Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
コンピュートリソースと トリガーから考える サーバーレスアーキテクチャ in Develope...
Search
sinofseven
July 24, 2023
Technology
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
コンピュートリソースと トリガーから考える サーバーレスアーキテクチャ in DevelopersIO 2023 福岡
サーバーレスアーキテクチャを考えるための基礎として、使うことのできるコンピュートリソースとそのトリガーとなるサービスについて簡単にまとめてみました。
sinofseven
July 24, 2023
More Decks by sinofseven
See All by sinofseven
サーバーレス開発の勘所
sinofseven_
0
1.7k
CircleCI_のJobを_並列で実行してみる
sinofseven_
1
1.5k
サーバーレスの概要と応用 - プログラミング生放送勉強会 第55回@福岡
sinofseven_
0
1.6k
Other Decks in Technology
See All in Technology
1台から試せる!Edge IoTを使った位置情報の活用設計【SORACOM Discovery 2026】
soracom
PRO
0
110
Amazon Bedrock Managed Knowledge Base Dive Deep
ren8k
0
250
文字起こし基盤の信頼性
abnoumaru
0
150
人依存からAIネイティブの体制へ:バックエンド開発の裏側【SORACOM Discovery 2026】
soracom
PRO
0
130
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
31
25k
Retriever と Reranker、結局どうする?
kazuaki
1
460
データエンジニアこそ組織のオントロジーに向き合うべき — 問いに答えるAIから、事業を動かすAIへ
gappy50
4
1.6k
AI研修(Day2)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
1.5k
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
140
信頼できるテスティングAIをどう育てるか?
odan611
0
160
