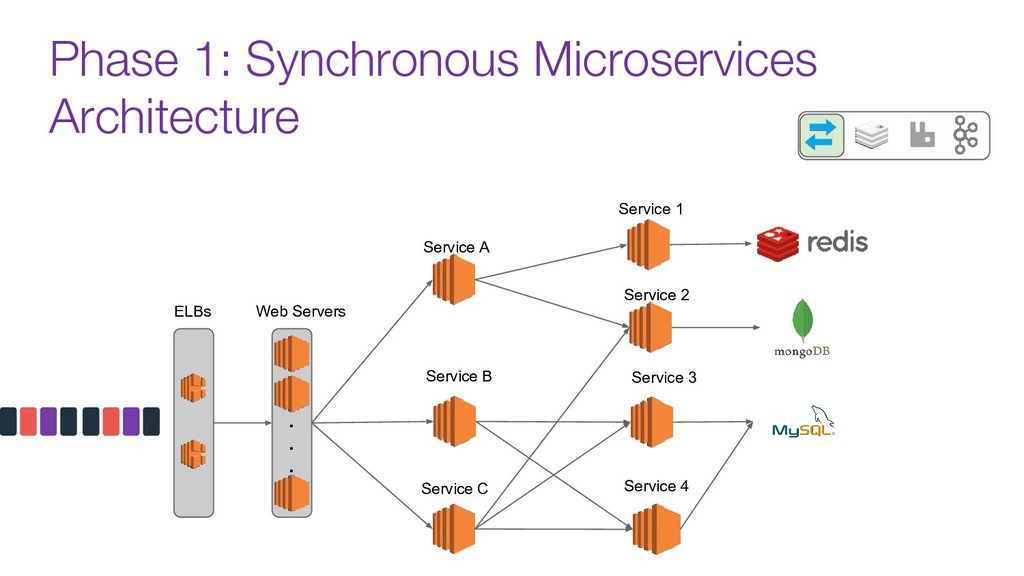
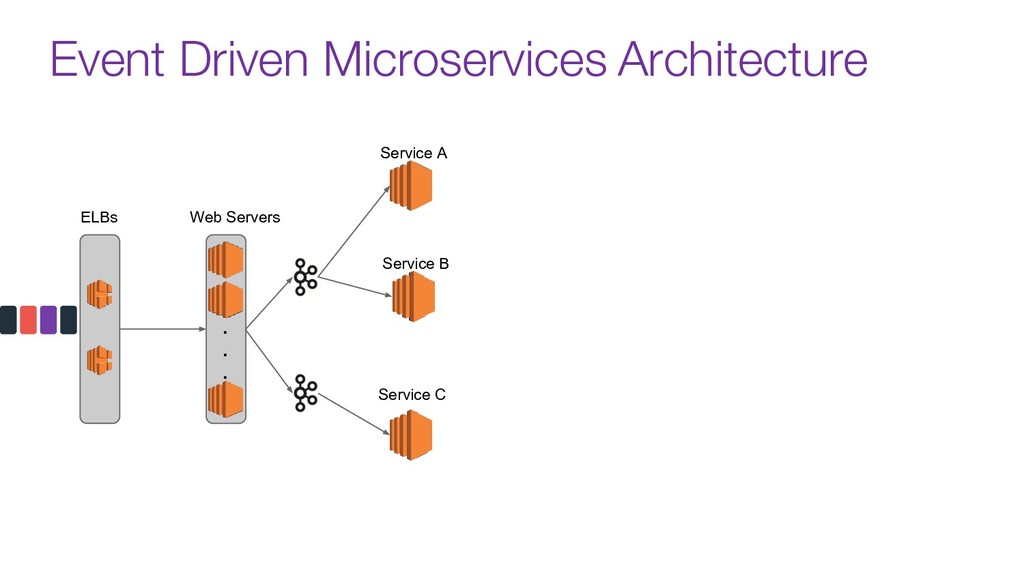
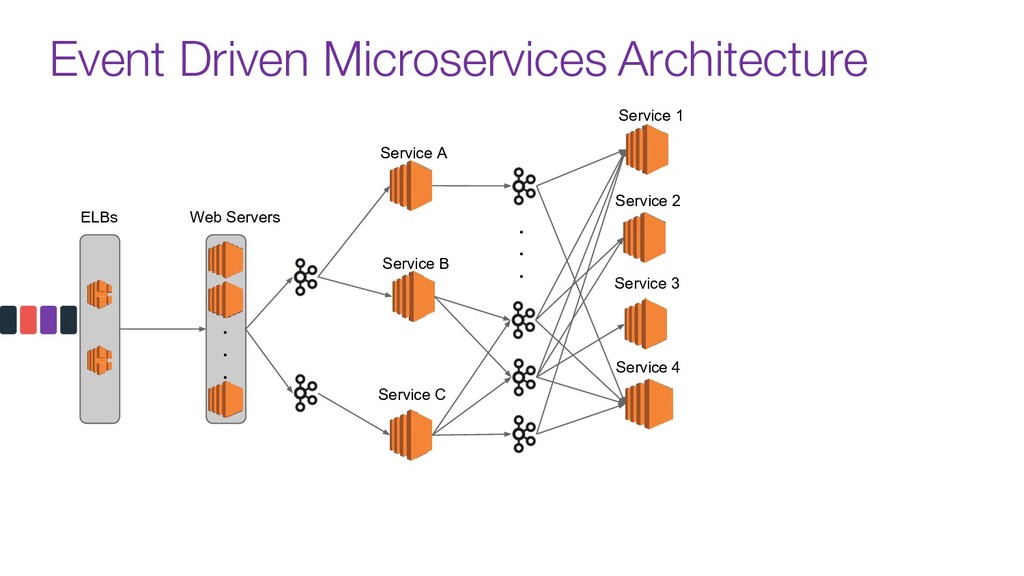
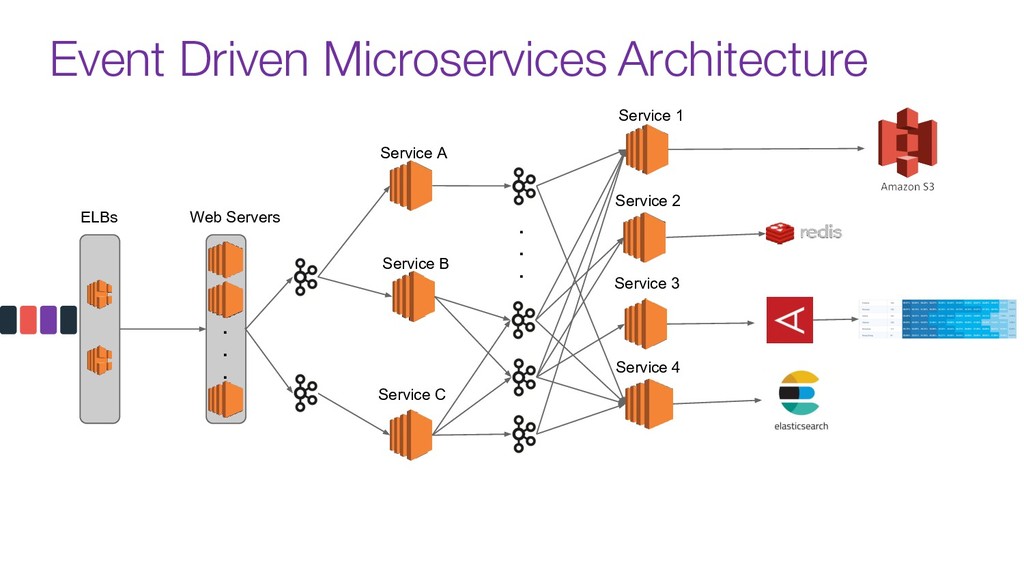
