Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Adequate Full Text Search
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Florian Gilcher
November 25, 2014
Programming
180
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Adequate Full Text Search
given at Elasticsearch UG in November 2014
Florian Gilcher
November 25, 2014
More Decks by Florian Gilcher
See All by Florian Gilcher
A new contract with users
skade
1
530
Using Rust to interface with my dive computer
skade
0
310
async/.await with async-std
skade
1
810
Training Rust
skade
1
150
Internet of Streams - IoT in Rust
skade
0
130
How DevRel is failing communities
skade
0
140
The power of the where clause
skade
0
710
Three Years of Rust
skade
1
240
Rust as a CLI language
skade
1
250
Other Decks in Programming
See All in Programming
symfony/aiとlaravel/boost
77web
0
120
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
840
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
110
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
2.3k
Creating Composable Callables in Contemporary C++
rollbear
0
200
コンテキストの使い捨てをやめる — ビジネスルール駆動開発と miko —
ioki
0
270
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
480
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.4k
Claude Team Plan導入・ガイド
tk3fftk
0
160
AIエージェントで 変わるAndroid開発環境
takahirom
2
490
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
580
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
Featured
See All Featured
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
HDC tutorial
michielstock
2
740
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
AI: The stuff that nobody shows you
jnunemaker
PRO
8
820
How GitHub (no longer) Works
holman
316
150k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Transcript
None