DevOps Agentで運用判断をチーム資産にする ~Agent InstructionsとAgent Skillを継続的に育てる~
fujioka6789
0
170
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
320
Featured
See All Featured
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
460
Raft: Consensus for Rubyists
vanstee
141
7.6k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Skip the Path - Find Your Career Trail
mkilby
1
170
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
470
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Transcript
コンピュートリソースと トリガーから考える サーバーレスアーキテクチャ 2023/07/24 CX事業本部 夏目祐樹 1
自己紹介 • 夏目祐樹 (ナツメ ユウタ) • CX事業本部 Delivery部 サーバーサイドチーム •
好きなAWS サービス ◦ Lamba ◦ DynamoDB ◦ SQS • 近況 ◦ 刃をスルーつもりだったら 1発で確定演出が来た (スターレイル) ◦ 零式サボりすぎて3層も クリアできぬヤバい (FF14) ◦ その他やること多い 2
前提知識
サーバーレスとは • 今回の発表における前提としては以下のもの • ユーザーがサーバーを管理しなくて良いもの ◦ Server Management Less •
実際に動いている時間だけ課金されるもの ◦ 待機時間は原則課金が発生しないようなもの 4
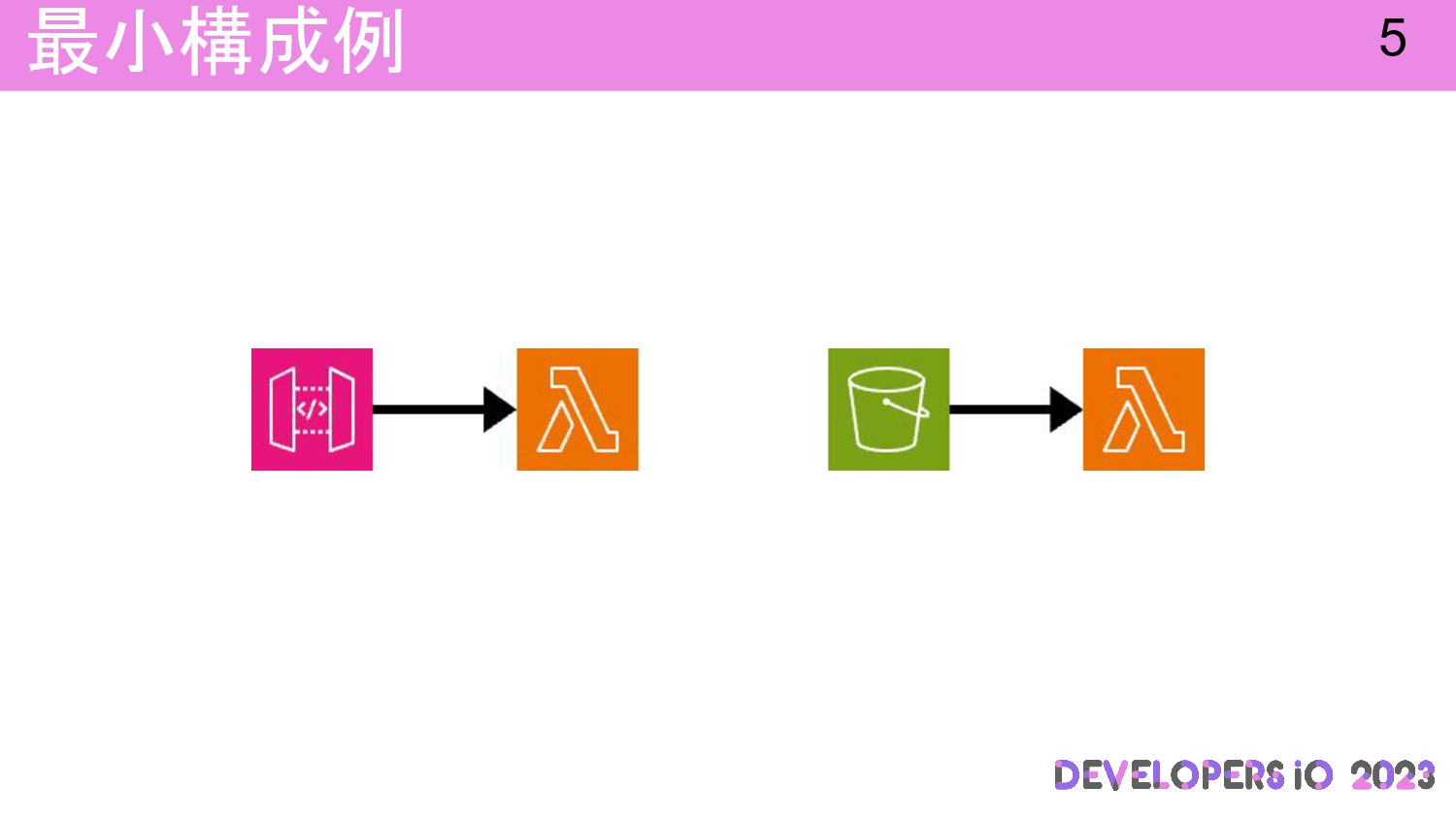
最小構成例 5
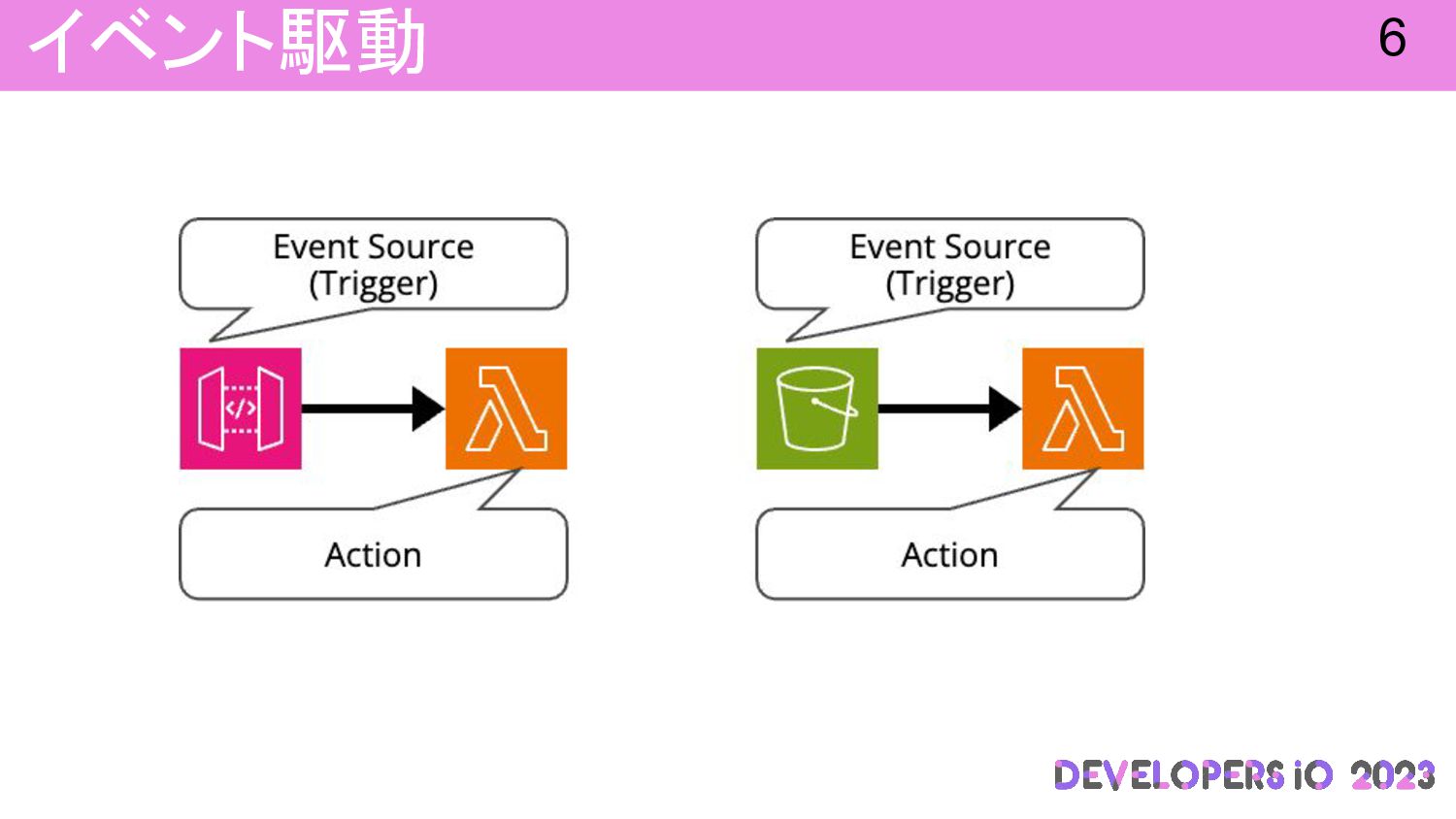
イベント駆動 6
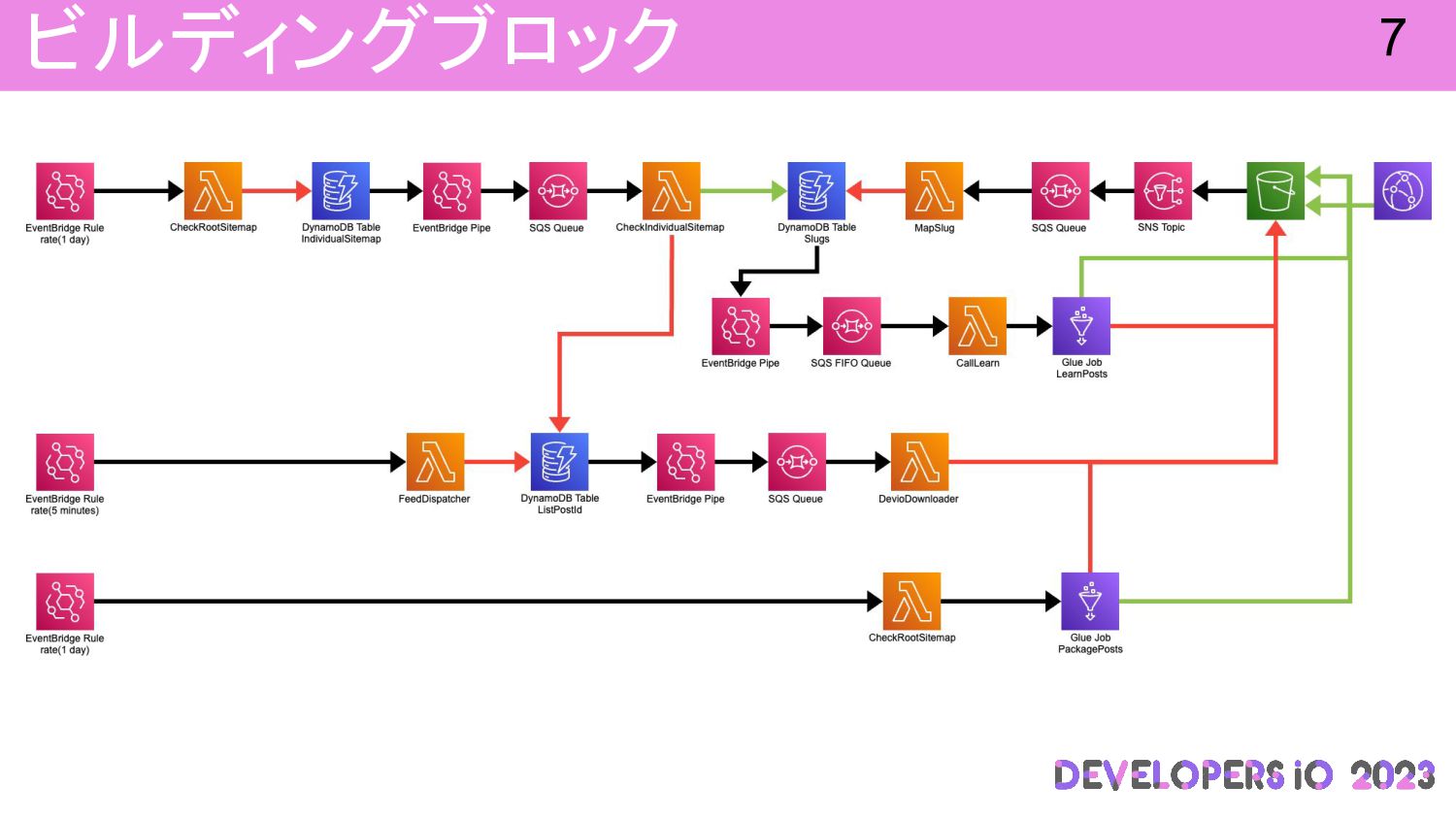
ビルディングブロック 7
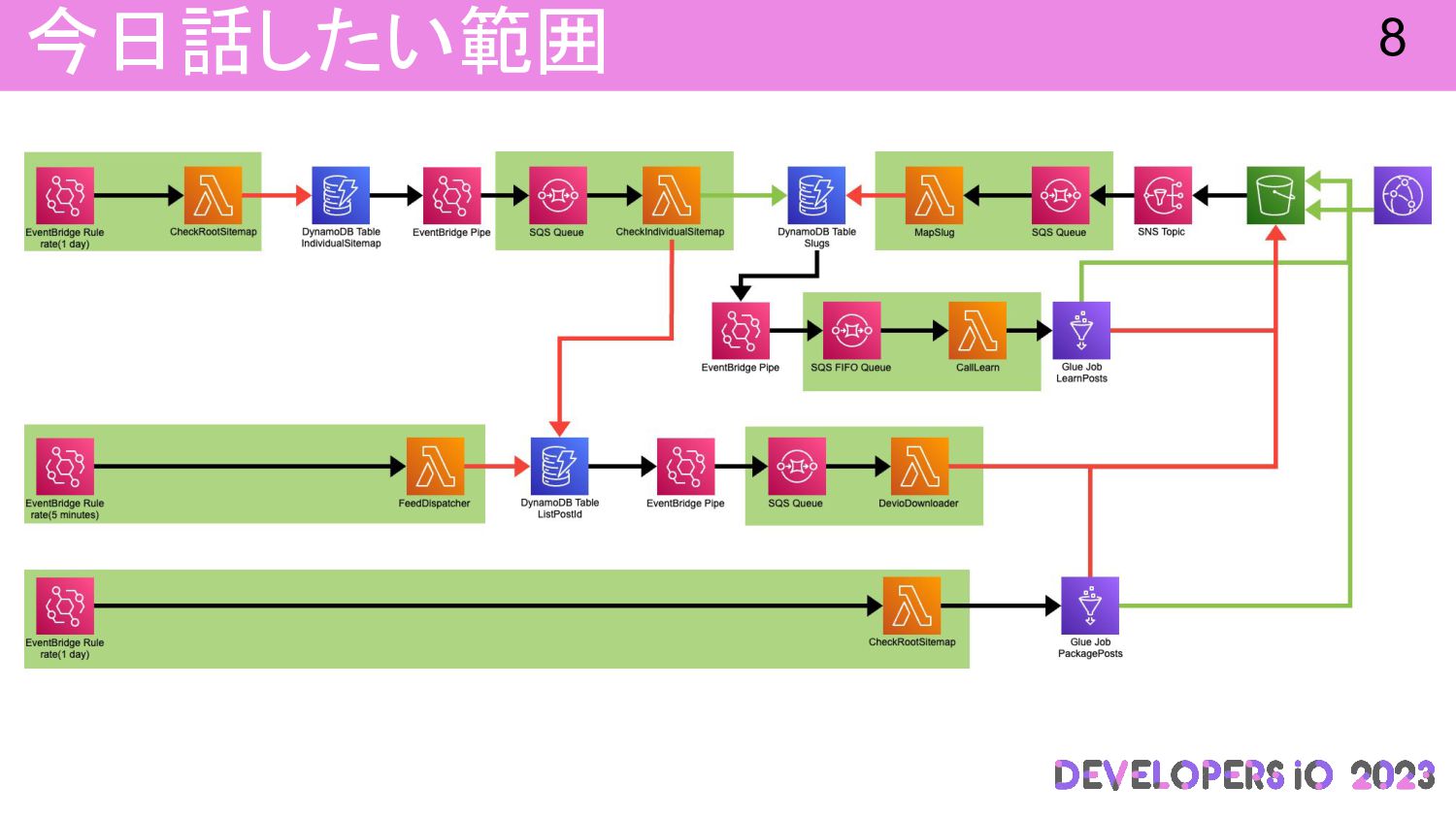
今日話したい範囲 8
今日話さない範囲 9
アジェンダ 1. サーバーレスなコンピュートリソース a. Fargate b. Glue Job c. Lambda
