Share
title : 入力データの構造を考慮したLowProFoolアルゴリズムによる敵対的サンプルの生成に関する研究 presen at 13.02.2025 東京都市大学 メディア情報学部 情報システム学科 卒業研究発表会登壇資料
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
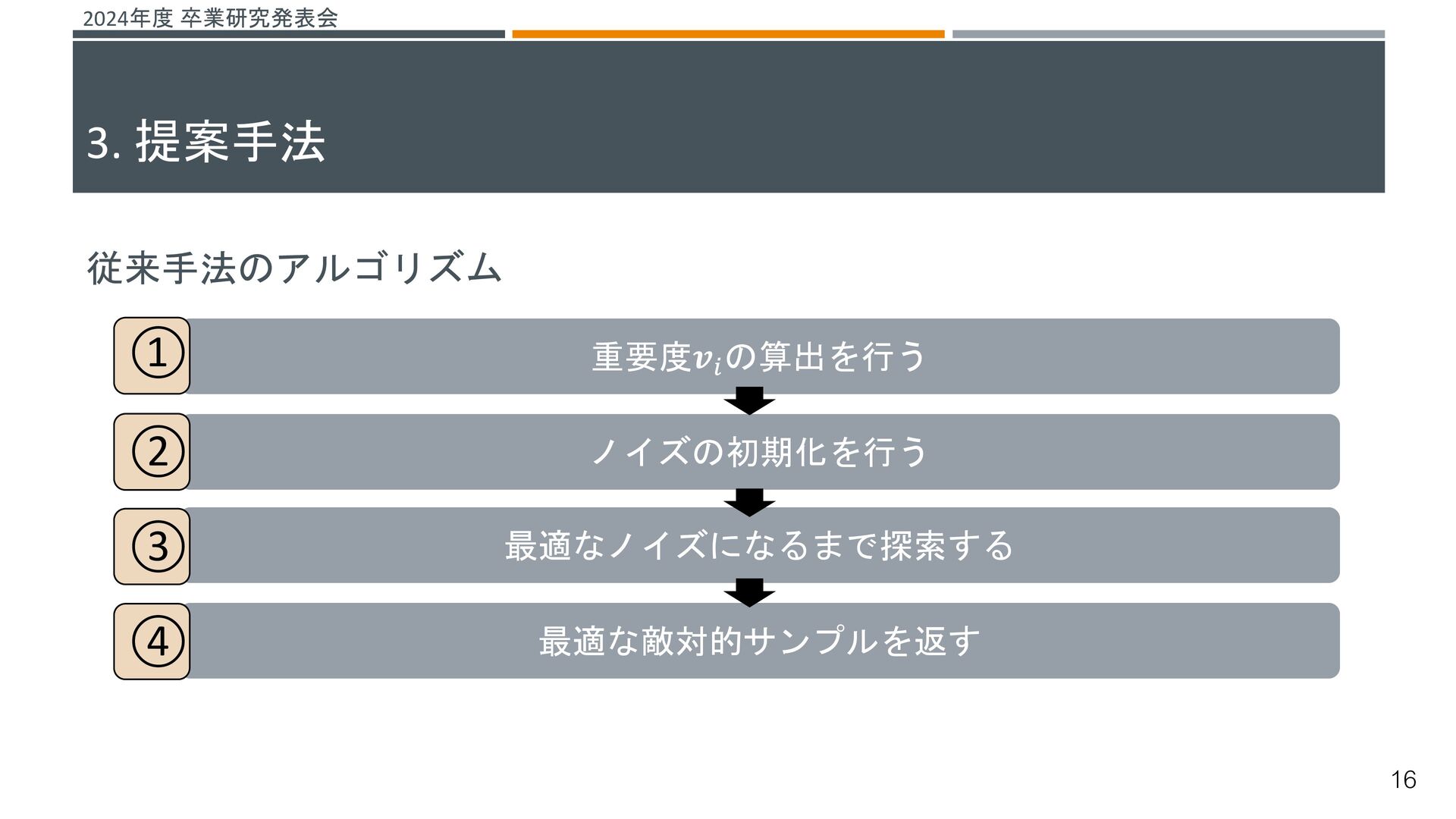
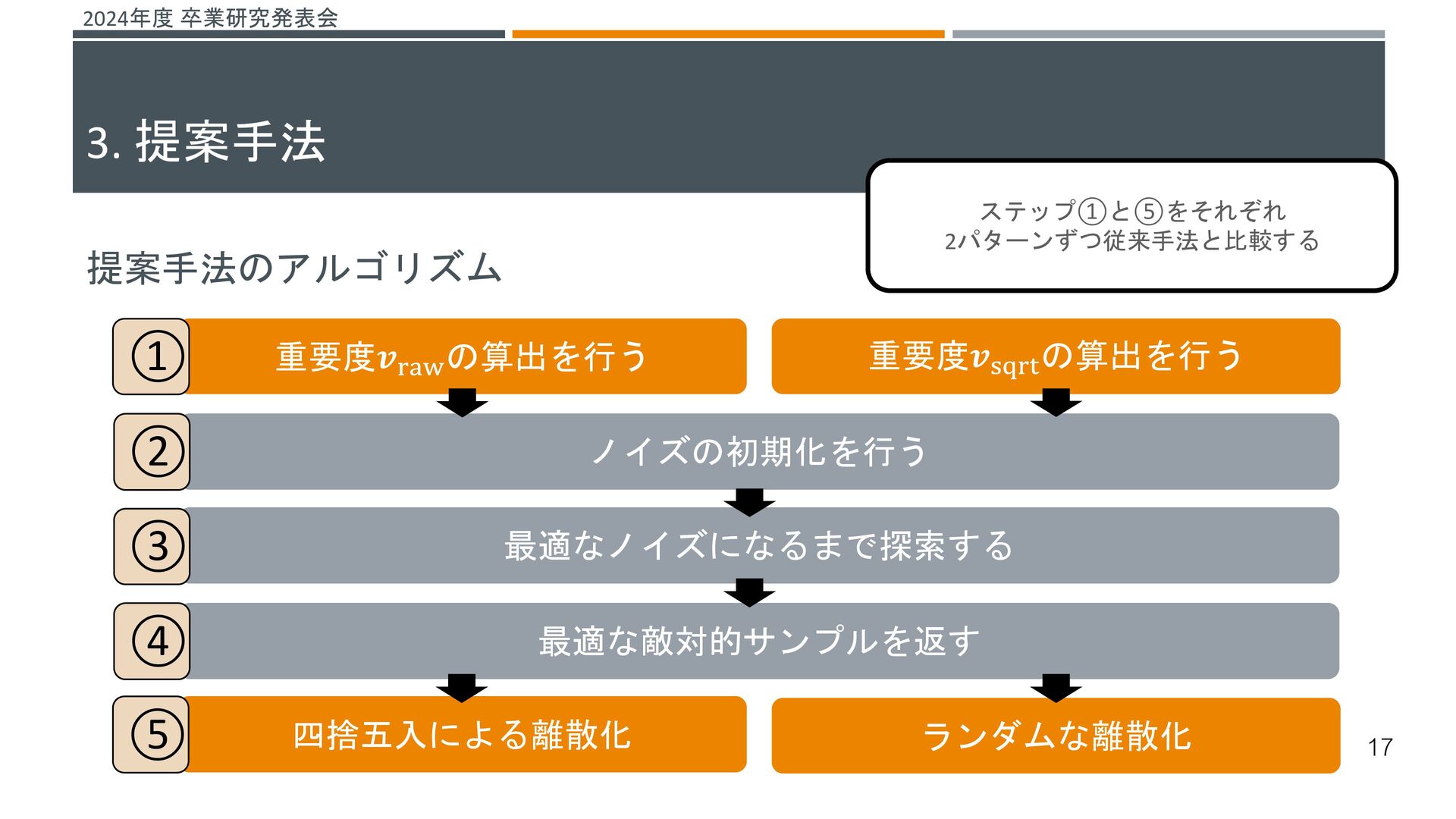
