Share
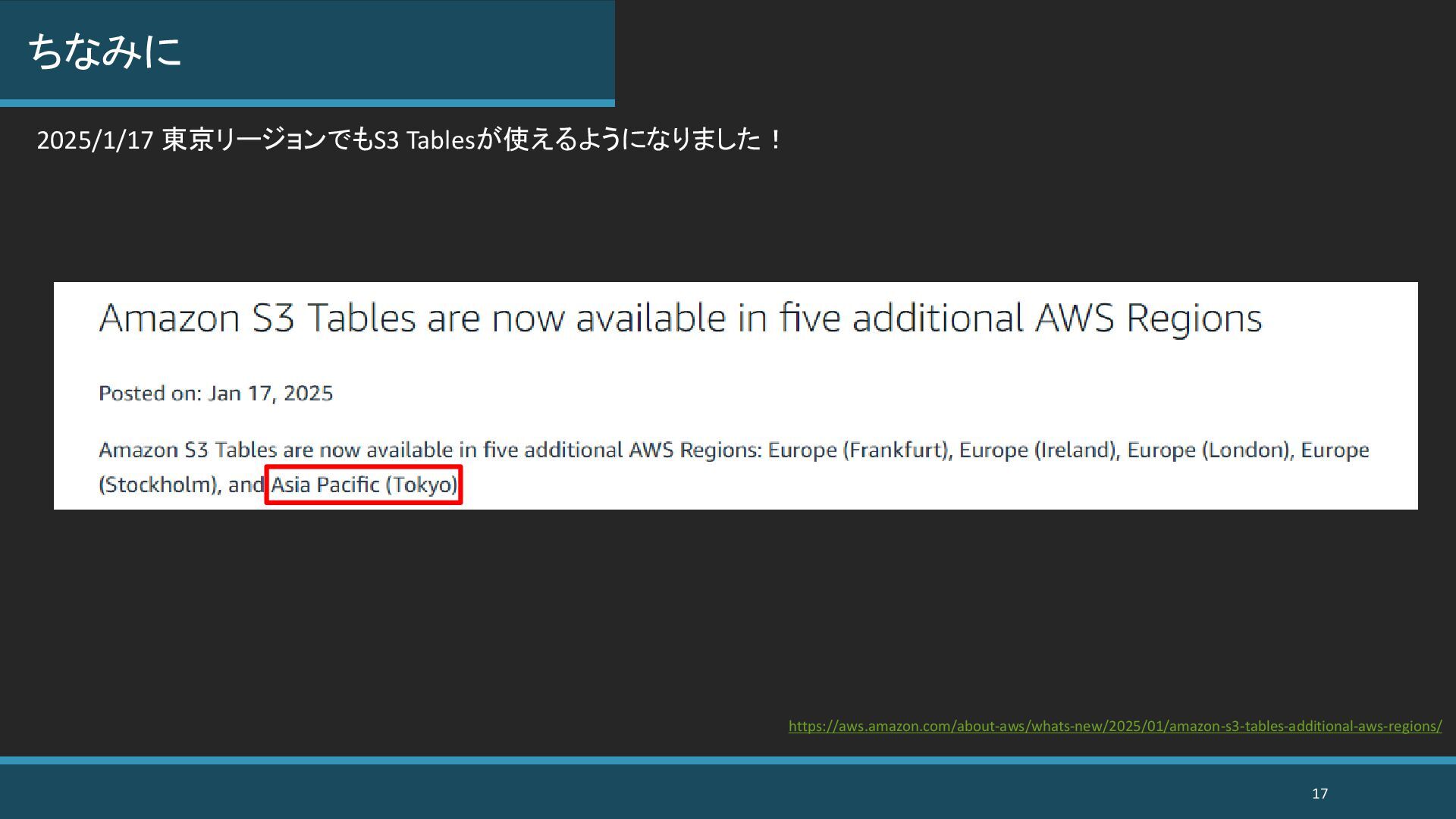
BigData-JAWS 勉強会 #28 (re:Invent 2024 