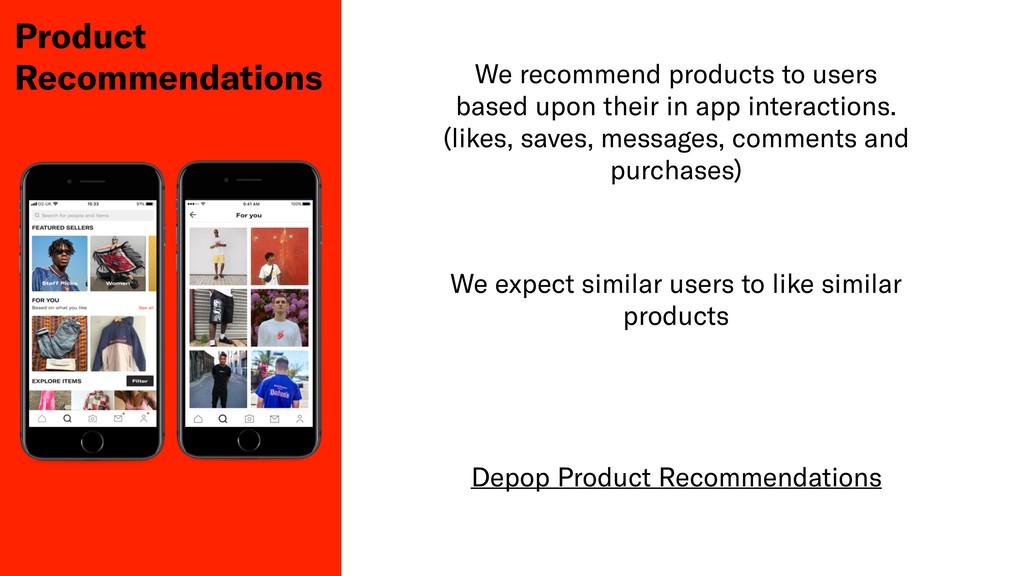
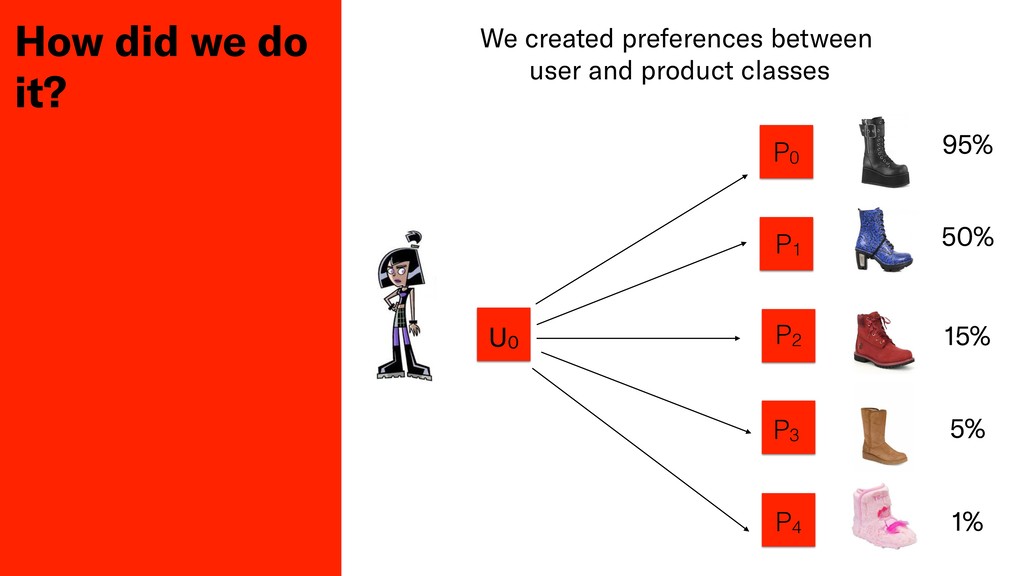
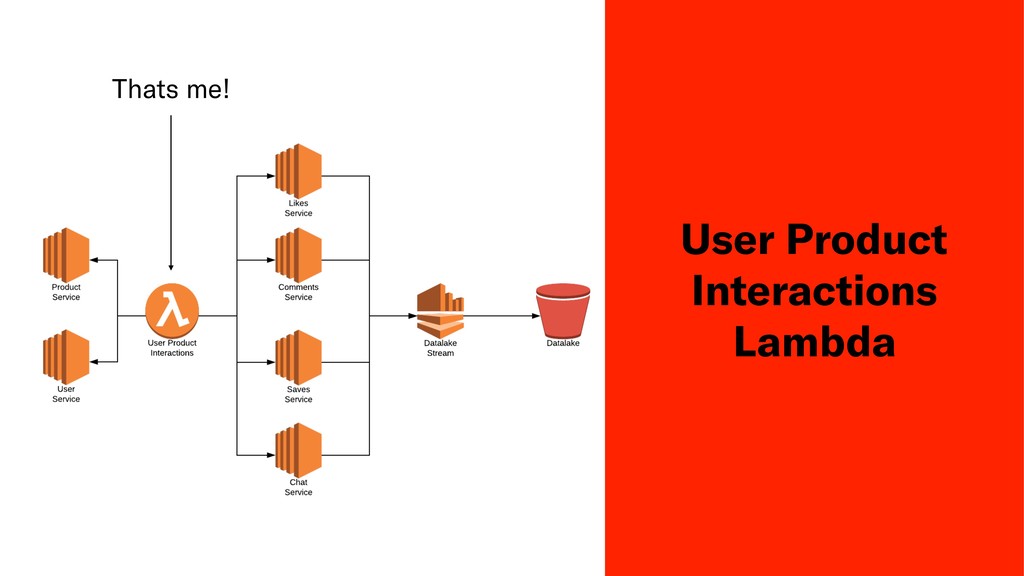
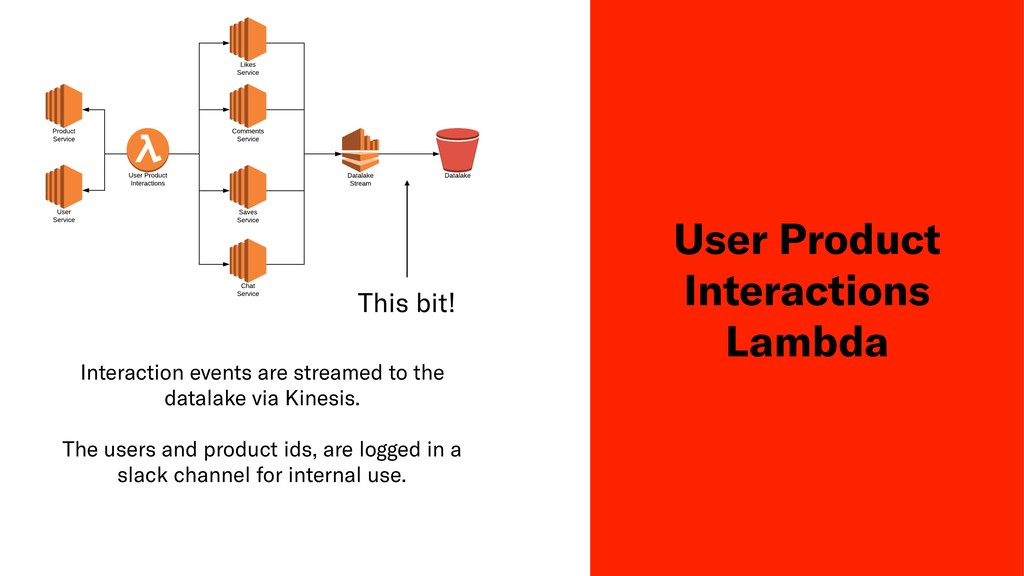
