Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
著者と読み解くAIエージェント現場導入の勘所 Lancers TechBook#2
Search
Shumpei Miyawaki
December 03, 2025
Technology
14k
24
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
著者と読み解くAIエージェント現場導入の勘所 Lancers TechBook#2
https://lancersagent.connpass.com/event/373327/
Shumpei Miyawaki
December 03, 2025
More Decks by Shumpei Miyawaki
See All by Shumpei Miyawaki
AIネイティブな組織を問い直す
smiyawaki0820
14
5.4k
ITエンジニア本大賞_現場で活用するためのAIエージェント実践入門 / 2026.02.19
smiyawaki0820
2
390
LLMアプリの地上戦開発計画と運用実践 / 2025.10.15 GPU UNITE 2025
smiyawaki0820
4
2.1k
「高い不確実性」を解消する「高い再現性」 / 2025.09.14 プロダクトヒストリーカンファレンス(YOUTRUST)
smiyawaki0820
2
520
AIエージェントを現場で使う / 2025.08.07 著者陣に聞く!現場で活用するためのAIエージェント実践入門(Findyランチセッション)
smiyawaki0820
10
2.9k
「良さそう」と「とても良い」の間には 「良さそうだがホンマか」がたくさんある / 2025.07.01 LLM品質Night
smiyawaki0820
8
3.5k
AIエージェント開発における「攻めの品質改善」と「守りの品質保証」 / 2024.04.09 GPU UNITE 新年会 2025
smiyawaki0820
3
1.5k
AIエージェントの地上戦 〜開発計画と運用実践 / 2025/04/08 Findy ランチセッション #19
smiyawaki0820
35
18k
2024.02.19 W&B AIエージェントLT会 / AIエージェントが業務を代行するための計画と実行 / Algomatic 宮脇
smiyawaki0820
15
7.1k
Other Decks in Technology
See All in Technology
穢れた技術選定について
watany
19
6.2k
書籍セキュアAPIについて
riiimparm
0
250
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
200
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
人とエージェントが高め合う協業設計
kintotechdev
0
750
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
430
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
750
[Droidcon Orlando '26] The Android Lens: Applying Mobile Forensics to AI Performance
amanda_hinchman
1
110
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
14
4.6k
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
300
Featured
See All Featured
The Cult of Friendly URLs
andyhume
79
7k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
GraphQLとの向き合い方2022年版
quramy
50
15k
Discover your Explorer Soul
emna__ayadi
2
1.2k
The Language of Interfaces
destraynor
162
27k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
Building the Perfect Custom Keyboard
takai
2
820
Six Lessons from altMBA
skipperchong
29
4.3k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Transcript
AIエージェント 実践入門 1
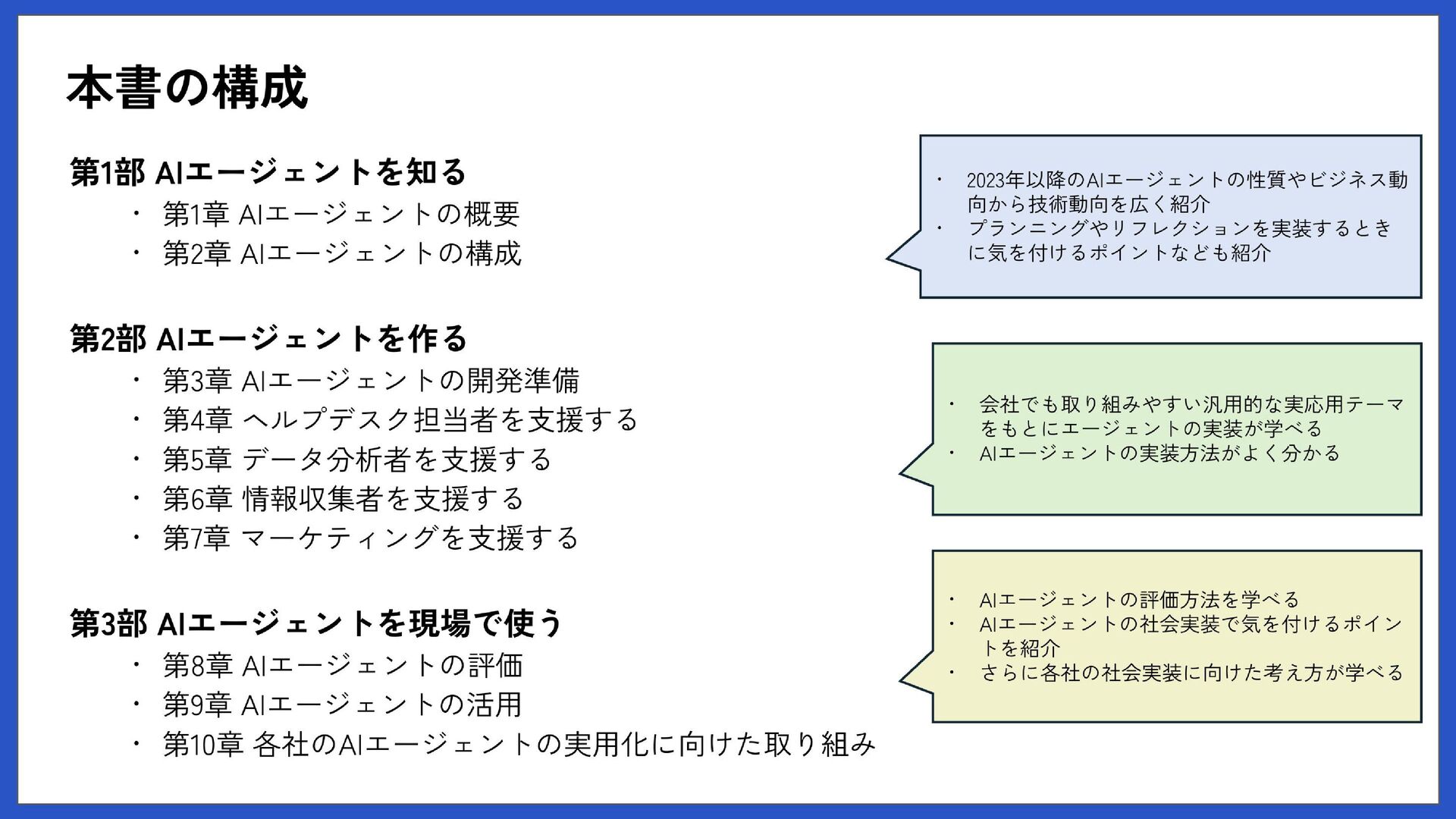
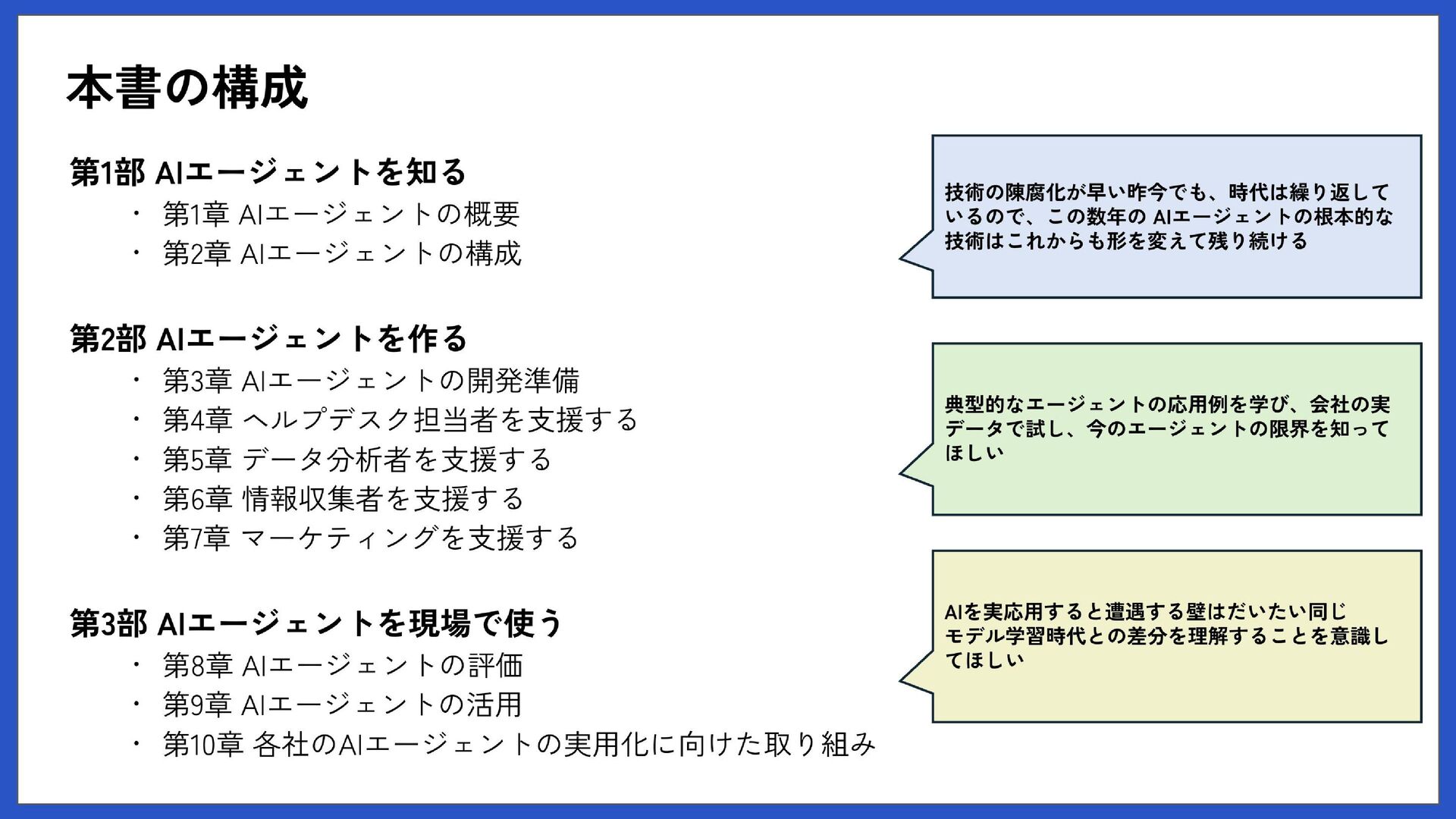
3 書籍の要点 本では語り切れなかった実践的な知見 最新の技術動向 技術背景、設計の意図、実務での応用ポイントなど https://www.shoeisha.co.jp/campaign/award/vote/ あなたのオススメ書籍に投票してね! “ITエンジニア本大賞2026”
かんたん書籍紹介 開発する前に 継続的な改善 01 02 開発のポイント 03 04 Contents 3
かんたんな 書籍紹介 1 4
None
None
None