$ cat .profile GIT_AUTHOR_NAME=Florian Gilcher
[email protected]
TM_COMPANY=Asquera GmbH TWITTER_HANDLE=argorak GITHUB_HANDLE=skade
• Backend developer • Focused on infrastructure and databases
• Elasticsearch Usergroup • mrgn.in meetup • Rust Usergroup (co-org)
• organizer alumni eurucamp • organizer alumni JRubyConf.EU • Ruby Berlin board member
Adequate Full Text Search
The evaluation problem
Given almost no time and an unknown problem space, how
do I evaluate "fitness for purpose"?
You can't
Given almost no time and only a glimpse of the
problem space, how do I evaluate "fitness for purpose"?
How much of a glimpse do I need?
In this talk, I’ll present: • a solution unfit for
purpose • a solution fit for purpose, but only in cer- tain boundaries • a comparison to a fully fledged solution
To the daily practitioners: I’ll gloss over a lot of
points.
• Elasticsearch • PostgreSQL • MongoDB
Issue 1 Search systems are not binary. Faults in the
system degrade the quality of the system, rarely break it.
Issue 2 Full text searchers are far more focused on
inputs then on output.
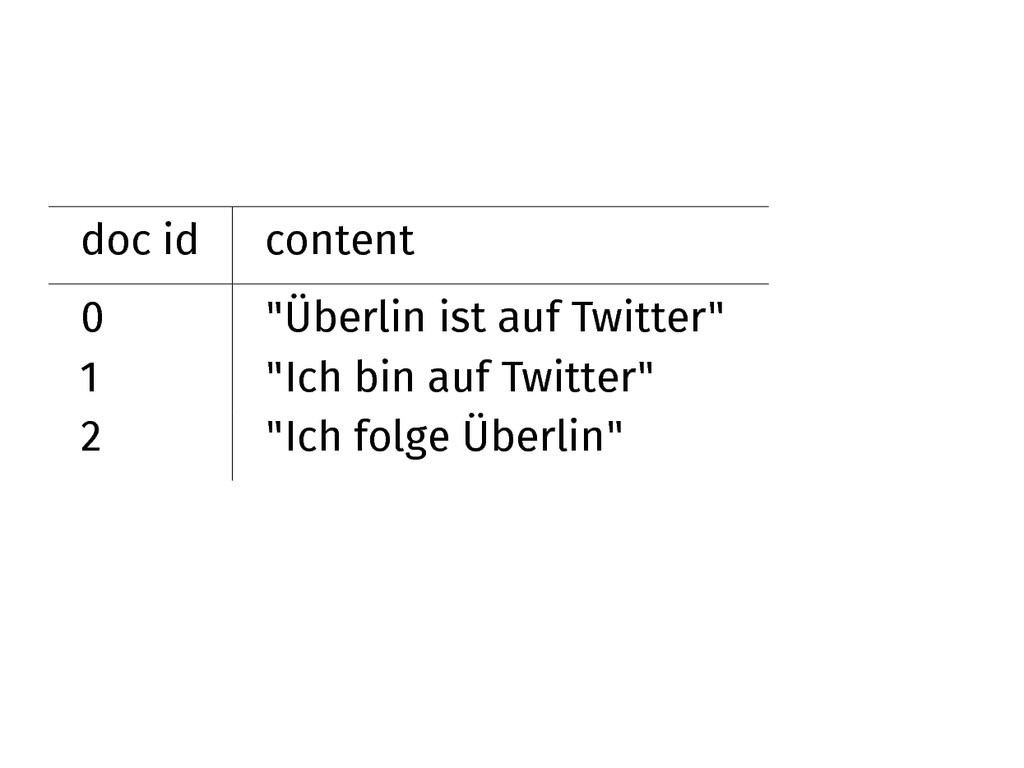
Building Block 1 An inverted index
doc id content 0 "Überlin ist auf Twitter" 1 "Ich
bin auf Twitter" 2 "Ich folge Überlin"
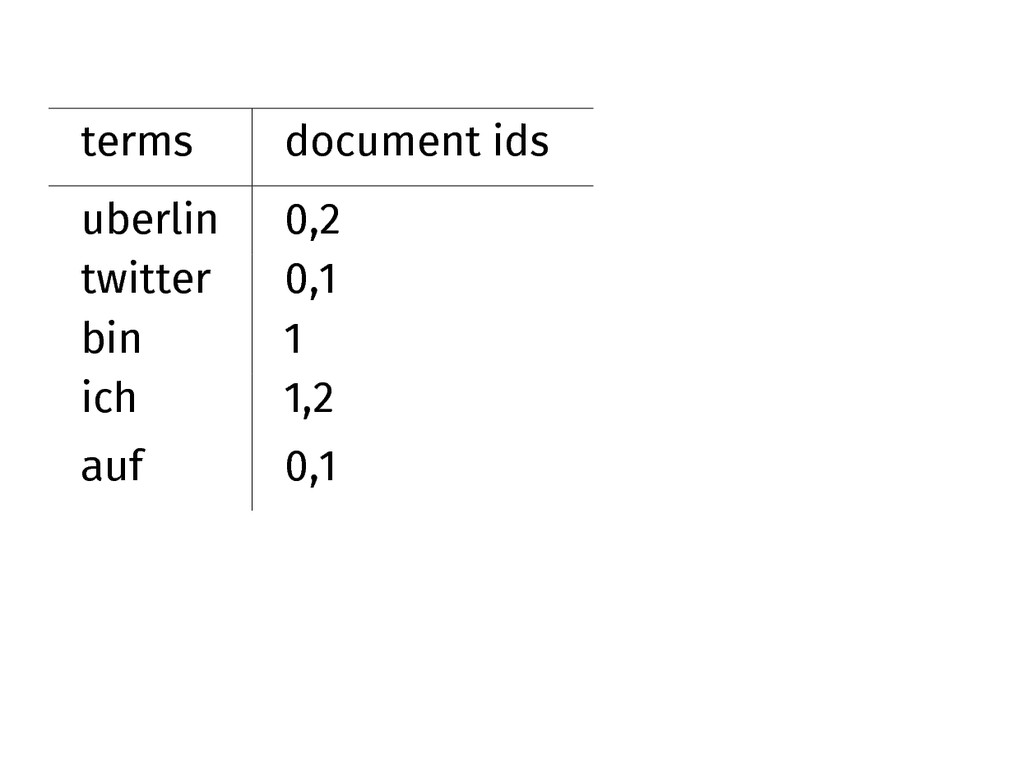
terms document ids uberlin 0,2 twitter 0,1 bin 1 ich
1,2 auf 0,1
Initial search rules are easy: if one or more of
the terms to the left is searched for, find the document that matches. Count the matches.
Building Block 2 Textual input
Full text searchers generally work on real world text. Get
hold of as many samples as possible. If necessary, write some on your own.
Don’t use an random generator. Or spend your next weeks
writing a sophisticated one.
Your system should bring capabilities handling real world text.