2. 各コンピュートリソースのトリガーとなるサービス a. EventBridge Rule b. Step Functions c. Lambdaのトリガー注意点 i. イベントソースマッピング ii. 同期実行 iii. 非同期実行 10
1. サーバーレスなコンピュートリソース Lambda • 一番多くの トリガーに対応 • メモリ上限が 10GB •
実行時間の上限が 15分 • 基本的にこれ使う 11 Glue Job • ETL用に用意された 実行環境 • Spark用とPython用 がある • 実行時間に上限ない • 強力な計算リソースや 時間がかかる処理に 使う Fargate • マネージドな コンテナ実行環境 • これ単体では 動かせない • ECS, EKS, AWS Batchで使う • 強力な計算リソースや 時間がかかる処理、 GPUやミドルウェアが 必要な際に使う
1-a. Fargate • 広義のサーバーレス • 単体では動かせないため、ECS, EKS, AWS Batchで使う ◦
ここではECS Taskのみを扱う • Container Imageを実行する • 使用するvCPU数とメモリ量を指定する ◦ 原則これと実行時間で課金量が決まる ◦ 指定したvCPU数によって 使用できるメモリ量の範囲が決まる • GPUや追加のストレージも使用できる ◦ 追加料金 12
1-b. Glue Job • 忘れがちなコンピュートリソース • ETL処理のために比較的強力な計算リソースを使用できる • Spark JobとPython
Shell Jobがある ◦ ここではPython Shell Jobの話をする • Lambdaと比べると比較的強力な実行環境 ◦ 1 DPUもしくは 0.0625 DPU (1/16 DPU) ◦ 1 DPU = 4 vCPU & 16 GB メモリ • Pythonのバージョンは3.6か3.9 • あらかじめ用意されたライブラリを使用したり、 自分で追加したりすることができる 13
1-c. Lambda • サーバーレスの代名詞とも言えるコンピュートリソース • 最大15分実行可能 • メモリ量は128MBから10GBまで使用可能 ◦ メモリ量が増えると使用できるvCPUの数も増える
• 事前に用意されたRuntimeは、 Python, Node.js, Ruby, Java, C# • カスタムランタイムを使えばそれ以外も使える • デプロイパッケージの上限は非圧縮で250MB • Container Imageも使用できる ◦ このときImageサイズの上限は非圧縮で10GBまで増える 14
2. 各コンピュートリソースのトリガー Lambda • いっぱい! ◦ EventBridge Ruleや Step Functionsでも
