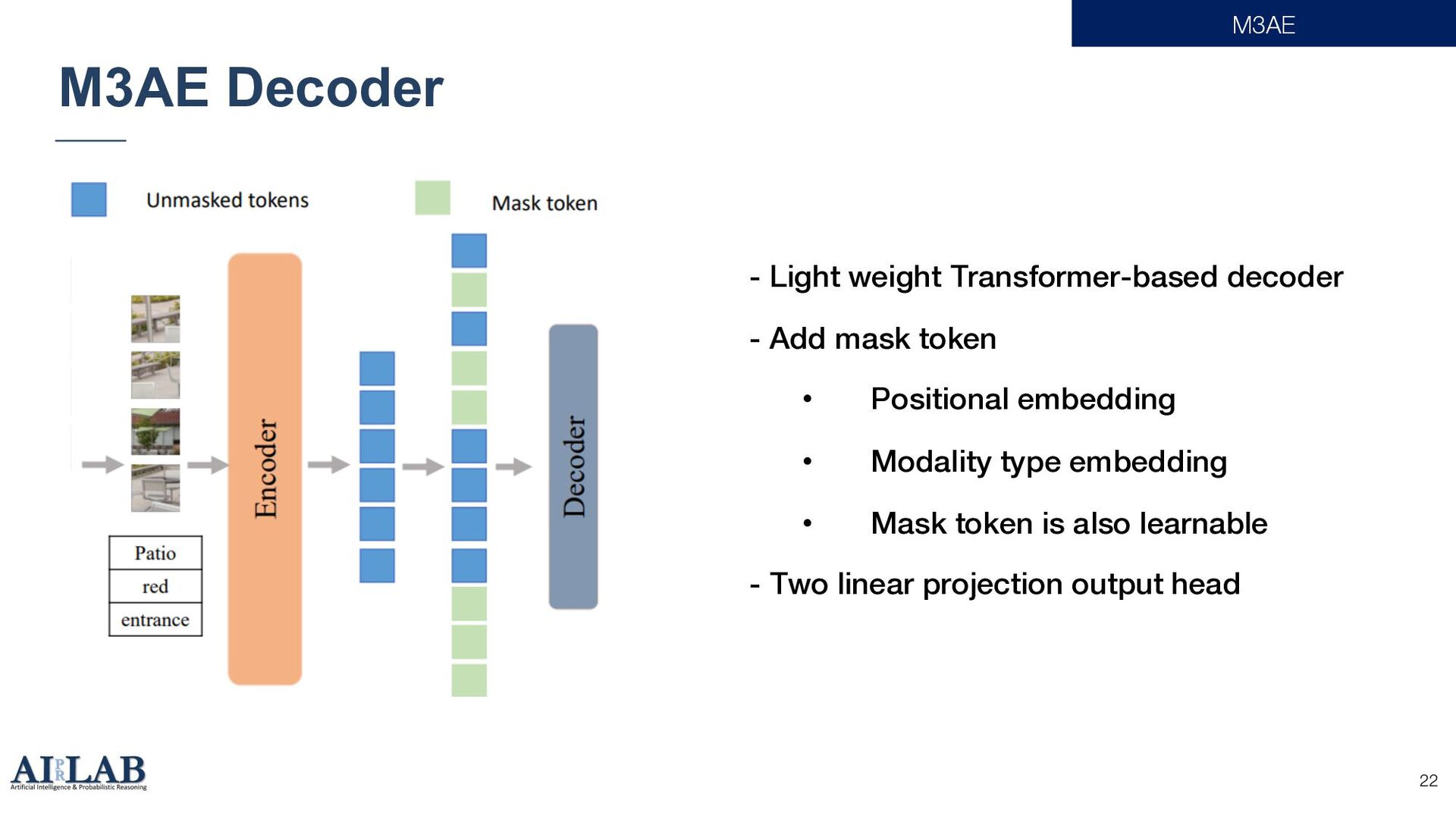{kind=link}
