Azure ML is a complex Microsoft offering for Data Scientists, and sometimes it seems too complex to just start using it. In this talk, I will demonstrate a simple way to start with Azure ML using Visual Studio Code, and then proceed to show more complex examples, such as training GANs to produce artistic paintings and using pre-trained BERT with DeepPavlov library for answering questions on COVID-19. I will also give a general overview of how and when Machine Learning and AI can be effectively used, and cover some practical cases.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Toy Problem: MNIST Digit Recognition http://yann.lecun.com/exdb/mnist/ mnist=fetch_openml('mnist_784’) X = mnist[‘data’]](https://files.speakerdeck.com/presentations/9aa4c643ac4d449f8432171bec54d131/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
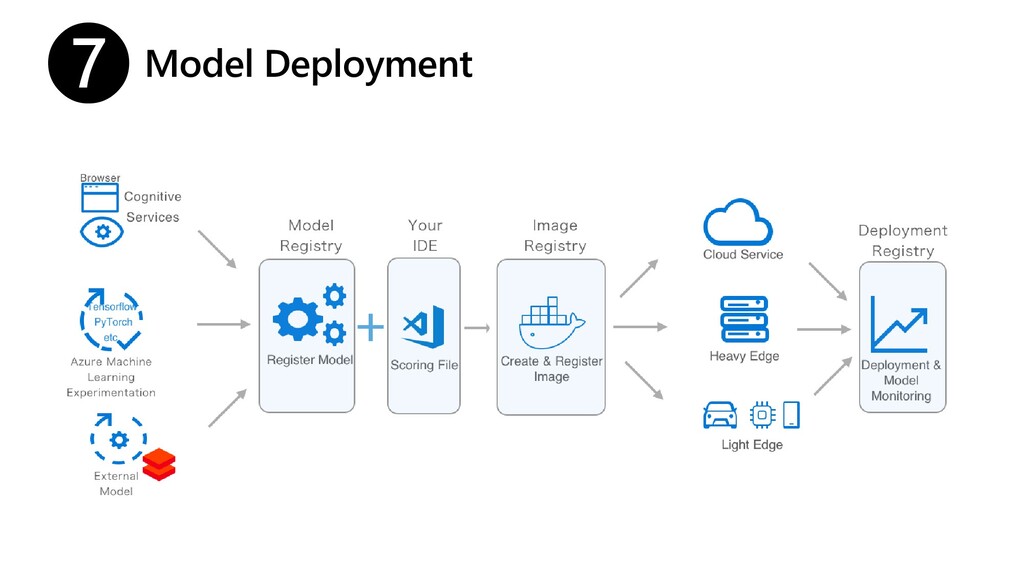{kind=link}
{kind=link}
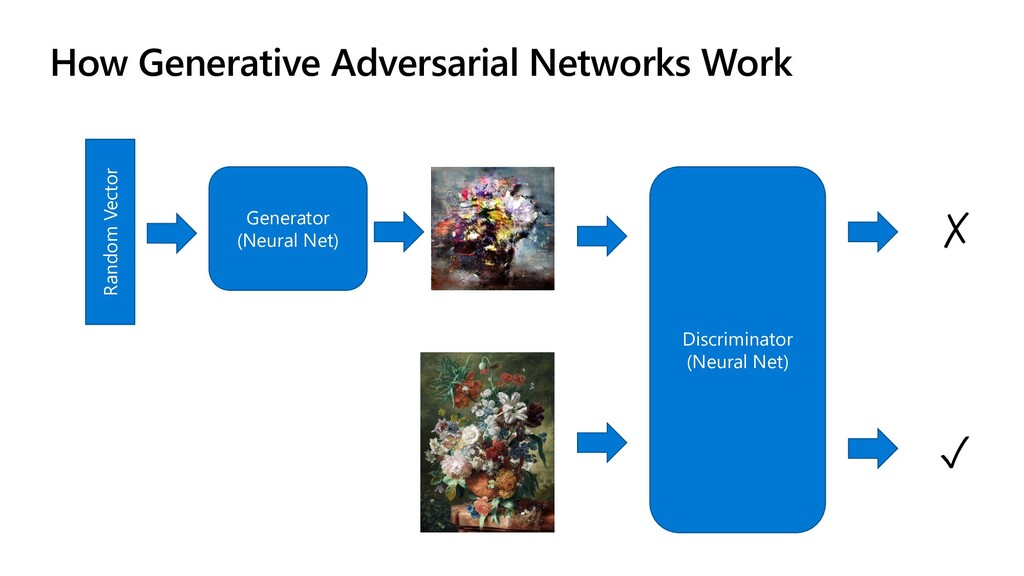{kind=link}
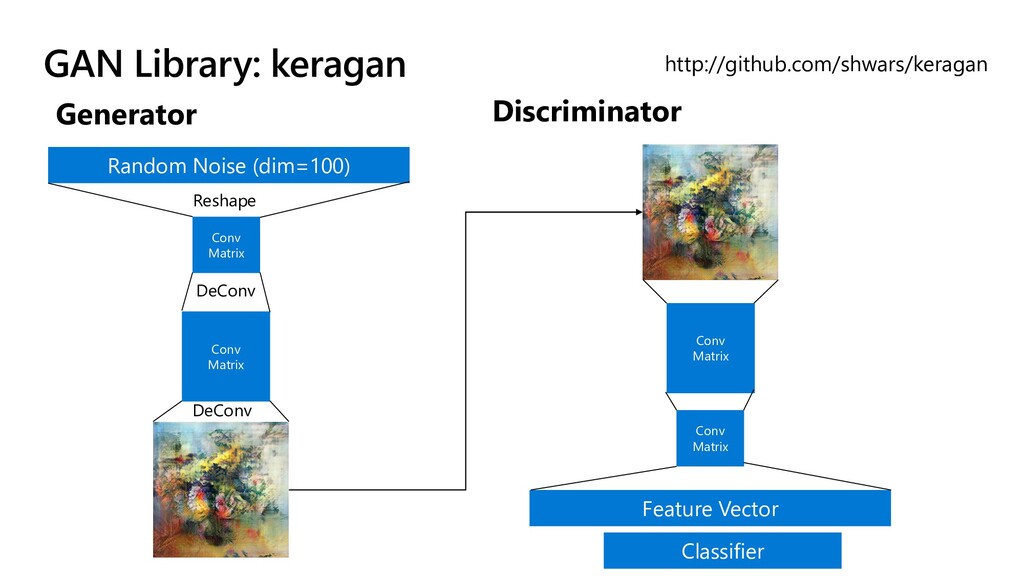{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