re:Cap) https://jawsug-bigdata.connpass.com/event/341224/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
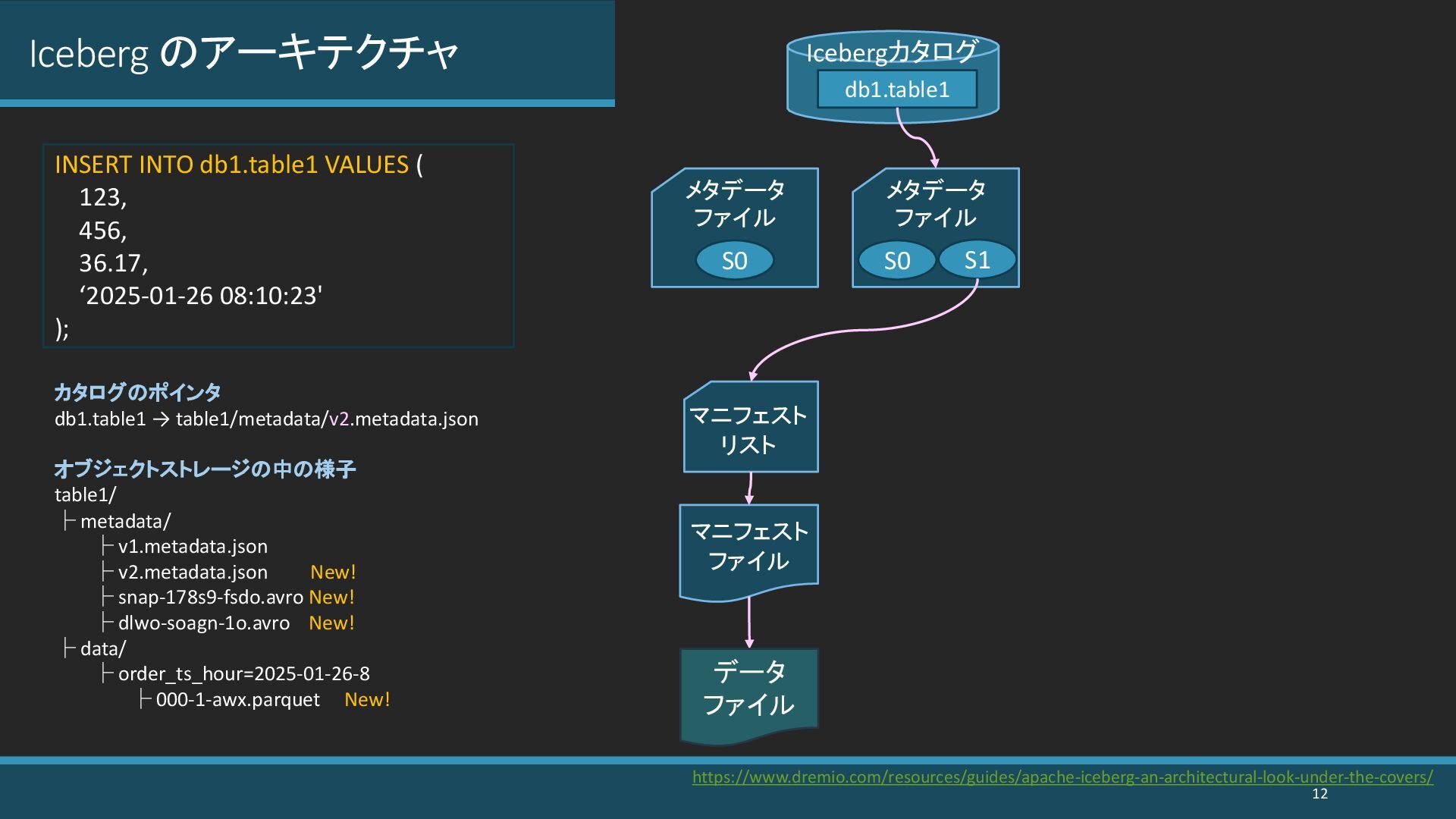{kind=link}
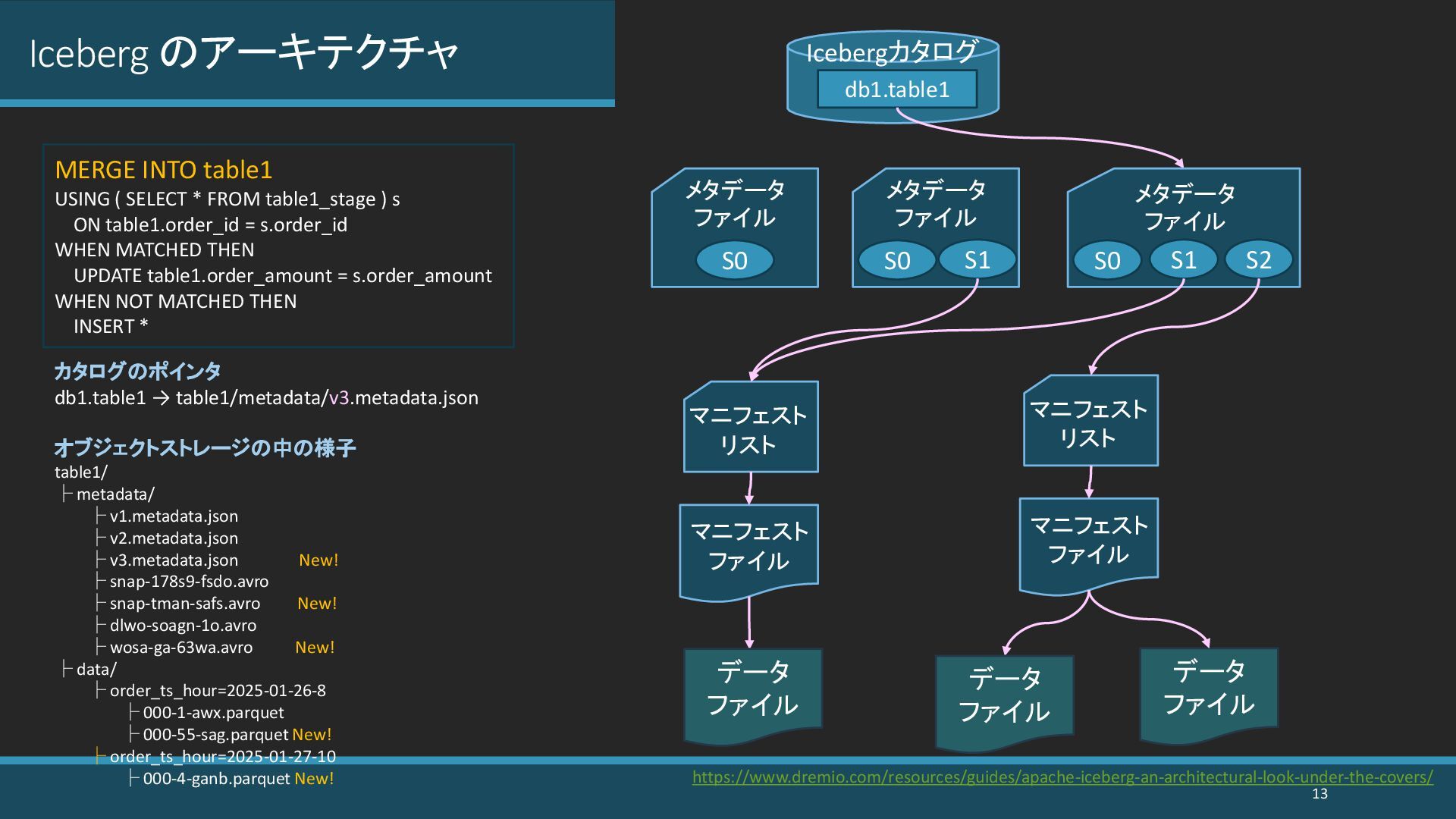