Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
時系列データの異常検知
Search
SnowGushiGit
April 08, 2018
Science
11k
11
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
時系列データの異常検知
本資料の内容
・異常とは
・異常検知問題のタイプ
・時系列データのタイプ
・データの前処理
・異常検知手法
・性能検証
・発展
SnowGushiGit
April 08, 2018
Other Decks in Science
See All in Science
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
220
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
tagtag
PRO
0
210
第67回コンピュータビジョン勉強会論文紹介「RoboWheel: A Data Engine from Real-World Human Demonstrations for Cross-Embodiment Robotic Learning」
x_ttyszk
0
120
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
390
フィードフォワードニューラルネットワークを用いた記号入出力制御系に対する制御器設計 / Controller Design for Augmented Systems with Symbolic Inputs and Outputs Using Feedforward Neural Network
konakalab
0
160
プロジェクト「Azayaka」のSARの数式とジオメトリ
syuchimu
0
380
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.4k
Endel Tulvingとエピソード記憶
rmaruy
0
150
大黒市で発生した大規模インシデント の ポストモーテムから読み解く、 記憶媒体消去の大切さ
shucho0103
0
210
Van Dare naar Durf
voginip
0
260
ダメな自分の育て方―性格タイプの「劣等機能」から理解するニガテ克服術
ppillc
0
220
Build your own LLM, Live, with MicroGPT
ianozsvald
0
110
Featured
See All Featured
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Building AI with AI
inesmontani
PRO
1
1.1k
Accessibility Awareness
sabderemane
1
160
GitHub's CSS Performance
jonrohan
1033
470k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
Code Review Best Practice
trishagee
74
20k
Google's AI Overviews - The New Search
badams
0
1.1k
Transcript
時系列データの異常検知
自己紹介 ・大串 正矢 ・株式会社カブク ・機械学習エンジニア Twitter: @SnowGushiGit 2
プレゼン内容に関係する notebook goo.gl/B6GjLA 3
Table of Contents 1. 異常とは 2. 異常検知問題のタイプ 3. 時系列データのタイプ 4.