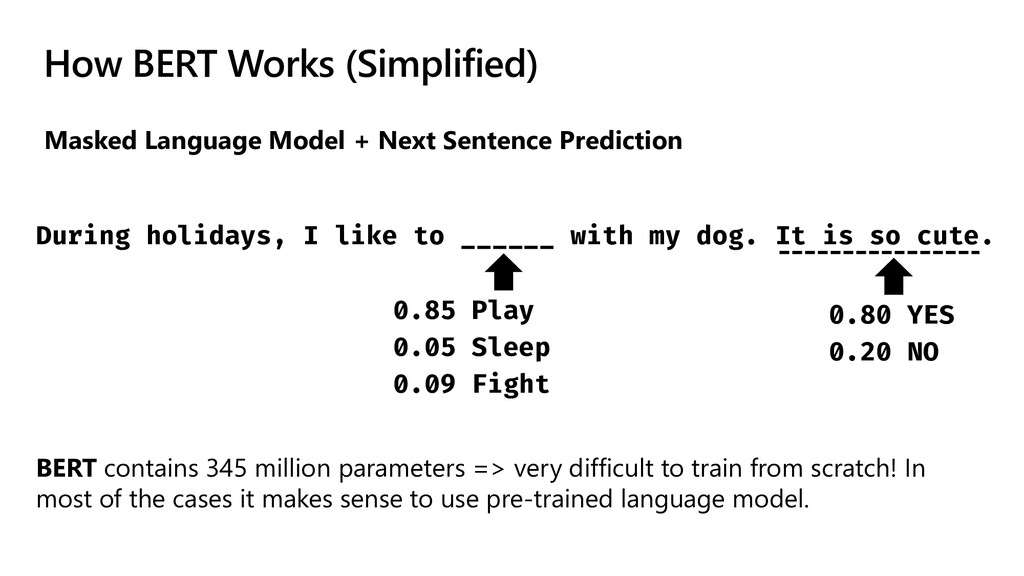{kind=link}
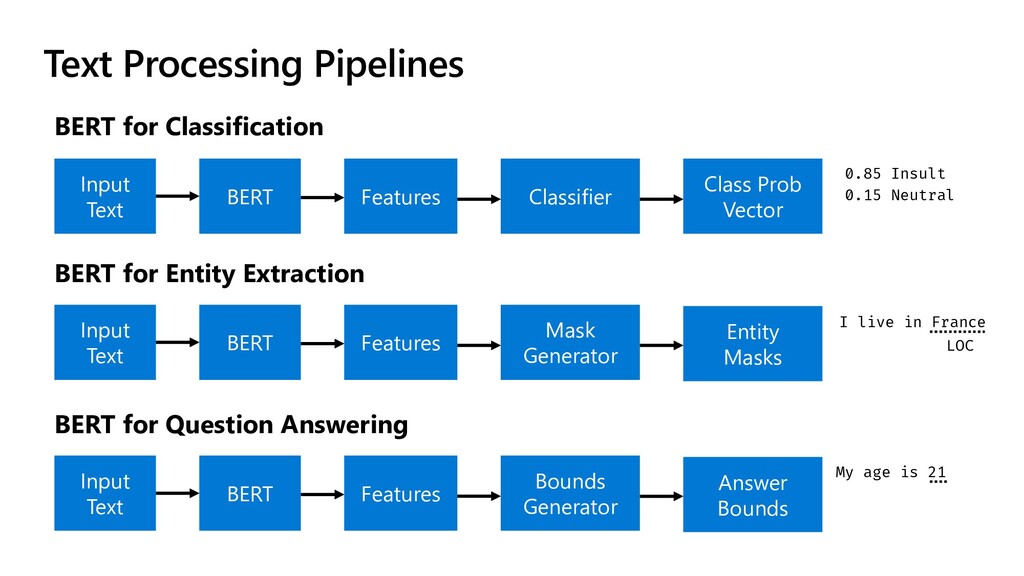{kind=link}
{kind=link}
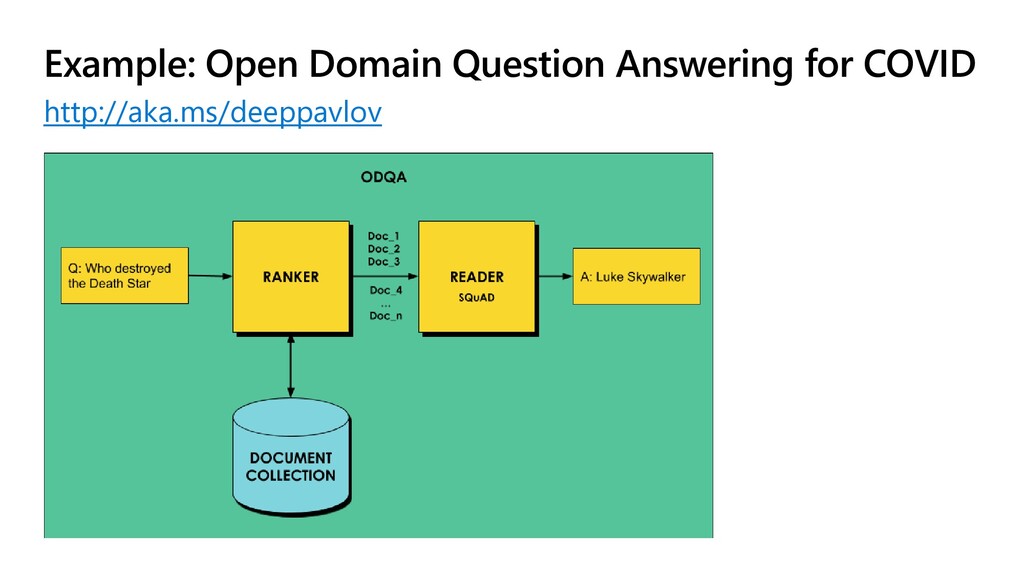{kind=link}
{kind=link}
{kind=link}
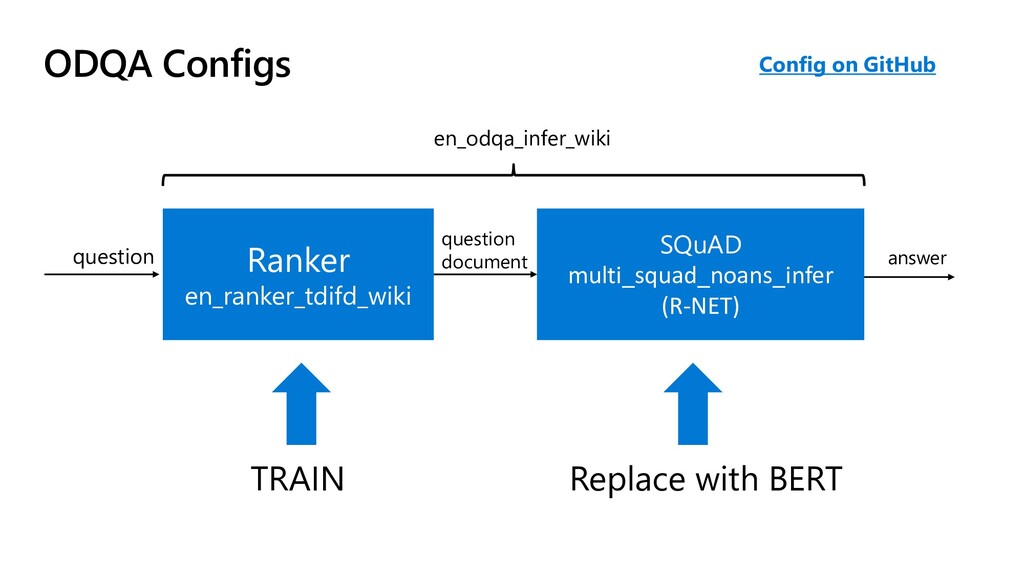{kind=link}
{kind=link}
{kind=link}
{kind=link}
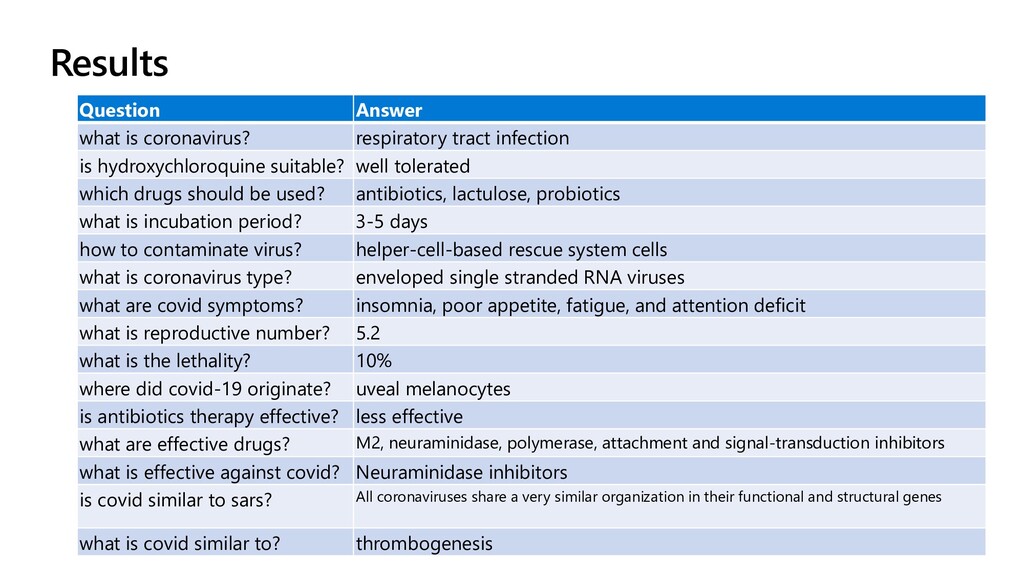{kind=link}
{kind=link}
{kind=link}
{kind=link}