AIエージェント 開発する前に 2 11
9 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 技術視点における「AIエージェント」の絶対的な位置付け 技術視点 目標に向けて環境と 相互作用する知能システム \\
書籍の対象はココ // 「AIエージェント作って」依頼に技術視点だけで応えると、顧客要求を満たすことができない
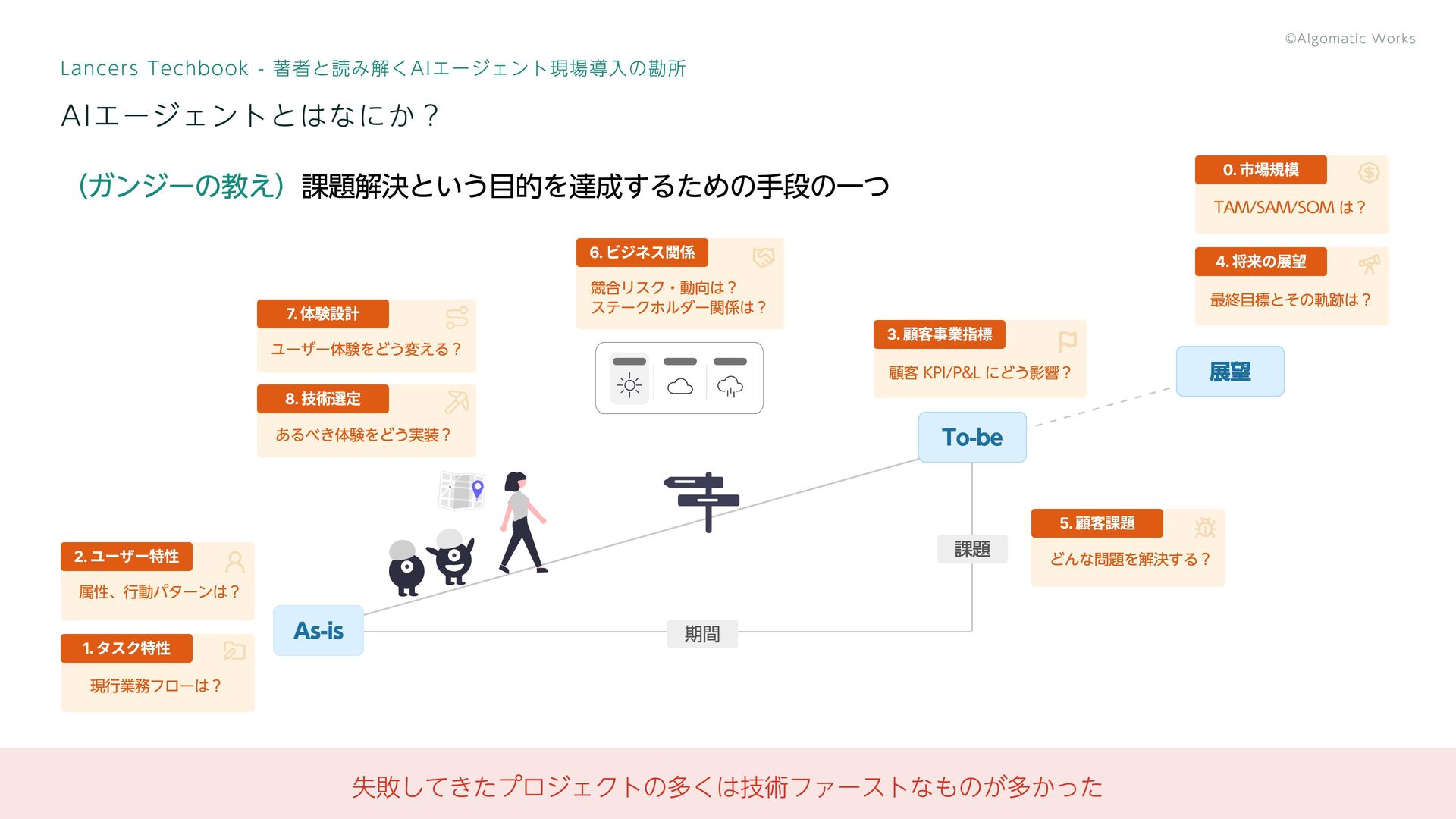
10 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 顧客課題に対する「AIエージェント」の相対的な位置付け 技術視点 顧客がほしいもの ガンジーの教え 細かな指示をしなくても
人間の代わりに 業務を遂行する代行者 目標に向けて環境と 相互作用する知能システム 課題解決という 目的を達成するための 手段の一つ \\ 書籍の対象はココ // 技術視点と顧客視点で 解釈の相違 があることを認識し、AIエージェントが最適手段であるか疑う
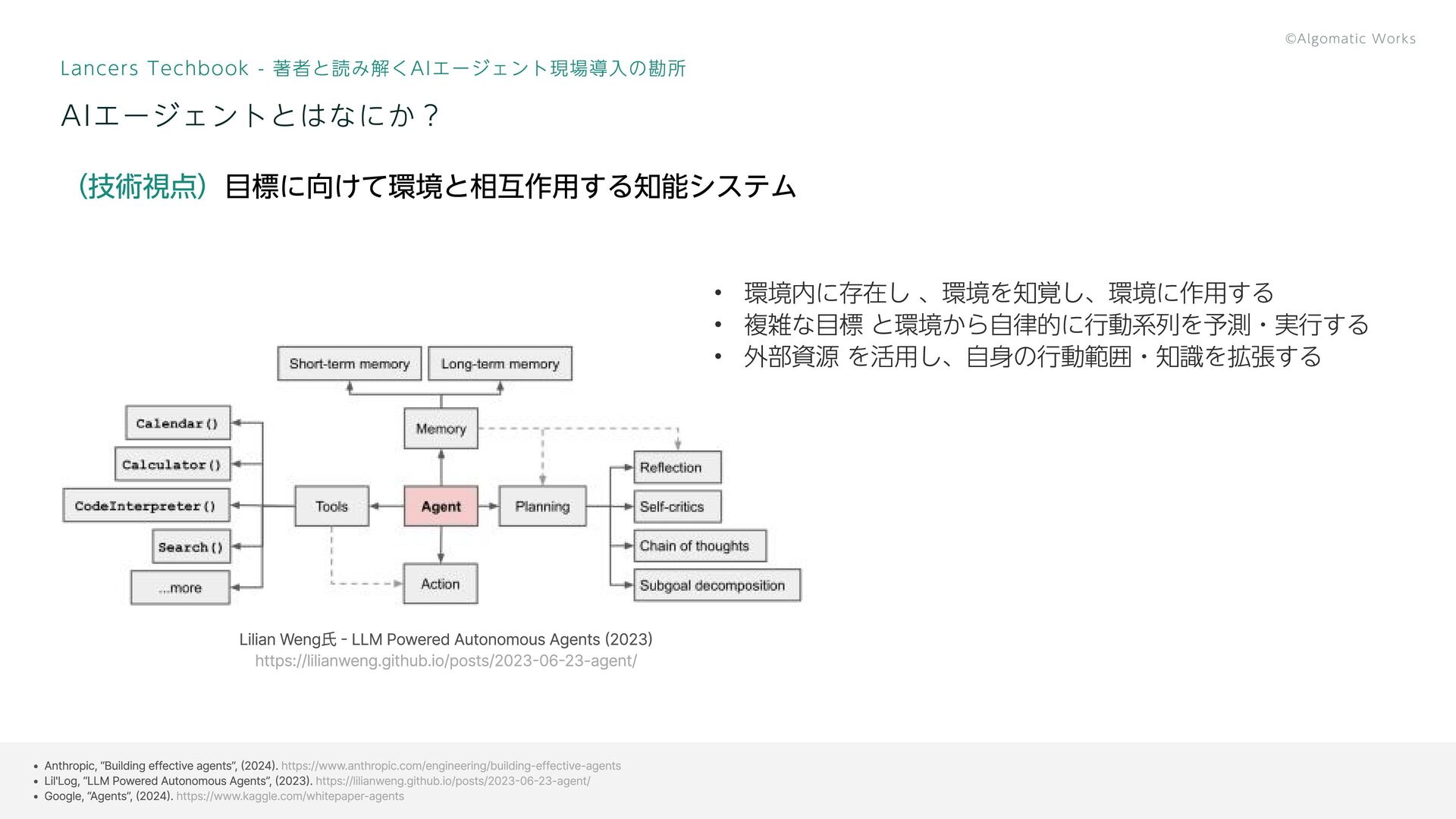
11 (技術視点)目標に向けて環境と相互作用する知能システム Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 AIエージェントとはなにか? Lilian Weng氏 -
LLM Powered Autonomous Agents (2023) https://lilianweng.github.io/posts/2023-06-23-agent/ 環境内に存在し 、環境を知覚し、環境に作用する 複雑な目標 と環境から自律的に行動系列を予測・実行する 外部資源 を活用し、自身の行動範囲・知識を拡張する Anthropic, “Building effective agents”, (2024). Lil'Log, “LLM Powered Autonomous Agents”, (2023). Google, “Agents”, (2024). https://www.anthropic.com/engineering/building-effective-agents https://lilianweng.github.io/posts/2023-06-23-agent/ https://www.kaggle.com/whitepaper-agents
12 (顧客視点)細かな指示をしなくても人間の代わりに業務を遂行する代行者 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 AIエージェントとはなにか? 宮脇 - AIエージェントの解釈について整理してみる
(2025), Algomatic Tech Blog Noessel, “Designing Agentive Technology”, (2017). https://rosenfeldmedia.com/books/designing-agentive-technology/ OpenAI, “Practices for Governing Agentic AI Systems”, (2023). https://openai.com/index/practices-for-governing-agentic-ai-systems/ Agenticness: 人間による部分的な管理下において、複雑な目標を複雑な環境で適応的に達成する度合い
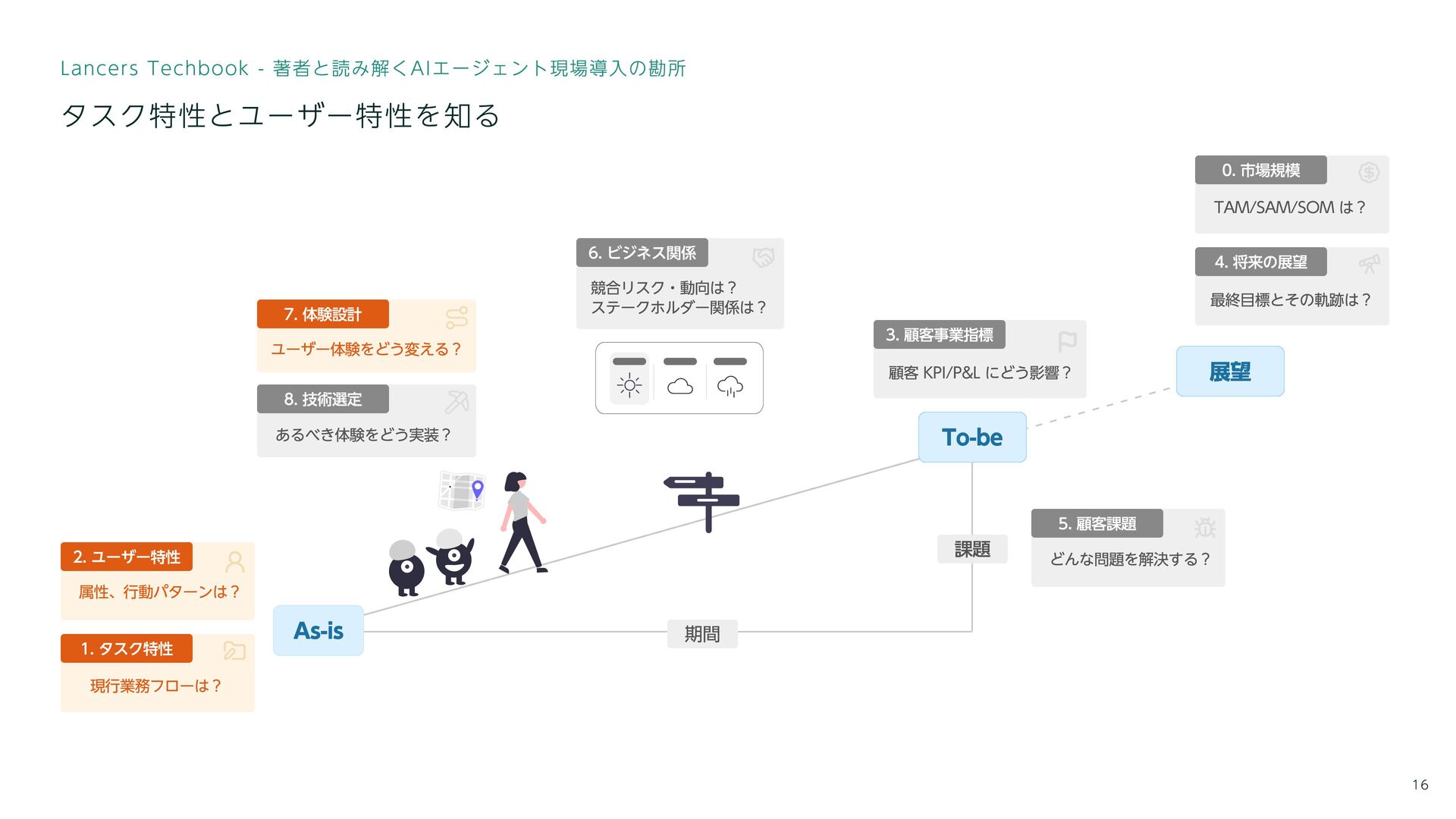
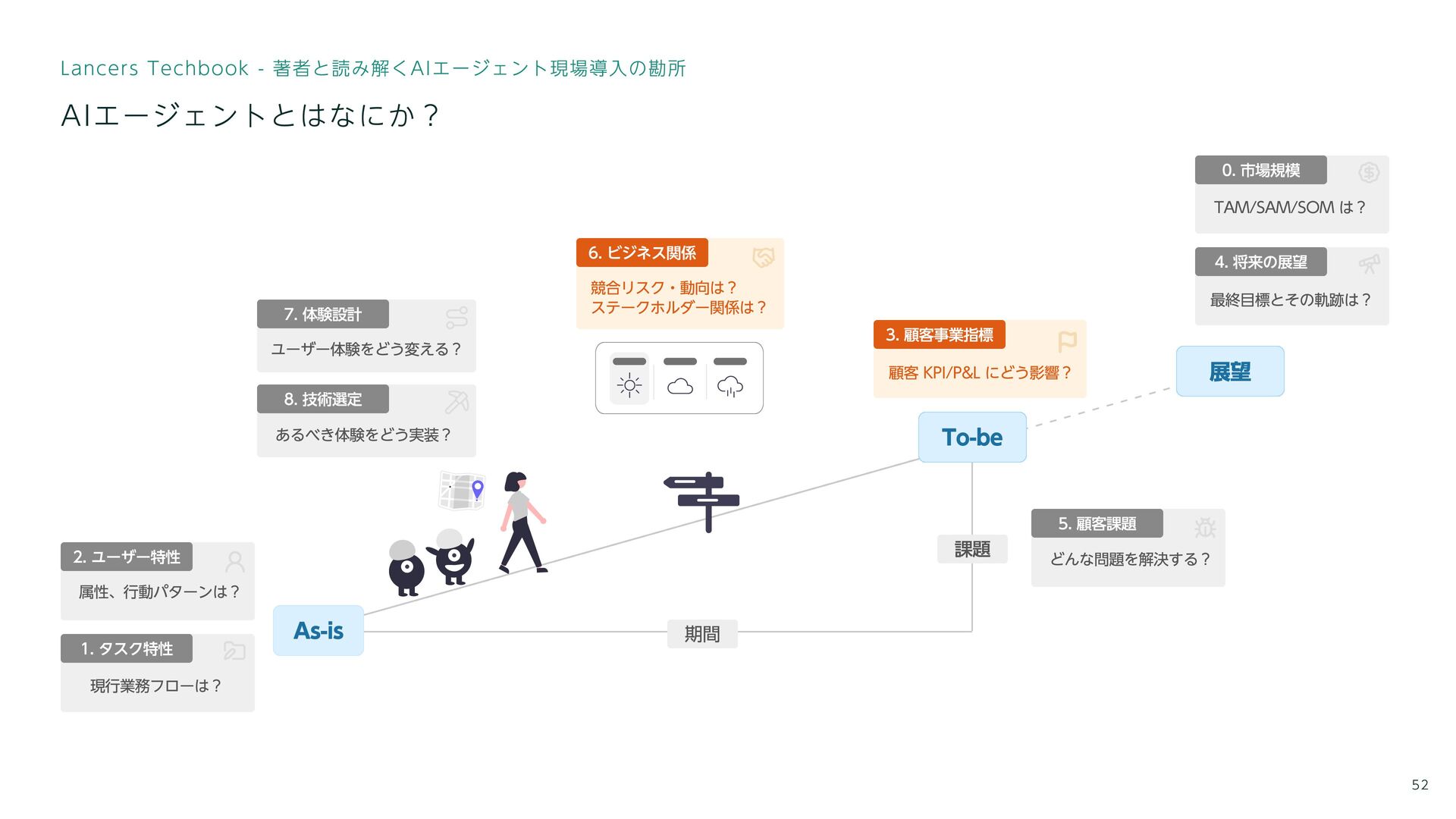
最終目標とその軌跡は? 4. 将来の展望 TAM/SAM/SOM は? 0. 市場規模 どんな問題を解決する? 5. 顧客課題
競合リスク・動向は? ステークホルダー関係は? 6. ビジネス関係 ユーザー体験をどう変える? 7. 体験設計 あるべき体験をどう実装? 8. 技術選定 属性、行動パターンは? 2. ユーザー特性 13 (ガンジーの教え)課題解決という目的を達成するための手段の一つ Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 AIエージェントとはなにか? As-is To-be 期間 課題 現行業務フローは? 1. タスク特性 顧客 KPI/P&L にどう影響? 3. 顧客事業指標 展望 失敗してきたプロジェクトの多くは技術ファーストなものが多かった
14 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 現状のAIエージェント活用の多くは、業務代行パーツは揃っているものの設計図がない状態 専門知識の運用による壁打ち 高速な下書き生成による省力化 第三者視点でダブルチェックできる プロセス間を連携できる(構造化出力)
イベント駆動でのプッシュ通知 24-365 体制での稼働 気づいたら完成している体験 環境への作業による状態更新 MCP による外部ツール連携 社内文書・外部知識の利用 メモリによるパーソナライズ LLM 外部リソース インフラ 顧客の P&L にどう影響するかを常に考慮しつつ、パーツを組み立てていく これまで の ML タスクは翻訳や OCR など一部の業務を遂行していた AIエージェントでは業務プロセス全体がその対象であり、業務代行の成果創出 に期待が高まっている 外部リソースやインフラの恩恵を享受することで「質、量、スピード」にアクセスしやすくなった
PJキックオフ後 なにから始めるか?