データの前処理 a. データのクリーニング b. データの選定 5. 異常検知手法 6. 性能検証 a. 異常データの作成 b. 評価 7. 発展 4
異常とは 5
異常とは ▸ 異常 ▹ 自然現象 ▹ 外れ値 ▹ 変動 ▹
ノイズ ▹ 人間起因 ▹ 不正 ▹ 侵入 ▹ 不適切動作 6
異常とは ▸ 異常 ▹ システム起因 ▹ 故障 ▹ エラー 7
データごとの異常 ▸ 数値ベクトルデータ ▹ 偏差値 ▹ 母集団からの外れ値検知 ▸ センサー系 ▹
工場監視センサー ▹ 故障検知 ▹ 故障予兆検知 8
データごとの異常 ▸ イベント系列 ▹ クレジットカード利用履歴 ▹ クレジット不正利用検知 ▸ ネットワーク系 ▹
トラフィック流量 ▹ DDos攻撃検知 9
データごとの異常 ▸ 非構造化データ ▹ 音声 ▹ 異音検知 ▹ 画像・動画 ▹
異常状態・侵入者検知 ▹ テキスト ▹ ノイズ文章除去 ▹ トレンドワード検出 10
異常検知問題のタイプ 11
異常検知問題のタイプ ▸ ここからの問題の分離はデータマイニング による異常検知に基づく ▹ https://www.amazon.co.jp/dp/4320018826 12
外れ値検出問題 ▸ データが分布の範囲を超えているものを検 知 ▹ 個々のデータ点の分布のみ考慮 13
変化点検知 ▸ 単一の観測対象の時系列データ 14 変化点
異常状態検知 ▸ 複数の観測対象の時系列データ ▹ 別の入力によって状態が変わるケー ス ▹ 入力がないのに変わっているケース は異常状態とする 15
異常状態 連動して変化
3つの問題の関係性 ▸ 変化点検出&異常状態検出 ▹ 時系列データを多次元ベクトルデータに変換して外れ 値検出として扱う ▸ 外れ値検出 ▹ 個々のデータの分布のみ考慮
16
本発表で扱う範囲 ▸ 変化点検知 ▹ 単一の観測対象の時系列データ 17 異常値
時系列データのタイプ 18
時系列データの捉え方 ▸ 複数の時系列データ(一定の区間で区切っ たデータ) ▹ センサー系 19
時系列データの捉え方 ▸ 単一の時系列データ ▹ イベント系列 ▹ ネットワーク系 20
時系列データのタイプ ▸ 時系列データはこれから見せる2つに大きく 分類されます。 ▹ 複数の時系列データがある場合のみ ▹ 周期性 ▹ 定期的に同じことが繰り返される事象
▹ 同期性 ▹ 複数の事象が同時に起こること 21
時系列データのタイプ ▸ 周期性と同期性をもつ 22
時系列データのタイプ ▸ 非周期性と非同期性をもつ 23
データのクリーニング 24
データのクリーニング ▸ クリーニングの必要性 ▹ 正常データ中のノイズ除去 ▹ 計測不具合で混ざった計測対象外なデータの除去 25
データのクリーニング ▸ クリーニングの手法 ▹ ノイズ除去 ▹ 時系列データの傾向のみを把握したい ▹ 時系列データの選定(時系列データが複数ある場合 のみ)
▹ 完全なノイズデータは除きたい 26
データのクリーニング ▸ ノイズ除去 ▹ スムージング ▹ 移動平均などの手法でノイズを除去して波形の 傾向のみを明らかにする 27 スムージング
複数の時系列データ があるケースのみ 28
データの選定 ▸ 波形の選定 ▹ 目で検査 ▹ 利点 ▹ 全ての時系列データに対して適用可能 ▹
欠点 ▹ 時間がかかる ▹ 人によってばらつきが生じる 29
データの選定 ▸ 時系列データの選定 ▹ 正常な時系列データを1件用意しMSE(略称:Mean Squared Error)が一定以下のデータを取得 30
データの選定 ▸ 時系列データの選定 ▹ MSEとは 31
データの選定 ▸ 時系列データの選定 ▹ MSE ▹ 制約条件 ▹ 同期性がある時系列データの選定に有効 32
データの選定 ▸ 時系列データの選定 ▹ 時系列データを1件用意しDTW(略称:Dynamic Time Wrapping)が一定以下のデータを取得 33
データの選定 ▸ 時系列データの選定 ▹ DTWとは ▹ ユークリッド距離が最小 になるように各点を選 択 34