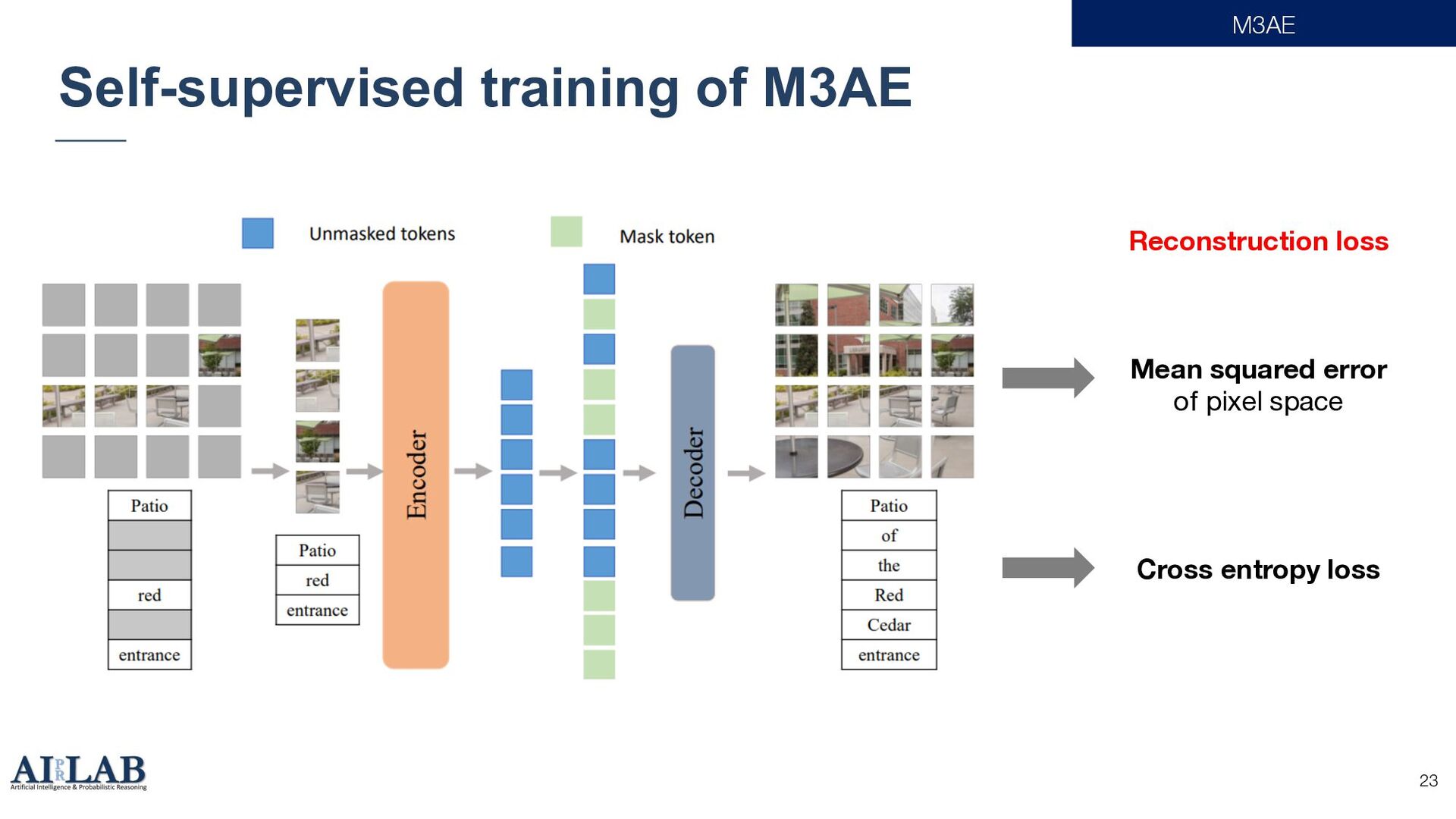{kind=link}