最終目標とその軌跡は? 4. 将来の展望 TAM/SAM/SOM は? 0. 市場規模 どんな問題を解決する? 5. 顧客課題
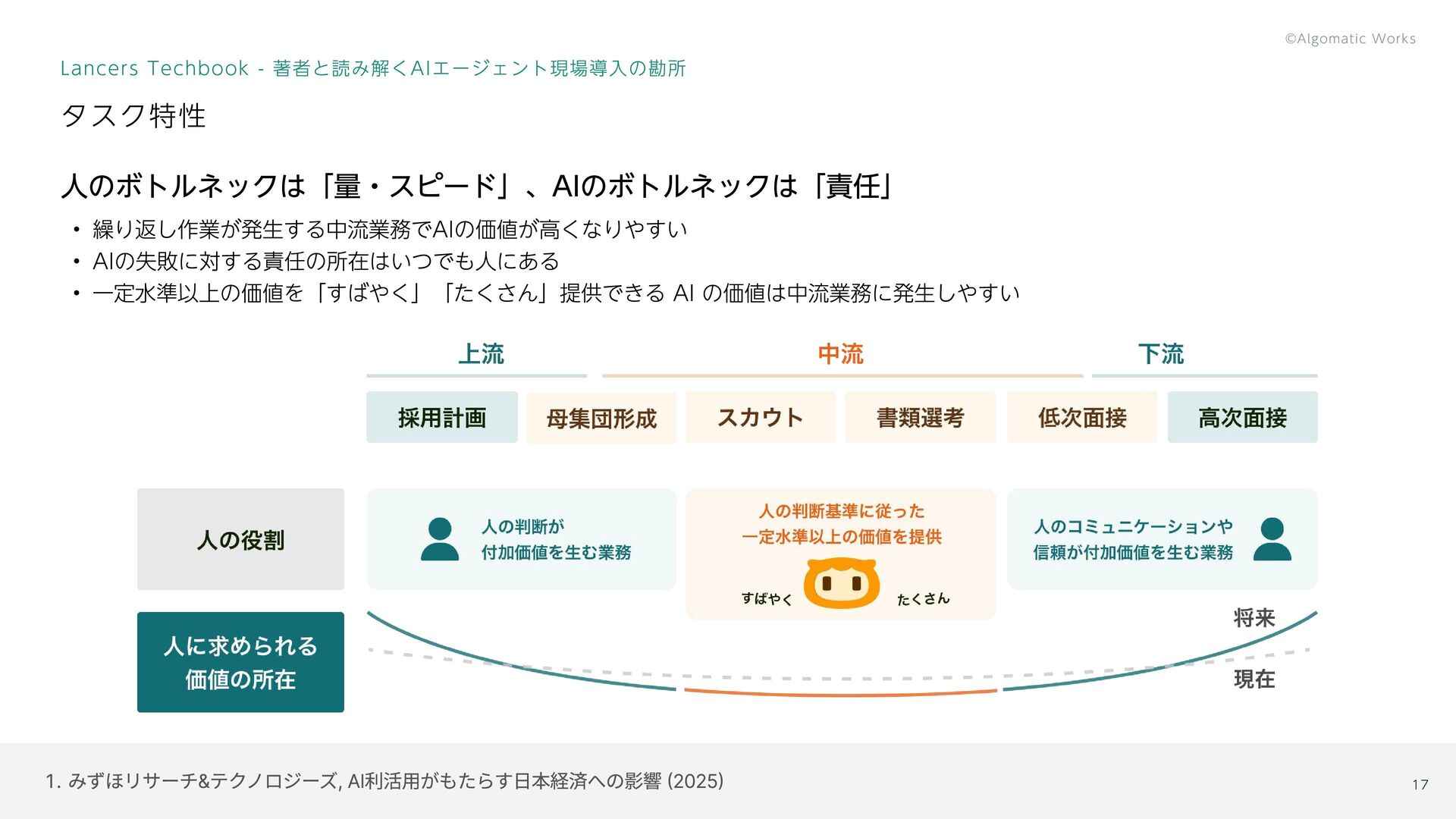
競合リスク・動向は? ステークホルダー関係は? 6. ビジネス関係 ユーザー体験をどう変える? 7. 体験設計 あるべき体験をどう実装? 8. 技術選定 属性、行動パターンは? 2. ユーザー特性 16 As-is To-be 期間 課題 現行業務フローは? 1. タスク特性 顧客 KPI/P&L にどう影響? 3. 顧客事業指標 展望 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 タスク特性とユーザー特性を知る
人のボトルネックは「量・スピード」、AIのボトルネックは「責任」 繰り返し作業が発生する中流業務でAIの価値が高くなりやすい AIの失敗に対する責任の所在はいつでも人にある 一定水準以上の価値を「すばやく」「たくさん」提供できる AI の価値は中流業務に発生しやすい タスク特性 Lancers Techbook -
著者と読み解くAIエージェント現場導入の勘所 みずほリサーチ&テクノロジーズ, AI利活用がもたらす日本経済への影響 (2025) 17
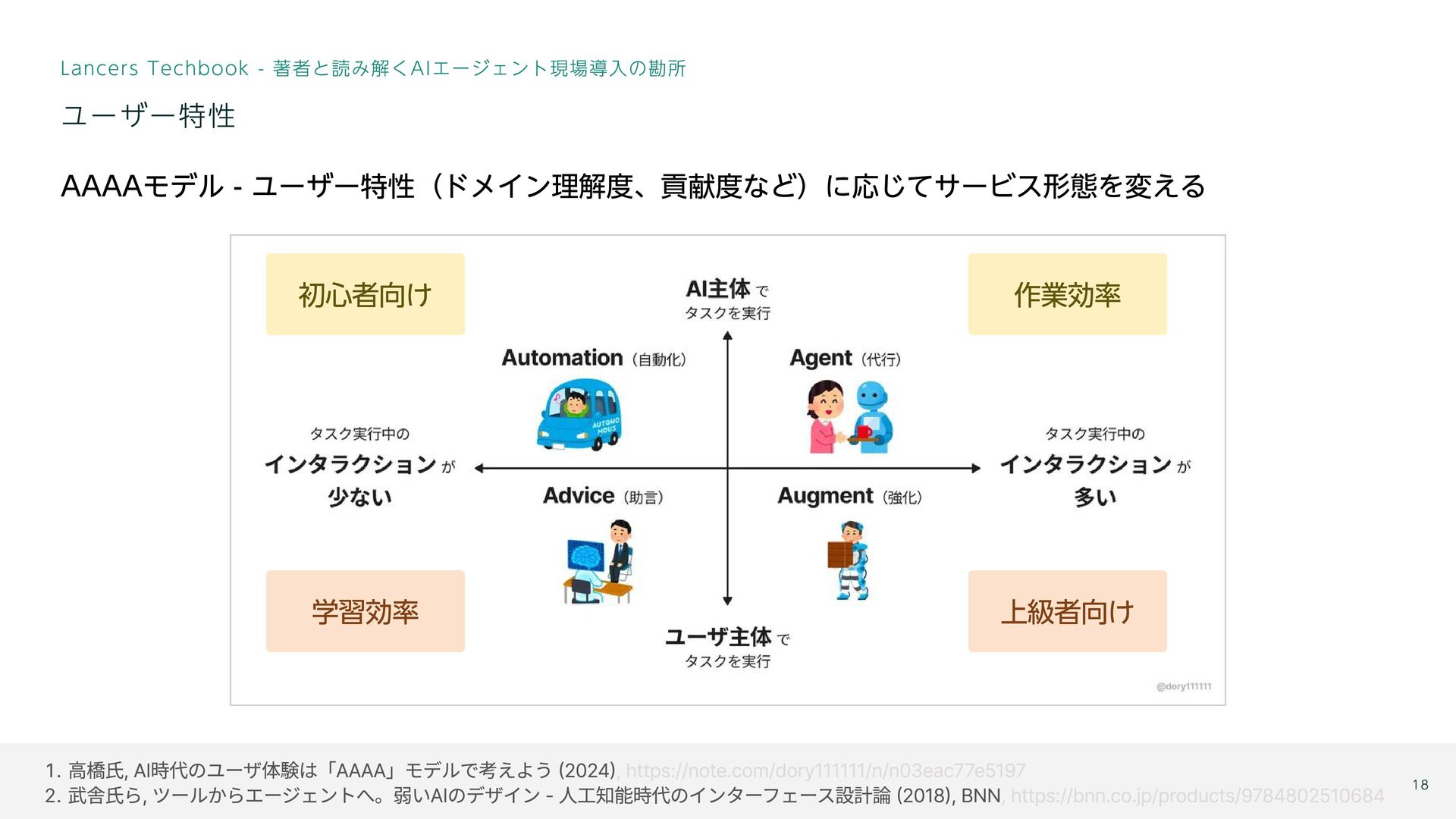
高橋氏, AI時代のユーザ体験は「AAAA」モデルで考えよう (2024) 武舎氏ら, ツールからエージェントへ。弱いAIのデザイン - 人工知能時代のインターフェース設計論 (2018), BNN ,
https://note.com/dory111111/n/n03eac77e5197 , https://bnn.co.jp/products/9784802510684 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 AAAAモデル - ユーザー特性(ドメイン理解度、貢献度など)に応じてサービス形態を変える ユーザー特性 18 上級者向け 学習効率 初心者向け 作業効率
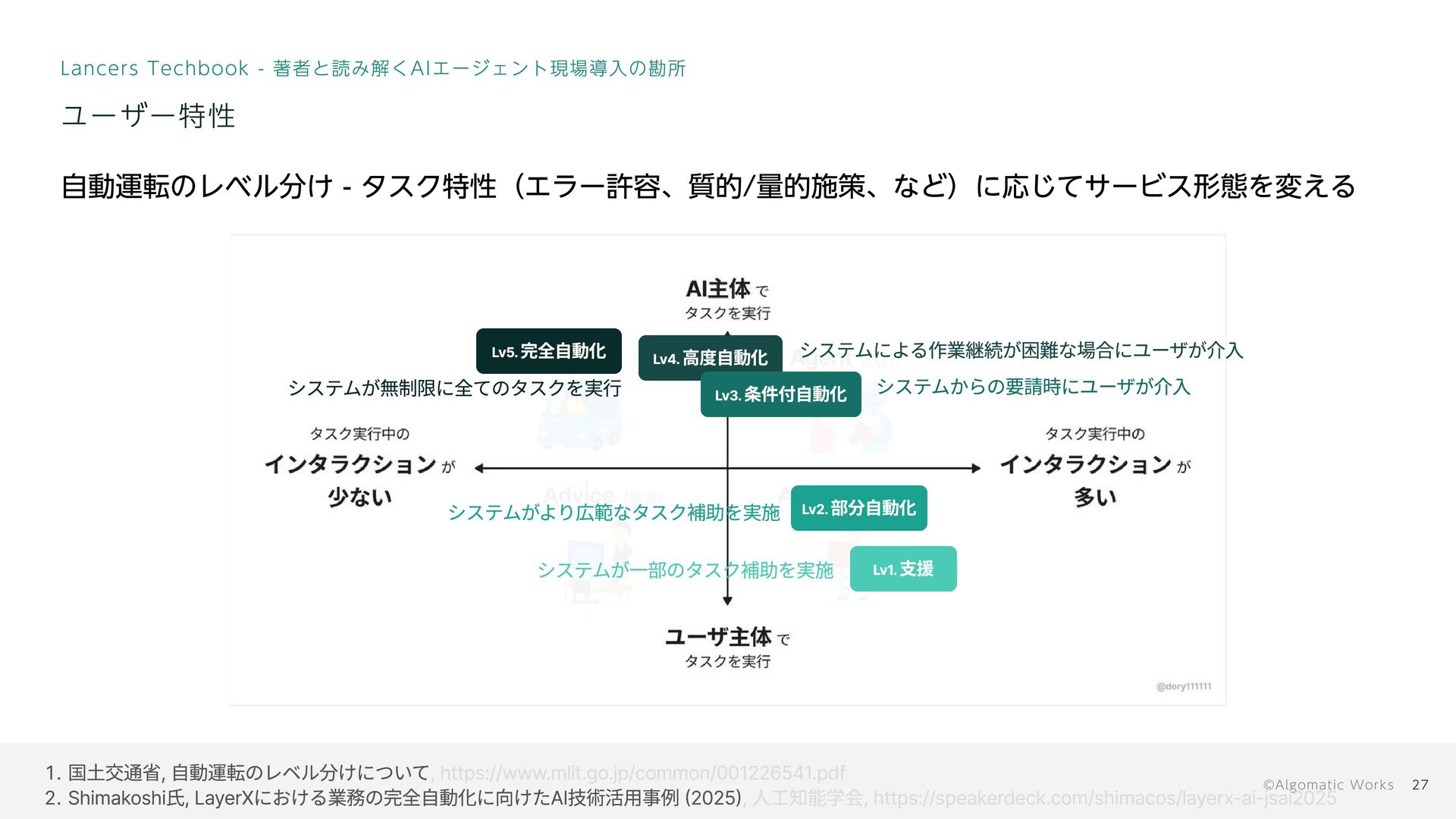
Lv5. 完全自動化 Lv4. 高度自動化 Lv3. 条件付自動化 Lv2. 部分自動化 Lv1. 支援
システムからの要請時にユーザが介入 システムがより広範なタスク補助を実施 システムが一部のタスク補助を実施 システムが無制限に全てのタスクを実行 国土交通省, 自動運転のレベル分けについて Shimakoshi氏, LayerXにおける業務の完全自動化に向けたAI技術活用事例 (2025) , https://www.mlit.go.jp/common/001226541.pdf , 人工知能学会, https://speakerdeck.com/shimacos/layerx-ai-jsai2025 自動運転のレベル分け - タスク特性(エラー許容、質的/量的施策、など)に応じてサービス形態を変える 27 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 ユーザー特性 システムによる作業継続が困難な場合にユーザが介入
AIエージェント 開発のポイント 3 36
タスク要件 自律型と特化型のあいだにはタスク要件が存在する どちらが優れているかは「明確なタスク要件、タスク特性・ユーザー特性」の有無によって異なる セキュリティや保守性でみるとエージェント型ワークフローが優れているため、多くの開発者に好まれている 変更の影響範囲を最小限にできる ノードごとにテストしやすい ノード単位で再利用性が高い 業務プロセスを反映しやすい 変更が大変 中断されたり、破滅の方向へ向かったりす
る 設計難易度が高い 決められたタスク以外に対応できない 設計難易度が低い(捨てやすい) 汎用性は高い 自律型エージェント v.s. エージェント型ワークフロー Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 21 特化タスク 汎用タスク 特化タスク 自律型エージェント 本番環境での業務代行に向かない 簡単な技術検証に向いている 簡単な技術検証には向かない 本番環境での業務代行に向いている エージェント型ワークフロー
LLM は何が苦手か?
23 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 なにをもって「これは LLM が苦手なタスク設定だから」と判断するのか? タスク設定? 分類タスクは、既に定義されているラベル一覧から選択するだけだし簡単そう
抽出タスクは、既にコンテキストに手がかりや答えの表層情報が含まれているし簡単そう 生成タスクは、ゼロから文章を生成しないといけないし難しそう 分類・回帰 情報抽出 文章生成 タスク指向対話 入力文に対して 定義済みのラベルから 該当するものを選択する タスク 概要 文章から関心対象を見つけ 定められた形式に変換する 指示や文脈に従って 新しい文章を生成する 目的達成のために 対話を通じて情報を揃え タスクを完了させる かんたん? むずかしい? ※ もちろん計算やドメイン外のタスクが苦手といった側面はある ※ ここでは形式的な言語能力と機能的な言語能力の比較を取り上げている
24 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 我々はなにをもって「これは LLM が苦手なタスク設定だから」と判断するのか? タスク設定? 分類タスクは、既に定義されているラベル一覧から選択するだけだし簡単そう
抽出タスクは、既にコンテキストに手がかりや答えの表層情報が含まれているし簡単そう 生成タスクは、ゼロから文章を生成しないといけないし難しそう 分類・回帰 情報抽出 文章生成 タスク指向対話 入力文に対して 定義済みのラベルから 該当するものを選択する タスク 概要 文章から関心対象を見つけ 定められた形式に変換する 指示や文脈に従って 新しい文章を生成する 目的達成のために 対話を通じて情報を揃え タスクを完了させる かんたん? むずかしい? ※ もちろん計算やドメイン外のタスクが苦手といった側面はある ※ ここでは形式的な言語能力と機能的な言語能力の比較を取り上げているため っぽいけど そうじゃない e.g. 書類が受理されるかの判別は難しい
正解の基準や、包含・除外の条件を明確に定義できるか 正解の判定には、最終的な出力結果だけでなく、推論過程(その回答に至った根拠や理由)も含まれる 金額を回答させる場合でも、表記・税区分・単位など、正解の判断基準の厳密な制約によって難易度が変わる 単なる情報処理だけでなく、入力の妥当性を踏まえた上で異常値を例外処理する判断も求められる 25 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 なにをもって「これは
LLM が苦手なタスク設定だから」と判断するのか? 分類・回帰 情報抽出 文章生成 タスク指向対話 ラベル定義や採点基準は 明確に記述できるか? 難しさ 表記揺れや同義語の扱いを 明確に記述できるか? 構成や文体規則、 テンプレートなどが 明確に記述できるか? 入力パターンや応答規則、 話題遷移の分岐条件など 明確に記述できるか? 判断基準・条件は 現場 によって定義される = 業務での規則や思考を正確に落とし込む必要がある 5点 ... 〇〇 3点 ... 〇〇 (A) □□□ 1200円 ¥1,200 -
AIエージェントを含む LLMアプリケーション開発の 3つのポイント
AI依存の分離 1 2 意図しない生成の検知 3 現行の業務フローから問題点を捉える 良質なプロンプトは人にとっても良質である 下流プロセスをAIから分離していく ガードレールによる多重・多層防御 フェイルセーフの実装
40 暗黙知の言語化
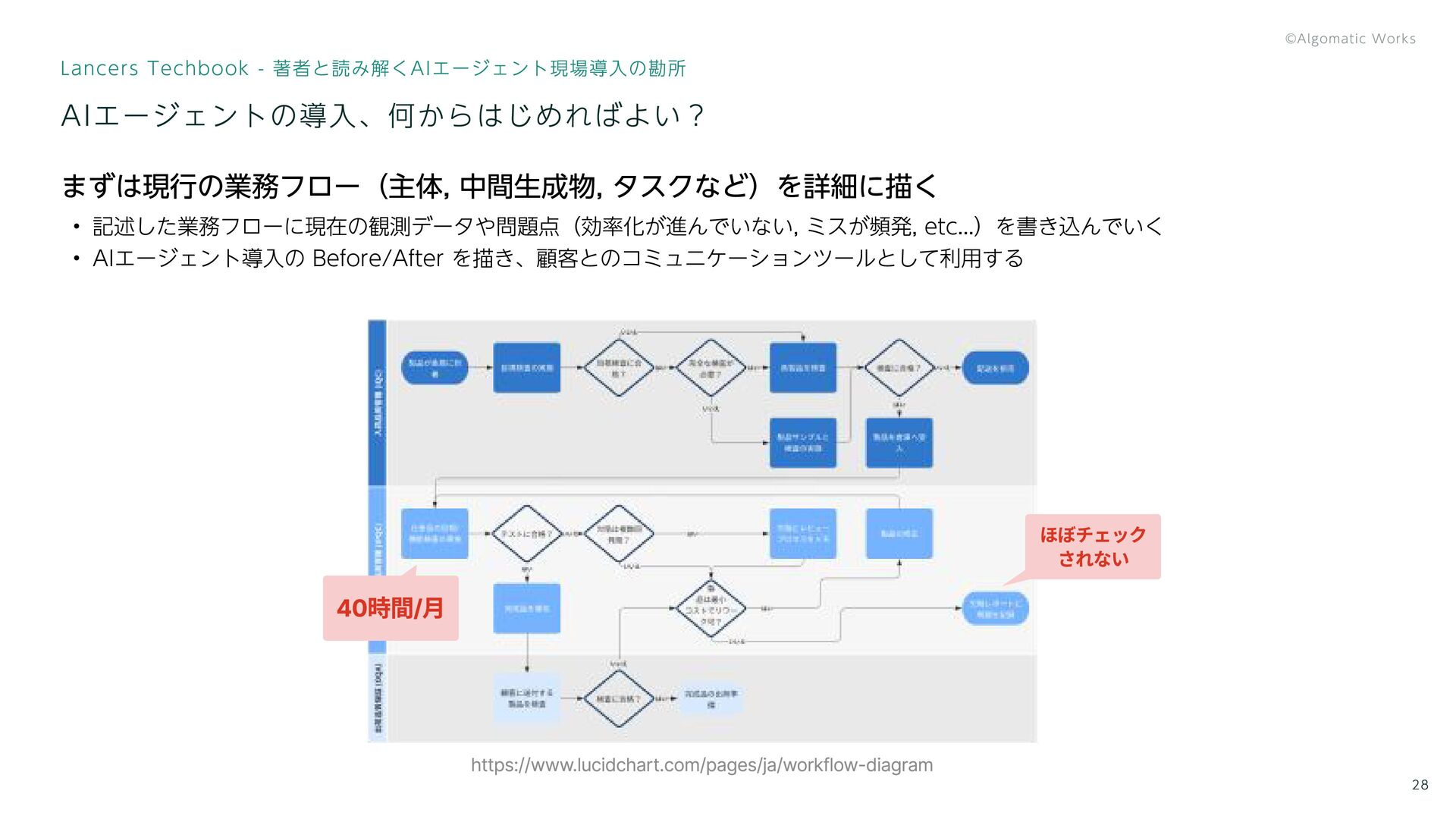
まずは現行の業務フロー(主体, 中間生成物, タスクなど)を詳細に描く 記述した業務フローに現在の観測データや問題点(効率化が進んでいない, ミスが頻発, etc...)を書き込んでいく AIエージェント導入の Before/After を描き、顧客とのコミュニケーションツールとして利用する AIエージェントの導入、何からはじめればよい?
Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 28 https://www.lucidchart.com/pages/ja/workflow-diagram ほぼチェック されない 40時間/月
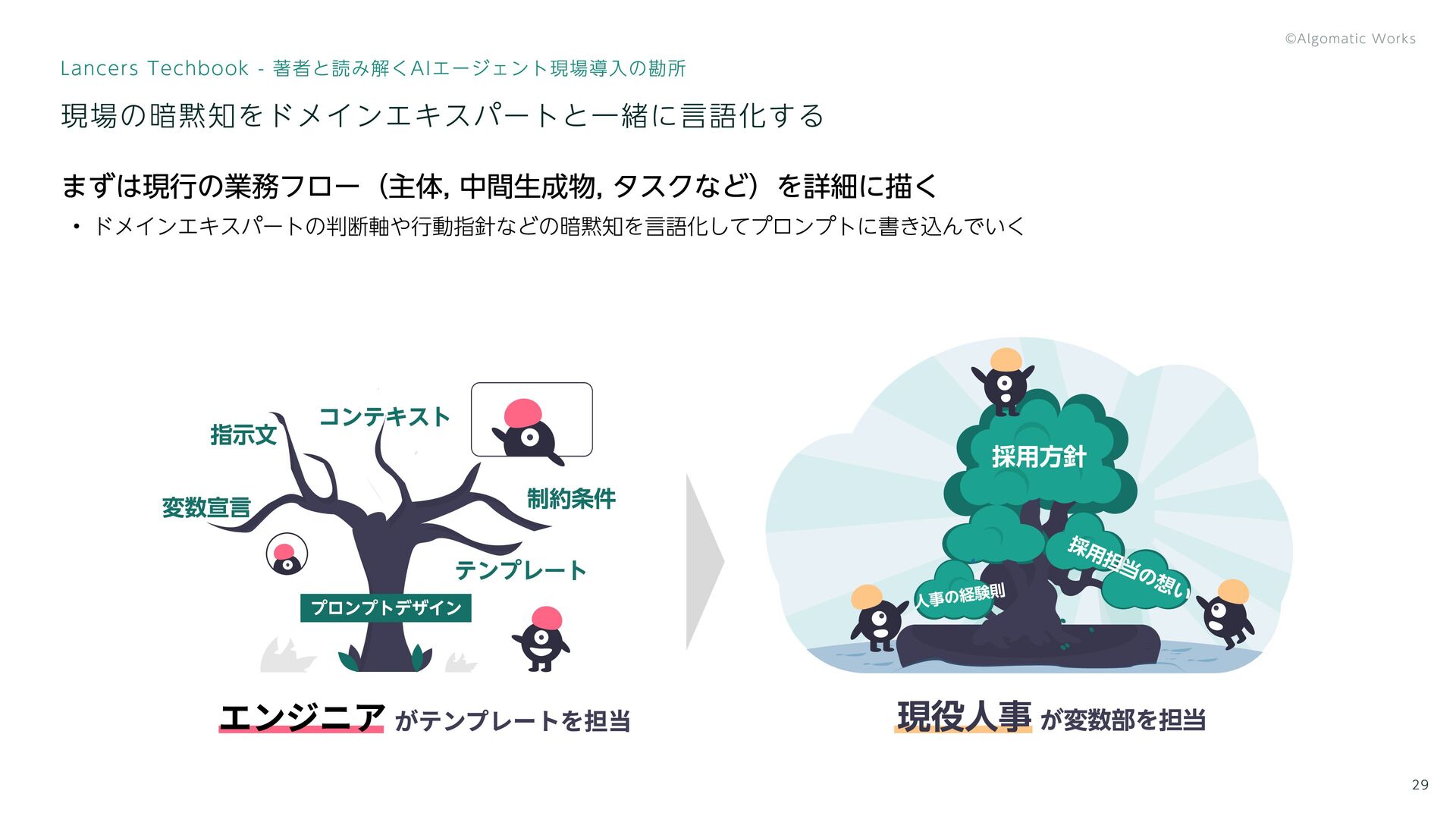
29 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 現場の暗黙知をドメインエキスパートと一緒に言語化する エンジニア がテンプレートを担当 採用担当の想い 人事の経験則
採用方針 現役人事 が変数部を担当 変数宣言 指示文 テンプレート 制約条件 コンテキスト プロンプトデザイン まずは現行の業務フロー(主体, 中間生成物, タスクなど)を詳細に描く ドメインエキスパートの判断軸や行動指針などの暗黙知を言語化してプロンプトに書き込んでいく
いかにして良質なコンテキストを与えるか LLMアプリケーションの開発計画 47 ツール実行の結果、検索で取得したデータ、過去の対話履歴などの蓄積による トークン数の肥大化を防ぐために、情報を 取捨選択 、圧縮、分割しながら管理する手法 コンテキストエンジニアリング 系列長の限界 Context
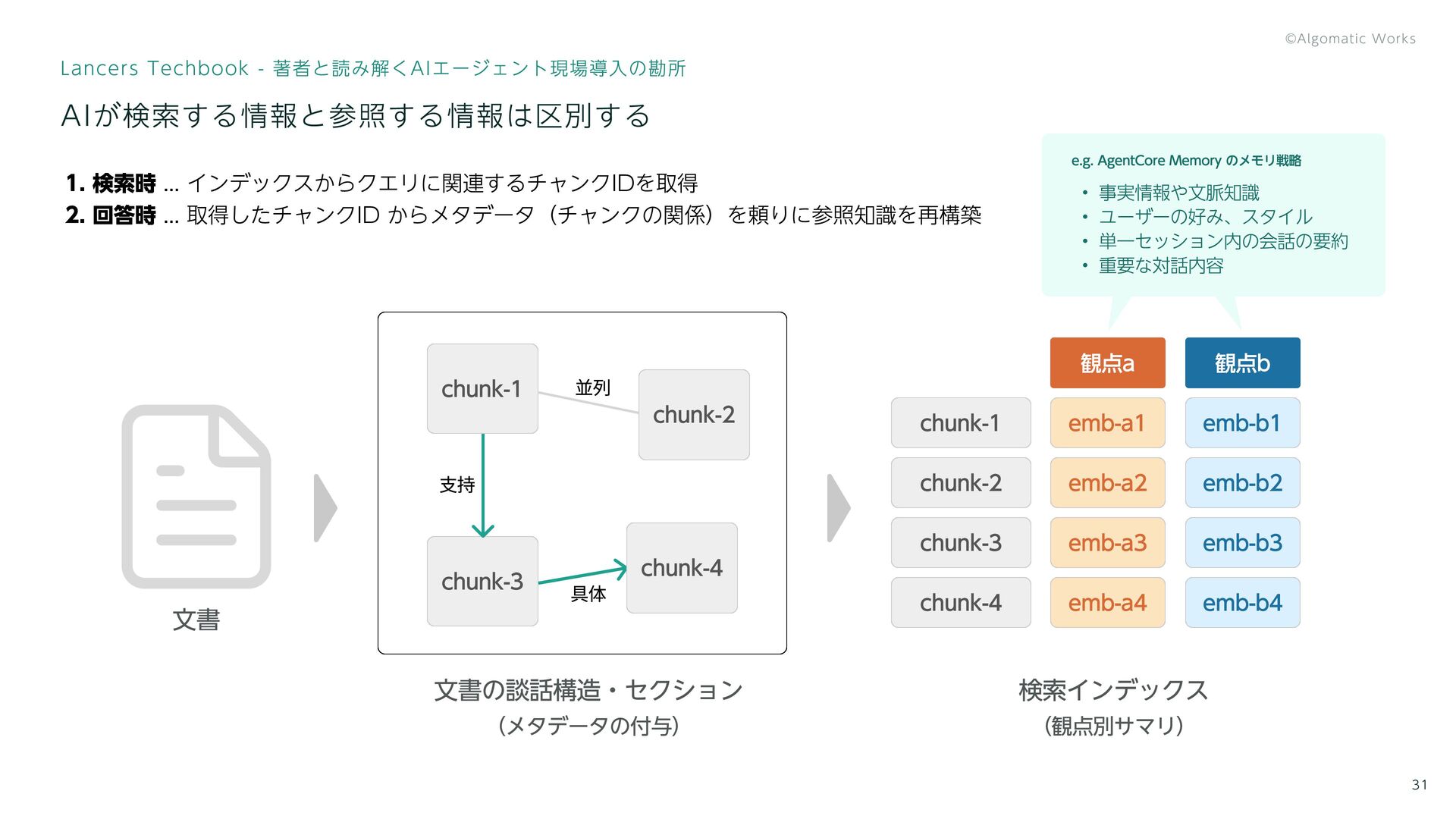
Rot ... LLM が処理可能なトークン数が決まっている ... トークン数が増えるほど有益な情報を読み解く能力が低下する 取捨選択は基本ながらに難しい フィルタリング ... カテゴリ, 登録日 参照情報の再構築 ... チャンク間の関係性, セッションID 検索対象と参照対象は区別する チャンクに対するメタデータを適切に付与する
31 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 AIが検索する情報と参照する情報は区別する chunk-1 chunk-1 chunk-2 chunk-3
chunk-4 emb-a1 emb-a2 emb-a3 emb-a4 emb-b1 観点a 観点b emb-b2 emb-b3 emb-b4 chunk-2 chunk-3 並列 具体 支持 chunk-4 文書の談話構造・セクション (メタデータの付与) 検索インデックス (観点別サマリ) 文書 e.g. AgentCore Memory のメモリ戦略 事実情報や文脈知識 ユーザーの好み、スタイル 単一セッション内の会話の要約 重要な対話内容 検索時 ... インデックスからクエリに関連するチャンクIDを取得 回答時 ... 取得したチャンクID からメタデータ(チャンクの関係)を頼りに参照知識を再構築
良質なコンテキストは人にとっても良質である 48 LLM への情報提供 再現・説明しやすい 運用しやすい 第三者が理解できる形式で記述されているか? 整理された制約条件のもとテストできるようになっているか? 要件の抜けもれがなく詳細に記載されているか? 顧客要求を反映した推論手順が丁寧に記載されていること
どのような情報がどのような形式で含まれているか? コンテキスト間の関係性(時間経過にともなう事実関係の遷移)は? コンテキストエンジニアリングで焦点になるのは基本的にここ Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所
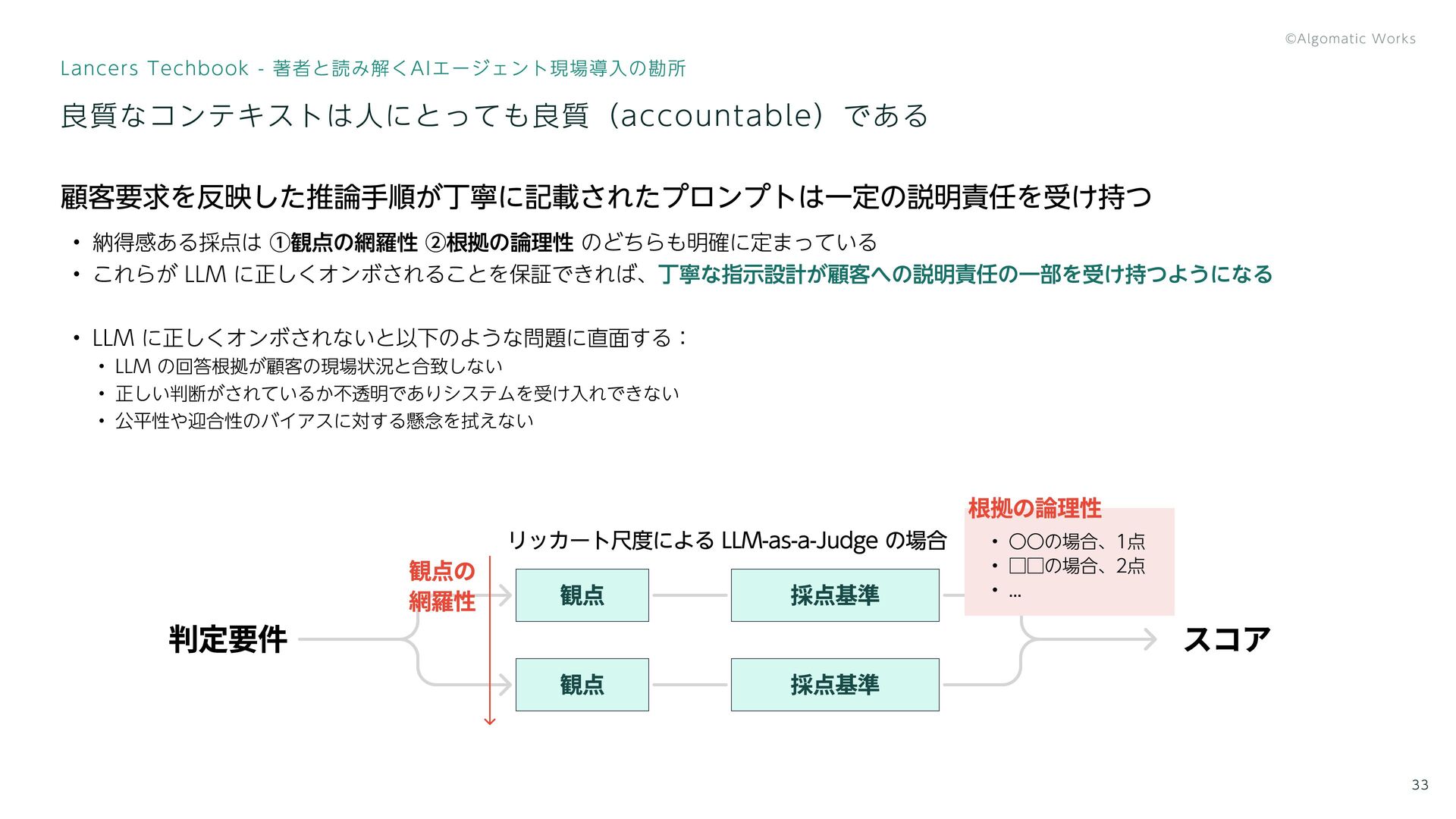
顧客要求を反映した推論手順が丁寧に記載されたプロンプトは一定の説明責任を受け持つ 納得感ある採点は ①観点の網羅性 ②根拠の論理性 のどちらも明確に定まっている これらが LLM に正しくオンボされることを保証できれば、 LLM に正しくオンボされないと以下のような問題に直面する:
LLM の回答根拠が顧客の現場状況と合致しない 正しい判断がされているか不透明でありシステムを受け入れできない 公平性や迎合性のバイアスに対する懸念を拭えない 丁寧な指示設計が顧客への説明責任の一部を受け持つようになる 良質なコンテキストは人にとっても良質(accountable)である リッカート尺度による LLM-as-a-Judge の場合 スコア 判定要件 観点 観点 採点基準 採点基準 観点の 網羅性 根拠の論理性 〇〇の場合、1点 □□の場合、2点 ... 33 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所
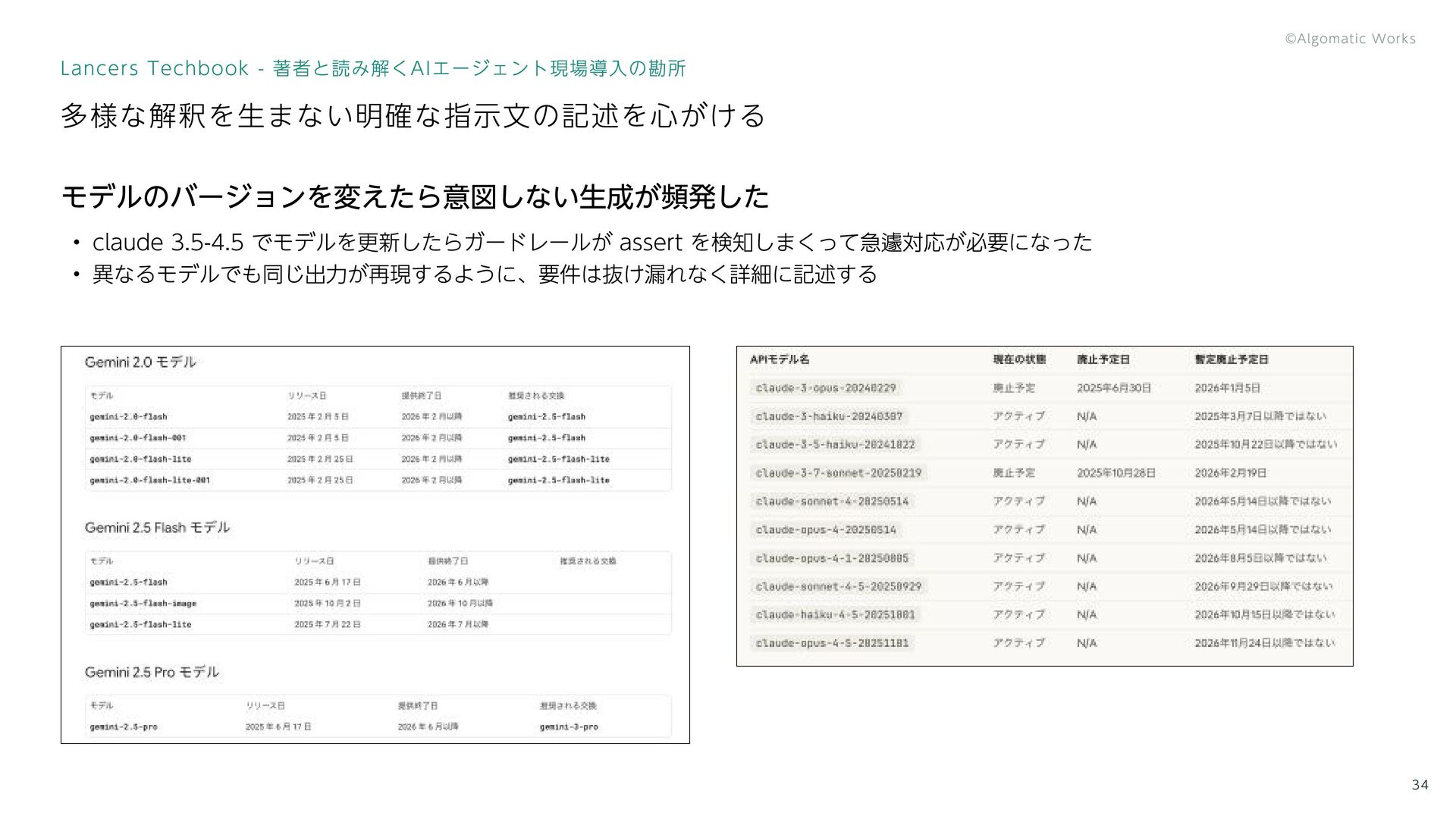