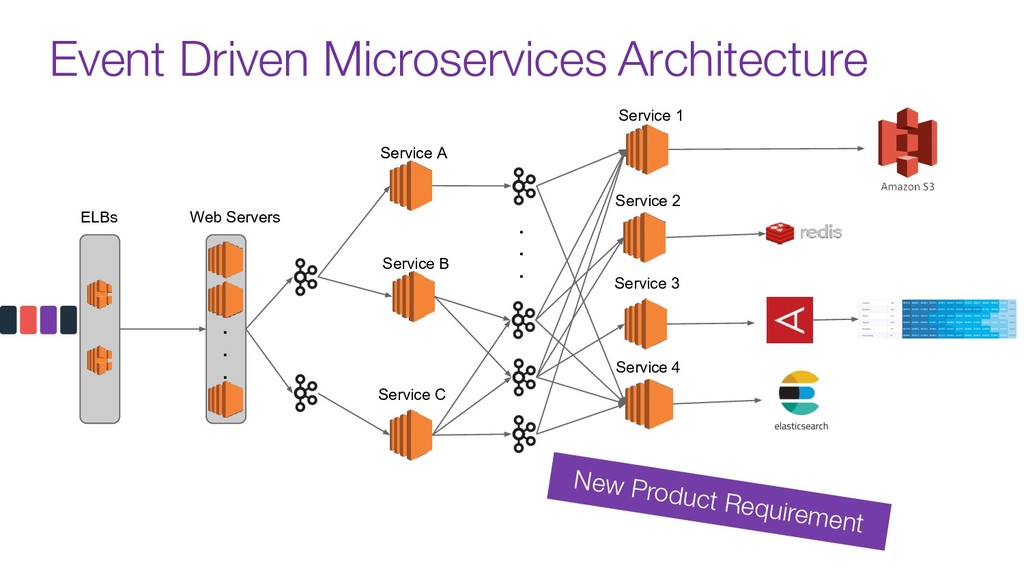
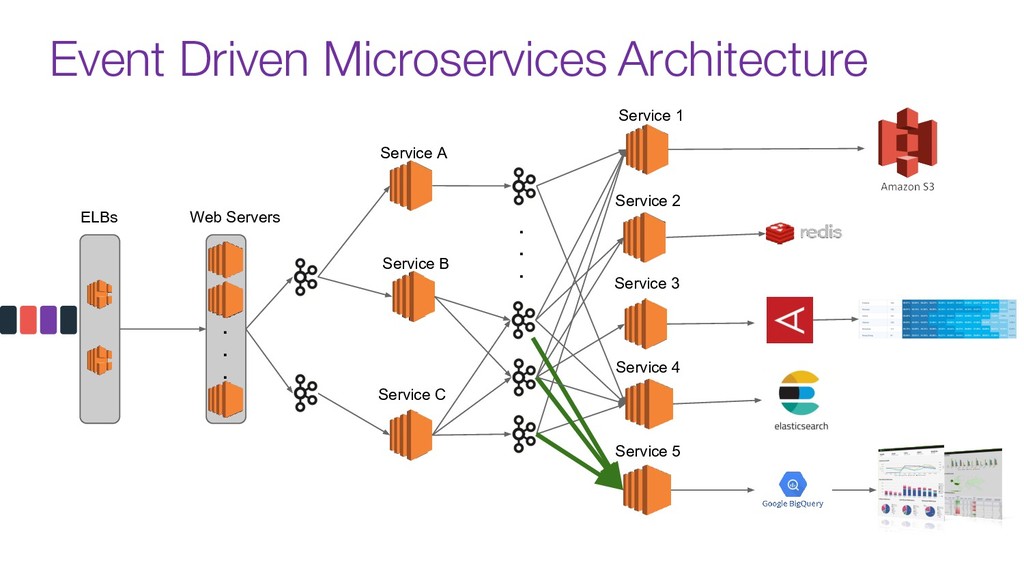
Modern data pipelines have come a long way since the traditional publisher-subscriber and asynch execution.
