社内のCV輪講で使用した資料です。
LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models (CVPR 2025 Highlight)について紹介しました。
以下スライド中の参考文献のリンク
[1]: https://arxiv.org/abs/2112.03857
[2]: https://arxiv.org/abs/2206.05836
[3]: https://arxiv.org/abs/2103.00020
[4]: https://arxiv.org/abs/2303.02489
[5]: https://arxiv.org/abs/2404.09216
[6]: https://arxiv.org/abs/2305.06500
[7]: https://arxiv.org/abs/2303.05499
[8]: https://arxiv.org/abs/2401.02361
[9]: https://huggingface.co/lmms-lab/llava-onevision-qwen2-0.5b-ov
[10]: https://arxiv.org/abs/2304.03752
[11]: https://arxiv.org/abs/2304.08485
[12]: https://huggingface.co/Qwen/Qwen2-VL-72B
{kind=link}
{kind=link}
{kind=link}
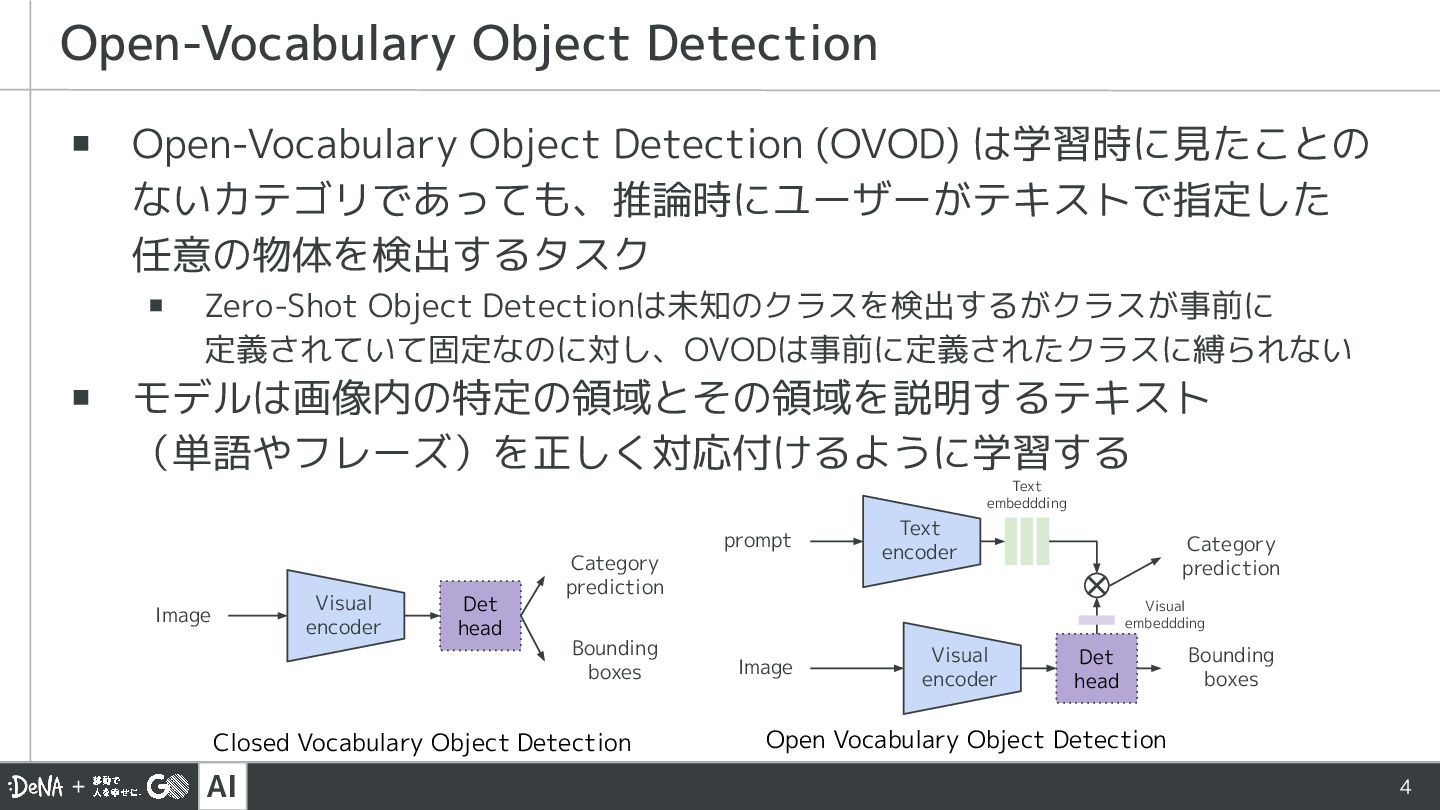{kind=link}
![AI 5 ▪ CLIP[3]では画像特徴とテキスト特徴を同じ特徴空間に埋め込むように学習 するが、GLIPではテキストプロンプト内のフレーズと画像領域を 対応付けるように学習する ▪ 具体的には、物体検出ラベルを連結した文字列と画像キャプション両方のテ キスト特徴、画像から検出した物体領域の特徴のマッチングを行う 関連研究:GLIP[1]・GLIPv2[2]](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_4.jpg){kind=link}