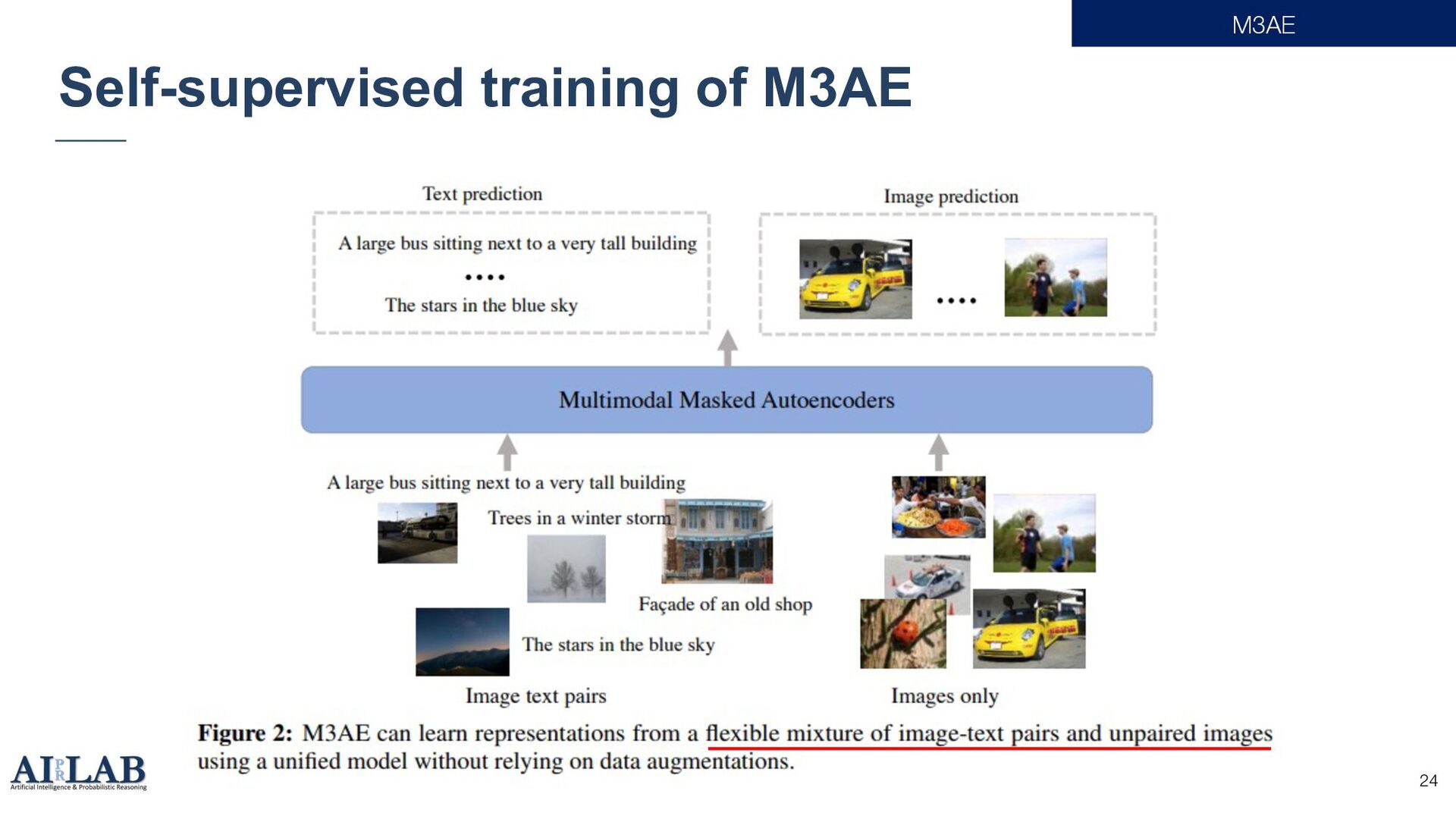{kind=link}
{kind=link}
{kind=link}