モデルのバージョンを変えたら意図しない生成が頻発した claude 3.5-4.5 でモデルを更新したらガードレールが assert を検知しまくって急遽対応が必要になった 異なるモデルでも同じ出力が再現するように、要件は抜け漏れなく詳細に記述する 多様な解釈を生まない明確な指示文の記述を心がける 34 Lancers
Techbook - 著者と読み解くAIエージェント現場導入の勘所
AI依存の分離 1 2 意図しない生成の検知 3 現行の業務フローから問題点を捉える 良質なプロンプトは人にとっても良質である 下流プロセスをAIから分離していく ガードレールによる多重・多層防御 フェイルセーフの実装
35 暗黙知の言語化
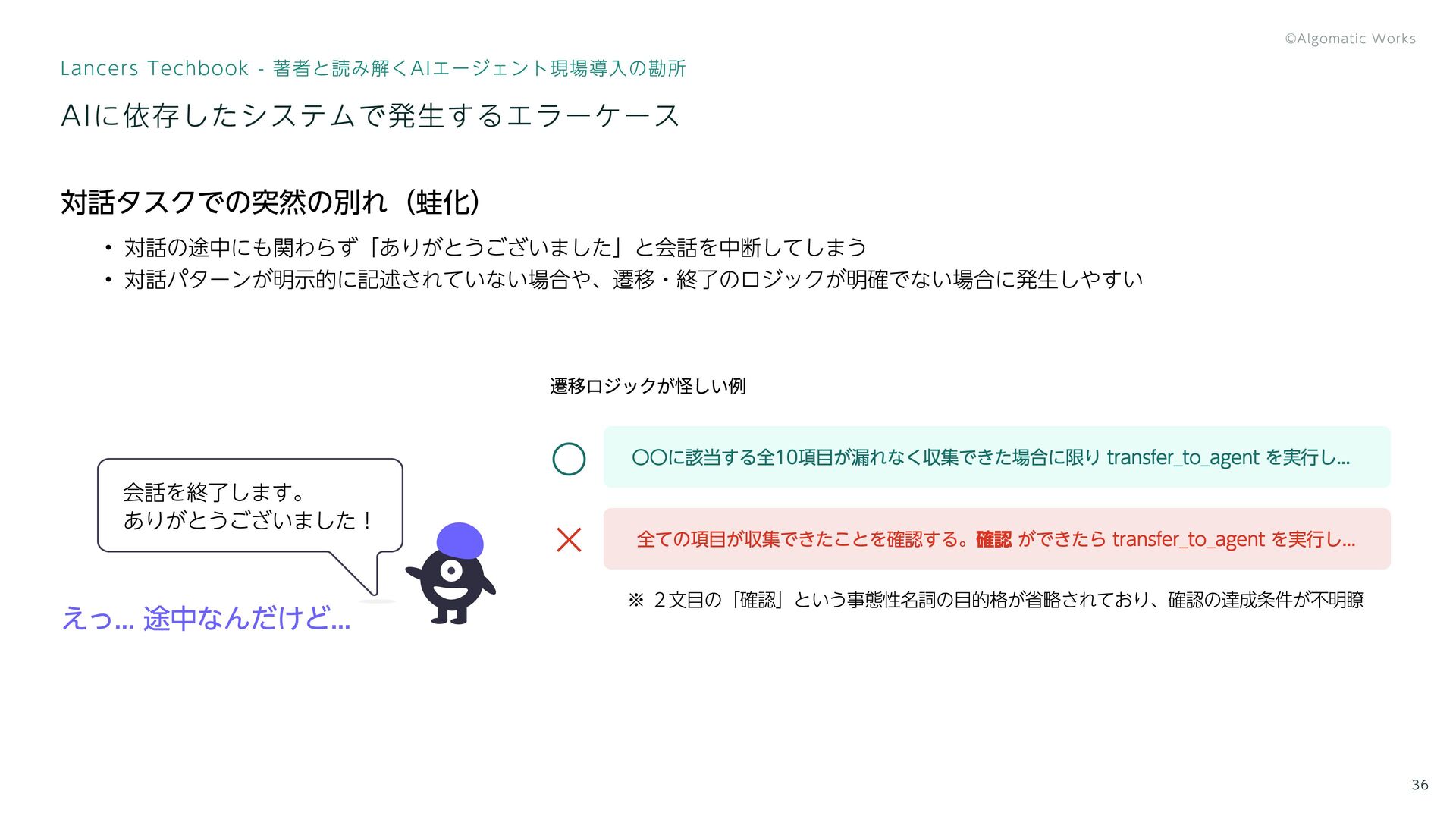
AIに依存したシステムで発生するエラーケース Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 36 対話タスクでの突然の別れ(蛙化) 対話の途中にも関わらず「ありがとうございました」と会話を中断してしまう 対話パターンが明示的に記述されていない場合や、遷移・終了のロジックが明確でない場合に発生しやすい 全ての項目が収集できたことを確認する。確認
ができたら transfer_to_agent を実行し... 会話を終了します。 ありがとうございました! えっ... 途中なんだけど... 〇〇に該当する全10項目が漏れなく収集できた場合に限り transfer_to_agent を実行し... ◯ × 遷移ロジックが怪しい例 ※ 2文目の「確認」という事態性名詞の目的格が省略されており、確認の達成条件が不明瞭
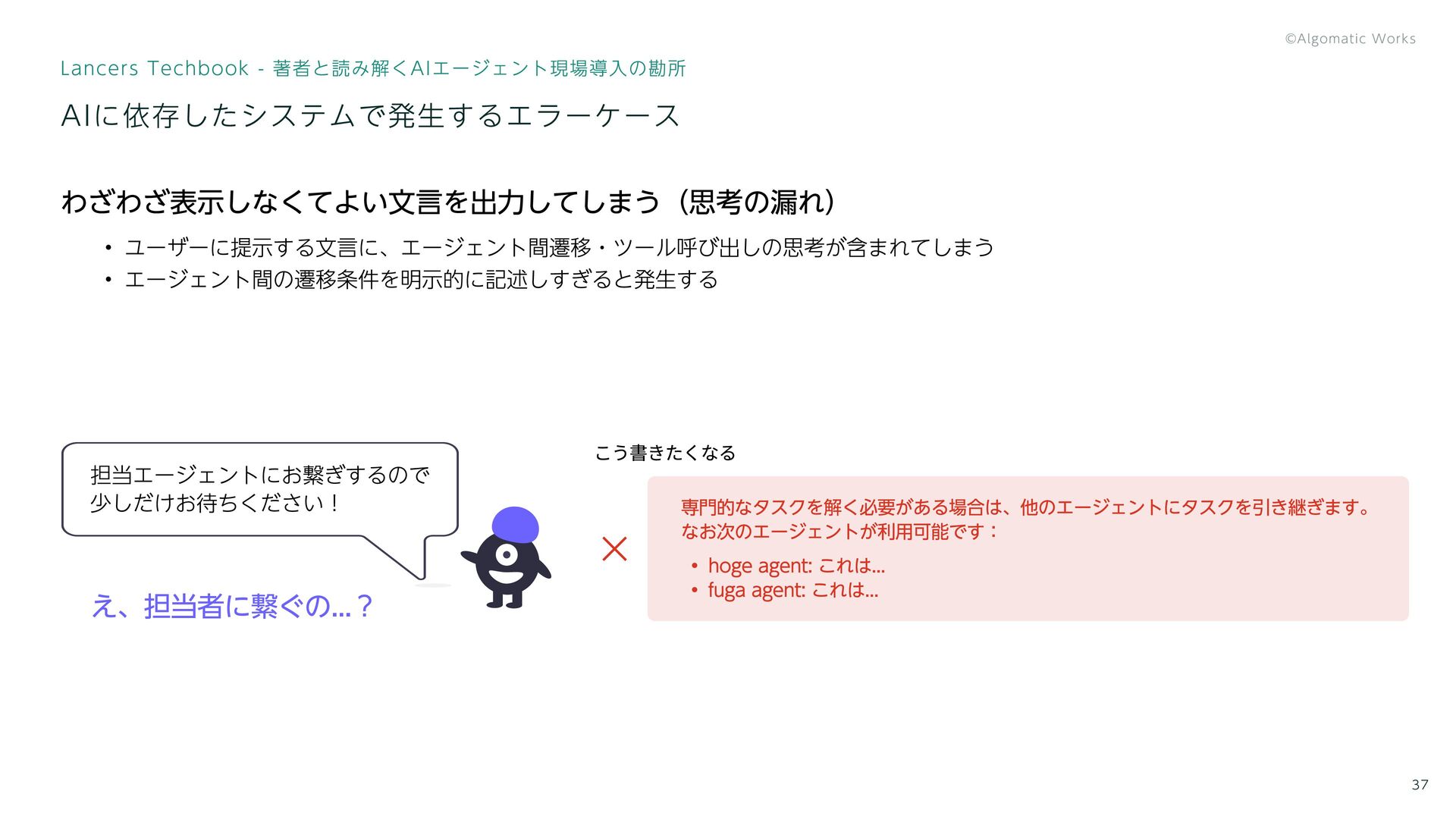
AIに依存したシステムで発生するエラーケース Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 37 わざわざ表示しなくてよい文言を出力してしまう(思考の漏れ) ユーザーに提示する文言に、エージェント間遷移・ツール呼び出しの思考が含まれてしまう エージェント間の遷移条件を明示的に記述しすぎると発生する 担当エージェントにお繋ぎするので
少しだけお待ちください! え、担当者に繋ぐの...? 専門的なタスクを解く必要がある場合は、他のエージェントにタスクを引き継ぎます。 なお次のエージェントが利用可能です: hoge agent: これは... fuga agent: これは... × こう書きたくなる
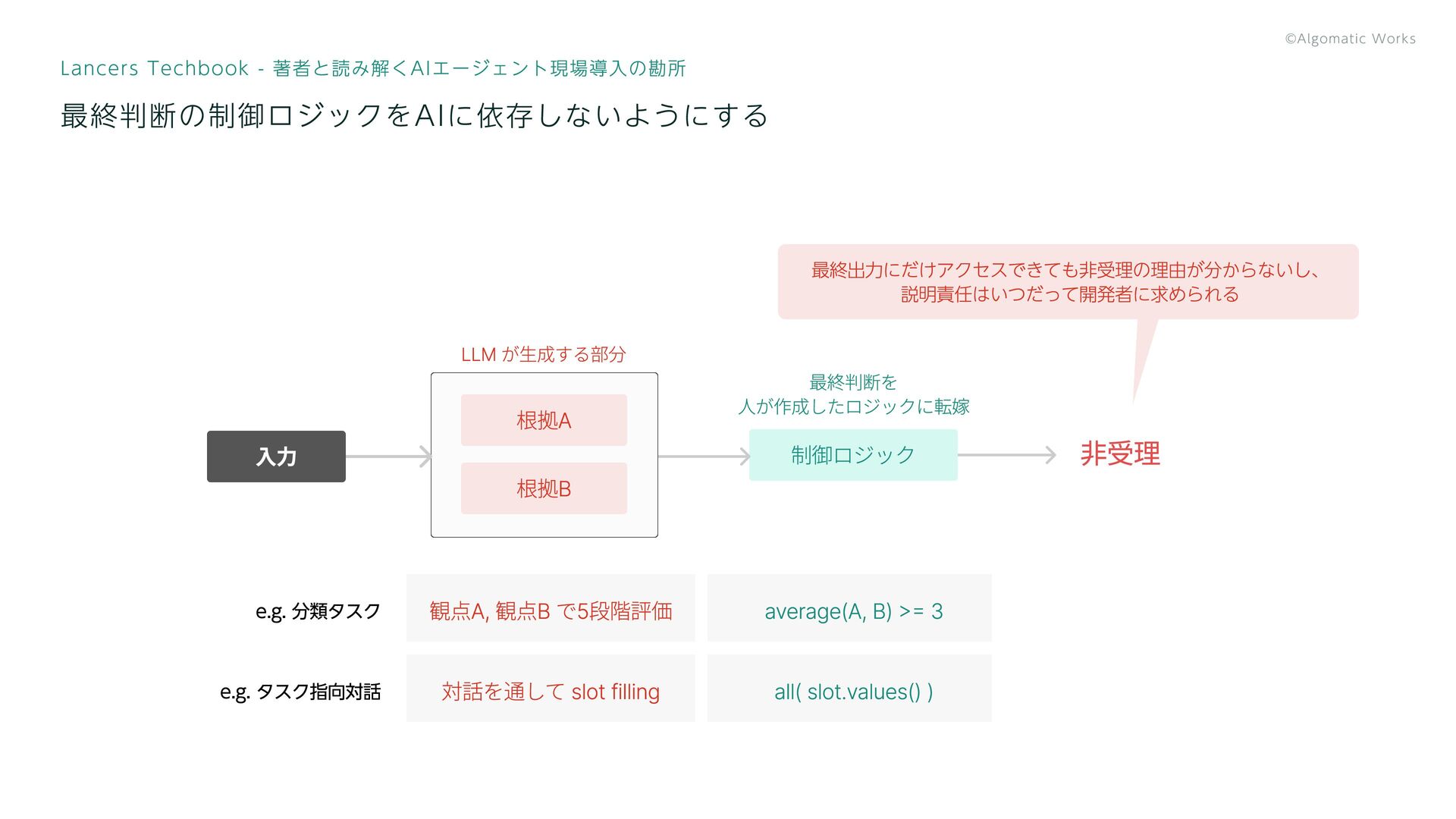
最終判断の制御ロジックをAIに依存しないようにする Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 非受理 根拠A 根拠B 入力 制御ロジック
average(A, B) >= 3 観点A, 観点B で5段階評価 最終判断を 人が作成したロジックに転嫁 LLM が生成する部分 all( slot.values() ) 対話を通して slot filling e.g. タスク指向対話 e.g. 分類タスク 最終出力にだけアクセスできても非受理の理由が分からないし、 説明責任はいつだって開発者に求められる
AI依存の分離 1 2 意図しない生成の検知 3 現行の業務フローから問題点を捉える 良質なプロンプトは人にとっても良質である 下流プロセスをAIから分離していく ガードレールによる多重・多層防御 フェイルセーフの実装
39 暗黙知の言語化
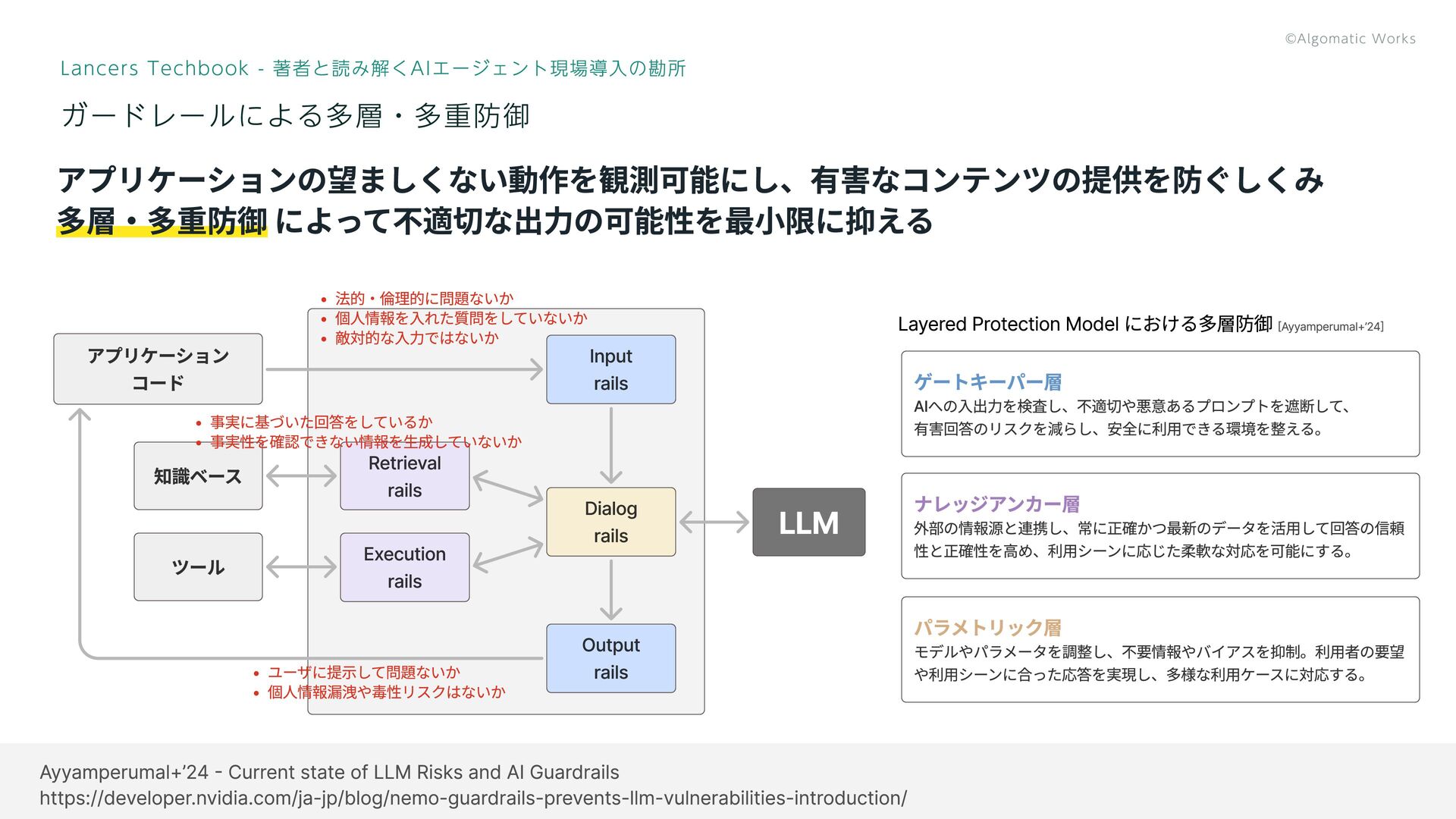
ガードレールによる多層・多重防御 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 40 アプリケーションの望ましくない動作を観測可能にし、有害なコンテンツの提供を防ぐしくみ 多層・多重防御 によって不適切な出力の可能性を最小限に抑える ゲートキーパー層