Analysis
Analysis determines which terms end up at the left side
of the table in the first place.
analysis result "ich folge Überlin" whitespace "ich" "folge" "Überlin" lowercase
"ich" "folge" "überlin" normalize "ich" "folge" "uberlin" stemming "ich" "folg" "uberlin"
analysis result "ich folge ueberlin" whitespace "ich" "folge" "ueberlin" lowercase
"ich" "folge" "ueberlin" normalize "ich" "folge" "ueberlin" stemming "ich" "folg" "uberlin"
This step happens both on indexing and queries.
Manipulating analysis is the basis for manipulating matches.
Can I manipulate analysis?
MongoDB Only choose between language presets PostgreSQL Analysis happens through
normal PL/SQL functions Elasticsearch Analyser configura- tion with a wide vari- ety of choice
Ü
Does your system comfortably speak Unicode?
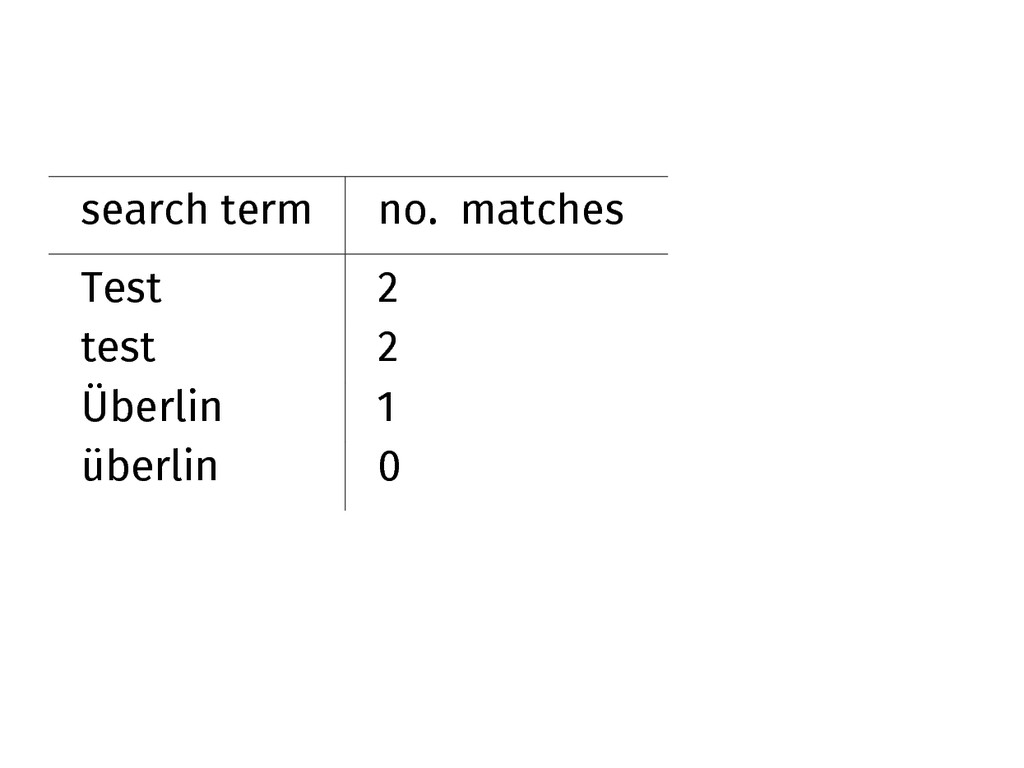
doc id field value 1 Test 2 test 3 Überlin
token doc ids test 1,2 uberlin 3
MongoDB
search term no. matches Test 2 test 2 Überlin 1
überlin 0
token doc ids test 1,2 Überlin 3
input result überlin überlin Überlin Überlin
MongoDB fails at the simplest case, lowercasing german umlauts, in
german settings.
The exact analysis behaviour is not user-controllable, for simplicities sake.
The suggestion is to preprocess yourself.
None
Further down the Unicode
How well does you system handle "creative" codes?
"\u0055\u0308" "\u0075\u0308"
"\u0055\u0308" #=> Ü "\u0075\u0308" #=> ü
PostgreSQL
postgres=# SELECT unaccent(U&’\0075\0308’); unaccent ———- ü (1 row)
PostgreSQL handles UCS-2 level 1, not UTF.
No combining chars.