![AI 6 ▪ 物体検出に加え、検出領域に基づいたキャプション生成も同時に学習させる ことで検出性能の向上を図る ▪ GLIPなどは推論時に指定するカテゴリリストに推論結果が依存するが、 CapDetではキャプションを生成することでカテゴリリストに 含まれない状況にも対応できる 関連研究:CapDet[4]](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_5.jpg){kind=link}
![AI 7 ▪ CapDetと同じく領域に対するキャプションを生成することができるが、 階層的に領域を説明するキャプションを生成するように学習する ▪ それによって、画像内に未知の物体があったとしても説明の粒度を下げて 検出できるようになる ▪ データセットはInstructBLIP[6]を用いて作成](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
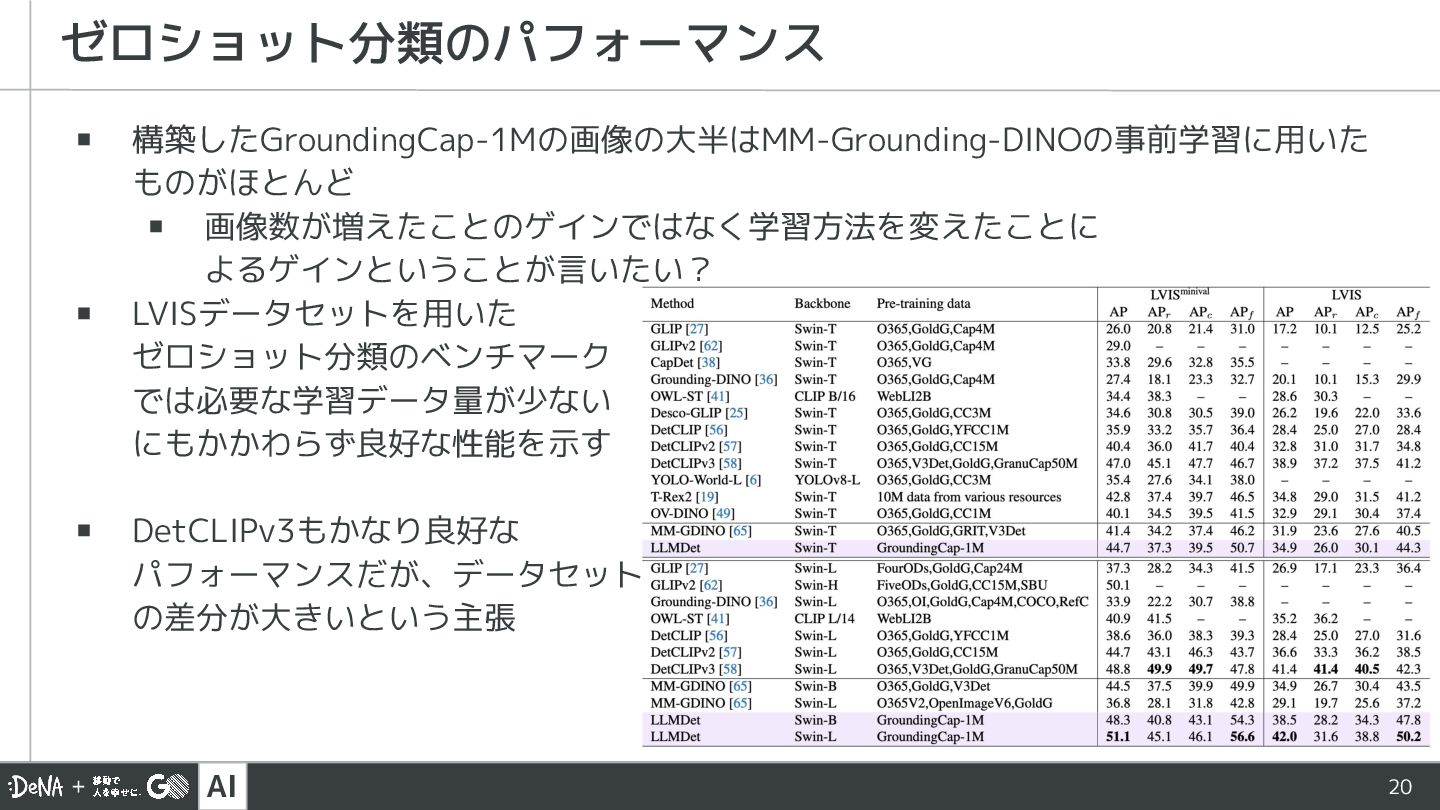