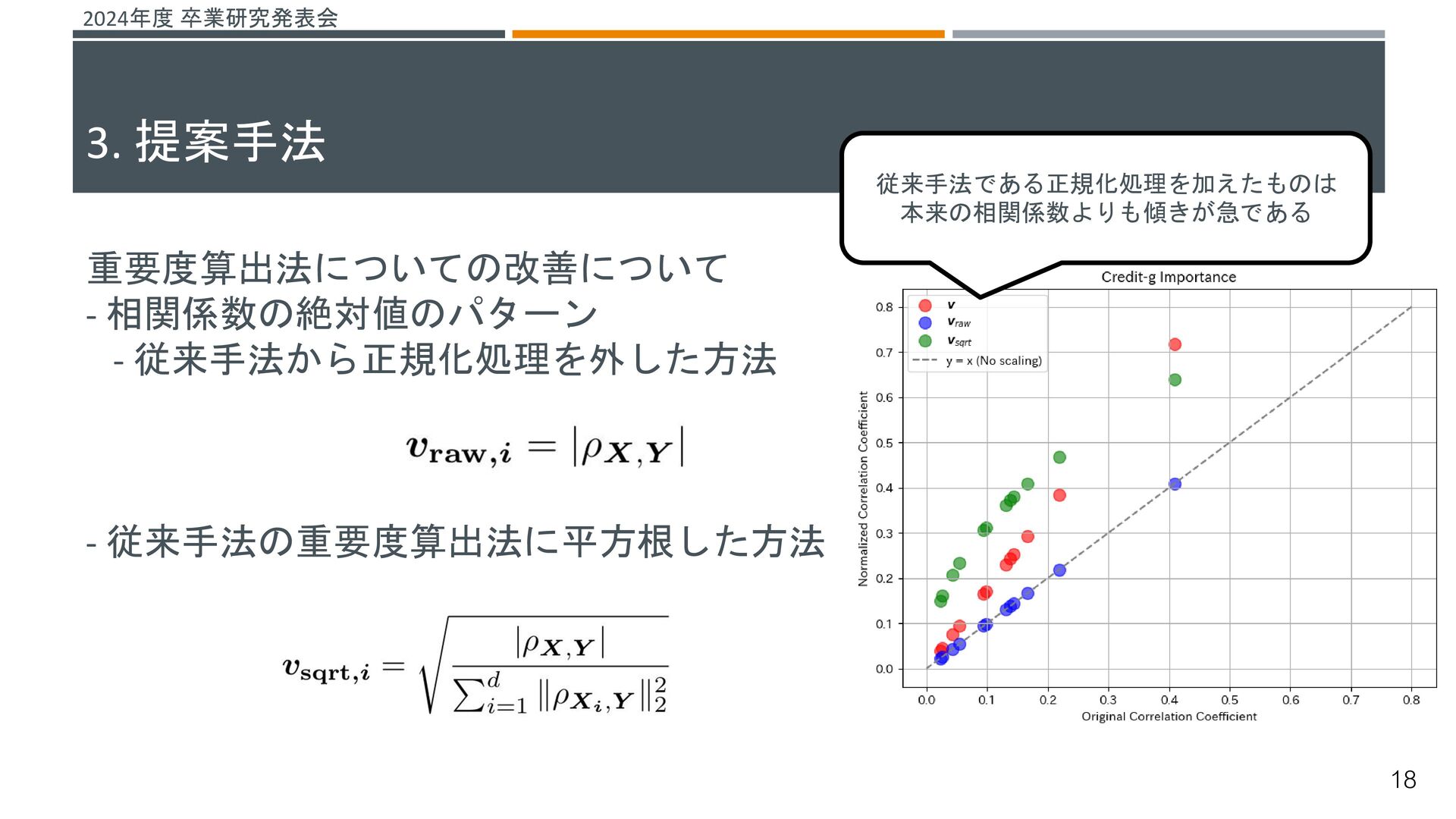
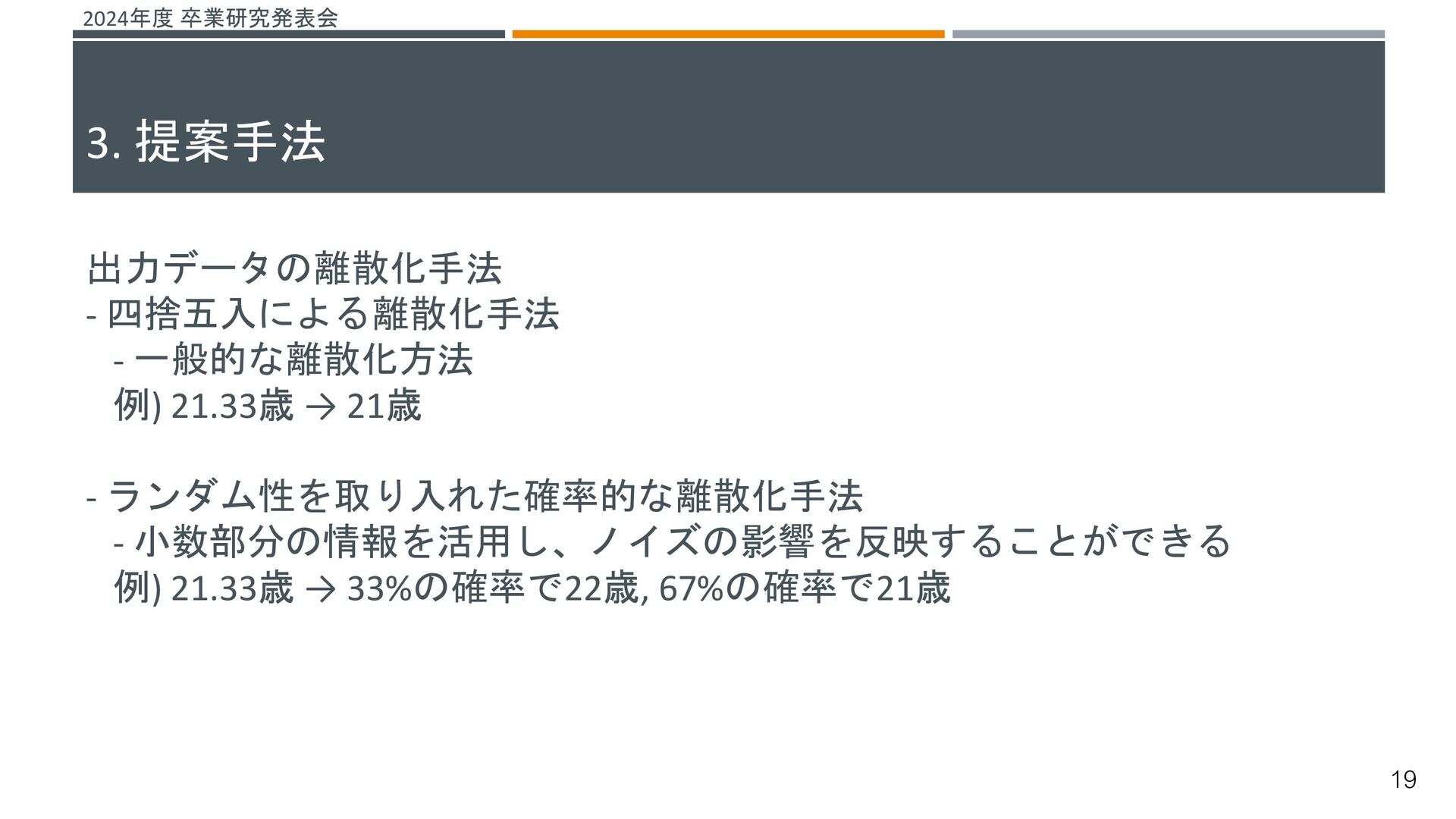
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