{kind=link}
{kind=link}
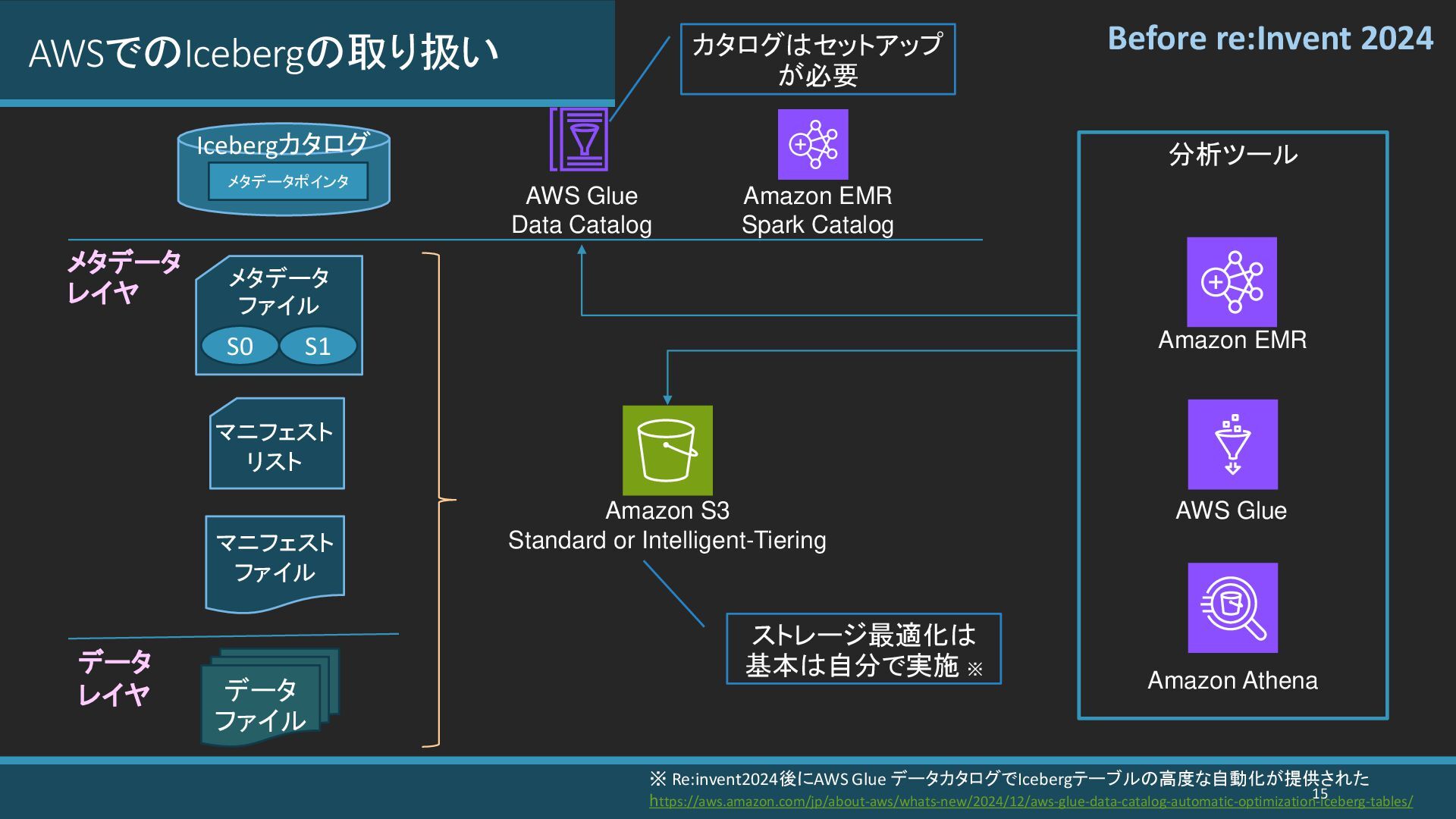{kind=link}