![AI 10 ▪ Grounding-DINO[7]をベースとして、LLMも同時に追加学習させることで 画像単位の長いキャプションからよりリッチな情報を Detectorに伝搬することができる ▪ モデルを学習するために、画像単位のキャプションとオブジェクト単位のラ ベルの両方を備えたデータセットGroundingCap-1Mを収集 LLMDetの概観](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_9.jpg){kind=link}
![AI 11 ▪ Detector ▪ 学習済みMM-Grounding-DINO[8]を使用 ▪ オブジェクトクエリと領域特徴を生成し、これを後段のLLMに供給する ▪ Projector](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_10.jpg){kind=link}
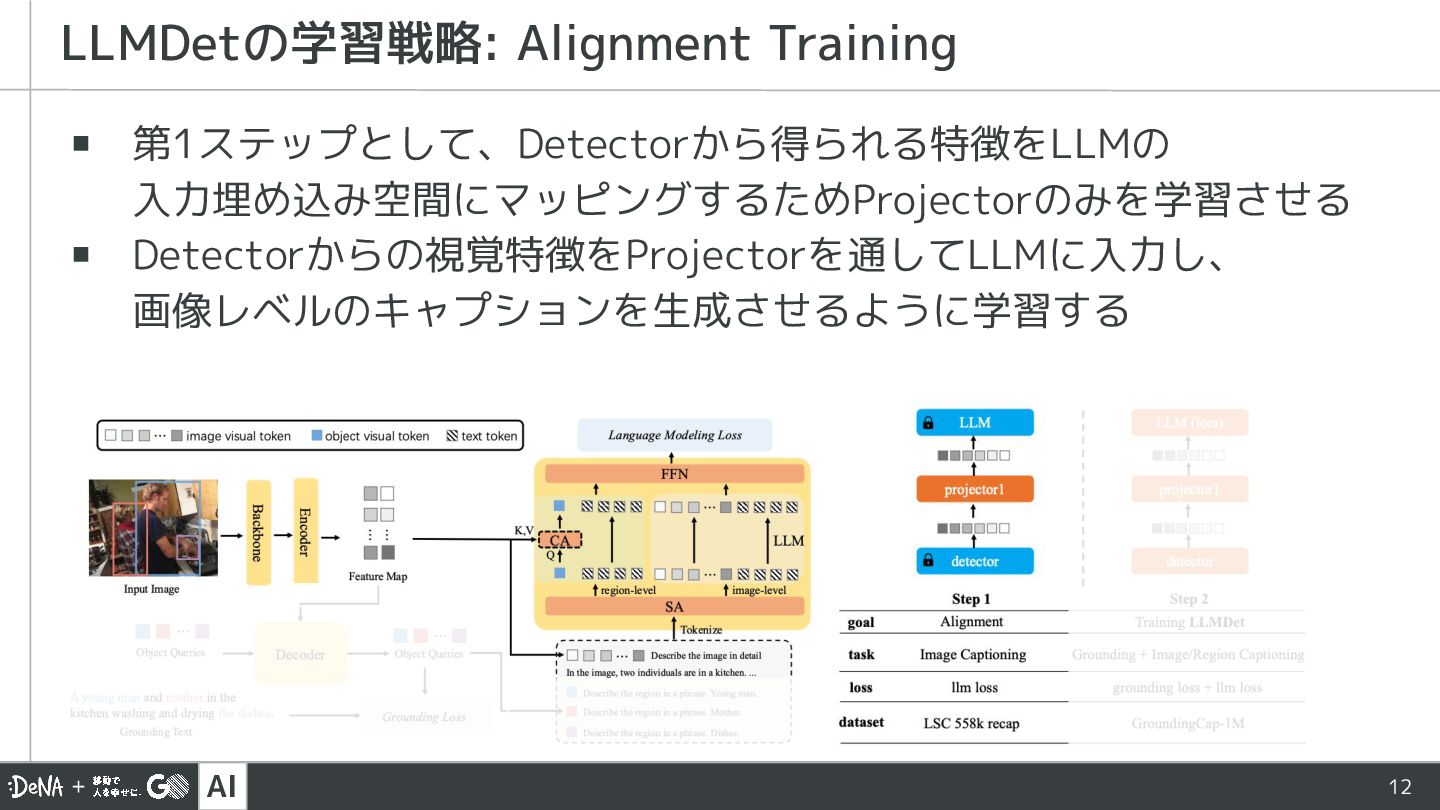{kind=link}
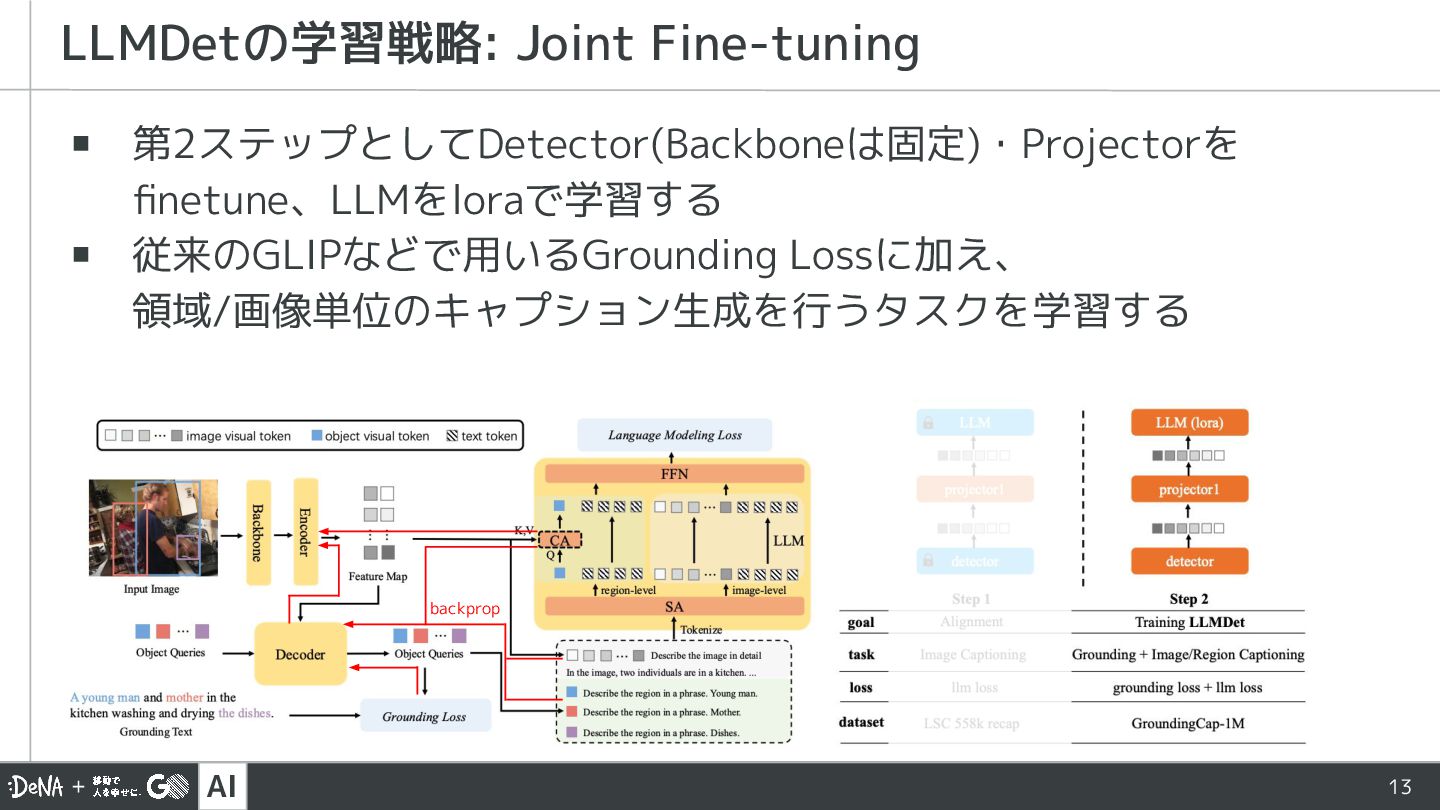{kind=link}