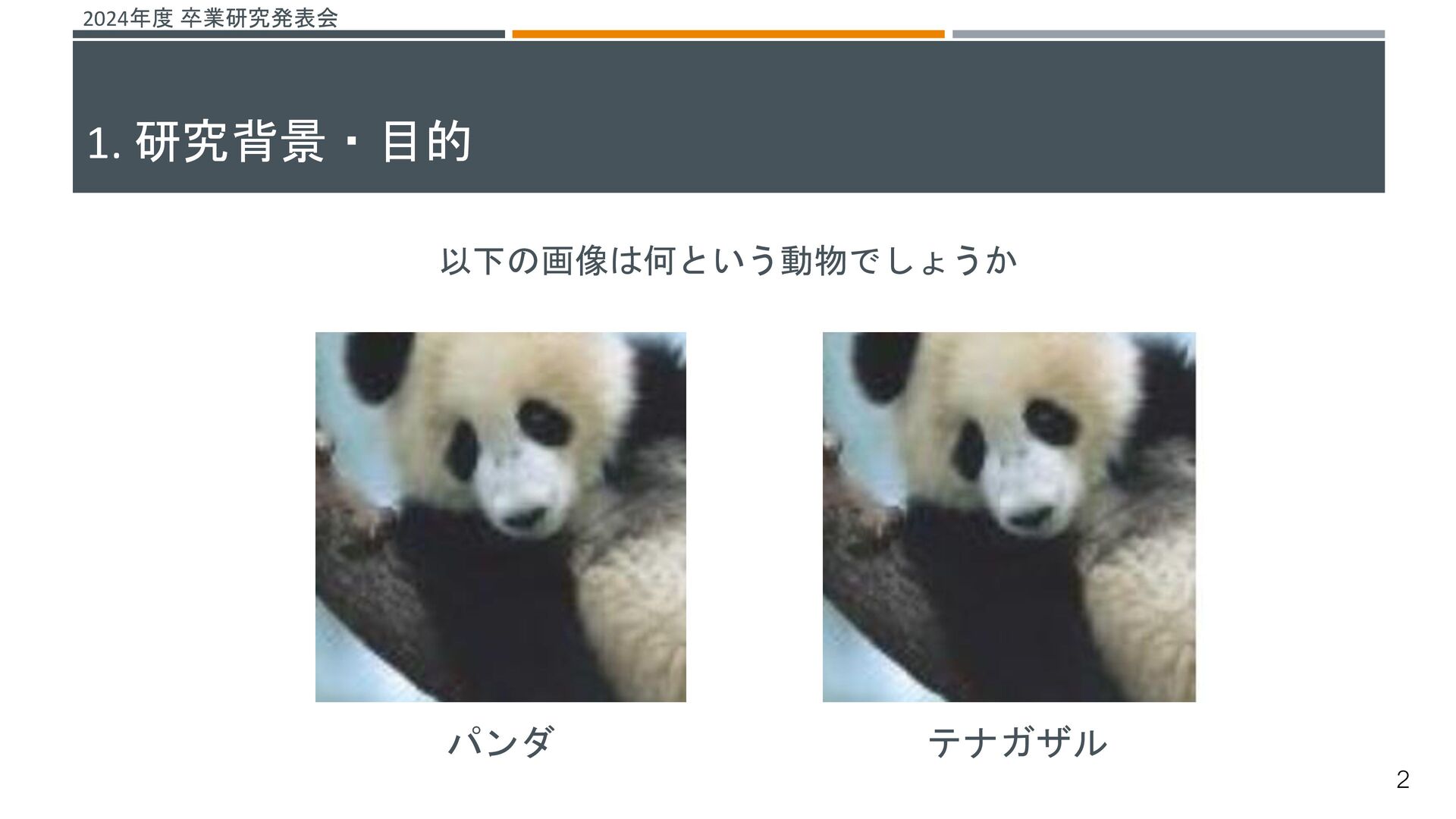
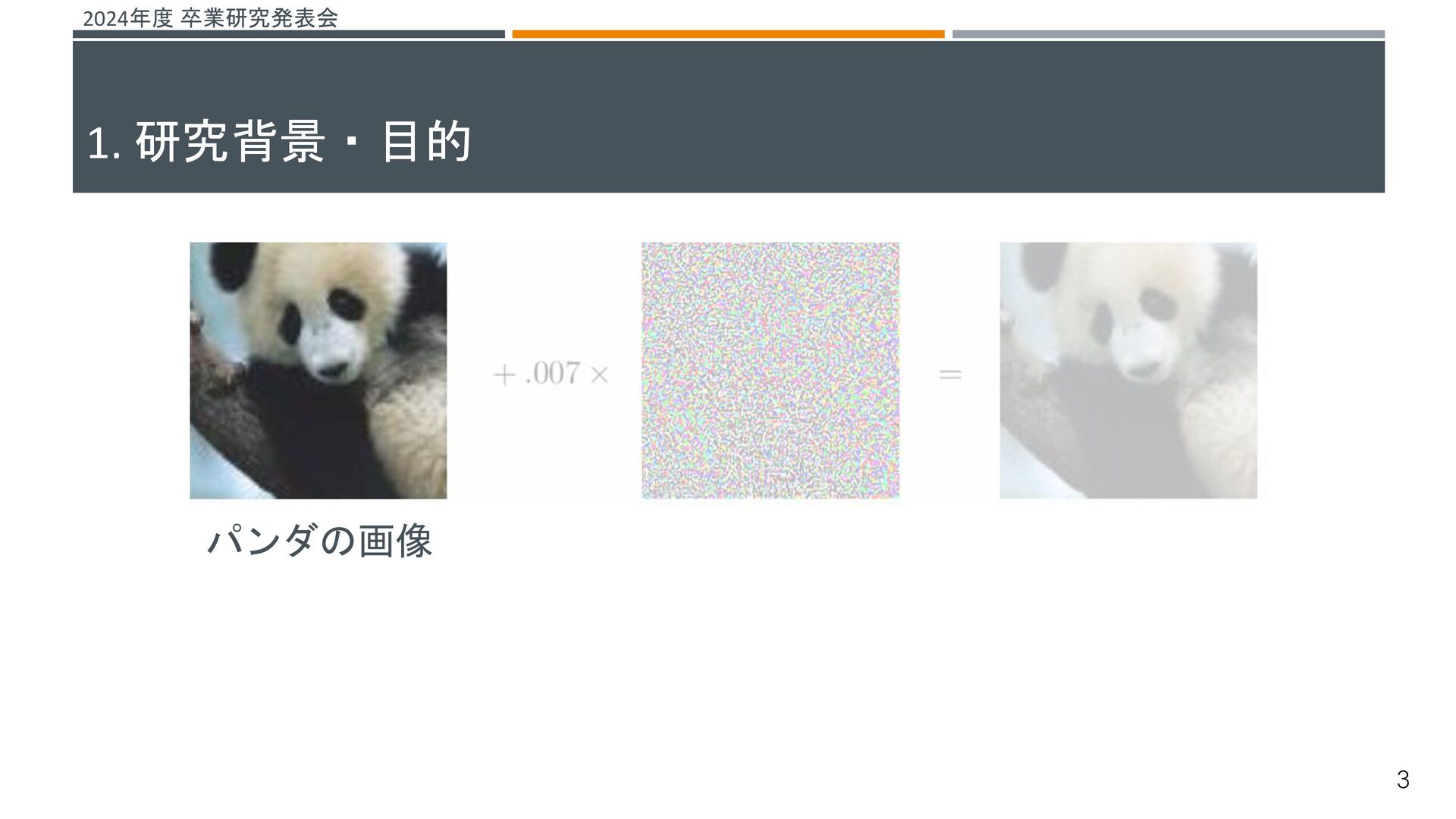
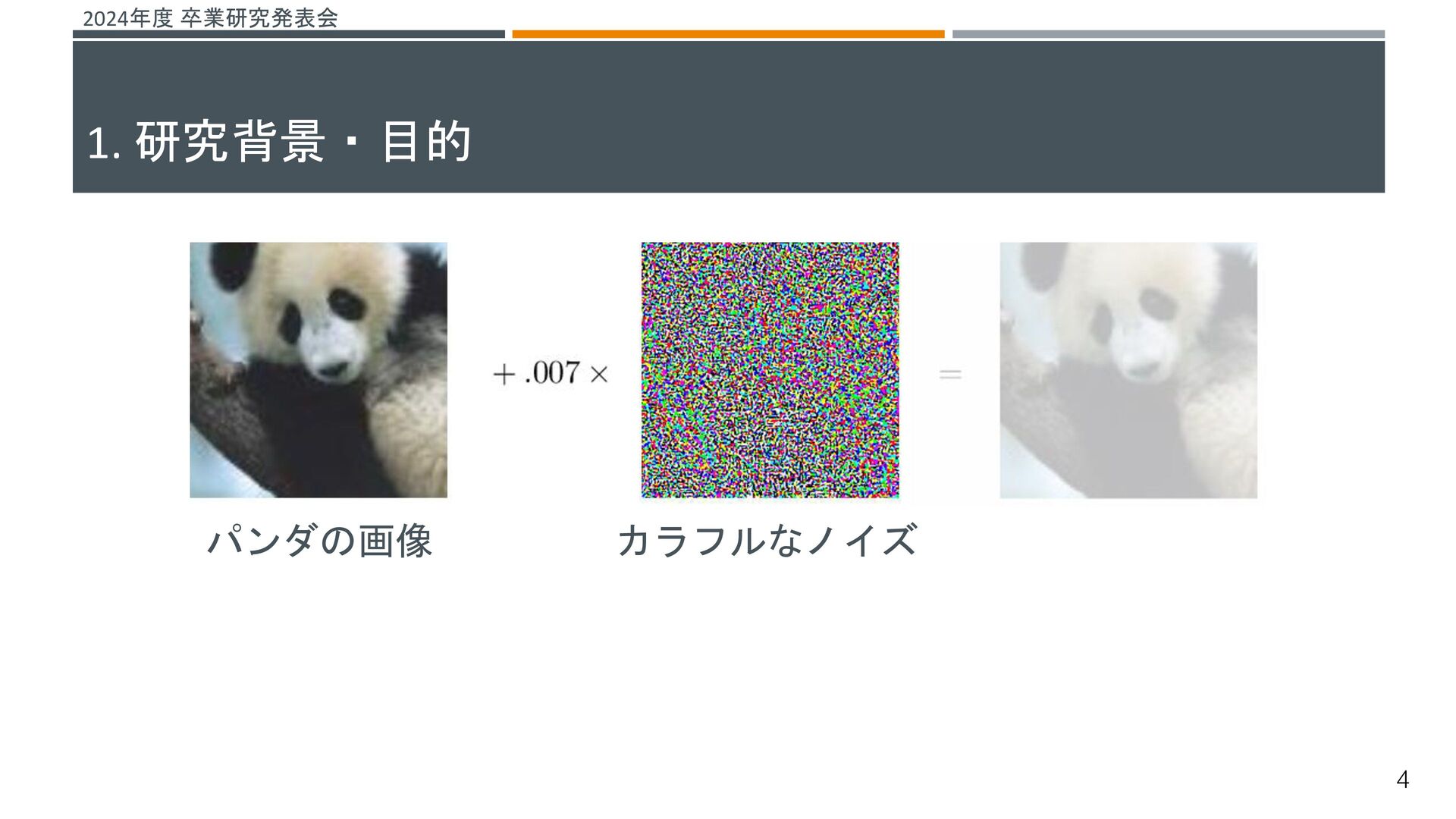