ユークリッド距離が最小の点を選択
データの選定 ▸ 時系列データの選定 ▹ DTW ▹ 利点 ▹ 同期性がない波形の選定に有効 ▹
欠点 ▹ 計算時間がかかる(波形サイズをnとすると) ▹ 35
データの選定 ▸ 時系列データの選定 ▹ Windowごとにユークリッド距離を計算してその合 計値が一定以下のものを使用 36 windowごとにユーク リッド距離を計算
データの選定 ▸ 時系列データの選定 ▹ Window ▹ 利点 ▹ 波形が安定しないものでも適用可能 ▹
欠点 ▹ Window幅の適切な設定が必要 ▹ Windowの移動幅(ストライド)の適切な設定が必要 37
異常検知手法 38
異常検知手法 39 手法 教師あり機械学習 教師なし機械学習 (異常ラベルデータが ないことを意味) ルールベース メリット 明確化できない既知
の異常に効果を発揮 異常ラベルをつけた データが不要 明確化できる特定 のケースに有効 デメリット 異常データが必要 性能検証や性能保証 が難しい 複雑なルールの組 み合わせや属人 性が上がる
異常検知手法 ▸ 今回はルールベースと教師なし機械学習を 紹介 ▹ 異常データが存在しないもしくは十分にない場合 が多い ▹ 未知の異常にも対応したい ▹
組み合わせが容易 ▹ ルールベースで数を絞ってから教師なし機械 学習で検知 40
ルールベース 41
異常検知手法 ▸ 境界値 ▹ 異常を判定する境界値を設定 ▹ 利点 ▹ 運用が単純 ▹
欠点 ▹ 波形変化などの異常は検知不可 42
異常検知手法 ▸ K近傍法 43 1: 新しい点 2: Window内の点と新しい 点との距離を全て計算 3:
2で計算した距離の最も 短いものK個選びその平均 値を新しい点の異常スコア とする 4: 閾値を超えているか チェック 短い距離のデータK個 平均値 (異常スコア)
異常検知手法 ▸ K近傍法 ▹ 距離の種類 ▹ ユークリッド距離 ▹ ばらつきがないデータに有効 ▹
マハラノビス距離 ▹ データのばらつきがある場合に有効 ▹ σはqの標準偏差 ▹ 他の距離尺度 ▹ http://wikiwiki.jp/cattail/?%CE%E0%BB%F7%C5%D9%A4%C8%B5%F7%CE%A5#fc 29bc1e 44
異常検知手法 ▸ K近傍法 ▹ 利点 ▹ 波形変化も検出可能 ▹ 欠点 ▹
K点の適切な決め方が難しい ▹ window幅の適切な決め方が難しい ▹ 周期性のあるデータは周期に合わせたwindow幅を設定 ▹ それ以外はバリデーションデータで決定 45
教師なし機械学習 46
異常検知手法 ▸ 教師なし機械学習 ▹ 自己回帰モデル(ARモデル:Auto Regressionモデ ル) ▹ 時間依存性について ▹
定常性 ▹ モデリング 47
時間依存性について ▸ 過去の値と同じ値が出やすい ▹ 時間差(ラグと呼ぶ)を考慮した自分自身との相関 関係を自己相関関係と呼ぶ 48 時間差をつけた自分自 身との相関
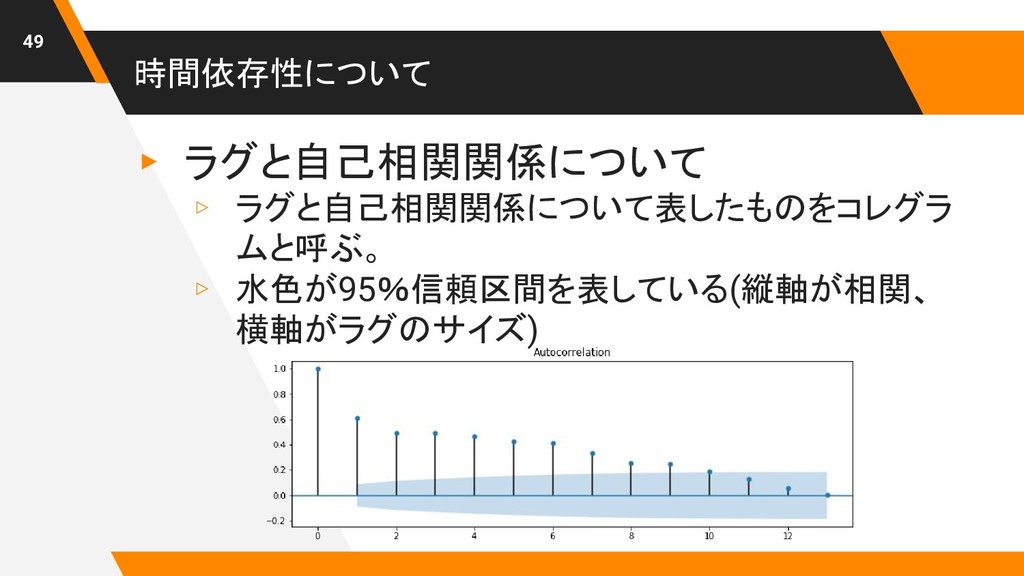
時間依存性について ▸ ラグと自己相関関係について ▹ ラグと自己相関関係について表したものをコレグラ ムと呼ぶ。 ▹ 水色が95%信頼区間を表している(縦軸が相関、 横軸がラグのサイズ) 49
定常性について ▸ 定常性 ▹ 平均が一定 ▹ 分散が一定 ▹ 自己共分散がラグのみ に依存
50 緑が定常性あり 赤が定常性なし
定常性について ▸ 定常性 ▹ 平均が一定 ▹ 分散が一定 ▹ 自己共分散がラグのみに依存(一定のラグのサイズ で自己共分散が周期的な特徴を持っている)
51
定常性について ▸ モデリング ▹ データに対する仮定 ▹ 自分自身の値と自己相関関係がある ▹ 定常性を満たしており自己共分散がラグに依 存(ラグのサイズのみ考慮)
▹ 仮説 ▹ 自分自身の過去の値に対してラグを設定しそ の線形結合により次の値を予測可能では ▹ 自己回帰モデル 52