実行できる 15 Glue Job • Glue Job備え付けの トリガー ◦ 一定周期 ◦ JobやCrawlerの 実行状況とか • EventBridge Rule ◦ Glue Workflowを 間に挟む • Step Functions Fargate(ECS Task) • EventBridge Rule • Step Functions
2-a. EventBridge Rule • イベント駆動でよく使うサービスの一つ • Scheduleかイベントパターンどちらかを使用する • Scheduleは一定間隔(rate式)か定期実行(cron式)、 どちらかを指定する
• イベントパターンではAWSイベントか EventBridgeパートナーイベントを指定する ◦ 最終的にはJSONでイベント発火条件を書く ◦ AWSイベントではAWSの各サービスで定義されたイベントか CloudTrailで補足されたAPI Callを使用できる ◦ EventBridgeパートナーイベントは AWSとは別のSaaSのイベントを使用できるようにするもの • 周辺サービス含めて色々できる 16
2-b. Step Functions • 複雑なワークフローを記述/実行するためのサービス ◦ 特定の順番で実行したり、並列処理させたり、 要素の数だけループして実行したり、条件分岐させたり • JSONでState
Machine (ワークフロー)を定義する ◦ Workflow Studioでブロックを並べるように定義できる • LambdaやGlue Jobなどを 実行する他に、 直接AWSの別のサービスを 使うこともできる 17
2-c. Lambdaのトリガー注意点 • Lambdaのトリガーは大きく分けると3種類に分類できる a. イベントソースマッピング ▪ キューからデータを取ってきて実行するトリガー b. 同期実行
▪ Lambdaの完了を待って何かを返すトリガー c. 非同期実行 ▪ 呼び出すだけ呼び出して、あとは知らないトリガー • リトライの仕組みが異なったりするので注意が必要 18
2-c-i. イベントソースマッピング • キューからデータを取ってきて実行するトリガー • AWSサービス ◦ Kinesis Data Stream,
DynamoDB Stream, SQS Queue, Amazon Managed Streaming for Apache Kafka, セルフマネージド Apache Kafka, Amazon MQ • Lambdaが処理に成功するとキューからデータが削除される ◦ 失敗するとデータが残る ◦ Kinesis Data StreamやDynamoDB Streamでは直列的に データを取り出すので失敗するとよくデータが詰まる ◦ SQS Queueはデフォルトでは取り出す順序が 順不同なのでつまらない (FIFOキューは別) 19