AIへの入出力を検査し、不適切や悪意あるプロンプトを遮断して、 有害回答のリスクを減らし、安全に利用できる環境を整える。 ナレッジアンカー層 外部の情報源と連携し、常に正確かつ最新のデータを活用して回答の信頼 性と正確性を高め、利用シーンに応じた柔軟な対応を可能にする。 パラメトリック層 モデルやパラメータを調整し、不要情報やバイアスを抑制。利用者の要望 や利用シーンに合った応答を実現し、多様な利用ケースに対応する。 Layered Protection Model における多層防御 [Ayyamperumal+’24] アプリケーション コード 知識ベース Retrieval rails Execution rails Input rails Dialog rails Output rails ツール LLM 事実に基づいた回答をしているか 事実性を確認できない情報を生成していないか 法的・倫理的に問題ないか 個人情報を入れた質問をしていないか 敵対的な入力ではないか ユーザに提示して問題ないか 個人情報漏洩や毒性リスクはないか Ayyamperumal+’24 - Current state of LLM Risks and AI Guardrails https://developer.nvidia.com/ja-jp/blog/nemo-guardrails-prevents-llm-vulnerabilities-introduction/
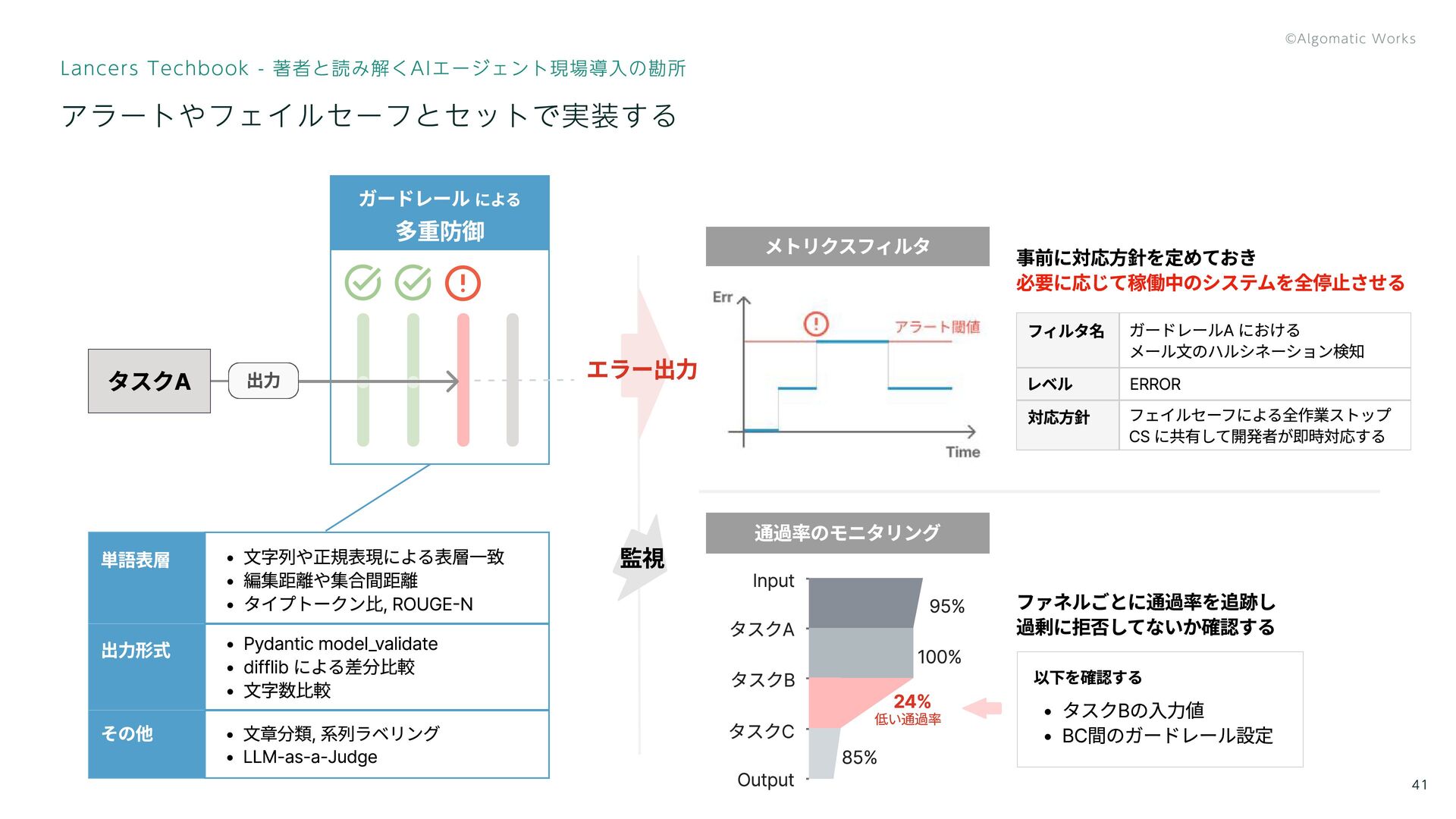
アラートやフェイルセーフとセットで実装する Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 41 単語表層 文字列や正規表現による表層一致 編集距離や集合間距離 タイプトークン比,
ROUGE-N Pydantic model_validate difflib による差分比較 文字数比較 出力形式 その他 文章分類, 系列ラベリング LLM-as-a-Judge タスクA 出力 事前に対応方針を定めておき 必要に応じて稼働中のシステムを全停止させる ファネルごとに通過率を追跡し 過剰に拒否してないか確認する メトリクスフィルタ 通過率のモニタリング ガードレールA における メール文のハルシネーション検知 ERROR レベル 対応方針 フィルタ名 フェイルセーフによる全作業ストップ CS に共有して開発者が即時対応する 監視 Input 95% 100% 85% 24% 低い通過率 タスクA タスクB タスクC Output エラー出力 以下を確認する タスクBの入力値 BC間のガードレール設定 ガードレール による 多重防御 41
継続的な改善 4 55
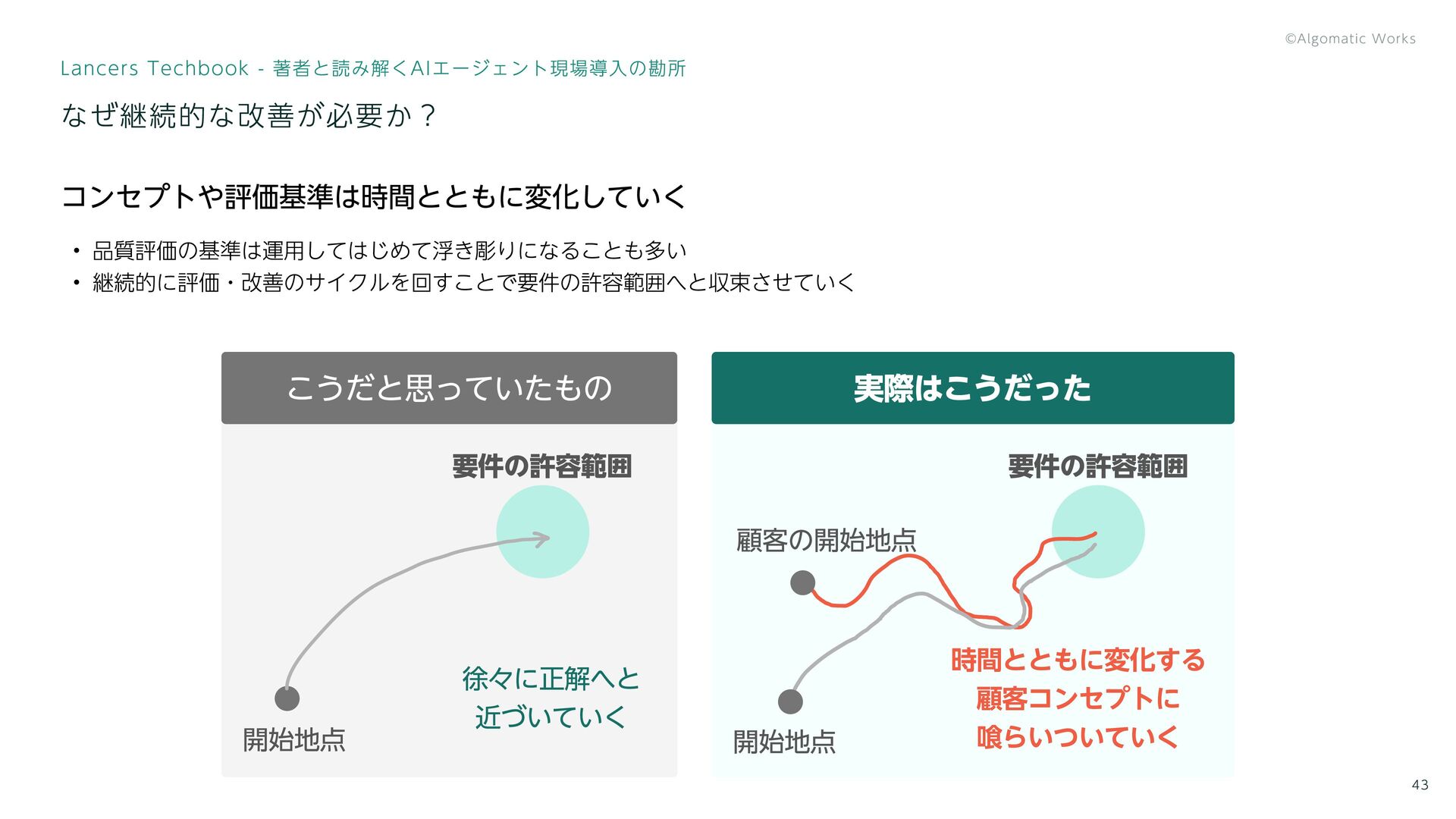
なぜ継続的な改善が必要か? コンセプトや評価基準は時間とともに変化していく 品質評価の基準は運用してはじめて浮き彫りになることも多い 継続的に評価・改善のサイクルを回すことで要件の許容範囲へと収束させていく 徐々に正解へと 近づいていく 要件の許容範囲 時間とともに変化する 顧客コンセプトに 喰らいついていく
開始地点 開始地点 顧客の開始地点 こうだと思っていたもの 実際はこうだった 要件の許容範囲 43 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所
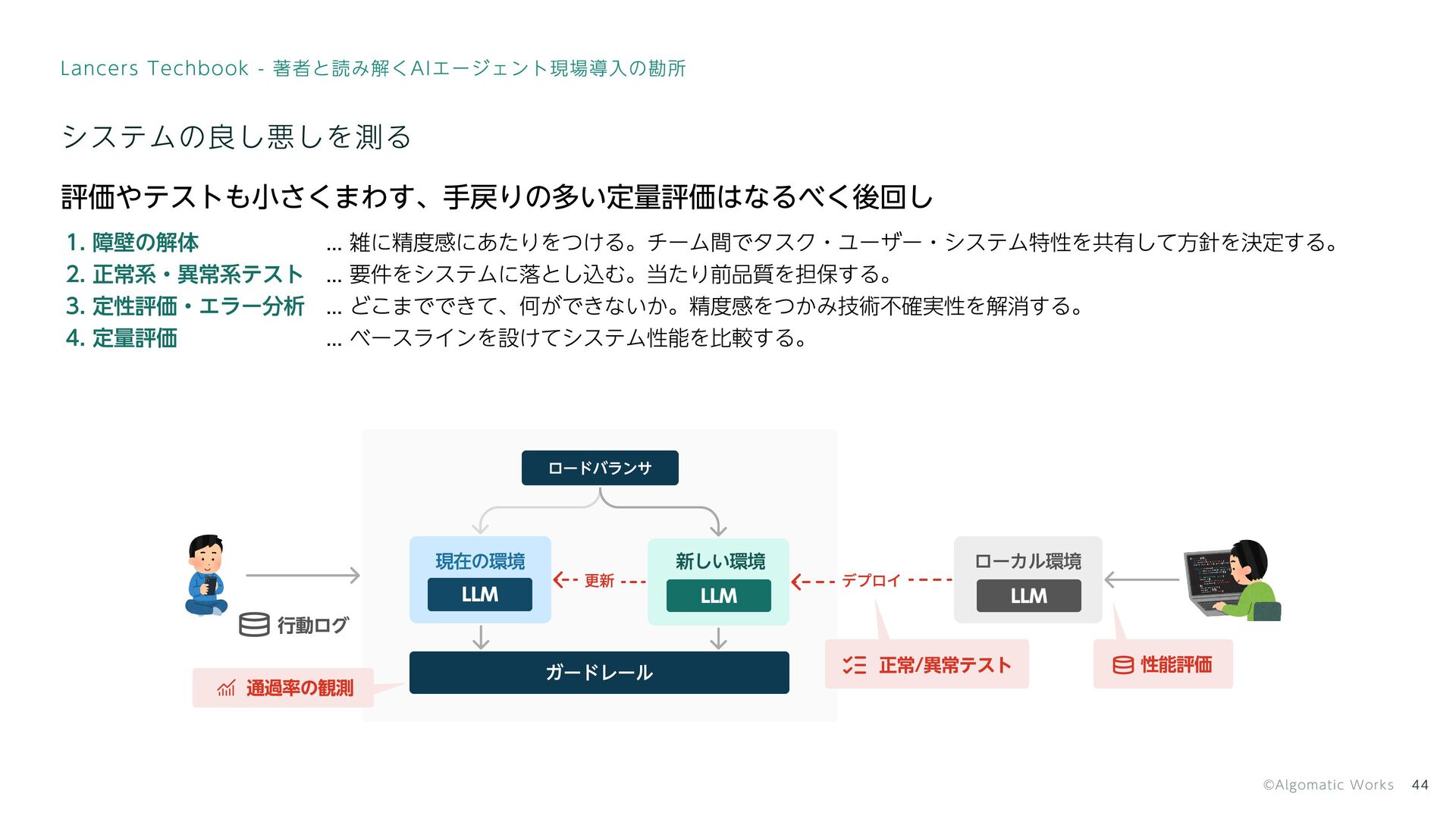
システムの良し悪しを測る 評価やテストも小さくまわす、手戻りの多い定量評価はなるべく後回し ... 雑に精度感にあたりをつける。チーム間でタスク・ユーザー・システム特性を共有して方針を決定する。 ... 要件をシステムに落とし込む。当たり前品質を担保する。 ... どこまでできて、何ができないか。精度感をつかみ技術不確実性を解消する。 ... ベースラインを設けてシステム性能を比較する。
障壁の解体 正常系・異常系テスト 定性評価・エラー分析 定量評価 LLM LLM ロードバランサ LLM 行動ログ 性能評価 ガードレール 新しい環境 現在の環境 ローカル環境 デプロイ 更新 正常/異常テスト 通過率の観測 44 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所
45 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 タスクごとの評価・テスト 分類・回帰 情報抽出 文章生成 タスク指向対話
正常系・異常系のシナリオを作成して動作確認(自動テスト 〜 モンキーテスト) ガードレールを作成して通過率を観測 + 目 grep 5点 ... 〇〇 3点 ... 〇〇 (A) □□□ 1200円 ¥1,200 - 評価データセットを作成 メタモルフィックテスト
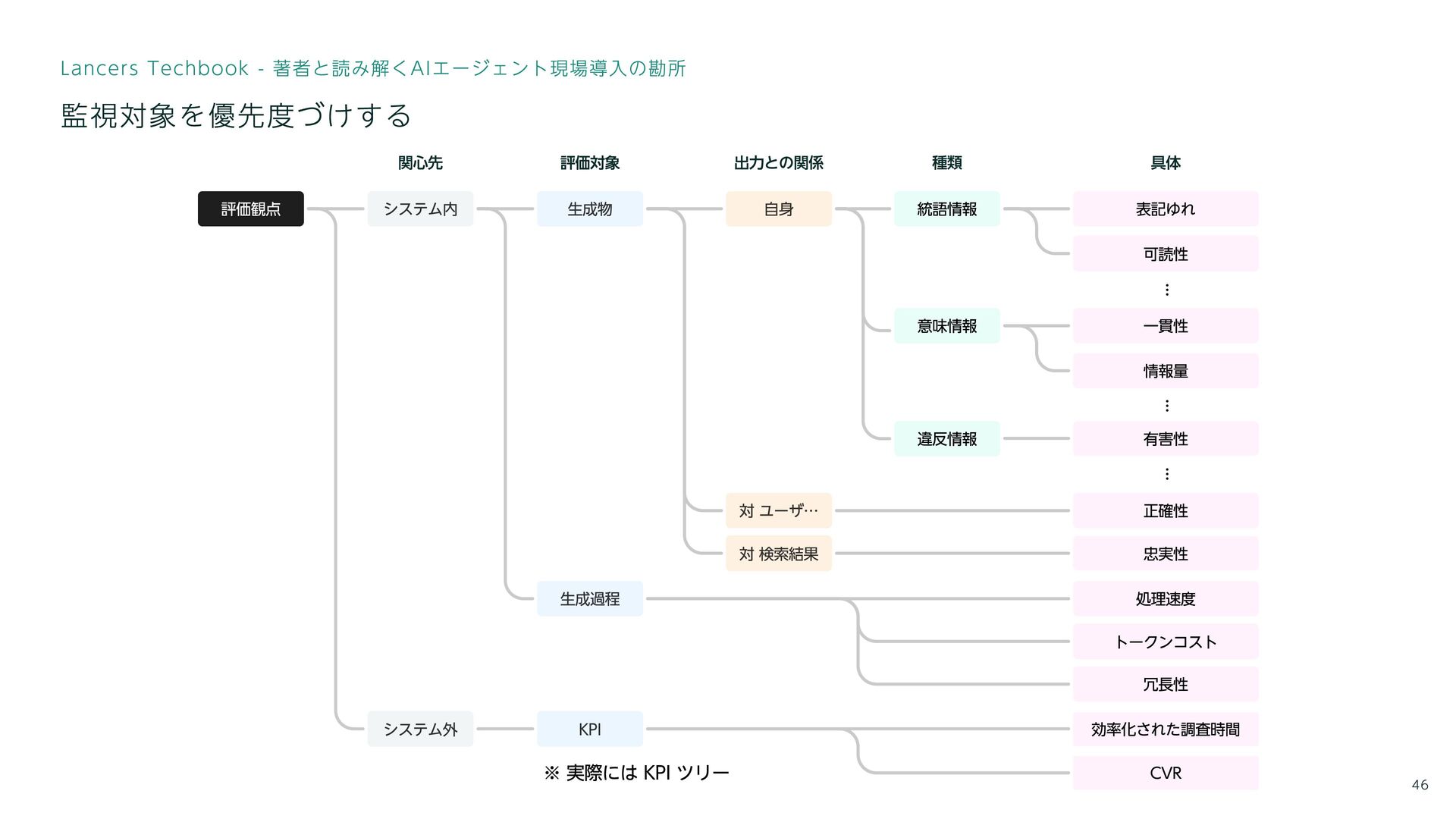
46 統語情報 意味情報 生成物 生成過程 処理速度 トークンコスト 冗長性 システム外 KPI