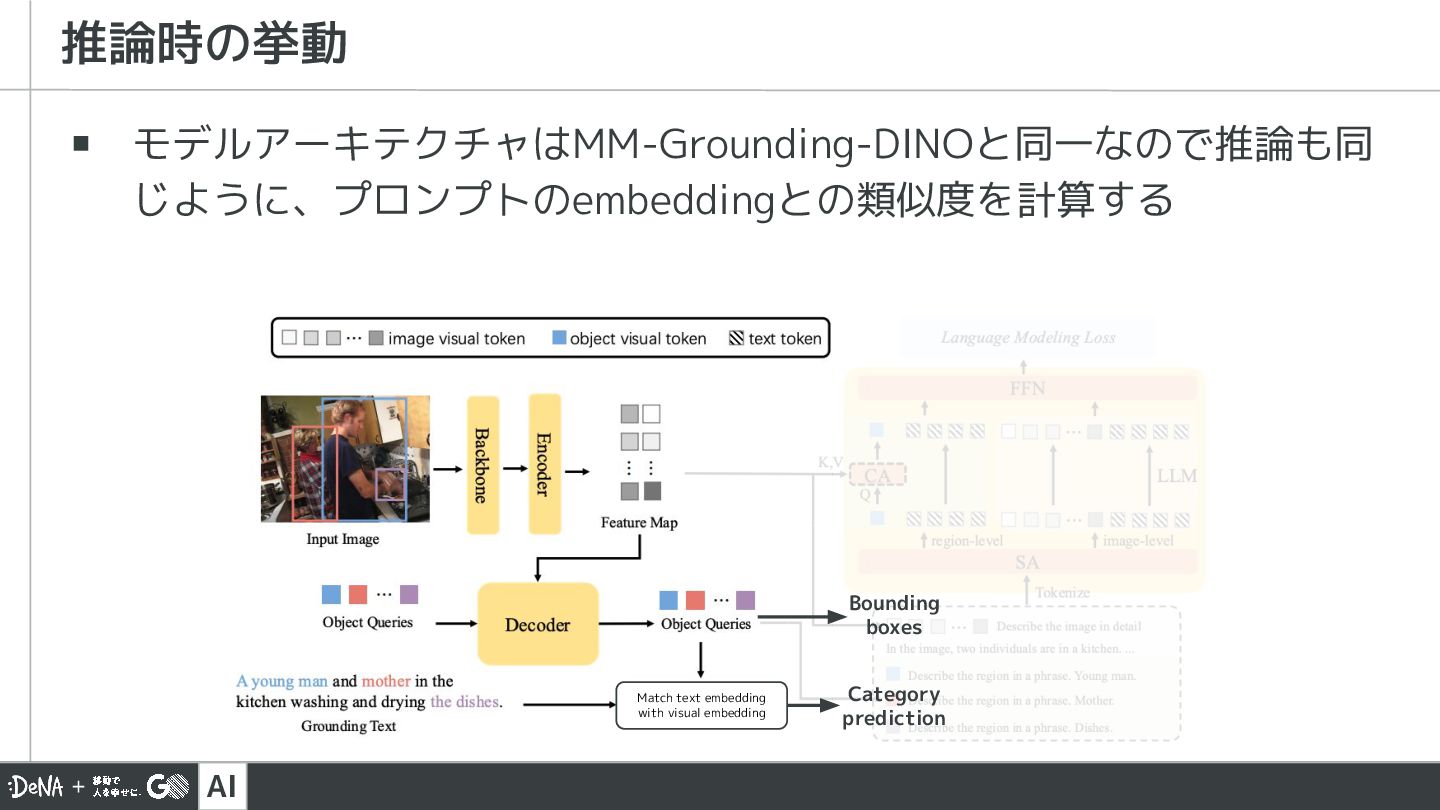{kind=link}
{kind=link}
![AI 16 ▪ COCO・V3Det[10]・GoldG・LCS[11]などBounding Boxesまたは キャプションを含む既存のデータセットから収集 ▪ V3Det・GoldGに関しては ▪ Short](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_15.jpg){kind=link}
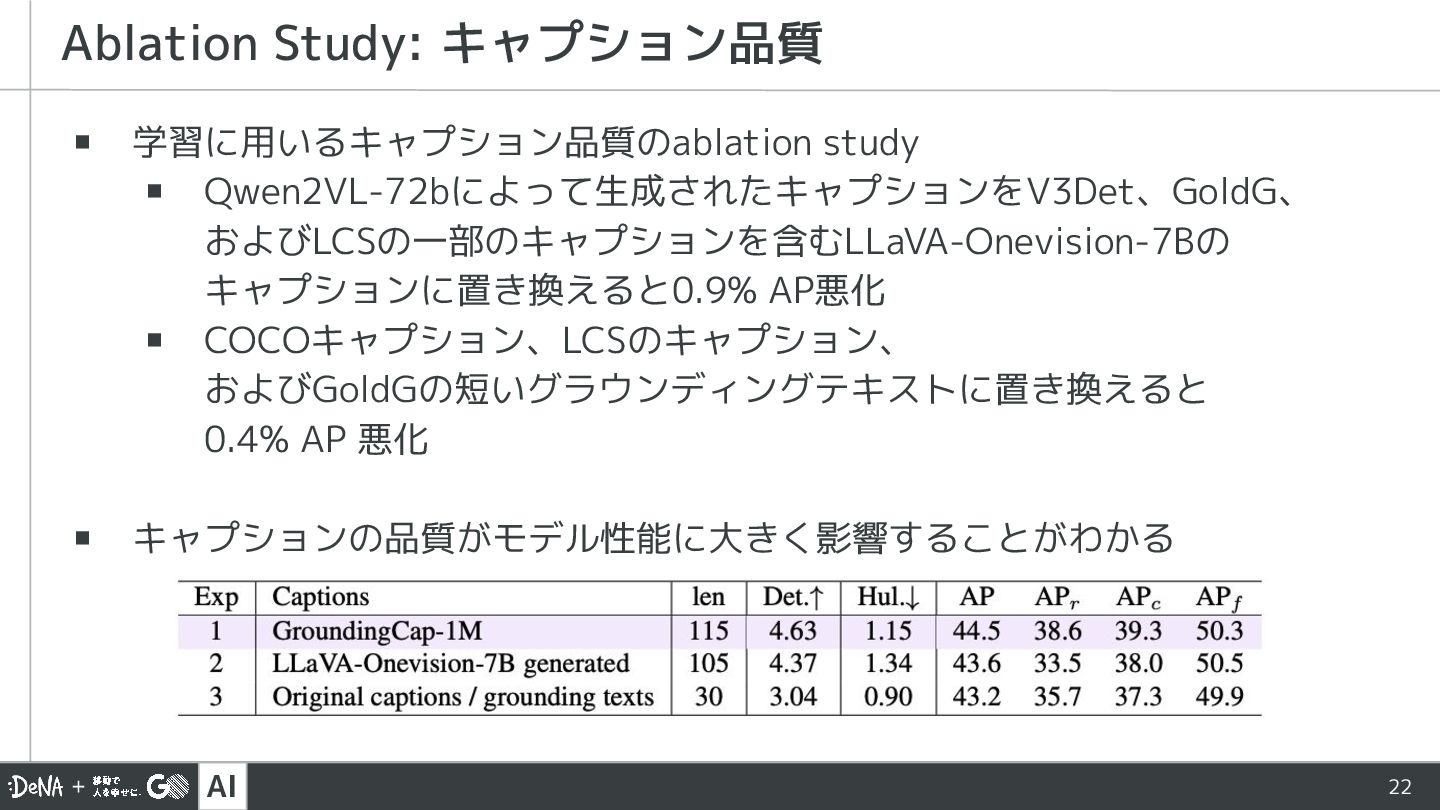
![AI 17 ▪ 図中の”Grounding Text”はGoldG元々のキャプション ▪ Qwen2-VL-72b[12]を用いてオブジェクトの種類、テクスチャ、色、 オブジェクトの部位、オブジェクトの動作、正確な位置の情報が 豊富に含まれるようにキャプション生成を行う GroundingCap-1Mの構築:](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AI 25 [1]: https://arxiv.org/abs/2112.03857 [2]: https://arxiv.org/abs/2206.05836 [3]: https://arxiv.org/abs/2103.00020 [4]: https://arxiv.org/abs/2303.02489](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_24.jpg){kind=link}
![AI 26 [10]: https://arxiv.org/abs/2304.03752 [11]: https://arxiv.org/abs/2304.08485 [12]: https://huggingface.co/Qwen/Qwen2-VL-72B 参考文献 (1/2)](https://files.speakerdeck.com/presentations/850d95be468c4eafa926500d4508ab39/slide_25.jpg){kind=link}