2-c-i-1. Kinesis Data Stream • 大量のStreaming Dataをキューイングできるサービス • IoT Coreの後ろなど1秒間に大量のデータがやってくる
ような時に使うと効果的 ◦ 処理がパンクしてデータを消失したりしない • Shard数によってさばけるデータの上限が決まる ◦ Lambdaは1つのShardあたりいくつ並列で実行するとか 設定する • 必ず直列的にデータを取り出すので、 Lambdaの実行に失敗し続けるといつまでも同じデータが残り、 詰まってしまう 20
2-c-i-2. DynamoDB Stream • DynamoDB Tableに対するデータの操作履歴が来るストリーム ◦ INSERT, MODIFY, REMOVEのイベントタイプがある
• Kinesis Data Streamと同じくShardの概念があるが、 自動的にスケールする (設定できない) ◦ Lambdaは1つのShardあたりの並列実行数を設定できる • DynamoDBは検索がRDBMSほど自由にはできないので、 これを使って検索用のテーブルを作ったりすることもできる • 必ず直列的にデータを取り出すので、 Lambdaの実行に失敗し続けるといつまでも同じデータが残り、 詰まってしまう 21
2-c-i-3. SQS Queue • 純粋なキューのサービス • キューとは言ってもデータを取り出すだけじゃ削除されず、 明示的にデータを削除する必要がある ◦ Lambdaのトリガーとして使う場合は、勝手に消してくれる
• 可視性タイムアウトというものをQueueや Queueに入れるメッセージに設定できる ◦ 一度取り出してから次に取り出せるようになるまでの時間 • 標準キューの場合は取り出す順序は順不同なので、 処理に失敗してもデータが詰まることはない • 注意点: ◦ Lambdaは一度にキューから とれるだけデータを取って処理しようとするので、 Lambdaに対して最大同時実行数の制限をいれた方が良い 22
2-c-ii. 同期実行 • Lambdaを同期的に実行し、結果を再利用するトリガー • 対象のサービス ◦ API Gateway, ALB,
CloudFront (Lambda@Edge), Kinesis Data Firehose, Cognito User Pool, Amazon Connect, Alexa, S3 Batch, Step Functions • 基本的に各サービスやその用途に応じた レスポンスを返す必要がある • 処理に失敗しても再実行しない 23