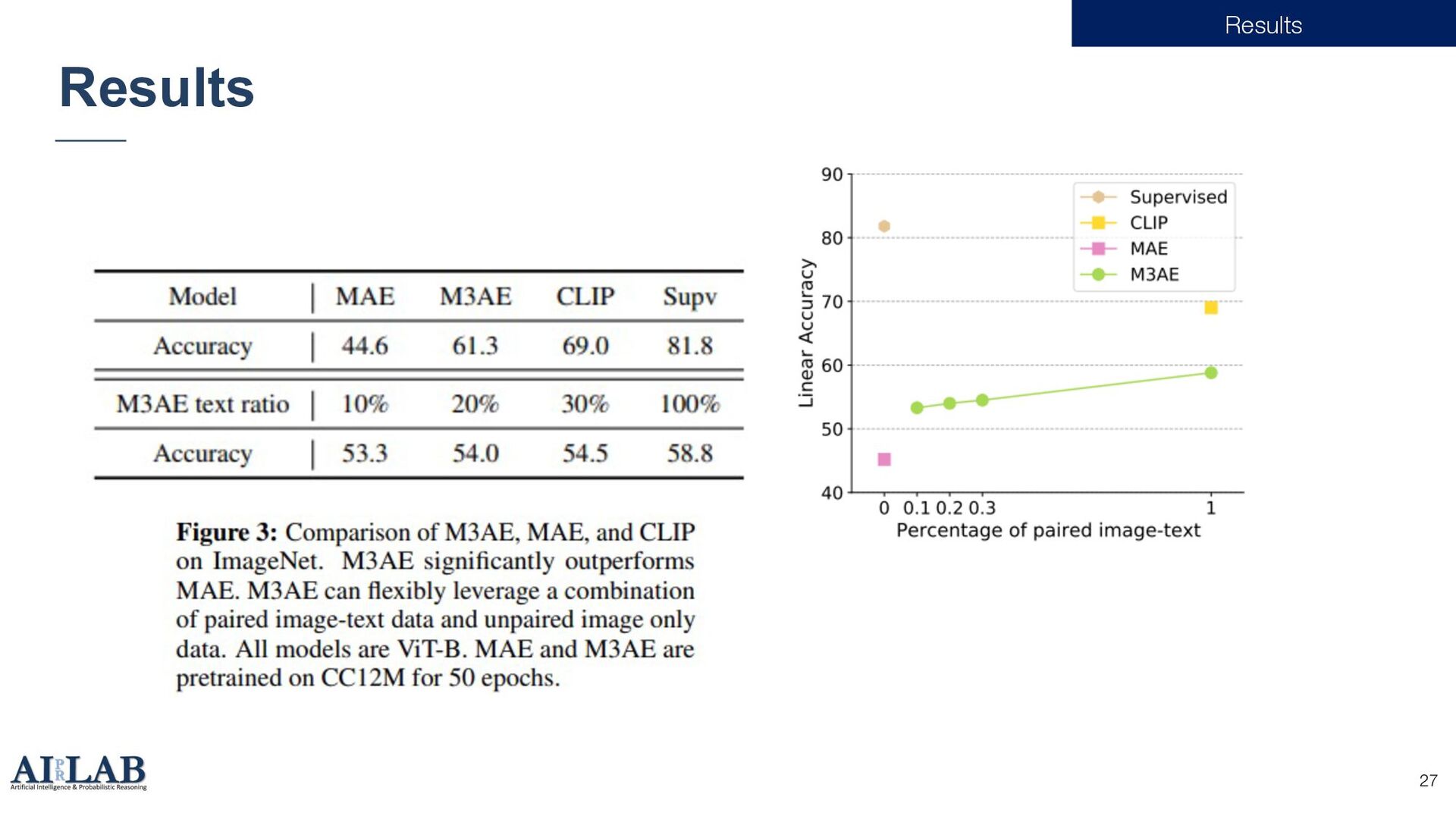{kind=link}