システム内 効率化された調査時間 評価観点 関心先 忠実性 違反情報 自身 対 ユーザ 対 検索結果 CVR 表記ゆれ 正確性 可読性 一貫性 有害性 情報量 評価対象 出力との関係 種類 具体 ... ... ... Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 監視対象を優先度づけする ※ 実際には KPI ツリー
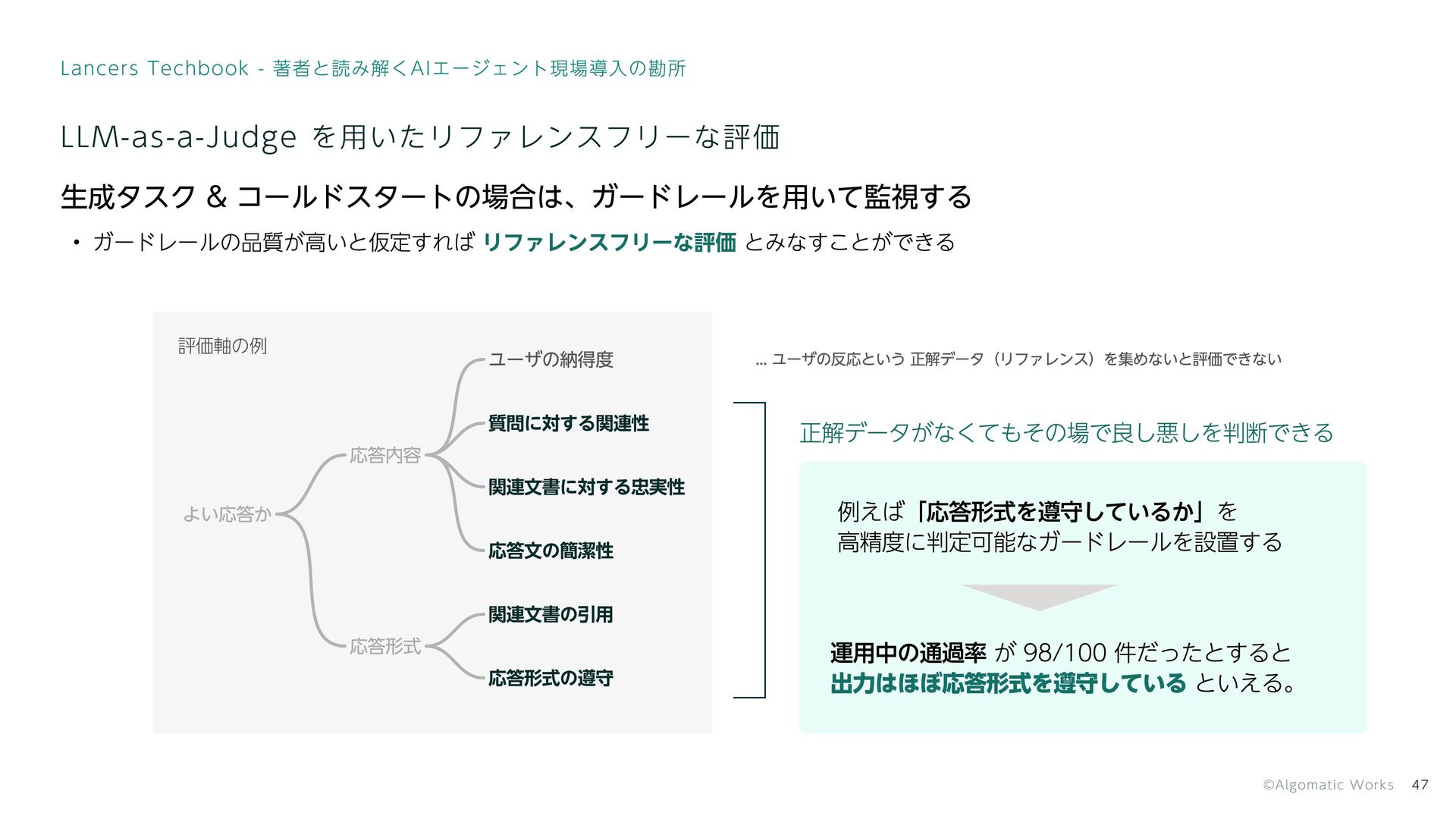
LLM-as-a-Judge を用いたリファレンスフリーな評価 評価軸の例 よい応答か 応答形式の遵守 関連文書の引用 応答文の簡潔性 関連文書に対する忠実性 質問に対する関連性 ユーザの納得度
応答形式 応答内容 ... ユーザの反応という 正解データ(リファレンス)を集めないと評価できない 正解データがなくてもその場で良し悪しを判断できる 運用中の通過率 が 98/100 件だったとすると といえる。 出力はほぼ応答形式を遵守している 例えば「応答形式を遵守しているか」を 高精度に判定可能なガードレールを設置する 生成タスク & コールドスタートの場合は、ガードレールを用いて監視する ガードレールの品質が高いと仮定すれば とみなすことができる リファレンスフリーな評価 47 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所
システムの堅牢性を測る メタモルフィックテストによる動作テスト まずはシナリオ通りに LLM が動作するかテストする 入力に対してある一定の摂動を与えたときに出力変化が予想できる関係( )に着目 メタモルフィック関係 出力が変化しない 出力が変化しなかったか
出力が変化する 出力が変化したか 範囲で摂動を加え、 実際に 確認する ような摂動を加え、 実際に 確認する メタモルフィックテスティングによる動作検証 入力データから1位の商品を削除 加点基準に影響する用語の削除 順位の入れ替わりはない 採点が低くなる 採点が高くなる RAG の場合 レコメンデーションの場合 スコアリングの場合 検索結果のチャンクを入れ替え 不正解チャンクを検索結果から削除 答えは変わらない 答えは変わらない 加点基準に影響する用語の追加 Ribeiro+’20, Beyond Accuracy: Behavioral Testing of NLP Models with CheckList (ACL) Lanham+’23, Measuring Faithfulness in Chain-of-Thought Reasoning 48 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所
システムの堅牢性を測る メタモルフィックテストによる動作テスト 右のような摂動パターンを定義 実際のハッピー/エラーパスをベースに摂動を加える 作成したデータセットで評価する Ribeiro+’20, Beyond Accuracy: Behavioral Testing
of NLP Models with CheckList (ACL) Lanham+’23, Measuring Faithfulness in Chain-of-Thought Reasoning 49 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所
評価セットの作成 層化サンプリング 多様性サンプリング 不確実性サンプリング ユーザーの属性や利用シーン、タスクの種類など、重要なカテゴリごとにバランスよくサンプルを抽出します。 入力パターンの多様性を最大化するようにサンプルを選択します。 幅広いデータを採用することで、システムの汎化性能を測ります。 モデルが判断に迷いやすいケースを優先的に選択します。 これにより、システムの弱点を効率的に発見します。 50
Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 セクションA セクションB 記述量やカテゴリ分布 多様性を確保 評価データ件数 Input-00 Input-01 Input-02
おまけ 51
最終目標とその軌跡は? 4. 将来の展望 TAM/SAM/SOM は? 0. 市場規模 どんな問題を解決する? 5. 顧客課題
競合リスク・動向は? ステークホルダー関係は? 6. ビジネス関係 ユーザー体験をどう変える? 7. 体験設計 あるべき体験をどう実装? 8. 技術選定 属性、行動パターンは? 2. ユーザー特性 52 As-is To-be 期間 課題 現行業務フローは? 1. タスク特性 顧客 KPI/P&L にどう影響? 3. 顧客事業指標 展望 Lancers Techbook - 著者と読み解くAIエージェント現場導入の勘所 AIエージェントとはなにか?