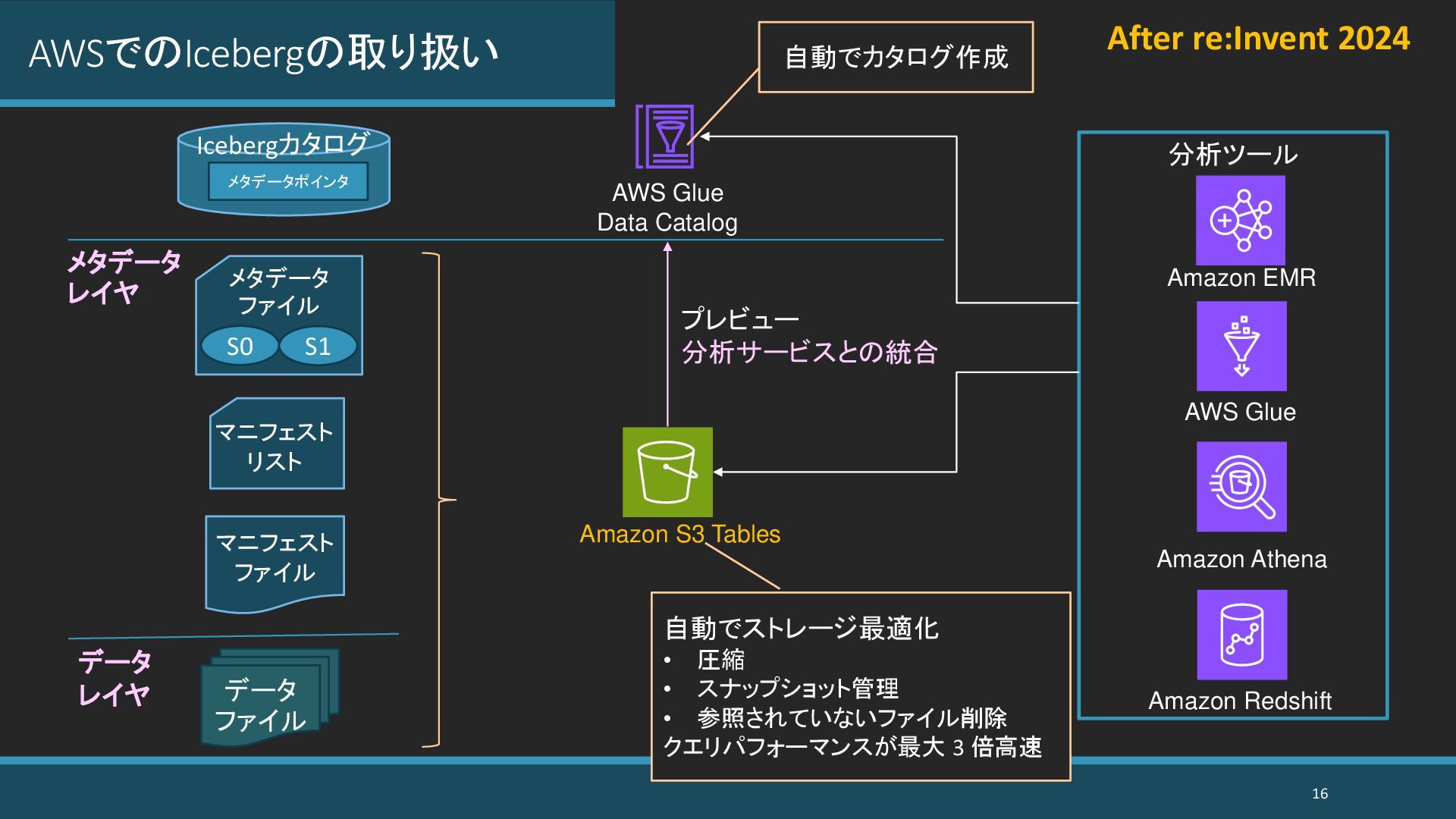{kind=link}
{kind=link}
{kind=link}
{kind=link}