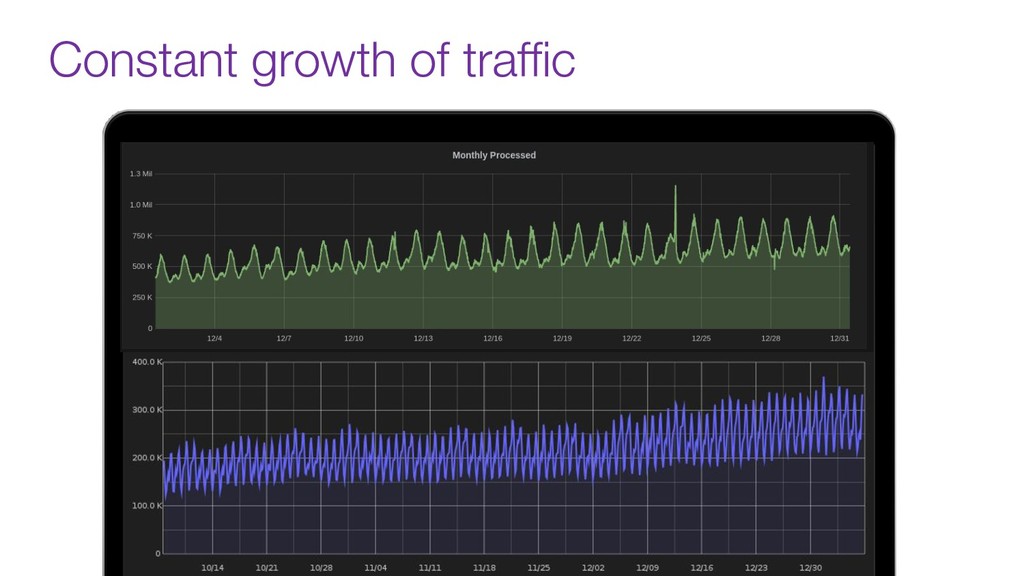
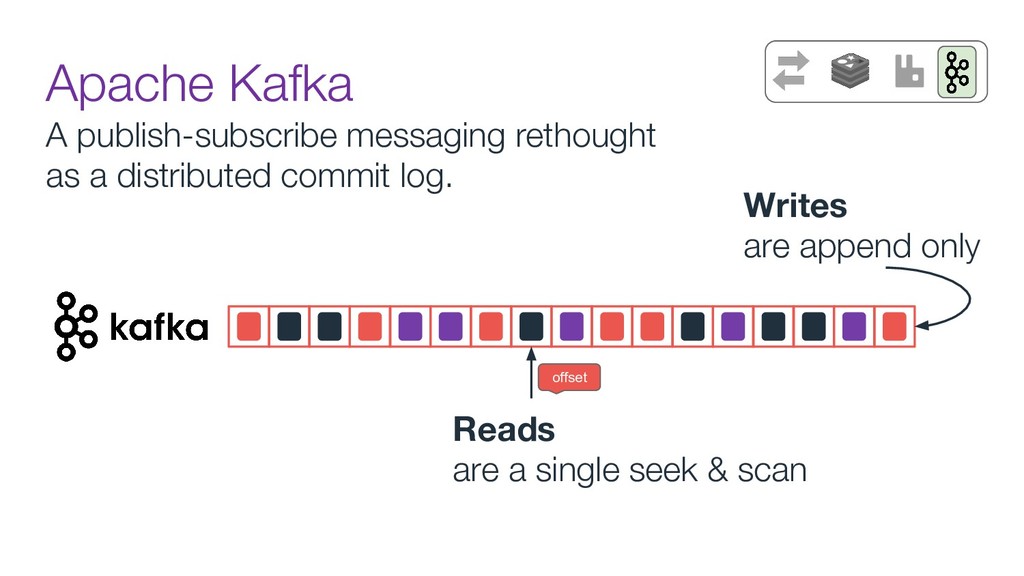
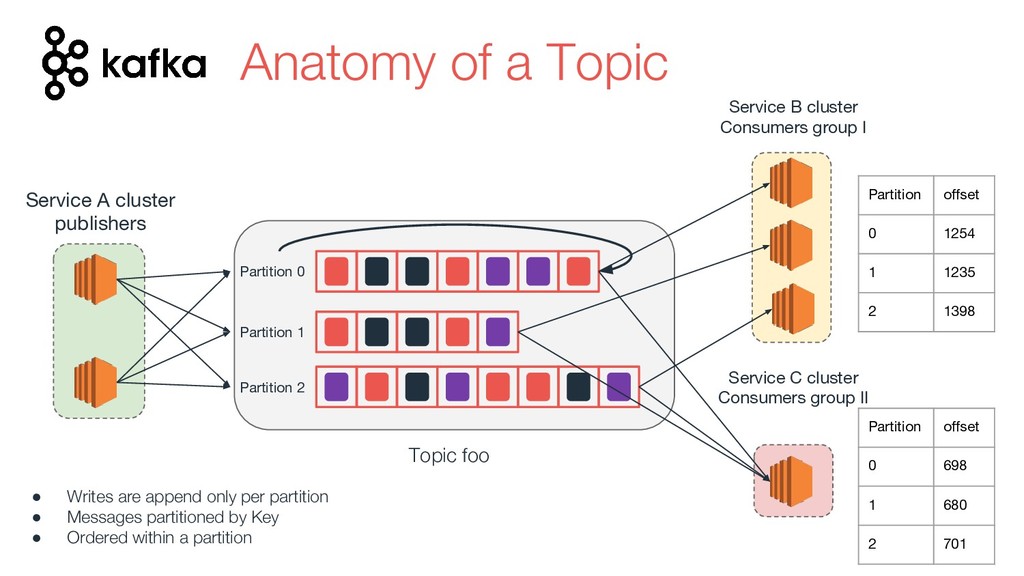
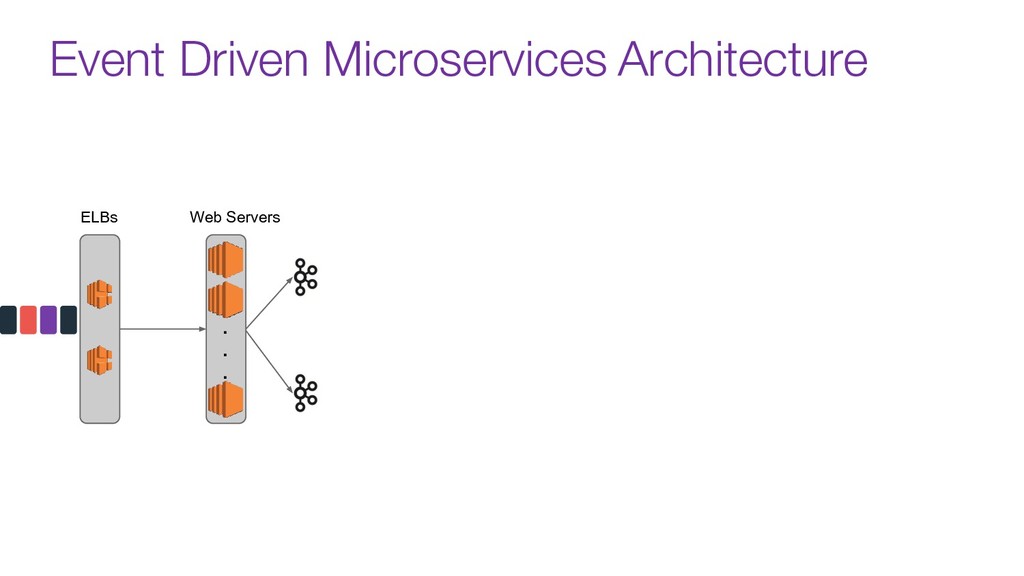