“ we should really reject combining chars, but can’t do
that w/o breaking BC.”
sigh, Software
If you use PostgreSQL and text manipulation, you probably have
a bug in the hiding there.
UCS-2 for all textual data is a doable constraint, though.
input result überlin überlin Überlin überlin \u0055 \u0308 Invalid input
\u0075 \u0308 Invalid input
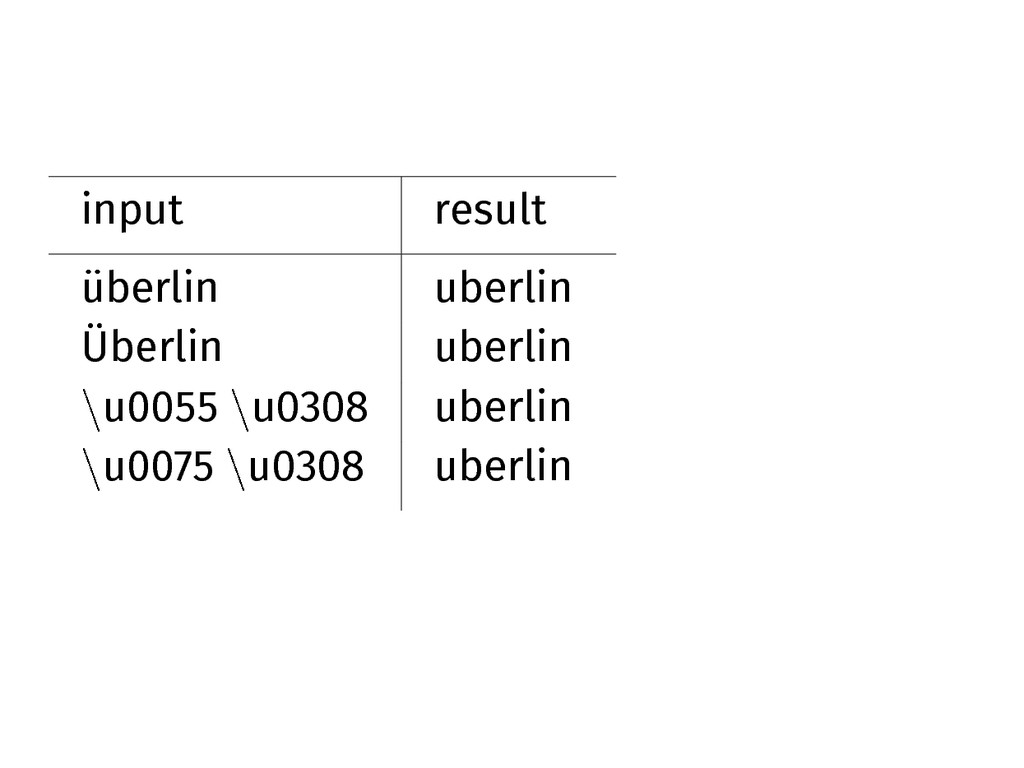
Elasticsearch
Elasticsearch can handle all those cases and then some, using
the analysis-icu plugin.
Install it and use it.
curl -XGET ’localhost:9200/_analyze?\ tokenizer=\ icu_tokenizer\ &token_filters=\ icu_folding,icu_normalizer’\ -d ’Überlin’
input result überlin uberlin Überlin uberlin \u0055 \u0308 uberlin \u0075
\u0308 uberlin
The way the system supports you in safely inserting textual
input is of paramount importance!
Find the worst shenanegans of you language, try it out.
l’elision, c’est magnifique
Building Block 3 Scoring
Search is all about relevance and combinations thereof.
Was the match in the title or the body of
a document?
How many options do I have?
All three systems can weight matches on fields differently.