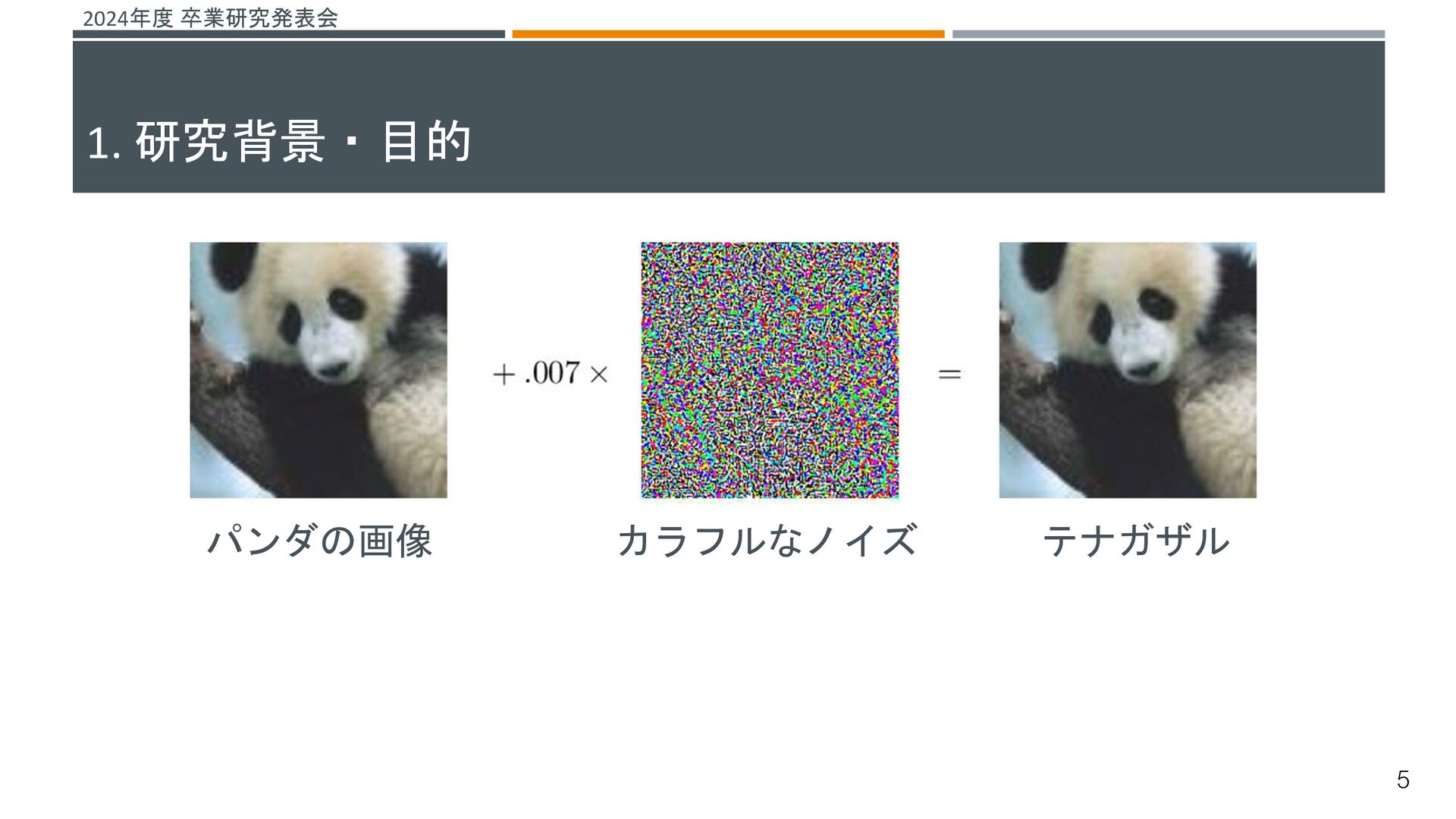
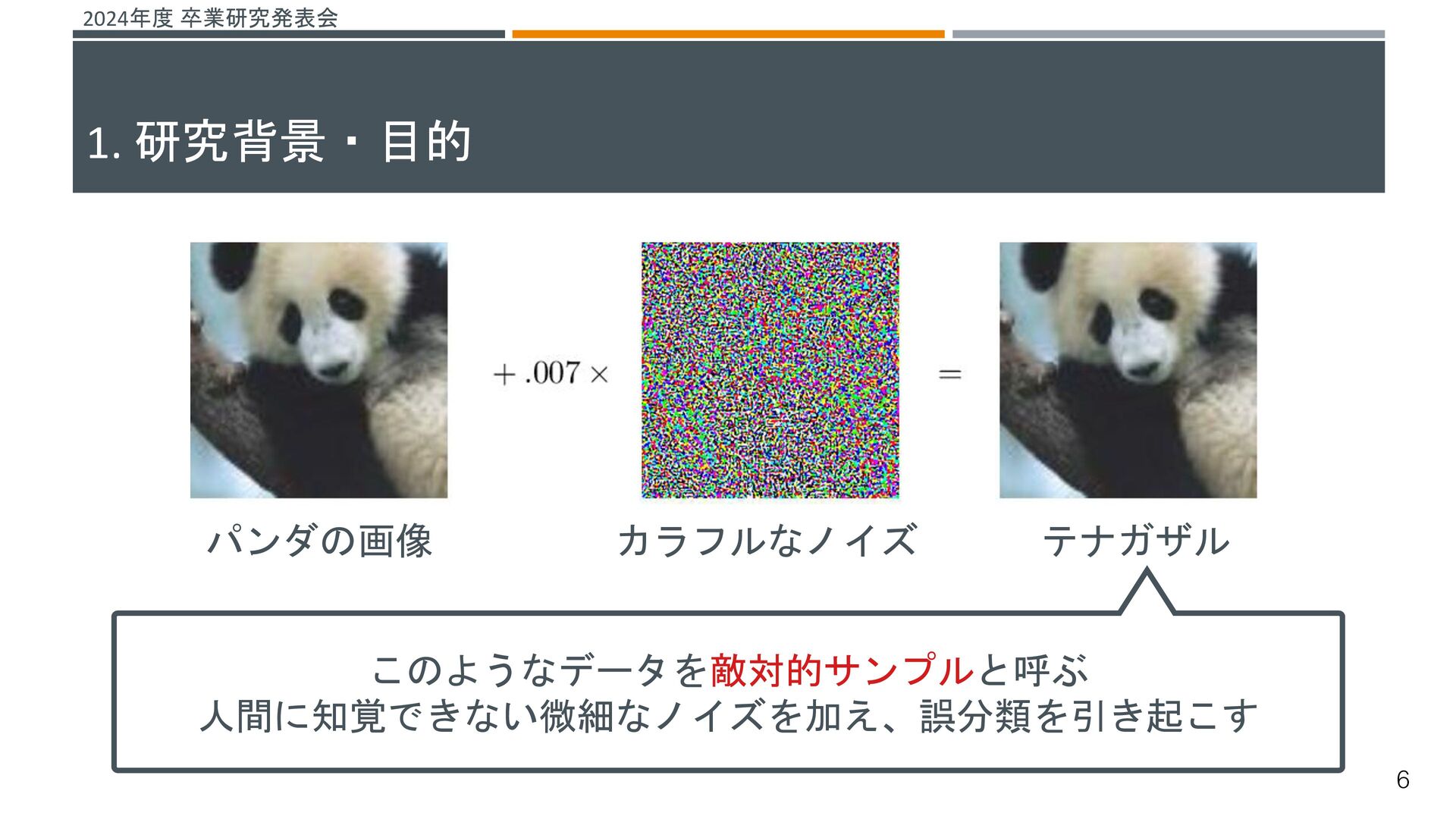
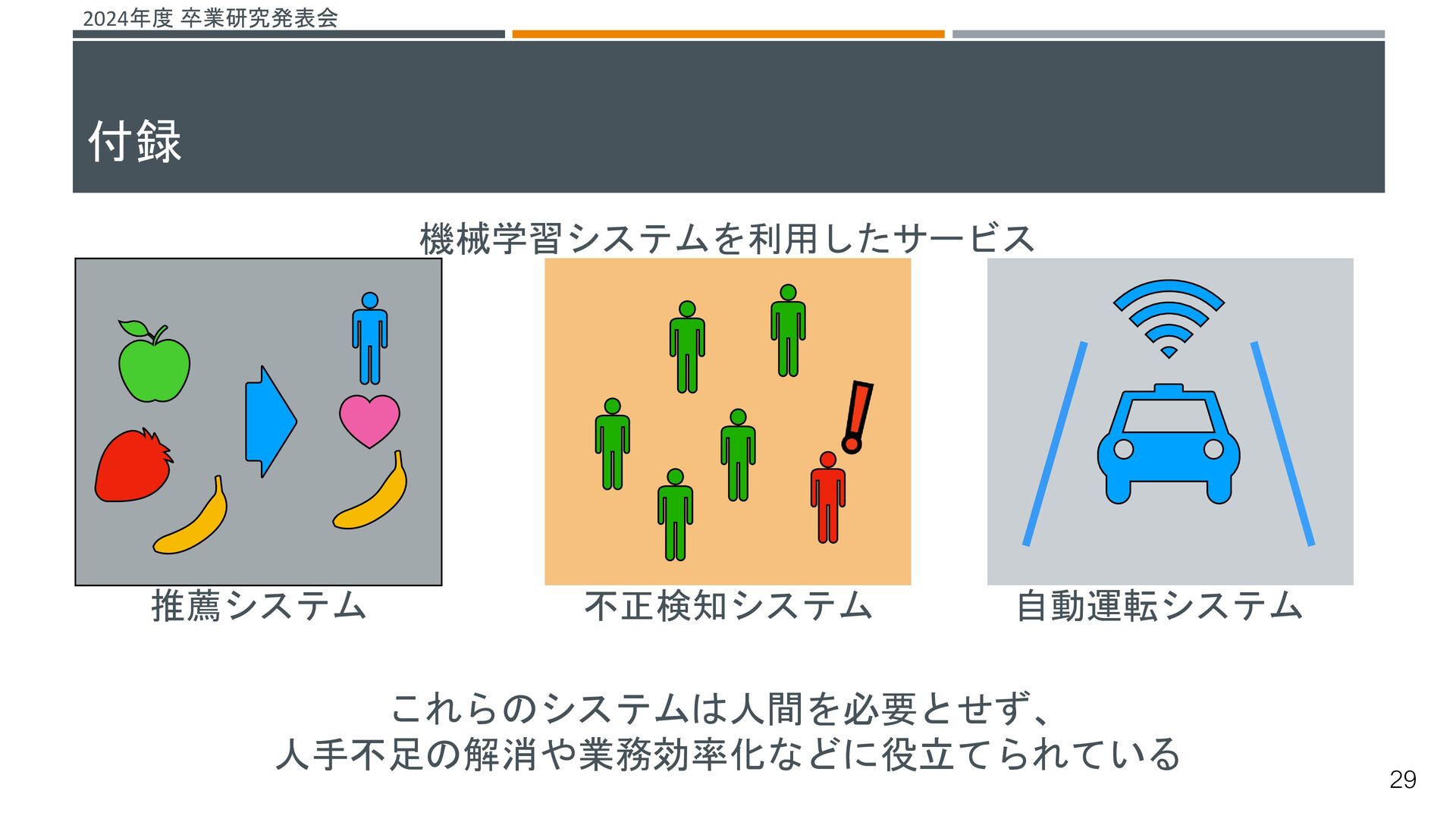