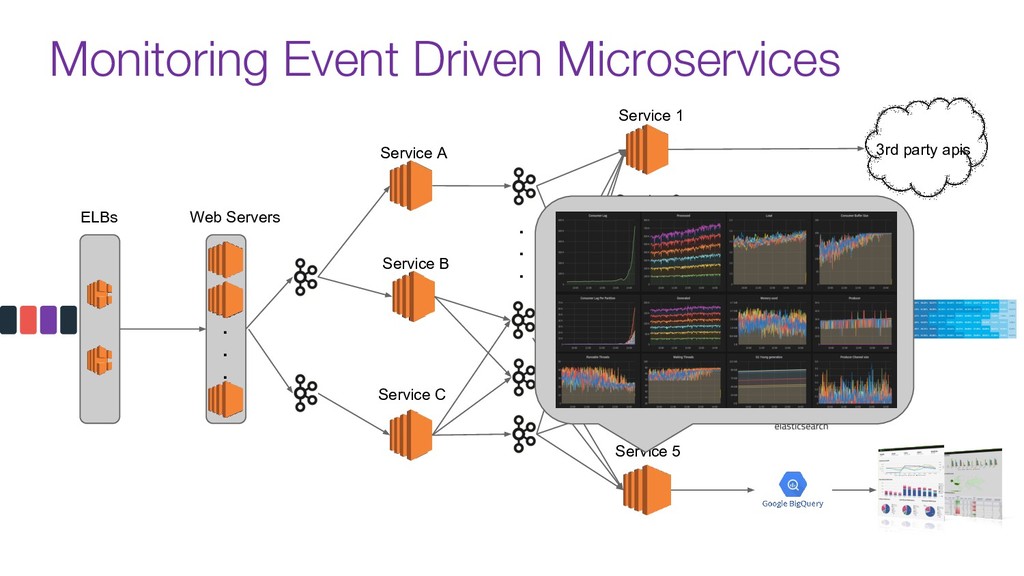
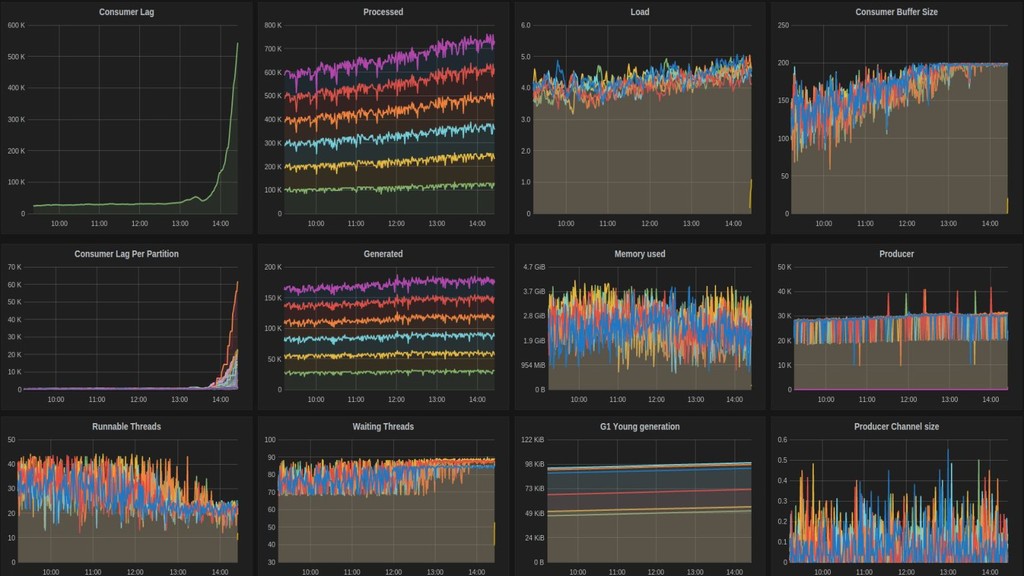
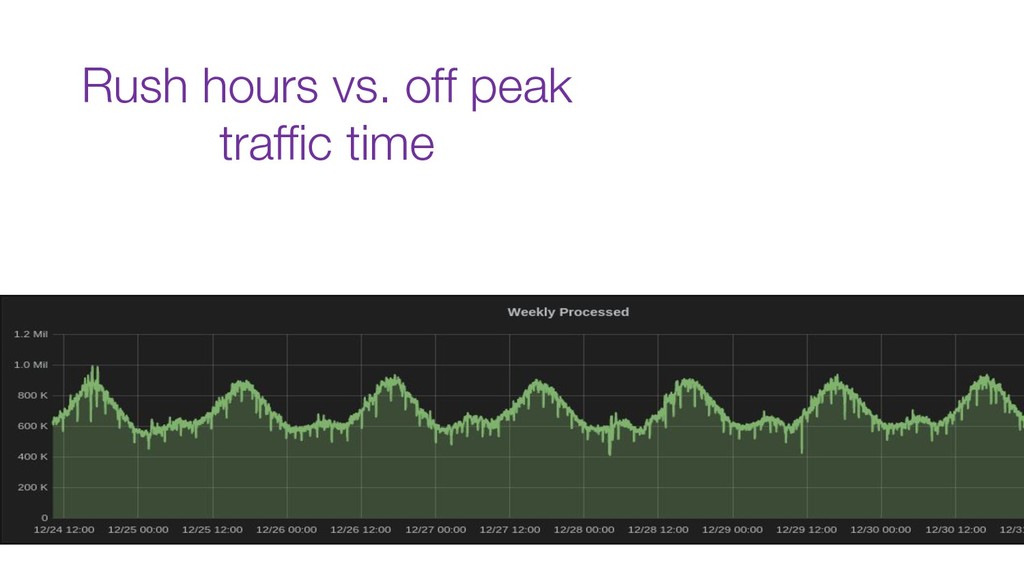
Now days tools like Kafka are used as the organization's data backbone, processing Terabytes of daily data across real-time microsservices and batch processing using different data stores and tools.