ARモデル ▸ 自己回帰モデル(ARモデル:Auto Regressionモデル)の定義 ▹ 自分自身の値と自己相関関係がある ▹ 定常性を満たしており自己共分散がラグに依存 ▹ 今回は簡易化のため、ホワイトノイズは考慮しない
53 平均0,分散が一定の ホワイトノイズ ラグのサイズのデータで予測
ARモデル ▸ 自己回帰モデル(ARモデル:Autoregressive モデル) ▹ 今回は自己回帰モデルのみ ▹ 発展系 ▹ ARMA(自己回帰移動平均モデル)
▹ ARIMA(自己回帰和分移動平均モデル) ▹ SARIMA(季節自己回帰和分移動平均モデル) ▹ 別のモデル ▹ 状態空間モデル ▹ ローカルレベルモデル ▹ LSTM, GRU 54
ARモデル ▸ 線形結合で過去の値を用いて次の出力値 を予測する ▹ 予測する一つ前の過去の値から線形結合する 55 Window幅: r 予測
ARモデル ▸ 自身の過去の値を用いて予測 56 Window幅: r Window幅: r Windowを1ずらす 終端まで繰り返す
予測 予測
ARモデル ▸ パラメータαの導出 ▹ 最小2乗法 ▹ 定義したモデル式の予測値と実測値が最小に なるようにモデルのパラメータを設定 ▹ 最尤推定
▹ 確率分布を仮定し、実測値をもっとも導出する ような確率分布のパラメータを設定 ▹ 最小2乗法は最尤推定法で分布をガウス分布と仮 定した場合は等価 ▹ https://mathwords.net/saisyonijoho 57
ARモデル ▸ 最尤推定 ▹ データは正規分布から得られると仮定 ▹ 定常性(再掲) ▹ 平均、分散は一定のため時間に依存しない ▹
ラグt+1の値はラグtの値の線形結合で導出できる (再掲) ▹ 平均が自己回帰モデルと等しい正規分布は下記 58
ARモデル ▸ 対数にして計算を楽にする 59 ▸ 1つ先だけでなくn個先まで考慮
ARモデル ▸ 誤差が最小になるように先ほどの式を で微分し0と等価として表す 60
ARモデル ▸ 展開すると下記のような連立方程式に書き 換えられる(ユールウォーカー方程式) ▹ 連立方程式を解くと導出可能 ▹ 自己相関関数がラグに依存することが前提 61
ARモデル ▸ Windowの幅rの決定方法 ▹ AIC(赤池情報量基準) ▹ 下記の数式の値が最小になるようにrを設定す る ▹ AICにより導出される分散σはrが大きいほど減
少するがrが大きいほどモデルの複雑性が上が るため、罰則項として追加 62
ARモデル ▸ データを表現できているか性能検証 ▹ MSE ▹ 実測値と予測値の差が少ないことを確認 ▹ 決定係数 ▹
データのばらつき度合いも考慮して評価 ▹ 平均から離れた値が多いと小さくなる 63 : 実測値 : 予測値 : 実測値の平均 : 実測値 : 予測値
ARモデル ▸ 異常スコアを計算し閾値を超えているか チェック 64 ARモデルなどで予測 差分を異常値として利用 (分散でスケーリングして検証データと学習 データのスケールを揃える) 学習データの異常度の分散
実測値 予測値 分散は時刻tに依存しない(定常性が成り立 つデータと仮定)
異常検知手法 ▸ 教師なし機械学習 ▹ 利点 ▹ 波形変化も検知可能かつ、理想的なwindow サイズはモデルから導出可能 ▹ 欠点
▹ モデルの定期更新が必須のため運用が複雑に なる 65
性能検証 66
性能検証 ▸ 性能検証に必要なもの ▹ 異常データ ▹ ない場合は作成が必要 ▹ 評価 ▹
閾値決定と性能検証に使用 ▹ 時系列データの閾値 ▹ 時系列データの場合は複数パターン存在 67
異常データの作成 68
異常データの作成 ▸ 異常データの作成が必要な理由 ▹ 異常データがないケース ▹ 検知可能な異常を明確化するケース ▸ 注意点 ▹