2-c-ii-1. API Gateway, ALB • APIのフロント部分になるサービス • これらと組み合わせることで APIのバックエンドとしてLambdaを使用できる •
API Gateway自体は叩かれた回数で課金されるが、 ALB (Application Load Balancer)では時間課金 • API Gatewayのバックエンドとして使う場合、 Lambdaは29秒以内にレスポンスを返さないと タイムアウトになってしまう 24
2-c-ii-2. CloudFront (Lambda@Edge) • CloudFrontのレスポンスなどを書き換えるのに使用する • レスポンスヘッダーを増やしてみたり、 リクエストで求められたファイルとは別のものを返させたり、 色々できる •
他のトリガーのときと違って、 色々な制限がかかっているので注意が必要 25
2-c-ii. Kinesis Data Firehose • データをキューイングしながらS3などに データを書き込むサービス • データの元としてはKinesis Data
Streamを使ったり、 直接Firehoseに入れさせたりできる • Lambdaを使って、データの加工やフィルタリングができる 26
2-c-ii-3. Cognito User Pool • AWSが提供する認証基盤 • User Pool自体でサインアップさせるほかに、 OpenID
Connectを使用することができる • Cognito User Poolが提供するログイン用のWeb UIもある • ユーザーがサインアップしたときやサインインしたときなどに Lambdaを動かすことができる 27
2-c-iii. 非同期実行 • Lambdaを非同期で実行し結果を待たないトリガー • 対象のサービス ◦ S3, SNS Topic,
IoT Core Rule, IoT Events, CloudWatch Logs Subscription Filter, SES, CloudFormation, CodeCommit, CodePipeline, Config, EventBridge Rule • 結果を待たないので、レスポンスの形式は自由 • 失敗時デフォルトでは最大2回のリトライを行う ◦ 初回も含めて最大3回実行する ◦ 設定で実行回数は減らせる (増やせない) 28
2-c-iii-1. S3 • オブジェクトストレージサービス • イレブンナインの堅牢性を持つ ◦ 可用性は99.99ぐらいなので注意 • S3