![2024年度 卒業研究発表会 機械学習システムに対する脅威がある その一つとして、敵対的サンプルによる攻撃が挙げられる[1] これらの攻撃を防ぐ仕組みとして敵対的学習という研究が行われている 敵対的学習 既存の機械学習モデルが誤分類しない堅牢性を高める学習 敵対的サンプル 入力データに人間が知覚できないノイズを加え、誤分類を引き起こすデータ →よりノイズの小さい敵対的サンプルを生成することで、より堅牢な機械学習](https://files.speakerdeck.com/presentations/fdc181f6814643fbae1e168e005166e8/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
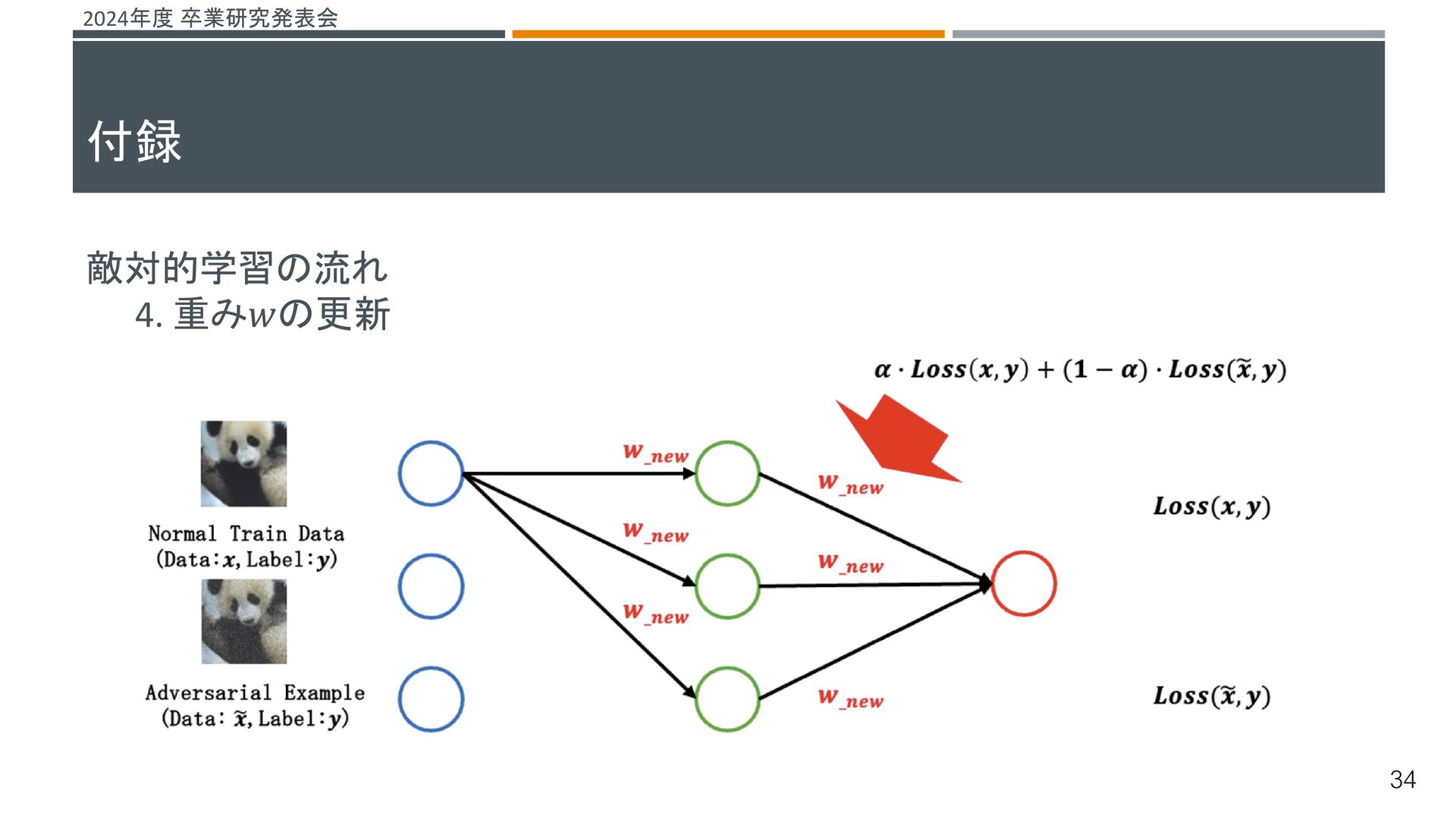
{kind=link}
{kind=link}