異常データの作成はあくまで検証程度。実環境で は予想外の異常が発生するため実データを使える 環境では実データで検証すべき 69
異常データの作成 ▸ 異常データの作成の注意点 ▹ 観測する時系列データの知識がないと異常とノイ ズまたは観測される正常な時系列データの性質の 区別が出来ない ▹ 先に観測する時系列データの知識を取得する 70
異常データの作成 ▸ 異常データの種類 ▹ 全ての波形タイプに共通 ▹ スパイク型 ▹ 波形変化形 ▹
レベルシフト ▹ 波形タイプの変化 ▹ 同期性 -> 非同期 71
異常データの種類 ▸ スパイク型 72 スパイクのように異常が発生
異常データの種類 ▸ 波形変化形 73 波形が変化
異常データの種類 ▸ レベルシフト 74 レベルシフト
異常データの種類 ▸ 同期性 -> 非同期 75 開始位置がずれている
評価 76
評価 ▸ 前提 ▹ 正常データの異常スコアもしくは距離は小さいはず、 異常データの異常スコアもしくは距離は大きいはず ▹ 横軸が異常スコア ▹ 縦軸が密度
▹ 赤が正常な分布 ▹ 青が異常な分布 77
評価指標 ▸ 正常データを正常とした割合と異常データを 異常とした割合 78 Positive Negative Positive (Predict) True
Positive (TP: 略称) False Positive (FP: 略称) Negative (Predict) False Negative (FN: 略称) True Negative (TN: 略称) 正常データの異常度の正 規分布 異常データの異常度の正 規分布 TP 閾値 FN FP TN TN と FN TPも含まれる 異常 正常
評価指標 ▸ 下記のようなケースに定義した場合 ▹ Positive ▹ 健康 ▹ Negative ▹
病気 ▸ 閾値の決め方 ▹ False Positiveを減らす ▹ 医者が限られているので治療する人は限定 ▹ False Negativeを減らす ▹ 軽い症状でも病気と診断して治療 79
評価指標 ▸ 異常データの数が少ないのでTrue Positive とTrue Negativeだけでは不十分 ▹ ROC AUC(Receiver operating
characteristic area under the curve): ▹ 異常データは少ないので分布で評価 80
評価指標 ▸ 上の分布が分かれており、赤の分布が左側 にあると下の図の面積が大きくなる ▹ 赤が正常データの分布 ▹ 青が正常データの分布 81
時系列データの閾値 82
時系列データの閾値 ▸ 単一の閾値(False Positive許容) ▹ 利点 ▹ 単純なので運用が楽 ▹ 欠点
▹ 異常値が各点において異なると検知不可能 83
時系列データの閾値 ▸ 各点に設定(False Negative許容) ▹ 利点 ▹ 細かい設定が可能で検出率増加 ▹ 欠点
▹ ノイズや波形変化に弱いので誤検出が増加の 可能性あり 84
発展 85
発展 ▸ より表現力の高いモデルを扱いたい ▹ 深層学習: LSTM、GRUなど ▸ 複数の時系列を扱いたい ▹ Multivariate
LSTM, VARXなど ▸ データを変換して扱う ▹ スペクトログラム, Wavelet変換 ▸ 状態推定 ▹ HMMによる時系列状態推定 86
“We are hiring!! https://www.wantedly.com/projects/154408 機械学習エンジニア https://www.kabuku.co.jp/jobs/machine-learning-engineer フロントエンドエンジニア https://www.kabuku.co.jp/jobs/front-end-developer サーバーサイドエンジニア https://www.kabuku.co.jp/jobs/backend-developer
エンジニア以外も https://www.wantedly.com/companies/kabuku