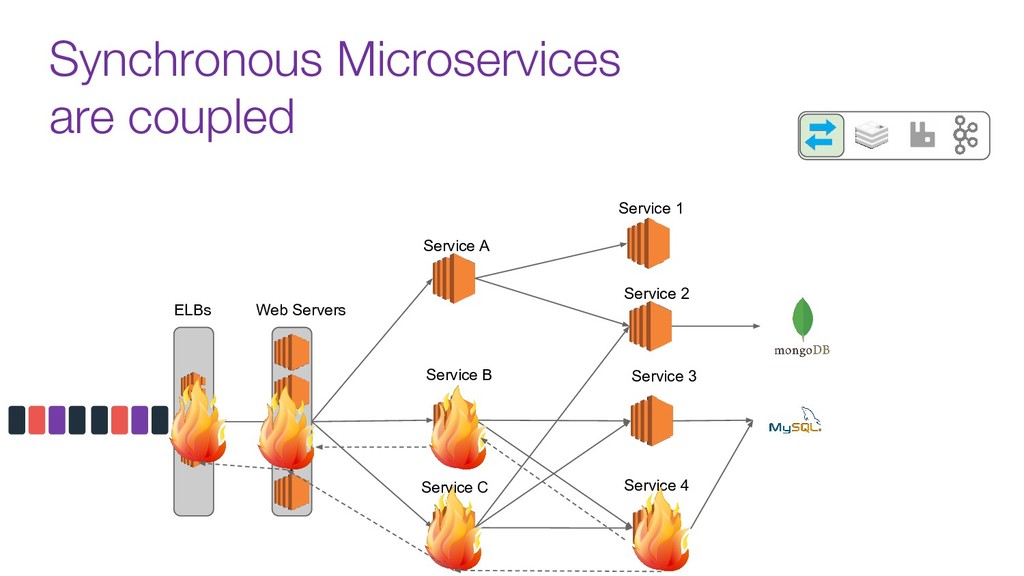
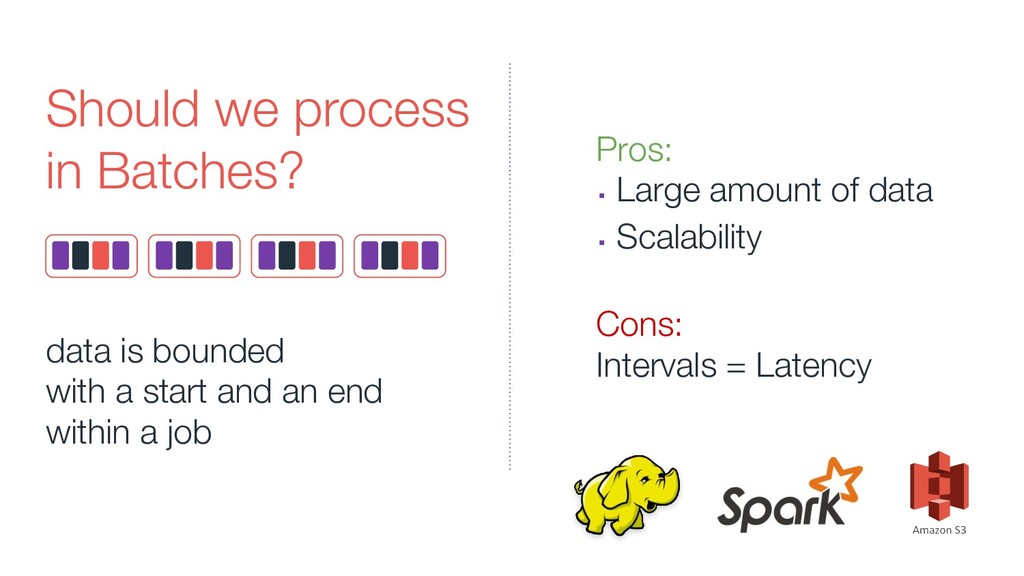
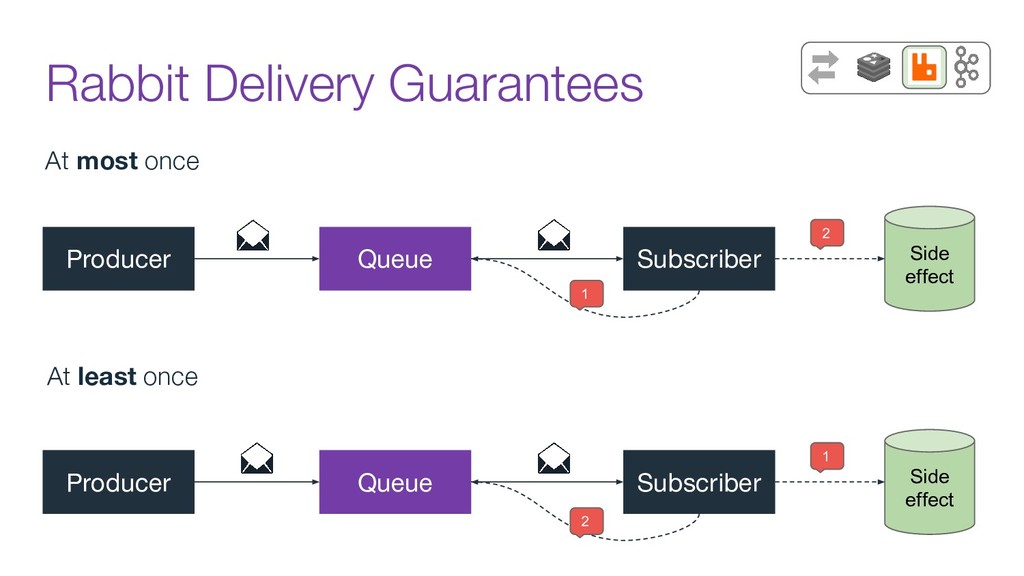
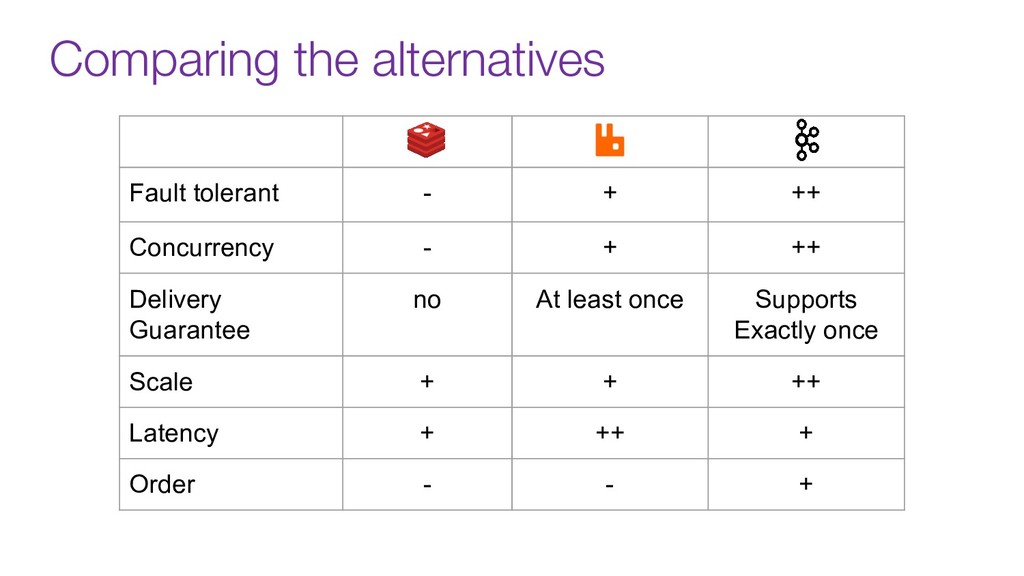
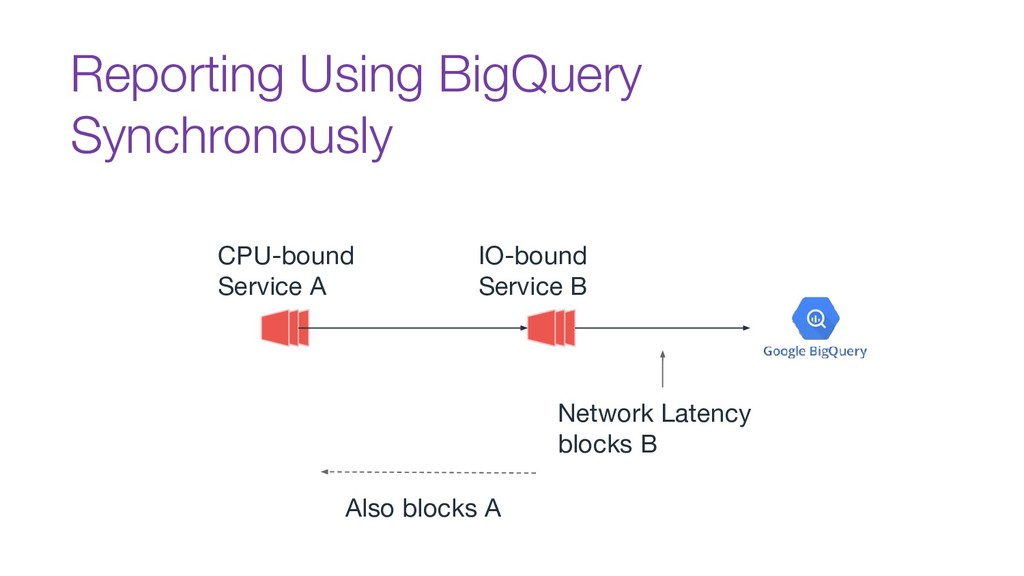
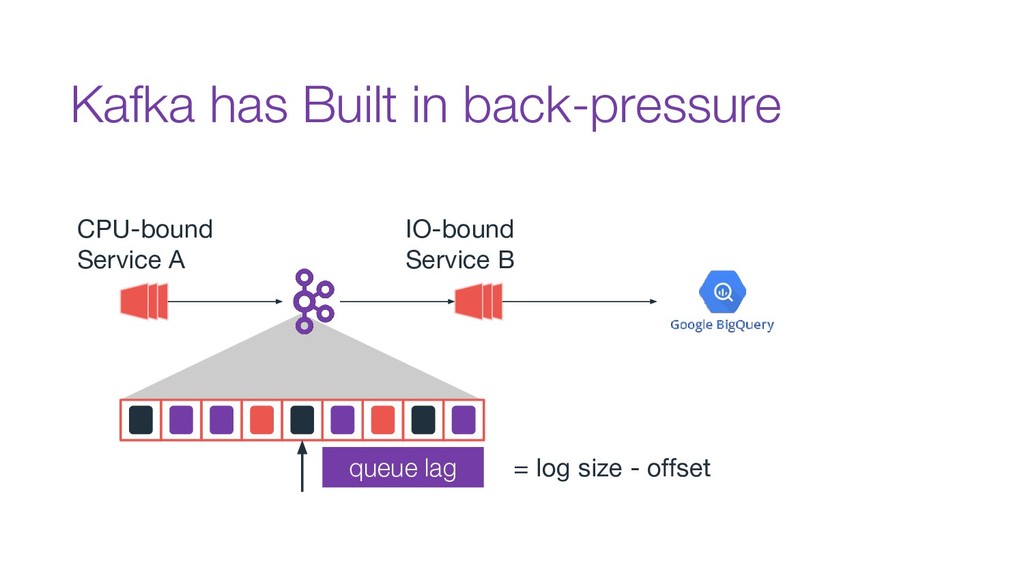
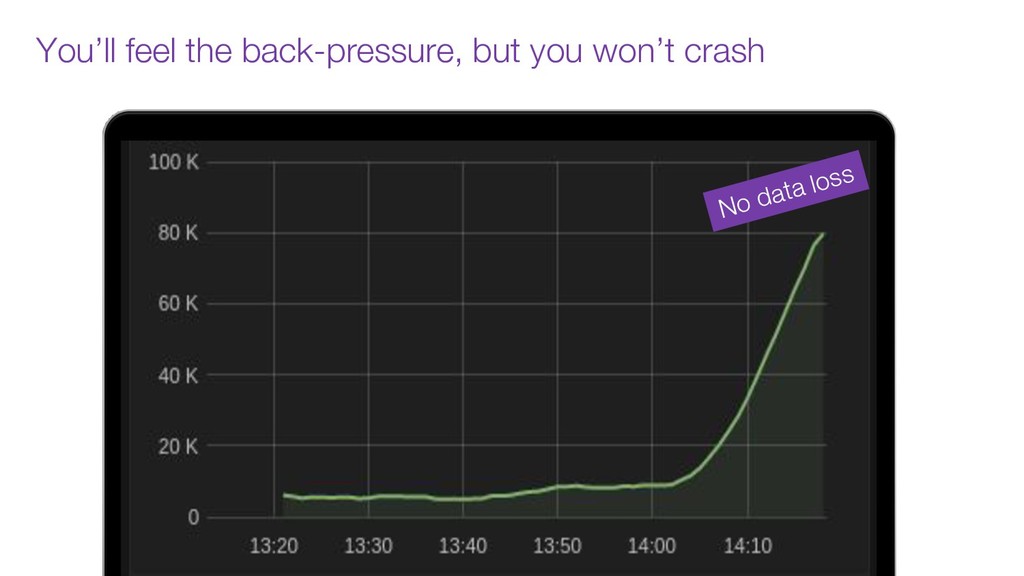
In this talk we will discuss the key differences between kafka and traditional queues, how data pipelines transformed the backend architecture for many big data companies providing better resiliency using concepts like back pressure, distributed logs and stream processing
![linkedin/shlomish github.com/shlomsh [email protected] Shlomi Shemesh Head of R&D, WixCode The](https://files.speakerdeck.com/presentations/7c08fa3257264aa58c173af4165f035c/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] linkedin/shlomish github.com/shlomsh Than-Queue](https://files.speakerdeck.com/presentations/7c08fa3257264aa58c173af4165f035c/slide_63.jpg){kind=link}
![Q&A [email protected] linkedin/shlomish github.com/shlomsh](https://files.speakerdeck.com/presentations/7c08fa3257264aa58c173af4165f035c/slide_64.jpg){kind=link}
{kind=link}