高橋 - AI導入で企業が挫折するのはなぜ? ― AI「以外」の壁にどう立ち向かうか (2024) , https://note.com/dory111111/n/na817a0544da3 AI活用による業務変革をはかるとき、必ずぶつかるのは「AI以外」の壁である に加えて
も同時に必要 「AIによる業務効率化」「誤り生成の許容コスト」の両側面を理解する 人間中心のシステム設計 AI中心の業務設計 なぜ「AIの導入だけ」ではうまくいかないのか? LLMアプリケーションの開発計画 29
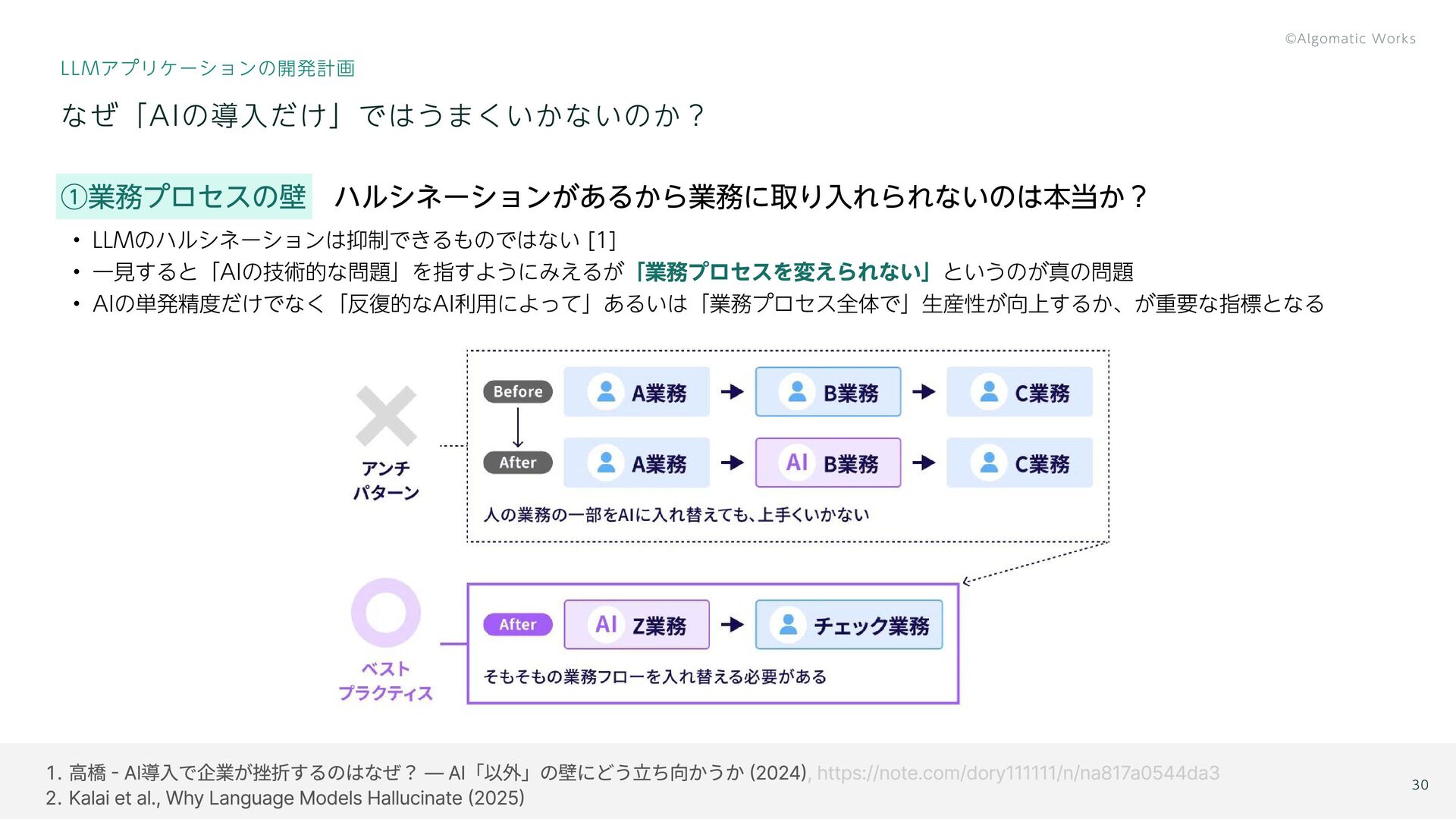
高橋 - AI導入で企業が挫折するのはなぜ? ― AI「以外」の壁にどう立ち向かうか (2024) Kalai et al., Why
Language Models Hallucinate (2025) , https://note.com/dory111111/n/na817a0544da3 なぜ「AIの導入だけ」ではうまくいかないのか? LLMアプリケーションの開発計画 ①業務プロセスの壁 「業務プロセスを変えられない」 ハルシネーションがあるから業務に取り入れられないのは本当か? LLMのハルシネーションは抑制できるものではない [1] 一見すると「AIの技術的な問題」を指すようにみえるが というのが真の問題 AIの単発精度だけでなく「反復的なAI利用によって」あるいは「業務プロセス全体で」生産性が向上するか、が重要な指標となる 30
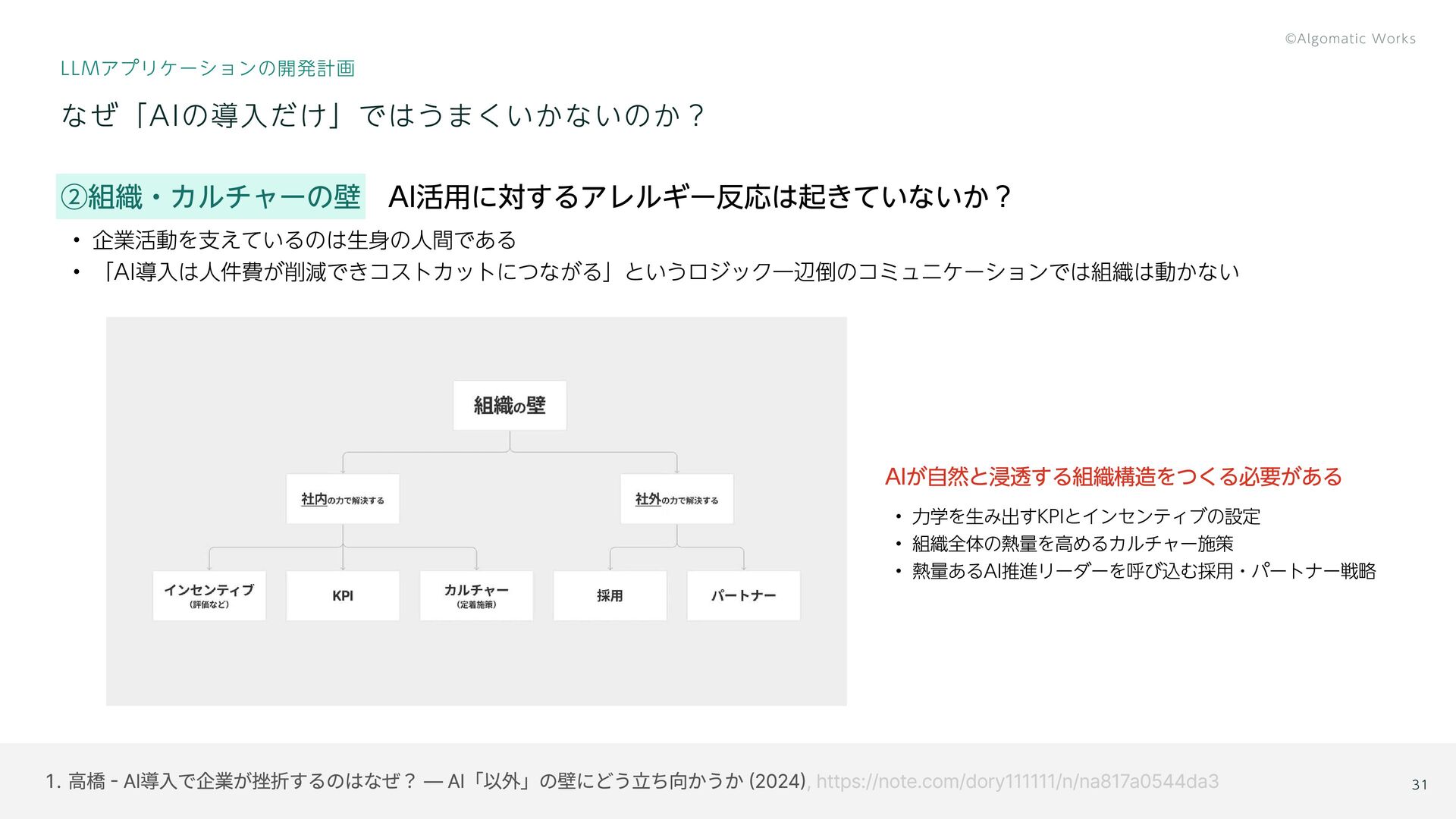
高橋 - AI導入で企業が挫折するのはなぜ? ― AI「以外」の壁にどう立ち向かうか (2024) , https://note.com/dory111111/n/na817a0544da3 ②組織・カルチャーの壁 AI活用に対するアレルギー反応は起きていないか?
企業活動を支えているのは生身の人間である 「AI導入は人件費が削減できコストカットにつながる」というロジック一辺倒のコミュニケーションでは組織は動かない なぜ「AIの導入だけ」ではうまくいかないのか? LLMアプリケーションの開発計画 AIが自然と浸透する組織構造をつくる必要がある 力学を生み出すKPIとインセンティブの設定 組織全体の熱量を高めるカルチャー施策 熱量あるAI推進リーダーを呼び込む採用・パートナー戦略 31
AIで作業工数が半分になれば請求金額も半分になってしまう 人月契約のため生産性向上が与えるインパクトが小さい AIツールの利用可否がお客様に委ねられるため、 自社として積極的に導入を推し進めようとは思わない 高橋 - AI導入で企業が挫折するのはなぜ? ― AI「以外」の壁にどう立ち向かうか (2024)
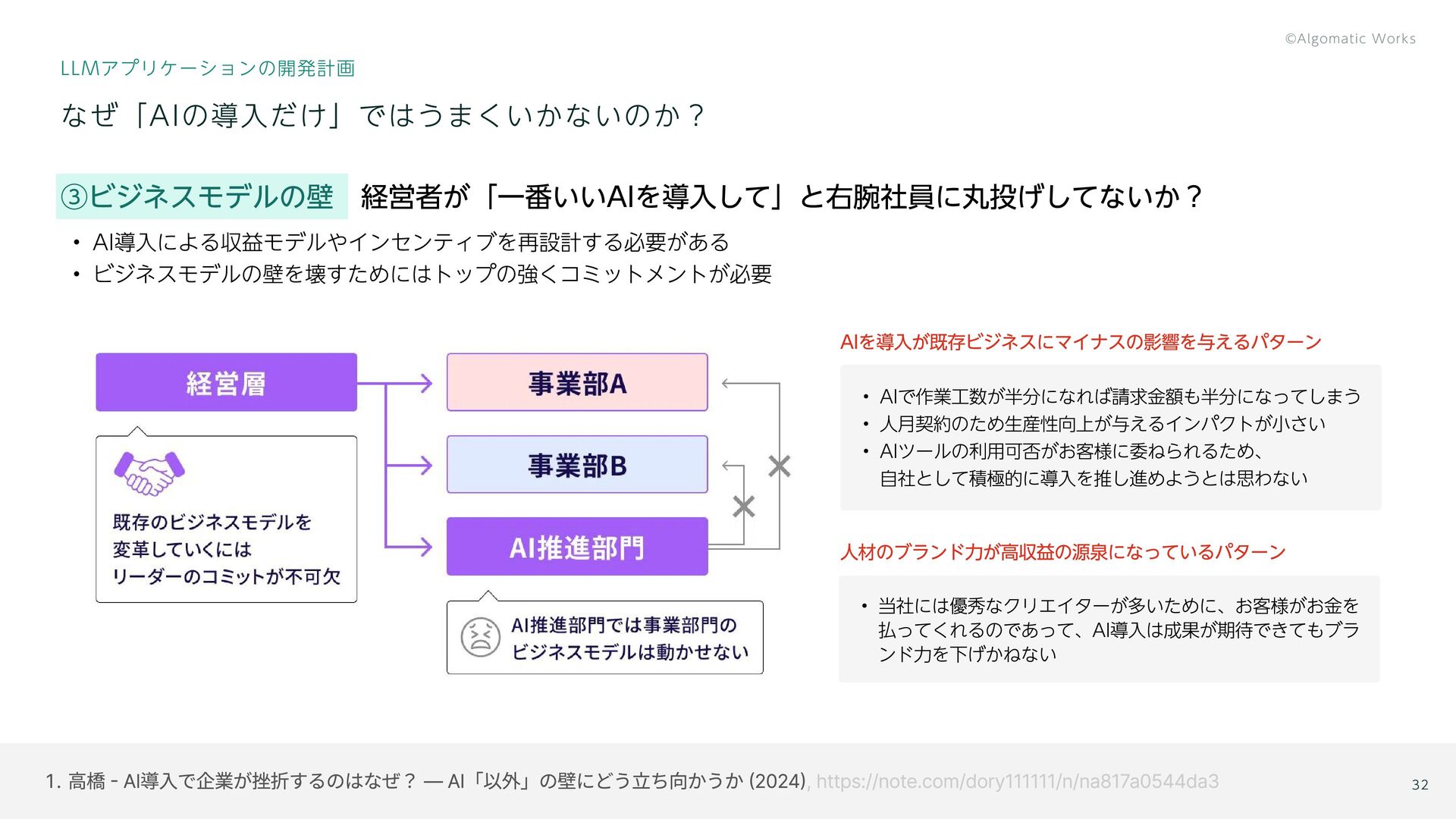
, https://note.com/dory111111/n/na817a0544da3 ③ビジネスモデルの壁 経営者が「一番いいAIを導入して」と右腕社員に丸投げしてないか? AI導入による収益モデルやインセンティブを再設計する必要がある ビジネスモデルの壁を壊すためにはトップの強くコミットメントが必要 AIを導入が既存ビジネスにマイナスの影響を与えるパターン 人材のブランド力が高収益の源泉になっているパターン なぜ「AIの導入だけ」ではうまくいかないのか? LLMアプリケーションの開発計画 当 社には優秀なクリエイターが多いために、お客様がお金を 払ってくれるのであって、AI導入は成果が期待できてもブラ ンド力を下げかねない 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}