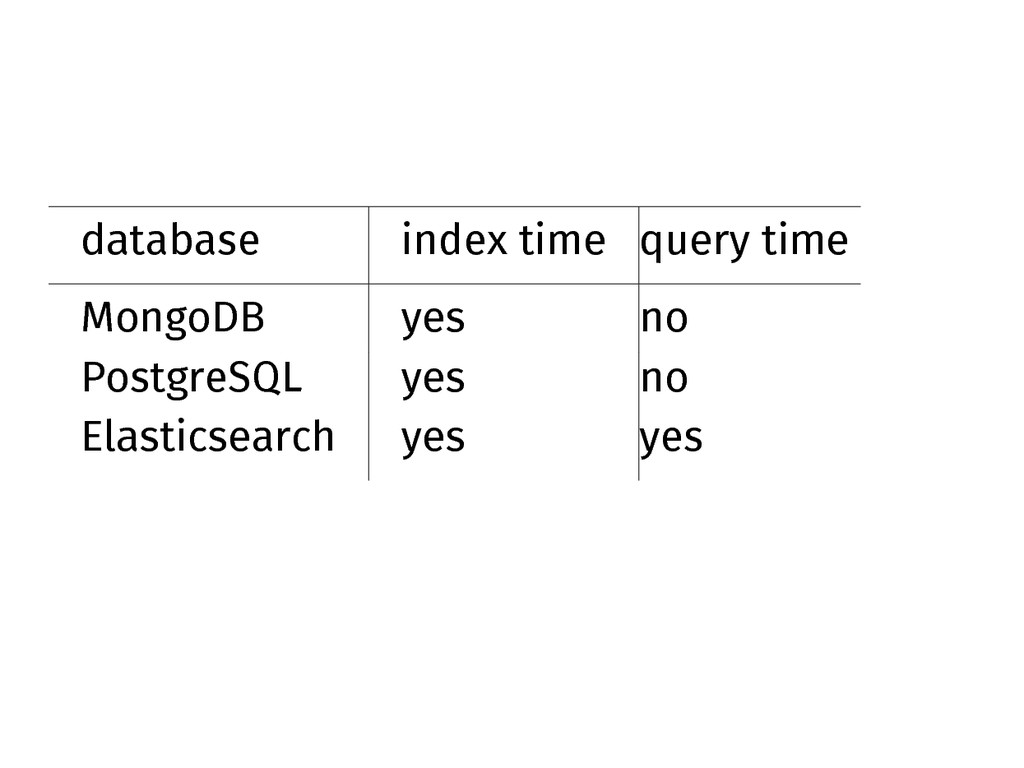
When can I decide those weights?
database index time query time MongoDB yes no PostgreSQL yes
no Elasticsearch yes yes
Weights during index time need a rebuild of the index
every time you change them.
If in doubt, choose query time weights.
Can I influence the scoring/ranking further?
database MongoDB no PostgreSQL yes, using PL/SQL functions Elasticsearch yes,
in many fashions (geo, distance, etc.)
Building Block 4 Documentation
I glossed over a lot of details.
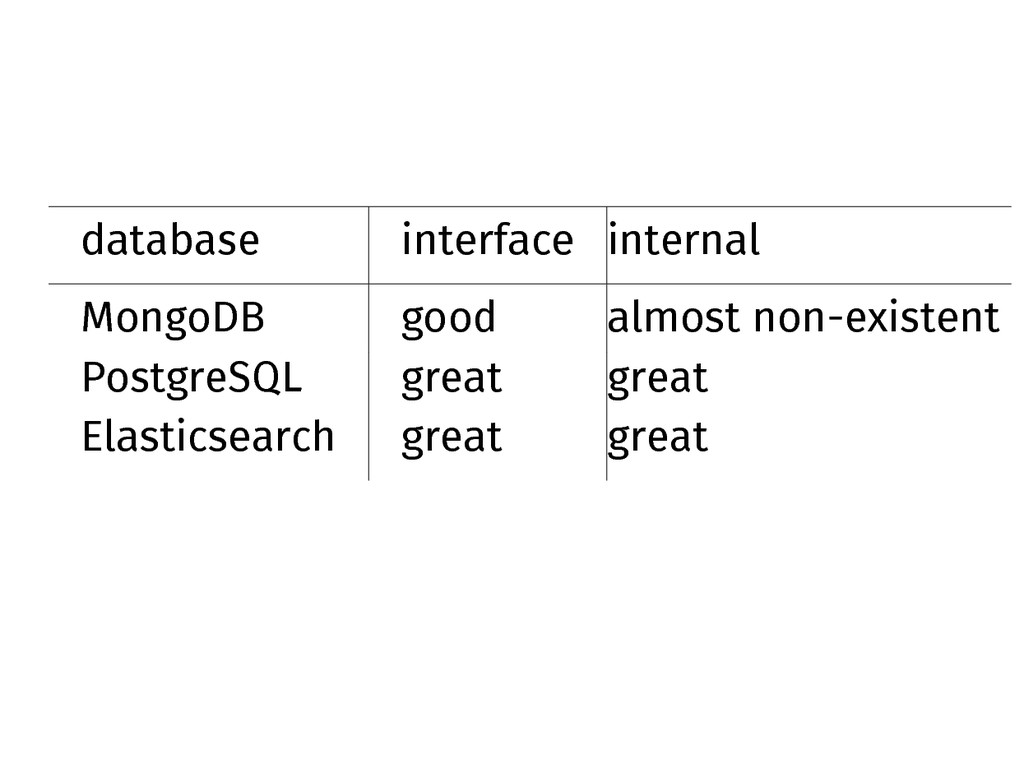
How well is the process documented, internally and interface-wise?