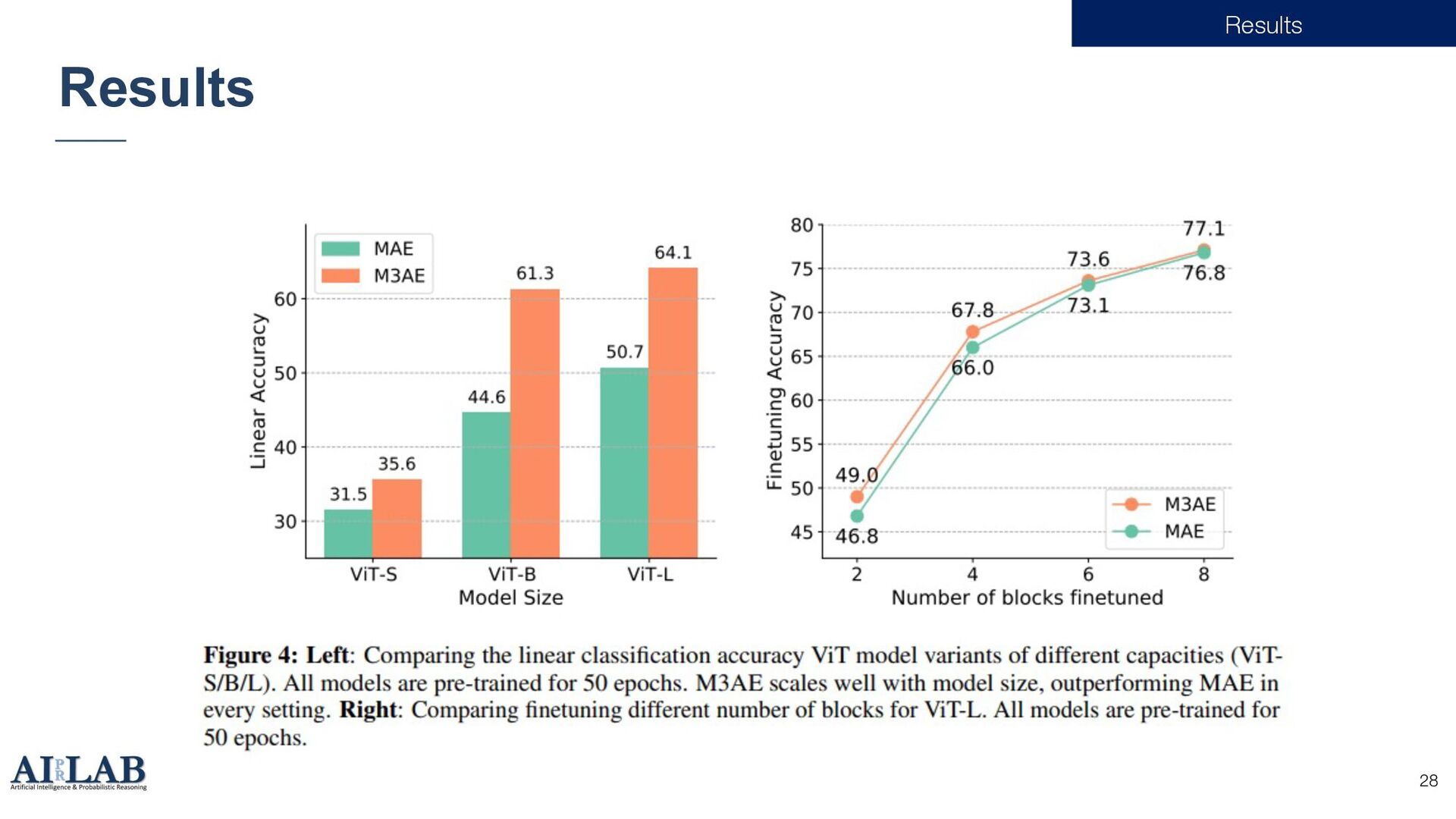{kind=link}