88 THANKS! Twitter @SnowGushiGit
参考 89
References 90 ▸ Deep Learning Lab 異常検知入門 ▹ https://www.slideshare.net/shoheihido/deep-learning-lab-88299 985/
▸ How DTW (Dynamic Time Warping) algorithm works ▹ https://www.youtube.com/watch?v=_K1OsqCicBY ▸ 【統計学】ROC曲線とは何か、アニメーションで理解する。 ▹ https://qiita.com/kenmatsu4/items/550b38f4fa31e9af6f4f#3-roc %E6%9B%B2%E7%B7%9A%E3%81%AE%E5%BD%A2%E7 %8A%B6%E3%81%AE%E8%80%83%E5%AF%9F ▸ 定常性についてのまとめ ▹ https://dev.classmethod.jp/statistics/stationarity-reading/ ▸ 異常検知の世界へようこそ ▹ https://research.preferred.jp/2013/01/outlier/
References 91 ▸ Stationary process ▹ https://en.wikipedia.org/wiki/Stationary_process#Differencing ▸ Rで計量時系列分析:AR, MA,
ARMA, ARIMAモデル, 予測 ▹ https://tjo.hatenablog.com/entry/2013/07/12/184704 ▸ scikit-learn で回帰モデルの結果を評価する ▹ https://pythondatascience.plavox.info/scikit-learn/%E5%9B%9E %E5%B8%B0%E3%83%A2%E3%83%87%E3%83%AB%E3% 81%AE%E8%A9%95%E4%BE%A1 ▸ PRML 1.2.4-1.4 ▹ https://qiita.com/mochio/items/5cf3ad0b76729ca16346#%E3%8 2%AC%E3%82%A6%E3%82%B9%E5%88%86%E5%B8%83 %E3%81%AE%E6%9C%9F%E5%BE%85%E5%80%A4%E5% B9%B3%E5%9D%87%E5%80%A4
References 92 ▸ ARモデルのパラメータ最尤推定を思い出す ▹ http://nekopuni.holy.jp/2014/01/rar%E3%83%A2%E3%83%87% E3%83%AB%E3%81%AE%E3%83%91%E3%83%A9%E3%83 %A1%E3%83%BC%E3%82%BF%E6%9C%80%E5%B0%A4% E6%8E%A8%E5%AE%9A%E3%82%92%E6%80%9D%E3%81 %84%E5%87%BA%E3%81%99/
▸ 最小二乗法と最尤法の関係 ▹ https://mathwords.net/saisyonijoho ▸ A Complete Tutorial on Time Series Modeling in R ▹ https://www.analyticsvidhya.com/blog/2015/12/complete-tutorial -time-series-modeling/ ▸ 入門 機械学習による異常検知―Rによる実践ガイド ▸ 時系列解析入門
References 93 ▸ 異常検知と変化検知 (機械学習プロフェッショナルシリーズ) ▸ 現場ですぐ使える時系列データ分析~データサイエンティストのための基 礎知識~
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}