database interface internal MongoDB good almost non-existent PostgreSQL great great
Elasticsearch great great
Can I grow beyond?
And this is where the fun starts and we stop.
What’s adequate?
• Allows to manipulate analysis • Assists with real world
input • Allows you to build combined, extensible queries • Good documentation
MongoDB is not fit for purpose with holes that can
only be fixed by careful preparation of that data.
That preparation needs lots of detail knowledge you probably don’t
want to aquire.
PostgreSQL is adequate and in the PostgreSQL tradition of stable,
well-documented features. It doesn’t win prices, but is workable and reliable.
A good solution if search is just a bystander. A
thousand times better than LIKE.
Elasticsearch is based on Lucene and comes with all the
goodies and also has great documentations and guides.
If search is at the core of your product, use
a proper search engine.
References on the meetup group tomorrow.
Thank you!
None
COURSES
Elasticsearch for managers: http://esmanagers2014.asquera.de/
None
December 2nd
Getting started workshop: http://purchases.elastic- search.com/class/elasticsearch/elk-work- shop/berlin-germany/2014-12-15
None
December 15th
{kind=link}
![$ cat .profile GIT_AUTHOR_NAME=Florian Gilcher [email protected] TM_COMPANY=Asquera GmbH TWITTER_HANDLE=argorak GITHUB_HANDLE=skade](https://files.speakerdeck.com/presentations/59ff7c00578c0132e46d22f70b3d6249/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
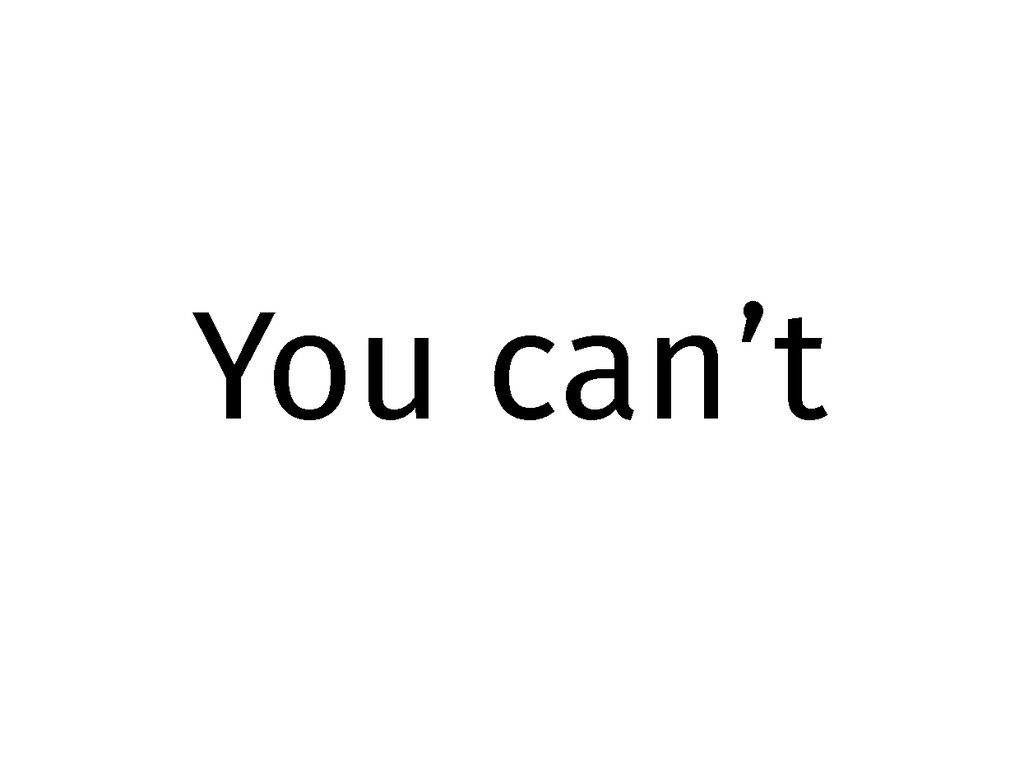{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
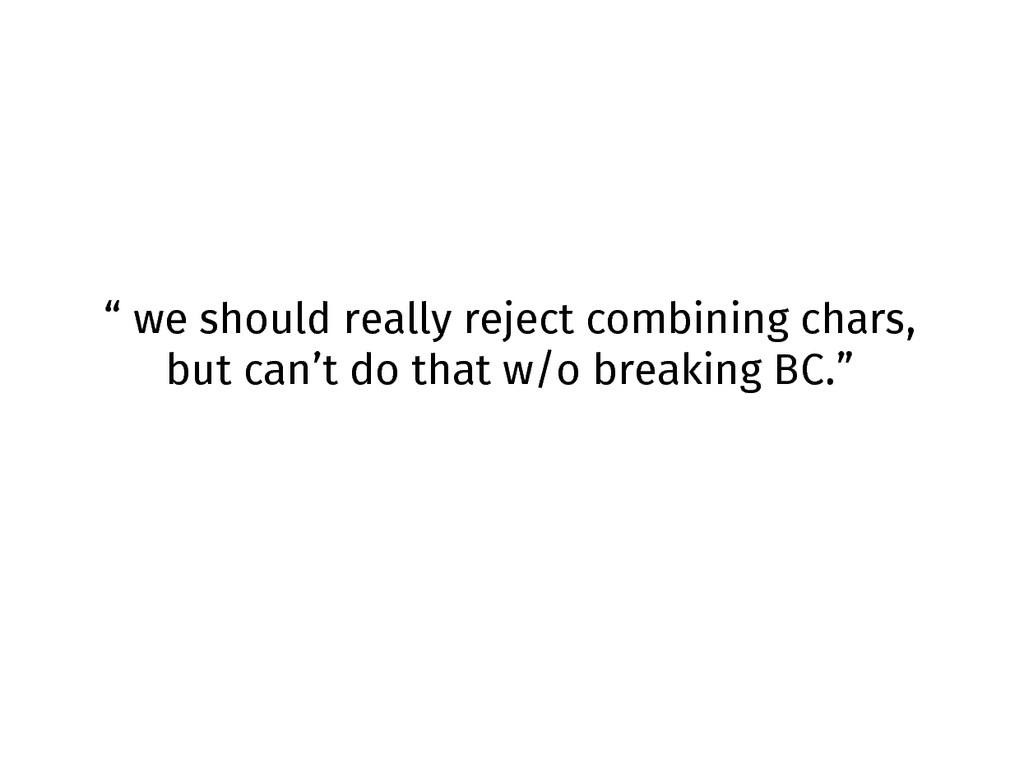{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
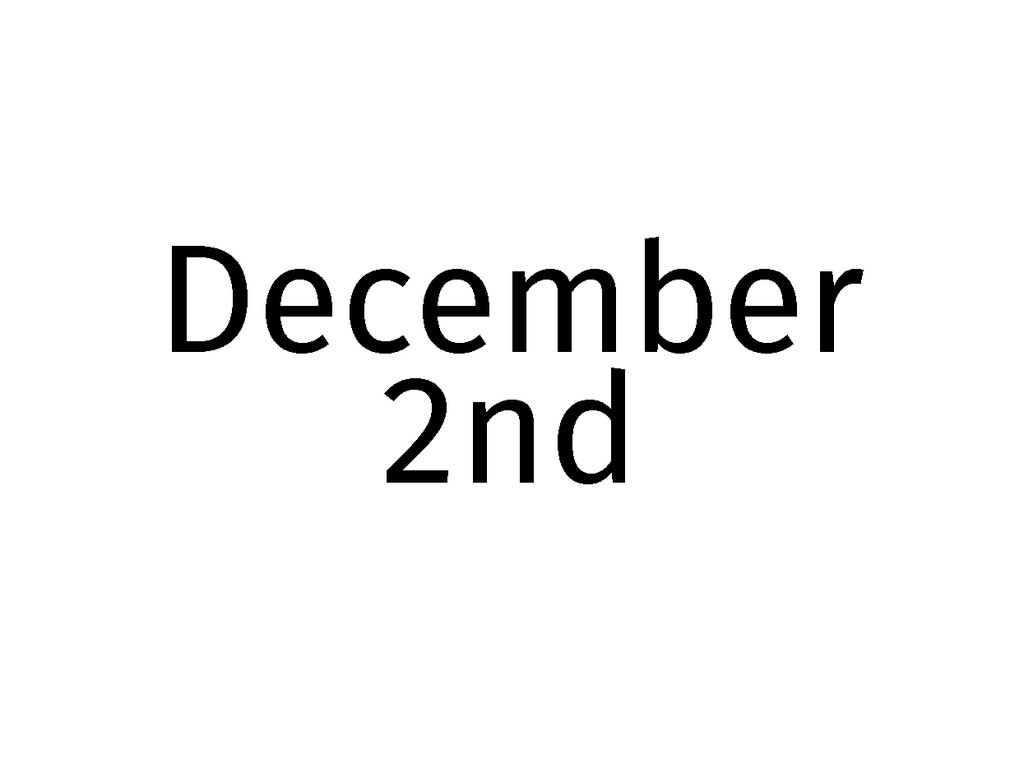{kind=link}
{kind=link}
{kind=link}
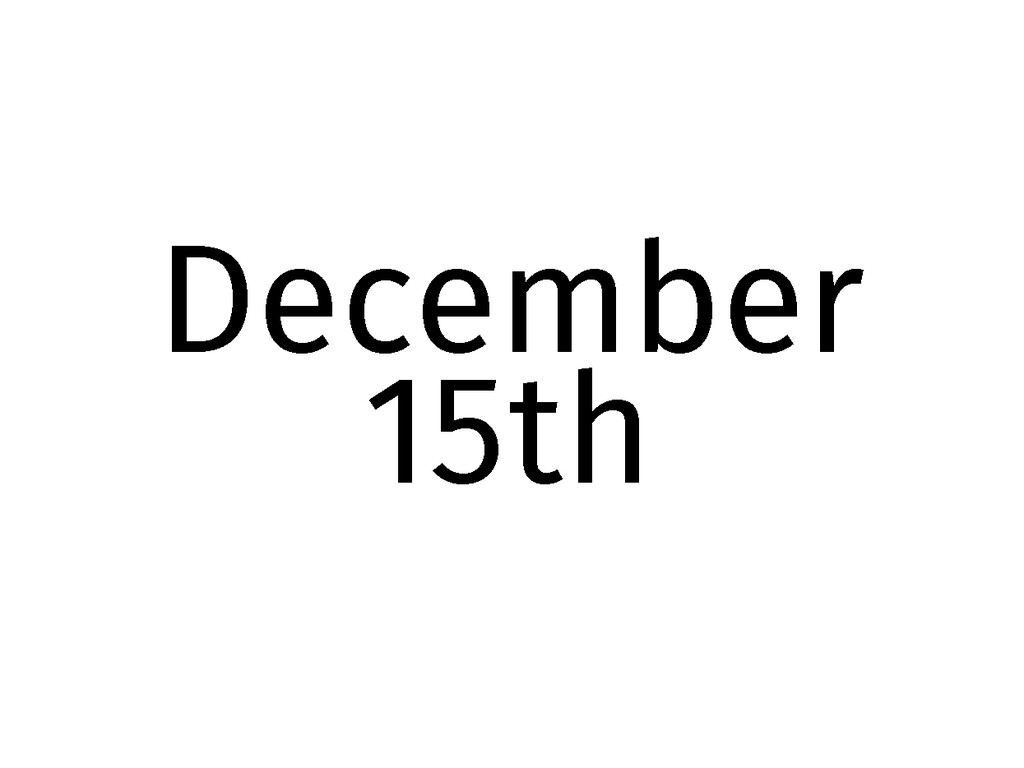{kind=link}