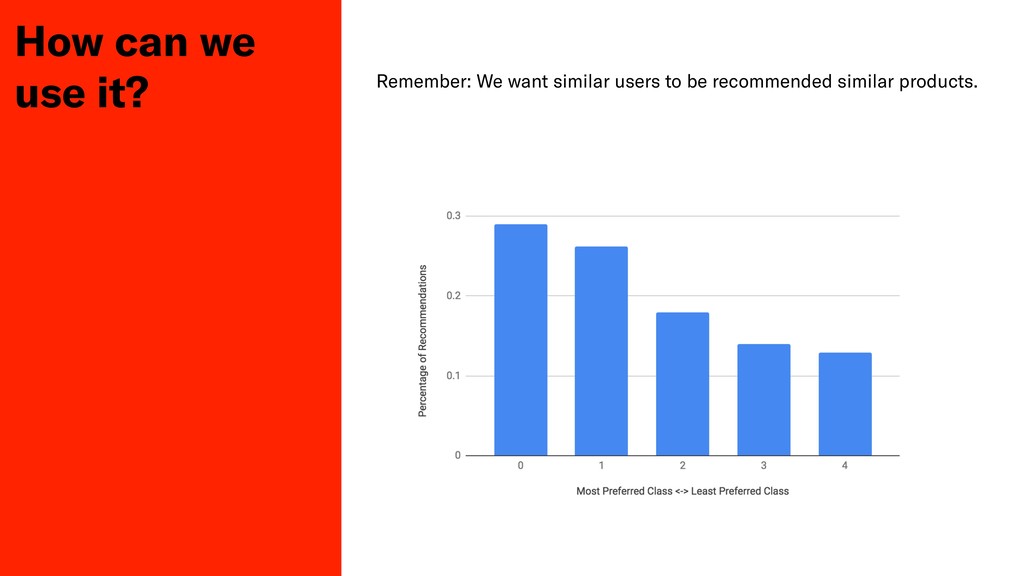
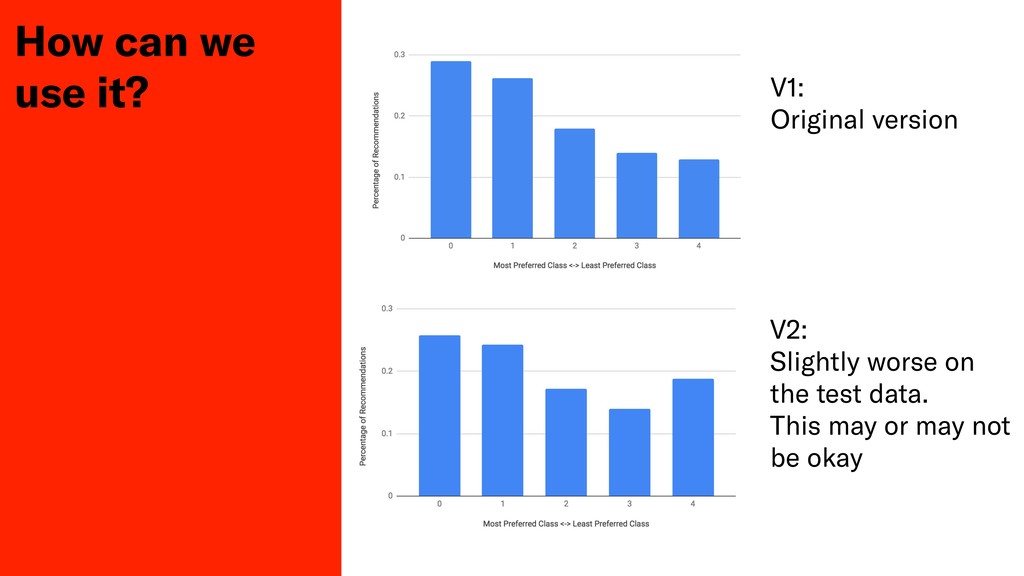
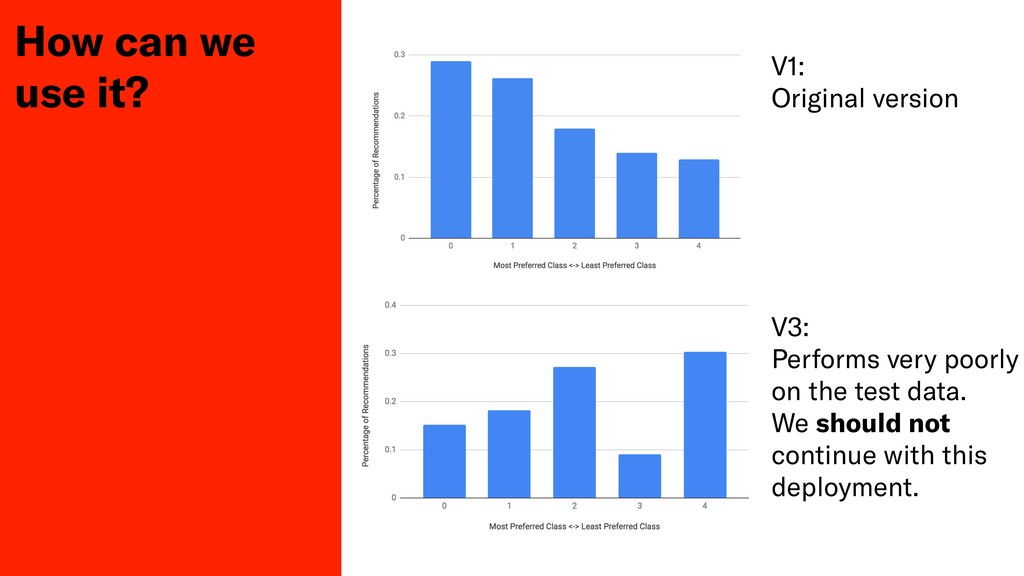
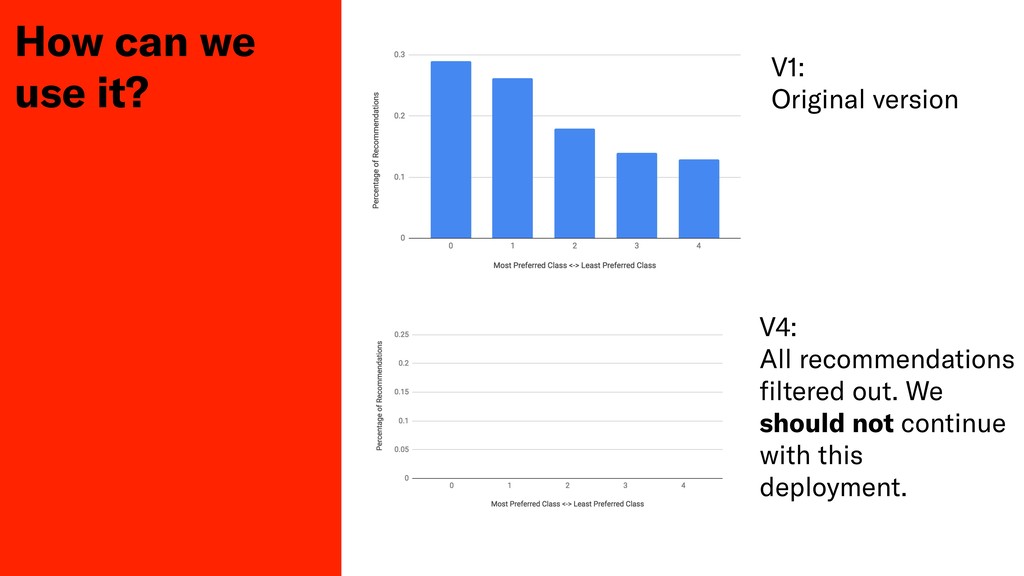
Testing the qualitative performance of a ML model is a difficult task, usually only done by measuring fluctuations of key business metrics in production. In this session John will discuss his teams attempts to produce a deterministic test of algorithmic performance in Depop's staging environment for their product recommendation system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}