Notificationという機能で、オブジェクトが置かれたり、 消されたりした際にLambdaを動かすことができる 29
2-c-iii-2. SNS Topic • AWSのPub/Subのサービス • TopicにデータをPublishすると、 登録された全てのSubscriberにデータが届く • Lambdaの他のSubscriberとして次のようなものもある
◦ email ◦ json形式のemail ◦ SQS Queue ◦ HTTP/HTTPS Request (POST) ◦ …etc 30
2-c-iii-3. IoT Core Rule • AWSのIoT系サービスの1機能 • IoT CoreでMQTTなどの形式でEdgeからデータを受け取る •
IoT Core RuleではSQL形式で Edgeから来たデータをフィルタリングと簡単な整形して、 登録したActionにデータを渡すことができる ◦ Lambdaもデータを渡すことができるものの一つ ◦ 他にもKinesis Data StreamやDynamoDB, SQS Queue, IoT Eventsなどにデータを渡すことができる 31
2-c-iii-4. IoT Events • 状態を管理して状態が変化した際に Lambdaなどを動かすことができるサービス • 事前に状態とその遷移条件などを定義して使用する ◦ 状態遷移した際にLambdaを動かすことができる
• IoT EventsはダイレクトにMQTTの中身を見ていない • IoT Core RuleなどでIoT Eventsに Key-Valueを渡してあげる必要がある 32
2-c-iii-5. CloudWatch Logs Subscription Filter • AWSのログ収集サービスにおいて、 特定のパターンのログが来たときに登録しておいた先に ログの内容を送信する機能 •
ログの送信先は次の3つのどれか ◦ Lambda, Kinesis Data Stream, Kinesis Data Firehose • 一つのLog Groupに2つまでしか登録できない • Lambdaの実行ログもCloudWatch Logsに送られるので、 エラー通知のために使用することもある 33
まとめ • AWSのサーバーレスなコンピュートリソースと そのトリガーとして使用できるサービスについて まとめてみました • サーバーレスなアプリケーションを組む際の 参考になれば幸いです。 34
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}