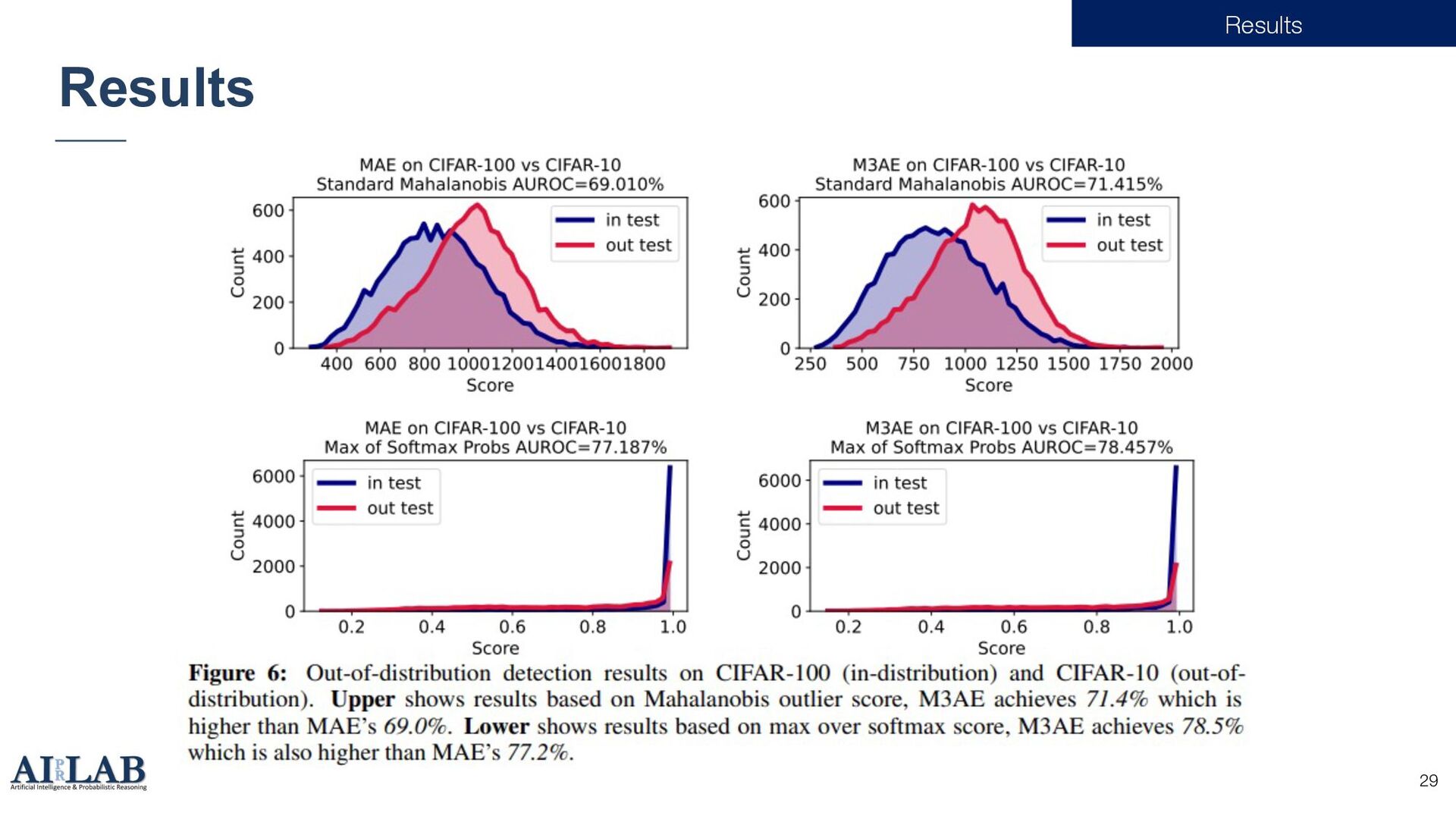{kind=link}
{kind=link}
{kind=link}